Genomic Diversity and Evolution of Quasispecies in Newcastle Disease Virus Infections

 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Cell Culture
2.2. RNA Extraction and Sequencing
2.3. In Vivo Studies
2.4. Bioinformatic Analyses
- SNP density: (where ind[y] is 1 if y is true and 0 otherwise)
- Pairwise nucleotide diversity:
- Entropy:
- Tajima’s D:
3. Results
3.1. Samples and Read Depth
3.2. Overall Genetic Diversity Show Higher Diversity in the In Vivo Samples
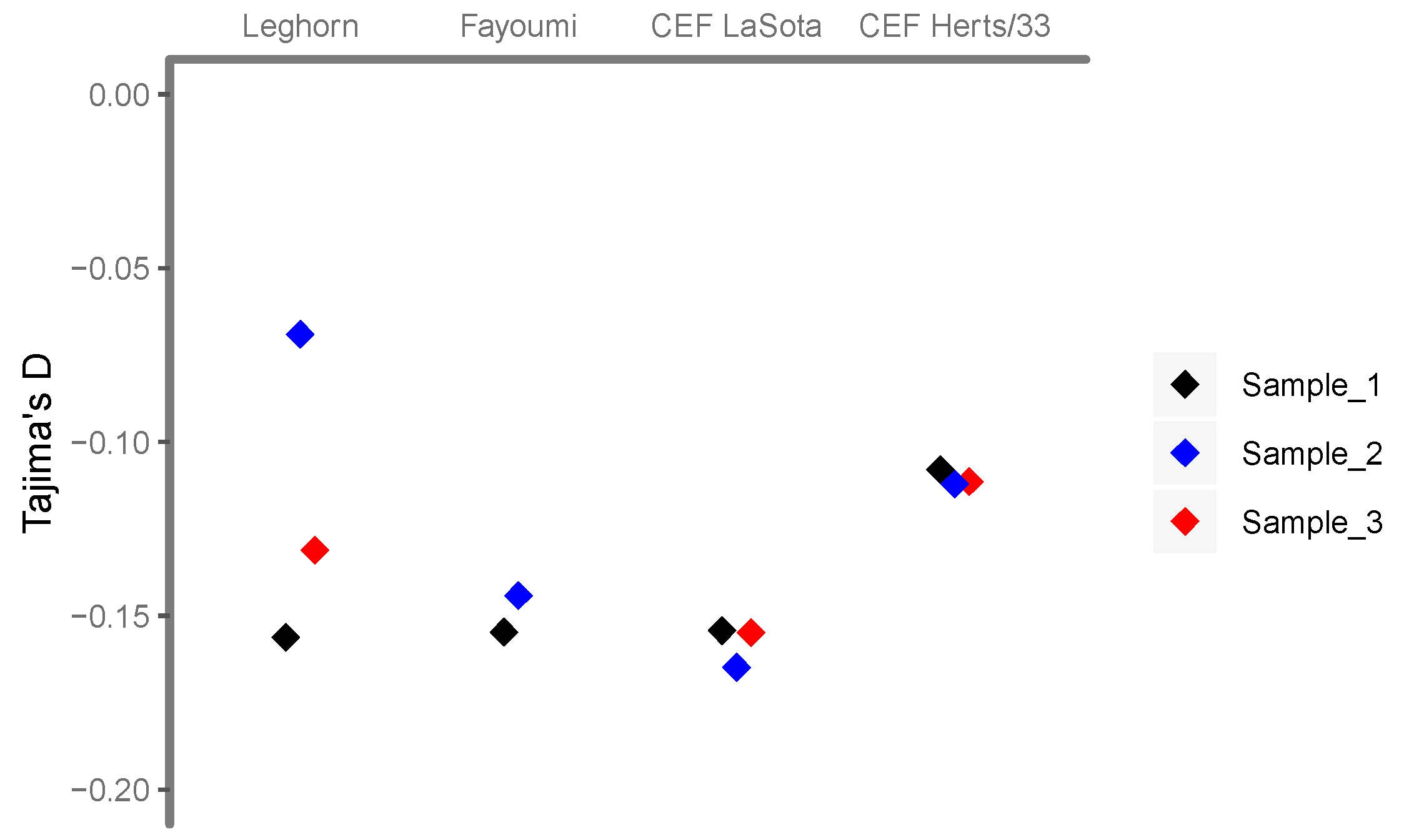
3.3. An Excess of Low-Frequency Variants is Compatible with an Exponential Growth Rate within Host/Culture
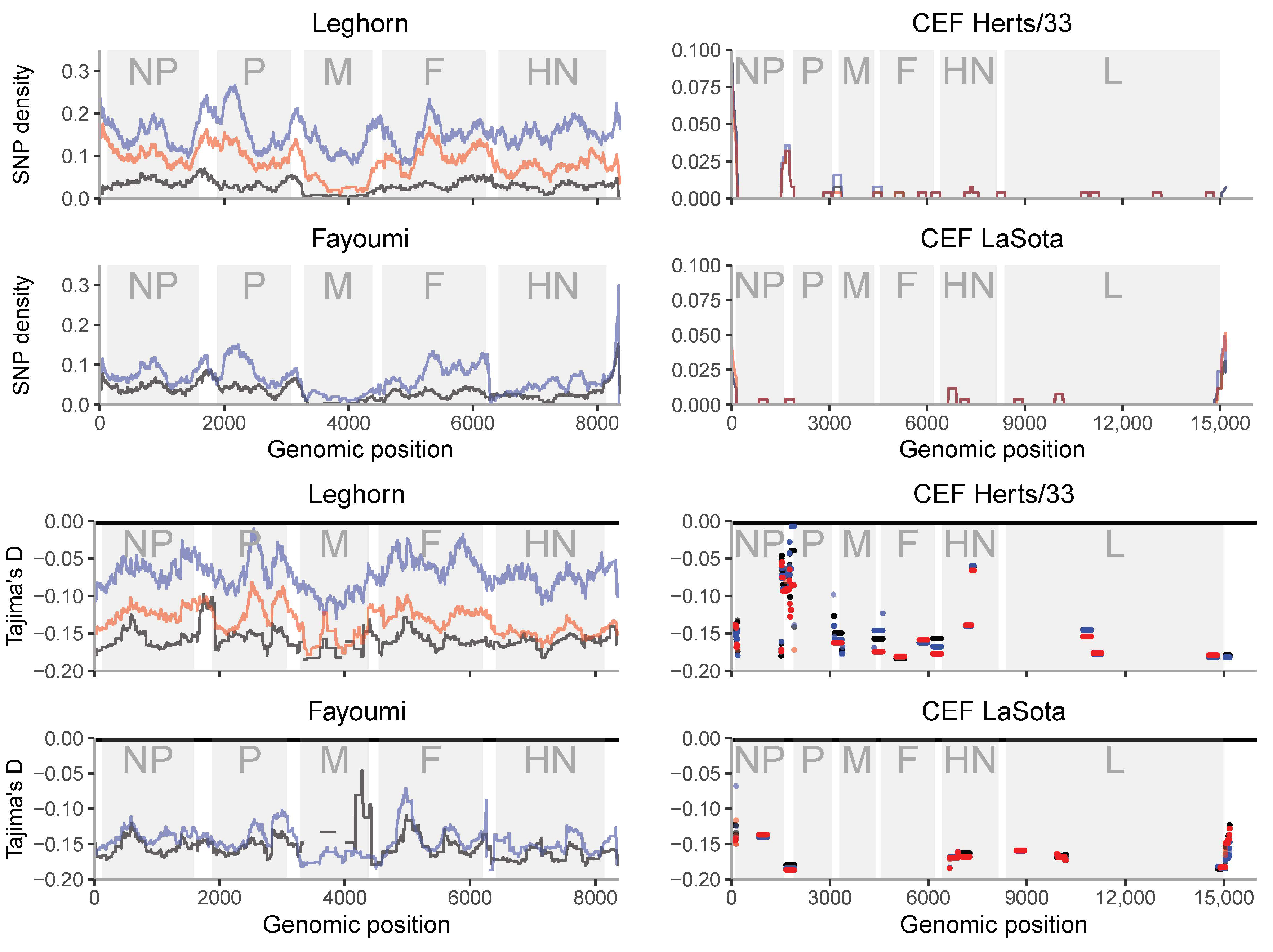
3.4. Genetic Diversity along the Genome Shows Regions of High Diversity and/or Hypermutability
3.5. The Site Frequency Spectrum (SFS) Gives Clues about Evolutionary Events Occurring within Host
3.6. Looking for Signatures of Selection: Non-Synonymous, Synonymous and Non-Coding Variants
3.6.1. Ratios of Polymorphism within-Host at Functional Versus Non-Functional Positions
3.6.2. The Patterns of Polymorphism within-Host Versus the Divergence between-Host Are not Always Correlated
3.6.3. Contrasting the Patterns of Polymorphism within-Host Versus the Divergence between-Host at Functional Versus Non-Functional Positions: Differential Selective Patterns at Different Stages
4. Discussion
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Lauring, A.S.; Andino, R. Quasispecies theory and the behavior of RNA viruses. PLoS Pathog. 2010, 6, e1001005. [Google Scholar] [CrossRef] [PubMed]
- Vignuzzi, M.; Stone, J.K.; Arnold, J.J.; Cameron, C.E.; Andino, R. Quasispecies diversity determines pathogenesis through cooperative interactions in a viral population. Nature 2006, 439, 344–348. [Google Scholar] [CrossRef] [PubMed]
- Domingo, E.; Perales, C. Viral quasispecies. PLoS Genet. 2019, 15, e1008271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brown, V.R.; Bevins, S.N. A review of virulent Newcastle disease viruses in the United States and the role of wild birds in viral persistence and spread. Vet. Res. 2017, 48, 68. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schirrmacher, V. Fifty Years of Clinical Application of Newcastle Disease Virus: Time to Celebrate! Biomedicines 2016, 4, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schirrmacher, V.; Van Gool, S.; Stuecker, W. Breaking Therapy Resistance: An Update on Oncolytic Newcastle Disease Virus for Improvements of Cancer Therapy. Biomedicines 2019, 7, 66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amarasinghe, G.K.; Ayllón, M.A.; Bào, Y.; Basler, C.F.; Bavari, S.; Blasdell, K.R.; Briese, T.; Brown, P.A.; Bukreyev, A.; Balkema-Buschmann, A.; et al. Taxonomy of the order Mononegavirales: Update 2019. Arch. Virol. 2019, 164, 1967–1980. [Google Scholar] [CrossRef] [Green Version]
