
On Enhancement of Text Classification and Analysis of Text Emotions Using Graph Machine Learning and Ensemble Learning Methods on Non-English Datasets



Abstract
:1. Introduction
2. Related Works
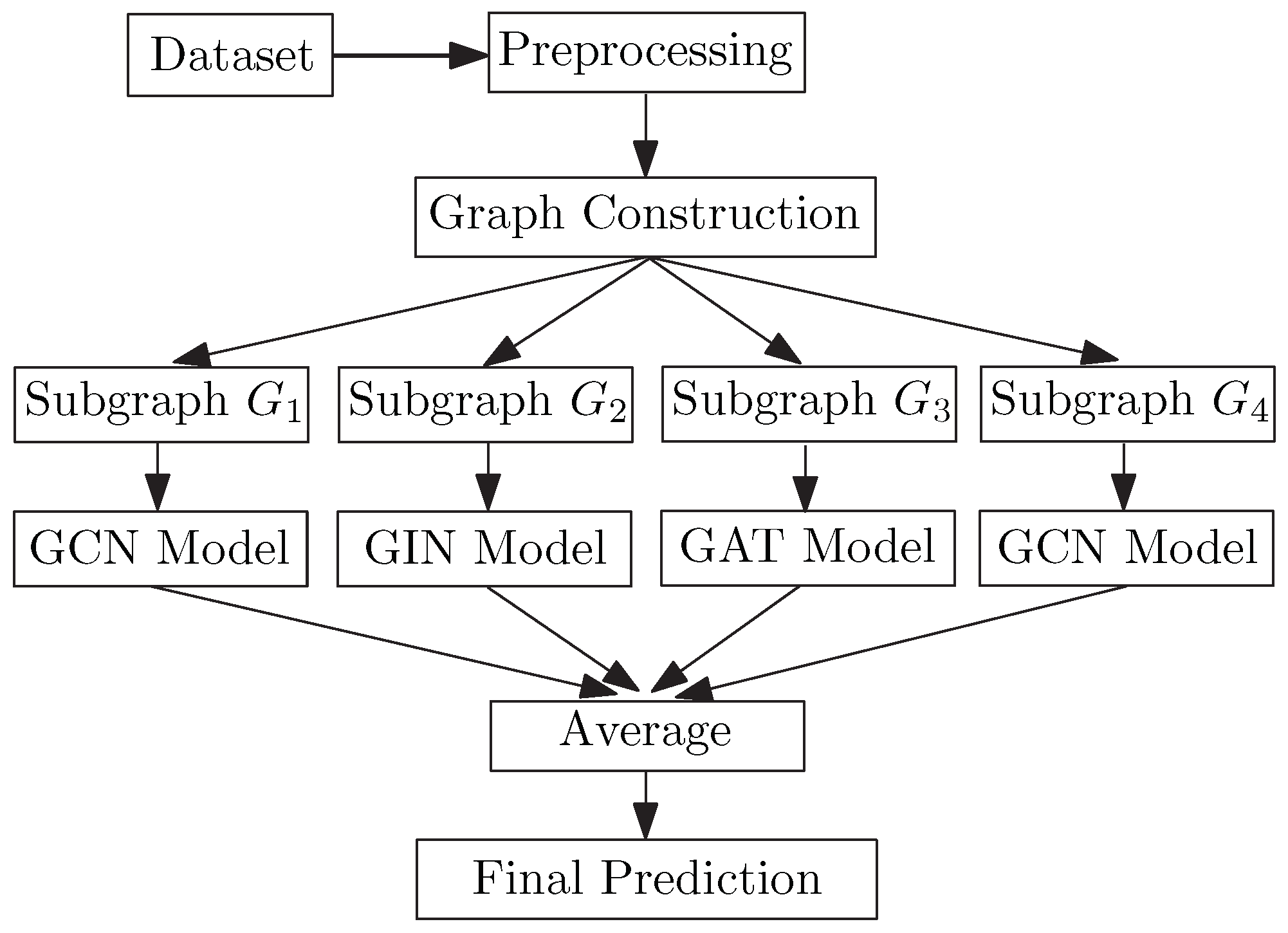
3. Methods
3.1. Preprocessing
3.2. Graph Construction
3.3. Graph Partitioning
3.4. Ensemble Learning
4. Datasets
5. Experimental Results
5.1. Experiment 1: Applying ParsBERT, BERT, and GCN on Our Dataset
5.2. Experiment 2: Ensemble Learning via Combining Different GNN Structures
5.3. Brief Report of Some Additional Experiments
6. Conclusions and Further Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–41. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Dis. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C.; Aggarwal, C.C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012; pp. 163–222. [Google Scholar]
- Zeng, Z.; Deng, Y.; Li, X.; Naumann, T.; Luo, Y. Natural language processing for ehr-based computational phenotyping. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 139–153. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Liu, J.; Ren, X.; Xu, Z. Adversarial training based multi-source unsupervised domain adaptation for sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; pp. 7618–7625. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Farahani, M.; Gharachorloo, M.; Farahani, M.; Manthouri, M. Parsbert: Transformer-based model for persian language understanding. Neural Process. Lett. 2021, 53, 3831–3847. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Medsker, L.R.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016; AAAI Press: Washington, DO, USA, 2016; pp. 2873–2879. [Google Scholar]
- Luo, Y. Recurrent neural networks for classifying relations in clinical notes. J. Biomed. Inform. 2017, 72, 85–95. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015. [Google Scholar]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. Stat 2018, 1050, 4. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019.
