
Overview of Distributed Machine Learning Techniques for 6G Networks




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Ultra-high data rate (up to 1 terabit per second (Tbps)) and ultra-low latency communications.
- High energy efficiency for resource-constrained devices.
- Ubiquitous global network coverage.
- Trusted and intelligent connectivity across the whole network.
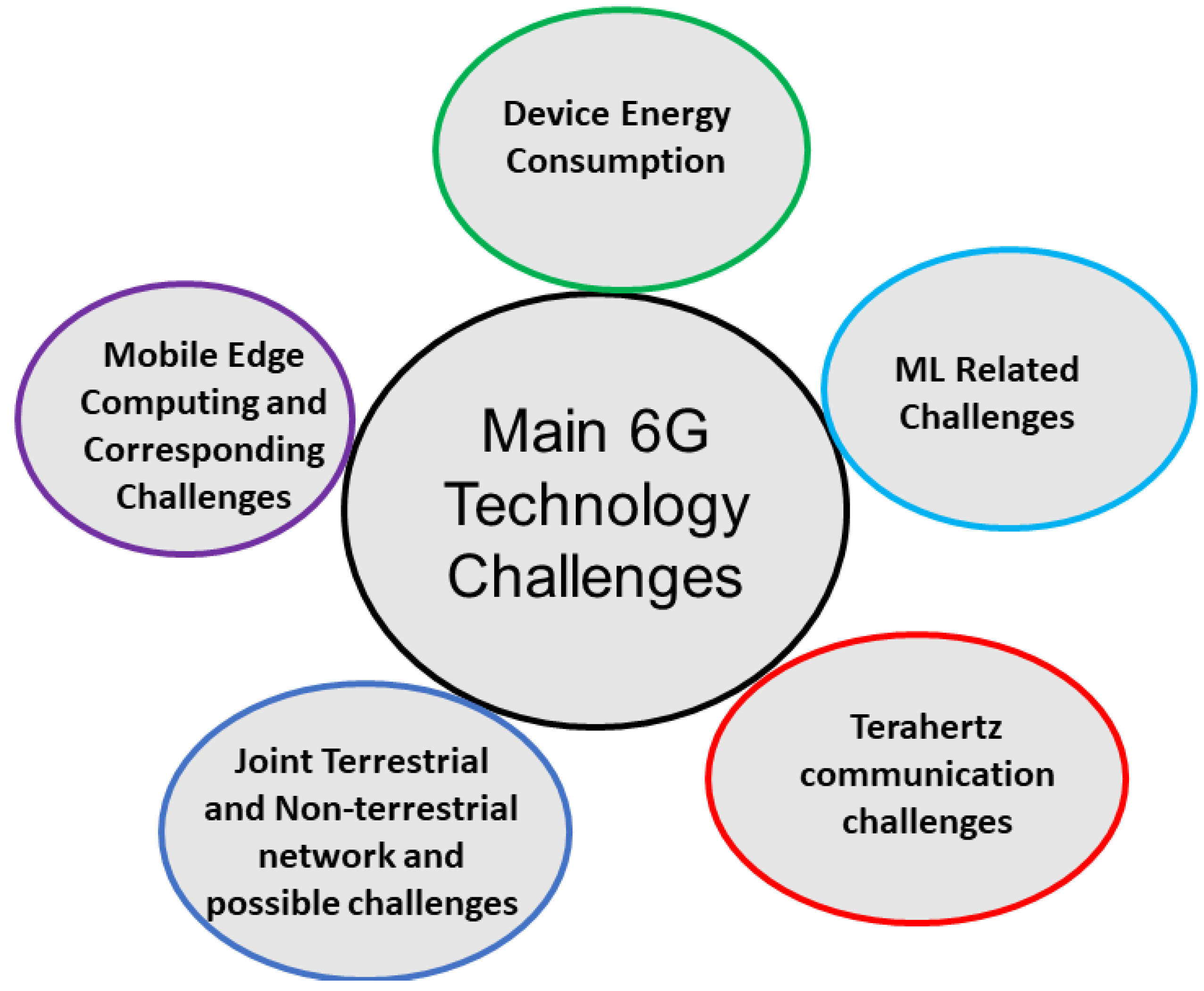
2. Wireless Communication Technology
- Device energy consumption: With the emerging trends of IoT technology, it is expected that the 6G network will provide communication services for a large set of IoT devices with limited energy supply. Therefore, the 6G network will be required to support various energy-saving mechanisms for higher energy efficiency. Various energy harvesting techniques with energy-efficient communication and computation paradigms can help 6G to overcome the devices’ energy scarceness.
- ML-related challenges: Several new artificial intelligence applications will be integrated into the 6G network for creating an intelligent networking platform. However, this can also present several challenges, including higher resource requirements, additional energy costs, security, privacy aspects, etc. The edge-based distributed learning and the split learning technologies are expected to play key roles.
- Terahertz (THz) communication and corresponding challenges: The upcoming 6G technology is expected to use the THz frequency band to fulfill the users’ data requirements. However, higher propagation loss and limited communication ranges are some of the main challenges that need to be addressed.
- Joint Terrestrial and Non-terrestrial network and possible challenges: Various new non-terrestrial networking platforms are expected to be integrated into the traditional terrestrial communication network for creating a more reliable 6G communication network. However, proper channel models, mobility management, savior channel loss due to natural causes such as rain fading, and proper resource allocation are some of the main challenges that need to be handled.
- Mobile edge computing (MEC) and corresponding challenges: MEC has emerged as a promising technology that brings cloud computing resources to the proximity of end-users. However, size and coverage restrictions often limit the MEC servers’ computation and communication capabilities. With upcoming 6G technology, various new latency-critical and data-intensive applications are expected to be enabled. Allocating the proper networking services to the edge servers, proper user-server assignments, proper resource allocation, and user mobility issues are some of the main challenges that require proper attention.
