
Improving Traffic Load Distribution Fairness in Mobile Social Networks


Abstract
:1. Introduction
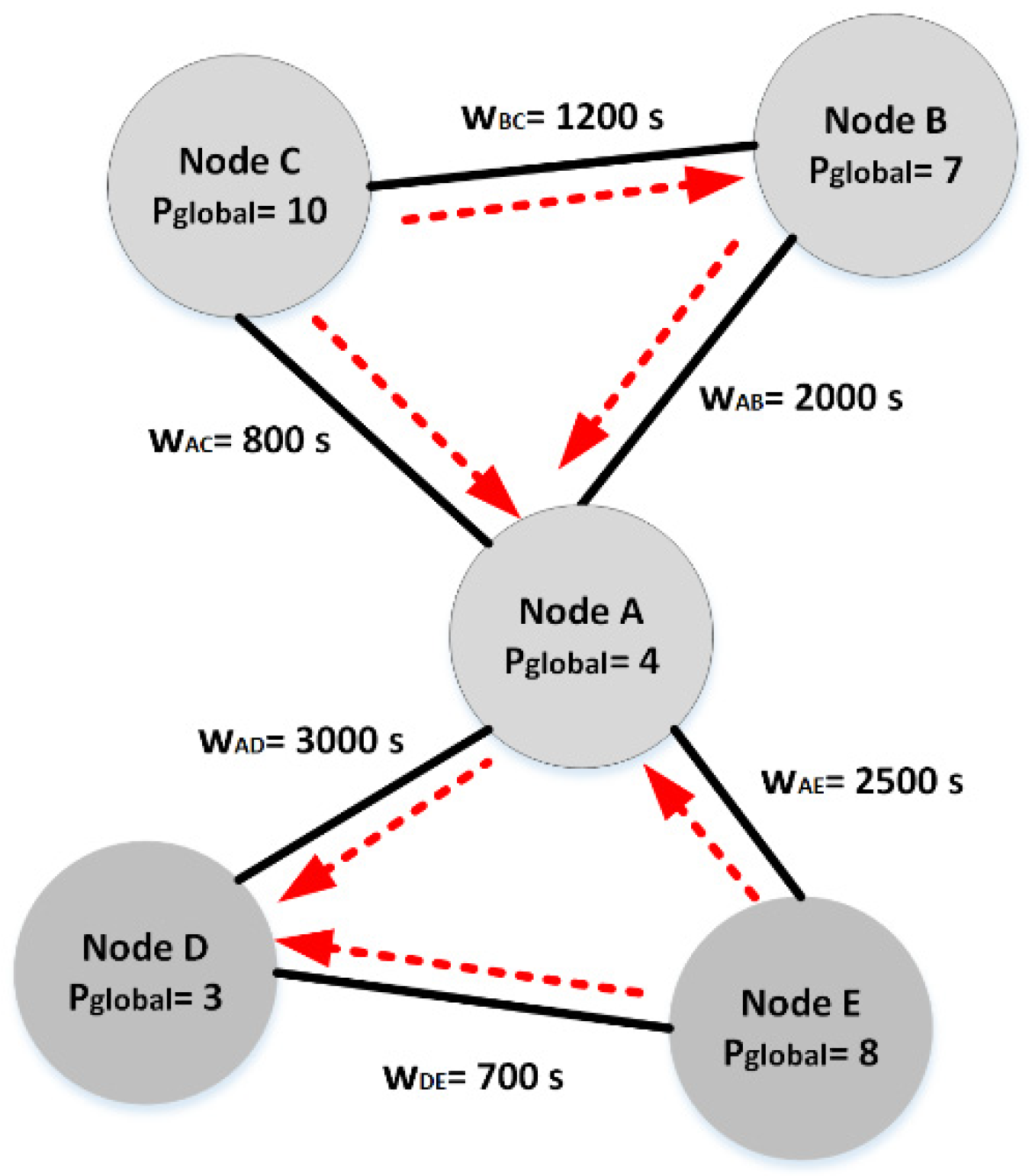
- To increase fairness in forwarding of social-based routing algorithms in mobile social networks, we propose TraLDA, a framework of traffic load distribution aware. We offer a new method for calculating node global popularity, a function of both node inherent and social-relations popularity.
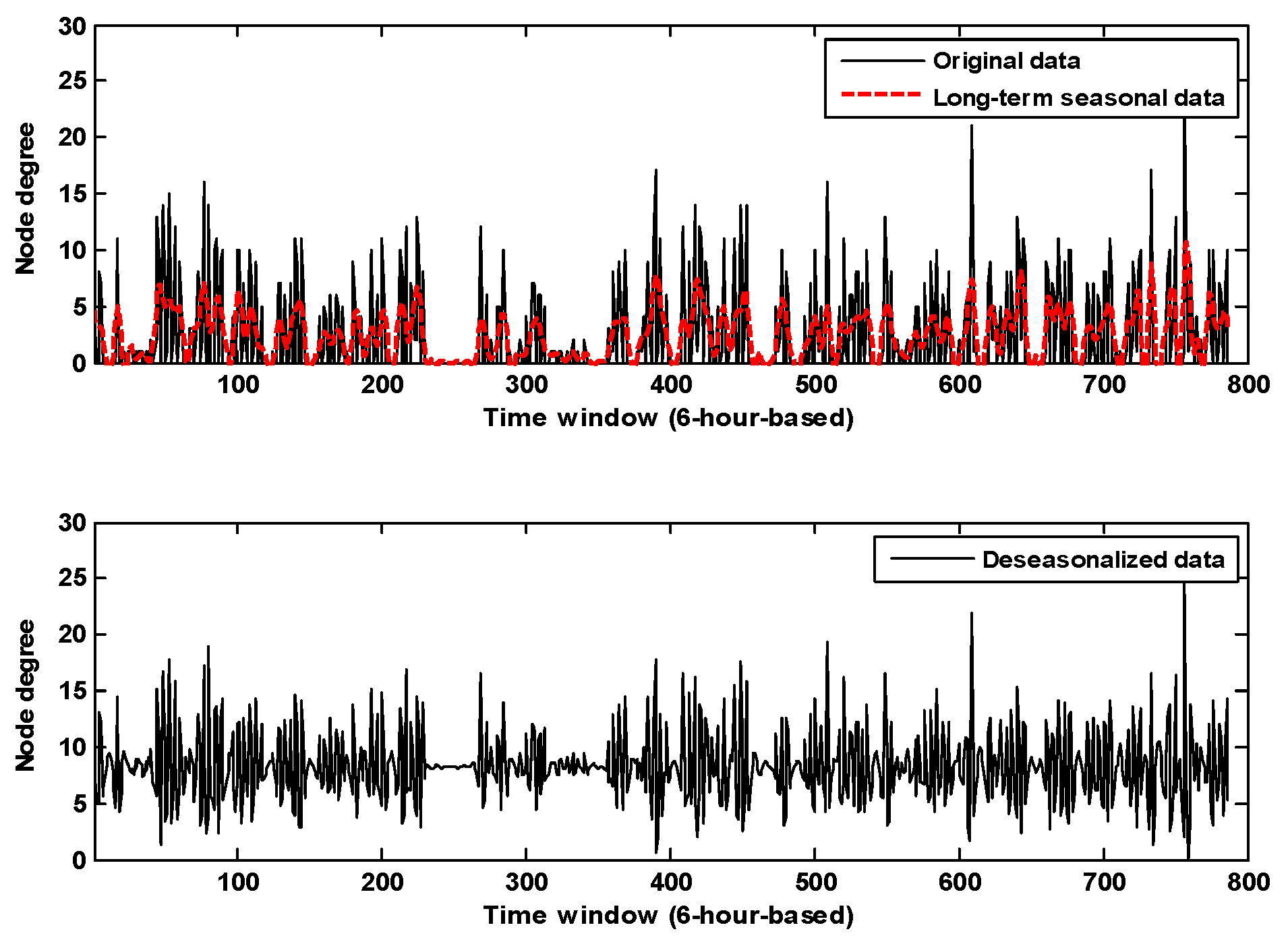
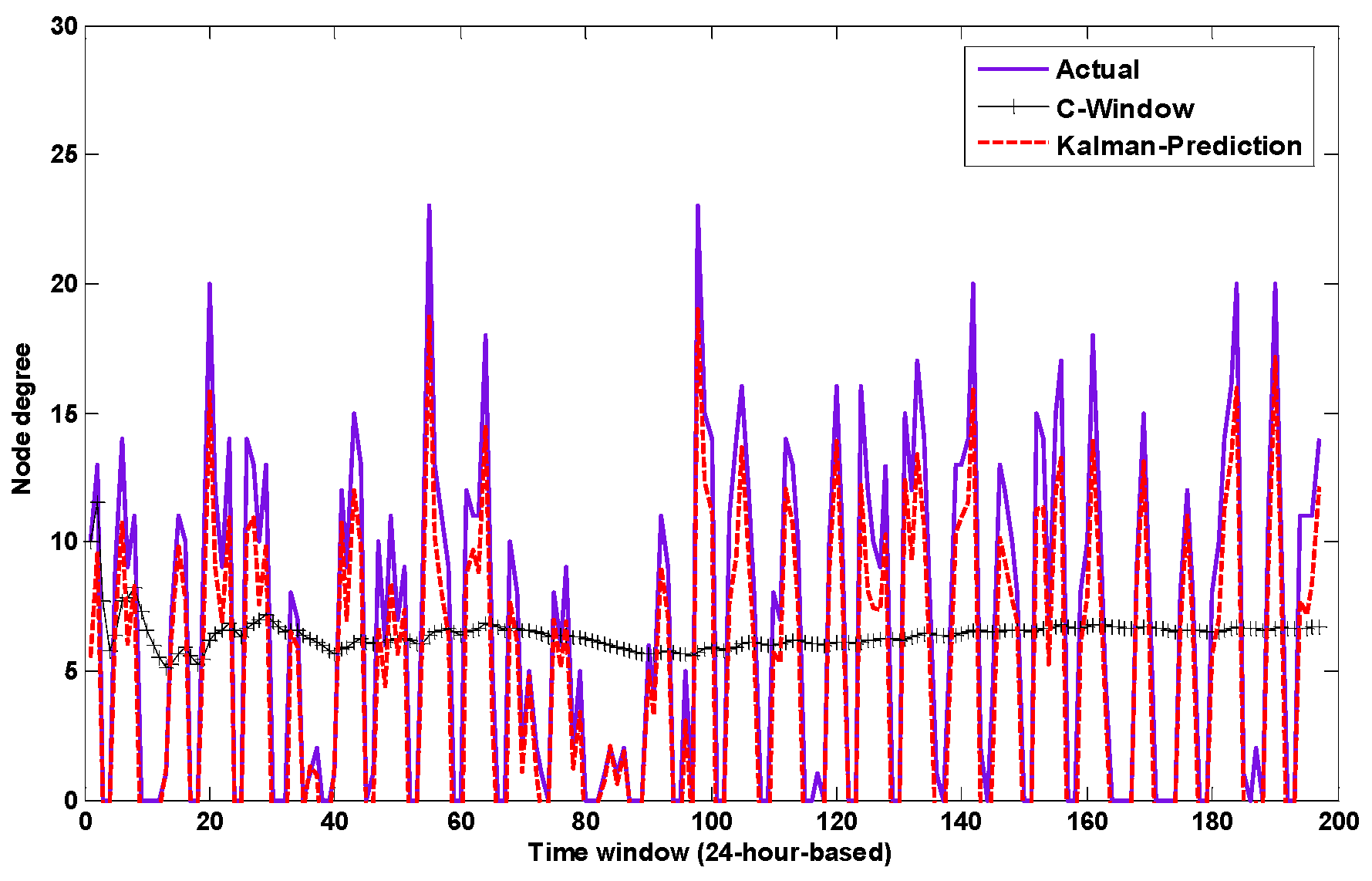
- The inherent popularity of a node is solely determined by the node’s own mobility pattern or sociability level in the network, and in TraLDA it is computed using the Kalman prediction which accounts for the regularity (periodicity) of human behaviour.
- Node social-relation popularity, on the other hand, represents the advantages of connections with more popular or central nodes (individuals). It shares the popularity of more popular nodes to their less popular counterparts.
- Finally, we apply TraLDA on the calculation of node global popularity and centrality in BubbleRap and SimBet, respectively, in order to improve the traffic load balancing among network nodes. Using