In this section, comprehensive experimental evaluations were conducted using our custom-developed RS dataset, ACGF, alongside the LoveDA, LandCoverNet, and PASCAL-VOC datasets. Furthermore, the proposed methodology of this paper was juxtaposed against a spectrum of contemporary RS semantic segmentation models. This comparative analysis was undertaken to substantiate the efficacy of the RRMSA-Net framework.
3.2. Ablation Study
- (1)
Evaluation on different components:
We conducted related ablation experiments on the ACGF dataset to validate the performance of the different modules proposed.
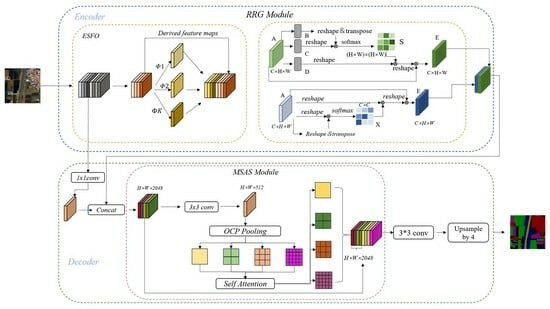
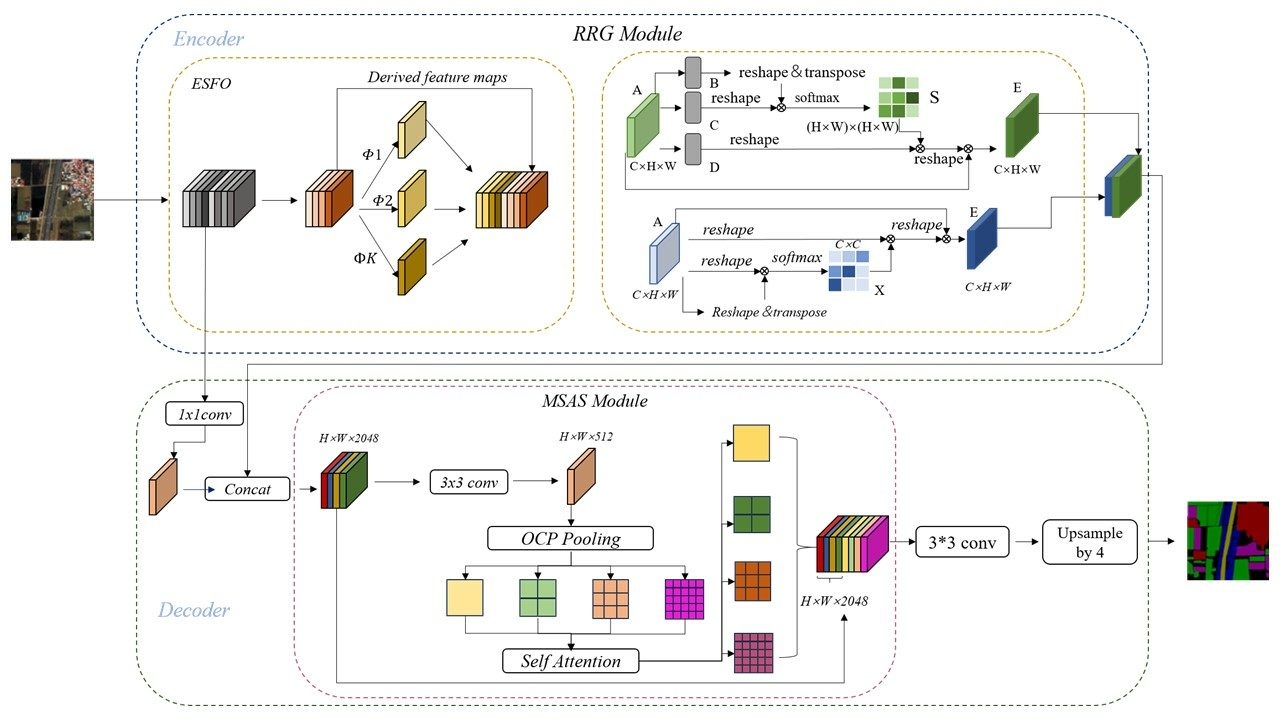
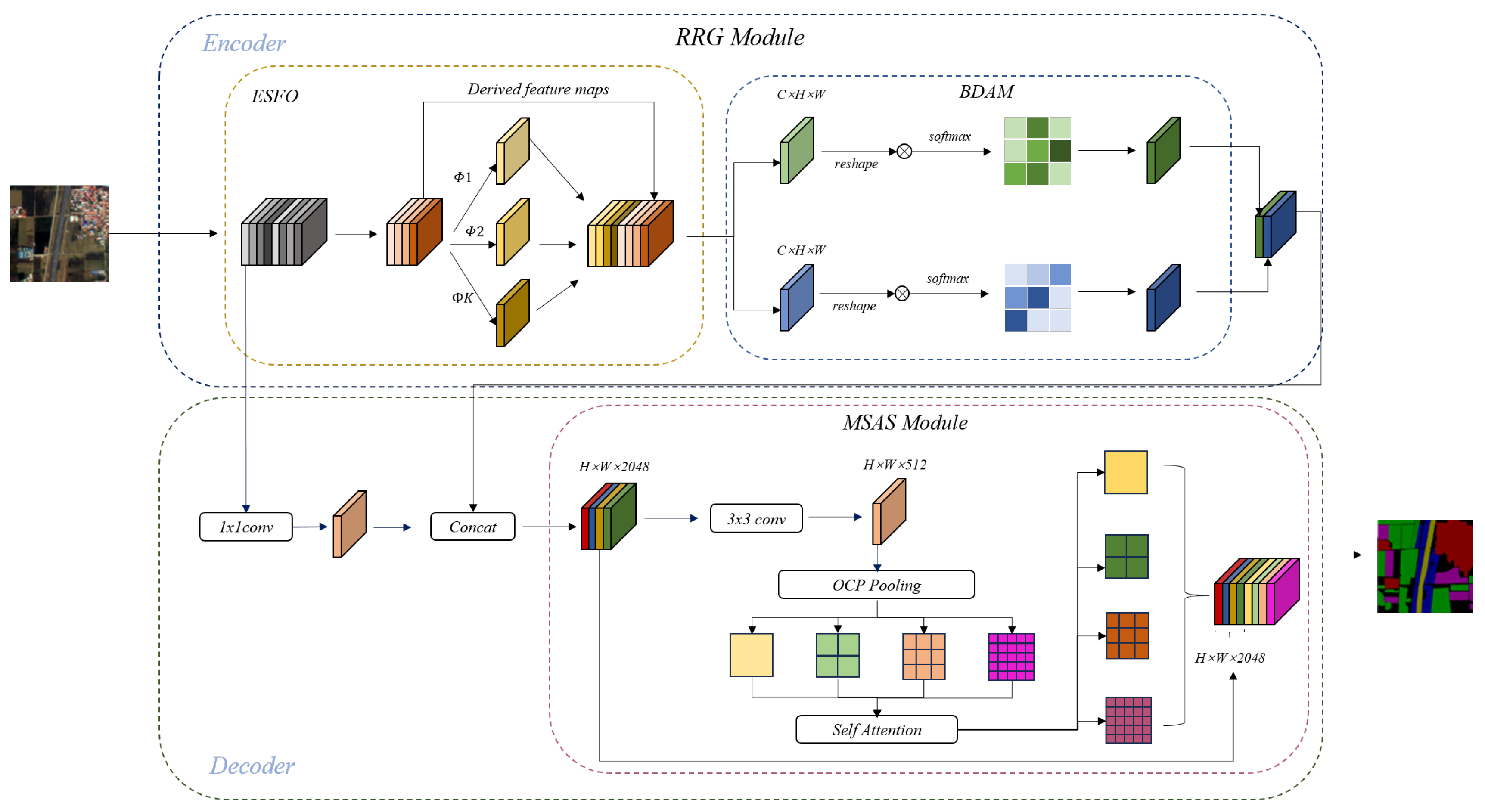
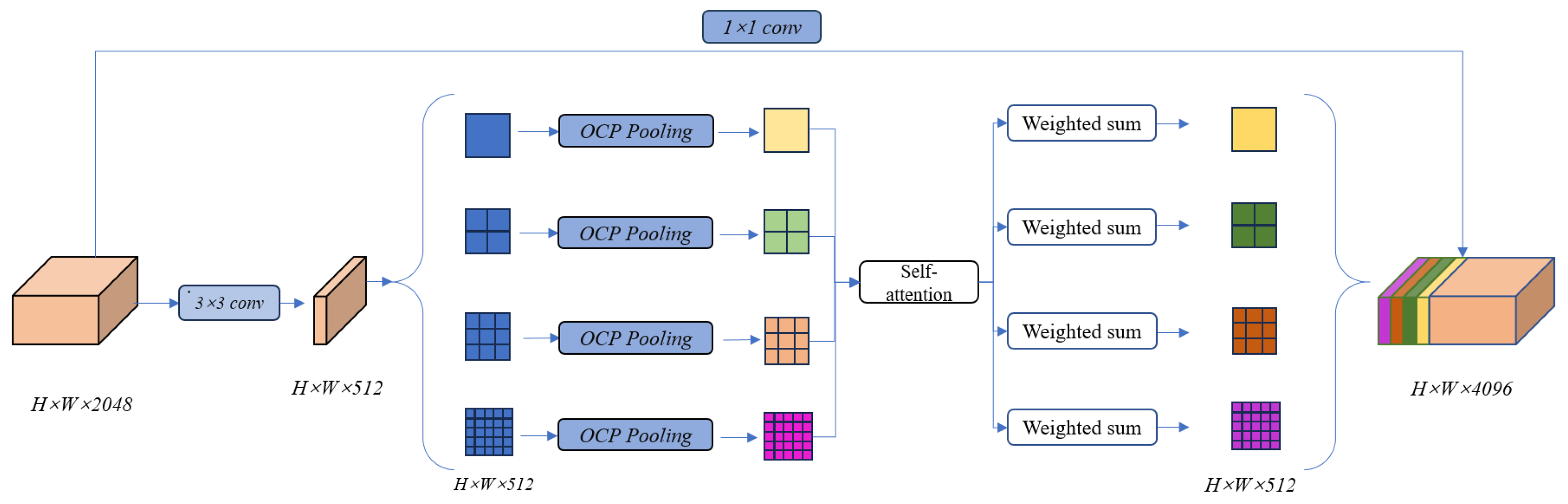