3. Machine Learning in Wireless Communication
3.1. Deep Learning with Artificial Neural Networks (DL-ANN)
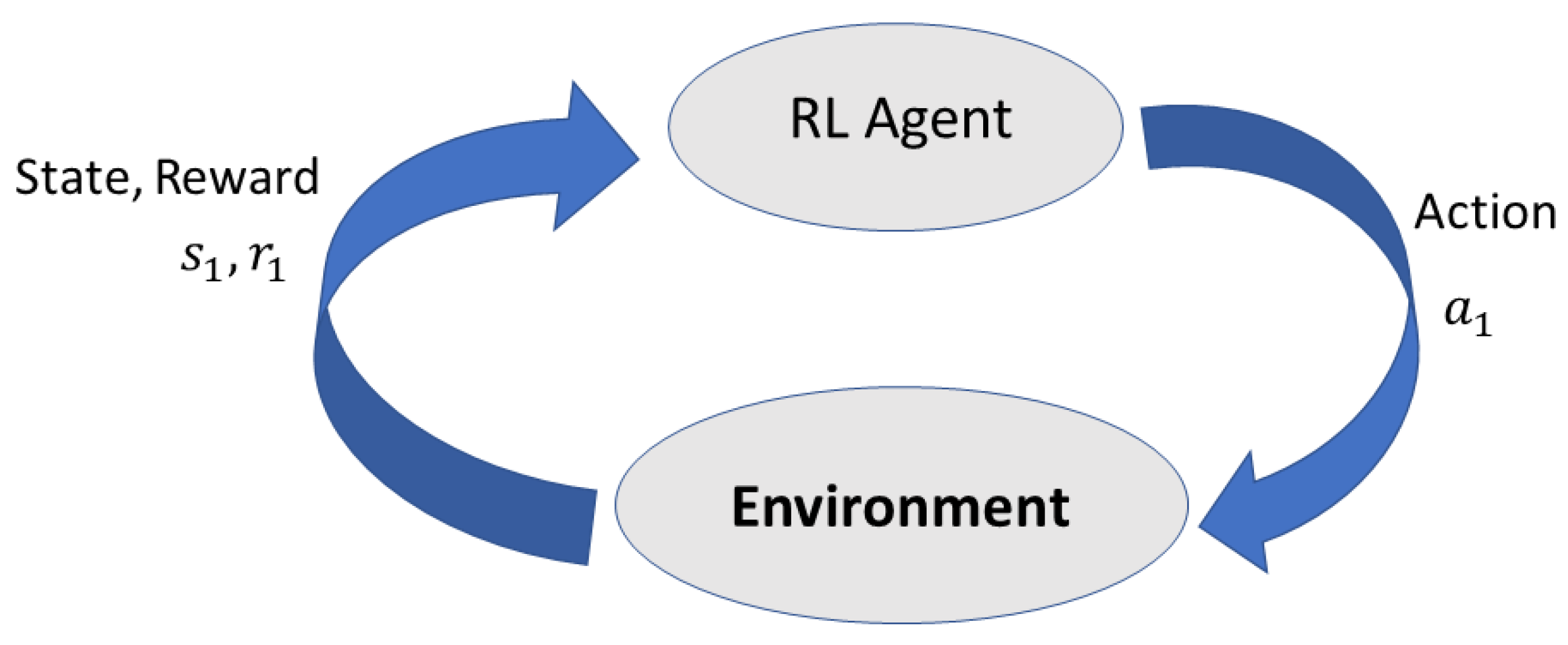
3.2. Reinforcement Learning
4. Distributed Machine Learning Algorithms
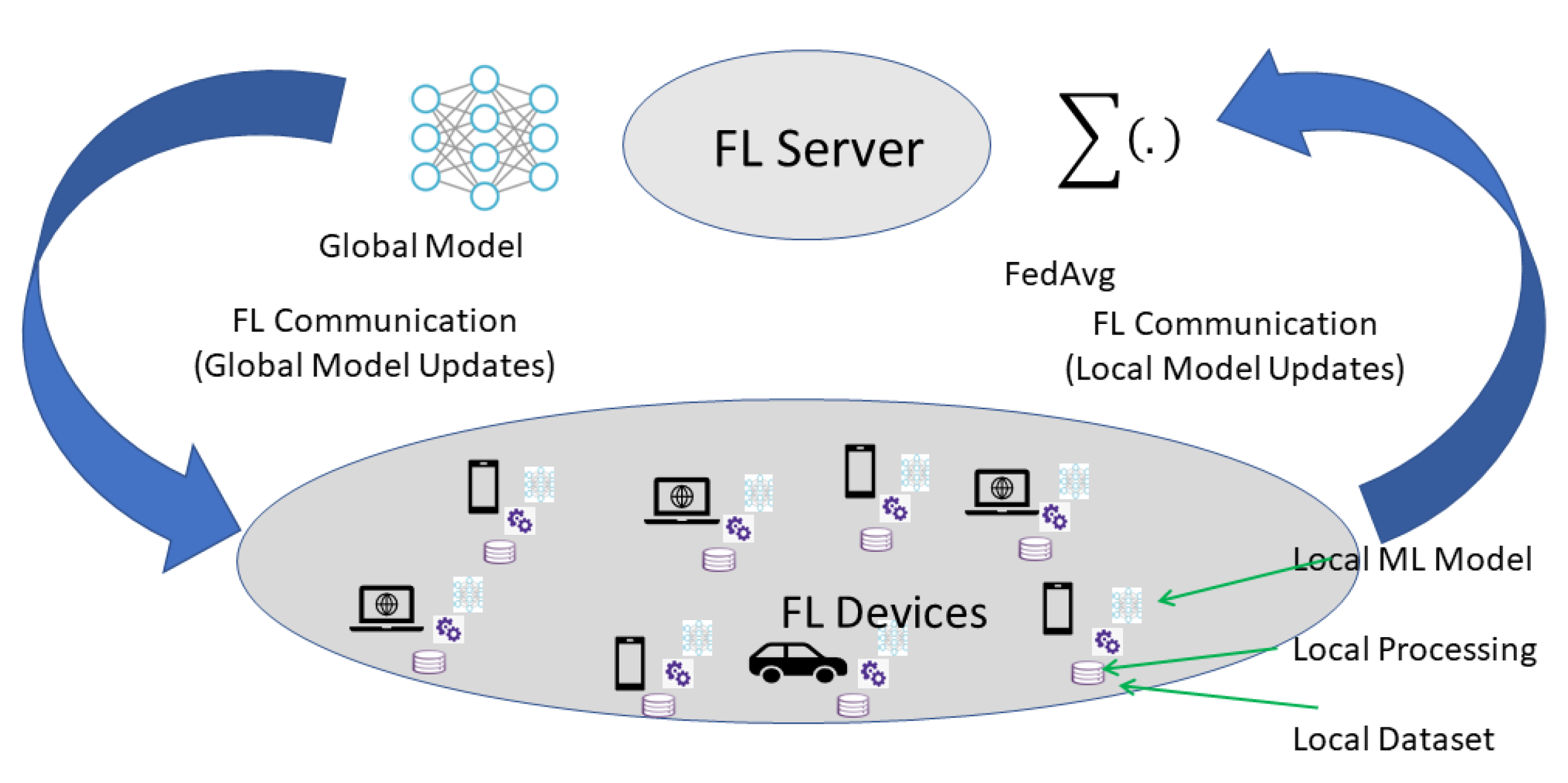
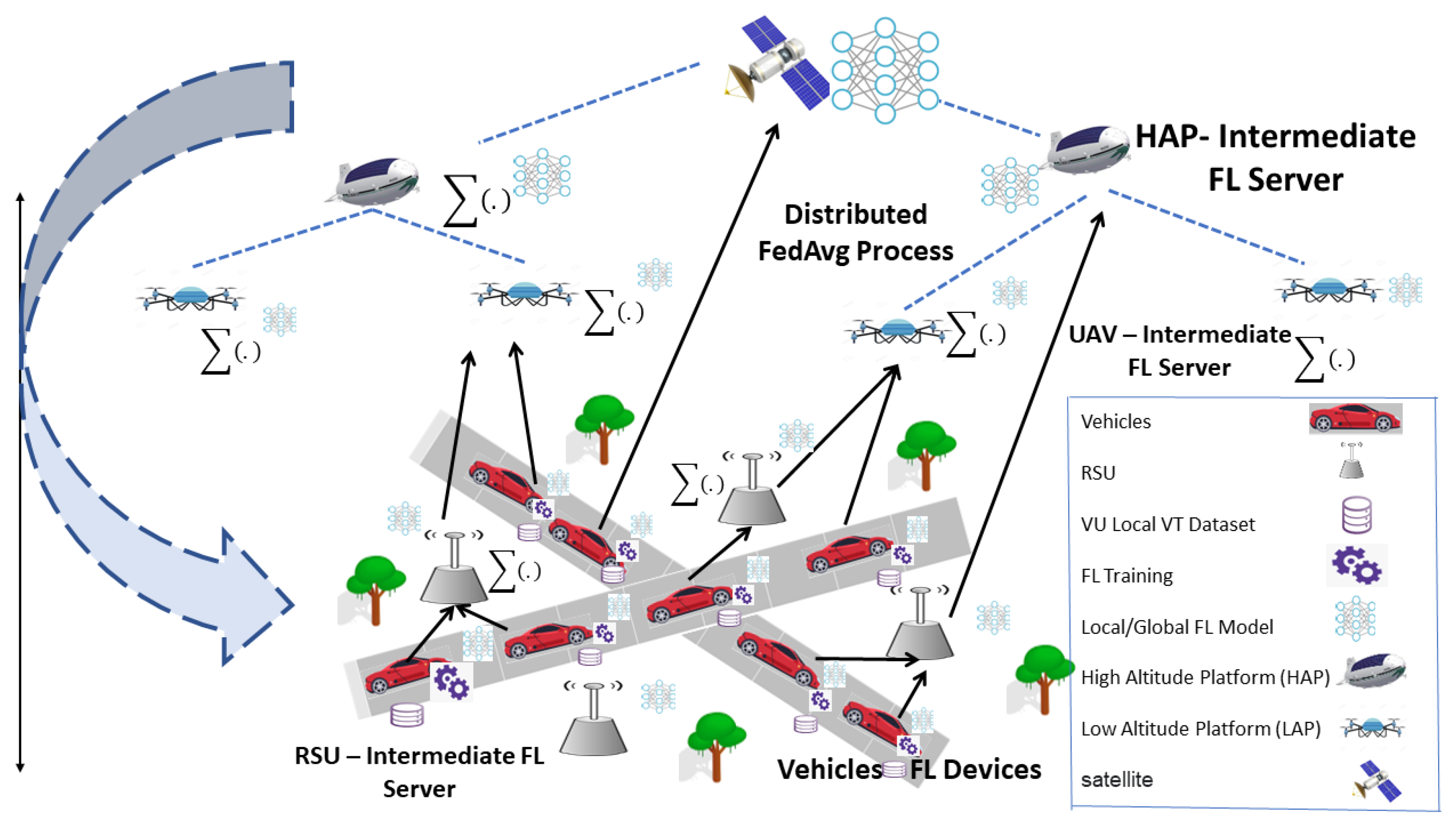
4.1. Federated Learning
- Real-world data training on mobile devices has an advantage over training data obtained via proxy and storage in data centers.
