
CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques


Abstract
:1. Introduction
1.1. BRON
1.2. CVE Transformer (CVET)
1.3. Unsupervised Labeling Technique of CVEs
1.4. Automated Mapping to ATT&CK: The Threat Report ATT&CK Mapper (TRAM) Tool
- Introducing a new publicly available dataset of 1813 CVEs annotated with all corresponding MITRE ATT&CK techniques;
- Experiments with classical machine learning and Transformer-based models, coupled with data augmentation techniques, to establish a strong baseline for the multi-label classification task;
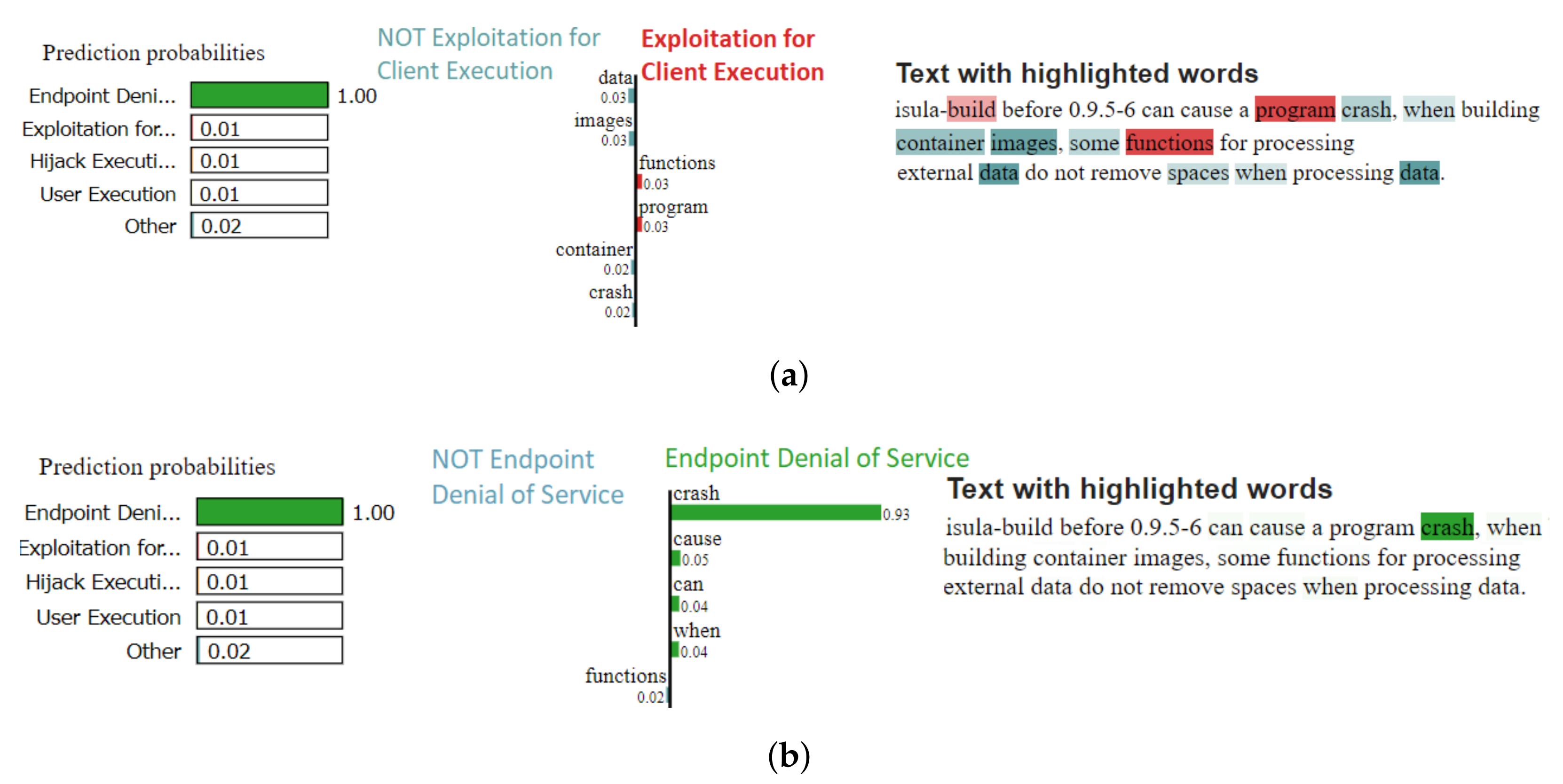
- A qualitative analysis of the best performing model, coupled with error analysis that considers Lime explanations [18] to point out limitations and future research directions.
2. Method
2.1. Our Labeled CVE Corpus
2.1.1. Data Collection
- Inter-rater—A collection of 24 CVEs evaluated by all experts to ensure high agreement and consistent annotations; this collection was used for training the raters until perfect consensus was achieved;
- Double-rater—A collection of 295 CVE evaluated by pairs of two raters; this collection was created after some experience was accumulated and consensus among raters was achieved using direct discussions;
- Individual—A collection of 674 CVE evaluated by only one rater; this collection was annotated after the initial training phase was complete and raters gained experience.
