
Verification of a Deep Learning-Based Tree Species Identification Model Using Images of Broadleaf and Coniferous Tree Leaves


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Sites
2.2. Photographic Methods
2.3. Image Processing and Data Augmentation
2.4. CNN Algorithms
2.5. Learning Environment and Models for the CNNs
2.6. Simulation Conditions and Performance Evaluation
3. Results
3.1. Classification Accuracy of Tree Species Identification for Test Data When Simultaneously Identifying Broadleaf and Coniferous Trees
3.2. Classification Accuracy of Tree Species Identification for Test Data When Either Broadleaf or Coniferous Trees Were Used
3.3. Classification Accuracy of Tree Species Identification According to Learning Method
3.4. Comparison between Simultaneous and Individual Identification
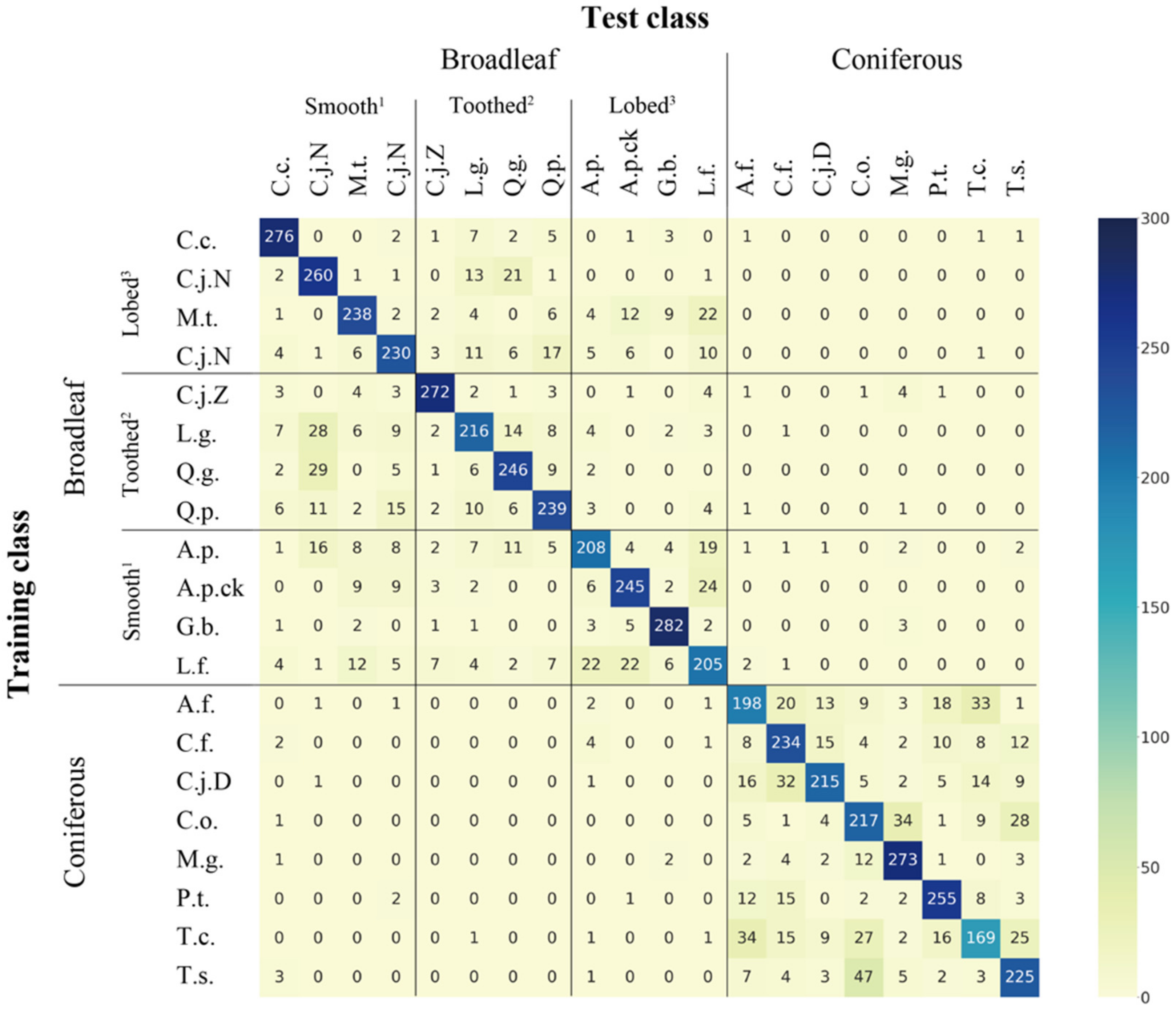
3.5. Misclassification Patterns According to Tree Species
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| MCC | Matthews correlation coefficient |
| TP | true positive |
| TN | true negative |
| FP | false positive |
| FN | false negative |
| C.c. | Cinnamomun camphora (Linn.) Sieb. |
| C.j.N | Cinnamomum japonicum Sieb. ex Nakai |
| M.t. | Maclura tricuspidata (syn. Cudrania tricuspidata) |
| S.s. | Sapium sebiferum (Linn.) Roxb. |
| C.j.Z | Cercidiphyllum japonicum Sieb. et Zucc. |
| L.g. | Lithocarpus glaber Thunb. |
| Q.g. | Quercus glauca Thunb. |
| Q.p. | Quercus philyraeoides A. Gray |
| A.p. | Acer palmatum Thunb. |
| A.p.ck | Acer platanoides cv. crimson king |
| G.b. | Ginkgo biloba Linn. |
| L.f. | Liquidambar formosana Hance. |
| A.f. | Abies firma |
| C.f. | Calocedrus formosana |
| C.j.D | Cryptomeria japonica D. Don |
| C.o. | Chamaecyparis obtusa |
| M.g. | Metasequoia glyptostroboides |
| P.t. | Pinus thunbergii |
| T.c. | Taxus cuspidata |
| T.s. | Tsuga sieboldii |
References
- Minowa, Y.; Akiba, T.; Nakanishi, Y. Classification of a leaf image using a self-organizing map and tree based model. J. For. Plan. 2011, 17, 31–42. [Google Scholar] [CrossRef]
- Minowa, Y.; Takami, T.; Suguri, M.; Ashida, M.; Yoshimura, Y. Identification of tree species using a machine learning algorithm based on leaf shape and venation pattern. Jpn. J. Plann 2019, 53, 1–13. [Google Scholar] [CrossRef]
- Minowa, Y.; Asao, K. Tree species identification based on venation pattern of leaf images photographed with a mobile device in the outdoors. Jpn. J. Plann 2020, 53, 43–52. [Google Scholar] [CrossRef]
