
A Study of the Distribution of Forest Density in Inner Mongolia Based on Environmental Factors



Abstract
:1. Introduction
2. Materials and Methods
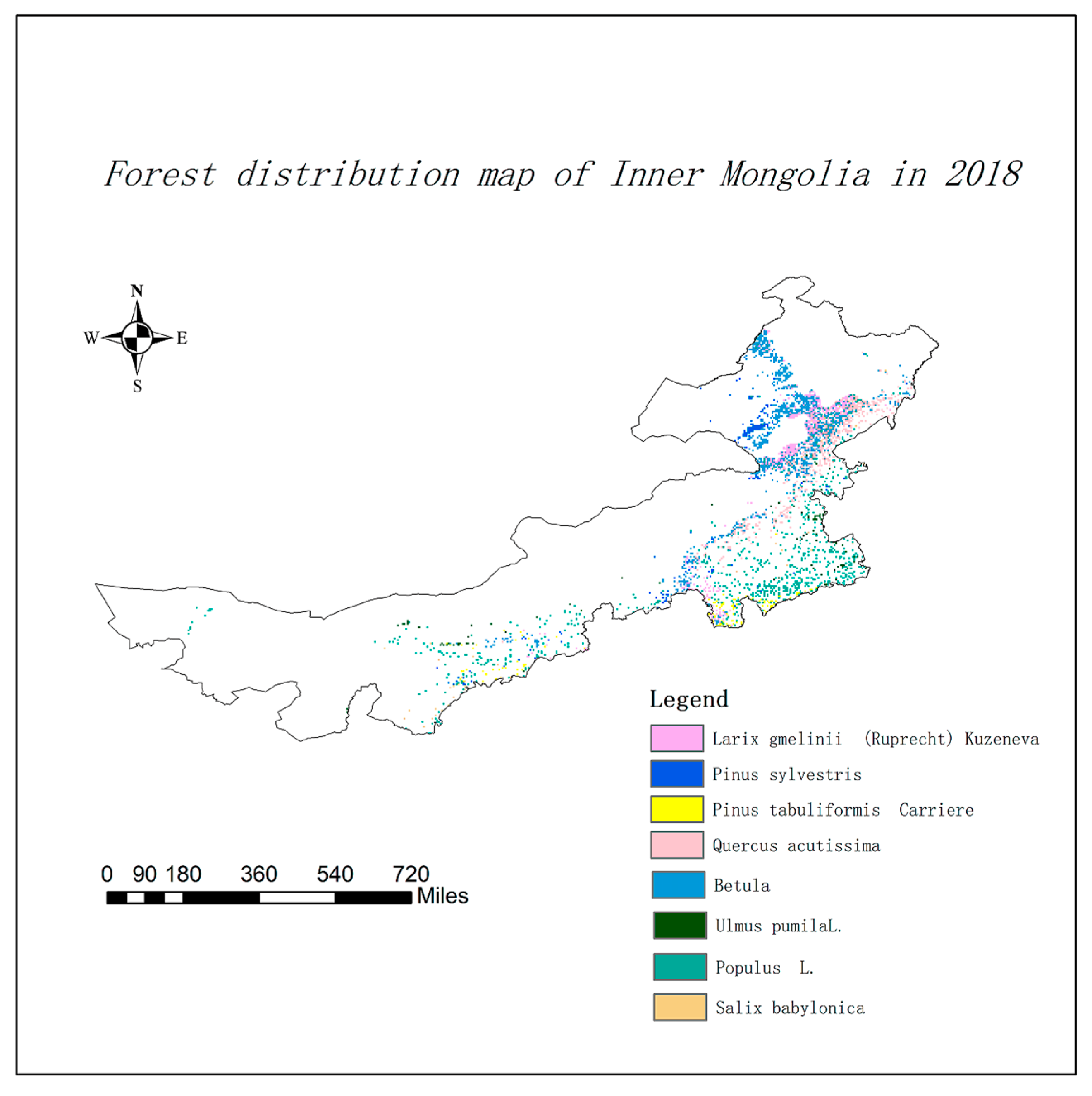
2.1. Overview of the Study Area
2.2. Forest Data
2.3. Relevant Environmental Factor Data
2.4. Data Preprocessing
2.5. Construction of Random Forest Regression Model Based on Particle Swarm Optimization
| Algorithm 1 10-fold cross validation |
|
- (1)
- In the training phase, random forest resamples n samples from the original data using bootstrap as the training set.
- (2)
- The training set generates a decision tree by choosing m features that are not repeated at each decision tree node as the current node-splitting feature set and then splits that node in the best way of m features.
- (3)
- All samples are sequentially trained to construct different decision trees.