Table 1 lists the results obtained on ACGF. The baseline model only achieved an average accuracy (MIoU) of 82.9%, due to the original backbone network’s inability to effectively capture the redundant features and edge texture characteristics of winter wheat in the dataset. After using RRG, the performance of the segmenter improved by 2.5%, indicating that RRG can retain redundant feature maps while reducing memory usage, thus optimizing the overall model performance without sacrificing accuracy. With the addition of MSAS, it enables high-quality feature extraction based on the corresponding target semantic information.
In
Table 1, a check mark (🗸) indicates the usage of our designed module, while a cross mark (×) indicates otherwise. Our MSAS module has established a robust feature representation capability, leading to a 0.8% performance improvement in our RRMSA-Net. The addition of RRG resulted in a 1.5% increase in model accuracy, demonstrating that proper lightweight model design and multi-level spatial feature aggregation can further enhance segmentation precision. Similar experimental results were obtained on the VOC dataset.
Compared to networks with a single module, those with a combination of different modules achieved better performance. The integration of RRG and MSAS brought about optimization in model computational efficiency and improvement in feature quality, thereby achieving superior segmentation accuracy and classification results. Furthermore, the experiments also showed that there were no conflicts between the proposed modules. When employing the proposed approach, the model demonstrated an optimal performance of 91.3% MIoU.
