
Prediction of Road Transport of Wood in Uruguay: Approach with Machine Learning

 , , and
, , and
Abstract
:1. Introduction
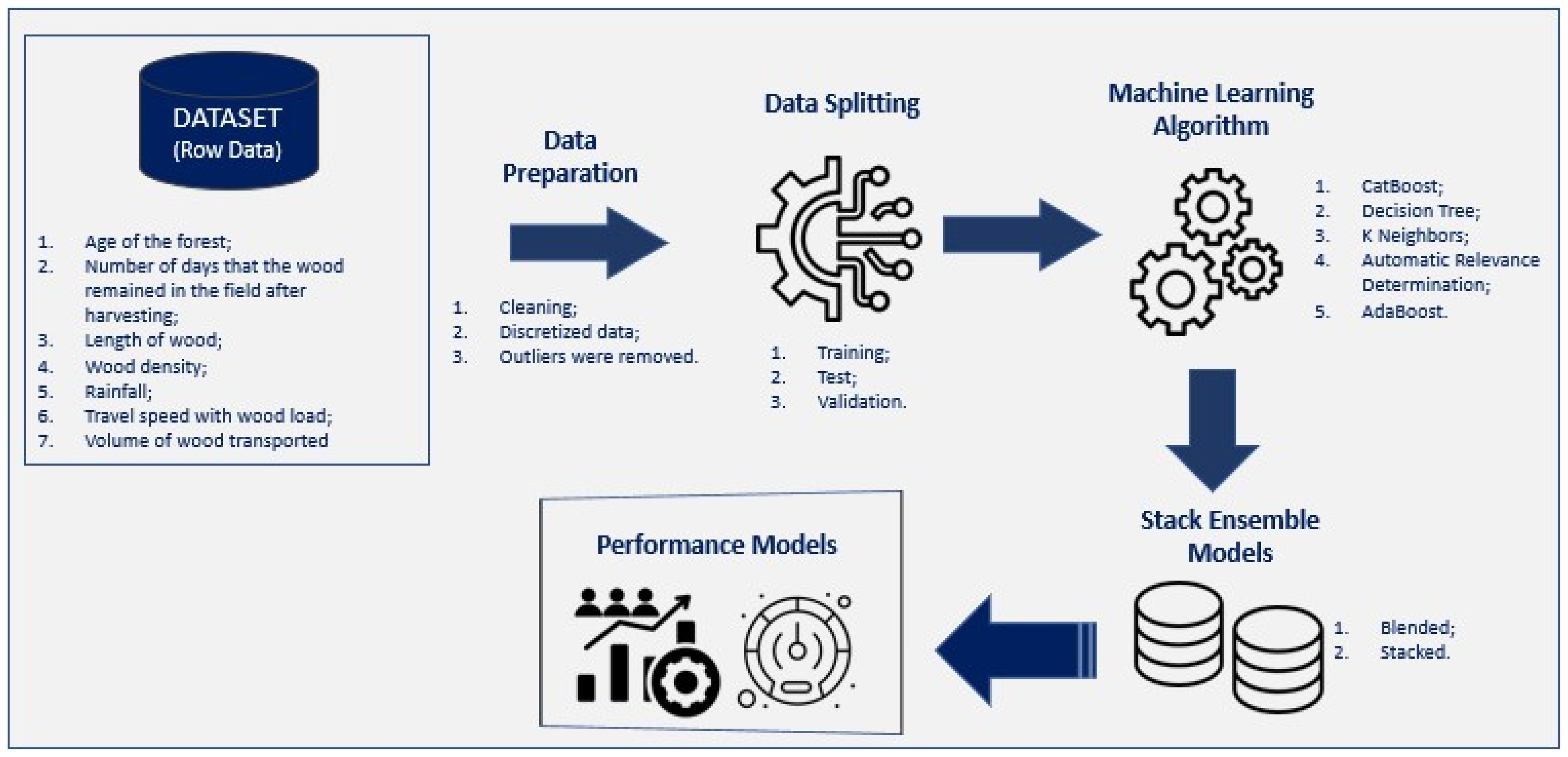
2. Materials and Methods
2.1. Case Study
2.2. Exploratory Analysis
2.3. Model
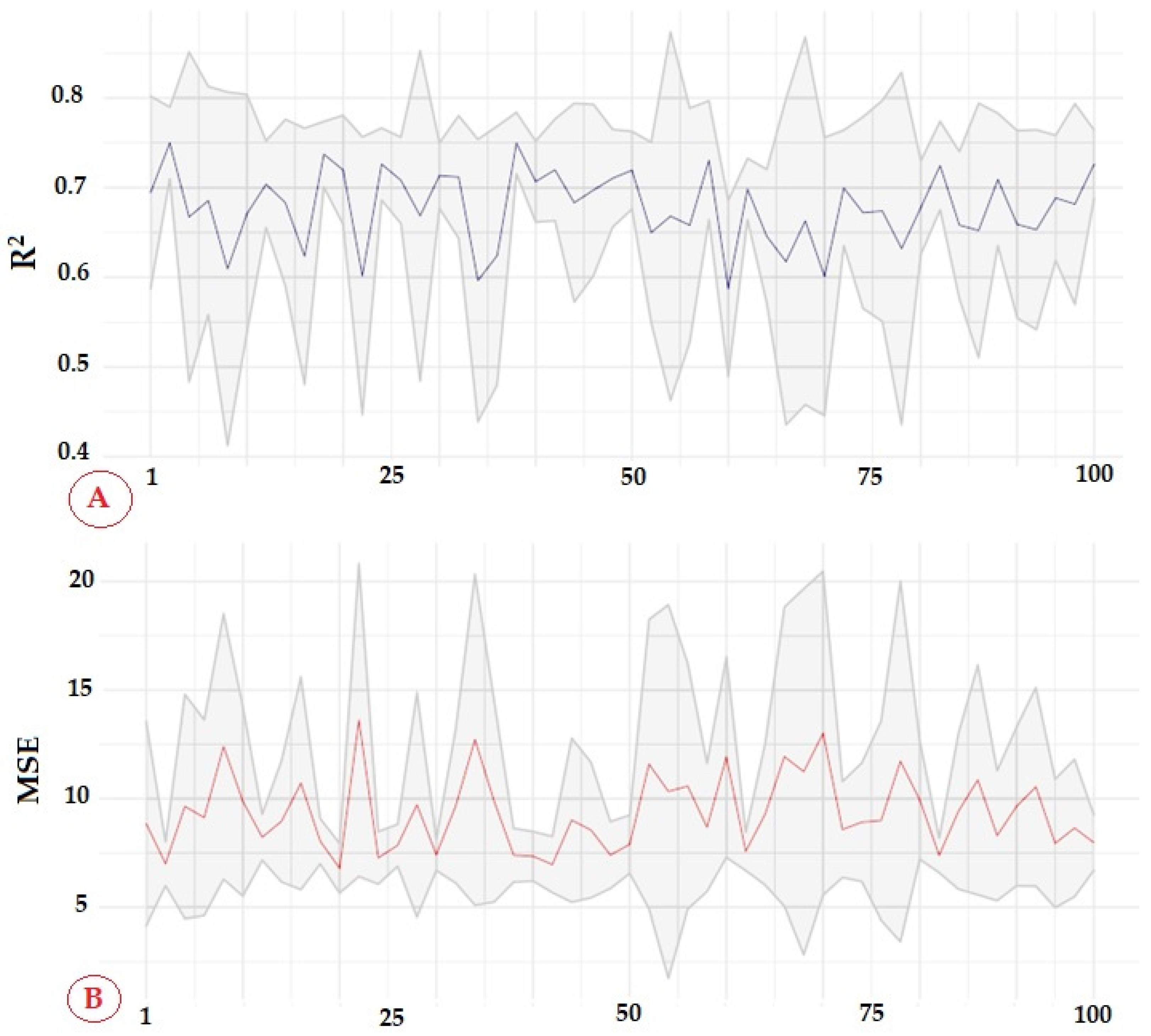
3. Results
Modeling
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Allaoui, H.; Guo, Y.; Sarkis, J. Decision support for collaboration planning in sustainable supply chains. J. Clean. Prod. 2019, 229, 761–774. [Google Scholar] [CrossRef]
- Aspland, E.; Gartner, D.; Harper, P. Clinical pathway modelling: A literature review. Health Syst. 2021, 10, 1–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akhtari, S.; Sowlati, T. Hybrid optimization-simulation for integrated planning of bioenergy an biofuel supply chains. Appl. Energy 2020, 259, 114124. [Google Scholar] [CrossRef]
- Pereira, D.F.; Oliveira, J.F.; Carravilla, M.A. Tactical sales and operations planning: A holistic framework and a literature review of decision-making models. Int. J. Prod. Econ. 2020, 228, 107695. [Google Scholar] [CrossRef]
- George, B.; Walker, R.M.; Monster, J. Does Strategic Planning Improve Organizational Performance? A Meta-Analysis. Public Adm. Rev. 2019, 79, 810–819. [Google Scholar] [CrossRef]
- Teixeira, G.F.G.; Canciglieri Junior, O. How to make strategic planning for corporate sustainability? J. Clean. Prod. 2019, 230, 1421–1431. [Google Scholar] [CrossRef]
- Bolland, E.J. Evolution of Strategy: Origin, Planning, Strategic Planning and Strategic Management. In Strategizing; Emerald Publishing Limited: Bingley, UK, 2020; pp. 25–48. [Google Scholar] [CrossRef]
- Sara, I.M.; Saputra, K.A.K.; Utama, I.W.K.J. The Effects of Strategic Planning, Human Resource and Asset Management on Economic Productivity: A Case Study in Indonesia. J. Asian Financ. Econ. Bus. 2021, 8, 381–389. [Google Scholar] [CrossRef]
- Akhtari, S.; Sowlati, T.; Griess, V.C. Integrated strategic and tactical optimization of forest-based biomass supply chains to consider medium-term supply and demand variations. Appl. Energy 2018, 213, 626–638. [Google Scholar] [CrossRef]
- Laschi, A.; Foderi, C.; Fabiano, F.; Neri, F.; Cambi, M.; Mariotti, B.; Marchi, E. Forest road planning, construction and maintenance to improve forest fire fighting: A review. Croat. J. For. Eng. 2019, 40, 207–219. [Google Scholar]