- (4)
- In the prediction phase, the most common result in the decision tree is the predicted result.
| Algorithm 2 Stochastic Forest optimization algorithm |
|
| Algorithm 3 Postprocessing algorithm |
|
2.6. Model Evaluation
3. Results
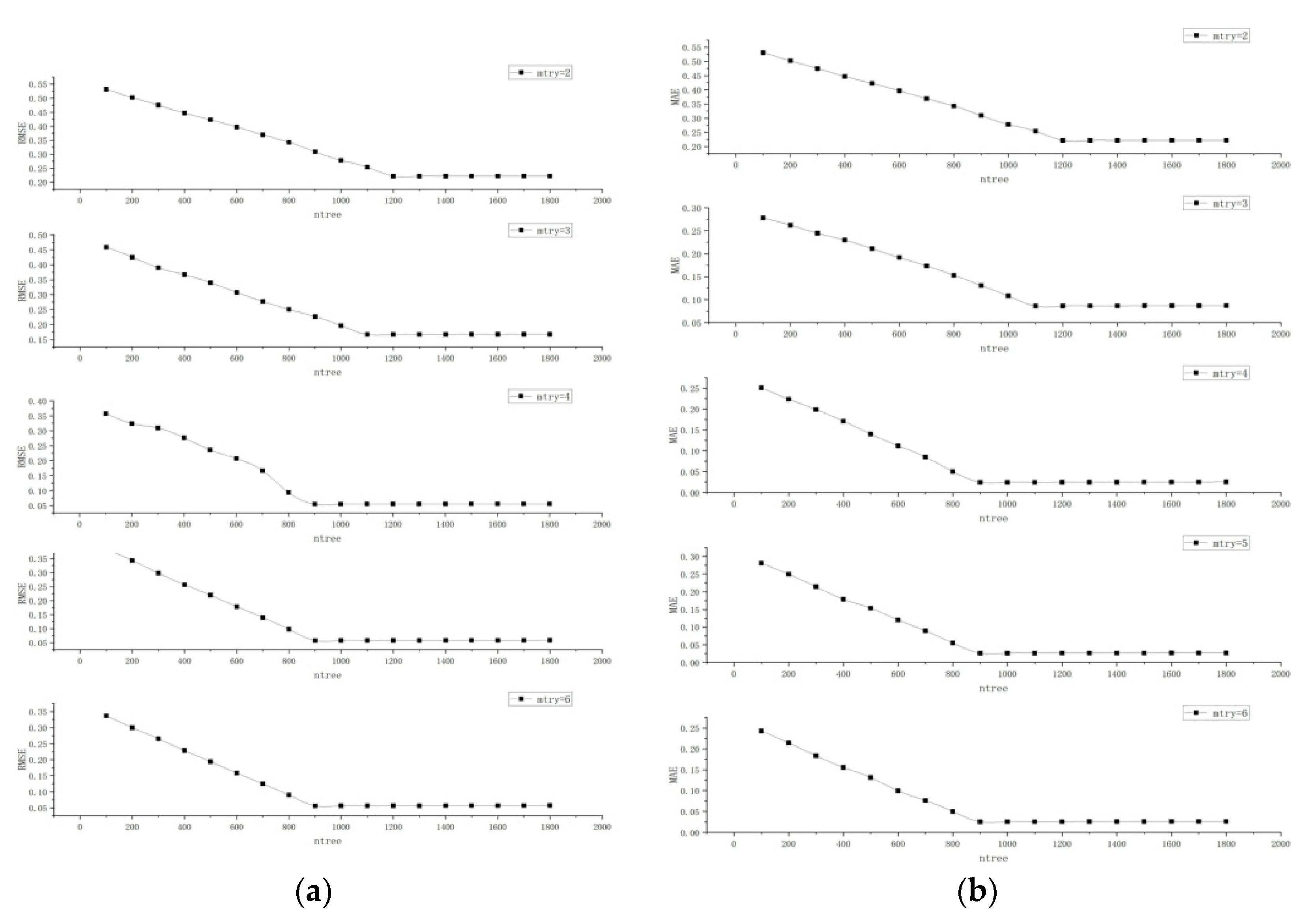
3.1. Particle Swarm Algorithm Iterative Optimization Search Analysis
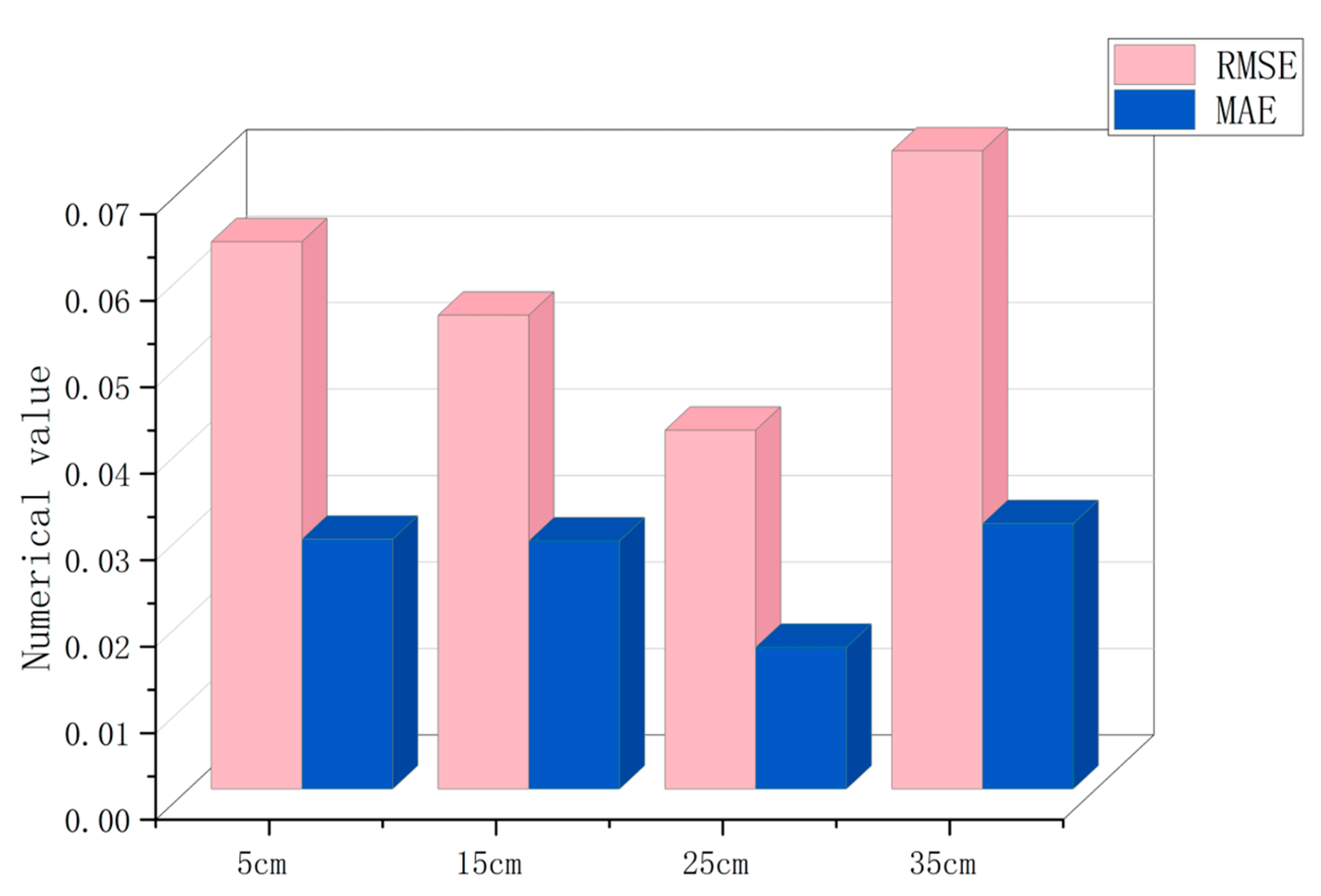
3.2. Model Accuracy Analysis
4. Discussion
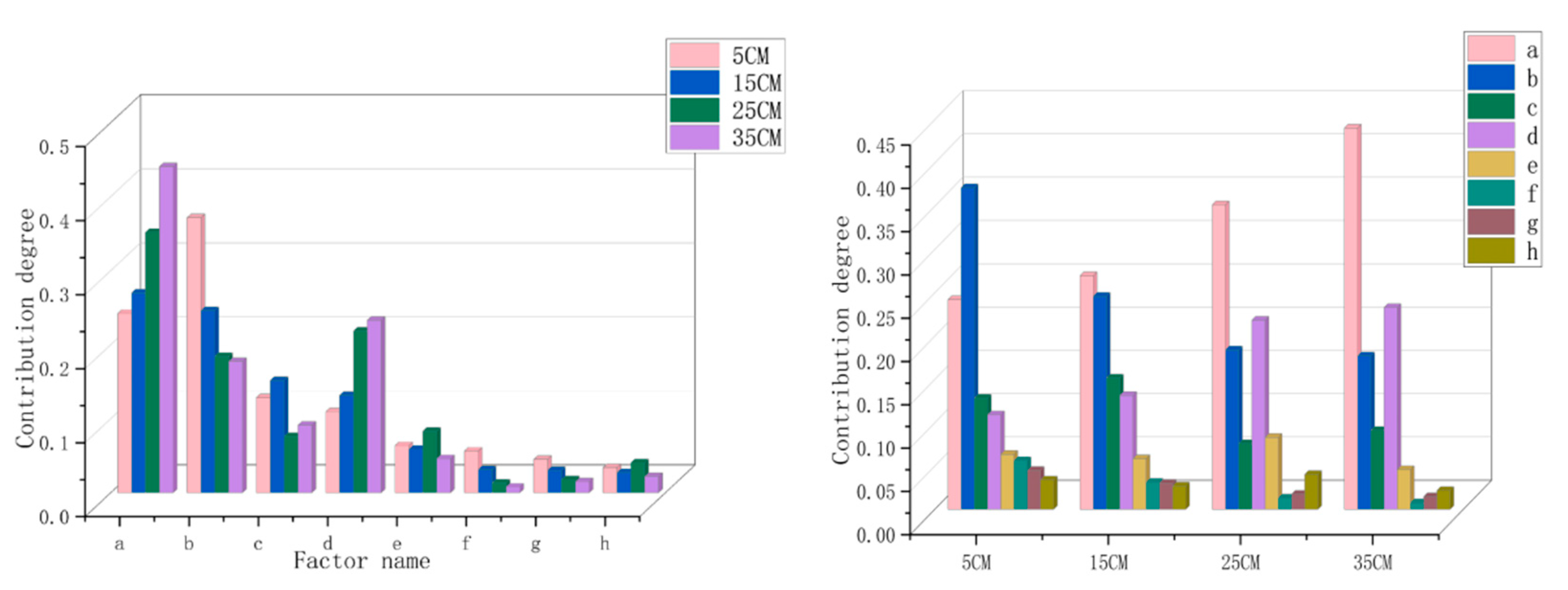
4.1. Effect of Environmental Factors on Forest Density
4.2. Effect of Environmental Factors on Forest Density
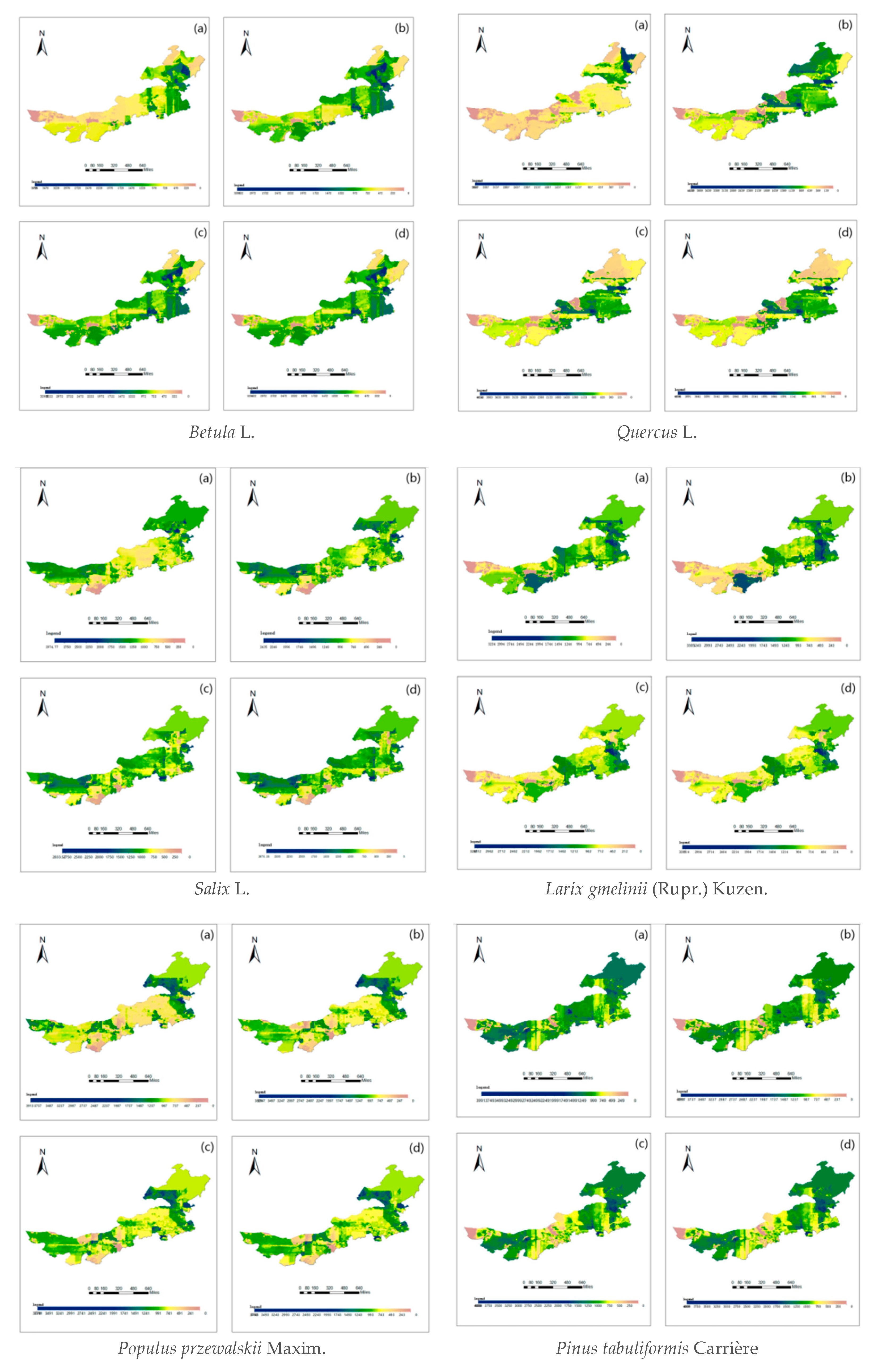
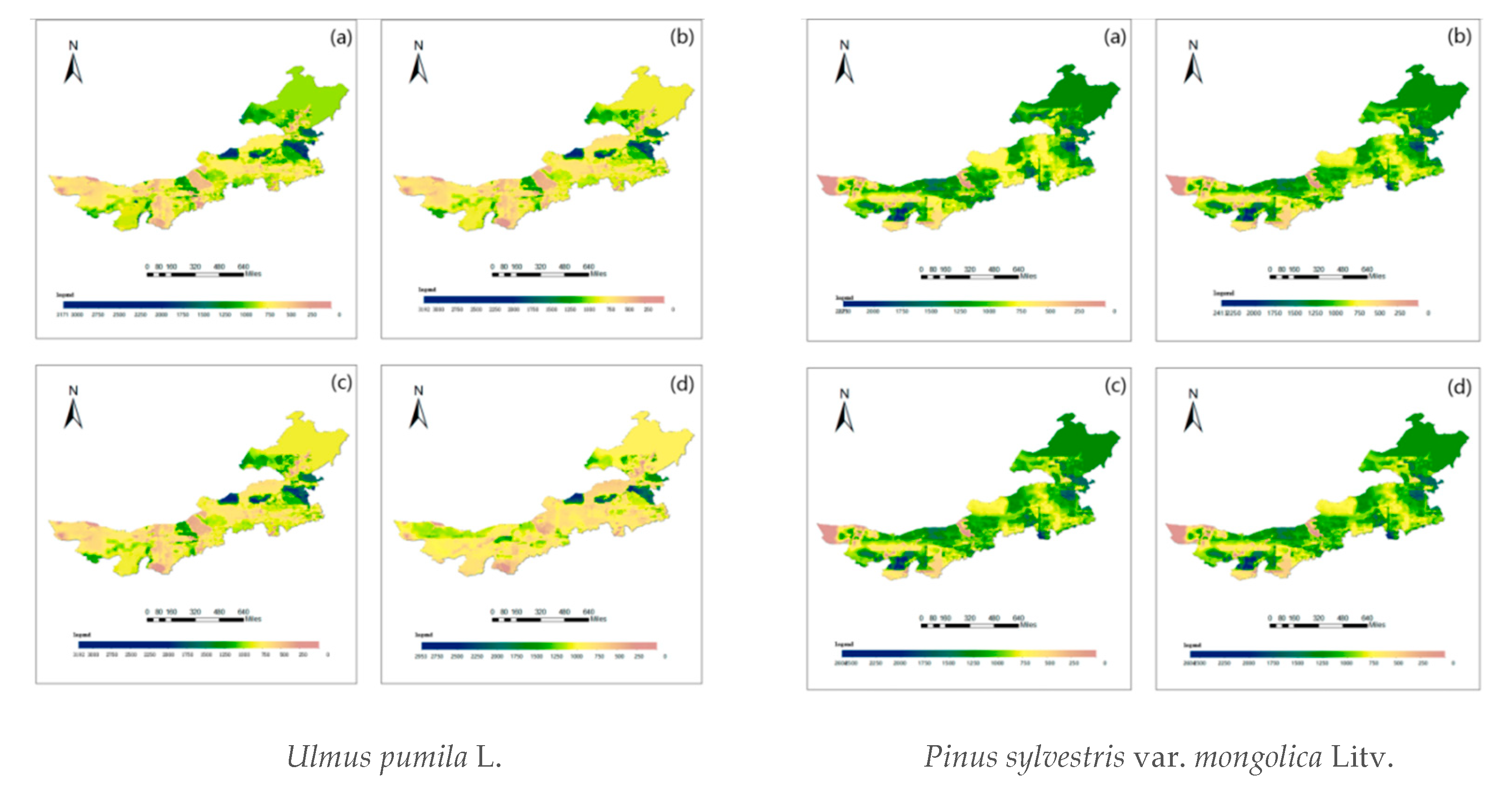
4.3. Raster Plot of Diameter Order Density Distribution of Various Tree Species in Inner Mongolia
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Evans, J. Plantation Forestry in the Tropics: Tree Planting for Industrial, Social, Environmental, and Agroforestry Purposes; Clarendon Press, Oxford University Press: Oxford, UK, 1992. [Google Scholar]
- Hans, M.; Xiao, C.; He, M. Afforestation is Based on Community and Ecology. In Principles of Silvicultur; China Forestry Press: Beijing, China, 1986; Volume I. [Google Scholar]
- Zhang, J. Cultivation Technology of Fast-Growing and High-Yield Forest and Development Trend of Plantation in North China; China Forestry Industry: Beijing, China, 2004; Volume 5, p. 2. [Google Scholar]