- Ganar, K.; Das, M.; Sinha, S.; Kumar, S. Newcastle disease virus: Current status and our understanding. Virus Res. 2014, 184, 71–81. [Google Scholar] [CrossRef]
- Nagai, Y.; Hamaguchi, M.; Toyoda, T. Molecular biology of Newcastle disease virus. Prog. Vet. Microbiol. Immunol. 1989, 5, 16–64. [Google Scholar]
- Lamb, R.A.; Parks, G.D. Paramyxoviridae: The viruses and their replication. Fields Virol. 2007, 5, 1449–1496. [Google Scholar]
- Ramanujam, P.; Tan, W.S.; Nathan, S.; Yusoff, K. Pathotyping of Newcastle disease virus with a filamentous bacteriophage. Biotechniques 2004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aldous, E.W.; Alexander, D.J. Detection and differentiation of Newcastle disease virus (avian paramyxovirus type 1). Avian Pathol. 2001, 30, 117–128. [Google Scholar] [CrossRef] [PubMed]
- Alexander, D.J.; Campbell, G.; Manvell, R.J.; Collins, M.S.; Parsons, G.; McNulty, M.S. Characterisation of an antigenically unusual virus responsible for two outbreaks of Newcastle disease in the Republic of Ireland in 1990. Vet. Rec. 1992, 130, 65–68. [Google Scholar] [CrossRef] [PubMed]
- Gould, A.R.; Kattenbelt, J.A.; Selleck, P.; Hansson, E.; Della-Porta, A.; Westbury, H.A. Virulent Newcastle disease in Australia: Molecular epidemiological analysis of viruses isolated prior to and during the outbreaks of 1998–2000. Virus Res. 2001, 77, 51–60. [Google Scholar] [CrossRef]
- Tirumurugaan, K.G.; Kapgate, S.; Vinupriya, M.K.; Vijayarani, K.; Kumanan, K.; Elankumaran, S. Genotypic and pathotypic characterization of Newcastle disease viruses from India. PLoS ONE 2011, 6, e28414. [Google Scholar] [CrossRef] [PubMed]
- Miller, P.J.; Decanini, E.L.; Afonso, C.L. Newcastle disease: Evolution of genotypes and the related diagnostic challenges. Infect. Genet. Evol. 2010, 10, 26–35. [Google Scholar] [CrossRef] [PubMed]
- De Almeida, R.S.; Hammoumi, S.; Gil, P.; Briand, F.X.; Molia, S.; Gaidet, N.; Cappelle, J.; Chevalier, V.; Balança, G.; Traoré, A.; et al. New avian paramyxoviruses type I strains identified in Africa provide new outcomes for phylogeny reconstruction and genotype classification. PLoS ONE 2013, 8, e76413. [Google Scholar] [CrossRef] [Green Version]
- Diel, D.G.; Da Silva, L.H.A.; Liu, H.; Wang, Z.; Miller, P.J.; Afonso, C.L. Genetic diversity of avian paramyxovirus type 1: Proposal for a unified nomenclature and classification system of Newcastle disease virus genotypes. Infect. Genet. Evol. 2012. [Google Scholar] [CrossRef]
- Dimitrov, K.M.; Abolnik, C.; Afonso, C.L.; Albina, E.; Bahl, J.; Berg, M.; Briand, F.-X.; Brown, I.H.; Choi, K.-S.; Chvala, I.; et al. Updated unified phylogenetic classification system and revised nomenclature for Newcastle disease virus. Infect. Genet. Evol. 2019, 74, 103917. [Google Scholar] [CrossRef]