- (2)
Evaluating the effectiveness of the Rapid Redundant Feature-Generation (RRG) module:
From
Table 2, we observe the following results for RRG (
) at different depths, d = 1, d = 3, d = 5, and d = 7, with corresponding values in
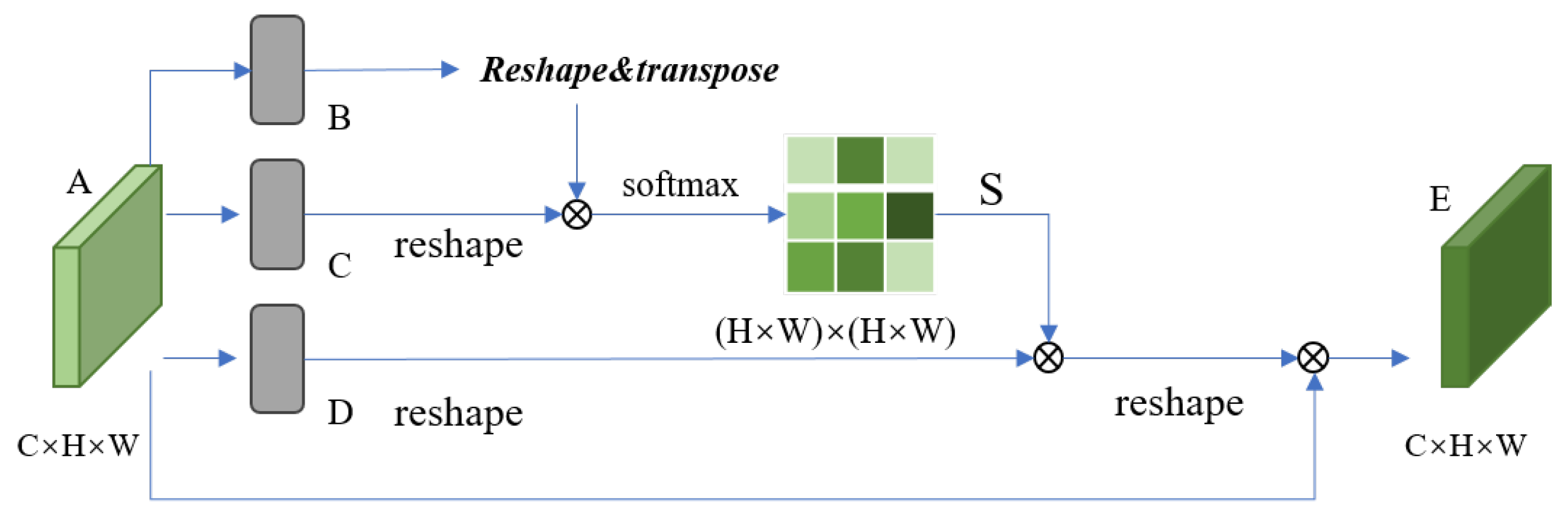
Figure 5 red, yellow, and green categories as 4.0, 3.4, 3.3, 3.2; 25.0, 24.5, 24.2, 23.7; and 12.0, 11.1, 11.0, 10.9, respectively. All the Mean-Squared Error (MSE) values are very small, indicating strong correlations between feature maps in deep neural networks, and that these redundant feature maps can be generated from a few intrinsic feature maps. Based on this correlation, excess feature maps can be efficiently derived from core feature maps. Although convolution operations were primarily used in our experiments, other low-cost linear operations could also be considered for constructing this module. However, convolution, as an efficient operation, is already well-supported by hardware devices and can implement a variety of common linear operations such as smoothing, blurring, and motion processing. Theoretically, we could adjust the size of each filter in the linear operations, but such irregular modules might reduce the computational efficiency of processing units (like CPUs and GPUs). Therefore, in our RRMSA-Net, using the RRG module is the optimal choice for achieving the best performance.
