
Similarity Measurement and Classification of Temporal Data Based on Double Mean Representation


Abstract
:1. Introduction
2. Related Work
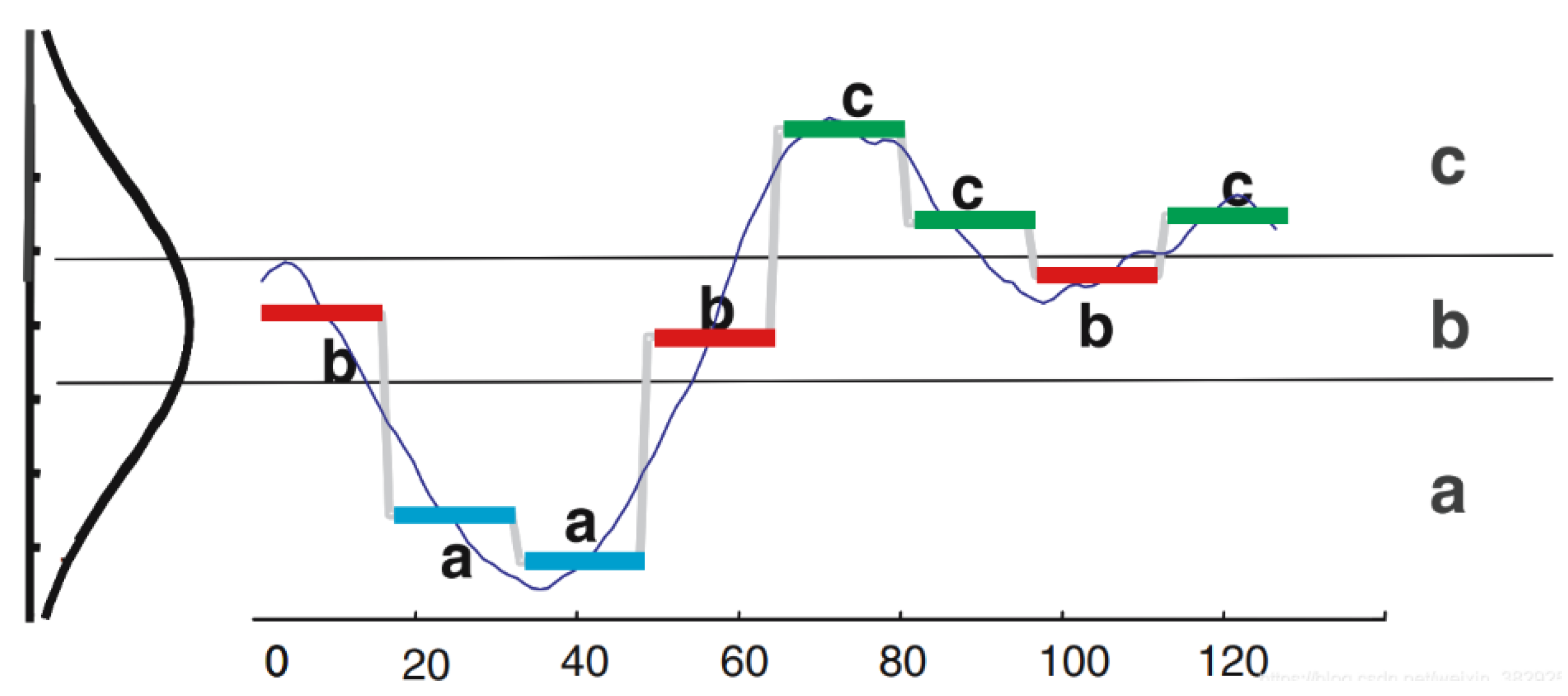
2.1. Distance Calculation by SAX
2.2. Two Improvements of SAX Distance Measure for Time Series
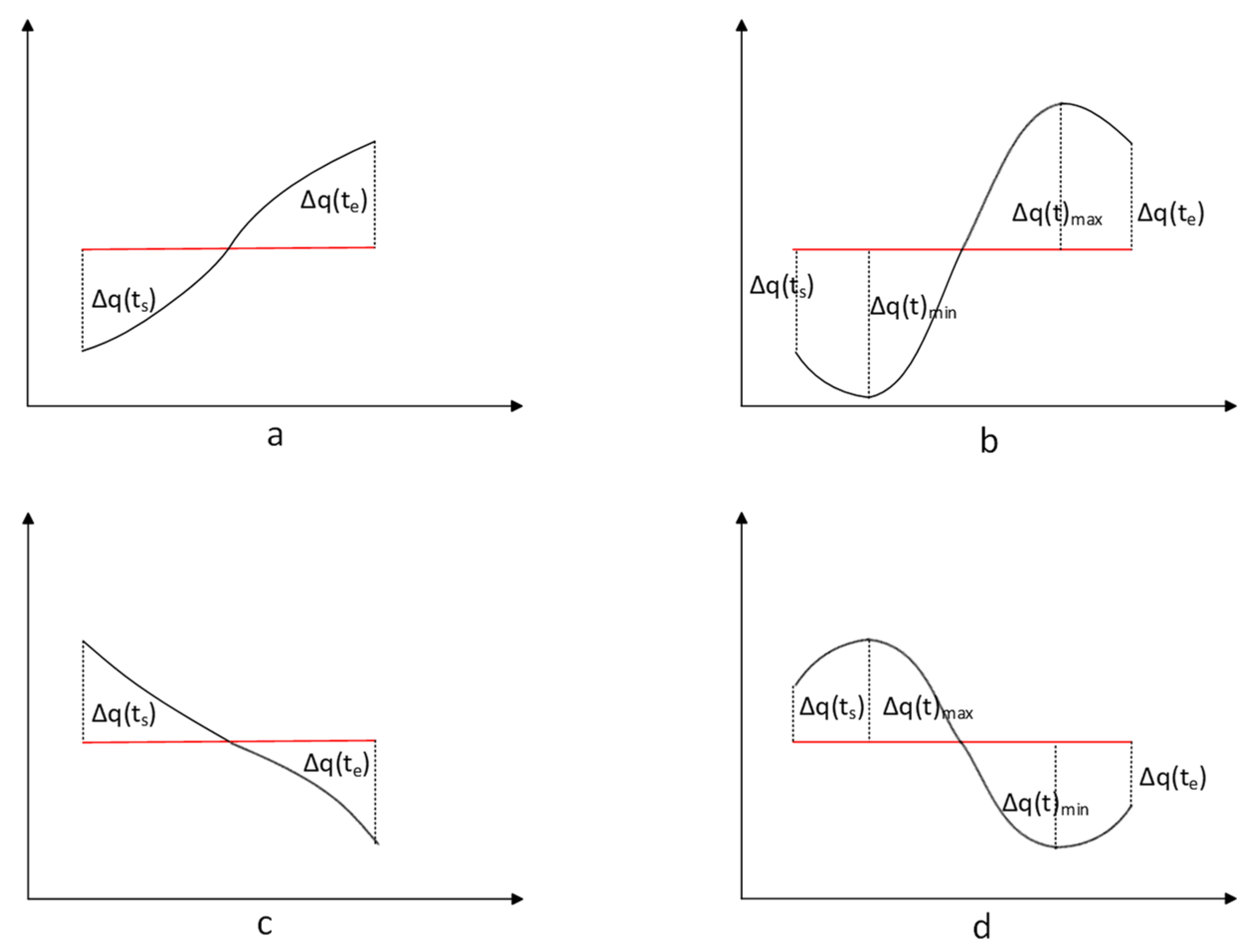
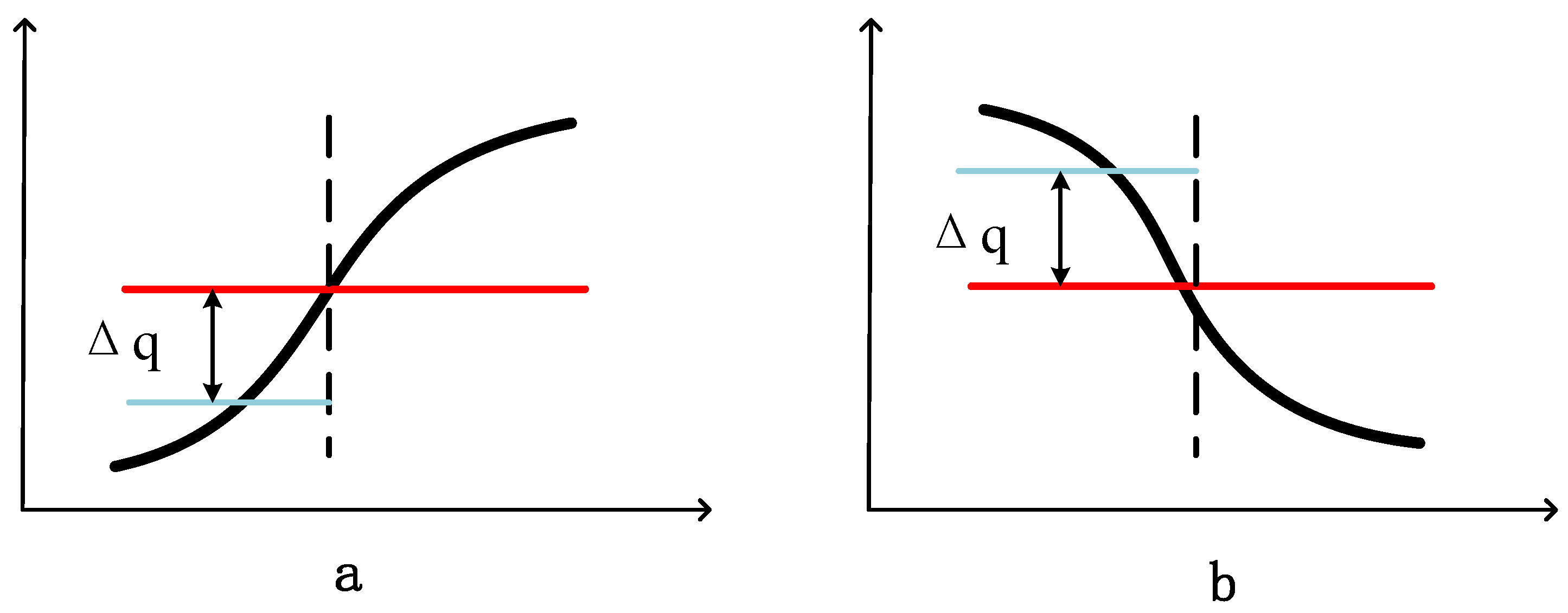
2.2.1. SAX-TD
2.2.2. SAX-BD
- for case c,
- for case d,