- Schröder, T.; Lauven, L.P.; Sowlati, T.; Geldermann, J. Strategic planning of a multi-product wood-biorefinery production system. J. Clean. Prod. 2019, 211, 1502–1516. [Google Scholar] [CrossRef]
- Falcone, P.M.; Tani, A.; Tartiu, V.E.; Imbriani, C. Towards a sustainable forest-based bioeconomy in Italy: Findings from a SWOT analysis. For. Policy Econ. 2020, 110, 101910. [Google Scholar] [CrossRef]
- Conrad, J.L. Costs and challenges of log truck transportation in Georgia, USA. Forests 2018, 9, 650. [Google Scholar] [CrossRef] [Green Version]
- Kühmaier, M.; Erber, G. Research trends in European forest fuel supply chains: A review of the last ten years (2007–2016)—Part two: Comminution, transport & logistics. Croat. J. For. Eng. 2018, 39, 139–152. [Google Scholar]
- Mokhirev, A.P.; Pozdnyakova, M.O.; Medvedev, S.O.; Mammatov, V.O. Assessment of availability of wood resources using geographic information and analytical systems (the krasnoyarsk territory as a case study). J. Appl. Eng. Sci. 2018, 16, 313–319. [Google Scholar] [CrossRef]
- Keramati, A.; Lu, P.; Sobhani, A.; Haji Esmaeili, S.A. Impact of Forest Road Maintenance Policies on Log Transportation Cost, Routing, and Carbon-Emission Trade-Offs: Oregon Case Study. J. Transp. Eng. Part A Syst. 2020, 146, 04020028. [Google Scholar] [CrossRef]
- Koirala, A.; Kizha, A.R.; Roth, B.E. Perceiving Major Problems in Forest Products Transportation by Trucks and Trailers: A Cross-sectional Survey. Eur. J. For. Eng. 2017, 3, 23–34. [Google Scholar]
- Malladi, K.T.; Sowlati, T. Optimization of operational level transportation planning in forestry: A review. Int. J. For. Eng. 2017, 28, 198–210. [Google Scholar] [CrossRef]
- Johannes, E.; Ekman, P.; Huge-Brodin, M.; Karlsson, M. Sustainable timber transport-economic aspects of aerodynamic reconfiguration. Sustainability 2018, 10, 1965. [Google Scholar] [CrossRef] [Green Version]
- Olegovna Pozdnyakova, M.; Petrovich Mokhirev, A.; Ryabova, T.G. Comprehensive evaluation of technological measures for increasing availability of wood resources. J. Appl. Eng. Sci. 2018, 16, 565–569. [Google Scholar] [CrossRef]
- Sarrazin, F.; Lebel, L.; Lehoux, N. Analyzing the impact of implementing a logistics center for a complex forest network. Can. J. For. Res. 2019, 49, 179–189. [Google Scholar] [CrossRef]
