1. Introduction
Microwave imaging technology is a potential imaging method that aims to provide inexpensive, portable and wearable imaging devices. It was originally proposed for breast cancer detection [
1] and was later extended for brain stroke or brain injuries [
2]. The basic principle is the difference in the dielectric values (relative permittivity and conductivity) in healthy and malignant tissues [
3,
4]. Several wearable antennas are used as sensors that transmit ultra-wideband (UWB) signals to the imaging domain, and the reflected and transmitted data are stored. An imaging algorithm then uses these data to reconstruct images of the targeted object/tissue.
Microwave head imaging is a biomedical imaging application, and a number of microwave head imaging systems have been proposed targeting brain tumours [
5], stroke [
6] and recently neurodegenerative disease detection [
7]. Microwave imaging systems are composed of two important components: the hardware and software. The hardware components include the sensors, the patient interface, the transceiver and switching system, and a PC. The software components include data preprocessing and an imaging algorithm. The reliability of these systems is substantially dependent on imaging algorithms [
8].
In terms of imaging algorithms, there are typically two types, namely tomography and radar-based. Microwave tomography finds the location, shape or size of the malignant tissue by reconstructing the dielectric profile using electromagnetic properties such as permittivity and conductivity [
9]. It is a well-known quantitative method and provides accurate reconstruction of the dielectric properties. The scattered field data are processed using a suitable inversion method to obtain the dielectric profile. The accuracy and rate of convergence is improved by using nonlinear inversion techniques [
10,
11]. However, it is computationally complex and therefore cannot be used for real-time applications. On the other hand, radar-based imaging aims to localise strong reflected scatters in the area of interest. There are two types of radar-based beamformers: data-independent [
12] and data-adaptive beamformers [
13]. In data-independent beamforming algorithms, the coherent addition of signals is performed on the basis of an assumed propagation model. Data-adaptive algorithms, on the other hand, use scattered signals to estimate the propagation model and to then apply compensation factors based on the estimated channel model. Data-independent beamformers take less time in image reconstruction, while data-adaptive beamformers have excessive computational complexity but produce accurate results [
14].
Radar-based beamforming techniques in microwave imaging aim to reconstruct a reflective map of the imaged tissues, where high contrast regions (malignant tissue) are prominently detected. The basic image reconstruction method in radar-based microwave imaging is the delay and sum (DAS) beamformer [
15]. This technique thoroughly delays the collected time domain signals and sums it up to reconstruct an image. Several improvements have been made to the DAS beamformer, including delay multiply and sum (DMAS) [
16], improved delay and sum (IDAS) [
15], and channel-ranked delay and sum (CR-DAS) [
17]. These improvements to the DAS have primarily focused on coherence between reflected or transmitted radar signals or on tackling path dependency. A recent study compared these radar-based algorithms using clinical data for breast cancer detection. The results demonstrated that DMAS produces more accurate and high-resolution results [
18]. It reduces clutter and background noise that leads to more accurate localisation of the tumour in resulting images [
19].
The computational complexity of DAS is O(M). The DMAS gains better resolution and contrast at the cost of increasing the computational complexity to O(M
) [
16]. The advantages of using DMAS over DAS has been proven in [
20,
21]. The iterative variant of DMAS was proposed in [
22], where the background clutter was removed in the resulting images. Due to its advantages, DMAS is used in many research works instead of DAS [
22]. The downside of using DMAS in comparison to DAS is the significant increase in computational load [
23].
Hadoop and MapReduce are commonly used in commerce, social media and video streaming. However, they are not widely integrated into the healthcare sector. For example, a pipeline for functional magnetic resonance imaging (fMRI) was proposed using the PySpark [
24]. In the proposed pipeline, the template method is used to extricate brain networks from fMRI data. The pipeline is four times faster due to in-memory data processing in parallel compared to sequential execution. Similarly, Spark was used for genomics sequencing to reduce the processing time [
25]. Spark cloud computing platform was used for parallel implementation of the MAX-MIN Ant System algorithm [
26]. Experimental results showed significant improvement in speed for a large number of ants. Similarly, the most commonly used K-means clustering algorithm was improved in terms of scalability, accuracy and effectiveness by using a Tabu Search Strategy and Spark framework [
27]. Computational experiments indicated that the proposed parallel algorithm yields better results in terms of quality, stability and efficiency than the K-means algorithm of SparkMLLib.
Field programmable gates arrays [
28] and graphics processing unit-based parallel approaches are mostly used to decrease computation time [
29]. A GPU-based implementation of CMI algorithms was presented for breast cancer detection [
30]. Although these approaches significantly increase processing speed, they are non-scalable and costly. An alternative approach is to use high-performance computing (HPC) or a Cloud platform such as Google Cloud or Amazon Web Services (AWS) to improve the efficiency of imaging modalities. HPC has been used for quantitative imaging such as tomography [
31,
32], where the data obtained for human head imaging was wirelessly transferred to a remote HPC for postprocessing. Big data frameworks such as Hadoop and Spark have recently gained attention to make the most of these platforms. Therefore, these frameworks need to be considered as accelerators for medical imaging algorithms [
33].
In our previous work [
34], a parallel microwave image reconstruction algorithm (PMIR) was proposed based on the Spark framework. The proposed algorithm was tested on a high-performance computing (HPC) cluster and Google Cloud platform. The results demonstrated that the parallel is about 128 % faster than its sequential version. The objective of this work is to investigate the use of big data frameworks, especially Spark, to improve the efficiency of the DMAS algorithm. The parallel version of the DMAS algorithm is compared with the sequential version as well as Python built-in multiprocessing library. The increase in processing speed is evaluated on both a standalone PC and on HPC.
The main contributions of this paper are as follows.
We examine the potential gains in performance and scalability of DMAS using big data framework.
We use parallel implementation of the DMAS algorithm using Pyspark and Python multiprocessing library.
We evaluate the sequential and parallel versions of DMAS on a standalone PC and on an HPC cluster for efficiency.
The proposed parallel version of the DMAS algorithm is implemented in Python programming language and deployed using PySpark API for Apache Spark. The algorithm is deployed on both the standalone and cluster modes. The computational results demonstrate that the parallel DMAS fully inherits the parallelism of the DMAS algorithm, resulting in an efficient reconstruction of images.
