Composite Estimators for Growth Derived from Repeated Plot Measurements of Positively-Asymmetric Interval Lengths

Abstract
:1. Introduction
- The historic average annual for a long time period (say 10 years or greater);
- The average annual value for the current cycle length (this varies, but say five years);
- The average for each year estimated.
2. Materials and Methods
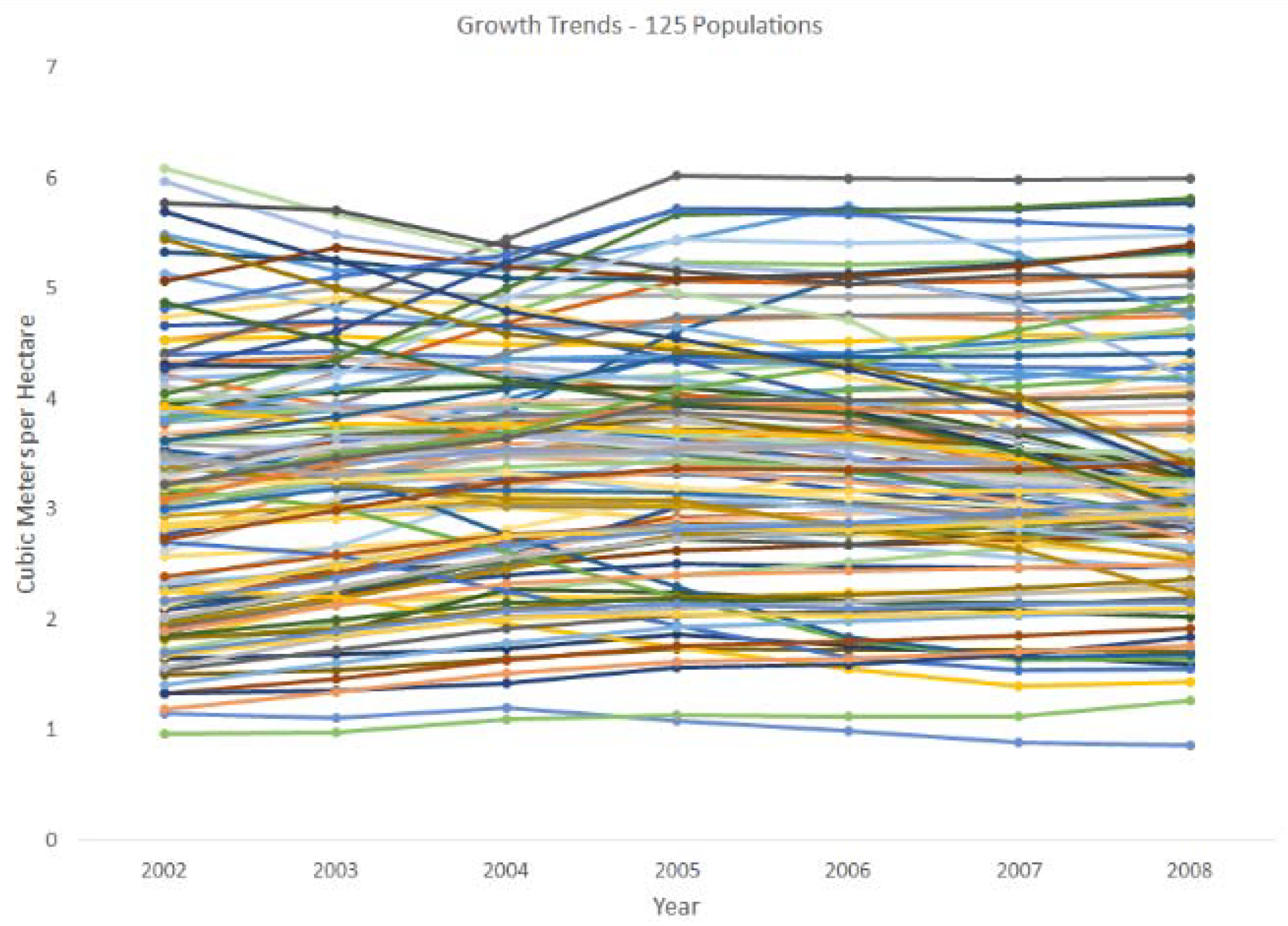
2.1. Exploratory Data Analysis
2.2. From Pseudo-Estimators to Estimators
