
Boundary Loss-Based 2.5D Fully Convolutional Neural Networks Approach for Segmentation: A Case Study of the Liver and Tumor on Computed Tomography


Abstract
:1. Introduction
- A boundary loss function is proposed to help capture more boundary and contour features of the liver and tumor, from CT images, and to make the segmentation boundaries smoother;
- A cascading 2.5D FCNs based on the residual network is proposed, which can effectively segment the liver and tumor in CT images and can reduce VRAM cost;
- A post-processing method for the image boundary is presented to reduce false-positive cases, which can further improve segmentation accuracy.
2. Related Work
2.1. The Methods Based on Hand-Crafted Features
2.2. The Methods Based on Deep Learning
2.3. The Loss Function for Networks Optimization
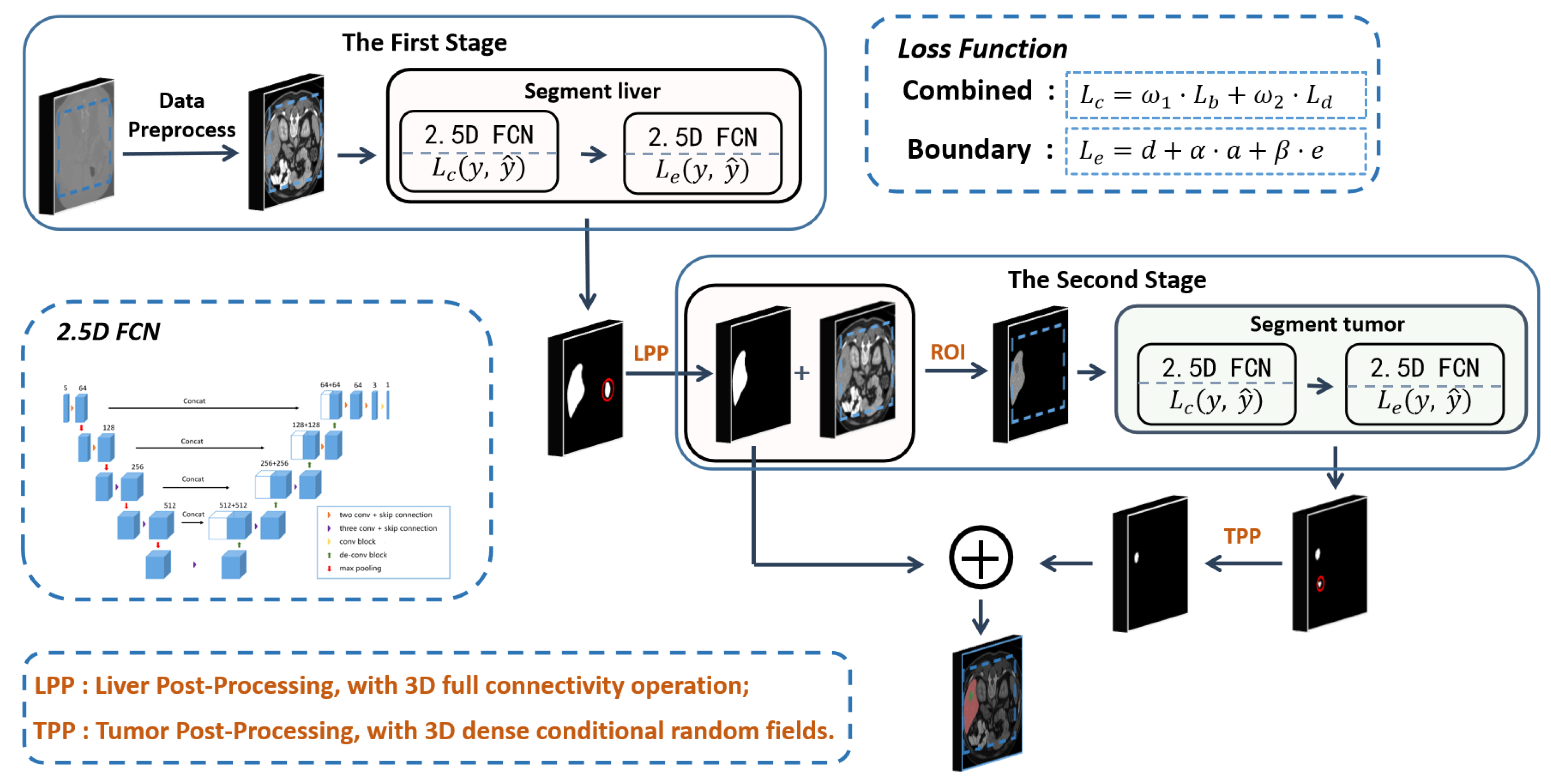
3. Method
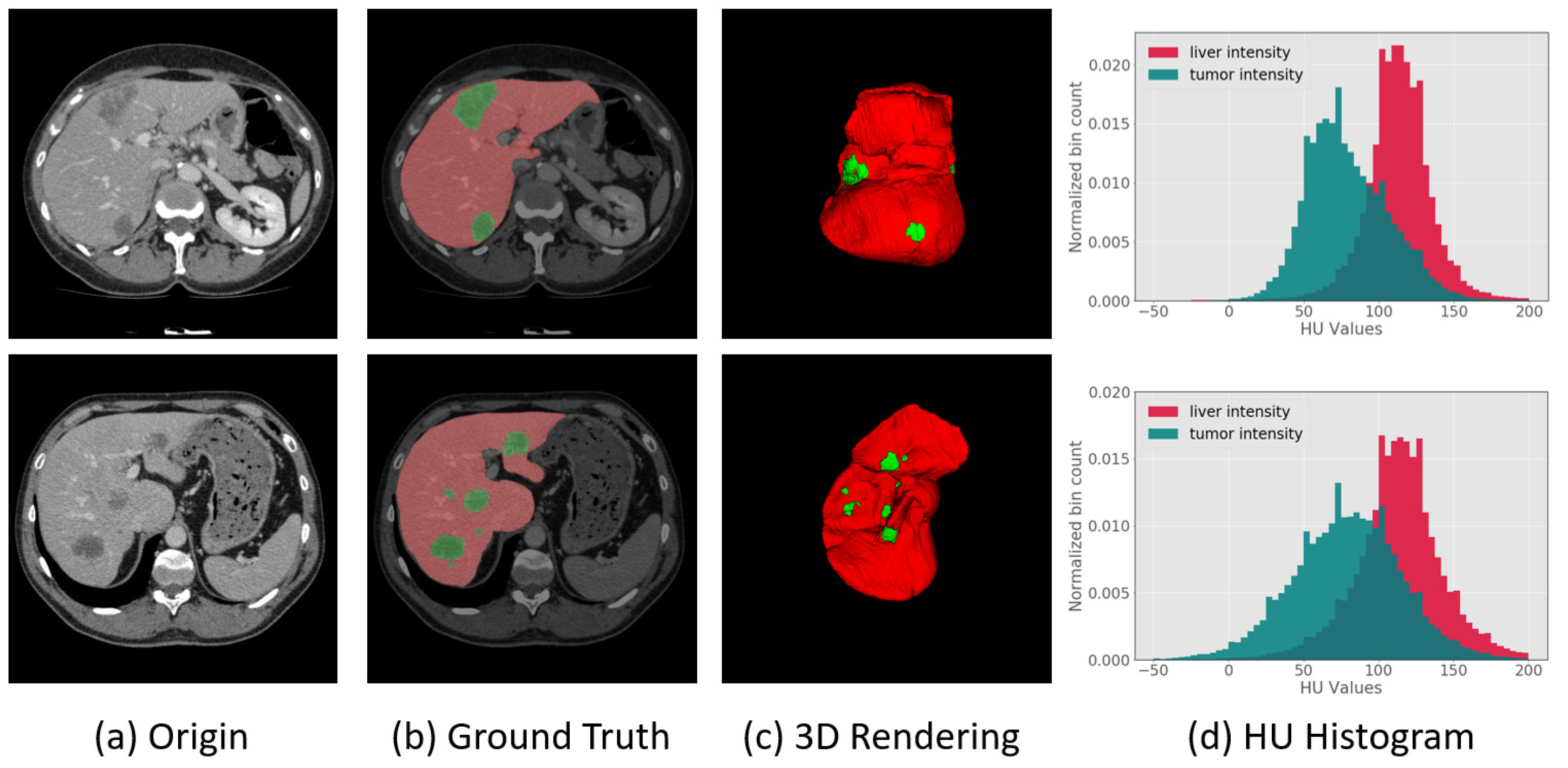
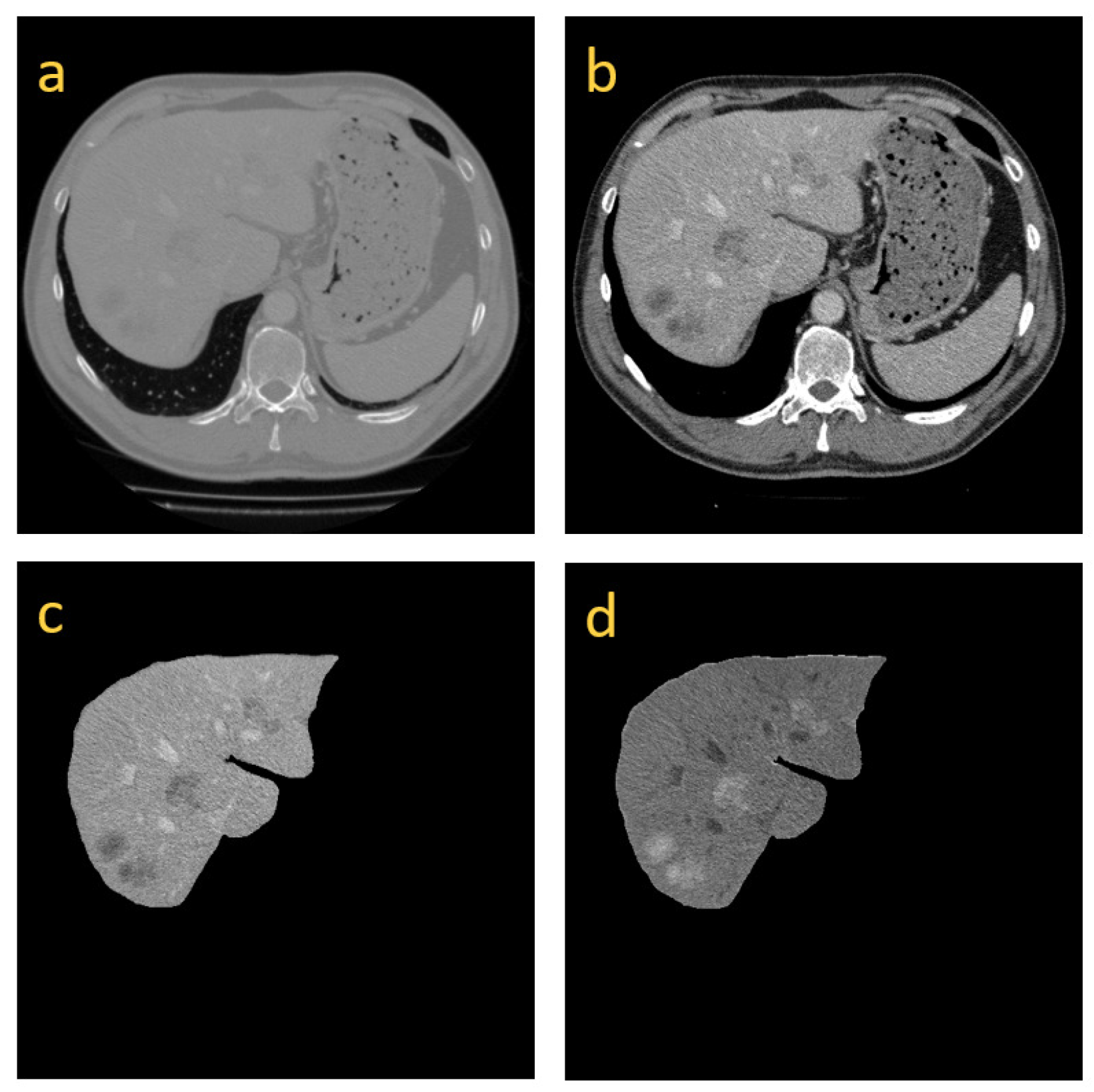
3.1. Image Preprocessing
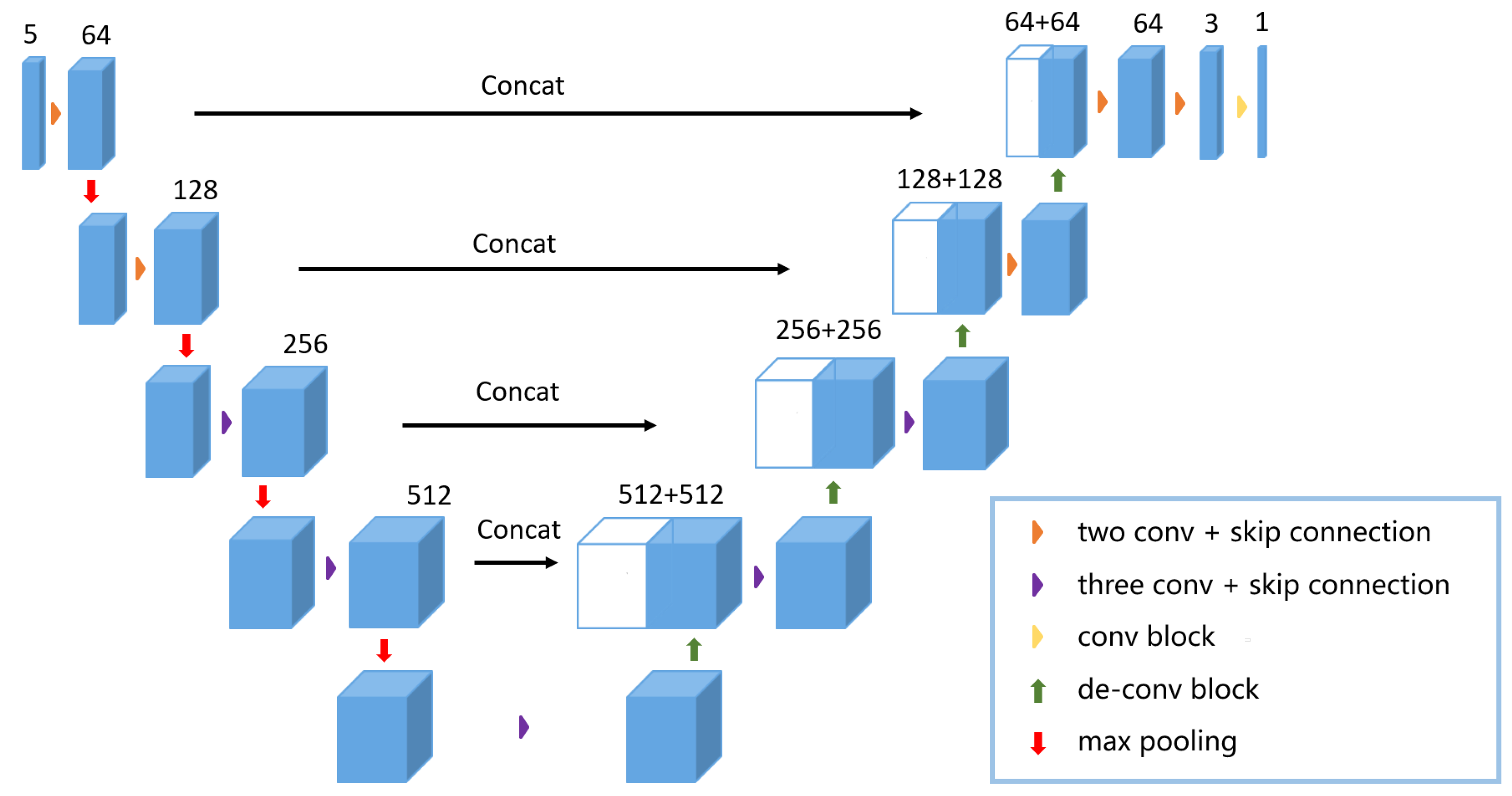
3.2. Model Structure
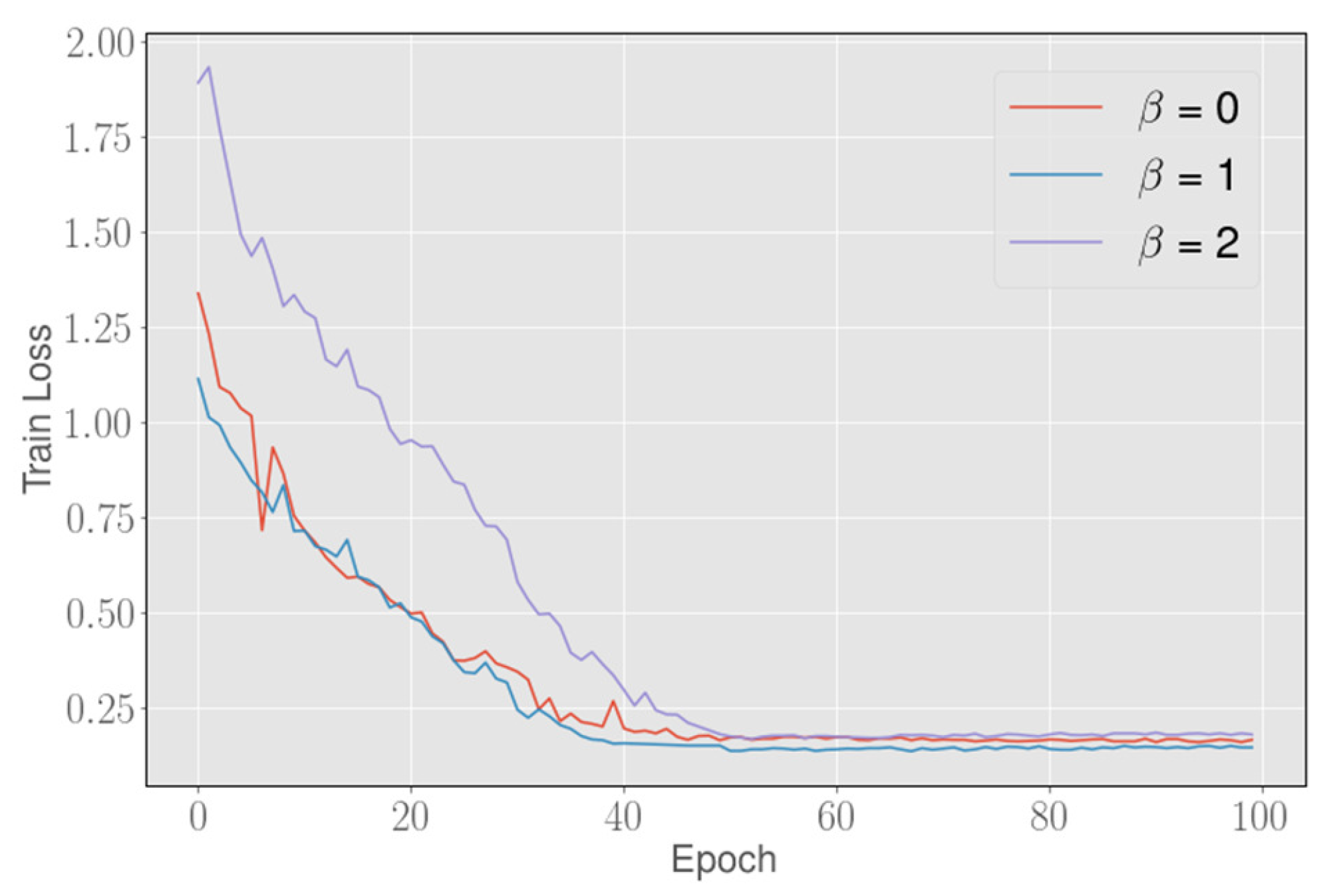
3.3. Boundary Loss Function
3.4. Training and Testing
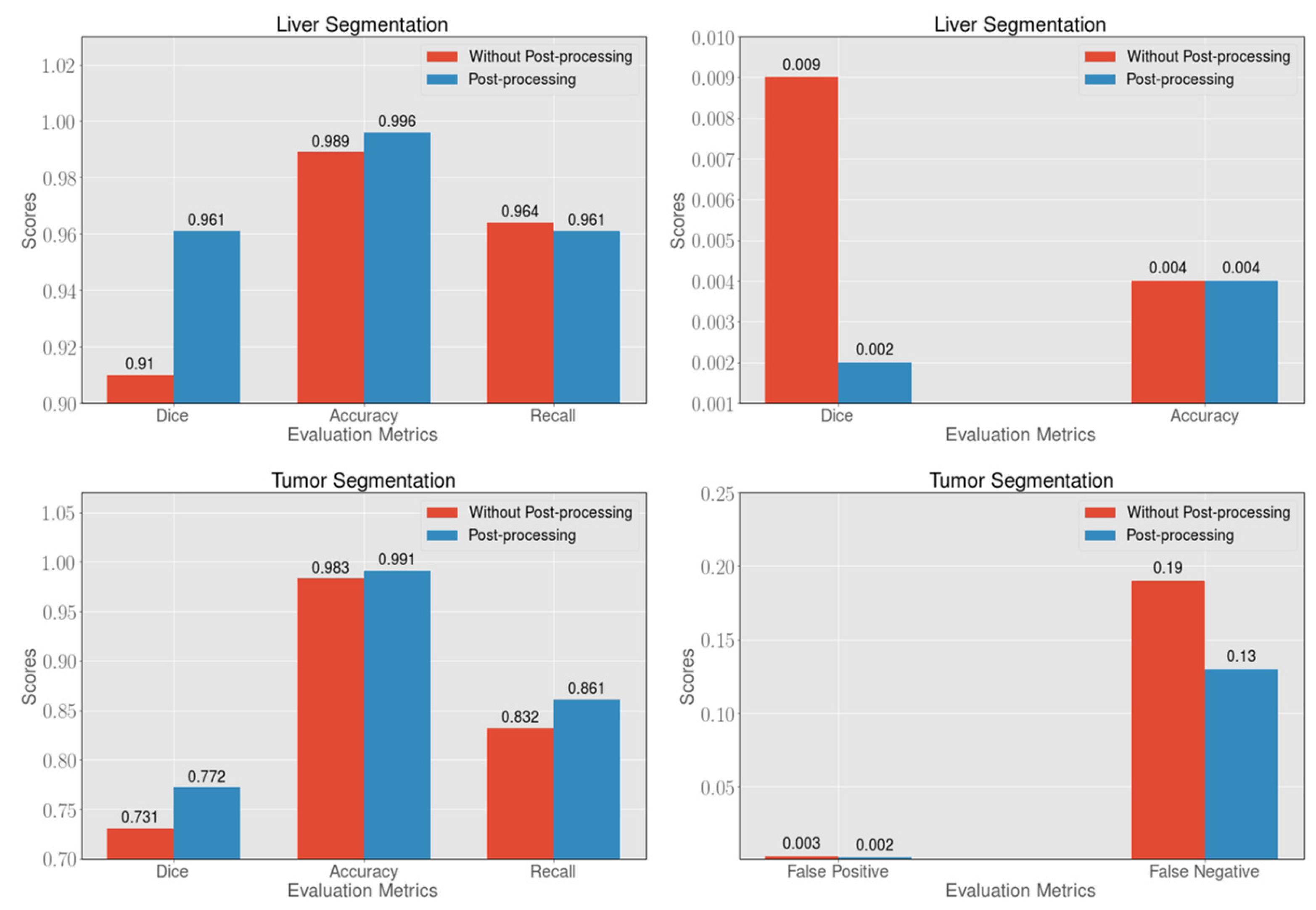
3.5. Image Post-Processing
4. Experiments and Results
4.1. Experimental Environment
4.2. Ablation Study on the LiTS Dataset
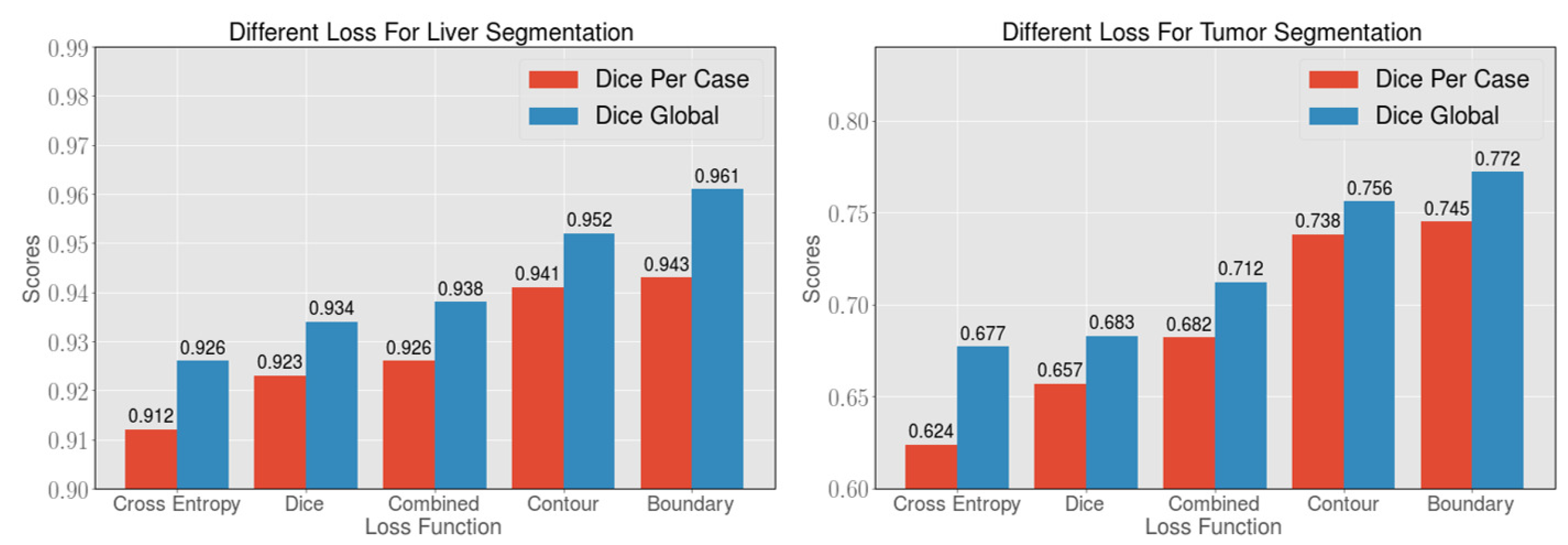
4.3. Loss Analysis on the LiTS Dataset
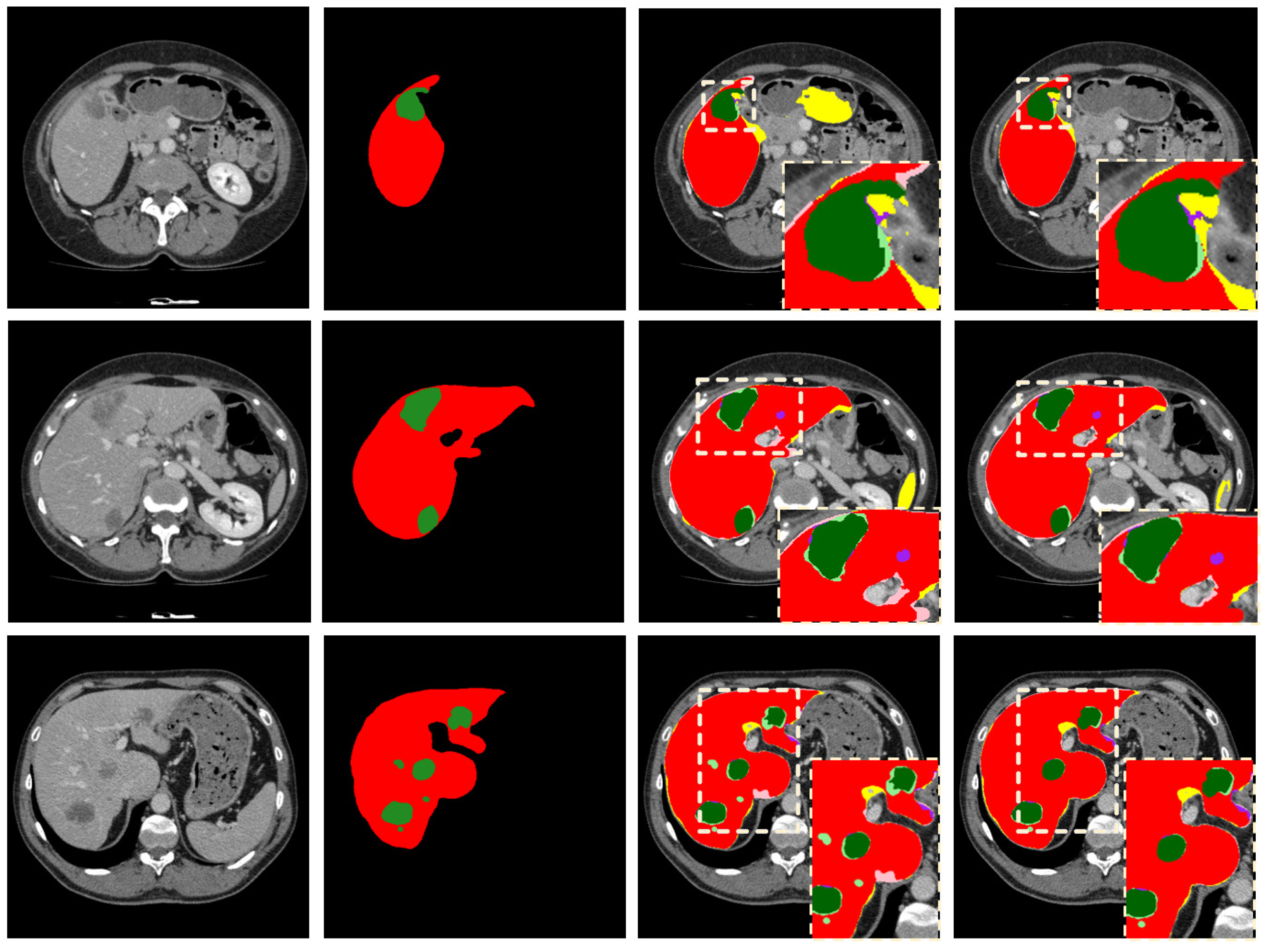
4.4. Methods Analysis on the 3DIRCADb Dataset
4.5. Methods Analysis on the LiTS Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Soler, L.; Delingette, H.; Malandain, G.; Montagnat, J.; Ayache, N.; Koehl, E.; Dourthe, O.; Malassagne, B.; Smith, M.; Mutter, D.; et al. Fully automatic anatomical, pathological, and functional segmentation from CT scans for hepatic surgery. Comput. Aided Surg. 2001, 6, 131–142. [Google Scholar] [CrossRef] [PubMed]
