
An LSM-Tree Index for Spatial Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose a new spatial data index SER-tree (embedded R-tree on an SSTable), introduce Hilbert spatial data sorting, and combine an R-tree index with an SSTable to reduce the read amplification caused by R-tree multiplex queries and dual index queries.
- Based on an SER-tree, we present an ER-tree (embedded R-tree) on LSM to further improve the index query and the update efficiency by organising the SER-tree hierarchically through a binary linked list.
- We implemented the ER-tree index structure for spatial data on the open-source NoSQL database RocksDB. By experimenting with a stand-alone LSM R-tree index, we conclude that there is a better improvement in query performance.
2. Related Works
2.1. LSM-Tree Structure
2.2. Related Work
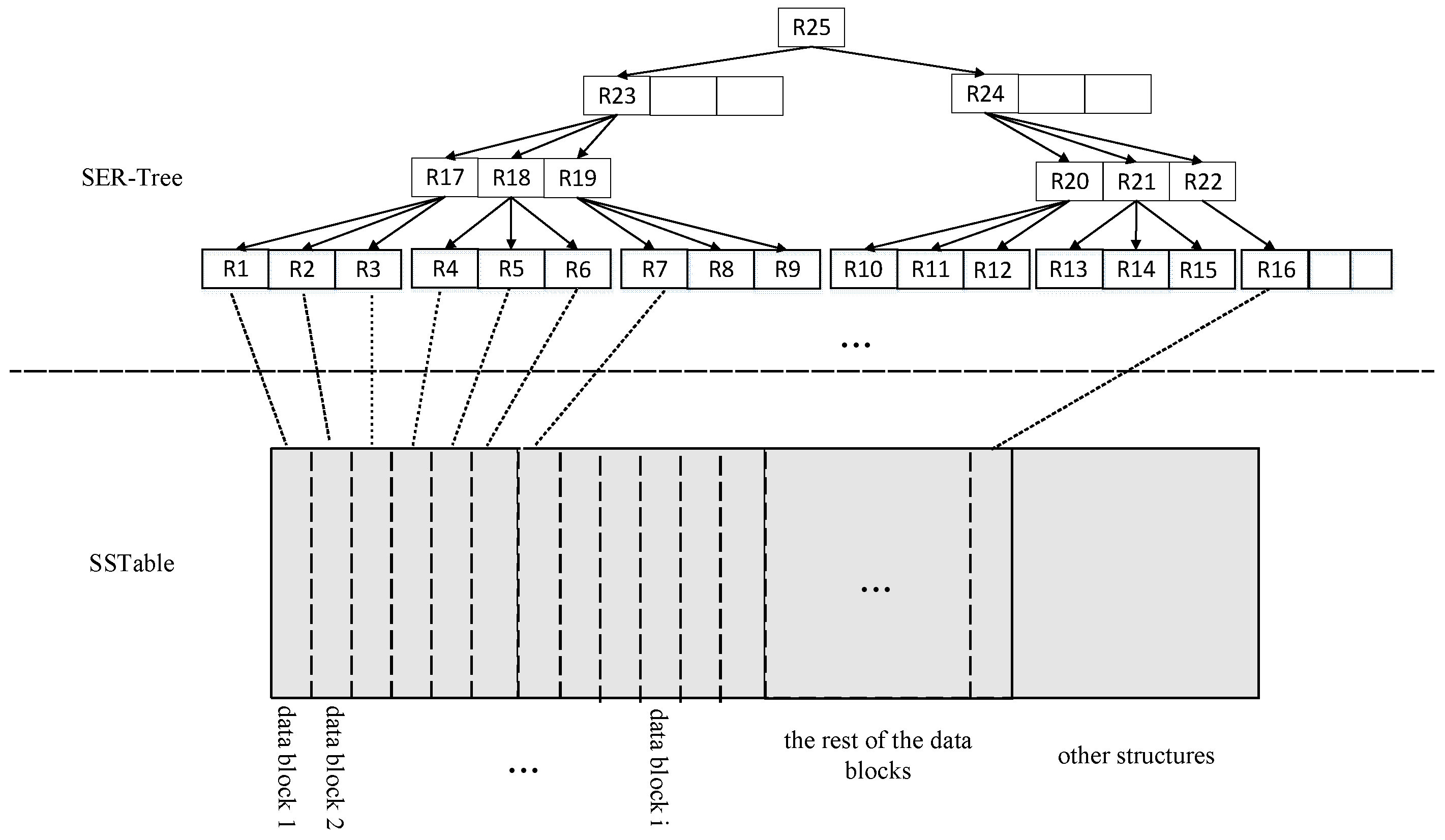
3. SER-Tree Index
3.1. SER-Tree Index Design
3.2. SER-Tree Index Build
| Algorithm 1 SER-tree build algorithm |
| Input: S: SSTable; k: the capacity of SER-Tree node. Output: T: an SER-Tree on SSTable. 