
Weekly Nowcasting of New COVID-19 Cases Using Past Viral Load Measurements

 , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Patient Population
2.2. Study Design
2.3. Predictive Modeling
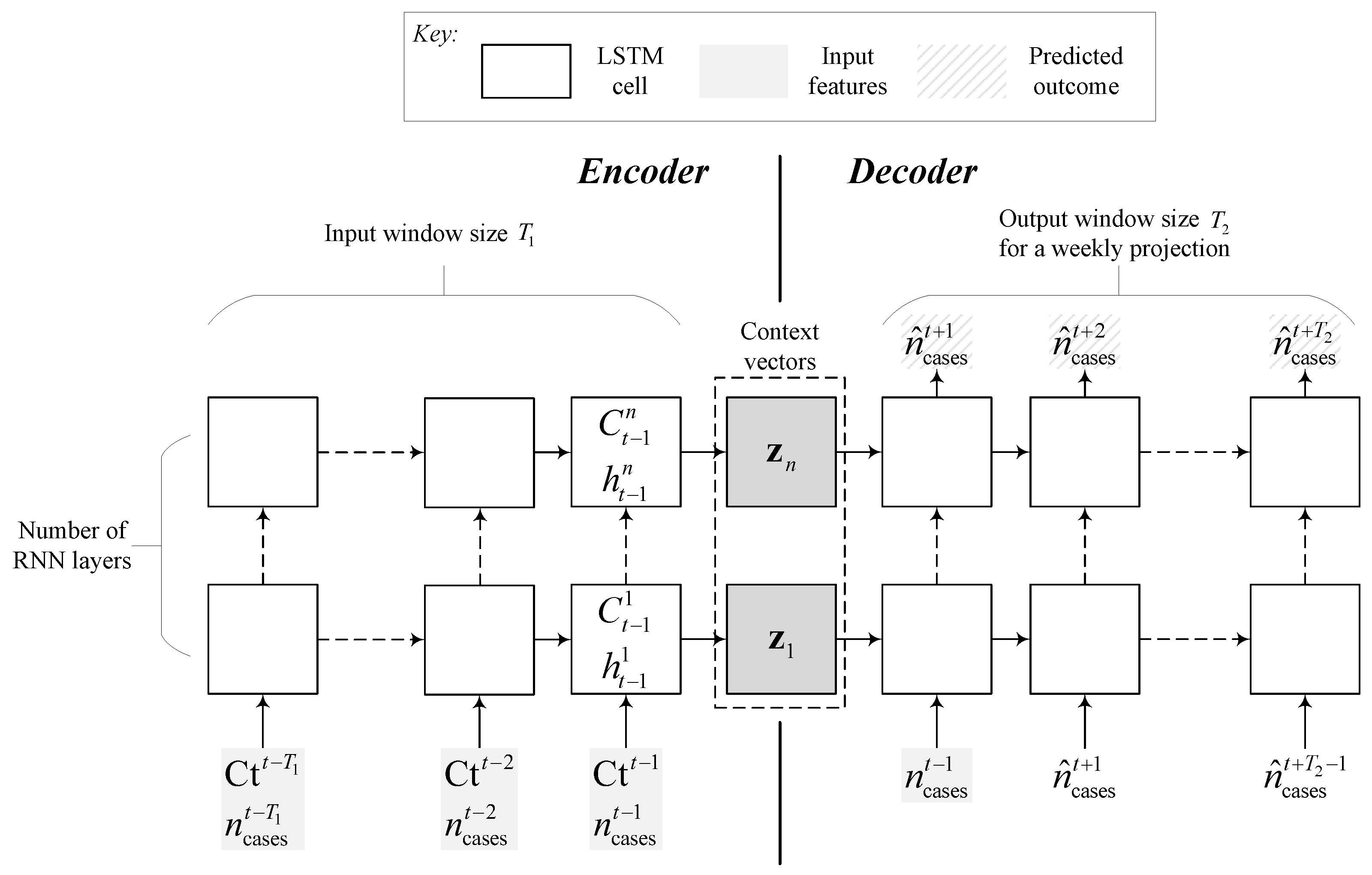
2.3.1. Recurrent Neural Network (RNN) Models
2.3.2. Feedforward Neural Network (DNN) Model
2.3.3. Regression Models
2.3.4. Hyperparameter Tuning
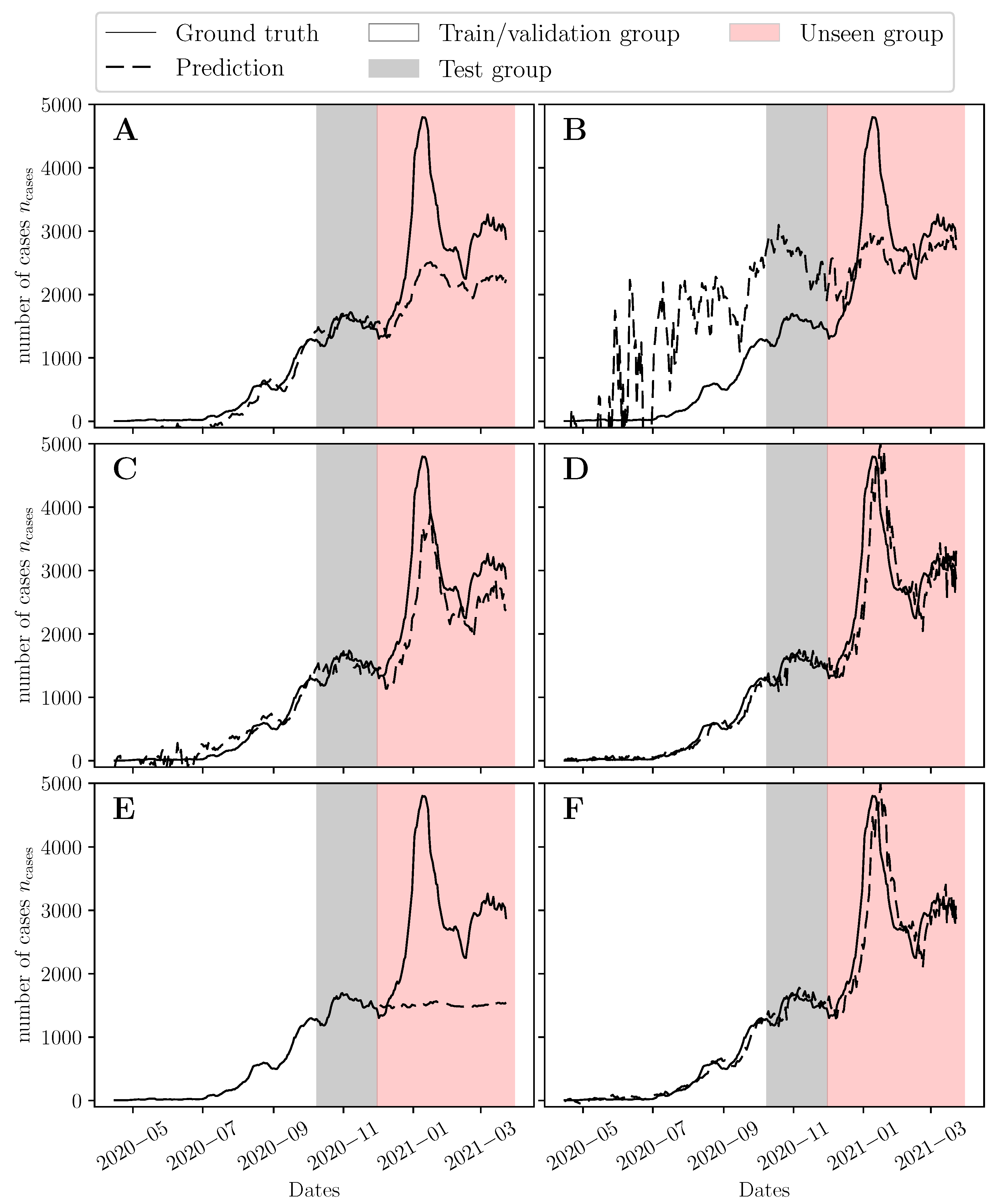
3. Results
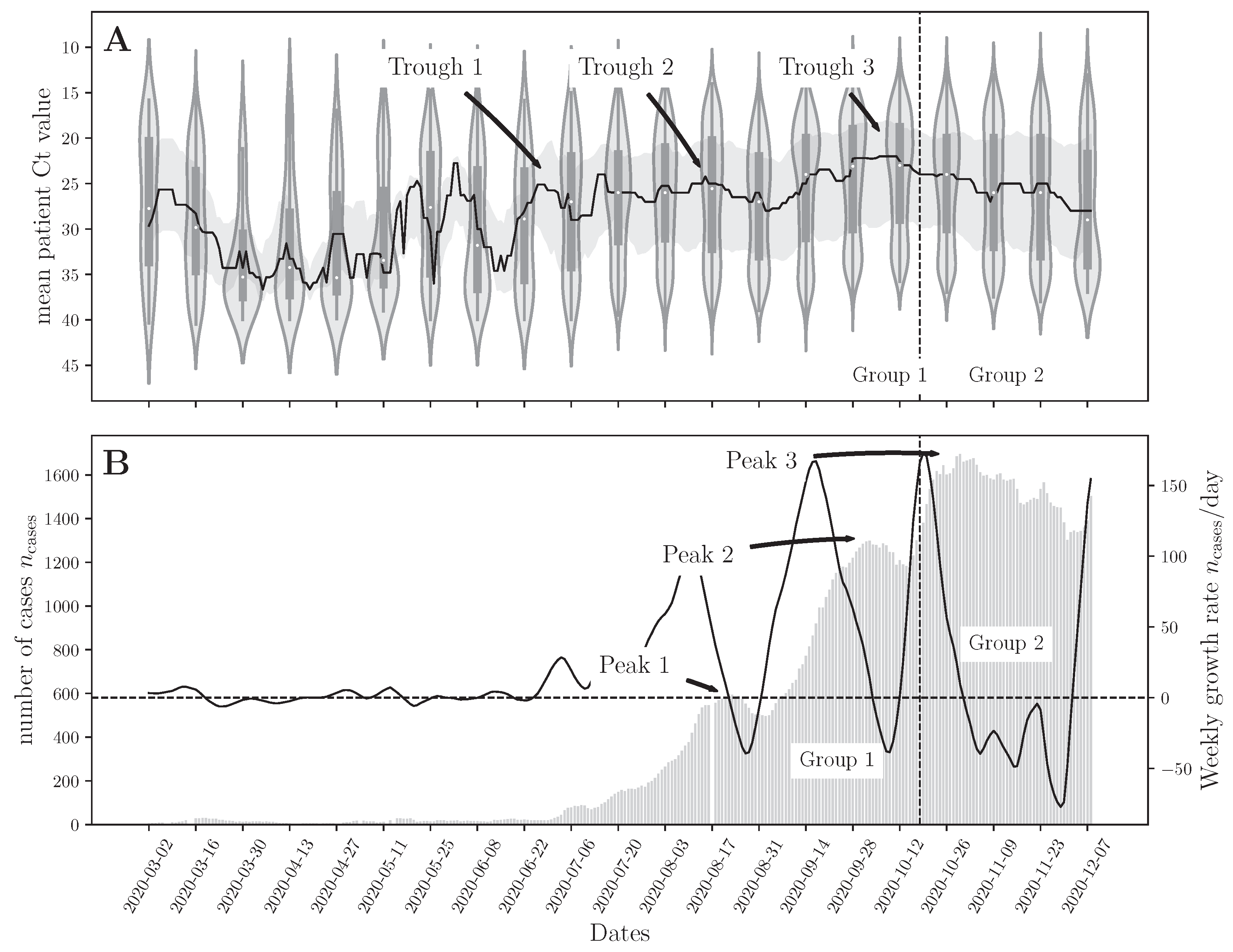
3.1. Patient Population
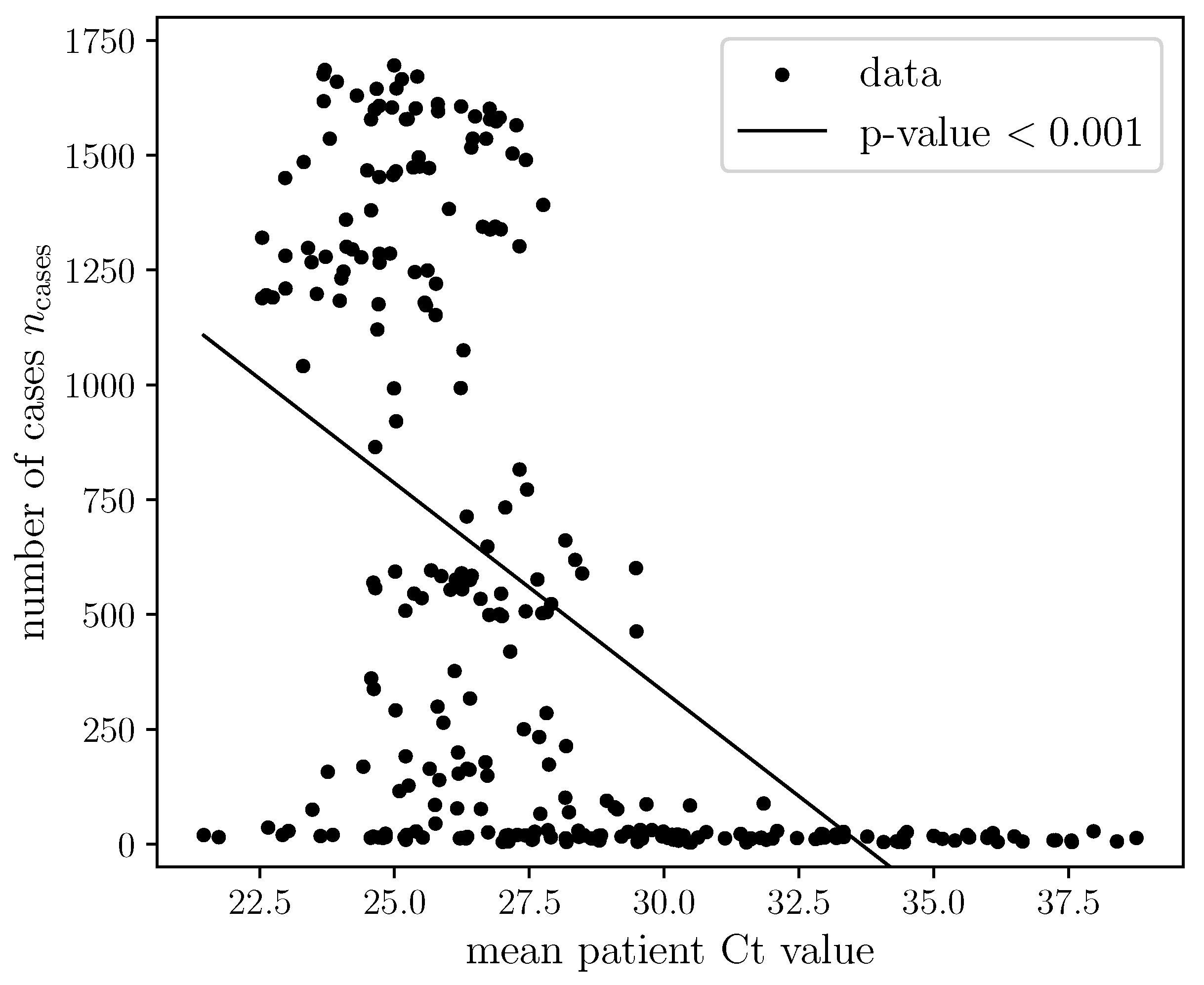
3.2. Correlation between the National Daily Number of COVID-19 Cases and Mean Ct
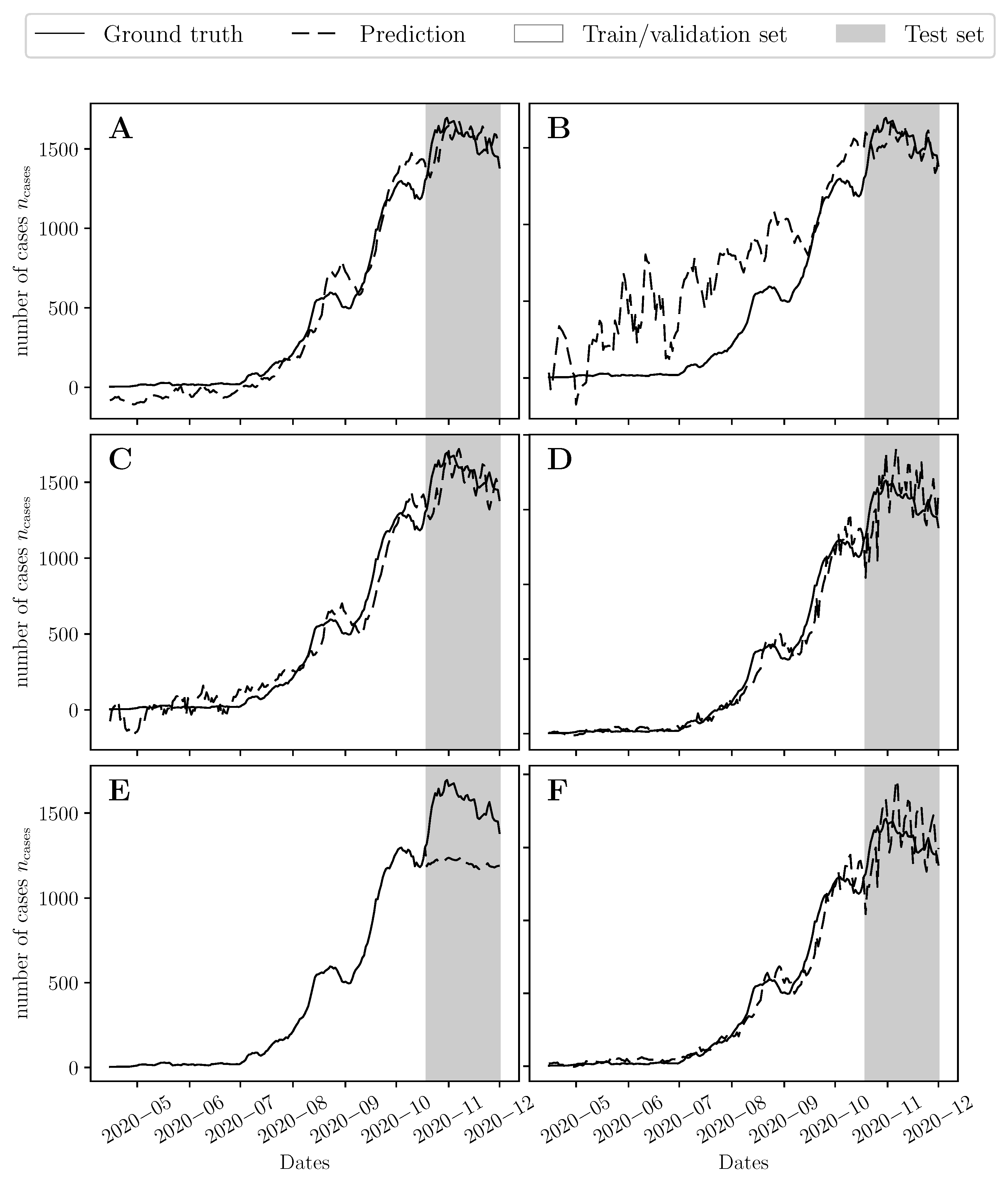
3.3. Now-Casting the Epidemic Trajectories
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization Declares Global Emergency: A Review of the 2019 Novel Coronavirus (COVID-19). Int. J. Surg. 2020, 76, 71–76. [CrossRef] [PubMed]