2. Principle of Radar-Based Algorithms
The mechanism of the microwave imaging is based on the difference in the dielectric property (relative permittivity and conductivity) for healthy and malignant tissues [
35]. The dielectric property is an inherent characteristic of the tissue that characterises the transmission, absorption and reflection of electromagnetic energy. An array of antennas is used to penetrate the targeted tissue, and the reflected and transmitted signals are stored. These signals are used as input to imaging algorithms. The most common microwave imaging algorithm used in medicine is CMI. These methods are usually referred to as radar-based methods. It uses the reflected or transmitted signals from the imaged object to reconstruct the resulting image using different beamformers [
36]. These beamformers calculate the energy from a focal point and integrate the information to reconstruct an energy map.
The basic principle of a radar-based algorithm is to thoroughly delay and sum the signals to reconstruct the image. Each antenna in the microwave imaging system transmits a signal to each focal point in the imaging domain, and the reflected and transmitted signals are stored. The time delay is calculated for each measured signal from the antenna to the focal point and back to the transmitting antenna (monostatic mode) or and receiving antenna (multistatic mode). In time delay calculation, the propagation speed of the signals depends on the relative permittivity of the medium. The signals are thoroughly delayed and summed to calculate energy. When the energy distribution of the whole imaging area for each antenna is obtained, a 2D image is formed.
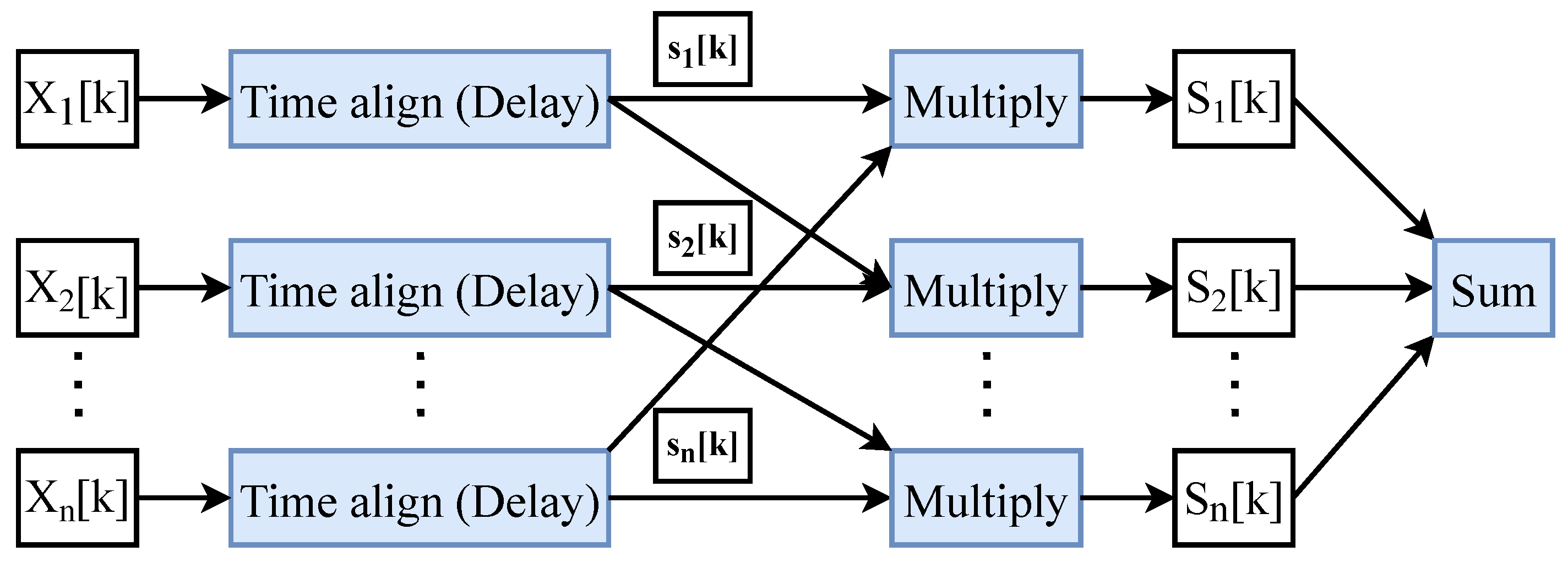
DMAS is an extended version of the DAS algorithm. It produces more accurate and high-resolution results. Similar to DAS, the reflected or transmitted signals are first aligned and then summed to reconstruct the image. The signal energy corresponding to each pixel in the resulting images is equal to the square of the sum of the product of the signal. DMAS increases the sample size by multiplying the signals in pairs before summation, as shown in
Figure 1, significantly increasing its computation time.
The DMAS algorithm performs a correlation process for each focal point to obtain data with a high degree of similarity. The improvement in the accuracy of the resulting images is due to the substantial increase in the sample size. The observations are shifted according to focal points in the imaging domain using delay values calculated as follows:
where
is the delay factor for a focal point
for the signal transmitted by an antenna located at
and receiving antenna located at
,
denotes the speed of light in space and
is the relative permittivity of the human head.
Assume that there are M observations (
;
i = 1..
M,
k = 1..
L), each with L samples, shifted using (
1). Then, the output of DAS is as follows:
where
is the
ith delayed signal
On the other hand, the output of DMAS is as follows:
where
M is the total number of received signals and
and
are delayed signals according to the positions of the transmitter and receiver antennas.
DAS requires M summations and one multiplication for M observations to estimate the desired value. On the other hand, the DMAS method requires multiplications and summations, increasing the computations and requiring M times longer to reconstruct an image.
A faster version of DMAS (FDMAS) was proposed in [
20], where energy is calculated as follows:
Although the outputs of DMAS and FDMAS are mathematically equal, the FDMAS is best suited for parallel implementation due to its ability to update the results without redundant calculation.
3. Overview of Spark MapReduce
MapReduce was introduced by Google in 2004. MapReduce aimed to process big data by leveraging the capacity of commodity hardware in a distributed manner [
37]. The key benefit of the MapReduce programming model is that it does not require users or developers to be experts in parallel or distributed systems in order to exploit its capabilities. Furthermore, MapReduce is highly scalable and can process data up to terabytes.
