
Identification of Pine Wilt Disease Infected Wood Using UAV RGB Imagery and Improved YOLOv5 Models Integrated with Attention Mechanisms




Abstract
:1. Introduction
2. Materials and Methods
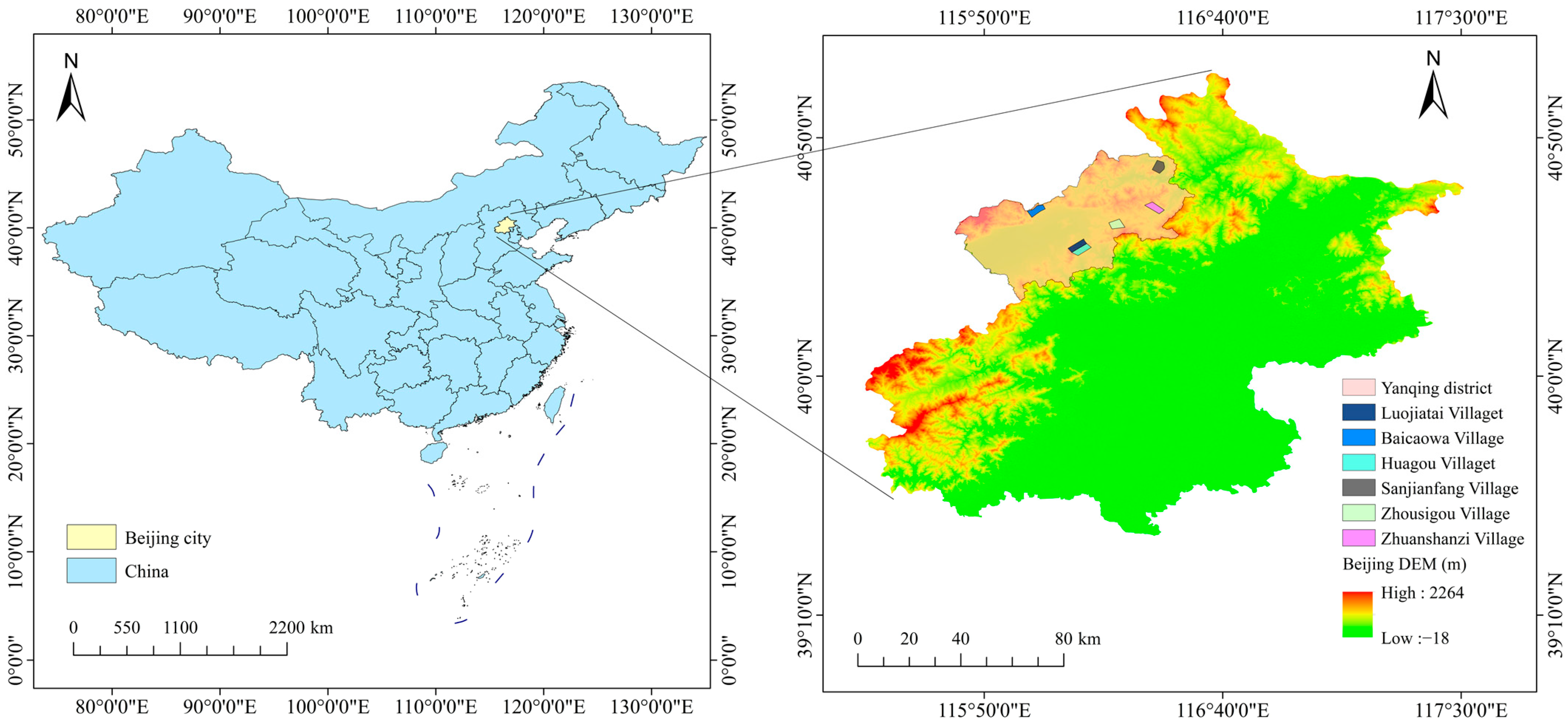
2.1. Study Area
2.2. UAV Flights and Field Survey
2.2.1. Take off Check
2.2.2. Layout of Image Control Points
2.2.3. Quality Inspection
2.3. Data Set Preparation
2.3.1. Identification of Infected Wood
2.3.2. Preprocessing for Imagery Consistency
2.3.3. Manual Labeling of Infected Wood
2.3.4. Data Set for Formal Analysis
2.4. Machine Learning Methods
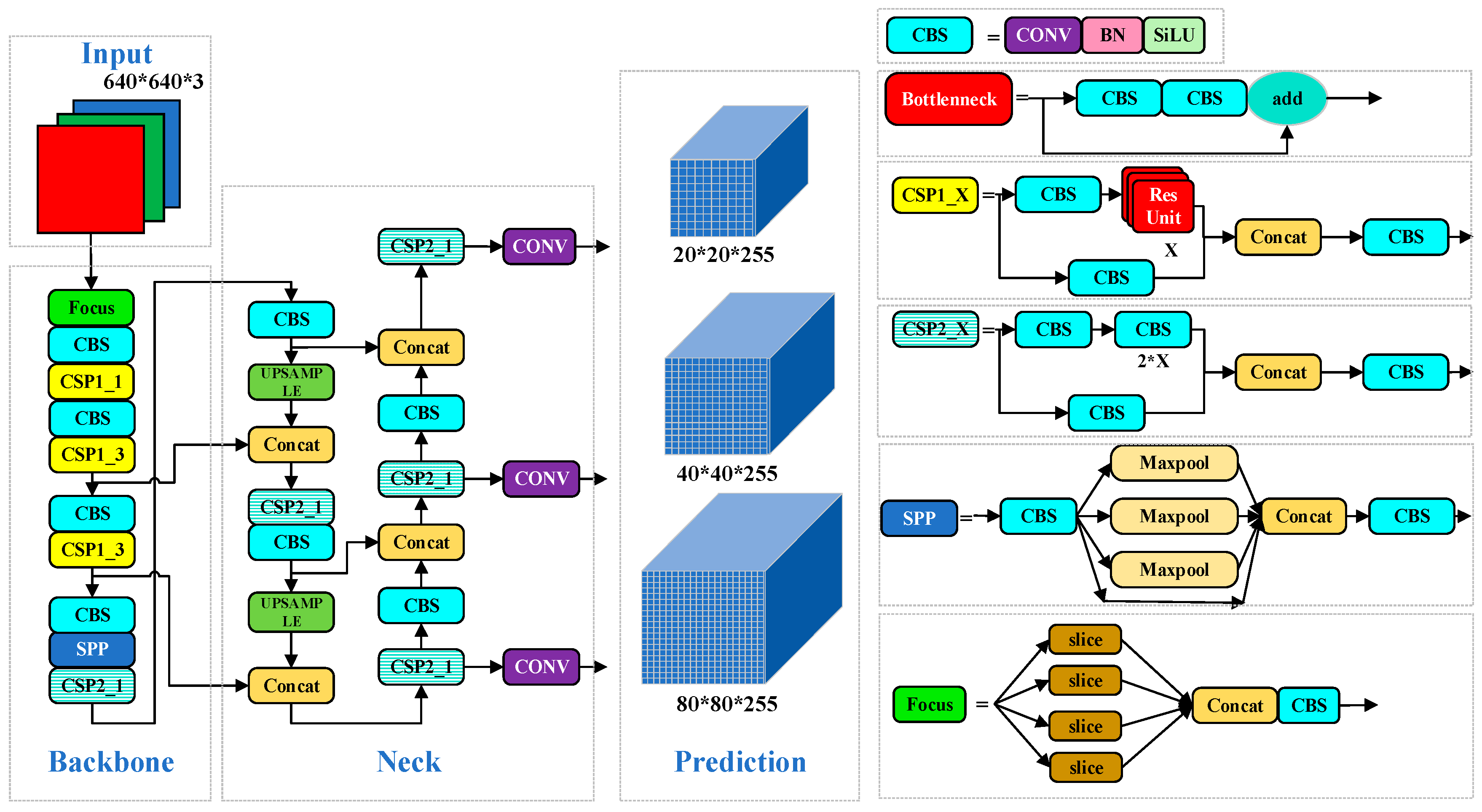
2.4.1. YOLOv5s Structure
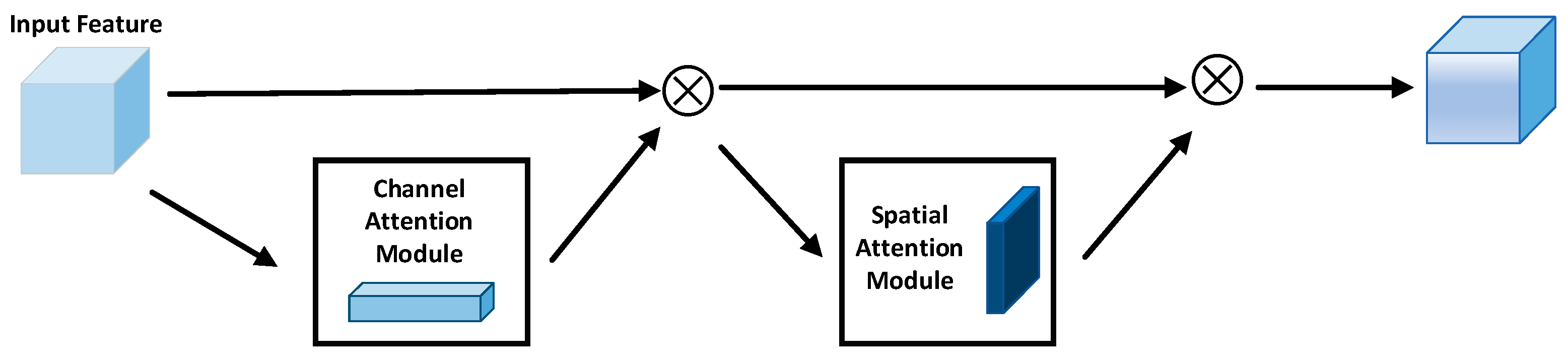
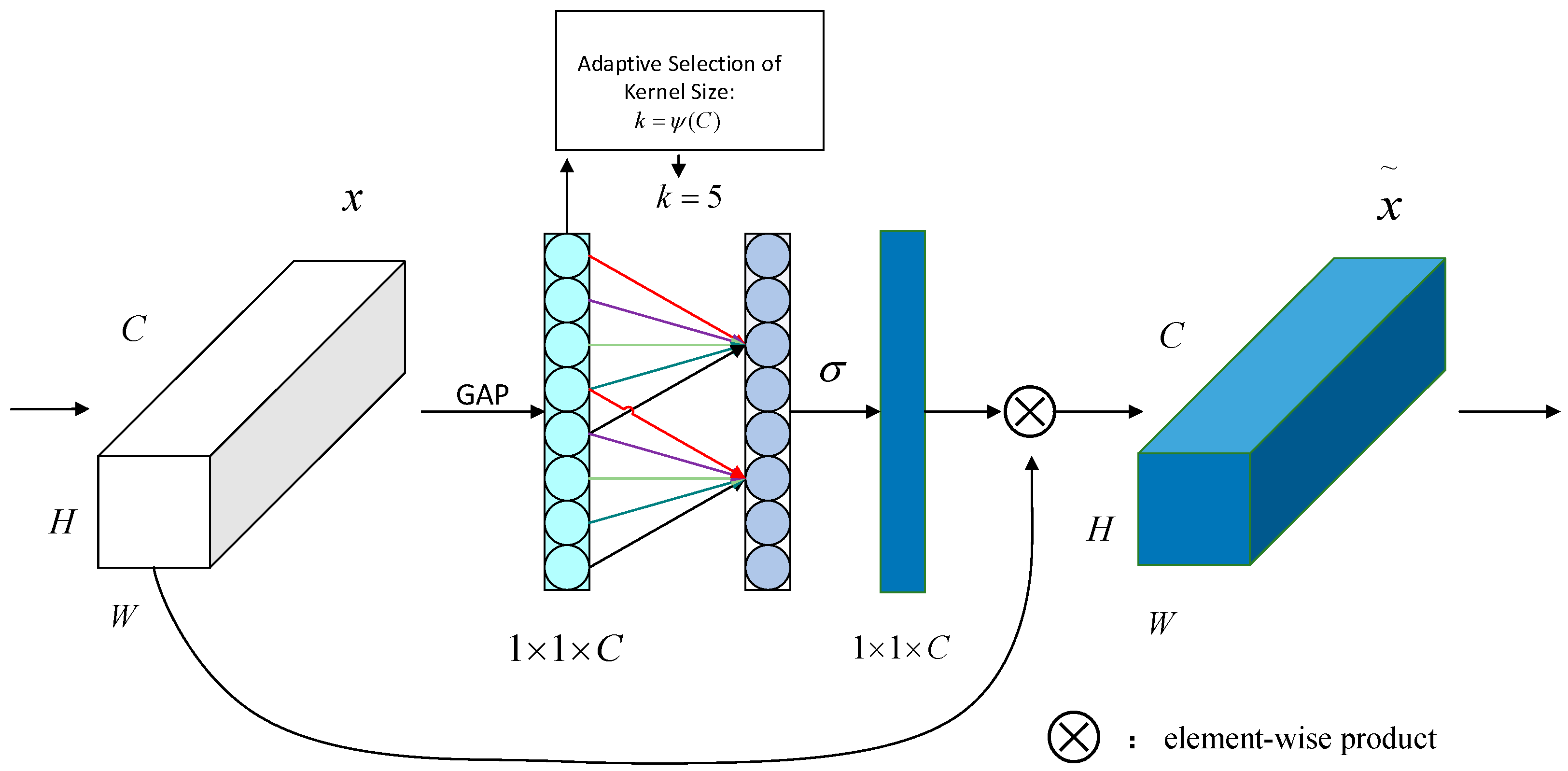
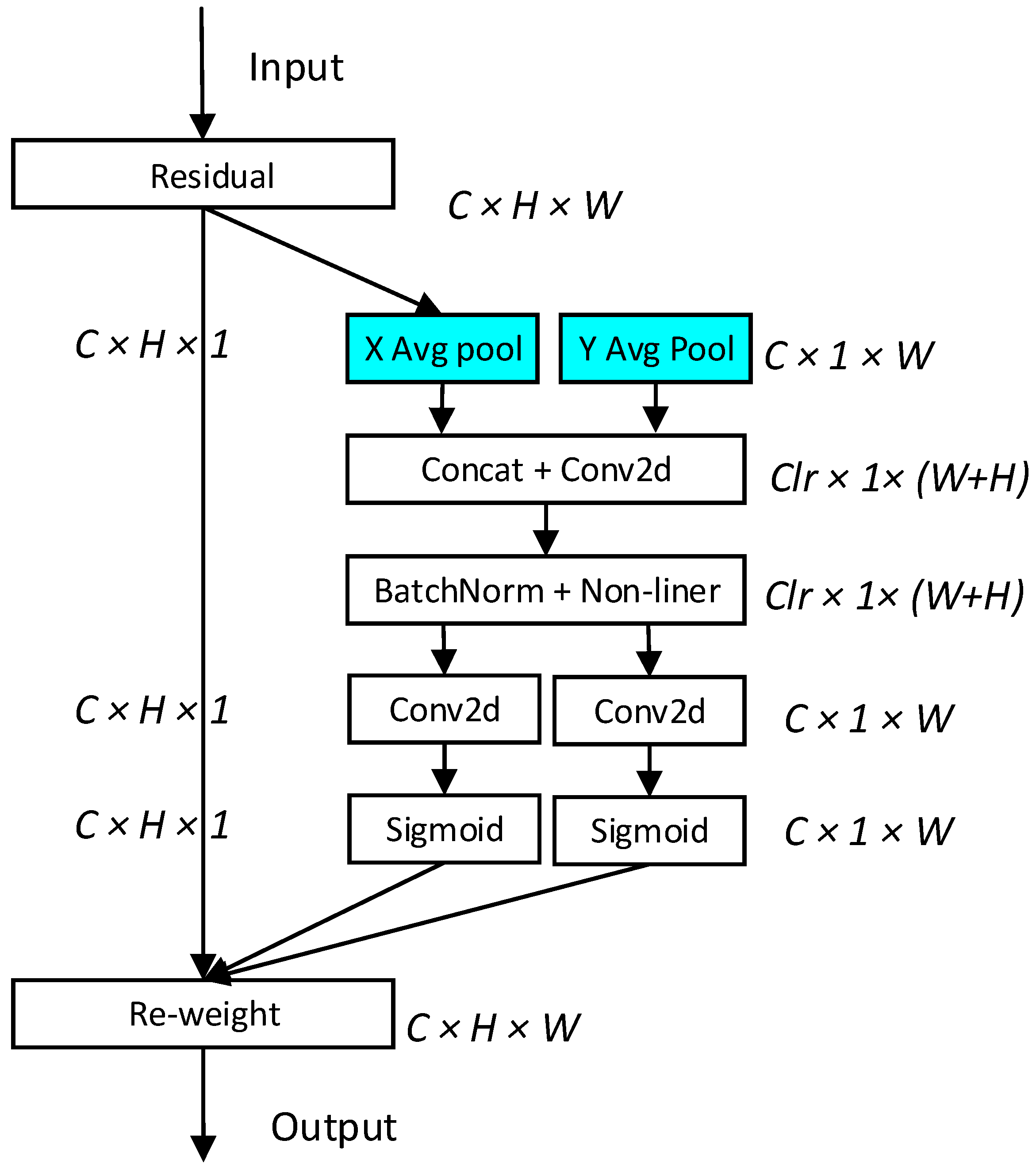
2.4.2. Attention Mechanism
2.5. Implementation and Assessment Methods
2.5.1. Experimental Platform and Parameter Settings
2.5.2. Evaluation Indicators
3. Results and Discussion
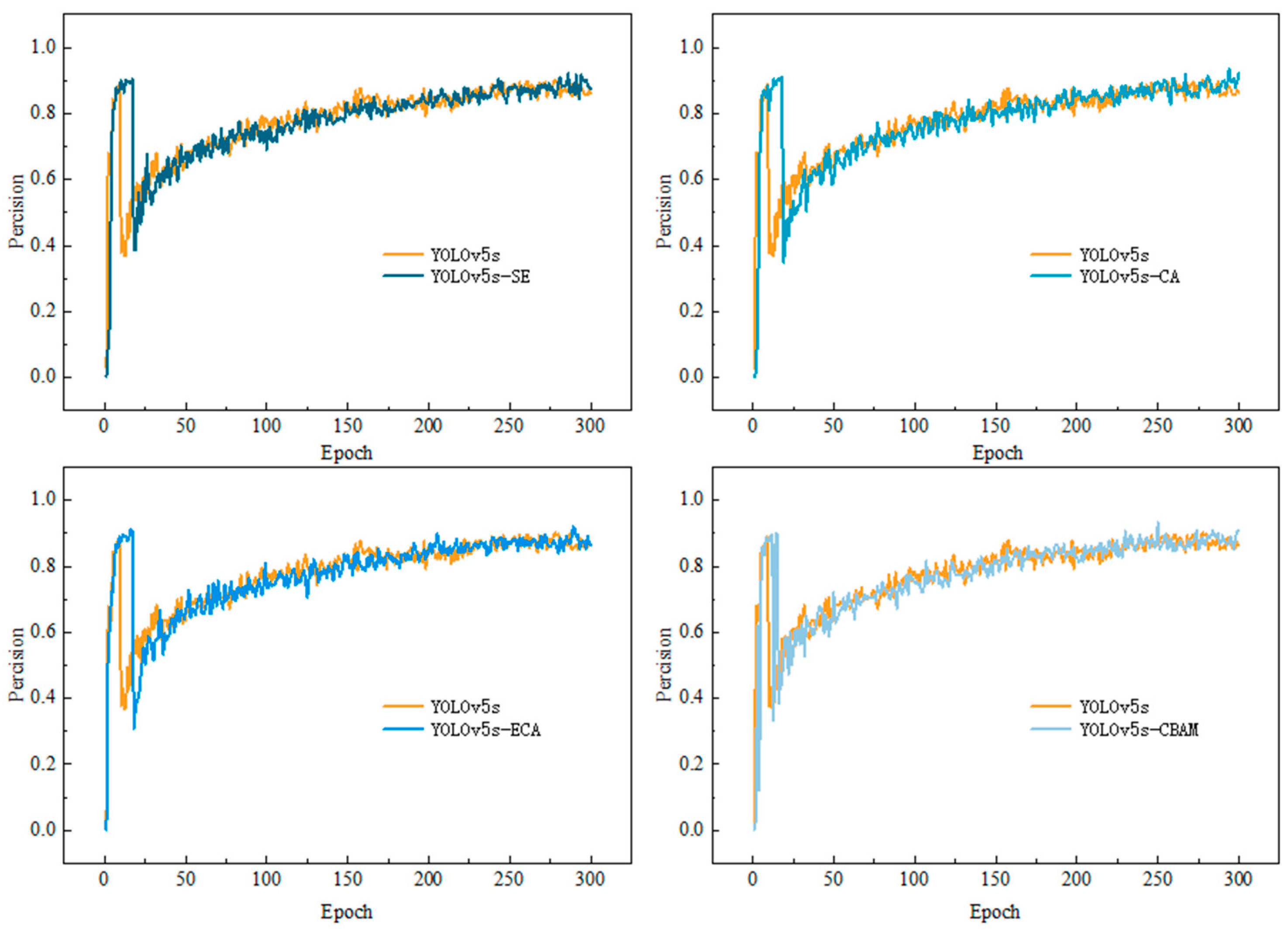
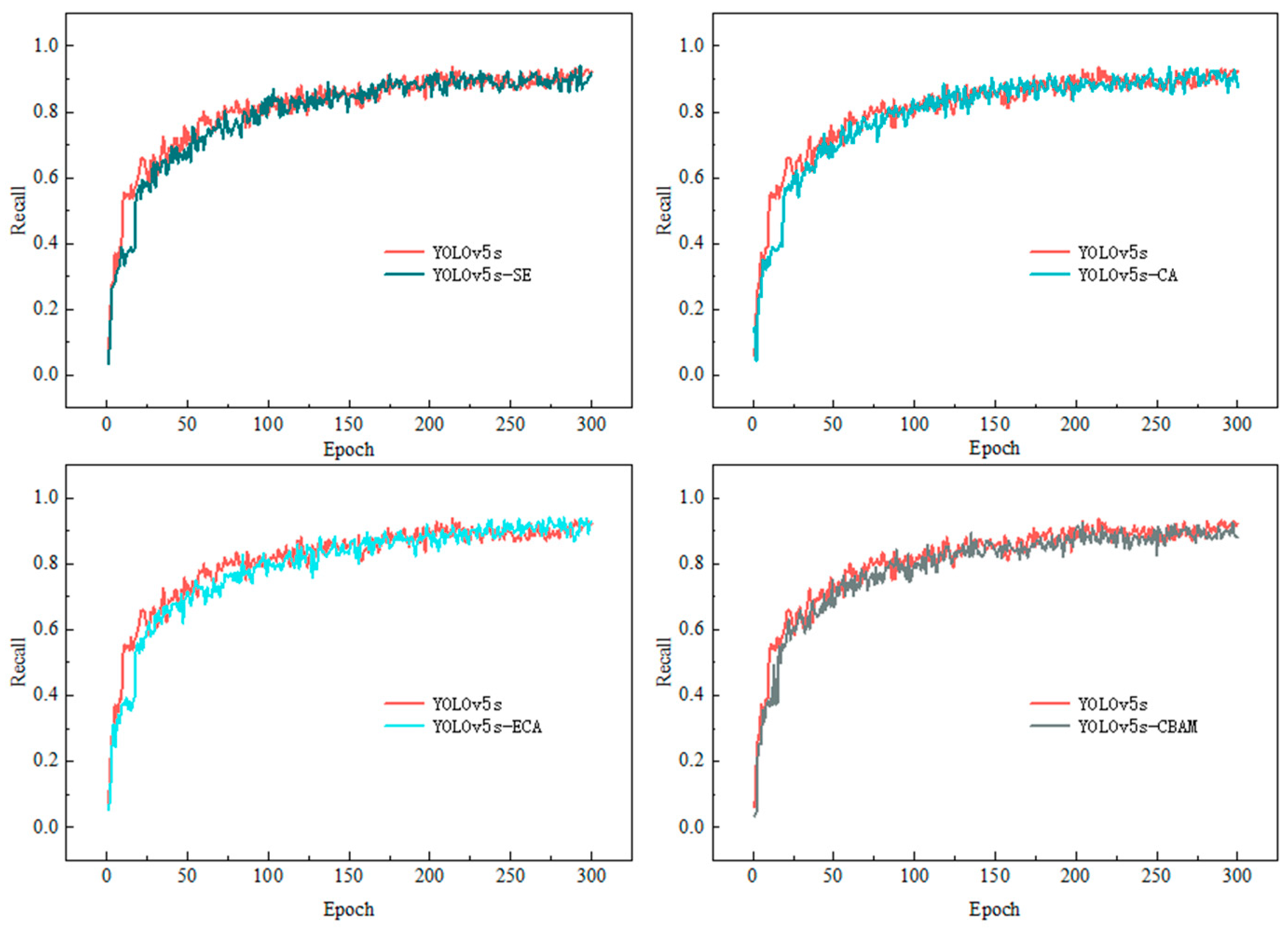
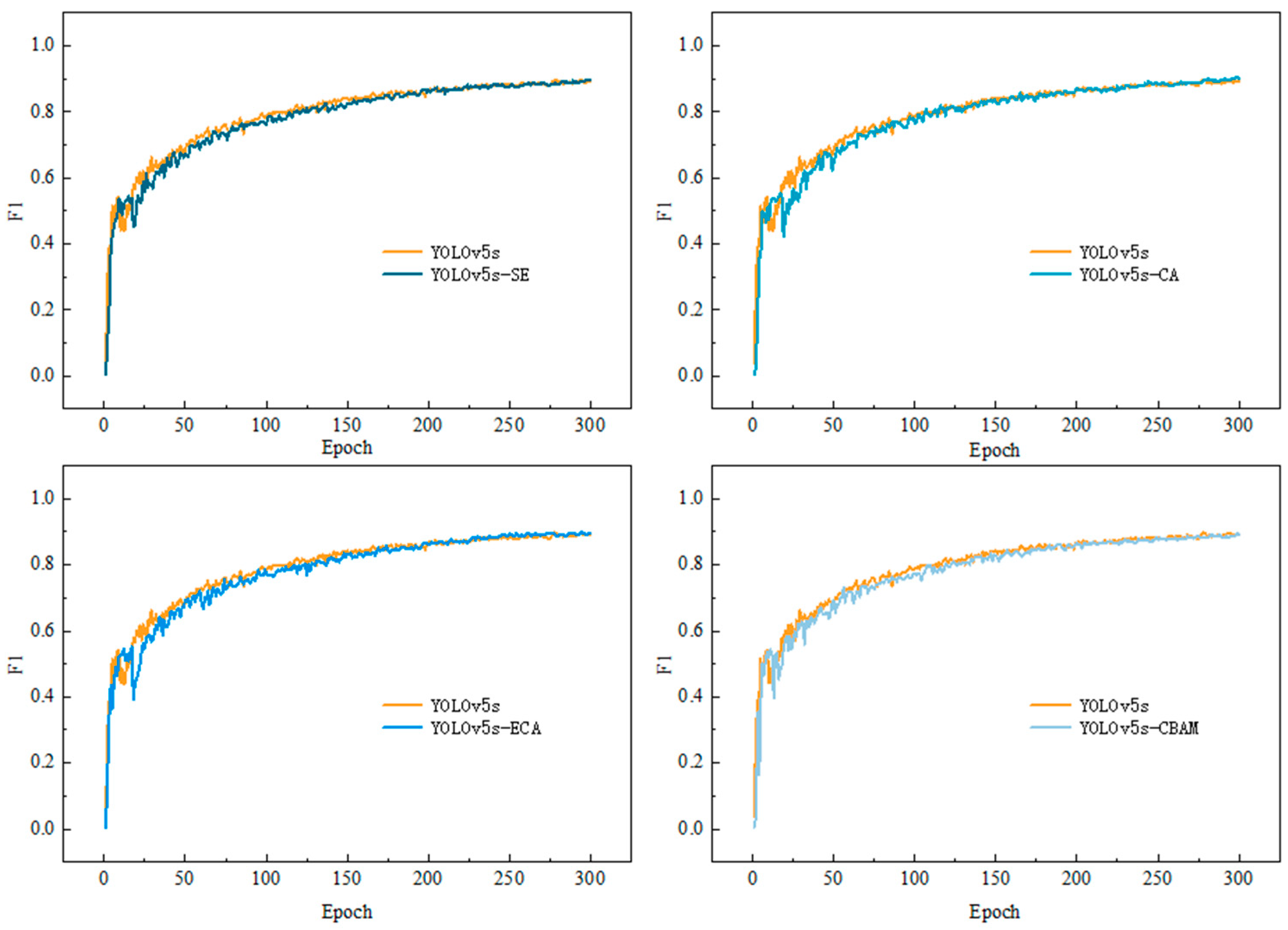
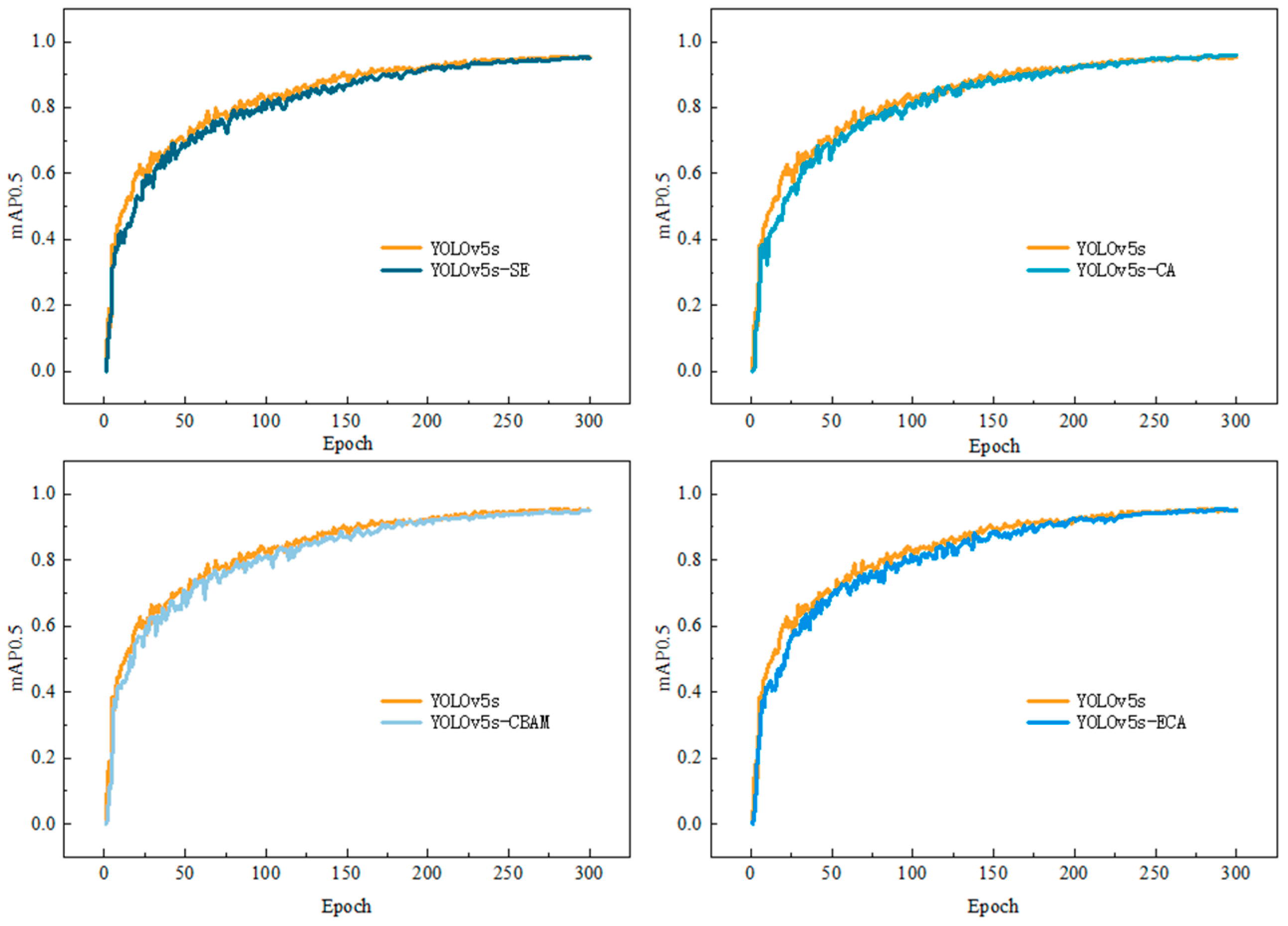
3.1. Training Set Results
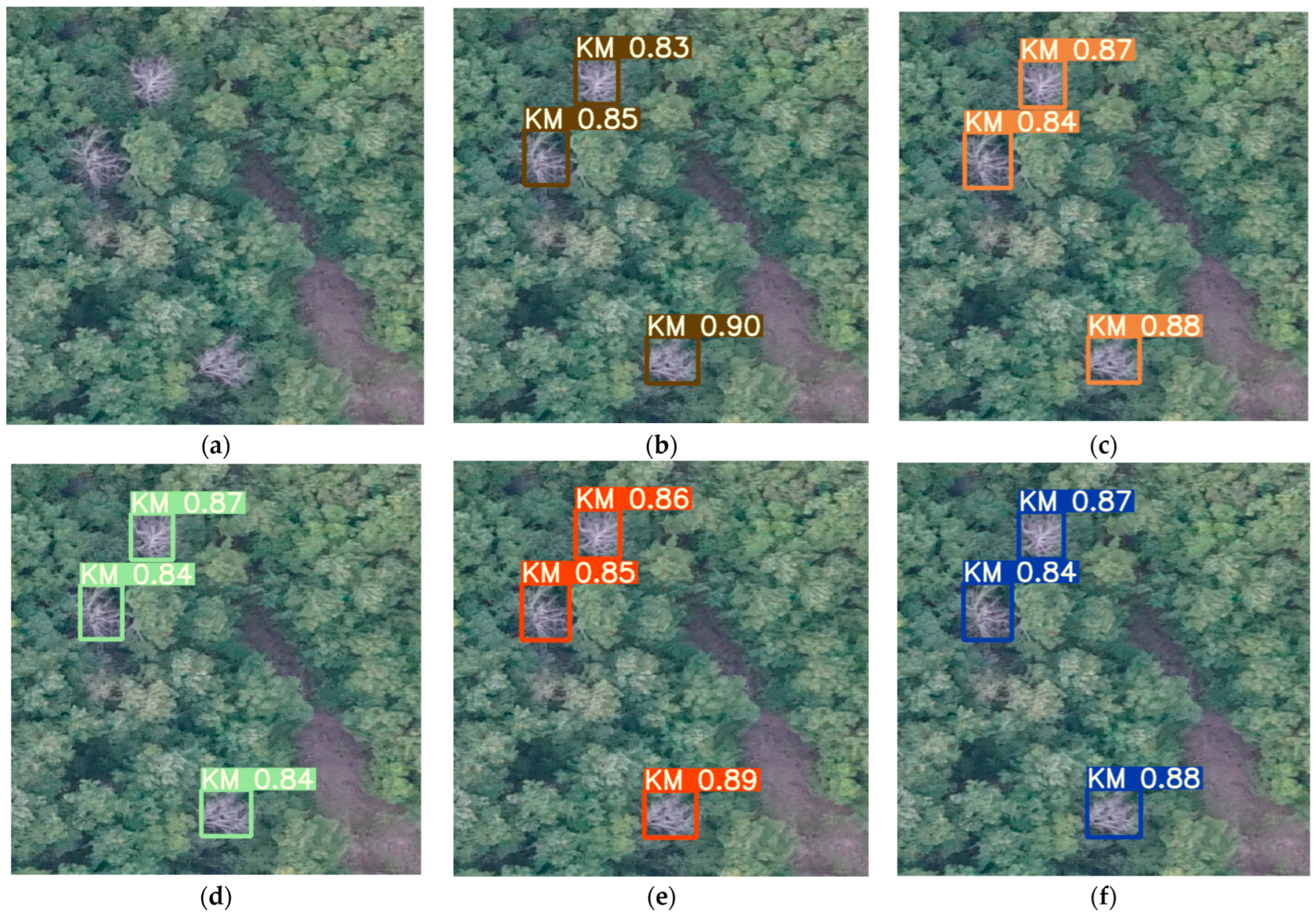
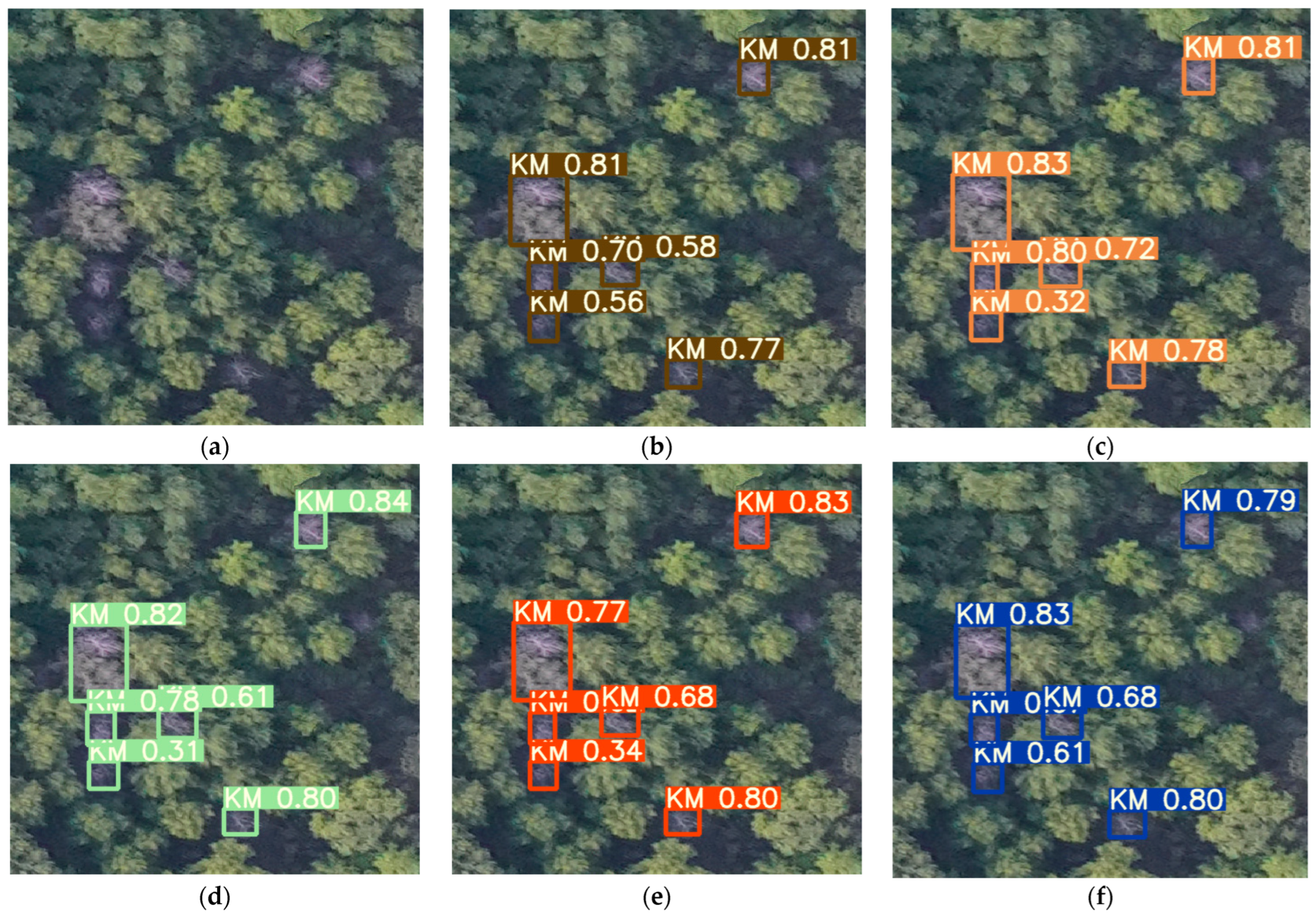
3.2. Test Set Result
3.3. Improvements and Deficiencies
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hao, Z.; Huang, J.; Li, X.; Sun, H.; Fang, G. A multi-point aggregation trend of the outbreak of pine wilt disease in China over the past 20 years. For. Ecol. Manag. 2022, 505, 119890. [Google Scholar] [CrossRef]
- Li, M.; Li, H.; Sheng, R.-C.; Sun, H.; Sun, S.-H.; Chen, F.-M. The First Record of Monochamus saltuarius (Coleoptera; Cerambycidae) as Vector of Bursaphelenchus xylophilus and Its New Potential Hosts in China. Insects 2020, 11, 636. [Google Scholar] [CrossRef] [PubMed]