- Li, M.; Li, C.; Xu, Z.; Li, X.; Sun, Y. Natural Rarefaction Model of Larch Leaf Tree Artificial Forest and Preparation of A Growth Process Table; Forest Investigation Design: Harbin, China, 1995; pp. 30–33. [Google Scholar]
- Webb, C.O.; Gilbert, G.S.; Donoghue, M.J. Phylodiversity-Dependent Seedling Mortality, Size Structure, and Disease in a Bornean Rain Forest. Ecology 2006, 87, S123–S131. [Google Scholar] [CrossRef] [Green Version]
- Metz, M.R.; Sousa, W.P.; Valencia, R. Widespread density-dependent seedling mortality promotes species coexistence in a highly diverse Amazonian rain forest. Ecology 2010, 91, 3675–3685. [Google Scholar] [CrossRef] [PubMed]
- Qin, J.; Zhang, Z.; Geng, Y.; Zhang, C.; Song, Z.; Zhao, X. Variations of density-dependent seedling survival in a temperate forest. For. Ecol. Manag. 2020, 468, 118158. [Google Scholar] [CrossRef]
- Liu, X.; Liang, M.; Etienne, R.; Wang, Y.; Staehelin, C.; Yu, S. Experimental evidence for a phylogenetic Janzen-Connell effect in a subtropical forest. Ecol. Lett. 2011, 15, 111–118. [Google Scholar] [CrossRef]
- Ness, J.H.; Morales, M.A.; Kenison, E.; Leduc, E.; Leipzig-Scott, P.; Rollinson, E.; Swimm, B.J.; Von Allmen, D.R. Reciprocally beneficial interactions between introduced plants and ants are induced by the presence of a third introduced species. Oikos 2013, 122, 695–704. [Google Scholar] [CrossRef]
