
PFSegIris: Precise and Fast Segmentation Algorithm for Multi-Source Heterogeneous Iris


Abstract
:1. Introduction
- Different from traditional methods and other iris segmentation algorithms based on deep learning, a more precise segmentation algorithm, PFSegIris, was designed to segment multi-source heterogeneous irises without any preprocessing or postprocessing. We proved that accurate iris segmentation can be realized for images with heterogeneous spectra (visible and near-infrared), different iris region sizes, and uneven quality.
- While ensuring accuracy, PFSegIris is lightweight, significantly reducing the number of parameters, storage space, and calculations in comparison with other methods, and the average prediction time on seven heterogeneous databases was less than 0.10 s, which is a fast iris segmentation algorithm. In addition, the algorithm proposed can be applied to devices with low computing performance and storage capacity.
2. Methods
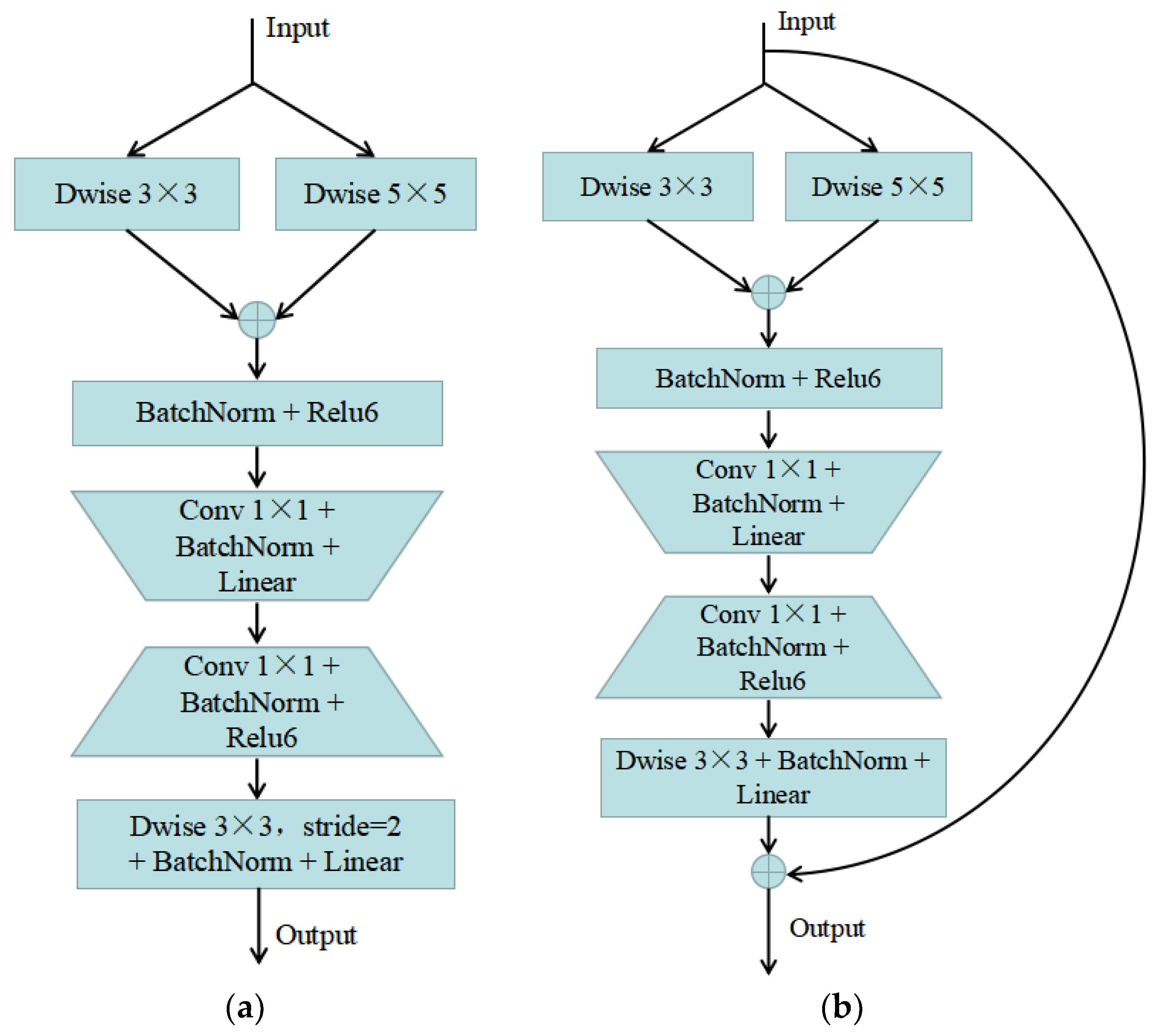
- An original iris image was directly input to the network model without any preprocessing. The encoder downsampled the image until it could be represented by its tiny features, which can fully constitute iris information of various sizes.
- The parallel position–channel attention mechanism was used to enhance the feature representation of iris region and suppress the influence of noise on iris segmentation.
- The decoder upsampled the iris image to its original dimensions and predicted the pixels of the iris region and the non-iris region.

2.1. Encoder
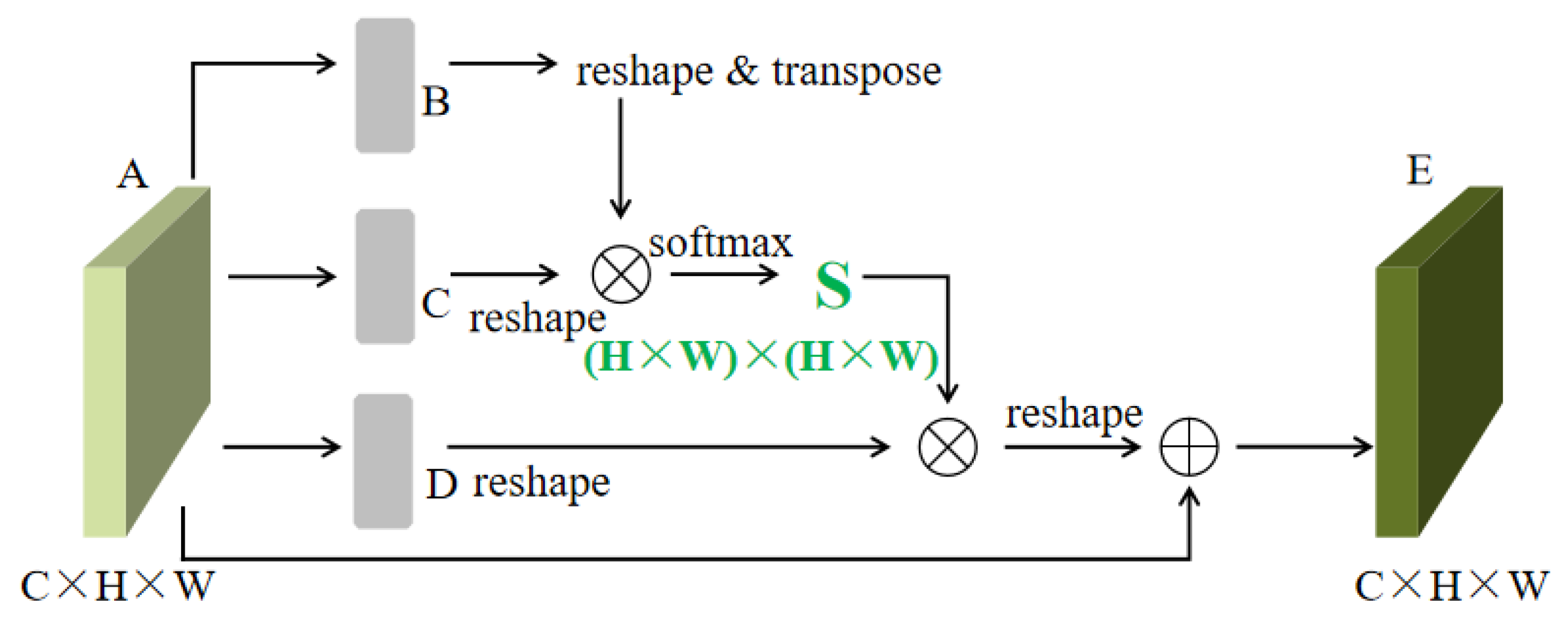
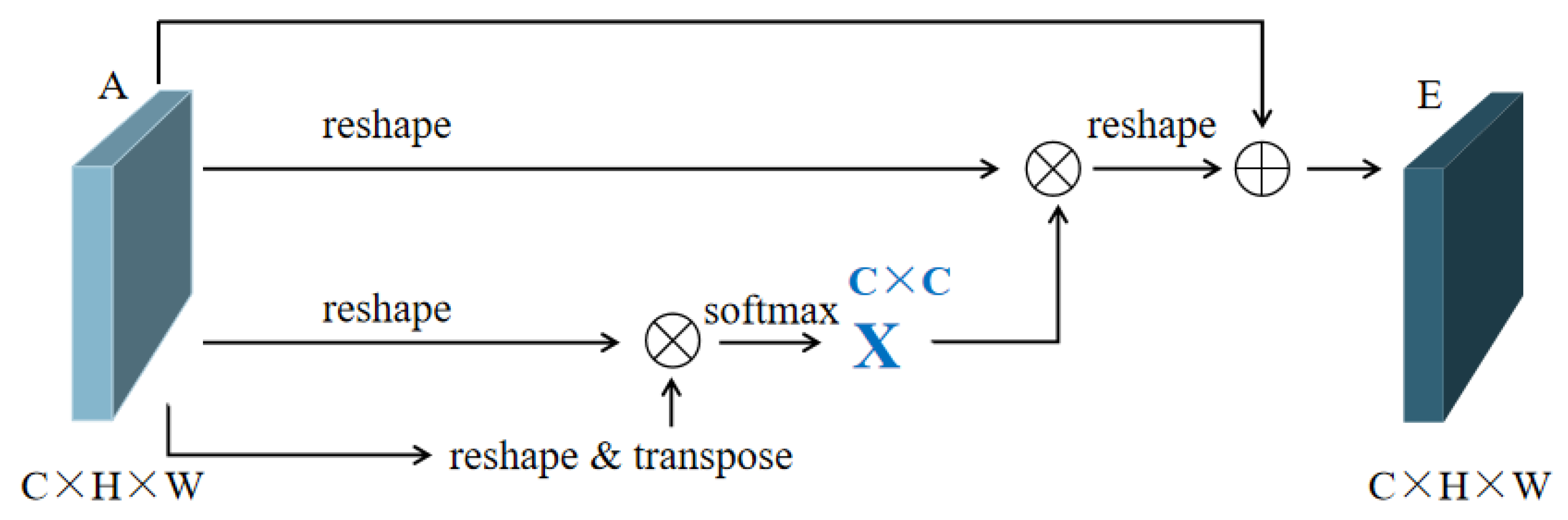
2.2. Parallel Dual Attention Mechanism
- due to the influence of different factors such as spectra and noises, the prediction results of some pixels are likely to be affected; and
