1. Introduction
Scheduling problems, in general, have been extensively studied across a wide range of domains due to their relevance for optimizing resource allocation, improving productivity, and reducing operational costs. Efficient scheduling has a direct impact on overall system performance, making it a critical area of research in operations management and industrial engineering. Flow-shop scheduling belongs to the broader class of multi-resource and multi-operation scheduling problems. With all its variants, it belongs to the class of NP-hard problems, which are known to have no polynomial time solution method. As a matter of course, small tasks or very special cases may be handled in reasonable time, but in general these problems are intractable. Obviously, the time complexity of finding a good solution in a shorter time may essentially effect the efficiency and the costs of real industrial and logistics applications. Alas, in such problems, the complexity increases exponentially in terms of the number of jobs, machines, and processing steps involved. Additionally, the presence of parallel machines and precedence constraints further complicates the optimization process. These challenges make it computationally infeasible to find optimal solutions for large-scale instances, necessitating the adoption of heuristic and metaheuristic methods. Apart from some exceptional cases, there are no explicit algorithms for finding the optimal permutation in multi-machine environments. Therefore, different heuristic approaches and evolutionary algorithms are used to calculate solutions that are close to the optimal solution. Evolutionary and population-based algorithms, inspired by the principles of natural selection and geneticsor by the behavior of groups of animals have demonstrated rather good efficiency at solving various optimization problems, including flow-shop scheduling.
In recent years, the field of metaheuristic algorithms has witnessed fast growing interest. After the “plain” evolutionary approaches, like the didactically important genetic algorithm (GA), a series of combines methods were proposed that increased the efficiency. An important step was Moscato et al.’s idea, the memetic algorithm family that applied traditional mathematical optimization techniques for local search while keeping the evolutionary method for global search where the former was nested in [
1]. This idea was further developed by our group; the concept was extended to discrete problems, and various simple graph theoretic and similar exhaustive optimization techniques were applied to local search [
2]. The advantage of this combination is that evolutionary techniques usually lead to good results but they are rather slow, while more classical optimization may be much faster; however, they tend to stick in local optima.
As a rather straightforward question, we started to investigate further combinations of nested search algorithms. As so far simulated annealing (SA) delivered rather good results, we did some tests with the discrete memetic algorithm we had proposed as “outer” search, and SA as “inner” search. Here, it is senseless to differentiate global and local search techniques as both heuristic algorithms could be directly applied as global searchers. Nevertheless, the result was rather promising [
3], and we found that the combined hybrid metaheuristic delivered in most benchmark cases was a better approximation than either of the two, without combination.
We continued these investigations and found that the development of hybrid algorithms combining multiple optimization techniques leverages the components’ individual strengths and mitigates their weaknesses. Earlier, we established some results proving that memetic algorithms have gained prominence for their ability to incorporate problem-specific local search procedures into the evolutionary search process [
4]. Even though those comparisons between various evolutionary approaches and their memetic extensions were tested on continuous benchmarks, the efficiency of the memetic extension of the bacterial evolutionary algorithm [
5] presented clear advantages compared to the original GA and even compared to the rather successful particle swarm optimization, but especially the memetic extension of each proved to be much better for medium and large instances of the benchmarks.
This integration of global and local search allows for a more robust exploration of the solution space and improves the speed of finding high-quality solutions reducing the likelihood of premature convergence to local optima. As mentioned above, the term memetic algorithm was first introduced by Moscato et al. drawing inspiration from some Darwinian principles of natural evolution and Richard Dawkins’ meme concept [
6]. The memes are ideas—messages broadcasted throughout the whole population via a process that, in the broad sense, can be called imitation.
The no-free-lunch theorem states that any search strategy performs the same when averaged over the set of all optimization problems [
7]. If an algorithm outperforms another on some problems, then the latter one must outperform the former one on others. General purpose global search algorithms like most evolutionary algorithms perform well on a wide range of optimization problems, but they may not approximate the performance of highly specialized algorithms specially designed for a given problem. Nevertheless, the no-free-lunch principle is only true in an approximate sense. In [
8], we showed that under certain conditions the balance of speed and accuracy my be optimised, and it is not to be excluded that such optima always, or at least often, exist. Some general ideas concerning this balance were given in [
9]. Nevertheless, the insight of balanced advantages and disadvantages leads directly to the recommendation to extend generally (globally) applicable metaheuristics with classical application-specific (locally optimal) methods, or even heuristics, leading to more efficient problem solvers, an observation that fits well with the basic concept of applying memetic and hybrid heuristic algorithms.
Above, the GA was mentioned. The bacterial evolutionary algorithm (BEA) may be considered as its further development, where some of the operators have been changed in a way inspired by the reproduction of bacteria [
10], and so the algorithm became faster and produced unambiguously better approximations [
4].
Let us provide an overview of the basic algorithm. As mentioned above, the BEA model replicates the process of bacterial gene crossing as seen in the nature. This process has two essential operations: bacterial mutation and gene transfer. At the start of the algorithm, an initial random population is generated, where each bacterium represents a candidate for the solution in an encoded form. The new generation is created by using the two operations mentioned above. The individual bacteria from the second generation onward are ranked according to an objective function. Some bacteria are terminated, and some are prioritized based on their traits. This process is repeated until the termination criteria are met.
Its memetic version was first applied for continuous optimization [
11]. This was an extension of the original memetic algorithm to the class of bacterial evolutionary approaches, where the BEA replaced the GA. Various benchmark tests proved that the algorithm was very effective for many other application domains for optimization tasks. Several examples showed that the BEA could be applied in various fields with success, for example, timetable creation problems, automatic data clustering [
12], and determining optimal 3D structures [
13] as well. The first implementations of the bacterial memetic evolutionary algorithms (BMEA) were used for finding the optimal parameters of fuzzy rule-based systems. The BMEA was later successfully extended also to discrete problems, like, among others, the flow-shop scheduling problem itself, produced considerably better efficiency for some problems. A novel hybrid algorithm version with a BEA wrapper and nested SA showed remarkably good results on numerous benchmarks [
3].
As discussed above, initially, the combination of bacterial evolutionary algorithms with local search methods was proposed only for the very special aim of increasing the ability to find the optimal estimation of fuzzy rules. In the original BEA paper, mechanical, chemical, and electrical engineering problems were presented as benchmark applications. In addition, a fascinating mathematical research field, namely, solving transcendental functions, completed the list of first applications. In the first version of BMEA, where the local search method applied was the second-order gradient method, the Levenberg-Marquard [
14] algorithm was tested on all these benchmarks.
The benchmark tests with the BMEA obtained better results than any former ones in the literature and outscored all other approaches used to estimate the parameters of the trapezoidal fuzzy membership functions [
15]. Later, first-order gradient-based algorithms were also investigated as local search, which seemed promising [
11].
In the next, the idea of BMEA was extended towards discrete problems, where gradient-based local search was replaced by traditional discrete optimization, such as exhaustive search, inbounded sub-graphs. This new family of algorithms was named discrete bacterial memetic evolutionary algorithms (DBMEA). DBMEA algorithms were first tested on vairous extensions of the travelling salesman problem and produced rather promising results. DBMEA algorithms have also been investigated on discrete permutation-based problems, where the local search methods were matching bounded discrete optimization techniques.
In a GA-based discrete memetic type approach,
n-opt local search algorithms were suggested by Yamada et al. [
16]. The investigations with simulations reduced the algorithms to the consecutive running 2-opt and 3-opt methods. In the case of
, the computational time was too high, thus limiting the pragmatical usability of the algorithm. The 2-opt algorithm was first applied to solve various routing problems [
17], where in the bounded sub-graph, two graph edges were always swapped in the local search phase. It is worth noting that 3-opt [
18] is similar to the 2-opt operator; here, three edges are always deleted and replaced in a single step, which results in seven different ways to reconnect the graph, in order to find the local optimum.
In this research, another class of discrete optimization problems, the flow-shop, came to focus. Thus, in the next
Section 2, the paper will give a detailed explanation of the flow-shop scheduling problem.
Section 3 is a detailed survey of commonly used classic and state-of-the-art algorithms. The algorithms used by the novel HDBMEA algorithm proposed in this paper will be detailed in
Section 4,
Section 5 and
Section 6.
Section 7 deals with the results from the Taillard flow-shop benchmark set and with the comparison to relevant algorithms selected from
Section 3.
Section 8 extensively analyses each parameter’s impact on the HDBMEA algorithm’s scheduling performance and run-time. The result of our analysis is a chosen parameter set with which we prove the abilities of our proposed algorithm.
2. The Flow-Shop Problem
Flow-shop scheduling for manufacturing is a production planning and control technique used to optimize the sequence of operations that each job must undergo in a manufacturing facility. In a flow-shop environment, multiple machines are arranged in a specific order, and each job must pass through the same sequence of operations on these machines. The objective of flow-shop scheduling is to minimize the total time required to complete all jobs (makespan) or to achieve other performance measures such as minimizing the total completion time, total tardiness, or maximizing resource utilization. The storage buffer between machines is considered to be infinite. If the manufactured products are small in physical size, it is often easy to store them in large quantities between operations [
19]. Permutation flow shop is a specific type of flow-shop scheduling problem in manufacturing where a set of jobs must undergo a predetermined sequence of operations on a series of machines. In the permutation flow shop, the order of operations for each job remains fixed throughout the entire manufacturing process. However, the order in which the jobs are processed on the machines can vary, resulting in different permutations of jobs [
20].
