1. Introduction
The flow shop problem (FSP) is a largely studied scheduling problem, as it models a wide set of industrial manufacturing environments [
1], such as in the chemical, food-processing, automobile, and assembly industries. The purpose of solving the stated problem lies in determining the best processing sequence from n production jobs to process on m machines placed in series, aiming to optimize one or several KPIs such as the flowtime, makespan, earliness, or tardiness. A permutation flow shop scheduling problem (PFSP), which is an extension case of the FSP, considers only permutation schedules, i.e., the processing sequence of the jobs is the same for all m machines. The PFSP is considered an NP-complete problem for three or more machines [
2] and an NP-hard problem for one or more machines when minimizing tardiness [
3]. Furthermore, this problem augments the complexity when the uncertainty is considered for its resolution. From several approaches, a preliminary approach for tackling the stochastic permutation flow shop problems is elaborating a systematic procedure that includes uncertainties within the scheduling problems [
4]. In fact, the scheduling problem and the associated complexity could be as important for designing a proper systematic technique to solve these problems [
4].
After analyzing the literature on the FSP and PFSP, four aspects should be highlighted. At first, a set of approaches in the literature considers a single performance indicator as the objective function. The most common approaches are related to the makespan, due date, or just-in-time characteristics. The makespan or the expected makespan indicator, which is an absolute performance indicator, focuses on minimizing the lapsed time from the start to the end of the execution [
5,
6]. The due date indicator, which is a relative performance indicator, compares the objective function regarding the expected processing completion. The just-in-time indicator, which is an accuracy performance indicator, indicates the positive or negative deviation occurring from an expected completion time. Certainly, the use of each performance indicator depends on the aim from the scheduling perspective.
Second, another set of approaches is focused on single-objective problems rather than multicriteria problems. Certainly, even industrial problems must solve various objectives simultaneously [
7], and researchers have focused on optimizing a single objective function rather than multiple ones. This issue can be addressed by considering earliness and tardiness objectives jointly in a JIT environment.
Third, most studies consider only quantitative decision criteria. However, researchers have recently become interested in qualitative criteria as this approach might reduce the gap between the theoretical concept of problems and the execution. Some examples are Chang and Lo [
8] and Chang et al. [
9]. These authors studied a multicriteria job shop, whereas the customers’ strategic importance was considered as a qualitative criterion. While Chang and Lo [
8] proposed a hybridized genetic algorithm, tabu search, analytic hierarchy process, and fuzzy theory to solve the problem, Chang et al. [
9] proposed a hybridization of an ant colony algorithm and an analytic hierarchy process for solving the FSP. Another approach minimized the expected costs of tardiness as a quantitative criterion and strategic customer importance as a qualitative criterion in a stochastic hybrid FSP [
10]. The authors employed a GRASP metaheuristic and a Monte Carlo simulation method with a stochastic multicriteria acceptability analysis to handle both qualitative and quantitative criteria.
Finally, some research approaches consider scheduling under uncertain conditions, and these are generally divided into two approaches: the stochastic approach, in which parameters are modeled with probability distributions (PDs) aiming to minimize the expected value of a selected metric, and the robust approach (RA), in which uncertain parameters are modeled with intervals and the schedule obtained is more stable and less variable. Nonetheless, previous studies have not dealt with a combination of stochastic and robust approaches for solving the flow shop problem. Companies can collect production data in a short time, yielding enough data to accurately estimate the probability distribution of uncertain parameters. Then, we believe that the latter approach leverages the robust schedule as it can be more easily adjusted than other schedules in which uncertainties are modeled with intervals.
One of the recent approaches to solve stochastic combinatorial optimization problems is simheuristics. These hybridize a metaheuristic approach with a simulation to obtain solutions for stochastic problems. Simheuristics have been successfully used in vehicle routing problems [
11,
12,
13], inventory routing problems [
14], facility location problems [
15], and scheduling problems [
16,
17,
18,
19].
In this sense, this paper attempts to contribute to the literature by proposing a systematic technique for solving the stochastic permutation flow shop problem (SPFSP) considering stochastic processing times and sequence-dependent setup times to optimize multiple criteria. To the best of our knowledge, no previous study has included the simultaneous analysis of a JIT environment with stochastic parameters, quantitative metrics, and qualitative metrics for obtaining robust solutions. Therefore, the current research proposes a multicriteria simheuristic approach to solve an SPFSP, including both quantitative and qualitative objectives, providing robust solutions. On the one hand, for quantitative objectives, the proposed approach addresses the expected earliness/tardiness (E[E/T]) and the standard deviation of earliness/tardiness (SD(E/T)), for estimating the JIT metrics and obtaining several robust schedules. On the other hand, as qualitative metrics, this research considers the expected customer importance of jobs (E[CI]) and the expected product importance (E[PI]), favoring the job priority for the company. Then, this paper considers both customer and product importance as a company might be more interested in delivering high-profitability products regardless of the customer or, conversely, it might be more interested in delivering frequently with high-spending customers rather than sporadic ones. This paper is an extension of a previous conference work [
20] that only considered one qualitative criterion and solved a partial set of benchmark instances. This work includes one more qualitative criterion (the maximization of the accomplishment of product importance) and executes more computational experiments by evaluating 180 instances proposed by [
21] and analyzing the behavior of Pareto frontiers with more coefficients of variation of processing times and sequence-dependent setup times.
The remainder of this paper is organized as follows.
Section 2 presents a literature review of the single-objective stochastic FSP (SFSP), robust FSP, and multi-objective SFSP.
Section 3 describes the proposed solution for the SPFSP under qualitative and quantitative decision criteria.
Section 4 provides the results of the computational experiments that validate the proposed approach. Finally, conclusions and recommendations for future work are presented in
Section 5.