- Khalil, A.; Kamar, A.; Nemer, G. Thalidomide-Revisited: Are COVID-19 Patients Going to Be the Latest Victims of Yet Another Theoretical Drug-Repurposing? Front. Immunol. 2020, 11, 1248. [Google Scholar] [CrossRef] [PubMed]
- Rabaan, A.A.; Al-Ahmed, S.H.; Al-Malkey, M.; Alsubki, R.; Ezzikouri, S.; Hassan Al-Hababi, F.; Sah, R.; Mutair, A.A.; Alhumaid, S.; Al-Tawfiq, J.A.; et al. Airborne transmission of SARS-CoV-2 is the dominant route of transmission: Droplets and aerosols. Infez. Med. 2021, 29, 10–19. [Google Scholar] [PubMed]
- Hoertel, N.; Blachier, M.; Blanco, C.; Olfson, M.; Massetti, M.; Rico, M.S.; Limosin, F.; Leleu, H. A stochastic agent-based model of the SARS-CoV-2 epidemic in France. Nat. Med. 2020, 26, 1417–1421. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.T.; Leung, K.; Lam, L.T.; Ni, M.Y.; Wong, C.K.; Peiris, J.S.; Leung, G.M. Nowcasting epidemics of novel pathogens: Lessons from COVID-19. Nat. Med. 2021, 27, 388–395. [Google Scholar] [CrossRef] [PubMed]
- Irons, N.J.; Raftery, A.E. Estimating SARS-CoV-2 infections from deaths, confirmed cases, tests, and random surveys. Proc. Natl. Acad. Sci. USA 2021, 118, e2103272118. [Google Scholar] [CrossRef]
- Alaimo Di Loro, P.; Divino, F.; Farcomeni, A.; Jona Lasinio, G.; Lovison, G.; Maruotti, A.; Mingione, M. Nowcasting COVID-19 incidence indicators during the Italian first outbreak. Stat. Med. 2021, 40, 3843–3864. [Google Scholar] [CrossRef]
- Kamar, A.A.; Maalouf, N.; Hitti, E.; El Eid, G.; Isma’eel, H.; Elhajj, I.H. The Challenge of Forecasting Demand of Medical Resources and Supplies during a Pandemic: A Comparative Evaluation of Three Surge Calculators for COVID-19. Epidemiol. Infect. 