
21st Century Planning Techniques for Creating Fire-Resilient Forests in the American West



Abstract
:1. Introduction
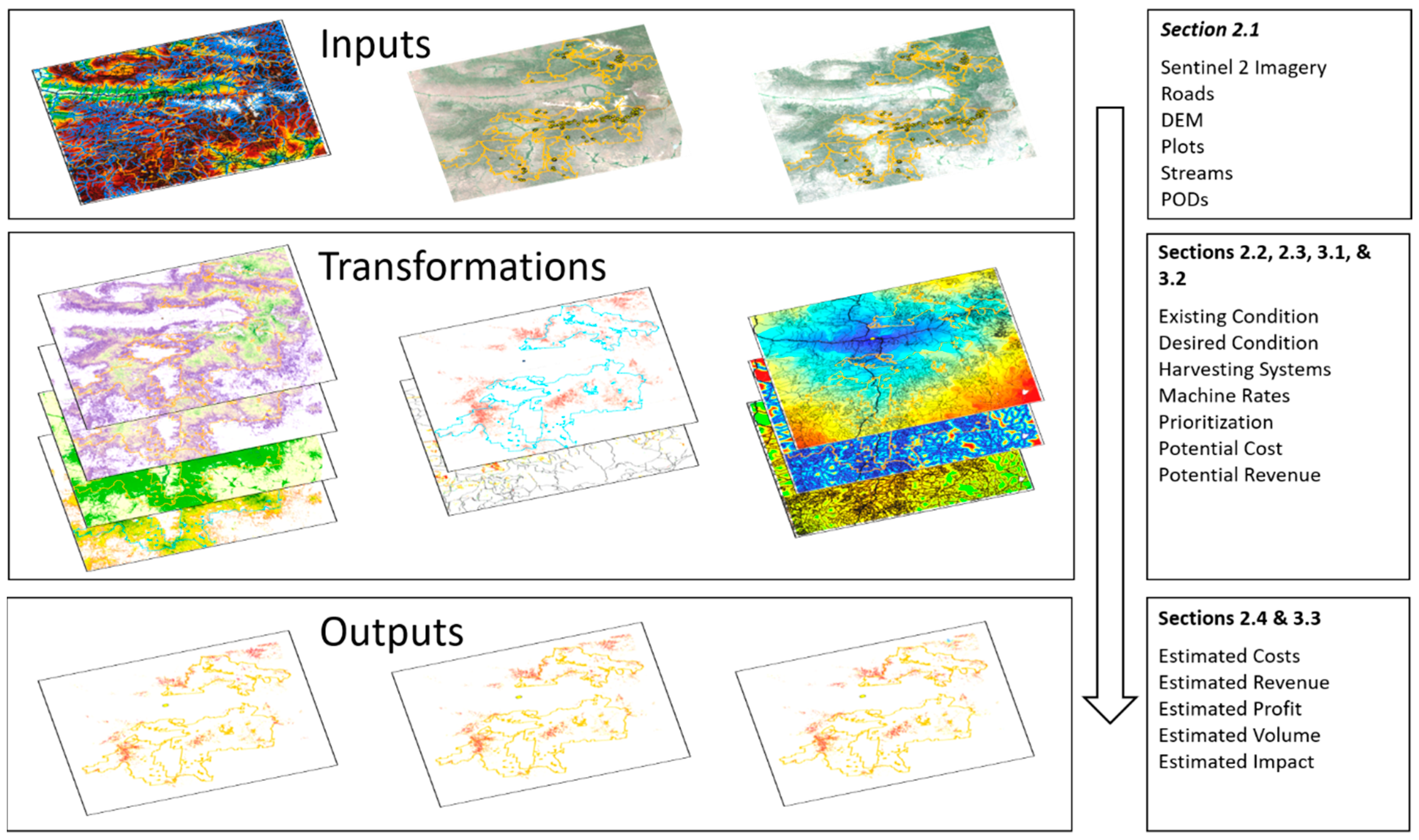
2. Materials and Methods
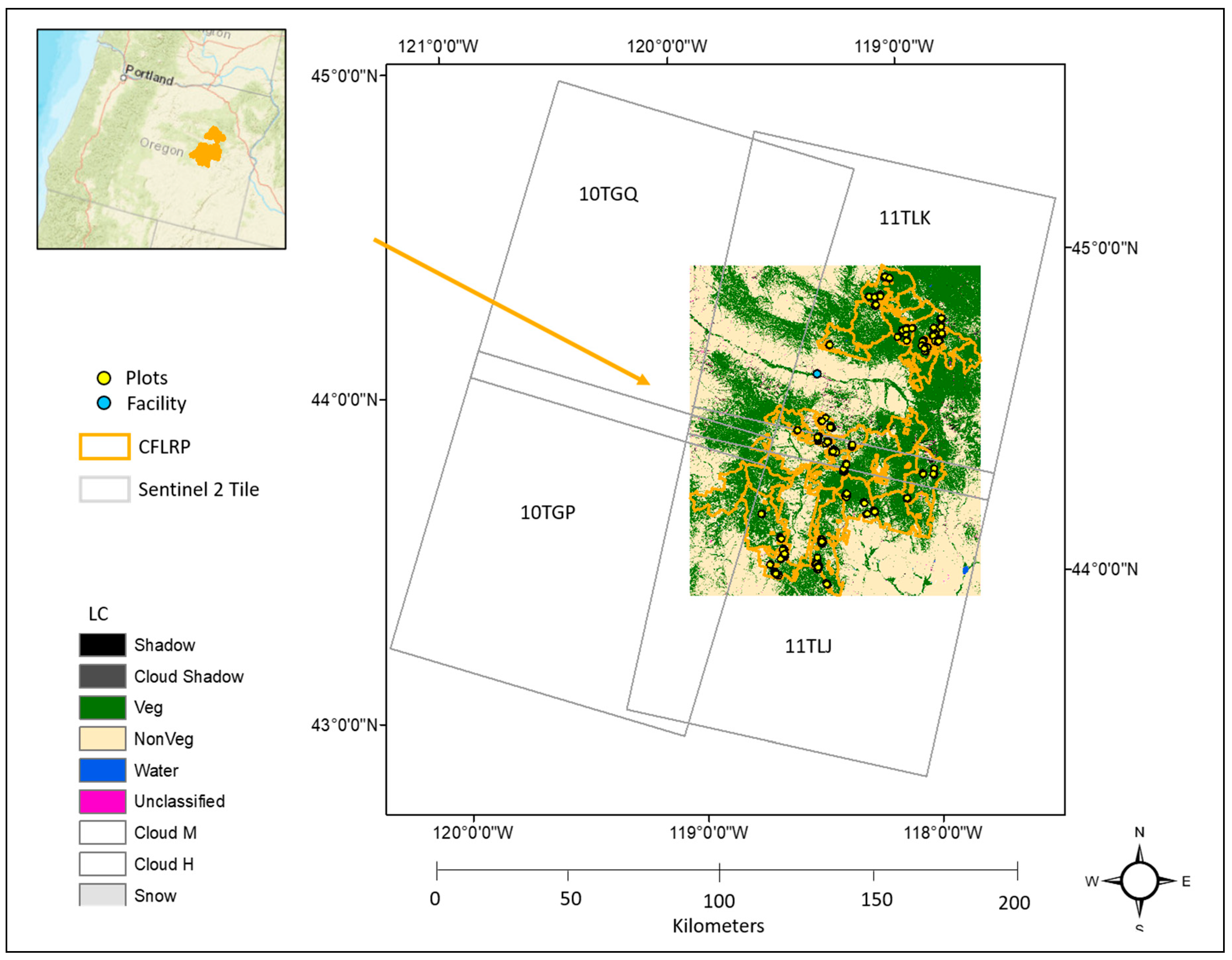
2.1. Study Site & Primary Data
2.2. Existing Condition
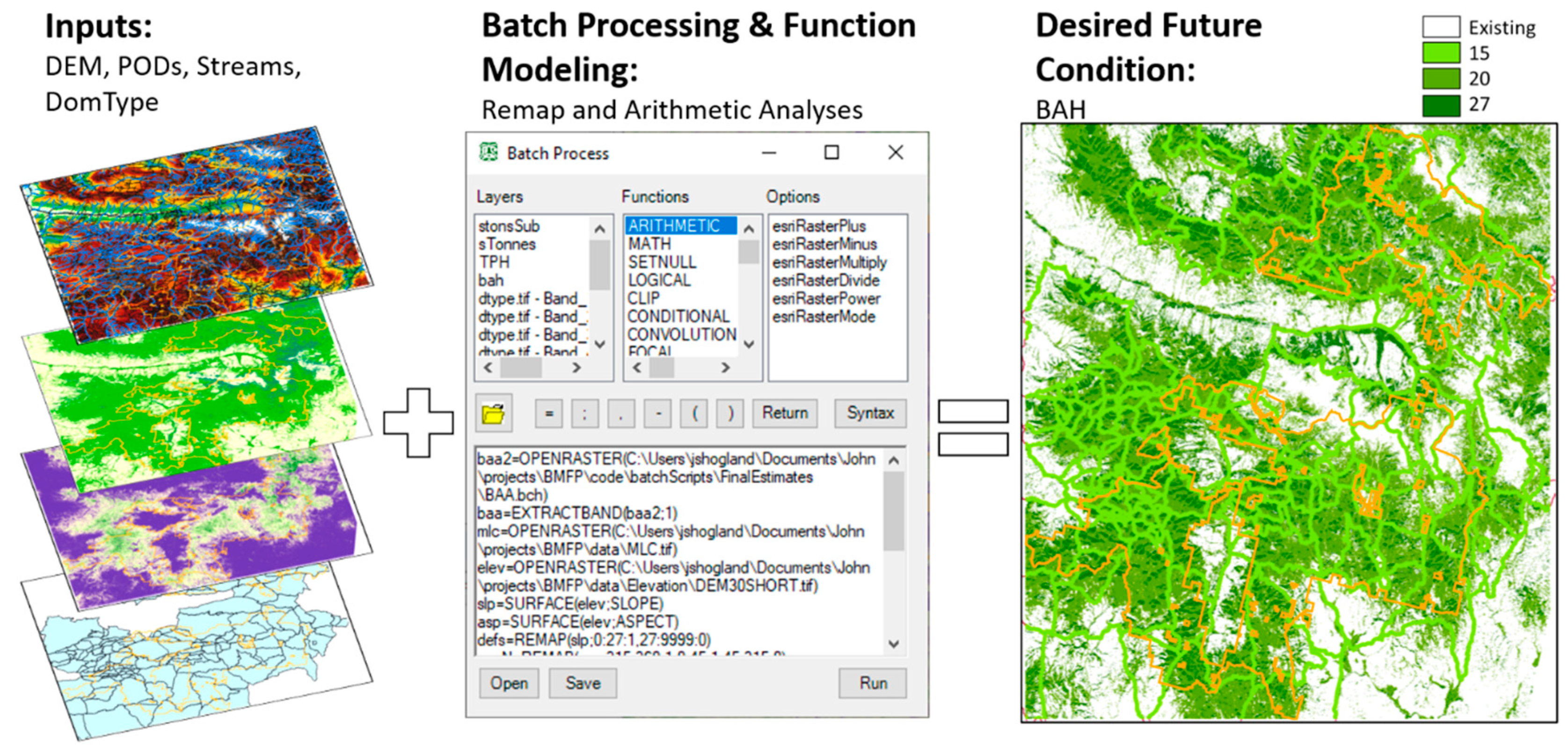
2.3. Desired Future Condition (DFC) & Biomass Removal
2.4. Cost Revenue Assessment (CRA)
3. Results
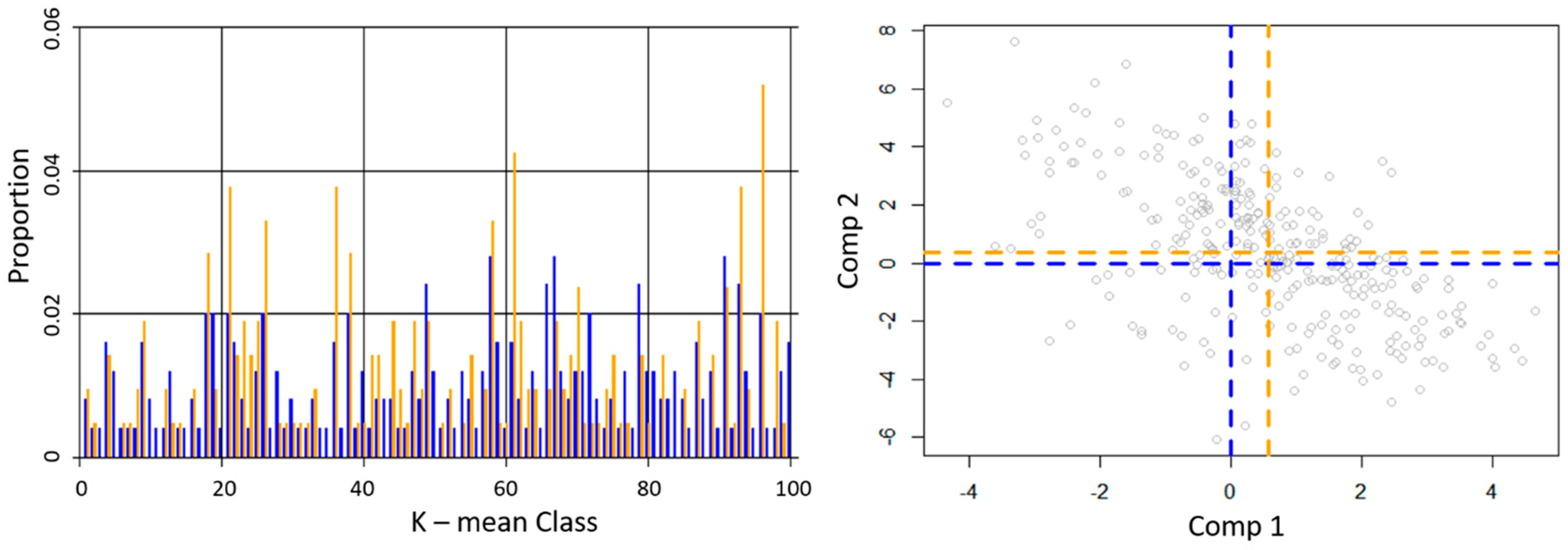
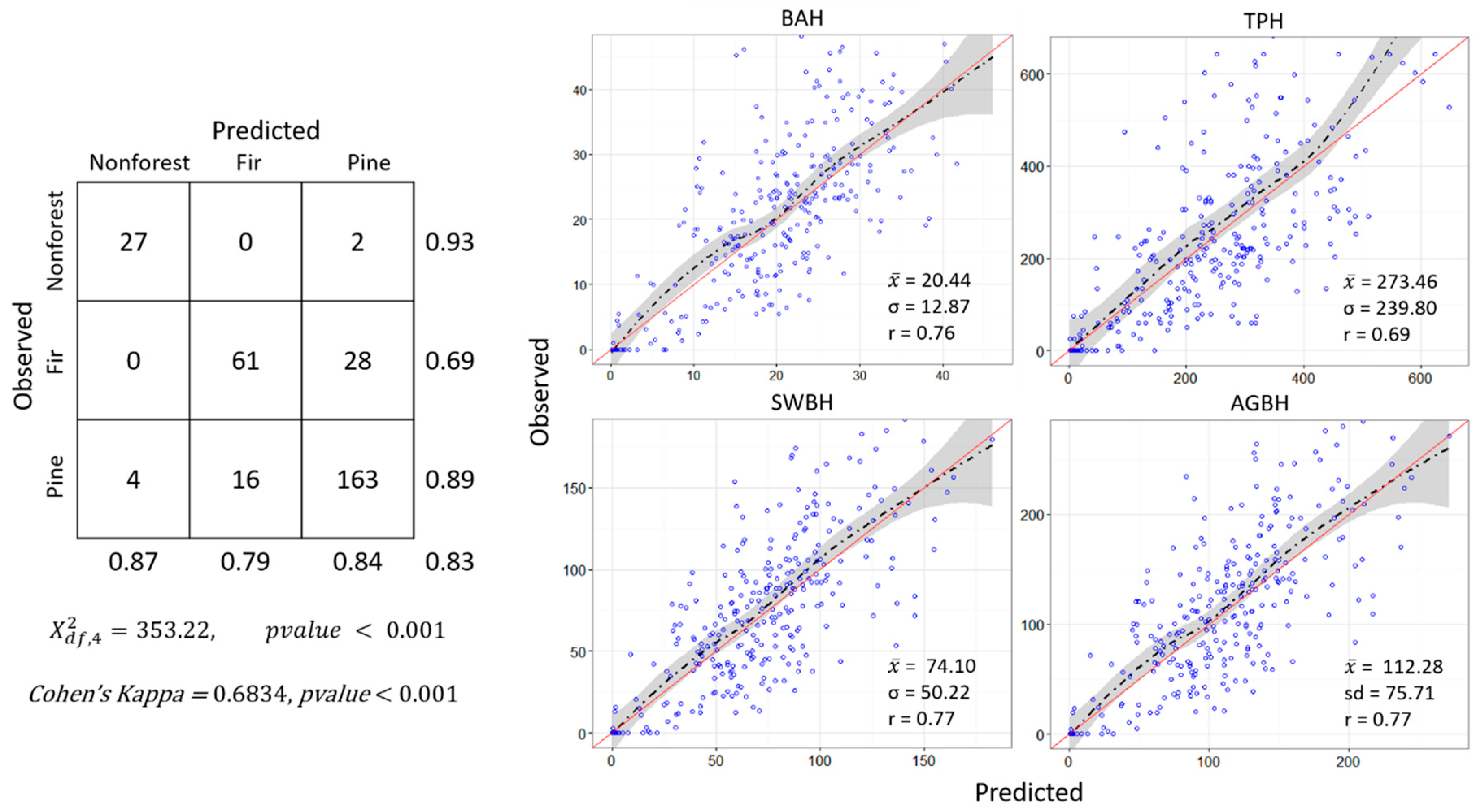
3.1. Quantifying Existing Condition
3.2. Desired Future Condition & Biomass Removals
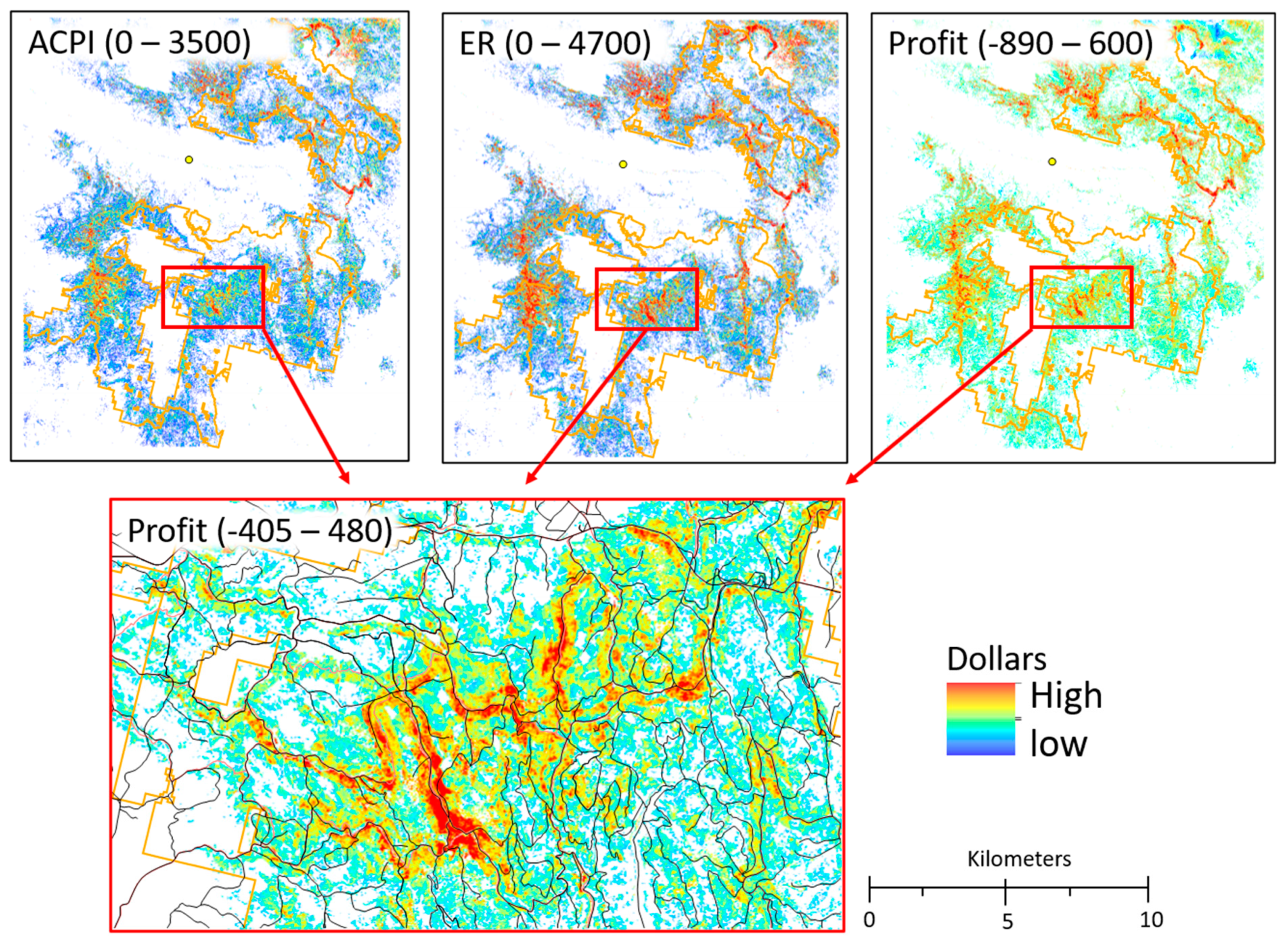
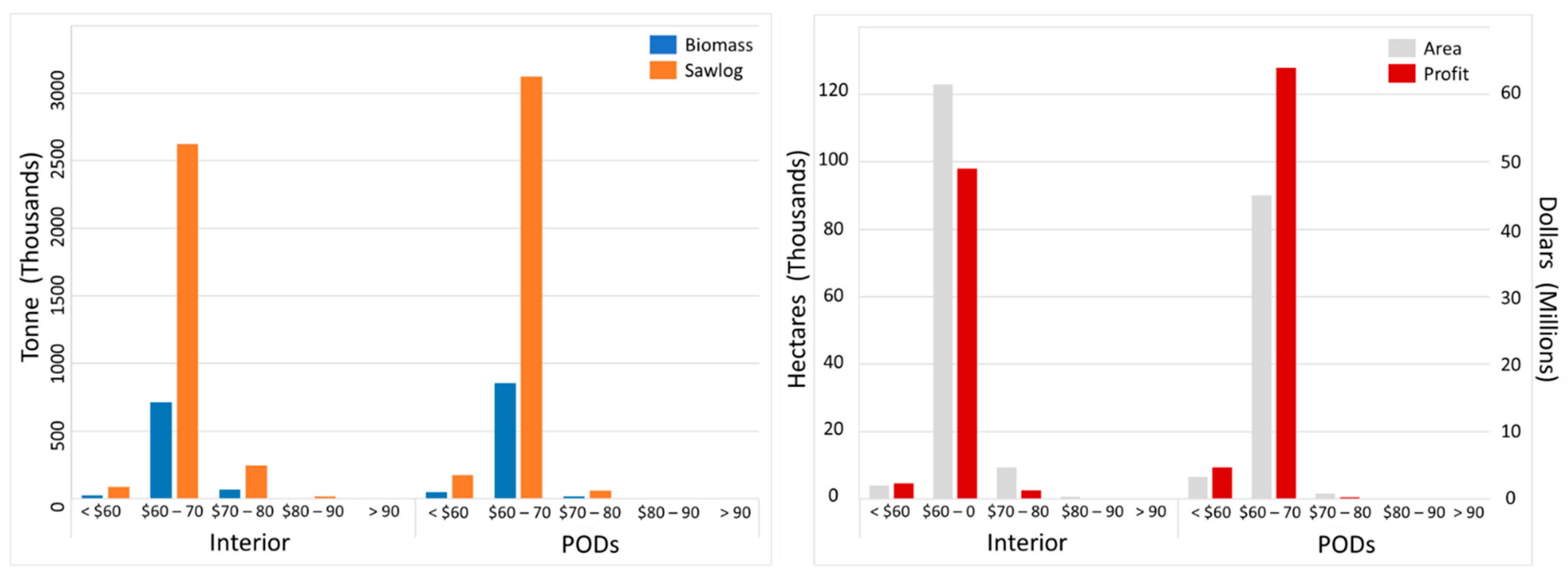
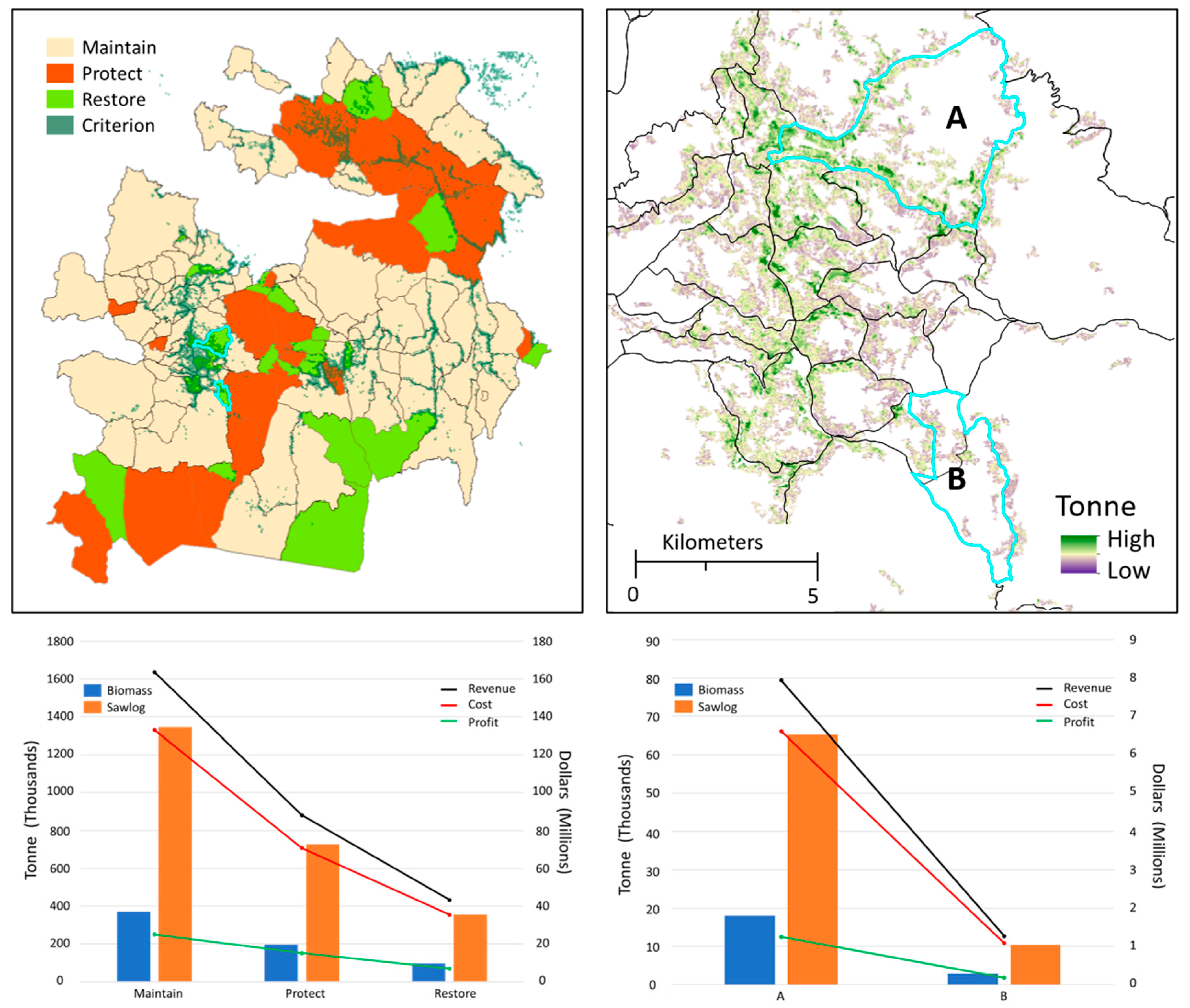
3.3. Cost Revenue Assessment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. List of Acronyms
| BAH = Basal Area Per Hectare |
| CRA = Cost Revenue Analysis |
| POD = Potential Operational Delineations |
| TPH = Trees Per Hectare |
