A Regularized Raking Estimator for Small-Area Mapping from Forest Inventory Surveys

Abstract
:1. Introduction
- Accommodate multiple sources of ancillary information;
- Be applicable to all survey characteristics;
- Allow mathematical consistency with published estimates at large-scales;
- Maintain reasonable properties regarding the increase of uncertainty and variance that can be expected with small-area estimation.
2. Background
2.1. Survey Estimation
2.1.1. The Raking Estimator
2.1.2. The Generalized Regression Estimator
2.1.3. Regularized GREG
2.1.4. Regularized Raking
2.2. Related Work
3. Data
Forest Inventory and Analysis
4. Methods
- Patch level: estimates of the nine-class land use/forest-type classification (180 unique patches × 9 classes × 3 survey units = 4860 ancillary totals);
- Patch level estimates of the two-class forest/non-forest land use (180 × 2 × 3) = 1080 ancillary totals);
- Patch level estimates of forest volume (180 × 3 = 540 ancillary totals);
- County size (45 ancillary totals), where the variance of county size was set to 0 so that the expansion factors could reproduce them accurately.
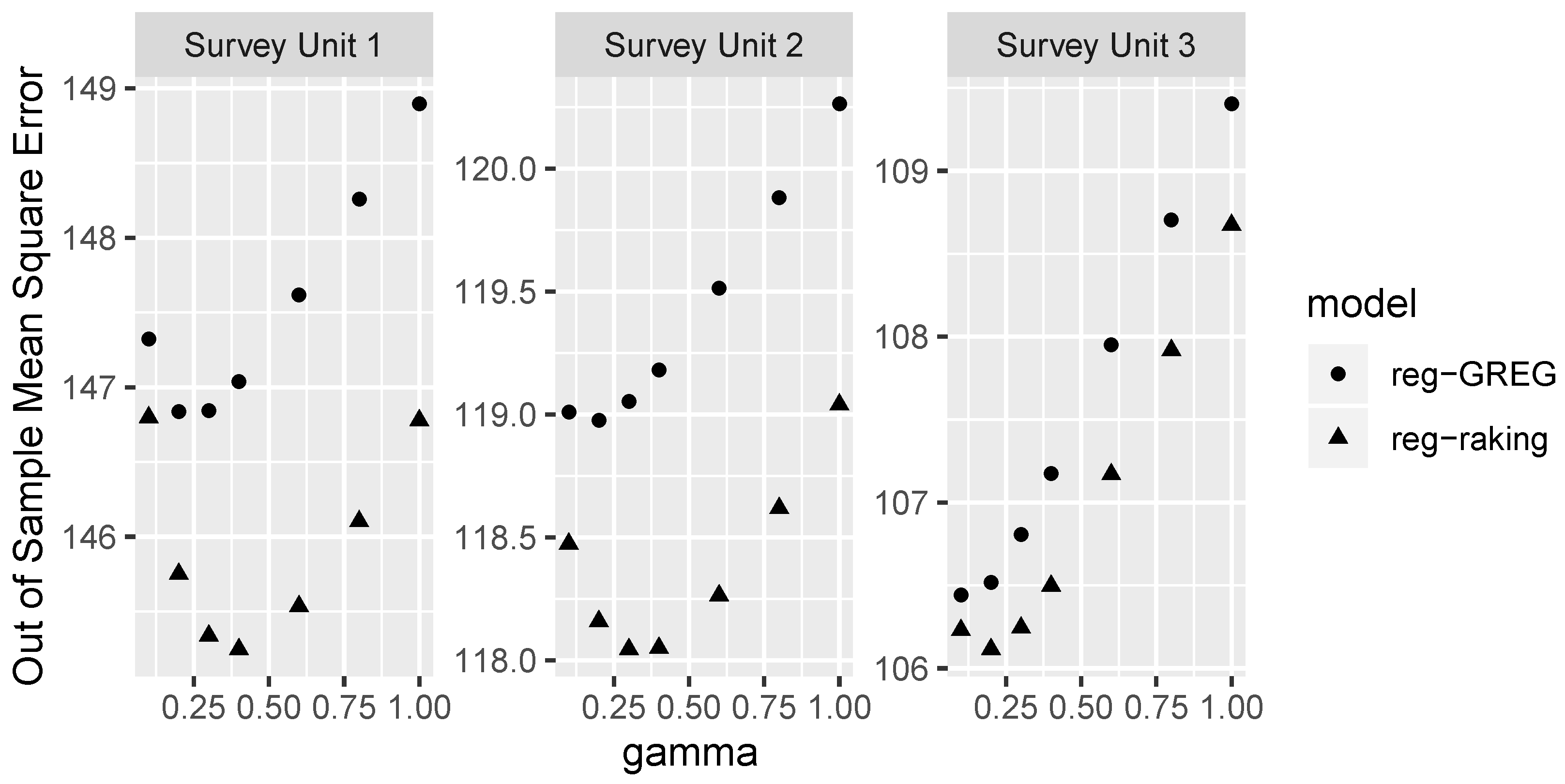
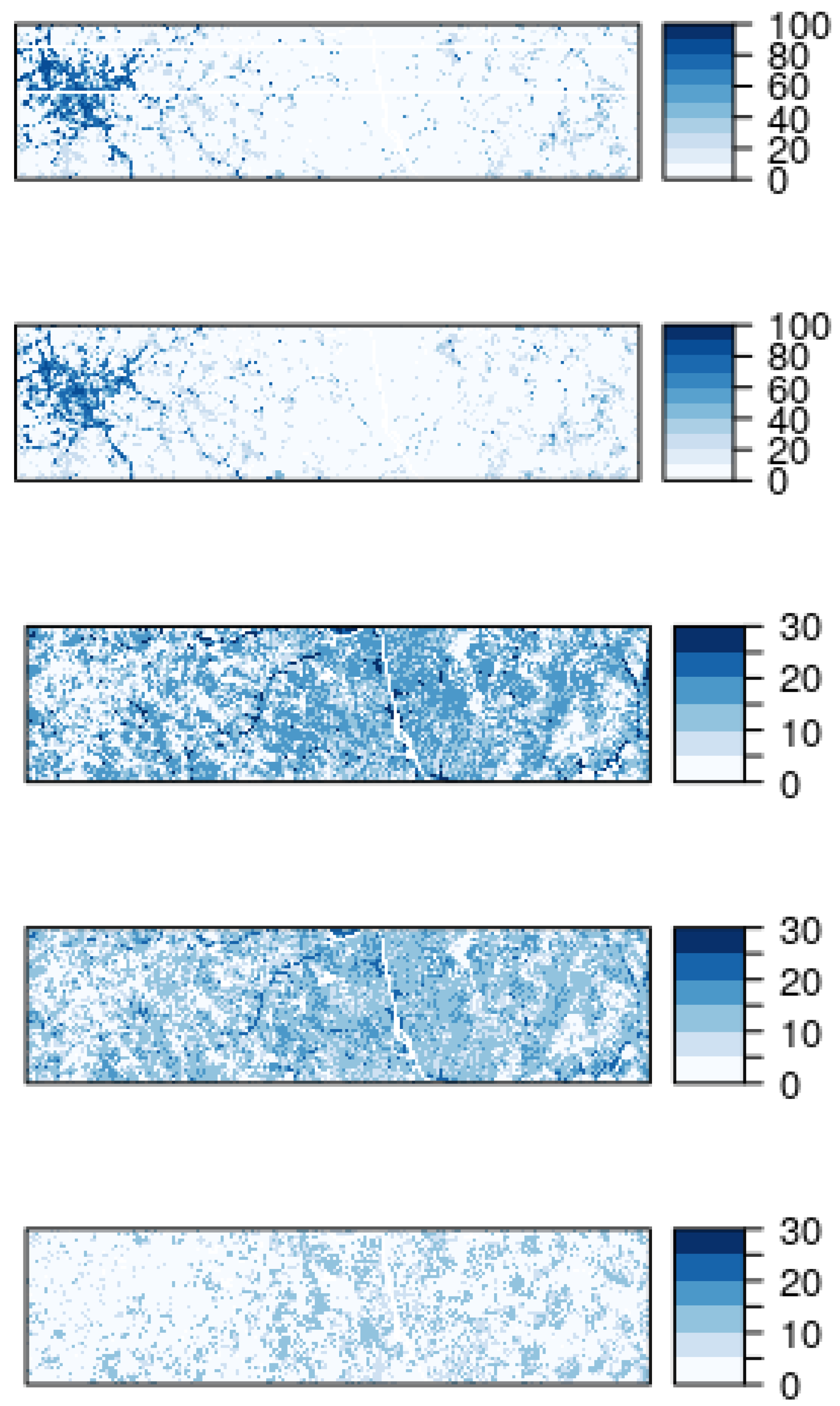
5. Results
5.1. Comparison of Raking and GREG Expansion Factors
5.2. Prediction Maps
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random Forests for Classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Healey, S.P.; Cohen, W.B.; Yang, Z.; Kenneth Brewer, C.; Brooks, E.B.; Gorelick, N.; Hernandez, A.J.; Huang, C.; Hughes, M.J.; Kennedy, R.E.; et al. Mapping forest change using stacked generalization: An ensemble approach. Remote Sens. Environ. 2018, 204, 717–728. [Google Scholar] [CrossRef]
- Schroeder, T.A.; Schleeweis, K.G.; Moisen, G.G.; Toney, C.; Cohen, W.B.; Freeman, E.A.; Yang, Z.; Huang, C. Testing a Landsat-based approach for mapping disturbance causality in U.S. forests. Remote Sens. Environ. 2017, 195, 230–243. [Google Scholar] [CrossRef]