2021, 149, e51. [Google Scholar] [CrossRef]
- Abrams, S.; Wambua, J.; Santermans, E.; Willem, L.; Kuylen, E.; Coletti, P.; Libin, P.; Faes, C.; Petrof, O.; Herzog, S.A.; et al. Modelling the early phase of the Belgian COVID-19 epidemic using a stochastic compartmental model and studying its implied future trajectories. Epidemics 2021, 35, 100449. [Google Scholar] [CrossRef]
- Reiner, R.C. Modeling COVID-19 scenarios for the United States. Nat. Med. 2021, 27, 94–105. [Google Scholar] [CrossRef]
- Pinto Neto, O.; Kennedy, D.M.; Reis, J.C.; Wang, Y.; Brizzi, A.B.; Zambrano, G.J.; de Souza, J.M.; Pedroso, W.; de Mello Pedreiro, R.C.; de Matos Brizzi, B.; et al. Mathematical model of COVID-19 intervention scenarios for São Paulo—Brazil. Nat. Commun. 2021, 12, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Péré, H.; Podglajen, I.; Wack, M.; Flamarion, E.; Mirault, T.; Goudot, G.; Hauw-Berlemont, C.; Le, L.; Caudron, E.; Carrabin, S.; et al. Nasal swab sampling for SARS-CoV-2: A convenient alternative in times of nasopharyngeal swab shortage. J. Clin. Microbiol. 2020, 58, e00721-20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ade, C.; Pum, J.; Abele, I.; Raggub, L.; Bockmühl, D.; Zöllner, B. Analysis of cycle threshold values in SARS-CoV-2-PCR in a long-term study. J. Clin. Virol. 2021, 138, 104791. [Google Scholar] [CrossRef] [PubMed]
- Understanding Cycle Threshold (Ct) in SARS-CoV-2 RT-PCR A Guide for Health Protection Teams Understanding Cycle Threshold (Ct) in SARS-CoV-2 RT-PCR 2; Technical Report; Public Health England: London, UK, 2020.
