
Root Cause Tracing Using Equipment Process Accuracy Evaluation for Looper in Hot Rolling

Abstract
:1. Introduction
- This paper initiates its approach from the foundational layer of production stability and analyzes problems that may arise in the production process, which is different from most existing work on fault diagnosis.
- An EPAE model based on the actual working process of the looper is proposed. This model aims to improve the interpretability of subsequent causal relationship modeling.
- A root-cause-tracing algorithm is proposed and its viability is assessed by using available actual production data.
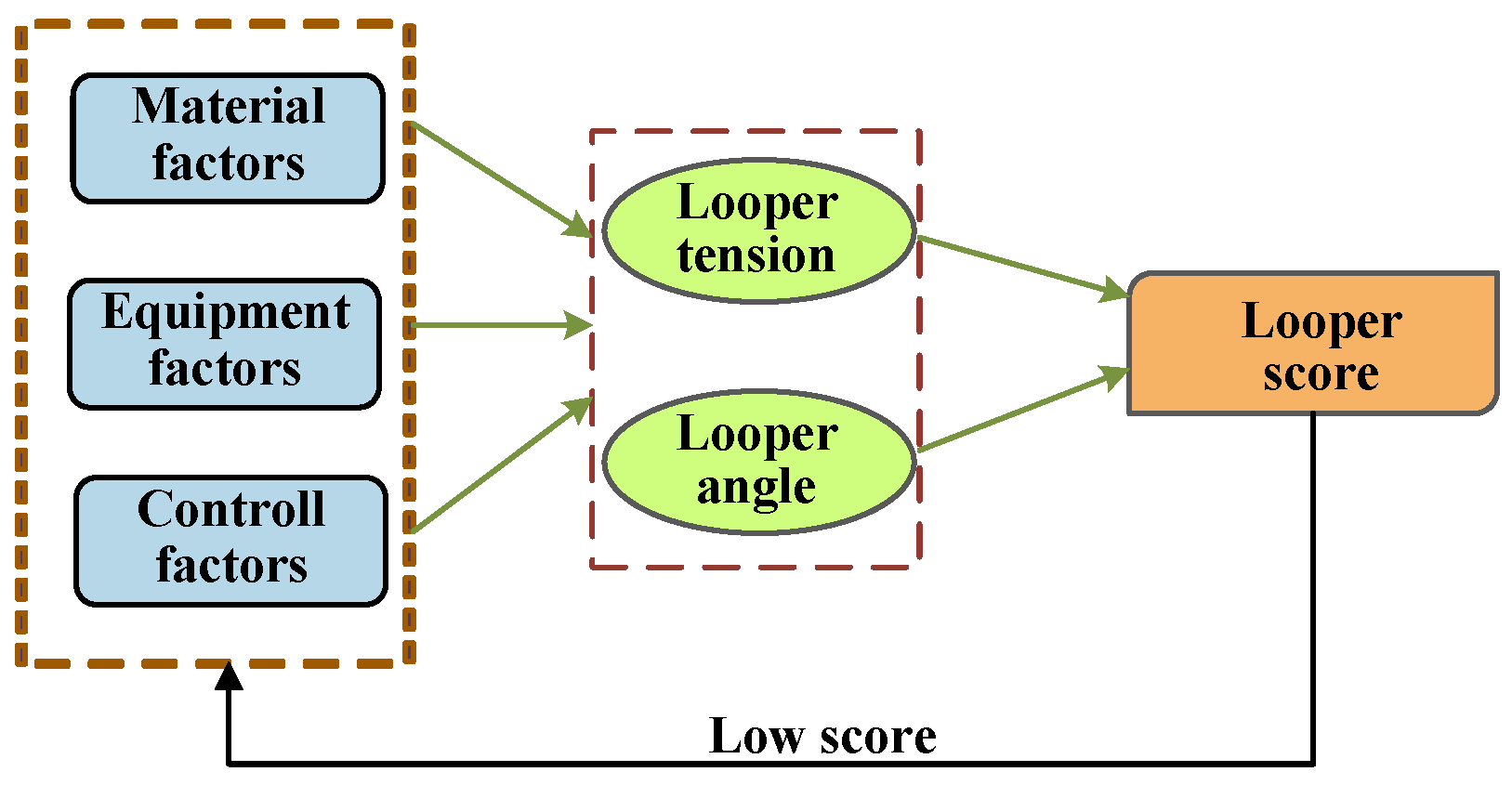
2. EPAE Model of Looper
2.1. Physical Structure of the Looper
2.2. Working Principle of the Looper
2.3. Control Accuracy of the Looper
2.3.1. Entry Process
2.3.2. Steady State Process
2.3.3. Exit Process
2.4. EPAE Model Construction of Looper
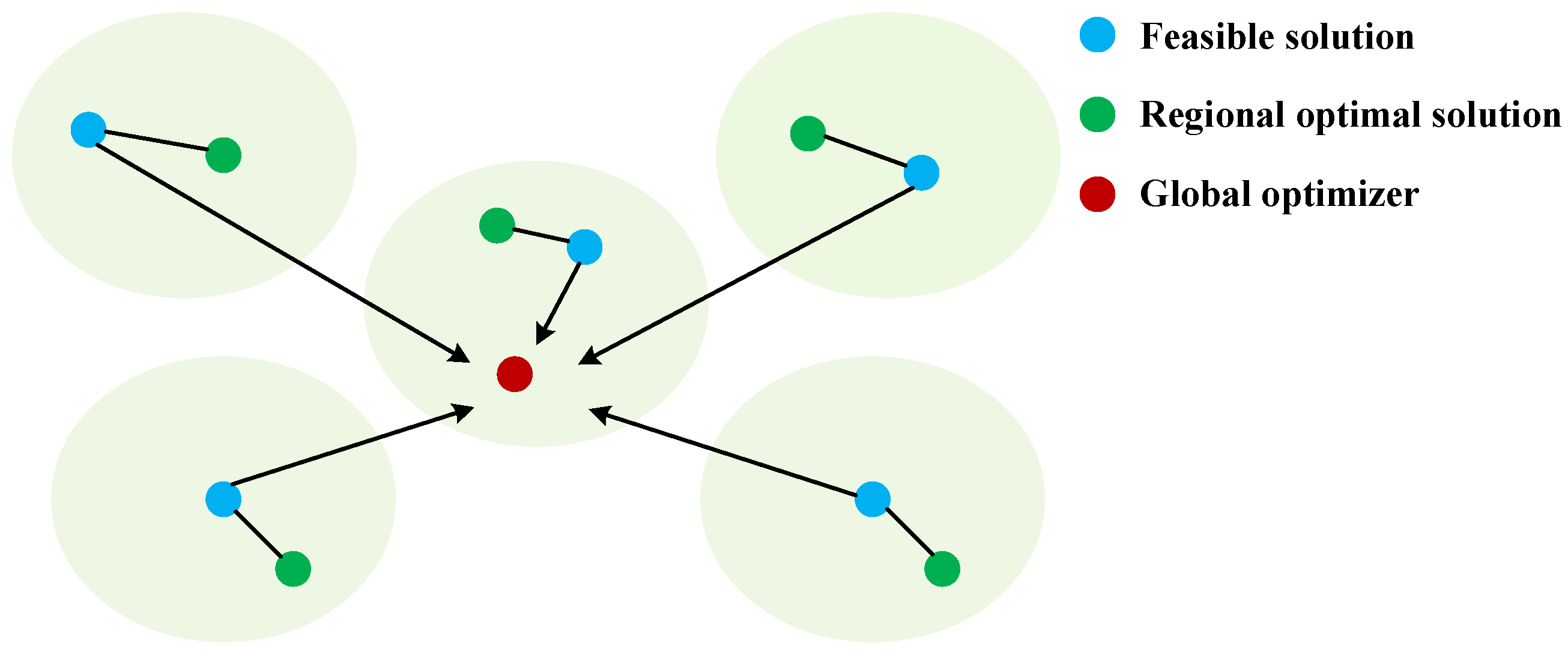
3. Root-Cause-Tracing Algorithm
3.1. Correlation Analysis between EPAE and Production Stability
3.2. Construction of Root-Cause-Tracing Algorithm
Algorithm Construction Technology
| Algorithm 1 Root-cause-tracing algorithm |
|
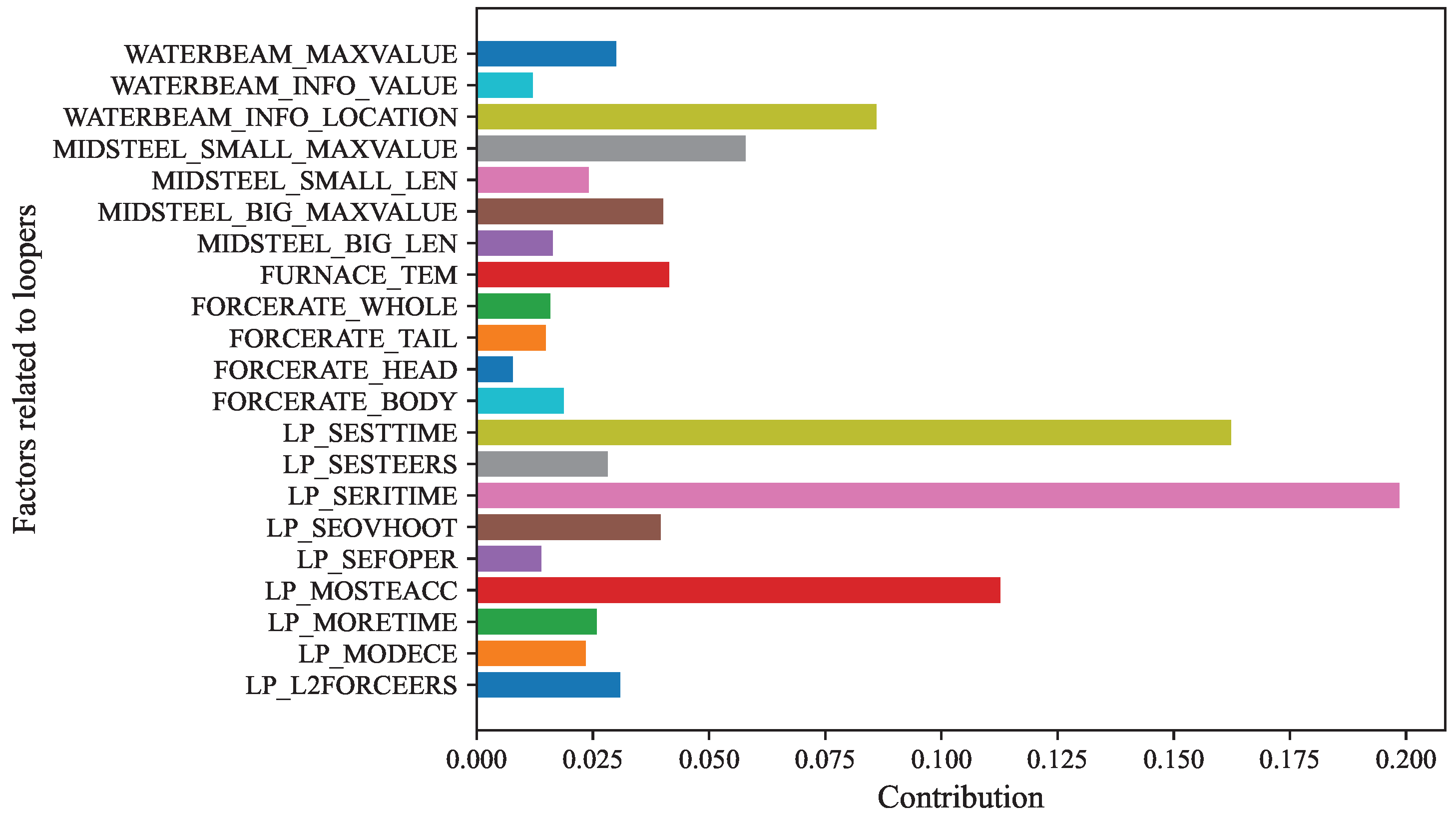
4. Experimental Results and Analysis
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pittner, J.; Simaan, M.A. An initial model for control of a tandem hot metal strip rolling process. IEEE Trans. Ind. Appl. 2009, 46, 46–53. [Google Scholar] [CrossRef]
- Brengelmans, A.; Jones, T.; Tunstall, J. Dynamic simulation of rolling on a six stand hot strip mill. In IEE Seminar on Tools for Simulation and Modelling; IET: Stevenage, UK, 2000; pp. 3/1–3/6. [Google Scholar]