- Cushman, S.A.; Macdonald, E.A.; Landguth, E.L.; Malhi, Y.; Macdonald, D.W. Multiple-scale prediction of forest loss risk across Borneo. Landsc. Ecol. 2017, 32, 1581–1598. [Google Scholar] [CrossRef]
- Kumar, R.; Nandy, S.; Agarwal, R.; Kushwaha, S.P.S. Forest cover dynamics analysis and prediction modeling using logistic regression model. Ecol. Indic. 2014, 45, 444–455. [Google Scholar] [CrossRef]
- Dlamini, W.M. A data mining approach to predictive vegetation mapping using probabilistic graphical models. Ecol. Informat. 2011, 6, 111–124. [Google Scholar] [CrossRef]
- Blackard, J.A.; Finco, M.V.; Helmer, E.H.; Holden, G.R.; Hoppus, M.L.; Jacobs, D.M.; Lister, A.J.; Moisen, G.G.; Nelson, M.D.; Riemann, R.; et al. forest biomass using nationwide forest inventory data and moderate resolution information. Remote Sens. Environ. 2008, 112, 1658–1677. [Google Scholar] [CrossRef]
- Powell, S.L.; Cohen, W.B.; Healey, S.P.; Kennedy, R.E.; Moisen, G.G.; Pierce, K.B.; Ohmann, J.L. Quantification of live aboveground forest biomass dynamics with Landsat time-series and field inventory data: A comparison of empirical modeling approaches. Remote Sens. Environ. 2010, 114, 1053–1068. [Google Scholar] [CrossRef]
- Ruefenacht, B.; Finco, M.V.; Nelson, M.D.; Czaplewski, R.; Helmer, E.H.; Blackard, J.A.; Holden, G.R.; Lister, A.J.; Salajanu, D.; Weyermann, D.; et al. Conterminous U.S. and Alaska Forest Type Mapping Using Forest Inventory and Analysis Data. Photogramm. Eng. Remote Sens. 2008, 74, 1379–1388. [Google Scholar] [CrossRef]
- Moisen, G.G.; Meyer, M.C.; Schroeder, T.A.; Liao, X.; Schleeweis, K.G.; Freeman, E.A.; Toney, C. Shape selection in Landsat time series: A tool for monitoring forest dynamics. Glob. Chang. Biol. 2016, 22, 3518–3528. [Google Scholar] [CrossRef] [PubMed]
- Finley, A.O.; McRoberts, R.E. Efficient k-nearest neighbor searches for multi-source forest attribute mapping. Remote Sens. Environ. 2008, 112, 2203–2211. [Google Scholar] [CrossRef]