- Wong, D.; Liu, J.; Yin, F.; Tian, Q.; Xiong, W.; Zhou, J.; Qi, Y.; Han, T.; Venkatesh, S.; Wang, S.-c. A semi-automated method for liver tumor segmentation based on 2D region growing with knowledge-based constraints. In MICCAI Workshop; New York, NY, USA, 2008; Volume 41, p. 159. Available online: https://www.researchgate.net/profile/Sudhakar_Venkatesh/publication/28359603_A_semi-automated_method_for_liver_tumor_segmentation_based_on_2D_region_growing_with/links/02bfe50d078e31a511000000.pdf (accessed on 1 April 2021).
- Vorontsov, E.; Abi-Jaoudeh, N.; Kadoury, S. Metastatic liver tumor segmentation using texture-based omni-directional deformable surface models. In Abdominal Imaging. Computational and Clinical Applications; Springer: Cham, Switzerland, 2014; pp. 74–83. [Google Scholar]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.M.; Larochelle, H. Brain tumor segmentation with deep neural networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Dou, Q.; Chen, H.; Fu, C.W.; Qi, X.; Belavỳ, D.L.; Armbrecht, G.; Felsenberg, D.; Zheng, G.; Heng, P.A. 3D multi-scale FCN with random modality voxel dropout learning for intervertebral disc localization and segmentation from multi-modality MR images. Med. Image Anal. 2018, 45, 41–54. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Christ, P.; Ettlinger, F.; Grün, F.; Elshaer, M.; Lipková, J.; Schlecht, S.; Ahmaddy, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; et al. Automatic Liver and Tumor Segmentation of CT and MRI Volumes using Cascaded Fully Convolutional Neural Networks. arXiv 2017, arXiv:abs/1702.05970. [Google Scholar]
- Ben-Cohen, A.; Diamant, I.; Klang, E.; Amitai, M.; Greenspan, H. Fully Convolutional Network for Liver Segmentation and Lesions Detection; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhu, Q.; Du, B.; Wu, J.; Yan, P. A Deep Learning Health Data Analysis Approach: Automatic 3D Prostate MR Segmentation with Densely-Connected Volumetric ConvNets. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar]
