
Extended High Order Algorithms for Equations under the Same Set of Conditions


 , ,
, ,
Abstract
:1. Introduction
- (1’)
- Higher order derivatives (not on the algorithms) should exist although convergence may be possible without these conditions.
- (2’)
- We do not know in advance how many iterations should be performed to reach a certain error tolerance.
- (3’)
- The choice of initial points is limited, since we do not know a convergence ball.
- (4’)
- No information is provided on the uniqueness of .
- (5’)
- Results are limited on the multidimensional Euclidean space.
- (1”)
- We only use the derivative that actually appears on these algorithms. The convergence order is recovered again, since we by pass Taylor series, (which require the higher order derivatives) and use instead the computational order of convergence (COC) given byand the approximate computational order of convergence (ACOC) given byThese formulae use the algorithms (which depend on the first derivative). In the case of ACOC no knowledge of is needed.
- (2”)
- We use generalized Lipschitz-type conditions which allow us to provide upper bounds on which in turn can be used to determine the smallest number of iterations to reach the error tolerance.
- (3”)
- Under our local convergence analysis a convergence ball is determined. Hence, we know from where to pick the stater so that convergence to the solution can be achieved.
- (4”)
- A uniqueness ball is provided.
- (5”)
- The results are presented in the more general setting of Banach space valued operators.
- SM1:
- SM2:
2. Ball Convergence
- (i)
- has a smallest root in for some function which is non-decreasing and continuous. Set .
- (ii)
- has a smallest root in for some functions , which are non-decreasing and continuous with defined by
- (iii)
- has a smallest root in . Set and .
- (iv)
- has a smallest root in , where
- (v)
- has a smallest root in . Set and .
- (vi)
- has a smallest root in , where
- For eachSet .
- For eachand
- for some to be defined later.
- There exists satisfyingSet .Next, the main convergence result for SM1 is developed utilizing conditions .