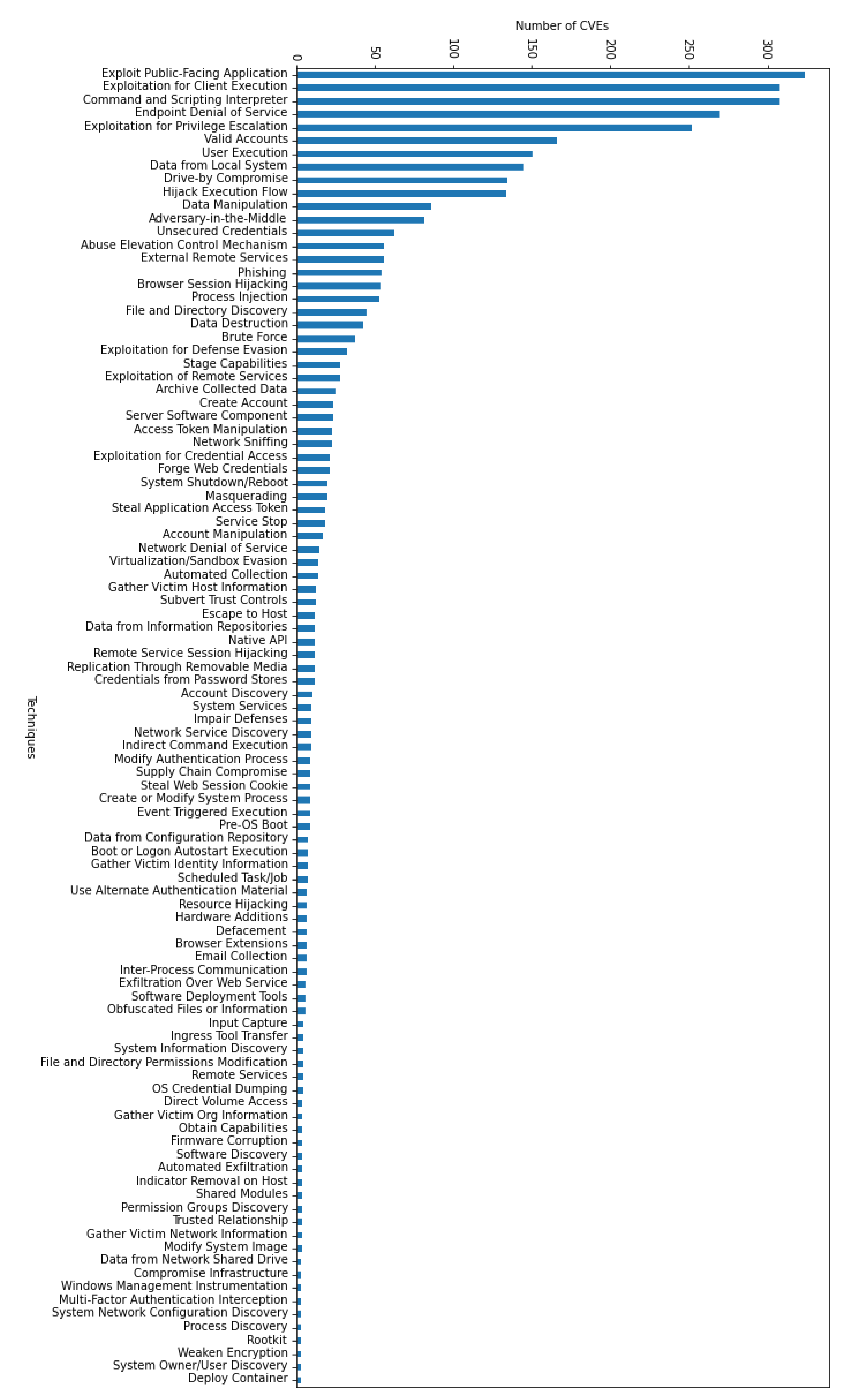
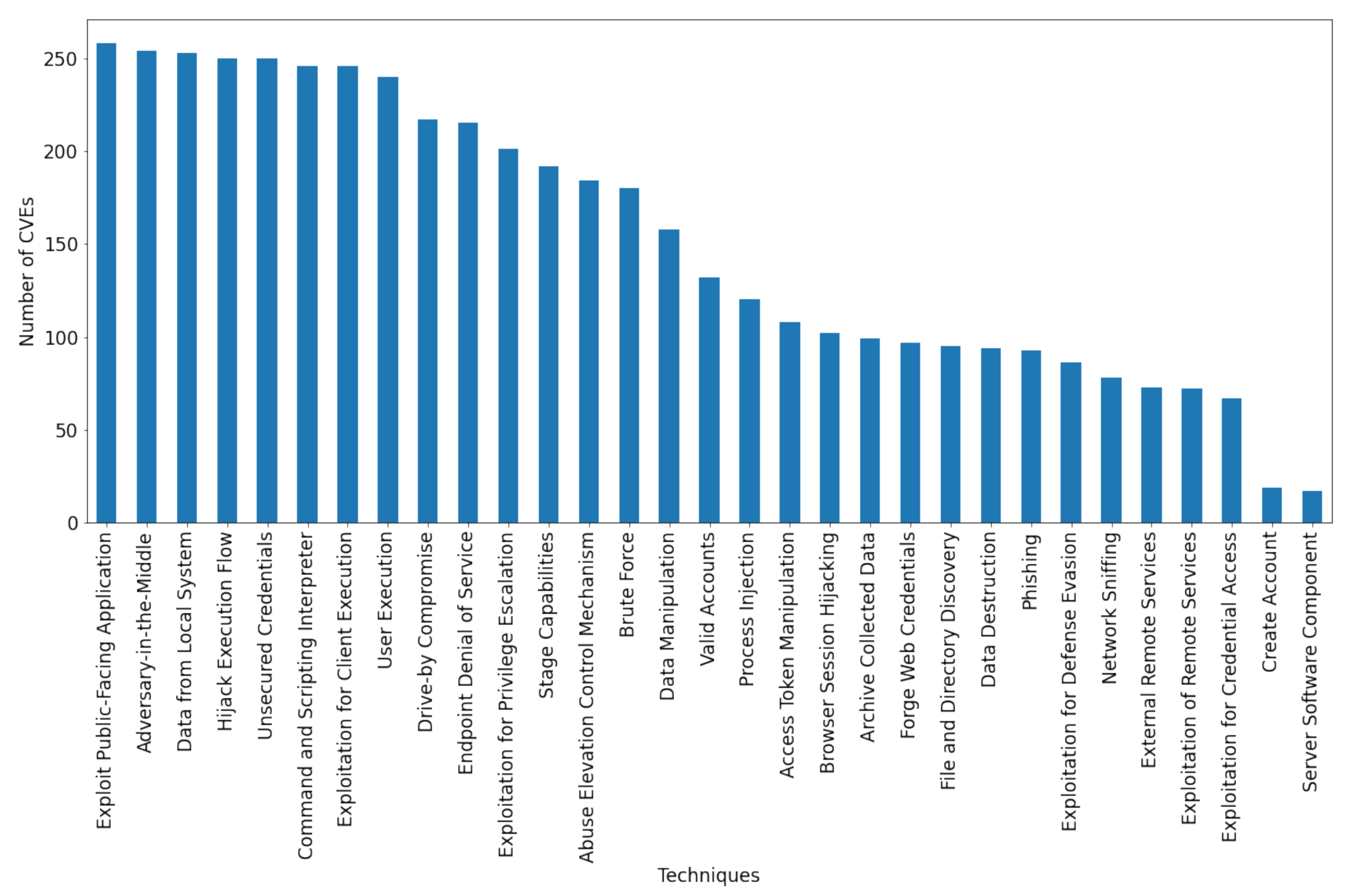
2.1.2. Data Analysis
2.1.3. Data Augmentation
2.2. Machine Learning and Neural Architectures
2.2.1. Classical Machine Learning
Multi-Label Learning
- One versus Rest. This method splits the multi-label problem into multiple binary classification tasks, one for each label, treated independently. The N different binary classifiers are separately trained to distinguish the examples of a single class from all the examples from the other labels [32];
- Label Powerset. This method considers every unique combination of labels as a single class, reducing the multi-label problem to a multi-class classification problem [29]. The real advantage of this strategy is that correlations between labels are exploited for a more accurate labelling process;
- Binary Relevance. This linear strategy groups all positive and negative examples within a label into a set, later training a classifier for each resulted set. The final prediction is then computed by merging