
Model Retraining: Predicting the Likelihood of Financial Inclusion in Kiva’s Peer-to-Peer Lending to Promote Social Impact


Abstract
:1. Introduction
Significance of Research
- (1)
- How can a company (specifically in the peer-to-peer lending industry) monitor financial inclusion, given the wide range of investment opportunities to promote social responsibility, with the use of AI?
- (2)
- How can model retraining contribute to a risk management framework that helps detect issues including bias with social impact investments?
2. Materials and Methods
- I.
- CROWDFUNDING
- (a)
- Rewards-based crowdfunding: With this type of crowdfunding, an investor provides an online contribution in return for a reward. This can include providing a product that was launched with the funding for free or at a discount.
- (b)
- Equity crowdfunding: With this type of crowdfunding, investors support the goal of raising capital online in exchange for a percentage of equity ownership in the business itself.
- (c)
- Peer-to-peer (P2P) lending: Similar to acquiring a bank loan, this type of lending instead comes from an individual as opposed to a financial institution. The loan is expected to be repaid over a certain time.
- (d)
- Donations: Similar to GoFundMe, this type of crowdfunding allows individuals or groups to benefit from funding (without repayment) to support an individual cause or project.
- (1)
- Natural language processing (NLP), a program trained to read the transcript of a company’s quarterly earnings and investments public meetings, can analyze the CEO’s use of words, and assess which parts of the discussion focus on social-justice-related topics and, ultimately, develop an understanding of a company’s commitment to ESG factors.
- (2)