3. Our Method, SAX-DM
3.1. SAX-DM Design and Analysis
3.2. Similarity Measurement Based on SAX-DM Expression Method
3.3. Lower Bound
4. Experimental Validation
4.1. Datasets
4.2. Experimental Methods and Parameter Settings
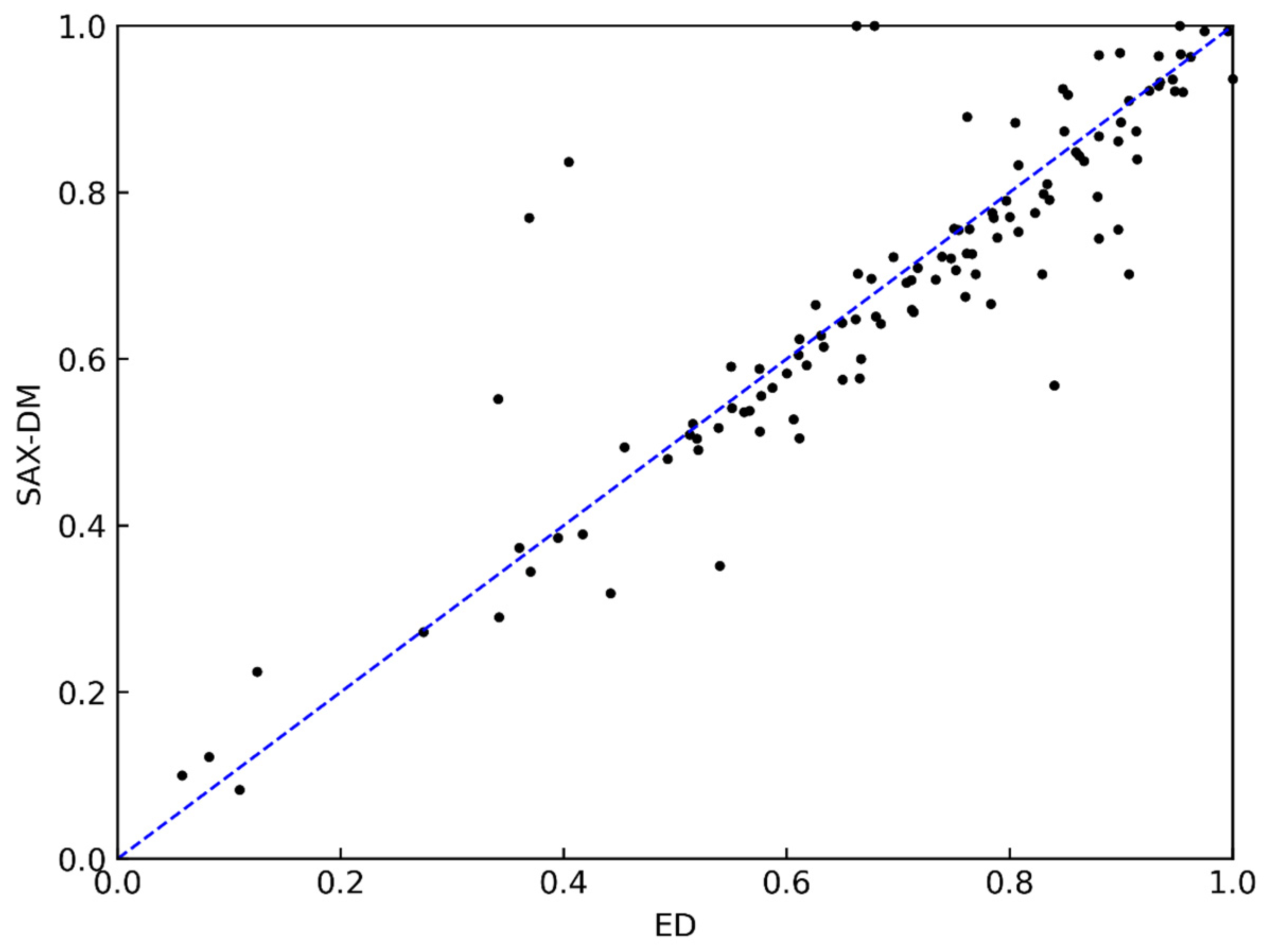
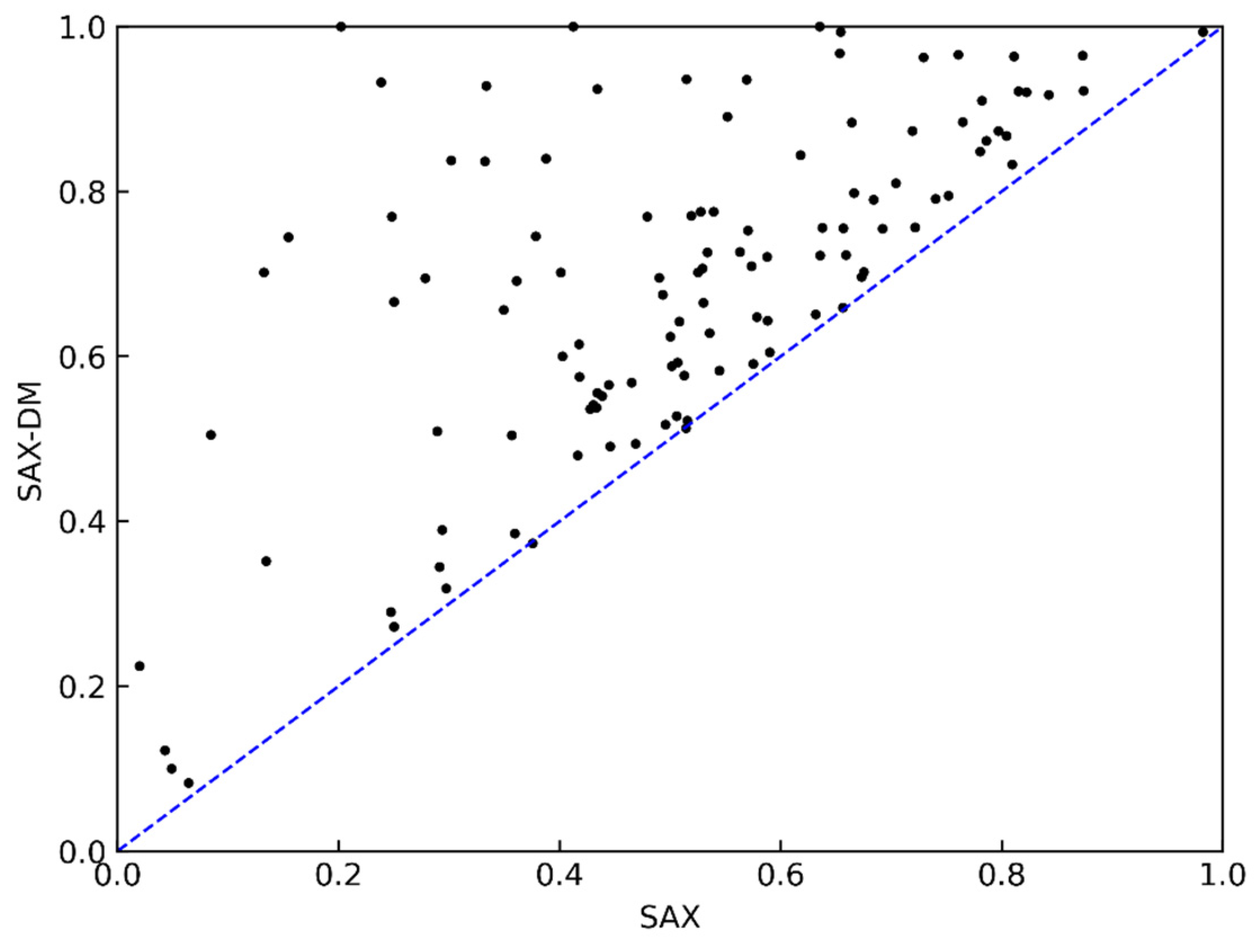
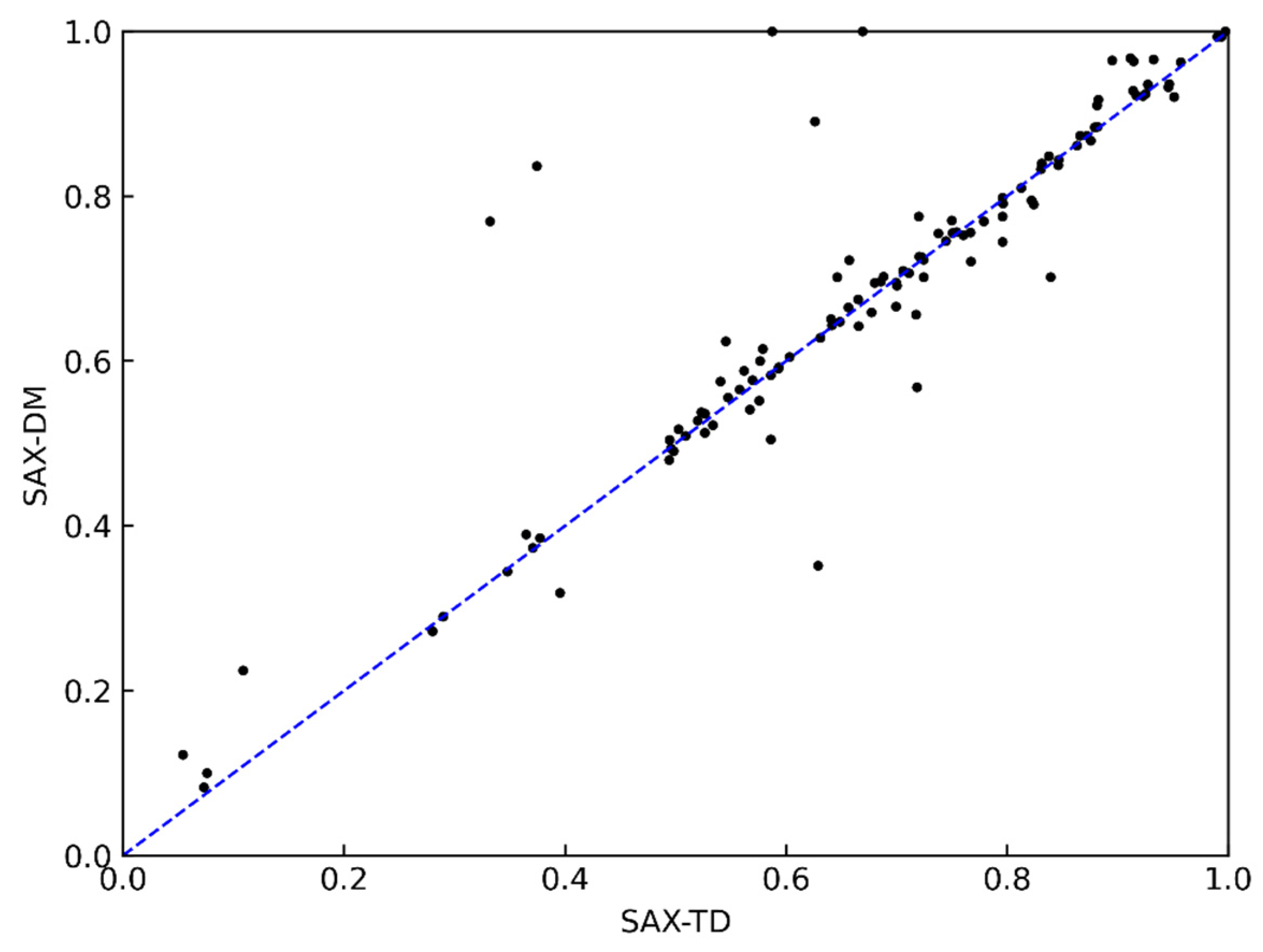
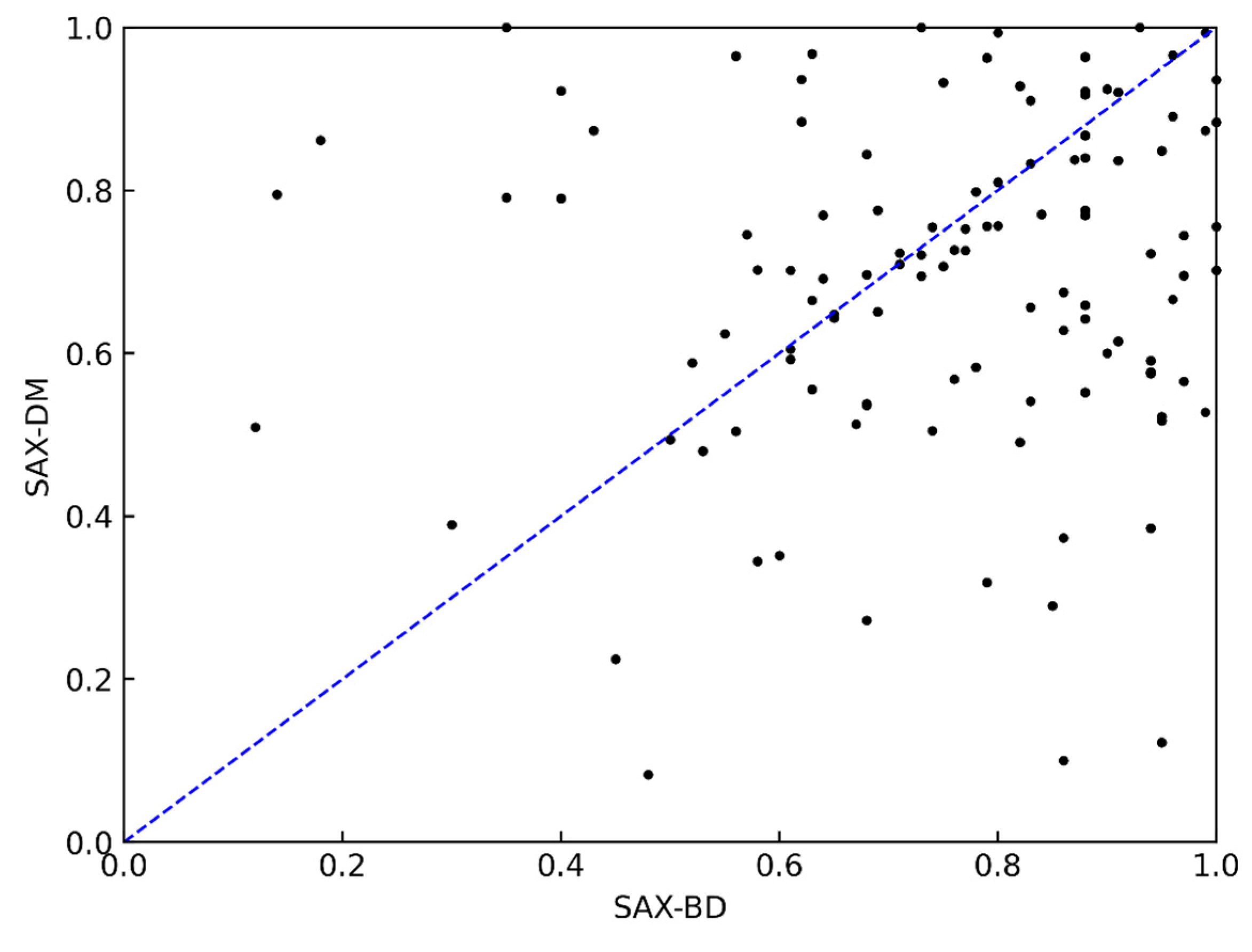
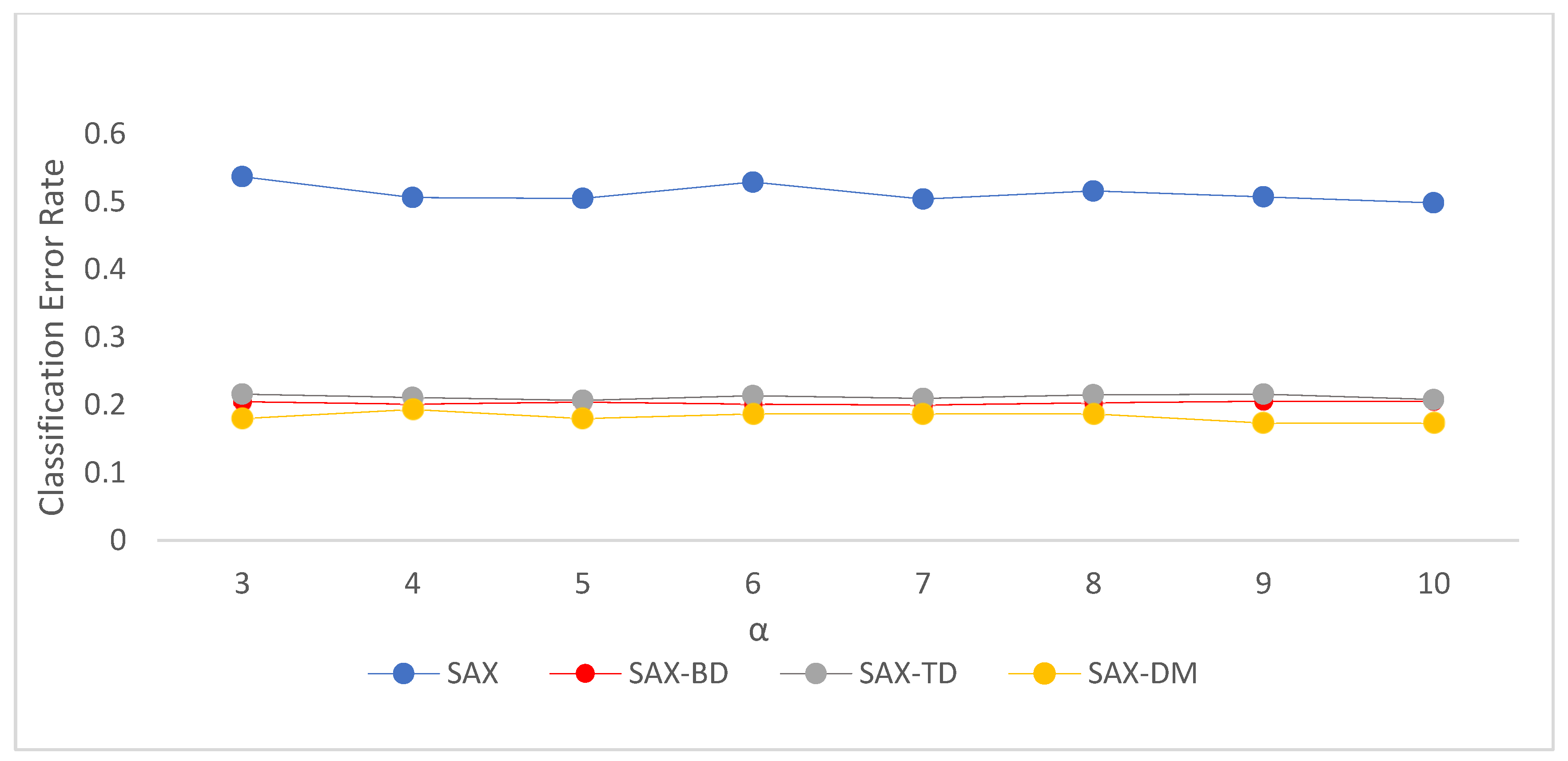