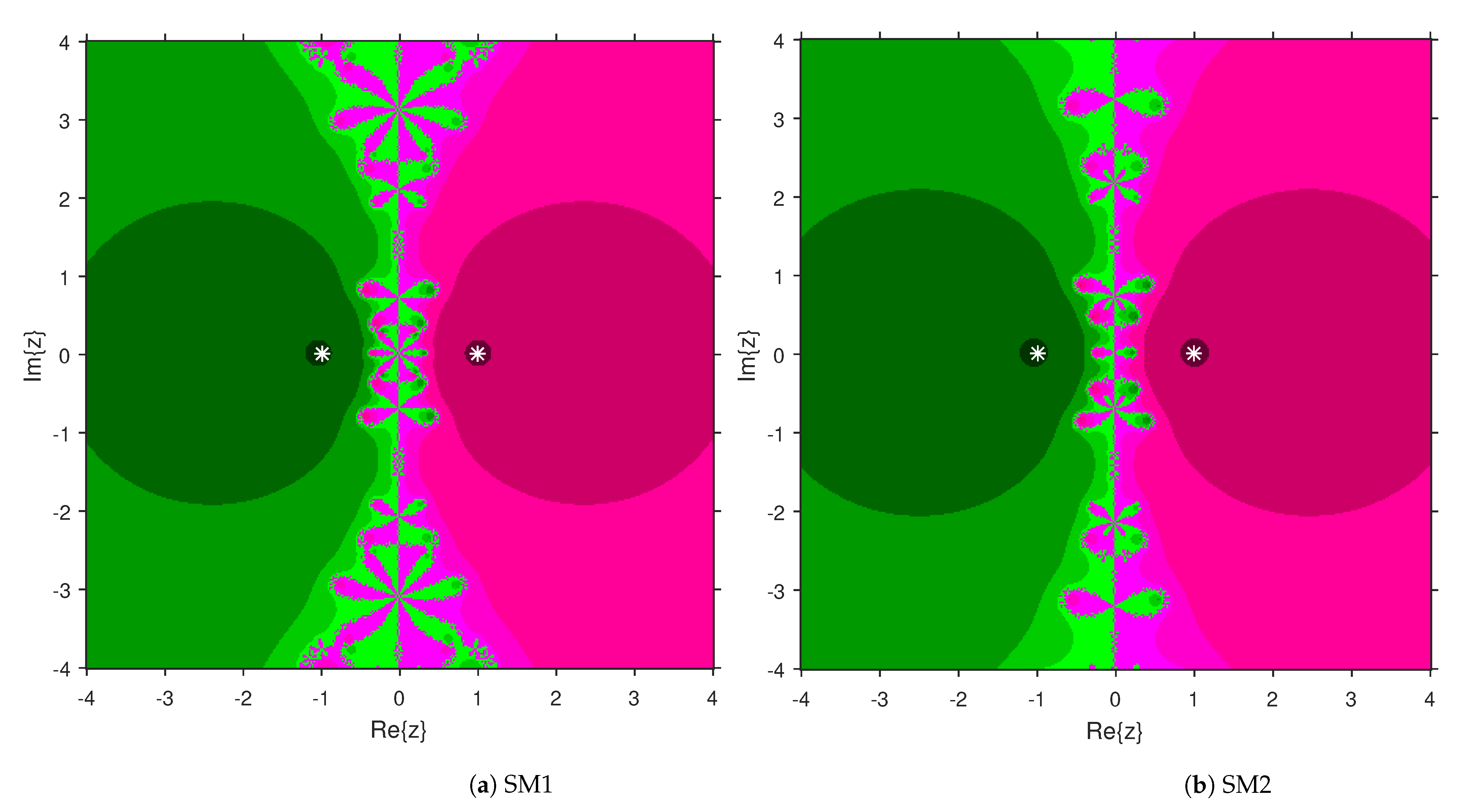
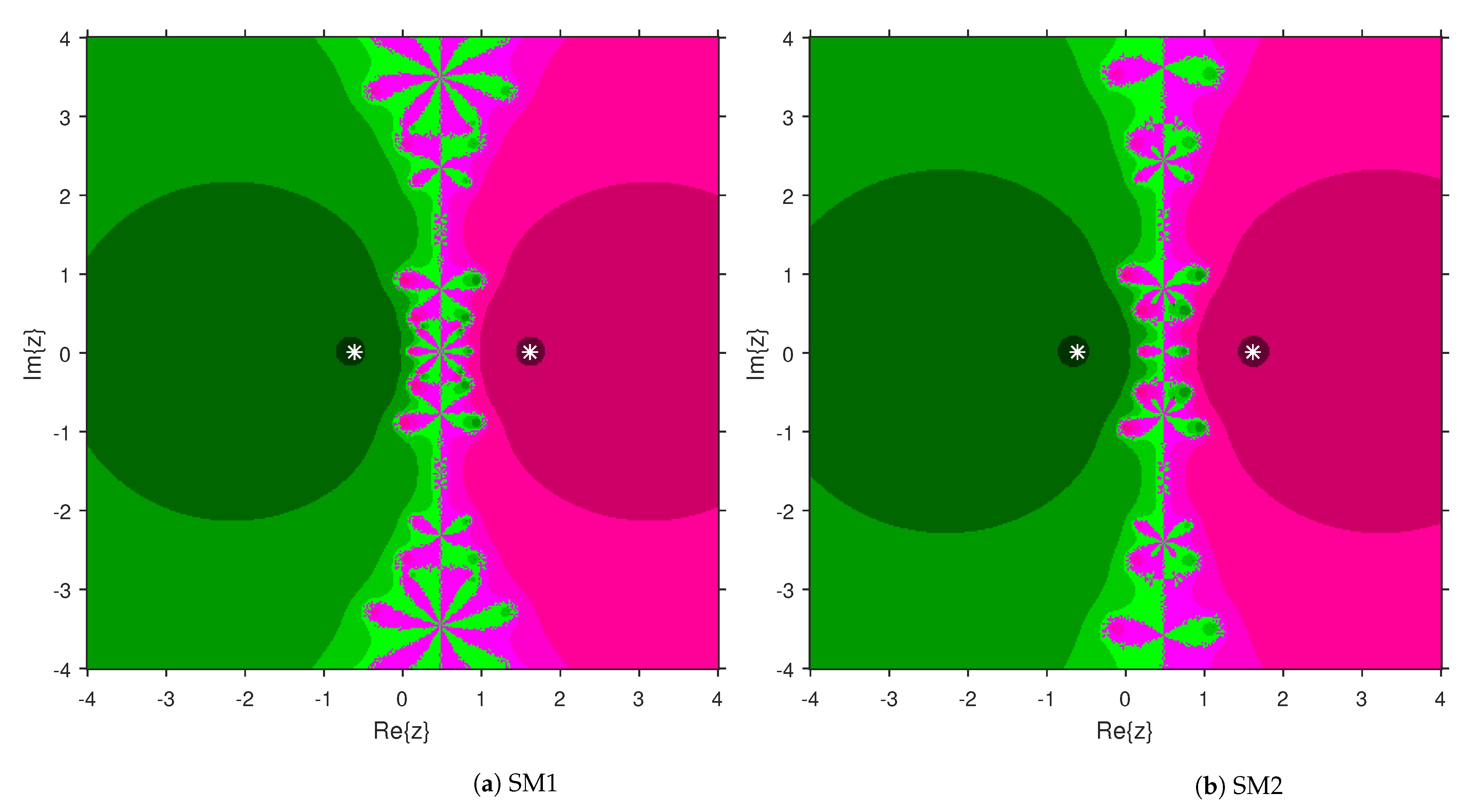
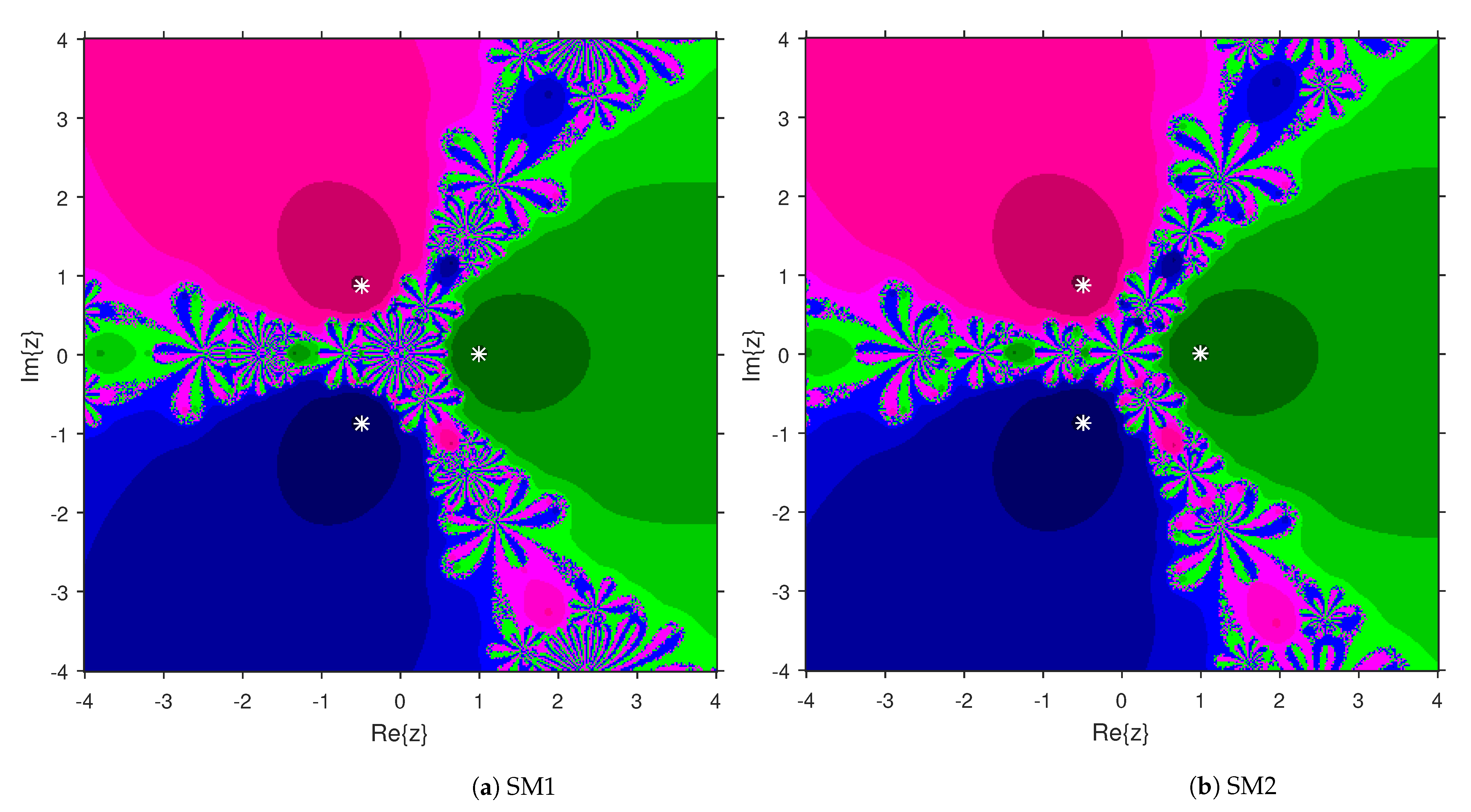
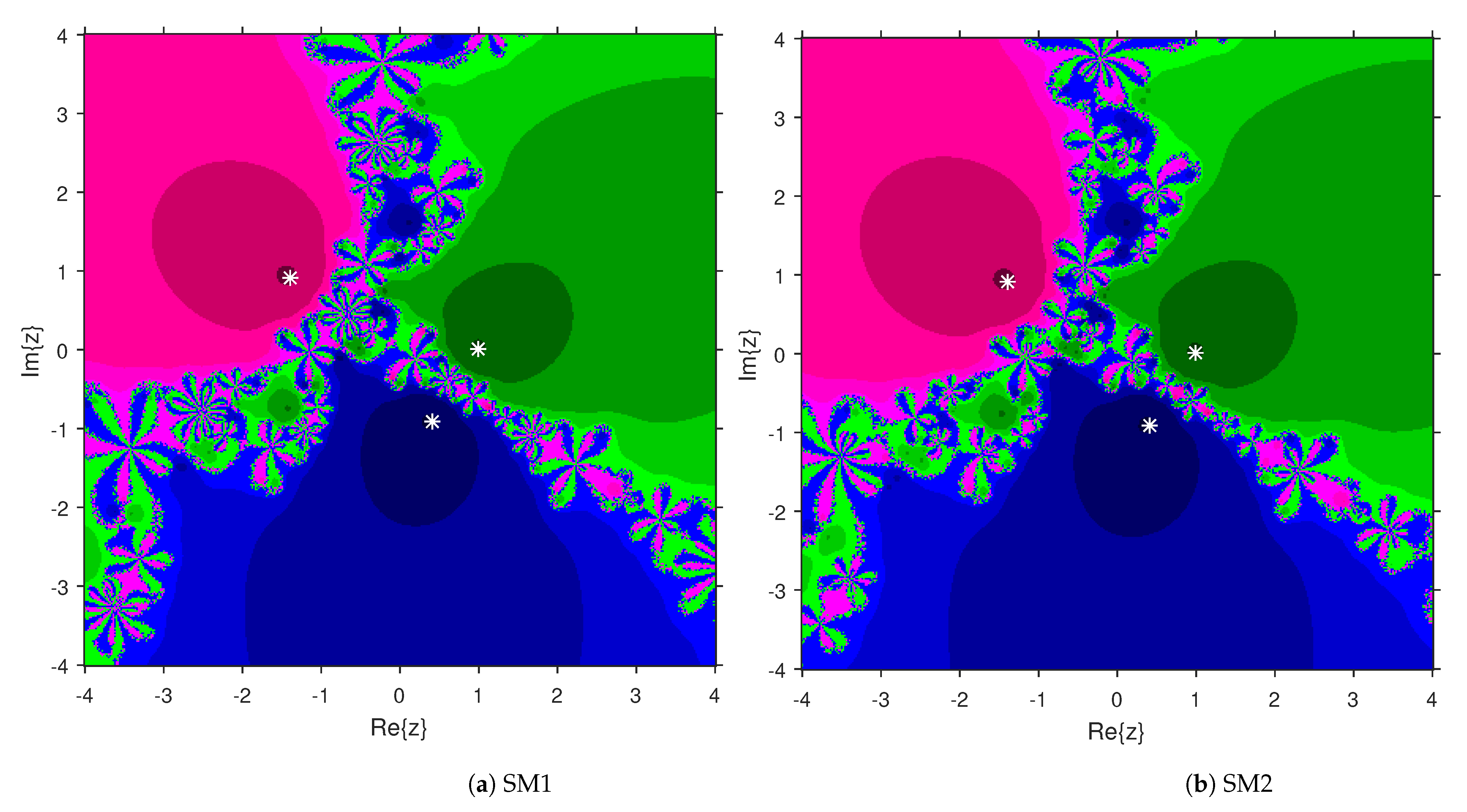
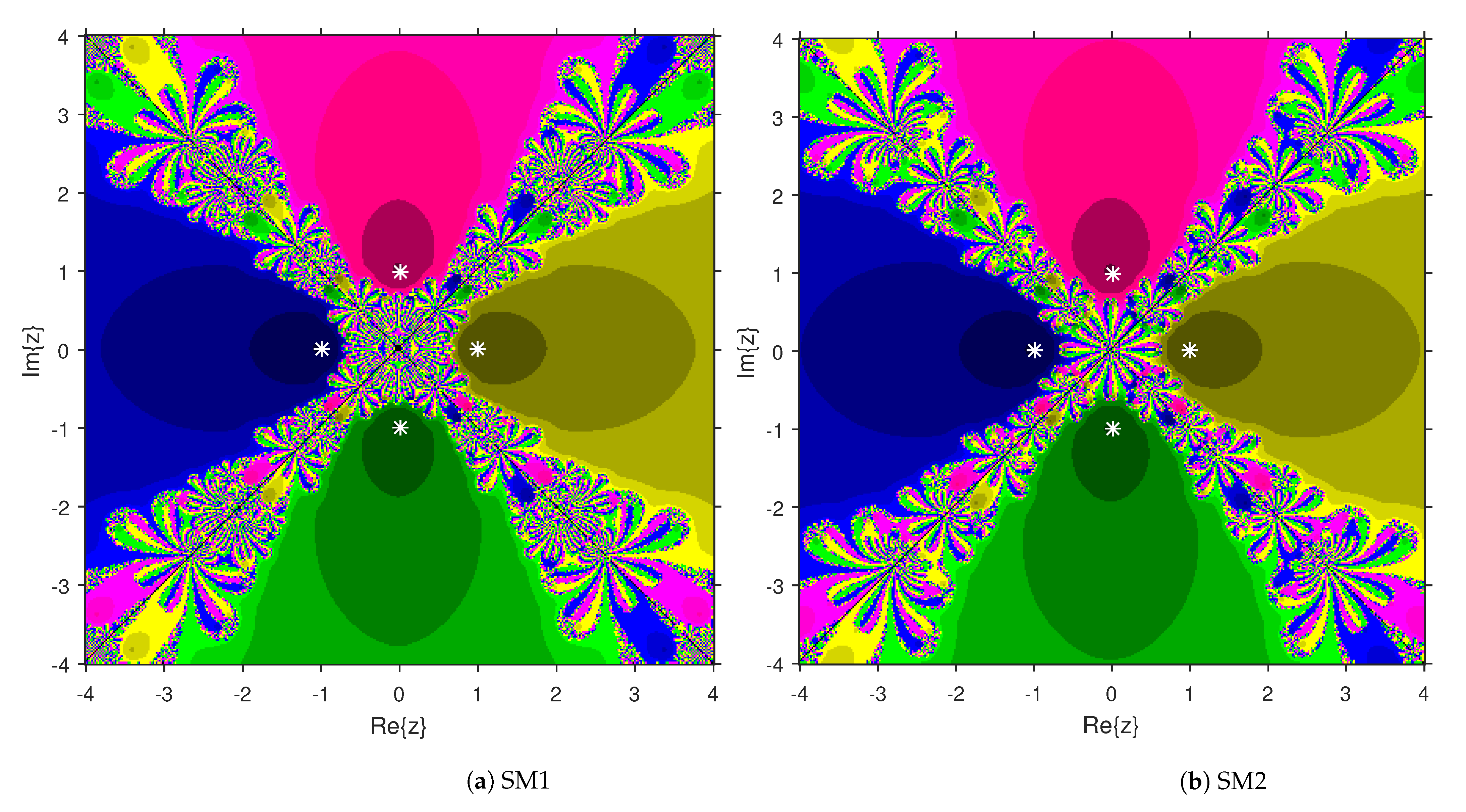
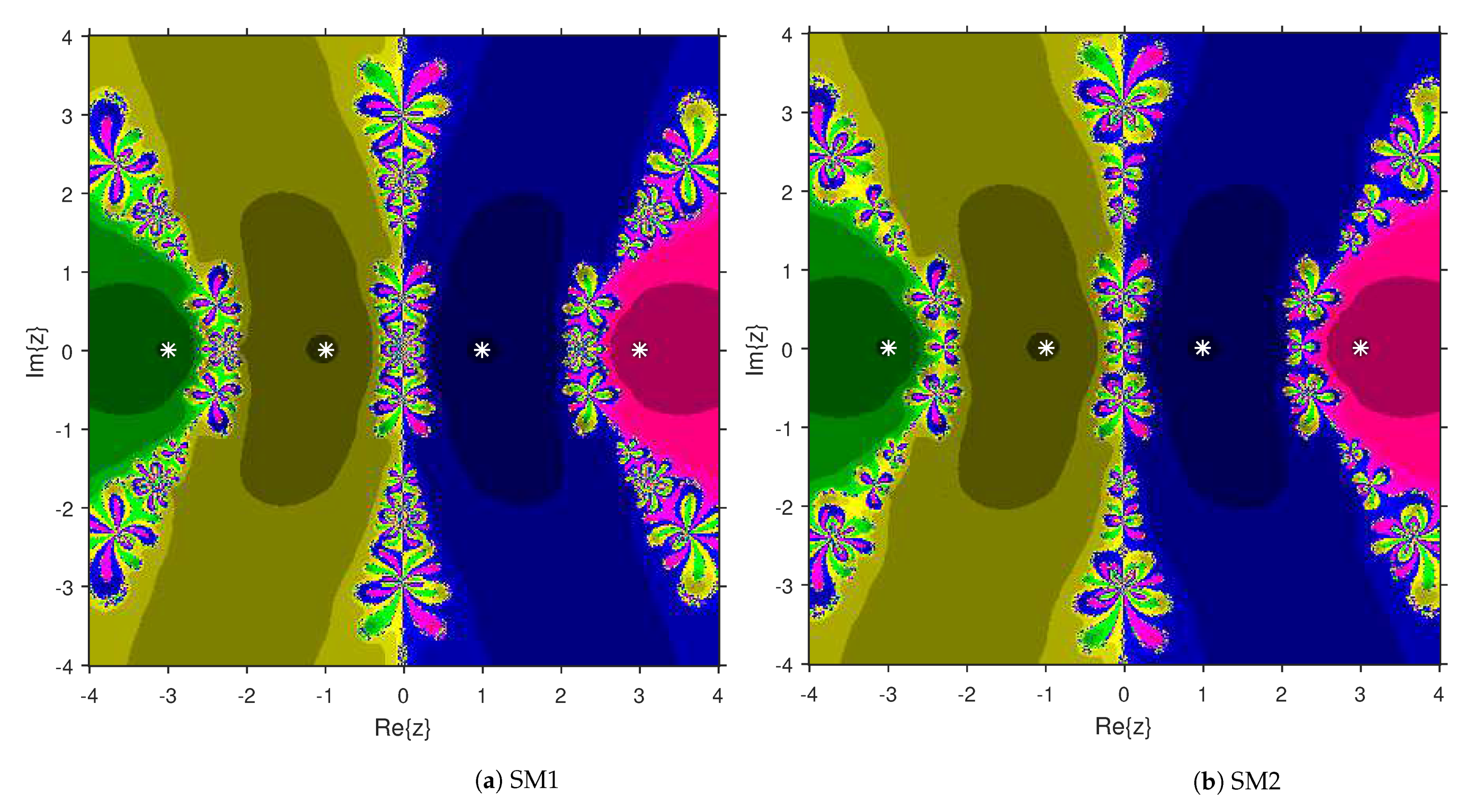
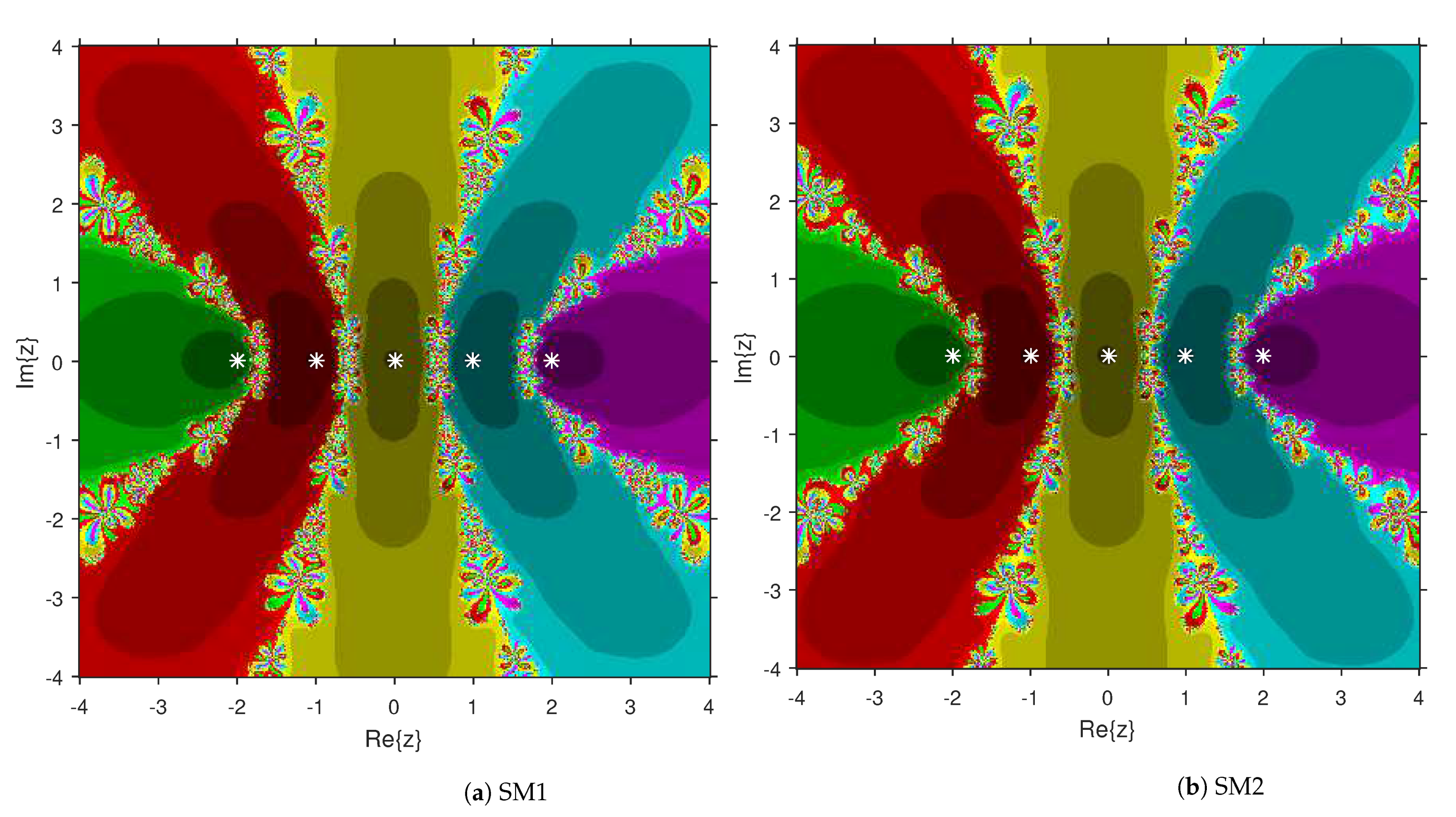
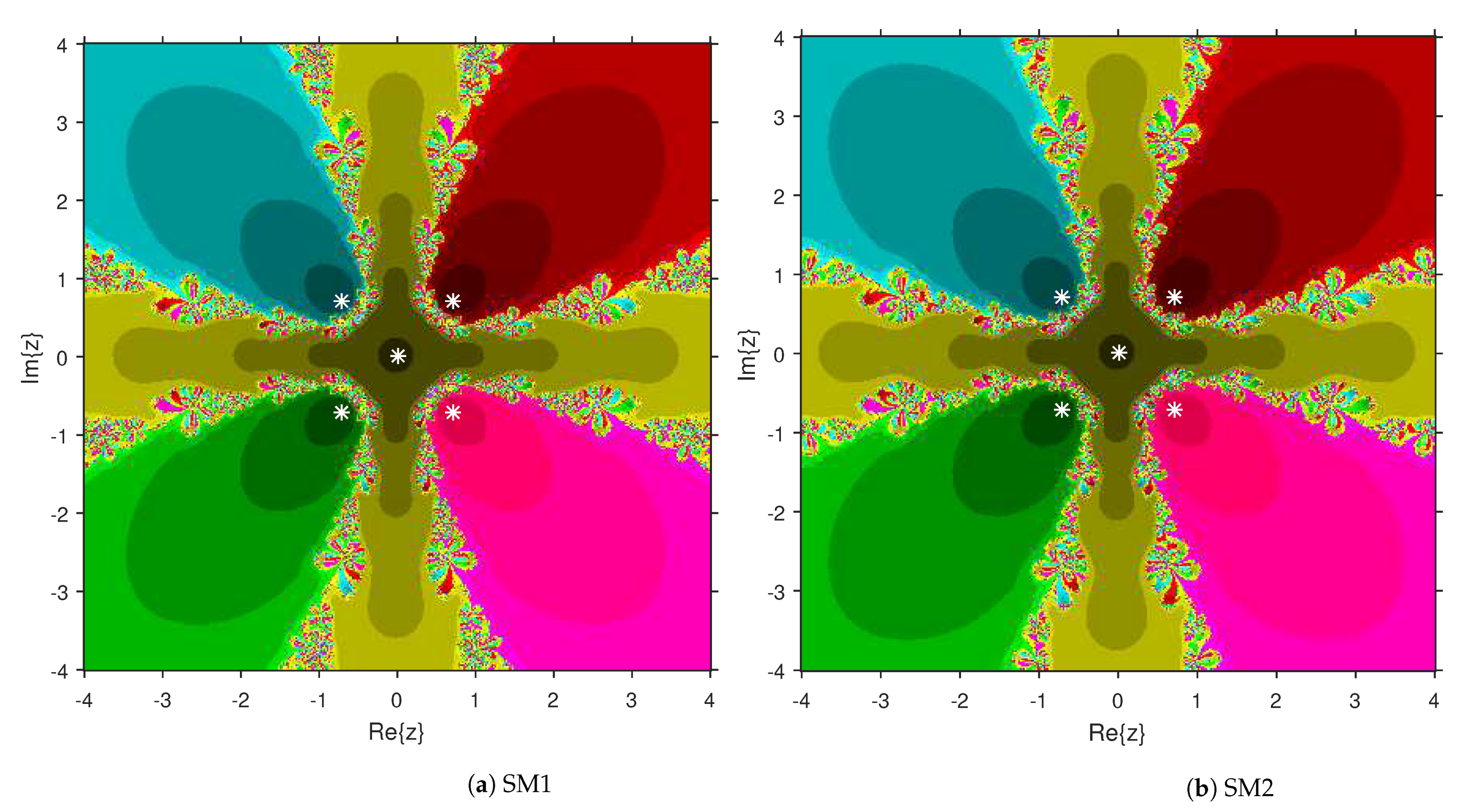
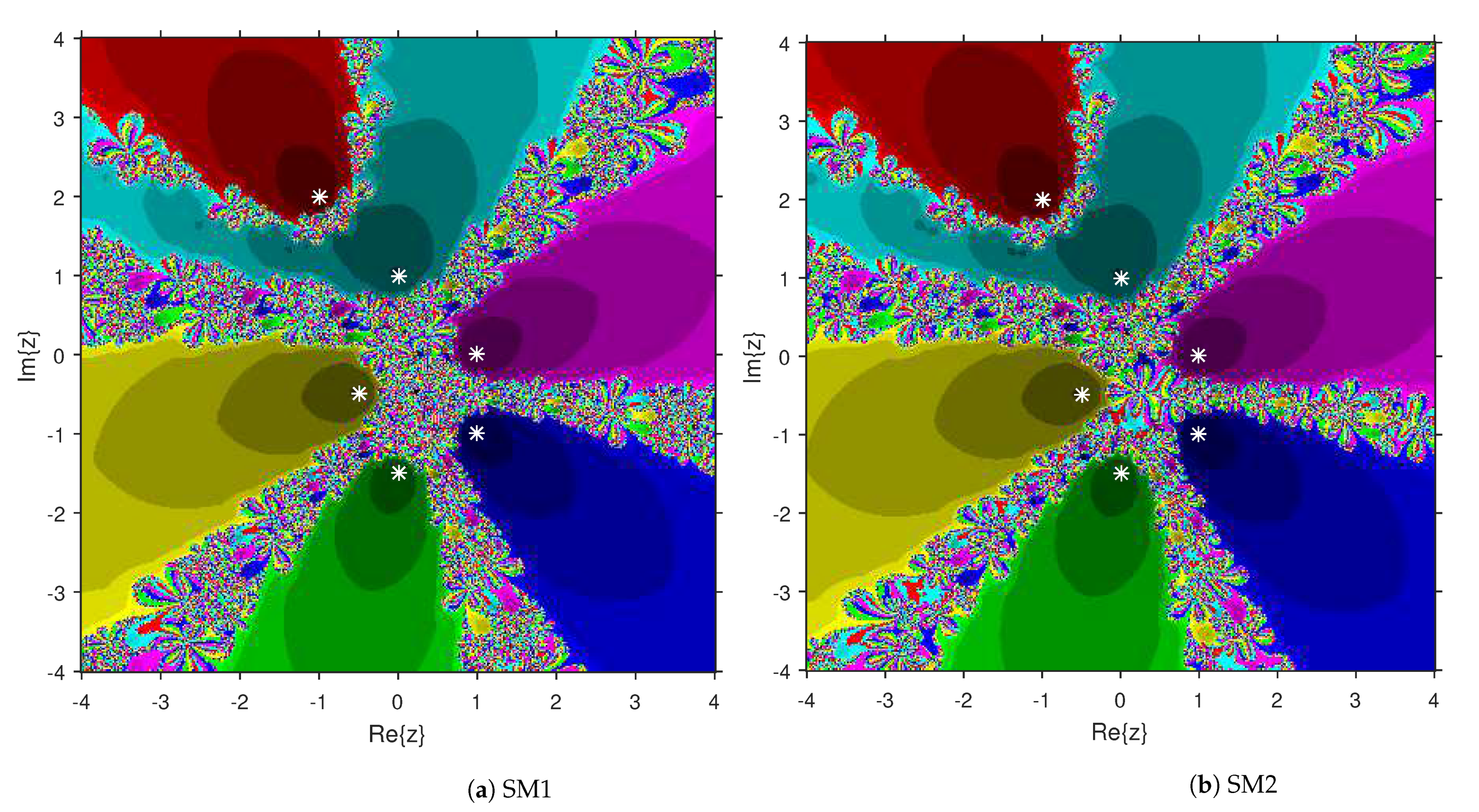
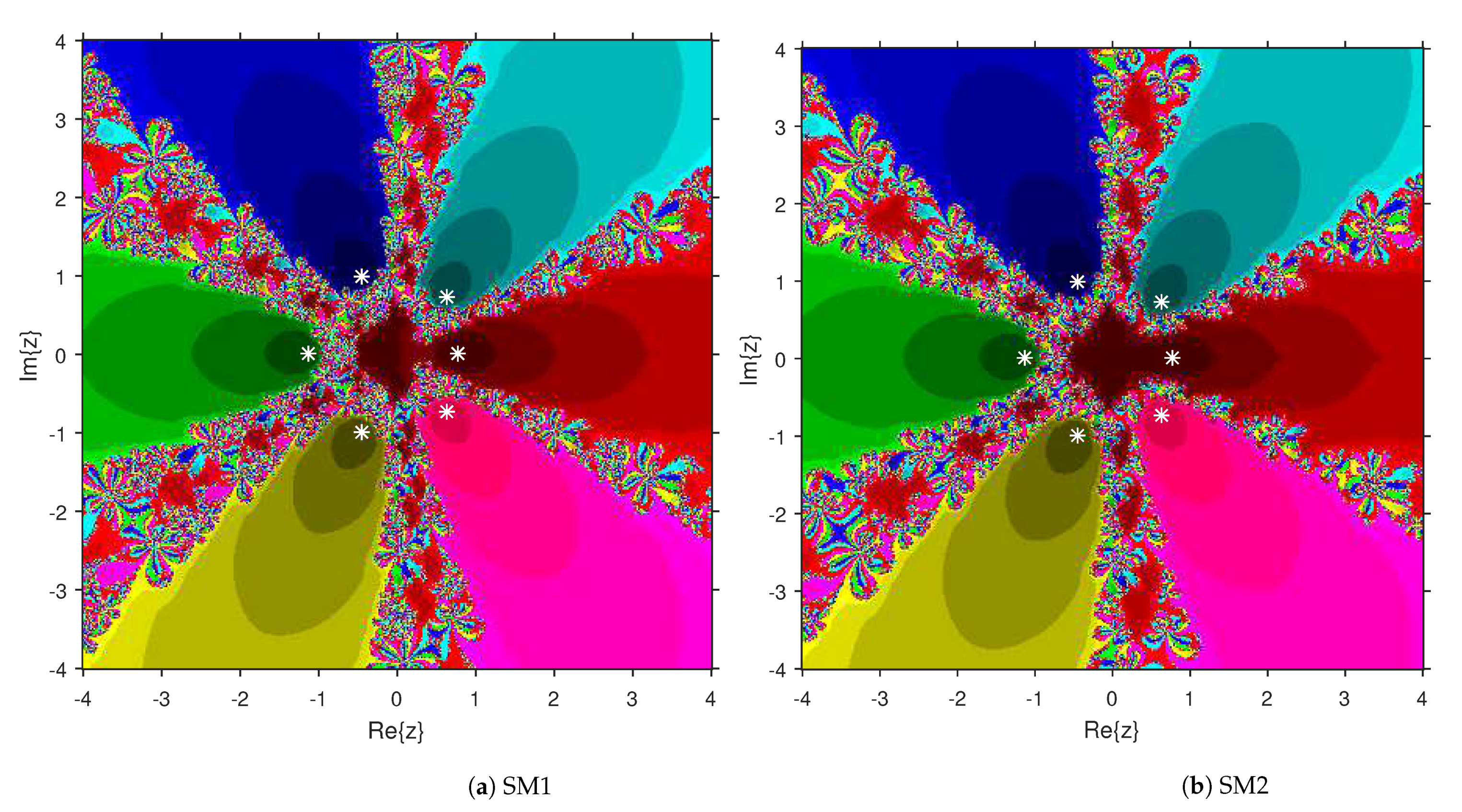
3. Comparison of Attraction Basins
4. Numerical Examples
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abro, H.A.; Shaikh, M.M. A new time-efficient and convergent nonlinear solver. Appl. Math. Comput. 2019, 355, 516–536. [Google Scholar] [CrossRef]
- Cordero, A.; Torregrosa, J.R.; Vassileva, M.P. Design, Analysis, and Applications of Iterative Methods for Solving Nonlinear Systems. In Nonlinear Systems-Design, Analysis, Estimation and Control; IntechOpen: Rijeka, Croatia, 2016. [Google Scholar]
- Waseem, M.; Noor, M.A.; Noor, K.I. Efficient method for solving a system of nonlinear equations. Appl. Math. Comput. 2016, 275, 134–146. [Google Scholar] [CrossRef]