extensive simulations in the Opportunistic Network Environment (ONE) [22] driven by realistic human mobility scenarios, we show that TraLDA enhances fairness in forwarding of both schemes, without negatively affecting the overall delivery performances.
2. Related Literature
3. Research Background
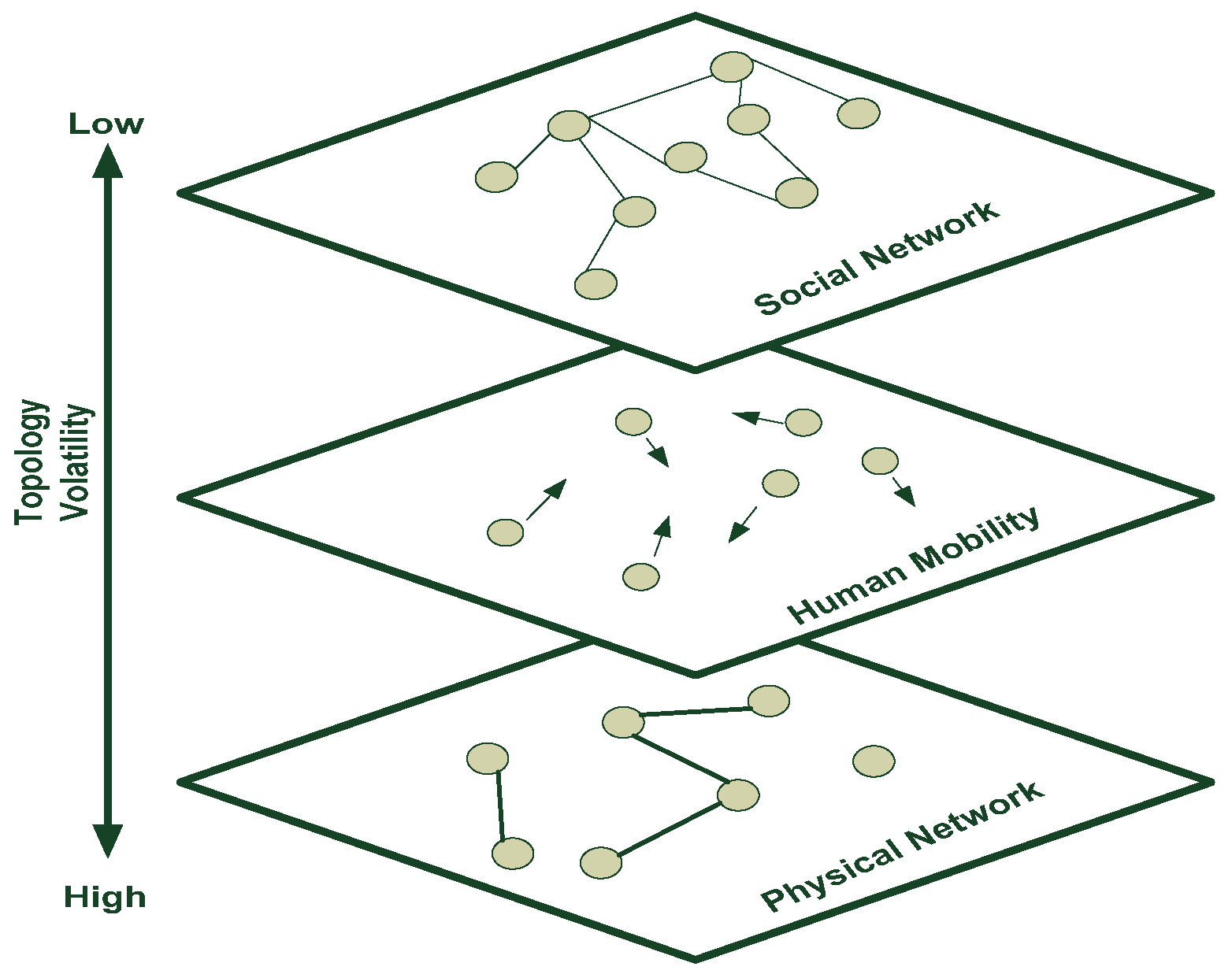
3.1. Topology Structures of Mobile Social Networks
3.2. Social-Based Routing Algorithms
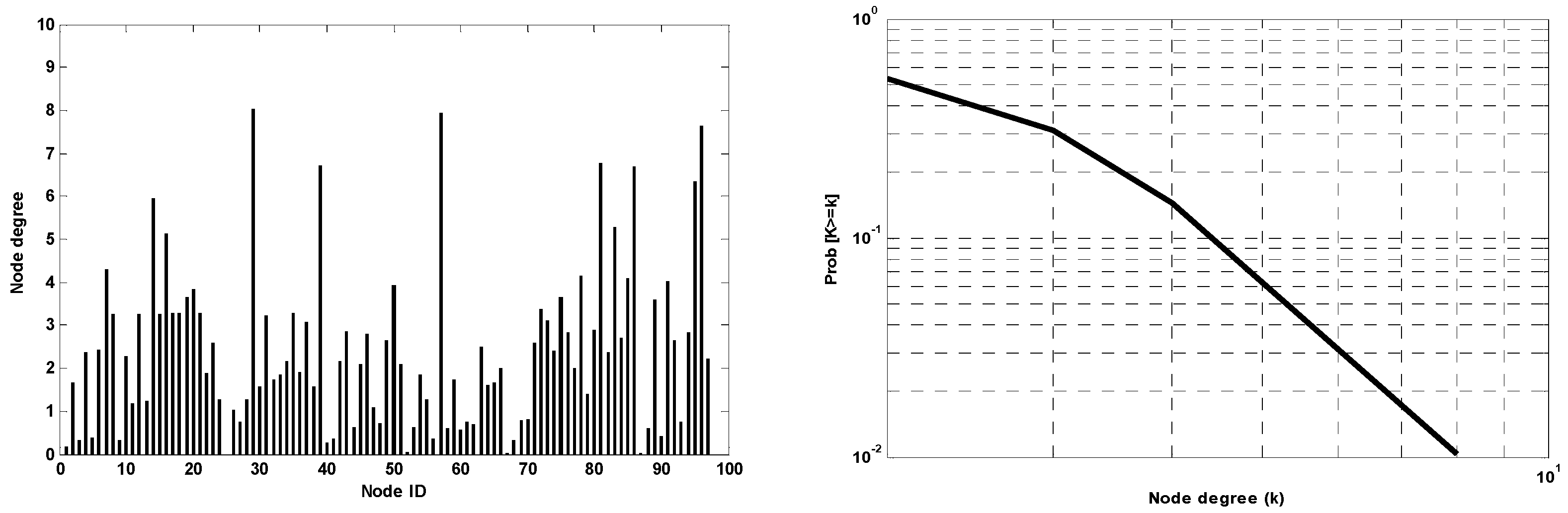
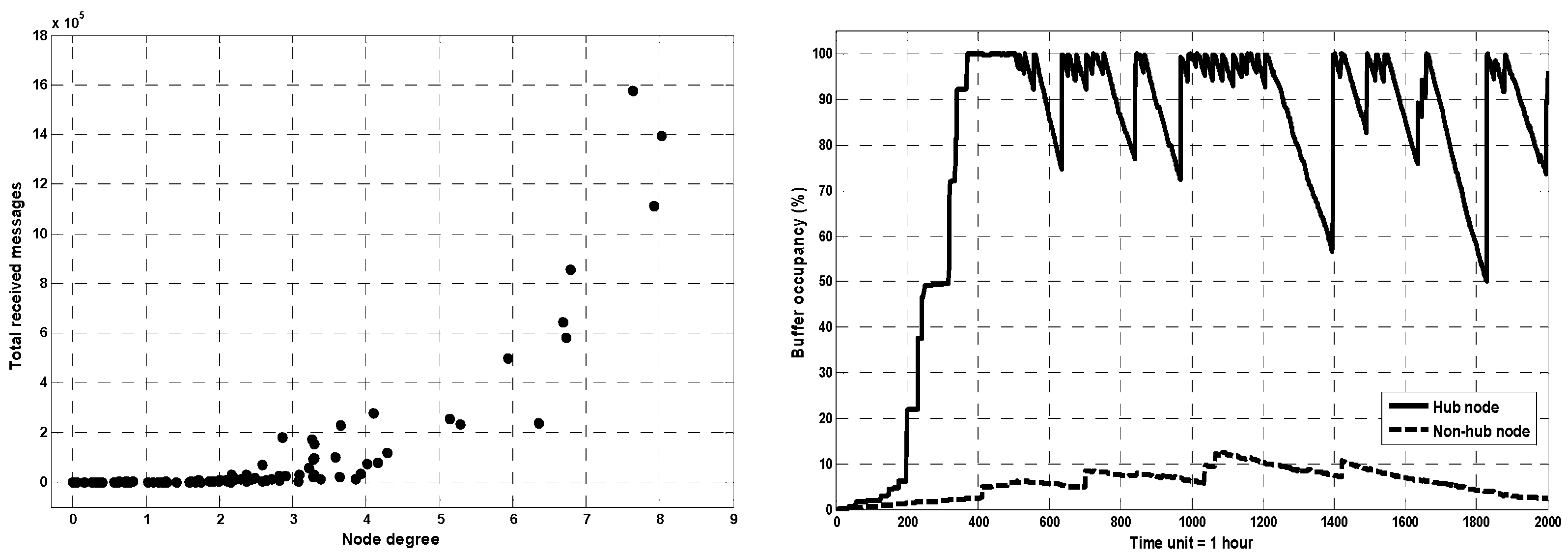
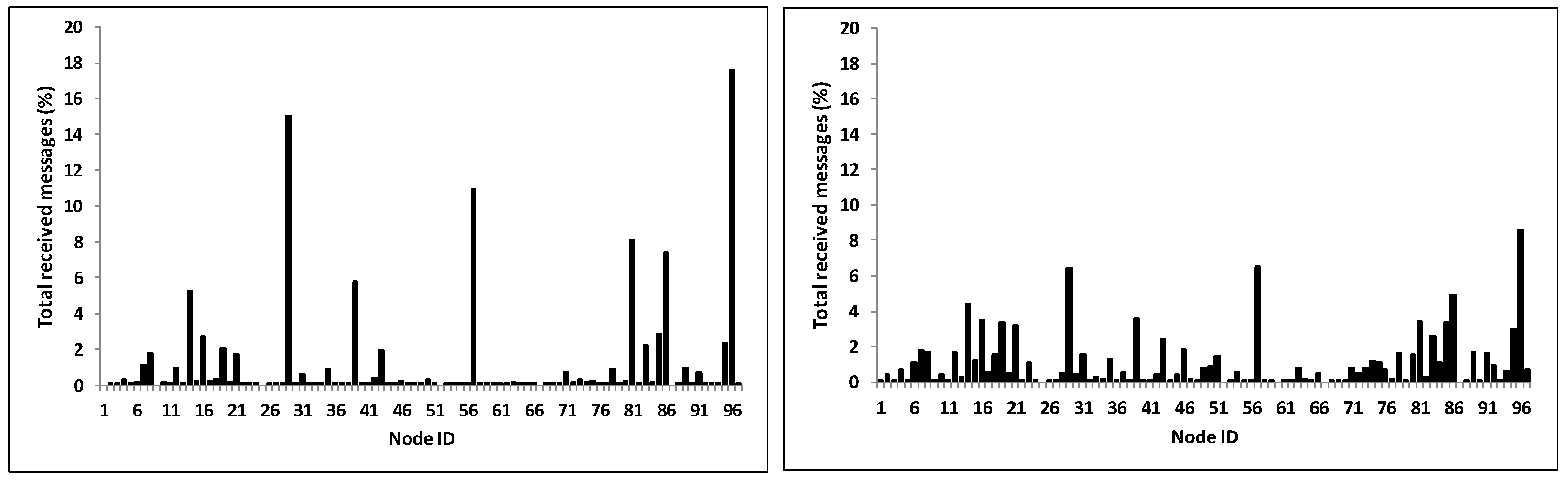
- Hill-climbing heuristic forwarding is a pure greedy approach that sends the message to the nodes with the highest utility at each contact (hop). Fan et al. [11] used a Markov model to show that under this forwarding technique, the probability of a message reaching the greatest utility node(s) is one, implying that messages will always find the highest utility nodes in mobile social networks. Furthermore, in the following we show mathematically that the forwarding heuristic, which is biased towards higher value nodes, guides the routing algorithm to send the bulk of network traffic through the highest utility node(s) as follows. We first assume a