

Decision-Tree Application to Predict and Spatialize the Wood Productivity Probabilities of Eucalyptus Plantations

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
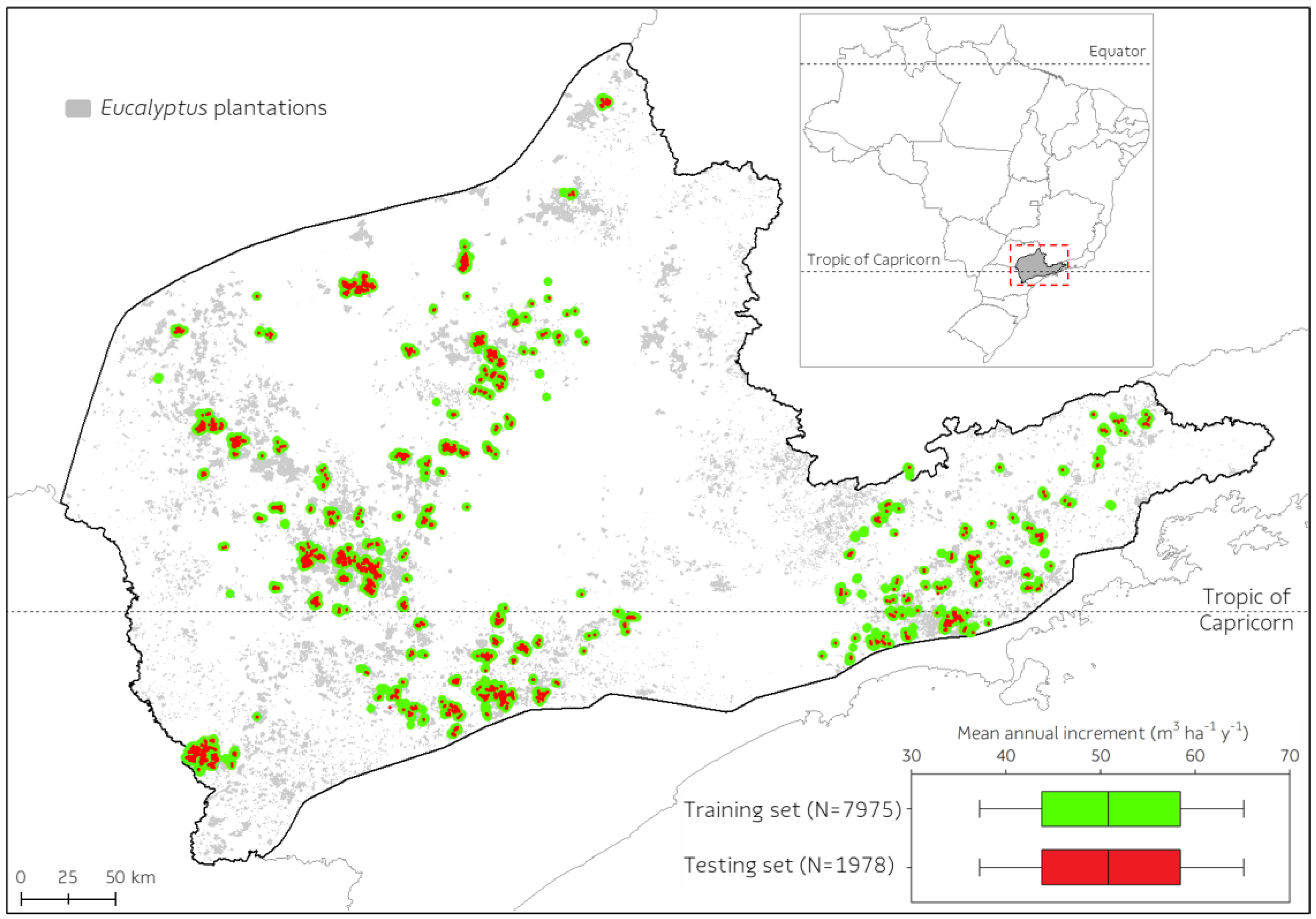
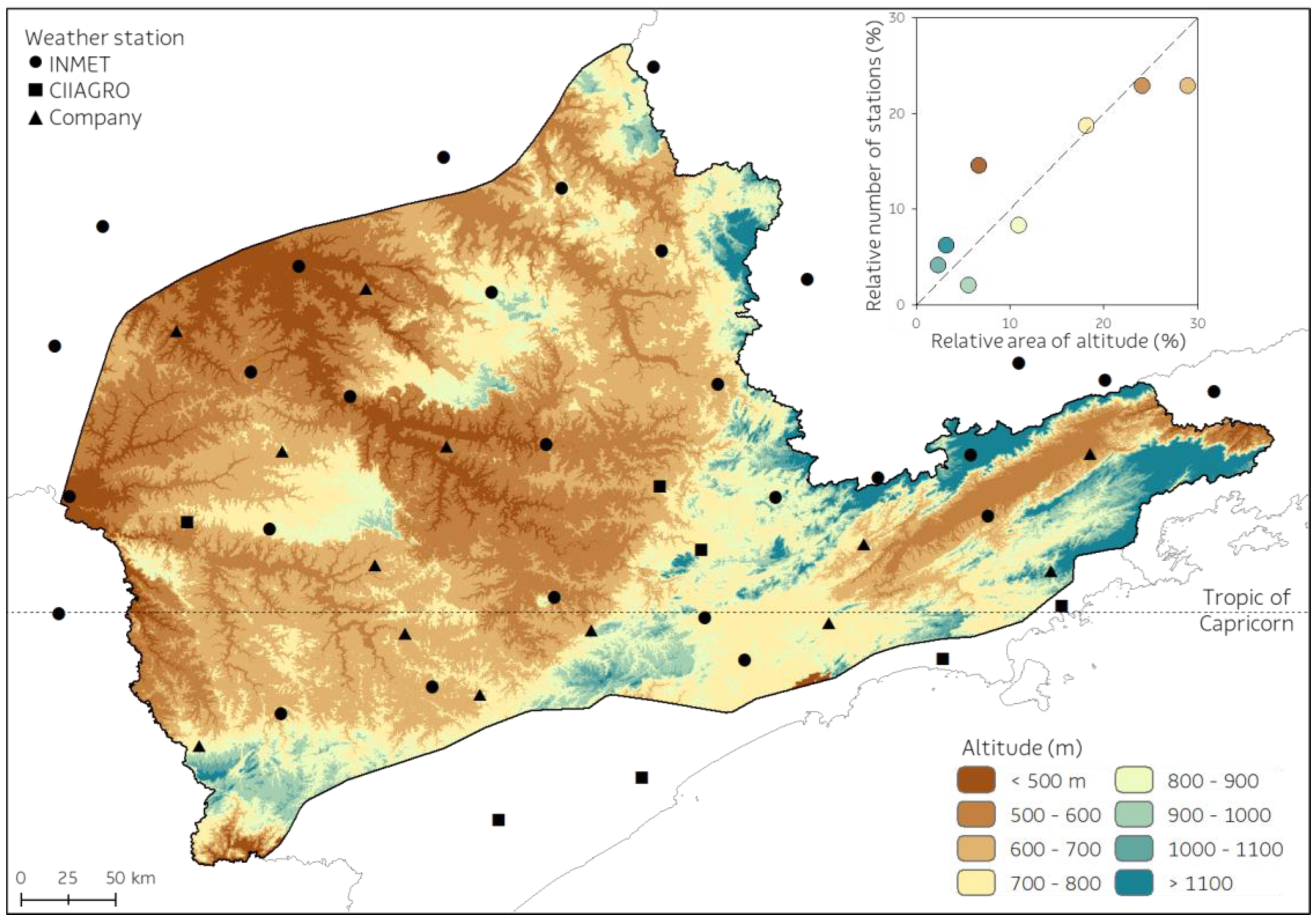
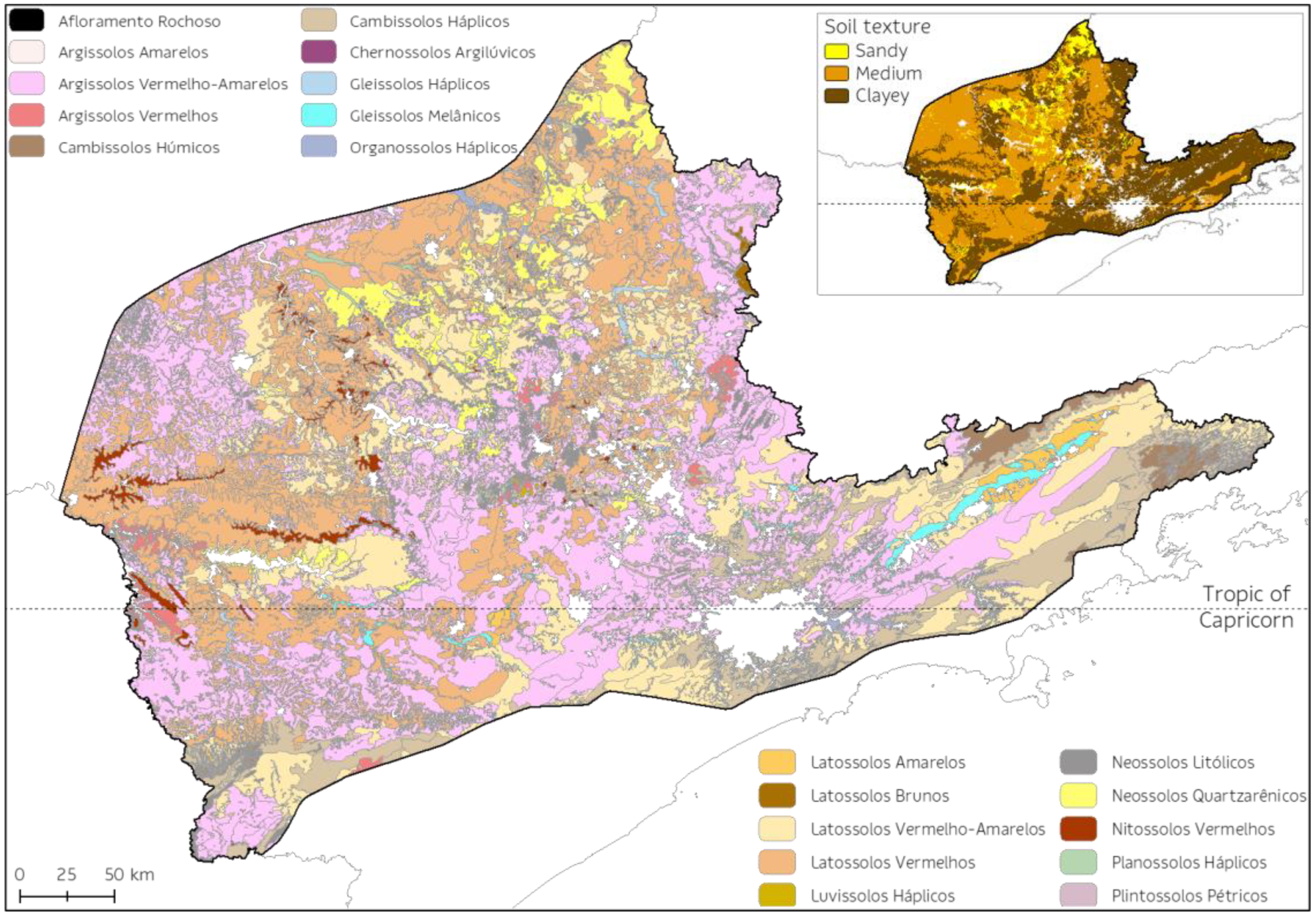
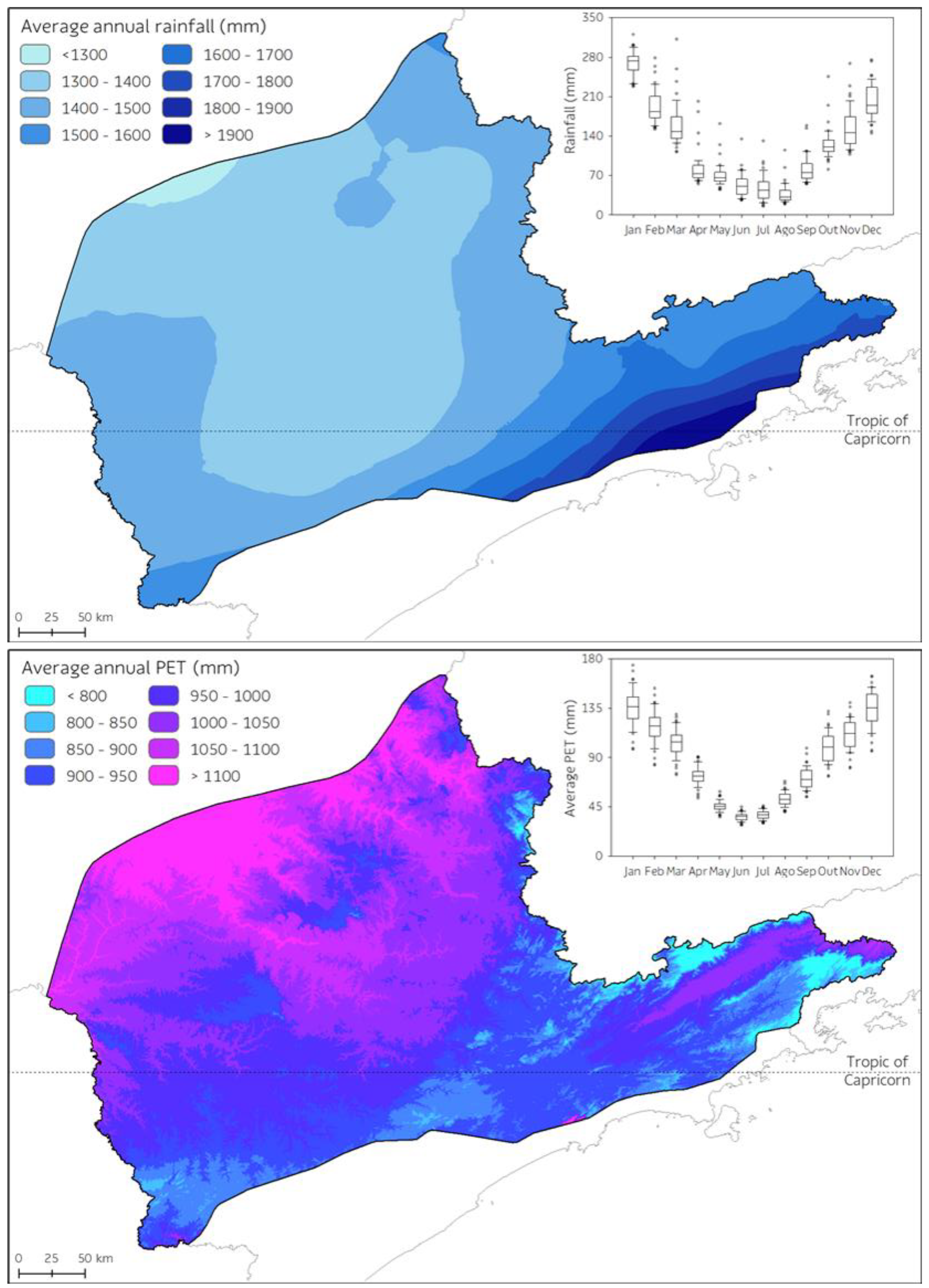
2.1. Study Area
2.2. Forest Datasets
2.3. Environmental Datasets
2.4. Decision-Tree Modeling
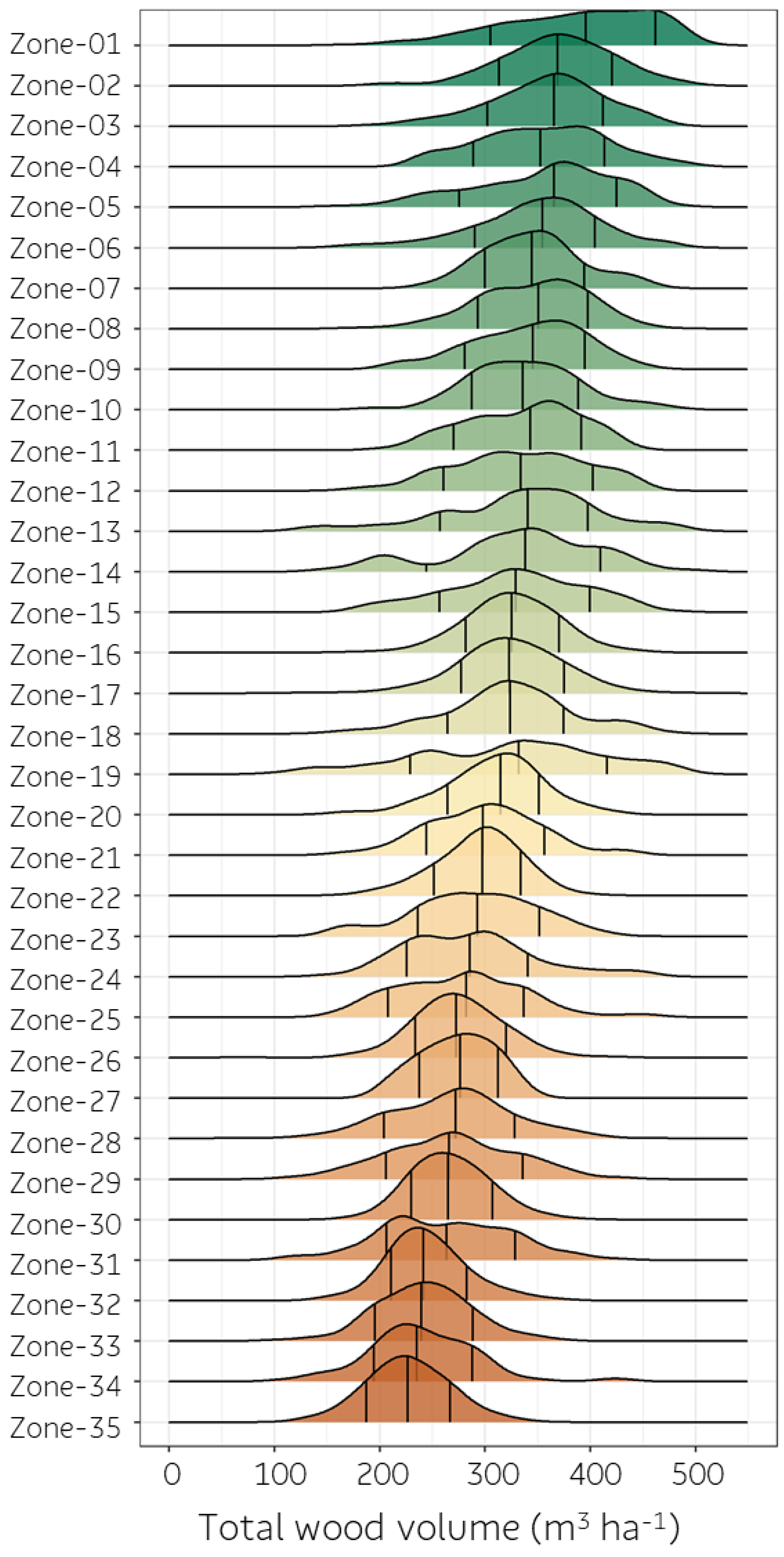
2.5. Eucalyptus Forest Productivity Zoning
3. Results and Discussion
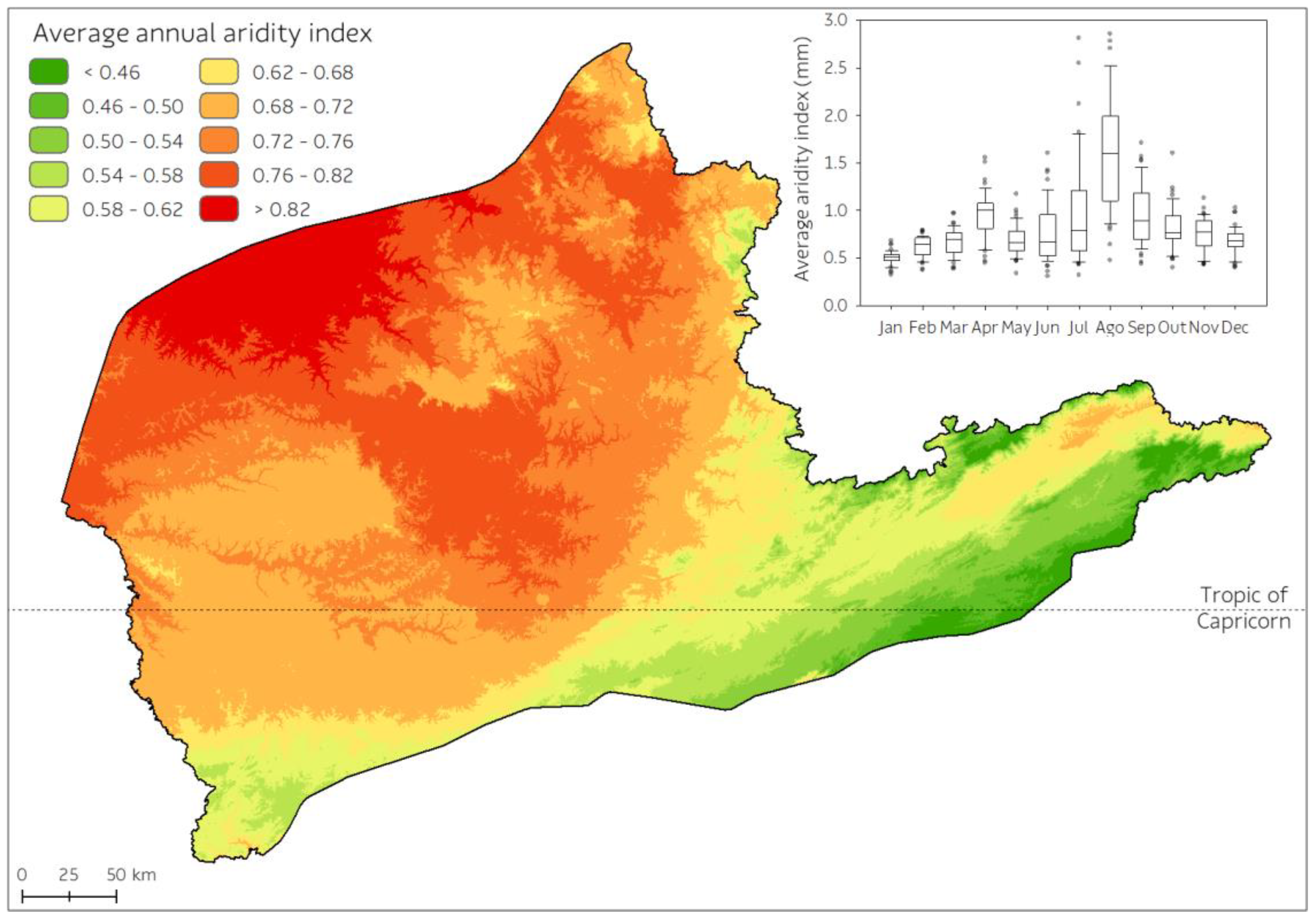
3.1. Climate Modeling
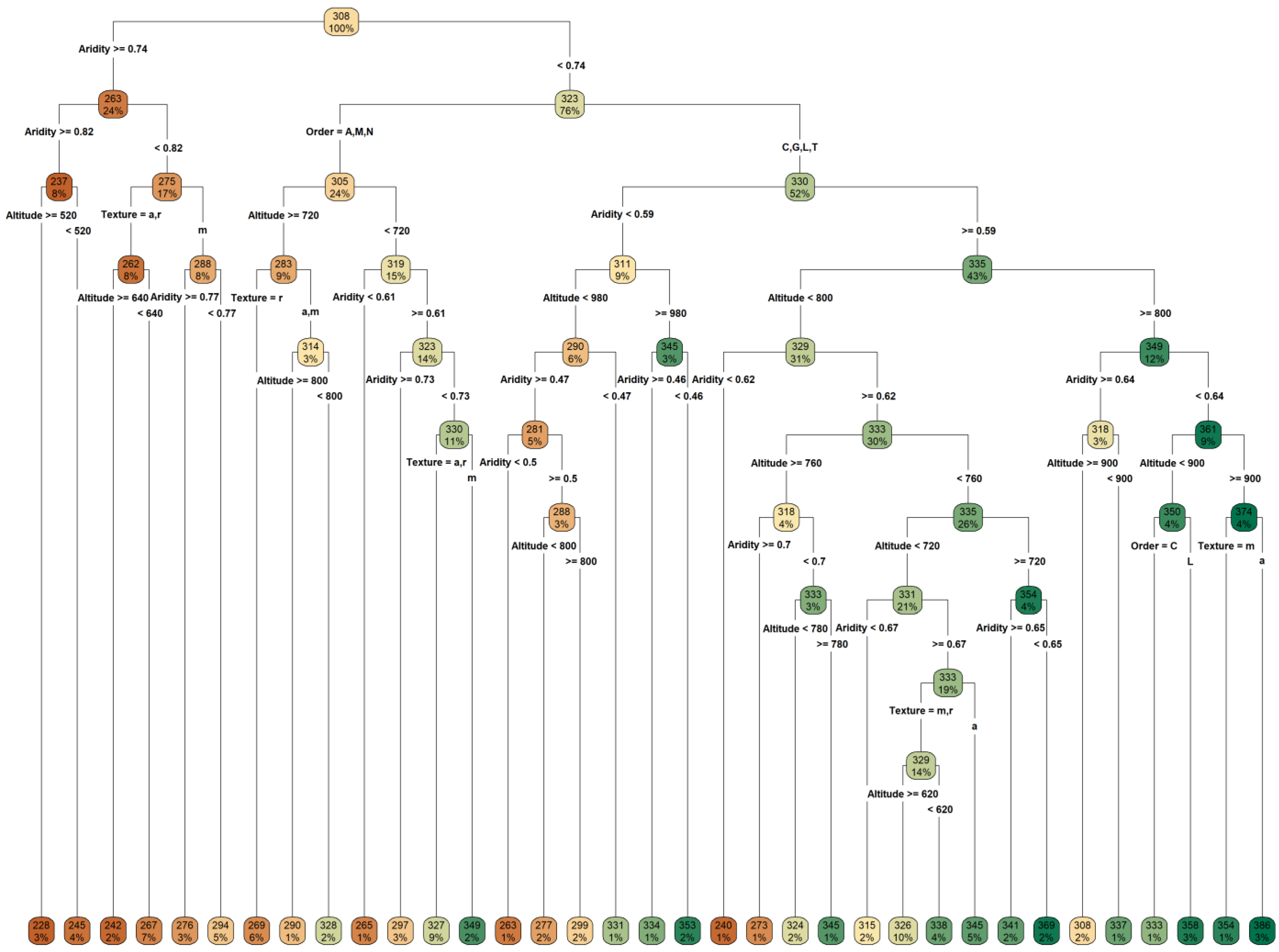
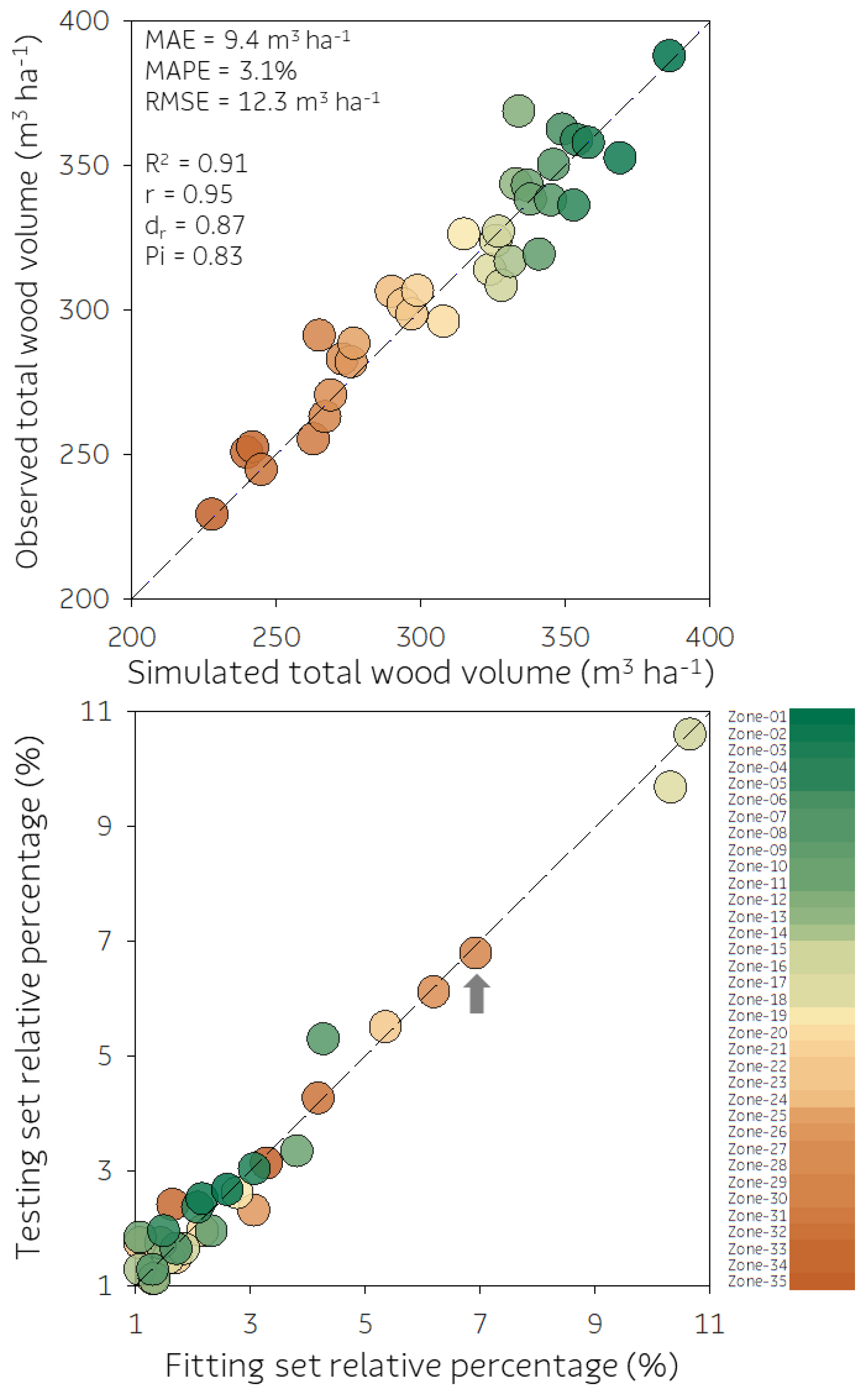
3.2. Decision-Tree Modeling

3.3. Innovations in Decision-Tree Use



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
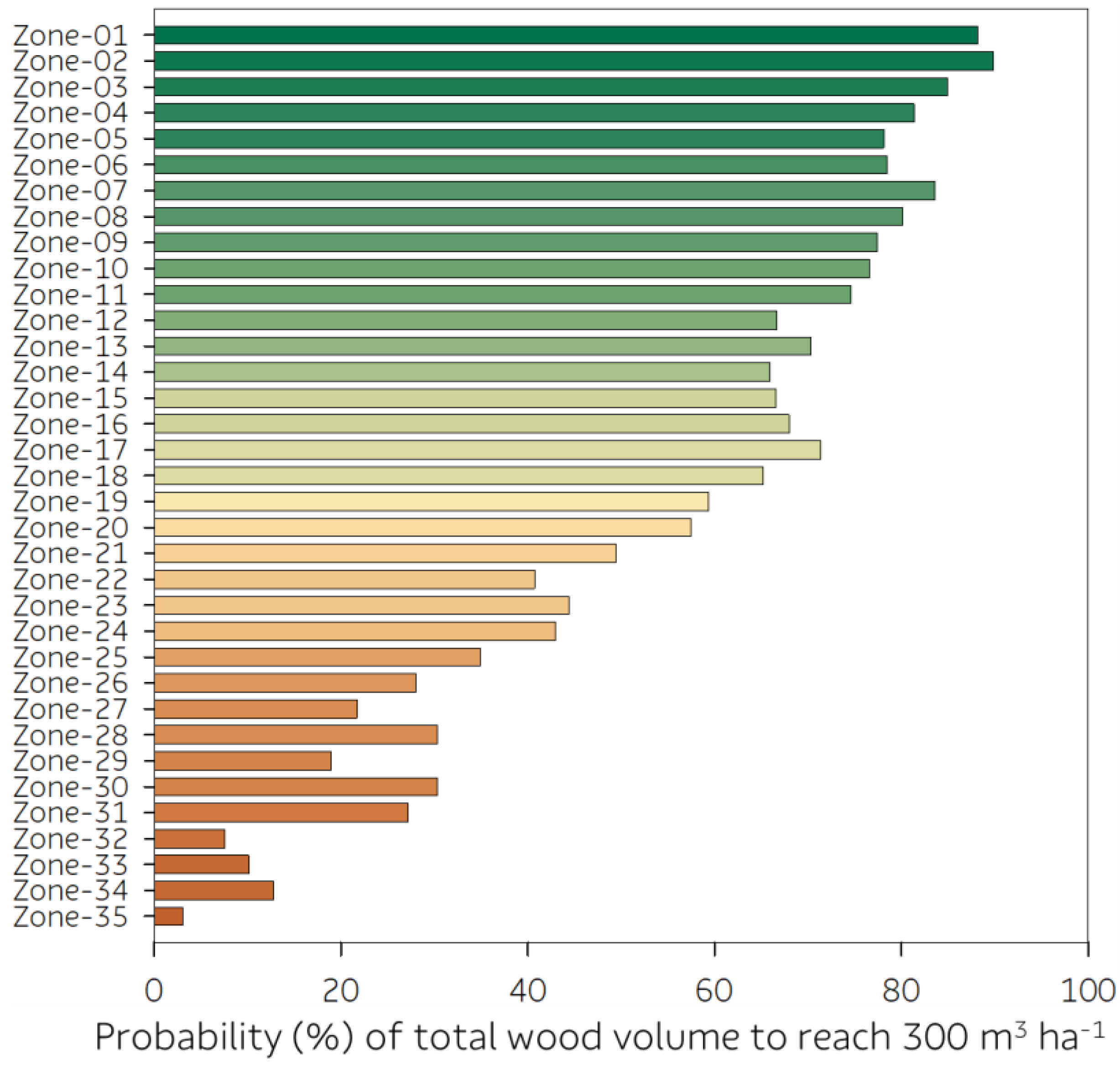
| Forest Zone | Leaf Node (m3 ha−1) | Aridity (PET/R) | Altitude (m) | Soil Order | Soil Texture | 15th (m3 ha−1) | 50th (m3 ha−1) | 85th (m3 ha−1) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Zone 01 | 386 | when | is | 0.59 | to | 0.64 | and | >= | 900 | and | is | C, G, L, or T | and | is | a | 308 | 395 | 462 | ||
| Zone 02 | 369 | when | is | 0.62 | to | 0.65 | and | is | 720 | to | 760 | and | is | C, G, L, or T | 307 | 368 | 419 | |||
| Zone 03 | 358 | when | is | 0.59 | to | 0.64 | and | is | 800 | to | 900 | and | is | L | 300 | 364 | 412 | |||
| Zone 04 | 354 | when | is | 0.59 | to | 0.64 | and | >= | 900 | and | is | C, G, L, or T | and | is | m | 291 | 351 | 418 | ||
| Zone 05 | 353 | when | < | 0.46 | and | >= | 980 | and | is | C, G, L, or T | 275 | 362 | 420 | |||||||
| Zone 06 | 349 | when | is | 0.61 | to | 0.73 | and | < | 720 | and | is | A, M, or N | and | is | m | 292 | 354 | 410 | ||
| Zone 07 | 346 | when | is | 0.62 | to | 0.70 | and | is | 780 | to | 800 | and | is | C, G, L, or T | 302 | 344 | 397 | |||
| Zone 08 | 345 | when | is | 0.67 | to | 0.74 | and | < | 720 | and | is | C, G, L, or T | and | is | a | 290 | 348 | 397 | ||
| Zone 09 | 341 | when | is | 0.65 | to | 0.74 | and | is | 720 | to | 760 | and | is | C, G, L, or T | 272 | 342 | 396 | |||
| Zone 10 | 338 | when | is | 0.67 | to | 0.74 | and | < | 620 | and | is | C, G, L, or T | and | is | m or r | 288 | 338 | 389 | ||
| Zone 11 | 337 | when | is | 0.64 | to | 0.74 | and | is | 800 | to | 900 | and | is | C, G, L, or T | 270 | 346 | 393 | |||
| Zone 12 | 334 | when | is | 0.46 | to | 0.59 | and | >= | 980 | and | is | C, G, L, or T | 261 | 349 | 405 | |||||