- Rao, S.N.; Manissero, S.; Steele, V.R.; Pareja, J. A Narrative Systematic Review of the Clinical Utility of Cycle Threshold Values in the Context of COVID-19. Infect. Dis. Ther. 2020, 9, 573–586. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Grande, C.; Catalán, P.; Alcalá, L.; Buenestado-Serrano, S.; Adán-Jiménez, J.; Rodríguez-Maus, S.; Herranz, M.; Sicilia, J.; Acosta, F.; Pérez-Lago, L.; et al. Different dynamics of mean SARS-CoV-2 RT-PCR Ct values between the first and second COVID-19 waves in the Madrid population. Transbound. Emerg. Dis. 2021, 68, 3103–3106. [Google Scholar] [CrossRef] [PubMed]
- Miller, E.H.; Zucker, J.; Castor, D.; Annavajhala, M.K.; Sepulveda, J.L.; Green, D.A.; Whittier, S.; Scherer, M.; Medrano, N.; Sobieszczyk, M.E.; et al. Pretest Symptom Duration and Cycle Threshold Values for Severe Acute Respiratory Syndrome Coronavirus 2 Reverse-Transcription Polymerase Chain Reaction Predict Coronavirus Disease 2019 Mortality. Open Forum Infect. Dis. 2021, 8, ofab003. [Google Scholar] [CrossRef]
- COVID-19: Management of Staff and Exposed Patients or Residents in Health and Social Care Settings; Technical Report; UK Health Security Agency: London, UK, 2022.
- Sarkar, B.; Sinha, R.; Sarkar, K. Initial viral load of a COVID-19-infected case indicated by its cycle threshold value of polymerase chain reaction could be used as a predictor of its transmissibility—An experience from Gujarat, India. Indian J. Community Med. 2020, 45, 278. [Google Scholar] [CrossRef]
- Avadhanula, V.; Nicholson, E.G.; Ferlic-Stark, L.; Piedra, F.A.; Blunck, B.N.; Fragoso, S.; Bond, N.L.; Santarcangelo, P.L.; Ye, X.; McBride, T.J.; et al. Viral load of Severe Acute Respiratory Syndrome Coronavirus 2 in adults during the first and second wave of Coronavirus Disease 2019 pandemic in Houston, Texas: The potential of the superspreader. J. Infect. Dis. 2021, 223, 1528–1537. [Google Scholar] [CrossRef]
- Singanayagam, A.; Patel, M.; Charlett, A.; Bernal, J.L.; Saliba, V.; Ellis, J.; Ladhani, S.; Zambon, M.; Gopal, R. Duration of infectiousness and correlation with RT-PCR cycle threshold values in cases of COVID-19, England, January to May 2020. Eurosurveillance 2020, 25, 2001483. [Google Scholar] [CrossRef]
- Walker, A.S.; Pritchard, E.; House, T.; Robotham, J.V.; Birrell, P.J.; Bell, I.; Bell, J.I.; Newton, J.N.; Farrar, J.; Diamond, I.; et al. CT threshold values, a proxy for viral load in community sars-cov-2 cases, demonstrate wide variation across populations and over time. eLife 2021, 10, e64683. [Google Scholar] [CrossRef]
- Abdulrahman, A.; Mallah, S.I.; Alawadhi, A.; Perna, S.; Janahi, E.M.; AlQahtani, M.M. Association between RT-PCR Ct values and COVID-19 new daily cases: A multicenter cross-sectional study. Le Infez. Med. 2021, 29, 416. [Google Scholar] [CrossRef]
- Hay, J.A.; Kennedy-Shaffer, L.; Kanjilal, S.; Lennon, H.J.; Gabriel, S.B.; Lipsitch, M.; Mina, M.J. Estimating epidemiologic dynamics from cross-sectional viral load distributions. Science 2021, 373, eabh0635. [Google Scholar] [CrossRef] [PubMed]
- Khalil, A.; Feghali, R.; Hassoun, M. The Lebanese COVID-19 Cohort; A Challenge for the ABO Blood Group System. Front. Med. 2020, 7, 585341. [Google Scholar] [CrossRef] [PubMed]
- Epidemiological Surveillance; Technical Report; Ministry of Public Health: Baabda, Lebanon, 2022.
- Worldometer. Daily New Cases in Lebanon. Available online: https://www.worldometers.info/coronavirus/country/lebanon/ (accessed on 31 March 2022).