routing strategy that determines the next-hop nodes in a random manner. The message forwarding is therefore a random walk over the graph G(V, E) mentioned above, with the transition probability matrix P, where its element is defined in (1). Under this random forwarding, is equal to the inverse of node i’s degree , or . In a steady state traffic flow, the chance to find a message m in node j, which also equals to j’s traffic load, can be computed as the first eigenvector of the distribution matrix , with . Then, it is easy to see that the eigenvector for distribution matrices of networks with a non-random (heterogeneous) connectivity distribution such as mobile social networks will be skewed towards the highly connected nodes (hub nodes) under this random scheme. Eventually, this confirms the natural traffic load imbalance in the social networks. Further, if the forwarding strategy is not random, but biased towards connectivity (i.e., favouring nodes with a higher degree), the probability of hub nodes receiving relay traffic increases and the traffic load distribution becomes more unbalanced. Furthermore, using simulation in the Reality mobility scenario [39] we illustrate in Figure 3 (left) the node degree vs. node traffic load when the hill-climbing heuristic forwarding is applied on the network (here, node traffic load is defined as the total relay messages carried by a node). The graphic depicts a few the highest degree nodes handle a big portion of traffic, yet most of network nodes only process a small one. This quickly depletes the hub nodes’ constrained resources such as power and storage. For instance, we show in Figure 3 (right) the buffer occupancy changes of illustrative hub node and non-hub node in Reality. Clearly, the buffer occupancy in the hub node is regularly saturated, whereas the buffer queue on the non-hub node is normally low during the experiment.
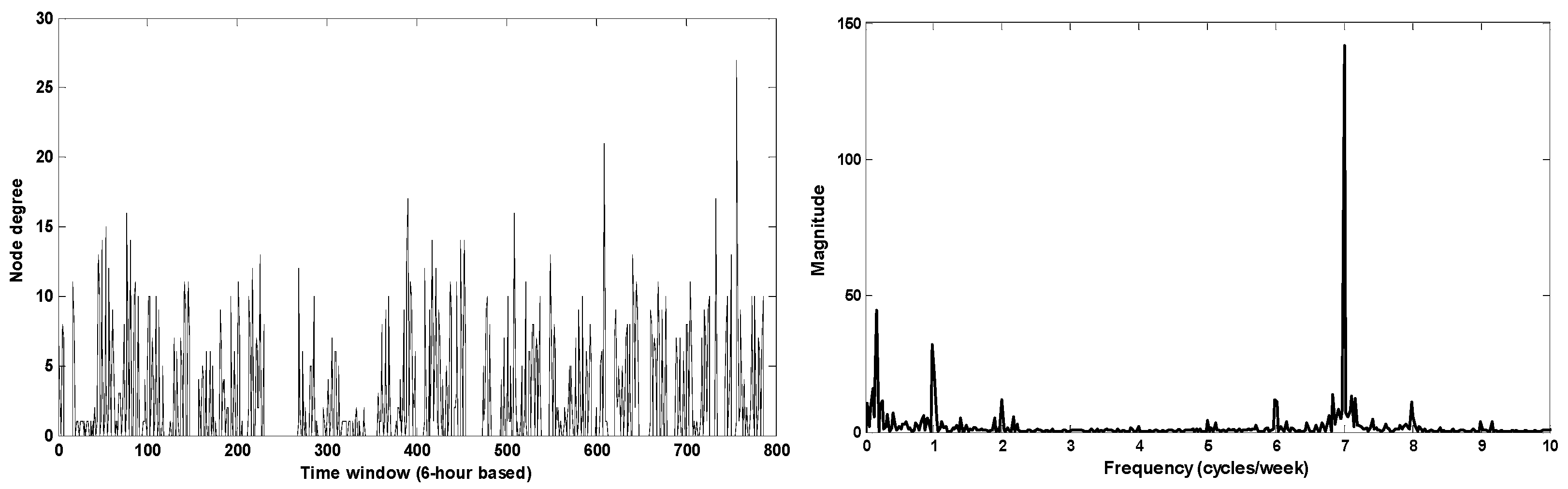
- In mobile social networks, node utility can change over time, and a low utility node at the present time could become a good relay in the future. Most conventional utility-based forwarding algorithms, however, often ignores this. Furthermore, the studies in [18,19] showed that node popularity in human-based networks varies over time and has a periodic pattern. Considering this, when TraLDA calculates node popularity, these features will be taken into account.