| AGBH = Above Ground Biomass Per Hectare (tonne) |
| SWBH = Sawlog Biomass Per Hectare (tonne) |
| EF = Expansion Factor |
| m = meters |
| = mean |
| σ = standard deviation |
| ha = hectares |
| LC = Land Cover |
| CFLRP = Collaborative Forest Landscape Restoration Program |
| NED = National Elevation Dataset |
| DEM = Digital Elevation Model |
| TIGER = Topologically Integrated Geographic Encoding and Referencing |
| FVF = Forest Vegetation and Fuels |
| ESRI = Environmental Systems Research Institute |
| NHD = National Hydrography Dataset |
| EGAM = ensemble generalized additive models |
| GAM = generalized additive models |
| GRTS = generalized random tessellations stratification |
| CS = comparative surface |
| PCA = principal component analysis |
| SMZ = stream side management zone |
| DFC = desired future condition |
| ST = Sawlog tonne |
| BT = Biomass tonne |
| OPTC = optimal potential total cost |
| ACPI = actual cost of prescription implementation |
| ER = expected revenue |
| EAI = estimated anticipated income |
| MLC = Most likely Class |
| r = Person’s correlation coefficient |
| USDA = United States Department of Agriculture |
| SDI = Suppression Difficulty Index |
| PCL = Potential Control Locations |
| GIS = Geographic Information System |
| HVRAs = High Value Resources and assets |
Appendix B. Strategic Response Zones
References
- Kenward, A.; Sanford, T.; Bronzan, J. Western Wildfires: A Fiery Future; Climate Central: Princeton, NJ, USA, 2016; p. 42. [Google Scholar]
- USDA Forest Service. Towards Shared Stewardship across Landscapes: An Outcome-Based Investment Strategy; FS-118; USDA Forest Service: Washington, DC, USA, 2018.
- USDA Forest Service. The Rising Cost of Fire Operations: E_ects on the Forest Service’s Non-Fire Work. Available online: http://www.bren.ucsb.edu/academics/documents/Rising_Cost_Wildfire_Ops.pdf (accessed on 25 April 2020).