- Carrasquinho, I.; Lisboa, A.; Inácio, M.L.; Gonçalves, E. Genetic variation in susceptibility to pine wilt disease of maritime pine (Pinus pinaster Aiton) half-sib families. Ann. For. Sci. 2018, 75, 85. [Google Scholar] [CrossRef] [Green Version]
- Dou, G.; Yan, D.-H. Research Progress on Biocontrol of Pine Wilt Disease by Microorganisms. Forests 2022, 13, 1047. [Google Scholar] [CrossRef]
- Hu, G.; Yin, C.; Wan, M.; Zhang, Y.; Fang, Y. Recognition of diseased Pinus trees in UAV images using deep learning and AdaBoost classifier. Biosyst. Eng. 2020, 194, 138–151. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Z.; Zheng, L.; Han, C.; Wang, X.; Xu, J.; Wang, X. Research Progress on the Early Monitoring of Pine Wilt Disease Using Hyperspectral Techniques. Sensors 2020, 20, 3729. [Google Scholar] [CrossRef]
- Li, M.; Li, H.; Ding, X.; Wang, L.; Wang, X.; Chen, F. The Detection of Pine Wilt Disease: A Literature Review. Int. J. Mol. Sci. 2022, 23, 10797. [Google Scholar] [CrossRef]
- Lausch, A.; Borg, E.; Bumberger, J.; Dietrich, P.; Heurich, M.; Huth, A.; Jung, A.; Klenke, R.; Knapp, S.; Mollenhauer, H.; et al. Understanding Forest Health with Remote Sensing, Part III: Requirements for a Scalable Multi-Source Forest Health Monitoring Network Based on Data Science Approaches. Remote Sens. 2018, 10, 1120. [Google Scholar] [CrossRef] [Green Version]
- Brovkina, O.; Cienciala, E.; Surovy, P.; Janata, P. Unmanned aerial vehicles (UAV) for assessment of qualitative classification of Norway spruce in temperate forest stands. Geo-Spat. Inf. Sci. 2018, 21, 12–20. [Google Scholar] [CrossRef] [Green Version]
- Kuswidiyanto, L.W.; Noh, H.H.; Han, X.Z. Plant Disease Diagnosis Using Deep Learning Based on Aerial Hyperspectral Images: A Review. Remote Sens. 2022, 14, 6031. [Google Scholar] [CrossRef]
