
Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass




Abstract
:1. Introduction
- (1)
- Compare and analyze AGB prediction models of different forest types by combining three feature selection methods (recursive feature elimination (RFE), variable selection using random forests (VSURF) and least absolute shrinkage and selection operator (LASSO)) and three regression algorithms (random forest regression (RFR), XGBoost, and CatBoost);
- (2)
- Evaluate the accuracy of the CatBoost algorithm for AGB estimation and compare it with the RFR and XGBoost algorithms;
- (3)
- Identify the best input variables for AGB estimation by feature selection.
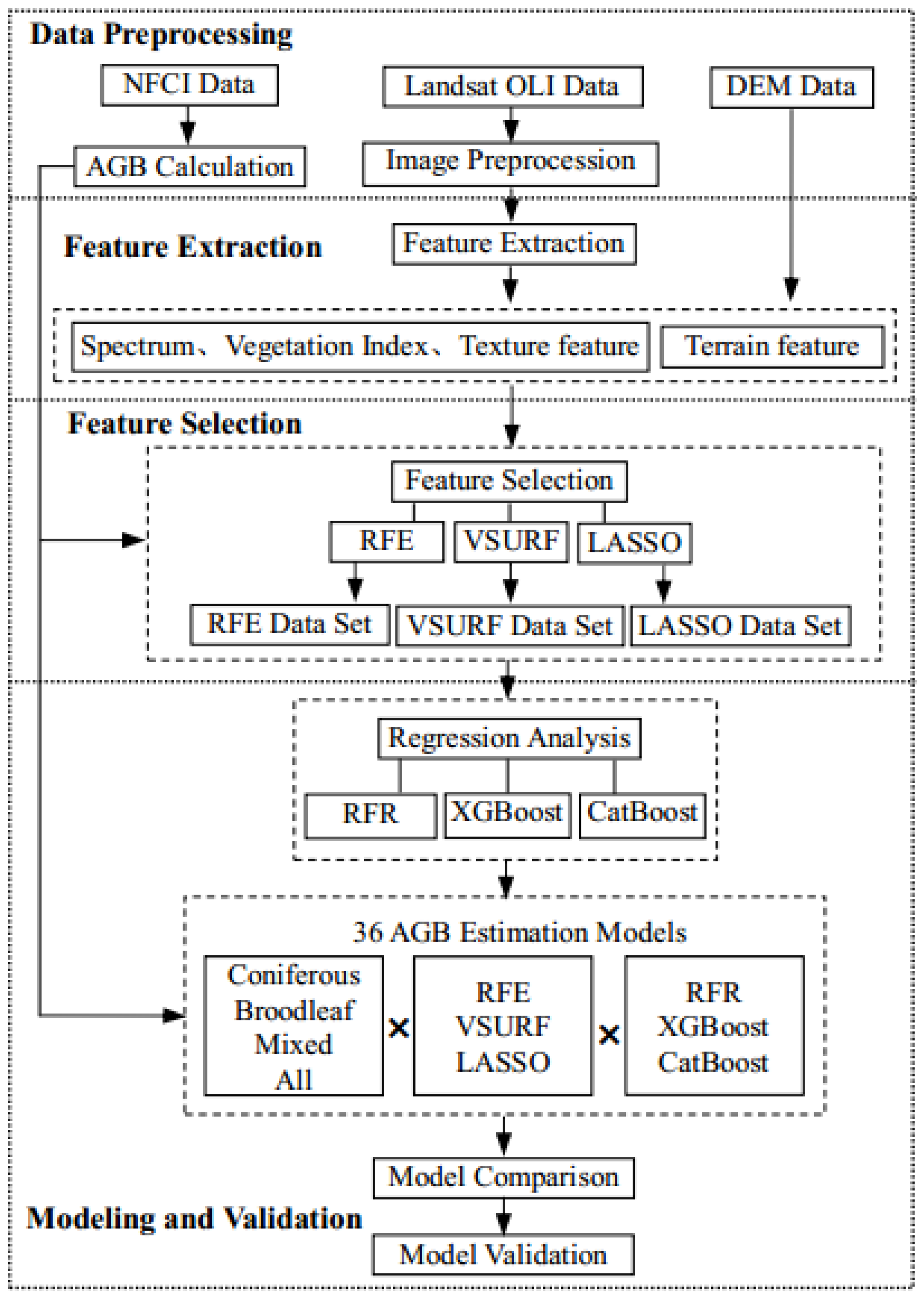
2. Materials and Methods
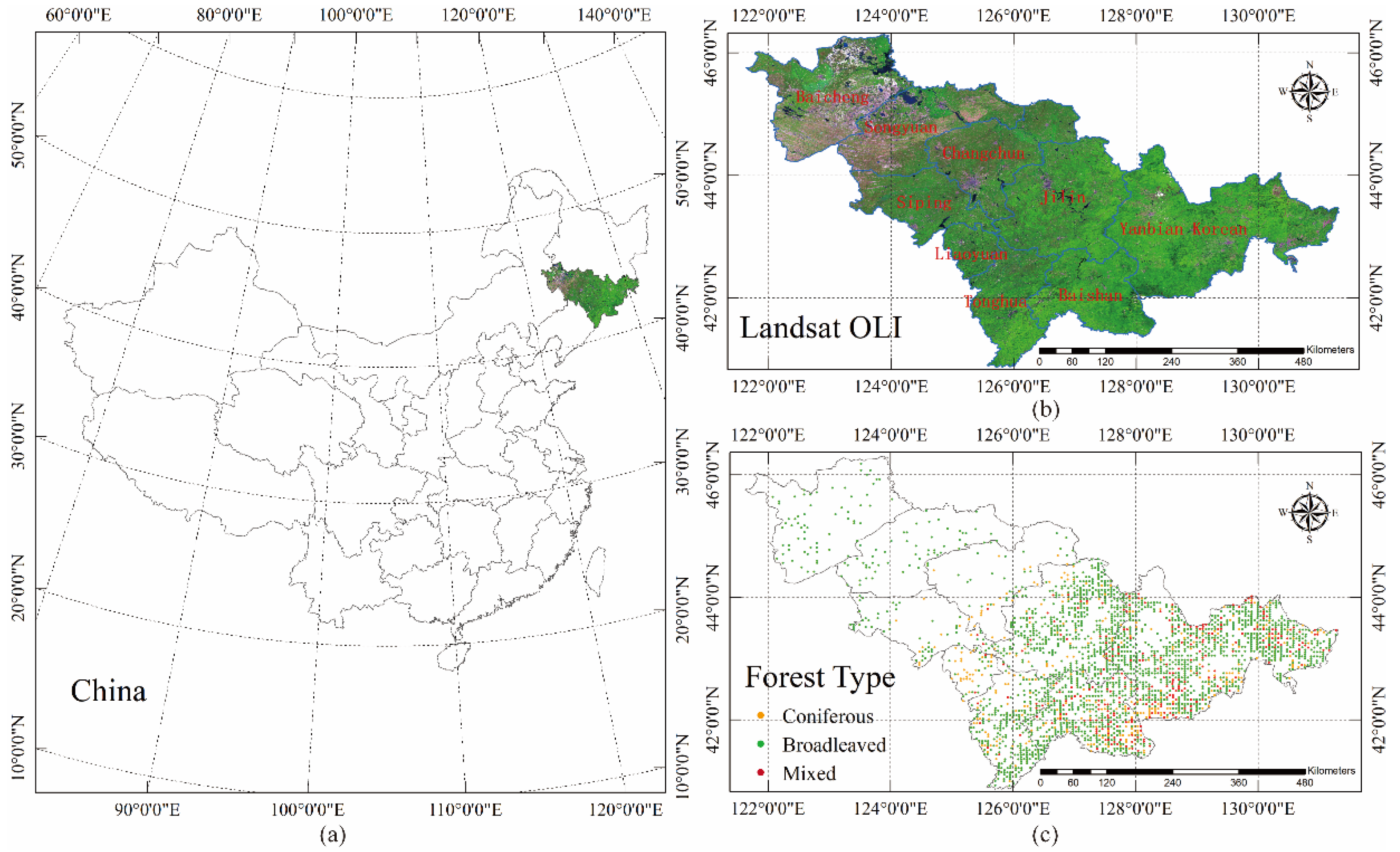
2.1. Study Area
2.2. Data Collection and Preprocessing
2.2.1. Field Data Collection and Preprocessing
2.2.2. Remote Sensing Data Collection and Preprocessing
2.3. Predictive Variables
2.4. Feature Selection Methods
2.4.1. Recursive Feature Elimination
2.4.2. Variable Selection Using Random Forests
2.4.3. Least Absolute Shrinkage and Selection Operator
2.5. Machine Learning Algorithms
2.5.1. Random Forest Regression
2.5.2. Extreme Gradient Boosting
- (1)
- The algorithm controls the complexity of the tree and then reduces overfitting by adding a regularization term to the objective function.