- As these data are massive and sensitive to privacy, it is better to avoid storing them in a data center for the sole purpose of training on a certain model.
- In supervised tasks, data labeling can be done directly by the user.
Federated Averaging (FedAvg) Algorithm
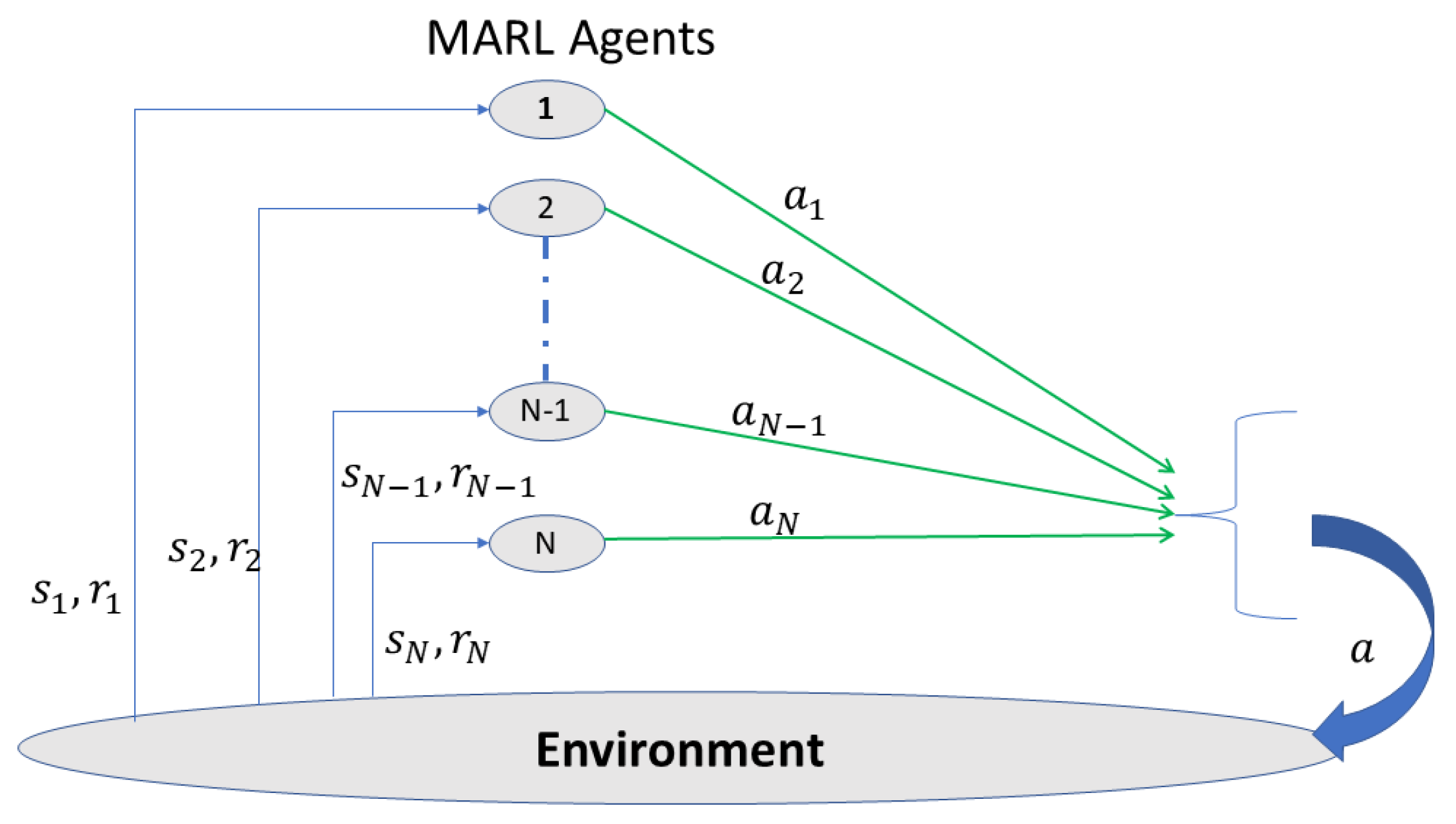
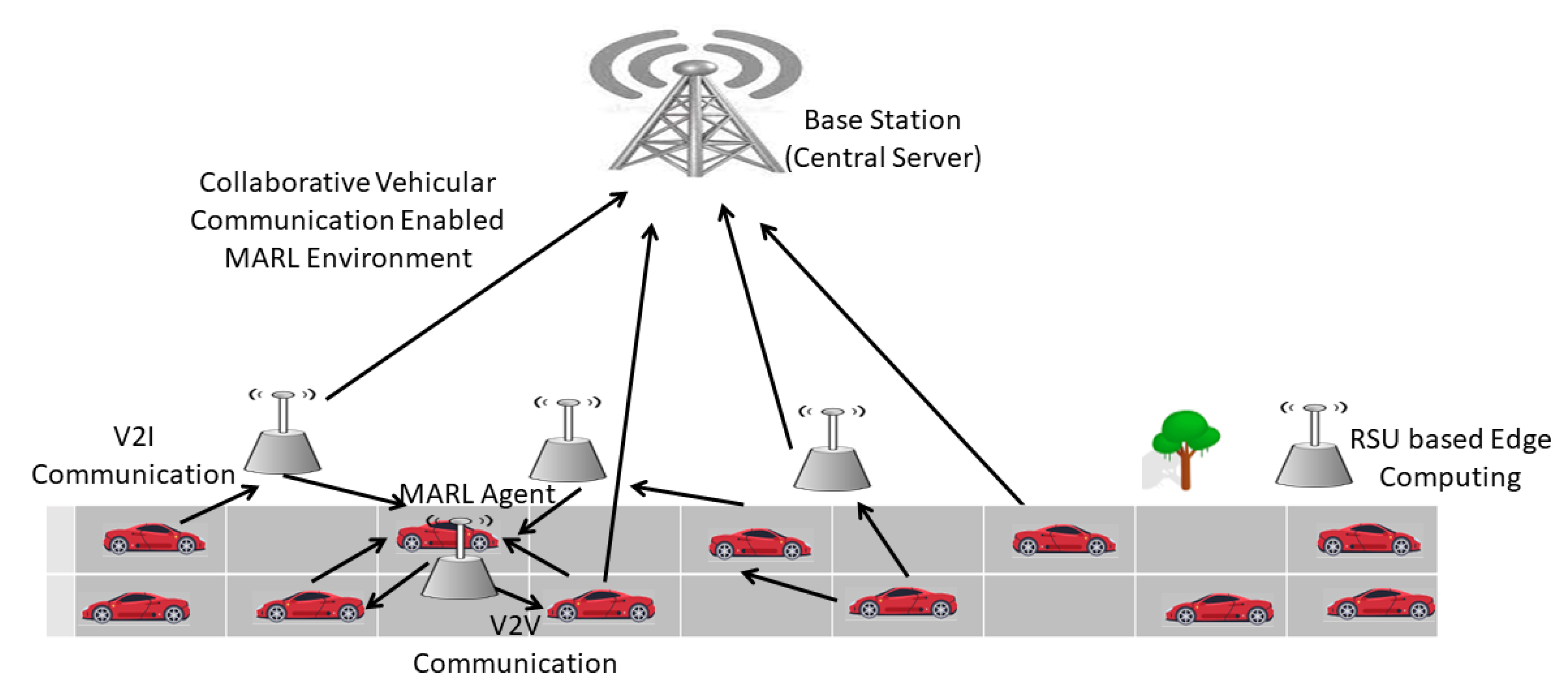
4.2. Multi-Agent Reinforcement Learning (MARL)
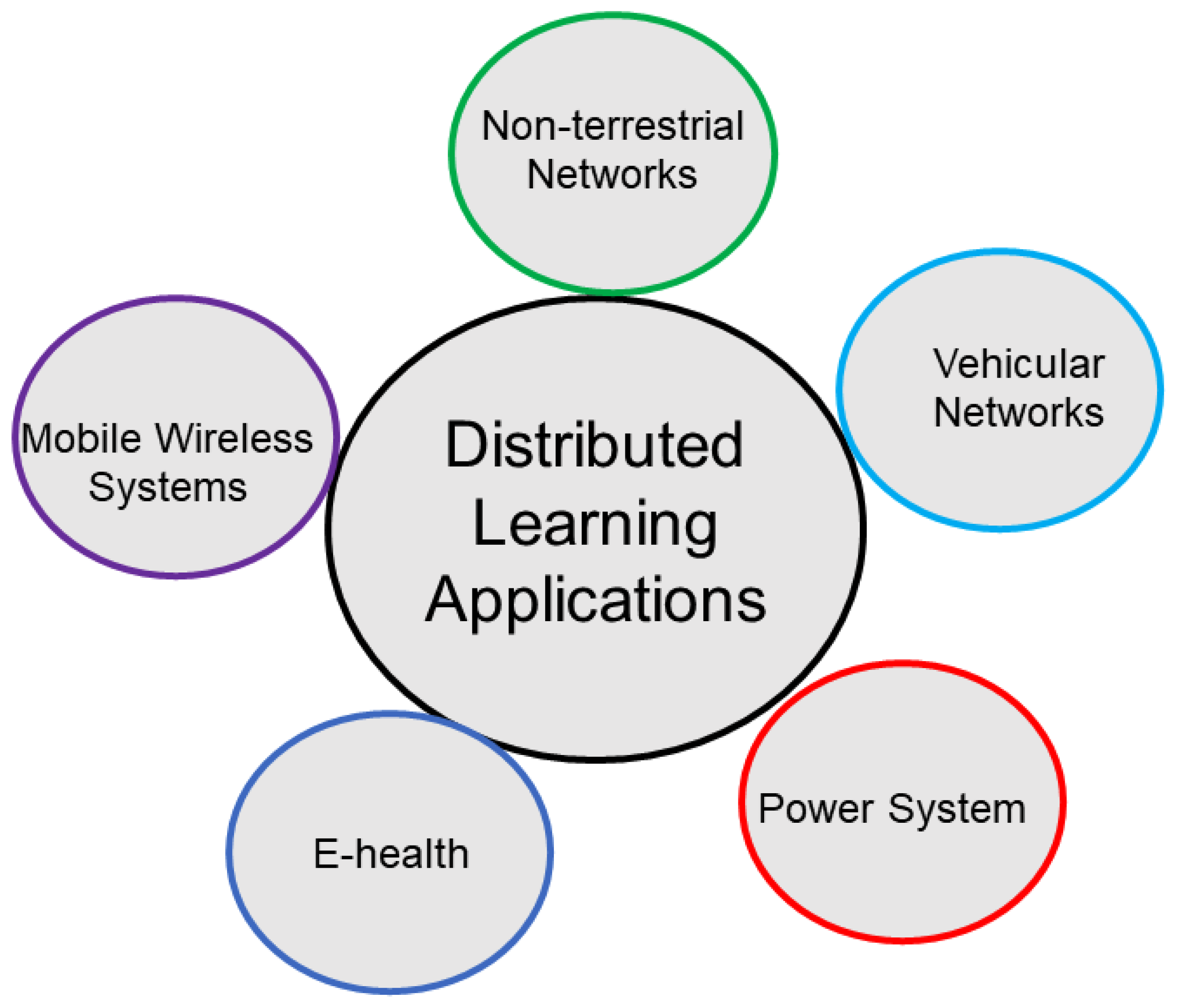
4.3. Main Applications
- Non-terrestrial Networks: Recently, various new non-terrestrial networking platforms have been integrated into the terrestrial networking systems to increase the available resource pool, limit the security-related challenges, and add flexibility and more sustainability to plans for natural disasters. Various distributed learning techniques have found their applications in the newly added non-terrestrial networks. The main applications include the cooperative spectrum sharing [30], trajectory design [31], traffic optimization [32], security [33], and task and resource allocation [34].
- Vehicular Networks: Distributed learning methods are widely used to solve the challenging problems in vehicular networks. The main applications include intelligent object detection [35], network resource allocation, vehicular data sharing [36], computation offloading to edge-computing-enabled systems [37], traffic light control [38], spectrum sharing [39], and intrusion detection [40].
- Power System: Recently, various distributed learning methods hav been used to solve power system-related problems [41]. Voltage control [42], energy management [43], demand predictions [44], transient stability enhancement, and resilience enhancement [45] are some of the main areas of power systems where distributed learning is succinctly used.
- E-health: E-health systems are getting packed with various new applications with high computational complexities and resource requirements [46]. Various distributed learning techniques have found applications in e-health systems. Given the sensitive nature of medical data, privacy-preserving FL approaches have gained a lot of interest. The recent advances in FL technology, the motivations, and the requirements of using FL in smart healthcare, especially for the Internet of Medical Things, are presented in [47]. In [48], main security challenges and the mitigation techniques for using an FL for healthcare systems are discussed. Additionally, a multilayered privacy-protective FL platform is proposed for healthcare-related applications.
5. Distributed Machine Learning for 6G
5.1. Communication-Efficient Federated Learning
- The FMTL algorithm directly optimizes the customized model of each device, while the federated MAML optimizes the initial model of all devices.
- When working with IID data, the FedAvg algorithm is essential, although FMTL and MAML are more practical for non-IID data.
- The parameter server (PS) must be aware of the data distributions in the devices to choose between FMTL and MAML.