1: Q ← ∅; // Q: auxiliary queue 2: for each data block in S, do 3: Build a leaf node N to store the data points in a data block; 4: Q.enqueue (<N,1>); 5: end for 6: while Q.size ()>1 do 7: Dequeue the first k nodes of the same level t from Q; //t: the level of SER-Tree 8: Build a node N to store MBRs of the nodes and pointers of the nodes; 9: Q.enqueue (<N,t+1>); 10: end while 11: T ← Q.LastNode; 12: return T; |
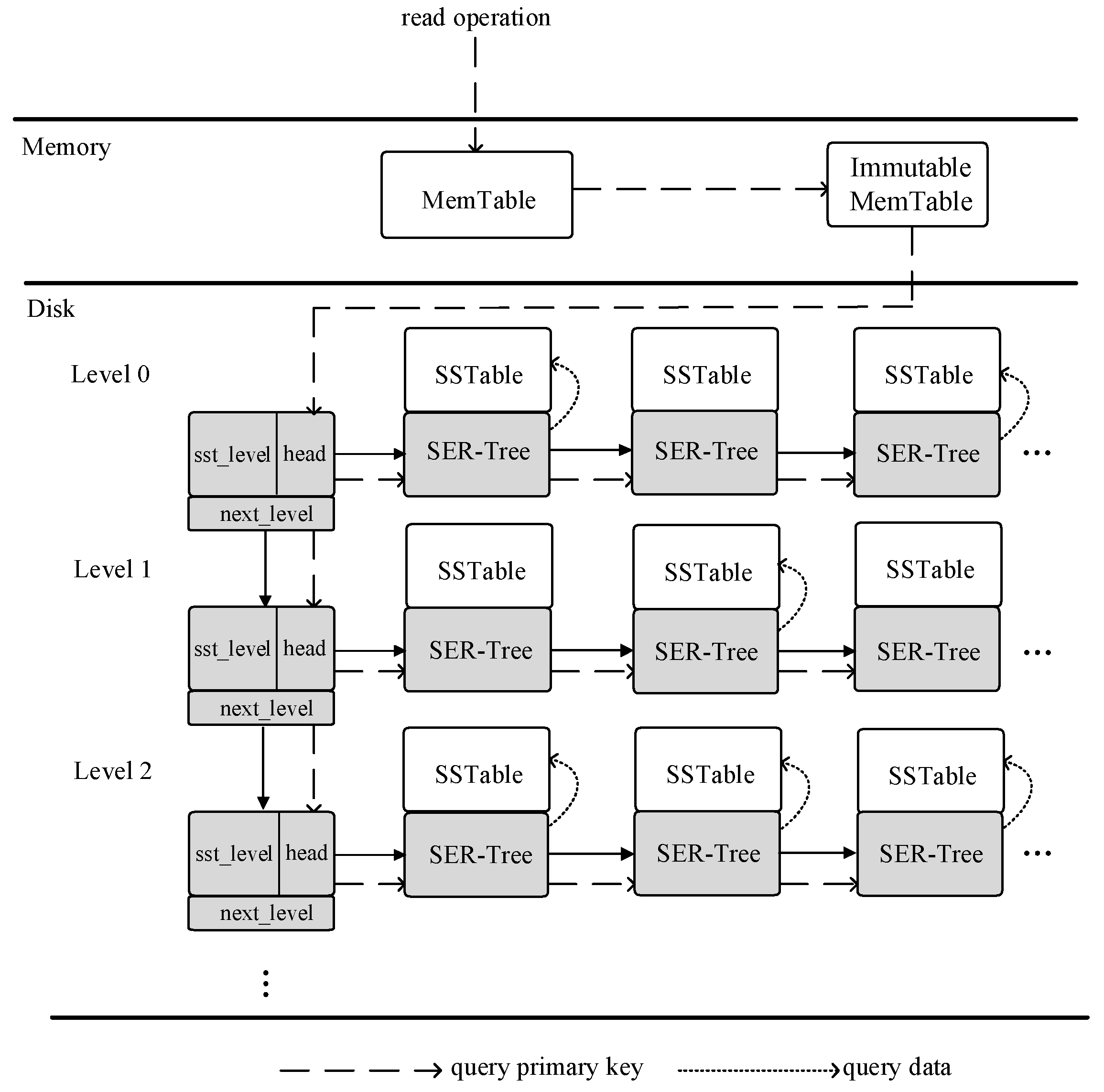
4. ER-Tree Index
4.1. ER-Tree Index Design
4.2. ER-Tree Index Build
4.3. ER-Tree Index Improve
- For read-only workloads, ER-tree indexes can provide higher query performance. However, for mixed read-write workloads, the indexes are constantly updated with frequent data writing, resulting in increased overheads, which does not seem to work well with the high writing performance of the LSM-tree structure. However, although writing changes the structure of the LSM-tree, most of its structure remains unchanged, especially for the SSTable in the high levels and a large amount of writing does not cause compaction operations to occur in the high-level SSTable. Therefore, indexes built on these high-level SSTables are effective and improve the data query performance. However, for a low-level SSTable, the data change process is faster and whether to build SER-tree indexes on them needs further analysis.
- In the LSM-tree, many SSTable files have a short lifetime, especially for a low-level SSTable and when a large amount of writing occurs, they are quickly compacted to the next-level SSTable and their lifetime is less than the index build time. Therefore, it is necessary to set a threshold value. If the lifetime of an SSTable file is less than this threshold, there is no need to build an SER-tree index. In this paper, we experimentally measured that for a 4MB SSTable file and the time to build its index was approximately 45 ms. Therefore, we set a time threshold of Tw = 50 ms. If the lifetime of the SSTable is greater than Tw, then the index is built for the SSTable; otherwise, it is not built.
- In addition to the above issues, it is also necessary to consider that even if an SSTable file has a long lifetime, it is not urgent to build indexes on it if there are almost no query tasks. To build an SER-tree index for an SSTable, we need to consider the query gain and the building loss from the index, which are denoted by Gindex and Lindex, respectively, in this paper. If Gindex is larger than Lindex, it means that it is appropriate to build an SER-tree index on this SSTable and if Gindex is smaller than Lindex, it is not applicable to build an index on this SSTable.