- Said Solaiman, O.; Hashim, I. Efficacy of optimal methods for nonlinear equations with chemical engineering applications. Math. Probl. Eng. 2019, 2019, 1728965. [Google Scholar] [CrossRef] [Green Version]
- Argyros, I.K.; Hilout, S. Computational Methods in Nonlinear Analysis; World Scientific Publishing House: New Jersey, NJ, USA, 2013. [Google Scholar]
- Argyros, I.K.; Magreñán, Á.A. Iterative Methods and Their Dynamics with Applications: A Contemporary Study; CRC Press: New York, NY, USA, 2017. [Google Scholar]
- Argyros, I.K.; Magreñán, Á.A. A Contemporary Study of Iterative Methods; Elsevier: New York, NY, USA, 2018. [Google Scholar]
- Cordero, A.; Hueso, J.L.; Martínez, E.; Torregrosa, J.R. A modified Newton-Jarratt’s composition. Numer. Algor. 2010, 55, 87–99. [Google Scholar] [CrossRef]
- Cordero, A.; García-Maimó, J.; Torregrosa, J.R.; Vassileva, M.P. Solving nonlinear problems by Ostrowski-Chun type parametric families. J. Math. Chem. 2015, 53, 430–449. [Google Scholar] [CrossRef] [Green Version]