4. TraLDA Design
4.1. Inherent Popularity Calculation
4.2. Social-Relations Popularity Calculation
4.3. TraLDA Distributed Algorithm
| Algorithm 1: TraLDA node global popularity calculation (i). |
while i encounters j in time window t do /*update current node’s global popularity based on the peer’s information*/ if then (14) (9)–(12) (16) (15) end if /* exchange instantaneous node global popularity */ /*when the contact ends*/ then update if end if end if end while |
5. Simulation and Discussion
5.1. Simulation Setup
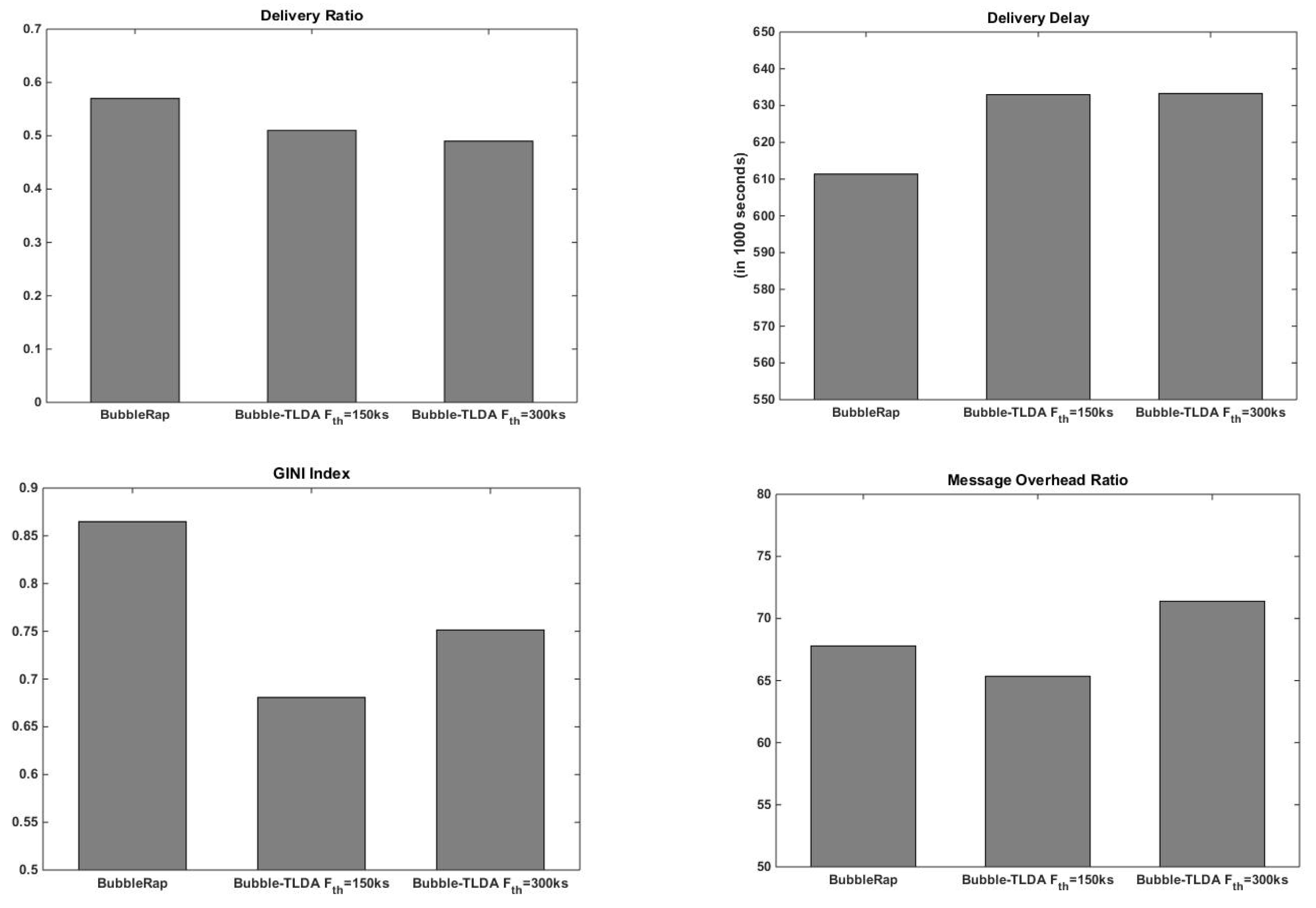
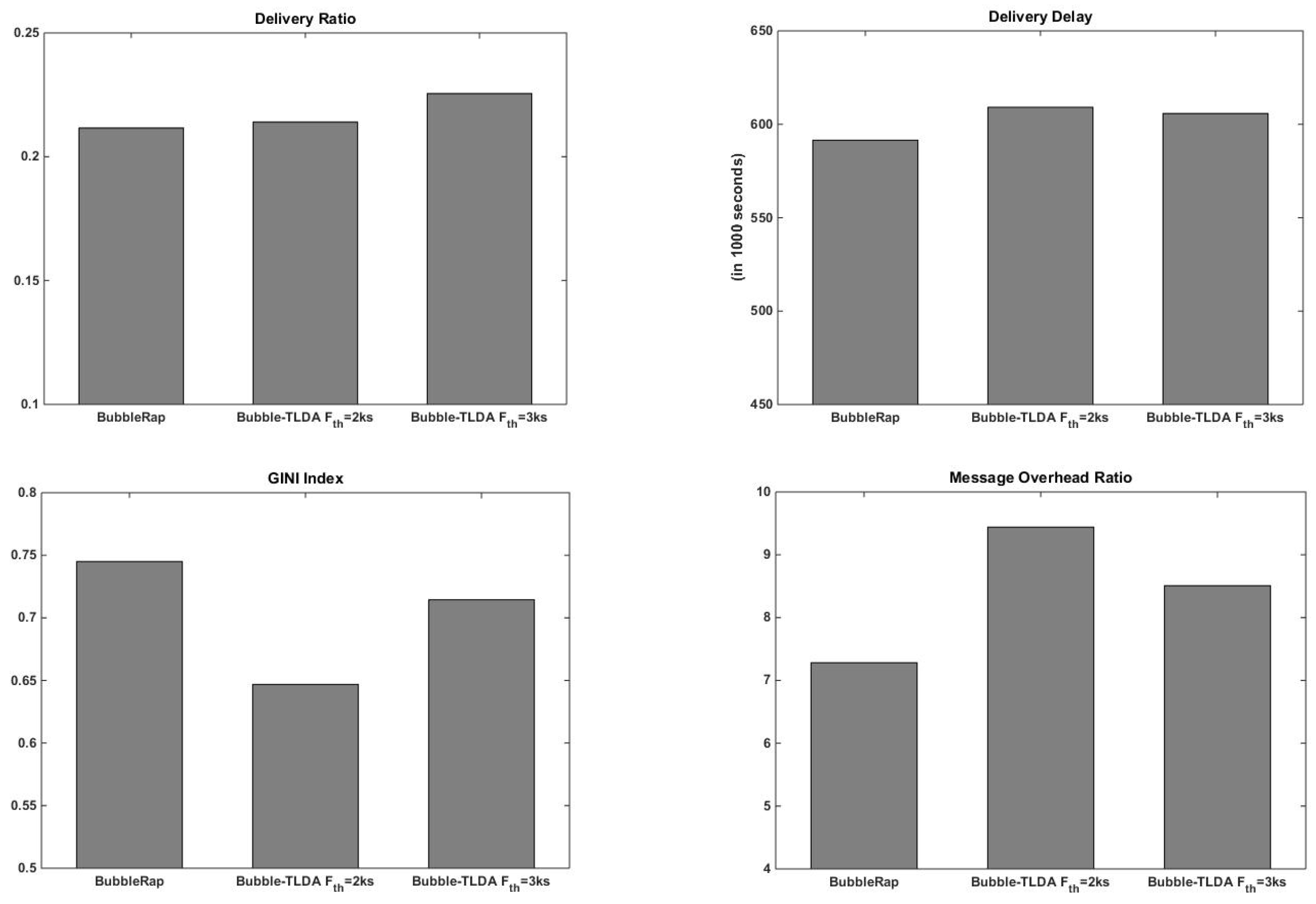
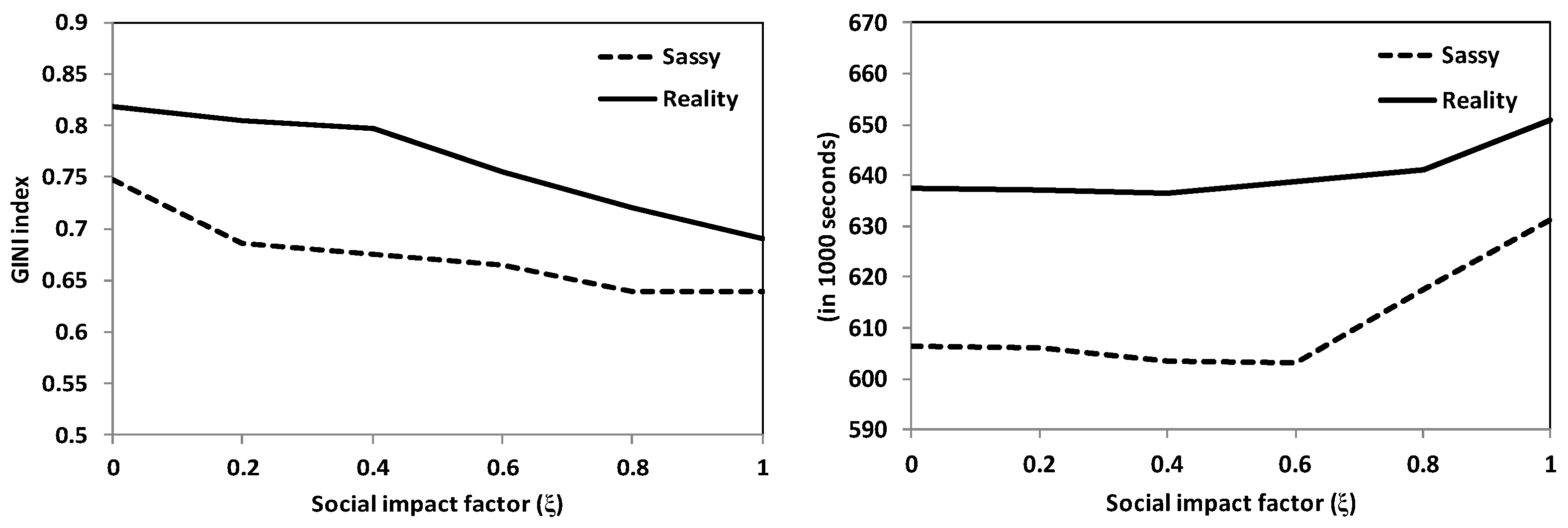
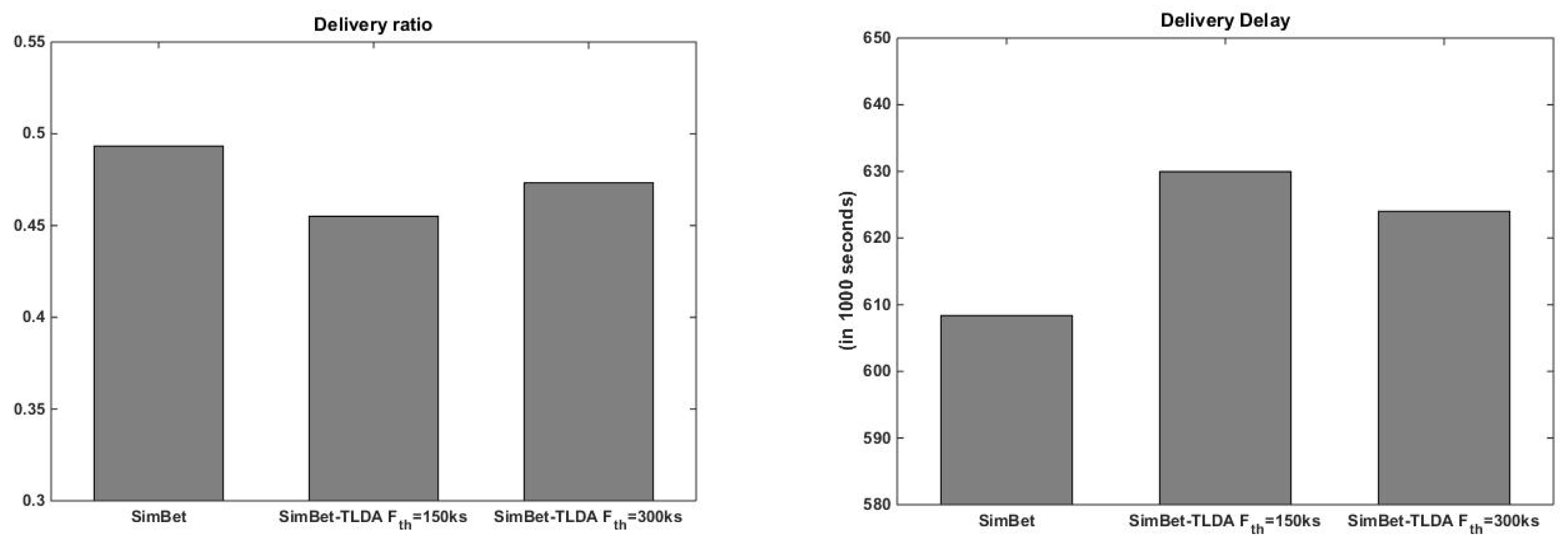
- Delivery ratio: the ratio of the number of messages delivered to the number of new messages created.