- Jenkins, G.M.; Rambaut, A.; Pybus, O.G.; Holmes, E.C. Rates of molecular evolution in RNA viruses: A quantitative phylogenetic analysis. J. Mol. Evol. 2002, 54, 156–165. [Google Scholar] [CrossRef]
- Miller, P.J.; Kim, L.M.; Ip, H.S.; Afonso, C.L. Evolutionary dynamics of Newcastle disease virus. Virology 2009, 391, 64–72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meng, C.; Qiu, X.; Yu, S.; Li, C.; Sun, Y.; Chen, Z.; Liu, K.; Zhang, X.; Tan, L.; Song, C.; et al. Evolution of Newcastle disease virus quasispecies diversity and enhanced virulence after passage through chicken air sacs. J. Virol. 2015, 90, 2052–2063. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kattenbelt, J.A.; Stevens, M.P.; Selleck, P.W.; Gould, A.R. Analysis of Newcastle disease virus quasispecies and factors affecting the emergence of virulent virus. Arch. Virol. 2010, 155, 1607–1615. [Google Scholar] [CrossRef] [PubMed]
- Braun, T.; Bordería, A.V.; Barbezange, C.; Vignuzzi, M.; Louzoun, Y. Long-term context-dependent genetic adaptation of the viral genetic cloud. Bioinformatics 2019, 35, 1907–1915. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Qiu, X.; Song, C.; Sun, Y.; Meng, C.; Liao, Y.; Tan, L.; Ding, Z.; Liu, X.; Ding, C. Deep sequencing-based transcriptome profiling reveals avian interferon-stimulated genes and provides comprehensive insight into Newcastle disease virus-induced host responses. Viruses 2018, 10, 162. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Kaiser, M.G.; Deist, M.S.; Gallardo, R.A.; Bunn, D.A.; Kelly, T.R.; Dekkers, J.C.M.; Zhou, H.; Lamont, S.J. Transcriptome analysis in spleen reveals differential regulation of response to Newcastle disease virus in two chicken lines. Sci. Rep. 2018, 8, 1278. [Google Scholar] [CrossRef] [Green Version]
- Deist, M.S.; Gallardo, R.A.; Bunn, D.A.; Dekkers, J.C.M.; Zhou, H.; Lamont, S.J. Resistant and susceptible chicken lines show distinctive responses to Newcastle disease virus infection in the lung transcriptome. BMC Genom. 2017, 18, 989. [Google Scholar] [CrossRef] [Green Version]
- Deist, M.S.; Gallardo, R.A.; Bunn, D.A.; Kelly, T.R.; Dekkers, J.C.M.; Zhou, H.; Lamont, S.J. Novel mechanisms revealed in the trachea transcriptome of resistant and susceptible chicken lines following infection with Newcastle disease virus. Clin. Vaccine Immunol. 2017, 24, e00027-17. [Google Scholar] [CrossRef]
- Marco-Sola, S.; Sammeth, M.; Guigó, R.; Ribeca, P. The GEM mapper: Fast, accurate and versatile alignment by filtration. Nat. Methods 2012, 9, 1185–1188. [Google Scholar] [CrossRef]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. The sequence alignment/map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [Green Version]