- Minowa, Y.; Nagasaki, Y. Convolutional neural network applied to tree species identification based on leaf images. J. For. Plan. 2020, 26, 1–11. [Google Scholar] [CrossRef]
- Minowa, Y.; Kubota, Y. Identification of broad-leaf trees using deep learning based on field photographs of multiple leaves. J. For. Res. 2022, 1–9. [Google Scholar] [CrossRef]
- Minowa, Y.; Nakatsukasa, S. Identification of coniferous tree species using deep learning. Jpn J. Plann 2021, 13, 162. [Google Scholar]
- Wang, Z.; Chi, Z.; Feng, D.; Wang, Q. Leaf image retrieval with shape features. Lect. Notes Comput. Sci. 2000, 1929, 477–487. [Google Scholar]
- Nam, Y.; Hwang, E. A shape-based retrieval scheme for leaf image. Lec. Notes Comput. Sci. 2005, 3767, 876–887. [Google Scholar]
- Shen, Y.; Zhou, C.; Lin, K. Leaf Image Retrieval Using a Shape Based Method. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Boston, MA, USA, 7–9 September 2005; pp. 711–719. [Google Scholar]
- Neto, J.C.; Meyer, G.E.; Jones, D.D.; Samal, A.K. Plant species identification using elliptic Fourier leaf shape analysis. Comput. Electron. Agric. 2006, 50, 121–134. [Google Scholar] [CrossRef]
- Du, J.X.; Wang, X.; Zhang, G.J. Leaf shape based plant species recognition. Appl. Math. Comput. 2007, 185, 883–893. [Google Scholar] [CrossRef]
- Beghin, T.; Cope, J.S.; Remagnino, P.; Barman, S. Shape and texture based plant leaf classification. Lect. Notes Comput. Sci. 2010, 6475, 345–353. [Google Scholar]
- Aptoula, E.; Yanikoglu, B. Morphological features for leaf based plant recognition. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 1496–1499. [Google Scholar]
- Li, Y.; Chi, Z.; Feng, D.D. Leaf vein extraction using independent component analysis. In Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; pp. 3890–3894. [Google Scholar]
- Cope, J.S.; Remagnino, P.; Barman, S.; Wilkin, P. The extraction of venation from leaf images by evolved vein classifiers and ant colony algorithms. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Sydney, Australia, 13–16 December 2010; Volume 6474, pp. 135–144. [Google Scholar]
- Wilf, P.; Zhang, Z.; Chikkerur, S.; Little, S.A.; Wing, S.L.; Serre, T. Computer vision cracks the leaf code. Proc. Natl. Acad. Sci. USA 2016, 113, 3305–3310. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ghazi, M.M.; Yanikoglu, B.; Aptoula, E. Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing 2017, 235, 228–235. [Google Scholar] [CrossRef]