2. Literature Review
The deterministic FSP is one of the most frequently studied problems in the scheduling literature, but the stochastic version has been addressed less often. The FSP under the conditions of uncertainty has received more attention recently because it is closer to real manufacturing environments. Nevertheless, there are fewer FSP studies under uncertain conditions than there are deterministic FSP studies. For the literature reviews, deterministic FSPs and its solution methods have more than ten literature reviews, including Yenisey and Yagmahan [
7], Pan and Ruiz [
22], Arora and Agarwal [
23], Nagano and Miyata [
24], Rossit et al. [
25], and Fernandez-Viagas et al. [
26]. Meanwhile, their stochastic and uncertain counterparts have had only two literature reviews in the past 18 years, Gourgand et al. [
5] and González-Neira et al. [
27]. Studies of the FSP with uncertainty generally use one of three approaches to deal with uncertain parameters: the stochastic approach, the robustness approach, and the fuzzy approach. The most frequently used approach is stochastic, with the uncertain parameters modeled using probability distributions. Examples of this approach can be found in Framinan and Perez-Gonzalez [
28], Lin and Chen [
29], and Qin et al. [
30]. For the robustness approach, there is no need for acknowledging the distribution of the data of uncertain parameters due to this being modeled with intervals or datasets. Examples of this approach can be found in Fazayeli et al. [
31] and Ying [
32]. For the fuzzy approach, uncertain parameters are modeled using fuzzy numbers, as in Behnamian and Fatemi Ghomi [
33] and Huang et al. [
34].
The aim of this paper is to obtain robust schedules for the stochastic permutation flow shop problem (SPFSP), considering both quantitative and qualitative objective criteria. Then, the literature review in this paper is organized into four subsections:
Section 2.1 presents the literature review for single-objective SFSPs.
Section 2.2 presents an overview of studies using the robust FSP with a single objective.
Section 2.3 examines current approaches for a multi-objective FSP under uncertain conditions, including robust, stochastic, and fuzzy approaches.
Section 2.4 presents a review of qualitative production criteria.
2.1. Single-Objective SFSP
Since the 1950s, the deterministic FSP has received considerable attention, but the SFSP has been less studied because it is more difficult to solve than the deterministic version. Nevertheless, with the advances in computation, the SFSP has been studied more in the last few years. Therefore, we present in chronological order the most important studies on the SFSP since its beginnings.
From the early days of this topic until the 2010s, the following approaches have been found. Makino [
35] presented an optimal solution for the expected makespan in an SFSP with two jobs and general distributions for two machines, as well as with three machines, considering the exponential and Erlang distributions of the processing times. Talwar [
36] proposed a rule to optimally sequence n jobs and two machines with exponentially distributed processing times, and this was proved optimal by Cunningham and Dutta [
37]. Alcaide et al. [
38] developed a dynamic procedure for considering stochastic machine breakdowns in an SFSP. This procedure can obtain an optimal solution for the initial stochastic problem when the associated without-breakdowns stochastic partial problems are solved optimally. Gourgand et al. [
39] proposed simulated annealing with a Markovian model to solve the SPFSP with stochastic processing times and limited buffers. Wang et al. [
40] presented a genetic ordinal optimization approach that hybridizes ordinal optimization, optimal computing budget allocation, and a genetic algorithm with uniformly distributed processing times. Kalczynski and Kamburowski [
41] developed a new rule that enables optimal solutions when processing times are Weibull distributed. This rule includes Johnson’s and Talwar’s rules as special cases. Portougal and Trietsch [
42] proposed a heuristic called API that consists of two steps: (1) the ordering of jobs with expected processing times through Johnson’s rule and (2) applying all possible interchanges of two jobs in the sequence.
Then, in the early 2010s, Baker and Trietsch [
43] compared Talwar’s, Johnson’s, and the API rules, testing different types of probability distributions. The authors concluded that for a high coefficient of variation, Talwar’s and Johnson’s rules yield better results, but when the coefficients of variation are low, Johnson’s rule alone provides good results. Baker and Altheimer [
44] compared three heuristic procedures adapted from rules that performed well in deterministic counterparts. The procedures used were CDS/Johnson, CDS/Talwar, and NEH. The authors found that NEH had the best results. Elyasi and Salmasi [
45] solved the SFSP considering normally distributed processing times and variances proportional to their means, as well as gamma distributed processing times with the same scale parameter for all jobs. The authors aimed to minimize the expected tardy jobs by using chance constraint programming. Elyasi and Salmasi [
46] proposed a dynamic method to solve the SFSP in which the stochastic parameters were the due dates of jobs, in order to minimize the expected tardy jobs. Juan et al. [
18] developed a simheuristic that involves an iterated local search metaheuristic considering stochastic processing times distributed lognormally. Framinan and Perez-Gonzalez [
28] compared well-known heuristics through a simulation procedure with a variable number of iterations and different probability distributions. The procedures compared were stochastic NEH, stochastic CDS/Talwar, deterministic NEH, deterministic CDS/Talwar, and deterministic NEH using CDS/Talwar as the initial solution. These authors found that stochastic NEH obtained the best results.
Finally, in the late 2010s and the beginning of the 2020s, Gonzalez-Neira et al. [
47] minimized the expected makespan in a distributed assembly PFSP with stochastic processing times through a GRASP simheuristic, evaluating the robustness of the problem as well. González-Neira et al. [
48] compared thirteen dispatching rules through a simulation procedure with variable iterations for ten different objective functions (five expected values and five standard deviations of the makespan, flowtime, tardiness, maximum tardiness, and tardy jobs) under lognormal, uniform, and exponential distributions of processing times. Hatami et al. [
17] addressed a parallel SFSP where products had components produced in different parallel flow shops. The authors developed a simheuristic that embeds an iterated local search algorithm to minimize the expected makespan and makespan percentiles. Marichelvam and Geetha [
49] considered uncertain processing times and machine breakdowns to minimize the makespan. To solve the problem, a hybridization of a firefly algorithm and a variable neighborhood algorithm was designed, demonstrating promising results with extensive computational experiments. Villarinho et al. [
50] proposed a simheuristic that integrates a biased randomized heuristic into a variable neighborhood descent with Monte Carlo simulation to maximize the expected payoff in an SFSP that considers stochastic processing times.