4.4. ER-Tree Index Query
4.4.1. Point Query
| Algorithm 2 Point query algorithm |
| Input: QP: query point, ERT: LSM ER-Tree index Output: result: <key, value>, whose value= QP 1: level_ptr ← ERT. head; 2: while(level_ptr! = null) do 3: ptr ← level_ptr. head; 4: while(ptr! = null) do 5: if include(ptr.tMBR, QP) then //include: judge whether the point QP is within the MBR range 6: LeafNode ← QPFindLeaf (ptr.SERT, QP); //SERT: SER-Tree index on SSTable 7: temp_result. append (LeafNode.db_ptr); 8: end if 9: ptr ← ptr.next; 10: end while 11: level_ptr ← level_ptr.next_level; 12: end while 13: foreach(<key, value>in temp_result) 14: if equals(value, QP) then 15: result. append(<key, value>); end if 16: end for 17: return result; 18: function QPFindLeaf (T, QP) 19: begin 20: if T is a LeafNode, then 21: if include(T.mbr, QP), then 22: return T; else return ∅; 23: else 24: for each child u of T, do 25: if(include (u.mbr, QP)) then 26: QPFindLeaf (u, QP); end if 27: end for 28: end function |
4.4.2. Rectangular Range Query
| Algorithm 3 Rectangular range query algorithm |
| Input: QR: query spatial range, ERT: LSM ER-Tree index. Output: result_c: <key, value>collection, whose value in QR1. Level_ptr ← ERT. head; 1: level_ptr ← ERT. head; 2: while(level_ptr! = null) do 3: ptr ← level_ptr. head; 4: while(ptr! = null) do 5: if intersect (ptr. tMBR, QR) then // intersect: judge whether the range QR is within or intersects the MBR 6: LeafNode ← QRFindLeaf (ptr.SERT,QR); //SERT: SER-Tree index on SSTable 7: temp. append(LeafNode.db_ptr); end if 8: ptr ← ptr. next; 9: end while 10: end while 11: foreach(<key, value>in temp) 12: if(include(QR, value)) then //include:judge whether the point value is within the QR range 13: result_c. append(<key, value>); end if; 14: end for 15: return result_c; 16: function QRFindLeaf (T, QR) 17: begin 18: if T is a LeafNode, then 19: if (intersect(T.mbr, QR)) then 20: return T; else return ∅; 21: else 22: for each child u of T, do 23: if(intersect(u.mbr, QR)) then 24: QRFindLeaf (u, QR); end if; 25: end for 26: end function |