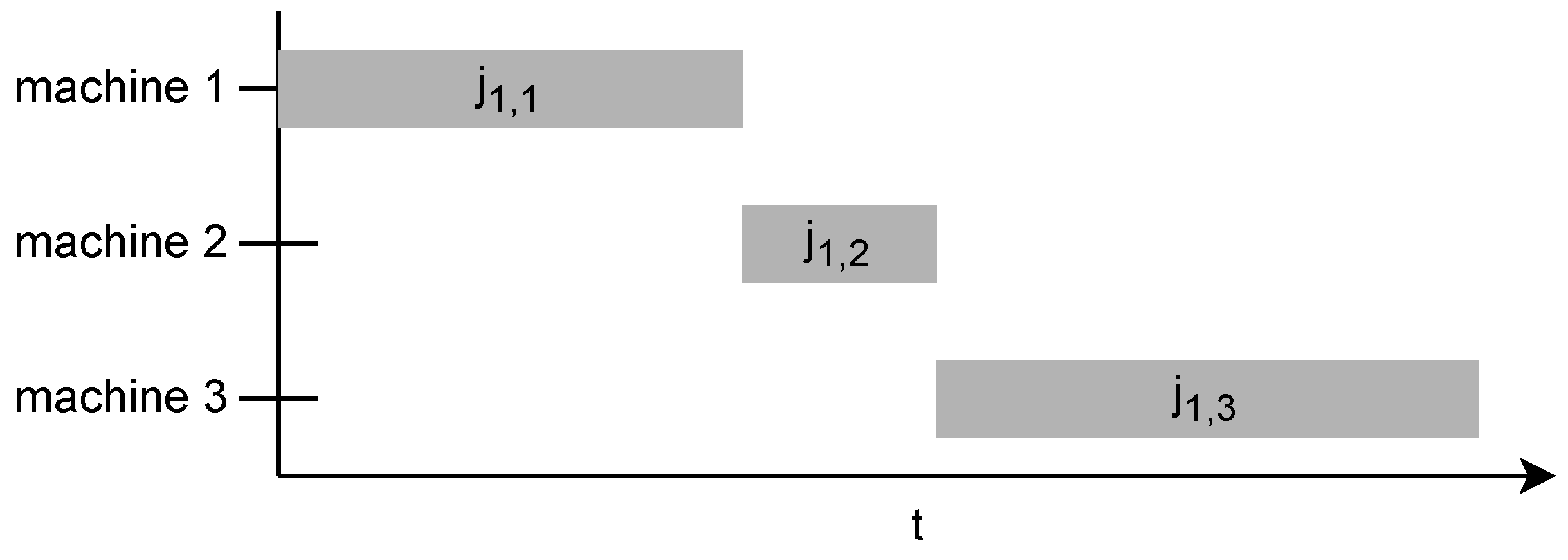
Consider a flow-shop environment, where denotes the number of jobs and is the number of resources (machines). A given permutation , where i is the index of the job, represents the processing times, is the rth resource in the manufacturing line, is the starting times of job on machine r, and is the completion time of job on resource r, has the following constraints:
A resource can only process one job at a time; therefore, the start time of the next job must be equal to or greater than the completion time of its predecessor on the same resource:
A job can only be present on one resource at a given time; therefore, the start time of the same job on the next resource must be greater then or equal to the completion time of its preceding operation:
The first scheduled job does not have to wait for other jobs and is available from the start. The completion time of the first job on the current machine is the sum of its previous operations on preceding machines in the chain and its processing time on the current machine:
Figure 1 shows how the first scheduled job has only one contingency: its own operations on previous machines.
Jobs on the first resource are only contingent on jobs on the same resource; therefore, the completion time of the job is the sum of the processing times of previously scheduled jobs and its own processing time:
Figure 2 shows how there is only on contingency on the first machine; therefore, operations can follow each other without downtime.
When it comes to subsequent jobs on subsequent machines, (
) the completion times depend on the same job on previous machines (Equation (
2)) and previously scheduled jobs on previous machines in the chain (Equation (
1)):
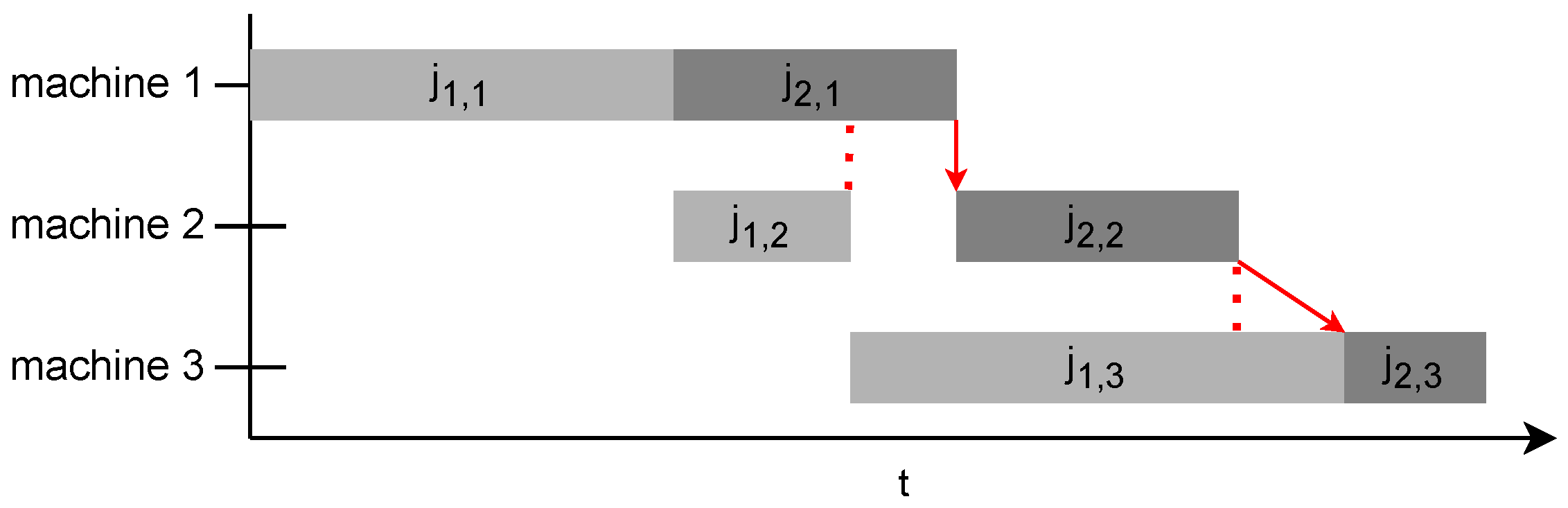
Figure 3 shows the contingency of jobs.
is contingent upon
and
, where it has to wait for
to finish despite the availability of machine 2.
is contingent upon
and
, where it has to wait for machine 3 to become available despite being completed on machine 2.
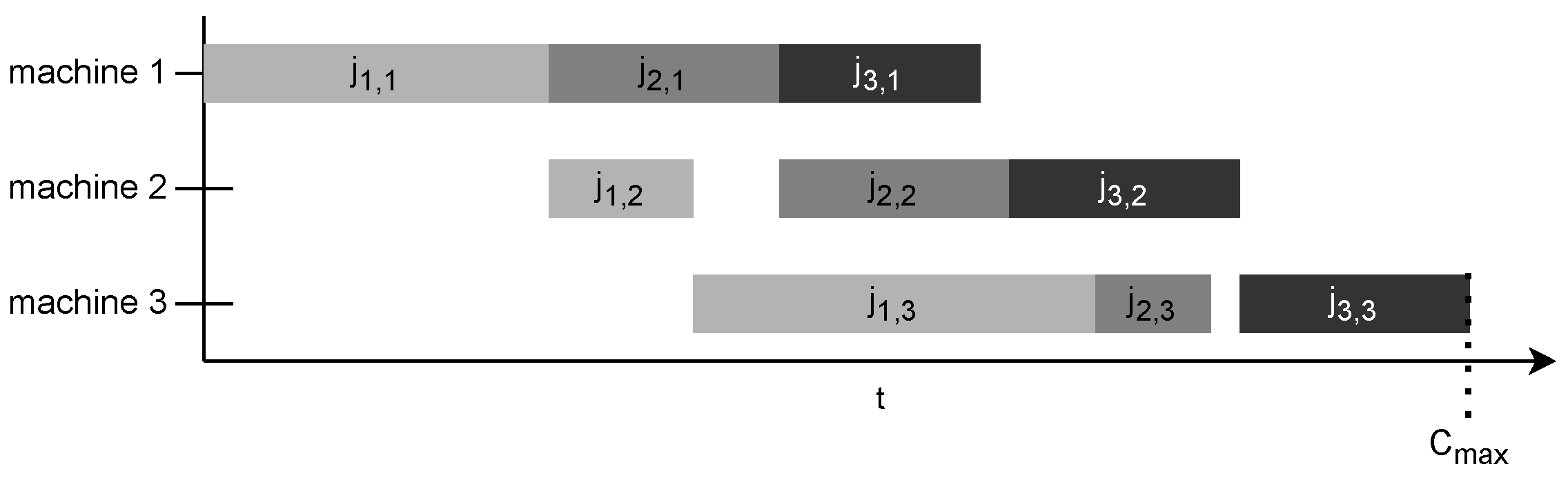
The completion time of the last job on the last resource is to be minimized and is called the makespan.
One of the most widely used objective function is to minimize the makespan:
Figure 4 illustrates how the completion time of the last scheduled job on the last machine in the manufacturing chain determines the makespan.
8. Parameter Sensitivity Analysis
Since the proposed HDBMEA algorithm contains three distinct search algorithms, the number of parameters adds up to eleven. The determination of each parameter must be backed by an analysis. A subset of the Taillard benchmark set was used, where the number of machines and jobs equals twenty, to visualize the impact of each parameter on the overall scheduling performance and runtime. Each of the ten instances was run ten times for each parameter set (100 runs total). We considered the mean and standard deviation. The formula for obtaining the quality of each solution is detailed in Equation (
11).
Each plot shows the overall set of values obtained (light blue ribbon), the standard deviation (mid-blue ribbon), and the mean of all runs (dark blue line). Plots showing the change in standard deviation are also included. These plots confirm our chosen set of parameters for the final benchmark results.