- Cope, J.S.; Corney, D.P.A.; Clark, J.Y.; Remagnino, P.; Wilkin, P. Plant species identification using digital morphometrics: A review. Expert. Syst. Appl. 2012, 39, 7562–7573. [Google Scholar] [CrossRef]
- Yamashita, T. Irasuto de Manabu Deep Learning [An Illustrated Guide to Deep Learning]; Kodansha: Tokyo, Japan, 2016. [Google Scholar]
- Deng, Y. Deep learning on mobile devices—A review. Mob. Multimed. /Image Process. Secur. Appl. 2019, 10993, 52–66. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context; Springer: Tokyo, Japan, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Goëau, H.; Bonnet, P.; Joly, A. LifeCLEF plant identification task 2015. CLEF (Working Notes). In Proceedings of the Working Notes for CLEF 2014 Conference, Sheffield, UK, 15–18 September 2014. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Torrey, L.; Shavlik, J. Transfer Learning. 2009. Available online: https://ftp.cs.wisc.edu/machine-learning/shavlik-group/torrey.handbook09.pdf (accessed on 25 August 2021).
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep neural networks based recognition of plant diseases by leaf image classification. Comput. Intell. Neurosci. 2016, 2016, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Boulent, J.; Foucher, S.; Théau, J.; St-Charles, P. Convolutional neural networks for the automatic identification of plant diseases. Front. Plant Sci. 2019, 40, 941. [Google Scholar] [CrossRef] [Green Version]
- Yun, S.; Donghui, M.; Jie, L.; Jie, L. ACTL: Asymmetric convolutional transfer learning for tree species identification based on deep neural network. IEEE Access 2021, 9, 13643–13654. [Google Scholar]
- Li, H.; Hu, B.; Li, Q.; Jing, L. CNN-based individual tree species classification using high-resolution satellite imagery and airborne LiDAR data. Forests 2021, 12, 1697. [Google Scholar] [CrossRef]
- Nezami, S.; Khoramshahi, E.; Nevalainen, O.; Pölönen, I.; Honkavaara, E. Tree species classification of drone hyperspectral and RGB imagery with deep learning convolutional neural networks. Remote Sens. 2020, 12, 1070. [Google Scholar] [CrossRef] [Green Version]
- Bisen, D. Deep convolutional neural network based plant species recognition through features of leaf. Multimed. Tools Appl. 2020, 80, 6443–6456. [Google Scholar] [CrossRef]
- Gyires-Tóth, B.P.; Osváth, M.; Papp, D.; Szűcs, G. Deep learning for plant classification and content-based image retrieval. Cybern. Inf. Technol. 2019, 19, 88–100. [Google Scholar] [CrossRef] [Green Version]