- Hlatká, M.; Kampf, R.; Fedorko, G.; Molnár, V. Optimization of logistics processes during the production of wood chips. TEM J. 2020, 9, 889–898. [Google Scholar] [CrossRef]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Batta, M. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar] [CrossRef]
- Machine Learning and the City: Applications in Architecture and urban Design, 1st ed.; Carta, S. (Ed.) Wiley-Blackwell: Hoboken, NJ, USA, 2022; ISBN 978-1-119-74963-9. [Google Scholar]
- Athey, S. The Economics of Artificial Intelligence: An Agenda. In The Economics of Artificial Intelligence; Agrawal, A., Gans, J., Goldfarb, A., Eds.; University of Chicago Press: Chicago, IL, USA, 2019; pp. 507–547. ISBN 9780226613338. [Google Scholar]
- Ayoubi, S.; Limam, N.; Salahuddin, M.A.; Shahriar, N.; Boutaba, R.; Estrada-Solano, F.; Caicedo, O.M. Machine Learning for Cognitive Network Management. IEEE Commun. Mag. 2018, 56, 158–165. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of machine learning and IoT in smart transportation. Futur. Internet 2019, 11, 94. [Google Scholar] [CrossRef] [Green Version]
- Verbraeken, J.; Wolting, M.; Katzy, J.; Kloppenburg, J.; Verbelen, T.; Rellermeyer, J.S. A Survey on Distributed Machine Learning. ACM Comput. Surv. 2020, 53, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.C.; Kim, J.H.; Hong, J.Y. Characterizing perceived aspects of adverse impact of noise on construction managers on construction sites. Build. Environ. 2019, 152, 17–27. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, J.; Du, B.; Ding, C.; Sun, L. Parallel Architecture of Convolutional Bi-Directional LSTM Neural Networks for Network-Wide Metro Ridership Prediction. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2278–2288. [Google Scholar] [CrossRef]
- Barua, L.; Zou, B.; Zhou, Y. Machine learning for international freight transportation management: A comprehensive review. Res. Transp. Bus. Manag. 2020, 34, 100453. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Tizghadam, A.; Khazaei, H.; Moghaddam, M.H.Y.; Hassan, Y. Machine Learning in Transportation. J. Adv. Transp. 2019, 2019, 4359785. [Google Scholar] [CrossRef]
- Li, J.P.; Mirza, N.; Rahat, B.; Xiong, D. Machine learning and credit ratings prediction in the age of fourth industrial revolution. Technol. Forecast. Soc. Change 2020, 161, 120309. [Google Scholar] [CrossRef]