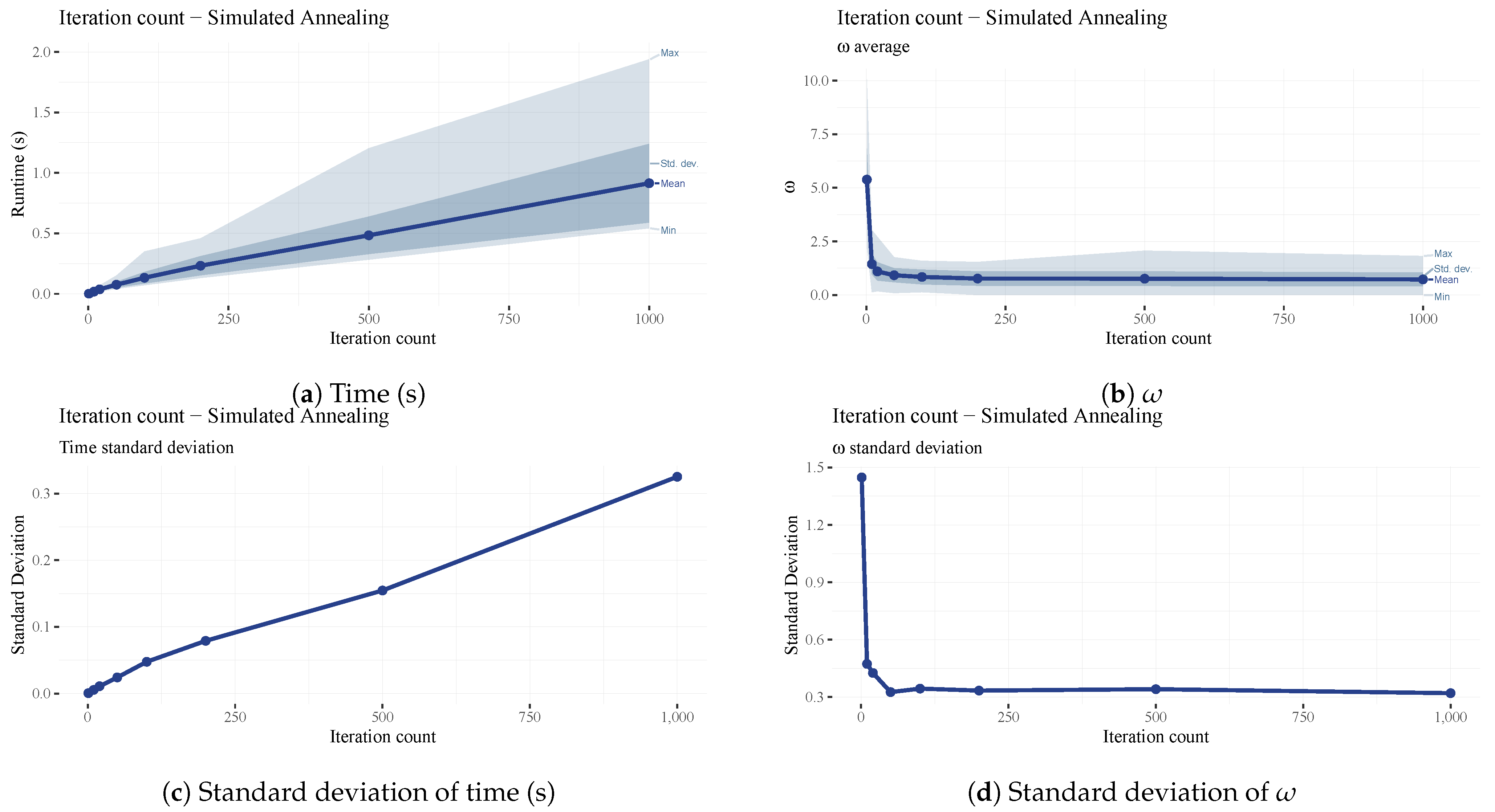
The iteration count of the simulated annealing algorithm is the maximum number of iterations since the last improvement in the makespan. This parameter dramatically impacts the results and runtime and their standard deviation (See
Figure 11). The omega and standard deviation decrease dramatically until our chosen iteration count of 100 (see
Figure 11b and
Figure 12d), after which the improvements are negligible while the runtime keeps increasing linearly (See
Figure 11a).
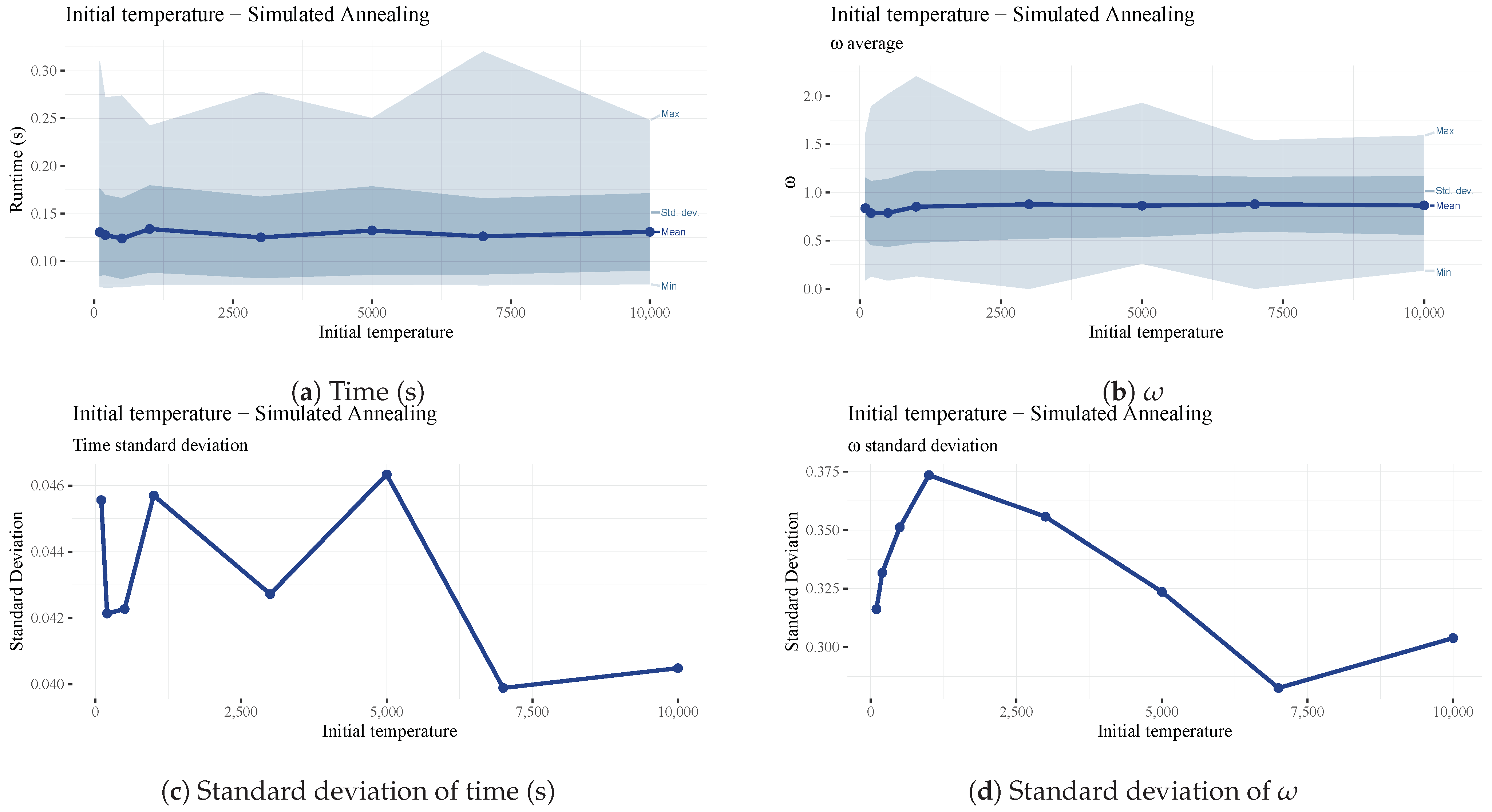
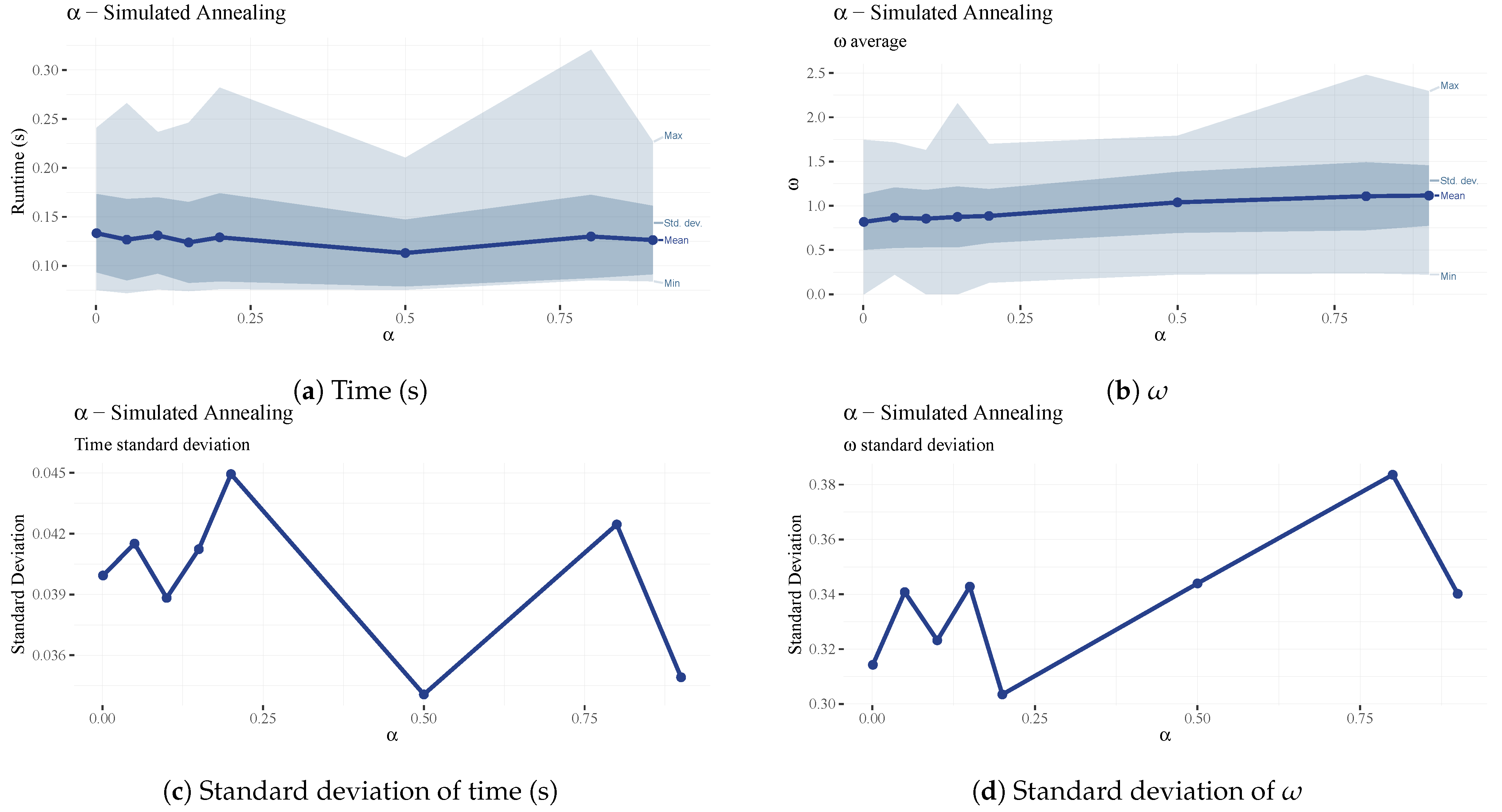
The starting temperature for the simulated annealing algorithm has little impact on the results and runtime (
Figure 12); however, there is a slight dip in
at the 300 mark (See
Figure 12b), which is our chosen final value.