- Delivery latency: the time it takes for a message to be created and forwarded to the intended recipient.
- Message overhead ratio: the fraction between total overhead messages and total delivered messages. The total overhead messages is computed as the number of forwarded messages minus the number of messages successfully delivered
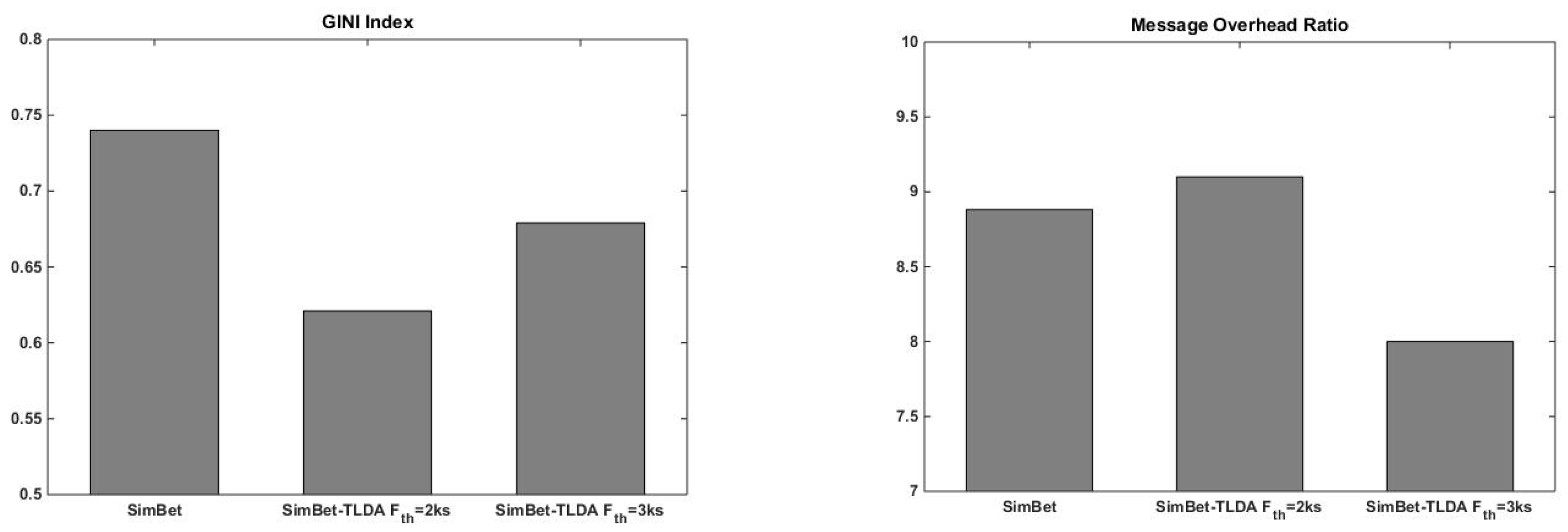
- GINI index: this statistical dispersion measure [52] computes the disparity between values of a frequency distribution. Here, the GINI index is used to quantify the fairness level of traffic load distribution in the network: a value of “0” indicates that traffic is divided equally among network nodes, while a value of “1” indicates that all network traffic is processed by a single node.
