
Efficient Construction of the Equation Automaton


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminaries
2.1. Regular Expressions and Finite Automata
2.1.1. Regular Expressions and Languages
- ,
- ,
- E is in Star-Normal Form (SNF) [16].
2.1.2. Finite Automata and Recognizable Languages
- (final and non-final states are not ∼-equivalent),
- for any , , if , then .
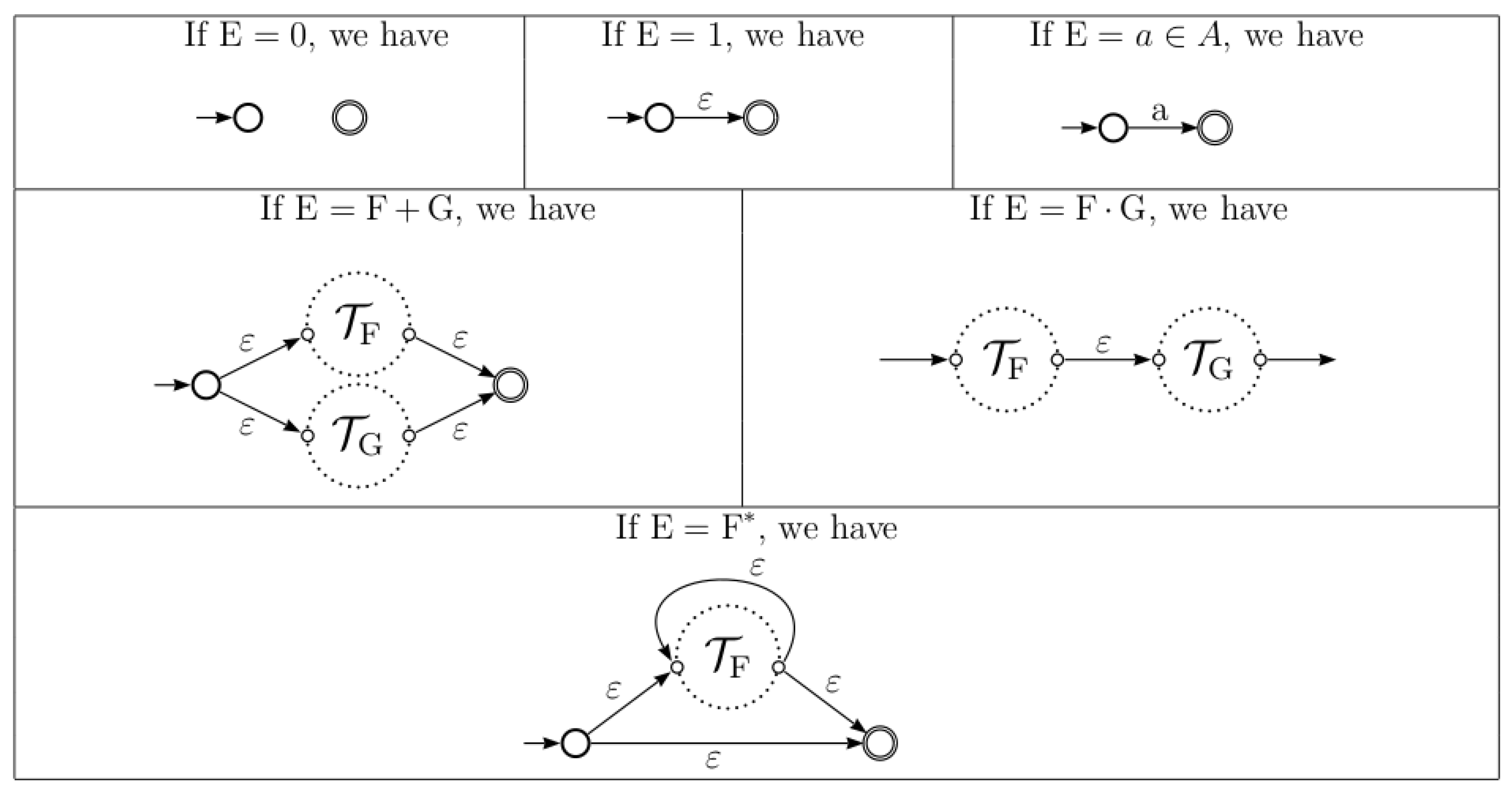
2.2. Thompson Automaton
3. Equation Automaton
- ,
- .
3.1. C-Continuation Automaton
- ,
- ,
- ,
- .