- Ibrahim, I.; Abdulazeez, A. The Role of Machine Learning Algorithms for Diagnosing Diseases. J. Appl. Sci. Technol. Trends 2021, 2, 10–19. [Google Scholar] [CrossRef]
- R Development Core Team. R: A language and environment for Statistical, statistical computing. In Vienna (Austria): R Foundation for Computing; R Development Core Team: Vienna, Austria, 2021; ISBN 3-900051-07-0. [Google Scholar]
- Munis, R.A.; Almeida, R.O.; Camargo, D.A.; Barbosa, R.; Wojciechowski, J.; Sim, D. Machine Learning Methods to Estimate Productivity of Harvesters: Mechanized Timber Harvesting in Brazil. Forests 2022, 13, 1068. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, C.; Wu, B. Crown Profile Modeling and Prediction Based on Ensemble Learning. Forests 2022, 13, 410. [Google Scholar] [CrossRef]
- Bueno, G.F.; Costa, E.A.; Guimar, A.; Liesenberg, V. Machine Learning: Crown Diameter Predictive Modeling for Open-Grown Trees in the Cerrado Biome, Brazil. Forests 2022, 13, 1295. [Google Scholar] [CrossRef]
- PyCaret Org. 2021. Available online: https://pycaret.org/about (accessed on 10 July 2022).
- Borz, S.A.; Forkuo, G.O.; Oprea-sorescu, O.; Proto, A.R. Development of a Robust Machine Learning Model to Monitor the Operational Performance of Fixed-Post Multi-Blade Vertical Sawing Machines. Forests 2022, 13, 1115. [Google Scholar] [CrossRef]
- Dai, S.; Zheng, X.; Gao, L.; Xu, C.; Zuo, S.; Chen, Q.; Wei, X.; Ren, Y. Improving plot-level model of forest biomass: A combined approach using machine learning with spatial statistics. Forests 2021, 12, 1663. [Google Scholar] [CrossRef]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Hyperparameter tuning and performance assessment of statistical and machine-learning algorithms using spatial data. Ecol. Modell. 2019, 406, 109–120. [Google Scholar] [CrossRef] [Green Version]
- Andonie, R. Hyperparameter optimization in learning systems. J. Membr. Comput. 2019, 1, 279–291. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Shahabi, H.; Mirchooli, F.; Valizadeh Kamran, K.; Lim, S.; Aryal, J.; Jarihani, B.; Blaschke, T. Gully erosion susceptibility mapping (GESM) using machine learning methods optimized by the multi-collinearity analysis and K-fold cross-validation. Geomat. Nat. Hazards Risk 2020, 11, 1653–1678. [Google Scholar] [CrossRef]