- Peer-to-peer lending has resulted in widely known impactful societal outcomes across the globe. There are still challenges that exist in the P2P market, including limited information to assess creditworthiness, volumes of applicant data for humans to review to inform decision-making, fraudulent activities, data privacy, biased decisions, loan defaults, the feasibility of lending platforms to collect information and process applications in a timely manner, and the pace of evolving regulation. Fortunately, as with social impact, even many of these challenges can be addressed with the use of AI, and several indicators through existing research demonstrate this thought. There are several examples demonstrating how AI can play a key and evolving role in peer-to-peer lending markets.
- (3)
- In the Indian P2P market, Kanwal Anil and Anil Misra explore the use of AI, concluding how implementing AI capabilities would transform core financial processes more securely and faster, including the underwriting phase (which at the time was very manual), and offering predictive intelligence as a framework to inform process efficiency, cost optimization, and client engagement [22].
- (4)
- Turiel and Aste researched the use of AI in the P2P loan acceptance process and default prediction and recommend an automated approach to predict loan defaults and amplify the opportunity to transform the credit screening process [23].
- (5)
- In research conducted by Klimowicz and Spirzewski, the use of logistic regression machine learning is used to automatically build a credit scorecard to inform P2P lending [24].
- (6)
- Niu Beibei researched P2P lending platforms specifically regarding the integration of social network information using machine learning to build more effective credit scoring models. To predict the likelihood of a loan default, several machine learning algorithms were used, including random forest, LightGBM, and AdaBoost along with a logistic regression, to understand if any correlation exists between social network information and loan default [25].
- II.