- the sizes of the iris regions collected by different devices differ greatly, but the features of different scales should be treated equally.
2.2.1. Position Attention Module (PAM)
2.2.2. Channel Attention Module (CAM)
2.3. Decoder
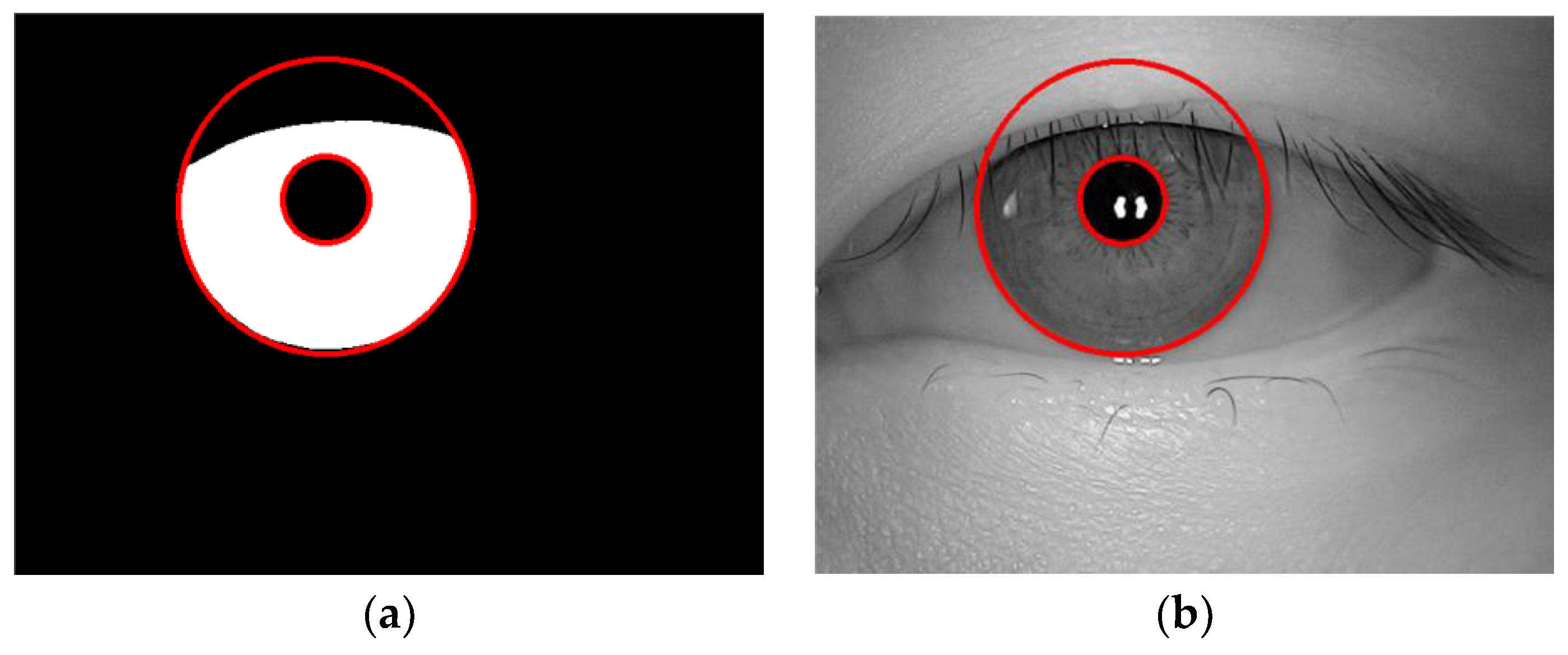
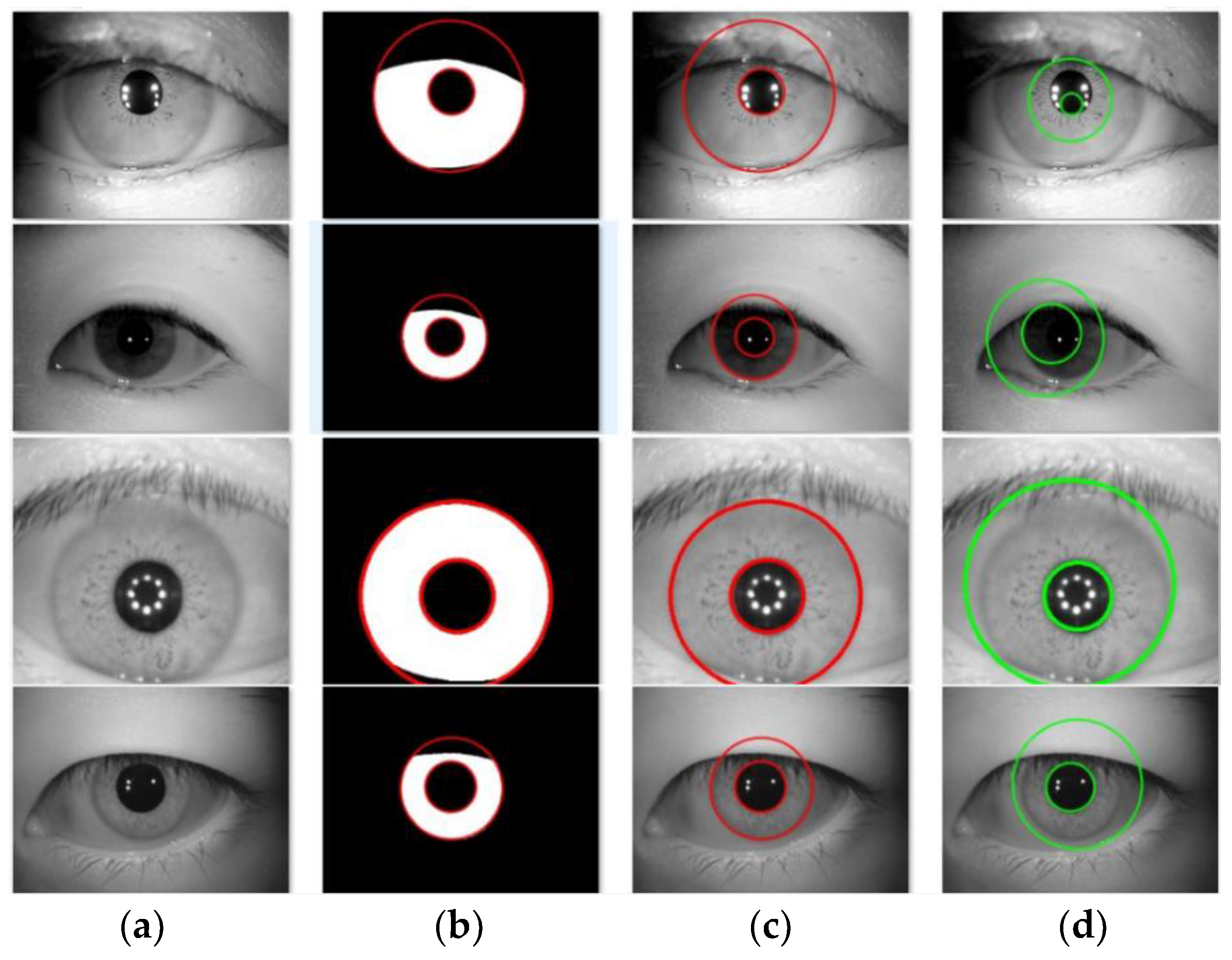
2.4. Positioning of Iris Inner and Outer Circles
3. Experiments and Analysis
3.1. Experimental Details
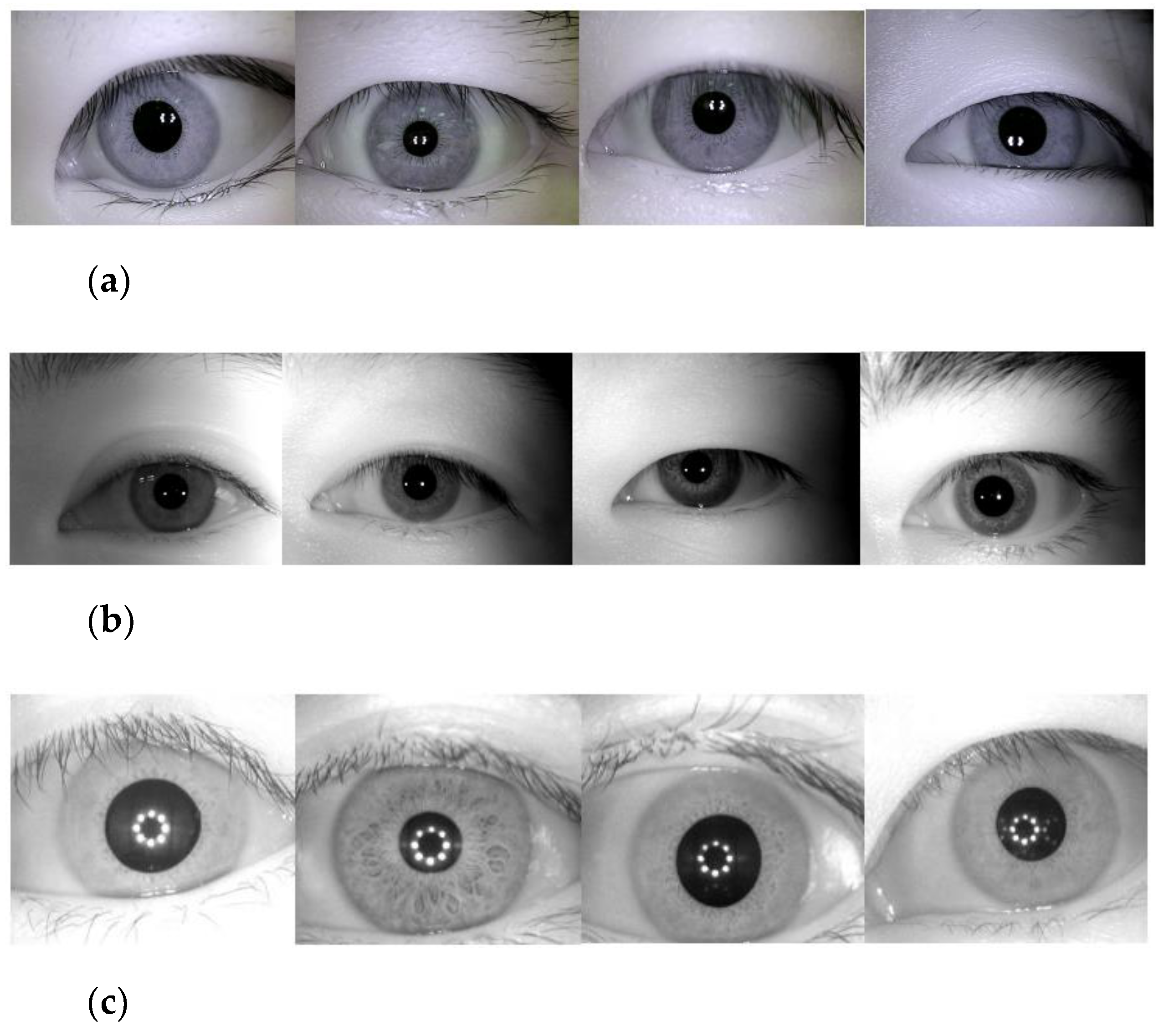
3.2. Iris Datasets and Data Augmentation
- The JLU-6.0 iris dataset is characterized by large iris regions with various quality iris images, taken at close range and in near-infrared light. We selected 100 classes for the experiments. After data augmentation, the total number of images used was 10,006, of which the training set contained 7004 images, the validation set contained 2001 images, and the test set contained 1001 images.