- Ferretti, L.; Tennakoon, C.; Silesian, A.; Freimanis, G.; Ribeca, P. SiNPle: Fast and sensitive variant calling for deep sequencing data. Genes 2019, 10, 561. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, L.; Illingworth, C.J.R. Measurements of intrahost viral diversity require an unbiased diversity metric. Virus Evol. 2019, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferretti, L.; Ramos-Onsins, S.E.; Pérez-Enciso, M. Population genomics from pool sequencing. Mol. Ecol. 2013, 22, 5561–5576. [Google Scholar] [CrossRef] [PubMed]
- Achaz, G. Frequency spectrum neutrality tests: One for all and all for one. Genetics 2009, 183, 249–258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferretti, L.; Marmorini, G.; Ramos-Onsins, S. Properties of neutrality tests based on allele frequency spectrum. arXiv 2010, arXiv:1011.1470. [Google Scholar]
- Gascuel, O. BIONJ: An improved version of the NJ algorithm based on a simple model of sequence data. Mol. Biol. Evol. 1997, 14, 685–695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hollich, V.; Milchert, L.; Arvestad, L.; Sonnhammer, E.L.L. Assessment of protein distance measures and tree-building methods for phylogenetic tree reconstruction. Mol. Biol. Evol. 2005, 22, 2257–2264. [Google Scholar] [CrossRef] [PubMed]
- Paradis, E.; Schliep, K. ape 5.0: An environment for modern phylogenetics and evolutionary analyses in R. Bioinformatics 2019, 35, 526–528. [Google Scholar] [CrossRef]
- Rafajlović, M.; Klassmann, A.; Eriksson, A.; Wiehe, T.; Mehlig, B. Demography-adjusted tests of neutrality based on genome-wide SNP data. Theor. Popul. Biol. 2014, 95, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Ferretti, L.; Perez-Enciso, M.; Ramos-Onsins, S. Optimal neutrality tests based on the frequency spectrum. Genetics 2010, 186, 353–365. [Google Scholar] [CrossRef] [Green Version]
- Hudson, R.R.; Kreitman, M.; Aguadé, M. A test of neutral molecular evolution based on nucleotide data. Genetics 1987, 116, 153–159. [Google Scholar] [PubMed]
- Schilling, M.A.; Katani, R.; Memari, S.; Cavanaugh, M.; Buza, J.; Radzio-Basu, J.; Mpenda, F.N.; Deist, M.S.; Lamont, S.J.; Kapur, V. Transcriptional innate immune response of the developing chicken embryo to Newcastle disease virus infection. Front. Genet. 2018, 9, 61. [Google Scholar] [CrossRef] [PubMed]
- Ishida, N.; Taira, H.; Omata, T.; Mizumoto, K.; Hattori, S.; Iwasaki, K.; Kawakita, M. Sequence of 2,617 nucieotides from the 3′ end of Newcastle disease virus genome RNA and the predicted amino acid sequence of viral NP protein. Nucleic Acids Res. 1986, 14, 6551–6564. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, Y.; Samal, S.K. Role of intergenic sequences in newcastle disease virus RNA transcription and pathogenesis. J. Virol. 2008, 82, 1323–1331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marcos, F.; Ferreira, L.; Cros, J.; Park, M.-S.; Nakaya, T.; García-Sastre, A.; Villar, E. Mapping of the RNA promoter of Newcastle disease virus. Virology 2005, 331, 396–406. [Google Scholar] [CrossRef] [Green Version]