| Zone 13 | 333 | when | is | 0.59 | to | 0.64 | and | is | 800 | to | 900 | and | is | C | 266 | 335 | 402 | |||
| Zone 14 | 331 | when | < | 0.47 | and | < | 980 | and | is | C, G, L, or T | 256 | 336 | 403 | |||||||
| Zone 15 | 328 | when | < | 0.74 | and | is | 720 | to | 800 | and | is | A, M, or N | and | is | a or m | 246 | 324 | 404 | ||
| Zone 16 | 327 | when | is | 0.61 | to | 0.73 | and | < | 720 | and | is | A, M, or N | and | is | a or r | 277 | 324 | 377 | ||
| Zone 17 | 326 | when | is | 0.67 | to | 0.74 | and | is | 620 | to | 720 | and | is | C, G, L, or T | and | is | m or r | 281 | 324 | 370 |
| Zone 18 | 324 | when | is | 0.62 | to | 0.70 | and | is | 760 | to | 780 | and | is | C, G, L, or T | 264 | 322 | 373 | |||
| Zone 19 | 315 | when | is | 0.62 | to | 0.67 | and | < | 720 | and | is | C, G, L, or T | 229 | 332 | 420 | |||||
| Zone 20 | 308 | when | is | 0.64 | to | 0.74 | and | >= | 900 | and | is | C, G, L, or T | 260 | 308 | 351 | |||||
| Zone 21 | 299 | when | is | 0.50 | to | 0.59 | and | is | 800 | to | 980 | and | is | C, G, L, or T | 245 | 298 | 359 | |||
| Zone 22 | 297 | when | is | 0.73 | to | 0.74 | and | < | 720 | and | is | A, M, or N | 227 | 285 | 341 | |||||
| Zone 23 | 294 | when | is | 0.74 | to | 0.77 | and | is | m | 254 | 298 | 336 | ||||||||
| Zone 24 | 290 | when | < | 0.74 | and | >= | 800 | and | is | A, M, or N | and | is | a or m | 235 | 295 | 358 | ||||
| Zone 25 | 277 | when | is | 0.50 | to | 0.59 | and | < | 800 | and | is | C, G, L, or T | 215 | 286 | 340 | |||||
| Zone 26 | 276 | when | is | 0.77 | to | 0.82 | and | is | m | 232 | 274 | 321 | ||||||||
| Zone 27 | 273 | when | is | 0.70 | to | 0.74 | and | is | 760 | to | 800 | and | is | C, G, L, or T | 238 | 277 | 312 | |||
| Zone 28 | 269 | when | < | 0.74 | and | >= | 720 | and | is | A, M, or N | and | is | r | 204 | 272 | 326 | ||||
| Zone 29 | 267 | when | is | 0.74 | to | 0.82 | and | < | 640 | and | is | a or r | 230 | 264 | 307 | |||||
| Zone 30 | 265 | when | < | 0.61 | and | < | 720 | and | is | A, M, or N | 206 | 275 | 334 | |||||||
| Zone 31 | 263 | when | is | 0.47 | to | 0.50 | and | < | 980 | and | is | C, G, L, or T | 200 | 264 | 326 | |||||
| Zone 32 | 245 | when | >= | 0.82 | and | < | 520 | 210 | 241 | 284 | ||||||||||
| Zone 33 | 242 | when | is | 0.74 | to | 0.82 | and | >= | 640 | and | is | a or r | 199 | 244 | 288 | |||||
| Zone 34 | 240 | when | is | 0.59 | to | 0.62 | and | < | 800 | and | is | C, G, L, or T | 194 | 238 | 289 | |||||