- Yang, K.; Zhong, W.; Li, L. Leaf segmentation and classification with a complicated background using deep learning. Agronomy 2020, 10, 1721. [Google Scholar] [CrossRef]
- Hamrouni, L.; Kherfi, M.; Lamine, A.; Oussama, B.; Abdellah. Plant leaves recognition based on a hierarchical one-class learning scheme with convolutional auto-encoder and siamese neural network. Symmetry 2021, 13, 1705. [Google Scholar] [CrossRef]
- Quoc Bao, T.; Tan Kiet, N.T.; Quoc Dinh, T.; Hiep, H.X. Plant species identification from leaf patterns using histogram of oriented gradients feature space and convolution neural networks. J. Inf. Telecommun. 2020, 4, 140–150. [Google Scholar] [CrossRef] [Green Version]
- ImageCLEF2012. 2012. Available online: https://www.imageclef.org/2012/plant/ (accessed on 8 June 2022).
- Swedish Leaf Dataset. 2016. Available online: https://www.cvl.isy.liu.se/en/research/datasets/swedish-leaf/ (accessed on 8 June 2022).
- CoreML. 2017. Available online: https://developer.apple.com/documentation/coreml/ (accessed on 19 August 2021).
- Tsutsumi, S.; (iOS Engineer, Freelance, Tokyo, Japan). Personal Private communication, 2020.
- Nikon COOLPIX A900. 2016. Available online: https://www.nikon-image.com/products/compact/lineup/a900/ (accessed on 3 August 2021).
- Samsung Galaxy S9. 2018. Available online: https://www.samsung.com/global/galaxy/galaxy-s9/ (accessed on 5 January 2022).
- NIH. ImageJ. 2004. Available online: https://imagej.nih.gov/ij/ (accessed on 19 February 2021).
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015; pp. 1–12. [Google Scholar]
- Liu, M.; Chen, Q.; Yan, S. Network in network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- NVIDIA. 2016. Available online: https://developer.nvidia.com/cuda-toolkit/ (accessed on 19 February 2021).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Et Biophys. Acta (BBA)—Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Motoda, H.; Tsumoto, S.; Yamaguchi, T.; Numao, M. Fundamentals of Data Mining; Ohmsha: Tokyo, Japan, 2006. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining, Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Burlington, NJ, USA, 2011; pp. 163–180. [Google Scholar]
- Scikit-Learn. 2007. Available online: https://scikit-learn.org/stable/modules/model_evaluation.html#matthews-corrcoef (accessed on 5 February 2022).