- Dou, Q.; Chen, H.; Jin, Y.; Yu, L.; Qin, J.; Heng, P.A. 3D deeply supervised network for automatic liver segmentation from CT volumes. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2016; pp. 149–157. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2016; pp. 424–432. [Google Scholar]
- Han, X. Automatic liver lesion segmentation using a deep convolutional neural network method. arXiv 2017, arXiv:1704.07239. [Google Scholar]
- Zhu, Q.; Du, B.; Turkbey, B.; Choyke, P.; Yan, P. Exploiting interslice correlation for MRI prostate image segmentation, from recursive neural networks aspect. Complexity 2018, 2018, 4185279. [Google Scholar] [CrossRef] [Green Version]
- Chlebus, G.; Meine, H.; Moltz, J.H.; Schenk, A. Neural network-based automatic liver tumor segmentation with random forest-based candidate filtering. arXiv 2017, arXiv:1706.00842. [Google Scholar]
- Chlebus, G.; Schenk, A.; Moltz, J.H.; van Ginneken, B.; Hahn, H.K.; Meine, H. Automatic liver tumor segmentation in CT with fully convolutional neural networks and object-based postprocessing. Sci. Rep. 2018, 8, 15497. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Chen, X.; Williams, B.M.; Vallabhaneni, S.R.; Czanner, G.; Williams, R.; Zheng, Y. Learning active contour models for medical image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11632–11640. [Google Scholar]
- Woźniak, M.; Połap, D. Bio-inspired methods modeled for respiratory disease detection from medical images. Swarm Evol. Comput. 2018, 41, 69–96. [Google Scholar] [CrossRef]
- Whitcomb, E.; Choi, W.T.; Jerome, K.; Cook, L.; Landis, C.; Ahn, J.; Te, H.; Esfeh, J.; Hanouneh, I.; Rayhill, S.; et al. Biopsy Specimens From Allograft Liver Contain Histologic Features of Hepatitis C Virus Infection After Virus Eradication. Clin. Gastroenterol. Hepatol. 2017, 15, 1279–1285. [Google Scholar] [CrossRef]