- (2)
- A column sampling technique is employed to prevent overfitting, similar to the random forest algorithm.
- (3)
- The second-order Taylor expression of the objective function is used to make the definition of the objective function simpler and more precise when finding the optimal solution.
2.5.3. Categorical Boosting
- (1)
- An innovative algorithm is embedded to automatically treat categorical features as numerical characteristics.
- (2)
- It uses a combination of category features that take advantage of the connections between features, greatly enriching feature dimensions.
- (3)
- A perfectly symmetrical tree model is adopted to reduce overfitting and improve the accuracy and generalizability of the algorithm.
2.6. Evaluation of AGB Estimation Accuracy
3. Results
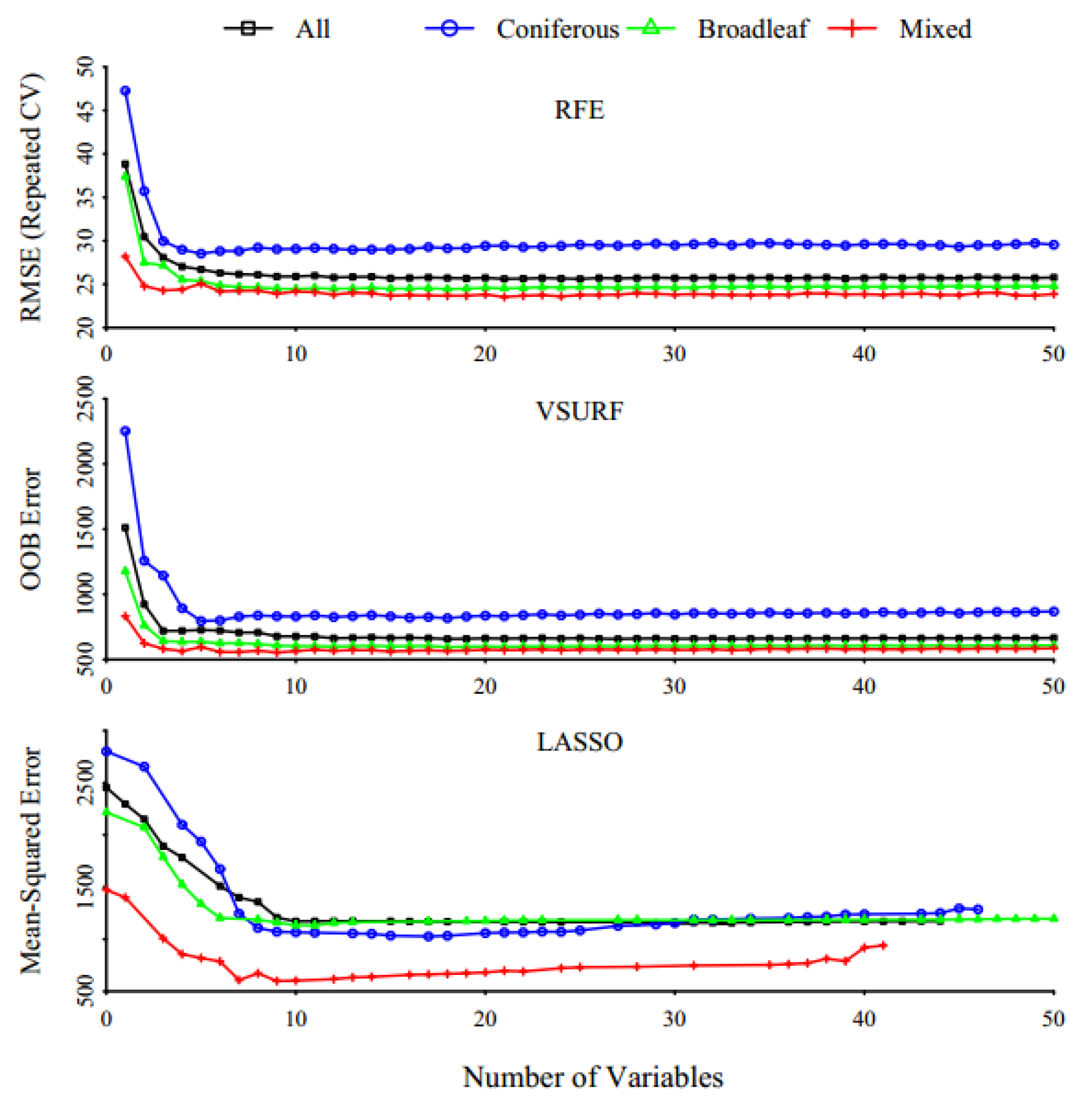
3.1. Determining the Optimal Number of Variables
3.2. Predictive Performance Using Feature Selection
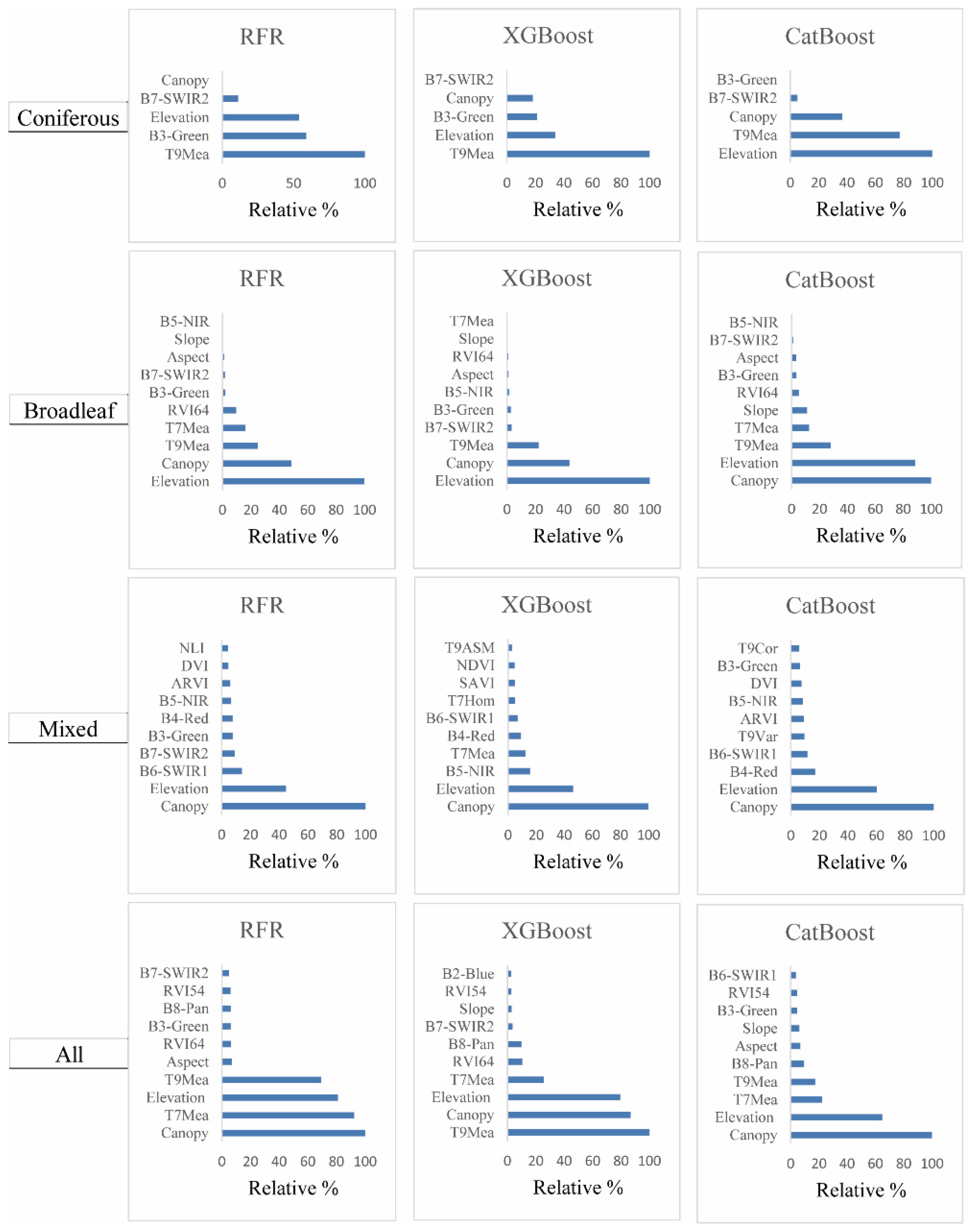