- Kim, S.-R.; Lee, W.-K.; Lim, C.-H.; Kim, M.; Kafatos, M.C.; Lee, S.-H.; Lee, S.-S. Hyperspectral Analysis of Pine Wilt Disease to Determine an Optimal Detection Index. Forests 2018, 9, 115. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.B.; Kim, E.S.; Lee, S.H. An Analysis of Spectral Pattern for Detecting Pine Wilt Disease Using Ground-Based Hyperspectral Camera. Korean J. Remote Sens. 2014, 30, 665–675. [Google Scholar] [CrossRef] [Green Version]
- Sun, C.; Huang, C.; Zhang, H.; Chen, B.; An, F.; Wang, L.; Yun, T. Individual Tree Crown Segmentation and Crown Width Extraction From a Heightmap Derived From Aerial Laser Scanning Data Using a Deep Learning Framework. Front. Plant Sci. 2022, 13. [Google Scholar] [CrossRef]
- Tao, H.; Li, C.; Cheng, C.; Jiang, L.; Hu, H. Research Progress on Remote Sensing Monitoring of pine wilt disease. Forest Research. 2020, 33, 172–183. [Google Scholar] [CrossRef]
- Zhang, B.; Ye, H.; Lu, W.; Huang, W.; Wu, B.; Hao, Z.; Sun, H. A Spatiotemporal Change Detection Method for Monitoring Pine Wilt Disease in a Complex Landscape Using High-Resolution Remote Sensing Imagery. Remote Sens. 2021, 13, 2083. [Google Scholar] [CrossRef]
- Li, X.; Tong, T.; Luo, T.; Wang, J.; Rao, Y.; Li, L.; Jin, D.; Wu, D.; Huang, H. Retrieving the Infected Area of Pine Wilt Disease-Disturbed Pine Forests from Medium-Resolution Satellite Images Using the Stochastic Radiative Transfer Theory. Remote Sens. 2022, 14, 1526. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, J.; Sun, H.; Lu, X.; Huang, J.; Wang, S.; Fang, G. Satellite Remote Sensing Identification of Discolored Standing Trees for Pine Wilt Disease Based on Semi-Supervised Deep Learning. Remote Sens. 2022, 14, 5936. [Google Scholar] [CrossRef]
