Proximate Causes of Land-Use and Land-Cover Change in Bannerghatta National Park: A Spatial Statistical Model

Abstract
:1. Introduction
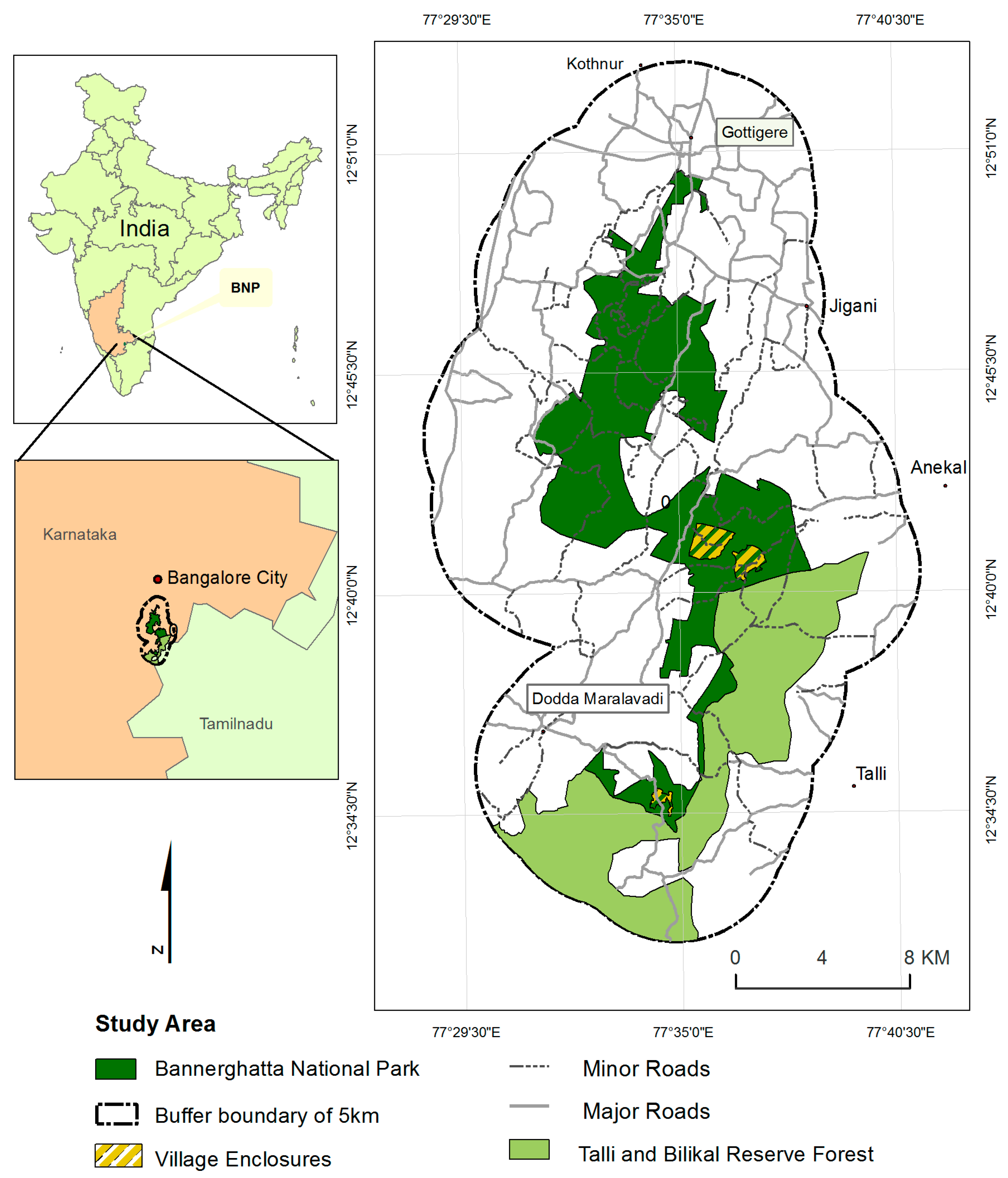
2. Site Description
3. Methods
3.1. Spatial Data
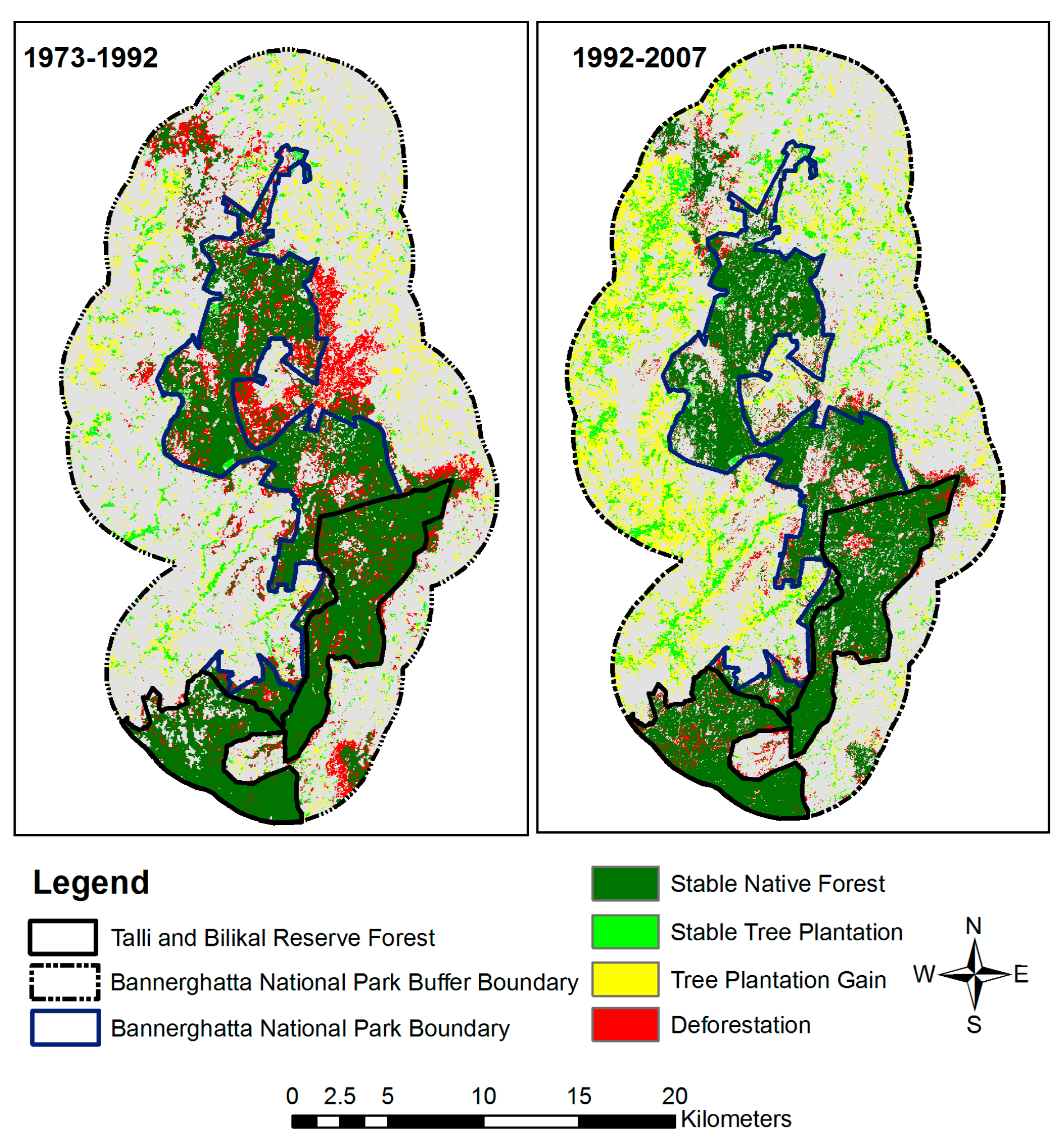
3.1.1. Dependent Variables
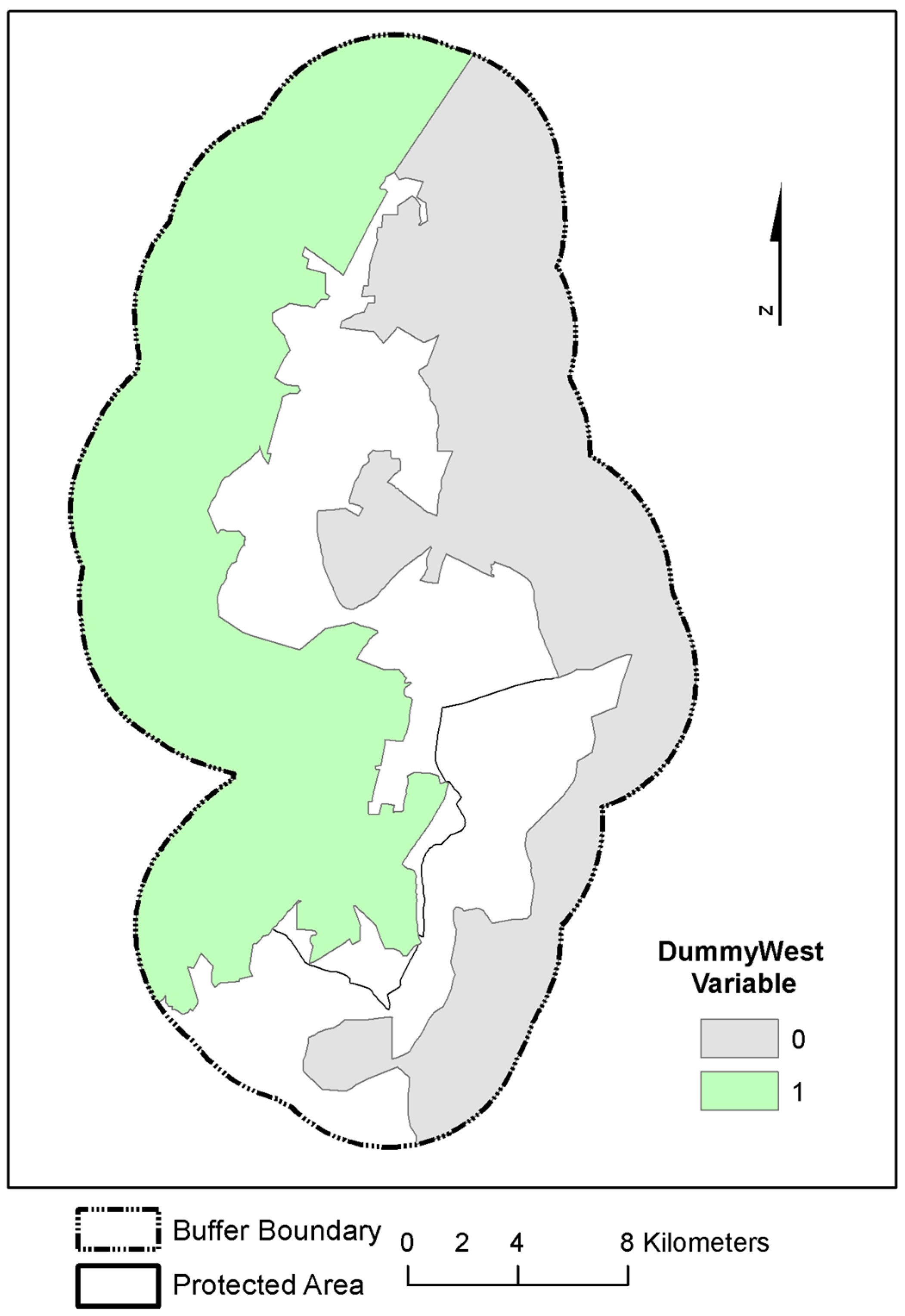
3.1.2. Independent Variables
3.2. Sampling Procedure
3.3. Test of Multicollinearity
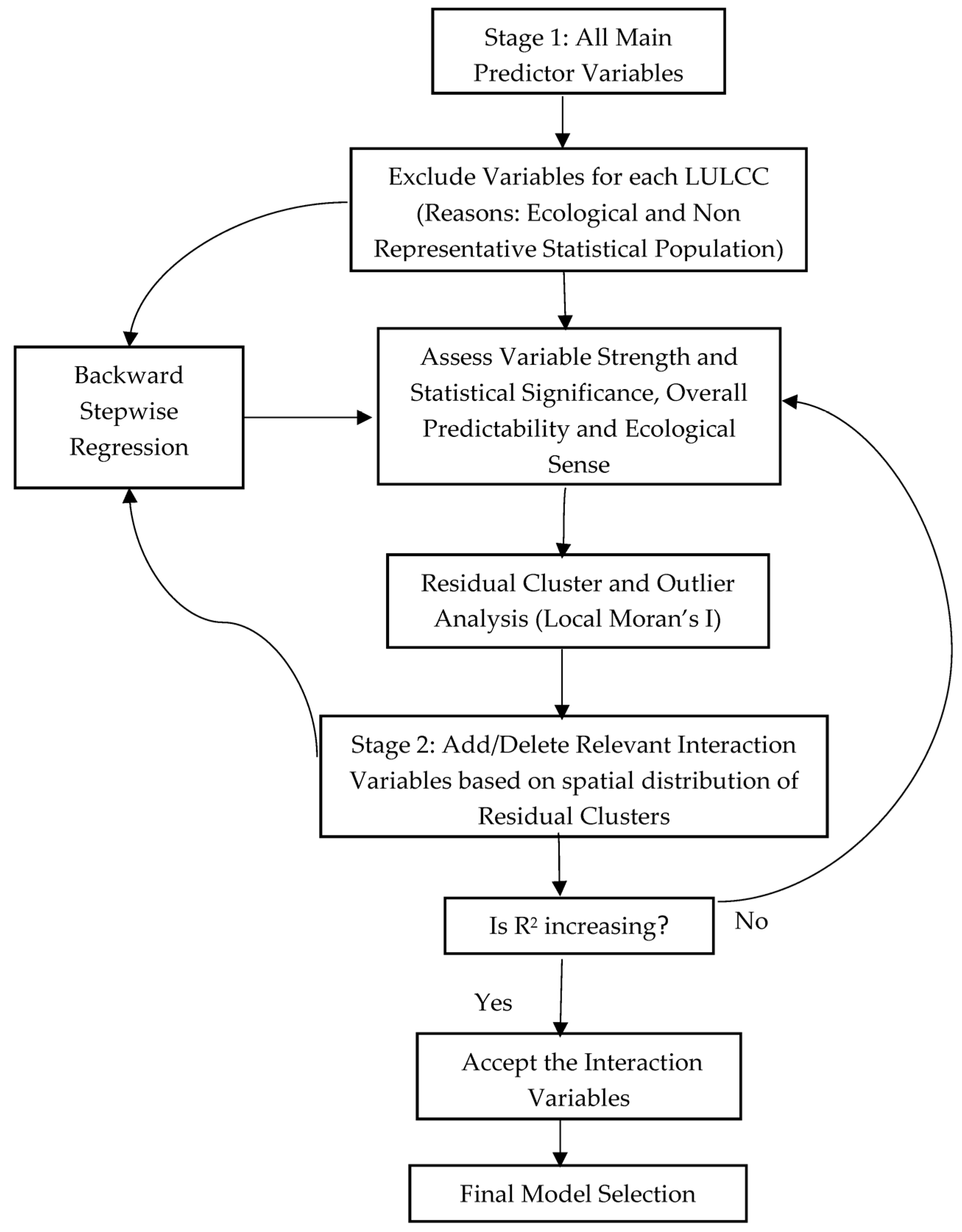
3.4. Logistic Regression Model
4. Results
4.1. Deforestation Model
4.2. Tree Plantation Gain Model
4.3. Residual Analysis of Models
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FORDIST73 | FORDIST92 | ALLRDDIST | MJRDDIST | MIRDDIST | VILLDIST | DWATER | MJTOWNDIST | BANGDIST | SLOPE | ELEV | PRO_UNPRO | DummyWest | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FORDIST73 | 1.000 | 0.497 | −0.032 | −0.127 | 0.067 | −0.031 | 0.020 | −0.066 | 0.085 | −0.201 | −0.184 | −0.173 | 0.043 | |
| FORDIST92 | 0.497 | 1.000 | −0.083 | −0.189 | −0.032 | −0.151 | −0.128 | −0.137 | −0.023 | −0.234 | −0.157 | −0.417 | 0.098 | |
| ALLRDDIST2 | −0.032 | −0.083 | 1.000 | 0.299 | 0.280 | 0.416 | 0.224 | −0.112 | 0.316 | 0.205 | −0.011 | 0.161 | −0.027 | |
| MJRDDIST2 | −0.127 | −0.189 | 0.299 | 1.000 | −0.111 | 0.370 | −0.022 | 0.039 | 0.213 | 0.263 | −0.120 | 0.377 | −0.061 | |
| MIRDDIST2 | 0.067 | −0.032 | 0.280 | −0.111 | 1.000 | 0.296 | 0.677 | 0.036 | 0.227 | 0.042 | 0.039 | −0.012 | 0.008 | |
| VILLDIST | −0.031 | −0.151 | 0.416 | 0.370 | 0.296 | 1.000 | 0.179 | 0.044 | 0.156 | 0.169 | −0.152 | 0.245 | −0.033 | |
| STWDIST | 0.020 | −0.128 | 0.224 | −0.022 | 0.677 | 0.179 | 1.000 | 0.158 | 0.319 | 0.084 | 0.276 | 0.175 | −0.016 | |
| MJTOWNDIST | −0.066 | −0.137 | −0.112 | 0.039 | 0.036 | 0.044 | 0.158 | 1.000 | −0.080 | 0.088 | −0.244 | 0.221 | −0.043 | |
| BANGDIST | 0.085 | −0.023 | 0.316 | 0.213 | 0.227 | 0.156 | 0.319 | −0.080 | 1.000 | 0.067 | −0.038 | 0.125 | 0.042 | |