- Grau-Sánchez, M.; Gutiérrez, J.M. Zero-finder methods derived from Obreshkovs techniques. Appl. Math. Comput. 2009, 215, 2992–3001. [Google Scholar]
- Hueso, J.L.; Martínez, E.; Teruel, C. Convergence, efficiency and dynamics of new fourth and sixth order families of iterative methods for nonlinear systems. J. Comput. Appl. Math. 2015, 275, 412–420. [Google Scholar] [CrossRef]
- Jarratt, P. Some fourth order multipoint iterative methods for solving equations. Math. Comp. 1966, 20, 434–437. [Google Scholar] [CrossRef]
- Petković, M.S.; Neta, B.; Petković, L.; Džunić, D. Multipoint Methods for Solving Nonlinear Equations; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Rheinboldt, W.C. An adaptive continuation process for solving systems of nonlinear equations. Math. Model. Numer. Methods 1978, 3, 129–142. [Google Scholar] [CrossRef]
- Traub, J.F. Iterative Methods for Solution of Equations; Prentice-Hall: Englewood Cliffs, NJ, USA, 1964. [Google Scholar]
- Wang, X.; Kou, J.; Li, Y. A variant of Jarratt method with sixth-order convergence. Appl. Math. Comput. 2008, 204, 14–19. [Google Scholar] [CrossRef]
- Sharma, J.R.; Guna, R.K.; Sharma, R. An efficient fourth order weighted-Newton method for systems of nonlinear equations. Numer. Algor. 2013, 62, 307–323. [Google Scholar] [CrossRef]
- Sharma, J.R.; Arora, H. Efficient Jarratt-like methods for solving systems of nonlinear equations. Calcolo 2014, 51, 193–210. [Google Scholar] [CrossRef]
- Sharma, J.R.; Arora, H. Improved Newton-like methods for solving systems of nonlinear equations. SeMA J. 2016, 74, 1–7. [Google Scholar] [CrossRef]
- Argyros, I.K.; George, S. Local convergence of Jarratt-type methods with less computation of inversion under weak conditions. Math. Model. Anal. 2017, 22, 228–236. [Google Scholar] [CrossRef]
- Argyros, I.K.; Sharma, D.; Argyros, C.I.; Parhi, S.K.; Sunanda, S.K. A Family of Fifth and Sixth Convergence Order Methods for Nonlinear Models. Symmetry 2021, 13, 715. [Google Scholar] [CrossRef]
- Kou, J.; Li, Y. An improvement of the Jarratt method. Appl. Math. Comput. 2007, 189, 1816–1821. [Google Scholar] [CrossRef]