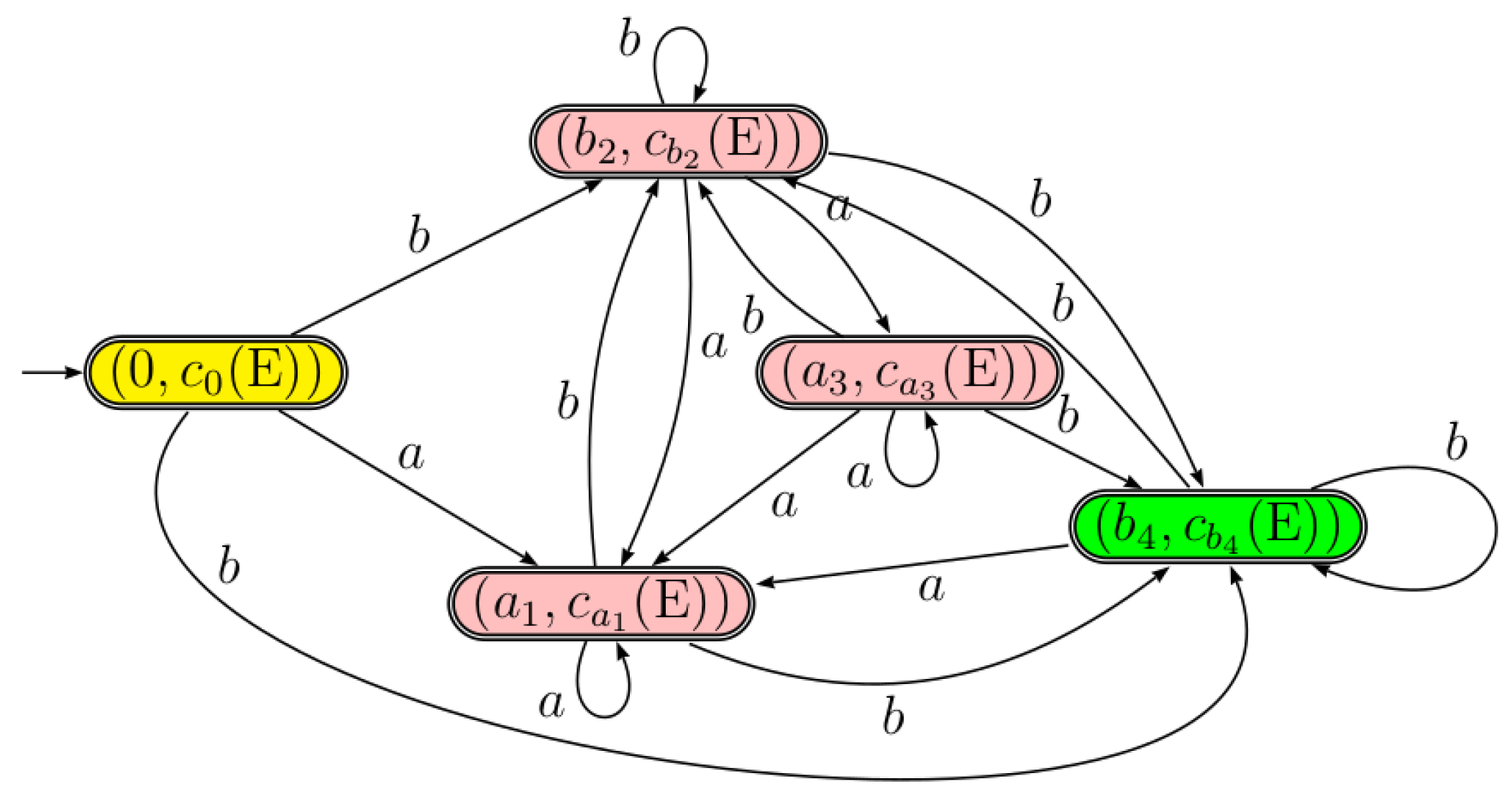
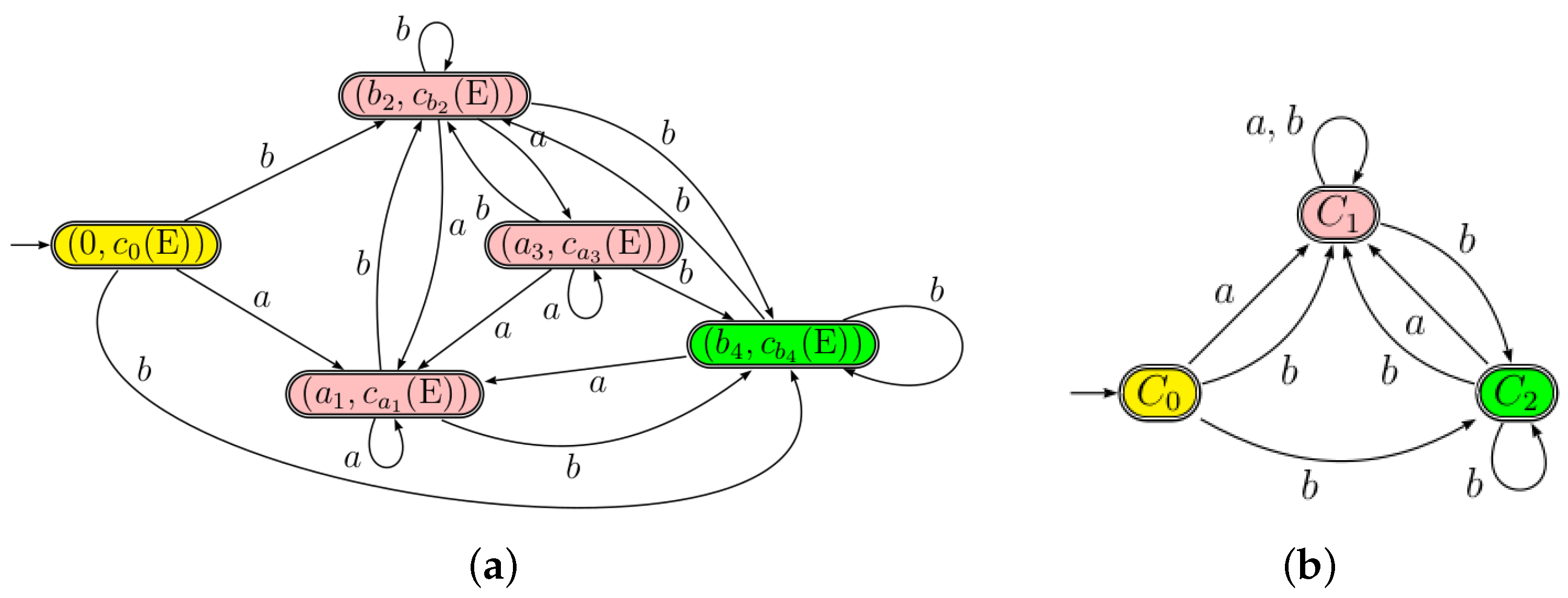
3.2. Equation Automaton as a Quotient of C-Continuation Automaton
- ,
- ,
- ,
- .
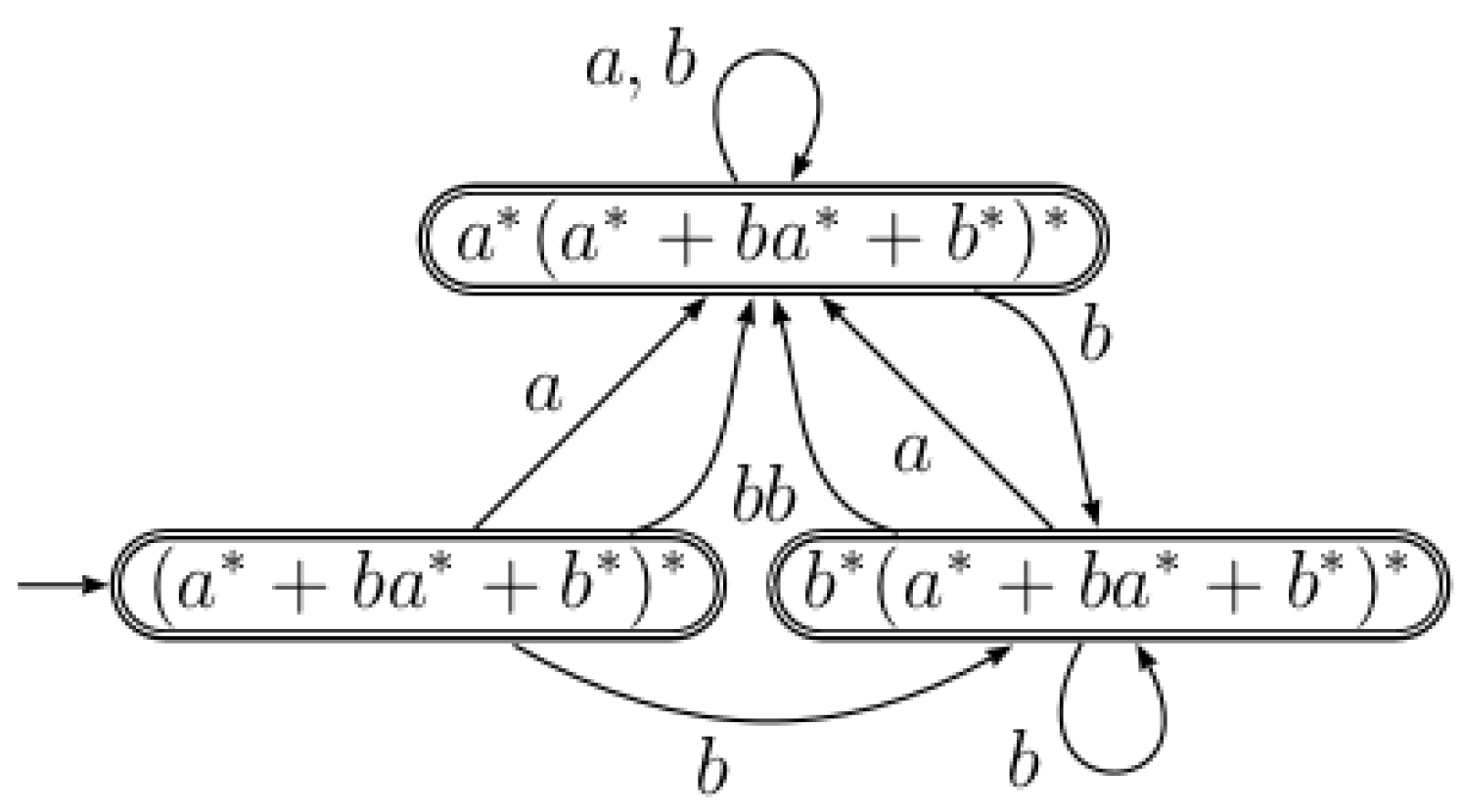
4. Allauzen and Mohri’s Algorithm

