1. Introduction
A design-unbiased point-to-particle sampling estimator recently proposed by Ducey [
1,
2] can easily be applied to sampling plantation forests. The method is easily adapted to aerial surveys, such as those common in ecology and forestry, by the use of variable area transects [
1]. Ducey [
1] also explained how his estimator can be adapted to other ecological sampling frameworks, such as sector sampling. The Ducey [
1] approach appears to be unique in that it provides a design-unbiased estimator (see Gregoire [
3]) regarding design-unbiasedness) for distance sampling which is practical for implementation in the field and which does not require information regarding the location or other attributes of non-sample particles. Ducey’s estimator is based on distances measured on lines that could be the centerlines of fixed-width strips located in naturally-occurring forests. However, plantation forest populations are already located in rows. Thus, these populations appear to be especially well adapted to the use of Ducey’s estimator.
Recently, Borders et al. [
4] described a method of plantation row sampling in which plantation row lengths are determined with remote sensing techniques, and this information is combined with a ground-based sample of trees selected from plantation rows. Borders et al. [
4] presented at least two alternative estimators. One estimator was based on the selection of a fixed number of fixed-length samples, randomly located within rows. This would be analogous to a fixed-size plot in a traditional forest inventory and would lead to design-unbiased estimators for tree numbers and sums of tree attributes, such as the volume or weight of wood. Borders et al. [
4] also suggested an estimator in which a fixed number of trees is selected from rows at each sample location, with the linear distance containing the number of trees being as a measured random variable. This led to ratio estimation for forest attributes. Generally, ratio estimators are not design-unbiased, although they may have low bias in applications. We intend to test this through simulation. The technique suggested by Ducey [
1] appears to be a viable alternative for these ratio estimators, since it also provides a fixed number of sample trees at each ground sample location and has design-unbiased estimators for the number of trees and sum of tree attributes within the forested area of interest. Because Ducey’s estimators are design-unbiased, unbiasedness does not depend on an assumed spatial distribution of trees along a row, as do some k-tree distance sampling estimators (e.g., [
5,
6,
7]).
Previous and widely-used estimators for ecological distance sampling have often been based on the assumption of a spatial distribution model, such as the Poisson distribution (e.g., [
6,
7,
8,
9,
10]). The Moore [
6] estimator utilized a “plot size”, based on the kth closest particle (e.g., tree or plant) to a randomly located plot center containing the k nearest particles. He derived a factor of (k − 1)/k to obtain an estimator of particle density that was unbiased under the assumption of a random (Poisson) spatial distribution. Eberhart [
5] demonstrated that the Moore [
6] estimator was unbiased under the assumption of a Poisson distribution or a negative binomial (clumped) distribution. However, many plant spatial distributions encountered by ecologists and foresters are not Poisson distributed. Furthermore, it may be inconvenient to verify the existence of a Poisson or other spatial distribution prior to the design of a field survey. Instead of having a Poisson spatial distribution of tree locations, plantation forests are established in an approximately uniform spatial pattern. However, due to to mortality and thinning, spatial distributions within rows may no longer be uniform at older ages.
In applications to naturally-occurring forests, it is often found that many have a clumped spatial distribution rather than a Poisson distribution. As a result, a variety of results have been reported from k-tree sampling in forests. Estimators using the traditional Moore [
6] correction factor worked well for Lessard et al. [
11] in Northern hardwood forests. Jonsson et al. [
12] also adapted k-tree sampling to forest inventory. However, when using a Moore [
6] estimator Lynch and Rusydi [
13] obtained underestimates of density and cubic volume in Indonesian teak plantations. An alternate estimator developed by Prodan [
14] had negligible bias for these Indonesian teak plantations [
13]. However, the question arises as to how one would haveprior knowledge when designing a sampling procedure for plantations to decide whether the Moore [
6] or the Prodan [
14] estimator would be better. It is not evident from the construction of the Prodan [
14] estimator that it would necessarily be better for plantations. Schreuder [
15] indicated many of the potential problems with respect to biases that could occur using standard forms of distance sampling from a forestry perspective. Kleinn and Vilčko [
16] utilized the average distance between the kth and (k + 1)th trees to develop a density estimator. Recently, Haxtema et al. [
17] employed simulation techniques on mapped forest stands, typical of Oregon headwater riparian forests, to compare the performance of some k-tree sampling estimators. For k ≥ 6, their study indicated a low level of bias for the estimation of the basal area and density for at least one of the estimators. But for clumped spatial distributions, k-tree sampling had biases that were significant. Results of this kind have stimulated the development of more complex estimators by authors such as Magnussen et al. [
18], Magnussen et al. [
19], Magnussen [
20] and others. While many of these estimators show improvements, it is not clear that any particular estimator can guarantee a negligible bias for all spatial distributions that could be encountered in the field.