- Palaiologou, P.; Essen, M.; Hogland, J.; Kalabokidis, K. Locating Forest Management Units Using Remote Sensing and Geostatistical Tools in North-Central Washington, USA. Sensors 2020, 20, 2454. [Google Scholar] [CrossRef] [PubMed]
- Merschel, A.G.; Beedlow, P.A.; Sahw, D.C.; Woodruff, D.R.; Lee, H.E.; Cline, S.P.; Comeleo, R.L.; Hagmann, R.K.; Reilly, M.J. An ecological perspective on living with fire in ponderosa pine forest of Oregon and Washington: Resistance, gone but not forgotten. Trees For. People 2021, 4, 100074. [Google Scholar] [CrossRef]
- Miller, J.D.; Safford, H.D.; Crimmins, M.; Thode, A.E. Quantitative Evidence for Increasing Forest Fire Severity in the Sierra Nevada and Southern Cascade Mountains, California and Nevada, USA. Ecosystems 2009, 12, 16–32. [Google Scholar] [CrossRef]
- Cansler, C.; McKenzie, D. Climate, fire size, and biophyusical setting control fire severity and spatial pattern in the northern Cascade Range, USA. Ecol. Soc. Am. 2014, 24, 1037–1056. [Google Scholar]
- Balch, J.; Bradley, B.; Abotzoglou, R.; Nagy, R.C.; Fusco, E.; Mahood, A.L. Human-started wildfires expand the fire niche across the United States. Proc. Natl. Acad. Sci. USA 2017, 114, 2946–2951. [Google Scholar] [CrossRef] [Green Version]
- Foley, M. The High Cost of Wildfire in 2018. In NFPA; 2019; Available online: https://www.nfpa.org/News-and-Research/Publications-and-media/NFPA-Journal/2019/November-December-2019/Features/Large-Loss/Wildfire-Sidebar (accessed on 12 May 2021).
- Rice, B. Statement to Oversight Hearing on Wildland Fire Management: Federal and Non-Federal Collaboration, Including Through the Use of Technology, to Reduce Wildland Rire Risk to Communities and Enhance Firefighting Safety and Effectiveness. 2017. Available online: https://www.doi.gov/ocl/wildfire-management (accessed on 12 May 2021).