The
parameter of the simulated annealing algorithm is the temperature decrease in each iteration. This method creates an exponential multiplicative cooling strategy, which was proposed by Kirpatrick et al. [
68], and the effects of which are considered in [
69]. The parameter did not significantly affect the overall performance of the algorithm, however (
Figure 13).
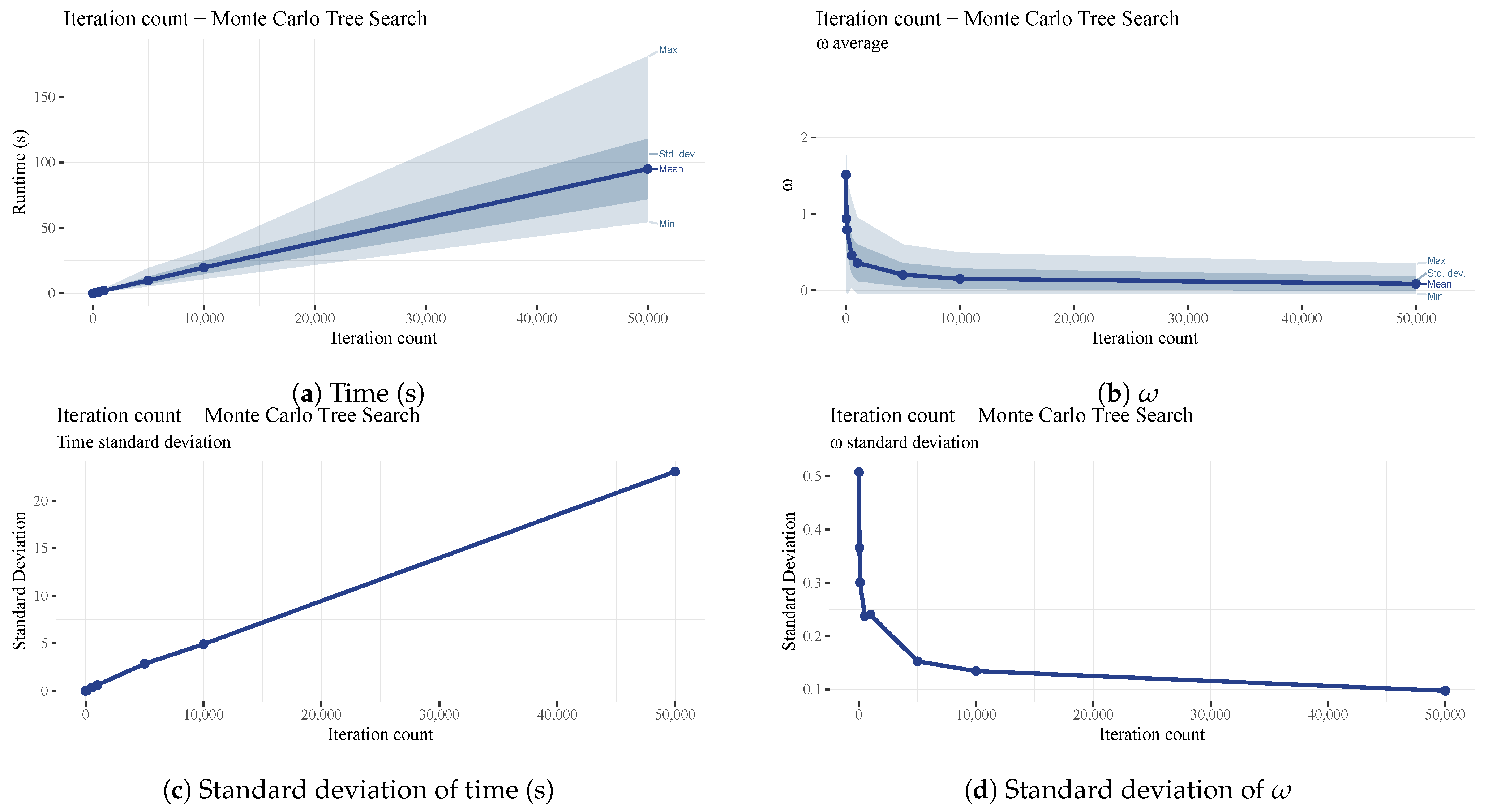
The iteration count of the MCTS algorithm is fixed; it does not take the number of iterations elapsed since the last improvement into account. This parameter improves the search results drastically (See
Figure 14b), while the runtime increases only linearly (See
Figure 14a). A high value of 10,000 was maintained throughout our testing since this proved to be a good middle-ground between scheduling performance (
) and runtimes. The benefit of a high iteration count is the decrease in the standard deviation of
(See
Figure 14d), meaning that the scheduling performance is increasingly less dependent on the processing times in the benchmark set. One downside of a high iteration count is the increase in the standard deviation of runtimes (See
Figure 14c) since the SA algorithm is called every iteration, which has no fixed iteration count.
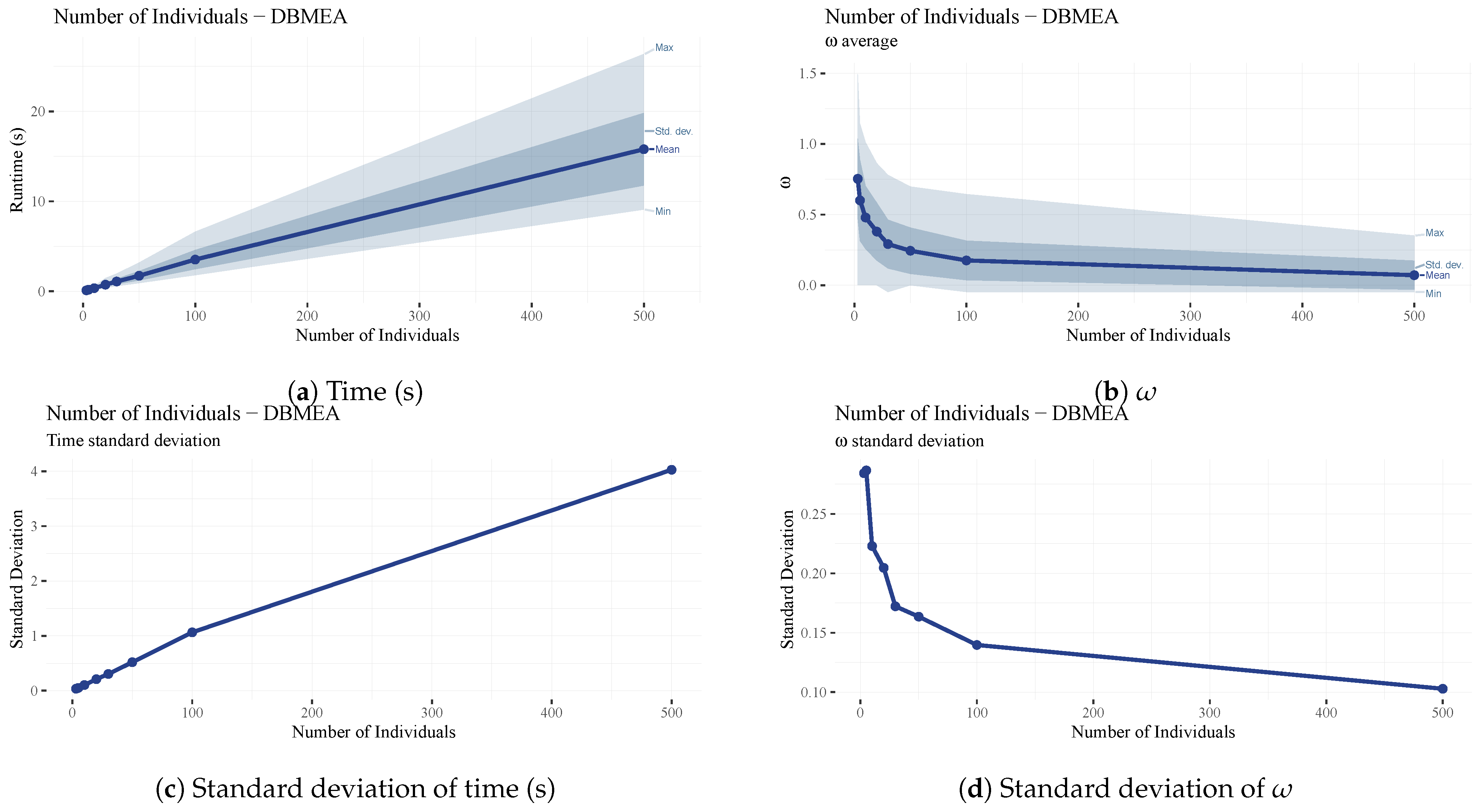
The number of individuals (
) in an iteration of the Discrete Bacterial Memetic Evolutionary Algorithm (the population size) dramatically affects both the scheduling performance and the runtime (See
Figure 15). A larger number of individuals means a broader range of solutions that MCTS and SA can further improve. However, a lower population count was maintained with a high iteration count in both MCTS and SA to reduce runtimes while keeping omega values low.