As Ducey [
1] pointed out, it is possible in principle to develop a Horvitz–Thompson [
21] estimator based on the Voronoi polygon for an object being sampled by a randomly-located point, since the probability of sampling the object is proportional to the area of its Voronoi polygon ([
22,
23,
24]). Kleinn and Vilčko [
25] demonstrated that a kth-order Voronoi polygon is proportional to the probability of including an object when the k objects nearest to a randomly located point (on a plane) are to be sampled. However, mapping the areas of these Voronoi polygons could require measurements on a large number of objects that are not samples. The number of such measurements can be considerably reduced by using the triangulation-based probabilities proposed by Fehrmann et al. [
26]. Even so, the measurements required may mitigate against the widespread use of the method [
26]. Working from a design-based perspective, Barabesi [
27] and Barabesi and Marcheselli [
28] developed a kernel-based approach to a distance estimator, but it has not achieved widespread practical application. Most of the approaches to estimation based on sampling a fixed number of k particles or objects have been based on the selection of the nearest k particles to a randomly-located point on the plane. However, the variable area transects initially proposed by Parker [
29] have also been used. Generally estimators for variable area transects have been model-based ([
29,
30]) assuming a Poisson spatial distribution. The method suggested by Borders et al. [
4] of sampling a fixed number of trees along a variable section of a plantation row may be similar in principle to a variable-length transect. Several simulation studies indicated positive results from variable area transect sampling ([
31,
32,
33]). However, variable area transects were found to have significant bias towards a clustered spatial distribution by Engman et al. [
34].
Ducey [
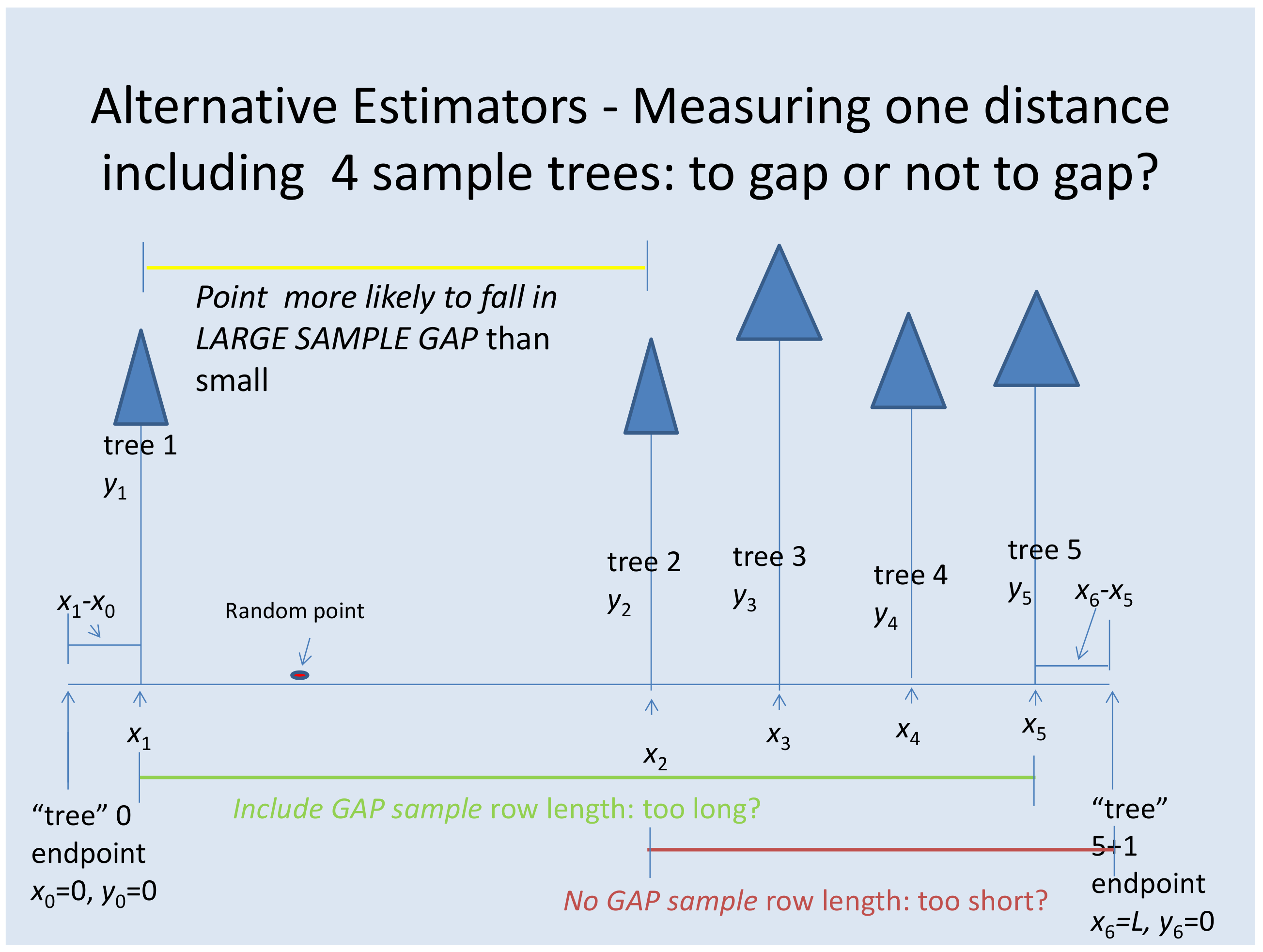
1] has recently taken a new approach to distance sampling by considering a population of particles located on a line, in contrast to the more typical approach of considering a population of particles in a two-dimensional plane. This fits well with plantation row sampling, since the population of a forest plantation is already located in rows. Ducey’s estimator is based on the location of a random sample point on a line containing a population of
N particles. His estimator is based on a sample of the
particles nearest to the sample point in opposite directions on the line so that the total fixed number of particles sampled is 2
. With this sample, Ducey [
1] has constructed a design-unbiased estimator of the population total for an arbitrary particle attribute,
y. He has shown how the line sampling model can be adapted to aerial sampling systems such as variable area transects. The purpose of this article is to adapt Ducey’s method to sampling on plantation rows and to use a simulation to compare the performance of this estimator to alternatives, including the Borders et al. [
4] ratio of means estimator, a new mean of ratios estimator which we propose, and a fixed-length row-plot estimation.