- The JLU-7.0 iris dataset has smaller iris regions compared with JLU-6.0 iris dataset and also has various quality iris images taken at close range and in near-infrared light. In all, 78 classes were selected for experiments, and after data augmentation, the total number of images was 986 for the test set entirely.
- The iris images from the CASIA-Iris-Interval-v4 iris dataset are of high quality, with detailed features of the iris clearly visible, taken at close range and in near-infrared light. Overall, 120 classes were selected. A total number of 960 images were used after augmentation, all of which were used for testing.
- The CASIA-Iris-Lamp-v4 iris dataset intentionally introduced ambient lighting variations, acquiring iris images with non-linear deformation. Since most of irises are from Orientals, the iris regions are heavily obscured by the upper and lower eyelids and eyelashes. Images were taken at close range and in visible light. We chose 120 classes for experiments. There were totally 9600 images after data augmentation, of which the training set contained 6720 images, the validation set contained 1920 images, and the test set contained 960 images.
- The UBIRIS.V2 iris dataset introduced more noises such as defocus blur, contact lens occlusion, and hair occlusion, taken at long distance and in visible light. From this dataset, 100 classes were selected. After data augmentation, 1000 images were used for the test set.
- The main feature of the MICHE-I iris dataset is that it was acquired by mobile devices, containing more realistic noises. Most of images were obtained under unconstrained conditions, closer to realistic situations. We used 75 classes and 9360 images totally after augmentation. The training set contained 6552 images, the validation set contained 1872 images, and the test set contained 936 images.
- The Mmu2 iris dataset has iris images from people of different races and ages in Asia, the Middle East, Africa, and Europe; with pupil spots, hair, eyelashes, eyebrows, and other noises; taken at close range and in near-infrared light. After augmentation, 974 iris images were all used for testing with 100 classes.


- Randomly flip horizontally with the probability of 0.5.
- Randomly rotate within a certain angle with the probability of 0.8. The rotation angle we used was a maximum of 30 degrees to the left and right.
- Randomly resize with the probability of 0.8. Four different scales of 0.5, 0.75, 1.25, and 1.5 times of the original images were used.
- Randomly enhance the brightness and contrast with the probability of 0.5. The values that define the minimum and maximum adjustment of image brightness were 0.5 and 1.5. The values that define the minimum and maximum adjustment of image contrast were 0.5 and 1.
3.3. Evaluation Indexes
- mIoU (mean Intersection over Union) is a commonly used performance index in semantic segmentation, which is the average of the ratio of the intersection and union of the two sets of real and predicted values. The value of mIoU is in the range of [0, 1]. The closer the value is to 1, the higher the accuracy of segmentation is. mIoU was calculated using Equation (5).where denotes the pixel whose real pixel is predicted to be , and denotes the pixel whose real pixel is i predicted to be . k + 1 is the number of classes.
- mPA (mean Pixel Accuracy) is a simple promotion of PA (Pixel Accuracy), which calculates the proportion of correctly classified pixels in each class and averages it over all classes. The value of mPA is in the range of [0, 1]. The closer the value is to 1, the higher the accuracy of segmentation is. mPA was calculated using Equation (6).where denotes the pixel whose real pixel is predicted to be , and denotes the pixel whose real pixel is predicted to be . k + 1 is the number of classes.