| SLOPE | −0.201 | −0.234 | 0.205 | 0.263 | 0.042 | 0.169 | 0.084 | 0.088 | 0.067 | 1.000 | 0.050 | 0.255 | −0.059 | |
| ELEV | −0.184 | −0.157 | −0.011 | −0.120 | 0.039 | −0.152 | 0.276 | −0.244 | −0.038 | 0.050 | 1.000 | 0.083 | −0.047 | |
| PRO_UNPRO | −0.173 | −0.417 | 0.161 | 0.377 | −0.012 | 0.245 | 0.175 | 0.221 | 0.125 | 0.255 | 0.083 | 1.000 | −0.114 | |
| Dumy_P7392 | 0.043 | 0.098 | −0.027 | −0.061 | 0.008 | −0.033 | −0.016 | −0.043 | 0.042 | −0.059 | −0.047 | −0.114 | 1.000 | |
Appendix B
| Variables | B | S.E. | Wald | Sig. | Exp(B) |
|---|---|---|---|---|---|
| Tree Plantation Gain 1973–1992 | |||||
| Constant | 0.566 | 0.022 | 662.487 | 0.000 | 1.762 |
| ELEV | −0.378 | 0.032 | 140.957 | 0.000 | 0.685 |
| VILLAGEDIST | −0.086 | 0.018 | 21.905 | 0.000 | 0.918 |
| WATERDIST | 0.115 | 0.018 | 42.848 | 0.000 | 1.122 |
| MJTOWNDIST | −0.287 | 0.026 | 118.837 | 0.000 | 0.751 |
| BANGDIST | 0.477 | 0.015 | 974.628 | 0.000 | 1.612 |
| MIRDIST | −0.052 | 0.014 | 13.843 | 0.000 | 0.950 |
| MJRDIST | −0.265 | 0.023 | 130.639 | 0.000 | 0.767 |
| ALLRDDIST | 0.046 | 0.011 | 18.137 | 0.000 | 1.047 |
| DummyWest × SLOPE | 0.079 | 0.019 | 16.599 | 0.000 | 1.082 |
| DummyWest × ELEV | 0.796 | 0.055 | 213.047 | 0.000 | 2.218 |
| DummyWest × VILLAGEDIST | 0.155 | 0.023 | 46.491 | 0.000 | 1.167 |
| DummyWest × MJTOWNDIST | 0.300 | 0.029 | 105.724 | 0.000 | 1.350 |
| DummyWest × MIRDIST | 0.050 | 0.022 | 5.099 | 0.024 | 1.051 |
| DummyWest × MJRDIST | 0.216 | 0.025 | 73.707 | 0.000 | 1.240 |
| DummyWest × WATERDIST | −0.359 | 0.022 | 262.580 | 0.000 | 0.698 |
| DummyWest × BANGDIST | −0.145 | 0.027 | 29.215 | 0.000 | 0.865 |
References
- Lambin, E.F.; Turner, B.L.; Geist, H.; Agbola, S.; Angelsen, A.; Bruce, J.W.; Coomes, O.T.; Dirzo, R.; Fischer, G.; Folke, C.; et al. The causes of land-use and land-cover change: Moving beyond the myths. Glob. Environ. Chang. Part A Hum. Policy Dimens. 2001, 11, 261–269. [Google Scholar] [CrossRef]