2.2. Robust FSP
Such as the studies on the SFSP, few studies have addressed the robustness for the FSP.
Table 1 presents the main characteristics of previous studies in this field. As the table shows, most of them studied the makespan as a single objective, and only three works addressed multiple objectives. These three studies included only one parameter under uncertainty conditions. While Liu et al. [
51] studied stochastic machine breakdowns, dynamic job arrivals, and unexpected job availability, Liao and Fu [
52] and Goli et al. [
53] considered uncertain processing times. It is important to note that none of these works simultaneously studied stochastic sequence-dependent setup times and stochastic processing times while considering robustness.
2.3. Multi-Objective FSP under Uncertainty Conditions
Few works have examined uncertainties simultaneously with multi-objective decisions in comparison with a single objective.
Table 2 presents the main characteristics of the studies performed in this area. Makespan, tardiness, and flowtime are the most analyzed measures, and earliness is not widely studied. In addition, stochastic setup times are not considered.
2.4. Qualitative Criteria
Within organizations, main processes have their own objectives, which are often in conflict. For instance, the objectives of marketing involve maximizing service levels and sales; procurement seeks the prioritization of products and order replenishment; and production and manufacturing aim to maximize throughput and minimize costs. That is why it is important to use an approach that takes into account all of these objectives simultaneously [
72]. In this context, production should consider marketing criteria (often qualitative) in the decision-making process in order to improve customer service and reduce conflicts between marketing and production [
73]. Among the marketing objectives, production planning is affected by the product importance and customer importance. Georgakopoulos and Mihiotis [
74] analyzed these two aspects in a distribution network design. Considering the product importance, aspects such as turnover, profit rate, image, and discount policies must be considered in order to categorize the product. With regard to customer importance, aspects such as turnover, image, and customer requirements must be considered in order to categorize the customer. For instance, González-Neira et al. [
10] included the customer importance in a hybrid FSP through the integral analysis method García Cáceres et al. [
75] based on stochastic multicriteria acceptability analysis Lahdelma et al. [