Apache Spark is a big data framework with built-in modules for streaming, structured query language, machine learning and graph processing. It is 100 times faster than Hadoop, another big data framework that uses the MapReduce Programming paradigm [
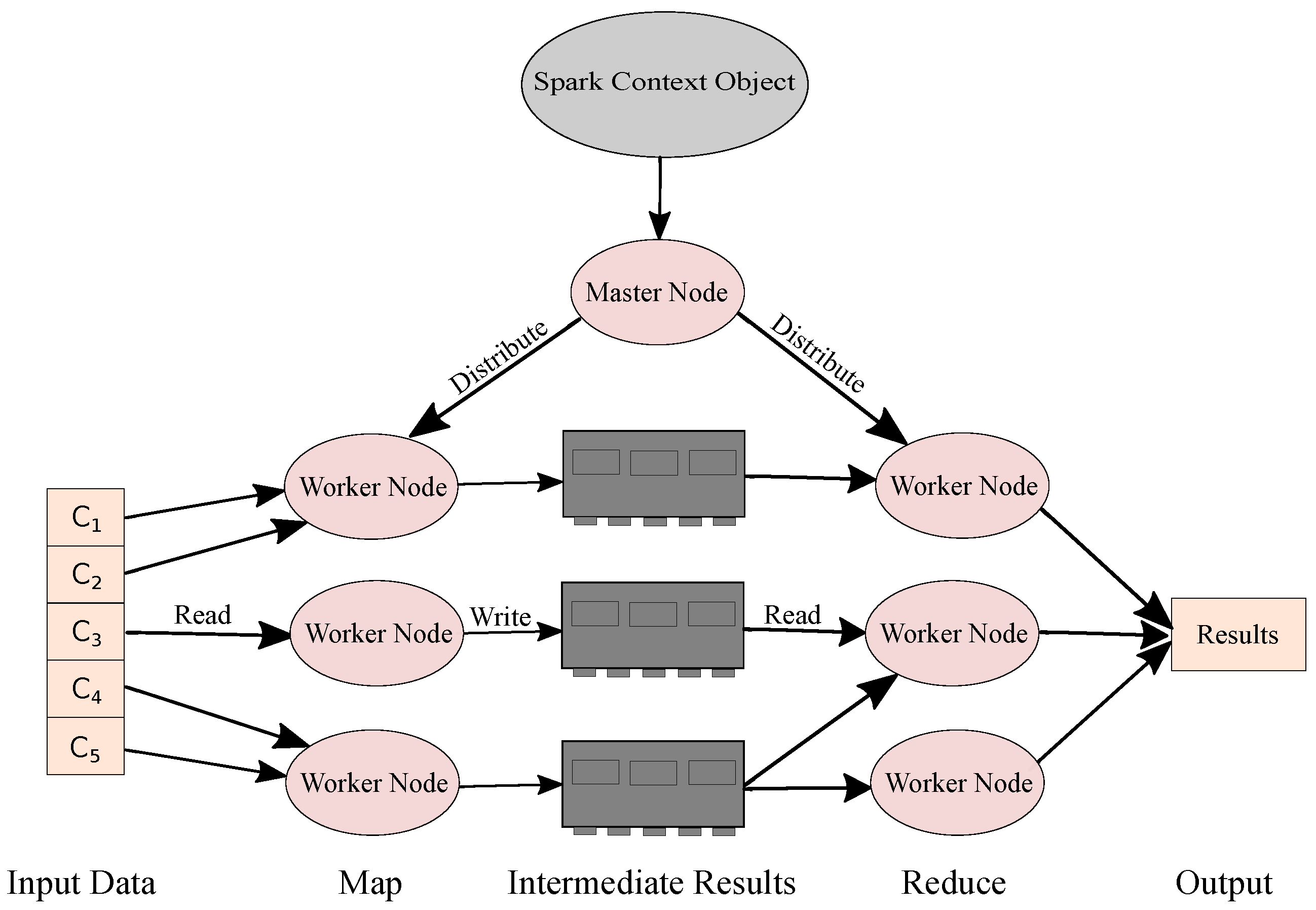
38]. Apache Spark, compared to Hadoop, achieved higher performance due to in-memory computations by introducing the resilient distributed datasets (RDDs). The RDD are read-only sets of data, split into logical partitions and spread over different machines in a cluster, being operated in parallel. These logical partitions of data are the main drivers for parallelism. Spark allows for two main operations, as shown in
Figure 2, to operate on these partitions: transformations (map), which create new RDDs and create dependency among them, and actions (reduce), which return intermediate results after any operation performed on the data.
Each RDD contains information about dependency with other RDDs, computation needed, accessible node and metadata regarding the RDD scheme [
39]. Apache Spark is based on a master–slave architecture. It divides a cluster into a master and several worker nodes. The master node deals with resource allocation, task scheduling and error management. The worker nodes are responsible for map and reduce operations in parallel.
4. Parallel Design and Implementation of DMAS Algorithm
In this paper, PySpark is used for the parallel implementation of DMAS. PySpark is an interface that gives access to the Spark framework using the Python programming language. It employs the RDDs to increase the execution speed by performing in-memory computations.
The iterative procedure of the FDMAS makes it suitable to be implemented using a big data framework such as Spark. The parallelism and dependency among different processes in the DMAS algorithm was first identified. There are multiple MapReduce operations for the parallel scheme of the DMAS algorithm. The entire input data are uploaded to the shared memory accessible to the master and all worker nodes. The master node converts these data into RDDs, and each map and reduce operation executes the required operation on the data block. These MapReduce operations are associated with one computing unit. When the entire data set is split and executed simultaneously, the execution time is expected to reduce.
The two most computationally intensive parts of the DMAS algorithm can be parallelised: delay and pixel value calculation. Since the delay values in the DMAS algorithm need to be calculated once, its parallel executions do not affect the overall performance [
34]. The most computationally and memory-intensive part is the multiplication of signals in pairs and the summation of all antennas for each focal point in the resulting images. In this part, each process is independent and can be executed in parallel by caching intermediate results in memory across iterative computations.
4.1. Parallel Design of DMAS Using Spark
The multiplication and summation steps of the DMAS are well suited for map and reduce operations. The steps of DMAS based on the MapReduce paradigm and Spark framework are as follows:
Data Parallelism: Retrieve and store the sensor data. Let the number of antennas used for data collection be M; an array of the same size in monostatic mode or size in multistatic mode needs to be created. Use the Spark context object to parallelise the data and to convert it to RDDs. Distribute these RDDs to the worker nodes. This also includes broadcasting an empty matrix to store pixel values to each worker node. These RDDs are input to the next step.