- Raschka, S.; Mirjalili, V. Python Machine Learning Programming; Impress: Tokyo, Japan, 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. arXiv 2020, arXiv:1911.11907. [Google Scholar]
- ML Kit. 2018. Available online: https://developers.google.com/ml-kit/ (accessed on 19 August 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Tree Species | No Data Augmentation | Data Augmentation | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GoogLeNet | AlexNet | GoogLeNet | AlexNet | |||||||||||
| 50 1 | 100 1 | 200 1 | 50 1 | 100 1 | 200 1 | 50 1 | 100 1 | 200 1 | 501 | 100 1 | 200 1 | |||
| Broadleaf trees | Smooth margins 2 | C.c. | 0.912 | 0.950 | 0.948 | 0.899 | 0.914 | 0.923 | 0.966 | 0.972 | 0.975 | 0.949 | 0.956 | 0.960 |
| C.j.N | 0.881 | 0.898 | 0.906 | 0.802 | 0.846 | 0.839 | 0.959 | 0.962 | 0.969 | 0.916 | 0.925 | 0.935 | ||
| M.t. | 0.846 | 0.917 | 0.914 | 0.810 | 0.859 | 0.850 | 0.953 | 0.964 | 0.974 | 0.942 | 0.944 | 0.956 | ||
| S.s. | 0.870 | 0.916 | 0.929 | 0.777 | 0.845 | 0.844 | 0.961 | 0.963 | 0.977 | 0.931 | 0.943 | 0.947 | ||
| Toothed margins 3 | C.j.Z | 0.943 | 0.946 | 0.962 | 0.913 | 0.939 | 0.940 | 0.974 | 0.975 | 0.981 | 0.965 | 0.966 | 0.972 | |
| L.g. | 0.788 | 0.847 | 0.872 | 0.740 | 0.761 | 0.766 | 0.924 | 0.925 | 0.940 | 0.885 | 0.895 | 0.904 | ||
| Q.g. | 0.863 | 0.904 | 0.908 | 0.808 | 0.833 | 0.834 | 0.952 | 0.962 | 0.969 | 0.928 | 0.945 | 0.947 | ||
| Q.p. | 0.841 | 0.926 | 0.928 | 0.797 | 0.861 | 0.885 | 0.969 | 0.976 | 0.985 | 0.944 | 0.954 | 0.958 | ||
| Lobed 4 | A.p. | 0.793 | 0.859 | 0.868 | 0.735 | 0.764 | 0.777 | 0.941 | 0.944 | 0.954 | 0.900 | 0.908 | 0.910 | |
| A.p.ck | 0.826 | 0.908 | 0.918 | 0.821 | 0.849 | 0.856 | 0.965 | 0.966 | 0.977 | 0.940 | 0.959 | 0.953 | ||
| G.b. | 0.929 | 0.949 | 0.968 | 0.925 | 0.942 | 0.941 | 0.964 | 0.969 | 0.972 | 0.956 | 0.968 | 0.963 | ||
| L.f. | 0.774 | 0.846 | 0.840 | 0.687 | 0.743 | 0.763 | 0.923 | 0.927 | 0.945 | 0.899 | 0.905 | 0.902 | ||
| Min. | 0.774 | 0.846 | 0.840 | 0.687 | 0.743 | 0.763 | 0.923 | 0.925 | 0.940 | 0.885 | 0.895 | 0.902 | ||
| Max. | 0.943 | 0.950 | 0.968 | 0.925 | 0.942 | 0.941 | 0.974 | 0.976 | 0.985 | 0.965 | 0.968 | 0.972 | ||
| Ave. | 0.855 | 0.906 | 0.914 | 0.809 | 0.846 | 0.852 | 0.954 | 0.959 | 0.968 | 0.930 | 0.939 | 0.942 | ||
| Coniferous trees | A.f. | 0.756 | 0.792 | 0.818 | 0.673 | 0.729 | 0.731 | 0.875 | 0.857 | 0.871 | 0.849 | 0.861 | 0.869 | |
| C.f. | 0.805 | 0.812 | 0.847 | 0.765 | 0.770 | 0.776 | 0.857 | 0.867 | 0.873 | 0.846 | 0.843 | 0.833 | ||
| C.j.D | 0.768 | 0.829 | 0.861 | 0.745 | 0.750 | 0.758 | 0.920 | 0.925 | 0.930 | 0.909 | 0.903 | 0.904 | ||
| C.o. | 0.826 | 0.862 | 0.883 | 0.696 | 0.762 | 0.776 | 0.929 | 0.923 | 0.935 | 0.880 | 0.897 | 0.886 | ||
| M.g. | 0.872 | 0.912 | 0.917 | 0.863 | 0.881 | 0.874 | 0.929 | 0.918 | 0.934 | 0.907 | 0.911 | 0.914 | ||