- Precision and Recall are a pair of contradictory measures, and F1-score is the harmonic average of the two. The value of F1-score is in the range of [0, 1]. The closer the value is to 1, the higher the accuracy of segmentation is. F1-score was calculated using Equation (7).
- Time complexity:
- FLOPs is the abbreviation of floating point operations. A smaller value of FLOPs indicates that the network model is less computational intensive.
- Average Time is the average time to predict an iris mask image. The smaller the value of Average Time is, the better performance the practical application has.
- Space complexity:
- Params is the total number of weight parameters of all parameter layers in the network model. The smaller the value of Params is, the smaller the number of parameters of the network is.
- Storage Space is the storage space of the network model. The smaller the Storage Space value is, the better the practical application of the model is.
3.4. Experimental Results and Analysis
3.4.1. Mixed Iris Dataset for Training and Testing
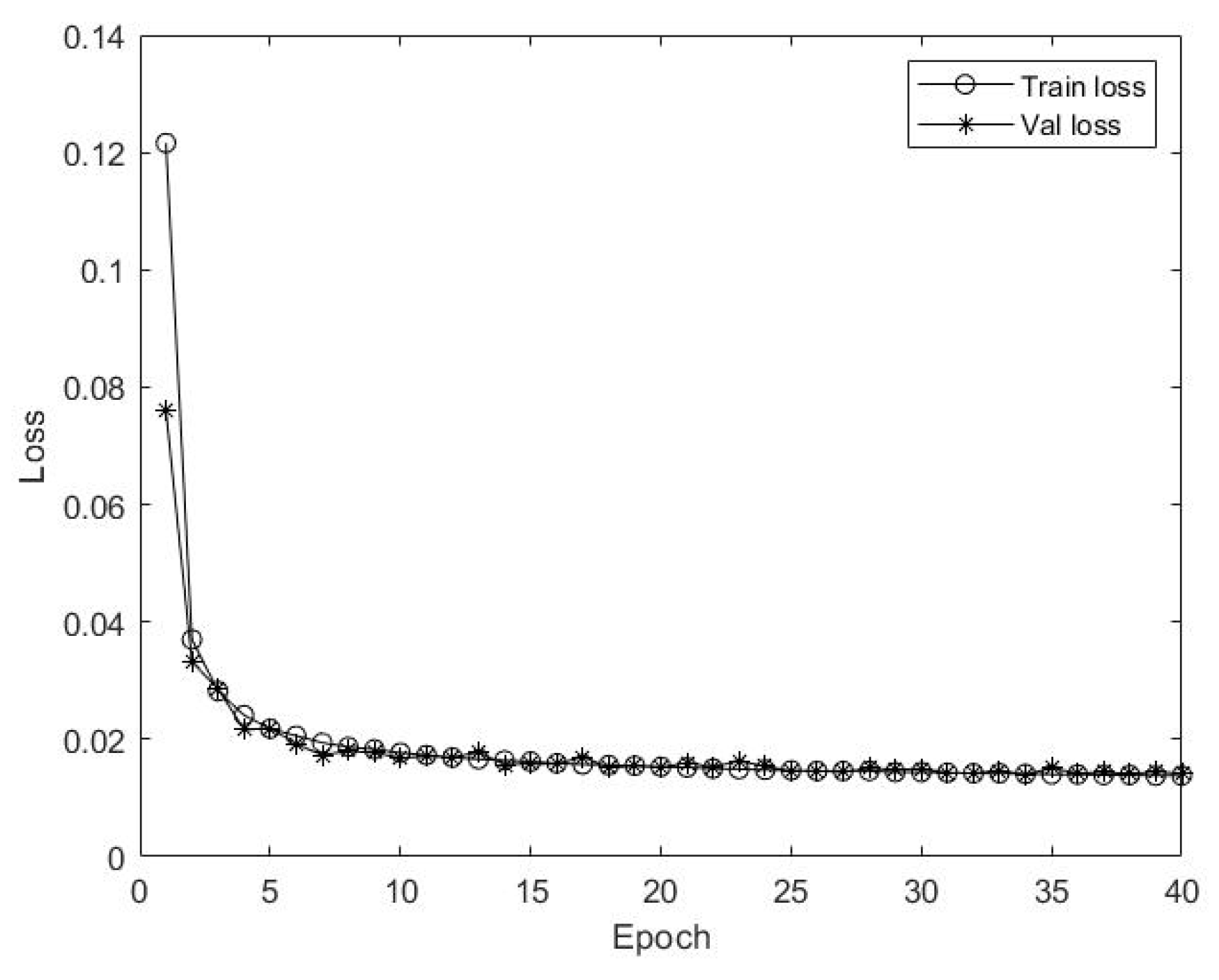
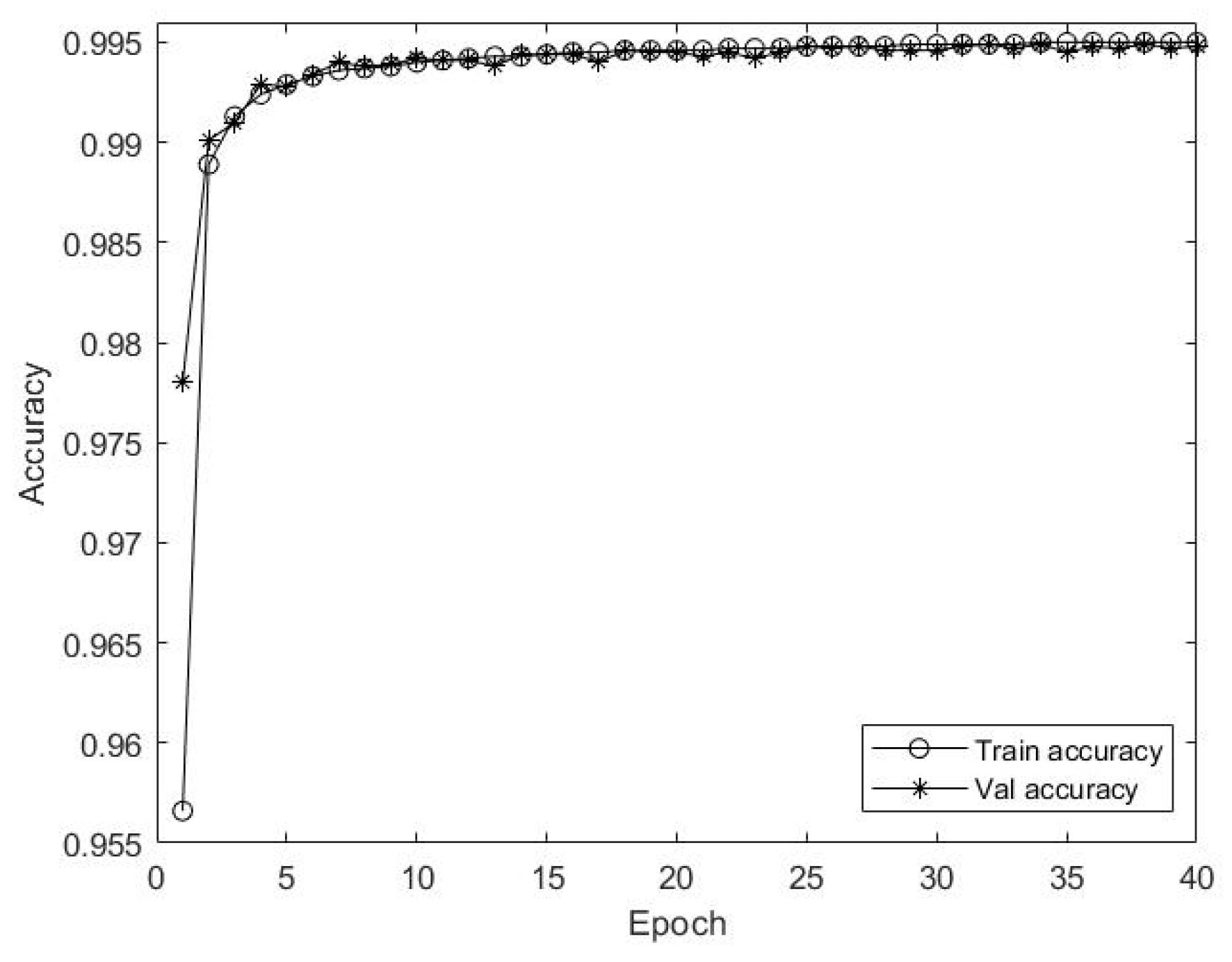
- The loss and accuracy curves converged fast with increasing epochs in the process of training and validation, and the curves were stable without oscillations, indicating that the model did not overfit, which avoids the emergence of complex models.
- PFSegIris performed well on all three kinds of heterogeneous iris images and handled the details of small targets well. It performed best on the JLU-6.0 iris dataset. The main reason was that the JLU-6.0 dataset has high-quality near-infrared images with large iris area, while the other two are visible-light iris images with more noise.
- The average prediction times of the three heterogeneous iris images were all short.
3.4.2. Cross-Dataset Evaluation of PFSegIris
- The test results on four cross-datasets were still good, indicating that PFSegIris had learned the real iris features, had a certain migration ability and generalization ability, and had universality for multi-source heterogeneous iris image segmentation.
- Among the four heterogeneous datasets, the effect of the CASIA-Iris-Interval-v4 was remarkably better than that of the other three datasets. The reason was that the images from CASIA-Iris-Interval-v4 were of high quality in near-infrared light, with large iris regions and almost no noise interference. Iris images from UBIRIS.V2 had more noise and therefore showed less generalization ability.
- Fast segmentation was still realized on four cross-dataset iris images.
3.4.3. Comparison with Existing Segmentation Algorithms
- Compared with other methods, PFSegIris achieved higher segmentation accuracy on multi-source heterogeneous iris images, with mIoU reaching 97.38%, 97.15%, 96.69%, and 96.24% and F1-score reaching 98.68%, 97.71%, 97.29%, and 97.13% on four iris datasets of JLU-6.0, CASIA-Iris-Lamp-v4, UBIRIS.V2, and MICHE-I, respectively, further verifying the universal applicability of the algorithm proposed for multi-source heterogeneous iris segmentation.
- Compared with other network models, PFSegIris had a faster segmentation speed on multi-source heterogeneous iris images. It is an algorithm that can quickly segment multi-source heterogeneous iris.
- Compared with the classic semantic segmentation methods and the latest lightweight iris segmentation methods, the proposed algorithm has fewer parameters, less storage space, and less computation with obvious application advantages.