- APPLICATION OF AI ALGORITHMS ON KIVA’S FUNDING DATA
- Loan ID
- Loan Name
- Funded Amount
- Loan Use
- Sector Name
- Currency
- Posted Time
- Planned Expiration Time
- Raised Time
- Tags
- Borrower Information
- Status
- (1)
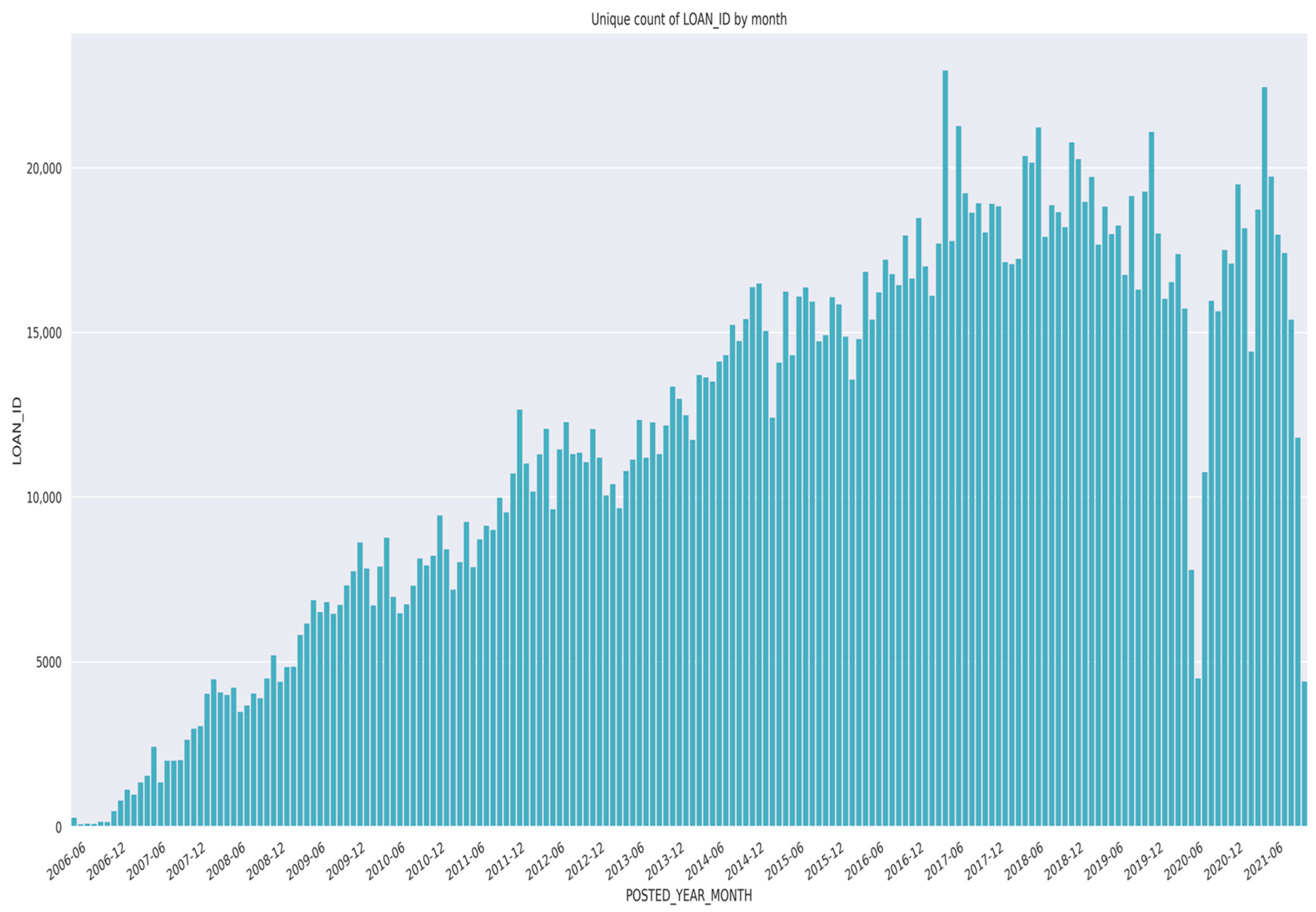
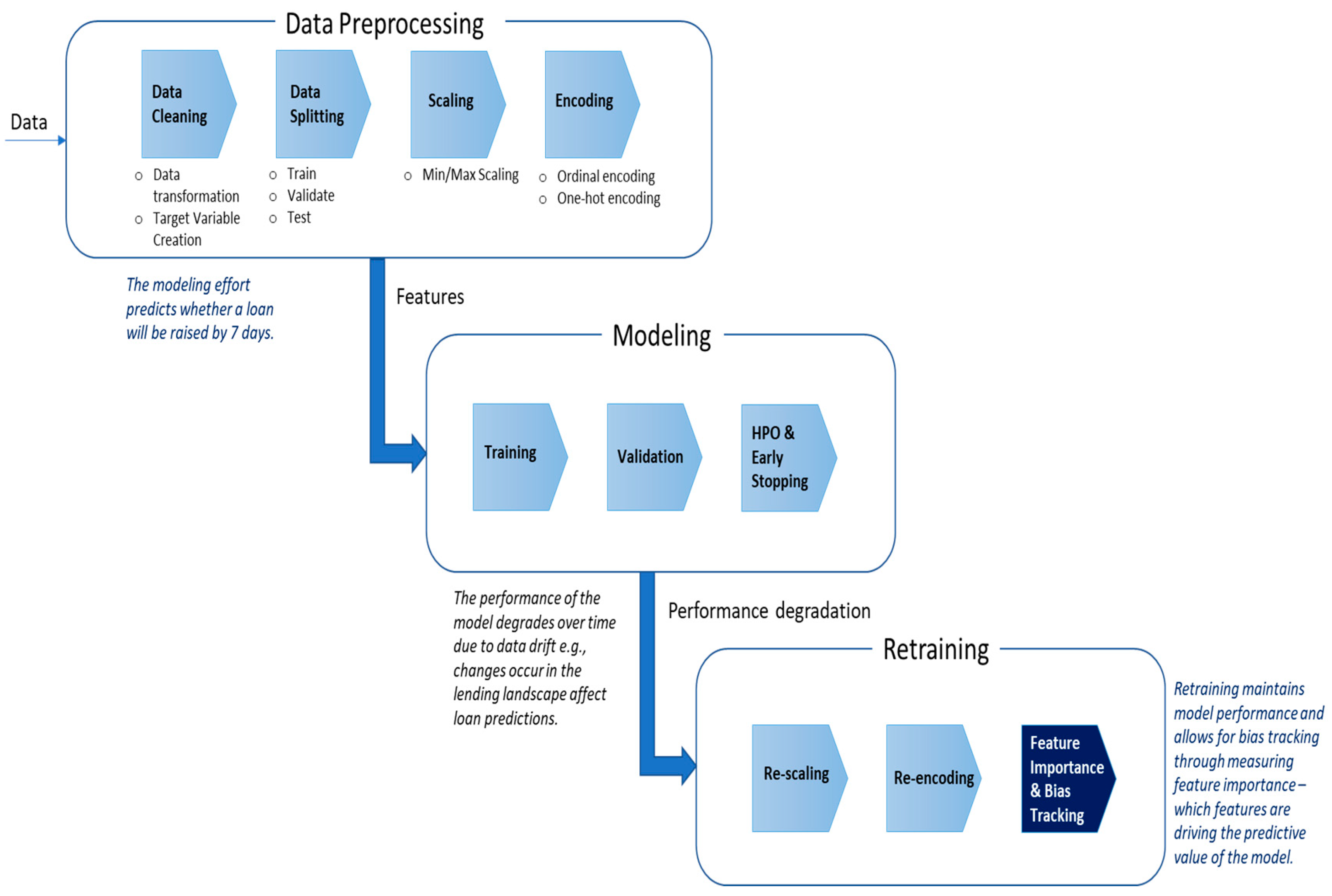
- Given the nature and range of values in Kiva’s raw data, preprocessing activities were performed to account for missing data, potential data quality issues, loans with multiple requestors, data attributes that were added to Kiva’s existing dataset since data inception, and changes in Kiva’s lending policies over time. To address some of this, data cleansing and formatting are applied to the loan dataset.
- (2)
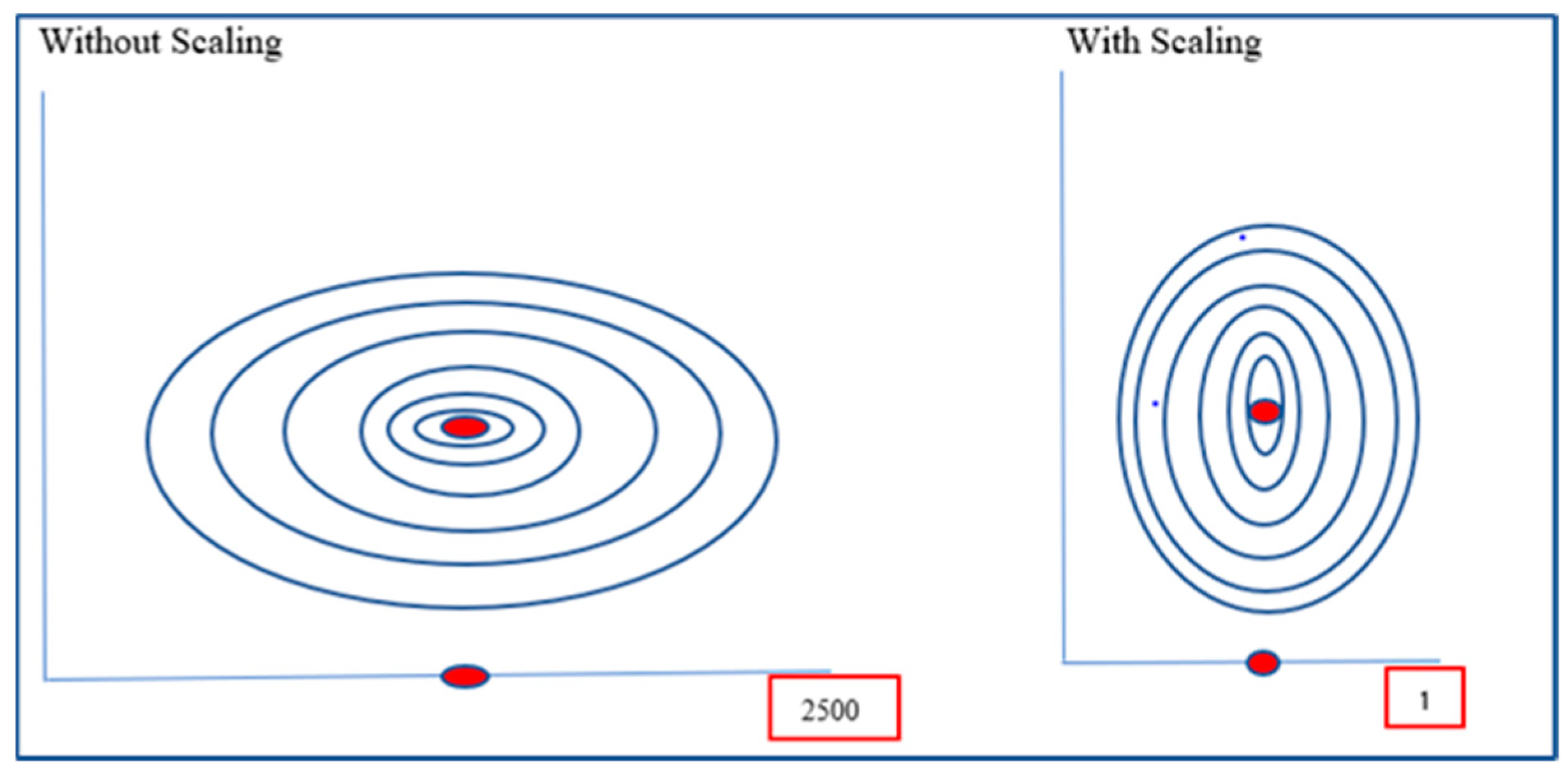
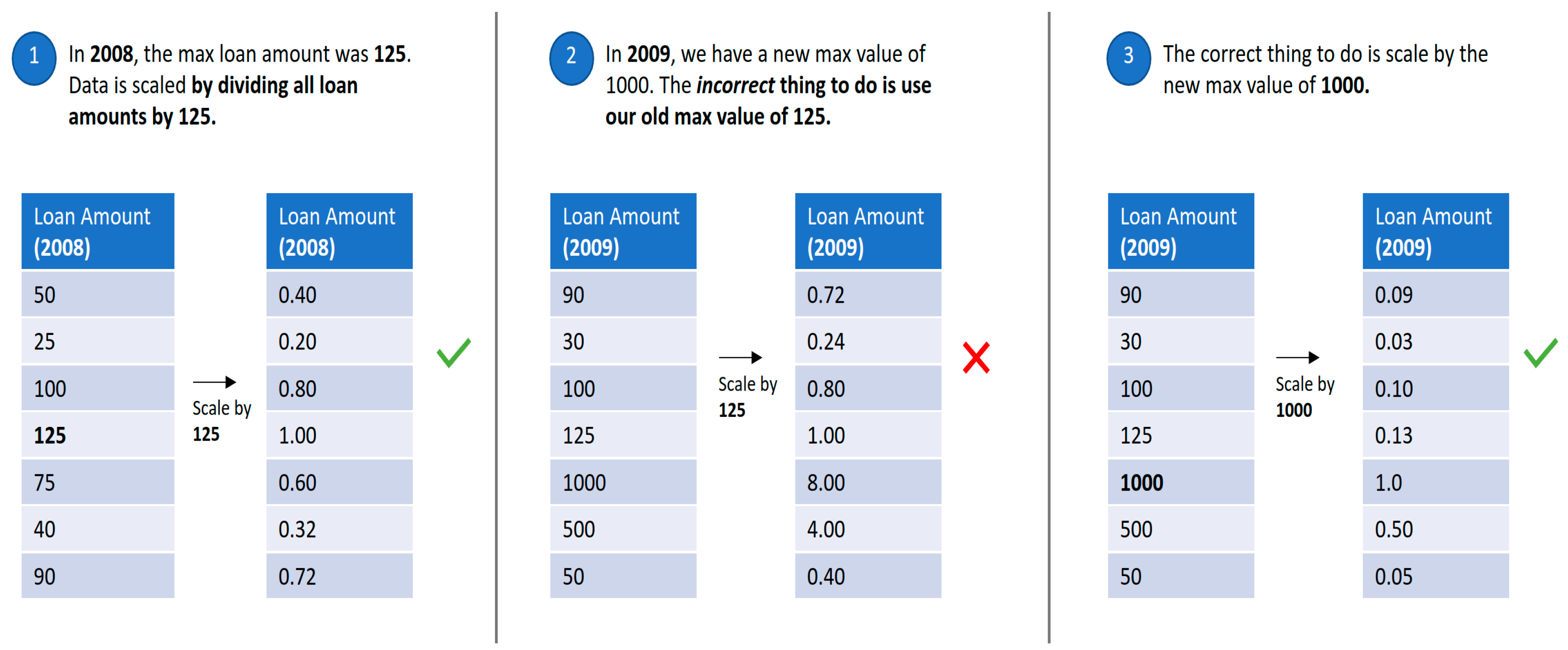
- Furthermore, several data attributes consist of continuous features that are on different scales, making this a critical area to address before we can apply machine learning techniques to reduce bias in the model. To address this, data scaling, as depicted in Figure 2 below, is performed to incorporate standardization. We also use encoding to transform our categorical/text data into numerical data given that most machine learning models can only interpret numerical data [26].
- (3)
- To create the target variable, “Posted Time Plus Seven Days”, the existing data attribute “Posted Time” is used, and 7 days is added to this value. To create the target variable “Raised by Seven Days”, we denote “True” or “False” depending on whether the existing attribute “Raised Time” is less than “Posted Time Plus Seven Days”. These calculations are important to get the model to ultimately predict if a loan will be funded in less than 7 days of it being posted.
- (4)
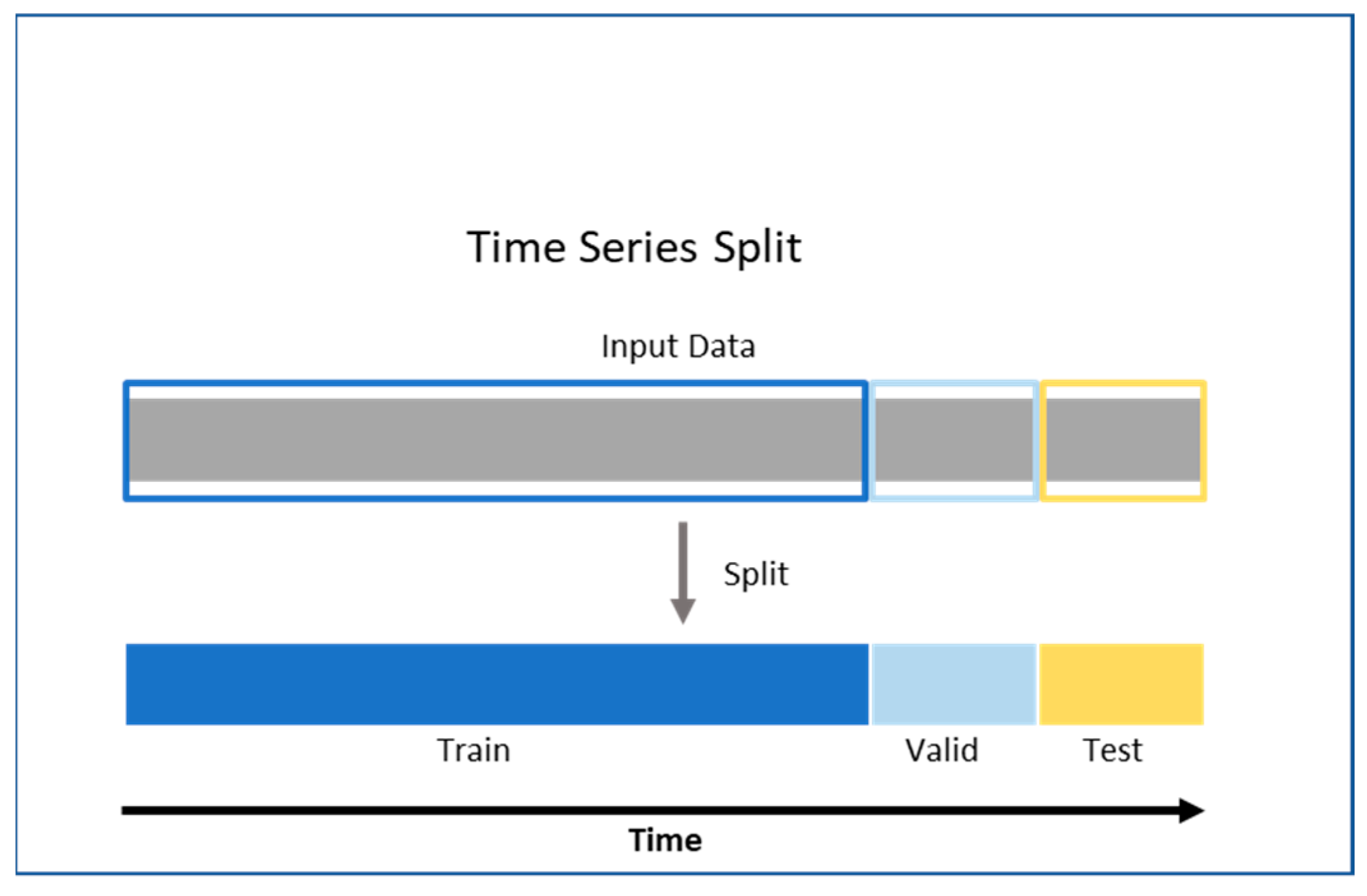
- As depicted in Figure 3 below, time-series data splitting [27] is performed where the following datasets are established:
- a.