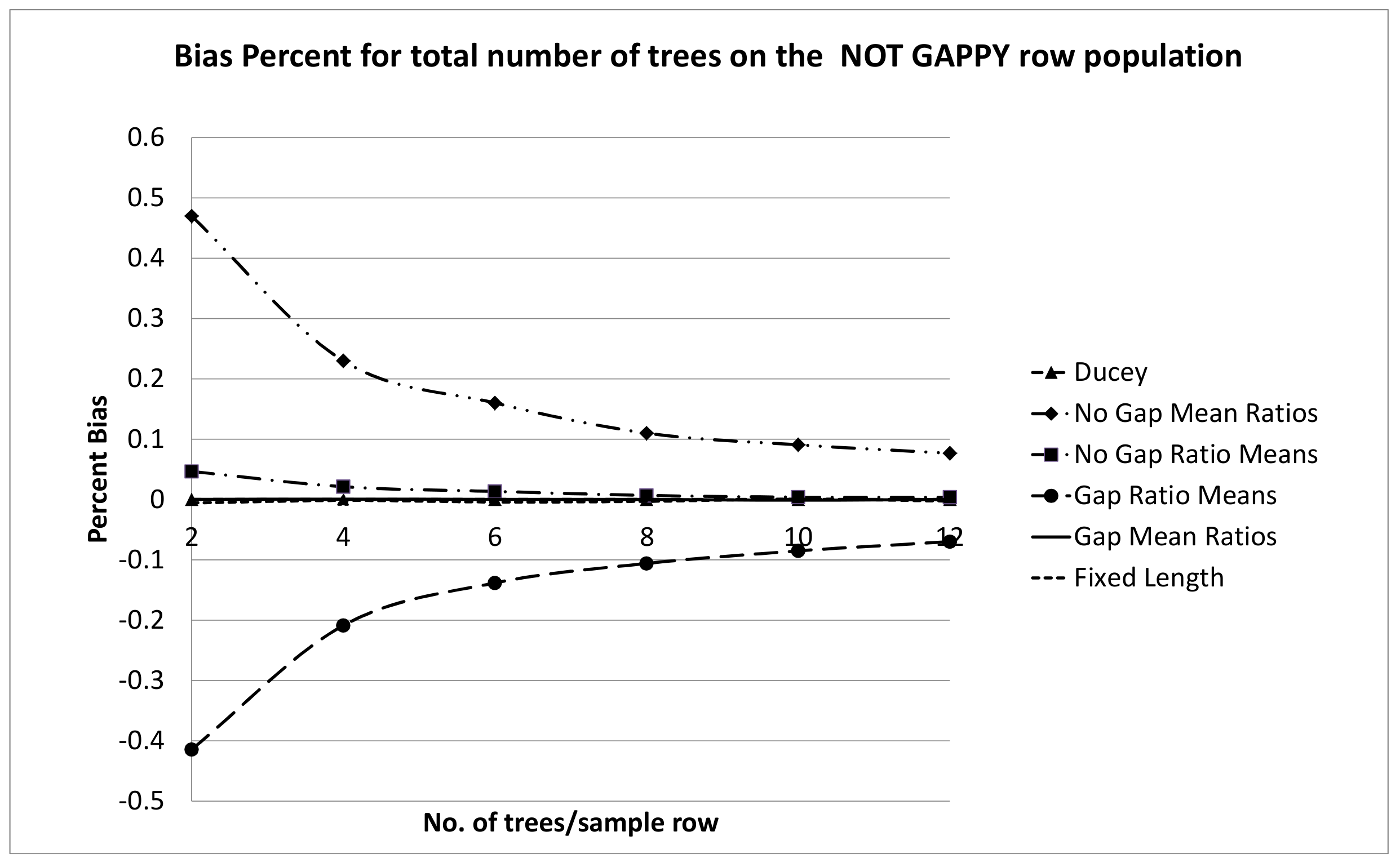
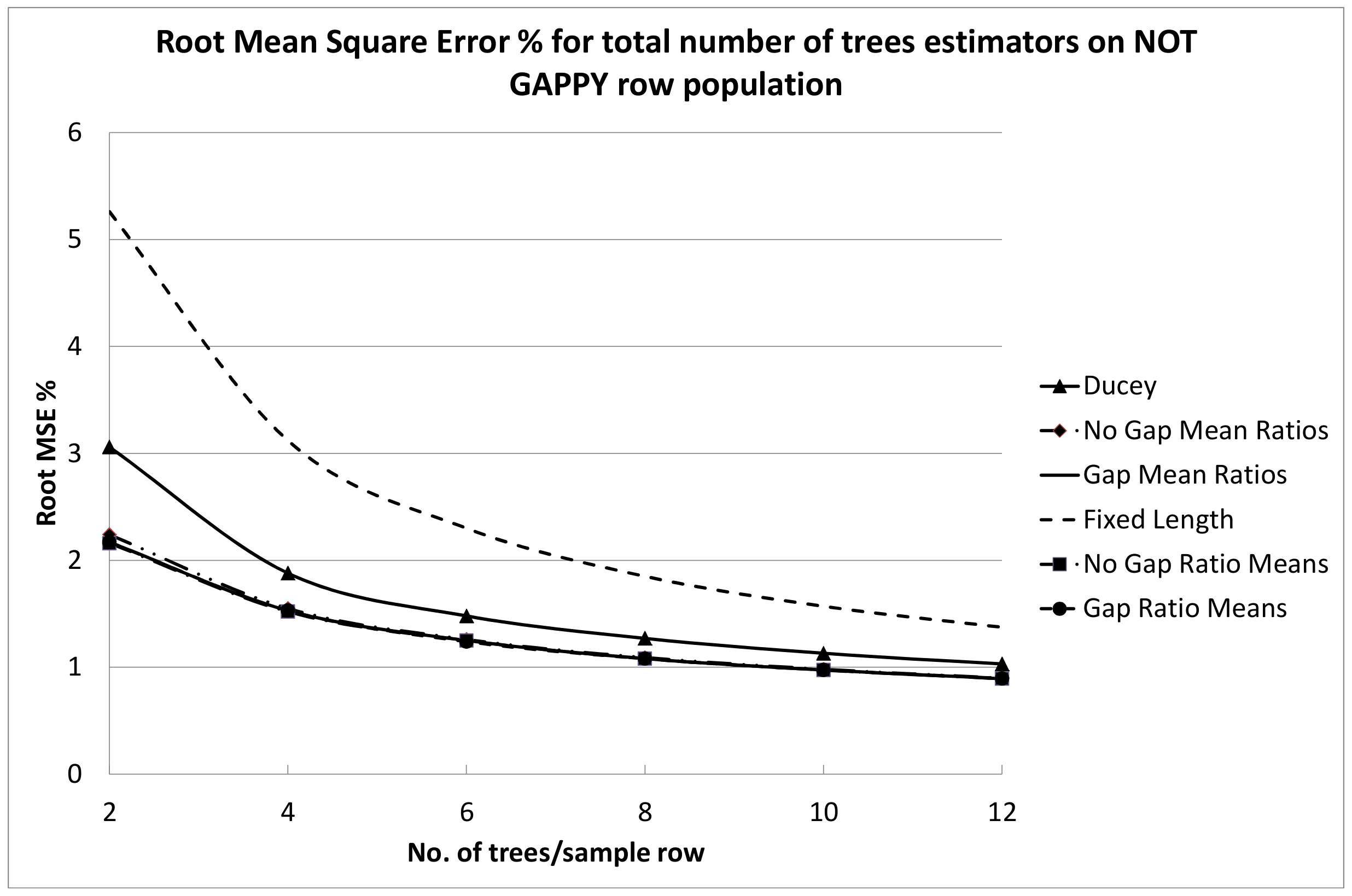
4. Discussion
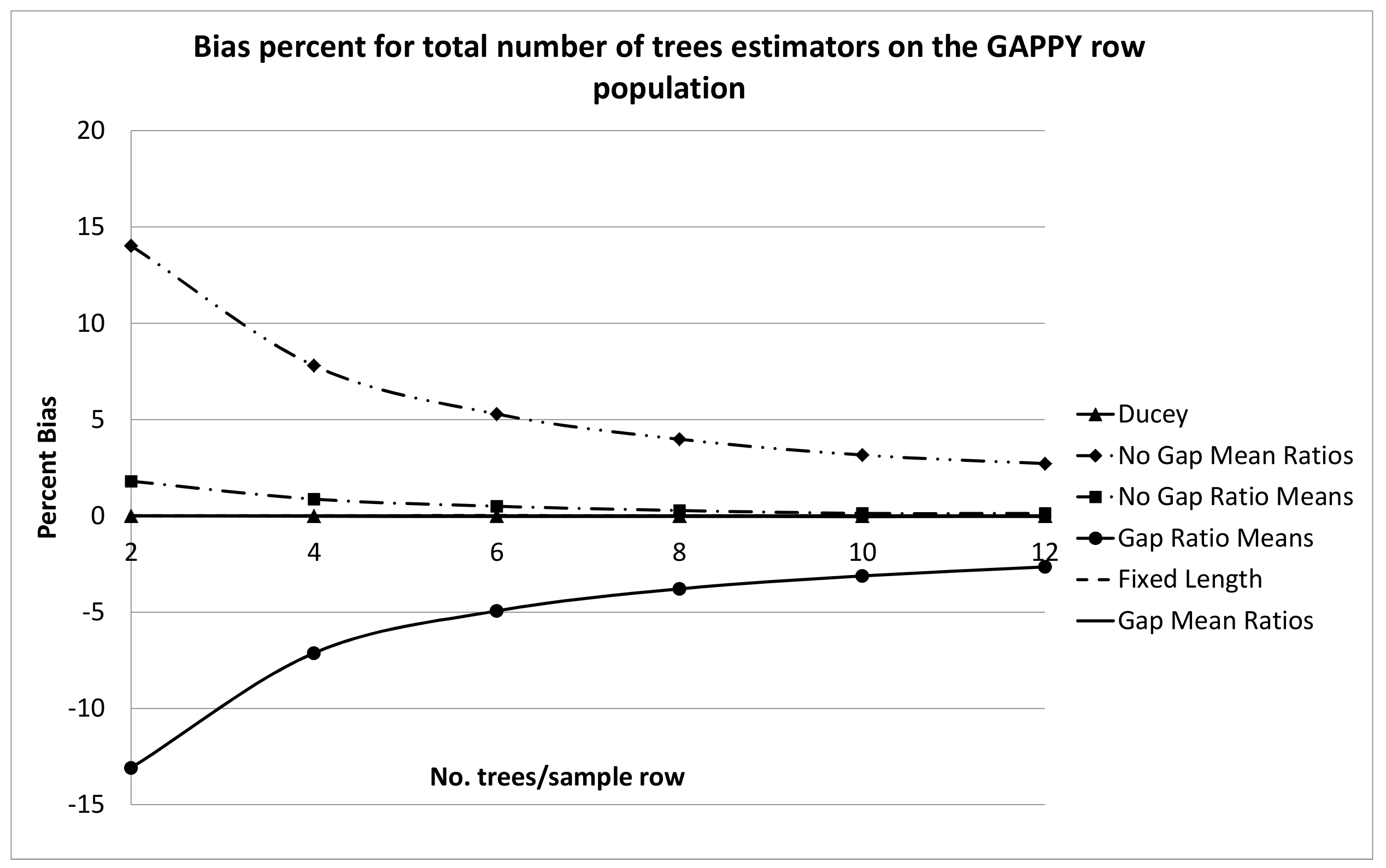
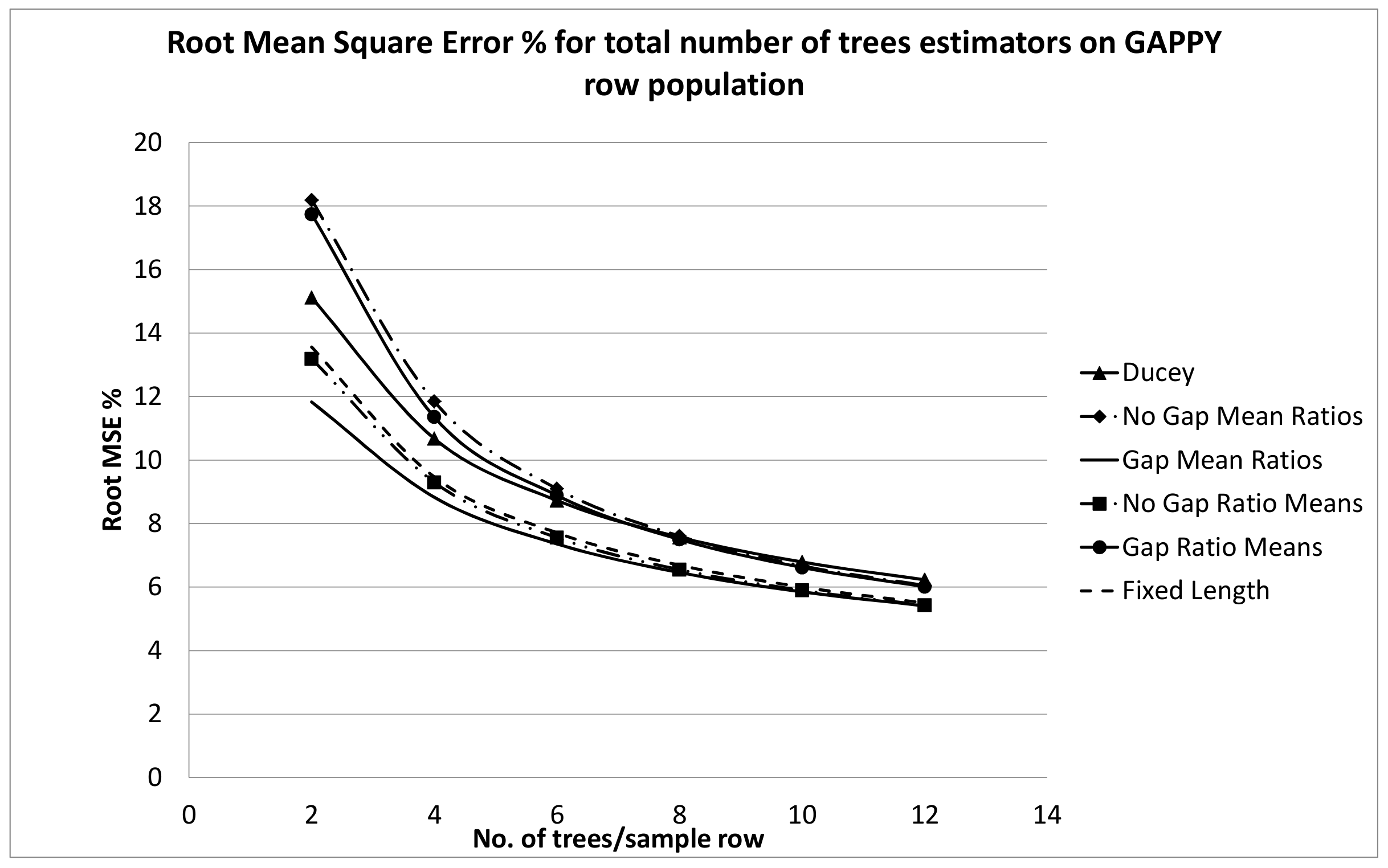
There was very little practical difference between the row sampling estimators tested on the NOT GAPPY row population. This is probably due to the substantially lower variation in gap sizes compared to the GAPPY population. Practically significant differences between the methods emerged in the simulations on the GAPPY row population. There is probably no good reason to use the ratio of means estimator including the sample gap,
(Equation (
10)) or the mean of ratios estimator not including the gap,
(Equation (
17)) due to the possibility of substantial bias, as illustrated in
Figure 8 for the GAPPY row population, and the fact that it is no easier to collect data for the latter two estimators than for alternative estimators that show zero or negligible bias on both the GAPPY and NOT GAPPY row populations.
The ratio of means estimator not including the sample gap,
, performed well on both the GAPPY and NOT GAPPY row populations. It displayed somewhat more bias in the GAPPY simulation for lower numbers of trees per sample row segment than
(Equation (
12)), Ducey’s estimator,
(Equation (