- Gaikwad, S.S.; Lee, H.-J.; Kim, J.-Y.; Choi, K.-S. Expression and serological application of recombinant epitope-repeat protein carrying an immunodominant epitope of Newcastle disease virus nucleoprotein. Clin. Exp. Vaccine Res. 2019, 8, 27–34. [Google Scholar] [CrossRef]
- Fan, W.; Xu, Y.; Zhang, P.; Chen, P.; Zhu, Y.; Cheng, Z.; Zhao, X.; Liu, Y.; Liu, J. Analysis of molecular evolution of nucleocapsid protein in Newcastle disease virus. Oncotarget 2017, 8, 97127–97136. [Google Scholar] [CrossRef]
- Steward, M.; Vipond, I.B.; Millar, N.S.; Emmerson, P.T. RNA editing in Newcastle disease virus. J. Gen. Virol. 2015, 74, 2539–2547. [Google Scholar] [CrossRef]
- Locke, D.P.; Sellers, H.S.; Crawford, J.M.; Schultz-Cherry, S.; King, D.J.; Meinersmann, R.J.; Seal, B.S. Newcastle disease virus phosphoprotein gene analysis and transcriptional editing in avian cells. Virus Res. 2000, 69, 55–68. [Google Scholar] [CrossRef]
- Childs, K.S.; Andrejeva, J.; Randall, R.E.; Goodbourn, S. Mechanism of mda-5 inhibition by paramyxovirus V proteins. J. Virol. 2009, 83, 1465–1473. [Google Scholar] [CrossRef] [Green Version]
- Chu, Z.; Wang, C.; Tang, Q.; Shi, X.; Gao, X.; Ma, J.; Lu, K.; Han, Q.; Jia, Y.; Wang, X.; et al. Newcastle disease virus V protein inhibits cell apoptosis and promotes viral replication by targeting cacybp/SIP. Front. Cell. Infect. Microbiol. 2018, 8, 304. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Chu, Z.; Liu, W.; Pang, Y.; Gao, X.; Tang, Q.; Ma, J.; Lu, K.; Adam, F.E.A.; Dang, R.; et al. Newcastle disease virus V protein inhibits apoptosis in DF-1 cells by downregulating TXNL1. Vet. Res. 2018, 49, 102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Z.; Krishnamurthy, S.; Panda, A.; Samal, S.K. Newcastle disease virus V protein is associated with viral pathogenesis and functions as an alpha interferon antagonist. J. Virol. 2003, 77, 8676–8685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alamares, J.G.; Elankumaran, S.; Samal, S.K.; Iorio, R.M. The interferon antagonistic activities of the V proteins from two strains of Newcastle disease virus correlate with their known virulence properties. Virus Res. 2010, 147, 153–157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rao, P.L.; Gandham, R.K.; Subbiah, M. Molecular evolution and genetic variations of V and W proteins derived by RNA editing in Avian Paramyxoviruses. Sci. Rep. 2020. [Google Scholar] [CrossRef]