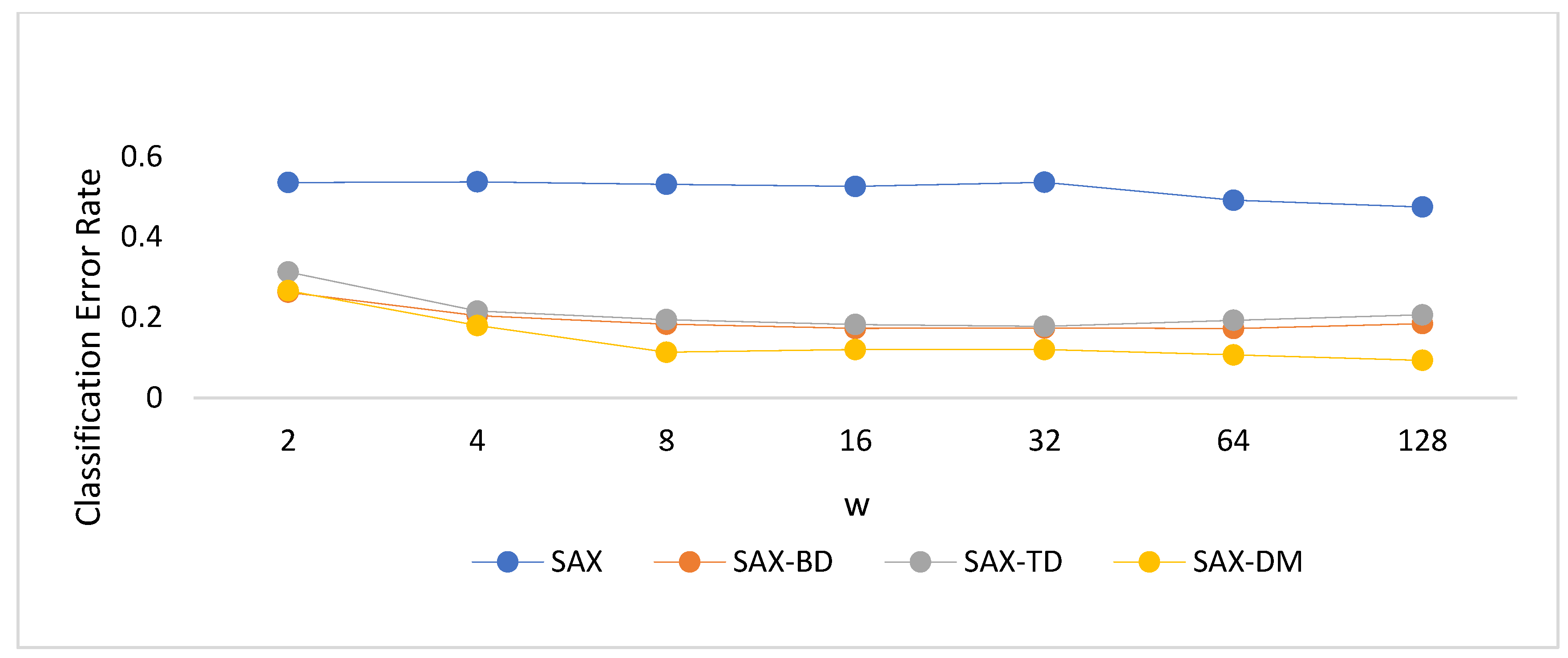
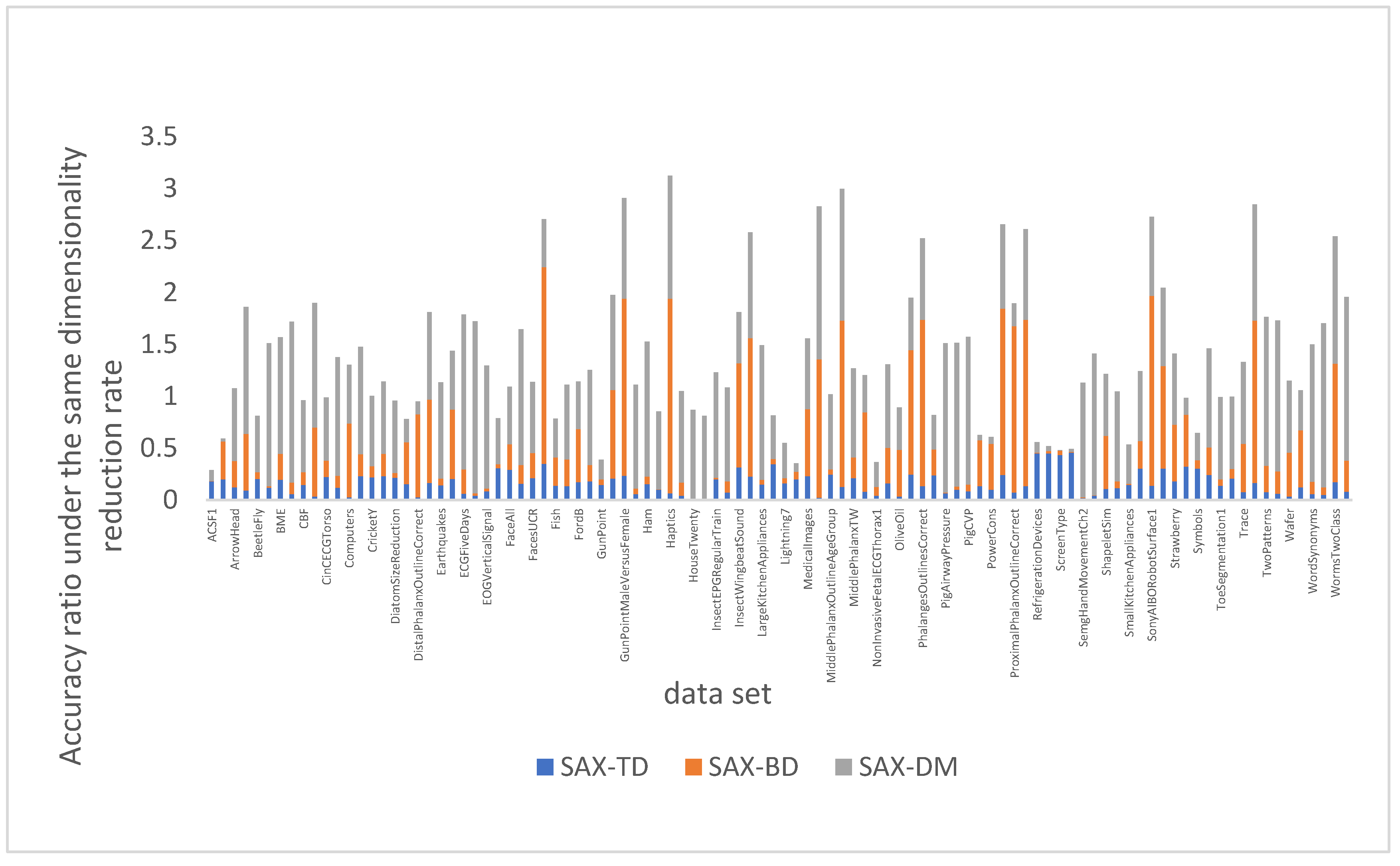
4.3. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, Z.; Wu, C.; Liu, G.; Tian, Y.; Zhang, X.; Chen, Q. Overview of similarity measurement and indexing methods for geoscience time series Big data. Bull. Geol. Sci. Technol. 2020, 39, 44–50. [Google Scholar]
- Agrawal, R.; Faloutsos, C.; Swami, A. Efficient similarity search in sequence databases. In Proceedings of the Foundations of Data Organization and Algorithms: 4th International Conference, FODO’93, Chicago, IL, USA, 13–15 October 1993; Springer: Berlin/Heidelberg, Germany, 1993; pp. 69–84. [Google Scholar]
- Chan, K.P.; Fu AW, C. Efficient time series matching by wavelets. In Proceedings of the 15th International Conference on Data Engineering (Cat. No. 99CB36337), Sydney, Australia, 23–26 March 1999; pp. 126–133. [Google Scholar]
- Korn, F.; Jagadish, H.V.; Faloutsos, C. Efficiently supporting ad hoc queries in large datasets of time sequences. SIGMOD Rec. 1997, 26, 289–300. [Google Scholar] [CrossRef]
- Yi, B.K.; Faloutsost, C. Fast Time Sequence Indexing for Arbitrary Lp Norms. 2000, pp. 385–394. Available online: https://www.vldb.org/conf/2000/P385.pdf (accessed on 10 February 2023).