3.4.4. Ablation Study
- After adding the attention mechanism to the baseline network, the average time to predict heterogeneous iris images was greatly reduced.
- With the attention mechanism, the model had higher accuracy than baseline segmentation, and both mIoU and F1-score were improved. The channel attention module had a stronger boosting performance than the position attention module.
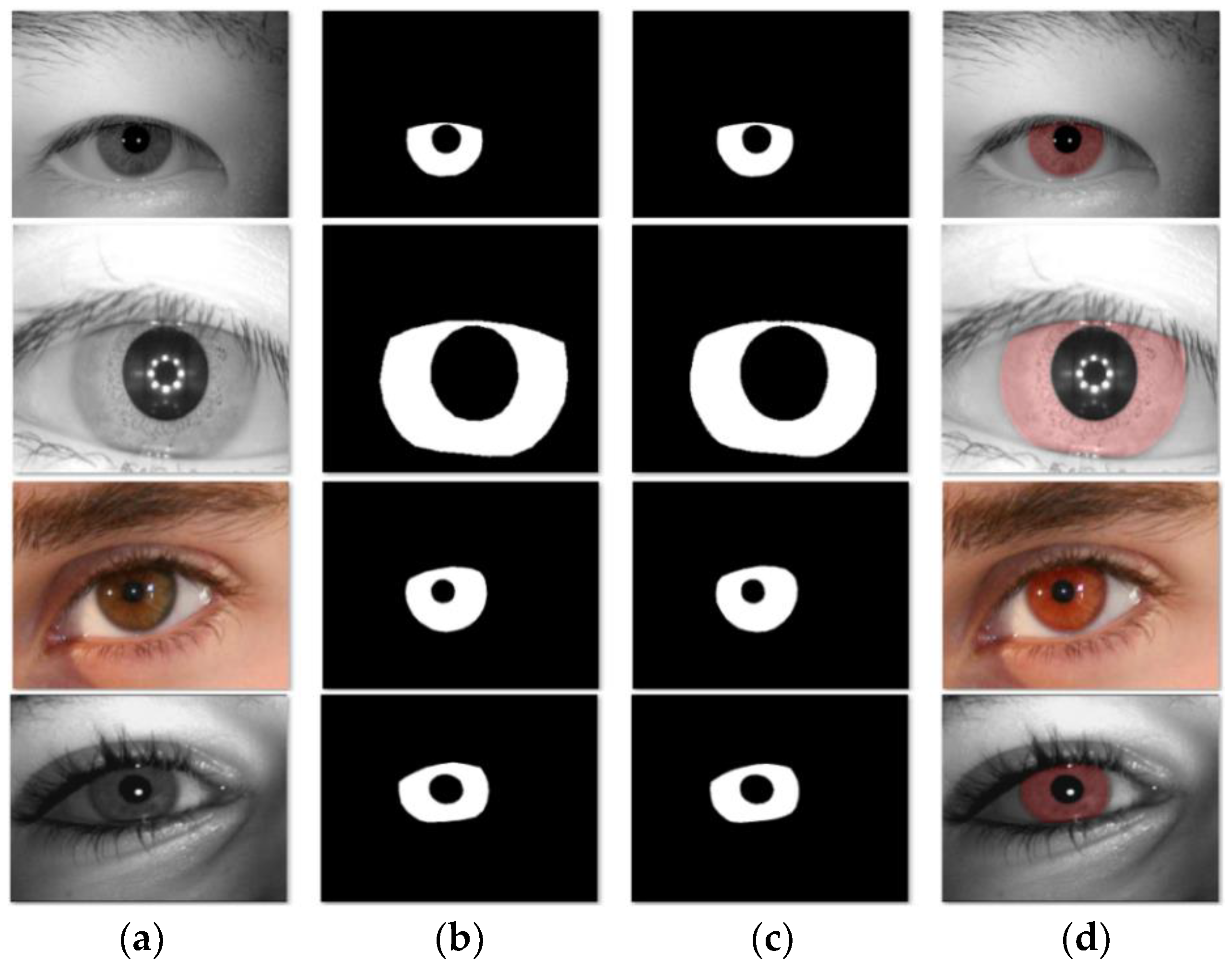
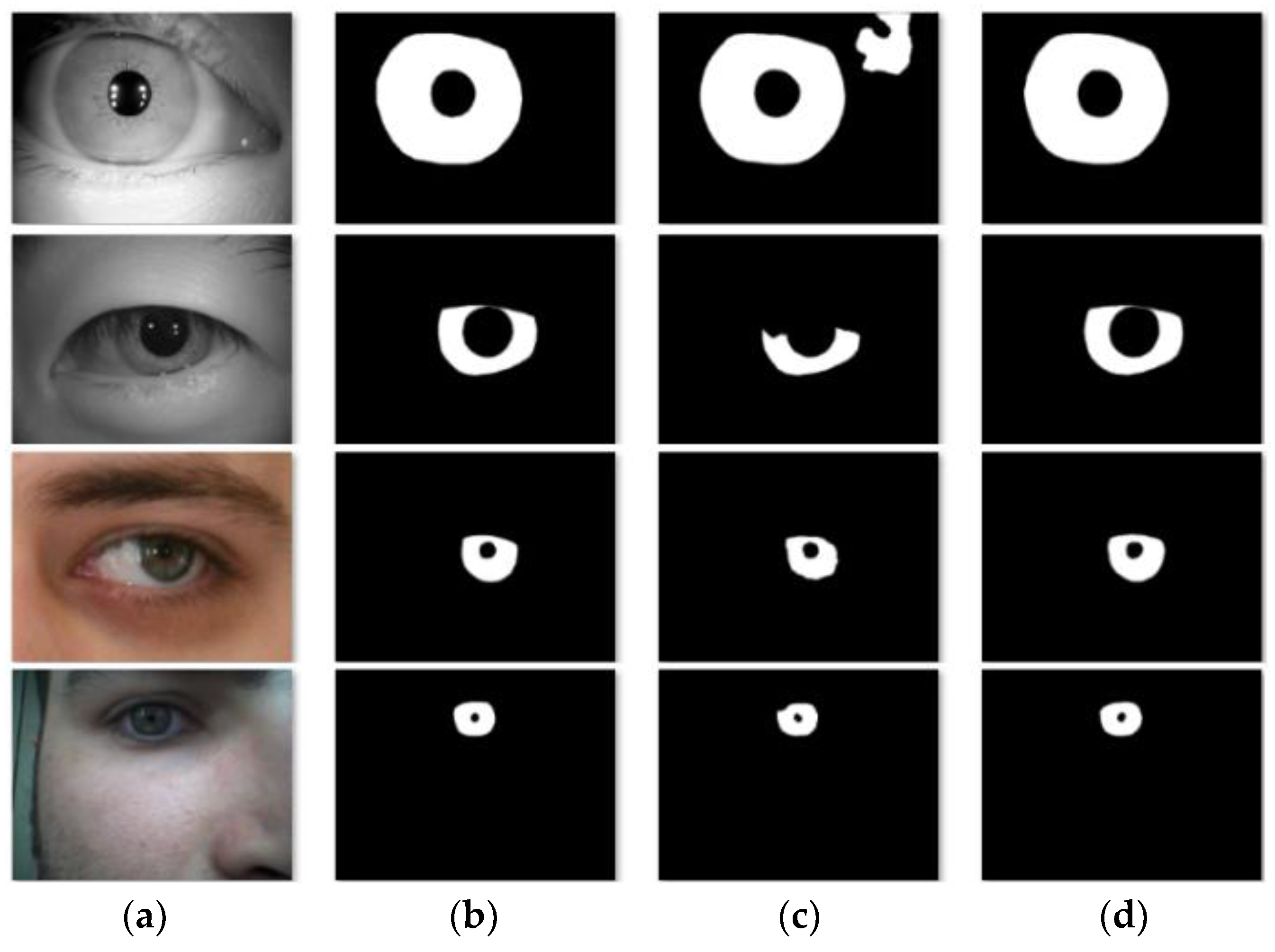
- It can be seen from the subjective vision that the baseline did not work well for iris segmentation with more noises and small targets, while our algorithm performed well and accurately segmented small iris regions on heterogeneous iris images, avoiding the interference of noise such as lighting. Thus, this experiment illustrates the effectiveness of the parallel dual attention mechanism combination to improve the segmentation precision of multi-source heterogeneous iris images.
