1. Introduction
Unpredictable strings, often associated with chaos theory, represent data sequences that exhibit complex and disorderly behavior, making them an intriguing subject of study in various scientific disciplines. In chaos theory, unpredictable strings are characterized by their sensitivity to initial conditions, where even small changes in the initial values can lead to entirely different outcomes, emphasizing the nonlinear nature of chaotic systems [
1].
Research on unpredictable strings and randomly determined unpredictable functions has significant potential advantages in various domains today. Specifically, this research field plays a significant role in cryptography and information security for generating reliable encryption keys, random initialization vectors, and secure random numbers. It also plays a crucial role in ensuring the confidentiality and integrity of communication channels, which can enhance communication protocols protecting confidential data from interception and tampering.
For example, in [
2], a method for synchronizing two fast random bit generators (RBG), based on coupled chaotic lasers, was developed. This research addresses the issue of ensuring security in synchronizing RBGs in fast physical systems, where predictability is eliminated. Furthermore, the study of unpredictable strings has introduced a new concept of unpredictable sequences of a finite number of symbols [
3]. The first and second laws of large sequences for random processes in discrete time were proven, with the latter being closely related to Bernoulli’s theorem.
If we consider an infinite sequence , then an unpredictable string of length k is defined as a finite array , where s and k are positive integers, subject to the following conditions: = for , and . In other words, we consider a section of a sequence of length k, starting from position s, where the values are repeated in increments of k, but the next element after this section differs from the element standing at the position of the first element of the repeating sequence. This definition allows you to identify a part of the sequence with predictable repetition and the unpredictable part following it. These unpredictable strings play an important role in defining unpredictable sequences with a limited number of characters. The sequence itself is considered unpredictable if it allows the existence of unpredictable strings of arbitrary length.
This definition describes an array with a repeating sequence of length
k, starting at position s, and it is considered unpredictable if the element following the repeated sequence
is different from the element at the same position as the first element of the sequence
. This means that the array has a predictable part followed by an unpredictable part. Unpredictable strings are used to define unpredictable sequences of a finite number of symbols. A sequence
is unpredictable if it allows unpredictable strings of arbitrarily large length. Stochastic processes with discrete time and finite state spaces allow for a countable set of realizations that are unpredictable sequences [
3].
Researching this topic will allow for a better understanding of fundamental concepts related to chaos in statistics, random processes, probability theory, and dynamic processes [
4].
In the paper [
5], the application and evaluation of a cryptosystem based on chaotic mappings are investigated. An analysis was conducted to assess the impact of the chosen chaotic mapping on the properties of messages and the security of the cryptosystem using methods from statistical mechanics and information theory.
The paper [
6] explores a synchronization scheme for complex networks of chaotic systems. Chaotic systems, including Rössler, Chen, Lorenz, and Lü, are considered as complex chaotic systems within complex networks. This work specifically focuses on the application of the control law obtained for synchronizing an irregular network consisting of six different chaotic systems. The paper underscores the utility and advantages of the proposed synchronization scheme through numerical simulations of complex chaotic networks.
In another work [
7], the possibility of creating a secure optoelectronic communication system using chaotic Rössler oscillators and semiconductor lasers is investigated. The results confirm that the system is viable.
In the paper [
3], a numerical analysis of the Bernoulli process with periodic realizations is carried out. Overall, the study of periodic sequences allows for a deeper understanding and analysis of the structure and characteristics of unpredictable sequences, as well as the identification of regular patterns and other key aspects [
8].
This paper represents the first step in exploring unpredictability through deep learning methods. The research focuses on the periodicity of random symbolic sequences, which is one of the elements of chaos [
9]. Therefore, the investigation of this problem serves as a prerequisite for further delving into the subject matter. In this paper, the object of the study was a binary sequence.
The study of periodic sequence is due to a wide range of applications in science and practice. For example, in signal processing, periodic sequences are important. The study of their properties will allow you to gain a good understanding in the generation and control of signals, as well as in solving problems related to filtering and signal processing. It can also be useful in the field of data encoding and decoding. They can be used as part of a code system that monitors the need to transmit information [
10].
The advantages and disadvantages of the aforementioned papers in this section are outlined in the following
Table 1.
3. Problem Statement
Studying unpredictable strings and functions will enable the improvement of specific algorithms in terms of enhancing their efficiency because many of these types of algorithms heavily rely on the unpredictability of input data. Researching the role of unpredictability allows for the optimization of these algorithms and the enhancement of quality assurance. This is particularly significant as the quality and unpredictability of generated sequences hold key importance in many applications [
11].
Our task is to obtain all possible periodicity options for a given sequence. A new genetic algorithm is used to solve the problem. In turn, the development of this genetic algorithm consists in finding optimal solutions in a finite set of objects that will meet certain criteria.
A logistic mapping is used to construct the sequence under test. This is a discrete mapping that is often used to model dynamic systems with limited resources or to generate binary sequences [
12]. Despite the simplicity of the logistic mapping, it allows you to model very complex processes. Our choice to use the logistic mapping is justified by the desire to take advantage of the simplicity of the formula, but we also emphasize that the logistic mapping is, in fact, a special case of a more general class of chaotic maps. Chaotic mappings, including logistic mappings, provide important tools for creating dynamic and complex sequences with interesting characteristics. Although we used a specific logistic mapping to create a sequence, it is also important in our study to further consider more general concepts of chaos. The logistic equation has the form
where
is the current value, and
is the next value. The parameter
controls the behavior of the system.