- Ferlay, J.; Shin, H.; Bray, F.; Forman, D.; Mathers, C.; Parkin, D. Estimates of worldwide burden of cancer in 2008: GLOBOCAN 2008. Int. J. Cancer 2010, 127, 2893–2917. [Google Scholar] [CrossRef]
- Bi, L.; Kim, J.; Kumar, A.; Feng, D. Automatic Liver Lesion Detection using Cascaded Deep Residual Networks. arXiv 2017, arXiv:abs/1704.02703. [Google Scholar]
- Almotairi, S.; Kareem, G.; Aouf, M.; Almutairi, B.; Salem, M. Liver Tumor Segmentation in CT Scans Using Modified SegNet. Sensors 2020, 20, 1516. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Le, T.N.; Huynh, H.T. Liver tumor segmentation from MR images using 3D fast marching algorithm and single hidden layer feedforward neural network. BioMed Res. Int. 2016, 2016, 3219068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuo, C.L.; Cheng, S.C.; Lin, C.L.; Hsiao, K.F.; Lee, S.H. Texture-based treatment prediction by automatic liver tumor segmentation on computed tomography. In Proceedings of the 2017 International Conference on Computer, Information and Telecommunication Systems (CITS), Dalian, China, 21–23 July 2017; pp. 128–132. [Google Scholar]
- Rundo, L.; Beer, L.; Ursprung, S.; Martín-González, P.; Markowetz, F.; Brenton, J.; Crispin-Ortuzar, M.; Sala, E.; Woitek, R. Tissue-specific and interpretable sub-segmentation of whole tumour burden on CT images by unsupervised fuzzy clustering. Comput. Biol. Med. 2020, 120, 103751. [Google Scholar] [CrossRef]
- Hoogi, A.; Beaulieu, C.F.; Cunha, G.M.; Heba, E.; Sirlin, C.B.; Napel, S.; Rubin, D.L. Adaptive local window for level set segmentation of CT and MRI liver lesions. Med. Image Anal. 2017, 37, 46–55. [Google Scholar] [CrossRef] [Green Version]