- Zhou, H.; Yuan, X.; Zhou, H.; Shen, H.; Ma, L.; Sun, L.; Fang, G.; Sun, H. Surveillance of pine wilt disease by high resolution satellite. J. For. Res. 2022, 33, 1401–1408. [Google Scholar] [CrossRef]
- Nevalainen, O.; Honkavaara, E.; Tuominen, S.; Viljanen, N.; Hakala, T.; Yu, X.; Hyyppä, J.; Saari, H.; Pölönen, I.; Imai, N.N.; et al. Individual Tree Detection and Classification with UAV-Based Photogrammetric Point Clouds and Hyperspectral Imaging. Remote Sens. 2017, 9, 185. [Google Scholar] [CrossRef] [Green Version]
- Duarte, A.; Borralho, N.; Cabral, P.; Caetano, M. Recent Advances in Forest Insect Pests and Diseases Monitoring Using UAV-Based Data: A Systematic Review. Forests 2022, 13, 911. [Google Scholar] [CrossRef]
- Yu, R.; Luo, Y.; Zhou, Q.; Zhang, X.; Wu, D.; Ren, L. Early detection of pine wilt disease using deep learning algorithms and UAV-based multispectral imagery. For. Ecol. Manag. 2021, 497, 119493. [Google Scholar] [CrossRef]
- Qin, J.; Wang, B.; Wu, Y.; Lu, Q.; Zhu, H. Identifying Pine Wood Nematode Disease Using UAV Images and Deep Learning Algorithms. Remote Sens. 2021, 13, 162. [Google Scholar] [CrossRef]
- Ye, W.; Lao, J.; Liu, Y.; Chang, C.-C.; Zhang, Z.; Li, H.; Zhou, H. Pine pest detection using remote sensing satellite images combined with a multi-scale attention-UNet model. Ecol. Inform. 2022, 72, 101906. [Google Scholar] [CrossRef]
- Hu, G.; Wang, T.; Wan, M.; Bao, W.; Zeng, W. UAV remote sensing monitoring of pine forest diseases based on improved Mask R-CNN. Int. J. Remote Sens. 2022, 43, 1274–1305. [Google Scholar] [CrossRef]
- Zang, H.; Wang, Y.; Ru, L.; Zhou, M.; Chen, D.; Zhao, Q.; Zhang, J.; Li, G.; Zheng, G. Detection method of wheat spike improved YOLOv5s based on the attention mechanism. Front. Plant Sci. 2022, 13. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Feng, Z.; Lu, J.; Liu, J. Estimation of Forest Biomass in Beijing (China) Using Multisource Remote Sensing and Forest Inventory Data. Forests 2020, 11, 163. [Google Scholar] [CrossRef] [Green Version]