- Dunn, C.J.; O’Connor, C.D.; Abrams, J.; Thompson, M.P.; Calkin, D.E.; Johnston, J.D.; Stratton, R.; Gilbertson-Day, J. Wildfire risk science facilitates adaptation of fire-prone social-ecological systems to the new fire reality. Environ. Res. Lett. 2020, 15, 1–13. [Google Scholar] [CrossRef]
- Finney, M.A. An Overview of FlamMap Fire Modeling Capabilities. In Fuels Management—How to Measure Success: Conference Proceedings, Portland, OR, USA, 28–30 March 2006; Proceedings RMRS-P-41; United States Department of Agriculture: Washington, DC, USA, 2006; pp. 213–220. [Google Scholar]
- Carbone, A.; Jensen, M.; Sato, A. Challenges in data science: A complex systems perspective. Chaos Solitons Fractals 2016, 90, 1–7. [Google Scholar] [CrossRef]
- Elshawi, R.; Sakr, S.; Talia, D.; Trunflo, P. Big Data Systems Meet Machine Learning Challenges: Towards Big Data Sciences as a Service. Big Data Res. 2018, 14, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Fernandes, P.; Botelho, H. A review of prescribed burning effectiveness in fire hazard reduction. Int. J. Wildland Fire 2003, 12, 117–128. [Google Scholar] [CrossRef] [Green Version]
- Kolden, C. We’re Not Doing Enough Prescribed Fire in the Western United States to Mitigate Wildfire Risk. Fire 2019, 2, 30. [Google Scholar] [CrossRef] [Green Version]
- Hiers, J.K.; O’Brien, J.J.; Varner, M.; Butler, B.W.; Dickinson, M.; Furman, J.; Gallagher, M.; Godwin, D.; Goodrick, S.L.; Hood, S.M.; et al. Prescribed fire science: The case for a refined research agenda. Fire Ecol. 2020, 16, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Thompson, M.P.; Wei, Y.; Calkin, D.E.; O’connor, C.D.; Dunn, C.J.; Anderson, N.M.; Hogland, J.S. Risk Management and Analytics in Wildfire Response. Curr. For. Rep. 2019, 5, 226–239. [Google Scholar] [CrossRef] [Green Version]
- Baig, M.J.; Shuib, L.; Yadegaridehkordi, E. Big data adoption: State of the art and research challenges. Inf. Process. Manag. 2019, 56, 102095. [Google Scholar] [CrossRef]
- Côrte-Real, N.; Ruivo, P.; Oliveira, T. Leveraging internet of things and big data analytics initiatives in European and American Firs: Is data quality a way to extract business value? Inf. Manag. 2020, 57, 103141. [Google Scholar] [CrossRef]
- Thompson, M.P.; MacGregor, D.G.; Dunn, C.J.; Calkin, D.E.; Phipps, J. Rethinking the Wildland Fire Management System. J. For. 2018, 116, 382–390. [Google Scholar] [CrossRef] [Green Version]
- RMRS. RMRS Raster Utility. 2014. Available online: http://www.fs.fed.us/rm/raster-utility (accessed on 7 June 2021).
- Hogland, J.; Affleck, D.L.R.; Anderson, N.; Seielstad, C.; Dobrowski, S.; Graham, J.; Smith, R. Estimating Forest Characteristics for Longleaf Pine Restoration Using Normalized Remotely Sensed Imagery in Florida USA. Forests 2020, 11, 426. [Google Scholar] [CrossRef]
- Hogland, J.; Anderson, N.; Chung, W. New geospatial approaches for efficiently mapping forest biomass logistics at high resolution over large areas. Int. J. Geo-Inf. 2018, 7, 156. [Google Scholar] [CrossRef] [Green Version]
- Hogland, J.; Anderson, N. Function modeling improves the efficiency of spatial modeling using big data from remote sensing. Big Data Cogn. Comput. 2017, 1, 3. [Google Scholar] [CrossRef] [Green Version]
- LANDFIRE. LANDFIRE: Vegetation. U.S. Department of Agriculture and U.S. Department of the Interior. Available online: https://landfire.gov/vegetation.php (accessed on 7 August 2021).
- LANDFIRE. LANDFIRE: Fuel. U.S. Department of Agriculture and U.S. Department of the Interior. Available online: https://landfire.gov/fuel.php (accessed on 7 August 2021).
- Thompson, M.P.; Vaillant, N.M.; Haas, J.R.; Gebert, K.M.; Stockmann, K.D. Quantifying the potential impacts of fuel treatments on wildfire suppression costs. J. For. 2012, 111, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Finney, M.A.; Mchugh, C.W.; Stratton, R.D.; Riley, K.L. A simulation of probabilistic wildfire risk components for the continental United States. Stoch. Environ. Res. Risk Assess. 2011, 25, 973–1000. [Google Scholar] [CrossRef] [Green Version]
- Thompson, M.P.; Calkin, M.A.; Finney, M.A.; Ager, A.A.; Gilbertson-Day, J.W. Integrated national-scale assessment of wildfire risk to human and ecological values. Stoch. Environ. Res. Risk Assess. 2011, 25, 761–780. [Google Scholar] [CrossRef]
- U.S. Department of Agriculture Forest Service (USFS). Forest Inventory and Analysis National Core Field Guide: Field Data Collection Procedures for Phase 2 Plots, 2019 Version 9.0. Vol. 1. Internal Report. Available online: https://www.fia.fs.fed.us/library/field-guides-methods-proc/docs/2019/core_ver9-0_10_2019_final_rev_2_10_2020.pdf (accessed on 14 May 2021).
- Johnston, J.D.; Greenler, S.M.; Miller, B.A.; Reilly, M.J.; Lindsay, A.A.; Dunn, C.J. Diameter limits impede restoration of historical conditions in dry mixed-conifer forests of eastern Oregon, USA. Ecosphere 2021, 12, e03394. [Google Scholar] [CrossRef]
- USCB. TIGER/Line Shapefiles [Machine-Readable Data Files]. Available online: https://www2.census.gov/geo/tiger/TGRGDB20/ (accessed on 12 May 2021).
- Earth Observing System [EOS]. Sentinel-2. Available online: https://eos.com/sentinel-2 (accessed on 5 December 2019).
- Gesch, D.; Oimoen, M.; Geenlee, S.; Nelson, C.; Steuck, M.; Tyler, D. The National Elevation Dataset. Photogramm. Eng. Remote Sens. 2002, 68, 5–11. [Google Scholar]
- Schultz, C.A.; Jedd, T.; Beam, R.D. The collaborative forest landscape restoration program: A history and overview of the first projects. J. For. 2012, 110, 381–391. [Google Scholar] [CrossRef]
- Simpson, M. Forested Plant Associations of the Oregon East Cascades; Technical Paper R6-NR-ECOL-TP-03-2007; USDA Forest Service, Pacific Northwest Region: Portland, OR, USA, 2007.