7)), or the fixed-length sample row, but that bias would not be practically significant especially when six or more trees per random sample location are used. This ratio estimator was the estimator first proposed by Borders et al. [
4]. It should be recalled (as indicated above where the ratio of means estimators were introduced) that the ratio of means estimators presented in this article differ from the classical ratio of means estimators discussed in standard sampling references, such as Cochran [
37] (pp. 150–151). Therefore, it is not clear that theorems which show that ratio of means estimators can be consistently applied to the estimators used here. This is one reason why we evaluated these estimators using simulations.
The superior performance of the mean of ratios estimator, including the sample gap,
(Equation (
12)), is likely to be due to the fact that the randomly located point,
z, falls into a gap with probability proportional to its size. Because the sample gap is part of the sample row length, this makes
roughly similar to an inverse probability estimator, as the denominators of the ratios become roughly (but not exactly) proportional to the probability that that particular row segment is selected as a sample segment. Schreuder et al. [
38] (p. 90) pointed out that if the denominators of the ratios for the mean of ratios estimator are proportional to the probability of sample selection, then the mean of ratios estimator is unbiased. However, the
estimator is not mathematically unbiased because the proportion is not exact. Nevertheless, this latter estimator showed extremely small biases in simulations on the GAPPY and NOT GAPPY row populations, which were practically negligible.
For the mean of ratios estimator that does not include the sample gap,
(Equation (
17)) the similarity to an inverse probability estimator was completely lost, resulting in poor bias performance on the GAPPY row population. As indicated above, the ratio of means estimator that does not include the sample gap,
(Equation (
11)) is probably superior to
(Equation (
10)) because the mean row length in the latter estimator tends to be too large, since the random point,
z, tends to select larger sample gaps. Because of their algebraic formulation, the ratio of means estimators cannot be formulated to be similar to inverse probability estimators. The inclusion of the sample gap was beneficial to the mean of ratios estimator (decreased bias), but detrimental to the ratio of means estimator (increased bias).
The fixed length plot sample performed well, although it clearly had a higher RMSE% for the NOT GAPPY population than for the other row sampling estimators. This may be due to the fact that the number of trees per fixed length row can still vary due to random starting points while the number of trees per sample location is, of course, the same for the fixed number of trees estimators, and in the NOT GAPPY simulation there is less variation in sample segment length for these estimators. For the GAPPY simulation, much of the RMSE% advantage of the fixed number of trees estimators was lost, because in this population, there was much more variation in sample segment row lengths for these estimators. There are practical advantages to the estimators that use a fixed number of trees per plot. To be design-unbiased, the beginning point for the fixed-length row estimator is assumed be assigned randomly along the plantation row length. This means the beginning point should be located where it falls within the gap between the two trees where it is located. This may be difficult to actually do in the field, and crews may tend to gravitate to a consistent location within sample gaps, such as the middle of the gap or either end of the gap. With Ducey’s method and the ratio estimators tested here which select a fixed number of trees associated with each randomly located point, z, it is only necessary for crews to locate the gap into which the random point falls, because the location of the sample point within the gap does not affect the fixed number of trees per sample segment estimators.