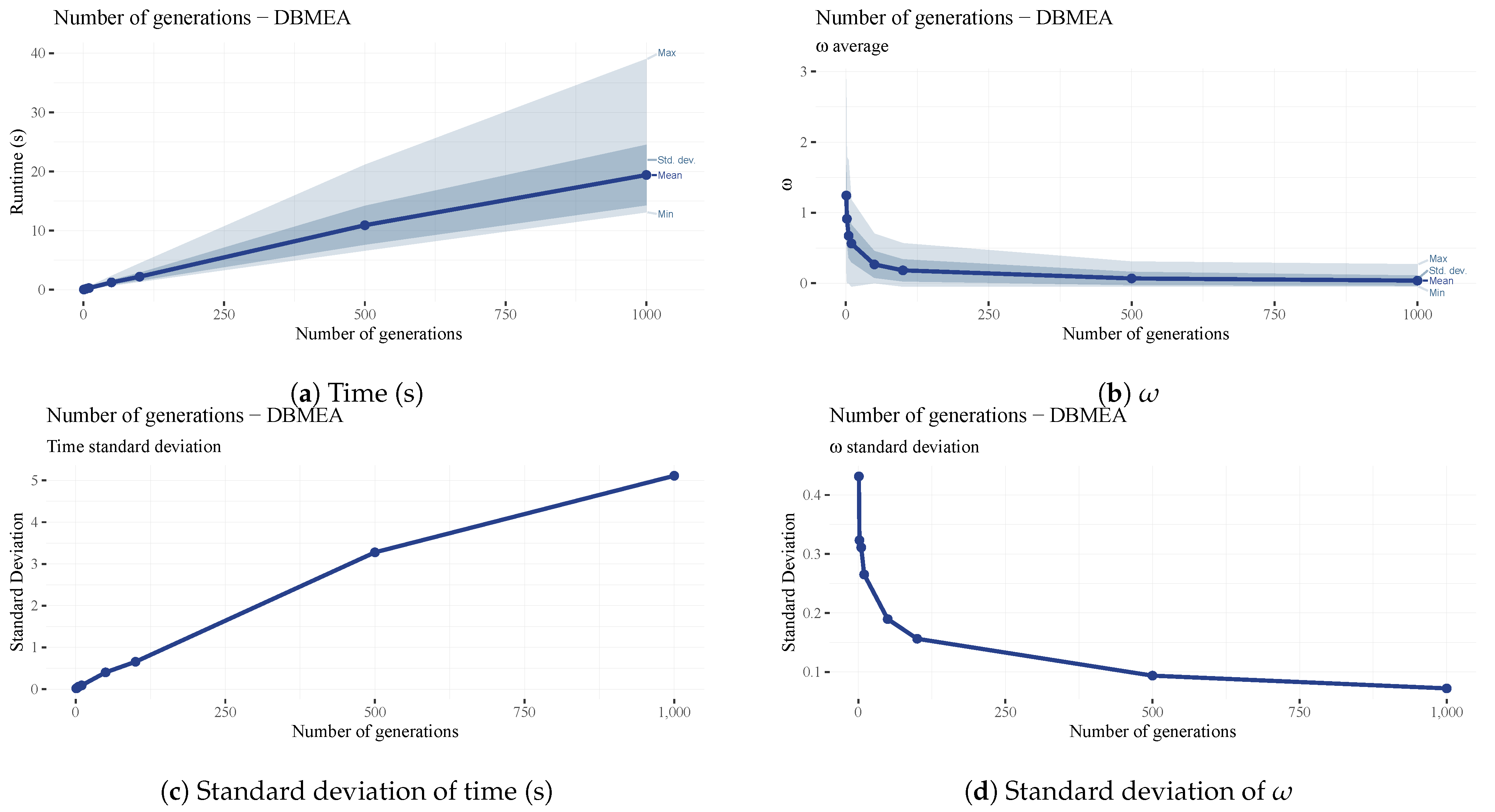
The maximum iteration count (generation count) of the DBMEA algorithm is the maximum number of iterations since the last improvement in makespan. This parameter impacts the scheduling performance and runtime significantly.
and its standard deviation keep decreasing as the number of iterations increases (see
Figure 16b,d), while the runtime is coupled linearly to the number of generations (see
Figure 16a). Similarly to the population size (
), the number of iterations was set to a lower value to keep MCTS and SA iteration counts high while keeping runtimes manageable.
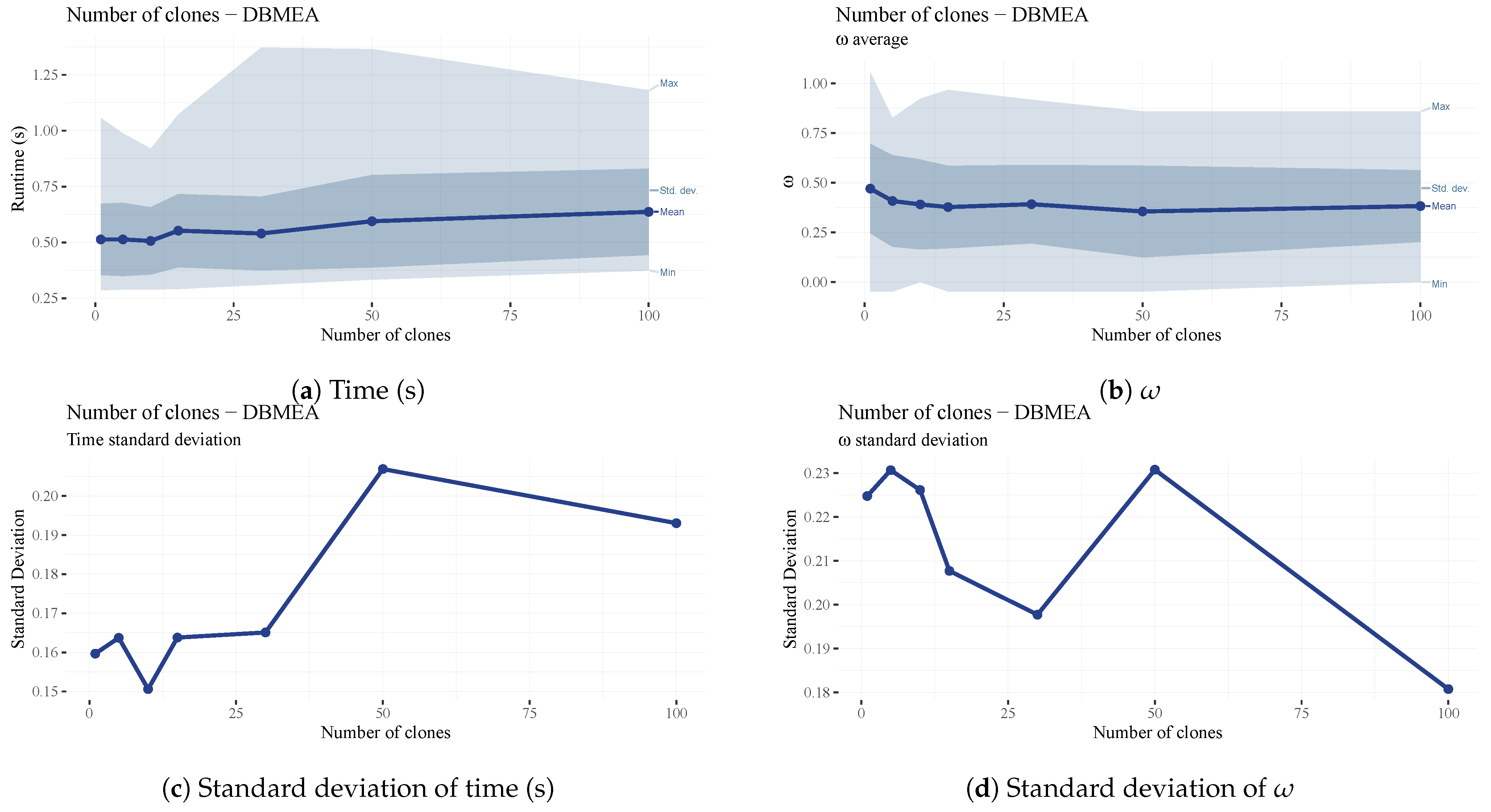
The number of clones (
) parameter is the number of clones generated in each bacterial mutation operation. An overly large number of clones creates many bacteria with the same permutation; therefore, going over a certain amount yields negligible or no improvement in overall scheduling performance (
Figure 17b) while increasing runtimes (
Figure 17a).