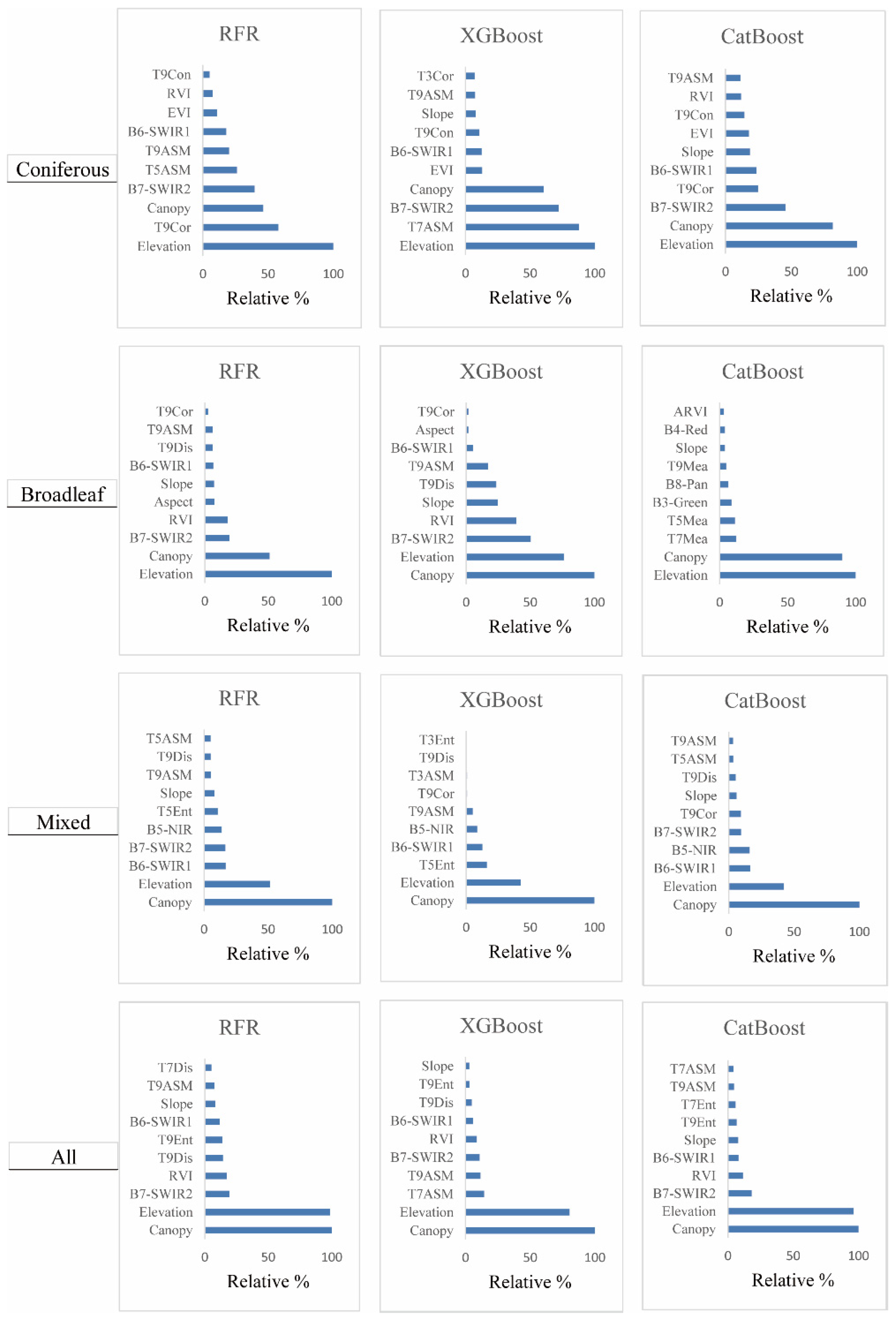
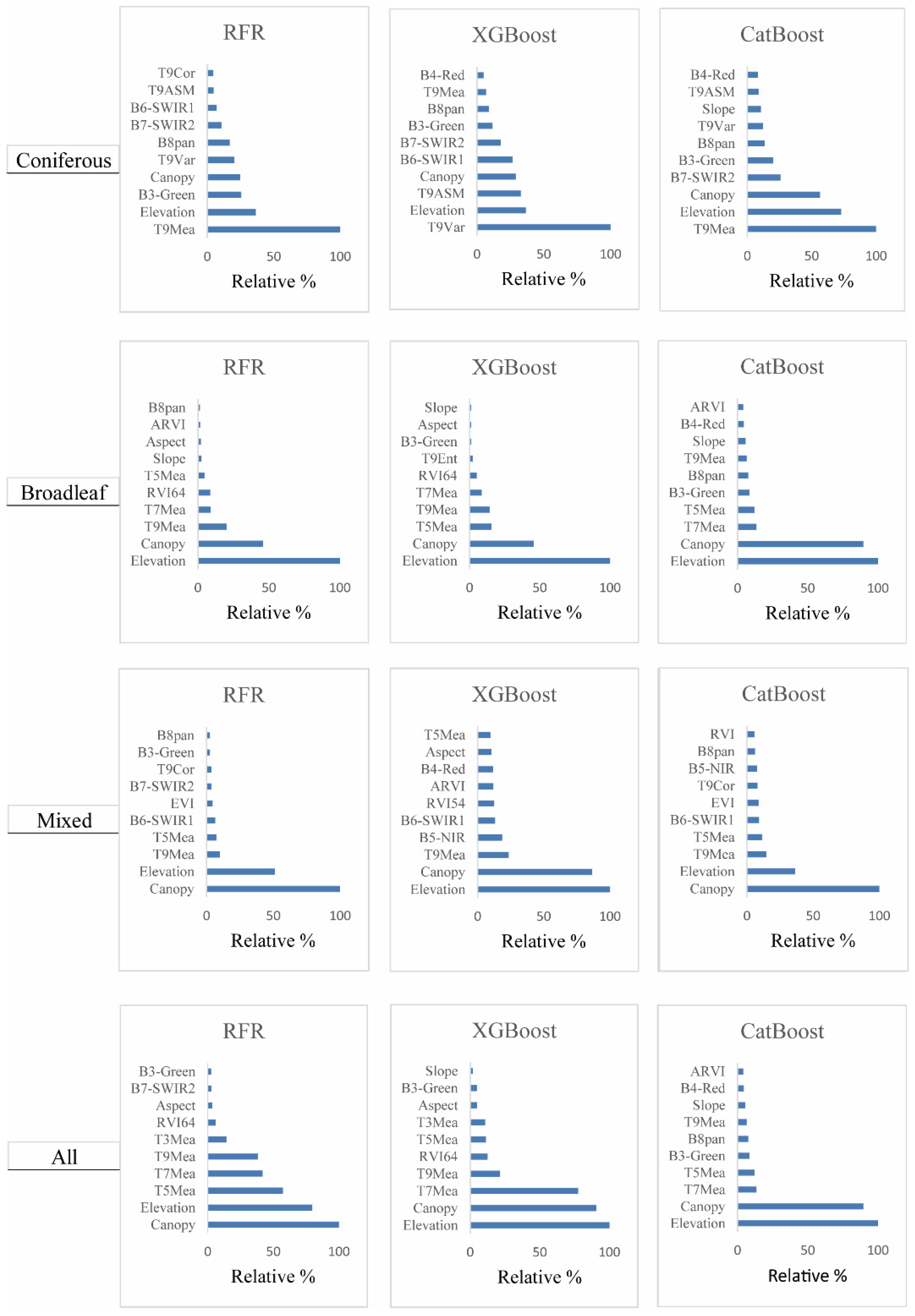
3.2.1. Variable Importance Measures
3.2.2. Comparison of Model Performance
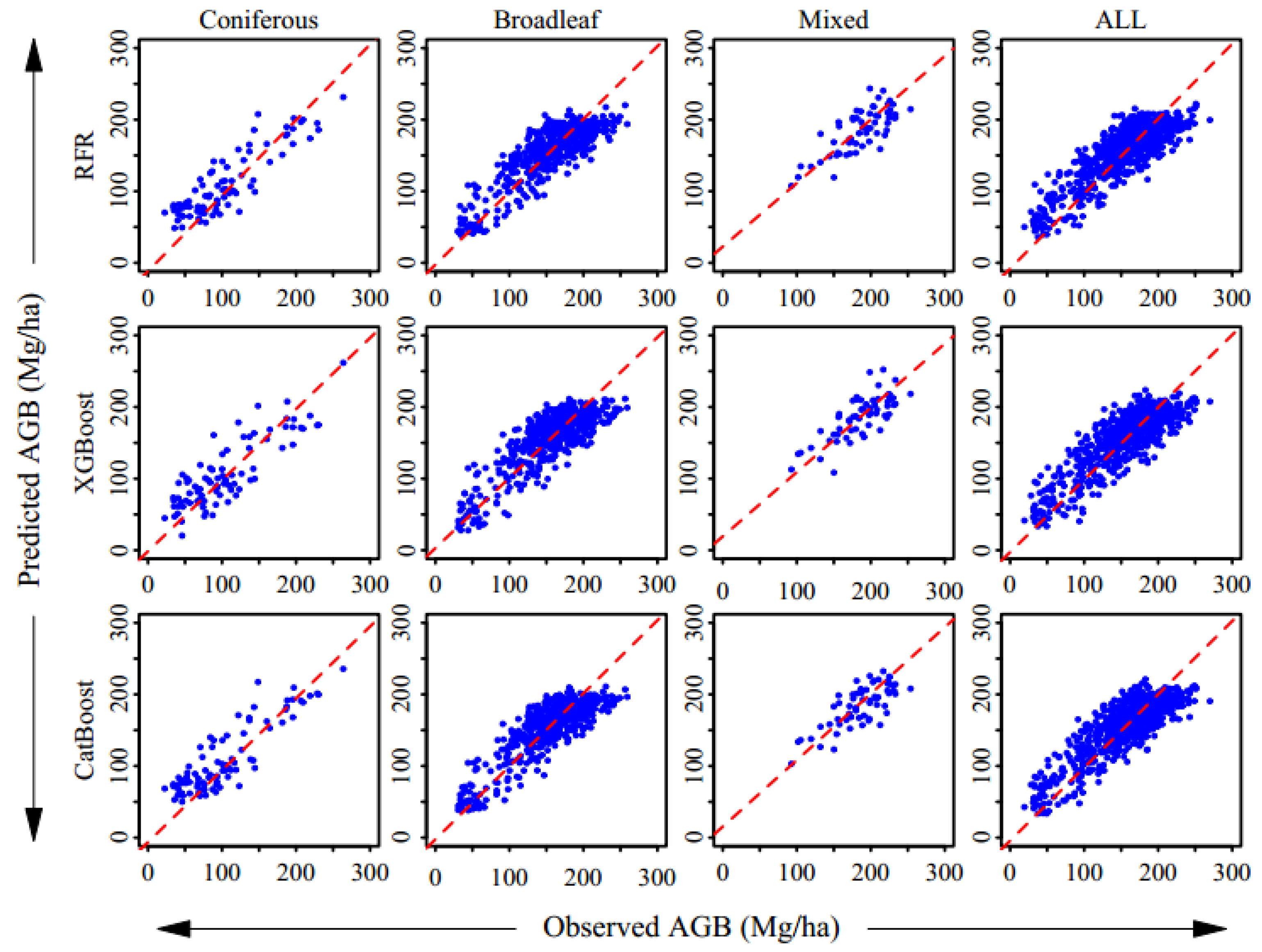
3.3. Evaluation of AGB Estimation
4. Discussion
5. Conclusions
- (1)
- Feature selection has a significant influence on the predictive performance of the AGB models. The RFE algorithm is one of the most appropriate feature selection methods for AGB estimation from optical remote sensing data.