- Fu, T.C.; Chung, F.L.; Luk, R.; Ng, C.-M. Representing financial time series based on data point importance. Eng. Appl. Artif. Intell. 2008, 21, 277–300. [Google Scholar] [CrossRef]
- Cai, Y.; Ng, R.T. Indexing Spatio-Temporal Trajectories with Chebyshev Polynomials. In Proceedings of the 2004 ACM SIGMOD International Conference on Management of Data, Paris, France, 13–18 June 2004; pp. 599–610. [Google Scholar]
- Chen, Q.; Chen, L.; Lian, X.; Liu, Y.; Yu, X. Indexable PLA for Efficient Similarity Search. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 435–446. [Google Scholar]
- Stefan, A.; Athitsos, V.; Das, G. The Move-Split-Merge Metric for Time Series. IEEE Trans. Knowl. Data Eng. 2013, 25, 1425–1438. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Tang, P.; Duan, R. Dynamic time warping under pointwise shape context. Inf. Sci. 2015, 315, 88–101. [Google Scholar] [CrossRef]
- Keogh, E.J.; Pazzani, M.J. An enhanced representation of time series which allows fast and accurate classification, clustering and relevance feedback. InKdd 1998, 98, 239–243. [Google Scholar]
- Keogh, E.J. A Simple Dimensionality Reduction Technique for Fast Similarity Search in Large Time Series Databases. 2000, pp. 122–133. Available online: http://www.cs.ucr.edu/~eamonn/pakdd200_keogh.pdf (accessed on 16 February 2023).
- Chakrabarti, K.; Mehrotra, S.; Pazzani, M.; Keogh, E. Locally Adaptive Dimensionality Reduction for Indexing Large Time Series Databases. ACM Trans. Database Syst. 2002, 27, 188–228. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.; Keogh, E.J.; Lonardi, S.; Chiu, B. A symbolic representation of time series, with implications for streaming algorithms. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, San Diego, CA, USA, 13 June 2003; pp. 2–11. [Google Scholar]
- Lin, J.; Keogh, E.; Wei, L.; Lonardi, S. Experiencing SAX: A novel symbolic representation of time series. Data Min. Knowl. Discov. 2007, 15, 107–144. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Li, J.; Liu, J.; Sun, B.; Chow, C. An improvement of symbolic aggregate approximation distance measure for time series. Neurocomputing 2014, 138, 189–198. [Google Scholar] [CrossRef]
- He, Z.; Long, S.; Ma, X.; Zhao, H. A Boundary Distance-Based Symbolic Aggregate Approximation Method for Time Series Data. Algorithms 2020, 13, 284. [Google Scholar] [CrossRef]
- He, Z.; Zhang, C.; Ma, X.; Liu, G. Hexadecimal Aggregate Approximation Representation and Classification of Time Series Data. Algorithms 2021, 14, 353. [Google Scholar] [CrossRef]
- Yang, D.; Kang, Y. Distance- and Momentum-Based Symbolic Aggregate Approximation for Highly Imbalanced Classification. Sensors 2022, 22, 5095. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Xu, X.; Cui, X.; Kang, J.; Yang, H. Time series data symbol aggregation approximation method for fusing trend information. Appl. Res. Comput. 2023, 40, 86–90. [Google Scholar]
- Ratanamahatana, C.; Keogh, E.; Bagnall, A.J.; Lonardi, S. A novel bit level time series representation with implication of similarity search and clustering. In Advances in Knowledge Discovery and Data Mining, Proceedings of the 9th Pacific-Asia Conference, PAKDD 2005, Hanoi, Vietnam, 18–20 May 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 771–777. [Google Scholar]
- Baydogan, M.G.; Runger, G.C. Learning a symbolic representation for multivariate time series classification. Data Min. Knowl. Discov. 2015, 29, 400–422. [Google Scholar] [CrossRef]
- Azzouzi, M.; Nabney, I.T. Analysing time series structure with hidden Markov models. In Neural Networks for Signal Processing VIII, Proceedings of the 1998 IEEE Signal Processing Society Workshop (Cat. No. 98TH8378), Cambridge, UK, 31 August–3 September 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 402–408. [Google Scholar]
- Serra, J.; Kantz, H.; Serra, X.; Andrzejak, R.G. Predictability of Music Descriptor Time Series and its Application to Cover Song Detection. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 514–525. [Google Scholar] [CrossRef] [Green Version]
- Baydogan, M.G.; Runger, G.C. Time series representation and similarity based on local autopatterns. Data Min. Knowl. Discov. 2016, 30, 476–509. [Google Scholar] [CrossRef]
- Ye, Y.; Jiang, J.; Ge, B.; Dou, Y.; Yang, K. Similarity measures for time series data classification using grid representation and matrix distance. Knowl. Inf. Syst. 2019, 60, 1105–1134. [Google Scholar] [CrossRef]