- Training Set (2 months of data);
- b.
- Validation Set (one month of data);
- c.
- Test Set (one month of data).
- (5)
- To achieve better predictions, data transformations are conducted on several data attributes (e.g., Posted Time, Borrower Gender, Video ID, Image ID), and one hot encoding, another method used to convert categorical data into numerical data (binary features 0 and 1) for use in machine learning, is performed on several data attributes (e.g., Activity Name, Currency, Country Name, Partner ID) [28].
- (6)
- Mix Max Scaling is conducted on several data attributes to normalize our data (e.g., Loan Amount, Lender Term).
3. Results
3.1. Machine Learning to Predict
- (1)
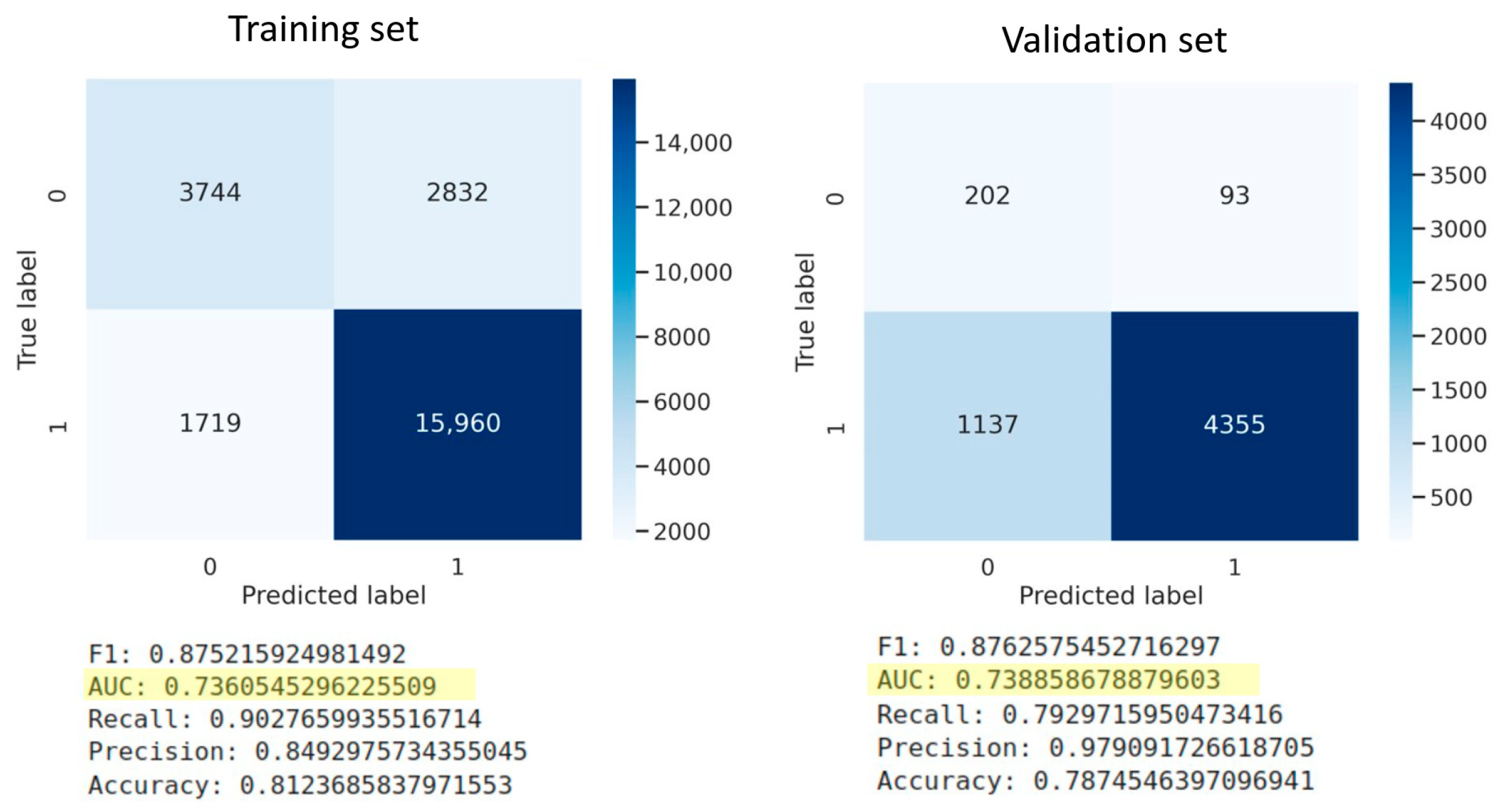
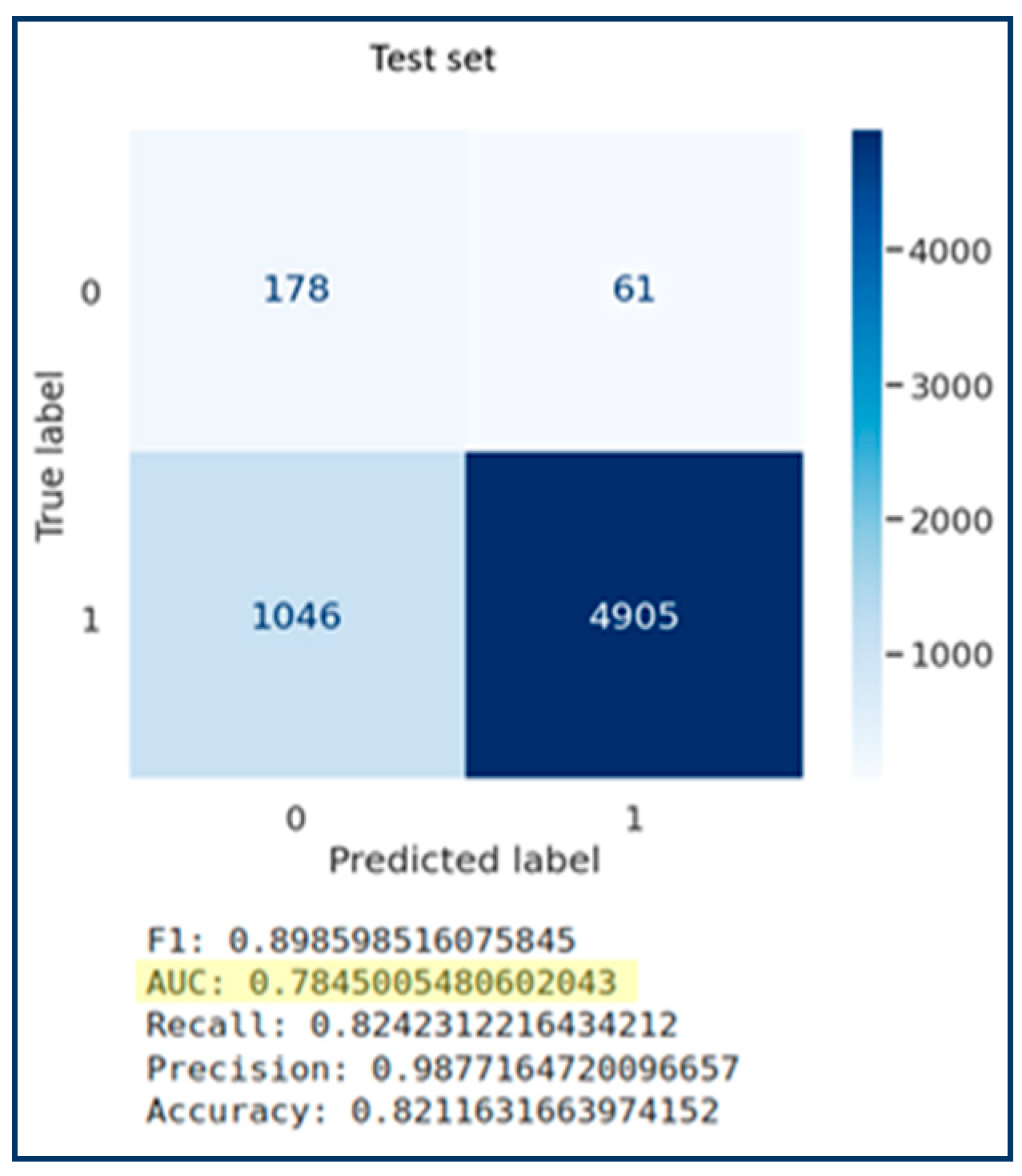
- Gradient Boosting, a technique leveraged for regression and classification analysis, is used in this research to build the desired predictive model, and reliance is placed on the Area Under the Curve (AUC) given by the equation (Percent Concordant + 0.5 * Percent Tied)/100 to evaluate the performance of the model. Table 1 below shows performance outcomes across the range of AUC values [29].
- (2)
- To improve model performance, Hyperparameter Optimization (HPO) is used, while model settings can take on very arbitrary amounts where one can try a number of combinations to determine those settings which give the best model performance. There are six techniques used to conduct HPO, which include manual search, random search, grid search, evolutionary algorithms, Bayesian optimization, and gradient-based methods.
- (3)
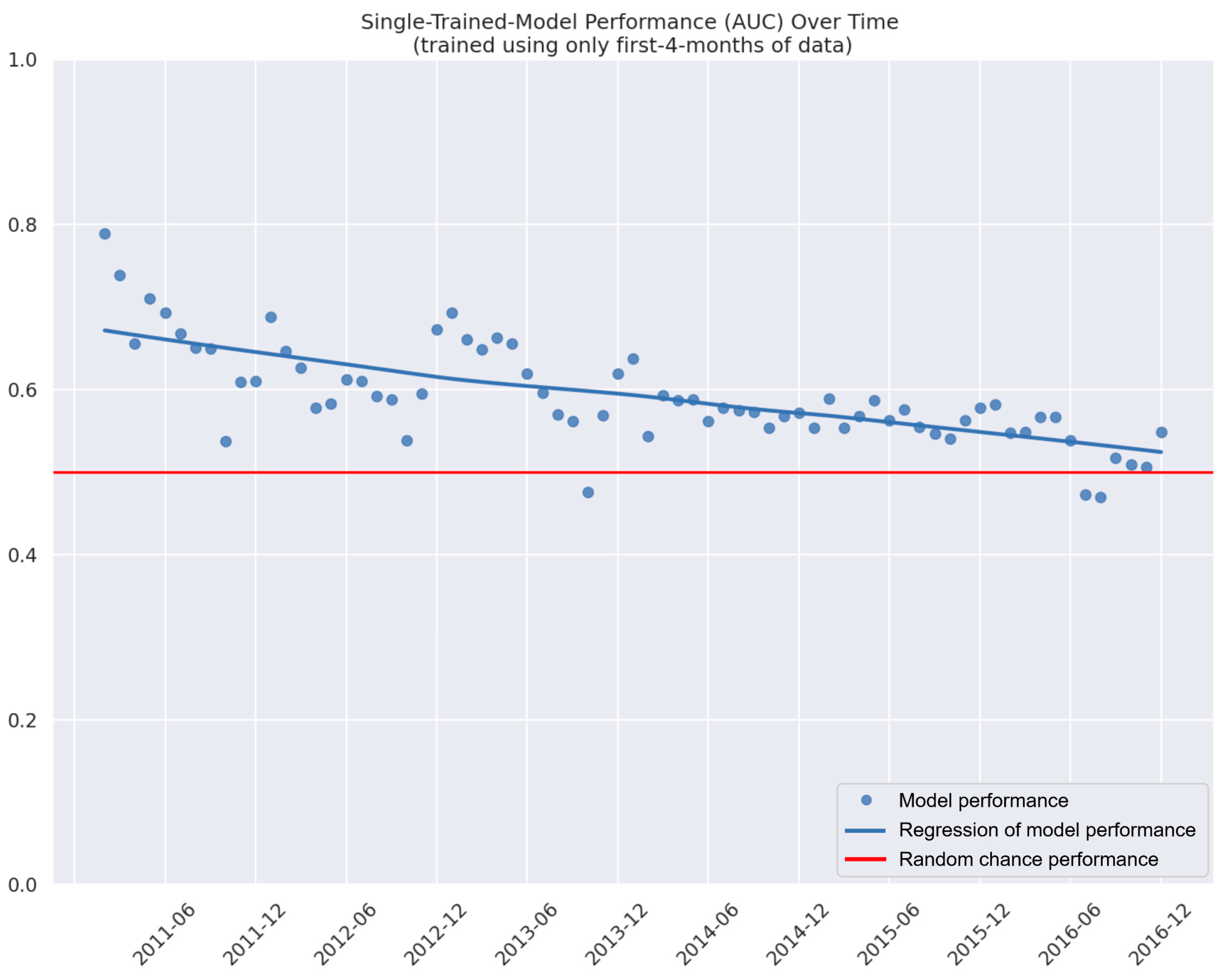