- Rindfuss, R.R.; Walsh, S.J.; Turner, B.L., II; Fox, J.; Mishra, V. Developing a science of land change: Challenges and methodological issues. Proc. Natl. Acad. Sci. USA 2004, 101, 13976–13981. [Google Scholar] [CrossRef] [PubMed]
- Adhikari, S.; Southworth, J.; Nagendra, H. Understanding forest loss and recovery: A spatio-temporal analysis of land change in and around Bannerghatta National Park, India. J. Land Use Sci. 2015, 10, 402–424. [Google Scholar] [CrossRef]
- Lambin, E.F.; Baulies, X.; Bockstael, N.; Fischer, G.; Krug, T.; Leemans, R.; Moran, E.F.; Rindfuss, R.R.; Sato, Y.; Skole, D.; et al. Land-Use and Land-Cover Change (LUCC): Implementation Strategy; IGBP Report 48; IHDP Report 10; IGBP Secretariat: Stockholm, Sweden, 1999. [Google Scholar]
- Serneels, S.; Lambin, E.F. Proximate causes of land-use change in Narok District, Kenya: A spatial statistical model. Agric. Ecosyst. Environ. 2001, 85, 65–81. [Google Scholar] [CrossRef]
- Turner, B.L., II; Moss, R.H.; Skole, D.L. Relating Land Use and Global Land-Cover Change: A Proposal for An IGBP-HDP Core Project; A Report from the IGBP/HDP Working Group on Land-use/Land-cover Change; A Study of Global Change and the Human Dimensions of Global Environmental Change Programme; IGBP: Stockholm, Sweden, 1993. [Google Scholar]
- Aspinall, R. Modelling land use change with generalized linear models-a multi-model analysis of change between 1860 and 2000 in Gallatin Valley, Montana. J. Environ. Manag. 2004, 72, 91–103. [Google Scholar] [CrossRef] [PubMed]
- Kim, I.; Le, Q.B.; Park, S.J.; Tenhunen, J.; Koellner, T. Driving Forces in Archetypical Land-Use Changes in a Mountainous Watershed in East Asia. Land 2014, 3, 957–980. [Google Scholar] [CrossRef]
- Brown, D.G.; Walker, R.; Manson, S.; Seto, K.C. Modeling land use and land cover change. In Land Change Science: Observing, Monitoring, and Understanding Trajectories of Change on the Earth’s Surface; Gutman, G., Janetos, A., Justice, C., Moran, E., Mustard, J., Rindfuss, R., Skole, D., Turner, B.L., II, Cochrane, M.A., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2004; pp. 395–409. [Google Scholar]