Map Operations: Since pixel values are calculated using the same equation (Equation (
4) in this work), they can be calculated in parallel. The Map operation is used to multiply the signals in pairs and to sum it up to calculate pixel values.
Reduce Operations: Integrate the subsets of pixel values using the “reduce” operation.
Iterate: Update the empty matrix of pixel values according to the values obtained from the “reduce” operation. Iterate the map and reduce tasks until all signals are processed.
4.2. PDMAS Implementation Using Spark
The proposed PDMAS is implemented using PySpark API for Spark. Algorithm 1 provides the pseudo-code for parallel implementation of the DMAS algorithm using Spark. The master node reads the input data and antennas location in Cartesian coordinates. These antenna location are used to estimate the signal propagation time using Equation (
1). The estimated delay values along with the input data are converted into RDDs and distributed to all workers nodes to accelerate each calculation. Similarly, an empty matrix is created to store the subsets of pixel values and is broadcasted. This matrix is shared by different worker nodes. The worker nodes calculate the subsets of pixel values using the map operation from the MapReduce programming model. These subsets of pixel values being computed in parallel are integrated using the reduce operation and returned to the master node. Finally, the master node transforms the matrix of pixel values into an image using a simple Python function and and the results are stored.
| Algorithm 1 PDMAS algorithm using Spark. |
Input: RF Sensors Data
Output: Image Reconstruction
Master Node:- 1:
Read input data along with antenna locations - 2:
Estimate : signal propagation time for all focal points in the imaging domain using Equation ( 1) - 3:
Create a matrix for storing pixel values - 4:
Convert the input data and delay values into RDDs and broadcast it to each worker node Worker Node: - 5:
for subset of < range do - 6:
for subset of < range do - 7:
: Calculate the subset of pixel values in parallel using Map operation - 8:
end for - 9:
end for - 10:
Integrate to using Reduce operation - 11:
Return to master node Master Node - 12:
Convert into image and save.
|
4.3. DMAS Using Python Multiprocessing
The Pyspark version is compared with the Python built-in multiprocessing library [
40]. For this purpose, the SharedArray module [
41] was used to create a Numpy array to make it accessible to multiple processes at the same time. A SharedArray for input data was created on the master node. The process class of the multiprocessing library was used. The process was instantiated with two arguments: the matrix of input signal and a function for pixel value calculation using Equation (
4). Finally the processes were joined using the join function, and the resulting matrix was stored.
5. Experiments
The experiments were performed on data obtained for the detection of brain atrophy due to Alzheimer’s disease.
5.1. Imaging System Setup
A wearable and portable device in a hat-like shape proposed in our previous work [
42] was used. The device contains an array of six flexible antennas created using thin polyethylene terephthalate. The operating frequency of these antennas are 800 MHz to 2.5 GHz. The antennas were first created in CST studio suite [
43]. A vector network analyzer was used to transmit and receive the signals. The generated signals were sent to a PC for further processing. The proposed wearable device is radar-based and used planer monopole antennas due to its low cost.The use of only six antennas makes the device lightweight; however, it affects the spatial resolution of the reconstructed brain images.
The sensors were made using A8 silicon rubber with a relative permittivity of 2.99. An SMA was attached to the sensor using epoxy. The design of the sensor is based on a rectangular planar monopole antenna structure. The substrate of the antenna is made using a flexible textile, and the conductive part of the antenna is made using a 6 mm thick material. It operates from 1 to 4.2 GHz and exhibits a radiation pattern of 6 dB front-to-back ratio at 2.5 GHz. Further information about antenna can be found in [
44].
Furthermore, a flexible, low-cost switching system was developed that consists of SMA connectors and one-pole and one-throw (1P1T) switches. The sensors and switching systems were then combined into a wearable device. The total weight of the device (components include a hat, two switching circuits and six sensors) is 291.7 g. The insertion loss of the proposed system is −3.9 dB, which is slightly larger due to the flexibility of the device. Further information about the switching systems, VNA and a PC can be found in [
42].
5.2. Phantom Used
Phantoms are often used to validate the antennas and imaging algorithms as it avoids exposure towards a living human. To validate the results of the proposed parallel algorithm, Lamb brain phantom was used. These phantoms were used to mimic different stages of brain atrophy caused by Alzheimer’s disease.
5.3. Data Acquisition
According to the configuration of the imaging setup, an imaging algorithm needs to be used to reconstruct an image from measurements of the reflected or transmitted fields. The configuration of the imaging system can either be monostatic or multistatic, where one or more antennas are used as transmitters and receivers. In monostatic configuration, a single antenna serves as both transmitter and receiver. In multistatic configuration, each antenna transmits the microwave signal, and the scattered signals are captured by all other antennas. This procedure is repeated for all antennas until all signal samples are obtained. Although, the multistatic approach is more complex compared to the monostatic approach, it provides detailed information about the imaged area/object and hence improves the accuracy.
In this work, an array of six monopole directional antennas were placed around the phantom at equal distances. To achieve good penetration, the antennas were separated from the absorber using a 5 mm thick foam. The dielectric value of the foam is similar to that for air to ensure the integrity of antennas. The phantoms were penetrated in a way where one antenna transmitted the signal and where reflected and transmitted signals were captured by all other antennas. The experiments were repeated for each antenna to capture both the reflected signals (S) and transmitted signals (S). However, only the reflected signals are used for image reconstruction. The total number of 1001 frequency points were stored for each antenna. These points were organised as a matrix for each case.
Similarly, an empty skull was penetrated with the same configuration and the reflected data were stored. These data were used as a reference signal to remove strong reflections from the skin and skull.The matrix of signals was then converted to a time domain using Fourier transform. The resulting signals were used as input to the imaging algorithm for image reconstruction.