- Li, X.; He, Y.; Ding, J.; Luan, F.; Zhang, D. Predicting hot-strip finish rolling thickness using stochastic configuration networks. Inf. Sci. 2022, 611, 677–689. [Google Scholar] [CrossRef]
- Song, L.; Xu, D.; Wang, X.; Yang, Q.; Ji, Y. Application of machine learning to predict and diagnose for hot-rolled strip crown. Int. J. Adv. Manuf. Technol. 2022, 120, 881–890. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.; Hwang, S.M. An analytical model for the prediction of strip temperatures in hot strip rolling. Int. J. Heat Mass Transf. 2009, 52, 1864–1874. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, Q.; Qin, S.J.; Chai, T. Dynamic concurrent kernel CCA for strip-thickness relevant fault diagnosis of continuous annealing processes. J. Process Control 2018, 67, 12–22. [Google Scholar] [CrossRef]
- Fu, W.; Jiang, X.; Li, B.; Tan, C.; Chen, B.; Chen, X. Rolling bearing fault diagnosis based on 2D time-frequency images and data augmentation technique. Meas. Sci. Technol. 2023, 34, 045005. [Google Scholar] [CrossRef]
- Han, T.; Chao, Z. Fault diagnosis of rolling bearing with uneven data distribution based on continuous wavelet transform and deep convolution generated adversarial network. J. Braz. Soc. Mech. Sci. Eng. 2021, 43, 425. [Google Scholar] [CrossRef]
- Jo, H.N.; Park, B.E.; Ji, Y.; Kim, D.K.; Yang, J.E.; Lee, I.B. Chatter detection and diagnosis in hot strip mill process with a frequency-based chatter index and modified independent component analysis. IEEE Trans. Ind. Inform. 2020, 16, 7812–7820. [Google Scholar] [CrossRef]