- (3)
Evaluating the effectiveness of the multi-level spatial aggregation strategy (MSAS):
We selected MSAS as the baseline and summarize all the relevant results in
Table 3. We observed that ASP-MSAS consistently improved performance in both the spatial attention (SA) and Inter-scale Attention (ISA) schemes, while MSAS showed a slight performance increase compared to the baseline object context (OC) mechanism. In Formula (3), we found that our method consistently outperformed the baseline under different group settings, and achieved the best results when the number of groups was set to eight. Therefore, in all experiments, we defaulted the number of groups to eight, enabling the model to achieve optimal performance.
3.3. Comparative Experiment
In our latest research, we integrated the Rapid Redundant Feature-Generation module and the multi-level spatial aggregation strategy into the existing architecture of DeepLabv3+, with the aim of creating a more compact and efficient model. Comprehensive experiments were conducted on the LoveDA, LandCoverNet, and PASCAL-VOC datasets.
According to the data presented in
Table 4, our RRMSA-Net model achieved approximately twice the computational acceleration and model compression while maintaining the accuracy of the original DeepLabv3+ model architecture. Compared with the latest advanced methods including Thinet [
19], NISP [
20], Versatile filters [
21], and Sparse Structure Selection (SSS) [
22], our method exhibited significantly superior performance under a two-× acceleration condition. When we further increased the hyperparameter s to four, the RRMSA-Net model experienced only a 0.3% minor drop in accuracy, while gaining about a four-× increase in computational speed, demonstrating even higher performance efficiency. This study not only validates the effectiveness of RRMSA-Net in constructing efficient deep neural networks, but also proves its ability to maintain outstanding performance in processing large-scale image-recognition tasks, even under resource-constrained conditions.
To validate the RRMSA-Net model’s capabilities in domain adaptation and handling complex backgrounds, we conducted comparative experiments on the LoveDA dataset against the PSPNet, SeNet, and HRNet models, all of which utilize the lightweight MobileNetV2 as their backbone network. The results, presented in
Table 5, indicate segmentation accuracy with the PSPNet model recording the lowest Mean Intersection over Union (MIoU) value, followed by SeNet and HRNet [
23]. This outcome suggests a shortfall in the feature-extraction capabilities of PSPNet, SeNet, and HRNet, particularly in distinguishing between urban and rural scene features within the LoveDA dataset. Rural scenes are predominantly composed of a few man-made features, like buildings and roads, alongside a vast number of natural objects, such as woodlands. Urban scenes, conversely, feature a blend of buildings and roads, with fewer natural elements. This variance in sample distribution and scale diversity poses challenges for the compared models in accurately classifying land objects.
RRMSA-Net enhances feature representation through the RRG module, utilizing the Expand Spatial Feature Overlay (ESFO) strategy and the Boundary Definition and Management (BDAM) mechanism to highlight critical features. Concurrently, the Multi-Scale Aggregation Scheme (MSAS) module improves the model’s grasp on contextual semantics by aggregating neighboring pixels. This comprehensive approach propelled the RRMSA-Net’s MIoU value to 91.3%. These findings underscore RRMSA-Net’s superior performance in processing remote sensing images with pronounced urban–rural contrasts, showcasing its strengths in multi-scale target recognition and domain adaptation.
In
Table 6, to verify the generalization ability of the RRMSA-Net model in macro land cover classification tasks, we performed a comparative experiment using the LandCoverNet dataset with the RefineNet [
24], SGR [
25], and ACNet [
26] models. All the compared models utilize ResNet-101 as the backbone network, and the experimental results are presented in
Table 6. In terms of segmentation accuracy, RefineNet exhibited the lowest MIoU value, while SGR and ACNet showed marginal improvements compared to RefineNet. The analysis revealed that the macro-geographical nature of the LandCoverNet dataset poses a challenge, indicating limitations in the generalization performance of the compared models across varying geographical environments. Additionally, the dataset employed 10 m resolution remote sensing images, which cannot offer precise pixel information akin to other high-resolution remote sensing images. This might have posed difficulties for the comparison models in identifying and extracting fine details from the images, thereby affecting segmentation accuracy. In comparison to the other three models, RRMSA-Net achieved a superior MIoU value of 45.21%. This is due to the enhanced understanding of the underlying semantic information of target features in remote sensing imagery provided by the RRG and MSAS modules. The results underscore the versatility of the RRMSA-NET model in handling diverse geographical regions and land types.