all the intermediary predictions of the trained classifiers [29]. An advantage of this strategy consists of the possibility to perform parallel executions;
- RaKEL(Random k-Labelsets). This state-of-the-art approach builds an ensemble of Label Powerset classifiers trained on a different subset of the labels [33].
Naive Bayes Classifiers
Support Vector Machines
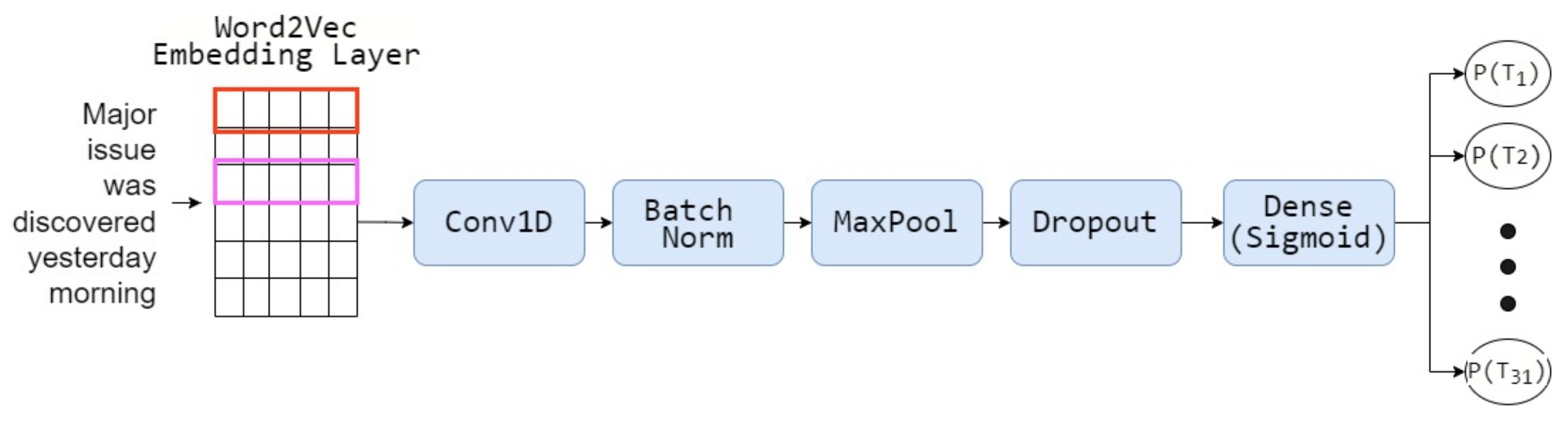
2.2.2. Convolutional Neural Network (CNN) with Word2Vec
2.2.3. BERT-Based Architecture with Multiple Output Layers
2.2.4. BERT-Based Architecture Adapted for Multi-Labeling
2.3. Performance Assessment
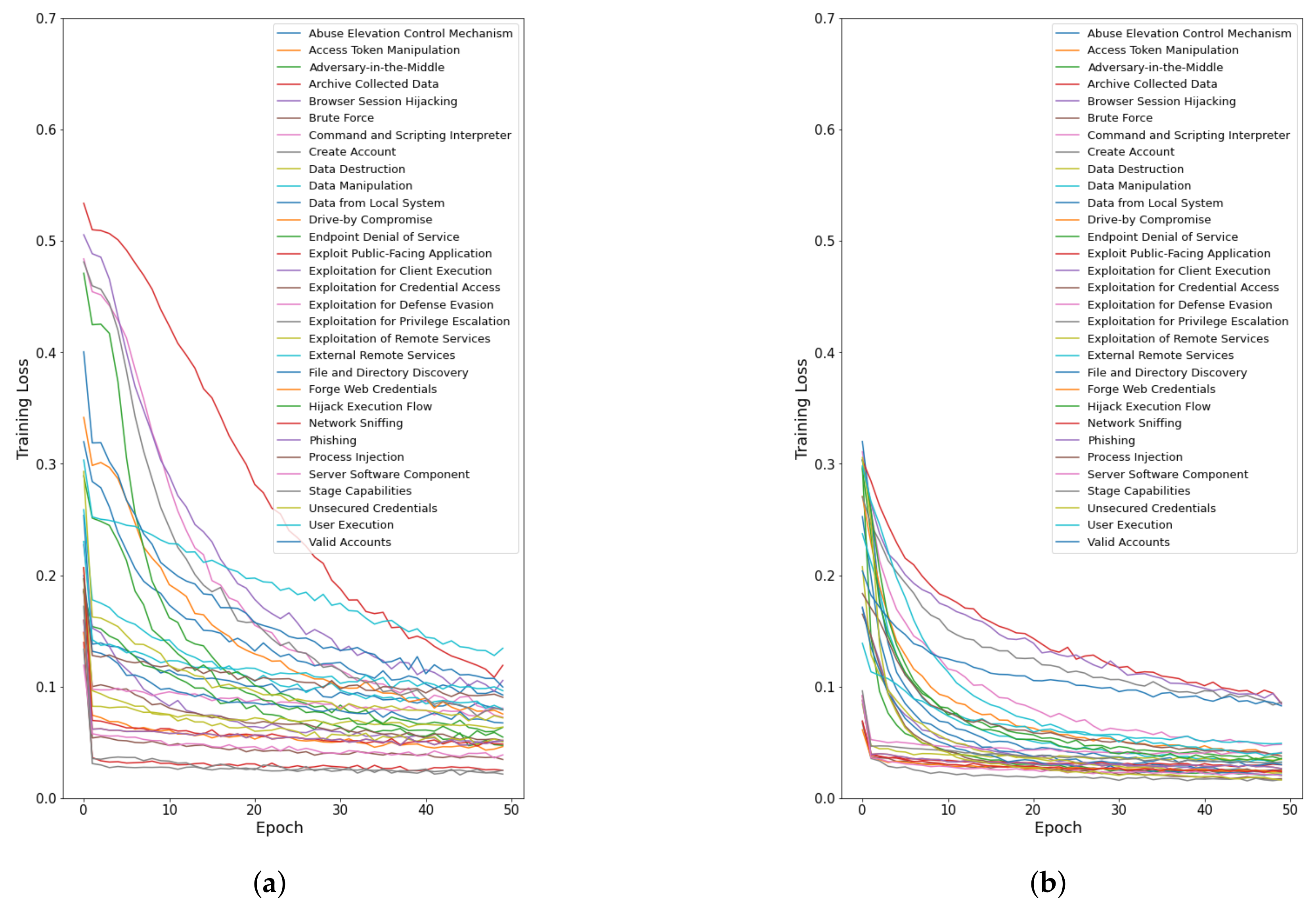
3. Results
4. Discussion
4.1. In-Depth Analysis of the Best Model
4.2. Error Analysis
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ATT&CK | Adversarial Tactics, Techniques, and Common Knowledge |
| BERT | Bidirectional Encoder Representations from Transformers |
| CAPEC | Common Attack Pattern Enumeration and Classification |
| CNN | Convolutional Neural Network |
| CVE | Common Vulnerabilities and Exposures |
| CVET | Common Vulnerabilities and Exposures Transformer |
| CWE | Common Weakness Enumeration |
| EDA | Easy Data Augmentation |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| SciBERT | Scientific Bidirectional Encoder Representations from Transformers |
| SecBERT | Security Bidirectional Encoder Representations from Transformers |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| TRAM | Threat Report ATT&CK Mapping |
References
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Dayalan, M. Cyber Risks, the Growing Threat. IJNRD-Int. J. Nov. Res. Dev. 2017, 2, 4–6. [Google Scholar] [CrossRef]
- Smith, Z.M.; Lostri, E. The Hidden Costs of Cybercrime; Technical Report; McAfee: San Jose, CA, USA, 2020. [Google Scholar]
- Fichtenkamm, M.; Burch, G.F.; Burch, J. Cybersecurity in a COVID-19 World: Insights on How Decisions Are Made. Available online: https://www.isaca.org/resources/isaca-journal/issues/2022/volume-2/cybersecurity-in-a-covid-19-world (accessed on 8 August 2022).