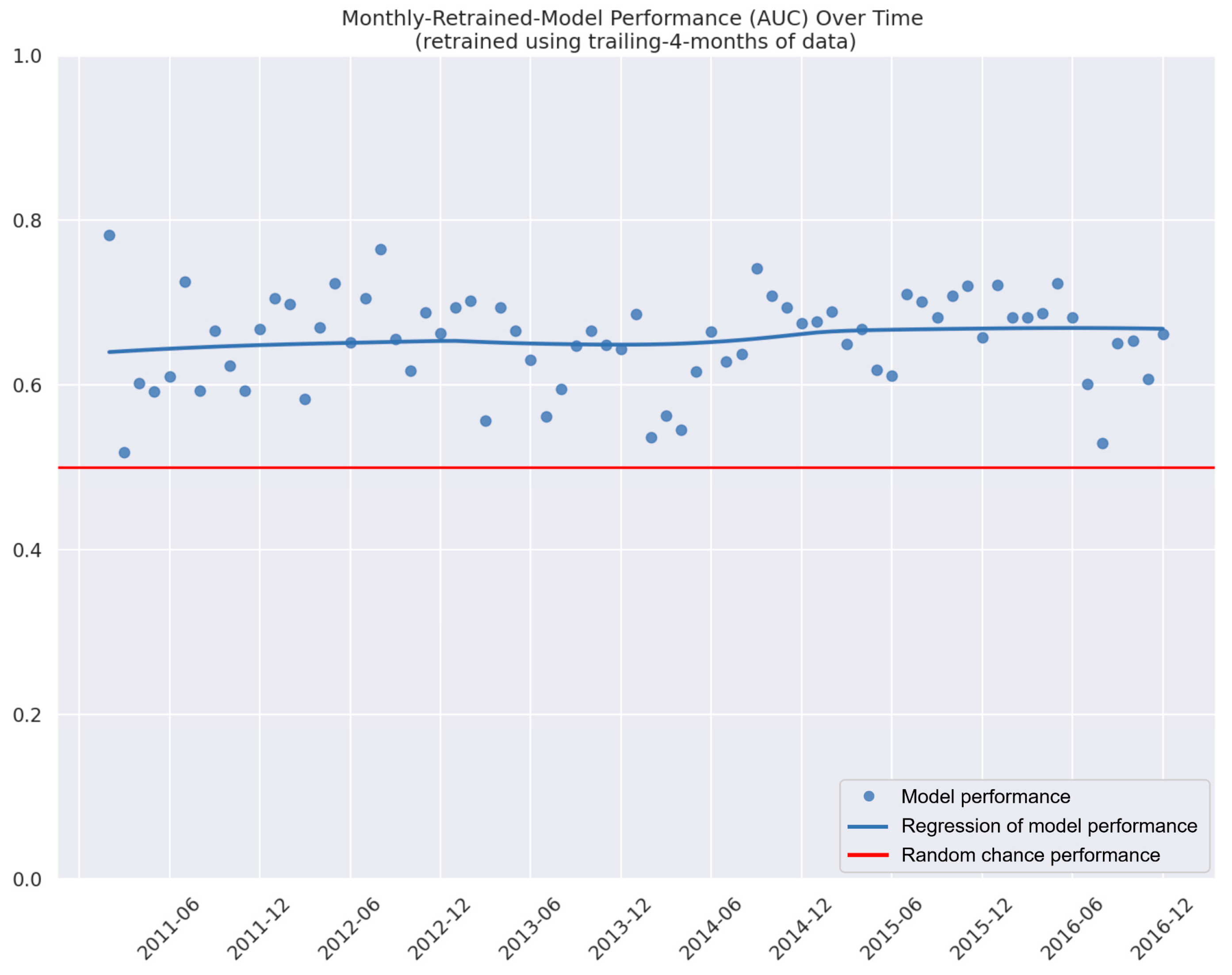
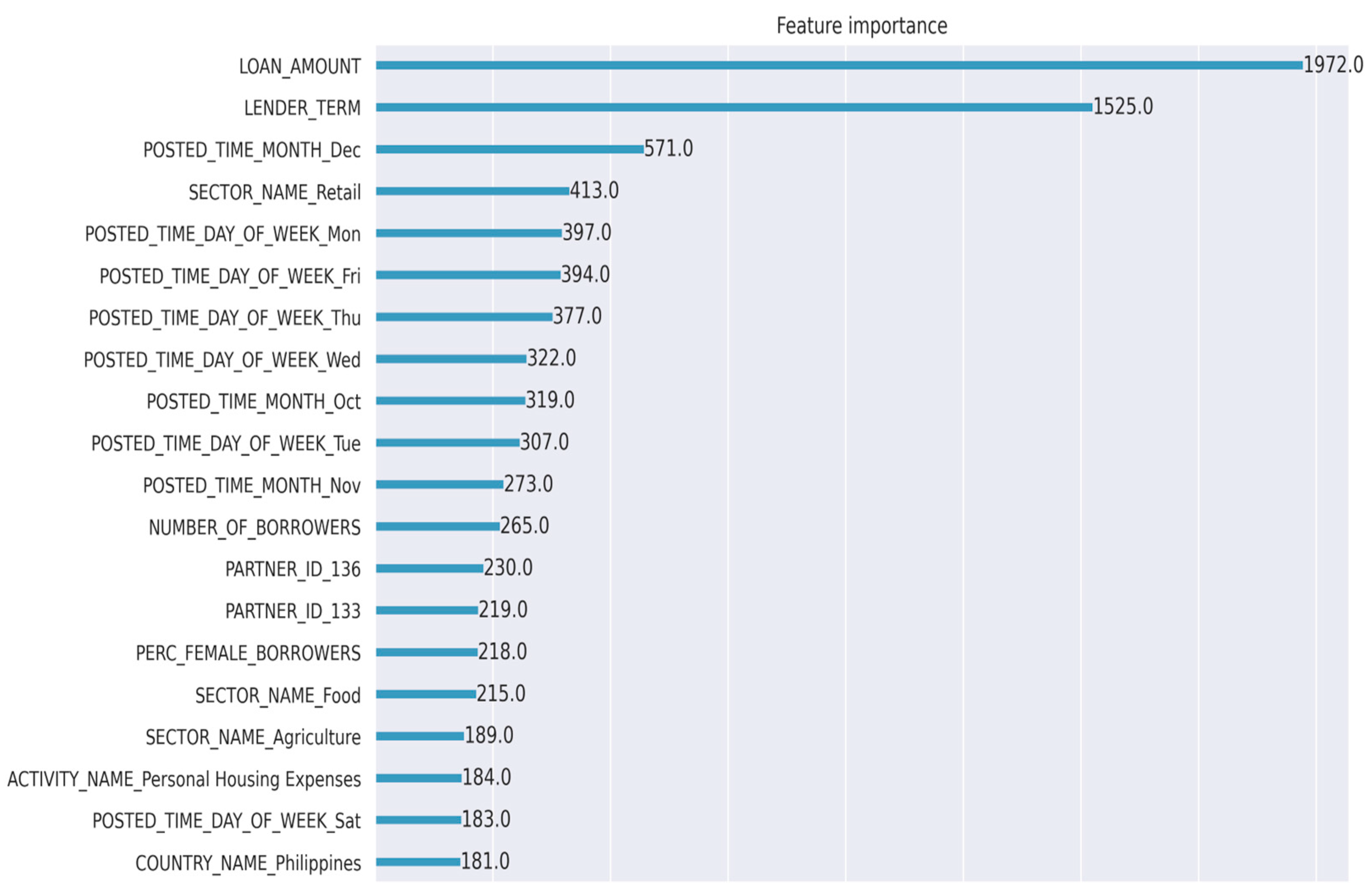
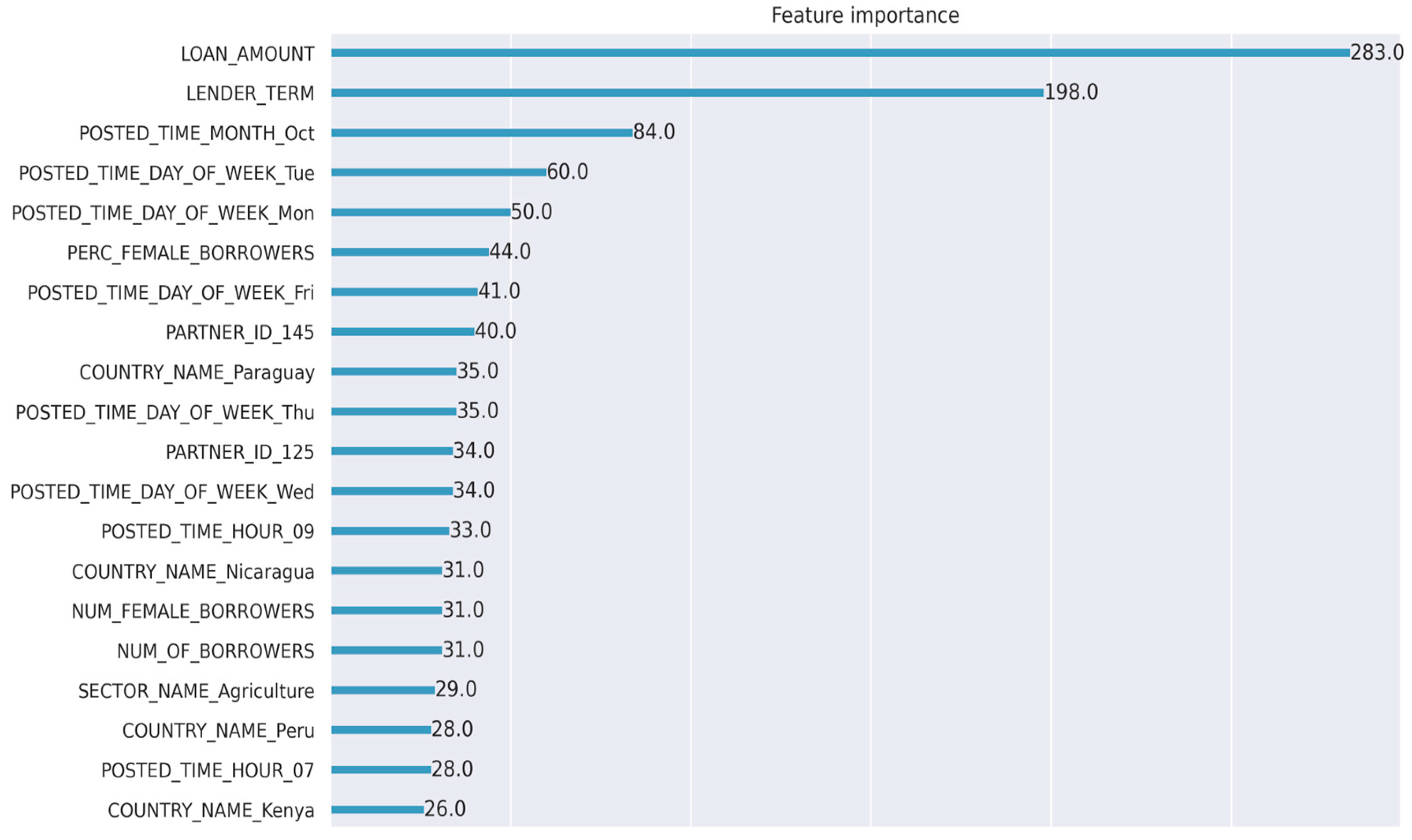
3.2. Model Retraining
4. Discussion
- (1)
- Are more loans being funded to men in any given month, and what attributes are highly correlated with men being funded a loan versus a woman being funded a loan?
- (2)
- Are more loans being funded quicker for a given sector, and what factors are causing those quick decisions (e.g., market trends, etc.)? What key attributes are highly correlated with a loan request not being funded?
- (3)
- In any given set of loan requests, how many are likely to be funded in 7, 10, or 20 days?
- (4)
- With the introduction of new data and/or policies, does re-training the model and model output highlight any risks or inconsistencies in achieving P2P lending expectations (e.g., does the number of funded loans suddenly decline)?
- (5)
- How is a company managing behavior biases in P2P lending, for example, familiarity bias, where a lender is likely to fund a borrower who shares a similar background, experiences, or ethnicity? How is feature importance contributing to potential bias?
- (a)
- AWS Clarify is an Amazon Web Services (AWS) machine learning (ML) service that streamlines the process of developing, training, and deploying correct computer vision models. It provides a collection of tools for data labeling, data management, and model training, as well as a suite of pre-built models, to let developers quickly design and deploy unique image and video analysis applications [30,31].Models that have already been built: Pre-built models for popular computer