1. Introduction
With the rapid development of artificial intelligence and deep learning, neural networks are widely applied to various fields ranging from computer vision [
1,
2], speech recognition [
3,
4], and natural language processing (NLP) [
5,
6,
7,
8]. The standard neural machine translation (NMT) model [
9,
10,
11,
12] employs the encoder to map the source sentence into a continuous representation vector, then it feeds the resulting vector to the decoder to generate the target sentence, which directly learns the translation relationship between two distinct languages from the bilingual parallel sentence pairs. Recently, by exploiting advanced neural networks, such as long short-term memory (LSTM) [
13], gate recurrent unit (GRU) [
14], and attention mechanism [
15], NMT has become the current dominant machine translation approach, and it achieves impressive performance on many high-resource language pairs, such as Chinese–English translation and English–German translation.
However, existing NMT models still struggle in the translation task of agglutinative languages with complex morphology and limited resources, such as Turkish to English and Uyghur to Chinese. The morpheme structure of the word in agglutinative language is formed by a stem followed by a sequence of suffixes (since the words only have a few prefixes, we simply combine the prefixes with a stem into the stem unit), which can be denoted as: word = stem + suffix1 + suffix2 + … + suffixN [
16]. For example, in the Turkish phrase “küçük fagernes kasabasındayım” (I’m in a small town of fagernes), the morpheme structure of the word “kasabasındayım” (I’m in town) is: kasaba + sı + nda + yım. Due to the fact that the suffixes have many inflected and morphological variants depending on the case, tense, number, gender, etc., the vocabulary size of an agglutinative language is considerable even in small-scale training data. Moreover, a word can express the meaning of a phrase or sentence. Thus, there are many rare and out-of-vocabulary (OOV) words in the training process, which leads to many inaccurate translation results [
17] and increases the NMT model complexity.
Recently, researchers attempted to explicitly use the source-side linguistic knowledge to further improve the NMT performance. Sennrich and Haddow generalized the word-embedding layer of the encoder to accommodate for additional linguistic input features including lemma, sub-word tag, part-of-speech (POS) tag, dependency label, and morphological tag for German–English translation [
18]. Eriguchi et al. proposed a tree-to-sequence-based model for English–Japanese translation, which encodes each phrase in the source parse tree and used the attention mechanism to align both the input words and phrases with the output words [
19]. Yang et al. improved the above work by encoding each node in the source parse tree with the local and global context information, and they utilized a weighted variant of the attention mechanism to adjust the proportion of the conditional information for English–German translation [
20]. Li et al. combined the source-side sentence with its linearized syntactic structure, which makes the NMT model automatically learn useful language information for Chinese–English translation [
21]. Currey and Heafield modified the multi-source technique [
22] for English–German translation, and they exploited the syntax structure of the source-side sentence by employing an additional encoder to encode the linearized parse tree [
23]. Li et al. presented a linguistic knowledge-aware neural model for both English–Chinese translation and English–German translation, which uses a knowledge gate and an attention gate to control the information from the source words and the linguistic features of POS tag, named entity (NE) tag, chunk tag and dependency label [
24].