- McRoberts, R.E. Estimating forest attribute parameters for small areas using nearest neighbors techniques. For. Ecol. Manag. 2012, 272, 3–12. [Google Scholar] [CrossRef]
- Ohmann, J.L.; Gregory, M.J. Predictive mapping of forest composition and structure with direct gradient analysis and nearest-neighbor imputation in coastal Oregon, U.S.A. Can. J. For. Res. 2002, 32, 725–741. [Google Scholar] [CrossRef]
- Oliver, M.A.; Webster, R. Kriging: A method of interpolation for geographical information systems. Int. J. Geogr. Inf. Syst. 1990, 4, 313–332. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G.G. Evaluating kriging as a tool to improve moderate resolution maps of forest biomass. Environ. Monit. Assess. 2007, 128, 395–410. [Google Scholar] [CrossRef]
- Temesgen, H.; Hoef, J.M.V. Evaluation of the spatial linear model, random forest and gradient nearest-neighbour methods for imputing potential productivity and biomass of the Pacific Northwest forests. Forestry 2015, 88, 131–142. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Ohmann, J.; Gregory, M.; Roberts, H.; Yang, Z.; Bell, D.M.; Kane, V.; Hughes, M.J.; Cohen, W.B.; Powell, S. An empirical, integrated forest biomass monitoring system. Environ. Res. Lett. 2018, 13, 025004. [Google Scholar] [CrossRef]
- Franco-Lopez, H.; Ek, A.R.; Bauer, M.E. Estimation and mapping of forest stand density, volume, and cover type using the k-nearest neighbors method. Remote Sens. Environ. 2001, 77, 251–274. [Google Scholar] [CrossRef]
- Wilson, B.T.; Lister, A.J.; Riemann, R.I. A nearest-neighbor imputation approach to mapping tree species over large areas using forest inventory plots and moderate resolution raster data. For. Ecol. Manag. 2012, 271, 182–198. [Google Scholar] [CrossRef]