- (2)
- The CatBoost algorithm better than the XGBoost and RFR algorithms and has great potential for AGB prediction.
- (3)
- Using the same machine learning algorithm for feature selection and regression is not always the best approach for AGB estimation. Combining separate feature selection methods with regression algorithms can improve the accuracy of AGB model estimates. The AGB estimations in which RFE was the feature selection method and CatBoost was the regression algorithm achieved greater accuracy, with RMSEs of 26.54 Mg/ha for the coniferous forest, 24.67 Mg/ha for the broad-leaved forest, 22.62 Mg/ha for the mixed forest, and 25.77 Mg/ha for all forests.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Forest Type | CatBoost | XGBoost | RFR | ||
|---|---|---|---|---|---|---|
| Depth | Learning Rate | Max Depth | Eta | Mtry | ||
| LASSO | Coniferous | 6 | 0.049787 | 2 | 0.3 | 17 |
| Broadleaf | 6 | 0.049787 | 2 | 0.3 | 9 | |
| Mixed | 6 | 0.049787 | 1 | 0.3 | 12 | |
| All | 4 | 0.135335 | 2 | 0.3 | 9 | |
| RFE | Coniferous | 4 | 0.049787 | 1 | 0.4 | 2 |
| Broadleaf | 6 | 0.049787 | 2 | 0.3 | 4 | |
| Mixed | 4 | 0.135335 | 1 | 0.3 | 10 | |
| All | 4 | 0.135335 | 3 | 0.3 | 9 | |
| VSURF | Coniferous | 2 | 0.135335 | 2 | 0.3 | 14 |
| Broadleaf | 6 | 0.135335 | 2 | 0.3 | 12 | |
| Mixed | 4 | 0.135335 | 2 | 0.3 | 20 | |
| All | 4 | 0.135335 | 3 | 0.3 | 12 | |


References
- Fang, J.Y.; Wang, Z.M. Forest biomass estimation at regional and global levels, with special reference to China’s forest biomass. Ecol. Res. 2001, 16, 587–592. [Google Scholar] [CrossRef]
- Zolkos, S.G.; Goetz, S.J.; Dubayah, R. A meta-analysis of terrestrial aboveground biomass estimation using lidar remote sensing. Remote Sens. Environ. 2013, 128, 289–298. [Google Scholar] [CrossRef]
- Nordh, N.E.; Verwijst, T. Above-ground biomass assessments and first cutting cycle production in willow (Salix sp.) coppice—A comparison between destructive and non-destructive methods. Biomass Bioenergy 2004, 27, 1–8. [Google Scholar] [CrossRef]
- Su, Y.J.; Guo, Q.H.; Xue, B.L.; Hu, T.Y.; Alvarez, O.; Tao, S.L.; Fang, J.Y. Spatial distribution of forest aboveground biomass in China: Estimation through combination of spaceborne lidar, optical imagery, and forest inventory data. Remote Sens. Environ. 2016, 173, 187–199. [Google Scholar] [CrossRef] [Green Version]
- Puliti, S.; Saarela, S.; Gobakken, T.; Stahl, G.; Naesset, E. Combining UAV and Sentinel-2 auxiliary data for forest growing stock volume estimation through hierarchical model-based inference. Remote Sens. Environ. 2018, 204, 485–497. [Google Scholar] [CrossRef]
- Samadzadegan, F.; Hasani, H.; Schenk, T. Simultaneous feature selection and SVM parameter determination in classification of hyperspectral imagery using Ant Colony Optimization. Can. J. Remote Sens. 2012, 38, 139–156. [Google Scholar] [CrossRef]
- Rasel, S.M.M.; Chang, H.C.; Ralph, T.J.; Saintilan, N.; Diti, I.J. Application of feature selection methods and machine learning algorithms for saltmarsh biomass estimation using Worldview-2 imagery. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Fayad, I.; Baghdadi, N.; Guitet, S.; Bailly, J.-S.; Herault, B.; Gond, V.; El Hajj, M.; Dinh Ho Tong, M. Aboveground biomass mapping in French Guiana by combining remote sensing, forest inventories and environmental data. Int. J. Appl. Earth Obs. Geoinf. 2016, 52, 502–514. [Google Scholar] [CrossRef] [Green Version]
- Mitchard, E.T.A.; Feldpausch, T.R.; Brienen, R.J.W.; Lopez-Gonzalez, G.; Monteagudo, A.; Baker, T.R.; Lewis, S.L.; Lloyd, J.; Quesada, C.A.; Gloor, M.; et al. Markedly divergent estimates of Amazon forest carbon density from ground plots and satellites. Glob. Ecol. Biogeogr. 2014, 23, 935–946. [Google Scholar] [CrossRef]
- Naesset, E.; Orka, H.O.; Solberg, S.; Bollandsas, O.M.; Hansen, E.H.; Mauya, E.; Zahabu, E.; Malimbwi, R.; Chamuya, N.; Olsson, H.; et al. Mapping and estimating forest area and aboveground biomass in miombo woodlands in Tanzania using data from airborne laser scanning, TanDEM-X, RapidEye, and global forest maps: A comparison of estimated precision. Remote Sens. Environ. 2016, 175, 282–300. [Google Scholar] [CrossRef]
- Vafaei, S.; Soosani, J.; Adeli, K.; Fadaei, H.; Naghavi, H.; Pham, T.D.; Bui, D.T. Improving Accuracy Estimation of Forest Aboveground Biomass Based on Incorporation of ALOS-2 PALSAR-2 and Sentinel-2A Imagery and Machine Learning: A Case Study of the Hyrcanian Forest Area (Iran). Remote Sens. 2018, 10, 172. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Q.; Yu, S.; Zhao, F.; Tian, L.; Zhao, Z. Comparison of machine learning algorithms for forest parameter estimations and application for forest quality assessments. For. Ecol. Manag. 2019, 434, 224–234. [Google Scholar] [CrossRef]
- Pham, T.D.; Yokoya, N.; Xia, J.; Ha, N.T.; Le, N.N.; Nguyen, T.T.T.; Dao, T.H.; Vu, T.T.P.; Pham, T.D.; Takeuchi, W. Comparison of Machine Learning Methods for Estimating Mangrove Above-Ground Biomass Using Multiple Source Remote Sens. Data in the Red River Delta Biosphere Reserve, Vietnam. Remote Sens. 2020, 12, 1334. [Google Scholar] [CrossRef] [Green Version]
- López-Serrano, P.M.; López-Sánchez, C.A.; Álvarez-González, J.G.; García-Gutiérrez, J. A Comparison of Machine Learning Techniques Applied to Landsat-5 TM Spectral Data for Biomass Estimation. Can. J. Remote Sens. 2016, 42, 690–705. [Google Scholar] [CrossRef]