- Cremer, F.; Sheehan, B.; Fortmann, M.; Kia, A.N.; Mullins, M.; Murphy, F.; Materne, S. Cyber risk and cybersecurity: A systematic review of data availability. Geneva Pap. Risk Insur. Issues Pract. 2022, 47, 698–736. [Google Scholar] [CrossRef] [PubMed]
- Martin, R.; Christey, S.; Baker, D. A Progress Report on the CVE Initiative; Technical Report; The MITRE Corporation: Bedford, MA, USA, 2002. [Google Scholar]
- Sönmez, F.Ö. Classifying Common Vulnerabilities and Exposures Database Using Text Mining and Graph Theoretical Analysis. In Machine Intelligence and Big Data Analytics for Cybersecurity Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 313–338. [Google Scholar] [CrossRef]
- Strom, B.E.; Applebaum, A.; Miller, D.P.; Nickels, K.C.; Pennington, A.G.; Thomas, C.B. MITRE ATT&CK™: Design and Philosophy; Technical Report; The MITRE Corporation: Bedford, MA, USA, 2018. [Google Scholar]
- Hemberg, E.; Kelly, J.; Shlapentokh-Rothman, M.; Reinstadler, B.; Xu, K.; Rutar, N.; O’Reilly, U.M. Linking threat tactics, techniques, and patterns with defensive weaknesses, vulnerabilities and affected platform configurations for cyber hunting. arXiv 2021, arXiv:2010.00533. [Google Scholar]
- NVD. NVD Dashboard. Available online: https://nvd.nist.gov/general/nvd-dashboard (accessed on 8 August 2022).
- The Center for Threat-Informed Defense. Mapping MITRE ATT&CK® to CVEs for Impact; The Center for Threat-Informed Defense: Bedford, MA, USA, 2021. [Google Scholar]
- Baker, J. CVE + MITRE ATT&CK to Understand Vulnerability Impact. Available online: https://medium.com/mitre-engenuity/cve-mitre-att-ck-to-understand-vulnerability-impact-c40165111bf7 (accessed on 8 August 2022).
- Roe, S. Using Mitre ATT&CK with threat intelligence to improve Vulnerability Management. Available online: https://outpost24.com/blog/Using-mitre-attack-with-threat-intelligence-to-improve-vulnerability-management (accessed on 24 August 2022).
- Ampel, B.; Samtani, S.; Ullman, S.; Chen, H. Linking Common Vulnerabilities and Exposures to the MITRE ATT&CK Framework: A Self-Distillation Approach. arXiv 2021, arXiv:2108.01696. [Google Scholar]
- Kuppa, A.; Aouad, L.; Le-Khac, N.A. Linking CVE’s to MITRE ATT&CK Techniques. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–12. [Google Scholar]
- Github. Threat Report ATT&CK Mapping (TRAM). Available online: https://github.com/center-for-threat-informed-defense/tram/ (accessed on 8 August 2022).
- Yoder, S. Automating Mapping to ATT&CK: The Threat Report ATT&CK Mapper (TRAM) Tool. Available online: https://medium.com/mitre-attack/automating-mapping-to-attack-tram-1bb1b44bda76 (accessed on 8 August 2022).
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Tagtog. CVE2ATT&CK Dataset. Available online: https://www.tagtog.com/readerbench/MitreMatrix/ (accessed on 8 August 2022).
- Github. CVE2ATT&CK Repository. Available online: https://github.com/readerbench/CVE2ATT-CK (accessed on 8 August 2022).
- Vulnerability Database. Available online: https://vuldb.com/ (accessed on 24 August 2022).
- Exploit Database-Exploits for Penetration Testers, Researchers, and Ethical Hackers. Available online: https://www.exploit-db.com/ (accessed on 24 August 2022).
- TagTog. API Documentation v1. Available online: https://github.com/tagtog/tagtog-doc/blob/master/API-projects-v1.md (accessed on 8 August 2022).
- Japkowicz, N.; Stephen, S. The Class Imbalance Problem: A Systematic Study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- TextAttack. Documentation Webpage. Available online: https://textattack.readthedocs.io/en/latest/index.html (accessed on 8 August 2022).
- Morris, J.; Lifland, E.; Yoo, J.Y.; Grigsby, J.; Jin, D.; Qi, Y. TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics; pp. 119–126. [Google Scholar] [CrossRef]
- TextAttack. Augmentation Recipes. Available online: https://textattack.readthedocs.io/en/latest/3recipes/augmenter_recipes.html (accessed on 8 August 2022).
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics; pp. 6382–6388. [Google Scholar] [CrossRef]
- Alazaidah, R.; Ahmad, F.K. Trending Challenges in Multi Label Classification. Int. J. Adv. Comput. Sci. Appl. 2016, 7. [Google Scholar] [CrossRef]
- spaCy. spaCy 101: Everything You Need to Know. Available online: https://spacy.io/usage/spacy-101 (accessed on 8 August 2022).
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Mining multi-label data. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 667–685. [Google Scholar]
- Rifkin, R.; Klautau, A. In Defense of One-Vs-All Classification. J. Mach. Learn. Res. 2004, 5, 101–141. [Google Scholar]
- Tsoumakas, G.; Vlahavas, I. Random k-labelsets: An ensemble method for multilabel classification. In Proceedings of the European Conference on Machine Learning, Warsaw, Poland, 17–21 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 406–417. [Google Scholar]
- Rish, I. An Empirical Study of the Naïve Bayes Classifier. IJCAI 2001 Work. Empir Methods Artif. Intell. 2001, 3, 41–46. [Google Scholar]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Scikit. Grid Search. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html (accessed on 8 August 2022).
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 319–345. [Google Scholar]
- Yih, W.T.; He, X.; Meek, C. Semantic parsing for single-relation question answering. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; Association for Computational Linguistics; Volume 2: Short Papers, pp. 643–648. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; Association for Computational Linguistics; Volume 1: Long Papers, pp. 655–665. [Google Scholar] [CrossRef] [Green Version]
- Github. Word Representation for Cyber Security Vulnerability Domain. Available online: https://github.com/unsw-cse-soc/Vul_Word2Vec (accessed on 8 August 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics; Volume 1: Long and Short Papers, pp. 4171–4186. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3615–3620. [Google Scholar]
- Huggingface. SecBERT Model. Available online: https://huggingface.co/jackaduma/SecBERT (accessed on 8 August 2022).