- Johnston, J.D.; Greenler, S.M.; Reilly, M.J.; Webb, M.R.; Merschel, A.G.; Johnson, K.N.; Franklin, J.F. Conservation of Dry Forest Old Growth in Eastern Oregon. J. For. 2021, 1, 13. [Google Scholar]
- Johnston, J.D.; Bailey, J.D.; Dunn, C.J.; Lindsay, A.A. Historical fire-climate relationships in contrasting interior Pacific Northwest forest types. Fire Ecol. 2017, 13, 18–36. [Google Scholar] [CrossRef]
- Hessburg, P.F.; Agee, J.K. An environmental narrative of inland northwest United States forests, 1800–2000. For. Ecol. Manag. 2003, 178, 23–59. [Google Scholar] [CrossRef]
- Jones, G.M.; Gutiérrez, R.J.; Kramer, H.A.; Tempel, D.J.; Berigan, W.J.; Whitmore, S.A.; Peery, M.Z. Megafire effects on spotted owls: Elucidation of a growing threat and a response to Hanson et al. (2018). Nat. Conserv. 2019, 37, 31. [Google Scholar] [CrossRef]
- Sankey, J.B.; Kreitler, J.; Hawbaker, T.J.; McVay, J.L.; Miller, M.E.; Mueller, E.R.; Vaillant, N.M.; Lowe, S.E.; Sankey, T.T. Climate, wildfire, and erosion ensemble foretells more sediment in western USA watersheds. Geophys. Res. Lett. 2017, 44, 8884–8892. [Google Scholar] [CrossRef] [Green Version]
- Williams, J. Exploring the onset of high-impact mega-fires through a forest land management prism. For. Ecol. Manag. 2013, 294, 4–10. [Google Scholar] [CrossRef]
- Stephens, S.L.; Ruth, L.W. Federal forest-fire policy in the United States. Ecol. Appl. 2005, 15, 532–542. [Google Scholar] [CrossRef] [Green Version]
- European Space Agency [ESA]. Sentinel-2 User Handbook; ESA, 2015; p. 64. Available online: https://sentinel.esa.int/documents/247904/685211/Sentinel-2_User_Handbook (accessed on 14 May 2021).
- Environment Systems Research Institute [ESRI]. Resampling. Available online: https://desktop.arcgis.com/en/arcmap/latest/extensions/spatial-analyst/performing-analysis/cell-size-and-resampling-in-analysis.htm#GUID-AF7ECF8C-5F85-4759-A1A8-D0C4BCF47E9B (accessed on 12 May 2021).
- National Hydrography Dataset [NHD]. Available online: http://prd-tnm.s3-website-us-west-2.amazonaws.com/?prefix=StagedProducts/Hydrography/NHD/State/HighResolution/GDB/ (accessed on 12 May 2021).
- Wood, S.N. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. B 2011, 73, 3–36. [Google Scholar] [CrossRef] [Green Version]
- Hogland, J.; Anderson, N.; Affleck, D.L.R.; St. Peter, J. Using Forest Inventory Data with Landsat 8 imagery to Map Longleaf Pine Forest Characteristics in Georgia, USA. Remote Sens. 2019, 11, 1803. [Google Scholar] [CrossRef] [Green Version]
- Hogland, J. R Ensemble Generalized Additive Model (EGAM) Example. Available online: https://colab.research.google.com/drive/1GnRagruTUCoPJQZSkZ2vMKS9aAKgnhEw#scrollTo=sMAFw5OTLz78 (accessed on 18 May 2021).
- Avery, T.; Burkhart, H. Forest Measurements, 4th ed.; McGraw Hill: Boston, MA, USA, 1994; p. 408. [Google Scholar]
- Jenkins, J.; Chojnacky, D.; Heath, L.; Birdsey, R. National-scale biomass estimation for United States tree species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- Stevens, D.L.; Olsen, A.R. Spatially-balanced sampling of natural resources. J. Am. Stat. Assoc. 2004, 99, 262–277. [Google Scholar] [CrossRef]
- Souza, C.R. Accord.Net Framework. Available online: http://accord-framework.net/ (accessed on 14 May 2021).
- Souza, C.R. A Tutorial on Principal Component Analysis with Accord.NET Framework, Department of Computing, Federal University of Sao Carlos. Technical Report. Available online: http://arxiv.org/ftp/arxiv/papers/1210/1210.7463.pdf (accessed on 14 May 2021).
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 5th ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Tille, Y.; Wilhelm, M. Probability Sampling Designs: Principles for Choice of Design and Balancing. Stat. Sci. 2017, 32, 176–189. [Google Scholar] [CrossRef] [Green Version]
- Grafström, A.; Saarela, S.; Ene, T. Efficient sampling strategies for forest inventories by spreading the sample in auxiliary space. Can. J. For. Res. 2014, 44, 1156–1164. [Google Scholar] [CrossRef]
- Grafström, A.; Lundström, N.L.P. Why well spread probability samples are balanced. Open J. Stat. 2013, 3, 36–41. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, S.P. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Knapp, E.E.; Lydersen, J.M.; North, M.P.; Collins, B.M. Efficacy of variable density thinning and prescribed fire for restoring forest heterogeneity to mixed-conifer forest in the central Sierra Nevada, CA. For. Ecol. Manag. 2017, 406, 228–241. [Google Scholar] [CrossRef]
- Hogland, J.; St. Peter, J. Predicting Culvert Cost Using Raster Utility Toolbar and Batch Processing. 2019. Available online: https://onedrive.live.com/?authkey=%21AKaqRPt9iInki0g&cid=6137CBFCC0085BC1&id=6137CBFCC0085BC1%211374&parId=6137CBFCC0085BC1%21853&action=locate (accessed on 14 May 2021).
- Environmental System Research Institute [ESRI]. What Is Map Algebra? Available online: https://desktop.arcgis.com/en/arcmap/latest/extensions/spatial-analyst/map-algebra/what-is-map-algebra.htm (accessed on 14 May 2021).
- Environmental System Research Institute [ESRI]. Cost Path. Available online: http://desktop.arcgis.com/en/arcmap/10.3/tools/spatial-analyst-toolbox/cost-path.htm (accessed on 14 May 2021).
- Inland Forest Management [IFM]. Log Prices in North Idaho and Inland Northwest (August 2020 Tonwood). Available online: http://inlandforest.com/log-prices/ (accessed on 14 May 2021).