- Ding, S.X.; Yin, S.; Peng, K.; Hao, H.; Shen, B. A novel scheme for key performance indicator prediction and diagnosis with application to an industrial hot strip mill. IEEE Trans. Ind. Inform. 2012, 9, 2239–2247. [Google Scholar] [CrossRef]
- Yin, F.C.; Sun, J.; Ma, G.S.; Zhang, D.H. Multivariable decoupling control of hydraulic looper system based on ADAMS-MATLAB Co-simulation. J. Northeast. Univ. (Nat. Sci.) 2016, 37, 500. [Google Scholar]
- Guo, J.; Jia, R.; Su, R.; Zhao, Y. Identification of FIR Systems with Binary-Valued Observations against Data Tampering Attacks. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 5861–5873. [Google Scholar] [CrossRef]
- Guo, J.; Wang, X.; Xue, W.; Zhao, Y. System Identification with Binary-Valued Observations Under Data Tampering Attacks. IEEE Trans. Autom. Control 2021, 66, 3825–3832. [Google Scholar] [CrossRef]
- Guo, J.; Diao, J.D. Prediction-based event-triggered identification of quantized input FIR systems with quantized output observations. Sci. China Inf. Sci. 2020, 63, 112201:1–112201:12. [Google Scholar] [CrossRef]
- Choi, I.S.; Rossiter, J.A.; Fleming, P.J. Looper and tension control in hot rolling mills: A survey. J. Process Control 2007, 17, 509–521. [Google Scholar] [CrossRef]
- Militzer, M.; Hawbolt, E.B.; Meadowcroft, T.R. Microstructural model for hot strip rolling of high-strength low-alloy steels. Metall. Mater. Trans. A 2000, 31, 1247–1259. [Google Scholar] [CrossRef]
- Wu, J.; Yan, X. Coupling vibration model for hot rolling mills and its application. J. Vibroeng. 2019, 21, 1795–1809. [Google Scholar] [CrossRef]
- Park, C.J.; Lee, D.M. Input selection technology of neural network and its application for hot strip mill. Ifac Proc. Vol. 2005, 38, 51–56. [Google Scholar] [CrossRef]