- Su, Z.; Liu, Q.; Zhao, C.; Sun, F. A Traffic Event Detection Method Based on Random Forest and Permutation Importance. Mathematics 2022, 10, 873. [Google Scholar] [CrossRef]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.-C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR Time Series Archive. IEEE/CAA J. Autom. Sin. 2019, 6, 6–18. [Google Scholar] [CrossRef]












{kind=link}
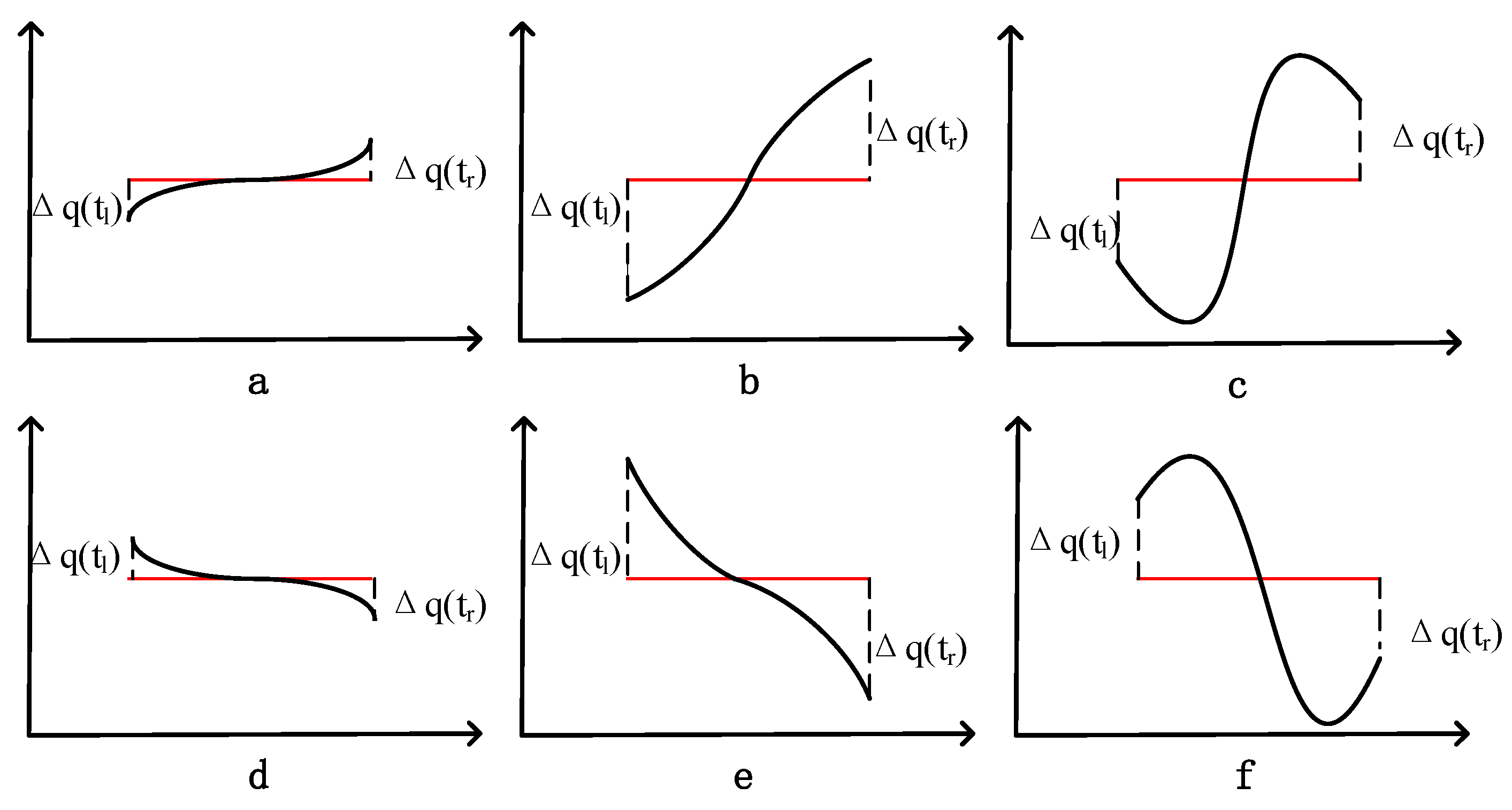{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Representation | Publication Time | Type | Algorithm Complexity | Method Source |
|---|---|---|---|---|
| Discrete Fourier Transform (DFT) | 1993 | T1 | O(n(log(n))) | [2] |
| Discrete Wavelet Transform (DWT) | 1999 | T1 | O(n) | [3] |
| Discrete Cosine Transform (DCT) | 1997 | T1 | N | [4] |
| Partitioned Aggregation Approximation (PAA) | 2000 | T1 | O(n) | [5] |
| Perceived Importance Points (PIPs) | 2001 | T1 | N | [6] |
| Chebyshev Polynomials (CHEBs) | 2004 | T1 | N | [7] |
| Indexable Piecewise Linear Approximation (IPLA) | 2007 | T1 | N | [8] |
| Move Split Merge (MSM) | 2013 | T1 | N | [9] |
| Graphical-Content-Based DTW (SC DTW) | 2015 | T1 | N | [10] |
| Singular Value Decomposition (SVD) | 1997 | T2 | O(Mn2) | [4] |
| Piecewise Linear Approximation (PLA) | 1998 | T2 | O(n(log(n))) | [11] |
| Piecewise Constant Approximation (PCA) | 2000 | T2 | N | [12] |
| Adaptive Partitioning Constant Approximation (APCA) | 2002 | T2 | O(n) | [13] |
| Symbolized Aggregate Approximation (SAX) | 2003 | T2 | O(n) | [14,15] |
| SAX Based on Trend Distance (SAX-TD) | 2014 | T2 | N | [16] |
| SAX Based on Boundary Distance (SAX-BD) | 2020 | T2 | N | [17] |
| Hexadecimal Aggregate Approximation (HAX) | 2021 | T2 | N | [18] |
| Point Aggregation Approximation (PAX) | 2021 | T2 | N | [18] |
| Symbol Aggregation Approximation Based on Distance and Momentum | 2022 | T2 | N | [19] |
| Convergence Trend Symbol Aggregation Approximation (SAX-TI) | 2023 | T2 | N | [20] |
| Clipped Data | 2005 | T3 | N | [21] |
| Tree-Based Representation Method | 2015 | T3 | N | [22] |
| Hidden Markov Models (HMMs) | 1998 | T4 | N | [23] |
| Automatic Regression Model | 2012 | T4 | N | [24] |
| Representation Method Based on Local Automatic Mode | 2016 | T4 | N | [25] |
| Grid-Based Representation Method | 2019 | T4 | N | [26] |
| Based on Random Forest and Ranking Importance | 2022 | T4 | N | [27] |
| Id | Type | Name | Train | Test | Class | Length |
|---|---|---|---|---|---|---|
| 1 | Device | ACSF1 | 100 | 100 | 10 | 1460 |
| 2 | Image | Adiac | 390 | 391 | 37 | 176 |
| 3 | Image | ArrowHead | 36 | 175 | 3 | 251 |
| 4 | Spectro | Beef | 30 | 30 | 5 | 470 |
| 5 | Image | BeetleFly | 20 | 20 | 2 | 512 |
| 6 | Image | BirdChicken | 20 | 20 | 2 | 512 |
| 7 | Simulated | BME | 30 | 150 | 3 | 128 |
| 8 | Sensor | Car | 60 | 60 | 4 | 577 |
| 9 | Simulated | CBF | 30 | 900 | 3 | 128 |
| 10 | Traffic | Chinatown | 20 | 343 | 2 | 24 |
| 11 | Sensor | CinCECGTorso | 40 | 1380 | 4 | 1639 |
| 12 | Spectro | Coffee | 28 | 28 | 2 | 286 |
| 13 | Device | Computers | 250 | 250 | 2 | 720 |
| 14 | Motion | CricketX | 390 | 390 | 12 | 300 |
| 15 | Motion | CricketY | 390 | 390 | 12 | 300 |
| 16 | Motion | CricketZ | 390 | 390 | 12 | 300 |
| 17 | Image | DiatomSizeReduction | 16 | 306 | 4 | 345 |
| 18 | Image | DistalPhalanxOutlineAgeGroup | 400 | 139 | 3 | 80 |
| 19 | Image | DistalPhalanxOutlineCorrect | 600 | 276 | 2 | 80 |
| 20 | Image | DistalPhalanxTW | 400 | 139 | 6 | 80 |
| 21 | Sensor | Earthquakes | 322 | 139 | 2 | 512 |
| 22 | ECG | ECG200 | 100 | 100 | 2 | 96 |
| 23 | ECG | ECGFiveDays | 23 | 861 | 2 | 136 |
| 24 | EOG | EOGHorizontalSignal | 362 | 362 | 12 | 1250 |
| 25 | EOG | EOGVerticalSignal | 362 | 362 | 12 | 1250 |
| 26 | Spectro | EthanolLevel | 504 | 500 | 4 | 1751 |
| 27 | Image | FaceAll | 560 | 1690 | 14 | 131 |
| 28 | Image | FaceFour | 24 | 88 | 4 | 350 |
| 29 | Image | FacesUCR | 200 | 2050 | 14 | 131 |
| 30 | Image | FiftyWords | 450 | 455 | 50 | 270 |
| 31 | Image | Fish | 175 | 175 | 7 | 463 |
| 32 | Sensor | FordA | 3601 | 1320 | 2 | 500 |
| 33 | Sensor | FordB | 3636 | 810 | 2 | 500 |
| 34 | HRM | Fungi | 18 | 186 | 18 | 201 |
| 35 | Motion | GunPoint | 50 | 150 | 2 | 150 |
| 36 | Motion | GunPointAgeSpan | 135 | 316 | 2 | 150 |
| 37 | Motion | GunPointMaleVersusFemale | 135 | 316 | 2 | 150 |