- Wu, C.; Chen, Y.; Peng, C.; Li, Z.; Hong, X. Modeling and estimating aboveground biomass of Dacrydium pierrei in China using machine learning with climate change. J. Environ. Manag. 2019, 234, 167–179. [Google Scholar] [CrossRef]
- Xie, Z.; Chen, Y.; Lu, D.; Li, G.; Chen, E. Classification of Land Cover, Forest, and Tree Species Classes with ZiYuan-3 Multispectral and Stereo Data. Remote Sens. 2019, 11, 164. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.S.; Chen, Q.; Wang, G.X.; Liu, L.J.; Li, G.Y.; Moran, E. A survey of remote sensing-based aboveground biomass estimation methods in forest ecosystems. Int. J. Digit. Earth 2016, 9, 63–105. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution Remote Sensing object-based urban application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Thapa, R.B.; Watanabe, M.; Motohka, T.; Shimada, M. Potential of high-resolution ALOS-PALSAR mosaic texture for aboveground forest carbon tracking in tropical region. Remote Sens. Environ. 2015, 160, 122–133. [Google Scholar] [CrossRef]
- Ploton, P.; Barbier, N.; Couteron, P.; Antin, C.M.; Ayyappan, N.; Balachandran, N.; Barathan, N.; Bastin, J.F.; Chuyong, G.; Dauby, G.; et al. Toward a general tropical forest biomass prediction model from very high resolution optical satellite images. Remote Sens. Environ. 2017, 200, 140–153. [Google Scholar] [CrossRef]
- Huang, H.; Liu, C.; Wang, X.; Zhou, X.; Gong, P. Integration of multi-resource remotely sensed data and allometric models for forest aboveground biomass estimation in China. Remote Sens. Environ. 2019, 221, 225–234. [Google Scholar] [CrossRef]
- Cao, L.; Pan, J.; Li, R.; Li, J.; Li, Z. Integrating Airborne LiDAR and Optical Data to Estimate Forest Aboveground Biomass in Arid and Semi-Arid Regions of China. Remote Sens. 2018, 10, 532. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Li, C.; Li, M.; Liu, Z. Influence of Variable Selection and Forest Type on Forest Aboveground Biomass Estimation Using Machine Learning Algorithms. Forests 2019, 10, 1073. [Google Scholar] [CrossRef] [Green Version]
- Yu, G.; Lu, Z.; Lai, Y. Comparative Study on Variable Selection Approaches in Establishment of Remote Sens. Model for Forest Biomass Estimation. Remote Sens. 2019, 11, 1437. [Google Scholar] [CrossRef] [Green Version]
- Freeman, E.A.; Moisen, G.; Coulston, J.W.; Wilson, B. Random Forests and Stochastic Gradient Boosting for Predicting Tree Canopy Cover: Comparing Tuning Processes and Model Performance. Can. J. For. Res. 2015, 46, 3. [Google Scholar] [CrossRef] [Green Version]
- Dube, T.; Mutanga, O. Evaluating the utility of the medium-spatial resolution Landsat 8 multispectral sensor in quantifying aboveground biomass in uMgeni catchment, South Africa. ISPRS J. Photogramm. Remote Sens. 2015, 101, 36–46. [Google Scholar] [CrossRef]
- An Thi Ngoc, D.; Nandy, S.; Srinet, R.; Nguyen Viet, L.; Ghosh, S.; Kumar, A.S. Forest aboveground biomass estimation using machine learning regression algorithm in Yok Don National Park, Vietnam. Ecol. Inform. 2019, 50, 24–32. [Google Scholar] [CrossRef]
- Montesano, P.M.; Cook, B.D.; Sun, G.; Simard, M.; Nelson, R.F.; Ranson, K.J.; Zhang, Z.; Luthcke, S. Achieving accuracy requirements for forest biomass mapping: A spaceborne data fusion method for estimating forest biomass and LiDAR sampling error. Remote Sens. Environ. 2013, 130, 153–170. [Google Scholar] [CrossRef]
- Carreiras, J.M.B.; Vasconcelos, M.J.; Lucas, R.M. Understanding the relationship between aboveground biomass and ALOS PALSAR data in the forests of Guinea-Bissau (West Africa). Remote Sens. Environ. 2012, 121, 426–442. [Google Scholar] [CrossRef]
- Gomez, C.; Mangeas, M.; Petit, M.; Corbane, C.; Hamon, P.; Hamon, S.; De Kochko, A.; Le Pierres, D.; Poncet, V.; Despinoy, M. Use of high-resolution satellite imagery in an integrated model to predict the distribution of shade coffee tree hybrid zones. Remote Sens. Environ. 2010, 114, 2731–2744. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Pickert, J.; Hostert, P. Towards national-scale characterization of grassland use intensity from integrated Sentinel-2 and Landsat time series. Remote Sens. Environ. 2020, 238, 111124. [Google Scholar] [CrossRef]
- Chrysafis, I.; Mallinis, G.; Gitas, I.; Tsakiri-Strati, M. Estimating Mediterranean forest parameters using multi seasonal Landsat 8 OLI imagery and an ensemble learning method. Remote Sens. Environ. 2017, 199, 154–166. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- Huang, G.M.; Wu, L.F.; Ma, X.; Zhang, W.Q.; Fan, J.L.; Yu, X.; Zeng, W.Z.; Zhou, H.M. Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Zhang, F.; Ma, X.; Wu, L. Predicting daily diffuse horizontal solar radiation in various climatic regions of China using support vector machine and tree-based soft computing models with local and extrinsic climatic data. J. Clean. Prod. 2020, 248, 119264. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.-C.; Lee, S.-J.; Park, N. Machine Learning Based Hybrid System for Imputation and Efficient Energy Demand Forecasting. Energies 2020, 13, 2681. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, J.; Liang, S.; Li, X.; Li, M. An Evaluation of Eight Machine Learning Regression Algorithms for Forest Aboveground Biomass Estimation from Multiple Satellite Data Products. Remote Sens. 2020, 12, 4015. [Google Scholar] [CrossRef]
- Chen, Z.; Jia, K.; Xiao, C.; Wei, D.; Wang, L. Leaf Area Index Estimation Algorithm for GF-5 Hyperspectral Data Based on Different Feature Selection and Machine Learning Methods. Remote Sens. 2020, 12, 2110. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, T.; Wang, S.; Wang, Z. Soil pH and C/N ratio determines spatial variations in soil microbial communities and enzymatic activities of the agricultural ecosystems in Northeast China: Jilin Province case. Appl. Soil Ecol. 2020, 155, 103629. [Google Scholar] [CrossRef]