- Pytorch. BCE with Logit Loss. Available online: https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html (accessed on 8 August 2022).
- Dong, Y.; Guo, W.; Chen, Y.; Xing, X.; Zhang, Y.; Wang, G. Towards the Detection of Inconsistencies in Public Security Vulnerability Reports. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; USENIX Association; pp. 869–885. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (csur) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Kasieczka, G.; Nachman, B.; Shih, D.; Amram, O.; Andreassen, A.; Benkendorder, K.; Bortolato, B.; Broojimans, G.; Canelli, F.; Collins, J.; et al. The LHC olympics 2020: A community challenge for anomaly detection in high energy physics. Rep. Prog. Phys. 2021, 84, 124201. [Google Scholar] [CrossRef] [PubMed]
- MITRE. Common Weakness Enumeration Webpage. Available online: https://cwe.mitre.org/ (accessed on 8 August 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Model | Multi-Label Strategy | Weighed P | Weighed R | Weighed F1-Score |
|---|---|---|---|---|---|
| Classical ML | Naive Bayes | OneVsRestClassifier | 57.35% | 9.18% | 14.47% |
| LabelPowerset | 31.40% | 24.59% | 24.76% | ||
| BinaryRelevance | 57.35% | 9.18% | 14.47% | ||
| RakelD | 53.71% | 9.83% | 15.31% | ||
| SVC | OneVsRestClassifier | 31.97% | 35.57% | 33.32% | |
| LabelPowerset | 46.73% | 34.75% | 37.98% | ||
| BinaryRelevance | 33.45% | 34.91% | 33.75% | ||
| RakelD | 36.20% | 33.77% | 34.50% | ||
| Deep Learning | CNN + Word2Vec | - | 48.32% | 35.40% | 39.39% |
| Multi-Output BERT | - | 46.85% | 31.47% | 35.92% | |
| Multi-label BERT | - | 55.25% | 30.98% | 37.43% | |
| Multi-label SciBERT | - | 59.26% | 34.42% | 41.87% | |
| Multi-label SecBERT | - | 57.66% | 35.40% | 42.34% |
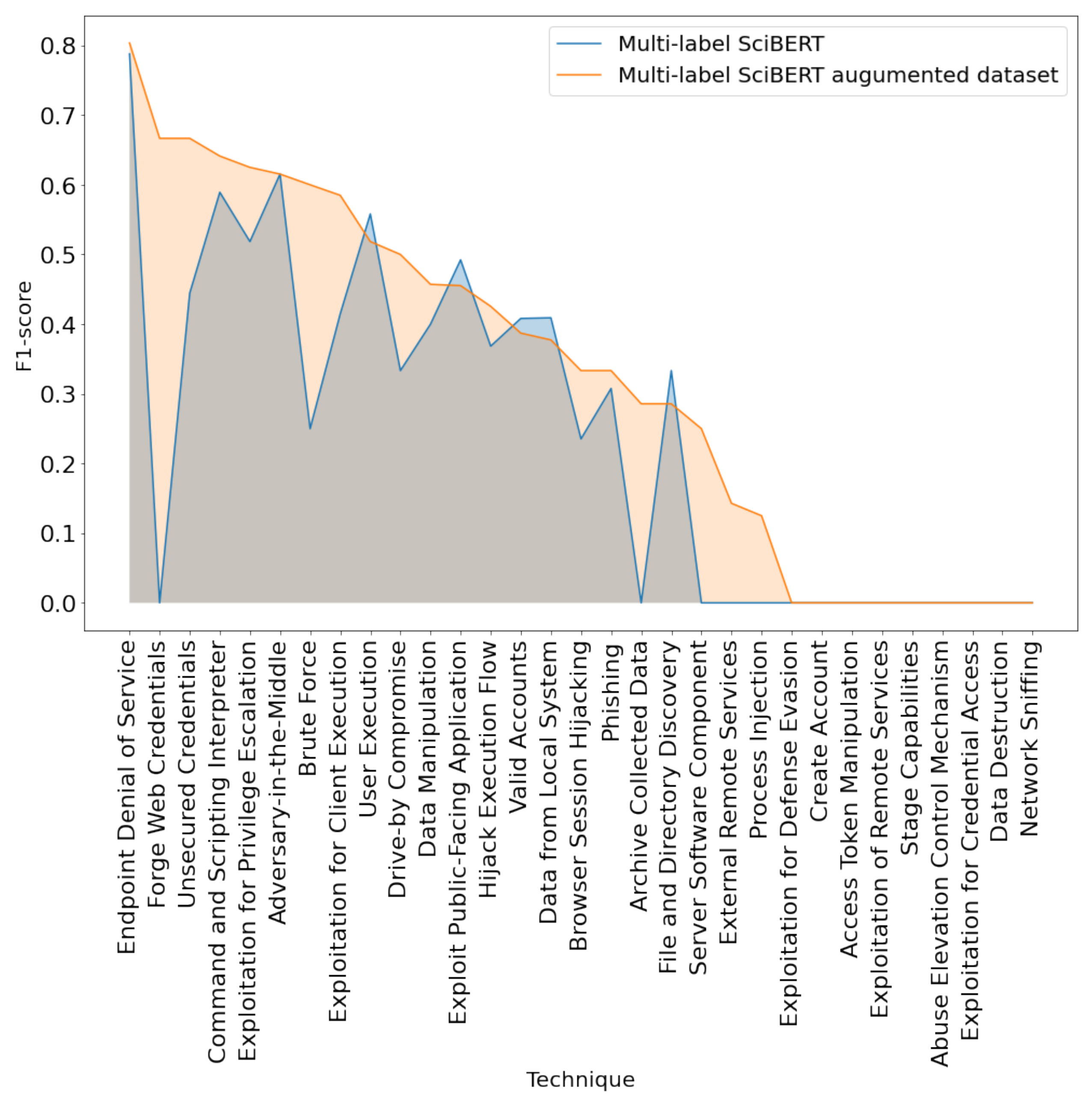
| Model | Data Augmentation | Weighted P | Weighted R | Weighted F1-Score |
|---|---|---|---|---|
| Naive Bayes (LabelPowerset) | No | 31.40% | 24.59% | 24.76% |
| Yes | 29.40% | 14.42% | 14.42% | |
| SVC (LabelPowerset) | No | 46.73% | 34.75% | 37.98% |
| Yes | 45.90% | 34.09% | 36.79% | |
| CNN + Word2Vec | No | 48.32% | 35.40% | 39.39% |
| Yes | 50.48% | 35.59% | 41.59% | |
| Multi-Output BERT | No | 46.85% | 31.47% | 35.92% |
| Yes | 49.81% | 35.57% | 39.66% | |
| Multi-label SciBERT | No | 59.26% | 34.42% | 41.87% |
| Yes | 52.52% | 45.90% | 47.84% | |
| Multi-label SecBERT | No | 57.66% | 35.40% | 42.34% |
| Yes | 54.70% | 42.45% | 46.54% |
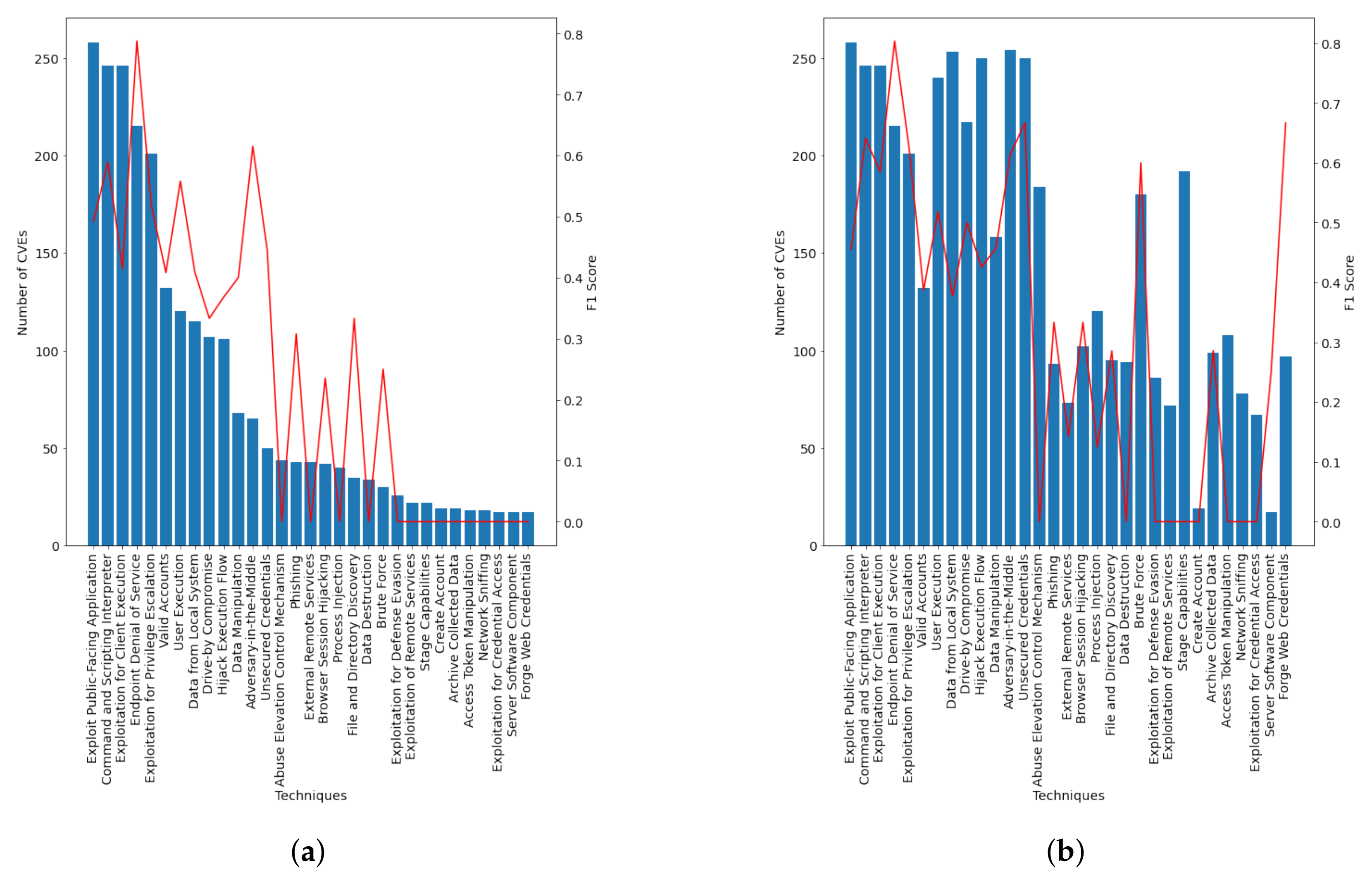