In
Table 7, to assess the capability of the RRMSA-Net model in processing unmanned aerial vehicle (UAV) imagery tasks, we conducted comparative experiments using the DroneDeploy dataset against models such as Attention+SSL [
27], CE2P [
28], and CNIF [
29], all of which incorporate the RRG module as their backbone network. The results are presented in
Table 3. In terms of segmentation accuracy, the model with Attention + SSL applied to PSPNet recorded the lowest Mean Intersection over Union (MIoU) value, followed by CE2P and CNIF. This outcome can be attributed to the susceptibility of UAV imagery to lighting conditions; shadows can obscure ground features, complicating the identification of areas concealed by shadows for the comparative models. Additionally, Attention + SSL, CE2P, and CNIF did not effectively retain sufficient detail when extracting higher level abstract features, failing to achieve a balance between global context and local detail information, which resulted in lower segmentation accuracy. In contrast, RRMSA-Net achieved the best performance with an MIoU value of 57.39%, thanks to the MSAS module’s employment of a sparse self-attention mechanism, which enhanced the model’s focus on target features, thereby improving segmentation accuracy. These findings underscore the RRMSA-Net model’s utility and robustness in handling UAV aerial imagery.
To validate the generalization ability of the RRMSA-Net model in macroscopic land cover classification tasks, comparative experiments were conducted based on the PASCAL VOC dataset against models such as U-Net [
30], the FCN, and SegNet [
31], all of which utilize RRG as their backbone network. The experimental results are shown in
Table 8. In terms of segmentation accuracy, the MIoU value of the FCN was the lowest, with U-Net and SegNet showing certain improvements over the FCN. The analysis suggests that this is due to the PASCAL VOC dataset including images under various illumination conditions, scales, and occlusions. The comparative models struggle to correctly identify areas obscured by