- Allen, D.M. The relationship between variable selection and data agumentation and a method for prediction. Technometrics 1974, 16, 125–127. [Google Scholar] [CrossRef]
- Moons, K.G.M.; Altman, D.G.; Reitsma, J.B.; Ioannidis, J.P.A.; Macaskill, P.; Steyerberg, E.W.; Vickers, A.J.; Ransohoff, D.F.; Collins, G.S. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): Explanation and elaboration. Ann. Intern. Med. 2015, 162, W1–W73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, M.R.; Trofimova, M.; Weber, A.; Duport, Y.; Kühnert, D.; von Kleist, M. Rapid incidence estimation from SARS-CoV-2 genomes reveals decreased case detection in Europe during summer 2020. Nat. Commun. 2021, 12, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar] [CrossRef]
- Goyal, A.; Lamb, A.; Zhang, Y.; Zhang, S.; Courville, A.; Bengio, Y. Professor forcing: A new algorithm for training recurrent networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4608–4616. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Prechelt, L. Automatic early stopping using cross validation: Quantifying the criteria. Neural Netw. 1998, 11, 761–767. [Google Scholar] [CrossRef] [Green Version]
- Drucker, H.; Surges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1997; pp. 155–161. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar] [CrossRef]
- Audet, C.; Dzahini, K.J.; Kokkolaras, M.; Le Digabel, S. Stochastic mesh adaptive direct search for blackbox optimization using probabilistic estimates. Comput. Optim. Appl. 2021, 79, 1–34. [Google Scholar] [CrossRef]
- Boulmaiz, T.; Guermoui, M.; Boutaghane, H. Impact of training data size on the LSTM performances for rainfall-runoff modeling. Model. Earth Syst. Environ. 2020, 6, 2153–2164. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An introductory review of deep learning for prediction models with big data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef] [Green Version]
- Heroku. COVID-19 Weekly Forecaster. Available online: https://covid-forecaster-lebanon.herokuapp.com (accessed on 31 March 2022).
- Clinical importance of reporting SARS-CoV-2 viral loads across the different stages of the COVID-19 pandemic. medRxiv 2020. [CrossRef]
- Booton, R.D.; Macgregor, L.; Vass, L.; Looker, K.J.; Hyams, C.; Bright, P.D.; Harding, I.; Lazarus, R.; Hamilton, F.; Lawson, D.; et al. Estimating the COVID-19 epidemic trajectory and hospital capacity requirements in South West England: A mathematical modelling framework. BMJ Open 2021, 11, 41536. [Google Scholar] [CrossRef]
- Liu, Y.; Gayle, A.A.; Wilder-Smith, A.; Rocklöv, J. The reproductive number of COVID-19 is higher compared to SARS coronavirus. J. Travel Med. 2020, 27, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Linka, K.; Peirlinck, M.; Kuhl, E. The reproduction number of COVID-19 and its correlation with public health interventions. Comput. Mech. 2020, 66, 1035–1050. [Google Scholar] [CrossRef]
- Fuhrman, J.D.; Gorre, N.; Hu, Q.; Li, H.; El Naqa, I.; Giger, M.L. A review of explainable and interpretable AI with applications in COVID-19 imaging. Med. Phys. 2022, 49, 1–14. [Google Scholar] [CrossRef]
- Al-Hajj, S.; Mokdad, A.H.; Kazzi, A. Beirut explosion aftermath: Lessons and guidelines. Emerg. Med. J. 2021, 38, 938–939. [Google Scholar] [CrossRef]
- Koweyes, J.; Salloum, T.; Haidar, S.; Merhi, G.; Tokajian, S. COVID-19 Pandemic in Lebanon: One Year Later, What Have We Learnt? mSystems 2021, 6, e00351-21. [Google Scholar] [CrossRef] [PubMed]
- Singanayagam, A.; Hakki, S.; Dunning, J.; Madon, K.J.; Crone, M.A.; Koycheva, A.; Derqui-Fernandez, N.; Barnett, J.L.; Whitfield, M.G.; Varro, R.; et al. Community transmission and viral load kinetics of the SARS-CoV-2 delta (B.1.617.2) variant in vaccinated and unvaccinated individuals in the UK: A prospective, longitudinal, cohort study. Lancet Infect. Dis. 2022, 22, 183–195. [Google Scholar] [CrossRef]
- Al Handawi, K.; Kokkolaras, M. Optimization of Infectious Disease Prevention and Control Policies Using Artificial Life. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 26–40. [Google Scholar] [CrossRef]
- Hinch, R.; Probert, W.J.; Nurtay, A.; Kendall, M.; Wymant, C.; Hall, M.; Lythgoe, K.; Bulas Cruz, A.; Zhao, L.; Stewart, A.; et al. OpenABM-COVID19—An agent-based model for non-pharmaceutical interventions against COVID-19 including contact tracing. PLoS Comput. Biol. 2021, 17, e1009146. [Google Scholar] [CrossRef] [PubMed]