5.4. Experimental Setup
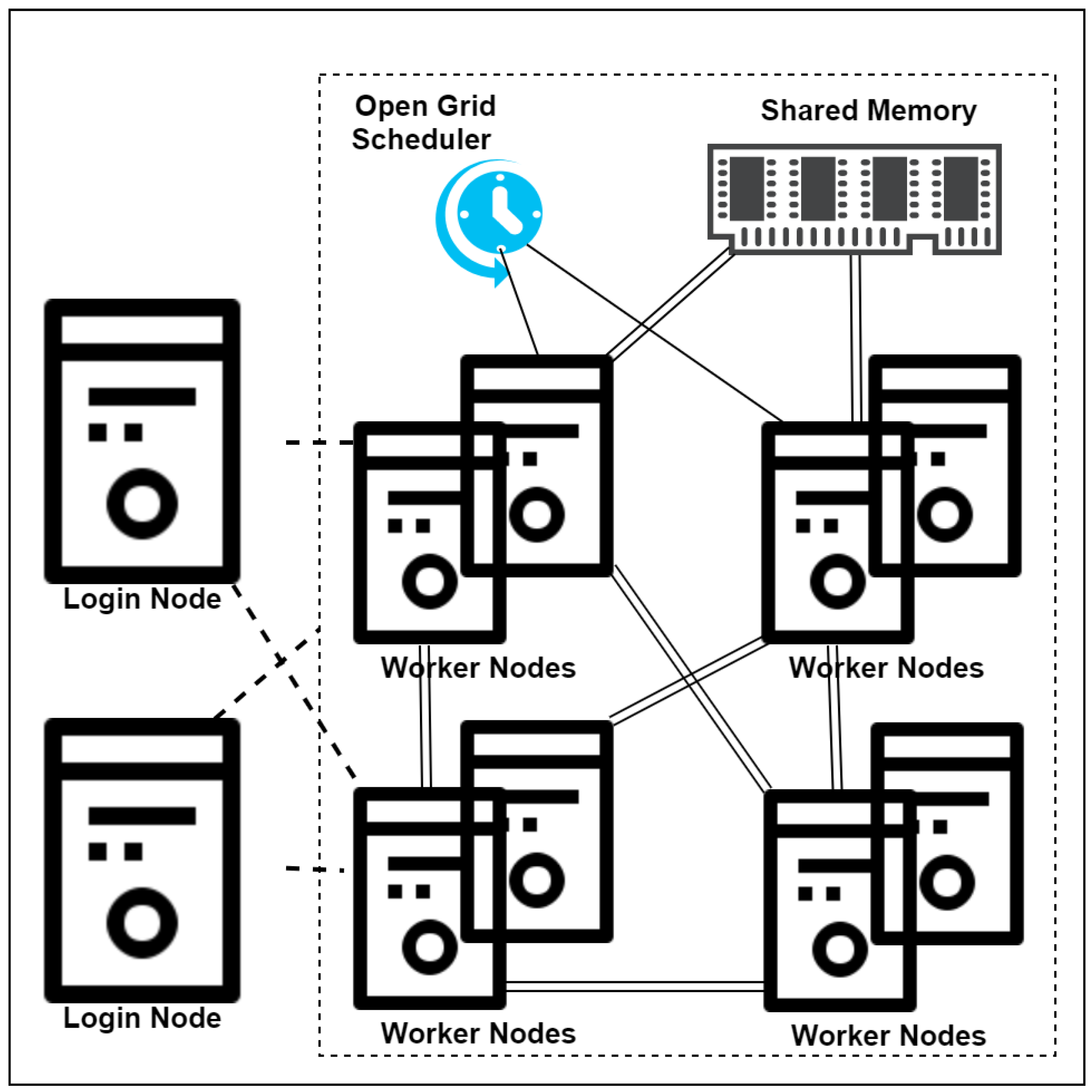
The experiments were performed on both a standalone PC and a high-performance computing cluster. For the cluster mode, Eddie (see
http://www.ecdf.ed.ac.uk, accessed on 22 February 2021), the University of Edinburgh high-performance computing cluster was used. It is the third iteration of the University’s compute cluster and consists of 7000 Intel Xeon cores. Each compute node has up to 3 TB of memory. It is suitable to increase the processing speed by running the task (algorithm) in parallel. It allows for breaking the task into several more easily addressable subtasks, each of which can be run on a separate CPU in parallel. It runs Open Grid scheduler and Scientific Linux 7. An overview of the Eddie architecture is shown in
Figure 3.
The login node allows users to either submit batch jobs or to start an interactive session, where the number of cores and memory per core can be specified. The compute node has local memory and is connected to shared memory called an Eddie distribute file system. Users can store the input data in the shared memory. All compute nodes are also interconnected with a 10 Gbps Ethernet network. It uses an Open Grid Scheduler for memory allocations and job scheduling.
Using the MapReduce programming model, the DMAS algorithm was designed and implemented using Pyspark API. A sequential version of DMAS was implemented in Python programming language. Similarly, a parallel version was implemented using Python multiprocessing library. The efficiency of all these approaches were tested on a standalone PC and Eddie. The configuration for both the standalone PC and the Eddie cluster can be found in
Table 1. After setting up the environment for PySpark and Python, PySpark was launched with a configuration with one master and multiple workers node. Each node has the same configuration, as shown in
Table 1.