- Zhu, Y.; Comita, L.S.; Hubbell, S.P.; Ma, K. Conspecific and phylogenetic density-dependent survival differs across life stages in a tropical forest. J. Ecol. 2015, 103, 957–966. [Google Scholar] [CrossRef]
- Wu, C.; Hong, H.; Jiang, Z. Study on the regulation law of density in the process of self thinning of Chinese fir forest. J. Trop. Subtrop. Plants 2000, 8, 7. [Google Scholar]
- Zhen, T.S.; Tong, S.W.; Zhang, J. Study on density effect of Chinese fir stand. For. Sci. Res. 2002, 1, 66–75. [Google Scholar]
- Aiguo, D.; Zhang, J.; Shuzhen, T.; Jiang, B.; He, H.Y. Dynamics of diameter structure and its density effect in Chinese fir plantation stands. For. Sci. Res. 2004, 17, 7. [Google Scholar]
- Zhang, H.Q.; Hao, D.W.; He, Y.; Li, H.P. Mathematical models for optimal control strategies of artificial forest forest density. J. Northeast. For. Univ. 2006, 34, 24–158. [Google Scholar]
- Wu, S.; Zhu, Q.; Yu, X.; Xue, P.Z. calculation and analysis of reasonable stand density of main forested tree species in the loess region of Jinxi, China. Soil Soil Conserv. Study 2008, 1, 83–86. [Google Scholar]