| Zone 35 | 228 | when | >= | 0.82 | and | >= | 520 | 187 | 226 | 268 | ||||||||||
3.4. Decision-Tree Spatialization

3.5. Yield Gap Approach
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tian, X.; Engel, B.A.; Qian, H.; Hua, E.; Sun, S.; Wang, Y. Will reaching the maximum achievable yield potential meet future global food demand? J. Clean. Prod. 2021, 294, 126285. [Google Scholar] [CrossRef]
- Ray, D.K.; West, P.C.; Clark, M.; Gerber, J.S.; Prishchepov, A.V.; Chatterjee, S. Climate change has likely already affected global food production. PLoS ONE 2019, 14, e0217148. [Google Scholar] [CrossRef] [PubMed]
- Verkerk, P.J.; Hassegawa, M.; Van Brusselen, J.; Cramm, M.; Chen, X.; Imparato Maximo, Y.; Koç, M.; Lovrić, M.; Tekle Tegegne, Y. The Role of Forest Products in the Global Bioeconomy—Enabling Substitution by Wood-Based Products and Contributing to the Sustainable Development Goals; FAO on Behalf of the Advisory Committee on Sustainable Forestbased Industries (ACSFI): Rome, Italy, 2021. [Google Scholar] [CrossRef]
- Binkley, D.; Campoe, O.C.; Alvares, C.A.; Carneiro, R.L.; Stape, J.L. Variation in whole-rotation yield among Eucalyptus genotypes in response to water and heat stresses: The TECHS project. For. Ecol. Manag. 2020, 462, 117953. [Google Scholar] [CrossRef]
- Binkley, D.; Campoe, O.C.; Alvares, C.; Carneiro, R.L.; Cegatta, R.L.; Stape, J.L. The interactions of climate, spacing and genetics on clonal Eucalyptus plantations across Brazil and Uruguay. For. Ecol. Manag. 2017, 405, 271–283. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, J.L.M.; Alvares, C.A.; Higa, A.R.; Silva, L.D.; Alfenas, A.C.; Stahl, J.; Ferraz, S.F.B.; Lima, W.P.; Brancalion, P.H.S.; Hubner, A.; et al. Integrating genetic and silvicultural strategies to minimize abiotic and biotic constraints in Brazilian eucalypt plantations. For. Ecol. Manag. 2013, 301, 6–27. [Google Scholar] [CrossRef]
- Alvares, C.A.; Sentelhas, P.C.; Chou, S.C. Future Climate Projections in South America and Their Influence on Forest Plantations, 1st ed.; IPEF—Instituto de Pesquisas e Estudos Florestais: Piracicaba, Brazil, 2021; 96p. [Google Scholar]
- Gonçalves, J.L.; Alvares, A.C.; Rocha, J.H.; Brandani, C.B.; Hakamada, R. Eucalypt plantation management in regions with water stress. South. For. J. For. Sci. 2017, 79, 169–183. [Google Scholar] [CrossRef]
- da Cunha, T.Q.G.; Santos, A.C.; Novaes, E.; Hansted, A.L.S.; Yamaji, F.M.; Sette Júnior, C.R. Eucalyptus expansion in Brazil: Energy yield in new forest frontiers. Biomass-Bioenergy 2020, 144, 105900. [Google Scholar] [CrossRef]