vision tasks such as object detection, semantic segmentation, and picture classification are available through AWS Clarify. These models are trained on large-scale datasets and can be tailored to specific use cases with custom data. Model deployment: AWS Clarify offers a simple deployment mechanism for models created using the service. Models can be deployed either on AWS or on premises [30,31].Developers can use AWS Clarify through following these steps:
- 1.
- Prepare the information: Collect and label the data used to train the model.
- 2.
- Train the model: On the labeled data, use AWS Clarify to train the model.
- 3.
- Examine the model: To determine the model’s accuracy, use the evaluation metrics offered by AWS Clarify.
- 4.
- Deploy the model: Deploy the model on AWS infrastructure or your servers.
- 5.
- AWS Clarify can be used for several tasks such as object detection, content moderation, and medical picture analysis.
- (b)
- (c)
- Developed by IBM, AI Fairness 360 is an open-source solution that can help detect and remove bias in large datasets and machine learning models and can be applied throughout the AI development lifecycle. This open-source Python solution is inclusive of several fairness metrics and bias mitigation algorithms that can be applied in many industries including the financial, talent and recruiting, healthcare, and law enforcement industries. The toolkit also provides a good amount of transparency and explainability around metrics and algorithms that can be applied to training data. IBM provides an on-demand user experience to explore these algorithms to gain an understanding of fairness and capabilities that can be leveraged to address bias, along with user guidance. [34]