The choice of the parameter
and the initial value
in the equation strongly affect the generation of the binary sequence. It is convenient to take the parameter
in the interval [0, 4] [
13]. Two areas,
and
, are also selected, which, depending on its value, will relate to
x. An element of a binary sequence will have the value 0 or 1 if it belongs to the domains
and
, respectively:
Thus, to construct a binary sequence, the value of the parameter = 3.91, and the initial value = 0.4. Since we needed to obtain the sequence , which will consist of 0 and 1, the regions were chosen as follows, respectively: = [0, 0.5] and = [0.5, 1].
For a computational program, a sequence consisting of 0 and 1 is considered as input data. A genetic algorithm is applied to it, which solves the problem by methodically iterating through states and state transitions in order to find a solution from the initial state to the final one. The task of the algorithm is to make a calculation based on a heuristic approach, which, for the initial length of the considered (input) sequence , checks it for periodicity P, after which it outputs all its received variants converted into a periodic form. The process of checking the sequence for periodicity P occurs by comparing the value of each element with , where N is the length of the sequence.
Heuristic algorithms are widely used to solve problems of high computational complexity. The idea is that instead of a complete search of options, which takes a time-consuming process, a relatively easy approach is used. The main disadvantage of this approach is an insufficiently theoretically sound algorithm [
14].
4. Genetic Algorithm
Genetic algorithms belong to a family of search algorithms whose ideas are suggested by the principles of evolution in nature (
Figure 1). The main task of such algorithms is to simulate the processes of natural selection and find high-quality solutions to problems. At the same time, the analogy with natural selection allows these algorithms to overcome some obstacles that stand in the way of traditional search and optimization algorithms, especially in problems with big data. Just as Darwinian evolution promotes the development of individual organisms in a population, genetic algorithms contribute to the development of a population of potential solutions to this problem, which are called “individuals”. These solutions are periodically evaluated and used to form a new generation of solutions. Those individuals who have shown the best results in solving the problem are more likely to be selected and pass on their positive characteristics to the next generation. Thus, gradually potential solutions become more perfect in solving this problem [
15].
In the natural environment, crossover, reproduction, and mutation are realized with the help of a genotype—a set of genes ordered in chromosomes. When two individuals are crossed and offspring arise, each chromosome of the offspring carries a mixture of genes from both parents. In the course of its work, a genetic algorithm always contains a set of individual solutions, which is called a population. Each of these individuals is represented by its own chromosome, which allows us to consider the population as a collection of chromosomes. For a software implementation, of course, this analogue will be like a set of arrays that store certain bit values created randomly at the beginning.
At each step of the algorithm execution, individual solutions are evaluated through the objective function. This function evaluates the quality of the solution of the considered problem of the genetic algorithm. All individuals in a generation receive their personal assessments from the fitness function. The most suitable individuals with a higher probability of their decision will be selected for reproduction and integration into the next generation. However, this does not deny that individuals with low fitness will not be selected. This allows their genetic material not to disappear, but their probability of selection will be low.
After that, a crossover operation takes place, which simulates biological crossover with the preservation of the genes of the parents’ heredity. This operation is used to combine the genetic information of two individual parents in the process of creating offspring. Crossover is not always used, but is applied with a certain probability. If the crossover is not performed, the genetic images of both parents are transmitted to the next generation without changes.
In the end, a
mutation operator is executed, the task of which is to periodically randomly update information in the population. This will allow the introduction of new combinations of genes into individuals, which in turn will allow the exploration of unexplored areas of the solution space. A mutation can manifest itself as a random change in a single gene [
16].
4.1. Genotype and Population
In this problem, we will consider the genotype as a binary string in which each element corresponds to one of the characters 0 and 1. Then, for the problem under consideration, the population will have the form
As can be seen from the
Figure 2, an area of sequences is considered as input data, the initial values of which will be randomly generated.
In the genotype of each individual of the population under consideration, a digital value of 0 or 1 is encoded. That is, we represent periodic structures in the form of a sequence of bits in the genotype. A population includes a set of such genotypes, where each genotype represents a potential solution to the problem. The genetic algorithm is focused on solving the problem of finding the periodicity in a binary sequence. The input data are a binary sequence of 0 and 1. The purpose of the genetic algorithm is to solve the problem of methodically iterating through states and transitions between states in order to find a solution from the initial state to the final one. The genetic algorithm uses a heuristic approach to effectively check the frequency of the input sequence. The verification process is based on comparing the values of each element of the sequence with the previous elements. The frequency checking algorithm compares the value of each element with the previous values for a possible period. This process helps to identify periodic sequences. The found periodic sequences are presented in the form of various variants in a periodic form. The search space is determined by the length of the input sequence, and the genetic algorithm goes through various combinations and state transitions in order to find periodic structures. The assessment of the fitness function includes a periodicity check to ensure that the sequence does not consist only of the values 0 and 1. This is done to prevent monotonous solutions with low adaptability. Defining the feature search space: The feature search space is defined through the genotype configuration.
4.2. Fitness Function
To evaluate the fitness function at each iteration for the problem under consideration, it was necessary to make a periodicity check so that the sequence did not consist of only the value 0 or 1.