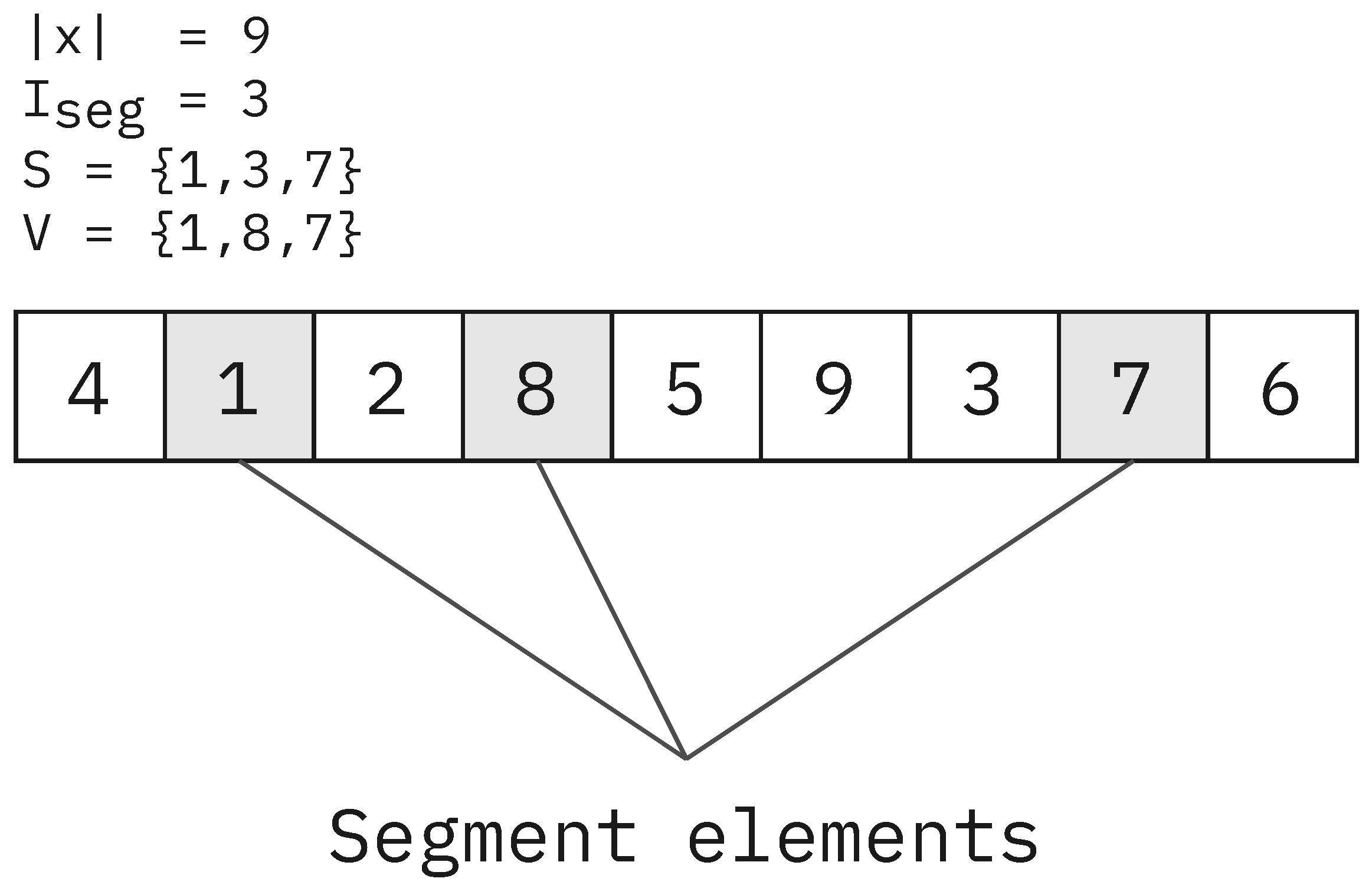
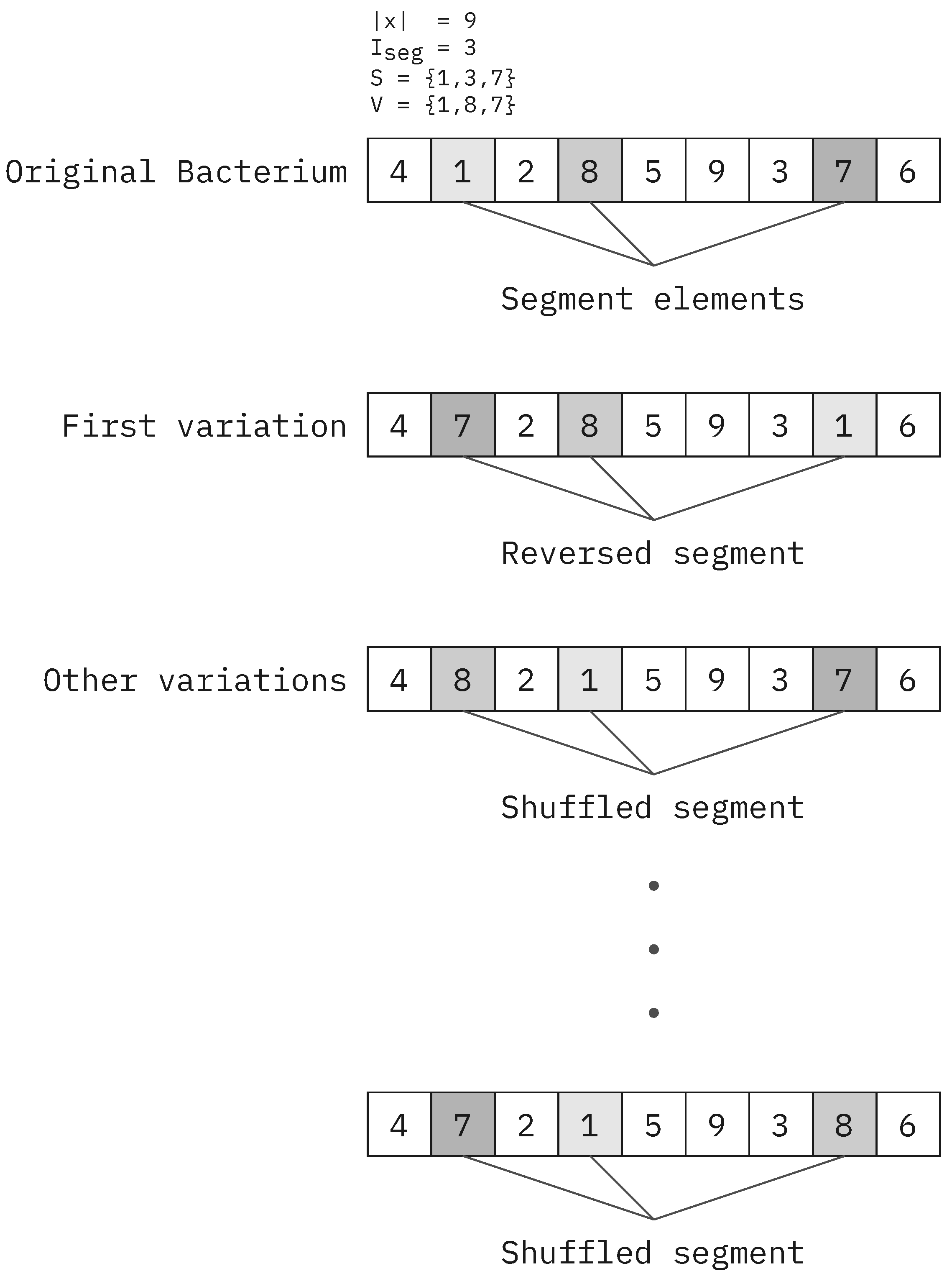
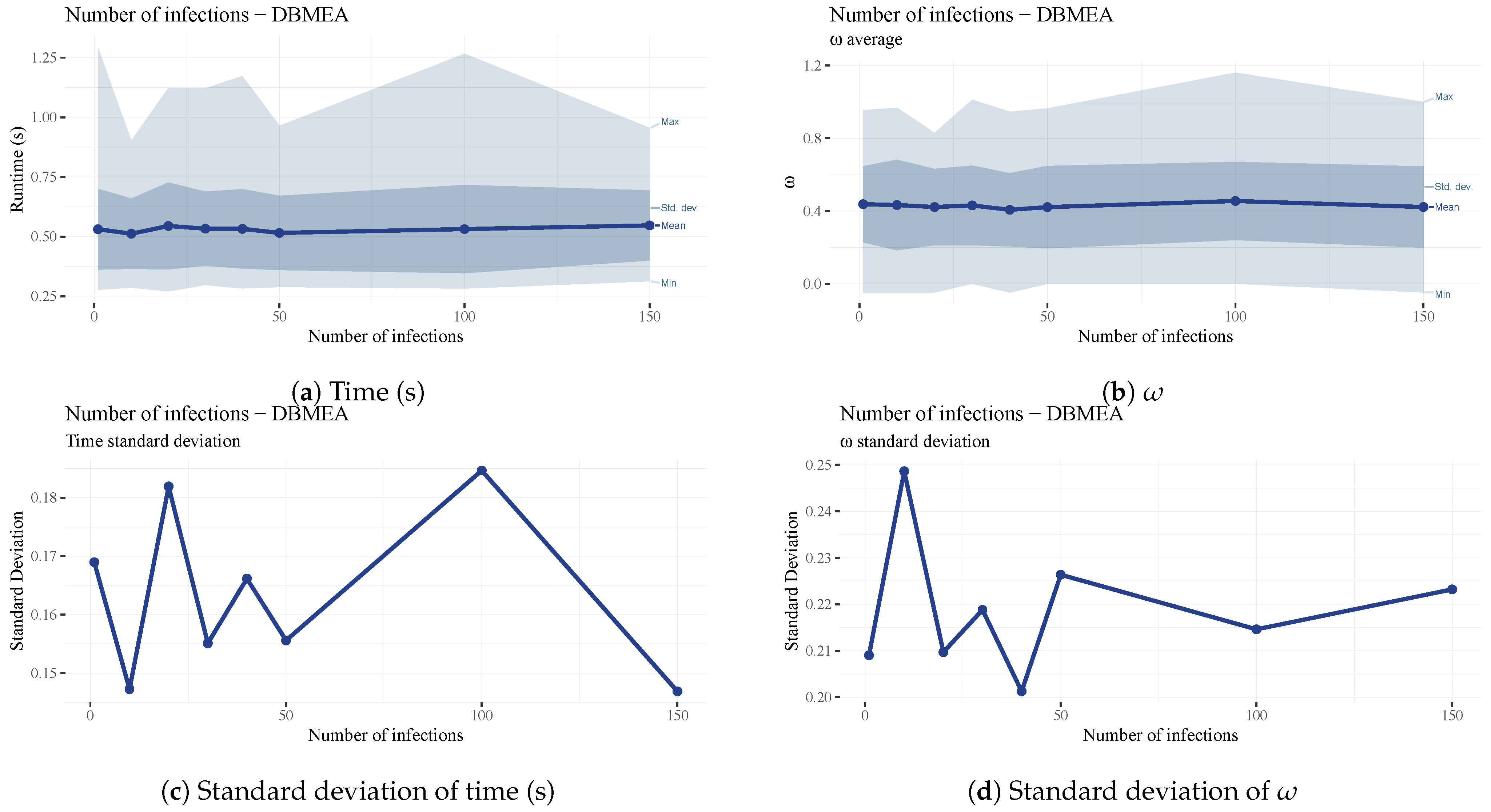
The number of infections (
) is the number of new bacteria created during the gene transfer operation. This may increase diversity in the population with negligible runtime differences (See
Figure 18); therefore, a higher value of forty was chosen to increase the chances of escaping local optima when scheduling larger problems.