shadows, as they lose detail information during the convolution and pooling processes. Furthermore, the presence of objects at different scales in the images makes it challenging for the models to segment all scale pairs accurately, thereby affecting the segmentation precision of the models. In contrast, the MIoU of RRMSA-Net reached the highest value of 86.35%, attributed to the RRG module and MSAS module enhancing the model’s understanding of the underlying semantic information of terrestrial objects in remote sensing images. This result demonstrates the RRMSA-NET model’s applicability in processing different geographical areas and land types.
The experimental results fully demonstrate the effectiveness of our proposed RRMSA-Net in enhancing the performance of deep neural networks, especially in handling complex semantic segmentation tasks, effectively improving the accuracy and efficiency of the model.
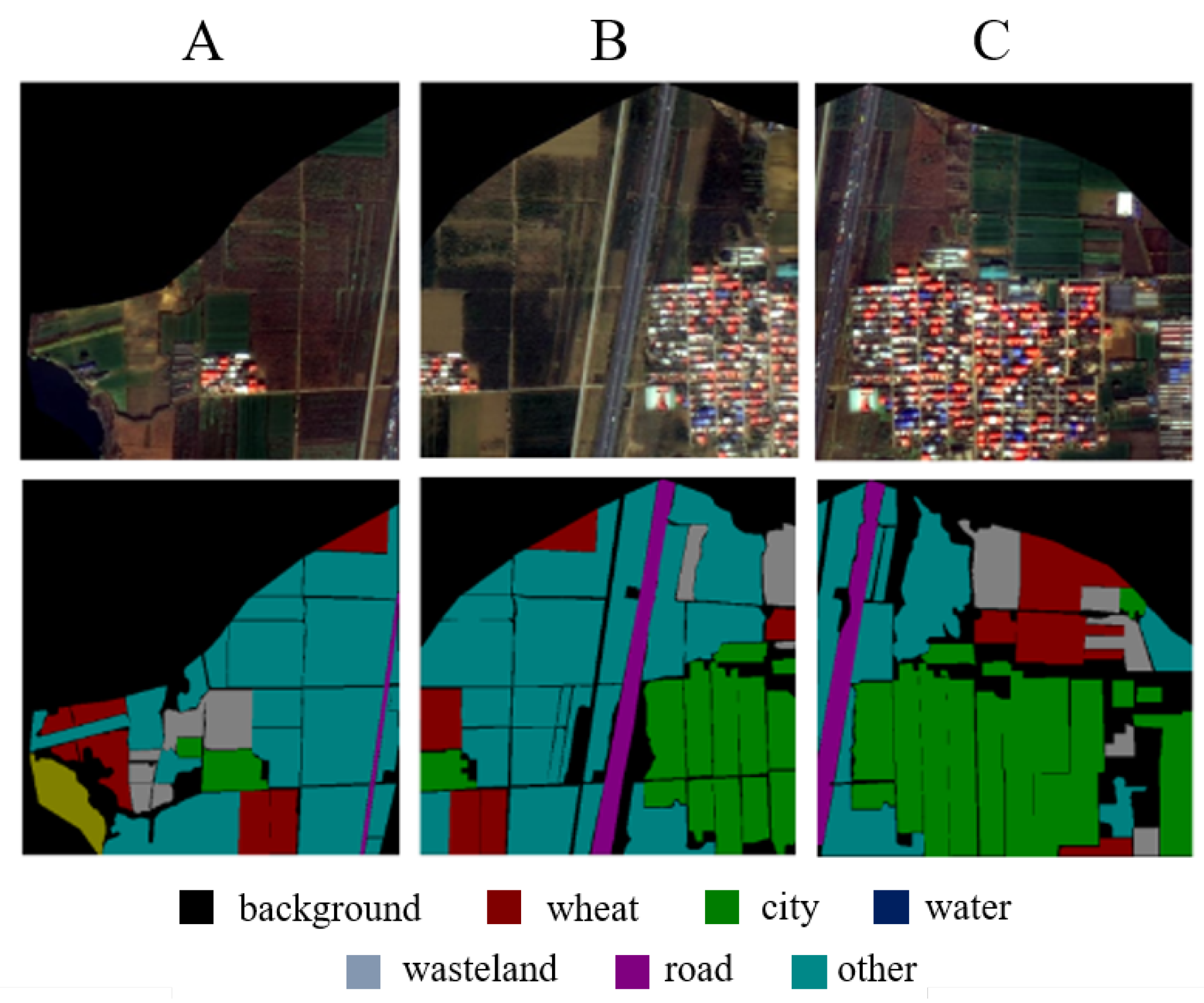
To validate the generalization capability of RRMSA-Net, we applied it to the ACGF agricultural dataset, focusing on the extraction of winter wheat distribution.
Figure 6A demonstrates the significant advantage of RRMSA-Net in extracting winter wheat, particularly in terms of boundary segmentation. The boundaries of the winter wheat are more distinct and retain finer details, avoiding excessive smoothing of edges.
Figure 6B highlights the model’s exceptional performance in extracting other crops, with smoother and more precise edge processing. The model accurately identifies the corners of crop fields, showing notable precision. Moreover, the extraction of urban roads is comprehensive, showcasing the model’s capability to achieve high segmentation accuracy.
Figure 6C illustrates precise urban area extraction, accurately segmenting different sections of the city and clearly delineating the boundaries between roads and their surroundings. This underscores RRMSA-Net’s proficiency in recognizing and segmenting edge features in complex urban scenes, further affirming its effectiveness in precise object recognition.