The work of the function to determine the periodicity of each individual has the following pseudocode (Algorithm 1):
| Algorithm 1 Function CheckPeriodOrNo(individual, Period) |
|
It is known that even sequences consisting of a single value of 0 or 1 are periodic. Therefore, we will not consider this solution. Thus, it was necessary to create two additional auxiliary functions: CheckSameOrNo and ExistOrNo. The CheckSameOrNo function just checks the above, and the second ExistOrNo function checks for the identity of the found solution in the solution area.
Thus, the objective function itself has the following pseudocode (Algorithm 2):
| Algorithm 2 Function CalculateFitness(individual) |
if then if then if then end if end if end if return fitness
|
4.3. Crossover and Mutation
The operations of crossover and mutation are the main operators for finding a solution to the problem under consideration. Crossover is necessary to combine the genetic information of two individuals acting as parents in the process of generating offspring. As a rule, the crossover operator is not always used, but with some probability. If crossover is not applied, then copies of both parents pass into the next generation without modification. For our task, we will consider three types of crossover: single-point, two-point or k-point, and uniform.
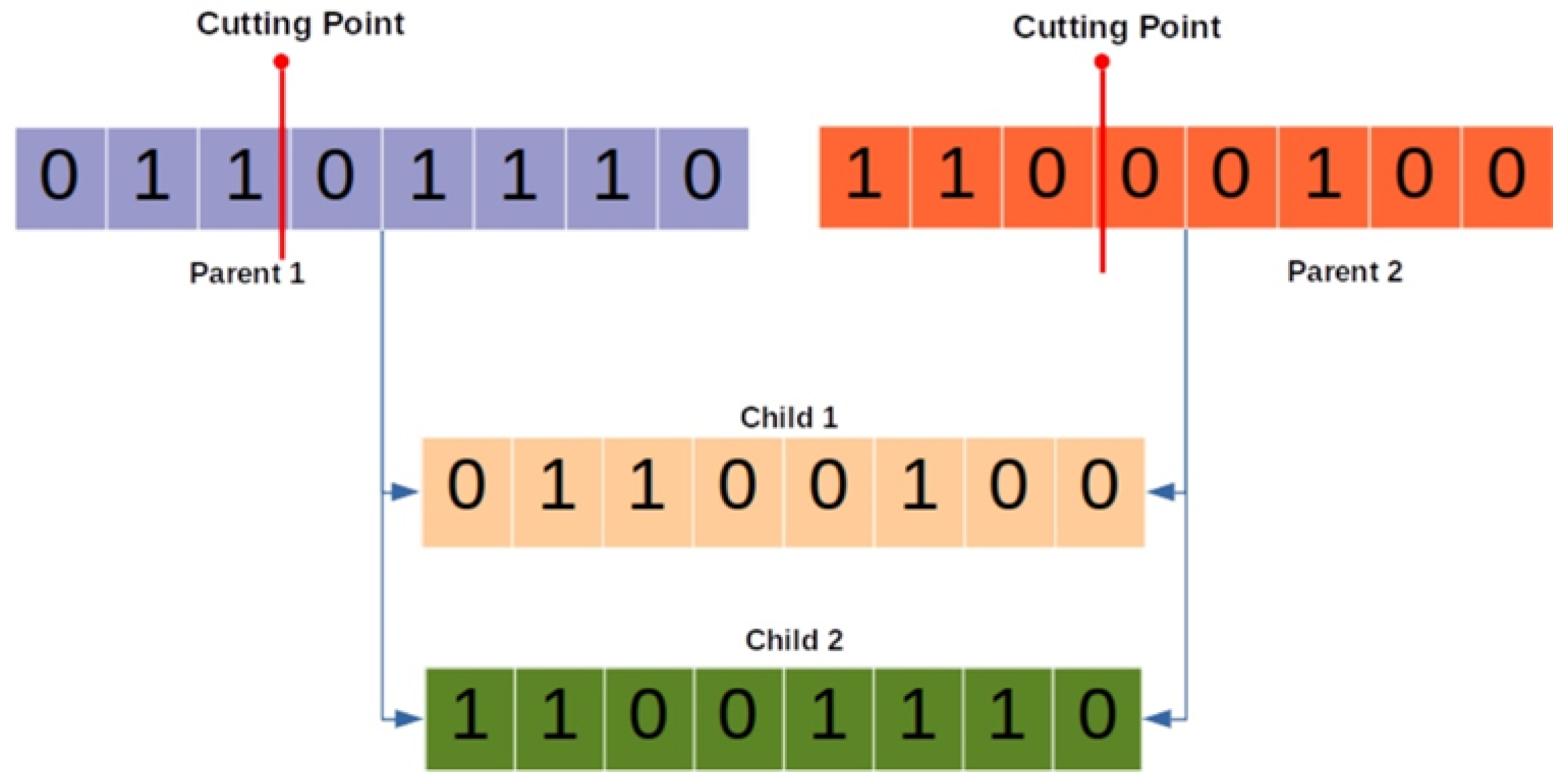
In the book [
17], the single-point crossover operator is considered as one of the most common methods for breeding in binary encoding. Single-point crossover is a method where two parental chromosomes selected from the population are cut at a random point known as the crossover point. The genetic information located to the left (or right) of this point is exchanged between the two parents, forming two new offspring.
