Low Delay Inter-Packet Coding in Vehicular Networks

 and
and 
Abstract
:1. Introduction
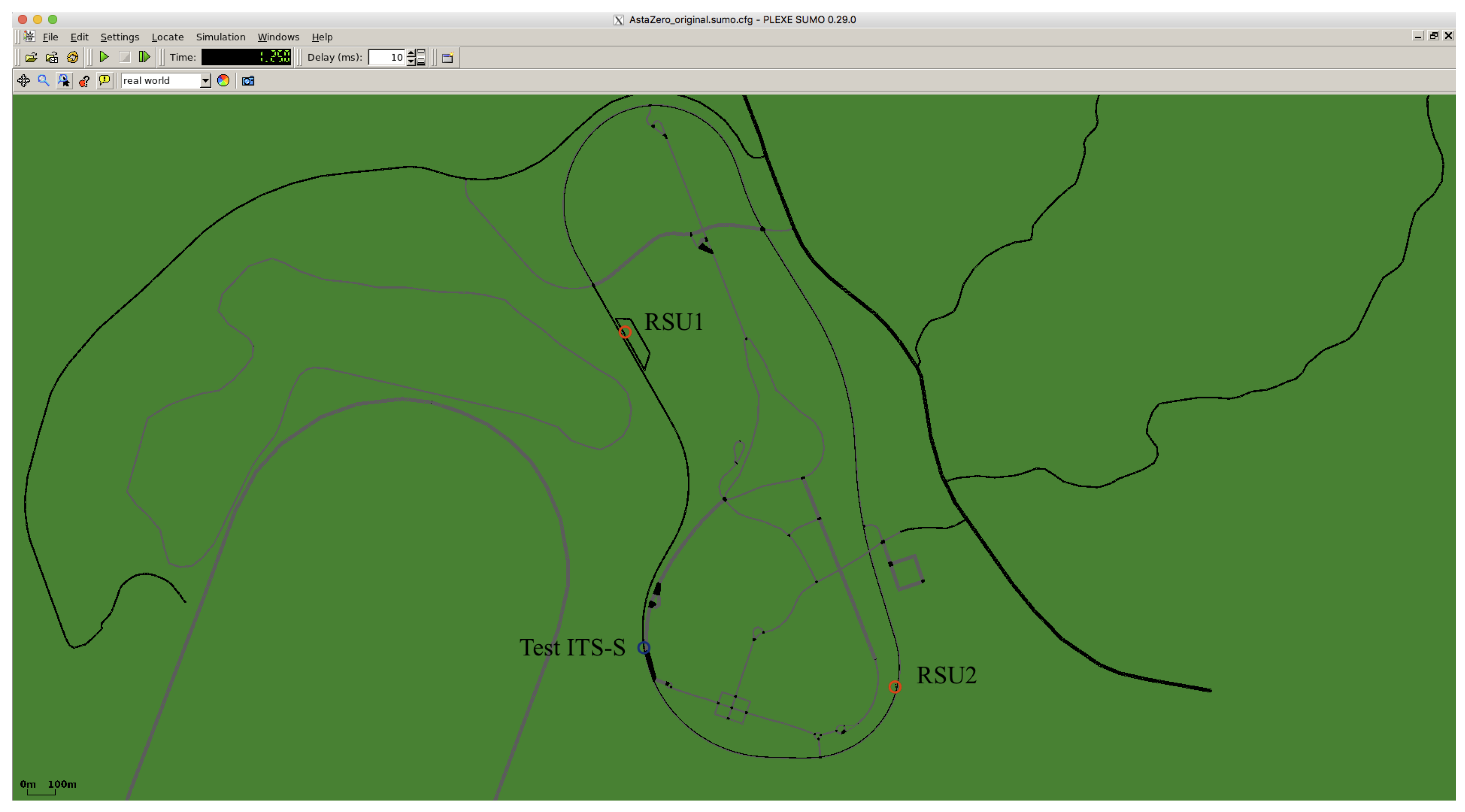
1.1. Safety Testing of C-ITS
1.2. Roadside Units and Quasi Real-Time Transfers
1.3. Convolutional Codes for Inter-Packet Coding
1.4. Contributions
- New low-complexity low-delay decoding algorithm for erasure correction by the Wyner–Ash code applied in V2R scenario.
- Erasure-correcting performance analysis for Wyner–Ash and Reed–Solomon convolutional codes.
- Comparative analysis of suggested codes and decoding algorithms for: (i) memoryless channels; (ii) channels with memory described by Gilbert–Elliott model; and (iii) real-life VANET provided by AstaZero facility.
1.5. Organization of the Paper
2. Preliminaries
2.1. Wireless Channels
2.2. Performance Metric
2.3. Convolutional Codes for Network Applications
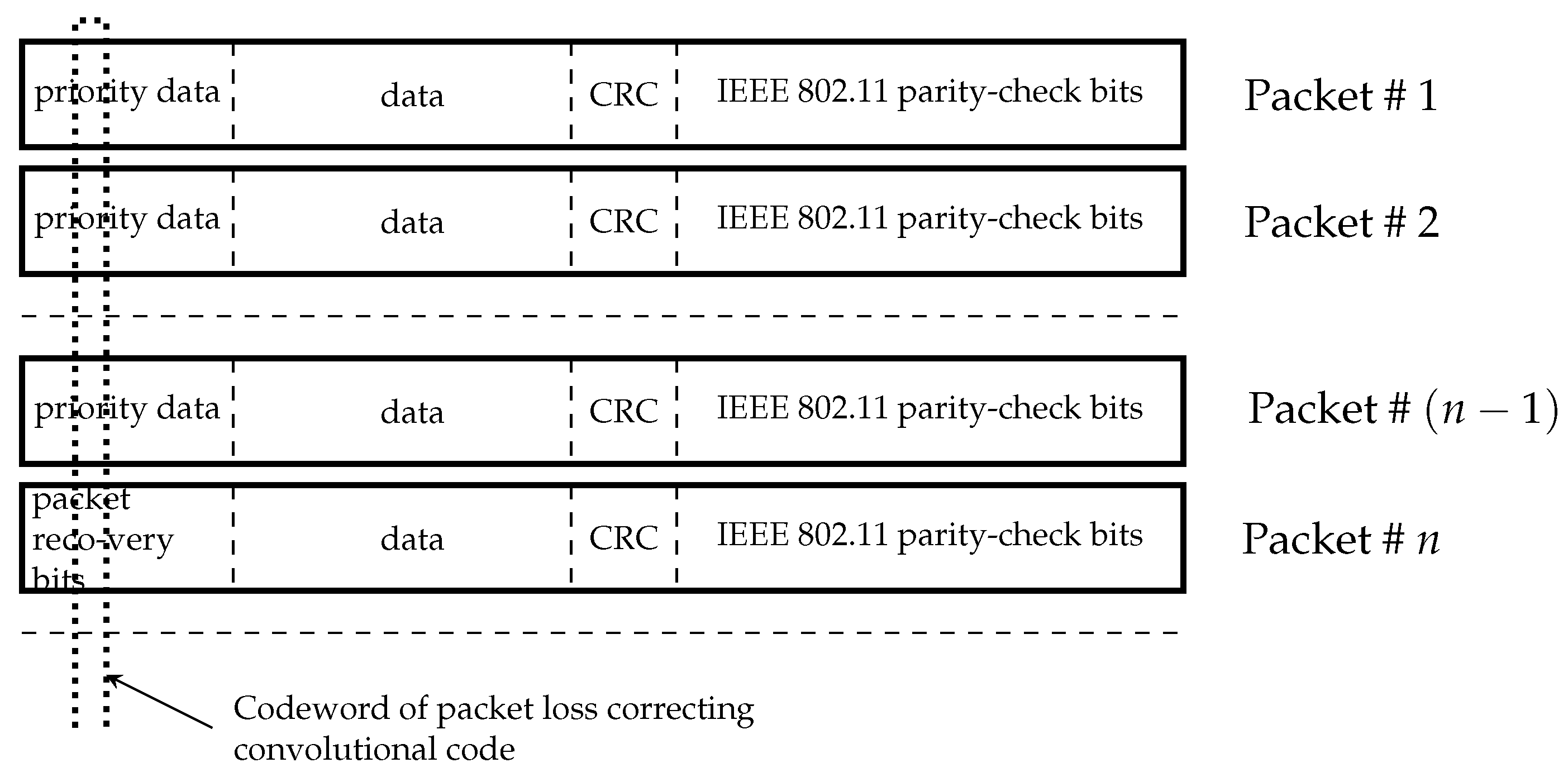
3. Packet Recovering Codes
3.1. Binary Wyner–Ash Codes
3.1.1. Code Description and Distance Properties
3.1.2. Encoding
3.1.3. Decoding

- Step 1.