4.4.3. Circle Range Query
| Algorithm 4 Circle query algorithm |
| Input: CP: query center of circle, r: query radius, ERT: LSM ER-Tree index Output: result_c: <key, value>collection, whose value in circle 1: QR←{(CP. x − r, CP. x + r),(CP. y − r, CP. y + r)}; 2: result_c←∅; 3: result_c ← range_query (QR,ERT); //range_query: Algorithm 3 4: foreach(<key, value> in result_c) 5: if(distance(value, CP)>r) then //distance: Calculate the distance between two points 6: remove <key, value>;end if; 7: end for 8: return result_c; |
5. Evaluation
5.1. Experimental Environment and Data
5.2. Experimental Results
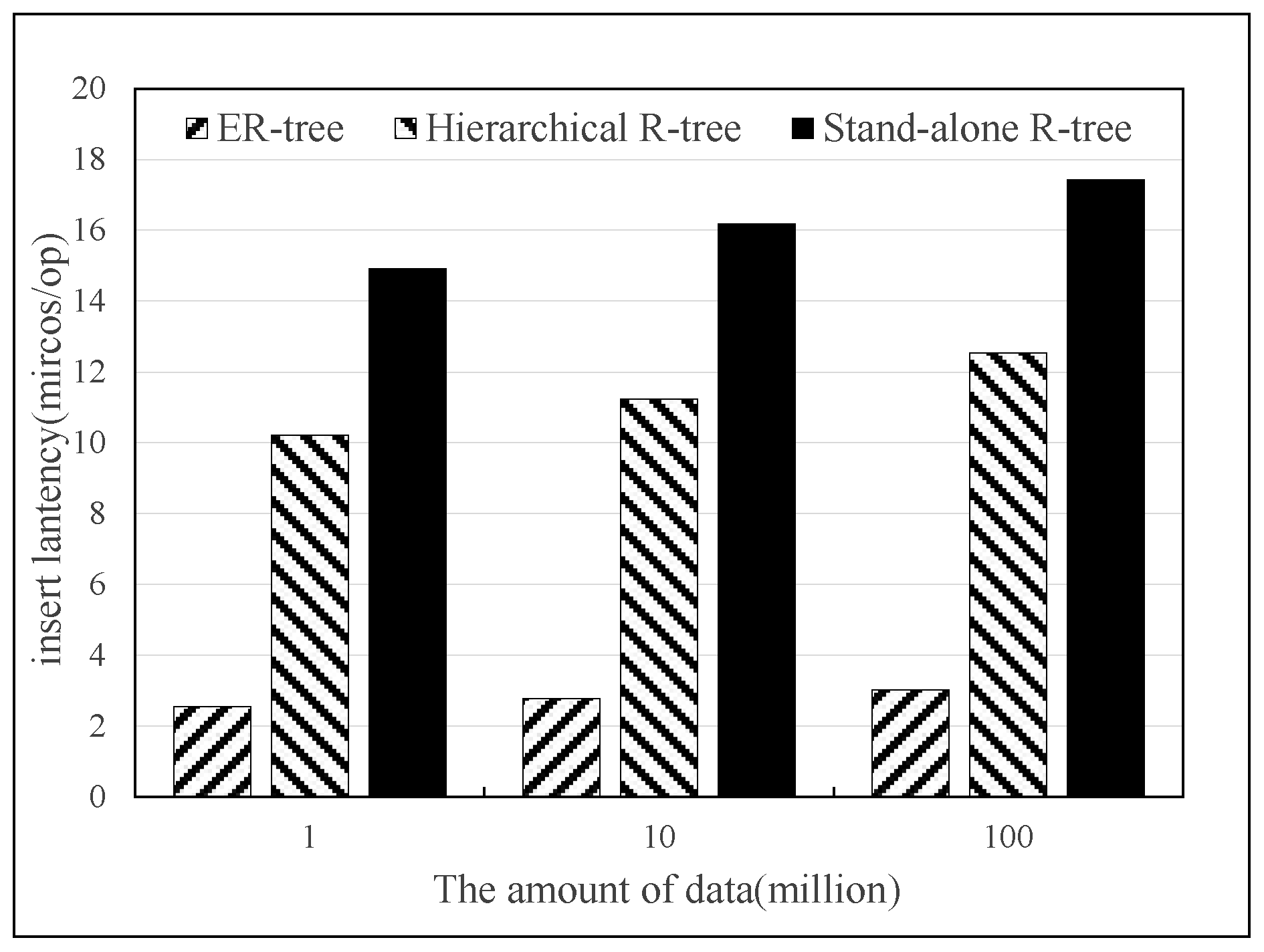
5.2.1. ER-Tree Index Building Performance
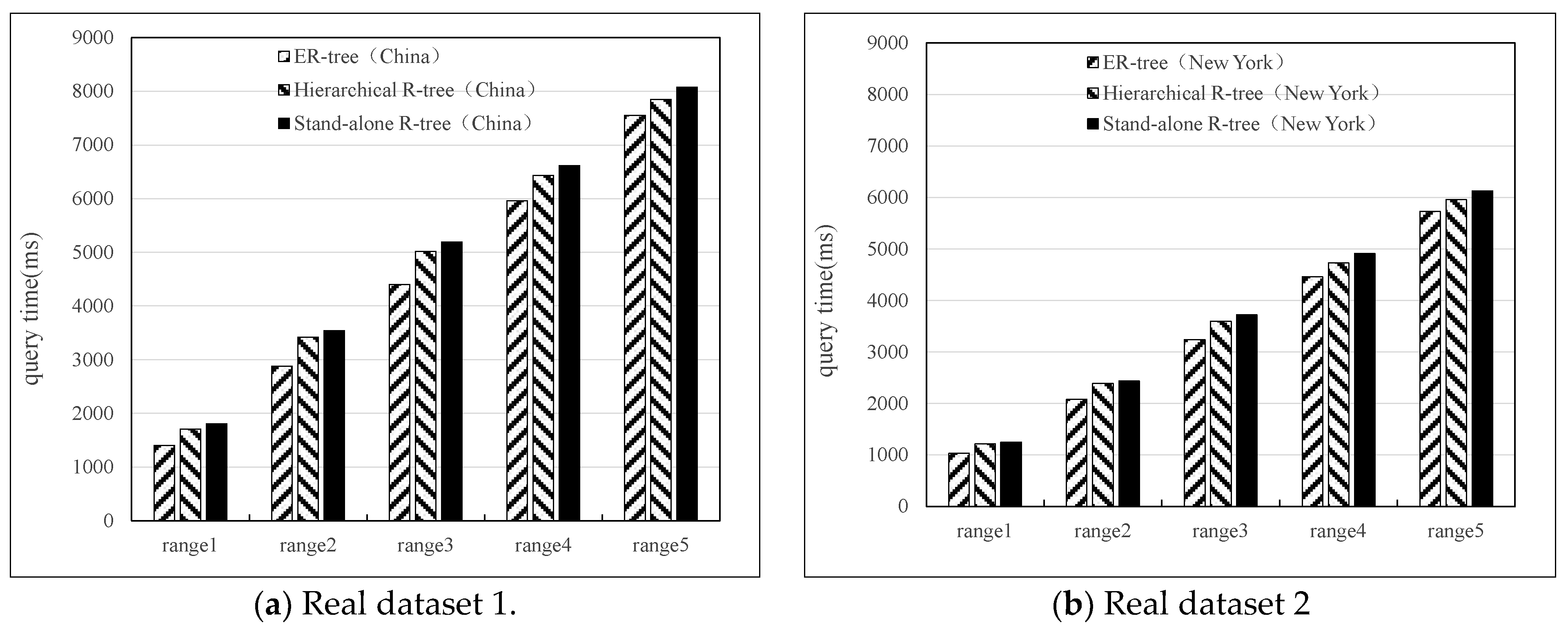
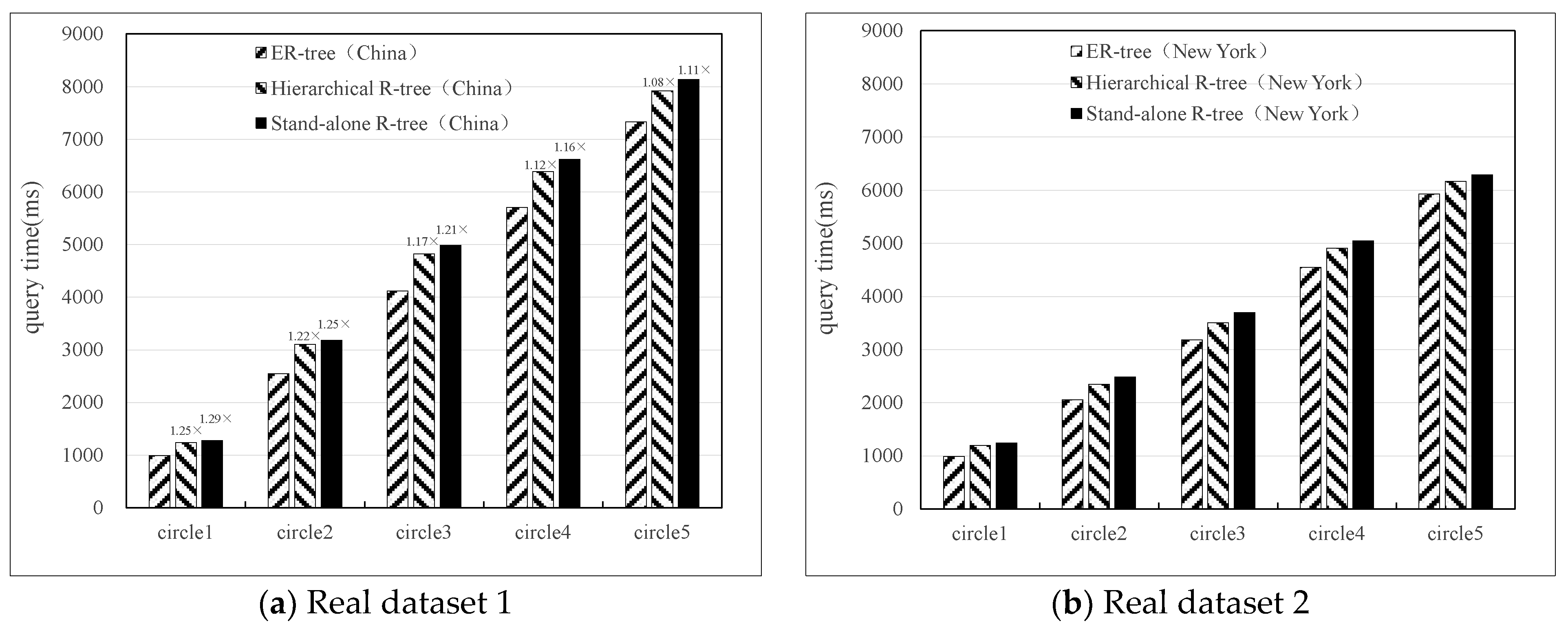
5.2.2. ER-Tree Index Query Performance
5.2.3. ER-Tree Index Space Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- O’Neil, P.; Cheng, E.; Gawlick, D.; O’Neil, E. The log-structured merge-tree (LSM-tree). Acta Inform. 1996, 33, 351–385. [Google Scholar] [CrossRef]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. TOCS 2008, 26, 1–26. [Google Scholar] [CrossRef]
- Ghemawat, S.; Dean, J. LevelDB. Available online: http://code.google.com/p/leveldb (accessed on 15 February 2022).
- Apache. Apache HBase: The Hadoop Database, a Distributed, Scalable, Big Data Store. Available online: https://hbase.apache.org/ (accessed on 15 February 2022).
- Alsubaiee, S.; Altowim, Y.; Altwaijry, H.; Behm, A.; Borkar, V.; Bu, Y.; Carey, M.; Cetindil, I.; Cheelangi, M.; Faraaz, K.; et al. AsterixDB: A scalable, open-source BDMS. Proc. VLDB Endow. 2014, 7, 1905–1916. [Google Scholar] [CrossRef]
- Team Facebook RocksDB. A Persistent Key-Value Store for Fast Storage Environments. Available online: https://rocksdb.org (accessed on 15 February 2022).