- Franklin, O.; Moltchanova, E.; Kraxner, F.; Seidl, R.; Böttcher, H.; Rokityiansky, D.; Obersteiner, M. Large-Scale Forest Modeling: Deducing Stand Density from Inventory Data. Int. J. For. Res. 2012, 2012, 934974. [Google Scholar] [CrossRef] [Green Version]
- Uhl, E.; Biber, P.; Ulbricht, M.; Heym, M.; Horváth, T.; Lakatos, F.; Gál, J.; Steinacker, L.; Tonon, G.; Ventura, M.; et al. Analysing the effect of stand density and site conditions on structure and growth of oak species using Nelder trials along an environmental gradient: Experimental design, evaluation methods, and results. For. Ecosyst. 2015, 2, 243–261. [Google Scholar] [CrossRef] [Green Version]
- Barrio-Anta, M.; Balboa-Murias, M.Á.; Castedo-Dorado, F.; Diéguez-Aranda, U.; Álvarez-González, J.G. An ecoregional model for estimating volume, biomass and carbon pools in maritime pine stands in Galicia (northwestern Spain). For. Ecol. Manag. 2006, 223, 24–34. [Google Scholar] [CrossRef]
- Lasky, J.R.; Sun, I.F.; Su, S.H.; Chen, Z.S.; Keitt, T.H. Trait-mediated effects of environmental filtering on tree community dynamics. J. Ecol. 2013, 101, 722–733. [Google Scholar] [CrossRef]
- Wu, J.; Swenson, N.G.; Brown, C.; Zhang, C.; Yang, J.; Ci, X.; Li, J.; Sha, L.; Cao, M.; Lin, L. How does habitat filtering affect the detection of conspecific and phylogenetic density dependence? Ecology 2016, 97, 1182–1193. [Google Scholar] [CrossRef]