- Tupinambá-Simões, F.; Bravo, F.; Guerra-Hernández, J.; Pascual, A. Assessment of drought effects on survival and growth dynamics in eucalypt commercial forestry using remote sensing photogrammetry. A showcase in Mato Grosso, Brazil. For. Ecol. Manag. 2022, 505, 119930. [Google Scholar] [CrossRef]
- Elli, E.F.; Sentelhas, P.C.; de Freitas, C.H.; Carneiro, R.L.; Alvares, C.A. Assessing the growth gaps of Eucalyptus plantations in Brazil–Magnitudes, causes and possible mitigation strategies. For. Ecol. Manag. 2019, 451, 117464. [Google Scholar] [CrossRef]
- Gava, J.L.; Gonçalves, J.L.M. Soil attributes and wood quality for pulp production in plantations of Eucalyptus grandis clone. Sci. Agricola 2008, 65, 306–313. [Google Scholar] [CrossRef] [Green Version]
- Elli, E.F.; Sentelhas, P.C.; de Freitas, C.H.; Carneiro, R.L.; Alvares, C.A. Intercomparison of structural features and performance of Eucalyptus simulation models and their ensemble for yield estimations. For. Ecol. Manag. 2019, 450, 117493. [Google Scholar] [CrossRef]
- Scolforo, H.F.; McTague, J.P.; Burkhart, H.; Roise, J.; Alvares, C.A.; Stape, J.L. Site index estimation for clonal eucalypt plantations in Brazil: A modeling approach refined by environmental variables. For. Ecol. Manag. 2020, 466, 118079. [Google Scholar] [CrossRef]
- Reddy, G.P.O.; Kumar, N. Data Science—Algorithms and Applications in Earth Observation. In Data Science in Agriculture and Natural Resource Management. Studies in Big Data; Reddy, G.P.O., Raval, M.S., Adinarayana, J., Chaudhary, S., Eds.; Springer: Singapore, 2022; Volume 96. [Google Scholar] [CrossRef]
- Divakaran, S. Data Science: Principles and Concepts in Modeling Decision Trees. In Data Science in Agriculture and Natural Resource Management. Studies in Big Data; Reddy, G.P.O., Raval, M.S., Adinarayana, J., Chaudhary, S., Eds.; Springer: Singapore, 2022; Volume 96. [Google Scholar] [CrossRef]
- Barbosa, L.O.; Costa, E.A.; Schons, C.T.; Finger, C.A.G.; Liesenberg, V.; Bispo, P.D.C. Individual Tree Basal Area Increment Models for Brazilian Pine (Araucaria angustifolia) Using Artificial Neural Networks. Forests 2022, 13, 1108. [Google Scholar] [CrossRef]
- Shi, M.; Xu, J.; Liu, S.; Xu, Z. Productivity-Based Land Suitability and Management Sensitivity Analysis: The Eucalyptus E. urophylla × E. grandis Case. Forests 2022, 13, 340. [Google Scholar] [CrossRef]