- Lakshman, A.; Malik, P. Cassandra: A decentralised structured storage system. SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Lawder, J.K. The Application of Space-Filling Curves to the Storage and Retrieval of Multi-Dimensional Data. Ph.D. Dissertation, University of London, London, UK, 2000. [Google Scholar]
- Mao, Q.; Qader, M.A.; Hristidis, V. Comprehensive comparison of LSM architectures for spatial data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 455–460. [Google Scholar] [CrossRef]
- Xu, R.; Zhou, X.; Liu, Z.; Hu, H. Implementation of LevelDB-based secondary index on two-dimensional data. Journal of East China Normal University. Nat. Sci. 2019, 5, 159–167. [Google Scholar] [CrossRef]
- Xu, R.; Liu, Z.; Hu, H.; Qian, W.; Zhou, A. An efficient secondary index for spatial data based on LevelDB. In Proceedings of the International Conference on Database Systems for Advanced Applications, DASFAA 2020, Jeju, Korea, 24–27 September 2020; pp. 750–754. [Google Scholar] [CrossRef]
- Alsubaiee, S.; Behm, A.; Borkar, V.; Heilbron, Z.; Kim, Y.; Carey, M.J.; Dreseler, M.; Li, C. Storage management in AsterixDB. Proc. VLDB Endow. 2014, 7, 841–852. [Google Scholar] [CrossRef] [Green Version]
- Bozhi, Q. Research on Linked Spatial Index Based on LSM-Tree. Master’s Thesis, Zhejiang University, Hangzhou, China, 2020. [Google Scholar]
- Wang, Y.; Wu, S.; Mao, R. Towards read-intensive key-value stores with tidal structure based on LSM-tree. In Proceedings of the 2020 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 307–312. [Google Scholar] [CrossRef]
- Cheng, W.; Guo, T.; Zeng, L.; Wang, Y.; Nagel, L.; Süß, T.; Brinkmann, A. Improving LSM-trie performance by parallel search. Softw. Pract. Exp. 2020, 50, 1952–1965. [Google Scholar] [CrossRef]
- Luo, C.; Carey, M.J. Efficient data ingestion and query processing for LSM-based storage systems. Proc. VLDB Endow. 2019, 12, 531–543. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Carey, M.J. LSM-based storage techniques: A survey. VLDB J. 2020, 29, 393–418. [Google Scholar] [CrossRef] [Green Version]
- Sears, R.; Ramakrishnan, R. BLSM: A general purpose log-structured merge tree. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘12), New York, NY, USA, 20–24 May 2012; pp. 217–228. [Google Scholar] [CrossRef]
- Guttman, A. R-trees: A dynamic index structure for spatial searching. In Proceedings of the 1984 ACM SIGMOD International Conference on Management of Data (SIGMOD ’84), Boston, MA, USA, 18–21 June 1984; pp. 47–57. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, T.; Carey, M.J.; Li, C. A Comparative Study of Log-Structured Merge-Tree-Based Spatial Indexes for Big Data. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 147–150. [Google Scholar] [CrossRef]
- Silva, Y.N.; Xiong, X.; Aref, W.G. The RUM-tree: Supporting frequent updates in R-trees using memos. VLDB J. 2009, 18, 719–738. [Google Scholar] [CrossRef]
- Shin, J.; Wang, J.; Aref, W.G. The LSM RUM Tree: A Log-Structured Merge R-Tree for Update-intensive Spatial Workloads. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2285–2290. [Google Scholar] [CrossRef]
- Li, F.; Lu, Y.; Yang, Z.; Shu, J. SineKV: Decoupled Secondary Indexing for LSM-based Key-Value Stores. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 1112–1122. [Google Scholar] [CrossRef]
- Lu, L.; Pillai, T.S.; Gopalakrishnan, H.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. WiscKey: Separating Keys from Values in SSD-Conscious Storage. ACM Trans. Storage 2017, 13, 1–28. [Google Scholar] [CrossRef] [Green Version]
- OpenStreetMap Contributors. OpenStreetMap Data. Available online: https://www.openstreetmap.org (accessed on 15 February 2022).


















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Chen, H. An LSM-Tree Index for Spatial Data. Algorithms 2022, 15, 113. https://doi.org/10.3390/a15040113
He J, Chen H. An LSM-Tree Index for Spatial Data. Algorithms. 2022; 15(4):113. https://doi.org/10.3390/a15040113
Chicago/Turabian StyleHe, Junjun, and Huahui Chen. 2022. "An LSM-Tree Index for Spatial Data" Algorithms 15, no. 4: 113. https://doi.org/10.3390/a15040113
APA StyleHe, J., & Chen, H. (2022). An LSM-Tree Index for Spatial Data. Algorithms, 15(4), 113. https://doi.org/10.3390/a15040113