- Willem, L.; Abrams, S.; Libin, P.J.; Coletti, P.; Kuylen, E.; Petrof, O.; Møgelmose, S.; Wambua, J.; Herzog, S.A.; Faes, C.; et al. The impact of contact tracing and household bubbles on deconfinement strategies for COVID-19. Nat. Commun. 2021, 12, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Kerr, C.C.; Stuart, R.M.; Mistry, D.; Abeysuriya, R.G.; Rosenfeld, K.; Hart, G.R.; Núñez, R.C.; Cohen, J.A.; Selvaraj, P.; Hagedorn, B.; et al. Covasim: An agent-based model of COVID-19 dynamics and interventions. PLoS Comput. Biol. 2021, 17, e1009149. [Google Scholar] [CrossRef] [PubMed]
- Lakhmiri, D.; Le Digabel, S.; Tribes, C. HyperNOMAD: Hyperparameter optimization of deep neural networks using mesh adaptive direct search. ACM Trans. Math. Softw. 2021, 47, 1–27. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Symbol | Value | Possible Values |
|---|---|---|---|
| Sequence-to-sequence model (S2S) | |||
| Sliding window size | 6 | 1–40 | |
| Number of hidden neurons | 1500 | 1–2500 | |
| Probability of dropout | 0.8 | 0.0–0.9 | |
| Number of hidden layers | 2 | 1–5 | |
| Teacher forcing probability | 0.3 | 0.0–0.9 | |
| Learning rate | – | ||
| batch size | 32 | 4–128 | |
| best epoch | 31 | 1– | |
| Sequence completion model (SEQ) | |||
| Number of hidden neurons | 2500 | 1–2500 | |
| Probability of dropout | 0.8 | 0.0–0.9 | |
| Number of hidden layers | 3 | 1–5 | |
| Learning rate | – | ||
| batch size | 64 | 4–128 | |
| best epoch | 1 | 1– | |
| Deep neural network (DNN) | |||
| Sliding window size | 6 | 1–40 | |
| Number of hidden neurons | 1000 | 1–2500 | |
| Probability of dropout | 0.9 | 0.0–0.9 | |
| Number of hidden layers | 1 | 1–5 | |
| Learning rate | – | ||
| batch size | 4 | 4–128 | |
| best epoch | 4 | 1– | |
| Support vector machine regression (SVR) | |||
| Sliding window size | 6 | 1–40 | |
| Ridge factor | − | ||
| Margin of tolerance | – | ||
| Stopping criteria tolerance | 0.1 | 1–5 | |
| Learning rate | – | ||
| Gradient boosting machine (GBM) | |||
| Sliding window size | 36 | 1–40 | |
| Subsample fraction | 0.8 | 0.1–1.0 | |
| Maximum portion of features | 0.1 | 0.1–1.0 | |
| Decision tree maximum depth | D | 7 | 1–5 |
| Learning rate | 0.01 | – | |
| Maximum number of boosting stages | 5000 | 50–5000 | |
| Polynomial regression (OLS) | |||
| Sliding window size | 6 | 1–40 | |
| Ridge factor | 1.0 | – | |
| Degree | 1 | 1–5 | |
| Common fixed parameters | |||
| Output window size (all models) | 7 | 1–40 | |
| Maximum number of epochs (all models) | 5000 | ||
| Kernel (SVR) | linear | ||
| Early stopping patience (S2S, SEQ, DNN) | 200 | ||
| Optimizer (S2S, SEQ, DNN) | Adam | ||
| Model | Figure 5 | Figure 6 | ||
|---|---|---|---|---|
| Train Error | Test Error | Train Error | Unseen Error | |
| Group 1 | Group 2 | Groups 1,2 | Group 3 | |
| Sequence-to-sequence (S2S) | 0.02462 | 0.02504 | 0.01309 | 0.57112 |
| Stacked LSTM (SEQ) | 0.38373 | 0.02724 | 0.78142 | 0.32584 |
| Feedforward neural network (DNN) | 0.02223 | 0.04179 | 0.00919 | 0.25547 |
| Support vector machine regression (SVR) | 0.01362 | 0.08347 | 0.00518 | 0.16754 |
| Gradient boosting machine (GBM) | 2.316 × 10 | 0.32589 | 2.316 × 10 | 1.44463 |
| Polynomial regression (OLS) | 0.01335 | 0.08954 | 0.00459 | 0.15954 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khalil, A.; Al Handawi, K.; Mohsen, Z.; Abdel Nour, A.; Feghali, R.; Chamseddine, I.; Kokkolaras, M. Weekly Nowcasting of New COVID-19 Cases Using Past Viral Load Measurements. Viruses 2022, 14, 1414. https://doi.org/10.3390/v14071414
Khalil A, Al Handawi K, Mohsen Z, Abdel Nour A, Feghali R, Chamseddine I, Kokkolaras M. Weekly Nowcasting of New COVID-19 Cases Using Past Viral Load Measurements. Viruses. 2022; 14(7):1414. https://doi.org/10.3390/v14071414
Chicago/Turabian StyleKhalil, Athar, Khalil Al Handawi, Zeina Mohsen, Afif Abdel Nour, Rita Feghali, Ibrahim Chamseddine, and Michael Kokkolaras. 2022. "Weekly Nowcasting of New COVID-19 Cases Using Past Viral Load Measurements" Viruses 14, no. 7: 1414. https://doi.org/10.3390/v14071414
APA StyleKhalil, A., Al Handawi, K., Mohsen, Z., Abdel Nour, A., Feghali, R., Chamseddine, I., & Kokkolaras, M. (2022). Weekly Nowcasting of New COVID-19 Cases Using Past Viral Load Measurements. Viruses, 14(7), 1414. https://doi.org/10.3390/v14071414