- Landis, J.D. The California Urban Future Model: A new generation of metropolitan simulation models. Environ. Plan. B Plan. Des. 1994, 21, 399–421. [Google Scholar] [CrossRef]
- Landis, J.; Zhang, M. The second generation of the California urban futures model. Part 1. Model logic and theory. Environ. B Plan. Des. 1998, 25, 657–666. [Google Scholar]
- Faour, G.; Mhawej, M. Mapping Urban Transitions in the Greater Beirut Area Using Different Space Platforms. Land 2014, 3, 941–956. [Google Scholar] [CrossRef]
- Braimoh, A.K.; Vlek, P.L.G. Land-cover change trajectories in Northern Ghana. Environ. Manag. 2005, 36, 356–373. [Google Scholar] [CrossRef] [PubMed]
- Wear, D.N.; Bolstad, P. Land-use changes in Southern Appalachian landscapes: Spatial analysis and forecast evaluation. Ecosystems 1998, 1, 575–594. [Google Scholar] [CrossRef]
- Pereira, J.M.C.; Itami, R.M. GIS-based habitat modeling using logistic multiple regression: A study of the Mt. Graham red squirrel. Photogramm. Eng. Remote Sens. 1991, 57, 1475–1486. [Google Scholar]
- Narumalani, S.; Jensen, J.R.; Althausen, J.D.; Burkhalter, S.; Mackey, H.E., Jr. Aquatic macrophyte modelling using GIS and multiple logistic regression. Photogramm. Eng. Remote Sens. 1997, 63, 41–49. [Google Scholar]
- Mertens, B.; Lambin, E.F. Spatial modelling of deforestation in southern Cameroon: Spatial disaggregation of diverse deforestation processes. Appl. Geogr. 1997, 17, 143–162. [Google Scholar] [CrossRef]
- Schneider, L.; Pontius, R.G., Jr. Modeling land-use change: The case of the Ipswich watershed, Massachusetts, USA. Agric. Ecosyst. Environ. 2001, 85, 83–94. [Google Scholar] [CrossRef]
- Peterson, L.K.; Bergen, K.M.; Brown, D.G.; Vashchuk, L.; Blam, Y. Forested land-cover patterns and trends over changing forest management eras in the Siberian Baikal region. For. Ecol. Manag. 2009, 257, 911–922. [Google Scholar] [CrossRef]
- Pir Bavaghar, M. Deforestation modelling using logistic regression and GIS. J. For. Sci. 2015, 61, 193–199. [Google Scholar] [CrossRef]