- Compute syndrome. The syndrome is equal to [0 0 1]. From Equation (8) followsThe number of unknowns is larger than the rank of the system which is equal to 2, that is, a unique solution does not exists. The decoder outputs only the information part of the first erasure-free block [1 1 0 0], i.e., output bits at this step are [1 1 0].
- Step 2.
- Shift the window. Input now is .The syndrome is equal to [0 0 1]. From Equation (8) followsThe unique solution is = [1 1 0]. The decoder decision is [1 1 0 1] and the output is [1 1 0]. At the next step the decoder will recover block [0 0 1 0] and the output bits are [0 0 1].
| Algorithm 1 BP-BEC. |
| while there exist parity checks with only one erased symbol do |
| Assign to the erased symbol the modulo-2 sum of all nonerased symbols participating in the same parity check. |
| end while |
3.2. Nonbinary Convolutional Codes
3.2.1. Code Description and Error-Correcting Properties
- 1.
- Any erasure pattern such that and , for any N will be corrected.
- 2.
- Any erasure pattern such that , will be corrected.
3.2.2. Encoding and Decoding for the RS-Convolutional Codes
4. Numerical Results
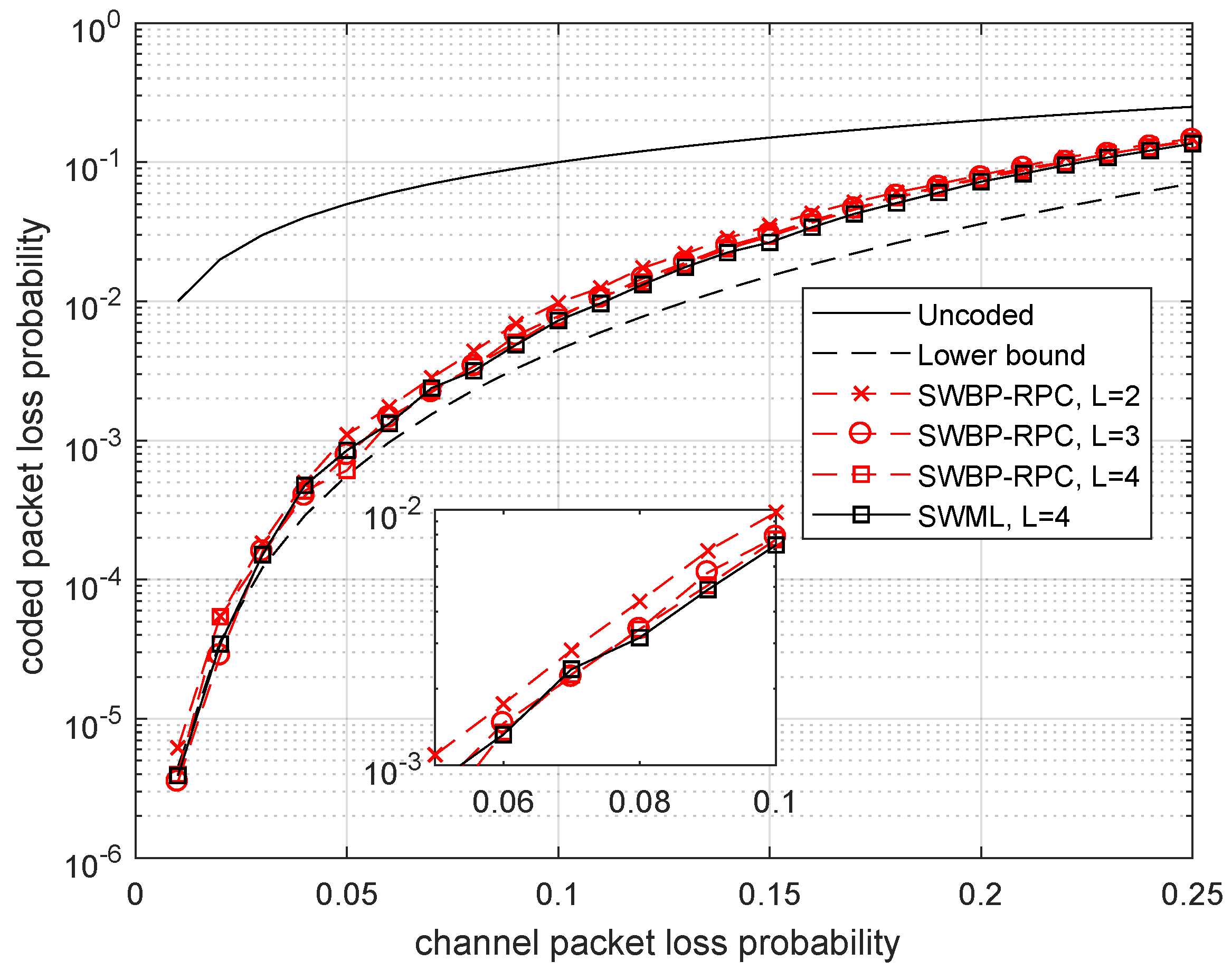
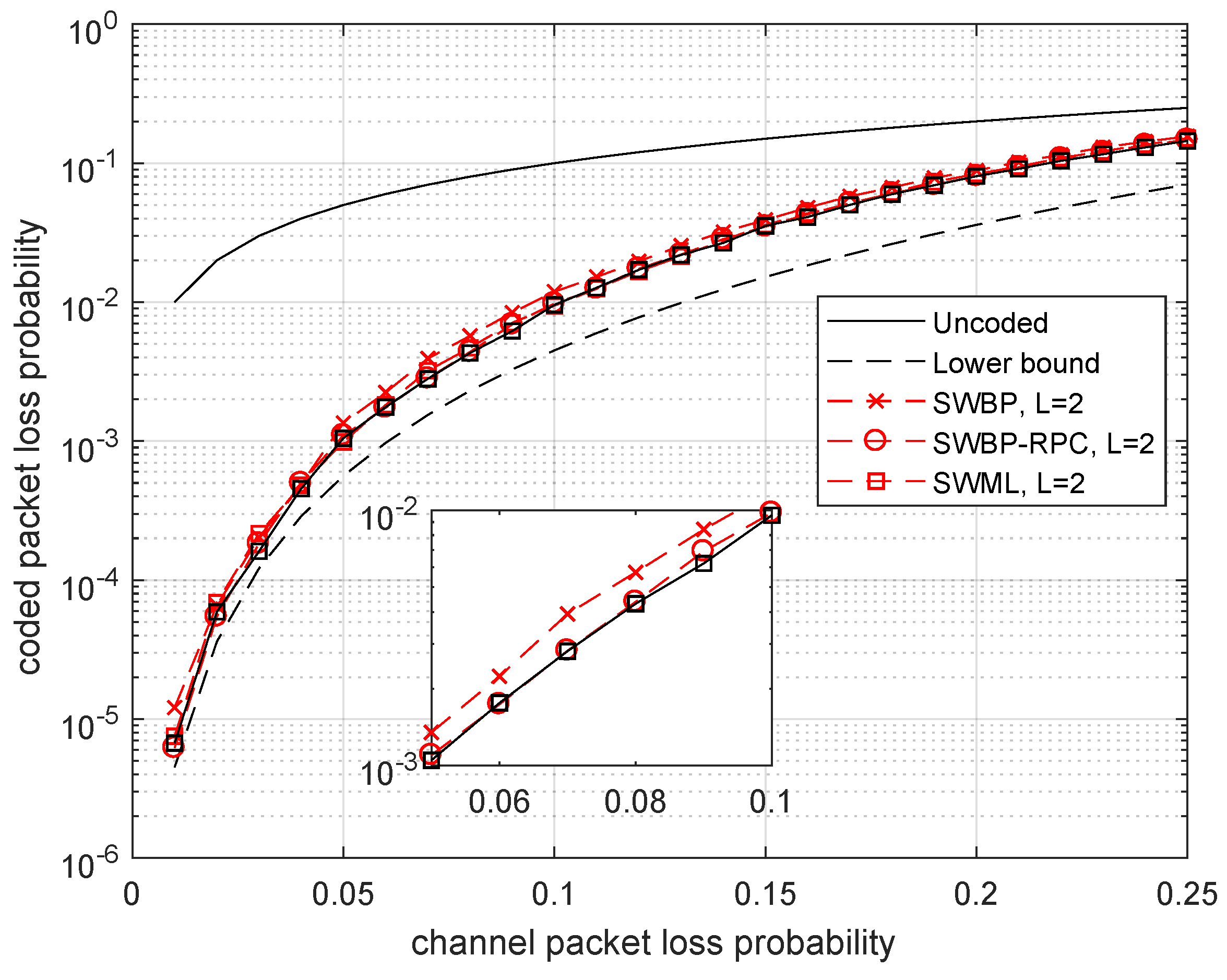
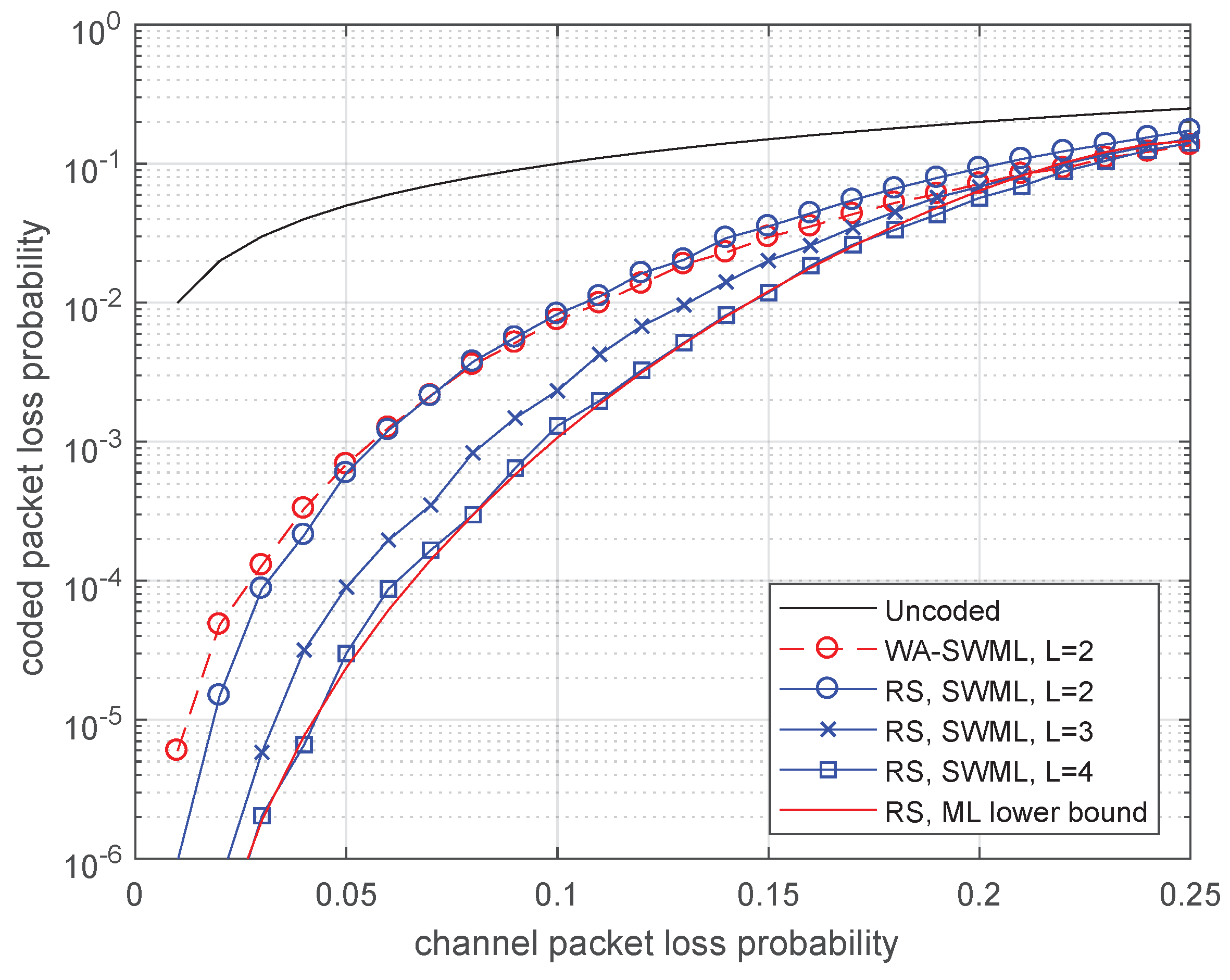
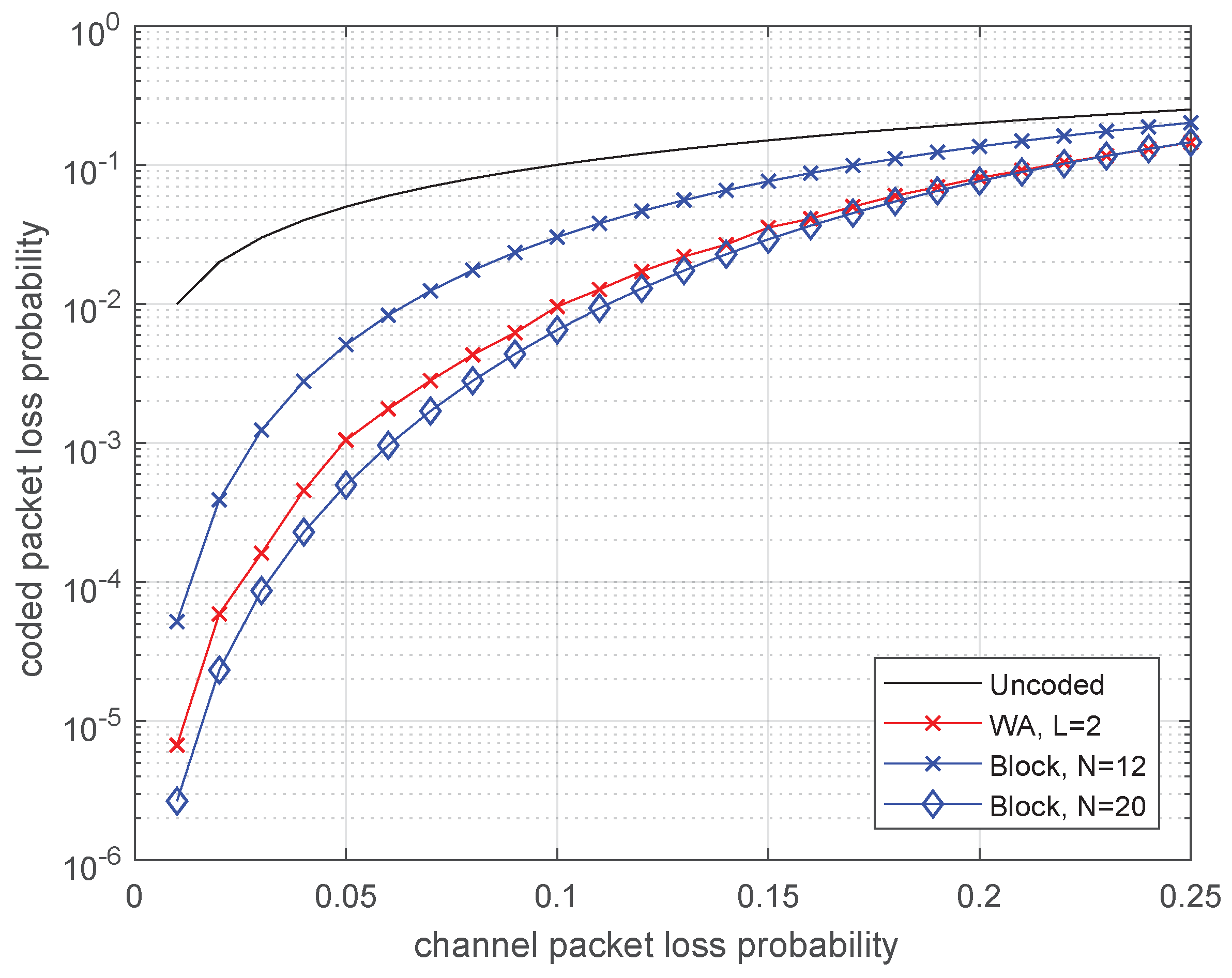
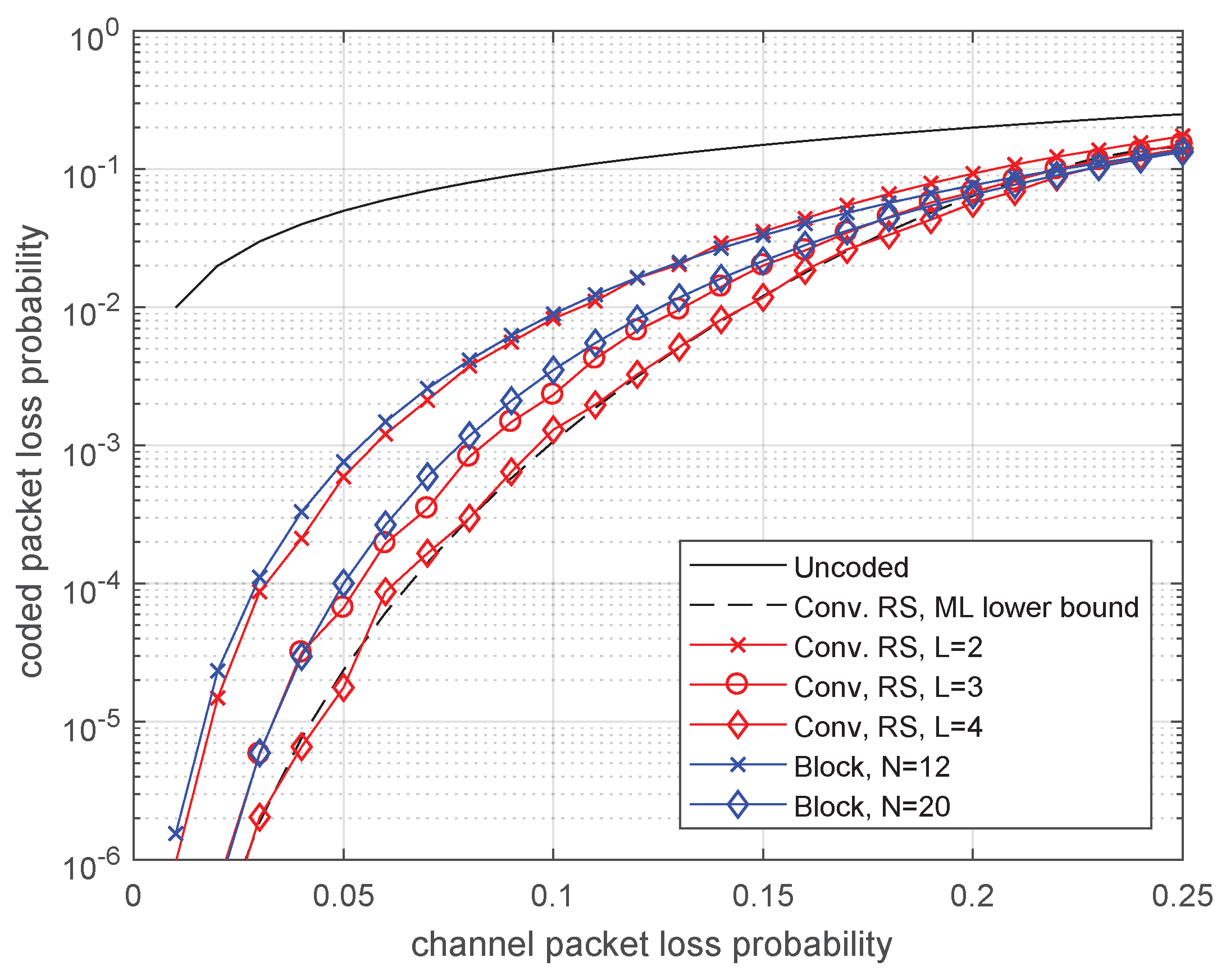
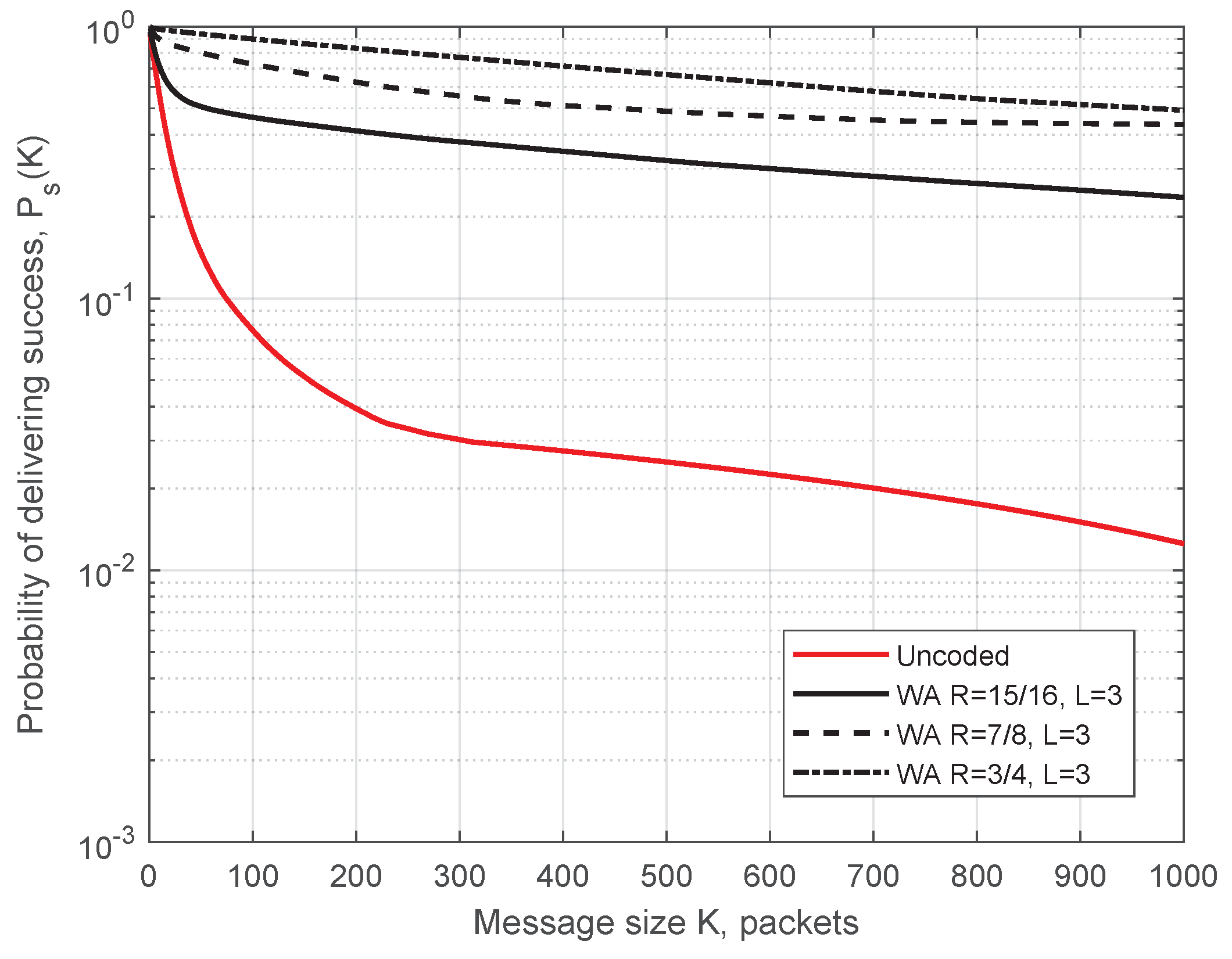
4.1. Memoryless Channel (BEC)
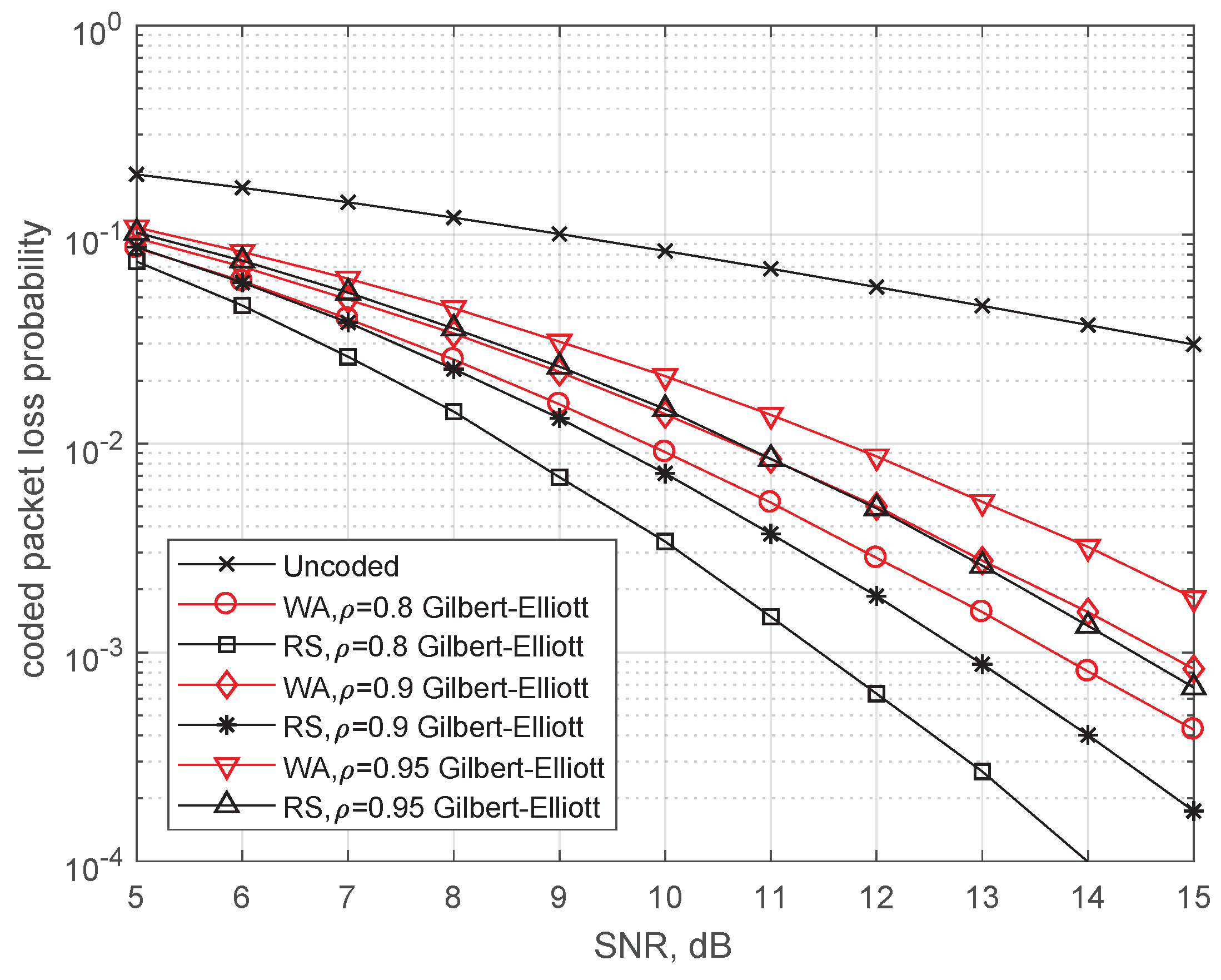
4.2. Channel with Memory (M-BEC)
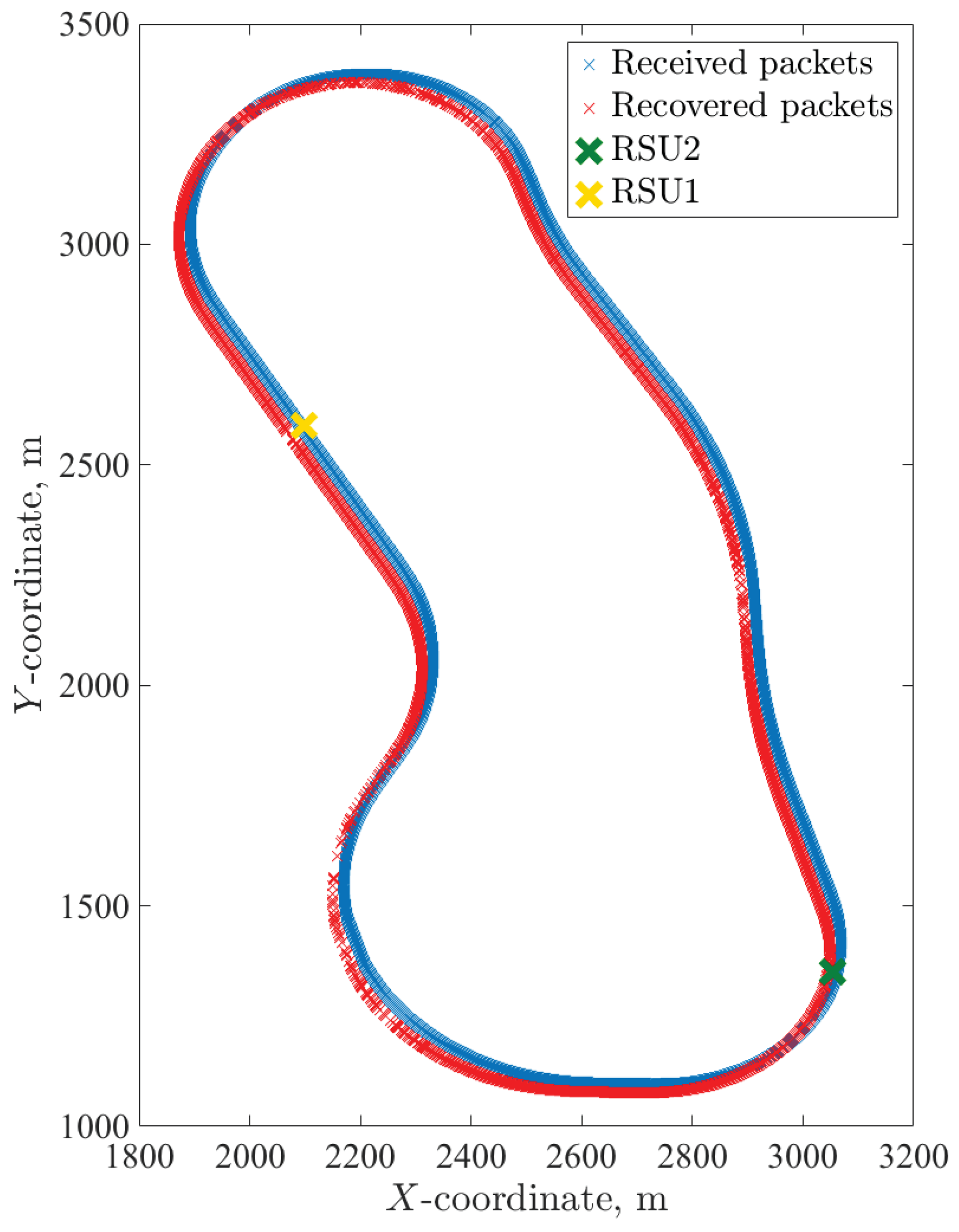
