1. Introduction
In this paper, we present an algorithm for the symbolic software package Mathematica to compute the asymptotic Fisher information matrix for a multivariate time series, more precisely a controlled vector autoregressive moving average stationary process, or VARMAX process. There are several ways to obtain the Fisher information matrix for time series models. The most used procedure is computing the Hessian of the Gaussian log-likelihood when a model is fitted to the time series, usually after non-linear optimization (since the model is non-linear with respect to the parameters except for the pure VAR case), e.g., [
1]. Another much less used method consists of determining the exact (Gaussian) Fisher information, see [
2,
3,
4,
5,
6,
7,
8]. This is nice when the data are available but, as [
9] indicates, it can be useful to know the matrix at a tentative parameter point before obtaining the data, in order to determine the series length necessary to reach some specific accuracy for the estimators of the parameters. Then, an algorithm for the computation of the so-called asymptotic Fisher information matrix at a given parameter point is what is needed. It was provided in the form of an algebraic expression for a handful of small-order (1 or 2) ARMA models by Box and Jenkins in 1970, see [
10]. Otherwise, there is a vast literature for scalar models, i.e., simple ARMA models, e.g., [
11,
12], seasonal ARMA models [
13], ARMAX models [
14], single input single output models [
15], and for vector models, i.e., VARMA models [
16,
17] and VARMAX models [
18,
19].
We introduce a new algorithm well-suited to symbolic computation software packages (here Mathematica) and we present an illustrative example. Then, we discuss the invertibility of the Fisher information matrices and provide other examples.
The proposed algorithm differs from the works of Zadrovny [
3,
20], see also Zadrozny and Mittnick [
21], who developed their methods for VARMAX models, in the sense that they are based on an approximation of the exact Fisher information. Here, we follow Whittle’s approach [
22] of expressing the asymptotic information matrix by computing a circular integral of a rational function, related to the autoregressive and moving average operators. That was the way used by Newton for VARMA models, see [
16], with the difference that we make the effective computation and that we consider VARMAX models. The more fundamental source is [
19], who obtained an explicit expression for the Fisher information matrix of a VARMAX model under the form of a sum of two integrals while [
18] contains expressions for each element of that matrix. As a matter of fact, we first need to generalize [
19], which is developed for the special case where the number of explanatory variables equals the number of variables of interest and, moreover, the coefficient matrix at lag 0 is the identity matrix. These restrictions were explained by the revealed objective of the paper which was to exploit tensor Sylvester matrices and try to extend to VARMAX models the resultant property of the Fisher information matrix wrongly claimed for VARMA models by [
17]. Indeed, in [
17] (p. 1986), it is written “
[a] representation [based on tensor Sylvester matrices] is more appropriate …to prove a possible resultant property of the Fisher information matrix of a VARMAX process”. Such a tensor Sylvester matrix is associated with two matrix polynomials and it becomes singular if, and only if, the two matrix polynomials have at least one common eigenvalue, see [
23].
In [
17], it is said that the Fisher information matrix of a VARMA process becomes invertible if, and only if, the tensor Sylvester matrix is invertible, in other words, if, and only if, the autoregressive and moving average matrix polynomials of the VARMA process have no common eigenvalue. This is called the Sylvester resultant property. In [
17], the Sylvester resultant property is shown for a scalar ARMAX process but it is no longer true, in general, for other than scalar ARMA or ARMAX processes. Indeed, in [
24] Mélard indicated the error in the claim and explained why the example in [
17] was wrong. In the present paper, we correct the assertion stated in [
17] for VARMA processes, and we extend the “if” part to a class of VARMAX processes. As will be shown, the “only if” part of that result is, however, wrong when the dimension of the process is larger than 1. We will also compare our algorithms with other algorithms proposed for special cases in the literature. Although the results are less powerful, they are what is needed in practice: a sufficient condition of invertibility of the Fisher information matrix, indicating a possible lack of identifiability so that parameter estimation is risky. A necessary condition that should involve more information about the matrix polynomials is not as useful.