- Sotomayor, L.N.; Cracknell, M.J.; Musk, R. Supervised machine learning for predicting and interpreting dynamic drivers of plantation forest productivity in northern Tasmania, Australia. Comput. Electron. Agric. 2023, 209, 107804. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, D.R.; Sharma, V.; Zomaya, A.Y.; Srinivasan, K. Forecasting yield by integrating agrarian factors and machine learning models: A survey. Comput. Electron. Agric. 2018, 155, 257–282. [Google Scholar] [CrossRef]
- Pant, J.; Pant, R.; Singh, M.K.; Singh, D.P.; Pant, H. Analysis of agricultural crop yield prediction using statistical techniques of machine learning. Mater. Today Proc. 2021, 46, 10922–10926. [Google Scholar] [CrossRef]
- van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Ghaffarian, S.; van der Voort, M.; Valente, J.; Tekinerdogan, B.; de Mey, Y. Machine learning-based farm risk management: A systematic mapping review. Comput. Electron. Agric. 2022, 192, 106631. [Google Scholar] [CrossRef]
- de Almeida, G.M.; Pereira, G.T.; Bahia, A.S.R.D.S.; Fernandes, K.; Júnior, J.M. Machine learning in the prediction of sugarcane production environments. Comput. Electron. Agric. 2021, 190, 106452. [Google Scholar] [CrossRef]
- Dos Reis, A.A.; Franklin, S.E.; de Mello, J.M.; Junior, F.W.A. Volume estimation in a Eucalyptus plantation using multi-source remote sensing and digital terrain data: A case study in Minas Gerais State, Brazil. Int. J. Remote Sens. 2019, 40, 2683–2702. [Google Scholar] [CrossRef]
- de Freitas, E.C.S.; de Paiva, H.N.; Neves, J.C.L.; Marcatti, G.E.; Leite, H.G. Modeling of eucalyptus productivity with artificial neural networks. Ind. Crops Prod. 2020, 146, 112149. [Google Scholar] [CrossRef]
- Miranda, E.N.; Barbosa, B.H.G.; Silva, S.H.G.; Monti, C.A.U.; Tng, D.Y.P.; Gomide, L.R. Variable selection for estimating individual tree height using genetic algorithm and random forest. For. Ecol. Manag. 2022, 504, 119828. [Google Scholar] [CrossRef]
- Silva, J.P.M.; da Silva, M.L.M.; de Mendonça, A.R.; da Silva, G.F.; de Barros Junior, A.A.; da Silva, E.F.; Aguiar, M.O.; Santos, J.S.; Rodrigues, N.M.M. Prognosis of forest production using machine learning techniques. Inf. Process. Agric. 2021, 10, 71–84. [Google Scholar]
- Santos, J.S.; de Mendonça, A.R.; Gonçalves, F.G.; da Silva, G.F.; de Almeida, A.Q.; Carvalho, S.d.P.C.E.; Silva, J.P.M.; Carvalho, R.C.; da Silva, E.F.; Aguiar, M.O. Predicting eucalyptus plantation growth and yield using Landsat imagery in Minas Gerais, Brazil. Ecol. Inform. 2023, 75, 102120. [Google Scholar] [CrossRef]