- Bechtold, W.A.; Patterson, P.L. The enhanced forest inventory and analysis program—National sampling design and estimation procedures. In General Technical Report SRS-80; Technical Report; US Department of Agriculture, Forest Service, Southern Research Station: Asheville, NC, USA, 2005. [Google Scholar]
- Nagle, N.N.; Buttenfield, B.P.; Leyk, S.; Spielman, S. Dasymetric Modeling and Uncertainty. Ann. Assoc. Am. Geogr. 2014, 104, 80–95. [Google Scholar] [CrossRef] [PubMed]
- Riley, K.L.; Grenfell, I.C.; Finney, M.A. Mapping forest vegetation for the western United States using modified random forests imputation of FIA forest plots. Ecosphere 2016, 7, e01472. [Google Scholar] [CrossRef]
- Guggemos, F.; Tille, Y. Penalized calibration in survey sampling: Design-based estimation assisted by mixed models. J. Stat. Plan. Inference 2010, 140, 3199–3212. [Google Scholar] [CrossRef]
- McConville, K.S.; Breidt, F.J.; Lee, T.C.M.; Moisen, G.G. Model-Assisted Survey Regression Estimation with the Lasso. J. Surv. Stat. Methodol. 2017, 5, 131–158. [Google Scholar] [CrossRef]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Thompson, S.K. Sampling; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- McRoberts, R.E.; Wendt, D.G.; Nelson, M.D.; Hansen, M.H. Using a land cover classification based on satellite imagery to improve the precision of forest inventory area estimates. Remote Sens. Environ. 2002, 81, 36–44. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Holden, G.R.; Nelson, M.D.; Liknes, G.C.; Gormanson, D.D. Using satellite imagery as ancillary data for increasing the precision of estimates for the Forest Inventory and Analysis program of the USDA Forest Service. Can. J. For. Res. 2005, 35, 2968–2980. [Google Scholar] [CrossRef]
- Burrill, E.A.; Wilson, A.M.; Turner, J.A.; Pugh, S.A.; Menlove, J.; Christiansen, G.; Conkling, B.L.; David, W. The Forest Inventory and Analysis Database; US Department of Agriculture, Forest Service. Available online: http://www.fia.fs.fed.us/library/database-documentation/ (accessed on 10 November 2019).