Consider the vector stochastic difference equation representation of a linear system of order
of the process
,
is the set of integers
where
, and
are, respectively, the
n-dimensional stochastic observed output, the
m-dimensional observed input, and the
n-dimensional unobserved errors, and where
,
,
,
, and
,
, are associated parameter matrices. We additionally assume
, the
identity matrix. We also assume that
is an invertible matrix. In the examples, we will sometimes take
fixed instead of being a matrix of parameters so that the maximum lag
is replaced by
r. Note that the absence of lag induced by (
1) is purely conventional. For example, a lagged effect of
on
can be produced by defining
. More precisely, we suppose that
is stochastic and that
is a Gaussian stochastic process. The error
is a sequence of independent zero-mean
n-dimensional Gaussian random variables with a strictly positive definite covariance matrix
. We denote this by
. We denote the transposition by
, the complex conjugate transposition by
, and the mathematical expectation is
. We assume
, for all
. We denote
z as the backward shift operator, for example,
. Then (
1) can be written as
where
are the associated matrix polynomials, where
(the duplicate use of
z as an operator and as a complex variable is usual in the signal and time series literature, e.g., [
25,
26,
27]). The assumptions det
for all
(causality) and det
for all
(invertibility) are imposed so that the eigenvalues of the matrix polynomials
and
will be outside the unit circle, see [
25]. Remind that the eigenvalues of an
matrix polynomial
are the roots of the equation det
(see [
28], p. 14). We will also use the reciprocal polynomial of
, with degree
d, say. It is
. If
is full-rank, there are
eigenvalues for
. The eigenvalues of
are the inverse of those of
, provided the missing eigenvalues of the former are treated as being at
∞.
Remark 1. Note that there are restrictions in the VARMAX model being considered. The dimensions of the unobserved errors and the observed output are the same. This is often the case in the literature, although [29], for example, consider a VARMA model where the dimension of the unobserved errors is smaller than that of the observed output. Except when we will mention the tensor Sylvester matrices, the dimensions of the observed input and the observed output need not be the same, like [7,18] but contrary to [19]. We store the VARMAX
coefficients in an
vector
defined as follows:
The vec operator transforms a matrix into a vector by stacking the columns of the matrix one underneath the other, according to vec
, see, e.g., [
30].
The observed input variable
is assumed to be a stationary
m-dimensional Gaussian VARMA process with white noise process
satisfying
and
where
and
are, respectively, the autoregressive and moving average matrix polynomials, such that
and det
far all
and det
for all
. The spectral density of process
is defined as, see, e.g., [
26]
where
i is the standard imaginary unit,
f is the frequency, the spectral density matrix
is Hermitian, and we further have,
and
. Therefore, there is at least one solution of (
1) which is stationary.
3. New Algorithm and Comparison with Other Algorithms
We propose an algorithm based on the method in the previous section and an implementation as a notebook for Mathematica. To make use of exact computations, the coefficients of the VARMAX model as well as
and
are entered as fractions, if possible. The algorithm is provided in
Figure 1 using some notations that are detailed here.