5. Conclusions
- (1)
- How can a company (specifically in the peer-to-peer lending industry) monitor financial inclusion, given the wide range of investment opportunities to promote social responsibility, with the use of AI?
- (2)
- How can model retraining contribute to a risk management framework that helps detect issues including bias with social-impact-related investments?
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Netz, P.A.; Starr, F.W.; Stanley, H.E.; Barbosa, M.C. Static and dynamic properties of stretched water. J. Chem. Phys. 2001, 115, 344–348. [Google Scholar] [CrossRef] [Green Version]
- Robbins, T. Hedy Lamarr and a Secret Communication System; Capstone: North Mankato, MN, USA, 2007. [Google Scholar]
- Bernhardt, S.; Braun, P.; Thomason, J. (Eds.) Gender Inequality and the Potential for Change in Technology Fields; IGI Global: Hershey, PA, USA, 2018. [Google Scholar]
- Pathak, S.; Raees, S.A. Digital Innovation for Financial Inclusion: With reference to Indian Women Entrepreneurs. Annu. Res. J. Scms Pune 2023, 11, 29. [Google Scholar]
- Uddin, M.J.; Vizzari, G.; Bandini, S.; Imam, M.O. A case-based reasoning approach to rate microcredit borrower risk in online Kiva P2P lending model. Data Technol. Appl. 2018, 52, 58–83. [Google Scholar] [CrossRef]
- Tedeschi, C. The Social Impact of Crowdfunding and the Increasing Microlending Potential: The Case Study of Kiva. 2023. Available online: http://dspace.unive.it/bitstream/handle/10579/22991/883594-1264955.pdf?sequence=2 (accessed on 20 July 2023).