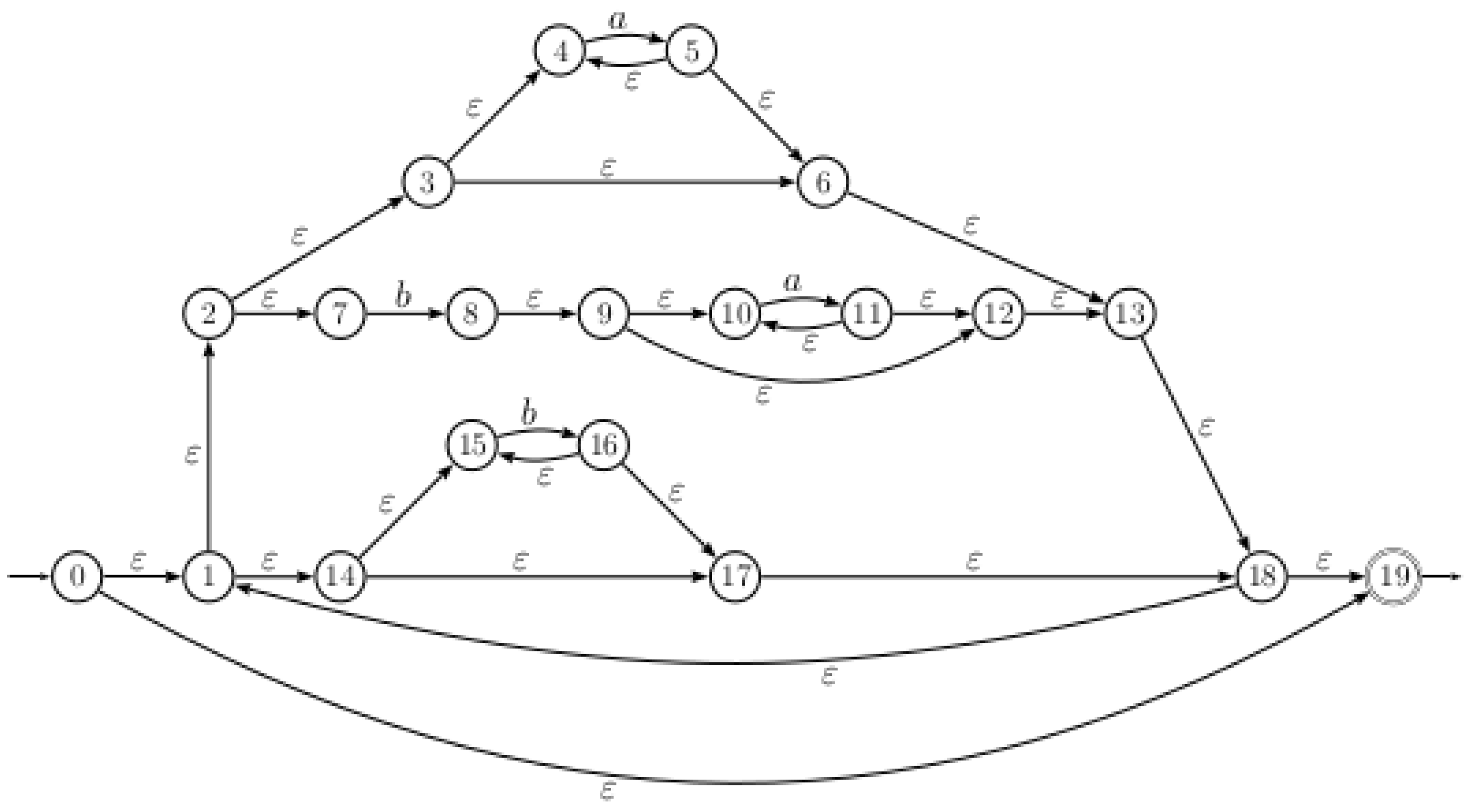
5. Efficient Conversion Algorithm
| Algorithm 1 Computation of the equation automaton. |
| input: The Thompson automaton associated with a regular expression E. output: The equation automaton associated with E. /* Computation of states */ |