- Takimoto, T.; Portner, A. Molecular mechanism of paramyxovirus budding. Virus Res. 2004, 106, 133–145. [Google Scholar] [CrossRef]
- Pantua, H.D.; McGinnes, L.W.; Peeples, M.E.; Morrison, T.G. Requirements for the assembly and release of Newcastle disease virus-like particles. J. Virol. 2006, 80, 11062–11073. [Google Scholar] [CrossRef] [Green Version]
- Seal, B.S.; King, D.J.; Meinersmann, R.J. Molecular evolution of the Newcastle disease virus matrix protein gene and phylogenetic relationships among the paramyxoviridae. Virus Res. 2000, 66, 1–11. [Google Scholar] [CrossRef]
- Peeters, B.P.; De Leeuw, O.S.; Koch, G.; Gielkens, A.L. Rescue of Newcastle disease virus from cloned cDNA: Evidence that cleavability of the fusion protein is a major determinant for virulence. J. Virol. 1999, 73, 5001–5009. [Google Scholar] [CrossRef] [Green Version]
- Swanson, K.; Wen, X.; Leser, G.P.; Paterson, R.G.; Lamb, R.A.; Jardetzky, T.S. Structure of the Newcastle disease virus F protein in the post-fusion conformation. Virology 2010, 402, 372–379. [Google Scholar] [CrossRef]
- Toyoda, T.; Gotoh, B.; Sakaguchi, T.; Kida, H.; Nagai, Y. Identification of amino acids relevant to three antigenic determinants on the fusion protein of Newcastle disease virus that are involved in fusion inhibition and neutralization. J. Virol. 1988, 62, 4427–4430. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nagai, Y.; Klenk, H.D.; Rott, R. Proteolytic cleavage of the viral glycoproteins and its significance for the virulence of Newcastle disease virus. Virology 1976, 72, 494–508. [Google Scholar] [CrossRef]
- McGinnes, L.W.; Morrison, T.G. The role of individual oligosaccharide chains in the activities of the HN glycoprotein of Newcastle disease virus. Virology 1995, 212, 398–410. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Panda, A.; Elankumaran, S.; Krishnamurthy, S.; Huang, Z.; Samal, S.K. Loss of N-linked glycosylation from the hemagglutinin-neuraminidase protein alters virulence of Newcastle disease virus. J. Virol. 2004, 78, 4965–4975. [Google Scholar] [CrossRef] [Green Version]
- García-Sastre, A.; Cabezas, J.; Villar, E. Proteins of newcastle disease virus envelope: Interaction between the outer hemagglutinin-neuraminidase glycoprotein and the inner non-glycosylated matrix protein. Biochim. Biophys. Acta Protein Struct. Mol. Enzymol. 1989, 999, 171–175. [Google Scholar] [CrossRef]
- Jin, J.; Cheng, J.; He, Z.; Ren, Y.; Yu, X.; Song, Y.; Yang, H.; Yang, Y.; Liu, T.; Zhang, G. Different origins of Newcastle disease virus hemagglutinin-neuraminidase protein modulate the replication efficiency and pathogenicity of the virus. Front. Microbiol. 2017, 8, 1607. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Panda, A.; Elankumaran, S.; Govindarajan, D.; Rockemann, D.D.; Samal, S.K. The hemagglutinin-neuraminidase protein of Newcastle disease virus determines tropism and virulence. J. Virol. 2004, 78, 4176–4184. [Google Scholar] [CrossRef] [Green Version]