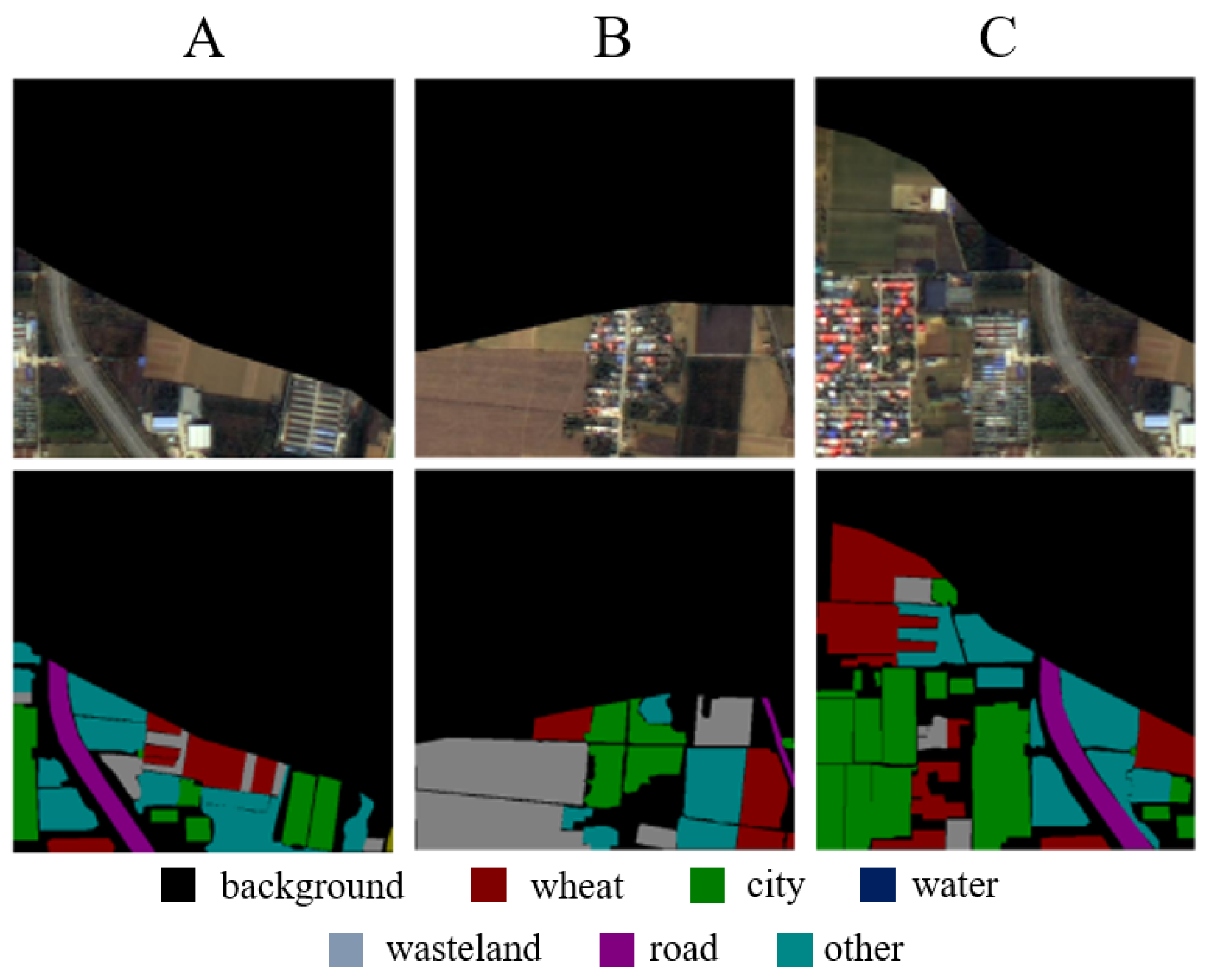
In
Figure 7A, RRMSA-Net successfully differentiates between other crops and winter wheat, achieving pronounced clarity in boundary delineation. It skillfully identifies urban and barren landscapes amidst winter wheat, accurately outlining their contours and perimeters. This demonstrates its ability to discern and distinguish between different terrain features. In
Figure 7B, the model adeptly navigates transitions between roads, urban spaces, and wheat fields, showcasing its precision in road delineation and maintaining segmentation accuracy across natural terrains.
Figure 7C introduces urban topographical segmentation, where RRMSA-Net precisely demarcates city areas with smoother boundaries. The consistency in edge detection across roads and various crops underscores the model’s ability to accurately capture category-specific information for distinct types of land.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}