For the performance evaluation on a standalone PC, all versions were run three times, and wall time was noted. Similarly, an interactive session on Eddie was started with four nodes, where one node acts as a master and the other three nodes act as workers. The master node reads and generates RDDs from the input data and antenna positions stored on the Eddie distributed file system. These RDDs are broadcasted to all worker nodes, along with an empty matrix to store pixel values. The worker nodes calculate subsets of pixel values based on the algorithm discussed in
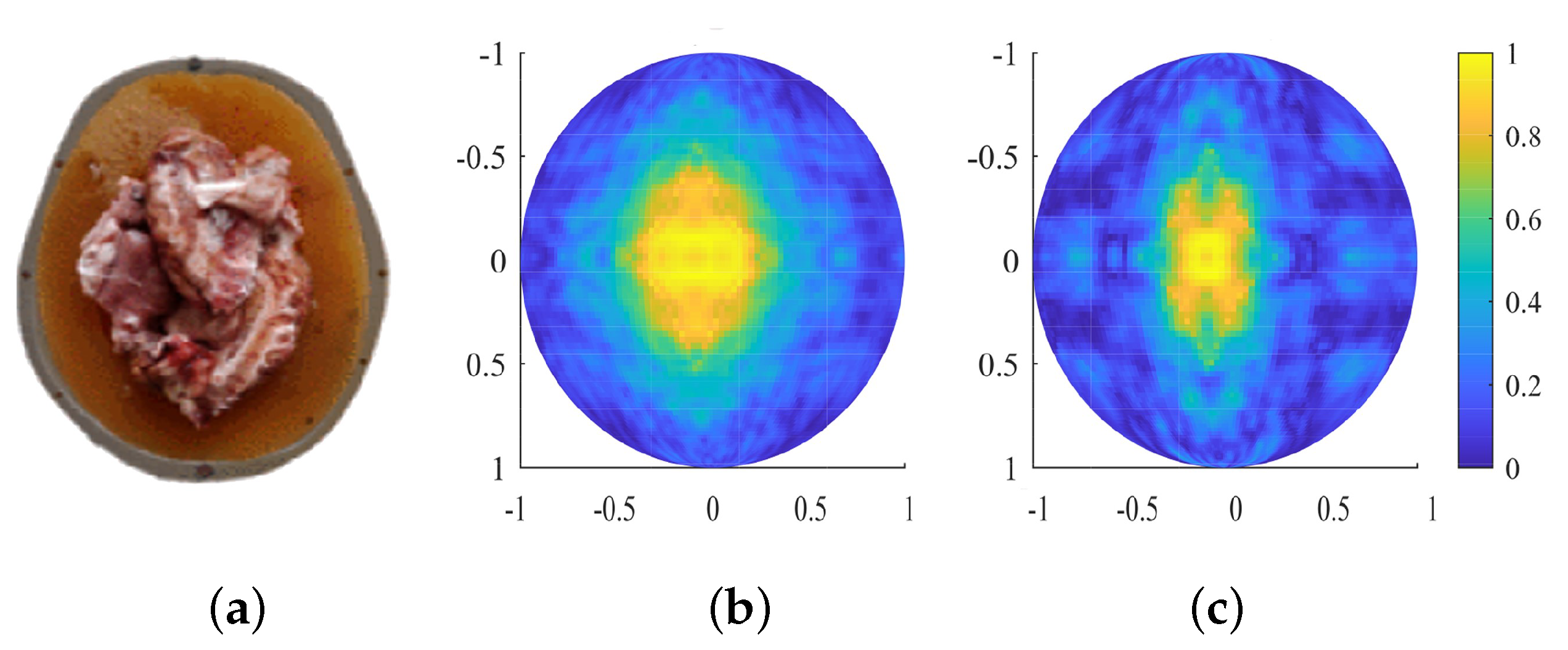
Section 4.1 and return the results to the master node using the MapReduce programming model. The master node transforms the resulting matrix into an image using Python built-in functions and saves the results to the Eddie storage. An example image generated using DMAS and DAS for a lamb brain phantom can be found in
Figure 4.
It can be noted that the DMAS reconstructs the brain volume more accurately compared to DAS. It is important to mention that the data were preprocessed before image reconstruction. The signal obtained for lamb brain phantom were subtracted from reference signals obtained from an empty skull model to remove strong reflections from skull.
5.5. Results Analysis and Validation
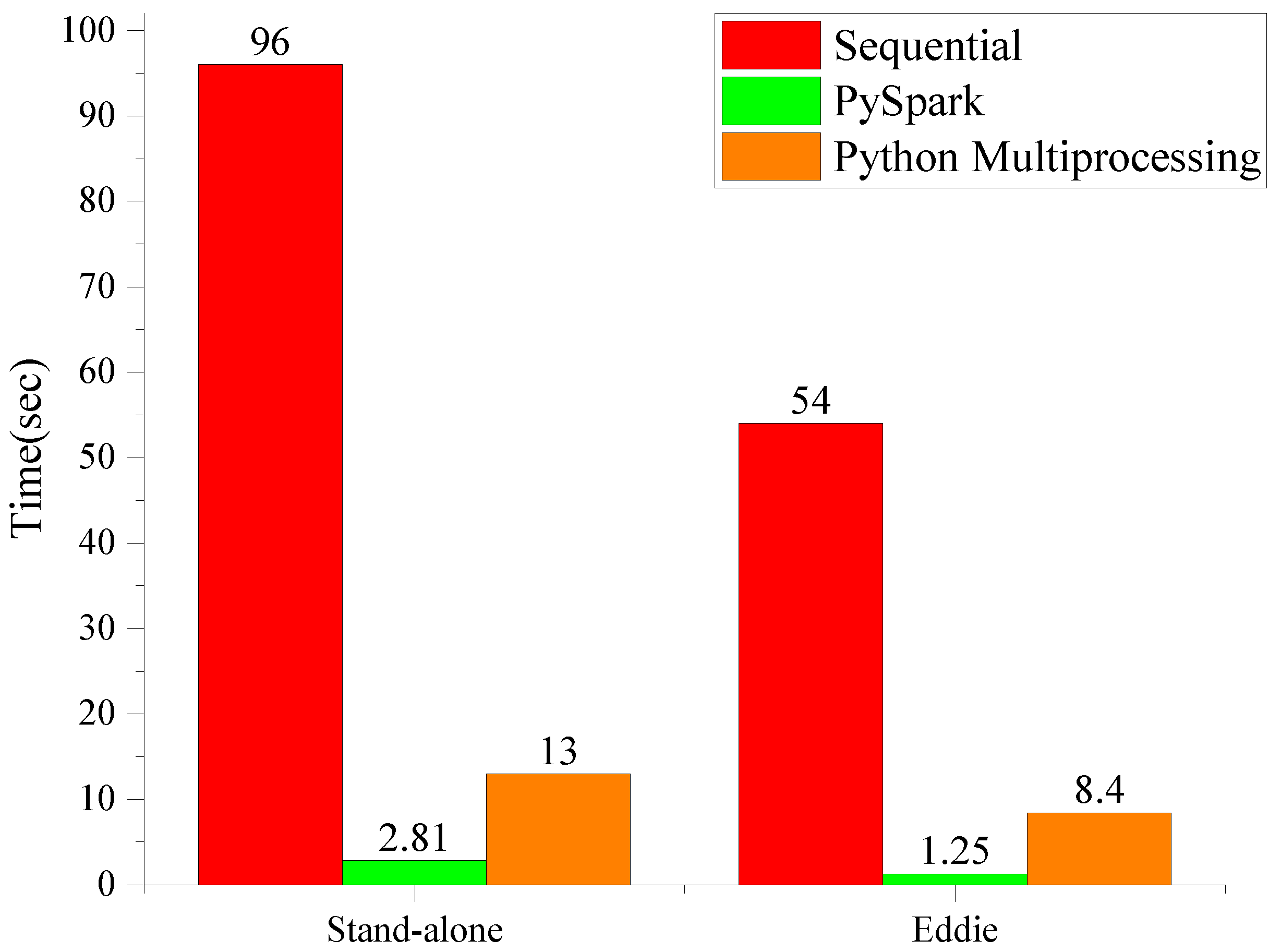
To validate the results of the proposed Spark-based parallel DMAS algorithm, the results are compared in terms of processing speed with both sequential and Python multiprocessing library. These three versions of algorithm were deployed on both a standalone PC and on Eddie and were run for three times, and the average wall time was noted. The computational results for sequential, Pyspark-based, and Python multiprocessing versions on both the standalone PC and on Eddie can be found in
Figure 5. It can be observed that the Pyspark version is 34.12 and 43.2 times faster than sequential implementation of DMAS on a standalone PC and on Eddie, respectively. The Pyspark version also outperforms the Python multiprocessing library and is 4.62 times faster on the standalone PC and 6.72 times faster on Eddie. It can be observed that the Python multiprocessing library also improves the speed significantly compared to the sequential version; however, Pyspark achieves better speed due to in-memory processing.