- Arabameri, A.; Arora, A.; Pal, S.C.; Mitra, S.; Saha, A.; Nalivan, O.A.; Panahi, S.; Moayedi, H. K-Fold and State-of-the-Art Metaheuristic Machine Learning Approaches for Groundwater Potential Modelling. Water Resour. Manag. 2021, 35, 1837–1869, ISBN 1126902102815. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning, 1st ed.; McGraw-Hill Science/Engineering/Math: New York, NY, USA, 1977; ISBN 978-0070428072. [Google Scholar]
- Arjasakusuma, S.; Kusuma, S.S.; Phinn, S. Evaluating variable selection and machine learning algorithms for estimating forest heights by combining lidar and hyperspectral data. ISPRS Int. J. Geo-Information 2020, 9, 507. [Google Scholar] [CrossRef]
- Lenherr, N.; Pawlitzek, R.; Michel, B. New universal sustainability metrics to assess edge intelligence. Sustain. Comput. Informatics Syst. 2021, 31, 100580. [Google Scholar] [CrossRef]
- Štambuk, N. Universal Metric Properties of the Genetic Code. Croat. Chem. Acta 2000, 73, 1123–1139. [Google Scholar]
- Picchio, R.; Tavankar, F.; Venanzi, R.; Lo Monaco, A.; Nikooy, M. Study of forest road effect on tree community and stand structure in three italian and Iranian temperate forests. Croat. J. For. Eng. 2018, 39, 57–70. [Google Scholar]
- Lotfalian, M.; Peyrov, S.; Adeli, K.; Pentek, T. Determination of Optimal Distribution and Transportation Network. Croat. J. For. Eng. 2022, 43, 313–323. [Google Scholar] [CrossRef]
- Jamhuri, J.; Norizah, K.; Mohd Hasmadi, I.; Azfanizam, A.S. Bees algorithm for Forest transportation planning optimization in Malaysia. Forest Sci. Technol. 2021, 17, 88–99. [Google Scholar] [CrossRef]
- Rix, G.; Rousseau, L.M.; Pesant, G. A column generation algorithm for tactical timber transportation planning. J. Oper. Res. Soc. 2014, 66, 278–287. [Google Scholar] [CrossRef]
- Visser, R.; Obi, O.F. Automation and Robotics in Forest Harvesting Operations. Croat. J. For. Eng. 2021, 42, 13–24. [Google Scholar] [CrossRef]
- Wang, M.; Wood, L.C.; Wang, B. Transportation capacity shortage influence on logistics performance: Evidence from the driver shortage. Heliyon 2022, 8, e09423. [Google Scholar] [CrossRef] [PubMed]
- Frisk, M.; Göthe-Lundgren, M.; Jörnsten, K.; Rönnqvist, M. Cost allocation in collaborative forest transportation. Eur. J. Oper. Res. 2010, 205, 448–458. [Google Scholar] [CrossRef] [Green Version]