- Jo, S.; Lee, B.; Oh, J.; Song, J.; Lee, C.; Kim, S.; Suk, J. Experimental Study of In-Flight Deployment of a Multicopter from a Fixed-Wing UAV. Int. J. Aeronaut. Space Sci. 2019, 20, 697–709. [Google Scholar] [CrossRef]
- Eskandari, R.; Mahdianpari, M.; Mohammadimanesh, F.; Salehi, B.; Brisco, B.; Homayouni, S. Meta-analysis of Unmanned Aerial Vehicle (UAV) Imagery for Agro-environmental Monitoring Using Machine Learning and Statistical Models. Remote Sens. 2020, 12, 3511. [Google Scholar] [CrossRef]
- Aslahishahri, M.; Stanley, K.G.; Duddu, H.; Shirtliffe, S.; Vail, S.; Stavness, I. Spatial Super Resolution of Real-World Aerial Images for Image-Based Plant Phenotyping. Remote Sens. 2021, 13, 2308. [Google Scholar] [CrossRef]
- Zaki, N.H.M.; Chong, W.S.; Muslim, A.M.; Reba, M.N.M.; Hossain, M.S. Assessing optimal UAV-data pre-processing workflows for quality ortho-image generation to support coral reef mapping. Geocarto Int. 2022, 37, 10556–10580. [Google Scholar] [CrossRef]
- Wu, H.-T.; Tang, S.; Huang, J.; Shi, Y.-Q. A novel reversible data hiding method with image contrast enhancement. Signal Process. Image Commun. 2018, 62, 64–73. [Google Scholar] [CrossRef]
- Wang, W.; Wang, H.; Yang, S.; Zhang, X.; Wang, X.; Wang, J.; Lei, J.; Zhang, Z.; Dong, Z. Resolution enhancement in microscopic imaging based on generative adversarial network with unpaired data. Opt. Commun. 2022, 503, 127454. [Google Scholar] [CrossRef]