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–28 January 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Han, S.C.; Yuan, Z.; Wang, K.; Long, S.; Poon, J. Understanding Graph Convolutional Networks for Text Classification. arXiv 2022, arXiv:2203.16060. [Google Scholar]
- Lin, Y.; Meng, Y.; Sun, X.; Han, Q.; Kuang, K.; Li, J.; Wu, F. BertGCN: Transductive Text Classification by Combining GNN and BERT. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1456–1462. [Google Scholar]
- Chiang, W.-L.; Liu, X.; Si, S.; Li, Y.; Bengio, S.; Hsieh, C. Cluster-GCN: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 257–266. [Google Scholar]
- Karypis, G.; Kumar, V. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 1998, 20, 359–392. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogateb, M.; Lia, J.; Jiangc, F.; Kongc, B.; Hussain, A. A Hybrid Persian Sentiment Analysis Framework: Integrating Dependency Grammar Based Rules and Deep Neural Networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef]
- Ghasemi, R.; Ashrafi Asli, S.A.; Momtazi, S. Deep Persian sentiment analysis: Cross-lingual training for low-resource languages. J. Inf. Sci. 2022, 48, 449–462. [Google Scholar] [CrossRef]
- Dai, Y.; Shou, L.; Gong, M.; Xia, X.; Kang, Z.; Xu, Z.; Jiang, D. Graph fusion network for text classification. Knowl.-Based Syst. 2022, 236, 107659. [Google Scholar] [CrossRef]


{kind=link}
| Digikala | Recommended | No-Idea | Not-Recommended | Total |
|---|---|---|---|---|
| Label | 1 | 0 | −1 | - |
| Number of Data | 36,960 | 10,528 | 16,098 | 63,586 |
| DeepSentiPers | Delighted | Happy | Natural | Angry | Furious | Total |
|---|---|---|---|---|---|---|
| Label | −2 | −1 | 0 | 1 | 2 | - |
| Number of Data | 1342 | 2184 | 3152 | 697 | 40 | 7415 |
| Model | Digikala | |||
|---|---|---|---|---|
| 2Class | 3Class | |||
| Balance | Imbalance | Balance | Imbalance | |
| ParsBERT | 68 | Accuracy = 87 = 72 Precision = 69 Recall = 80 | 57 | Accuracy = 62 = 55 Precision = 52 Recall = 54 |
| ParsBERT+GCN | 70 | Accuracy = 91.1 ± 0.06 = 74 Precision = 71 Recall = 80 | 58 | Accuracy = 63.9 ± 0.09 = 55 Precision = 52 Recall = 59 |
| BERT | 57 | Accuracy = 81 = 68 Precision = 66 Recall = 74 | 54 | Accuracy = 56 = 54 Precision = 51 Recall = 55 |
| BERT+GCN | 57 | Accuracy = 90.6 ± 0.08 = 71 Precision = 69 Recall = 80 | 55 | Accuracy = 57.2 ± 0.15 = 53 Precision = 51 Recall = 55 |
| Model (Graph) | Digikala | |||
|---|---|---|---|---|
| 2Class | 3Class | |||
| Balance | Imbalance | Balance | Imbalance | |
| GCN (G1) | 66 | 89 | 54 | 64 |
| GAT (G2) | 64 | 81 | 48 | 59 |
| GIN (G3) | 63 | 78 | 51 | 55 |
| GCN (G4) | 64 | 86 | 53 | 67 |
| Ensemble Learning | 69 | Accuracy = 93.2 ± 0.02 = 77 Precision = 78 Recall = 79 | 58 | Accuracy = 68.4 ± 0.09 = 58 Precision = 52 Recall = 60 |
| Accuracy on Test Data | Accuracy on Train Data | |
|---|---|---|
| AJGT | 82.8 ± 0.5 | 98 |
| MR | 86.3 ± 0.1 | 97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gholami, F.; Rahmati, Z.; Mofidi, A.; Abbaszadeh, M. On Enhancement of Text Classification and Analysis of Text Emotions Using Graph Machine Learning and Ensemble Learning Methods on Non-English Datasets. Algorithms 2023, 16, 470. https://doi.org/10.3390/a16100470
Gholami F, Rahmati Z, Mofidi A, Abbaszadeh M. On Enhancement of Text Classification and Analysis of Text Emotions Using Graph Machine Learning and Ensemble Learning Methods on Non-English Datasets. Algorithms. 2023; 16(10):470. https://doi.org/10.3390/a16100470
Chicago/Turabian StyleGholami, Fatemeh, Zahed Rahmati, Alireza Mofidi, and Mostafa Abbaszadeh. 2023. "On Enhancement of Text Classification and Analysis of Text Emotions Using Graph Machine Learning and Ensemble Learning Methods on Non-English Datasets" Algorithms 16, no. 10: 470. https://doi.org/10.3390/a16100470
APA StyleGholami, F., Rahmati, Z., Mofidi, A., & Abbaszadeh, M. (2023). On Enhancement of Text Classification and Analysis of Text Emotions Using Graph Machine Learning and Ensemble Learning Methods on Non-English Datasets. Algorithms, 16(10), 470. https://doi.org/10.3390/a16100470