- Jimenez-Carretero, D.; Fernandez-De-Manuel, L.; Pascau, J.; Tellado, J.M.; Ramon, E.; Desco, M.; Santos, A.; Ledesma-Carbayo, M.J. Optimal multiresolution 3D level-set method for liver segmentation incorporating local curvature constraints. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 3419–3422. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.J.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient Multi-Scale 3D CNN with Fully Connected CRF for Accurate Brain Lesion Segmentation. Med. Image Anal. 2016, 36, 61. [Google Scholar] [CrossRef]
- He, K.; Georgia, G.; Piotr, D.; Ross, G. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; Lecun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2016; pp. 415–423. [Google Scholar]
- Zormpas-Petridis, K.; Failmezger, H.; Raza, S.; Roxanis, I.; Jamin, Y.; Yuan, Y. Superpixel-Based Conditional Random Fields (SuperCRF): Incorporating Global and Local Context for Enhanced Deep Learning in Melanoma Histopathology. Front. Oncol. 2019, 9, 1045. [Google Scholar] [CrossRef]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P. Conditional Random Fields as Recurrent Neural Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Lapa, P.; Castelli, M.; Gonçalves, I.; Sala, E.; Rundo, L. A Hybrid End-to-End Approach Integrating Conditional Random Fields into CNNs for Prostate Cancer Detection on MRI. Appl. Sci. 2020, 10, 338. [Google Scholar] [CrossRef] [Green Version]
- Singh, V.K.; Abdel-Nasser, M.; Pandey, N.; Puig, D. LungINFseg: Segmenting COVID-19 Infected Regions in Lung CT Images Based on a Receptive-Field-Aware Deep Learning Framework. Diagnostics 2021, 11, 158. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, R.; Yan, P. Feature fusion encoder decoder network for automatic liver lesion segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 430–433. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Yun, J.; Park, J.; Yu, D.; Yi, J.; Lee, M.; Park, H.J.; Lee, J.; Seo, J.; Kim, N. Improvement of fully automated airway segmentation on volumetric computed tomographic images using a 2.5 dimensional convolutional neural net. Med. Image Anal. 2019, 51, 13–20. [Google Scholar] [CrossRef]