3.4.5. Comparison with Traditional Iris Positioning Algorithm
3.4.6. Qualitative Comparison of Extreme Images
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, W.H.; Zhu, Y.; Tan, T.N. Identification based on iris recognition. J. Autom. 2002, 28, 1–10. [Google Scholar]
- Jain, A.K. Technology: Biometric recognition. Nature 2007, 449, 38–40. [Google Scholar] [CrossRef] [PubMed]
- Hollingsworth, K.P.; Bowyer, K.W.; Flynn, P.J. Improved Iris Recognition through Fusion of Hamming Distance and Fragile Bit Distance. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2465–2476. [Google Scholar] [CrossRef]
- Kang, J.S. Mobile iris recognition systems: An emerging biometric technology. Procedia Comput. Sci. 2010, 1, 475–484. [Google Scholar] [CrossRef] [Green Version]
- Jillela, R.; Ross, A.A. Methods for Iris Segmentation. In Handbook of Iris Recognition, 2nd ed.; Bowyer, K.W., Burge, M.J., Eds.; Springer: Cham, Switzerland, 2016; Volume 4, pp. 137–184. [Google Scholar]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef] [Green Version]
- Wildes, R.P. Iris recognition: An emerging biometric technology. Proc. IEEE 1997, 85, 1348–1363. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE ICCV, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Owais, M.; Park, K.R. FRED-Net: Fully Residual Encoder-Decoder Network for Accurate Iris Segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Zhou, R.Y.; Shen, W.Z. PI-Unet: Research on precise iris segmentation neural network model for heterogeneous iris. Comput. Eng. Appl. 2021, 57, 223–229. [Google Scholar]
- Wang, C.; Jawad, M.; Wang, Y.; He, Z.; Sun, Z. Towards Complete and Accurate Iris Segmentation Using Deep Multi-Task Attention Network for Non-Cooperative Iris Recognition. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2944–2959. [Google Scholar] [CrossRef]
- Li, Y.H.; Putri, W.R.; Aslam, M.S.; Chang, C.C. Robust Iris Segmentation Algorithm in Non-Cooperative Environments Using Interleaved Residual U-Net. Sensors 2021, 21, 1–21. [Google Scholar]
- You, X.; Zhao, P.; Mu, X.; Bai, K.; Lian, S. Heterogeneous Noise Iris Segmentation Based on Attention Mechanism and Dense Multi-scale Features. Laser Optoelectron. Prog. 2021, in press. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- JLU Iris Image Database. Available online: http://www.jlucomputer.com/index/irislibrary/irislibrary.html (accessed on 7 September 2020).
- CASIA Iris Image Database. Available online: http://www.cbsr.ia.ac.cn/china/Iris%20Databases%20CH.asp (accessed on 7 September 2020).
- MMU2 Iris Image Database. Available online: http://pesona.mmu.edu.my/~ccteo (accessed on 7 September 2020).
- Marsico, M.D.; Nappi, M.; Riccio, D.; Wechsler, H. Mobile Iris Challenge Evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recognit. Lett. 2015, 57, 17–23. [Google Scholar] [CrossRef]
- MICHE-I Iris Image Database. Available online: http://biplab.unisa.it/MICHE/index_miche.htm (accessed on 7 September 2020).
- Proena, H.; Filipe, S.; Santos, R.; Oliveira, J.; Alexandre, L.A. The UBIRIS.v2: A Database of Visible Wavelength Iris Images Captured On-the-Move and At-a-Distance. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1529–1535. [Google Scholar] [CrossRef]
- UBIRIS.v2 Iris Image Database. Available online: http://iris.di.ubi.pt/ubiris2.html (accessed on 7 September 2020).
- NICE.I Iris Image Database. Available online: http://nice1.di.ubi.pt (accessed on 7 September 2020).
- Tan, M.X.; Le, Q.V. MixConv: Mixed depthwise convolutional kernels. arXiv 2019, arXiv:1907.09595. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. arXiv 2018, arXiv:1805.08318. [Google Scholar]
- Suzuki, S.; Abe, K. Topological Structural Analysis of Digitized Binary Images by Border Following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Wang, C.; Sun, Z. A Benchmark for Iris Segmentation. J. Comput. Res. Dev. 2020, 57, 395–412. [Google Scholar]
- Othman, N.; Dorizzi, B.; Garcia-Salicetti, S. OSIRIS: An open source iris recognition software. Pattern Recognit. Lett. 2016, 82, 124–131. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Dimension | Operator Type | Output Dimension | |
|---|---|---|---|
| H × W × C | Dwise 3 × 3 | Add, BatchNorm, Relu6 | H × W × C |
| Dwise 5 × 5 | |||
| H × W × C | Conv 1 × 1, BatchNorm, Linear | H × W × | |
| H × W × | Conv 1 × 1, BatchNorm, Relu6 | H × W × C’ | |
| H × W × C’ | Dwise 3 × 3, stride = s, BatchNorm, Linear | × × C’ | |
| Input Dimension | Operator Type | t | Stride | Output Dimension |
|---|---|---|---|---|
| 480 × 640 × 3 | Iris-feature module1 | 2 | 2 | 240 × 320 × 64 |
| 240 × 320 × 64 | Iris-feature module2 | 6 | 1 | 240 × 320 × 64 |
| 240 × 320 × 64 | Iris-feature module1 | 6 | 2 | 120 × 160 × 128 |
