
Mobile App Start-Up Prediction Based on Federated Learning and Attributed Heterogeneous Network Embedding



Abstract
:1. Introduction
2. Related Work
2.1. Mobile App Start-Up Prediction
2.2. Federated Learning
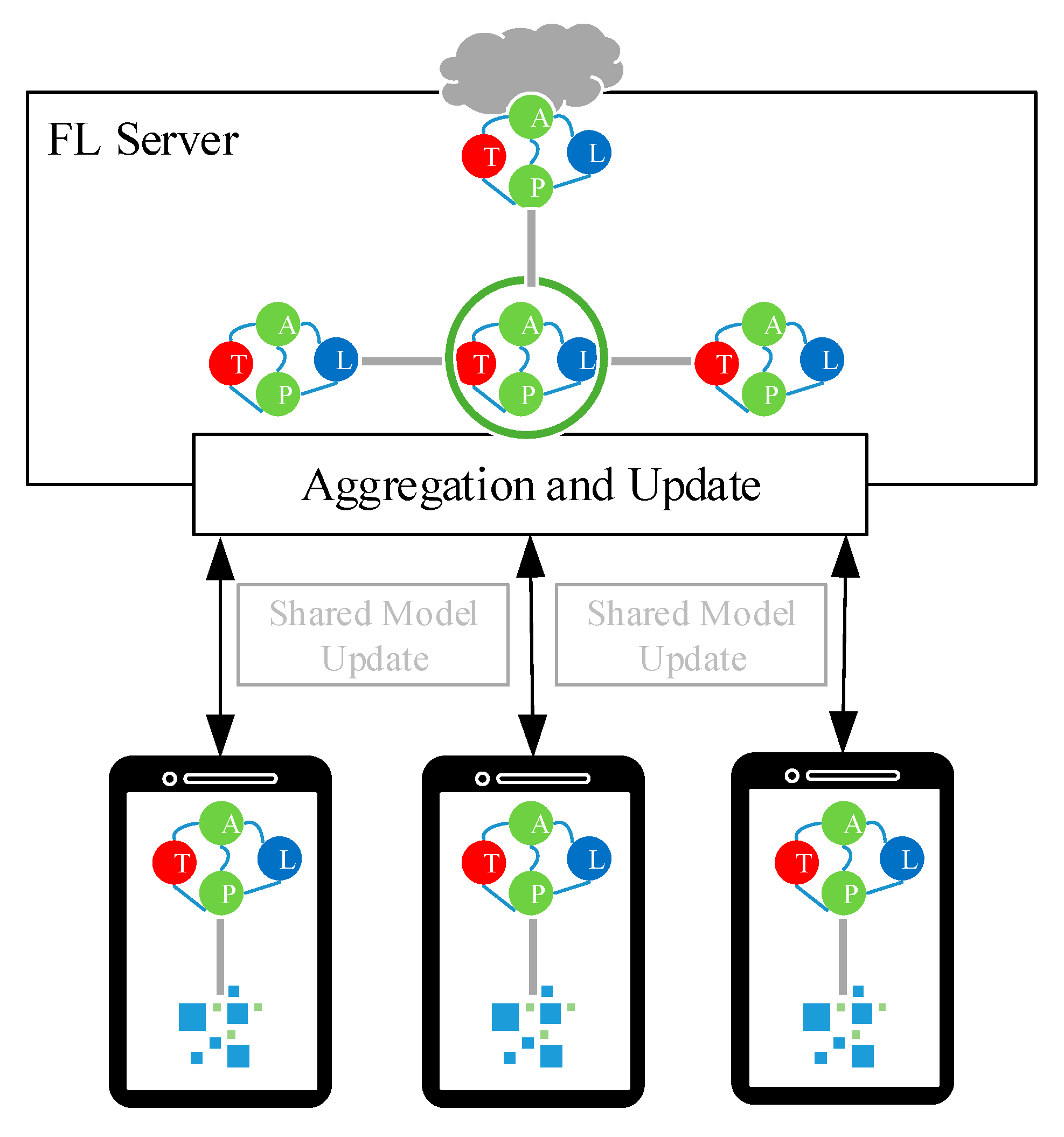
3. FL-AHNEAP for Mobile App Start-Up Prediction under Privacy Protection
3.1. Basic Idea
- Data pre-processing: extracting time, location, App information, and their relationships from the user’s historical App usage records to generate a heterogeneous network, and assigning attribute information to each node in the network;
- Representation learning on the attributed heterogeneous network: employing the random walk method in the attributed heterogeneous network to generate training sample pairs to train the representation learning model for the attributed heterogeneous network;
- Link prediction model based on the neural network: integrating three pieces of contextual information—time, location, and previous App—to predict the probability of links jointly generated by current time, location, previous App node, and other App nodes. Moreover, the processing of new nodes is included in the design of the AHNEAP method, and the new Apps in the network are represented by the new nodes. Therefore, the AHNEAP method alleviates the cold start problem of new Apps to a certain extent.