However, the above works mostly pay attention to the high-resource machine translation tasks with large-scale parallel data and sufficient semantic analysis tools, which lacks the consideration of agglutinative language translation with complex morphology and limited resources. In this paper, we propose a multi-source neural model for the machine translation task on agglutinative language. We consider that enhancing the ability of the NMT model in capturing the semantic information of the source-side sentence is beneficial to compensate for both the corpus scarcity and data sparseness. The followings are our main contributions:
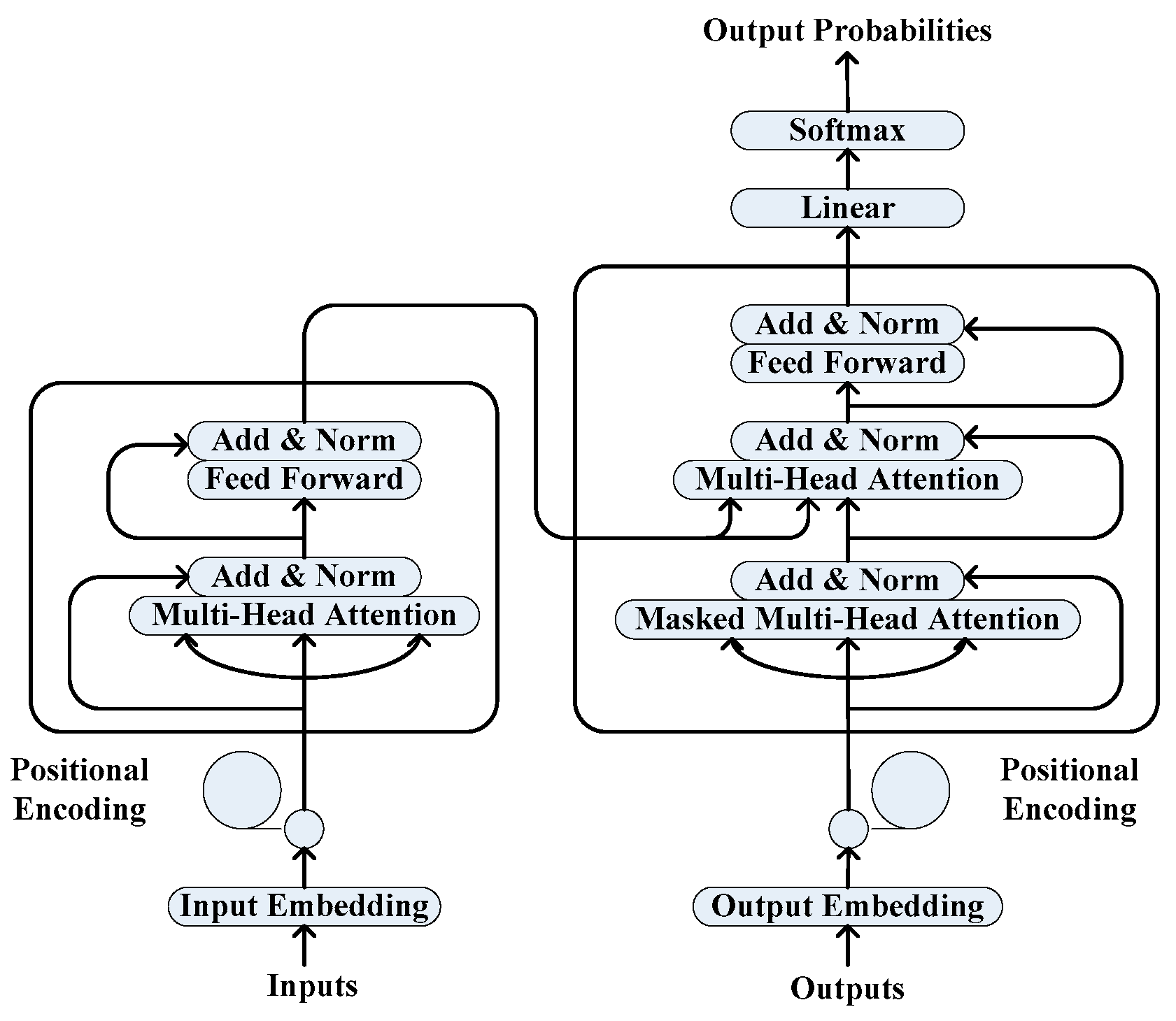
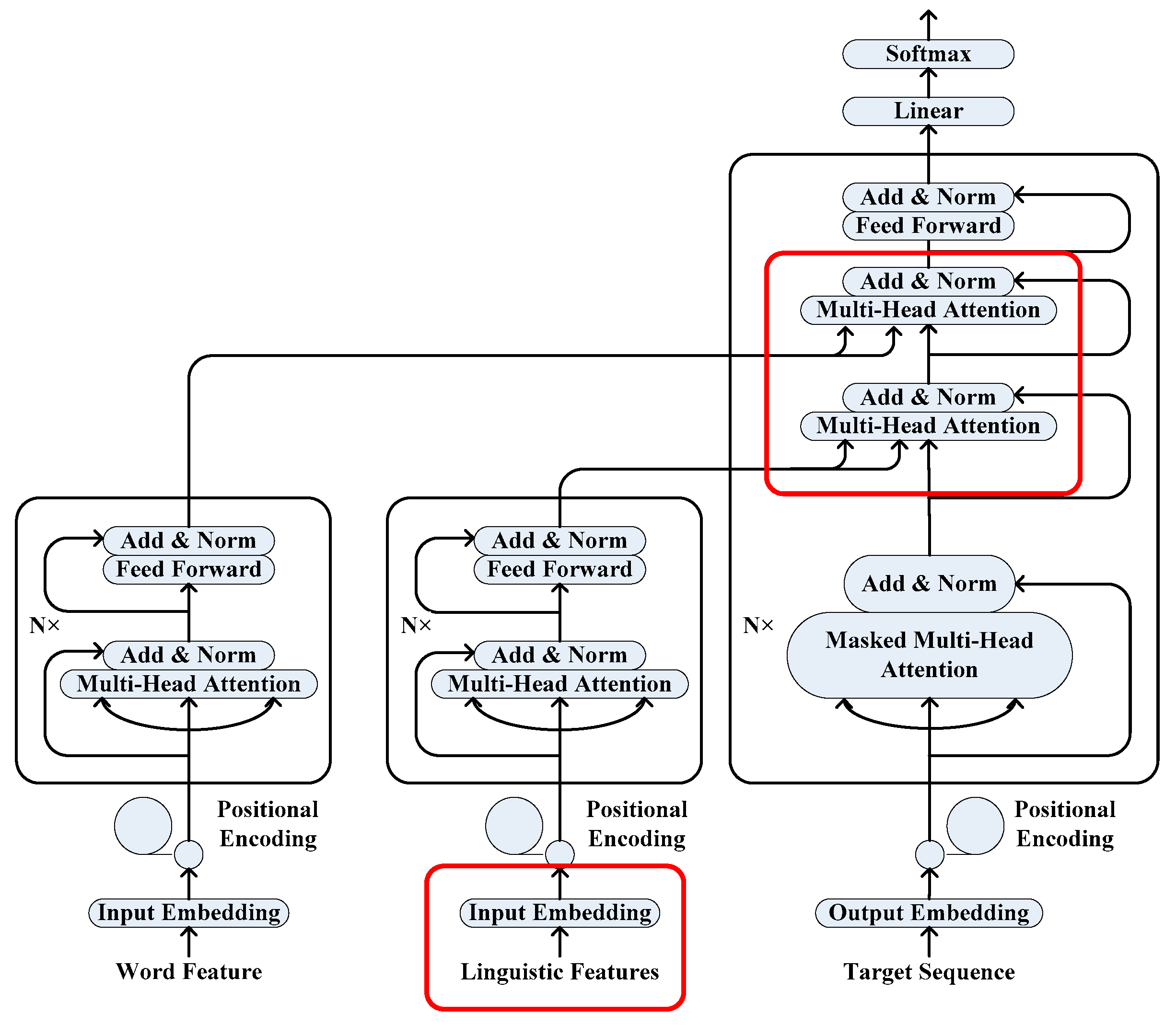
Focusing on the complex morphology of the agglutinative language, in contrast to the standard NMT model that uses a single encoder, we utilize a multi-source NMT framework consisting of a word-based encoder and a knowledge-based encoder to encode the word feature and the linguistic features, respectively, which aims to incorporate the source-side linguistic knowledge into the NMT model.