| 38 | Motion | GunPointOldVersusYoung | 136 | 315 | 2 | 150 |
| 39 | Spectro | Ham | 109 | 105 | 2 | 431 |
| 40 | Image | HandOutlines | 1000 | 370 | 2 | 2709 |
| 41 | Motion | Haptics | 155 | 308 | 5 | 1092 |
| 42 | Image | Herring | 64 | 64 | 2 | 512 |
| 43 | Device | HouseTwenty | 40 | 119 | 2 | 2000 |
| 44 | Motion | InlineSkate | 100 | 550 | 7 | 1882 |
| 45 | EPG | InsectEPGRegularTrain | 62 | 249 | 3 | 601 |
| 46 | EPG | InsectEPGSmallTrain | 17 | 249 | 3 | 601 |
| 47 | Sensor | InsectWingbeatSound | 220 | 1980 | 11 | 256 |
| 48 | Sensor | ItalyPowerDemand | 67 | 1029 | 2 | 24 |
| 49 | Device | LargeKitchenAppliances | 375 | 375 | 3 | 720 |
| 50 | Sensor | Lightning2 | 60 | 61 | 2 | 637 |
| 51 | Sensor | Lightning7 | 70 | 73 | 7 | 319 |
| 52 | Spectro | Meat | 60 | 60 | 3 | 448 |
| 53 | Image | MedicalImages | 381 | 760 | 10 | 99 |
| 54 | Traffic | MelbournePedestrian | 1194 | 2439 | 10 | 24 |
| 55 | Image | MiddlePhalanxOutlineAgeGroup | 400 | 154 | 3 | 80 |
| 56 | Image | MiddlePhalanxOutlineCorrect | 600 | 291 | 2 | 80 |
| 57 | Image | MiddlePhalanxTW | 399 | 154 | 6 | 80 |
| 58 | Sensor | MoteStrain | 20 | 1252 | 2 | 84 |
| 59 | ECG | NonInvasiveFetalECGThorax1 | 1800 | 1965 | 42 | 750 |
| 60 | ECG | NonInvasiveFetalECGThorax2 | 1800 | 1965 | 42 | 750 |
| 61 | Spectro | OliveOil | 30 | 30 | 4 | 570 |
| 62 | Image | OSULeaf | 200 | 242 | 6 | 427 |
| 63 | Image | PhalangesOutlinesCorrect | 1800 | 858 | 2 | 80 |
| 64 | Sensor | Phoneme | 214 | 189 | 39 | 1024 |
| 65 | Hemodynamics | PigAirwayPressure | 104 | 208 | 52 | 2000 |
| 66 | Hemodynamics | PigArtPressure | 104 | 208 | 52 | 2000 |
| 67 | Hemodynamics | PigCVP | 104 | 208 | 52 | 2000 |
| 68 | Sensor | Plane | 105 | 105 | 7 | 144 |
| 69 | Power | PowerCons | 180 | 180 | 2 | 144 |
| 70 | Image | ProximalPhalanxOutlineAgeGroup | 400 | 205 | 3 | 80 |
| 71 | Image | ProximalPhalanxOutlineCorrect | 600 | 291 | 2 | 80 |
| 72 | Image | ProximalPhalanxTW | 400 | 205 | 6 | 80 |
| 73 | Device | RefrigerationDevices | 375 | 375 | 3 | 720 |
| 74 | Spectrum | Rock | 20 | 50 | 4 | 2844 |
| 75 | Device | ScreenType | 375 | 375 | 3 | 720 |
| 76 | Spectrum | SemgHandGenderCh2 | 300 | 600 | 2 | 1500 |
| 77 | Spectrum | SemgHandMovementCh2 | 450 | 450 | 6 | 1500 |
| 78 | Spectrum | SemgHandSubjectCh2 | 450 | 450 | 5 | 1500 |
| 79 | Simulated | ShapeletSim | 20 | 180 | 2 | 500 |
| 80 | Image | ShapesAll | 600 | 600 | 60 | 512 |
| 81 | Device | SmallKitchenAppliances | 375 | 375 | 3 | 720 |
| 82 | Simulated | SmoothSubspace | 150 | 150 | 3 | 15 |
| 83 | Sensor | SonyAIBORobotSurface1 | 20 | 601 | 2 | 70 |
| 84 | Sensor | SonyAIBORobotSurface2 | 27 | 953 | 2 | 65 |
| 85 | Spectro | Strawberry | 613 | 370 | 2 | 235 |
| 86 | Image | SwedishLeaf | 500 | 625 | 15 | 128 |
| 87 | Image | Symbols | 25 | 995 | 6 | 398 |
| 88 | Simulated | SyntheticControl | 300 | 300 | 6 | 60 |
| 89 | Motion | ToeSegmentation1 | 40 | 228 | 2 | 277 |
| 90 | Motion | ToeSegmentation2 | 36 | 130 | 2 | 343 |
| 91 | Sensor | Trace | 100 | 100 | 4 | 275 |
| 92 | ECG | TwoLeadECG | 23 | 1139 | 2 | 82 |
| 93 | Simulated | TwoPatterns | 1000 | 4000 | 4 | 128 |
| 94 | Simulated | UDM | 36 | 144 | 3 | 150 |
| 95 | Sensor | Wafer | 1000 | 6164 | 2 | 152 |
| 96 | Spectro | Wine | 57 | 54 | 2 | 234 |
| 97 | Image | WordSynonyms | 267 | 638 | 25 | 270 |
| 98 | Motion | Worms | 181 | 77 | 5 | 900 |
| 99 | Motion | WormsTwoClass | 181 | 77 | 2 | 900 |
| 100 | Image | Yoga | 300 | 3000 | 2 | 426 |
| Method | Parameter |
|---|---|
| ED | null |
| SAX-DM | |
| SAX | |
| SAX-TD | |
| SAX-BD |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Zhang, C.; Cheng, Y. Similarity Measurement and Classification of Temporal Data Based on Double Mean Representation. Algorithms 2023, 16, 347. https://doi.org/10.3390/a16070347
He Z, Zhang C, Cheng Y. Similarity Measurement and Classification of Temporal Data Based on Double Mean Representation. Algorithms. 2023; 16(7):347. https://doi.org/10.3390/a16070347
Chicago/Turabian StyleHe, Zhenwen, Chi Zhang, and Yunhui Cheng. 2023. "Similarity Measurement and Classification of Temporal Data Based on Double Mean Representation" Algorithms 16, no. 7: 347. https://doi.org/10.3390/a16070347
APA StyleHe, Z., Zhang, C., & Cheng, Y. (2023). Similarity Measurement and Classification of Temporal Data Based on Double Mean Representation. Algorithms, 16(7), 347. https://doi.org/10.3390/a16070347