| Compute ): |
 |
| Compute : |
| • Compute pseudo-continuations for all position states of . • Merge equivalent states having the same pseudo-continuation. /* Computation of transitions and final states /* |
| Compute : |
| • Perform epsilon removal operation using function over . |
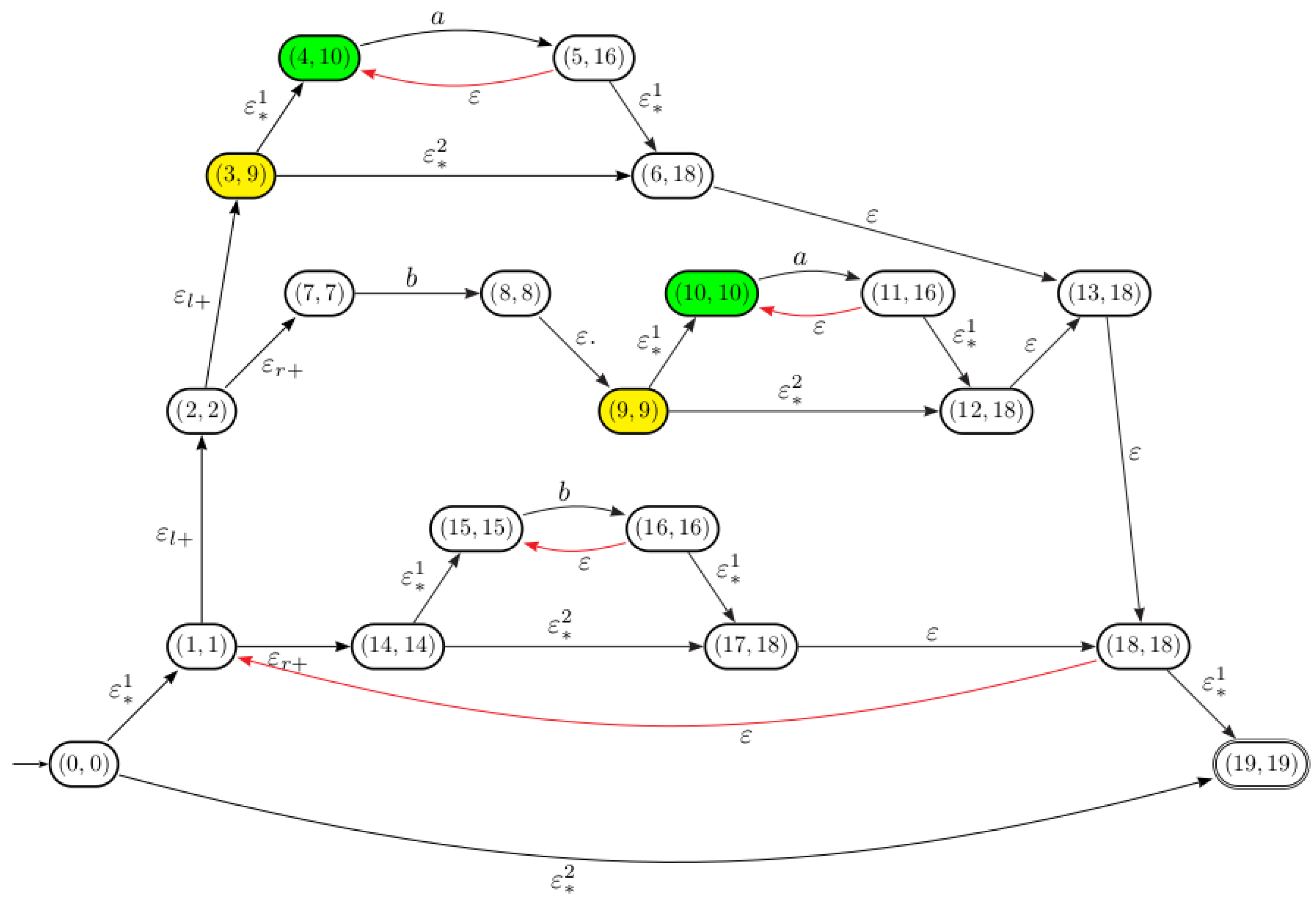
5.1. Computation of States
5.1.1. Sub-Expressions Identification
- where l (resp. r), denote left (resp. right),
- , i.e., a state in is augmented by the letter .