| Technique | Weighted P | Weighted R | Weighted F1-Score |
|---|---|---|---|
| Endpoint Denial of Service | 77.58% | 83.33% | 80.35% |
| Forge Web Credentials | 100.00% | 50.00% | 66.66% |
| Unsecured Credentials | 60.00% | 75.00% | 66.66% |
| Command and Scripting Interpreter | 60.00% | 68.85% | 64.12% |
| Exploitation for Privilege Escalation | 56.45% | 70.00% | 62.50% |
| Adversary-in-the-Middle | 80.00% | 50.00% | 61.53% |
| Brute Force | 100.00% | 42.85% | 60.00% |
| Exploitation for Client Execution | 50.87% | 50.81% | 58.49% |
| User Execution | 58.33% | 46.67% | 51.85% |
| Drive-by Compromise | 64.70% | 40.74% | 50.00% |
| Data Manipulation | 44.44% | 47.05% | 45.71% |
| Exploit Public-Facing Application | 48.27% | 43.07% | 45.52% |
| Hijack Execution Flow | 50.00% | 37.03% | 42.55% |
| Valid Accounts | 41.37% | 36.36% | 38.70% |
| Data from Local System | 41.66% | 34.48% | 37.73% |
| Browser Session Hijacking | 42.85% | 27.27% | 33.33% |
| Phishing | 42.85% | 27.27% | 33.33% |
| Archive Collected Data | 50.00% | 20.00% | 28.57% |
| File and Directory Discovery | 40.00% | 22.22% | 28.57% |
| Server Software Component | 50.00% | 16.66% | 25.00% |
| External Remote Services | 50.00% | 8.33% | 14.28% |
| Process Injection | 25.00% | 8.33% | 12.50% |
| Exploitation for Defense Evasion (26) | 0.00% | 0.00% | 0.00% |
| Create Account (19) | 0.00% | 0.00% | 0.00% |
| Access Token Manipulation(18) | 0.00% | 0.00% | 0.00% |
| Exploitation of Remote Services (22) | 0.00% | 0.00% | 0.00% |
| Stage Capabilities (22) | 0.00% | 0.00% | 0.00% |
| Abuse Elevation Control Mechanism (44) | 0.00% | 0.00% | 0.00% |
| Exploitation for Credential Access (17) | 0.00% | 0.00% | 0.00% |
| Data Destruction (34) | 0.00% | 0.00% | 0.00% |
| Network Sniffing (18) | 0.00% | 0.00% | 0.00% |
| # | CVE Text | True Techniques | Predicted Techniques |
|---|---|---|---|
| 1 | Jenkins Publish stores password unencrypted in its global configuration file on the Jenkins controller where it can be viewed by users with access to the Jenkins controller file system. | Unsecured Credentials, Valid Accounts | Unsecured Credentials |
| 2 | Due to improper input validation in InfraBox, logs can be modified by an authenticated user. | Valid Accounts, Exploitation for Client Execution | Valid Accounts |
| 3 | In Django 2.2 MultiPartParser, UploadedFile, and FieldFile allowed directory traversal via uploaded files with suitably crafted file name | File and Directory Discovery, Command and Scripting Interpreter | File and Directory Discovery, Exploit Public-Facing Application |