- All FL algorithms must be trained by a distributed iterative process.
5.1.1. Compression and Sparsification
5.1.2. Federated Learning Training Method Design
5.2. Privacy and Security Related Studies in FL Framework
Application of Blockchain Technology for Creating a Secure FL Platform
5.3. Collaborative Machine Learning for Energy-Efficient Edge Networks in 6G
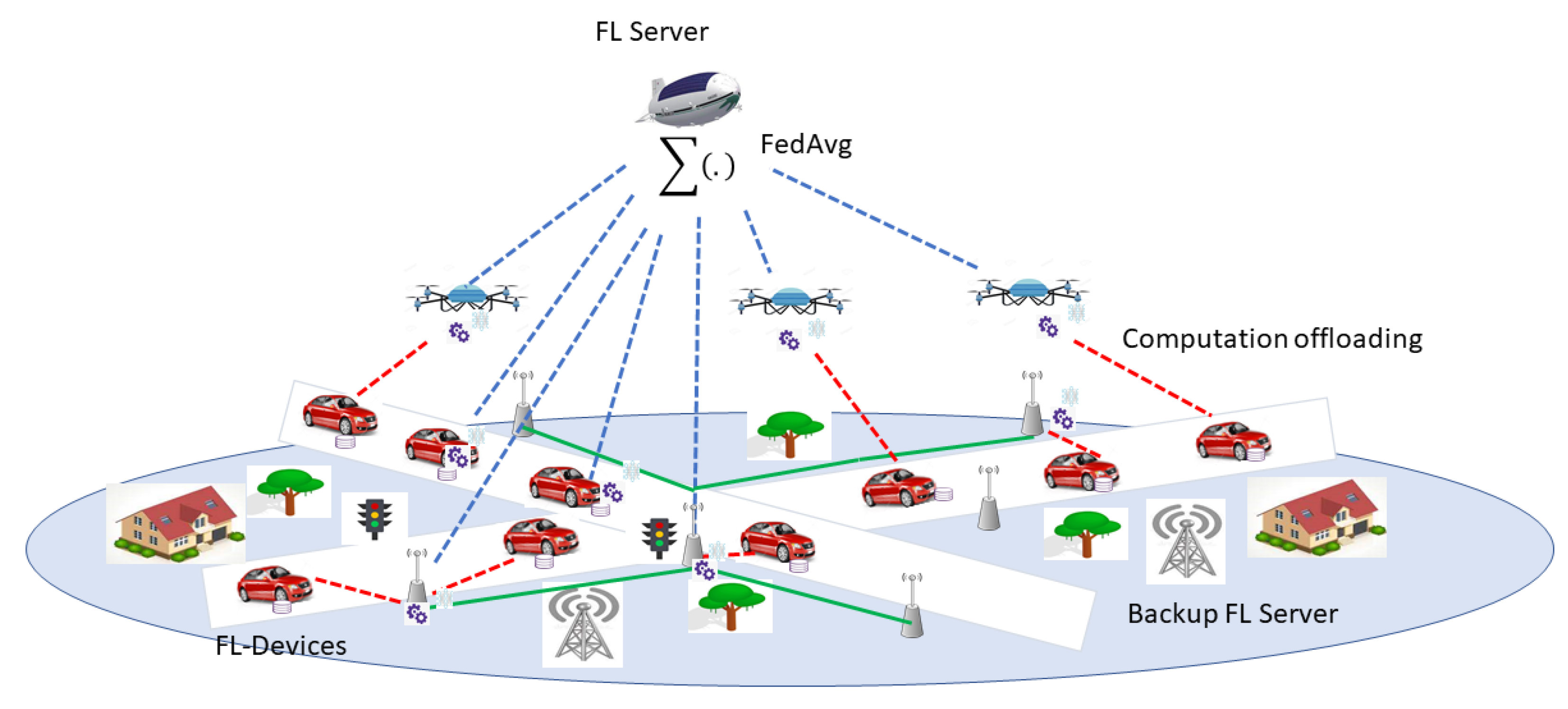
5.3.1. Energy Efficient Computational Offloading Empowered by Multiagent DRL
- Status: each SBS in a real network is unable to acquire the global state of the entire surrounding environment; instead, each SBS has its own limited knowledge. The channel gains of each agent’s signals for each channel, the interference power received, and information on the actions requested by the user within its coverage area are all part of the state observed by each agent for the characterization of the environment.
- Action: Each instant, each of the agents carries out an action based on its decisions. In this case, the action consists of the computational download decisions, channel and resource allocation for each user served, and uplink power control.
- Reward: Through a reward-based learning process, each SBS agent refines its rules. To increase performance and meet the goal of lowering global energy consumption, an incentives system can be devised to encourage collaboration among SBS agents.
5.3.2. Energy Efficient Computational Offloading Empowered by Federated DRL
5.3.3. Performance Evaluation
5.4. Federated Learning with Over-the-Air Computation
SignSGD in a Broadband AirComp-FEEL System
5.5. Federated Distillation
5.6. Multi-Agent Reinforcement Learning for UAV Trajectory
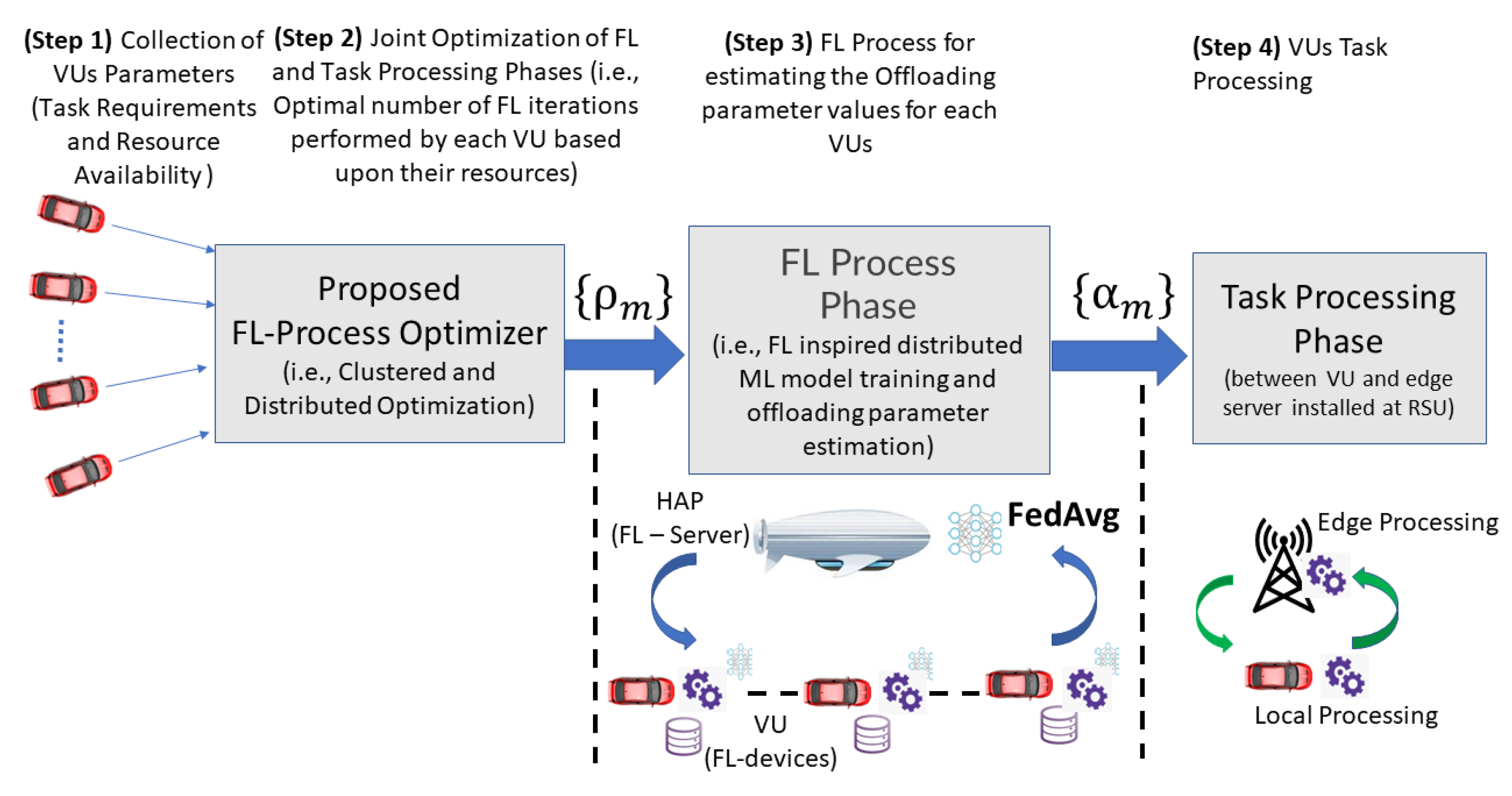
5.7. Adaptive FL for the Resource-Constrained Networking Scenarios with Stringent Task Requirements
5.8. Distributed Learning over the Joint Terrestrial and Non-Terrestrial Network
6. Future Directions