- Data pre-processing: In the context of federated learning, model training is performed on the terminal, and obviously data pre-processing is also performed on the terminal;
- Network representation learning under federated learning: Based on the idea of federated learning, the representation learning model for the attributed heterogeneous network is used to integrate multi-user data, and the FederatedAveraging algorithm is used as the optimization algorithm;
- Personalized link prediction: The personalized link prediction model is trained based on the neural network.
3.2. Network Representation Learning under Federated Learning
| Algorithm 1. Network Representation Learning under Federated Learning. |
| Inputs: , , . Model parameters: transformation matrix in network representation learning model , , , , , . Server: Choose samples from the training set ; Initialize the model parameters , , , , , ; for each round : Randomly select clients ; Parallel execution on each worker node : ; Calculate the parameter updates: in a similar way; ClientUpdate(): Divide the training set into parts according to the batch size ; for each epoch from 1 to : for each batch : Train the representation learning model for attributed heterogeneous network, and update ; return ; |
- Select a certain proportion of users from all client users to participate in this round of training;
- Each selected client trains the shared model obtained from the cloud using local data;
- The server waits for and obtains the updated model parameters of all selected clients, and aggregates the model parameters according to the proportion of client training samples to all training samples.
3.3. Analysis of Cold Start Prediction
4. Terminal Load and Communication
4.1. Analysis of Terminal Load
- Huawei P20: equipped with OS Android 10, HiSilicon Kirin 970 processor, CPU frequency 2.36GHz, 6GB RAM, 128GB ROM;
- Huawei Nova2S: equipped with OS Android 9, HiSilicon Kirin 960 processor, CPU frequency 1.8GHz, 4GB RAM, 64GB ROM.
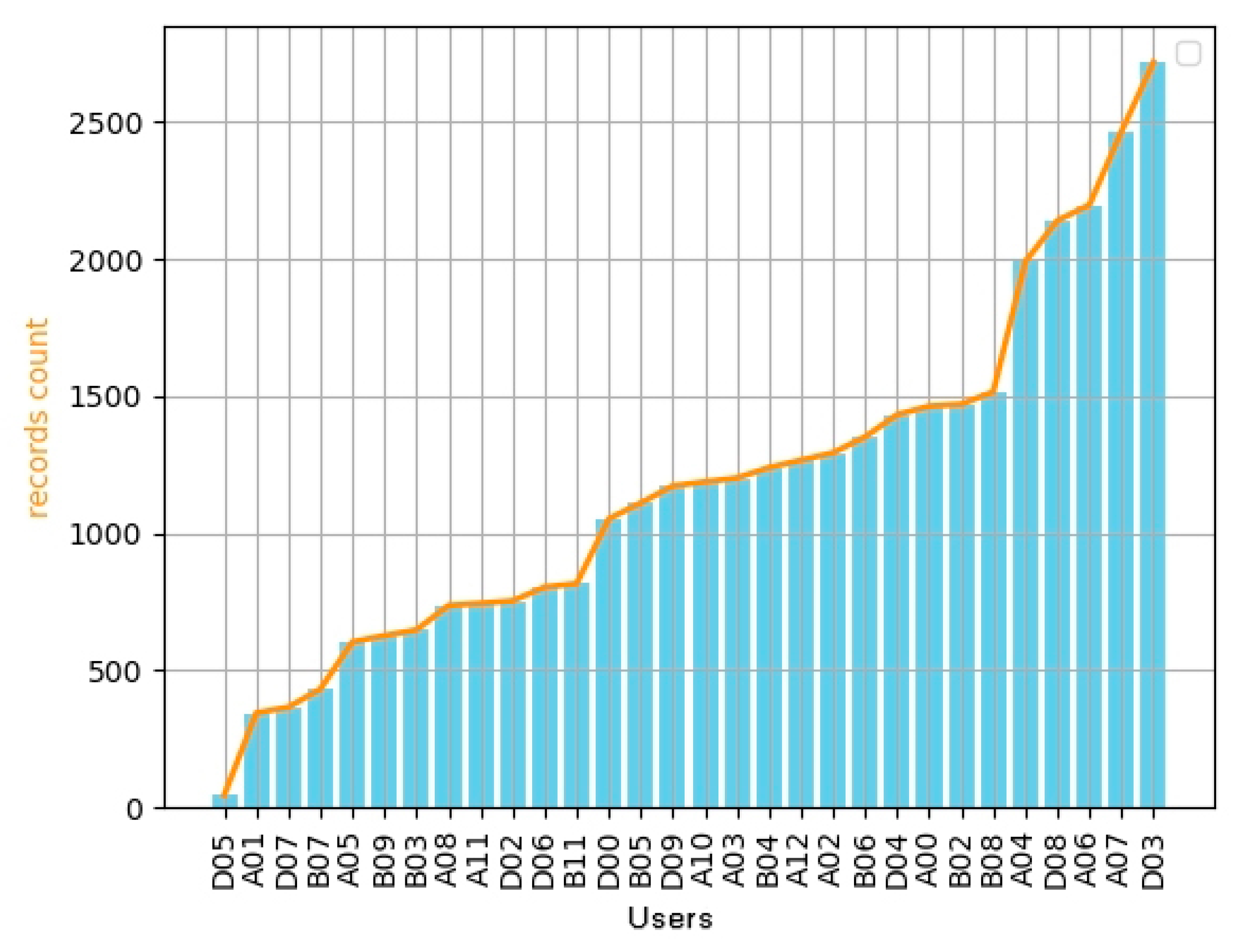
- One month’s data of user A11: a total of 745 records; 170 nodes and 2550 training sample pairs were generated;