- Zhou, Y.; Huang, W.; Dong, P.; Xia, Y.; Wang, S. D-UNet: A dimension-fusion U shape network for chronic stroke lesion segmentation. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Chen, J.; Ng, M.; Huang, R.; Li, Y.; Li, C.; Yang, X.; Martel, A. Loss odyssey in medical image segmentation. Med. Image Anal. 2021, 71, 102035. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Salehi, S.; Erdoğmuş, D.; Gholipour, A. Tversky Loss Function for Image Segmentation Using 3D Fully Convolutional Deep Networks. arXiv 2017, arXiv:abs/1706.05721. [Google Scholar]
- Karimi, D.; Salcudean, S.E. Reducing the Hausdorff Distance in Medical Image Segmentation with Convolutional Neural Networks. IEEE Trans. Med Imaging 2020, 39, 499–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heller, N.; Isensee, F.; Maier-Hein, K.; Hou, X.; Xie, C.; Li, F.; Nan, Y.; Mu, G.; Lin, Z.; Han, M.; et al. The state of the art in kidney and kidney tumor segmentation in contrast-enhanced CT imaging: Results of the KiTS19 Challenge. Med. Image Anal. 2021, 67, 101821. [Google Scholar] [CrossRef] [PubMed]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Li, C.; Wang, X.; Eberl, S.; Fulham, M.; Yin, Y.; Chen, J.; Feng, D.D. A likelihood and local constraint level set model for liver tumor segmentation from CT volumes. IEEE Trans. Biomed. Eng. 2013, 60, 2967–2977. [Google Scholar] [PubMed]
- Li, G.; Chen, X.; Shi, F.; Zhu, W.; Tian, J.; Xiang, D. Automatic liver segmentation based on shape constraints and deformable graph cut in CT images. IEEE Trans. Image Process. 2015, 24, 5315–5329. [Google Scholar] [CrossRef]
- Yuan, Y. Hierarchical convolutional-deconvolutional neural networks for automatic liver and tumor segmentation. arXiv 2017, arXiv:1710.04540. [Google Scholar]
- Liu, S.; Xu, D.; Zhou, S.; Mertelmeier, T.; Wicklein, J.; Jerebko, A.K.; Grbic, S.; Pauly, O.; Cai, T.; Comaniciu, D. 3D Anisotropic Hybrid Network: Transferring Convolutional Features from 2D Images to 3D Anisotropic Volumes. arXiv 2018, arXiv:abs/1711.08580. [Google Scholar]