On the other hand, the cluster mode significantly improves the speed; however, there is a slight difference in performance due to data retrieval from the shared memory.
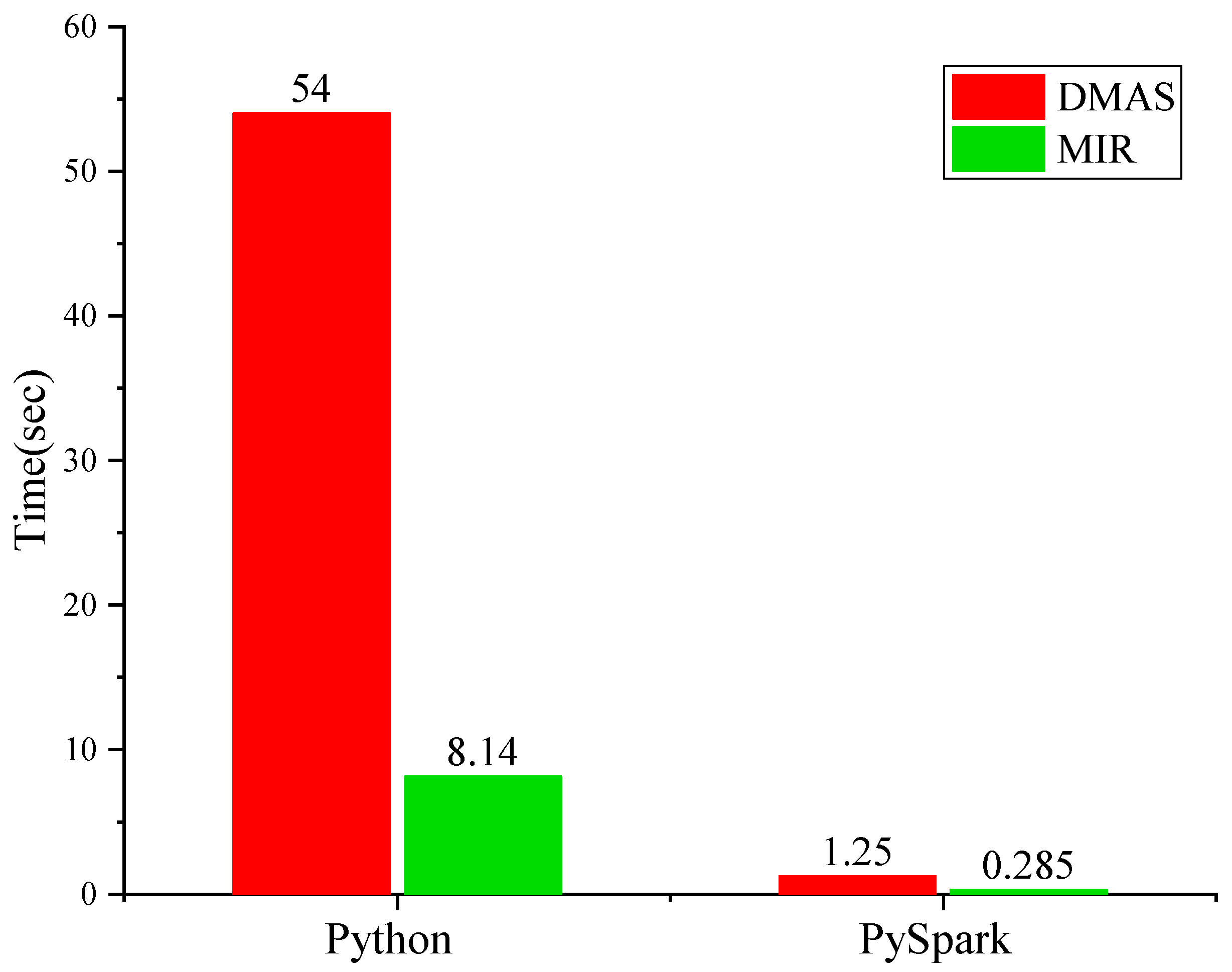
A comparison with the MIR algorithm, based on DAS, proposed in our previous work [
34], is also performed to further validate these results. The results can be found in
Figure 6. It can be observed that the parallel DMAS takes sightly longer due to
multiplications. This comparison aims to determine the effectiveness of using the Spark framework for health big data processing such as medical image reconstruction.
It can also be observed that the Spark MapReduce framework significantly improves the efficiency of these imaging algorithms. One of the downsides of the proposed algorithm is that it retrieves the data into a memory disk on every cycle to calculate pixel value, which results in considerable disk input/output. A potential solution is to copy the input data and algorithm to the computational nodes.