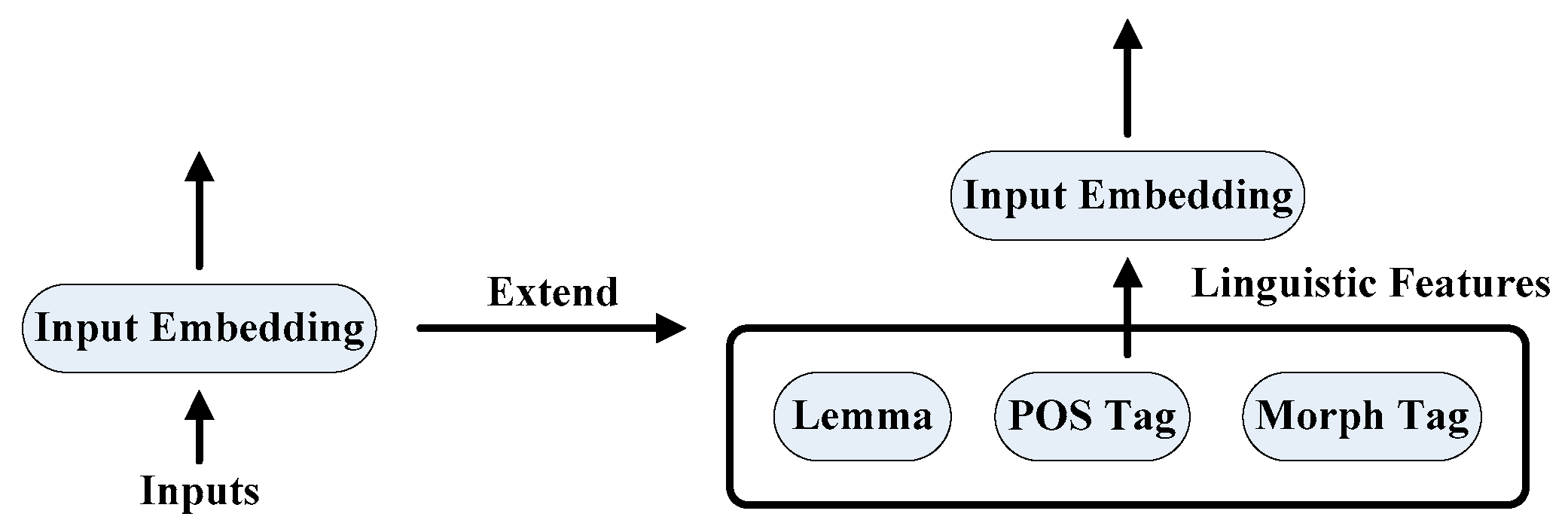
For the purpose of enriching each source word’s representation in the NMT model, we extend the input embedding layer of the knowledge-based encoder to allow for the word-level linguistic features of lemma, POS tag and morphological tag.
In the consideration of enhancing the NMT representation ability on the source-side sentence, we use a serial combination method to hierarchically combine the conditional information from the encoders, which helps to learn a high-quality context representation. Firstly, the representation of the source-side linguistic features integrates with the representation of the target sequence. Secondly, the resulting vector integrates with the representation of the source sequence to generate a context vector. Finally, the context vector is employed to predict the target word sequence.
Experimental results in Turkish–English and Uyghur–Chinese machine translation tasks show that the proposed approach can effectively improve the translation performance of the agglutinative language, which indicates the validity of the multi-source neural model on using the source-side linguistic knowledge for morphologically rich languages.
2. Related Works
Recently, many researchers showed their great interest in improving the NMT performance in the low-resource and morphologically-rich machine translation tasks. The first line of research attempted to utilize external monolingual data [
25,
26]. Gulcehre et al. presented an effective way to integrate a language model that trained on the target-side monolingual data into the NMT model [
27]. Sennrich et al. paired the target-side monolingual data with automatic back-translation and treated it as additional parallel data to train the standard NMT model [
28]. Ramachandran et al. employed an unsupervised learning method that first uses both the source-side and target-side monolingual data to train two language models to initialize the encoder and decoder, then fine-tunes the trained NMT model with the labelled dataset [
29]. Currey et al. utilized the target-side monolingual data and copied it to the source-side as additional training data, then mixed with the original training data to train the NMT [
30]. The second line of research attempts to leverage other languages for the zero-resource NMT [
31,
32]. Cheng et al. proposed a pivot-based method that first translates the source language into a pivot language, then translates the pivot language into the target-side language [
33]. Zoph et al. utilized a transfer learning method that first trains a parent model on the high-resource language pair, then transfers the learned parameters to initialize the child model on the low-resource language pair [
34].
The multi-source neural model was first used by Zoph and Knight for multilingual translation [
22]. It can be seen as a many-to-one setting in the multi-task sequence-to-sequence (se2seq) learning [
35]. The model consists of multiple encoders with one encoder per source language and a decoder to predict the required target language, which is effective to share the encoder parameters and enhance the model representation ability. Multi-source neural models are widely applied to the fields of machine translation [
36,
37], automatic post-editing (APE) [
38,
39] and semantic parsing [
40,
41].
NLP tasks are performed by using supervised learning with large-scale labelled training data. However, since the artificial labelled data is limited, it is valuable to utilize the additional resources to further improve the model performance. In recent years, many basic NLP tasks such as POS tagging, named entity recognition, and dependency parsing are used as prior knowledge to improve the higher-level NLP tasks such as summarization, natural language inference and machine translation [
42,
43,
44,
45]. Generally speaking, the usage of linguistic annotations is helpful to better identify the word in the context. Our approach follows this line of research.