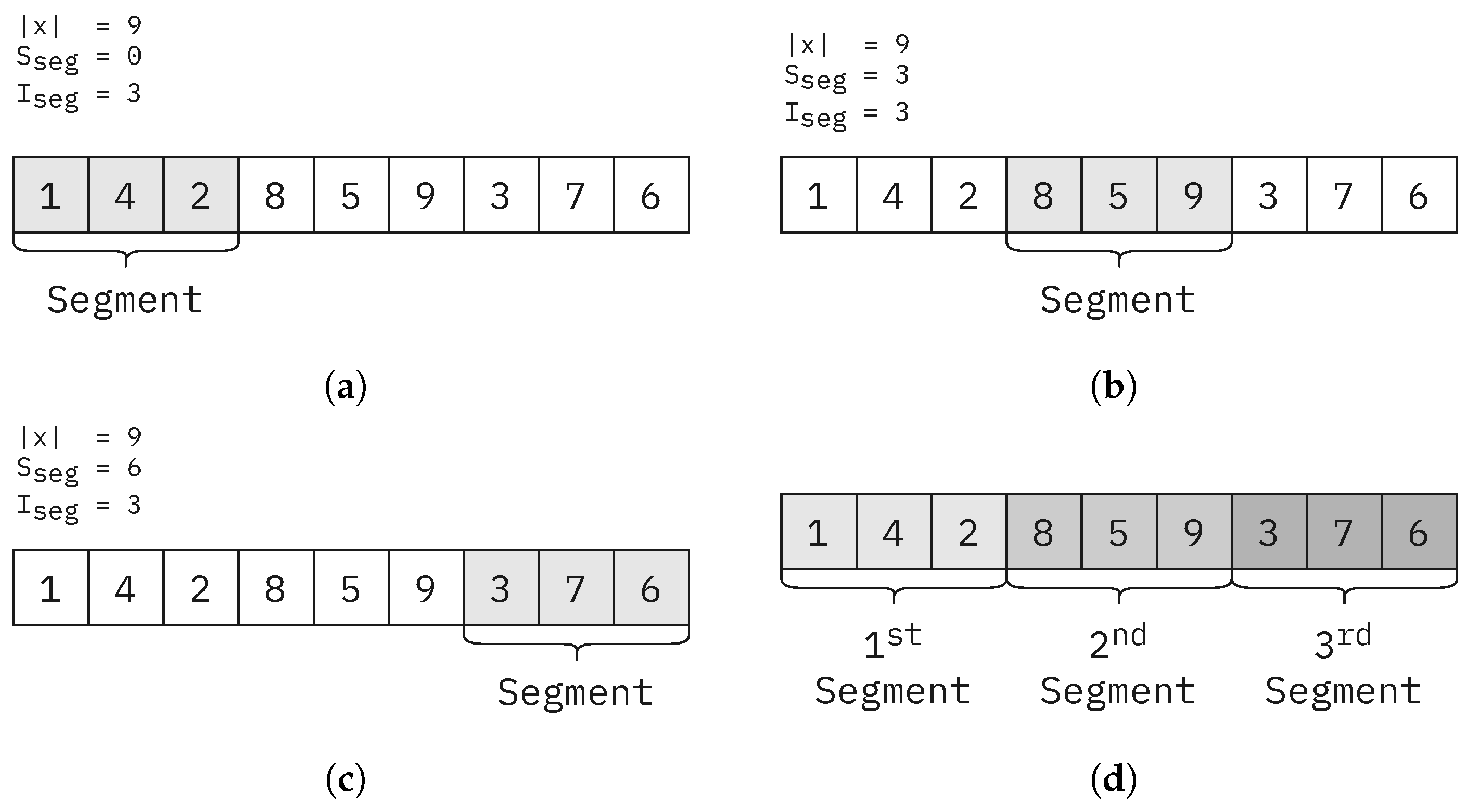
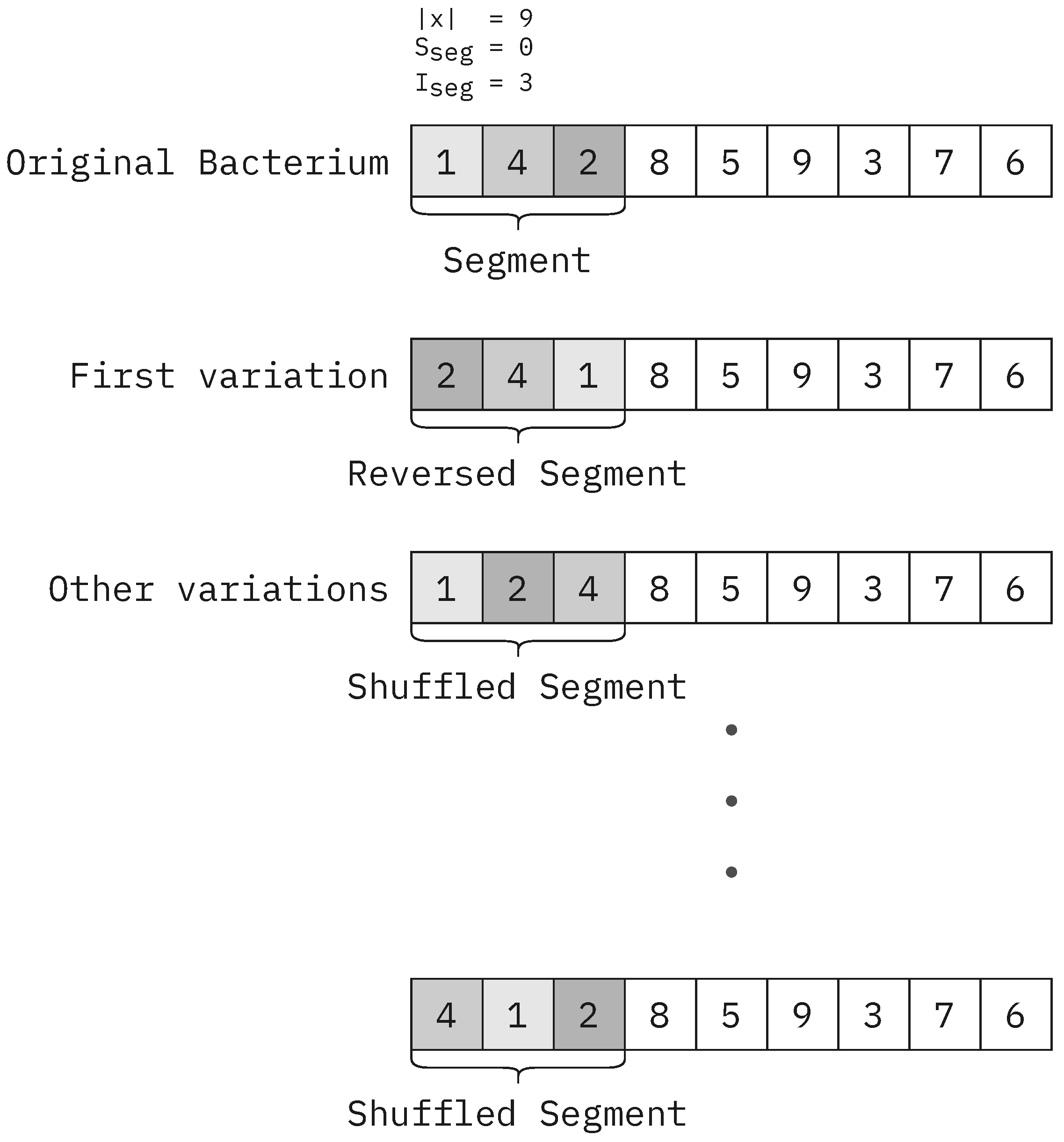
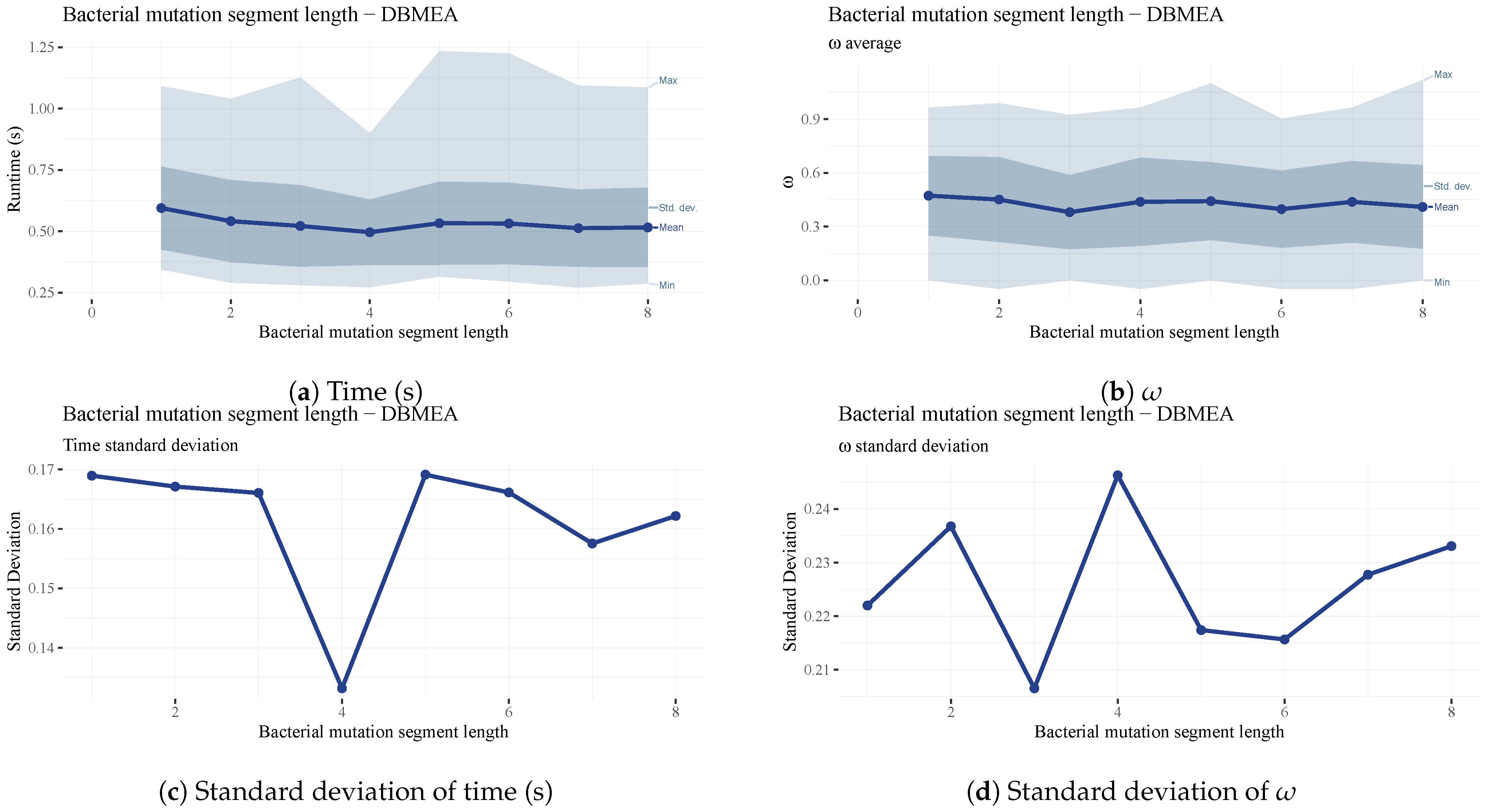
The
parameter is the length of the segment in the bacterial mutation operation. This value determines the size of the segment to be mutated to generate new mutant solutions. The larger the segment, the more varied the mutants will be. This parameter has a lesser impact on overall performance and runtime (See
Figure 19). However, a value of four yielded the lowest standard deviation in runtime (See
Figure 19c); therefore, it is the final parameter value chosen for our testing.