2.3. MSE-Weighted Composite Estimator
2.3.1. Ratio Estimator
2.3.2. Regression Estimators
2.4. Simulation
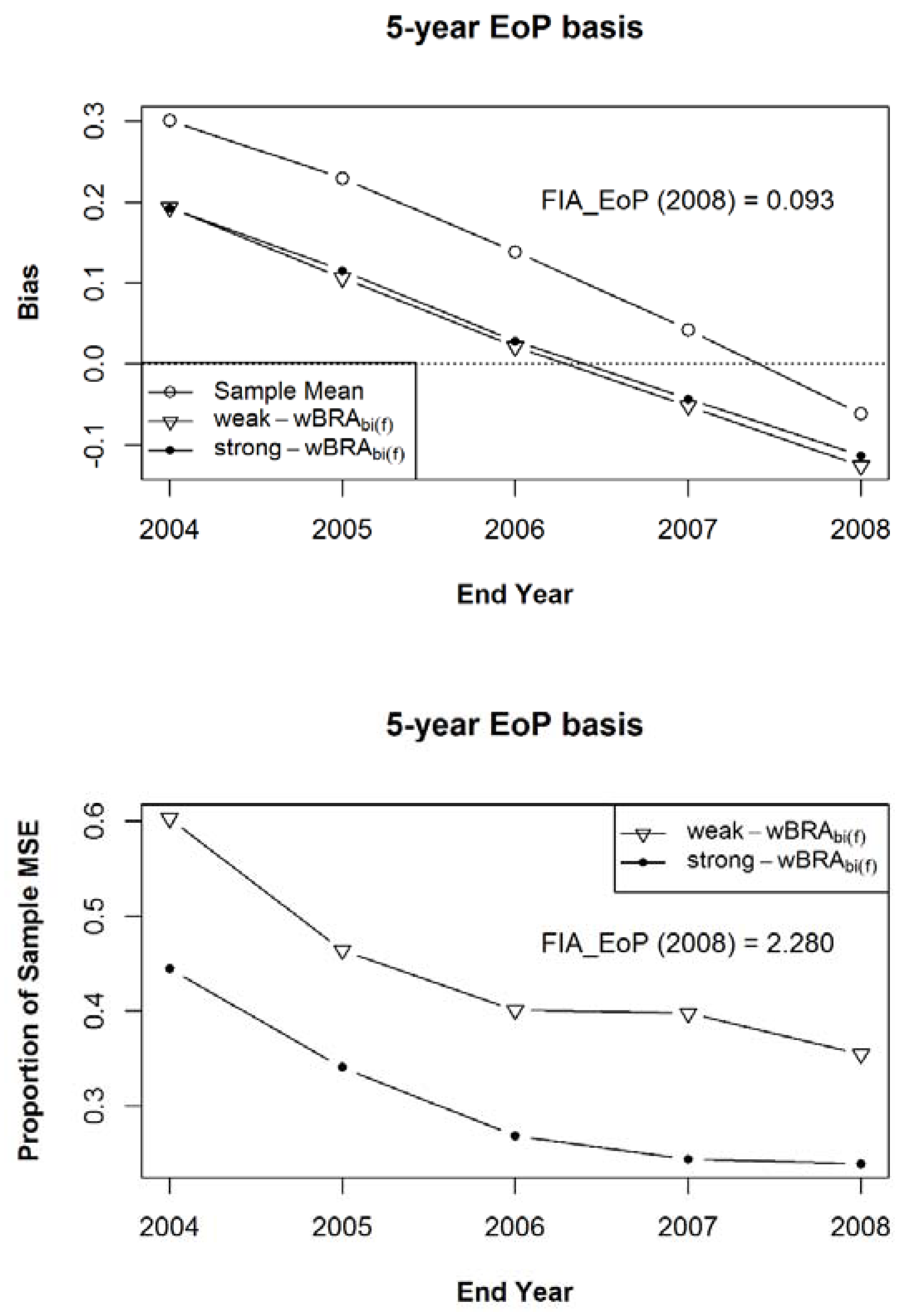
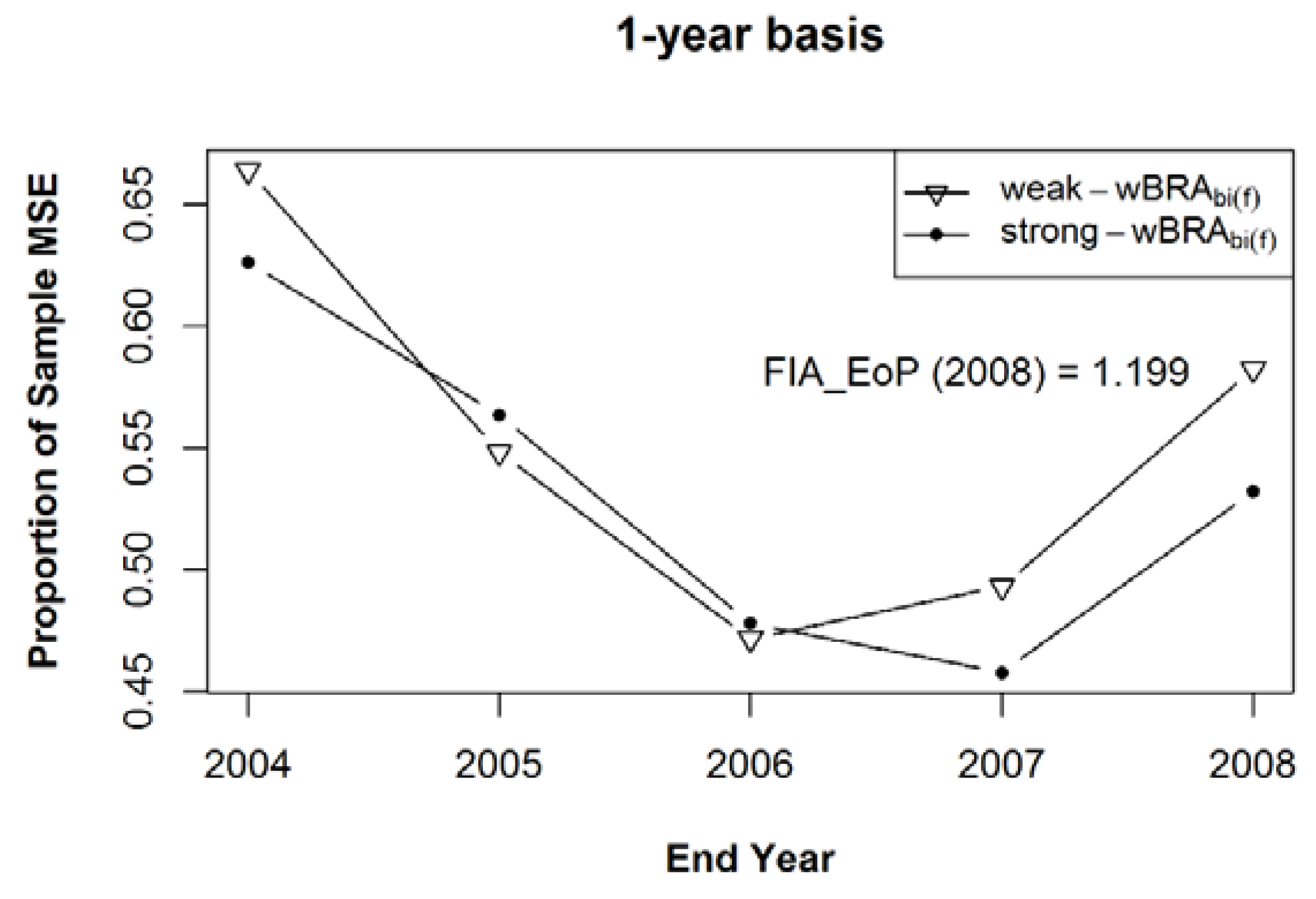
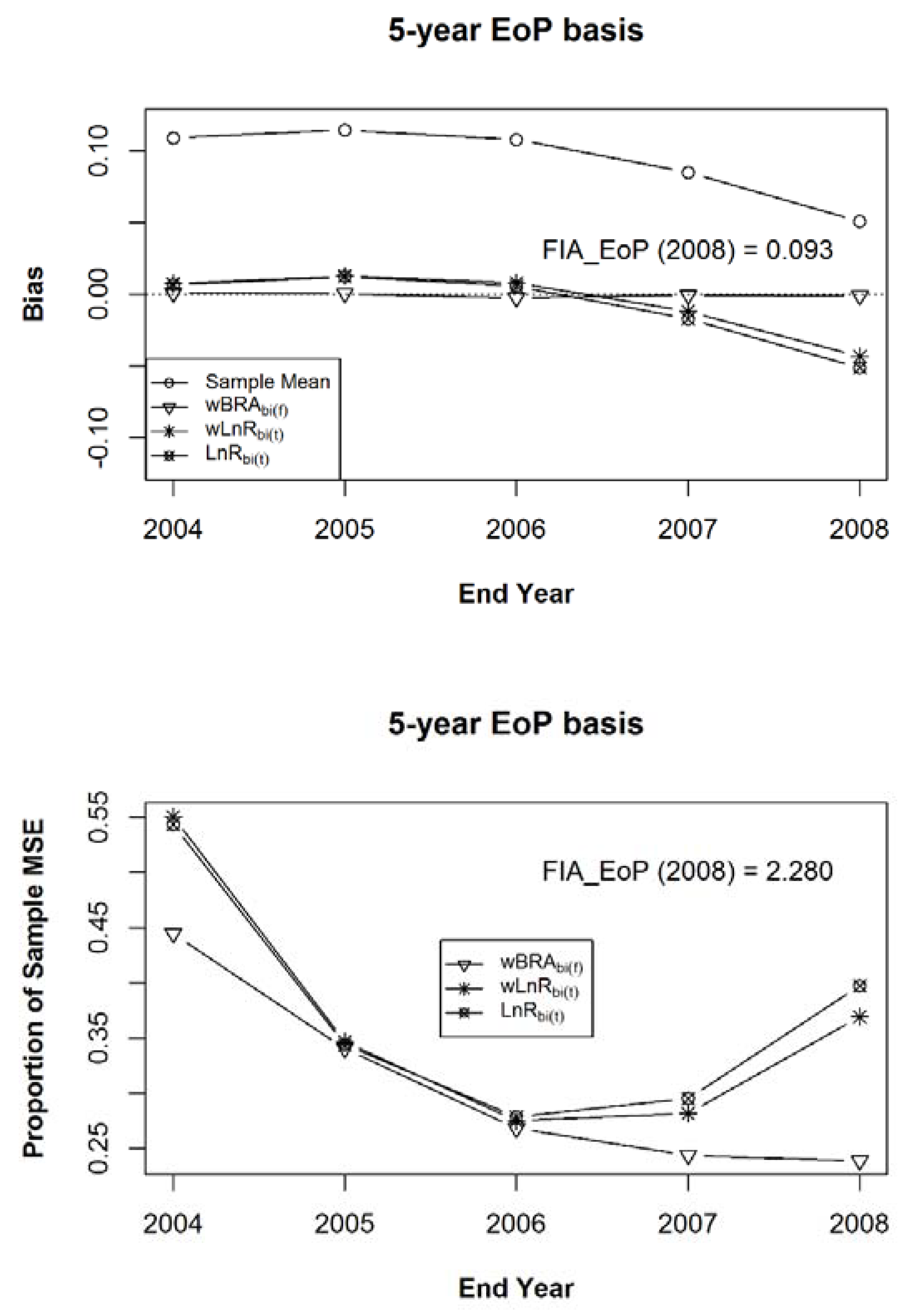
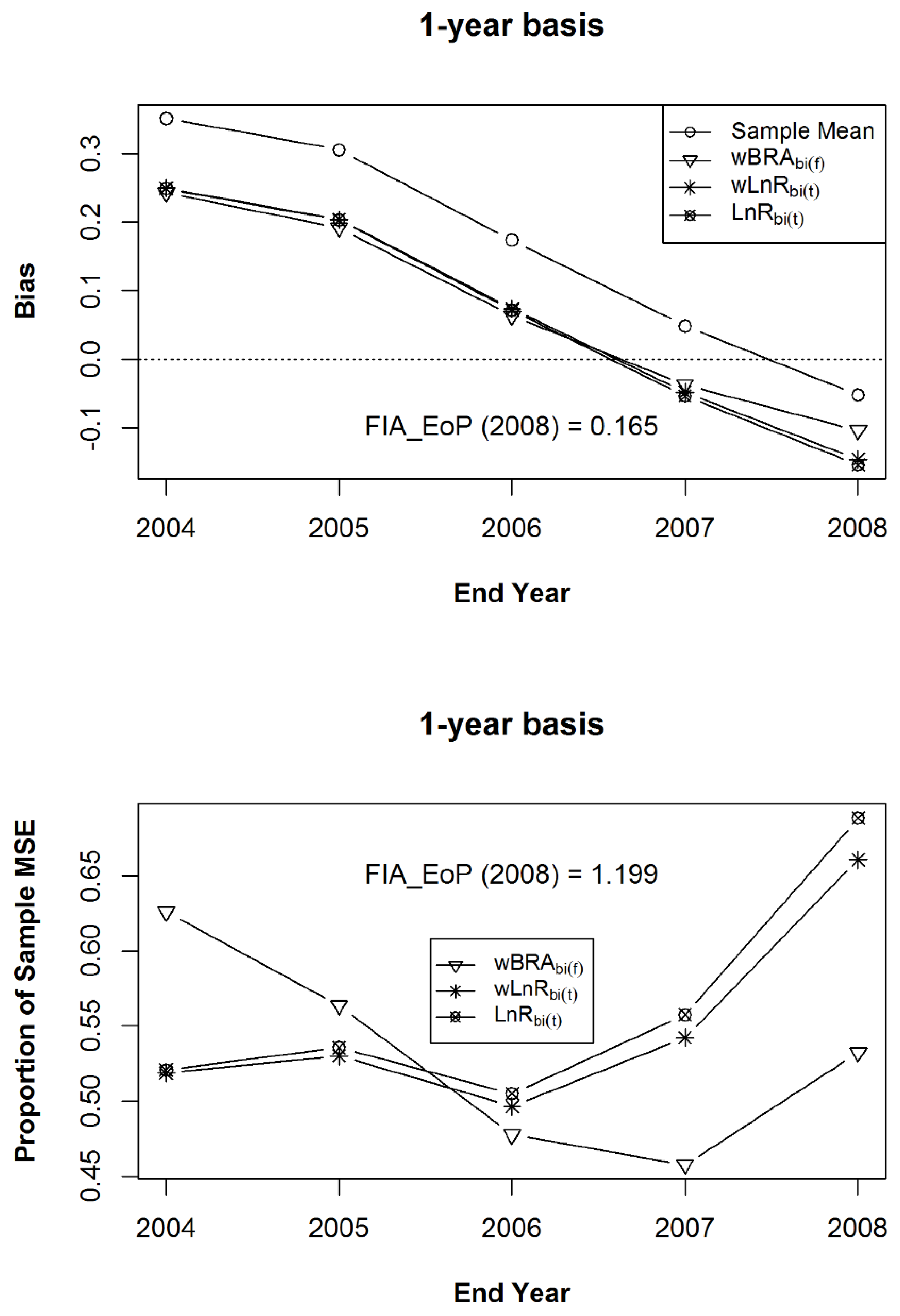
3. Results
4. Discussion
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Ott, L. An Introduction to Statistical Methods and Data Analysis; Duxbury Press: North Scituate, MA, USA, 1977; 730p. [Google Scholar]
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program-National Sampling Design and Estimation Procedures; U.S. Department of Agriculture Forest Service, Southern Research Station: Asheville, NC, USA, 2005. Available online: http://www.srs.fs.fed.us/pubs/20371 (accessed on 1 February 2018).