6.1. Collaborative MARL with Wireless Information Sharing
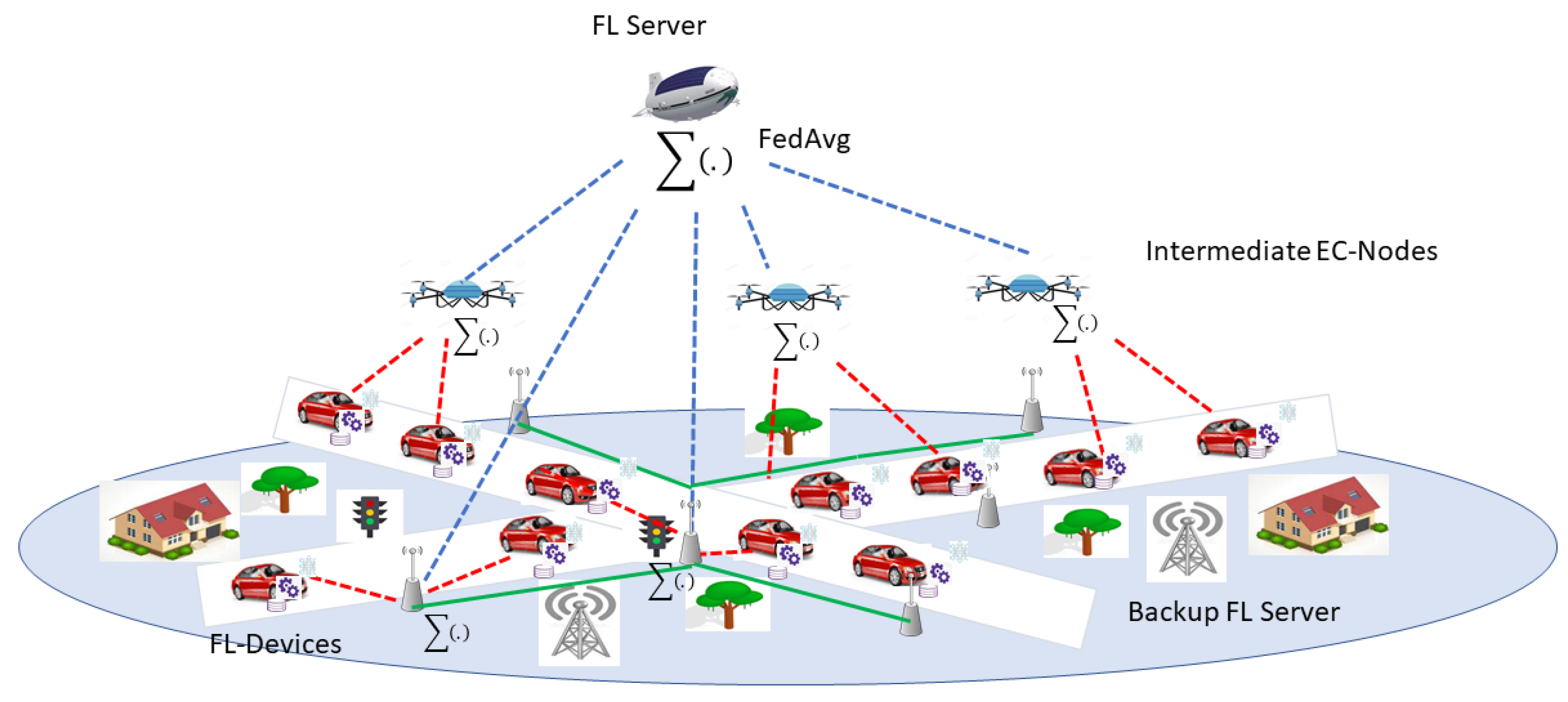
6.2. Distributing FL over Multi-EC Enabled Wireless Networks
6.3. Privacy and Security-Related Challenges
6.4. FL Hybridization with Heuristic and Meta-heuristic Techniques
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Saad, W.; Bennis, M.; Chen, M. A Vision of 6G Wireless Systems: Applications, Trends, Technologies, and Open Research Problems. IEEE Netw. 2020, 34, 134–142. [Google Scholar] [CrossRef] [Green Version]
- Yang, P.; Xiao, Y.; Xiao, M.; Li, S. 6G Wireless Communications: Vision and Potential Techniques. IEEE Netw. 2019, 33, 70–75. [Google Scholar] [CrossRef]
- Chen, M.; Gündüz, D.; Huang, K.; Saad, W.; Bennis, M.; Feljan, A.V.; Poor, H.V. Distributed Learning in Wireless Networks: Recent Progress and Future Challenges. IEEE J. Sel. Areas Commun. 2021, 39, 3579–3605. [Google Scholar] [CrossRef]
- Voigtländer, F.; Ramadan, A.; Eichinger, J.; Lenz, C.; Pensky, D.; Knoll, A. 5G for Robotics: Ultra-Low Latency Control of Distributed Robotic Systems. In Proceedings of the 2017 International Symposium on Computer Science and Intelligent Controls (ISCSIC), Budapest, Hungary, 20–22 October 2017; IEEE: Budapest, Hungary, 2017; pp. 69–72. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Ahmed, E.; Imran, M.; Zeadally, S. 5G for Vehicular Communications. IEEE Commun. Mag. 2018, 56, 111–117. [Google Scholar] [CrossRef]
- Bishoyi, P.K.; Misra, S. Enabling Green Mobile-Edge Computing for 5G-Based Healthcare Applications. IEEE Trans. Green Commun. Netw. 2021, 5, 1623–1631. [Google Scholar] [CrossRef]
- Huang, T.; Yang, W.; Wu, J.; Ma, J.; Zhang, X.; Zhang, D. A Survey on Green 6G Network: Architecture and Technologies. IEEE Access 2019, 7, 175758–175768. [Google Scholar] [CrossRef]
- Taking Communications to the Next Level. Position Paper, one6G. 2021. Available online: https://one6g.org/download/1350/ (accessed on 1 May 2022).