- Iorio, R.M.; Syddall, R.J.; Sheehan, J.P.; Bratt, M.A.; Glickman, R.L.; Riel, A.M. Neutralization map of the hemagglutinin-neuraminidase glycoprotein of Newcastle disease virus: Domains recognized by monoclonal antibodies that prevent receptor recognition. J. Virol. 1991. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Samples | Total Number of Sequenced High Quality Nucleotides | Number of Bases with Read Depth ≥100 | ||
|---|---|---|---|---|
| Host | Virus | Replicate | ||
| in vivo Leghorn (susceptible line) | LaSota | 1 | 7,863,831 | 7947 |
| 2 | 40,862,546 | 10,853 | ||
| 3 | 24,478,520 | 8116 | ||
| in vivo Fayoumi (resistant line) | 1 | 7,209,555 | 7961 | |
| 2 | 2,260,242 | 7387 | ||
| in vitro Chicken embryo fibroblast (CEF) cells | LaSota | 1 | 513,645,350 | 15,169 |
| 2 | 489,575,827 | 15,169 | ||
| 3 | 493,067,864 | 15,169 | ||
| Herts/33 | 1 | 2,297,752,521 | 15,162 | |
| 2 | 2,538,051,612 | 15,169 | ||
| 3 | 2,158,838,655 | 15,163 | ||
| Gene | NP | P | M | F | HN | HN |
|---|---|---|---|---|---|---|
| Feature | Peak in polymorphism | Correlated patterns pol-div. | Generally low polymorphisms | Dip in divergence | 1st peak in divergence | 2nd peak in divergence |
| Genomic position (±250 bp) | 683–684 (leghorn1) | Whole gene (3290–4384) | 5018–5019 | 6589–6593 | 7219–7220 |
| Protein | NP | P | M | F | F | HN | HN |
|---|---|---|---|---|---|---|---|
| Feature | dip | peak | dip | 1st peak | 2nd peak | 1st peak | 2nd peak |
| Location (dark gray in Figure 8) | 600–900 | 2300–2700 | 3550–3800 | 4750–4850 | 5200–5350 | 6600–6750 | 7100–7400 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jadhav, A.; Zhao, L.; Liu, W.; Ding, C.; Nair, V.; Ramos-Onsins, S.E.; Ferretti, L. Genomic Diversity and Evolution of Quasispecies in Newcastle Disease Virus Infections. Viruses 2020, 12, 1305. https://doi.org/10.3390/v12111305
Jadhav A, Zhao L, Liu W, Ding C, Nair V, Ramos-Onsins SE, Ferretti L. Genomic Diversity and Evolution of Quasispecies in Newcastle Disease Virus Infections. Viruses. 2020; 12(11):1305. https://doi.org/10.3390/v12111305
Chicago/Turabian StyleJadhav, Archana, Lele Zhao, Weiwei Liu, Chan Ding, Venugopal Nair, Sebastian E. Ramos-Onsins, and Luca Ferretti. 2020. "Genomic Diversity and Evolution of Quasispecies in Newcastle Disease Virus Infections" Viruses 12, no. 11: 1305. https://doi.org/10.3390/v12111305
APA StyleJadhav, A., Zhao, L., Liu, W., Ding, C., Nair, V., Ramos-Onsins, S. E., & Ferretti, L. (2020). Genomic Diversity and Evolution of Quasispecies in Newcastle Disease Virus Infections. Viruses, 12(11), 1305. https://doi.org/10.3390/v12111305