- Mood, A.M.; Graybill, F.A.; Boes, D.C. Introduction to the Theory of Statistics, 3rd ed.; McGraw-Hill, Inc.: New York, NY, USA, 1974; 564p. [Google Scholar]
- Roesch, F.A.; Van Deusen, P.C. Time as a Dimension of the Sample Design in National Scale Forest Inventories. For. Sci. 2013, 59, 610–622. [Google Scholar] [CrossRef]
- Roesch, F.A. The components of change for an annual forest inventory design. For. Sci. 2007, 53, 406–413. [Google Scholar]
- Green, E.J.; Strawderman, W.E. Combining inventory estimates with possibly biased auxiliary information. For. Sci. 1990, 36, 693–704. [Google Scholar]
- Roesch, F.A.; Schroeder, T.C.; Vogt, J.T. Effects of Cycle Length and Plot Density on Estimators for a National-Scale Forest Monitoring Sample Design. Forests 2017, 8, 325. [Google Scholar] [CrossRef]
- Green, E.J.; Strawderman, W.E. Combining Inventory Data with Model Predictions. In Proceedings of the Forest Growth Modelling and Prediction Conference, Minneapolis, MN, USA, 23–27 August 1987; pp. 676–682. [Google Scholar]
- Green, E.J.; Strawderman, W.E. A James-Stein type estimator for combining unbiased and possibly-biased estimators. JASA 1991, 86, 1000–1006. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State Code | State Name | Abbreviation |
|---|---|---|
| 1 | Alabama | AL |
| 5 | Arkansas | AR |
| 9 | Connecticut | CT |
| 10 | Delaware | DE |
| 12 | Florida | FL |
| 13 | Georgia | GA |
| 17 | Illinois | IL |
| 18 | Indiana | IN |
| 19 | Iowa | IA |
| 20 | Kansas | KS |
| 21 | Kentucky | KY |
| 23 | Maine | ME |
| 24 | Maryland | MD |
| 25 | Massachusetts | MA |
| 26 | Michigan | MI |
| 27 | Minnesota | MN |
| 28 | Mississippi | MS |
| 29 | Missouri | MO |
| 31 | Nebraska | NE |
| 33 | New Hampshire | NH |
| 34 | New Jersey | NJ |
| 36 | New York | NY |
| 37 | North Carolina | NC |
| 39 | Ohio | OH |
| 40 | Oklahoma | OK |
| 42 | Pennsylvania | PA |
| 44 | Rhode Island | RI |
| 45 | South Carolina | SC |
| 47 | Tennessee | TN |
| 48 | Texas | TX |
| 50 | Vermont | VT |
| 51 | Virginia | VA |
| 54 | West Virginia | WV |
| 55 | Wisconsin | WI |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roesch, F.A. Composite Estimators for Growth Derived from Repeated Plot Measurements of Positively-Asymmetric Interval Lengths. Forests 2018, 9, 427. https://doi.org/10.3390/f9070427
Roesch FA. Composite Estimators for Growth Derived from Repeated Plot Measurements of Positively-Asymmetric Interval Lengths. Forests. 2018; 9(7):427. https://doi.org/10.3390/f9070427
Chicago/Turabian StyleRoesch, Francis A. 2018. "Composite Estimators for Growth Derived from Repeated Plot Measurements of Positively-Asymmetric Interval Lengths" Forests 9, no. 7: 427. https://doi.org/10.3390/f9070427
APA StyleRoesch, F. A. (2018). Composite Estimators for Growth Derived from Repeated Plot Measurements of Positively-Asymmetric Interval Lengths. Forests, 9(7), 427. https://doi.org/10.3390/f9070427