The arguments
are written
[z] for the polynomials. Given the polynomial matrices
,
, and
(hence denoted
A[z],
B[z], and
C[z], respectively, in
Figure 1), the vectors
,
, and
(denoted
up[z],
uq[z], and
ur[z], respectively), the zero matrices
and
(denoted
Orm$n and
Oqn$m, respectively), the identity matrices
and
(denoted
In and
Imm, respectively, noting that
Im is a locked symbol), plus
(denoted
Sigma[z]) and
(denoted
Rx[z]). Then, the block matrices
(
Gcal[z]) and
(
Kcal[z]), are computed using the
ArrayFlatten command of Mathematica, plus
KroneckerProduct and
Inverse, then
(
sigma[z]),
(
Pcal[z]), and
(
Qcal[z]) using also the
Transpose function. Since Mathematica does not treat well circular integrals, we transform them into line integrals between 0 and
by using the change of variable
,
, hence
. We compute the two transformed integrals of matrices using the command
Integrate and sum them up. Contrary to the computations in (Appendix B, [
7]), where individual formulas (taken from [
18]) were used for each element and computed using the Cauchy rule, here the (two) integrals of the whole matrices are computed symbolically. To simplify the expressions as much as possible as rational functions of
z, we use several times the commands
Together and also
Simplify. The algorithm is shown in
Figure 1 as a Mathematica notebook. The example is related to a VARMAX model used by [
31] and also used by [
32]. The model is defined by:
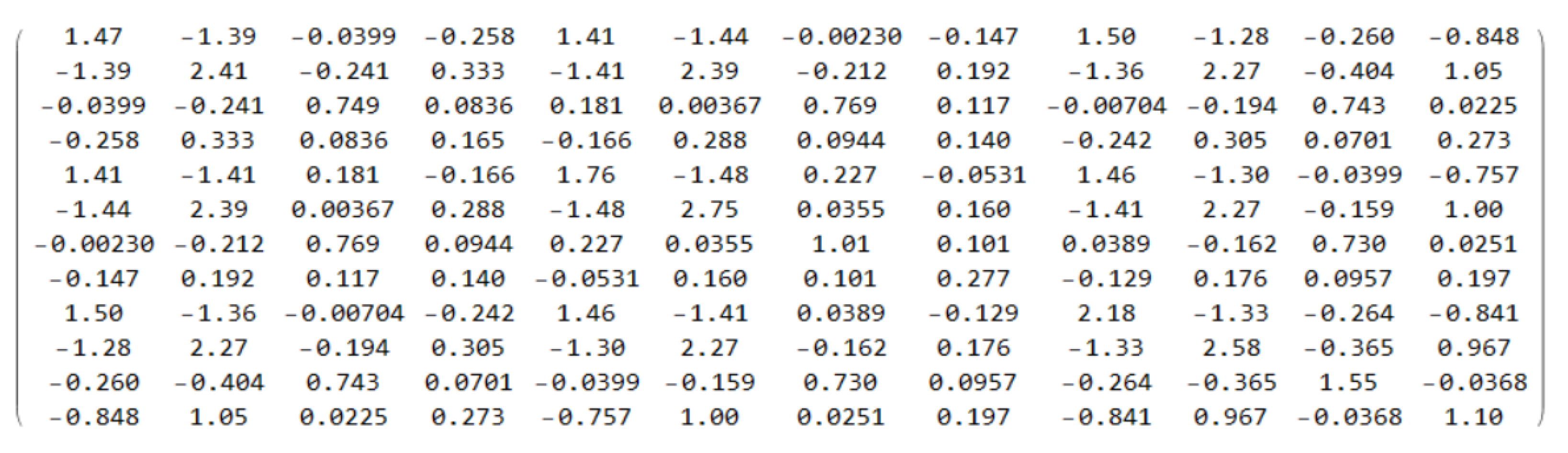
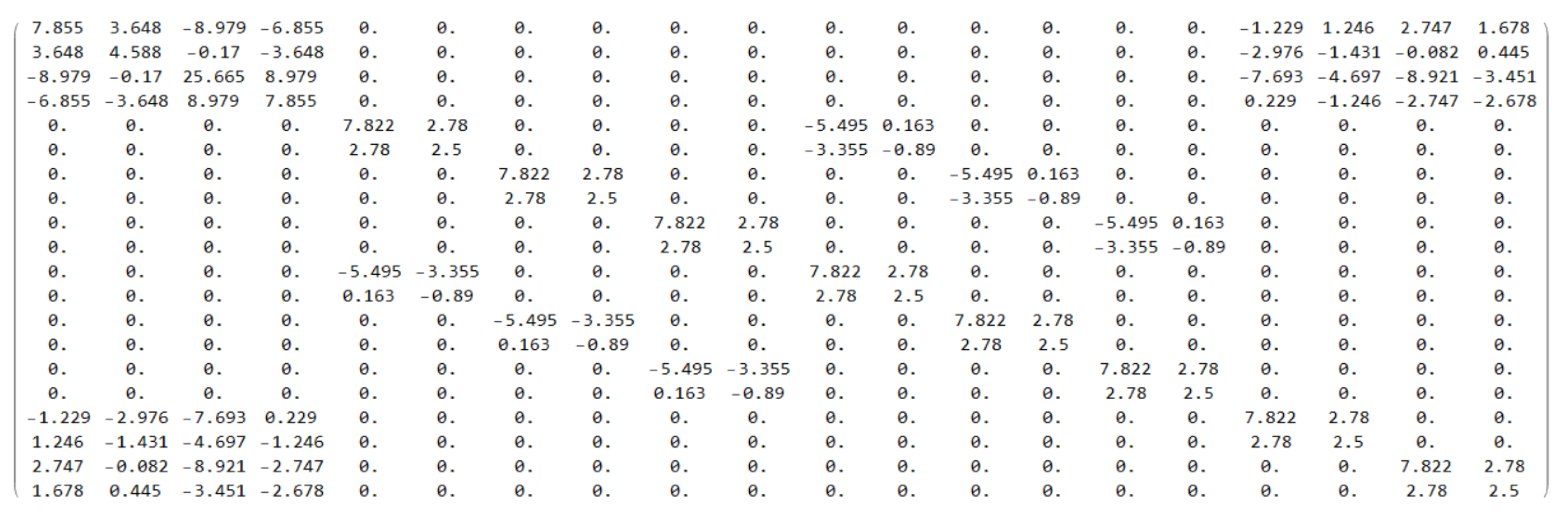
The coefficients are entered as fractions, hence
,
,
,
,
, and
. Part of the results are thus shown in
Figure 2,
Figure 3 and
Figure 4. It took about 7.2 min to produce the output. Making the computation using the numerical program described in [
32] on the same computer took 30 s but for one million evaluations.