- Tan, S.; Liu, J.; Wang, M. Research on the MR-ILQ design method to looper control system in hot strip rolling mills. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation, Jinan, China, 7–9 July 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2614–2617. [Google Scholar]
- Ji, Y.; Tian, M.; Guo, P.; Hu, X.; Liu, G. Optimization of Looper Control Systems for Hot Strip Mills. China Mech. Eng. 2017, 28, 410. [Google Scholar]
- Saaty, T.L. The analytic hierarchy process in conflict management. Int. J. Confl. Manag. 1990, 1, 47–68. [Google Scholar] [CrossRef]
- Wu, S.; Fu, Y.; Shen, H.; Liu, F. Using ranked weights and Shannon entropy to modify regional sustainable society index. Sustain. Cities Soc. 2018, 41, 443–448. [Google Scholar] [CrossRef]
- Wang, Y.M. Centroid defuzzification and the maximizing set and minimizing set ranking based on alpha level sets. Comput. Ind. Eng. 2009, 57, 228–236. [Google Scholar] [CrossRef]
- Cohen, I.; Huang, Y.; Chen, J.; Benesty, J.; Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Su, C.; Cao, J. Improving lazy decision tree for imbalanced classification by using skew-insensitive criteria. Appl. Intell. 2019, 49, 1127–1145. [Google Scholar] [CrossRef]
- Goh, A.T.C. Back-propagation neural networks for modeling complex systems. Artif. Intell. Eng. 1995, 9, 143–151. [Google Scholar] [CrossRef]
- Li, J.; Cheng, J.H.; Shi, J.Y.; Huang, F. Brief introduction of back propagation (BP) neural network algorithm and its improvement. In Advances in Computer Science and Information Engineering; Springer: Berlin/Heidelberg, Germany, 2012; pp. 553–558. [Google Scholar]