- Harris, N.; Goldman, E.D.; Gibbes, S. Spatial Database of Planted Trees (SDPT VERSION 1.0); WRI: Washington, DC, USA, 2019. [Google Scholar]
- Alvares, C.A.; Stape, J.L.; Sentelhas, P.C.; Gonçalves, J.L.M.; Sparovek, G. Köppen’s climate classification map for Brazil. Meteorol. Z. 2013, 22, 711–728. [Google Scholar] [CrossRef]
- Alvares, C.A.; Sentelhas, P.C.; Stape, J.L. Modeling monthly meteorological and agronomic frost days, based on minimum air temperature, in Center-Southern Brazil. Theor. Appl. Clim. 2018, 134, 177–191. [Google Scholar] [CrossRef]
- Radambrasil, P. Levantamento de Recursos Naturais; Ministério das Minas e Energia, Departamento Nacional da Produção Mineral, Projeto Radambrasil: Brasília, Brazil, 1973.
- IPT—Instituto de Pesquisas Tecnológicas. Mapa Geológico do Estado de São Paulo, 1:500,000, Nota Explicativa; IPT: São Paulo, Brazil, 1981; 126p. [Google Scholar]
- Perrota, M.M.; Salvador, E.D.; Lopes, R.C.; D’Agostinho, L.Z.; Peruffo, N.; Gomes, S.D.; Sachs, L.L.B.; Meira, V.T.; Garcia, M.G.M.; Lacerda Filho, J.V. Mapa Geológico do Estado de São Paulo, Escala 1:750,000; Programa Geologia do Brasil—PGB, CPRM: São Paulo, Brazil, 2005.
- Alvares, C.A. Mapeamento e Modelagem Edafoclimática da Produtividade de Plantações de Eucalyptus no Sul do Estado de São Paulo. Ph.D. Thesis, University of São Paulo, Piracicaba, Brazil, 2011. Available online: www.teses.usp.br/teses/disponiveis/11/11150/tde-23052011-161837/en.php (accessed on 5 January 2021).
- Flores, T.B.; Alvares, C.A.; Souza, V.C.; Stape, J.L. Eucalyptus in Brazil: Climatic Zoning and Identification Guide; IPEF: Piracicaba, Brazil, 2018.
- EMBRAPA. Sistema Brasileiro de Classificação de Solos, 3rd ed.; Embrapa Produção de Informação: Brasília, Brazil; Embrapa Solos: Rio de Janeiro, Brazil, 2015; 353p. [Google Scholar]
- Soil Survey Staff. Illustrated Guide to Soil Taxonomy; U.S. Department of Agriculture, Natural Resources Conservation Service, National Soil Survey Center: Lincoln, NE, USA, 2015.
- Xavier, A.C.; King, C.W.; Scanlon, B.R. Daily gridded meteorological variables in Brazil (1980–2013). Int. J. Clim. 2016, 36, 2644–2659. [Google Scholar] [CrossRef] [Green Version]
- Stackhouse, P.W.; Zhang, T.; Westber, D.; Barnett, A.J.; Bristow, T.; Macpherson, B.; Hoell, J.M.; Hamilton, B.A. POWER Release 8.0.1 (with GIS Applications) Methodology (Data Parameters, Sources, Validation); Technical Report; NASA Langley Research Center: Hampton, VA, USA, 2018.