5. Results and Discussion
The experimental results for the Turkish–English and Uyghur–Chinese machine translation tasks are shown in
Table 5 and
Table 6, respectively. For the Turkish–English machine translation task, from
Table 5 we can see that the multi-source neural model outperformed both the NMT baseline model and the single-source neural model. It achieved the highest BLEU scores and ChrF3 scores on all the test datasets. Moreover, it achieved the highest improvements on the tst2014 dataset of 2.4 BLEU points (24.98→27.37) and 1.6 ChrF3 points (48.05→49.74). For the Uyghur–Chinese machine translation task, from
Table 6 we can see that the multi-source neural model also outperformed both the NMT baseline model and single-source neural model, achieving an improvement of 0.6 BLEU points (27.60→28.21) and 0.7 ChrF3 points (36.73→37.44) on the test dataset. The experimental results show that the proposed approach is capable of effectively improving the translation performance for agglutinative languages.
In addition, we found that the performance improvements of both the multi-source neural model and single-source neural model for the Uyghur-Chinese machine translation task were not very obvious. The main reason was that the morphological analysis tool for the Uyghur word annotation was not accurate enough. Since the complex morphology of Uyghur, many words cannot be effectively identified and classified, thus the tool simply annotates all the unknown words with a uniform token “<unk>” as the same with their POS tags, which increases the complexity for model training. The experimental results indicate that the annotation quality of the source-side sentence makes a difference on the translation quality of the NMT model with linguistic input features.
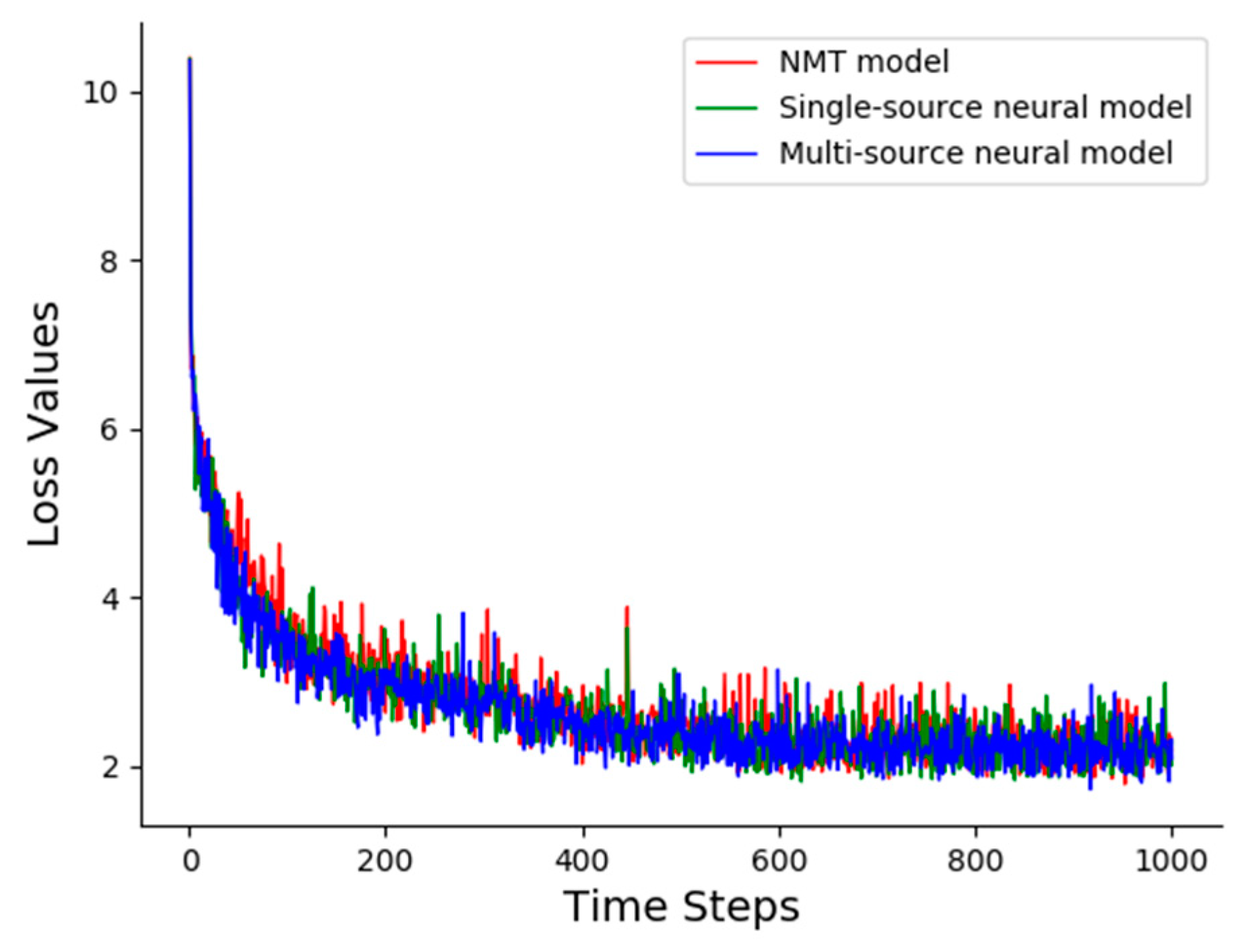
Figure 4 shows the loss values as a function of the time steps (saved every 100 steps) on the validation dataset in different neural translation models for the Turkish-English machine translation task. We can see that in spite of using two encoders, which leads to more model parameters and training time, the loss values of our proposed multi-source neural model is still consistent with the NMT baseline model and the single-source model. This fact indicates that our model was robust and feasible for the agglutinative language translation task. The loss value converges continuously until it achieves a lower value, then it oscillates in a small interval. Thus, we stop the NMT model training process after 10,000 steps without obvious reductions on the loss value.
To further evaluate the effect of using different linguistic features, we separately incorporated the linguistic features of lemma, POS tag, and morphological tag into the proposed multi-source neural model for comparison. The experimental results for the Turkish-English machine translation task are shown in