- Elbes, M.; Alzubi, S.; Kanan, T.; Al-Fuqaha, A.; Hawashin, B. A Survey on Particle Swarm Optimization with Emphasis on Engineering and Network Applications. Evol. Intell. 2019, 12, 113–129. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Name |
|---|---|
| Control factors | Final temperature hit Plate type Mechanical equipment |
| Material factors | Roll gap setting accuracy Surface quality Electrical equipment |
| Equipment factors | Roll force setting accuracy Width, thickness Water, gas, and thermal equipment |
| Object | Name | Symbol |
|---|---|---|
| Entry process | Starting angle | |
| Rising time | t | |
| Steady-state time | ||
| Steady-state process | Oscillation amplitude | a |
| Number of oscillations | ||
| Looper tension | ||
| Exit process | Falling time | |
| Steel-throwing tension | ||
| Small set time | ||
| Small set angle |
| Equipment | Correlation Coefficient | p-Value |
|---|---|---|
| Side Guide | −0.768 | 4.087 × |
| Looper | −0.113 | |
| Automatic Gauge Control | −0.458 | |
| Bending Roller | −0.855 | 6.627 × |
| Shifting Roller | −0.356 |
| Serial Number | Looper Corresponding Factors |
|---|---|
| 1 | LP_L2FORCEERS |
| 2 | LP_MODECE |
| 3 | LP_MORETIME |
| 4 | LP_MOSTEACC |
| 5 | LP_SEFOPER |
| 6 | LP_SEOVHOOT |
| 7 | LP_SERITIME |
| 8 | LP_SESTEERS |
| 9 | LP_SESTTIME |
| 10 | FORCERATE_HEAD |
| 11 | FORCERATE_BODY |
| 12 | FORCERATE_TAIL |
| 13 | FORCERATE_WHOLE |
| 14 | FURNACE_TEM |
| 15 | MIDSTEEL_BIG_LEN |
| 16 | MIDSTEEL_BIG_MAXVALUE |
| 17 | MIDSTEEL_SMALL_LEN |
| 18 | MIDSTEEL_SMALL_MAXVALUE |
| 19 | WATERBEAM_INFO_LOCATION |
| 20 | WATERBEAM_INFO_VALUE |
| 21 | WATERBEAM_MAXVALUE |
| Parameter | Value |
|---|---|
| Input layer node | 21 |
| Middle layer node | 7 |