Figure 3 shows an example of a single-point crossover of two pairs of individuals as parents and the creation of their new offspring:
In the paper [
18], operators of the k-point crossover type are investigated, along with their combinatorial, graphical, and topological properties. The authors demonstrated that k-point crossover operators have a more complex nature and correspond to objects of higher dimensionality, whereas single-point crossover operators correspond to circles, which are relatively simple two-dimensional objects [
19]. The principle of operation of a two-point crossover is similar to that of a single-point one, only two or more crossover points in each chromosome are randomly selected. Thus, information from one chromosome located between these points is exchanged by similarly located genes of another chromosome (
Figure 4).
In the paper [
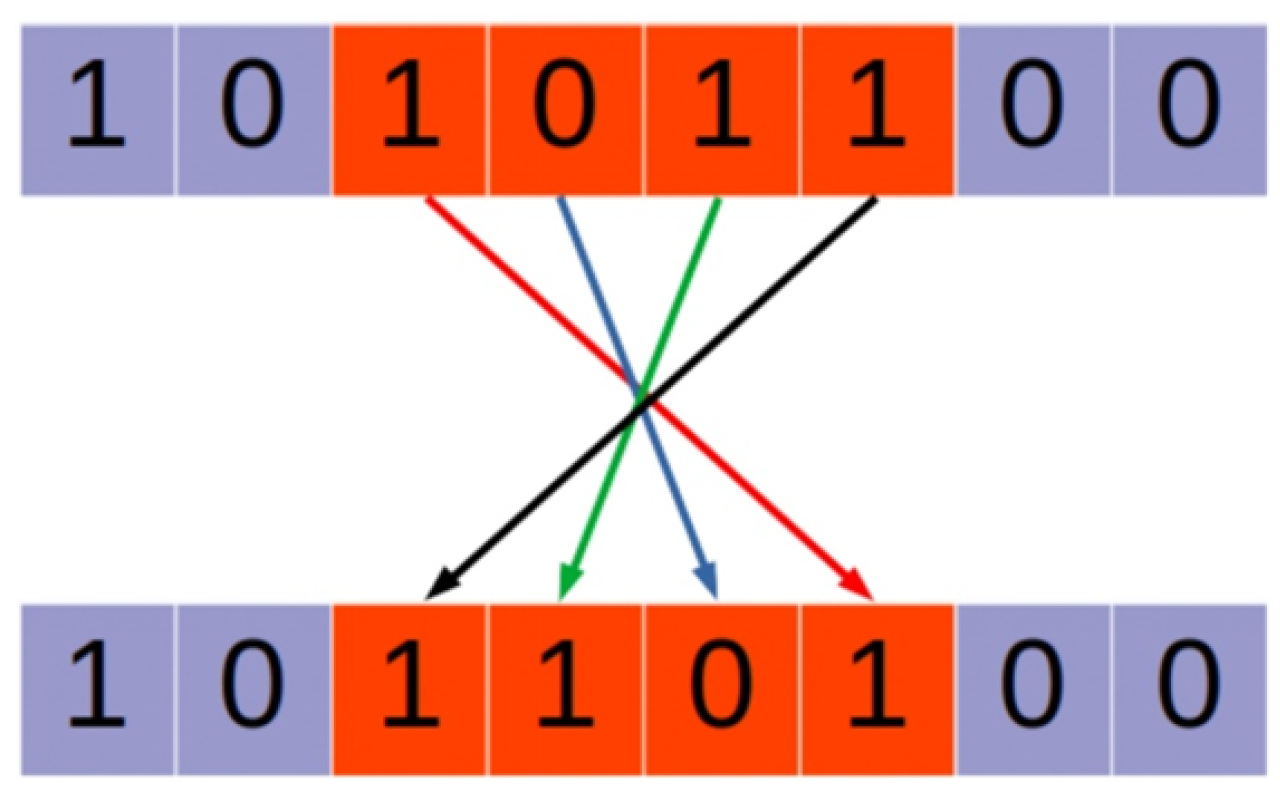
20], a genetic algorithm is proposed to solve the problem of ordering and scheduling the arrival of aircraft in systems with multiple runways, using uniform crossover. In this paper, the uniform crossover operator ensures efficient identification, transmission, and protection of common traffic subsequences, while preserving the ability to diversify chromosomes. With uniform crossover, each gene in the offspring is selected with the same probability either from the corresponding gene of the first parent or from the second. The bottom line is that for each gene, there is a 50% chance of choosing it from one parent and a 50% chance of choosing it from another parent. This method allows for a more diverse exploration of the solution space compared with other crossover methods, such as single-point or two-point crossover. Uniform crossover can be especially useful when solving a problem may require optimal mixing of different characteristics from both parents. Uniform crossover allows for maintaining genetic diversity in the population [
21]. An example of an illustration of the work of uniform crossover is shown in
Figure 5:
Child 1: 10110001 (1 from parent 1, 0 from parent 2, 1 from parent 1, 1 from parent 2, 0 from parent 1, 0 from parent 2, 0 from parent 1, 1 from parent 2).
Child 2: 11001110 (1 from parent 2, 1 from parent 2, 0 from parent 1, 0 from parent 1, 1 from parent 2, 1 from parent 1, 1 from parent 2, 0 from parent 1). Thus, each information from the genes of a descendant is selected from one parent with the same probability. A mutation for the binary chromosome in question consists in changing a random bit or several bits in the chromosome with some probability. Mutation introduces randomness into the genetic algorithm, helping to avoid getting stuck in local optima and ensuring diversity in the population.