Supplementary Materials Supplementary S1 contains the corresponding notebook (Figure1234.nb) that can be read using the free Wolfram’s CDF Player and its PDF copy (Figure1234.pdf). We will show and discuss other examples in the next Section. Note that we tried to implement the algorithm in two open-source packages for symbolic computation, Octave and Maxima. It is feasible because both programs allow us to integrate matrices but it appears that there is an error in the computation of the integrals being involved. We have informed the respective developers of the bug but the errors are not corrected yet.
Before showing other examples, let us look at other algorithms published in the literature. As said already, most of them are for the exact Fisher information, not the asymptotic Fisher information and we will not discuss them here, focusing instead on the asymptotic information matrix. Note that none of the existing algorithms is developed for VARMAX models, but only for VARMA or univariate models.
The first algorithm was due to Newton [
16] for VARMA models. It is based on [
22] who expressed the information matrix by a trigonometric integral involving the derivatives of the spectral density matrix of the process with respect to the parameters. The spectral density at frequency
f,
, of a VARMAX process, e.g., (
1) without the term
, is given by
. Newton [
16] does not indicate how to evaluate these matrix integrals that he obtained. It can be seen that the integrand of each element of these matrix integrals is a rational function of
. Furthermore, the condition of stationarity implies that the denominator has a factor with zeroes in the unit circle and zeroes outside of it. Peterka and Vidinčev [
33] have proposed an algorithm for evaluating circular integrals of a rational function around the unit circle and [
34] has proposed an implementation that consists of a series of reduction in the degrees of the involved polynomials. That method was used by [
12] for the evaluation of the Fisher information matrix of ARMA models.
A completely different early and effective method but restricted to ARMA models was proposed by Godolphin and Unwin [
11]. It makes use of simple matrix operations with the inversion of two matrices, one of order
p and one of order
q.