76].
The academic literature includes very few studies on scheduling problems that considered qualitative decision criteria. As stated above, Chang and Lo [
8] and Chang et al. [
9] proposed a multicriteria objective function that included qualitative aspects such as marketing considerations, the strategic importance of customers, and order profit/risk in a job shop environment with fuzzy parameters. Chang and Lo [
8] proposed a GA/TS approach hybridized with AHP, while Chang et al. [
9] examined an ant colony optimization with an AHP process to solve job shop problems. In our opinion, some possible reasons for the few studies on this research topic are the lack of objectivity while measuring these metrics and the difficulty of having unbiased indicators.
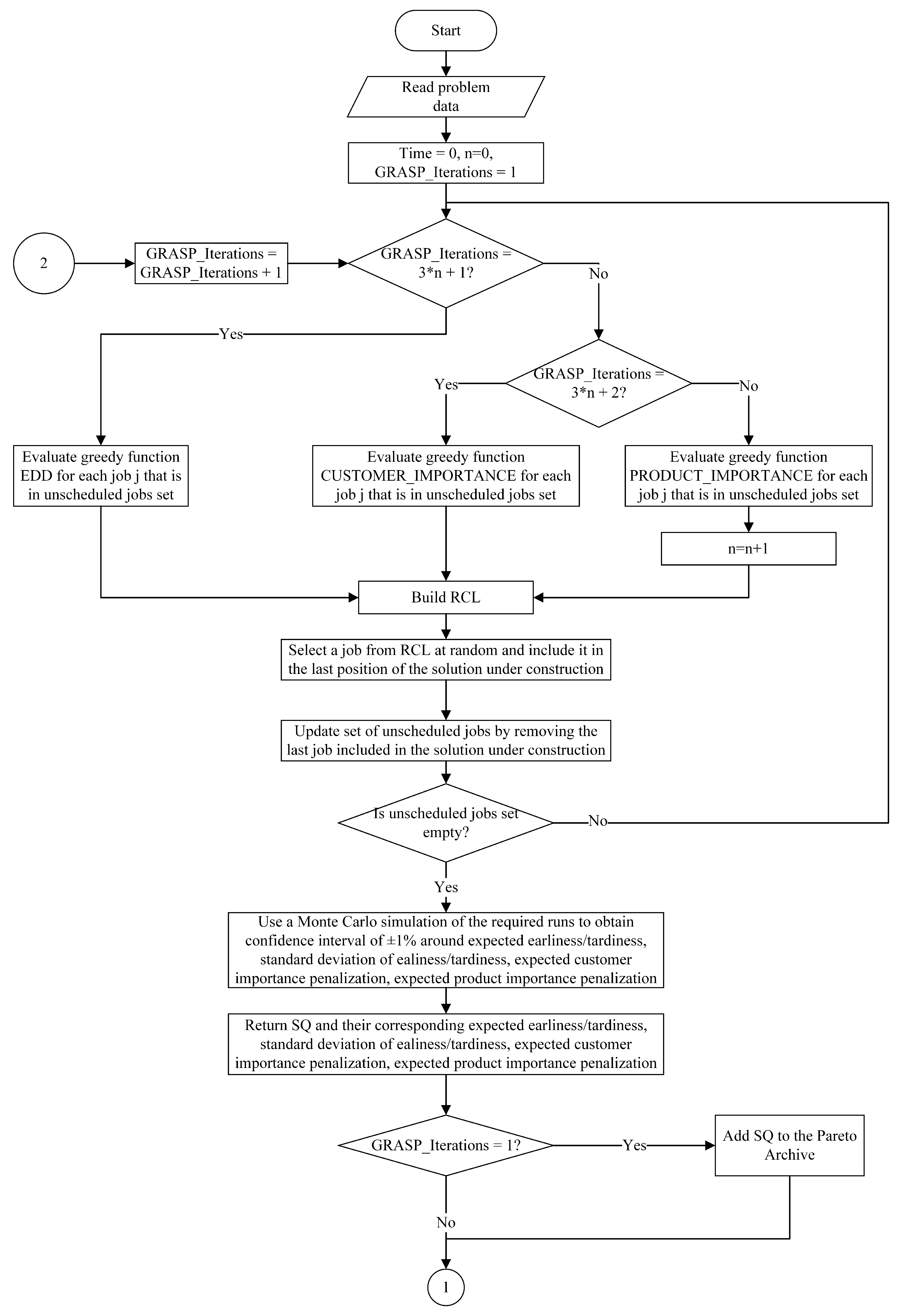
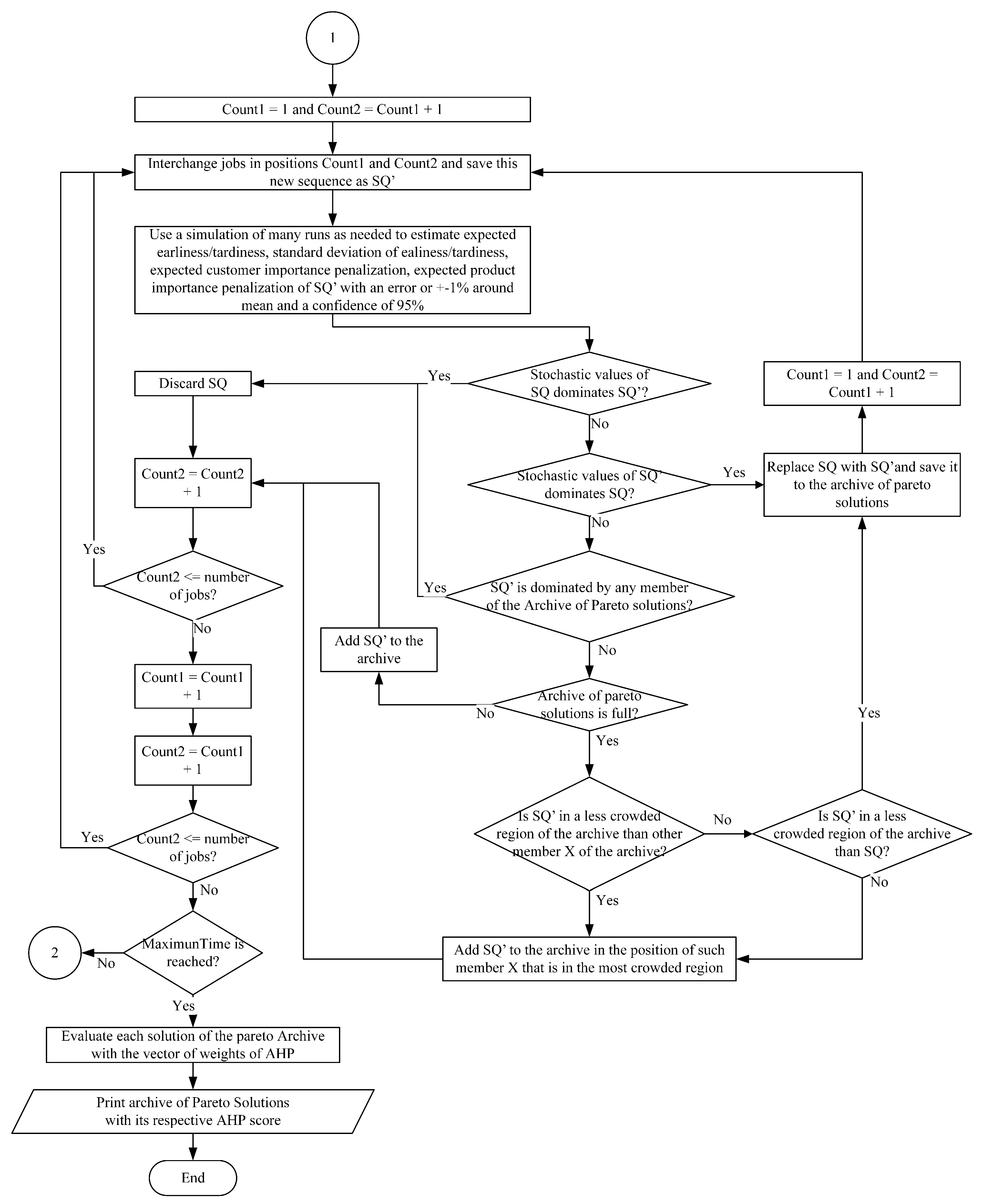
4. Computational Experiments and Statistical Analysis
For experimentation purposes, a set of 180 benchmark instances proposed by Ciavotta et al. [
21] were selected to evaluate the effects of different probability distributions (PDs) and coefficients of variation (CVs) of the processing and setup times in the objective functions. Specifically, the 180 instances were 10 instances for each combination of 20, 50, and 100 jobs with 5, 10, and 20 machines and a size of sequence-dependent setup times of 50% and 125%. Two PDs, lognormal, uniform, and three CVs, 0.3, 0.4, and 0.5, were selected to model both the stochastic processing and setup times. This corresponds to 6480 NDS archives. The proposed method was implemented in Java and run on an Intel Core i7-4770 with a 3.4 GHz processor and 8 GB of RAM. The stopping criterion for MC-SIM-GRASP was established as
. The best-qualified solution of each NDS archive was selected by using the AHP method. This results in a total of 51,840 solutions, each of which has an AHP score and a value for the four objective functions. Four ANOVAs were conducted to jointly analyze the effect of the eight factors on the four selected objective functions (E[E/T], SD[E/T], E[CI], and E[PI]). The factors selected for the experimental design are: probability distribution of processing times (PDPT), coefficient of variation of processing times (CVPT), probability distribution of setup times (PDST), coefficient of variation of setup times (CVST), the vectors of criteria weights of the AHP (WV), number of jobs, number of machines, and generation size of the standard deviation of sequence-dependent setup times (SDST). The factors and their levels are presented in
Table 7.