Mutation is a genetic operator applied to the offspring resulting from selection and crossover. The mutation operation is probabilistic and is employed to prevent stagnation and ensure diversity in the population. In the problem under consideration, three types of mutation were selected: bit inversion, mutation by exchange, mutation by reversion.
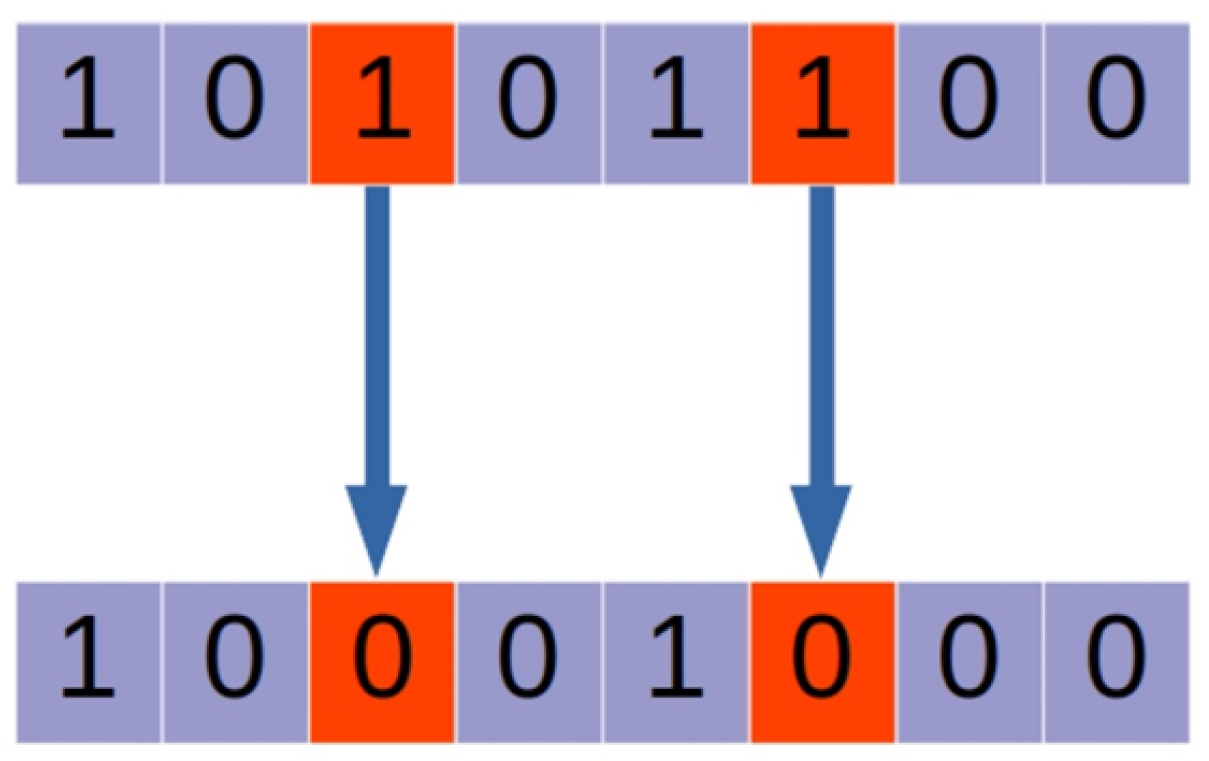
Inversion of bits is a mutation method proposed in the original genetic algorithm by Holland [
22]. This method is simple and effective for working with binary chromosomes. Inverting a bit means changing the value of the bit to the opposite: if the bit was equal to 0, then after inverting it, it becomes equal to 1, and vice versa (
Figure 6). In our task, we will apply as part of the mutation operator for diversity in the population and search for a wider solution space.
Swap mutation is a mutation method applicable to both binary and integer chromosomes. It involves randomly selecting two genes in the chromosome and exchanging their values. This mutation operation is suitable for chromosomes representing ordered lists since, after the mutation, the set of genes in the new chromosome remains the same as in the original, except for the random change in the positions of the two specific genes (
Figure 7).
Reverse mutation is a mutation method applied to both binary and integer chromosomes. In this method, a random sequence of genes is selected, and their order within the chromosome is reversed. Similar to the swap mutation, this method is suitable for chromosomes representing ordered lists since, after the mutation, the set of genes in the new chromosome remains the same as in the original, except for the reversal of the order of the selected genes (
Figure 8).