- Jung, H.-K.; Choi, G.-S. Improved YOLOv5: Efficient Object Detection Using Drone Images under Various Conditions. Appl. Sci. 2022, 12, 7255. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Wang, Y.; Hua, C.; Ding, W.; Wu, R. Real-time detection of flame and smoke using an improved YOLOv4 network. Signal Image Video Process. 2022, 16, 1109–1116. [Google Scholar] [CrossRef]
- Xie, F.; Lin, B.; Liu, Y. Research on the Coordinate Attention Mechanism Fuse in a YOLOv5 Deep Learning Detector for the SAR Ship Detection Task. Sensors 2022, 22, 3370. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Pan, H.; Shi, Y.; Lei, X.; Wang, Z.; Xin, F. Fast identification model for coal and gangue based on the improved tiny YOLO v3. J. Real-Time Image Process. 2022, 19, 687–701. [Google Scholar] [CrossRef]
- Lin, Y.; Cai, R.; Lin, P.; Cheng, S. A detection approach for bundled log ends using K-median clustering and improved YOLOv4-Tiny network. Comput. Electron. Agric. 2022, 194, 106700. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.-S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.F.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Kim, M.; Jeong, J.; Kim, S. ECAP-YOLO: Efficient Channel Attention Pyramid YOLO for Small Object Detection in Aerial Image. Remote Sens. 2021, 13, 4851. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Huang, L.; Huang, W. RD-YOLO: An Effective and Efficient Object Detector for Roadside Perception System. Sensors 2022, 22, 8097. [Google Scholar] [CrossRef] [PubMed]
- Kong, L.; Wang, J.; Zhao, P. YOLO-G: A Lightweight Network Model for Improving the Performance of Military Targets Detection. IEEE Access 2022, 10, 55546–55564. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Du, F.-J.; Jiao, S.-J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Ibrayim, M.; Hamdulla, A. Detection of Pine Wilt Nematode from Drone Images Using UAV. Sensors 2022, 22, 4704. [Google Scholar] [CrossRef]