- The transition function is defined over the Thompson automaton as follows:

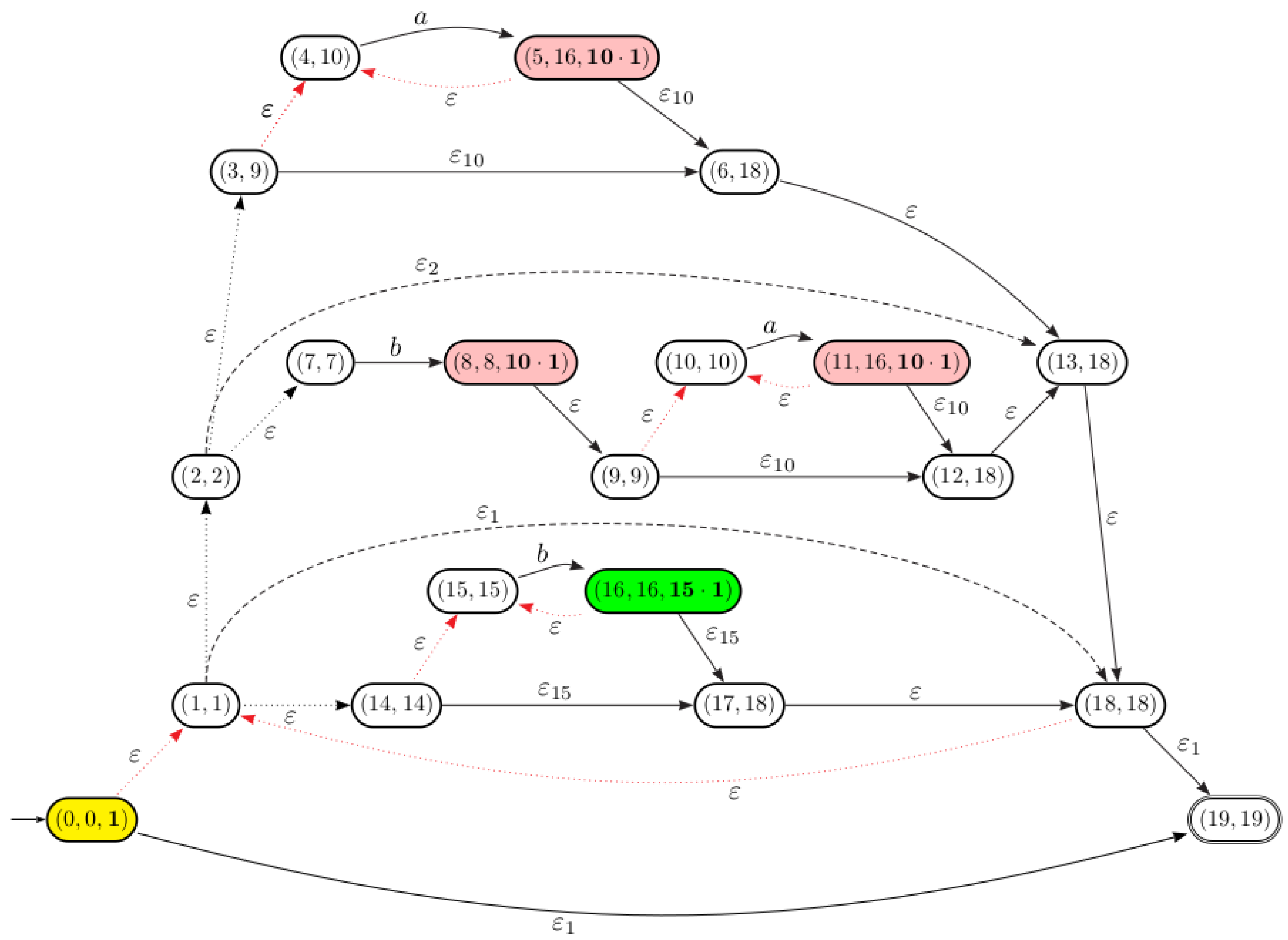
5.1.2. -Equivalent States Merging
- .
- , i.e., a state in is replaced by .