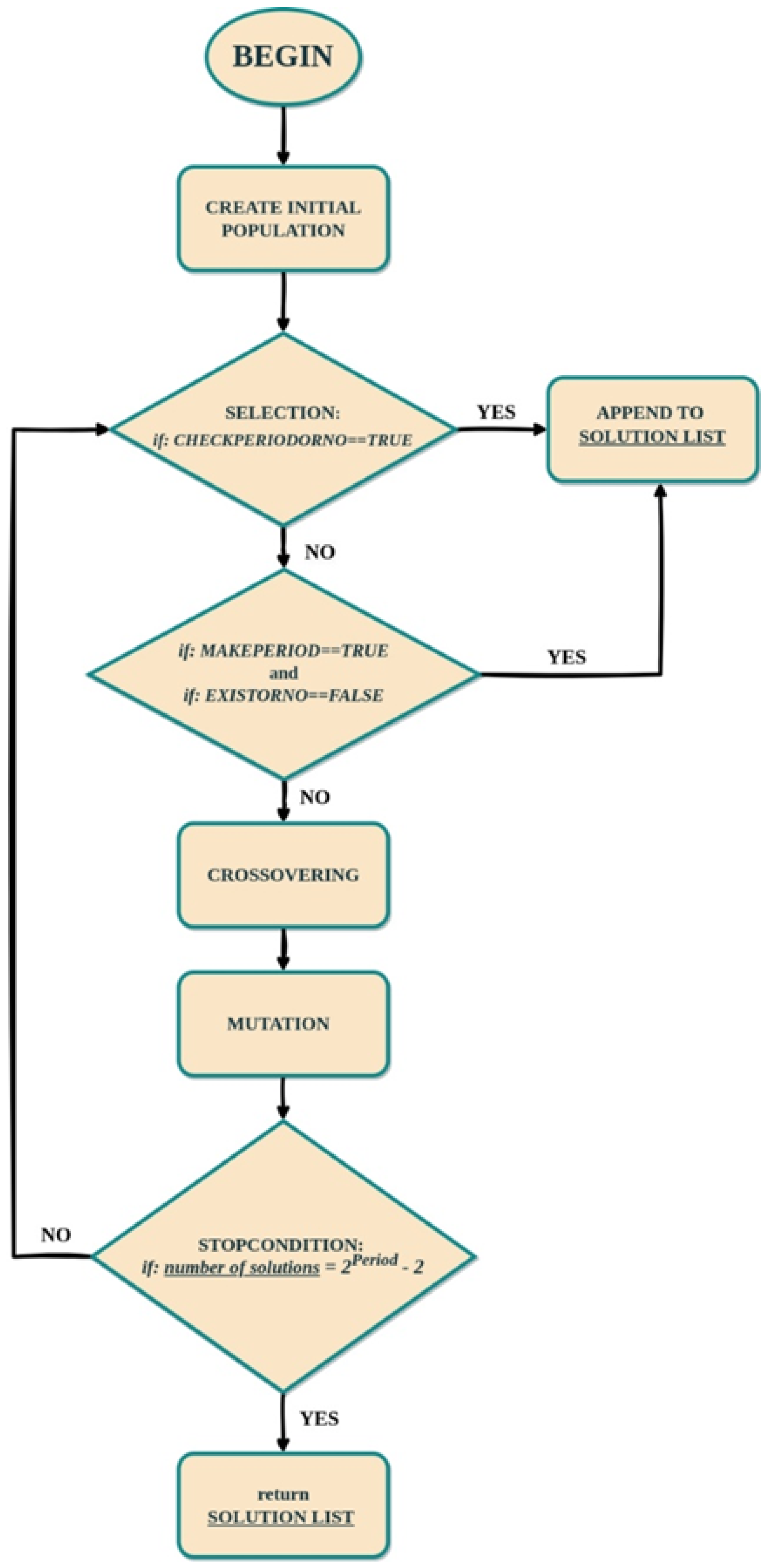
4.4. MakePeriod Method
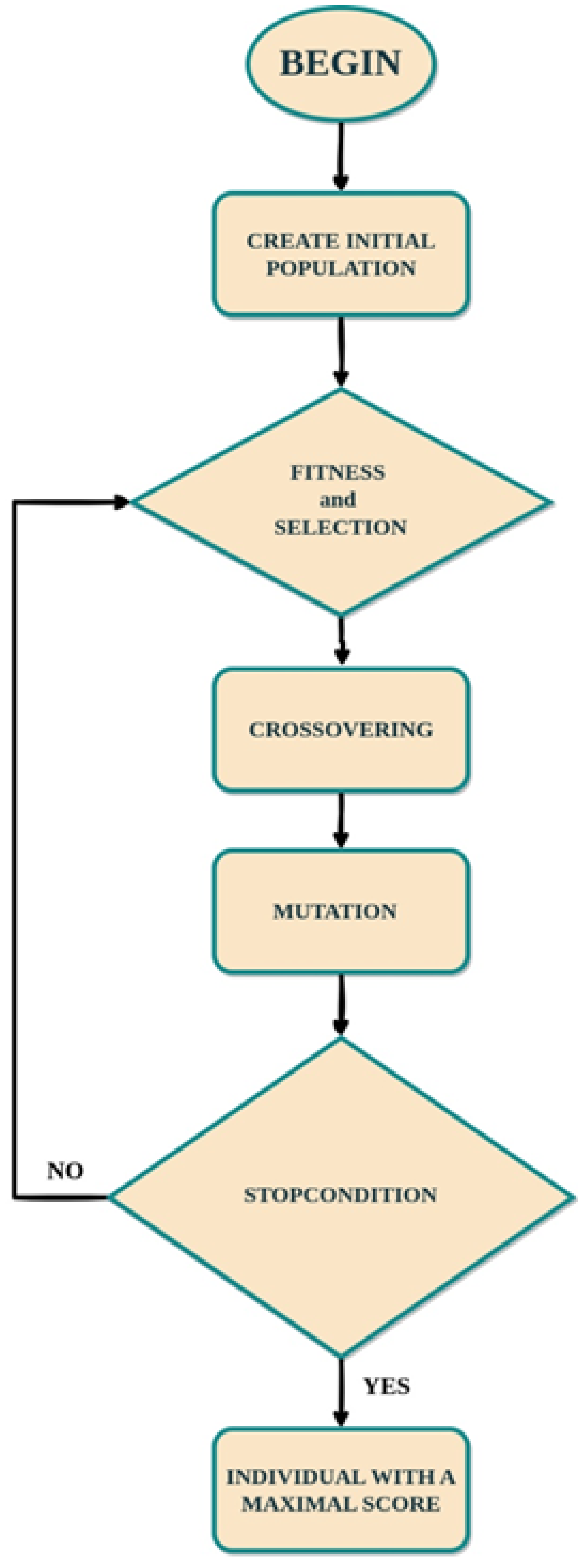
Finding all the periodicity variations for a larger sequence size did not show a very good result in time. More specifically, for the sequence size
, the algorithm did not find solutions for more than 30% of the total and got stuck for a very long time. In this regard, it was decided to optimize the algorithm. Thus, an additional MakePeriod method (Algorithm 3) was created, which performs a modification operation of a binary list in order to provide a certain periodic behavior inside this list. This method is used to create a periodic structure, ensuring that the elements of the list correspond to an alternating pattern in a given period
P.