- Chen, S.; Ma, K.; Zheng, Y. Med3D: Transfer Learning for 3D Medical Image Analysis. arXiv 2019, arXiv:abs/1904.00625. [Google Scholar]
- Alalwan, N.; Abozeid, A.; ElHabshy, A.A.; Alzahrani, A. Efficient 3D Deep Learning Model for Medical Image Semantic Segmentation. Alex. Eng. J. 2020, 60, 1231–1239. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, R.; Chen, Y.; Wang, Y. The application of panoramic segmentation network to medical image segmentation. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; Volume 1, pp. 640–645. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Loss | Tumor | Liver | ||
|---|---|---|---|---|
| Dice Per Case | IoU | Dice Per Case | IoU | |
| 2D FCN + Combined loss | 65.2 | 48.4 | 91.3 | 84.0 |
| 2D FCN + Contour loss | 72.4 | 56.8 | 93.2 | 87.3 |
| 2D FCN + Boundary loss | 73.6 | 58.3 | 93.9 | 88.5 |
| 2.5D FCN + Combined loss | 68.2 | 51.8 | 92.6 | 86.3 |
| 2.5D FCN + Contour loss | 73.8 | 58.5 | 94.1 | 88.9 |
| 2.5D FCN + Boundary loss | ||||
| Loss | Tumor | Liver | ||
|---|---|---|---|---|
| Dice Per Case | Dice Global | Dice Per Case | Dice Global | |
| Cross-entropy loss | 62.4 | 67.7 | 91.2 | 92.6 |
| Dice loss | 65.7 | 68.3 | 92.3 | 93.4 |
| Combined loss | 68.2 | 71.2 | 92.6 | 93.8 |
| Contour loss | 73.8 | 75.6 | 94.1 | 95.2 |
| Boundary loss | ||||
| Model | VOE | RVD | ASD | RSMS | Dice |
|---|---|---|---|---|---|
| 2D UNet [16] | 14.2 ± 5.7 | −0.05 ± 0.1 | 4.3 ± 3.3 | 8.3 ± 7.5 | 0.923 ± 0.03 |
| 2D FCN [9] | 10.7 | −1.4 | 1.5 | 24.0 | 0.943 |
| Han et al. [14] | 11.6 ± 4.1 | −0.03 ± 0.06 | 3.9 ± 3.9 | 8.1 ± 9.6 | 0.938 ± 0.02 |
| Li et al. [53] | −11.2 | 28.2 - | |||
| Li et al. [52] | - | - | - | - | 0.945 |
| our method | 8.5 ± 6.6 | 1.6 ± 2.0 |
| Model | VOE | RVD | ASD | RSMS | Dice |
|---|---|---|---|---|---|