The results showed that all main effects are statistically significant on the four objective functions except PDPT for E[CI] and E[PI] and the PDST and CVST for E[PI]. Nevertheless, some double and triple interactions that include the PDPT, PDST, and CVST have a significant effect on E[CI] and E[PI]. In fact, for at least one of the four objective functions, the double interaction effects are also significant (see
Table 8). This shows that the WV discriminates among the Pareto solutions, helping the decision-maker select a solution from the Pareto frontier. We identified in addition that as the CVPT and CVST increase, the expected value of earliness (E[E/T]) and the standard deviation of earliness tardiness indicator (SD[E/T]) augment as well. The same occurs with E[CI], but not to the same degree. Additionally, the measures tend to be greater for the lognormal distribution than for the uniform distribution. This shows the importance of accurately fitting the PD to obtain adjusted robust measures.
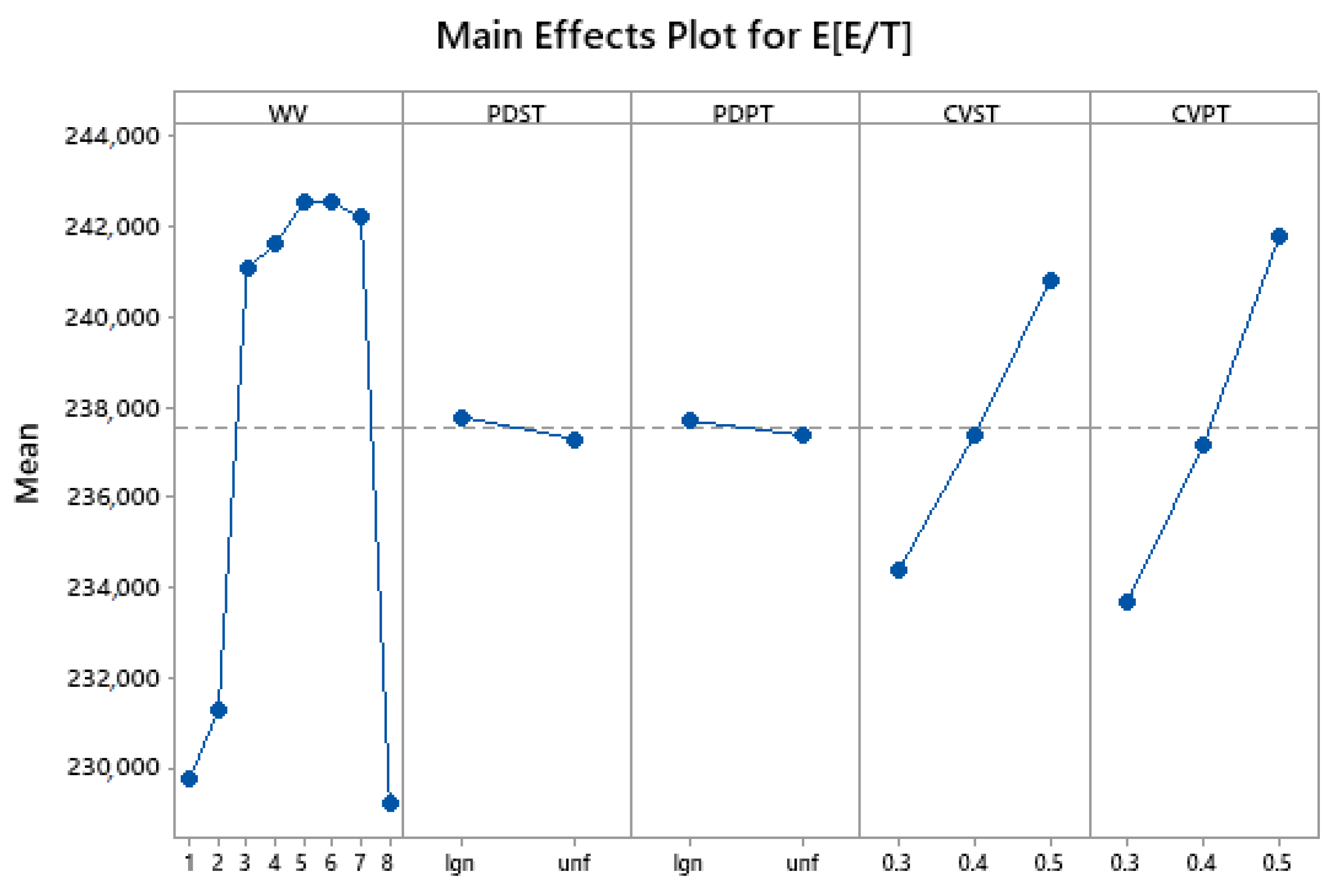
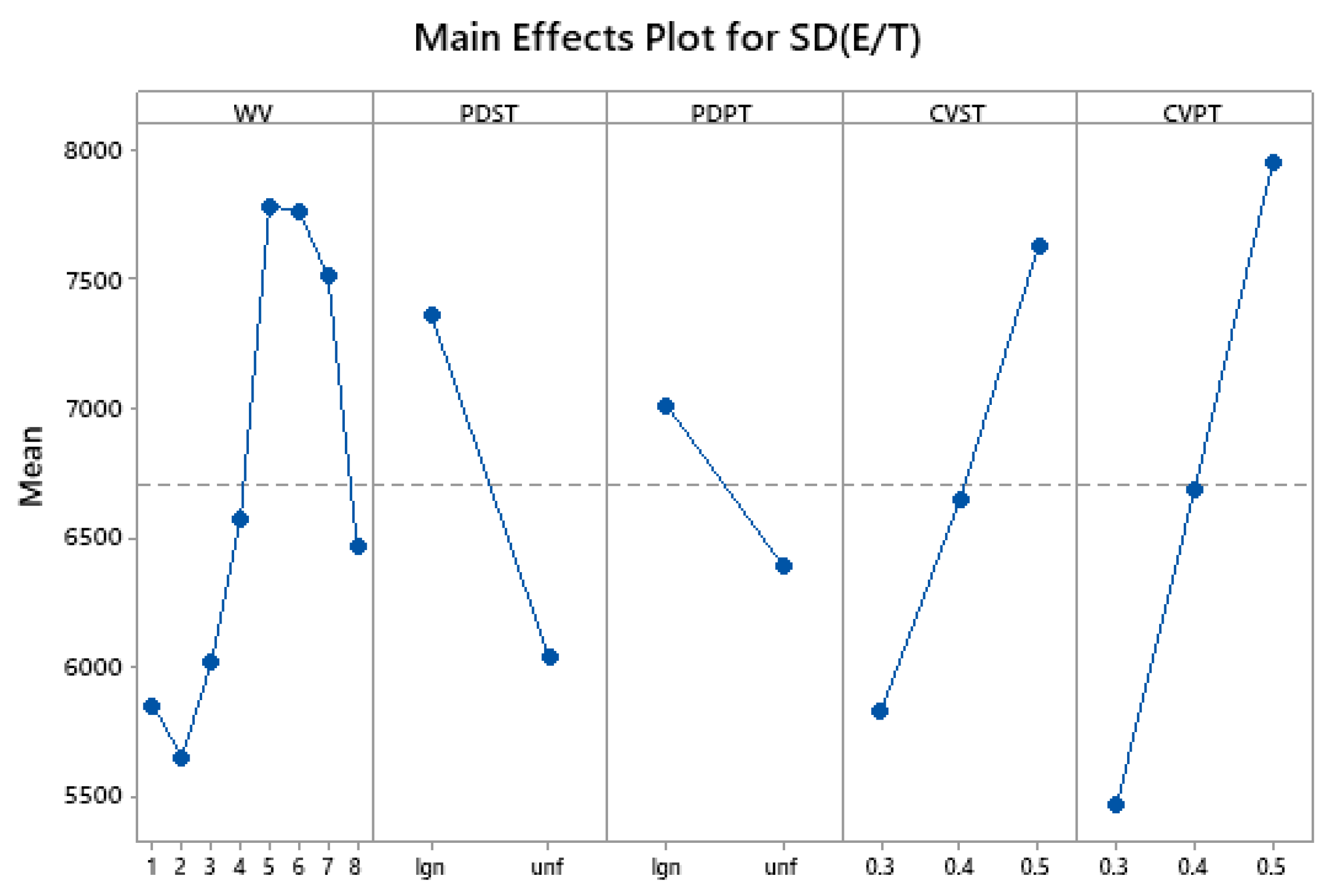
Figure 3 and
Figure 4 show the main effect plots of the factors WV, PDST, PDPT, CVST, and CVPT on E[E/T] and SD[E/T], respectively. The axes of the main effect plots are the levels of each factor. It can be seen that for different weight vectors, the objectives E[E/T] and SD[E/T] imply that the AHP is capable of selecting a different solution of the Pareto frontier according to the preferences given by the decision-maker in the AHP method. In the case of the probability distributions (the PDST and PDPT factors), the lognormal distribution presents a slightly greater E [E/T] and SD[E/T] in comparison with the uniform distribution, which gives the idea that despite using the same expected values of the processing and setup times under the same coefficient of variation, the solutions vary with the change of the distribution used. Additionally, as expected, as the coefficient of variation of the setup and the processing times increase (the CVST and CVPT factors) the objectives E[E/T] and SD[E/T] also increment, indicating a higher variability in the obtained solutions of the Pareto frontier. These aspects led us to highlight the importance of including uncertainty in the optimization problem when it is really present, and the value of making an accurate distribution fitting to make adequate decisions.