| Algorithm 3 Function MakePeriod(sequence, Period) |
for to do if then if then else end if end if end for return sequence
|
As a result of executing this method, the elements of the sequence list will be modified in such a way as to provide a given sequence periodic for a certain P. That is, this operation will allow the algorithm to change individuals who are nonperiodic to periodic ones, which significantly reduces the search time for a solution.
Example 1. Let the sequence be nonperiodic, and we will check it for the value of period 3, that is,
Starting from the third element, we see that the periodicity rule for 3 is not fulfilled for this sequence (the values of the elements in indexes 3 and 5 are different). However, we can change the value in index 5 to the opposite one, which has index 3 (Figure 9). This will avoid generating additional individuals and their checks, because without the MakePeriod method, our algorithm would simply not consider this sequence, since it is nonperiodic. Thus, a new sequence will be added to the area of potential solutions, which will allow us to narrow the search area of the solution and reduce the time.
The proposed algorithm is iterative; then it is known that a breakpoint must be determined to stop it. We need to find the number of possible sequences that are periodic. Experimentally, for the initial values of the periods, we obtained a pattern that these are two to the power of the period value under consideration (
). Given the fact that we will not consider the sequence as a solution that consists of identical elements (such sequences are 2), we have the following formula:
This Formula (4) determines the breakpoint; that is, if the number of solutions found is equal to this value, then the genetic algorithm stops working. It is important to note that determining the specific value of the breakpoint is one of the reasons for further research in this direction. The complete scheme of operation of the algorithm in question is indicated in the form of a block diagram (
Figure 10).
As can be seen from the diagram, each individual is checked for periodicity during selection; those that are really periodic are added to the list of solutions, and for those that are not periodic, the MakePeriod operation is performed. When executing the MakePeriod operation for a given sequence, if it meets the periodicity condition and is distinct within the list of solutions, it is also added to the list of solutions. If the above conditions are not met, then the crossover and mutation operations occur sequentially. After that, the stop condition is checked. If the number of solutions is equal to k, which is determined by Formula (1), then the algorithm stops working; if not, a selection operation is performed for already-changed individuals.
4.5. The Concept of Error for Nonperiodic Sequences
After we have received a certain amount of variation to transform nonperiodic sequences into periodic ones, we need to choose one of them for further research. Thus, the concept of error was defined for such sequences. We will call an error the deviation of a nonperiodic sequence from its considered periodic transformation. The error in converting a nonperiodic sequence into a periodic sequence can be defined as the difference between the original nonperiodic sequence and the best periodic approximation of the same sequence. This error is measured by a value that can be called an “error” between the original and approximated sequences. For each resulting solution (variation), we will compare it with the input periodic sequence and the number of its modified elements:
where
N = the size of the sequence in question
= an element of the input nonperiodic sequence at the position i
= the element of the periodic sequence at the position i
This formula is the sum of the values of the function for each pair of elements of two sequences, and , which will calculate the number of modified elements between them. In the end, we divide by the value , since this is a convergent series, i.e., the contribution to the error of those elements that are far away is small. In the beginning, the error values will be relatively significant. After calculating all the error values, the one that best approximates the original nonperiodic sequence to its periodic approximation is selected. Choosing the option with the smallest error is standard practice when optimizing and approximating data. It allows us to find the best solution for the problem of converting a nonperiodic sequence into a periodic form in terms of minimizing the differences between them.