- Burrough, P.A.; McDonnell, R.A. Principles of Geographical Information Systems; Oxford University Press: New York, NY, USA, 1998. [Google Scholar]
- Alvares, C.A.; Stape, J.L.; Sentelhas, P.C.; Gonçalves, J.L.M. Modeling monthly mean air temperature for Brazil. Theor. Appl. Climatol. 2013, 113, 407–427. [Google Scholar] [CrossRef]
- Tomlin, C.D. Geographic Information Systems and Cartographic Modelling; Prentice Hall: Englewood Cliffs, NJ, USA, 1990. [Google Scholar]
- ArcGIS 10; ESRI—Environmental Systems Research Institute, Inc.: Redlands, CA, USA, 2010; Available online: https://www.arcgis.com/index.html (accessed on 20 January 2021).
- Farr, T.G.; Kobrick, M. Shuttle Radar Topography Mission produces a wealth of data. Am. Geophys. Union Eos 2000, 81, 583–585. [Google Scholar] [CrossRef]
- Jarvis, A.; Reuter, H.I.; Nelson, A.; Guevara, E. Hole-Filled SRTM for the Globe Version 4. Available from the CGIAR-CSI SRTM 90m Database. 2008. Available online: http://srtm.csi.cgiar.org (accessed on 20 January 2021).
- Theobald, D.M. GIS Concepts and ArcGIS Methods, 3rd ed.; Conservation Planning Technologies: Fort Collins, CO, USA, 2007. [Google Scholar]
- Ormsby, T.; Napoleon, E.; Burke, R.; Groessl, C.; Bowden, L. Getting to know ArcGIS Desktop: Updated for ArcGIS 10, 2nd ed.; ESRI Press: Redlands, Australia, 2010. [Google Scholar]
- Allen, D.W. Getting to Know ArcGIS ModelBuilder; ESRI Press: Redlands, Australia, 2011. [Google Scholar]
- Thornthwaite, C.W. An Approach toward a Rational Classification of Climate. Geogr. Rev. 1948, 38, 55–94. [Google Scholar] [CrossRef]
- Zhou, G.; Wei, X.; Chen, X.; Zhou, P.; Liu, X.; Xiao, Y.; Sun, G.; Scott, D.F.; Zhou, S.; Han, L.; et al. Global pattern for the effect of climate and land cover on water yield. Nat. Commun. 2015, 6, 5918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hubbard, R.M.; Carneiro, R.L.; Campoe, O.; Alvares, C.A.; Figura, M.A.; Moreira, G.G. Contrasting water use of two Eucalyptus clones across a precipitation and temperature gradient in Brazil. For. Ecol. Manag. 2020, 475, 118407. [Google Scholar] [CrossRef]
- Therneau, T.; Atkinson, B.; Ripley, B. Rpart: Recursive Partitioning and Regression Trees. R Package Version 4.1-10. 2015. Available online: https://cran.r-project.org/web/packages/rpart/index.html (accessed on 1 February 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Project: Vienna, Austria, 2017; Available online: https://www.r-project.org/ (accessed on 20 January 2021).