| 4 | Whale browser for iOS before 1.14.0 has an inconsistent user interface issue that allows an attacker to obfuscate the address bar which may lead to address bar spoofing. | Browser Session Hijacking | User Execution |
| 5 | isula-build before 0.9.5-6 can cause a program crash, when building container images, part of the functions for processing external data do not remove spaces when processing data. | Exploitation for Client Execution | Endpoint Denial of Service |
| Technique | CVEs |
|---|---|
| Exploitation for Privilege Escalation | arbitrary |
| Data from Local System | arbitrary |
| Data Destruction | arbitrary |
| Browser Session Hijacking | arbitrary |
| Archive Collected Data | arbitrary |
| Create Account | arbitrary |
| Forge Web Credentials | bypass |
| Unsecured Credentials | bypass |
| External Remote Services | bypass |
| Adversary-in-the-Middle | trigger |
| Phishing | trigger |
| Stage Capabilities | trigger |
| Exploitation for Credential Access | wordpress |
| Brute Force | wordpress |
| Abuse Elevation Control Mechanism | xml |
| Endpoint Denial of Service | parameter |
| Network Sniffing | parameter |
| User Execution | remote |
| Drive-by Compromise | remote |
| Server Software Component | service |
| Data Manipulation | service |
| Exploit Public-Facing Application | version |
| Command and Scripting Interpreter | pointer |
| Exploitation for Client Execution | attack |
| Valid Accounts | system |
| Hijack Execution Flow | cause |
| Process Injection | privilege |
| File and Directory Discovery | execute |
| Exploitation for Defense Evasion | use |
| Exploitation of Remote Services | possibly |
| Access Token Manipulation | header |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grigorescu, O.; Nica, A.; Dascalu, M.; Rughinis, R. CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques. Algorithms 2022, 15, 314. https://doi.org/10.3390/a15090314
Grigorescu O, Nica A, Dascalu M, Rughinis R. CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques. Algorithms. 2022; 15(9):314. https://doi.org/10.3390/a15090314
Chicago/Turabian StyleGrigorescu, Octavian, Andreea Nica, Mihai Dascalu, and Razvan Rughinis. 2022. "CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques" Algorithms 15, no. 9: 314. https://doi.org/10.3390/a15090314
APA StyleGrigorescu, O., Nica, A., Dascalu, M., & Rughinis, R. (2022). CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques. Algorithms, 15(9), 314. https://doi.org/10.3390/a15090314