- Turner, B.L., II; Meyer, W.B. Land use and land cover in global environmental change: Considerations for study. Int. Soc. Sci. J. 1991, 130, 669–679. [Google Scholar]
- Sokal, R.R.; Oden, N.L. Spatial autocorrelation in biology I. Methodology. Biol. J. Linn. Soc. 1978, 10, 199–228. [Google Scholar] [CrossRef]
- Sokal, R.R.; Oden, N.L. Spatial autocorrelation in biology II. Some biological implications and four applications of evolutionary and ecological interest. Biol. J. Linn. Soc. 1978, 10, 229–249. [Google Scholar] [CrossRef]
- Fortin, M.J.; Dale, M.R.T. Spatial Analysis—A Guide for Ecologists; Cambridge University Press: Cambridge, UK, 2005; ISBN 100521009731. [Google Scholar]
- Munroe, D.K.; Southworth, J.; Tucker, C.M. Modeling spatially and temporally complex land cover change: The case of Western Honduras. Prof. Geogr. 2004, 56, 544–559. [Google Scholar]
- Mertens, B.; Poccard Chapuis, R.; Piketty, M.G.; Laques, A.E.; Venturieri, A. Crossing spatial analyses and livestock economics to understand deforestation processes in the Brazilian Amazon: The case of Sao Felix do Xingu in South Para. Agric. Econ. 2002, 27, 269–294. [Google Scholar]
- Miller, J.; Franklin, J.; Aspinall, R. Incorporating spatial dependence in predictive vegetation models. Ecol. Mod. 2007, 202, 225–242. [Google Scholar] [CrossRef]
- Agarwal, C.; Green, G.; Grove, J.M.; Evans, T.P.; Schweik, C.M. A Review and Assessment of Land-Use Change Models: Dynamics of Space, Time, and Human Choice; GTR NE-297. U.S.D.A.; United States Forest Service: Washington, DC, USA, 2002. [Google Scholar]
- Liu, T.; Yang, X. Land Change Modeling: Status and Challenges. In Monitoring and Modeling of Global Changes: A Geomatics Perspective; Li, J., Yang, X., Eds.; Springer: Dordrecht, The Netherlands, 2015; pp. 3–16. ISBN 978-94-017-9812-9. [Google Scholar]
- Champion, H.G.; Seth, S.K. A Revised Survey of Forest Types of India; Government of India: New Delhi, India, 1968; ISBN 8181580613.