- The transition function is defined as follows:

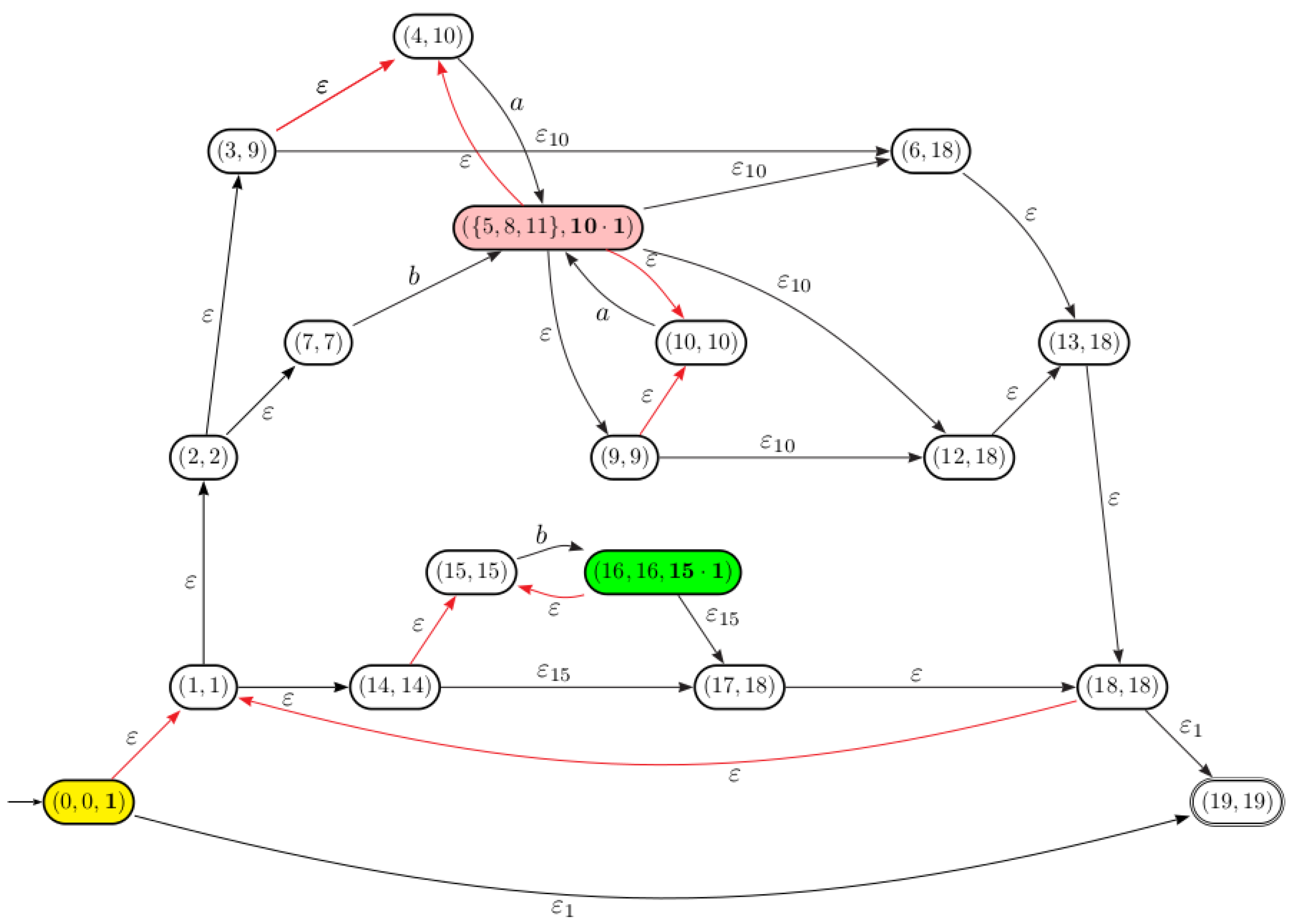
5.2. Computation of Transitions and Final States
- The set of states of the equation automaton are .
- Since the final state of is the state 19 and , , and , then the set of final states are .