- Richard, B.; Cai, Z.; Caril, C.G.; Clausen, C.A.; Dietenberger, M.A.; Falk, R.H.; Frihart, C.R.; Glass, S.V.; Hunt, C.G.; Ibach, R.E.; et al. Wood Handbook, Wood as an Engineering Material; Forest Products Laboratory General Technical Report FPL-GTR-190; USDA Forest Service: Madison, WI, USA, 2010; p. 508. Available online: https://www.fpl.fs.fed.us/documnts/fplgtr/fpl_gtr190.pdf (accessed on 14 May 2021).
- Gregoire, T.; Valentine, H. Sampling Strategies for Natural Resources and the Environment; Chapman & Hall: London, UK; Boca Raton, FL, USA; New York, NY, USA, 2008; 474p. [Google Scholar]
- Cochrane, M.A.; Moran, C.J.; Wimberly, M.C.; Baer, A.D.; Finney, M.A.; Beckendorf, K.L.; Eidenshink, J.; Zhu, Z. Estimation of wildfire size and risk changes due to fuels treatments. Int. J. Wildland Fire 2011, 21, 357–367. [Google Scholar] [CrossRef] [Green Version]
- Hogland, J. Delivered Cost Workshop (Google Class Code igys6jc). 2020. Available online: https://classroom.google.com/c/MTIyNjkxOTI5Njgw?cjc=igys6jc (accessed on 14 May 2021).
- Enquist, C.A.F.; Jackson, S.T.; Garfin, G.M.; Davis, F.W.; Gerber, L.R.; Littell, J.A.; Adam, J.L.T.; Terando, A.J.; Wall, T.U.; Halpern, B.; et al. Foundations of translational ecology. Front. Ecol. Environ. 2017, 15, 541–550. [Google Scholar] [CrossRef] [Green Version]
- Thompson, M.P.; Bowden, P.; Brough, A.; Scott, J.H.; Gilbertson-Day, J.; Taylor, A.; Anderson, J.; Haas, J. Application of Wildfire Risk Assessment Results to Wildfire Response Planning in the Southern Sierra Nevada, California, USA. Forests 2016, 7, 64. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Contribution |
|---|---|---|
| Roads | TIGER\Line road network | Cost Revenue Assessment |
| Streams | NHD Flowline | Cost Revenue Assessment |
| Waterbodies | NHD Waterbodies | Cost Revenue Assessment |
| Plots | FVF field plots | Existing Condition |
| PODs | Potential Operational Delineations | Cost Revenue Assessment & Desired Future Condition |
| Facilities | Malheur Lumber Company | Cost Revenue Assessment |
| CFLRP | Collaborative Forest Landscape Restoration Program | Analysis extent |
| DEM | Digital Elevation Model | Existing Condition, Cost Revenue Assessment & Desired Future Condition |
| Sentinel 2 | Satellite Imagery Bands (2–8, 8b, 11, and 12) | Existing Condition |
| Metric | Equation | Source |
|---|---|---|
| DomType | Boolean logic selecting the species with the greatest BAH. Class labels include Nonforest (BAH = 0), Pine, and Fir. | NA |
| BAH | [51] | |
| TPH | EF * tree count | [51] |
| SWBH | [52] | |
| AGBH | [52] |
| Metric | Description |
|---|---|
| Mean | Band cell mean value within a 3 by 3 moving window |
| Standard Deviation | Band cell standard deviation within a 3 by 3 moving window |
| Slope | Percent slope calculated from a digital elevation model |
| Northing | Northing calculation from azimuth |
| Easting | Easting calculation from azimuth |
| Description | Rule | Order | Desired BAH |
|---|---|---|---|
| Slope | >50% | 1 | Existing |
| SMZ | Within 30 m | 2 | Existing |
| POD Boundary | Within 0.4 km | 3 | 15 BAH |
| North Aspect | 270–90° Azimuth | 4 | 27 BAH |
| South Aspect | 90–270° Azimuth | 5 | 20 BAH |
| Component | Type | Value | Units |
|---|---|---|---|
| On-road | Machine Rate | 90 | USD h−1 |
| Speed | Table 6 | km h−1 | |
| Payload | 25.40 | tonne | |
| Off-road | Machine Rate | 80 | USD h−1 |
| Speed | 4.83 | km h−1 | |
| Payload | 3.63 | tonne | |
| Operations | Harvesting & Processing | 65 | USD tonne−1 |
| Other | Administrative | 0 | USD tonne−1 |
| Query | Speed km h−1 |
|---|---|
| MTFCC = “S1400”: Local Road, Rural Road, City Street | 88 |
| MTFCC = “S1200”: Secondary road | 56 |
| MTFCC = “S1100”: Primary road | 40 |
| NOT (MTFCC = “S1400” OR MTFCC = “S1200” OR MTFCC = “S1100”) | 40 |
| EGAM | Source | Predictors | Fit |
|---|---|---|---|
| BAH (a) | Sentinel Mean | summer bands—7, 11, and 12 fall bands—6, 8b, and 12 | 8.36 |
| DEM | elevation and slope | ||
| TPH (a) | Sentinel Mean | summer band—12 fall bands—2, 11, and 12 | 176.06 |
| Sentinel Standard Deviation | summer band—5 | ||
| DEM | elevation and easting | ||
| SWBH (a) | Sentinel Mean | summer band—7, 11, and 12 fall bands—6, 8b, 12 | 32.44 |
| Sentinel Standard Deviation | fall band—6 | ||
| DEM | elevation and slope | ||
| AGBH (a) | Sentinel Mean | summer band—7, 11, and 12 fall bands—6, 8b, 12 | 48.81 |
| Sentinel Standard Deviation | fall band—6 | ||
| DEM | elevation and slope | ||
| DomType (b) | Sentinel Mean | summer band—4, 6, 7, 8, 11, and 12 fall bands—2 | 83.38% |
| Sentinel Standard Deviation | fall band—2 | ||
| DEM | elevation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hogland, J.; Dunn, C.J.; Johnston, J.D. 21st Century Planning Techniques for Creating Fire-Resilient Forests in the American West. Forests 2021, 12, 1084. https://doi.org/10.3390/f12081084
Hogland J, Dunn CJ, Johnston JD. 21st Century Planning Techniques for Creating Fire-Resilient Forests in the American West. Forests. 2021; 12(8):1084. https://doi.org/10.3390/f12081084
Chicago/Turabian StyleHogland, John, Christopher J. Dunn, and James D. Johnston. 2021. "21st Century Planning Techniques for Creating Fire-Resilient Forests in the American West" Forests 12, no. 8: 1084. https://doi.org/10.3390/f12081084
APA StyleHogland, J., Dunn, C. J., & Johnston, J. D. (2021). 21st Century Planning Techniques for Creating Fire-Resilient Forests in the American West. Forests, 12(8), 1084. https://doi.org/10.3390/f12081084