- Radha Devi, A. Karnataka Forest Department Master Plan for Consolidation of Bannerghatta National Park Boundaries and Elephant Corridors; Forest Department: Bangalore, India, 2003; p. 2.
- USGS EarthExplorer. Available online: https://earthexplorer.usgs.gov/ (accessed on 12 September 2017).
- Adhikari, S.; Southworth, J. Simulating forest cover changes of Bannerghatta National Park based on a CA-Markov Model. Remote Sen. 2012, 4, 3215–3243. [Google Scholar] [CrossRef]
- Grainger, A. Controlling Tropical Deforestation; Earthscan: London, UK, 1993; ISBN 101853831425. [Google Scholar]
- Rudel, T.K. Tropical Deforestation: Small Farmers and Land Clearing in the Ecuadorian Amazon; Columbia University Press: New York, NY, USA, 1993; ISBN 023108045X. [Google Scholar]
- Chomitz, K.M.; Gray, D.A. Roads, land, markets and deforestation: A spatial model of land use in Belize. World Bank Econ. Rev. 1995, 10, 487–512. [Google Scholar] [CrossRef]
- Sader, S.A.; Joyce, A.T. Deforestation rates and trends in Costa Rica, 1940–1983. Biotropica 1988, 20, 11–19. [Google Scholar] [CrossRef]
- Angelsen, A.; Kaimowitz, D. Rethinking the causes of deforestation: Lessons from economic models. World Bank Res. Obs. 1999, 14, 73–98. [Google Scholar] [CrossRef] [PubMed]
- Ludeke, A.K.; Maggio, R.C.; Reid, L.M. An analysis of anthropogenic deforestation using logistic regression and GIS. J. Environ. Manag. 1990, 31, 247–259. [Google Scholar] [CrossRef]
- Liu, D.S.; Iverson, L.R.; Brown, S. Rates and Patterns of Deforestation in the Philippines: Applications of Geographic Information System Analysis. For. Ecol. Manag. 1993, 57, 1–16. [Google Scholar] [CrossRef]
- Census of India 2011. Available online: http://censusindia.gov.in/Data_Products/Library/Indian_perceptive_link/Census_Terms_link/censusterms.html (accessed on 2 August 2017).
- Audirac, I. Information-Age Landscapes outside the Developed World. J. Am. Plan. Assoc. 2003, 69, 16–32. [Google Scholar] [CrossRef]
- Ostrom, E.; Nagendra, H. Insights on linking forests, trees, and people from the air, on the ground, and in the laboratory. Proc. Natl. Acad. Sci. USA 2006, 103, 19224–19231. [Google Scholar] [CrossRef] [PubMed]
- Nagendra, H.; Pareeth, S.; Paul, S.; Dutt, S. Landscapes of protection: Forest change and fragmentation in northern West Bengal, India. Environ. Manag. 2009, 44, 853–864. [Google Scholar] [CrossRef] [PubMed]
- Maddala, G.S. Introduction to Econometrics; Macmillan: New York, NY, USA, 1988; ISBN 0471497282. [Google Scholar]
- Menard, S. Applied Logistic Regression Analysis, 1st ed.; Sage: Thousand Oaks, CA, USA, 1995; ISBN 0803957572. [Google Scholar]
- Field, A. Discovering Statistics Using SPSS, 3rd ed.; Sage Publications: Los Angeles, CA, USA, 2009; ISBN 101847879071. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; Wiley: New York, NY, USA, 1989; ISBN 0471615536. [Google Scholar]
- Agresti, A. Categorical Data Analysis, 2nd ed.; Wiley: New York, NY, USA, 2002; pp. 165–259. [Google Scholar]
- Nagelkerke, N.J.D. A Note on a General Definition of the Coefficient of Determination. Biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]
- Domencich, T.A.; McFadden, D.L. Urban Travel Demand: A Behavioral Analysis; North-Holland Publishing Co.: Amsterdam, The Netherlands, 1975; ISBN 0444108300. [Google Scholar]
- Rutherford, G.N.; Bebi, P.; Edwards, P.J.; Zimmermann, N.E. Assessing land-use statistics to model land cover change in a mountainous landscape in the European Alps. Ecol. Mod. 2008, 212, 460–471. [Google Scholar] [CrossRef]
- Overmars, K.P.; Koning, G.H.J.; Veldkamp, A. Spatial autocorrelation in multi-scale land use models. Ecol. Mod. 2003, 164, 257–270. [Google Scholar] [CrossRef]
- Mertens, B.; Kaimowitz, D.; Puntodewo, A.; Vanclay, J.; Mendez, P. Modelling deforestation at distinct geographic scales and time periods in Santa Cruz, Bolivia. Int. Reg. Sci. Rev. 2004, 27, 271–296. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association-LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Woods, C.H.; Skole, D. Linking satellite, census, and survey data to study deforestation in the Brazilian Amazon. In People and Pixels: Linking Remote Sensing and Social Science; Liverman, D., Moran, E.F., Rindfuss, R.R., Stern, P.C., Eds.; National Academy Press: Washington, DC, USA, 1998; pp. 70–93. ISBN 978-0-309-06408-8. [Google Scholar]