- There are two paths in from the state 0 to the state labeled respectively by and , then . Consequently, two transitions and are added to the equation automaton. The same process will be applied for other transitions.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mirkin, B.G. Novyj algoritm postroéniá bazisa v ázyké régularnyh vyražénij. Izvéstiá Akadémii Nauk SSSR. Engineering cybernetics, no. 5 (1966). English translation of the preceding: Brzozowski, J. An algorithm for constructing a base in a language of regular expressions. pp. 110–116. J. Symb. Log. 1971, 36, 694. [Google Scholar]
- Antimirov, V. Partial derivatives of regular expressions and finite automaton constructions. Theor. Comput. Sci. 1996, 155, 291–319. [Google Scholar] [CrossRef] [Green Version]
- Glushkov, V.M. The abstract theory of automata. Russ. Math. Surv. 1961, 16, 1–53. Available online: https://iopscience.iop.org/article/10.1070/RM1961v016n05ABEH004112 (accessed on 27 May 2021). [CrossRef]
- McNaughton, R.F.; Yamada, H. Regular expressions and state graphs for automata. IEEE Trans. Electron. Comput. 1960, 9, 39–57. [Google Scholar] [CrossRef]
- Ziadi, D.; Ponty, J.-L.; Champarnaud, J.-M. A New Quadratic Algorithm to Convert a Regular Expression into an Automaton. In Proceedings of the Workshop on Implementing Automata, London, ON, Canada, 29–31 August 1996; pp. 109–119. [Google Scholar]
- Champarnaud, J.-M.; Ziadi, D. Canonical derivatives, partial derivatives and finite automaton constructions. Theor. Comput. Sci. 2002, 289, 137–163. [Google Scholar] [CrossRef] [Green Version]
- Khorsi, A.; Ouardi, F.; Ziadi, D. Fast equation automaton computation. J. Discret. Algorithms 2008, 6, 433–448. [Google Scholar] [CrossRef] [Green Version]
- Allauzen, C.; Mohri, M. A Unified Construction of the Glushkov, Follow, and Antimirov Automata. In Proceedings of the International Conference of Mathematical Foundations of Computer Science, Stará Lesná, Slovakia, 28 August–1 September 2006; pp. 110–121. [Google Scholar]
- Ilie, L.; Yu, S. Follow automata. Inf. Comput. 2003, 186, 140–162. [Google Scholar] [CrossRef] [Green Version]
- Champarnaud, J.-M.; Nicart, F.; Ziadi, D. From the ZPC Structure of a Regular Expression to its Follow Automaton. IJAC 2006, 16, 17–34. [Google Scholar] [CrossRef]
- Kleene, S. Representation of Events in Nerve Nets and Finite Automata; Automata Studies, Ann. Math. Studies 34; Princeton University Press: Princeton, NJ, USA, 1956; pp. 3–41. [Google Scholar]
- Thompson, K. Regular Expression Search Algorithm. Commun. ACM 1968, 11, 410–422. [Google Scholar] [CrossRef]
- Hopcroft, J. An n log n Algorithm for Minimizing States in a Finite Automaton; Technical Report; Stanford University, CS Dept.: Stanford, CA, USA, 1971. [Google Scholar]
- Hopcroft, J.E.; Ullman, J.D. Introduction to Automata Theory, Languages and Computation; Addison-Wesley: Reading, MA, USA, 1979. [Google Scholar]
- Sakarovitch, J.; Thomas, R. Elements of Automata Theory; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Brüggemann-Klein, A. Regular expressions into finite automata. Theor. Comp. Sci. 1993, 120, 117–126. [Google Scholar] [CrossRef] [Green Version]
- Bubenzer, J. Cycle-aware minimization of acyclic deterministic finite-state automata. J. Discret. Appl. Math. 2014, 163, 238–246. [Google Scholar] [CrossRef]
- Revuz, D. Minimization of acyclic deterministic automata in linear time. Theor. Comput. Sci. 1992, 92, 181–189. [Google Scholar] [CrossRef] [Green Version]
- Giammarresi, D.; Ponty, J.-L.; Wood, D.; Ziadi, D. A characterization of Thompson digraphs. Discret. Appl. Math. 2004, 134, 317–337. [Google Scholar] [CrossRef]
- Myhill, J. Finite automata and the representation of events. In WADD TR-57-624; Wright Patterson AFB: Dayton, OH, USA, 1957; pp. 112–137. [Google Scholar]
- Nerode, A. Linear automata transformation. Proc. AMS 1958, 9, 541–544. [Google Scholar] [CrossRef]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouardi, F.; Lotfi, Z.; Elghadyry, B. Efficient Construction of the Equation Automaton. Algorithms 2021, 14, 238. https://doi.org/10.3390/a14080238
Ouardi F, Lotfi Z, Elghadyry B. Efficient Construction of the Equation Automaton. Algorithms. 2021; 14(8):238. https://doi.org/10.3390/a14080238
Chicago/Turabian StyleOuardi, Faissal, Zineb Lotfi, and Bilal Elghadyry. 2021. "Efficient Construction of the Equation Automaton" Algorithms 14, no. 8: 238. https://doi.org/10.3390/a14080238
APA StyleOuardi, F., Lotfi, Z., & Elghadyry, B. (2021). Efficient Construction of the Equation Automaton. Algorithms, 14(8), 238. https://doi.org/10.3390/a14080238