- Pu, X.; Jin, G. Conspecific and phylogenetic density-dependent survival differs across life stages in two temperate old-growth forests in Northeast China. For. Ecol. Manag. 2018, 424, 95–104. [Google Scholar] [CrossRef]
- Uriarte, M.; Muscarella, R.; Zimmerman, J.K. Environmental heterogeneity and biotic interactions mediate climate impacts on tropical forest regeneration. Glob. Chang. Biol. 2018, 24, e692–e704. [Google Scholar] [CrossRef]
- Johnson, D.J.; Condit, R.; Hubbell, S.P.; Comita, L.S. Abiotic niche partitioning and negative density dependence drive tree seedling survival in a tropical forest. Proc. R. Soc. B Biol. Sci. 2017, 284, 20172210. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, X.; Peng, J. A weighted random forest model based on particle swarm optimization. J. Zhengzhou Univ. 2018, 50, 72–76. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In International Workshop on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar]
- Wen, X. Research on Key Technologies and Methods of Forest Resources Class II Survey; Nanjing Forestry University: Nanjing, China, 2017. [Google Scholar]
- Zhang, Y. PML_V2 Global Evapotranspiration and Gross Primary Production (2002.07–2019.08). National Tibetan Plateau Data Center. Available online: https://data.tpdc.ac.cn/en/data/48c16a8d-d307-4973-abab-972e9449627c/ (accessed on 8 December 2021).