5.2. Simulation Results and Discussions
5.2.1. BubbleRap vs. Bubble-TLDA
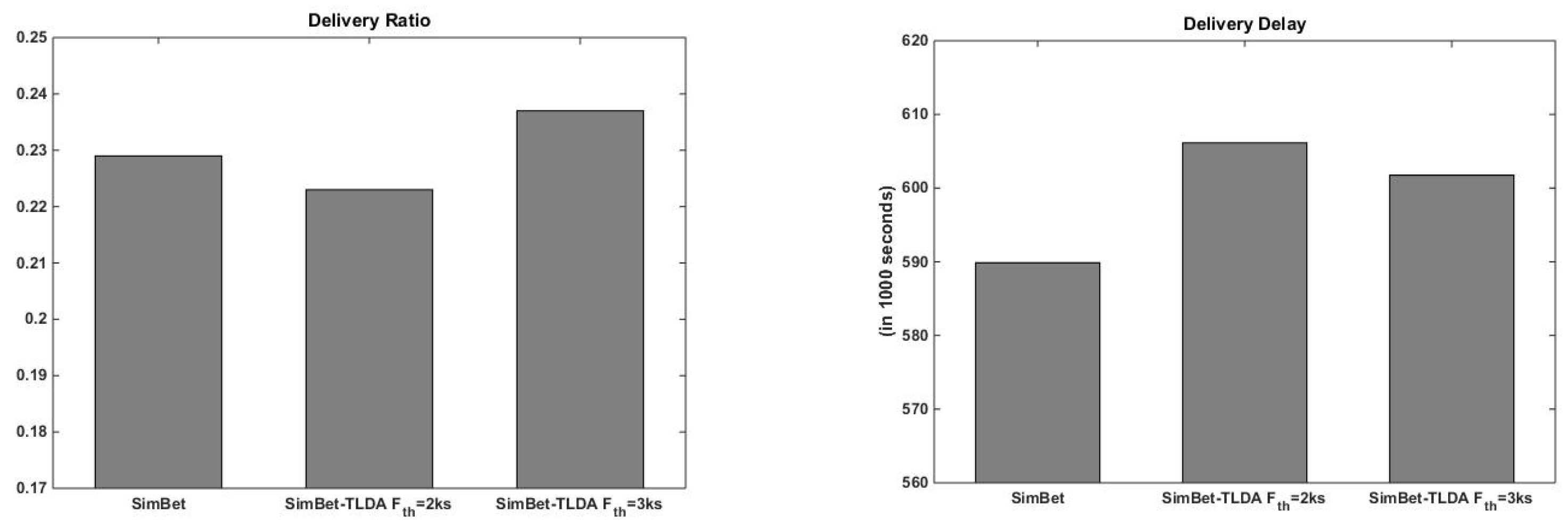
5.2.2. SimBet vs. SimBet-TLDA
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Conti, M.; Giordano, S.; May, M.; Passarella, A. From Opportunistic Networks to Opportunistic Computing. IEEE Commun. Mag. 2010, 48, 126–139. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, H.; Fan, Y.; Xia, H. A Survey on Routing Algorithms for Opportunistic Mobile Social Networks. China Commun. 2021, 18, 86–109. [Google Scholar] [CrossRef]
- Hu, X.; Chu, T.H.S.; Leung, V.C.M.; Ngai, E.C.-H.; Kruchten, P.; Chan, H.C.B. A Survey on Mobile Social Networks: Applications, Platforms, System Architectures, and Future Research Directions. IEEE Commun. Surv. Tutor. 2015, 17, 1557–1581. [Google Scholar] [CrossRef]
- Barbosa, H.; Barthelemy, M.; Ghoshal, G.; James, C.R.; Lenormand, M.; Louail, T.; Menezes, R.; Ramasco, J.J.; Simini, F.; Tomasini, M. Human Mobility: Models and Applications. Phys. Rep. 2018, 734, 1–74. [Google Scholar] [CrossRef] [Green Version]
- Hossmann, T.; Spyropoulos, T.; Legendre, F. A Complex Network Analysis of Human Mobility. In Proceedings of the 2011 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Shanghai, China, 10–15 April 2011; pp. 876–881. [Google Scholar]
- Borrel, V.; Legendre, F.; de Amorim, M.; Fdida, S. SIMPS: Using Sociology for Personal Mobility. IEEE/ACM Trans. Netw. 2009, 17, 831–842. [Google Scholar] [CrossRef] [Green Version]
- Mtibaa, A.; May, M.; Diot, C.; Ammar, M. PeopleRank: Social Opportunistic Forwarding. In Proceedings of the 2010 Proceedings IEEE INFOCOM, San Diego, CA, USA, 15–19 March 2010; pp. 1–5. [Google Scholar]
- Picu, A.; Spyropoulos, T. Distributed Optimization in DTNs: Towards Understanding Greedy and Stochastic Algorithms; TIK Report No. 326; ETH: Zurich, Germany, 2010; pp. 1–19. [Google Scholar]
- Yuan, P.; Pang, X.; Song, M. SSR: Using the Social Similarity to Improve the Data Forwarding Performance in Mobile Opportunistic Networks. IEEE Access 2019, 7, 44840–44850. [Google Scholar] [CrossRef]
- Mtibaa, A.; Harras, K.A. Fairness-Related Challenges in Mobile Opportunistic Networking. Comput. Netw. 2013, 57, 228–242. [Google Scholar] [CrossRef]
- Fan, X.; Li, V.O.K.; Xu, K. Fairness Analysis of Routing in Opportunistic Mobile Networks. IEEE Trans. Veh. Technol. 2014, 63, 1282–1295. [Google Scholar] [CrossRef]
- Sun, Y.; Yin, L.; Liu, W. Defending Sybil Attacks in Mobile Social Networks. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 27 April–2 May 2014; pp. 163–164. [Google Scholar]
- Helbing, D.; Brockmann, D.; Chadefaux, T.; Donnay, K.; Blanke, U.; Woolley-Meza, O.; Moussaid, M.; Johansson, A.; Krause, J.; Schutte, S.; et al. Saving Human Lives: What Complexity Science and Information Systems Can Contribute. J. Stat. Phys. 2015, 158, 735–781. [Google Scholar] [CrossRef]
- Jusup, M.; Holme, P.; Kanazawa, K.; Takayasu, M.; Romić, I.; Wang, Z.; Geček, S.; Lipić, T.; Podobnik, B.; Wang, L.; et al. Social Physics. Phys. Rep. 2022, 948, 1–148. [Google Scholar] [CrossRef]
- Hui, P.; Chaintreau, A.; Scott, J.; Gass, R.; Crowcroft, J.; Diot, C. Pocket Switched Networks and Human Mobility in Conference Environments. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking—WDTN’05, Philadelphia, PA, USA, 26 August 2005; ACM Press: Philadelphia, PA, USA, 2005; pp. 244–251. [Google Scholar]
- Spyropoulos, T.; Turletti, T.; Obraczka, K. Routing in Delay-Tolerant Networks Comprising Heterogeneous Node Populations. IEEE Trans. Mob. Comput. 2009, 8, 1132–1147. [Google Scholar] [CrossRef]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Fluids Eng. Trans. ASME 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Smeaton, A.F.; Newman, E.; Buman, M.P. Using Periodicity Intensity to Detect Long Term Behaviour Change. In Proceedings of the Adjunct Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, and Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1069–1074. [Google Scholar]
- Soelistijanto, B.; Adi Permatasari, E.K. Periodicity Detection of Node Behaviour in Opportunistic Mobile Social Networks. In Proceedings of the 2019 IEEE International Conference on Internet of Things and Intelligence System (IoTaIS), Bali, Indonesia, 5–7 November 2019; pp. 25–29. [Google Scholar]
- Daly, E.M.; Haahr, M. Social Network Analysis for Information Flow in Disconnected Delay-Tolerant MANETs. IEEE Trans. Mob. Comput. 2009, 8, 606–621. [Google Scholar] [CrossRef]
- Hui, P.; Crowcroft, J.; Yoneki, E. BUBBLE Rap: Social-Based Forwarding in Delay-Tolerant Networks. IEEE Trans. Mob. Comput. 2011, 10, 1576–1589. [Google Scholar] [CrossRef] [Green Version]
- Keränen, A.; Ott, J.; Kärkkäinen, T. The ONE Simulator for DTN Protocol Evaluation. In Proceedings of the SIMUTools 2009-2nd International ICST Conference on Simulation Tools and Techniques, Rome, Italy, 2–6 March 2009. [Google Scholar] [CrossRef] [Green Version]
- SHI, H.; Prasad, R.V.; Onur, E.; Niemegeers, I.G.M.M. Fairness in Wireless Networks: Issues, Measures and Challenges. IEEE Commun. Surv. Tutor. 2014, 16, 5–24. [Google Scholar] [CrossRef]
- Soelistijanto, B. The Efficiency-Fairness Trade-off of Social-Rank-Based Forwarding in Social Opportunistic Networks. In Proceedings of the 2016 IEEE Asia Pacific Conference on Wireless and Mobile (APWiMob), Bandung, Indonesia, 13–15 September 2016; pp. 113–119. [Google Scholar]
- Ying, B.; Xu, K.; Nayak, A. Fair and Social-Aware Message Forwarding Method in Opportunistic Social Networks. IEEE Commun. Lett. 2019, 23, 720–723. [Google Scholar] [CrossRef]
- Pujol, J.M.; Toledo, A.L.; Rodriguez, P. Fair Routing in Delay Tolerant Networks. In Proceedings of the IEEE INFOCOM, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 837–845. [Google Scholar] [CrossRef] [Green Version]
- Radenkovic, M.; Grundy, A. Efficient and Adaptive Congestion Control for Heterogeneous Delay-Tolerant Networks. Ad Hoc Netw. 2012, 10, 1322–1345. [Google Scholar] [CrossRef]
- Sermpezis, P.; Spyropoulos, T. Understanding the Effects of Social Selfishness on the Performance of Heterogeneous Opportunistic Networks. Comput. Commun. 2014, 48, 71–83. [Google Scholar] [CrossRef]