- Mobini, M.; Sowlati, T.; Sokhansanj, S. Forest biomass supply logistics for a power plant using the discrete-event simulation approach. Appl. Energy 2011, 88, 1241–1250. [Google Scholar] [CrossRef]
- Ojha, V.; Timmis, J.; Nicosia, G. Assessing ranking and effectiveness of evolutionary algorithm hyperparameters using global sensitivity analysis methodologies. Swarm Evol. Comput. 2022, 74, 101130. [Google Scholar] [CrossRef]
- Tsolaki, K.; Vafeiadis, T.; Nizamis, A.; Ioannidis, D.; Tzovaras, D. Utilizing machine learning on freight transportation and logistics applications: A review. ICT Express 2022, in press. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Forest Plantations | Average Age of the Forest (months) | Number of Trips | Volume of Wood Transported (m3) | Average Transport Distance (km) | Coordinates of the Area | |
|---|---|---|---|---|---|---|
| Latitude | Longitude | |||||
| FP_1 | 164.87 | 7608 | 282,913.31 | 147.88 | 32°32′ | 57°58′ |
| FP_2 | 143.79 | 7238 | 282,971.20 | 145.72 | 32°88′ | 57°53′ |
| FP_3 | 161.03 | 6189 | 241,512.68 | 284.00 | 32°53′ | 57°05 |
| FP_4 | 154.65 | 5726 | 216,345.03 | 169.72 | 31°88′ | 55°92′ |
| Described Variables | Mean | Sd | Min | Max | IQR | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| Age of the forest (months) | 156.14 | 19.96 | 24.00 | 193 | 29.00 | −1.07 | 5.67 |
| Number of days that the wood remained in the field after harvesting (days) | 100.67 | 76.60 | 1.00 | 1090 | 102.00 | 1.80 | 9.76 |
| Length of wood (meters) | 6.79 | 0.90 | 4.80 | 7.20 | 0.00 | −1.74 | 1.04 |
| Wood density (g cm−3) | 0.82 | 0.11 | 0.56 | 1.14 | 0.16 | −0.03 | −0.76 |
| Rainfall (mm) | 2.36 | 10.16 | 0.00 | 140 | 0.00 | 6.84 | 59.49 |
| Travel speed with wood load (km h−1) | 46.11 | 10.05 | 18.27 | 105.65 | 12.76 | 1.19 | 2.81 |
| Volume of wood transported (m3) | 38.25 | 5.31 | 7.11 | 58.81 | 7.46 | 0.05 | 0.15 |
| Model | MAE | MSE | RMSE | R2 | RMSLE | MAPE | TT (Sec) |
|---|---|---|---|---|---|---|---|
| CatBoost Regressor | 2.15 | 8.54 | 2.92 | 0.69 | 0.08 | 0.06 | 3.92 |
| Decision Tree Regressor | 2.29 | 9.86 | 3.14 | 0.65 | 0.09 | 0.06 | 0.24 |
| K Neighbors Regressor | 2.35 | 10.12 | 3.18 | 0.64 | 0.09 | 0.06 | 0.44 |