- Zhao, B.; Mao, K.B.; Cai, Y.L.; Shi, J.C.; Li, Z.L.; Qin, Z.H.; Meng, X.J.; Shen, X.Y.; Guo, Z.H. A combined Terra and Aqua MODIS land surface temperature and meteorological station data product for China from 2003 to 2017. Earth Syst. Sci. Data 2020, 12, 2555–2577. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]
- Cao, Z. Research on Optimization of Stochastic Forest Algorithm. Ph.D. Thesis, Capital University of Economics and Trade, Beijing, China, 2014. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Probst, P.; Boulesteix, A.L. To tune or not to tune the number of trees in random forest. J. Mach. Learn. Res. 2017, 18, 6673–6690. [Google Scholar]
- Boulesteix, A.L.; Janitza, S.; Kruppa, J.; König, I.R. Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 493–507. [Google Scholar] [CrossRef] [Green Version]
- Afanador, N.L.; Smolinska, A.; Tran, T.N.; Blanchet, L. Unsupervised random forest: A tutorial with case studies. J. Chemom. 2016, 30, 232–241. [Google Scholar] [CrossRef]
- Shi, Y.; Eberhart, R.C. Empirical study of particle swarm optimization. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1945–1950. [Google Scholar]
- Huang, J.; Tardif, J.C.; Bergeron, Y.; Denneler, B.; Berninger, F.; Girardin, M.P. Radial growth response of four dominant boreal tree species to climate along a latitudinal gradient in the eastern Canadian boreal forest. Glob. Change Biol. 2010, 16, 711–731. [Google Scholar] [CrossRef]
- Lv, S.; Wang, X. Climate response and winter precipitation reconstruction of Pinus sylvestris var. mongolica growth rings in Ali River in the north of Daxing’an Mountains. J. Northeast. Norm. Univ. 2014, 46, 110–116. [Google Scholar]
- Xi, B.; Di, N.; Jinqiang, L.; Li, D.; Cao, Z. Characteristics and mechanism of deep soil water absorption and utilization by trees: Enlightenment to plantation cultivation. J. Plant Ecol. 2018, 42, 21. [Google Scholar]
- Webb, C.O.; Peart, D.R. Seedling density dependence promotes coexistence of bornean rain forest trees. Ecology 1999, 80, 2006–2017. [Google Scholar] [CrossRef]
- Wills, C.; Condit, R.; Foster, R.B.; Hubbell, S.P. Strong density- and diversity-related effects help to maintain tree species diversity in a neotropicalforest. Proc. Natl. Acad. Sci. USA 1997, 94, 1252–1257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schupp, E.W. The Janzen-Connell Model for Tropical Tree Diversity: Population Implications and the Importance of Spatial Scale. Am. Nat. 1992, 140, 526–530. [Google Scholar] [CrossRef] [PubMed]
- Clark, D.A.; Clark, D.B. Spacing dynamics of a tropical rain-forest tree—Evaluation of the janzen-connell model. Am. Nat. 1984, 124, 769–788. [Google Scholar] [CrossRef]
- Zhu, Y. Study on Tree Death and Species Coexistence in Typical Broad-Leaved Korean Pine Forest. Ph.D. Thesis, Northeast Forestry University, Harbin, China, 2018. [Google Scholar]
- Yang, B. Response of Robinia Pseudoacacia Seedlings to Water Stress: Based on the Distribution and Dynamics of Growth, Physiology and Non Structural Carbon Diss; Northwest University of Agriculture and Forestry Science and Technology: Xianyang, China, 2019; pp. 21–23. [Google Scholar]
- Ying, H.; Ying, Y.; Yu, L.Z.; Zhang, X.B.; Yao, B. Research progress on the effects of soil moisture and nutrients on the growth dynamics and turnover of fine roots of trees. J. Northwest For. Univ. 2010, 25, 7. [Google Scholar]
- Luo, M.; Chen, S. Study on intraspecific and interspecific competition of Larix olgensis with different age groups. J. Beijing For. Univ. 2018, 40, 33–44. [Google Scholar] [CrossRef]
- Wei, X. Study on the Coupling Relationship between Typical Plantation Structure and Soil and Water Conservation Function in Loess Region of Western Shanxi. Ph.D. Thesis, Beijing Forestry University, Beijing, China, 2018. [Google Scholar]