- Abdelkader, T.; Naik, K.; Gad, W. A Game-Theoretic Approach to Supporting Fair Cooperation in Delay Tolerant Networks. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; pp. 1–7. [Google Scholar]
- Amah, T.E.; Kamat, M.; Bakar, K.A.; Moreira, W.; Oliveira, A., Jr.; Batista, M.A. Measuring Burden and Routing Fairness in Pocket Switched Networks. In Proceedings of the {XXXV} Brazilian Symposium on Computer Networks and Distributed Systems, Belém, Brazil, 15–19 May 2018; Abelém, A., Cerqueira, E., Eds.; SBRC: Linlithgow, UK, 2017. [Google Scholar]
- Ciobanu, R.I.; Dobre, C.; Cristea, V. Reducing Congestion for Routing Algorithms in Opportunistic Networks with Socially-Aware Node Behavior Prediction. In Proceedings of the Proceedings-International Conference on Advanced Information Networking and Applications, AINA, Barcelona, Spain, 25–28 March 2013; pp. 554–561. [Google Scholar]
- Freeman, L.C. Centrality in Social Networks. Soc. Netw. 1979, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Rusinowska, A.; Berghammer, R.; De Swart, H.; Grabisch, M. Social Networks: Prestige, Centrality, and Influence: (Invited Paper). In Relational and Algebraic Methods in Computer Science; de Swart, H., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6663, pp. 22–39. ISBN 978-3-642-21069-3. [Google Scholar]
- Sheikhahmadi, A.; Nematbakhsh, M.A. Identification of Multi-Spreader Users in Social Networks for Viral Marketing. J. Inf. Sci. 2017, 43, 412–423. [Google Scholar] [CrossRef]
- Ursino, D.; Virgili, L. An Approach to Evaluate Trust and Reputation of Things in a Multi-IoTs Scenario. Computing 2020, 102, 2257–2298. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Cinelli, L.; Fortino, G.; Savaglio, C.; Terracina, G.; Ursino, D.; Virgili, L. An Approach to Compute the Scope of a Social Object in a Multi-IoT Scenario. Pervasive Mob. Comput. 2020, 67, 101223. [Google Scholar] [CrossRef]
- Katz, L. A New Status Index Derived from Sociometric Analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Yoneki, E.; Hui, P.; Crowcroft, J. Distinct Types of Hubs in Human Dynamic Networks. In Proceedings of the 1st Workshop on Social Network Systems; Association for Computing Machinery: New York, NY, USA, 2008; pp. 7–12. [Google Scholar]
- Eagle, N.; Pentland, A. Reality Mining: Sensing Complex Social Systems. Pers. Ubiquitous Comput. 2006, 10, 255–268. [Google Scholar] [CrossRef]
- Ferretti, S.; Ghini, V.; Panzieri, F. Scale-Free Opportunistic Networks: Is It Possible? In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, Lugano, Switzerland, 19–23 March 2012; pp. 625–630. [Google Scholar]
- Musolesi, M.; Mascolo, C. CAR: Context-Aware Adaptive Routing for Delay-Tolerant Mobile Networks. IEEE Trans. Mob. Comput. 2009, 8, 246–260. [Google Scholar] [CrossRef] [Green Version]
- Williamson, G.; Cellai, D.; Dobson, S.; Nixon, P. Self-Management of Routing on Human Proximity Networks. In Proceedings of the Self-Organizing Systems; Spyropoulos, T., Hummel, K.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–12. [Google Scholar]
- Stoica, P.; Moses, R.L. Spectral Analysis of Signals; Pearson/Prentice Hall: Upper Saddle River, NJ, USA, 2005; ISBN1 0131139568. ISBN2 9780131139565. [Google Scholar]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2002; ISBN 9780387781884. [Google Scholar]
- Dagum, E.B. The X-II-ARIMA Seasonal Adjustment Method; Statistics Canada: Ottawa, ON, Canada, 1980; 119p.
- Durbin, J.; Koopman, S.J. Time Series Analysis by State Space Methods: Second Edition; Oxford University Press: Oxford, UK, 2012; ISBN 9780199641178. [Google Scholar]
- Musolesi, M.; Hailes, S.; Mascolo, C. Prediction of Context Information Using Kalman Filter Theory; UCL Research Note RN/04/22; University College London: London, UK, 2004. [Google Scholar]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Structural Analysis in the Social Sciences; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Bonacich, P. Power and Centrality: A Family of Measures. Am. J. Sociol. 1987, 92, 1170–1182. [Google Scholar] [CrossRef]
- Hui, P.; Yoneki, E.; Chan, S.Y.; Crowcroft, J. Distributed Community Detection in Delay Tolerant Networks. In Proceedings of the 2nd ACM/IEEE International Workshop on Mobility in the Evolving Internet Architecture, Kyoto, Japan, 27–30 August 2007; Association for Computing Machinery: New York, NY, USA, 2007. [Google Scholar]
- Bigwood, G.; Henderson, T.; Rehunathan, D.; Bateman, M.; Bhatti, S. {CRAWDAD} Dataset St_andrews/Sassy, v. 2011-06-03. 2011. Available online: https://crawdad.org/st_andrews/sassy/20110603/ (accessed on 20 July 2021).
- Gini, C. On the Measure of Concentration with Special Reference to Income and Statistics. Colo. Coll. Publ. Colo. Springs Gen. Ser. 1936, 208, 73–79. [Google Scholar]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Node 80 (Hub Node) | (b) Node 3 (Non-Hub Node) | ||
|---|---|---|---|
| Friendship Set (Node ID) | Friendship Set (Node ID) | ||
| 150 k | [5, 7, 13, 15, 17, 20, 22, 32, 82, 84, 85, 95] | 150 k | [45, 63, 82, 95, 96] |
| 200 k | [5, 7, 13, 17, 20, 22, 32, 82, 84, 95] | 200 k | [45, 63, 82, 95, 96] |
| 250 k | [5, 7, 13, 17, 20, 22, 82, 84, 95] | 250 k | [45, 63, 82, 95, 96] |
| 300 k | [5, 13, 17, 22, 82, 84, 95] | 300 k | [45, 63, 82, 95, 96] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soelistijanto, B.; Ayu, V. Improving Traffic Load Distribution Fairness in Mobile Social Networks. Algorithms 2022, 15, 222. https://doi.org/10.3390/a15070222
Soelistijanto B, Ayu V. Improving Traffic Load Distribution Fairness in Mobile Social Networks. Algorithms. 2022; 15(7):222. https://doi.org/10.3390/a15070222
Chicago/Turabian StyleSoelistijanto, Bambang, and Vittalis Ayu. 2022. "Improving Traffic Load Distribution Fairness in Mobile Social Networks" Algorithms 15, no. 7: 222. https://doi.org/10.3390/a15070222
APA StyleSoelistijanto, B., & Ayu, V. (2022). Improving Traffic Load Distribution Fairness in Mobile Social Networks. Algorithms, 15(7), 222. https://doi.org/10.3390/a15070222