Table 7. From the table we can find that for the test datasets of tst2011, tst2012, and tst2013, incorporating the lemma feature into the multi-source neural model achieved the highest BLEU and ChrF3 scores while for the test dataset of tst2014, incorporating the morphological feature achieved the highest BLEU and ChrF3 scores. The results indicate that different linguistic features are appropriate for different datasets. Moreover, the combination of all the linguistic features achieves the best translation quality, which demonstrates that the proposed approach enables the NMT model to better utilize the source-side linguistic features and effectively integrate them together.
Table 8 shows the translation samples of the NMT baseline model and multi-source neural model on Turkish–English machine translation. For the first translation sample, we can observe that the NMT baseline model misunderstands the subject in the source-side sentence and simply uses a pronoun to denote the Turkish word “amerika’da” (in America). Instead, the multi-source neural model captures the above information and generates an appropriate translation result. For the second translation sample, we can observe that the NMT baseline model makes a mistake on the meaning of the Turkish word “çekiminden” (from the shooting), which leads to an inaccurate translation result. Instead, the multi-source neural model understands the semantic information of the source sentence. The above translation examples indicate that the proposed model is more sensitive to the information of the subject, location, named entity, and the word class by utilizing the source-side linguistic knowledge.
6. Conclusions
In this paper, we proposed a multi-source neural model for the translation task on agglutinative language, which utilizes the source-side linguistic knowledge to enhance the representation ability of the encoder. The model employs two separate encoders to encode the word feature and the linguistic features, respectively. We first extended the input-embedding layer of an encoder to incorporate the linguistic information into NMT. Then, we used a serial combination method to hierarchically integrate the conditional information from the encoders with the outputs of the decoder, which aims to learn a high-quality context representation. The experimental results show that the proposed approach was beneficial to the translation task on the morphologically rich languages, which achieves the highest improvements of +2.4 BLEU points for the Turkish-English translation task and +0.6 BLEU points for the Uyghur-Chinese translation task. In addition, the experimental results show that the proposed multi-source neural model was capable of better exploiting the source-side linguistic knowledge and effectively integrating the linguistic features together.
In future work, we plan to utilize other combination methods to further enhance the connection between the encoder and decoder. We also plan to adjust the training parameters to find the optimal conditions for the NMT model on the low-resource and morphologically rich machine translation. Moreover, we plan to use the multi-source framework to perform transfer learning to make better generalizations on the agglutinative languages.






{kind=link}
{kind=link}
{kind=link}
{kind=link}