- Hong, L.; Lei, X.; Li, Y. Overall growth model of Mongolian oak forest and its application. For. Sci. Res. 2012, 25, 201–206. [Google Scholar] [CrossRef]
- Stankova, T.V.; Shibuya, M. Stand Density Control Diagrams for Scots pine and Austrian black pine plantations in Bulgaria. New For. 2007, 34, 123–141. [Google Scholar] [CrossRef]
- Yin, T.; Han, F.; Chi, J.; Wu, B. Compilation and application of stand density control chart. China For. Sci. 1978, 3, 1–11. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diameter Class | Total Number of Forest Subclasses | N ≤ 500 | 500 < N ≤ 1500 | 1500 < N ≤ 2500 | N > 2500 |
|---|---|---|---|---|---|
| 5 | 445,501 | 27,100 | 346,029 | 65,397 | 6975 |
| 15 | 509,709 | 53,531 | 364,313 | 74,249 | 17,616 |
| 25 | 47,207 | 10,735 | 29,165 | 3576 | 3731 |
| 35 | 5287 | 1492 | 3507 | 278 | 10 |
| Data Name | Data Type | Time | Data Resolution | Data Sources | Variable Type |
|---|---|---|---|---|---|
| Stand density | Continuous variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Response variable |
| Soil thickness | Continuous variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Input variables |
| Dominant tree species | Categorical variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Categorical variable |
| Soil type | Categorical variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Categorical variable |
| Slope | Categorical variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Categorical variable |
| Slope direction | Categorical variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Categorical variable |
| Slope position | Categorical variable | 2018 | Minor class size | Intelligent management platform for forest resources in China | Categorical variable |
| Average temperature | Continuous variable | 2008–2017 mean value | 0.05° | National Science and technology data center for Qinghai, Tibet Plateau | Input variables |
| Forest water consumption | Continuous variable | 2008–2017, mean value | 5600 m | National Science and technology data center for Qinghai, Tibet Plateau | Input variables |
| Model | Total Number of Samples | RMSE | MAE | |
|---|---|---|---|---|
| 5 cm diameter scale model | 445,501 | 0.0633 | 0.0157 | 0.6159 |
| 15 cm diameter scale model | 509,709 | 0.0548 | 0.0287 | 0.7097 |
| 25 cm diameter scale model | 47,207 | 0.0415 | 0.0164 | 0.7512 |
| 35 cm diameter scale model | 5287 | 0.0738 | 0.0307 | 0.7299 |
| Factor Name | 5 cm | 15 cm | 25 cm | 35 cm |
|---|---|---|---|---|
| Average temperature | 24.22% | 26.99% | 35.17% | 44.04% |
| Forest water consumption | 37.15% | 24.61% | 18.42% | 17.73% |
| Soil thickness | 12.85% | 15.17% | 7.60% | 9.12% |
| Dominant tree species | 10.92% | 13.15% | 21.85% | 23.31% |
| Soil type | 6.36% | 5.86% | 8.31% | 4.59% |
| Slope | 5.63% | 3.13% | 1.32% | 0.76% |
| Slope direction | 4.50% | 3.01% | 1.75% | 1.47% |
| Slope position | 3.40% | 2.71% | 4.04% | 2.18% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, C.; Feng, Z.; Liu, Z. A Study of the Distribution of Forest Density in Inner Mongolia Based on Environmental Factors. Forests 2022, 13, 313. https://doi.org/10.3390/f13020313
Chang C, Feng Z, Liu Z. A Study of the Distribution of Forest Density in Inner Mongolia Based on Environmental Factors. Forests. 2022; 13(2):313. https://doi.org/10.3390/f13020313
Chicago/Turabian StyleChang, Chen, Zhongke Feng, and Ziye Liu. 2022. "A Study of the Distribution of Forest Density in Inner Mongolia Based on Environmental Factors" Forests 13, no. 2: 313. https://doi.org/10.3390/f13020313
APA StyleChang, C., Feng, Z., & Liu, Z. (2022). A Study of the Distribution of Forest Density in Inner Mongolia Based on Environmental Factors. Forests, 13(2), 313. https://doi.org/10.3390/f13020313