- Cimini, D.; Tomao, A.; Mattioli, W.; Barbati, A.; Corona, P. Assessing impact of forest cover change dynamics on high nature value farmland under Mediterranean mountain landscape. Ann. Silvic. Res. 2013, 37, 29–37. [Google Scholar] [CrossRef]
- Johnson, B.A. Combining national forest type maps with annual global tree cover maps to better understand forest change over time: Case study for Thailand. Appl. Geogr. 2015, 62, 294–300. [Google Scholar] [CrossRef]
- Miranda, J.J.; Corral, L.; Blackman, A.; Asner, G.; Lima, E. Effects of protected areas on forest cover change and local communities: Evidence from the Peruvian Amazon. World Dev. 2016, 78, 288–307. [Google Scholar] [CrossRef]
- Gasparella, L.; Tomao, A.; Agrimi, M.; Corona, P.; Portoghesi, L.; Barbati, A. Italian stone pine forests under Rome’s siege: Learning from the past to protect their future. Landsc. Res. 2017, 42, 211–222. [Google Scholar] [CrossRef]
- Conklin, H.C. The study of shifting cultivation. Curr. Anthr. 1961, 2, 27–61. [Google Scholar] [CrossRef]
- Myers, N. Conservation of Tropical Forests; National Academy of Sciences: Washington, DC, USA, 1980. [Google Scholar]
- Chape, S.; Harrison, J.; Spalding, M.; Lysenko, I. Measuring the extent and effectiveness of protected areas as an indicator for meeting global biodiversity targets. Philos. Trans. R. Soc. B 2005, 360, 443–455. [Google Scholar] [CrossRef] [PubMed]
- Andam, K.S.; Ferraro, P.J.; Pfaff, A.; Sanchez-Azofeifa, G.A.; Robalino, J.A. Measuring the effectiveness of protected area networks in reducing deforestation. Proc. Natl. Acad. Sci. USA 2008, 105, 16089–16094. [Google Scholar] [CrossRef] [PubMed]
- Karanth, K.K.; Kramer, R.; Qian, S.; Christensen, N.L. Conservation attitudes, perspectives and challenges in India. Biol. Conserv. 2008, 141, 2357–2367. [Google Scholar] [CrossRef]
- Apan, A.A.; Peterson, J.A. Probing tropical deforestation: The use of GIS and statistical analysis of georeferenced data. Appl. Geogr. 1998, 18, 137–152. [Google Scholar] [CrossRef]
- Southworth, J.; Tucker, C.M. The influence of accessibility, local institutions, and socioeconomic factors on forest cover change in the mountains of western Honduras. Mt. Res. Dev. 2001, 21, 276–283. [Google Scholar] [CrossRef]
- Nagendra, H.; Southworth, J.; Tucker, C.M. Accessibility as a determinant of landscape transformation in western Honduras: Linking pattern and process. Landsc. Ecol. 2003, 18, 141–158. [Google Scholar] [CrossRef]
- Verburg, P.H.; Overmars, K.P.; Witte, N. Accessibility and land-use patterns at the forest fringe in the northeastern part of the Philippines. Geogr. J. 2004, 170, 238–255. [Google Scholar] [CrossRef]
- Von Thünen, J.H. Isolated State: An English Edition of der Isolierte Staat; Pergamon Press: Oxford, UK, 1966. [Google Scholar]




| Variables | Type | Unit | Abbreviations | |
|---|---|---|---|---|
| Dependent Variable | ||||
| Deforestation, 1973–1992 | Binary | 0–1 | ||
| Deforestation, 1992–2007 | Binary | 0–1 | ||
| Plantation Gain 1973–1992 | Binary | 0–1 | ||
| Plantation Gain 1992–2007 | Binary | 0–1 | ||
| Independent Variables | ||||
| Relief Related Variables | Elevation | Continuous | Meter | ELEV |
| Slope | Continuous | Degrees | SLOPE | |
| Proximity Variables | Distance to roads All Roads Major Roads Village Roads | |||
| Continuous | Meter | ALLRDDIST | ||
| MJRDDIST | ||||
| MIRDDIST | ||||
| Distance to edge of the forest | ||||
| 1973 | Continuous | Meter | FORDIST73 | |
| 1992 | FORDIST92 | |||
| Zoning Policy | Distance to Bangalore | Continuous | Meter | BANGDIST |
| Distance to towns | Continuous | Meter | MJTOWNDIST | |
| Distance to villages | Continuous | Meter | VILLDIST | |
| Distance to water | Continuous | Meter | WATERDIST | |
| Presence or absence of protected area | Binary | 0–1 | PA |
| Sample Pixels | Deforestation (1973–1992) | Deforestation (1992–2007) | Plantation Gain (1973–1992) | Plantation Gain (1992–2007) |
|---|---|---|---|---|
| Absent | 30,642 | 30,861 | n/a | 23,129 |
| Present | 34,826 | 34,531 | n/a | 34,516 |
| Total | 65,468 | 65,392 | n/a | 57,645 |
| Variables | B | S.E. | Wald | Sig. | Exp(B) |
|---|---|---|---|---|---|
| 1 Deforestation Model 1973–1992 | |||||
| Constant | −0.555 | 0.020 | 775.018 | 0.000 | 0.574 |