6. Discussion
Microwave imaging for biomedical imaging applications has gained much attention over the past few decades. It has many advantages such as fast diagnosis and non-ionizing radiation and is emerging as a potential imaging modality compared to the existing imaging modalities such as magnetic resonance imaging (MRI), computed tomography (CT) and ultrasound. The reliability of microwave medical imaging system is largely dependent on the efficiency and accuracy of preprocessing and imaging algorithms. The imaging algorithm can be divided into two types: tomography-based algorithm and radar-based imaging algorithm. The tomography-based methods reconstruct the electrical properties of the imaging area by solving an ill-posed inverse problem and is therefore complex and time-consuming. Conversely, radar-based methods use the reflected or transmitted signals to find the position/size of the targeted object, such as breast tumour, brain stroke or brain atrophy. Among the two types of radar-based beamformers, data-independent beamformers are faster at image restoration than data-adaptive beamformers; however, the latter yields better results.
Several data-independent and data adaptive algorithms are utilised for image reconstruction. However, DAS and its variations are mostly used due to their robust performance and simplicity. The most commonly used extension of DAS beamformer is DMAS, which provides improved contrast and resolution in the reconstructed images by trading the complexity of computation [
45]. The computation is further increased for the multistatic approach; however, it improves the accuracy. This work uses Spark as an accelerator to improve the efficiency of the DMAS algorithm. The most computationally intensive part of the algorithm is first identified. The algorithm is implemented using a MapReduce operation, where subsets of pixel values are calculated on different worker nodes in parallel and retrieved to a master node. The Spark-based parallel implementation is compared with a sequential and Python built-in multiprocessing library implementation. The comparison are performed on a standalone PC and in cluster mode.
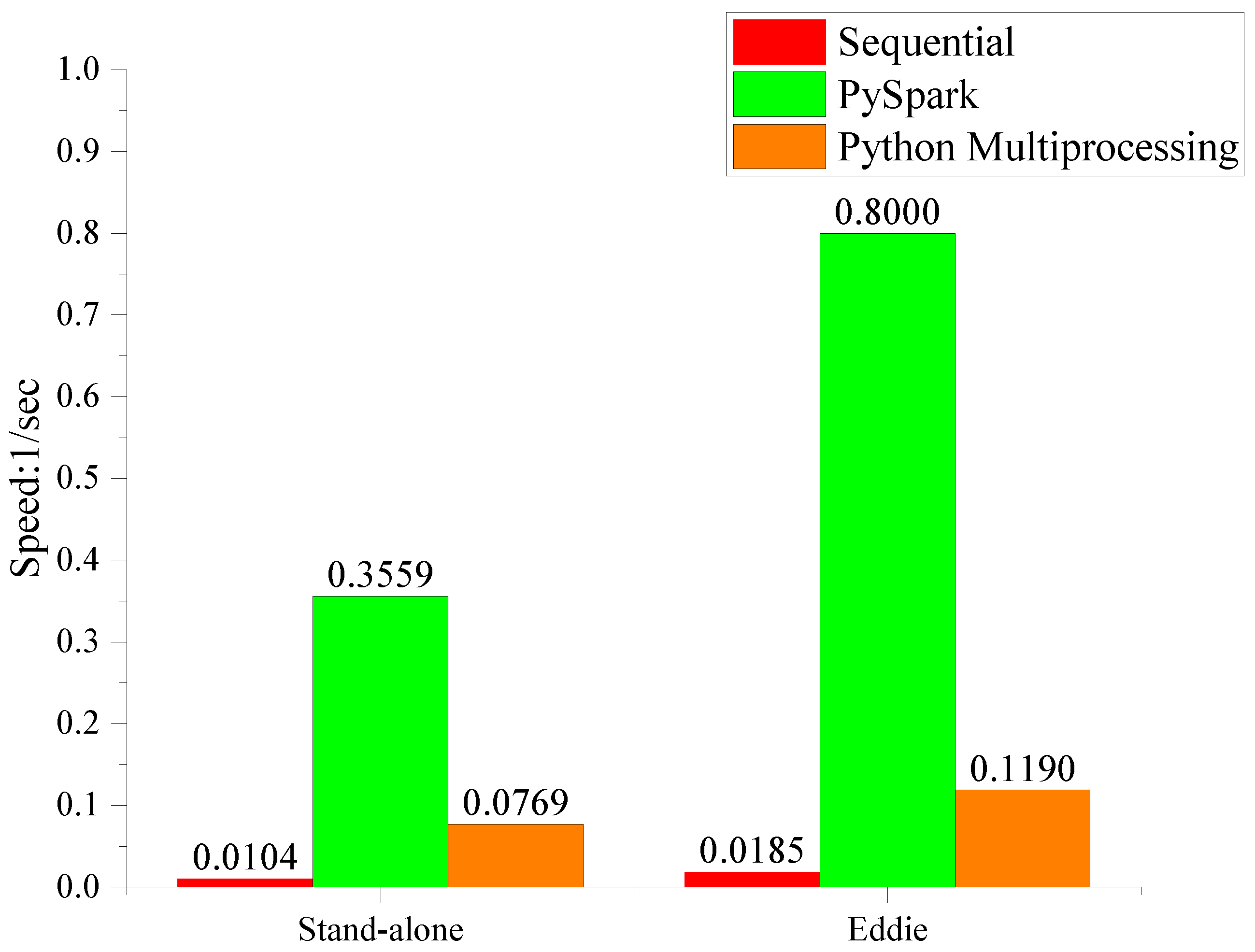
The experimental results shows that the Spark-based parallel algorithm performs an average of 34 and 43.2 times faster than the sequential one on a standalone PC and on HPC, respectively. Similarly, it outperforms Python multiprocessing due to in-memory processing. The comparison in terms of processing speed for all three versions of DMAS can be found in
Figure 7. The comparison indicates that the Pyspark version improves the speed significantly compared to both sequential and multiprocessing version of DMAS.
The downside of the proposed Spark-based algorithm is its retrieval of data to a memory disk on every cycle for image reconstruction, resulting in substantial disk input/output. The results revealed that the PDMAS achieves significant speed improvements on image reconstruction in parallel. The Spark-based results and comparison indicated that big data frameworks have the potential to improve the efficiency of microwave imaging algorithms. The master–slave architecture along with the Spark framework is generalisable and can be used for tomography-based algorithms as well as data-adaptive algorithms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}