- IEEE Std 802. 15.3d-2017 (Amendment to IEEE Std 802.15.3-2016 as Amended by IEEE Std 802.15.3e-2017); IEEE Standard for High Data Rate Wireless Multi-Media Networks–Amendment 2: 100 Gb/s Wireless Switched Point-to-Point Physical Layer. IEEE: Piscataway, NJ, USA, 2017; pp. 1–55. [CrossRef]
- Petrov, V.; Kurner, T.; Hosako, I. IEEE 802.15. 3d: First standardization efforts for sub-terahertz band communications toward 6G. IEEE Commun. Mag. 2020, 58, 28–33. [Google Scholar] [CrossRef]
- Shinde, S.S.; Marabissi, D.; Tarchi, D. A network operator-biased approach for multi-service network function placement in a 5G network slicing architecture. Comput. Netw. 2021, 201, 108598. [Google Scholar] [CrossRef]
- David, K.; Berndt, H. 6G Vision and Requirements: Is There Any Need for Beyond 5G? IEEE Veh. Technol. Mag. 2018, 13, 72–80. [Google Scholar] [CrossRef]
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge Intelligence: The Confluence of Edge Computing and Artificial Intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef] [Green Version]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An introductory review of deep learning for prediction models with big data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning–based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Feriani, A.; Hossain, E. Single and multi-agent deep reinforcement learning for AI-enabled wireless networks: A tutorial. IEEE Commun. Surv. Tutor. 2021, 23, 1226–1252. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep Learning in Mobile and Wireless Networking: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef] [Green Version]
- Skansi, S. Introduction to Deep Learning—From Logical Calculus to Artificial Intelligence; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2022, 55, 895–943. [Google Scholar] [CrossRef]
- Balkus, S.V.; Wang, H.; Cornet, B.D.; Mahabal, C.; Ngo, H.; Fang, H. A Survey of Collaborative Machine Learning Using 5G Vehicular Communications. IEEE Commun. Surv. Tutor. 2022, 24, 1280–1303. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, R.; Lai, S.; Fan, L.; Lei, X.; Karagiannidis, G.K. Distributed machine learning for multiuser mobile edge computing systems. IEEE J. Sel. Top. Signal Process. 2022, 16, 460–473. [Google Scholar] [CrossRef]
- Konečný, J.; McMahan, B.; Ramage, D. Federated Optimization:Distributed Optimization Beyond the Datacenter. arXiv 2015, arXiv:1511.03575. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Aguera y Arcas, B. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20–22 April 2017; Singh, A., Zhu, J., Eds.; Proceedings of Machine Learning Research; Volume 54, pp. 1273–1282. Available online: https://proceedings.mlr.press/v54/mcmahan17a.html (accessed on 1 April 2022).
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 12:1–12:19. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, Z.; Basar, T. Multi-Agent Reinforcement Learning: A Selective Overview of Theories and Algorithms. In Handbook of Reinforcement Learning and Control; Vamvoudakis, K.G., Wan, Y., Lewis, F.L., Cansever, D., Eds.; Springer: Cham, Switzerland, 2021; pp. 321–384. [Google Scholar] [CrossRef]
- Shamsoshoara, A.; Khaledi, M.; Afghah, F.; Razi, A.; Ashdown, J. Distributed cooperative spectrum sharing in uav networks using multi-agent reinforcement learning. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Wu, F.; Zhang, H.; Wu, J.; Song, L. Cellular UAV-to-device communications: Trajectory design and mode selection by multi-agent deep reinforcement learning. IEEE Trans. Commun. 2020, 68, 4175–4189. [Google Scholar] [CrossRef] [Green Version]
- Qin, Z.; Yao, H.; Mai, T. Traffic optimization in satellites communications: A multi-agent reinforcement learning approach. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 269–273. [Google Scholar]
- Zhang, Y.; Zhuang, Z.; Gao, F.; Wang, J.; Han, Z. Multi-agent deep reinforcement learning for secure UAV communications. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Wang, S.; Chen, M.; Yin, C.; Saad, W.; Hong, C.S.; Cui, S.; Poor, H.V. Federated Learning for Task and Resource Allocation in Wireless High-Altitude Balloon Networks. IEEE Internet Things J. 2021, 8, 17460–17475. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; She, J.; Yan, Z.; Kevin, I.; Wang, K. Two-layer federated learning with heterogeneous model aggregation for 6g supported internet of vehicles. IEEE Trans. Veh. Technol. 2021, 70, 5308–5317. [Google Scholar] [CrossRef]
- Li, X.; Cheng, L.; Sun, C.; Lam, K.Y.; Wang, X.; Li, F. Federated-learning-empowered collaborative data sharing for vehicular edge networks. IEEE Netw. 2021, 35, 116–124. [Google Scholar] [CrossRef]
- Prathiba, S.B.; Raja, G.; Anbalagan, S.; Dev, K.; Gurumoorthy, S.; Sankaran, A.P. Federated learning empowered computation offloading and resource management in 6G-V2X. IEEE Trans. Netw. Sci. Eng. 2021. [Google Scholar] [CrossRef]
- Wu, T.; Zhou, P.; Liu, K.; Yuan, Y.; Wang, X.; Huang, H.; Wu, D.O. Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks. IEEE Trans. Veh. Technol. 2020, 69, 8243–8256. [Google Scholar] [CrossRef]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum sharing in vehicular networks based on multi-agent reinforcement learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Zhang, S.; Zhang, P.; Zhou, X.; Shao, X.; Pu, G.; Zhang, Y. Blockchain and federated learning for collaborative intrusion detection in vehicular edge computing. IEEE Trans. Veh. Technol. 2021, 70, 6073–6084. [Google Scholar] [CrossRef]
- Gholizadeh, N.; Musilek, P. Distributed learning applications in power systems: A review of methods, gaps, and challenges. Energies 2021, 14, 3654. [Google Scholar] [CrossRef]
- Wang, S.; Duan, J.; Shi, D.; Xu, C.; Li, H.; Diao, R.; Wang, Z. A data-driven multi-agent autonomous voltage control framework using deep reinforcement learning. IEEE Trans. Power Syst. 2020, 35, 4644–4654. [Google Scholar] [CrossRef]
- Xu, X.; Jia, Y.; Xu, Y.; Xu, Z.; Chai, S.; Lai, C.S. A multi-agent reinforcement learning-based data-driven method for home energy management. IEEE Trans. Smart Grid 2020, 11, 3201–3211. [Google Scholar] [CrossRef] [Green Version]
- Saputra, Y.M.; Hoang, D.T.; Nguyen, D.N.; Dutkiewicz, E.; Mueck, M.D.; Srikanteswara, S. Energy demand prediction with federated learning for electric vehicle networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Wang, P.; Govindarasu, M. Multi-agent based attack-resilient system integrity protection for smart grid. IEEE Trans. Smart Grid 2020, 11, 3447–3456. [Google Scholar] [CrossRef]
- Bishoyi, P.K.; Misra, S. Towards Energy-and Cost-Efficient Sustainable MEC-Assisted Healthcare Systems. IEEE Trans. Sustain. Comput. 2022. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated learning for smart healthcare: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Kasyap, H.; Tripathy, S. Privacy-preserving decentralized learning framework for healthcare system. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–24. [Google Scholar] [CrossRef]
- Wikstrom, G.; Persson, P.; Parkvall, S.; Mildh, G.; Dahlman, E.; Balakrishnan, B.; Ohlrn, P.; Trojer, E.; Rune, G.; Arkko, J.; et al. 6G—Connecting a Cyber-Physical World. White Paper 28, Ericsson, 2022. Available online: https://www.ericsson.com/en/reports-and-papers/white-papers/a-research-outlook-towards-6g (accessed on 1 May 2022).