| 2D UNet [16] | 62.5 ± 22.3 | 0.38 ± 1.95 | 11.1 ± 12.0 | 16.7 ± 13.8 | 0.51 ± 0.25 |
| 2D FCN [9] | - | - | - | - | 0.56 ± 0.26 |
| Han et al. [14] | 56.4 ± 13.6 | −0.41 ± 0.21 | 6.3 ± 3.7 | 0.60 ± 0.12 | |
| Li et al. [18] | −0.33 ± 0.10 | 5.29 ± 6.1 | 11.1 ± 29.1 | 0.65 ± 0.02 | |
| our method | 57.5 ± 13.8 | 15.9 ± 12.3 |
| Loss | Tumor | Liver | ||
|---|---|---|---|---|
| Dice Per Case | Dice Global | Dice Per Case | Dice Global | |
| 2D UNet [16] | 65.0 | - | - | - |
| 2D FCN [9] | 67.0 | - | - | - |
| 3D V-Net [43] | - | - | - | 93.9 |
| Chlebus et al. [17] | 0.680 | 0.796 | - | - |
| Yuan et al. [54] | 65.7 | 82.0 | ||
| 3D H-DenseUNet [18] | 72.2 | 82.4 | 96.1 | 96.5 |
| 3D AH-Net [55] | 63.4 | - | - | |
| Med3D [56] | - | - | - | 94.6 |
| 3D-DenseUNet [57] | 69.6 | 80.7 | 96.2 | 96.7 |
| Wang et al. [58] | - | 70.2 | - | 95.1 |
| our method | 77.2 | 94.3 | 96.1 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Li, X.; Wang, B.; Wang, L. Boundary Loss-Based 2.5D Fully Convolutional Neural Networks Approach for Segmentation: A Case Study of the Liver and Tumor on Computed Tomography. Algorithms 2021, 14, 144. https://doi.org/10.3390/a14050144
Han Y, Li X, Wang B, Wang L. Boundary Loss-Based 2.5D Fully Convolutional Neural Networks Approach for Segmentation: A Case Study of the Liver and Tumor on Computed Tomography. Algorithms. 2021; 14(5):144. https://doi.org/10.3390/a14050144
Chicago/Turabian StyleHan, Yuexing, Xiaolong Li, Bing Wang, and Lu Wang. 2021. "Boundary Loss-Based 2.5D Fully Convolutional Neural Networks Approach for Segmentation: A Case Study of the Liver and Tumor on Computed Tomography" Algorithms 14, no. 5: 144. https://doi.org/10.3390/a14050144
APA StyleHan, Y., Li, X., Wang, B., & Wang, L. (2021). Boundary Loss-Based 2.5D Fully Convolutional Neural Networks Approach for Segmentation: A Case Study of the Liver and Tumor on Computed Tomography. Algorithms, 14(5), 144. https://doi.org/10.3390/a14050144