| Output layer node | 2 |
| Activation function | Sigmoid function |
| Error back-propagation | Derivative of sigmoid function |
| Threshold | 0 |
| Loss function | Mean square error function |
| Parameter | Setting Value |
|---|---|
| 0.8 | |
| 0.5 | |
| 0.5 | |
| Upper bound | 1 |
| Lower bound | 0 |
| Number of particles | 50 |
| Number of iterations | 1000 |
| Tensor | 21 |
| Test Serial Number | Largest Proportion | Second Proportion | Third Proportion |
|---|---|---|---|
| 1 | LP_SERITIME 0.1926 | LP_SESTTIME 0.1670 | LP_MOSTEACC 0.1156 |
| 2 | LP_SERITIME 0.1912 | LP_SESTTIME 0.1678 | LP_MOSTEACC 0.1144 |
| 3 | LP_SERITIME 0.1896 | LP_SESTTIME 0.1668 | LP_MOSTEACC 0.1107 |
| 4 | LP_SERITIME 0.1870 | LP_SESTTIME 0.1681 | LP_MOSTEACC 0.1116 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, F.; Li, F.; Song, Y.; Li, J.; Feng, Z.; Guo , J. Root Cause Tracing Using Equipment Process Accuracy Evaluation for Looper in Hot Rolling. Algorithms 2024, 17, 102. https://doi.org/10.3390/a17030102
Jing F, Li F, Song Y, Li J, Feng Z, Guo J. Root Cause Tracing Using Equipment Process Accuracy Evaluation for Looper in Hot Rolling. Algorithms. 2024; 17(3):102. https://doi.org/10.3390/a17030102
Chicago/Turabian StyleJing, Fengwei, Fenghe Li, Yong Song, Jie Li, Zhanbiao Feng, and Jin Guo . 2024. "Root Cause Tracing Using Equipment Process Accuracy Evaluation for Looper in Hot Rolling" Algorithms 17, no. 3: 102. https://doi.org/10.3390/a17030102
APA StyleJing, F., Li, F., Song, Y., Li, J., Feng, Z., & Guo , J. (2024). Root Cause Tracing Using Equipment Process Accuracy Evaluation for Looper in Hot Rolling. Algorithms, 17(3), 102. https://doi.org/10.3390/a17030102