- Xia, T.T.; Miao, Y.X.; Wu, D.L.; Shao, H.; Khosla, R.; Mi, G.H. Active Optical Sensing of Spring Maize for In-Season Diagnosis of Nitrogen Status Based on Nitrogen Nutrition Index. Remote Sens. 2016, 8, 605. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.H.; Yin, X.Q.; Li, X.Q. Soil mesofauna effects on litter decomposition in the coniferous forest of the Changbai Mountains, China. Appl. Soil Ecol. 2015, 92, 64–71. [Google Scholar] [CrossRef]
- Kan, B.; Wang, Q.; Wu, W. The influence of selective cutting of mixed Korean pine (Pinus koraiensis Sieb. et Zucc.) and broad-leaf forest on rare species distribution patterns and spatial correlation in Northeast China. J. For. Res. 2015, 26, 833–840. [Google Scholar] [CrossRef]
- Wulder, M.A.; White, J.C.; Fournier, R.A.; Luther, J.E.; Magnussen, S. Spatially explicit large area biomass estimation: Three approaches using forest inventory and remotely sensed imagery in a GIS. Sensors 2008, 8, 529–560. [Google Scholar] [CrossRef] [Green Version]
- Fang, J.; Chen, A.; Peng, C.; Zhao, S.; Ci, L. Changes in forest biomass carbon storage in China between 1949 and 1998. Science 2001, 292, 2320–2322. [Google Scholar] [CrossRef]
- Forestry Administration of Jilin. Volume Table of Jilin Province; Publisher of Forestry Administration of Jilin Province: Jilin, China, 1975. [Google Scholar]
- Reese, H.; Olsson, H. C-correction of optical satellite data over alpine vegetation areas: A comparison of sampling strategies for determining the empirical c-parameter. Remote Sens. Environ. 2011, 115, 1387–1400. [Google Scholar] [CrossRef] [Green Version]
- Astola, H.; Hame, T.; Sirro, L.; Molinier, M.; Kilpi, J. Comparison of Sentinel-2 and Landsat 8 imagery for forest variable prediction in boreal region. Remote Sens. Environ. 2019, 223, 257–273. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. Syst. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2020, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. VSURF: An R Package for Variable Selection Using Random Forests. R J. 2016, 7, 19–33. [Google Scholar] [CrossRef] [Green Version]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Palmer, D.S.; O"Boyle, N.M.; Glen, R.C.; Mitchell, J.B.O. Random forest models to predict aqueous solubility. J. Chem. Inf. Model. 2007, 47, 150–158. [Google Scholar] [CrossRef]
- Júnior ID, S.T.; Torres CM, M.E.; Leite, H.G.; de Castro NL, M.; Soares CP, B.; Castro RV, O.; Farias, A.A. Machine learning: Modeling increment in diameter of individual trees on Atlantic Forest fragments. Ecol. Indic. 2020, 117, 106685. [Google Scholar] [CrossRef]
- Bento, A.P.; Gaulton, A.; Hersey, A.; Bellis, L.J.; Chambers, J.; Davies, M.; Kruger, F.A.; Light, Y.; Mak, L.; Mcglinchey, S.J.R.N. Classification and Regression by randomForest. R News 2002, 23, 18–22. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: New York, NY, USA, 2016; Volume 785, p. 794. [Google Scholar] [CrossRef] [Green Version]
- Samat, A.; Li, E.; Wang, W.; Liu, S.; Lin, C.; Abuduwaili, J. Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sens. 2020, 12, 1973. [Google Scholar] [CrossRef]
- Jin, Q.; Fan, X.; Liu, J.; Xue, Z.; Jian, H. Estimating Tropical Cyclone Intensity in the South China Sea Using the XGBoost Model and FengYun Satellite Images. Atmosphere 2020, 11, 423. [Google Scholar] [CrossRef] [Green Version]
- Dong, H.; Xu, X.; Wang, L.; Pu, F. Gaofen-3 PolSAR Image Classification via XGBoost and Polarimetric Spatial Information. Sensors 2018, 18, 611. [Google Scholar] [CrossRef] [Green Version]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big data 2020, 7, 94. [Google Scholar] [CrossRef]
- Li, D.; Gu, X.; Pang, Y.; Chen, B.; Liu, L. Estimation of Forest Aboveground Biomass and Leaf Area Index Based on Digital Aerial Photograph Data in Northeast China. Forests 2018, 9, 275. [Google Scholar] [CrossRef] [Green Version]
- Montorio, R.; Perez-Cabello, F.; Alves, D.B.; Garcia-Martin, A. Unitemporal approach to fire severity mapping using multispectral synthetic databases and Random Forests. Remote Sens. Environ. 2020, 249, 112025. [Google Scholar] [CrossRef]
- Li, M.; Zhang, Y.; Wallace, J.; Campbell, E. Estimating annual runoff in response to forest change: A statistical method based on random forest. J. Hydrol. 2020, 589, 125168. [Google Scholar] [CrossRef]
- Poley, L.G.; McDermid, G.J. A Systematic Review of the Factors Influencing the Estimation of Vegetation Aboveground Biomass Using Unmanned Aerial Systems. Remote Sens. 2020, 12, 1052. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.C.; Li, M.Y.; Li, C.; Liu, Z.Z. Forest aboveground biomass estimation using Landsat 8 and Sentinel-1A data with machine learning algorithms. Sci. Rep. 2020, 10, 12. [Google Scholar] [CrossRef] [PubMed]
- Kelsey, K.C.; Neff, J.C. Estimates of Aboveground Biomass from Texture Analysis of Landsat Imagery. Remote Sens. 2014, 6, 6407–6422. [Google Scholar] [CrossRef] [Green Version]





| Species/Species Group | a | b |
|---|---|---|
| Betula platyphylla Suk. | 1.0687 | 10.2370 |
| Pinus sylvestris var. mongolica Litv., Pinus densiflora Sieb. et Zucc. | 1.0945 | 2.0040 |
| Pinus thunbergii Parlatore | 0.5168 | 33.2378 |
| Pinus koraiensis Siebold et Zuccarini | 0.5185 | 18.2200 |
| Larix gmelinii (Ruprecht) Kuzeneva | 0.6069 | 33.8060 |