| 120 × 160 × 128 | Iris-feature module2 | 6 | 1 | 120 × 160 × 128 |
| 120 × 160 × 128 | Iris-feature module1 | 6 | 2 | 60 × 80 × 256 |
| 60 × 80 × 256 | Iris-feature module2 | 6 | 1 | 60 × 80 × 256 |
| 60 × 80 × 256 | Iris-feature module1 | 6 | 2 | 30 × 40 × 512 |
| 30 × 40 × 512 | Iris-feature module2 | 6 | 1 | 30 × 40 × 512 |
| 30 × 40 × 512 | PAM, CAM | 30 × 40 × 512 | ||
| 30 × 40 × 512 | Add | 30 × 40 × 512 | ||
| 30 × 40 × 512 | Transposed Conv | 2 | 60 × 80 × 256 | |
| 60 × 80 × 256 | Iris-feature module2 | 6 | 1 | 60 × 80 × 256 |
| 60 × 80 × 256 | Transposed Conv | 2 | 120 × 160 × 128 | |
| 120 × 160 × 128 | Iris-feature module2 | 6 | 1 | 120 × 160 × 128 |
| 120 × 160 × 128 | Transposed Conv | 2 | 240 × 320 × 64 | |
| 240 × 320 × 64 | Iris-feature module2 | 6 | 1 | 240 × 320 × 64 |
| 240 × 320 × 64 | Transposed Conv | 2 | 480 × 640 × 1 | |
| 480 × 640 × 1 | Iris-feature module2 | 6 | 1 | 480 × 640 × 1 |
| 480 × 640 × 1 | Conv 1 × 1 | 1 | 480 × 640 × 1 | |
| 480 × 640 × 1 | Add | 480 × 640 × 1 | ||
| 480 × 640 × 1 | BN + Sigmoid | 480 × 640 × 1 |
| Dataset | mIoU/% | mPA/% | F1-Score/% | Average Time/s |
|---|---|---|---|---|
| JLU-6.0 | 97.38 | 99.33 | 98.68 | 0.12 |
| CASIA-Lamp | 97.15 | 98.97 | 97.91 | 0.10 |
| MICHE-I | 96.24 | 97.11 | 97.13 | 0.06 |
| Dataset | mIoU/% | mPA/% | F1-Score/% | Average Time/s |
|---|---|---|---|---|
| JLU-7.0 | 97.06 | 98.56 | 97.68 | 0.11 |
| CASIA-Interval | 98.27 | 99.40 | 99.13 | 0.10 |
| UBIRIS.V2 | 96.69 | 97.30 | 97.29 | 0.09 |
| Mmu2 | 96.82 | 97.62 | 97.47 | 0.09 |
| Method | Dataset | mIoU/% | F1-Score/% | Average Time/s |
|---|---|---|---|---|
| FCN-8s | JLU-6.0 | 85.35 | 92.16 | 0.29 |
| CASIA-Lamp | 83.24 | 90.73 | 0.28 | |
| UBIRIS.V2 | 77.72 | 86.85 | 0.15 | |
| MICHE-I | 77.29 | 87.67 | 0.19 | |
| U-Net | JLU-6.0 | 89.01 | 93.98 | 0.96 |
| CASIA-Lamp | 87.45 | 92.04 | 0.92 | |
| UBIRIS.V2 | 82.21 | 91.77 | 0.61 | |
| MICHE-I | 81.54 | 90.25 | 0.58 | |
| FRED-Net | JLU-6.0 | 94.08 | 95.78 | 0.34 |
| CASIA-Lamp | 92.50 | 94.63 | 0.31 | |
| UBIRIS.V2 | 91.89 | 93.84 | 0.28 | |
| MICHE-I | 91.03 | 93.15 | 0.25 | |
| PI-Unet | JLU-6.0 | 95.58 | 97.03 | 0.21 |
| CASIA-Lamp | 94.35 | 96.68 | 0.18 | |
| UBIRIS.V2 | 92.33 | 95.52 | 0.27 | |
| MICHE-I | 93.67 | 94.26 | 0.35 | |
| MFFIris-Unet | JLU-6.0 | 96.17 | 97.56 | 0.15 |
| CASIA-Lamp | 95.76 | 97.28 | 0.12 | |
| UBIRIS.V2 | 95.32 | 96.62 | 0.11 | |
| MICHE-I | 94.75 | 96.59 | 0.09 | |
| PFSegIris | JLU-6.0 | 97.38 | 98.68 | 0.12 |
| CASIA-Lamp | 97.15 | 97.91 | 0.10 | |
| UBIRIS.V2 | 96.69 | 97.29 | 0.09 | |
| MICHE-I | 96.24 | 97.13 | 0.06 |
| Method | Params/M | Storage Space/GB | FLOPs/G |
|---|---|---|---|
| FCN-8s | 134.27 | 0.500 | 83.42 |
| U-Net | 31.03 | 0.116 | 62.06 |
| FRED-Net | 9.7 | 0.036 | 19.5 |
| PI-Unet | 2.96 | 0.011 | 1.60 |
| MFFIris-Unet | 1.95 | 0.007 | 0.74 |
| PFSegIris | 1.86 | 0.007 | 0.65 |
| Network | Dataset | mIoU/% | F1-Score/% | Average Time/s |
|---|---|---|---|---|
| Baseline | JLU-6.0 | 96.42 | 97.78 | 0.24 |
| CASIA-Lamp | 96.27 | 96.83 | 0.21 | |
| UBIRIS.V2 | 95.80 | 96.47 | 0.19 | |
| MICHE-I | 95.41 | 96.39 | 0.11 | |
| Baseline + PAM | JLU-6.0 | 96.85 | 98.03 | 0.16 |
| CASIA-Lamp | 96.63 | 97.14 | 0.14 | |
| UBIRIS.V2 | 96.29 | 96.90 | 0.12 | |
| MICHE-I | 95.85 | 96.72 | 0.08 | |
| Baseline + CAM | JLU-6.0 | 97.03 | 98.32 | 0.14 |
| CASIA-Lamp | 96.85 | 97.55 | 0.13 | |
| UBIRIS.V2 | 96.41 | 97.01 | 0.11 | |
| MICHE-I | 96.03 | 96.95 | 0.07 | |
| PFSegIris | JLU-6.0 | 97.38 | 98.68 | 0.12 |
| CASIA-Lamp | 97.15 | 97.91 | 0.10 | |
| UBIRIS.V2 | 96.69 | 97.29 | 0.09 | |
| MICHE-I | 96.24 | 97.13 | 0.06 |
| Dataset | Method | Error Number | Error Rate |
|---|---|---|---|
| JLU-6.0 | PFSegIris | 23 | 0.023 |
| OSIRIS V4.1 | 285 | 0.285 | |
| JLU-7.0 | PFSegIris | 33 | 0.033 |
| OSIRIS V4.1 | 382 | 0.387 | |
| CASIA-Interval | PFSegIris | 16 | 0.017 |
| OSIRIS V4.1 | 127 | 0.132 | |
| CASIA-Lamp | PFSegIris | 29 | 0.030 |
| OSIRIS V4.1 | 368 | 0.383 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, L.; Liu, Y.; Zhu, X. PFSegIris: Precise and Fast Segmentation Algorithm for Multi-Source Heterogeneous Iris. Algorithms 2021, 14, 261. https://doi.org/10.3390/a14090261
Dong L, Liu Y, Zhu X. PFSegIris: Precise and Fast Segmentation Algorithm for Multi-Source Heterogeneous Iris. Algorithms. 2021; 14(9):261. https://doi.org/10.3390/a14090261
Chicago/Turabian StyleDong, Lin, Yuanning Liu, and Xiaodong Zhu. 2021. "PFSegIris: Precise and Fast Segmentation Algorithm for Multi-Source Heterogeneous Iris" Algorithms 14, no. 9: 261. https://doi.org/10.3390/a14090261
APA StyleDong, L., Liu, Y., & Zhu, X. (2021). PFSegIris: Precise and Fast Segmentation Algorithm for Multi-Source Heterogeneous Iris. Algorithms, 14(9), 261. https://doi.org/10.3390/a14090261