6. Conclusions
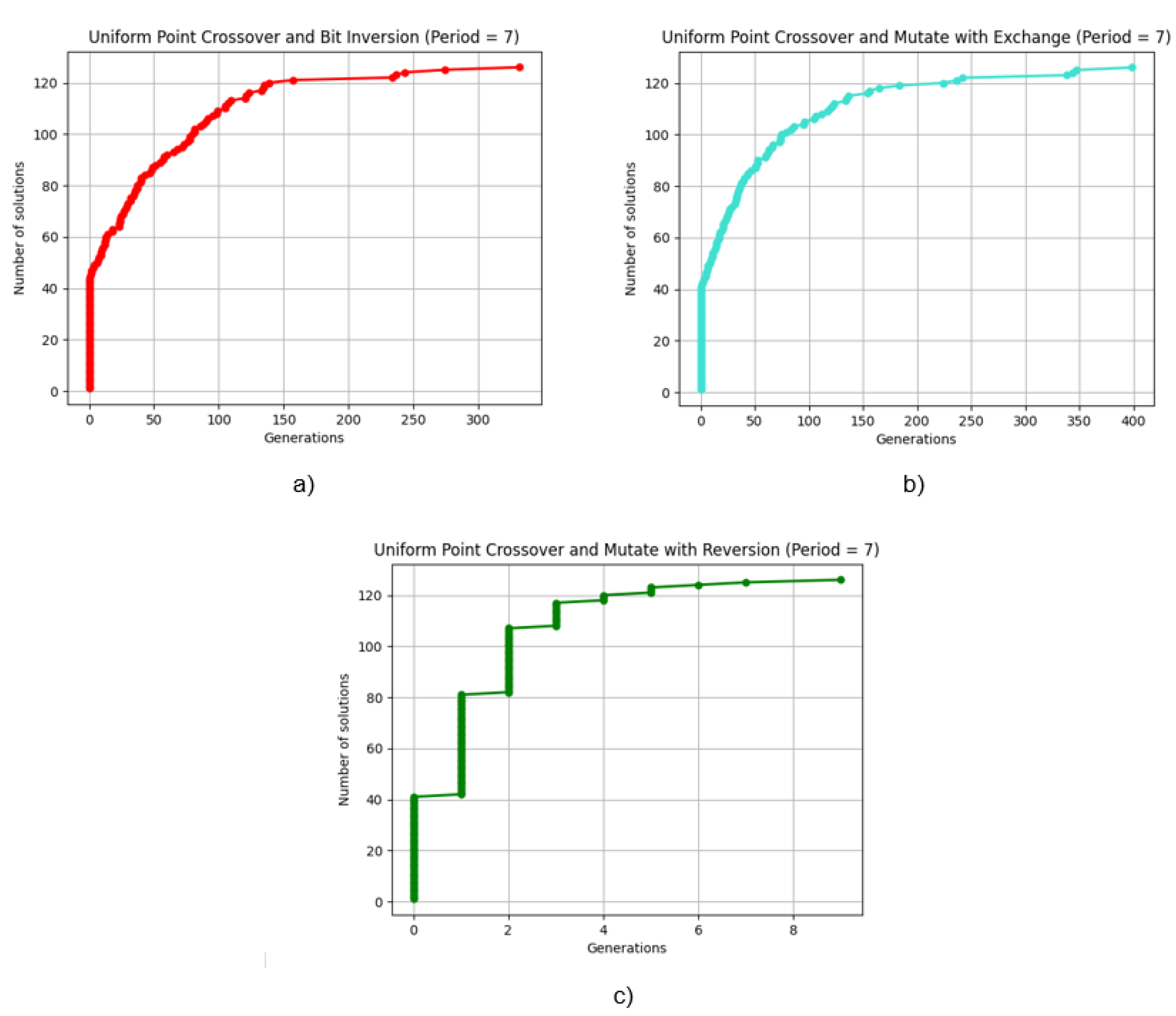
During the research, an efficient method utilizing a genetic algorithm was developed for transforming binary sequences with a size of over 100,000 elements into their periodic counterparts. This method allows for extracting all possible variations of transformation from the original sequence to its periodic form for a specific chosen period value. An analysis was conducted on all obtained variations using sequences generated with the logistic map. As a result of error calculations for a sequence of size n = 100,000 using a logistic map for periodicity, minimum errors were obtained for each value of the period from 2 to 11. For example, for period 7, the minimum error was 0.0031728354084733235. To optimize the genetic algorithm process, an algorithm called MakePeriod was developed, which yielded results in just 2 generations, as opposed to 2314 previously. The use of the MakePeriod method reduced the number of generations from 2314 to 2, which represents an improvement of 99.91%. The concept of error for nonperiodic sequences was introduced, and these errors were analyzed within the period values ranging from 2 to 11 for sequences with a size of 100,000. As the period value increases, the error value decreases, which in turn is due to the unpredictability property. The study of errors in the interval of period values can also be key to understanding which parameters and conditions can affect the accuracy of the approximation. Furthermore, a comparative analysis of three different crossover methods and three mutation methods was performed. The best results were achieved using single-point crossover with bit inversion, where a solution for a period of 7 was found in just 5 generations. As a result of analyzing the operation of the algorithm of single-point crossover with mutations, it can be noted that all three mutation variants (bit inversion, exchange, reversion) lead to a maximum value of 128. Single-point crossover with bit inversion reached the optimal solution with a period of 7 over 5 generations. This indicates the effectiveness of the algorithm when using these mutation methods in combination with single-point crossover. Crossover with uniform distribution showed the lowest performance, requiring 399 generations to reach a solution. The developed algorithm offers significant potential for application in cases involving large sequences and period values. This research approach presents significant potential for solving complex problems related to the approximation of nonperiodic sequences. The study in this work demonstrates that with an increase in the period value, the accuracy of approximation improves, making this method particularly useful for sequences with long periods. It is also important to note that this work emphasizes the importance of the correct selection of crossover and mutation methods when applying genetic algorithms to this problem, which, in turn, affects the convergence speed and efficiency of the algorithms.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}