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated Learning for Internet of Things: Recent Advances, Taxonomy, and Open Challenges. IEEE Commun. Surv. Tutor. 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Chen, M.; Poor, H.V.; Saad, W.; Cui, S. Wireless Communications for Collaborative Federated Learning. IEEE Commun. Mag. 2020, 58, 48–54. [Google Scholar] [CrossRef]
- Ma, C.; Li, J.; Ding, M.; Yang, H.H.; Shu, F.; Quek, T.Q.S.; Poor, H.V. On Safeguarding Privacy and Security in the Framework of Federated Learning. IEEE Netw. 2020, 34, 242–248. [Google Scholar] [CrossRef] [Green Version]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially private federated learning: A client level perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Kido, H.; Yanagisawa, Y.; Satoh, T. Protection of Location Privacy using Dummies for Location-based Services. In Proceedings of the 21st International Conference on Data Engineering Workshops (ICDEW’05), Tokyo, Japan, 3–4 April 2005; p. 1248. [Google Scholar] [CrossRef]
- Papernot, N.; Abadi, M.; Erlingsson, U.; Goodfellow, I.; Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv 2016, arXiv:1610.05755. [Google Scholar]
- Andreina, S.; Marson, G.A.; Möllering, H.; Karame, G. Baffle: Backdoor detection via feedback-based federated learning. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 852–863. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Lecture Notes in Computer Science; Chen, L., Li, N., Liang, K., Schneider, S., Eds.; Computer Security—ESORICS 2020; ESORICS 2020; Springer: Cham, Switzerland, 2020; Volume 12308, pp. 480–501. [Google Scholar]
- Cao, D.; Chang, S.; Lin, Z.; Liu, G.; Sun, D. Understanding Distributed Poisoning Attack in Federated Learning. In Proceedings of the 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019; pp. 233–239. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and Federated Learning for Privacy-Preserved Data Sharing in Industrial IoT. IEEE Trans. Ind. Inform. 2020, 16, 4177–4186. [Google Scholar] [CrossRef]
- Pokhrel, S.R.; Choi, J. Federated Learning With Blockchain for Autonomous Vehicles: Analysis and Design Challenges. IEEE Trans. Commun. 2020, 68, 4734–4746. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pham, Q.V.; Pathirana, P.N.; Le, L.B.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated Learning Meets Blockchain in Edge Computing: Opportunities and Challenges. IEEE Internet Things J. 2021, 8, 12806–12825. [Google Scholar] [CrossRef]
- Billah, M.; Mehedi, S.; Anwar, A.; Rahman, Z.; Islam, R. A Systematic Literature Review on Blockchain Enabled Federated Learning Framework for Internet of Vehicles. arXiv 2022, arXiv:2203.05192. [Google Scholar]
- Saraswat, D.; Verma, A.; Bhattacharya, P.; Tanwar, S.; Sharma, G.; Bokoro, P.N.; Sharma, R. Blockchain-Based Federated Learning in UAVs Beyond 5G Networks: A Solution Taxonomy and Future Directions. IEEE Access 2022, 10, 33154–33182. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, K.; Wu, F.; Leng, S. Collaborative Machine Learning for Energy-Efficient Edge Networks in 6G. IEEE Netw. 2021, 35, 12–19. [Google Scholar] [CrossRef]
- Zhu, G.; Wang, Y.; Huang, K. Broadband Analog Aggregation for Low-Latency Federated Edge Learning. IEEE Trans. Wirel. Commun. 2020, 19, 491–506. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Mishra, A.; Latorre, J.A.; Pool, J.; Stosic, D.; Stosic, D.; Venkatesh, G.; Yu, C.; Micikevicius, P. Accelerating sparse deep neural networks. arXiv 2021, arXiv:2104.08378. [Google Scholar]
- Chen, L.; Lin, S.; Lu, X.; Cao, D.; Wu, H.; Guo, C.; Liu, C.; Wang, F.Y. Deep Neural Network Based Vehicle and Pedestrian Detection for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3234–3246. [Google Scholar] [CrossRef]
- Hu, Y.; Chen, M.; Saad, W.; Poor, H.V.; Cui, S. Distributed Multi-Agent Meta Learning for Trajectory Design in Wireless Drone Networks. IEEE J. Sel. Areas Commun. 2021, 39, 3177–3192. [Google Scholar] [CrossRef]
- Shinde, S.S.; Bozorgchenani, A.; Tarchi, D.; Ni, Q. On the Design of Federated Learning in Latency and Energy Constrained Computation Offloading Operations in Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2022, 71, 2041–2057. [Google Scholar] [CrossRef]
- Rinaldi, F.; Maattanen, H.L.; Torsner, J.; Pizzi, S.; Andreev, S.; Iera, A.; Koucheryavy, Y.; Araniti, G. Non-Terrestrial Networks in 5G amp; Beyond: A Survey. IEEE Access 2020, 8, 165178–165200. [Google Scholar] [CrossRef]
- Verdone, R.; Mignardi, S. Joint Aerial-Terrestrial Resource Management in UAV-Aided Mobile Radio Networks. IEEE Netw. 2018, 32, 70–75. [Google Scholar] [CrossRef]
- Lin, X.; Rommer, S.; Euler, S.; Yavuz, E.A.; Karlsson, R.S. 5G from Space: An Overview of 3GPP Non-Terrestrial Networks. IEEE Commun. Stand. Mag. 2021, 5, 147–153. [Google Scholar] [CrossRef]
- Giordani, M.; Zorzi, M. Non-Terrestrial Networks in the 6G Era: Challenges and Opportunities. IEEE Netw. 2021, 35, 244–251. [Google Scholar] [CrossRef]
- Shah, H.A.; Zhao, L.; Kim, I.M. Joint Network Control and Resource Allocation for Space-Terrestrial Integrated Network Through Hierarchal Deep Actor-Critic Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 4943–4954. [Google Scholar] [CrossRef]
- Zhang, S.; Zhu, D.; Wang, Y. A survey on space-aerial-terrestrial integrated 5G networks. Comput. Netw. 2020, 174, 107212. [Google Scholar] [CrossRef]
- Shinde, S.S.; Tarchi, D. Towards a Novel Air-Ground Intelligent Platform for Vehicular Networks: Technologies, Scenarios, and Challenges. Smart Cities 2021, 4, 1469–1495. [Google Scholar] [CrossRef]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-Decomposition Networks For Cooperative Multi-Agent Learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Rashid, T.; Samvelyan, M.; de Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. J. Mach. Learn. Res. 2020, 21, 1–51. Available online: http://jmlr.org/papers/v21/20-081.html (accessed on 1 May 2022).
- Połap, D.; Woźniak, M. Meta-heuristic as manager in federated learning approaches for image processing purposes. Appl. Soft Comput. 2021, 113, 107872. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M. A hybridization of distributed policy and heuristic augmentation for improving federated learning approach. Neural Netw. 2022, 146, 130–140. [Google Scholar] [CrossRef]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muscinelli, E.; Shinde, S.S.; Tarchi, D. Overview of Distributed Machine Learning Techniques for 6G Networks. Algorithms 2022, 15, 210. https://doi.org/10.3390/a15060210
Muscinelli E, Shinde SS, Tarchi D. Overview of Distributed Machine Learning Techniques for 6G Networks. Algorithms. 2022; 15(6):210. https://doi.org/10.3390/a15060210
Chicago/Turabian StyleMuscinelli, Eugenio, Swapnil Sadashiv Shinde, and Daniele Tarchi. 2022. "Overview of Distributed Machine Learning Techniques for 6G Networks" Algorithms 15, no. 6: 210. https://doi.org/10.3390/a15060210
APA StyleMuscinelli, E., Shinde, S. S., & Tarchi, D. (2022). Overview of Distributed Machine Learning Techniques for 6G Networks. Algorithms, 15(6), 210. https://doi.org/10.3390/a15060210