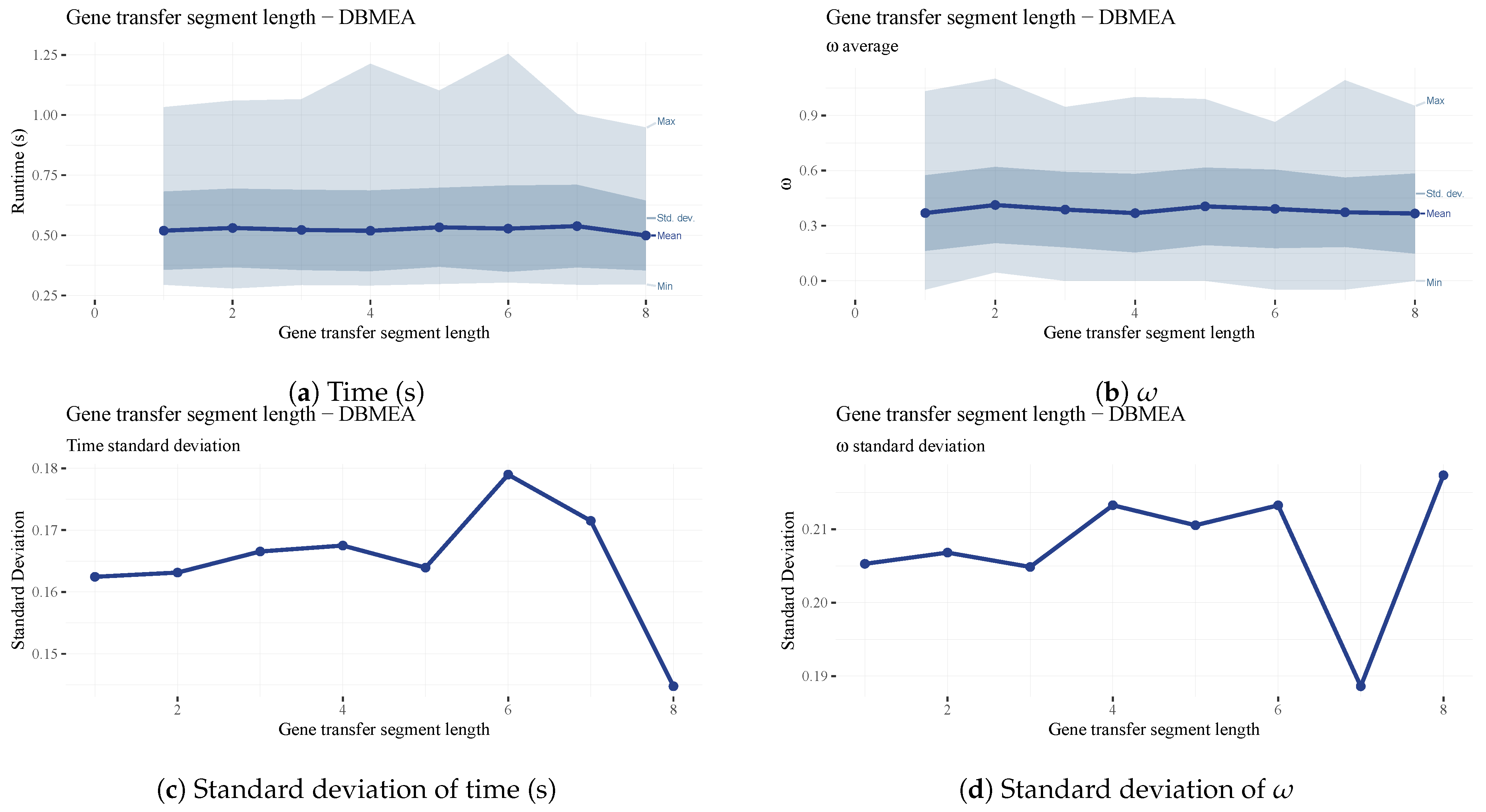
is the length of the transferred segment in the gene transfer operation. A longer segment may increase the variance in generated solutions. However, in our testing, it had little impact on the quality of solutions (See
Figure 20b,d) and runtimes (See
Figure 20a,c). A value of four was chosen since it is a good middle-ground and it illustrates the workings of the operator well.
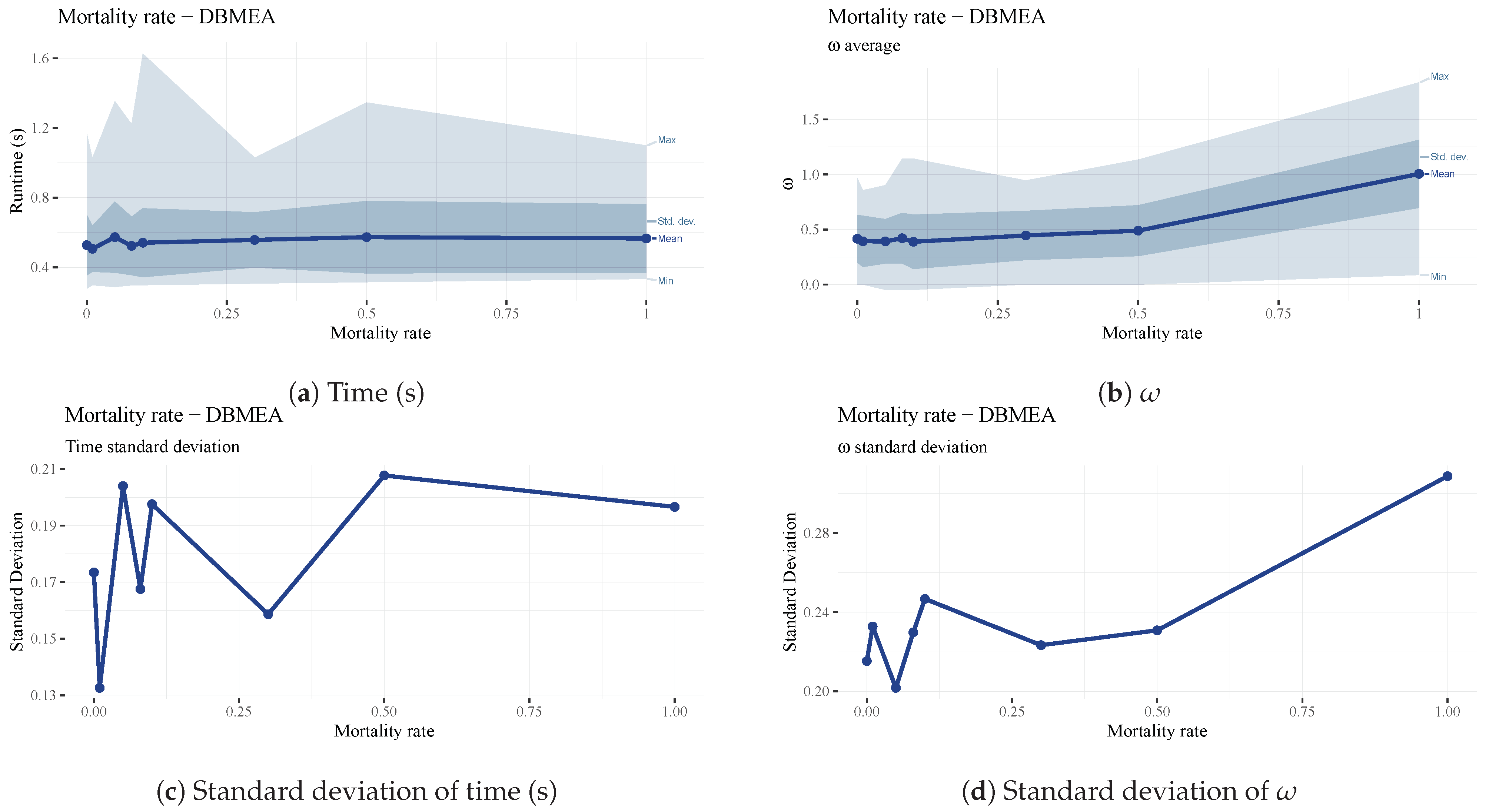
The mortality rate of
is the percentage of the population to be terminated at the end of each iteration (generation) and replaced with random solutions to increase diversity and escape local optima. A mortality rate of one creates a random population for each generation; a low mortality rate keeps more from the previous generation. Therefore, the mortality rate is an extension of elitism, where a portion of the population is kept instead of just one individual. It is evident that a high mortality rate (above 0.1) decreases the scheduling efficiency of the algorithm since the beneficial traits of previous generations are not carried forward (See
Figure 21b,d). Too low of a value may increase the chance of the search being stuck in local optima. The mortality rate must be kept as high as possible without negating the traits of previous iterations. The parameter has almost no impact on the runtime of the algorithm (see
Figure 21a,c). Considering the above, a mortality rate of 0.1 (10%) was chosen.
After our parameter analysis, a set of parameters were determined for the final testing on the entirety of the Taillard benchmark set.
Table 1 contains all of the parameters chosen. These running parameters were used to obtain the results presented in
Table A1,
Table A2,
Table A3 and
Table A4.






 ,
, 
{kind=link}
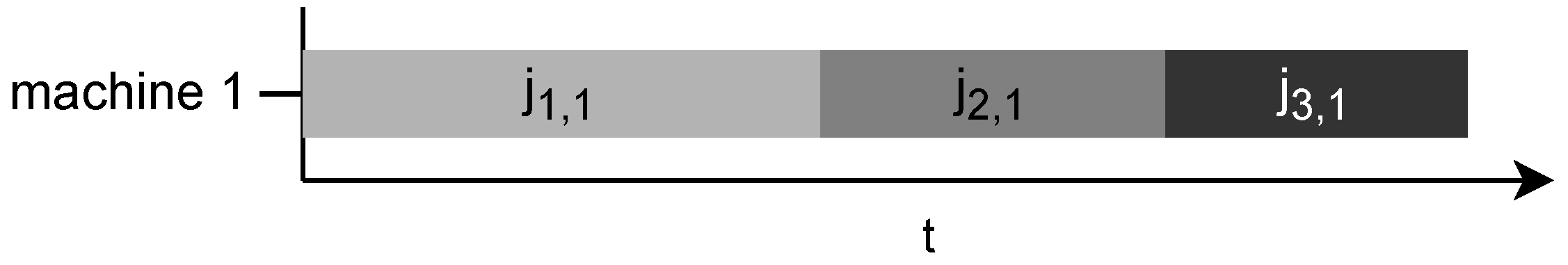{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