- Lumley, T. Complex Surveys; A Guide to Analysis Using R; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Deville, J.C.; Sarndal, C.E.; Sautory, O. Generalized Raking Procedures in Survey Sampling. J. Am. Stat. Assoc. 1993, 88, 1–9. [Google Scholar] [CrossRef]
- Deville, J.C.; Särndal, C.E. Calibration Estimators in Survey Sampling. J. Am. Stat. Assoc. 1992, 87, 376–382. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Drury, S.A.; Herynk, J.M. The national tree-list layer. In General Technical Report RMRS-GTR; U.S. Department of Agriculture, Forest Service: Fort Collins, CO, USA, 2011; Volume 254, pp. 1–26. [Google Scholar]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the Conterminous United States Representing a Decade of Land Cover Change Information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Breidt, F.J.; Opsomer, J.D. Endogenous post-stratification in surveys: Classifying with a sample-fitted model. Ann. Stat. 2008, 36, 403–427. [Google Scholar] [CrossRef]
- Huang, C.; Goward, S.N.; Masek, J.G.; Thomas, N.; Zhu, Z.; Vogelmann, J.E. An automated approach for reconstructing recent forest disturbance history using dense Landsat time series stacks. Remote Sens. Environ. 2010, 114, 183–198. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| i | index of (possible) location |
| s | the set of survey locations |
| n | the number of survey locations |
| U | Study domain (the set of locations in the population) |
| N | the size of the study domain U |
| t | index of patches |
| Patch t (a spatial unit) | |
| j | index of auxiliary total |
| auxiliary total | |
| standard deviation of | |
| Auxiliary region j (a spatial unit) | |
| k | index of survey characteristic |
| survey measurement of characteristic k at location i | |
| ℓ | index of auxiliary characteristic |
| survey measurement of characteristic ℓ at location i | |
| design weight | |
| expansion factor | |
| regularization factor |
| Group | Class | FIA Database Definition |
|---|---|---|
| Forest | Eastern Softwood | LAND_USE_SRS in (1,2) AND FORTYPCD in (100–199) |
| Oak/Pine | LAND_USE_SRS in (1,2) AND FORTYPCD in (400–499) | |
| Oak/Hickory | LAND_USE_SRS in (1,2) AND FORTYPCD in (500–599; 800–998) | |
| Bottomland Hardwood | LAND_USE_SRS in (1,2) AND FORTYPCD in (600–699) | |
| Not Forest | Not Stocked | LAND_USE_SRS in (1,2) AND FORTYPCD in 999 |
| Agriculture | LAND_USE_SRS in (10–19) | |
| Urban/Developed | LAND_USE_SRS in (30–39) | |
| Barren | LAND_USE_SRS in (40–49) | |
| Water/Wetland | LAND_USE_SRS in (90–99) |
| GREG Weights | Raking Weights | |||
|---|---|---|---|---|
| Gamma | min | max | min | max |
| 0.1 | −151.58 | 2381.00 | <1.00 | 2930.64 |
| 0.2 | −113.37 | 2029.45 | <1.00 | 2833.97 |
| 0.3 | −87.17 | 1776.99 | <1.00 | 2744.86 |
| 0.4 | −75.52 | 1586.54 | <1.00 | 2659.87 |
| 0.6 | −76.66 | 1317.79 | <1.00 | 2498.54 |
| 0.8 | −77.93 | 1136.75 | <1.00 | 2346.58 |
| 1.0 | −78.73 | 1006.18 | <1.00 | 2203.08 |
| 2.0 | −78.66 | 672.69 | 4.00 | 1604.76 |
| 8.0 | −72.25 | 323.54 | 1.49 | 465.47 |
| 30.0 | −49.23 | 203.38 | 4.51 | 219.71 |
| 100.0 | 5.75 | 161.34 | 5.80 | 161.60 |
| Variable | Plot | County |
|---|---|---|
| Forest Land Use | 0.65 | 0.83 |
| Oak Pine Forest Type | 0.49 | 0.86 |
| Eastern Softwood Forest Type | 0.59 | 0.91 |
| Volume | 0.27 | 0.79 |
| Basal Area | 0.68 | 0.88 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagle, N.N.; Schroeder, T.A.; Rose, B. A Regularized Raking Estimator for Small-Area Mapping from Forest Inventory Surveys. Forests 2019, 10, 1045. https://doi.org/10.3390/f10111045
Nagle NN, Schroeder TA, Rose B. A Regularized Raking Estimator for Small-Area Mapping from Forest Inventory Surveys. Forests. 2019; 10(11):1045. https://doi.org/10.3390/f10111045
Chicago/Turabian StyleNagle, Nicholas N., Todd A. Schroeder, and Brooke Rose. 2019. "A Regularized Raking Estimator for Small-Area Mapping from Forest Inventory Surveys" Forests 10, no. 11: 1045. https://doi.org/10.3390/f10111045
APA StyleNagle, N. N., Schroeder, T. A., & Rose, B. (2019). A Regularized Raking Estimator for Small-Area Mapping from Forest Inventory Surveys. Forests, 10(11), 1045. https://doi.org/10.3390/f10111045