| Picea asperata Mast. | 0.4642 | 47.4990 |
| Populus simonii var. przewalskii (Maxim.) H. L. Yang | 0.4754 | 30.6034 |
| Pinus tabuliformis Carriere | 0.7554 | 5.0928 |
| Quercus | 1.1453 | 8.5473 |
| Mixed coniferous broad-leaved forest | 0.8136 | 18.4660 |
| Mixed broad-leaved forest | 0.6255 | 91.0013 |
| Forest Type | Abbreviation | Standard of Division |
|---|---|---|
| Coniferous forest | Coniferous | Pure coniferous forest (single coniferous species stand volume ≥ 65%); coniferous mixed forest (coniferous species total stand volume ≥ 65%) |
| Broad-leaved forest | Broadleaf | Pure broadleaf forest (single broad-leaved species stand volume ≥ 65%); broadleaf mixed forest (broad-leaved species total stand volume ≥ 65%) |
| Mixed forest | Mixed | Broadleaf–coniferous mixed forest (total stand volume of coniferous or broad-leaved species accounting for 35%–65%) |
| Figure | Count | Minimum (Mg/ha) | Maximum (Mg/ha) | Mean (Mg/ha) | Standard Deviation | Sample Size (Training) | Sample Size (Validation) |
|---|---|---|---|---|---|---|---|
| Coniferous | 358 | 20.41 | 286.34 | 103.32 | 52.90 | 269 | 89 |
| Broadleaf | 2111 | 19.20 | 269.80 | 155.60 | 47.14 | 1583 | 528 |
| Mixed | 247 | 91.67 | 309.58 | 186.86 | 38.15 | 185 | 62 |
| All | 2716 | 19.20 | 309.58 | 153.80 | 49.58 | 2037 | 679 |
| Variable Type | Variable Number | Variable Name | Description |
|---|---|---|---|
| Spectral variables | 6 | Band2, Band3, Band4, Band5, Band6, Band7 | Landsat OLI Bands 2–7: Blue, Green, Red, NIR, SWIR1, SWIR2 |
| Vegetation indexes | 11 | NDVI | Normalized Difference Vegetation Index |
| RVI | Ratio Vegetation Index; RVI = NIR/RED | ||
| DVI | Difference Vegetation Index | ||
| RVI54 | Ratio Vegetation Index 1; VI54 = SWIR1/NIR | ||
| RVI64 | Ratio Vegetation Index 2; VI64 = SWIR2/NIR | ||
| SAVI | Soil Adjusted Vegetation Index | ||
| NLI | Optimize soil adjustment index; NLI = (NIR^2-RED)/(NIR^2 + RED) | ||
| ARVI | Atmospherically Resistant Vegetation Index | ||
| EVI | Enhanced Vegetation Index | ||
| TSAVI | Transformed Soil Adjusted Vegetation Index | ||
| PVI | Perpendicular vegetation Index | ||
| Texture measures | 32 | TjMea, TjVar, TjHom, TjCon, TjDis, TjEnt, TjASM, TjCor | Panchromatic band of Landsat OLI texture measurement using gray-level co-occurrence matrix based on four window sizes |
| Terrain factors | 3 | Elevation, slope, aspect | |
| Forest factors | 1 | Canopy density |
| Forest Type | Model | R2 | RMSE (Mg/ha) | Bias (Mg/ha) | Relative RMSE (%) | Run Times (min) |
|---|---|---|---|---|---|---|
| Coniferous | CatBoost | 0.77 | 26.54 | −5.56 | 25.62 | 0.78 |
| XGBoost | 0.72 | 28.81 | −2.15 | 27.81 | 20.17 | |
| RFR | 0.77 | 26.63 | −5.88 | 25.70 | 0.17 | |
| Broadleaf | CatBoost | 0.73 | 24.67 | 0.63 | 15.84 | 1.36 |
| XGBoost | 0.71 | 25.55 | 0.10 | 16.40 | 25.13 | |
| RFR | 0.73 | 24.74 | 0.13 | 15.87 | 5.37 | |
| Mixed | CatBoost | 0.59 | 22.62 | 2.14 | 12.10 | 1.51 |
| XGBoost | 0.60 | 22.44 | 0.20 | 12.01 | 20.14 | |
| RFR | 0.59 | 22.72 | 1.81 | 12.16 | 0.63 | |
| All | CatBoost | 0.73 | 25.77 | −0.86 | 16.80 | 1.81 |
| XGBoost | 0.72 | 26.21 | −0.91 | 17.08 | 29.81 | |
| RFR | 0.72 | 26.13 | −0.93 | 17.04 | 12.55 |
| Forest Type | Model | R2 | RMSE (Mg/ha) | Bias (Mg/ha) | Relative RMSE (%) | Run Times (min) |
|---|---|---|---|---|---|---|
| Coniferous | CatBoost | 0.73 | 28.12 | −3.35 | 27.14 | 1.59 |
| XGBoost | 0.74 | 28.30 | −5.50 | 27.31 | 20.91 | |
| RFR | 0.73 | 28.24 | −4.09 | 27.25 | 0.77 | |
| Broadleaf | CatBoost | 0.72 | 25.11 | 0.83 | 16.11 | 2.05 |
| XGBoost | 0.70 | 26.16 | 0.79 | 16.79 | 28.79 | |
| RFR | 0.71 | 25.54 | 0.36 | 16.39 | 8.26 | |
| Mixed | CatBoost | 0.60 | 22.73 | 1.05 | 11.10 | 1.51 |
| XGBoost | 0.57 | 23.73 | 2.64 | 12.70 | 19.78 | |
| RFR | 0.58 | 23.18 | 1.12 | 11.66 | 0.35 | |
| All | CatBoost | 0.71 | 26.65 | −0.97 | 17.37 | 1.85 |
| XGBoost | 0.69 | 27.73 | −0.74 | 18.08 | 28.11 | |
| RFR | 0.71 | 26.81 | −1.24 | 17.48 | 10.74 |
| Forest Type | Model | R2 | RMSE (Mg/ha) | Bias (Mg/ha) | Relative RMSE (%) | Run Times (min) |
|---|---|---|---|---|---|---|
| Coniferous | CatBoost | 0.74 | 27.72 | −4.91 | 26.76 | 1.72 |
| XGBoost | 0.73 | 28.51 | −5.17 | 27.52 | 19.62 | |
| RFR | 0.75 | 27.44 | −4.04 | 26.49 | 0.78 | |
| Broadleaf | CatBoost | 0.73 | 24.77 | 0.49 | 15.89 | 1.85 |
| XGBoost | 0.71 | 25.62 | 0.67 | 16.44 | 28.90 | |
| RFR | 0.72 | 25.08 | 0.88 | 16.09 | 9.01 | |
| Mixed | CatBoost | 0.59 | 22.89 | 0.76 | 12.25 | 1.20 |
| XGBoost | 0.56 | 23.69 | 1.03 | 12.68 | 17.45 | |
| RFR | 0.57 | 23.20 | 2.30 | 12.42 | 0.48 | |
| All | CatBoost | 0.74 | 25.79 | −1.15 | 16.67 | 3.18 |
| XGBoost | 0.72 | 26.25 | −0.68 | 17.11 | 36.82 | |
| RFR | 0.72 | 26.12 | −0.94 | 17.03 | 12.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, M.; Wang, Y.; Xie, Y.; Zhou, L.; Qiao, J.; Qiu, S.; Sun, Y. Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests 2021, 12, 216. https://doi.org/10.3390/f12020216
Luo M, Wang Y, Xie Y, Zhou L, Qiao J, Qiu S, Sun Y. Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests. 2021; 12(2):216. https://doi.org/10.3390/f12020216
Chicago/Turabian StyleLuo, Mi, Yifu Wang, Yunhong Xie, Lai Zhou, Jingjing Qiao, Siyu Qiu, and Yujun Sun. 2021. "Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass" Forests 12, no. 2: 216. https://doi.org/10.3390/f12020216
APA StyleLuo, M., Wang, Y., Xie, Y., Zhou, L., Qiao, J., Qiu, S., & Sun, Y. (2021). Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests, 12(2), 216. https://doi.org/10.3390/f12020216