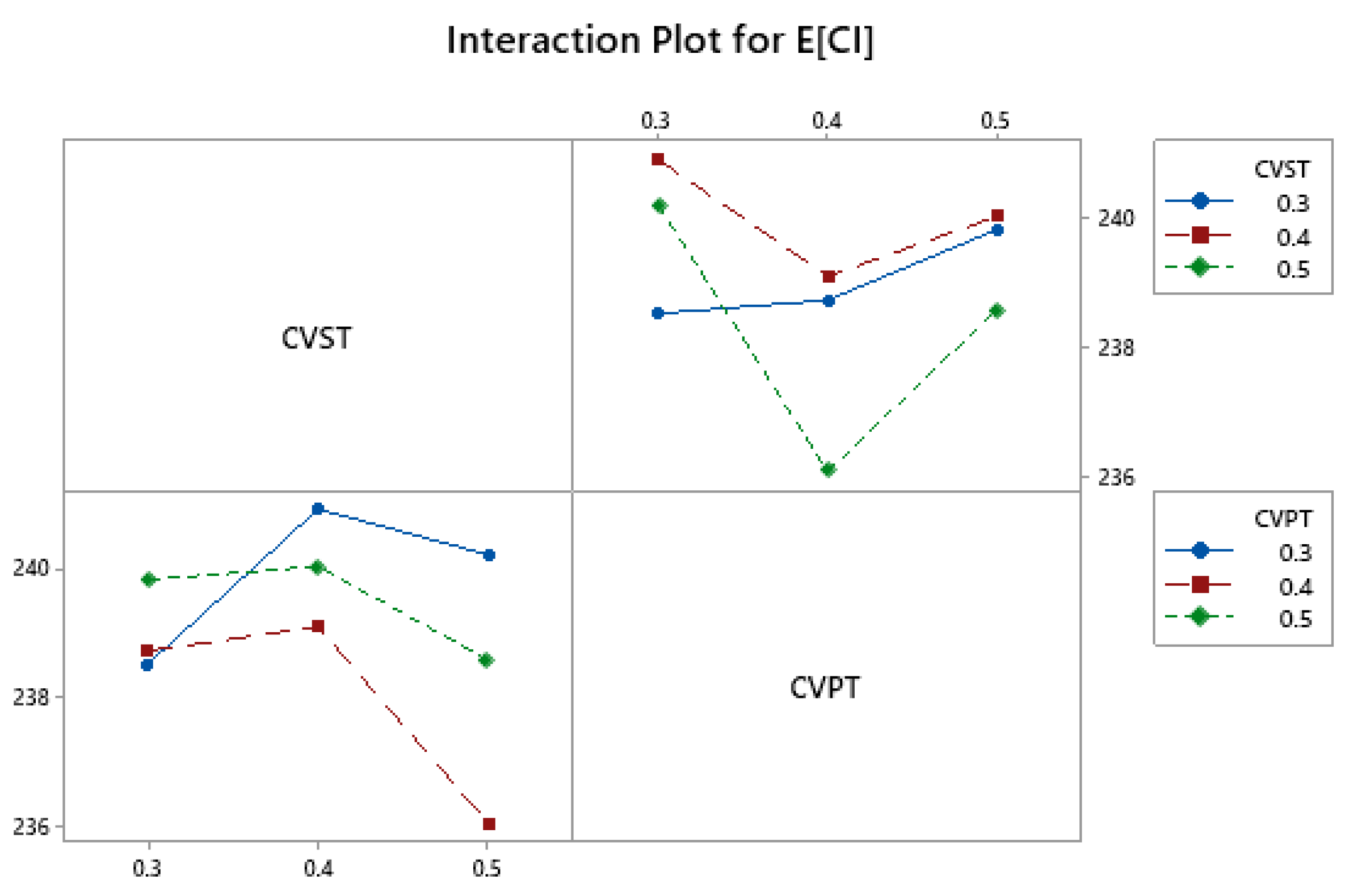
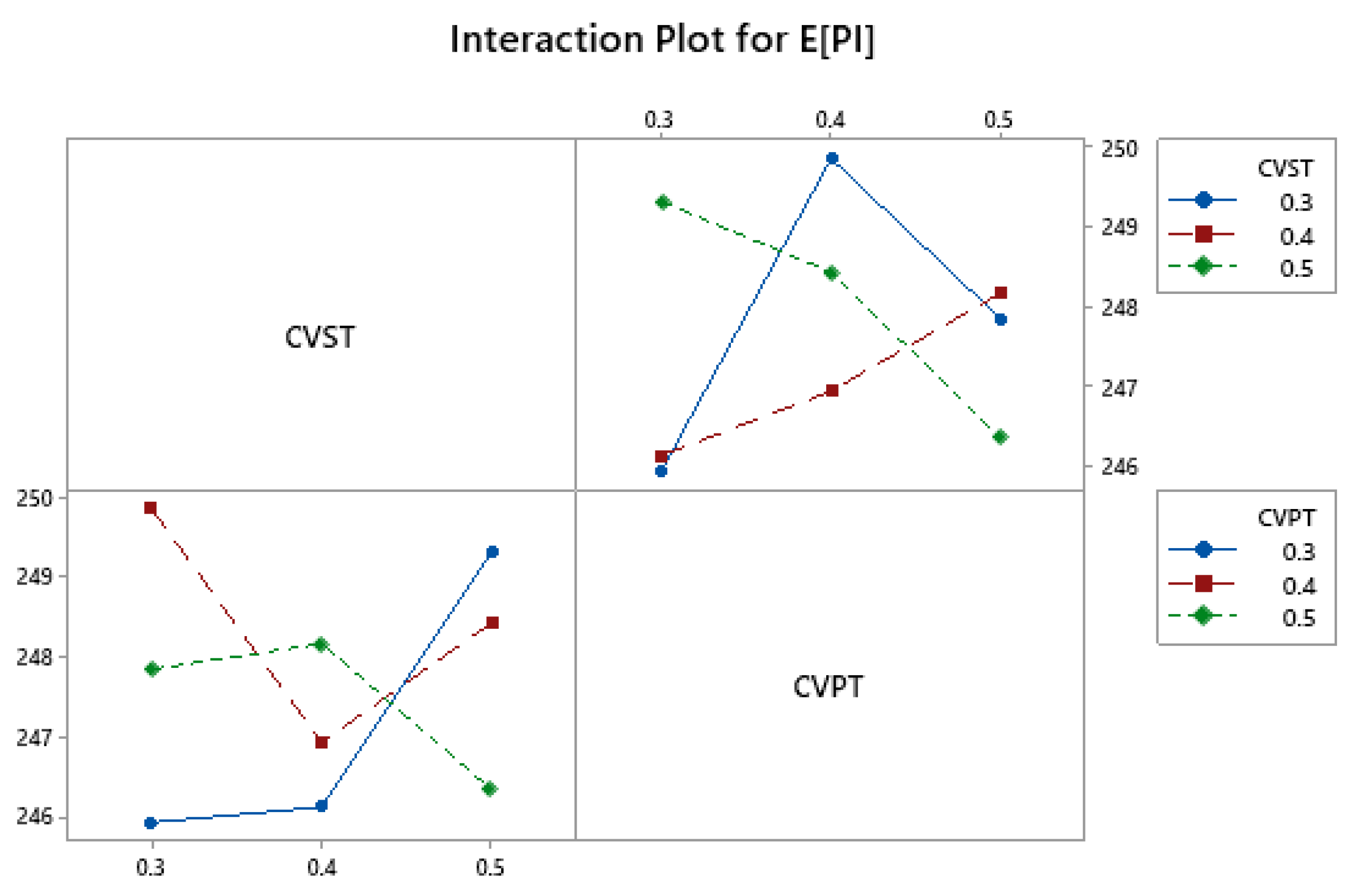
Figure 5 and
Figure 6 present the interaction plots between factors CVST and CVPT for the E[CI] and E[PI] objectives, respectively. The axes of the plots are the levels of the coefficients of variation. These plots confirm that for both qualitative objectives, there exists an interaction effect between the coefficients of variation of the processing times (CVPT) and the coefficients of variation of the setup times (CVST), which means that the best solution selected with the AHP method, in terms of the qualitative criteria, varies depending on the variability of the processing and setup times. This leads again to the relevance of including uncertainties in the optimization process and the execution of an accurate distribution fitting.
To conduct the experimental design and validate the validity and objectivity, the assumptions of homoscedasticity, normality, and independence were tested. Because the homoscedasticity and normality tests were not fulfilled, we performed a Friedman test to corroborate the ANOVA results.
Table 9 and
Table 10 present the detailed Friedman tests for E[E/T] and SD[E/T] in terms of the factors PDPT, CVPT, PDST, and CVST. To the best of our knowledge, this is the only work that has studied these four objective functions in an SPFSP. We present three indicators for the multi-objective problems proposed by Ebrahimi et al. [
80] and Karimi et al. [
81], which can be used for future comparisons. For this work, these indicators were adjusted for the four objective functions analyzed:
Table 11,
Table 12 and
Table 13 show the averages of the NPS, MID, and SNS for each instance size, each combination of the PDPT with CVPT, and each combination of the PDST with CVST, respectively. In
Table 11, it can be seen that the MID and SNS increase as the number of jobs or machines increases, and due to the increment of the jobs or machines, the expected and standard deviation of tardiness present a crescent behavior. Moreover, the NPS also tends to augment, giving more possible solutions to chose in scenarios with higher variability.
Table 12 shows the minimum difference in the MID and SNS between the lognormal and uniform distributions for the processing times, under the same coefficient of variation. Nevertheless, as the coefficient of variation of the processing times increases, independently of the probability distribution, the MID and SNS augment. That means that the quality of the Pareto frontier is worse as the coefficient of variation of the processing times increases. This suggests that production managers should encourage a continuous improvement of the production processes to reduce the variability of the process insofar as that is possible. Moreover, it is interesting to see that the NPS decreases as the coefficient of variation of the processing times increments, showing that high variability scenarios present fewer possible solutions to choose for the decision-maker.