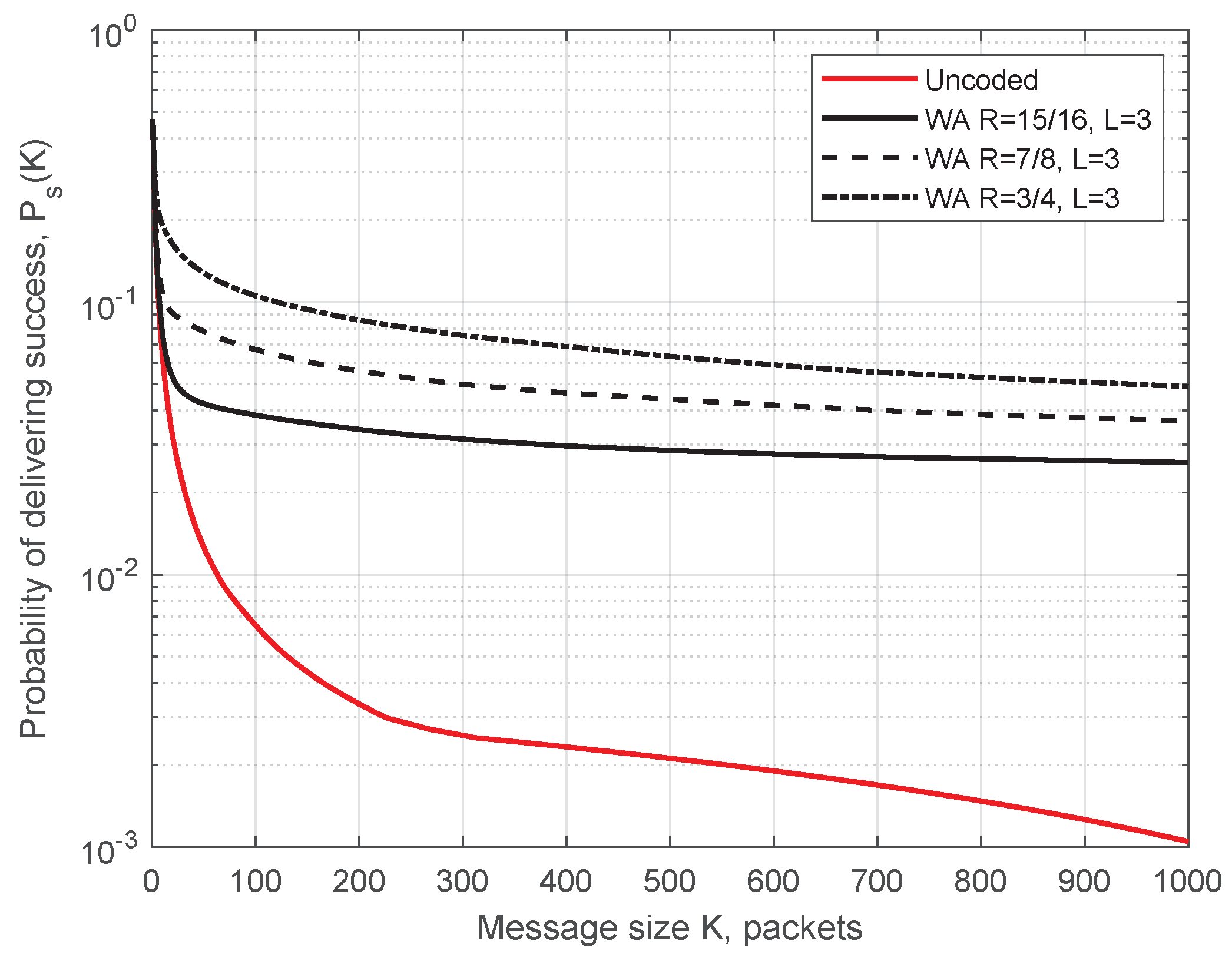
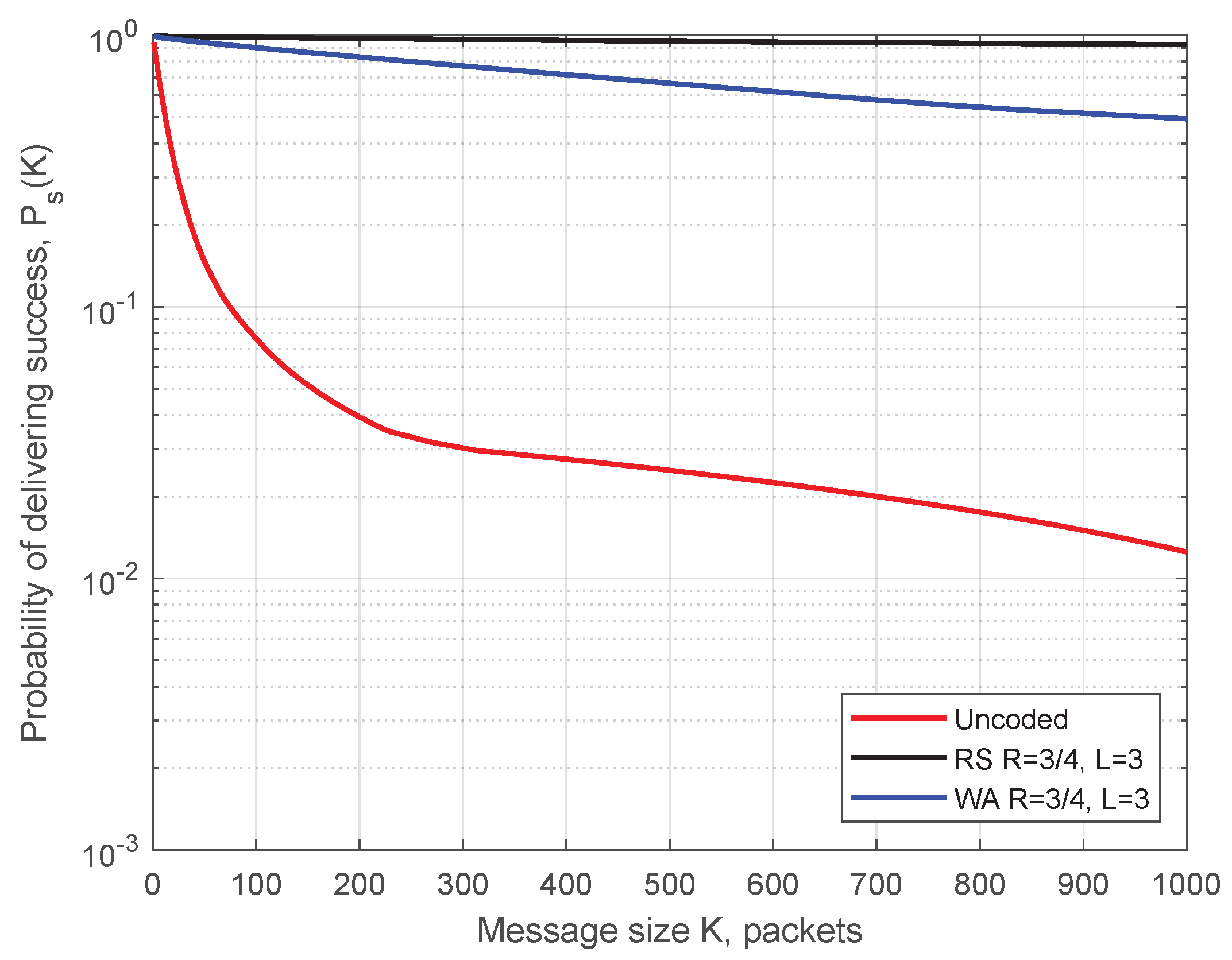
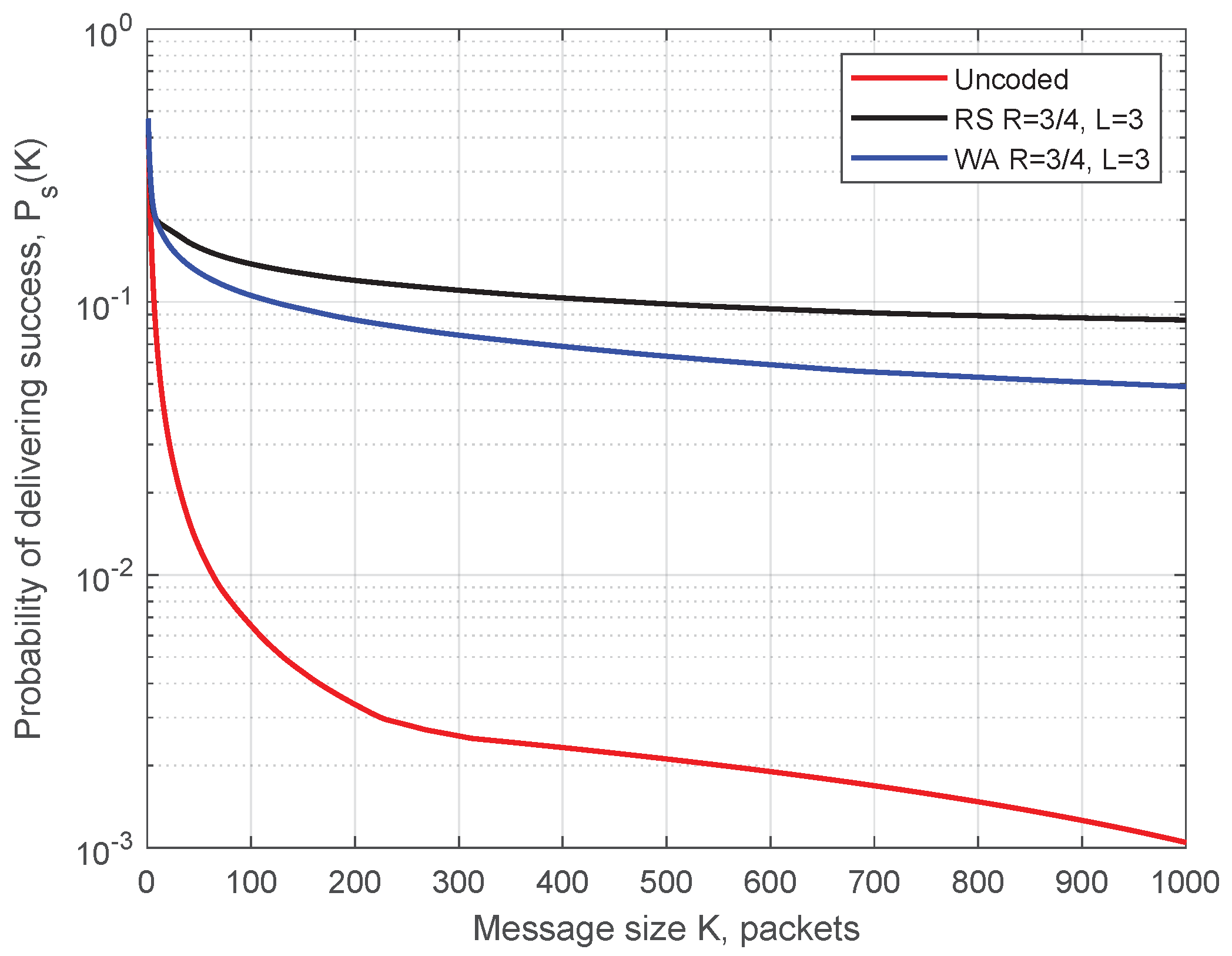
4.3. Probability of Message Successful Delivering for AstaZero Scenario
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zheng, K.; Zheng, Q.; Chatzimisios, P.; Xiang, W.; Zhou, Y. Heterogeneous Vehicular Networking: A Survey on Architecture, Challenges, and Solutions. IEEE Commun. Surv. Tutor. 2015, 17, 2377–2396. [Google Scholar] [CrossRef]
- Sjoberg, K.; Andres, P.; Buburuzan, T.; Brakemeier, A. Cooperative Intelligent Transport Systems in Europe: Current Deployment Status and Outlook. IEEE Veh. Technol. Mag. 2017, 12, 89–97. [Google Scholar] [CrossRef]
- AstaZero Test Site. Available online: http://www.astazero.com/ (accessed on 10 October 2019).