| P.t. | 0.890 | 0.913 | 0.929 | 0.837 | 0.826 | 0.845 | 0.942 | 0.946 | 0.954 | 0.942 | 0.954 | 0.944 | ||
| T.c. | 0.751 | 0.801 | 0.812 | 0.619 | 0.678 | 0.697 | 0.842 | 0.851 | 0.883 | 0.812 | 0.796 | 0.823 | ||
| T.s. | 0.834 | 0.888 | 0.899 | 0.739 | 0.784 | 0.813 | 0.931 | 0.942 | 0.952 | 0.900 | 0.903 | 0.907 | ||
| Min. | 0.751 | 0.792 | 0.812 | 0.619 | 0.678 | 0.697 | 0.842 | 0.851 | 0.871 | 0.812 | 0.796 | 0.823 | ||
| Max. | 0.890 | 0.913 | 0.929 | 0.863 | 0.881 | 0.874 | 0.942 | 0.946 | 0.954 | 0.942 | 0.954 | 0.944 | ||
| Ave. | 0.813 | 0.851 | 0.871 | 0.742 | 0.772 | 0.784 | 0.903 | 0.904 | 0.917 | 0.880 | 0.884 | 0.885 | ||
| Min. for overall | 0.751 | 0.792 | 0.812 | 0.619 | 0.678 | 0.697 | 0.842 | 0.851 | 0.871 | 0.812 | 0.796 | 0.823 | ||
| Max. for overall | 0.943 | 0.950 | 0.968 | 0.925 | 0.942 | 0.941 | 0.974 | 0.976 | 0.985 | 0.965 | 0.968 | 0.972 | ||
| Ave. for overall | 0.838 | 0.884 | 0.896 | 0.782 | 0.817 | 0.824 | 0.934 | 0.937 | 0.947 | 0.910 | 0.917 | 0.919 | ||
| Groups | Data Augmentation | GoogLeNet | AlexNet | ||||
|---|---|---|---|---|---|---|---|
| 50 1 | 100 1 | 200 1 | 50 1 | 100 1 | 200 1 | ||
| Broadleaf | - | 0.9965 | 0.9967 | 0.9967 | 0.9935 | 0.9953 | 0.9960 |
| ◯ 2 | 0.9981 | 0.9988 | 0.9982 | 0.9978 | 0.9983 | 0.9981 | |
| Coniferous | - | 0.9948 | 0.9950 | 0.9950 | 0.9902 | 0.9929 | 0.9940 |
| ◯ 2 | 0.9972 | 0.9982 | 0.9974 | 0.9967 | 0.9974 | 0.9972 | |
| Pattern | Data Augmentation | GoogLeNet | AlexNet | ||||
|---|---|---|---|---|---|---|---|
| 50 1 | 100 1 | 200 1 | 50 1 | 100 1 | 200 1 | ||
| SB 2 | - | −31 | −24 | −84 | 35 | 20 | −6 |
| ◯ 4 | −399 | −275 | −76 | −470 | −150 | −212 | |
| SC 3 | - | 65 | 39 | 16 | 49 | 14 | 30 |
| ◯ 4 | 772 | 945 | 900 | 462 | 536 | 294 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minowa, Y.; Kubota, Y.; Nakatsukasa, S. Verification of a Deep Learning-Based Tree Species Identification Model Using Images of Broadleaf and Coniferous Tree Leaves. Forests 2022, 13, 943. https://doi.org/10.3390/f13060943
Minowa Y, Kubota Y, Nakatsukasa S. Verification of a Deep Learning-Based Tree Species Identification Model Using Images of Broadleaf and Coniferous Tree Leaves. Forests. 2022; 13(6):943. https://doi.org/10.3390/f13060943
Chicago/Turabian StyleMinowa, Yasushi, Yuhsuke Kubota, and Shun Nakatsukasa. 2022. "Verification of a Deep Learning-Based Tree Species Identification Model Using Images of Broadleaf and Coniferous Tree Leaves" Forests 13, no. 6: 943. https://doi.org/10.3390/f13060943
APA StyleMinowa, Y., Kubota, Y., & Nakatsukasa, S. (2022). Verification of a Deep Learning-Based Tree Species Identification Model Using Images of Broadleaf and Coniferous Tree Leaves. Forests, 13(6), 943. https://doi.org/10.3390/f13060943