- Eccles, R.G.; Ioannou, I.; Serafeim, G. The impact of corporate sustainability on organizational processes and performance. Manag. Sci. 2014, 60, 2835–2857. [Google Scholar] [CrossRef] [Green Version]
- Grewal, J.S.; Rohatgi, P. Incorporating ESG factors in private equity investments: Opportunities and challenges. J. Appl. Financ. Bank. 2019, 9, 95–105. [Google Scholar]
- Eccles, R.G.; Serafeim, G.; Seth, D.; Ming, C.C.Y. The Performance Frontier: Innovating for a Sustainable Strategy: Interaction. Harv. Bus. Rev. 2013, 91, 17–18. [Google Scholar]
- Eccles, R.G.; Ioannou, I.; Serafeim, G. The impact of a corporate culture of sustainability on corporate behavior and performance. Natl. Bur. Econ. Res. 2012, 17950, 2835–2857. [Google Scholar] [CrossRef]
- Austin, T.; Rawal, B.S.; Diehl, A.; Cosme, J. AI for Equity: Unpacking Potential Human Bias in Decision Making in Higher Education. In AI, Computer Science and Robotics Technology; IntechOpen: London, UK, 2023. [Google Scholar]
- Chen, Y.; Guo, L.; Zhang, Y. A comparison of machine learning algorithms for crowdfunding success prediction. J. Bus. Res. 2019, 104, 23–34. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. Statistical Learning Theory; John Wiley & Sons: Hoboken, NJ, USA, 1998. [Google Scholar]
- Wang, B.; Wang, Y.; Chen, W.; Wu, J. Identifying influential backers in crowdfunding using Bayesian networks. Inf. Sci. 2016, 372, 78–94. [Google Scholar]
- Han, X.; Tang, Y.; Wang, Z. Optimal crowdfunding strategy based on reinforcement learning. IEEE Trans. Eng. Manag. 2020, 67, 843–855. [Google Scholar]
- Wang, L.; Wang, Y.; Zhao, X. Detecting fraudulent crowdfunding campaigns with deep learning. J. Bus. Res. 2020, 108, 186–198. [Google Scholar]
- Estrada, M.; Vargas-Quesada, B.; Chen, Z. Crowdfunding behavior modeling: An agent-based approach. J. Bus. Res. 2019, 100, 67–79. [Google Scholar]
- Cox, J.; Nguyen, T. Does the crowd mean business? An analysis of rewards-based crowdfunding as a source of finance for start-ups and small businesses. J. Small Bus. Enterp. Dev. 2018, 25, 147–162. [Google Scholar] [CrossRef] [Green Version]
- Anil, K.; Misra, A. Artificial intelligence in Peer-to-peer lending in India: A cross-case analysis. Int. J. Emerg. Mark. 2022, 17, 1085–1106. [Google Scholar] [CrossRef]
- Turiel, J.D.; Aste, T. Peer-to-peer loan acceptance and default prediction with artificial intelligence. R. Soc. Open Sci. 2020, 7, 191649. [Google Scholar] [CrossRef]
- Klimowicz, A.; Spirzewski, K. Concept of peer-to-peer lending and application of machine learning in credit scoring. J. Bank. Financ. Econ. 2021, 2, 25–55. [Google Scholar] [CrossRef]
- Niu, B.; Ren, J.; Zhao, A.; Li, X. Lender trust on the P2P lending: Analysis based on sentiment analysis of comment text. Sustainability 2020, 12, 3293. [Google Scholar] [CrossRef] [Green Version]
- Fitkov-Norris, E.; Vahid, S.; Hand, C. Evaluating the impact of categorical data encoding and scaling on neural network classification performance: The case of repeat consumption of identical cultural goods. In Proceedings of the Engineering Applications of Neural Networks: 13th International Conference, EANN 2012, London, UK, 20–23 September 2012; Proceedings 13. Springer: Berlin/Heidelberg, Germany, 2012; pp. 343–352. [Google Scholar]
- Cox, D.R. A note on data-splitting for the evaluation of significance levels. Biometrika 1975, 62, 441–444. [Google Scholar] [CrossRef]
- Jie, L.; Chen, J.; Zhang, X.; Zhou, Y.; Lin, J. One-hot encoding and convolutional neural network based anomaly detection. J. Tsinghua Univ. (Sci. Technol.) 2019, 59, 523–529. [Google Scholar]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef] [Green Version]
- AWS Clarify Documentation. Use Amazon SageMaker Clarify Bias Detection and Model Explainability—Amazon SageMaker. Available online: https://docs.aws.amazon.com/sagemaker/latest/dg/clarify-configure-processing-jobs.html (accessed on 25 April 2023).
- AWS Clarify Blog Post. Available online: https://aws.amazon.com/sagemaker/clarify/?sagemaker-data-wrangler-whats-new.sort-by=item.additionalFields.postDateTime&sagemaker-data-wrangler-whats-new.sort-order=desc (accessed on 25 April 2023).
- What-If Tool. Available online: https://pair-code.github.io/what-if-tool/ (accessed on 25 April 2023).
- Kazemi, S.M.; Goel, R.; Eghbali, S.; Ramanan, J.; Sahota, J.; Thakur, S.; Wu, S.; Smyth, C.; Poupart, P.; Brubaker, M. Time2Vec: Learning a Vector Representation of Time. arXiv 2017, arXiv:1907.05321. [Google Scholar]
- Bellamy, R.K.E.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilovic, A.; et al. AI Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 2019, 63, 4:1–4:15. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Area of Under the Curve (AUC) Values | Test Quality |
|---|---|
| 0.90–1.00 | Excellent |
| 0.80–0.90 | Very Good |
| 0.70–0.80 | Good |
| 0.60–0.70 | Satisfactory |
| 0.50–0.60 | Unsatisfactory |
| Algorithm | Time to Train (ms) | Inference Time | F1-Score | AUC | Recall | Precision | Accuracy |
|---|---|---|---|---|---|---|---|
| Linear Regression | 1020 | 98 | 0.974 | 0.5 | 1 | 0.948 | 0.948 |
| Logistic Regression | 4750 | 87 | 0.797 | 0.752 | 0.668 | 0.987 | 0.677 |
| K-Nearest Neighborhood | 151 | 16,300 | 0.854 | 0.618 | 0.766 | 0.964 | 0.751 |
| Multinomial Naive Bayes | 120 | 86 | 0.792 | 0.655 | 0.669 | 0.972 | 0.667 |
| Gradient Boosting | 1030 | 101 | 0.893 | 0.74 | 0.822 | 0.978 | 0.814 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Austin, T.; Rawal, B.S. Model Retraining: Predicting the Likelihood of Financial Inclusion in Kiva’s Peer-to-Peer Lending to Promote Social Impact. Algorithms 2023, 16, 363. https://doi.org/10.3390/a16080363
Austin T, Rawal BS. Model Retraining: Predicting the Likelihood of Financial Inclusion in Kiva’s Peer-to-Peer Lending to Promote Social Impact. Algorithms. 2023; 16(8):363. https://doi.org/10.3390/a16080363
Chicago/Turabian StyleAustin, Tasha, and Bharat S. Rawal. 2023. "Model Retraining: Predicting the Likelihood of Financial Inclusion in Kiva’s Peer-to-Peer Lending to Promote Social Impact" Algorithms 16, no. 8: 363. https://doi.org/10.3390/a16080363
APA StyleAustin, T., & Rawal, B. S. (2023). Model Retraining: Predicting the Likelihood of Financial Inclusion in Kiva’s Peer-to-Peer Lending to Promote Social Impact. Algorithms, 16(8), 363. https://doi.org/10.3390/a16080363