| Automatic Relevance Determination | 2.38 | 10.42 | 3.23 | 0.63 | 0.09 | 0.06 | 0.23 |
| AdaBoost Regressor | 2.59 | 12.08 | 3.47 | 0.57 | 0.09 | 0.07 | 0.10 |
| Model—Default | Fold | MAE | MSE | RMSE | R2 | RMSLE |
|---|---|---|---|---|---|---|
| CatBoost Regressor | 50 | 2.14 | 8.50 | 2.91 | 0.69 | 0.08 |
| Decision Tree Regressor | 30 | 2.27 | 9.64 | 3.10 | 0.65 | 0.08 |
| K Neighbors Regressor | 50 | 2.35 | 10.07 | 3.17 | 0.64 | 0.09 |
| Model—Tuned | Fold | Iteration | Adjustment Process | MAE | MSE | RMSE | R2 |
|---|---|---|---|---|---|---|---|
| CatBoost Regressor | 50 | 50 | Bayesian | 2.14 | 8.53 | 2.91 | 0.69 |
| Decision Tree Regressor | 30 | 50 | Bayesian | 2.19 | 8.88 | 2.98 | 0.68 |
| K Neighbors Regressor | 50 | 10 | random | 2.26 | 9.43 | 3.06 | 0.66 |
| Model | Fold | MAE | MSE | RMSE | R2 | Iteration | Adjustment Process | Method |
|---|---|---|---|---|---|---|---|---|
| CatBoost Regressor-Default | 50 | 2.14 | 8.50 | 2.91 | 0.69 | - | - | -- |
| Ensembled Tuned Decision Tree | 30 | 2.15 | 8.63 | 2.93 | 0.69 | 50 | Bayesian | Bagging |
| Ensembled Tuned K Neighbors | 50 | 2.24 | 9.21 | 3.03 | 0.67 | 10 | Random | Bagging |
| Model | MAE | MSE | RMSE | R2 |
|---|---|---|---|---|
| Blended | 2.16 | 8.60 | 2.93 | 0.69 |
| Stacked | 2.14 | 8.52 | 2.92 | 0.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almeida, R.O.; Munis, R.A.; Camargo, D.A.; da Silva, T.; Sasso Júnior, V.A.; Simões, D. Prediction of Road Transport of Wood in Uruguay: Approach with Machine Learning. Forests 2022, 13, 1737. https://doi.org/10.3390/f13101737
Almeida RO, Munis RA, Camargo DA, da Silva T, Sasso Júnior VA, Simões D. Prediction of Road Transport of Wood in Uruguay: Approach with Machine Learning. Forests. 2022; 13(10):1737. https://doi.org/10.3390/f13101737
Chicago/Turabian StyleAlmeida, Rodrigo Oliveira, Rafaele Almeida Munis, Diego Aparecido Camargo, Thamires da Silva, Valier Augusto Sasso Júnior, and Danilo Simões. 2022. "Prediction of Road Transport of Wood in Uruguay: Approach with Machine Learning" Forests 13, no. 10: 1737. https://doi.org/10.3390/f13101737
APA StyleAlmeida, R. O., Munis, R. A., Camargo, D. A., da Silva, T., Sasso Júnior, V. A., & Simões, D. (2022). Prediction of Road Transport of Wood in Uruguay: Approach with Machine Learning. Forests, 13(10), 1737. https://doi.org/10.3390/f13101737