- Willmott, C.J.; Robeson, S.M.; Matsuura, K. A refined index of model performance. Int. J. Climatol. 2012, 32, 2088–2094. [Google Scholar] [CrossRef]
- Rossi, M. Mapa Pedológico do Estado de São Paulo: Revisado e Ampliado; Instituto Florestal: São Paulo, Brazil, 2017; Volume 1, p. 118. [Google Scholar]
- Matheron, G. The Theory of Regionalized Variables and Its Applications; Ecole de Mines: Fontainbleau, France, 1971; 211p. [Google Scholar]
- Diniz, F.D.A.; Ramos, A.M.; Rebello, E.R.G. Normais Climatológicas do Brasil 1981–2010. Pesqui. Agropecuária Bras. 2018, 53, 131–143. [Google Scholar] [CrossRef]
- Ranhao, S.; Baiping, Z.; Jing, T. A Multivariate Regression Model for Predicting Precipitation in the Daqing Mountains. Mt. Res. Dev. 2008, 28, 318–325. [Google Scholar] [CrossRef] [Green Version]
- Dias, S.H.B.; Filgueiras, R.; Filho, E.I.F.; Arcanjo, G.S.; da Silva, G.H.; Mantovani, E.C.; da Cunha, F.F. Reference evapotranspiration of Brazil modeled with machine learning techniques and remote sensing. PLoS ONE 2021, 16, e0245834. [Google Scholar] [CrossRef]
- Ryan, M.G.; Stape, J.L.; Binkley, D.; Alvares, C.A. Cross-site patterns in the response of Eucalyptus plantations to irrigation, climate and intra-annual weather variation. For. Ecol. Manag. 2020, 475, 118444. [Google Scholar] [CrossRef]
- Rossit, D.A.; Olivera, A.; Céspedes, V.V.; Broz, D. A Big Data approach to forestry harvesting productivity. Comput. Electron. Agric. 2019, 161, 29–52. [Google Scholar] [CrossRef]
- Campoe, O.C.; Munhoz, J.S.; Alvares, C.A.; Carneiro, R.L.; de Mattos, E.M.; Ferez, A.P.C.; Stape, J.L. Meteorological seasonality affecting individual tree growth in forest plantations in Brazil. For. Ecol. Manag. 2016, 380, 149–160. [Google Scholar] [CrossRef]
- Scolforo, H.F.; McTague, J.P.; Burkhart, H.; Roise, J.; Alvares, C.A.; Stape, J.L. Modeling whole-stand survival in clonal eucalypt stands in Brazil as a function of water availability. For. Ecol. Manag. 2019, 432, 1002–1012. [Google Scholar] [CrossRef]
- Elli, E.F.; Huth, N.; Sentelhas, P.C.; Carneiro, R.L.; Alvares, C.A. Ability of the APSIM Next Generation Eucalyptus model to simulate complex traits across contrasting environments. Ecol. Model. 2020, 419, 108959. [Google Scholar] [CrossRef]
- Pinheiro, R.C.; Bouillet, J.-P.; Bordron, B.; Aló, L.L.; Costa, V.E.; Alvares, C.A.; Meersche, K.V.D.; Stape, J.L.; Guerrini, I.A.; Laclau, J.-P. Distance from the trunk and depth of uptake of labelled nitrate for dominant and suppressed trees in Brazilian Eucalyptus plantations: Consequences for fertilization practices. For. Ecol. Manag. 2019, 447, 95–104. [Google Scholar] [CrossRef]
- Silva, V.E.; Nogueira, T.A.R.; Abreu-Junior, C.H.; He, Z.; Buzetti, S.; Laclau, J.-P.; Filho, M.C.M.T.; Grilli, E.; Murgia, I.; Capra, G.F. Influences of edaphoclimatic conditions on deep rooting and soil water availability in Brazilian Eucalyptus plantations. For. Ecol. Manag. 2020, 455, 117673. [Google Scholar] [CrossRef]
- Almeida, A.C.; Landsberg, J.J.; Sands, P.J. Parameterisation of 3-PG model for fast-growing Eucalyptus grandis plantations. For. Ecol. Manag. 2004, 193, 179–195. [Google Scholar] [CrossRef]
- Lemos, C.C.Z.; Hakamada, R.E.; Carrero, O.; Alvares, C.A.; Stape, J.L. Estimation, zoning and sensitive analyses of forest productivity of Eucalyptus in northeast São Paulo using the 3-PG model. Sci. For. 2018, 119, 459–471. [Google Scholar]
- Attia, A.; Nouvellon, Y.; Cuadra, S.; Cabral, O.; Laclau, J.-P.; Guillemot, J.; Campoe, O.; Stape, J.-L.; Galdos, M.; Lamparelli, R.; et al. Modelling carbon and water balance of Eucalyptus plantations at regional scale: Effect of climate, soil and genotypes. For. Ecol. Manag. 2019, 449, 117460. [Google Scholar] [CrossRef]
- Caldeira, D.R.M.; Alvares, C.A.; Campoe, O.C.; Hakamada, R.E.; Guerrini, I.A.; Cegatta, R.; Stape, J.L. Multisite evaluation of the 3-PG model for the highest phenotypic plasticity Eucalyptus clone in Brazil. For. Ecol. Manag. 2020, 462, 117989. [Google Scholar] [CrossRef]
- Elli, E.F.; Sentelhas, P.C.; Huth, N.; Carneiro, R.L.; Alvares, C.A. Gauging the effects of climate variability on Eucalyptus plantations productivity across Brazil: A process-based modelling approach. Ecol. Indic. 2020, 114, 106325. [Google Scholar] [CrossRef]
- Marcatti, G.E.; Resende, R.T.; Resende, M.D.V.; Ribeiro, C.A.A.; dos Santos, A.R.; da Cruz, J.P.; Leite, H.G. GIS-based approach applied to optimizing recommendations of Eucalyptus genotypes. For. Ecol. Manag. 2017, 392, 144–153. [Google Scholar] [CrossRef]
- Scolforo, H.F.; McTague, J.P.; Burkhart, H.; Roise, J.; McCarter, J.; Alvares, C.A.; Stape, J.L. Stand-level growth and yield model system for clonal eucalypt plantations in Brazil that accounts for water availability. For. Ecol. Manag. 2019, 448, 22–33. [Google Scholar] [CrossRef]
- Smethurst, P.J.; Valadares, R.V.; Huth, N.I.; Almeida, A.C.; Elli, E.F.; Neves, J.C. Generalized model for plantation production of Eucalyptus grandis and hybrids for genotype-site-management applications. For. Ecol. Manag. 2020, 469, 118164. [Google Scholar] [CrossRef]
- Binkley, D. Editorial: Four tips for communicating clearly with readers: Designs, interpretations, and statistics. Trees For. People 2020, 2, 100010. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvares, C.A.; Cegatta, Í.R.; Scolforo, H.F.; Mafia, R.G. Decision-Tree Application to Predict and Spatialize the Wood Productivity Probabilities of Eucalyptus Plantations. Forests 2023, 14, 1334. https://doi.org/10.3390/f14071334
Alvares CA, Cegatta ÍR, Scolforo HF, Mafia RG. Decision-Tree Application to Predict and Spatialize the Wood Productivity Probabilities of Eucalyptus Plantations. Forests. 2023; 14(7):1334. https://doi.org/10.3390/f14071334
Chicago/Turabian StyleAlvares, Clayton Alcarde, Ítalo Ramos Cegatta, Henrique Ferraço Scolforo, and Reginaldo Gonçalves Mafia. 2023. "Decision-Tree Application to Predict and Spatialize the Wood Productivity Probabilities of Eucalyptus Plantations" Forests 14, no. 7: 1334. https://doi.org/10.3390/f14071334
APA StyleAlvares, C. A., Cegatta, Í. R., Scolforo, H. F., & Mafia, R. G. (2023). Decision-Tree Application to Predict and Spatialize the Wood Productivity Probabilities of Eucalyptus Plantations. Forests, 14(7), 1334. https://doi.org/10.3390/f14071334