- Magreñán, Á.A. Different anomalies in a Jarratt family of iterative root-finding methods. Appl. Math. Comput. 2014, 233, 29–38. [Google Scholar]
- Sharma, D.; Parhi, S.K.; Sunanda, S.K. Extending the convergence domain of deformed Halley method under ω condition in Banach spaces. Bol. Soc. Mat. Mex. 2021, 27, 32. [Google Scholar] [CrossRef]
- Soleymani, F.; Lotfi, T.; Bakhtiari, P. A multi-step class of iterative methods for nonlinear systems. Optim. Lett. 2014, 8, 1001–1015. [Google Scholar] [CrossRef]
- Chun, C.; Neta, B. Developing high order methods for the solution of systems of nonlinear equations. Appl. Math. Comput. 2019, 342, 178–190. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SM1 | SM2 |
|---|---|
| SM1 | SM2 |
|---|---|
| SM1 | SM2 |
|---|---|
| n | 1 Substep | 2 Substeps | 3 Substeps (SM1) |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 |
| n | 1 Substep | 2 Substeps | 3 Substeps (SM2) |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 |
| Algorithm | Elapsed Time | CPU Time |
|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Argyros, I.K.; Sharma, D.; Argyros, C.I.; Parhi, S.K.; Sunanda, S.K.; Argyros, M.I. Extended High Order Algorithms for Equations under the Same Set of Conditions. Algorithms 2021, 14, 207. https://doi.org/10.3390/a14070207
Argyros IK, Sharma D, Argyros CI, Parhi SK, Sunanda SK, Argyros MI. Extended High Order Algorithms for Equations under the Same Set of Conditions. Algorithms. 2021; 14(7):207. https://doi.org/10.3390/a14070207
Chicago/Turabian StyleArgyros, Ioannis K., Debasis Sharma, Christopher I. Argyros, Sanjaya Kumar Parhi, Shanta Kumari Sunanda, and Michael I. Argyros. 2021. "Extended High Order Algorithms for Equations under the Same Set of Conditions" Algorithms 14, no. 7: 207. https://doi.org/10.3390/a14070207
APA StyleArgyros, I. K., Sharma, D., Argyros, C. I., Parhi, S. K., Sunanda, S. K., & Argyros, M. I. (2021). Extended High Order Algorithms for Equations under the Same Set of Conditions. Algorithms, 14(7), 207. https://doi.org/10.3390/a14070207