- ETSI. Intelligent Transport Systems (ITS); Vehicular Communications; Basic Set of Applications; Definitions; ETSI TS 102 638 V1.1.1 (2009-06); ETSI: Valbonne, France, 2014. [Google Scholar]
- Zhang, K.; Mao, Y.; Leng, S.; Maharjan, S.; Vinel, A.; Zhang, Y. Contract-theoretic Approach for Delay Constrained Offloading in Vehicular Edge Computing Networks. Mob. Netw. Appl. 2018, 1–12. [Google Scholar] [CrossRef]
- Xing, M.; He, J.; Cai, L. Maximum-Utility Scheduling for Multimedia Transmission in Drive-Thru Internet. IEEE Trans. Veh. Technol. 2016, 65, 2649–2658. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, B.; Hou, F.; Luan, T.H.; Zhang, N.; Gui, L.; Yu, Q.; Shen, X.S. Spatial Coordinated Medium Sharing: Optimal Access Control Management in Drive-Thru Internet. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2673–2686. [Google Scholar] [CrossRef]
- Atallah, R.F.; Khabbaz, M.J.; Assi, C.M. Modeling and Performance Analysis of Medium Access Control Schemes for Drive-Thru Internet Access Provisioning Systems. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3238–3248. [Google Scholar] [CrossRef]
- Martinian, E.; Sundberg, C.E. Burst erasure correction codes with low decoding delay. IEEE Trans. Inform. Theory 2004, 50, 2494–2502. [Google Scholar] [CrossRef]
- Johnson, S.J. Burst erasure correcting LDPC codes. IEEE Trans. Commun. 2009, 57, 641–652. [Google Scholar] [CrossRef]
- Badr, A.; Khisti, A.; Tan, W.T.; Apostolopoulos, J. Streaming codes for channels with burst and isolated erasures. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2850–2858. [Google Scholar]
- Gao, Y.; Xu, X.; Guan, Y.L.; Chong, P.H.J. V2X content distribution based on batched network coding with distributed scheduling. IEEE Access 2018, 6, 59449–59461. [Google Scholar] [CrossRef]
- Yang, S.; Yeung, R.W. Batched sparse codes. IEEE Trans. Inf. Theory 2014, 60, 5322–5346. [Google Scholar] [CrossRef]
- Shokrollahi, A.; Luby, M. Raptor codes. Found. Trends Commun. Inf. Theory 2011, 6, 213–322. [Google Scholar] [CrossRef]
- Arai, M.; Yamaguchi, A.; Fukumoto, S.; Iwasaki, K. Method to recover lost Internet packets using (n, k, m) convolutional codes. Electron. Commun. Jpn. Part III Fundam. Electron. Sci. 2005, 88, 1–13. [Google Scholar] [CrossRef]
- Wyner, A.; Ash, R. Analysis of recurrent codes. IEEE Trans. Inform. Theory 1963, 9, 143–156. [Google Scholar] [CrossRef]
- Ebert, P.; Tong, S. Convolutional Reed-Solomon Codes. Bell Labs Tech. J. 1969, 48, 729–742. [Google Scholar] [CrossRef]
- Johannesson, R.; Zigangirov, K.S. Fundamentals of Convolutional Coding; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Bocharova, I.; Kudryashov, B.; Rabi, M.; Lyamin, N.; Dankers, W.; Frick, E.; Vinel, A. Modeling packet losses in communication networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1–5. [Google Scholar]
- Bocharova, I.; Kudryashov, B.; Rabi, M.; Lyamin, N.; Dankers, W.; Frick, E.; Vinel, A. Characterizing Packet Losses in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, in press. [Google Scholar] [CrossRef]
- Gabidulin, E.M. Theory of codes with maximum rank distance. Probl. Peredachi Inform. 1985, 21, 3–16. [Google Scholar]
- Roth, R.M. Maximum-rank array codes and their application to crisscross error correction. IEEE Trans. Inform. Theory 1991, 37, 328–336. [Google Scholar] [CrossRef]
- Blaum, M.; McEliece, R. Coding protection for magnetic tapes: A generalization of the Patel-Hong code. IEEE Trans. Inform. Theory 1985, 31, 690–693. [Google Scholar] [CrossRef]
- MacWilliams, F.J.; Sloane, N.J.A. The Theory of Error-Correcting Codes; Elsevier: Amsterdam, The Netherlands, 1977. [Google Scholar]
- Bocharova, I.E.; Kudryashov, B.D. Development of Discrete Models for Fading Channels. Probl. Peredachi Inform. 1993, 29, 58–67. [Google Scholar]
- Yakimenka, Y.; Skachek, V.; Bocharova, I.E.; Kudryashov, B.D. Stopping redundancy hierarchy beyond the minimum distance. IEEE Trans. Inform. Theory 2019, 65, 3724–3737. [Google Scholar] [CrossRef]
- Schwartz, M.; Vardy, A. On the stopping distance and the stopping redundancy of codes. IEEE Trans. Inform. Theory 2006, 52, 922–932. [Google Scholar] [CrossRef] [Green Version]
- Bocharova, I.E. Weight enumerators of high-rate convolutional codes based on the Hamming code. Probl. Peredachi Inform. 1991, 27, 86–91. [Google Scholar]
- Bocharova, I.E.; Kudryashov, B.D.; Skachek, V.; Yakimenka, Y. Distance Properties of Short LDPC Codes and their Impact on the BP, ML and Near-ML Decoding Performance. In Proceedings of the International Castle Meeting on Coding Theory and Applications, Vihula, Estonia, 28–31 August 2017; Springer: New York, NY, USA, 2017; pp. 48–61. [Google Scholar]
- Sadeghi, P.; Kennedy, R.A.; Rapajic, P.B.; Shams, R. Finite-state Markov modeling of fading channels—A survey of principles and applications. IEEE Signal Process. Mag. 2008, 25, 57–80. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m | R | Spectrum Coefficients |
|---|---|---|
| 2 | 3/4 | 6, 23, 80, 290, 1050, 3804, 13782, 49929, 180888, 655334 |
| 3 | 7/8 | 28, 275, 2456, 22468, 205826, 1885187, 17266158, 158138208, 1448368114, 13265417898 |
| 4 | 15/16 | 120, 2644, 52456, 1066592, 21738992, 442834486, 9021091078, 183772934474, 3743704654772, 76264411563598 |
| m | R | Series Expansion Coefficients |
|---|---|---|
| 2 | 3/4 | 1, 32, 342, 2282, 8756, 9657, −102562, −773838 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bocharova, I.; Kudryashov, B.; Lyamin, N.; Frick, E.; Rabi, M.; Vinel, A. Low Delay Inter-Packet Coding in Vehicular Networks. Future Internet 2019, 11, 212. https://doi.org/10.3390/fi11100212
Bocharova I, Kudryashov B, Lyamin N, Frick E, Rabi M, Vinel A. Low Delay Inter-Packet Coding in Vehicular Networks. Future Internet. 2019; 11(10):212. https://doi.org/10.3390/fi11100212
Chicago/Turabian StyleBocharova, Irina, Boris Kudryashov, Nikita Lyamin, Erik Frick, Maben Rabi, and Alexey Vinel. 2019. "Low Delay Inter-Packet Coding in Vehicular Networks" Future Internet 11, no. 10: 212. https://doi.org/10.3390/fi11100212
APA StyleBocharova, I., Kudryashov, B., Lyamin, N., Frick, E., Rabi, M., & Vinel, A. (2019). Low Delay Inter-Packet Coding in Vehicular Networks. Future Internet, 11(10), 212. https://doi.org/10.3390/fi11100212