| DummyPA | −0.628 | 0.026 | 600.853 | 0.000 | 0.534 |
| SLOPE | 0.583 | 0.021 | 806.010 | 0.000 | 1.791 |
| ELEV | 0.864 | 0.018 | 2386.039 | 0.000 | 2.373 |
| FORDIST73 | −3.862 | 0.037 | 10,639.472 | 0.000 | 0.021 |
| ZVILLDIST | −0.073 | 0.014 | 27.842 | 0.000 | 0.929 |
| MIRDDIST | −0.067 | 0.018 | 14.768 | 0.000 | 0.935 |
| MJRDDIST | 0.157 | 0.013 | 145.453 | 0.000 | 1.170 |
| ALLRDDIST | 0.099 | 0.013 | 55.421 | 0.000 | 1.104 |
| WATERDIST | −0.482 | 0.019 | 659.504 | 0.000 | 0.617 |
| DummyPA × SLOPE | −0.775 | 0.025 | 968.927 | 0.000 | 0.461 |
| DummyPA × ELEV | −0.421 | 0.029 | 214.057 | 0.000 | 0.656 |
| DummyPA × MIRDDIST | −0.384 | 0.031 | 155.111 | 0.000 | 0.681 |
| DummyPA × WATERDIST | 0.613 | 0.028 | 474.414 | 0.000 | 1.846 |
| 2 Deforestation Model 1992–2007 | |||||
| Constant | −3.796 | 0.053 | 5136.465 | 0.000 | 0.022 |
| DummyPA | −0.082 | 0.031 | 6.915 | 0.009 | 0.922 |
| SLOPE | 0.257 | 0.028 | 84.626 | 0.000 | 1.293 |
| ELEV | 0.138 | 0.025 | 31.656 | 0.000 | 1.148 |
| FORDIST92 | −11.209 | 0.110 | 10,439.912 | 0.000 | 1.6 × 10−5 |
| VILLAGEDIST | −0.203 | 0.017 | 145.991 | 0.000 | 0.817 |
| MIRDDIST | 0.084 | 0.024 | 12.623 | 0.000 | 1.088 |
| Variables | B | S.E. | Wald | Sig. | Exp(B) |
|---|---|---|---|---|---|
| 1 Tree Plantation Gain Model 1992–2007 | |||||
| Constant | 0.061 | 0.020 | 8.932 | 0.003 | 1.063 |
| SLOPE | −0.119 | 0.017 | 48.191 | 0.000 | 0.887 |
| ELEV | −0.411 | 0.029 | 201.656 | 0.000 | 0.663 |
| VILLDIST | −0.230 | 0.024 | 90.603 | 0.000 | 0.794 |
| WATERDIST | −0.058 | 0.018 | 10.410 | 0.001 | 0.944 |
| MIRDIST2 | −0.329 | 0.020 | 279.259 | 0.000 | 0.720 |
| MJRDIST2 | −0.175 | 0.023 | 60.370 | 0.000 | 0.839 |
| ALLRDDIST2 | −0.073 | 0.012 | 40.599 | 0.000 | 0.929 |
| MJTOWNDIST | −0.182 | 0.031 | 35.083 | 0.000 | 0.834 |
| BANGDIST | −0.265 | 0.016 | 270.242 | 0.000 | 0.767 |
| DUMMYWEST × SLOPE | −0.070 | 0.021 | 11.345 | 0.001 | 0.932 |
| DUMMYWEST × ELEV | −1.039 | 0.056 | 342.470 | 0.000 | 0.354 |
| DUMMYWEST × VILLDIST | −0.191 | 0.029 | 43.586 | 0.000 | 0.826 |
| DUMMYWEST × WATERDIST | −0.070 | 0.024 | 8.745 | 0.003 | 0.932 |
| DUMMYWEST × MIRDIST | 0.805 | 0.027 | 876.347 | 0.000 | 2.238 |
| DUMMYWEST × MJRDIST | 0.169 | 0.025 | 46.284 | 0.000 | 1.184 |
| DUMMYWEST × MJTOWNDIST | 0.437 | 0.034 | 163.255 | 0.000 | 1.548 |
| DUMMYWEST × BANGDIST | −0.288 | 0.030 | 90.645 | 0.000 | 0.749 |
| Independent Variables | Deforestation | Tree Plantation Gain | |
|---|---|---|---|
| 1973–1992 | 1992–2007 | 1992–2007 | |
| R2 = 0.602 | R2 = 0.761 | R2 = 0.223 | |
| SLOPE | + | + | − |
| ELEV | + | + | − |
| ALLRDDIST | + | + | − |
| MIRDDIST | − | + | − |
| VILLDIST | − | − | − |
| WATERDIST | − | − | − |
| MJRDDIST | + | n/s | − |
| FORDIST73 | − | − | n/a |
| FORDIST92 | n/a | − | n/a |
| TOWNDIST | n/a | n/a | − |
| BANGIDST | n/a | n/a | − |
| DummyPA | − | − | n/a |
| DummyPA × SLOPE | − | − | n/a |
| DummyPA × ELEV | − | − | n/a |
| DummyPA × MIRRDDIST | − | + | n/a |
| DummyPA × WATERDIST | + | n/a | n/a |
| DummyWest × SLOPE | n/a | n/a | − |
| DummyWest × ELEV | n/a | n/a | − |
| DummyWest × VILLDIST | n/a | n/a | − |
| DummyWest × WATERDIST | n/a | n/a | − |
| DummyWest × MIRDIST | n/a | n/a | + |
| DummyWest × ZMJRDIST | n/a | n/a | − |
| DummyWest × ALLRDDIST | n/a | n/a | n/s |
| DummyWest × MJTOWNDIST | n/a | n/a | − |
| DummyWest × BANGDIST | n/a | n/a | − |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adhikari, S.; Fik, T.; Dwivedi, P. Proximate Causes of Land-Use and Land-Cover Change in Bannerghatta National Park: A Spatial Statistical Model. Forests 2017, 8, 342. https://doi.org/10.3390/f8090342
Adhikari S, Fik T, Dwivedi P. Proximate Causes of Land-Use and Land-Cover Change in Bannerghatta National Park: A Spatial Statistical Model. Forests. 2017; 8(9):342. https://doi.org/10.3390/f8090342
Chicago/Turabian StyleAdhikari, Sanchayeeta, Timothy Fik, and Puneet Dwivedi. 2017. "Proximate Causes of Land-Use and Land-Cover Change in Bannerghatta National Park: A Spatial Statistical Model" Forests 8, no. 9: 342. https://doi.org/10.3390/f8090342
APA StyleAdhikari, S., Fik, T., & Dwivedi, P. (2017). Proximate Causes of Land-Use and Land-Cover Change in Bannerghatta National Park: A Spatial Statistical Model. Forests, 8(9), 342. https://doi.org/10.3390/f8090342