Another approach was proposed by [
35] which consists of replacing the computation of the integral by the evaluation of the cross-covariance of two ARMA processes based on the same white noise process, and this problem can be transformed in the computation of the autocovariance of a single AR process. There are excellent algorithms for that computation due to [
36,
37]. They require a number of operations which is quadratic in the AR order, much less than previous algorithms where a matrix of that order had to be inverted. The first algorithm was used by [
13] for the evaluation of the Fisher information matrix of seasonal ARMA models. Ref. [
38] have complained that several high-order AR models are sometimes involved and have proposed an alternative approach. Nevertheless, the algorithm making use of the autocovariances of an AR process using [
37] could be developed for SISO models [
15] and even for seasonal SISO models [
32]. For ARMAX models, ref. [
14] did not insist on algorithms but more on checking the invertibility of the Fisher information matrix, the subject of the next section. For ARMAX or SISO models, the Fisher information matrix is a sum of two integrals. The approach has however reached its limitations because the construction of the polynomials involved in the procedure becomes complex. For instance, the algorithm in [
32] made use of a table with letters identifying the regular polynomials (a to f) and the seasonal polynomials (A to F) among others (the constant and the regression coefficient) involved as numerators or denominators in the different integrals. For a VARMAX model, there are 3 polynomials, hence the information matrix is a
block matrix with, according to symmetry, 6 different blocks, including 1 corresponding to the parameters in the
where a sum of two integrals appears. A simple inspection of the expressions for the different blocks in [
18] reveals that obtaining the polynomials is a complex task.
4. A Sufficient Condition of Identifiability
The conditions for the identifiability of a VARMAX model have been studied by [
25], among others. They are repeated later. A clear indication of identifiability is the invertibility of the Fisher information matrix. In this section, we derive a sufficient condition of invertibility for the case where
and we enforce that the condition is not necessary, as could be deduced from the wrong arguments of [
17]. For an ARMAX model, i.e., when
, [
14] proved that a necessary and sufficient condition for invertibility of the Fisher information matrix is that the three polynomials have no common root. Indeed, as will be seen, the result of [
14] cannot be extended to vector processes.
We have already been reminded of the concepts of reciprocal polynomials and eigenvalues of matrix polynomials. There remains to define what are a unimodular polynomial matrix and the common left divisor of matrix polynomials, see, e.g., [
39].
A unimodular polynomial matrix is a polynomial square matrix such that its determinant is a non-zero constant, instead of being a polynomial in z. Consequently, is also a polynomial matrix. In general, the inverse of a square polynomial matrix is a matrix with rational elements, not polynomial elements.
Three matrix polynomials
,
, and
with the same number of rows
n have a common left divisor if there exist
polynomial matrices
,
,
, and
, such that
,
, and
. In matrix form, we can write
. Then
is called a right multiple of
. A left divisor
is called the greatest common left divisor of
if it is a right multiple of all left divisors. Multiplying a greatest common left divisor to the right by any unimodular polynomial matrix yields another greatest common left divisor. As indicated by (Section 2.2, [
25]), a greatest common left divisor can be constructed by elementary column operations: interchange any two columns, multiply any column by a real number different from 0, and add a polynomial multiple of any column to any column. Also, it corresponds to the right multiplication of
by an appropriate unimodular matrix. The concept can also be defined for rectangular matrices with the same number of rows although we will not consider that generalization.
Lemma 1. Assume that , , and have the prescribed degrees, respectively, p, q, and , with and , for z in the unit circle of , and is non-singular. Assume also that has an absolutely continuous spectrum with spectral-density non-zero on a set of positive measure on . Then a necessary and sufficient condition of identifiability of a stationary VARMAX process satisfying (1) is (i) , , and have as greatest common left divisor, (ii) the matrix has rank n. Proof. Since
is non-singular and given the assumptions on
and
, the conditions (8a), (8b), and (8c) of [
40] are satisfied for
, and the lemma is a special case of (Theorem 2, [
40]) in the case (iii)
. □
Since identifiability is equivalent to the inversibility of the Fisher information matrix, we are interested in finding a sufficient condition for identifiability. Equivalently, we are looking for a simple necessary condition for the lack of identifiability or the singularity of the Fisher information matrix, when .