In particular, when six or more trees per sample row segment were used, Ducey’s estimator,
(Equation (
7)) performed quite well, with an RMSE% that was not substantially worse than the best RMSE% performers. Ducey’s method is design-unbiased so it will be mathematically guaranteed to be unbiased for any sample row population. Although we tried to select two populations that would span a wide range of likely possibilities for gap distributions on plantation rows, it was impossible to test every possible gap distribution by simulation methods. Considering this fact, Ducey’s estimator becomes quite attractive.
In the field, it will be necessary to measure the location of each tree in the sample row segment if Ducey’s estimator,
(Equation (
7)) is used. In particular, for sample row segments with smaller fixed numbers of trees, such as 4 to 6, a tape could be stretched along the row between the trees on the ends of the row segment, and the position of each tree recorded, along with measurements of tree attributes, such as dbh and height, that may be desired. This information could be used to accomplish estimation with Ducey’s method in a software routine.
The RMSE% results in
Figure 7 and
Figure 9 tended to indicate that six to eight trees per sample segment should probably be sampled, because this provides a definite gain in RMSE% compared to sampling four or fewer trees. For the NOT GAPPY population especially, there seems to be little advantage to sampling more than eight trees per sample row segment, but RMSE% is substantially reduced by sampling at least six trees per sample row segment. This is fairly similar to guidelines that are often given for selection of the number of trees per point when choosing an angle gauge for horizontal point sampling. Iles [
40] (p. 526) stated that the best balances of cost for point sampling happen with an average of 4–8 trees per point.
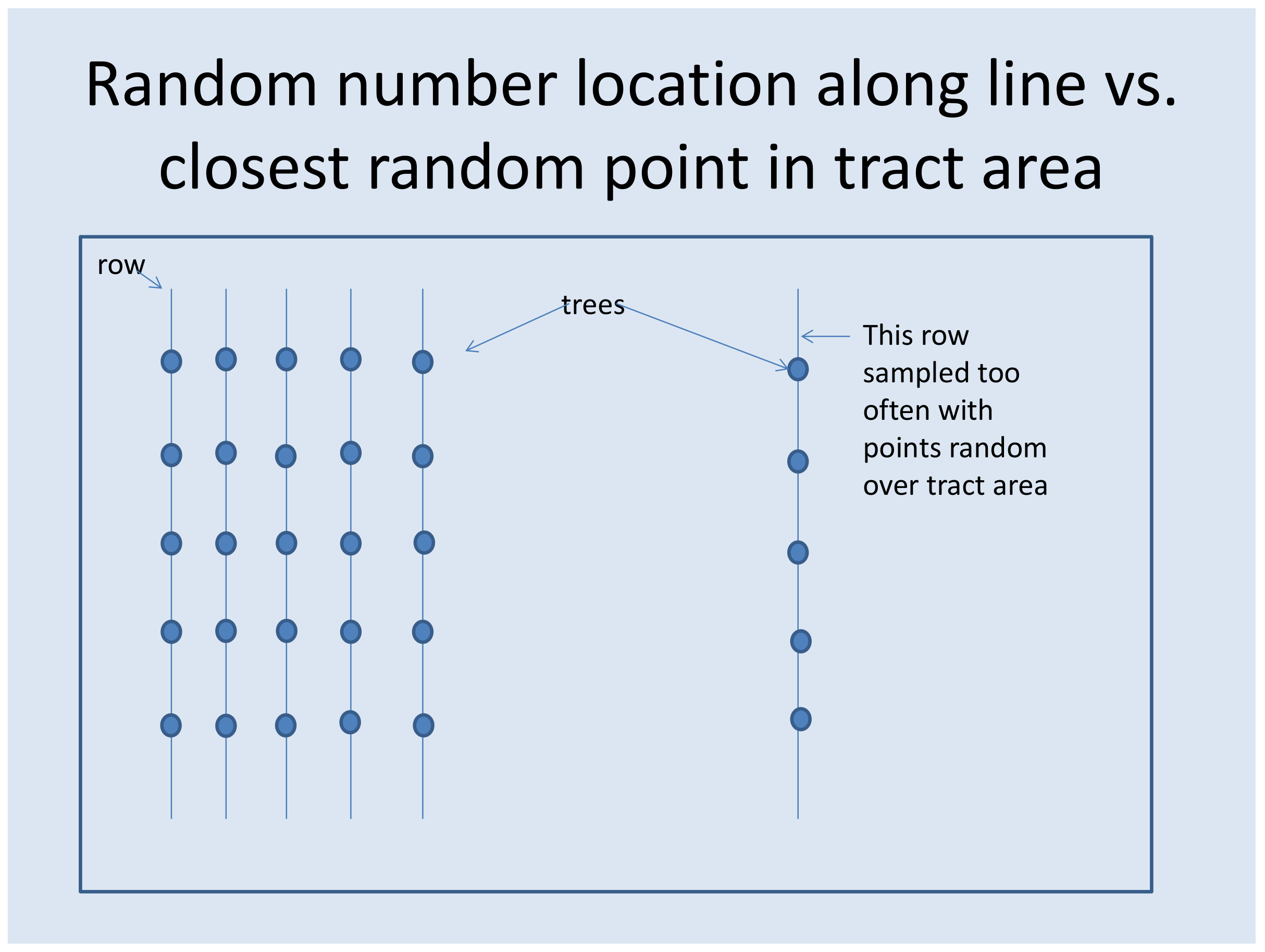
Figure 10 illustrates why it is important in plantation row sampling that the randomly located point,
z, is placed with uniform probability over the plantation row length,
L, rather than with uniform probability over a two-dimensional land area.