The measures presented in
Table 13 show a large difference in the SNS between the lognormal and uniform distributions of the sequence-dependent setup times, under the same coefficient of variation of the setup times, which is a different behavior than that presented for the coefficient of variation of the processing times. Moreover, the NPS also presents high differences between the uniform and lognormal distributions of the setup times, whereas for the coefficient of variation of the processing times, the NPS values were very close. This allowed us to conclude that each input parameter can cause different performances of the solutions, and thus, the AHP selects the corresponding solution of the Pareto frontier to fulfill the decision-maker’s expectations.
5. Conclusions and Recommendations
This paper presented a multicriteria simheuristic that hybridizes a GRASP, a PAES algorithm, and a Monte Carlo simulation (MC-SIM-GRASP) to solve a multi-objective stochastic permutation flow shop scheduling problem (SPFSP). The approach obtains a set of nondominated solutions for four objectives: for expected earliness/tardiness, standard deviation of earliness/tardiness, expected customer importance, and expected product importance in an SPFSP. It was used an analytical hierarchical process (AHP) to select the desired solution for the decision-maker from the set of solutions from the Pareto frontier. The purpose of this method was to ease the selection of a solution and include a qualitative criterion for the objective of the decision-making. This paper analyzed the effect of eight factors in the behavior of the four objective functions selected. To this end, four ANOVAs were carried out with seven factors: type of probability distribution (PD) of stochastic processing times, coefficient of variation (CV) of stochastic processing times, PD of sequence-dependent setup times, CV of sequence-dependent setup times, the vector weights of criteria in the AHP methodology, the number of jobs, and the number of machines. The outcomes showed that all factors had significant effects on the four objective functions. The results obtained in this paper support the importance of including uncertainty, modeled with adequate PDs, to obtain robust solutions. Additionally, a set of multi-objective metrics (number of Pareto solutions, means’ ideal distance, and spread of the nondominance solution) was calculated for future comparisons, as this problem has not been solved in the literature before. Future work may analyze other PDs and CVs. It would be useful to analyze a case in which the processing time PD of each job has a different CV, which is generally true in real cases. Finally, other qualitative criteria should be incorporated in the analysis.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}