- Wan, J.; Wu, L.; Zhang, S.; Liu, S.; Xu, M.; Sheng, H.; Cui, J. Monitoring of Discolored Trees Caused by Pine Wilt Disease Based on Unsupervised Learning with Decision Fusion Using UAV Images. Forests 2022, 13, 1884. [Google Scholar] [CrossRef]
- Xia, L.; Zhang, R.; Chen, L.; Li, L.; Yi, T.; Wen, Y.; Ding, C.; Xie, C. Evaluation of Deep Learning Segmentation Models for Detection of Pine Wilt Disease in Unmanned Aerial Vehicle Images. Remote Sens. 2021, 13, 3594. [Google Scholar] [CrossRef]
- You, J.; Zhang, R.; Lee, J. A Deep Learning-Based Generalized System for Detecting Pine Wilt Disease Using RGB-Based UAV Images. Remote Sens. 2021, 14, 150. [Google Scholar] [CrossRef]
- Wang, C.; Xu, C.; Yao, X.; Tao, D. Evolutionary Generative Adversarial Networks. IEEE Trans. Evol. Comput. 2019, 23, 921–934. [Google Scholar] [CrossRef] [Green Version]
- Sharma, N.; Sharma, R.; Jindal, N. An Improved Technique for Face Age Progression and Enhanced Super-Resolution with Generative Adversarial Networks. Wirel. Pers. Commun. 2020, 114, 2215–2233. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simple Plot Location | Area/km2 | Infected Wood |
|---|---|---|
| Cigou Village | 9.45 | 120 |
| Luojiatai Village | 13.08 | 15 |
| Baicaowa Village | 9.48 | 22 |
| Huagou Village | 12.52 | 17 |
| Sanjianfang Village | 11.61 | 19 |
| Zhousigou Village | 12.96 | 220 |
| Zhuanshanzi Village | 12.91 | 50 |
| Total | 842.05 | 463 |
| Sets | Number of Images |
|---|---|
| Training set | 1004 |
| Verification set | 144 |
| Test set | 287 |
| Item | Configuration |
|---|---|
| CPU | Intel Core i7-11800H (2.30 GHz) |
| GPU | NVIDIA RTX3050 (3072 CUDA cores) |
| Operating system | Windows 10 |
| Software tools | Anaconda 3 (Continuum Analytics, Austin, TX, USA), CUDA 11.2 (NVIDIA, Santa Clara City, CA, USA), Python 3.8 |