Clearly, if the point is distributed randomly over a two dimensional land area, and then the “closest gap” in plantation rows is selected, the isolated plantation row segment on the right side of
Figure 10 will be sampled more intensely than the remainder of the plantation row population. Although
Figure 10 is an extreme example, row removal thinning (removing all the trees in selected rows, such as every third row) is very common in plantations in Southeastern USA, and if the randomly-located sample point,
z, was distributed over a 2-dimensional land area, next to rows removed by thinning, it would be sampled more intensely than “interior rows” not adjacent to rows removed by thinning. This could have important consequences as it might be expected that trees on rows adjacent to removed rows may experience more diameter growth in years subsequent to thinning than “interior rows” that are not adjacent to removal rows.
In field applications, one will find the value of a random distance, z, with uniform probability for the interval , where L is the total row length. We envision that a plantation population can be treated as one long row of length L by joining the ends of adjacent rows in the field. Then, the two dimensional location (e.g., latitude and longitude) of this row distance would need to be determined, most likely in a GIS environment. Field crews would then use a GPS receiver to locate the sample point in the field. Because of possible error in the GPS location, the GPS field location may not always fall exactly on a row. In this case, we recommend choosing the gap between trees that has the closest perpendicular distance to the sample GPS coordinate in the field. A random-start, systematic sampling procedure would be also be possible with field crews locating sample gaps at fixed intervals along plantation rows; however, this would require the total plantation row length to be traversed.
It is important to recognize that accurate estimation of the total row length,
L, is vital for the accuracy of the row sampling estimators presented here. Let us formulate a general row sampling estimator as a product of an estimator per unit of row length multiplied by row length:
where
is the row sampling estimator per unit of
L using any of the row sampling estimators above. This could be obtained by setting
in any of the estimators above, and
is the estimated row length with
.
Clearly any substantial underestimation or overestimation of
L will have a major impact on the estimator, just as errors in the estimation of the total land area can have a large impact on more traditional estimators of forest volume and other attributes. It may be more difficult to accurately identify rows in very old plantations. Merging of multiple rows into one row may cause confusion. There is likely to be some error in the remote sensing technology used to estimate row lengths. It is likely that we can consider row length estimates,
, to be scholastically independent of
, because they are estimated by different procedures. In that case, we can apply the formula of Goodman [
41] to compute the variance of a product of independent random variables:
If
, then Equation (
18) trivially reduces to
According to Equation (
5) in [
41], an unbiased estimate of the variance given by Equation (
21) is
where
is an unbiased estimate of
,
is an unbiased estimate of
,
is an unbiased estimate of
L, and
is an unbiased estimate of
. It should be noted that according to [
41], the sign on the final term in Equation (
23) is negative, rather than the positive sign used for the final term in (
21). If unbiased estimators for
L and
are available, Ducey’s estimator (
1) and its associated variance estimator (
8) would fit these requirements.
The fact that Ducey’s estimator has a simple variance estimator that is unbiased for its true variance is a major advantage for Ducey’s method. As indicated above, the ratio estimators tested here do not exactly fit the paradigm for ratio estimators developed in standard sampling texts, such as [
37], so it is not clear how well approximations traditionally used to estimate the variances of the ratio of means estimators will work in the plantation row sampling application. However, as indicated above, we did present a variance estimator for the mean of ratios estimator including the sample gap, which should work well if the estimation bias is small as it was in our simulations. It may be that bootstrap methods could be employed to estimate variance in the ratio of means estimator if closed-form approximation formulas do not work well. However, we did not test variance estimation methods for the ratio of means estimators in this study.
When the measurement or estimation of row length,
L, is problematic, a possible solution is to develop row plots by measuring the distance between the middle of the spaces between rows on either side of the sample row segment,
, and using this to form a rectangular plot. This may permit one to use the tract area,
, to expand the estimate to tract level. As an example, consider the following adjustment to the Borders et al. (2012) ratio of means estimator (
11):
This formulation permits the expansion of the sample using the tract area, , which is generally known even when the total plantation row length may be difficult to measure or estimate. Similar adjustments could be made to the other row sampling estimators presented above.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