We can state the following theorem.
Theorem 1. Under the assumptions of Lemma 1 and if , a sufficient condition of invertibility of the Fisher information matrix, , associated with the VARMAX model with the matrix polynomials , and of degree , respectively, is that the reciprocal matrix polynomials , , and have no common eigenvalue.
Proof. If the lack of identifiability occurs because (i) in Lemma 1 is not satisfied, that means that there exists a non-unimodular polynomial matrix
, i.e., with
different from a constant and matrices
,
, and
, such that
. Since the three polynomial matrices are square, we can consider their determinant stored in a row vector for which
where det
is a polynomial different from a constant. Hence, the equations det
, det
, and det
have at least one common root. Consequently, the matrix polynomials
,
, and
have at least one common eigenvalue. The same is also true for the reciprocal matrix polynomials
,
, and
.
Now, if the lack of identifiability occurs because (ii) in Lemma 1 is not satisfied, that means that the matrix has a rank strictly smaller than n. Consequently, row n, say, of that matrix is a linear combination of the other rows and the matrices , , and do not have full rank. Hence the determinants det, det, and det are polynomials of degree strictly smaller than, respectively, , , and . Each of the reciprocal matrix polynomials , , and have at least an eigenvalue equal to 0, hence at least one common eigenvalue. □
Note that [
17] has implicitly assumed that the determinants of
and
have their maximum degrees. For a discussion of identifiability without co-primeness, see [
41]. For VARMA models, Ref. [
24] has shown that it is not true to say, as [
17] did, that the conditions in Theorem 1 are also necessary for invertibility of the Fisher information matrix. The approach of [
17] used tensor Sylvester matrices which are a generalization of Sylvester matrices for the case of matrix polynomials instead of scalar polynomials. Consequently, the expectations of [
19] mentioned in the second paragraph of
Section 1 are not met for VARMAX models. Moreover, since there are three matrix polynomials and
does not need to be a square matrix, the tensor Sylvester matrices are not useful. It is also not useful to detail the alternative representations to (
6) developed in (Sections 2.4 to 2.7, [
19]) using the tensor Sylvester matrices. Let us just say that these representations seem to be correct in the sense that we have checked on all our examples for which
that the Fisher information matrix obtained using them is identical to what is obtained using (
7)–(
9).
6. Conclusions
In this paper, we have proposed for the first time an exact method to compute the asymptotic Fisher information matrix of VARMAX processes, an algorithm for symbolic computation software, and an implementation for Mathematica. It is based on an extension of the method proposed in [
19].
Therefore, we could not compare it with other algorithms in the general case. Nevertheless, we could compare it to the special case of an ARMAX process where there exists alternative algorithms.
The open-source packages Octave and Maxima should be able to do the job since their symbolic integration procedure can work on matrices of functions, but they do not work presently. More developments would be needed to circumvent their failing integration.
We also provide a simple sufficient condition of invertibility of the asymptotic Fisher information matrix and Example 3 shows that the condition is not necessary.
We did not examine the complexity of our algorithm because the concept is not well-established for symbolic computation. Let us just say that, at this stage, it will take much more running time, as seen in the special case discussed in
Section 3. For instance, the timings given for the ARMAX model of
Section 3 show that the numerical method is considerably faster. Also, the program implementing the algorithm relies on the capabilities of the symbolic computation package and possible hardware and software limitations. This is the price to pay for the ability to provide exact results, at least when the matrix entries are given as fractions, not as decimal numbers. We believe, however, that the fact that, when it works at least, the notebook that we have produced the result for an arbitrary VARMAX model.
We should conclude with possible extensions of our results. There have been papers on the asymptotic information matrix for extended models like ARMA models with periodic coefficients [
45,
46], state-space models [
46], Markov switching VARMA models [
47], or VARFIMA models [
48]. It is possible that the approach described in this paper can be extended to these extended models.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