| Model Name | Precision/% | Recall/% | mAP/% | Size/Mb |
|---|---|---|---|---|
| YOLOv5s | 92.70 | 94.70 | 97.40 | 14.4 |
| YOLOv5s-SE | 93.50 | 95.10 | 97.50 | 15.5 |
| YOLOv5s-CA | 95.60 | 91.80 | 97.70 | 16.0 |
| YOLOv5s-ECA | 92.20 | 95.40 | 97.60 | 14.4 |
| YOLOv5s-CBAM | 94.20 | 93.50 | 97.50 | 15.5 |
| Model Name | Precision/% | Recall/% | mAP/% | FPS/Hz |
|---|---|---|---|---|
| YOLOv5s | 89.30 | 89.20 | 94.20 | 96 |
| YOLOv5s-SE | 92.10 | 84.30 | 95.50 | 98 |
| YOLOv5s-CA | 92.60 | 87.80 | 95.50 | 116 |
| YOLOv5s-ECA | 90.30 | 88.20 | 95.30 | 102 |
| YOLOv5s-CBAM | 91.10 | 89.30 | 95.50 | 102 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Wang, Z.; Rao, Y.; Zheng, J.; Zhang, N.; Wang, D.; Zhu, J.; Fang, Y.; Gao, X. Identification of Pine Wilt Disease Infected Wood Using UAV RGB Imagery and Improved YOLOv5 Models Integrated with Attention Mechanisms. Forests 2023, 14, 588. https://doi.org/10.3390/f14030588
Zhang P, Wang Z, Rao Y, Zheng J, Zhang N, Wang D, Zhu J, Fang Y, Gao X. Identification of Pine Wilt Disease Infected Wood Using UAV RGB Imagery and Improved YOLOv5 Models Integrated with Attention Mechanisms. Forests. 2023; 14(3):588. https://doi.org/10.3390/f14030588
Chicago/Turabian StyleZhang, Peng, Zhichao Wang, Yuan Rao, Jun Zheng, Ning Zhang, Degao Wang, Jianqiao Zhu, Yifan Fang, and Xiang Gao. 2023. "Identification of Pine Wilt Disease Infected Wood Using UAV RGB Imagery and Improved YOLOv5 Models Integrated with Attention Mechanisms" Forests 14, no. 3: 588. https://doi.org/10.3390/f14030588
APA StyleZhang, P., Wang, Z., Rao, Y., Zheng, J., Zhang, N., Wang, D., Zhu, J., Fang, Y., & Gao, X. (2023). Identification of Pine Wilt Disease Infected Wood Using UAV RGB Imagery and Improved YOLOv5 Models Integrated with Attention Mechanisms. Forests, 14(3), 588. https://doi.org/10.3390/f14030588