- One month’s data of user D03: a total of 2718 records; 570 nodes and 6694 training sample pairs were generated;
- Data of user B02 in the past year: 14,565 records in total; 3427 nodes and 37,602 training sample pairs were generated.
4.2. Analysis of Terminal Communication Overhead
5. Experimental Results and Analysis
5.1. Experiment Settings
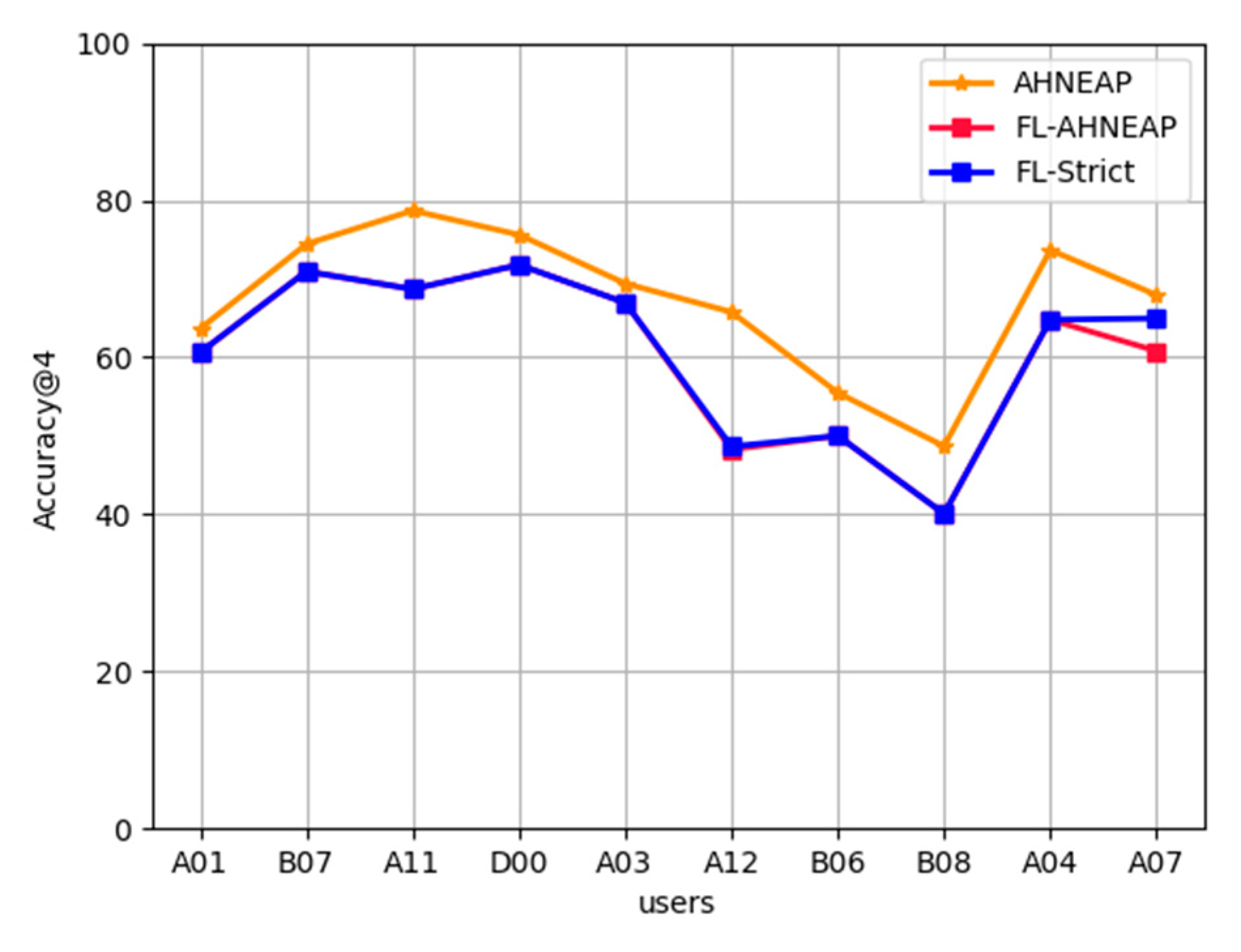
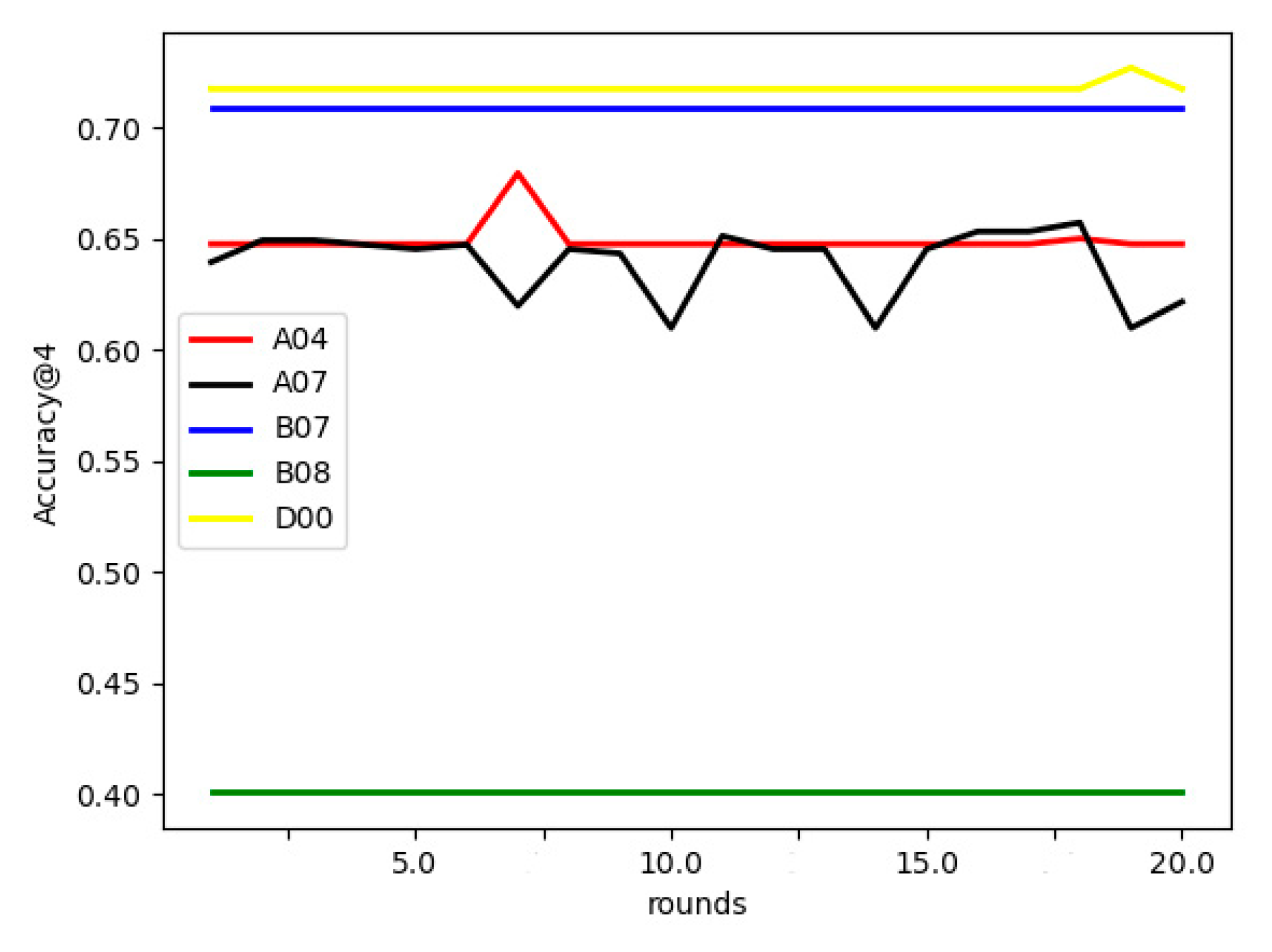
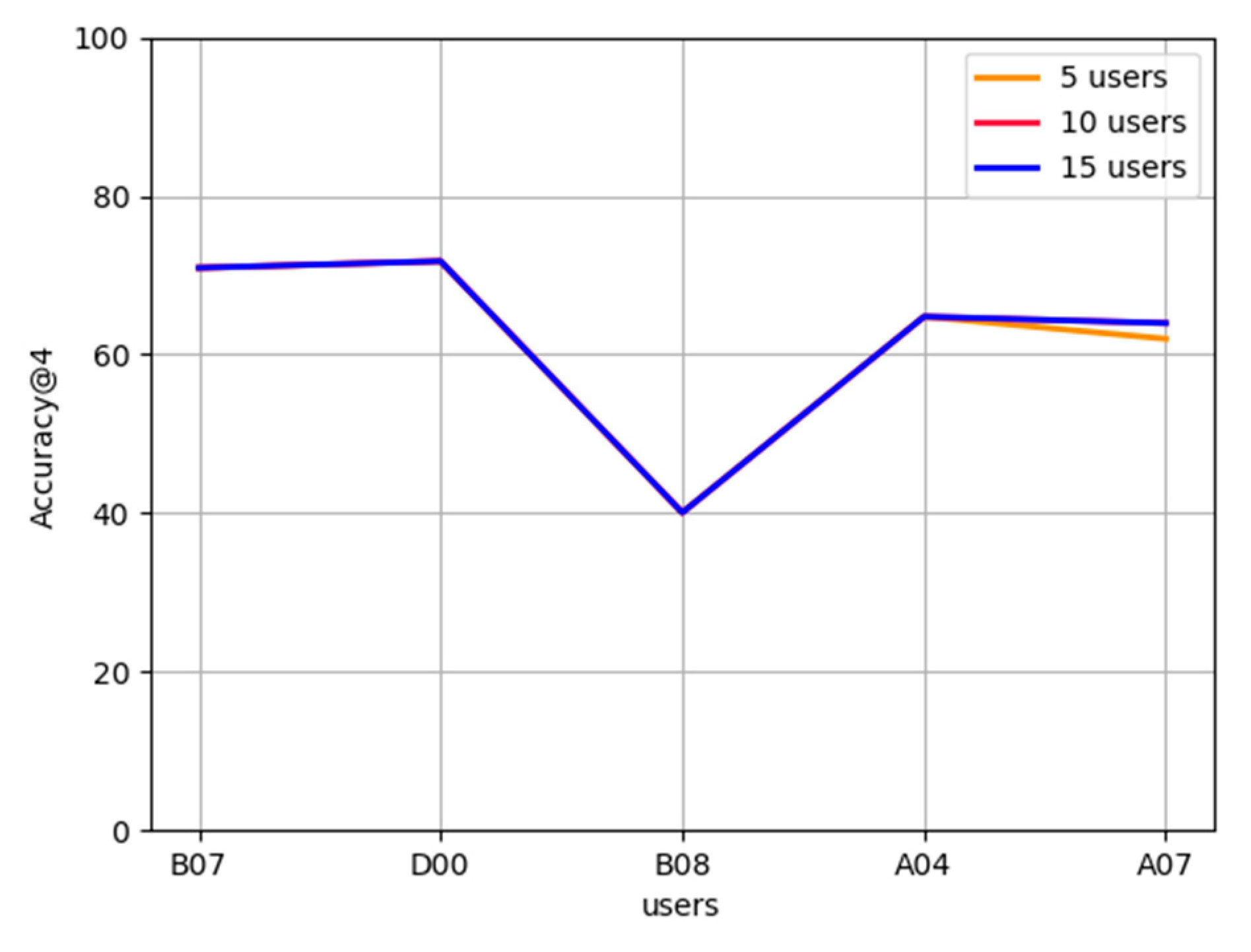
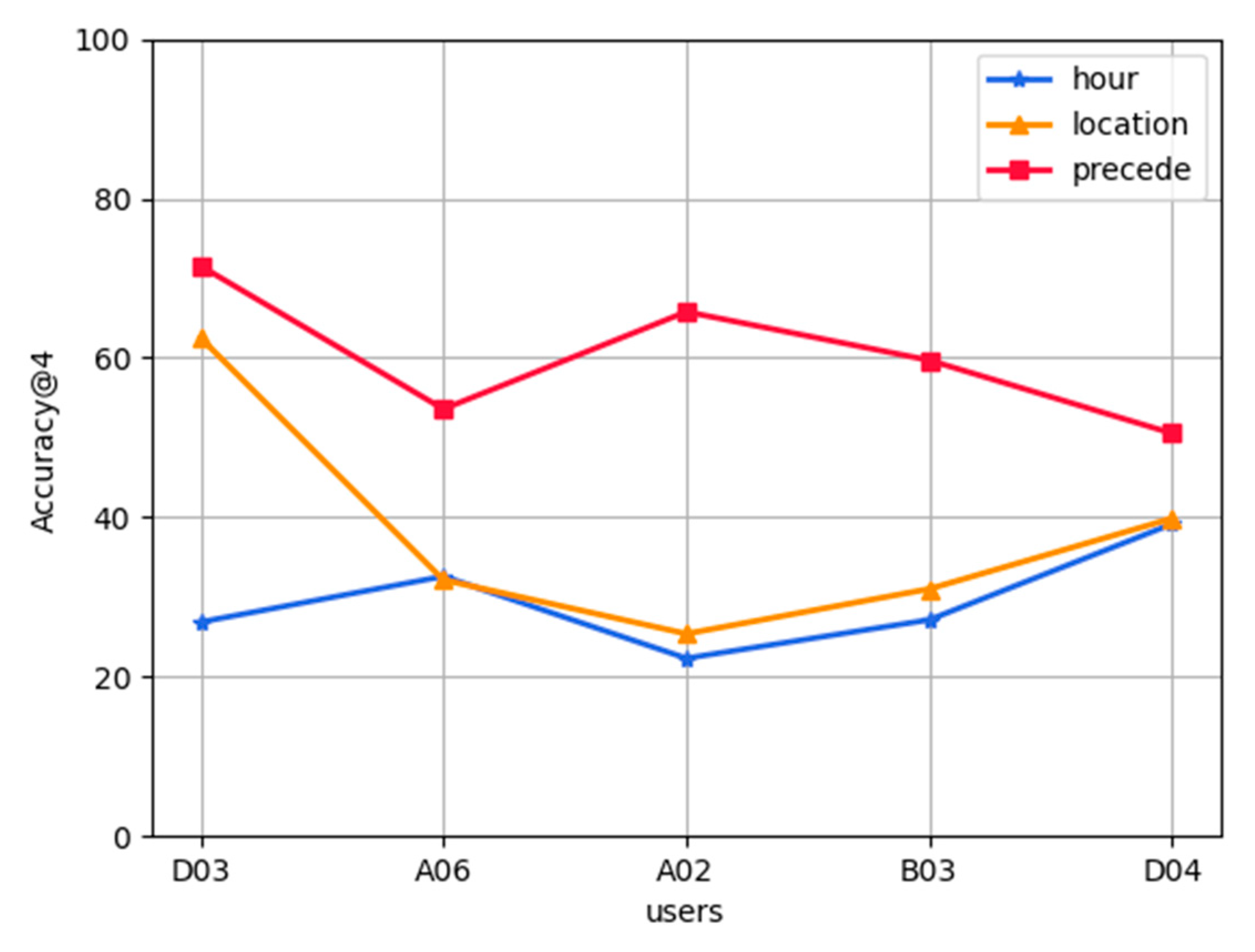
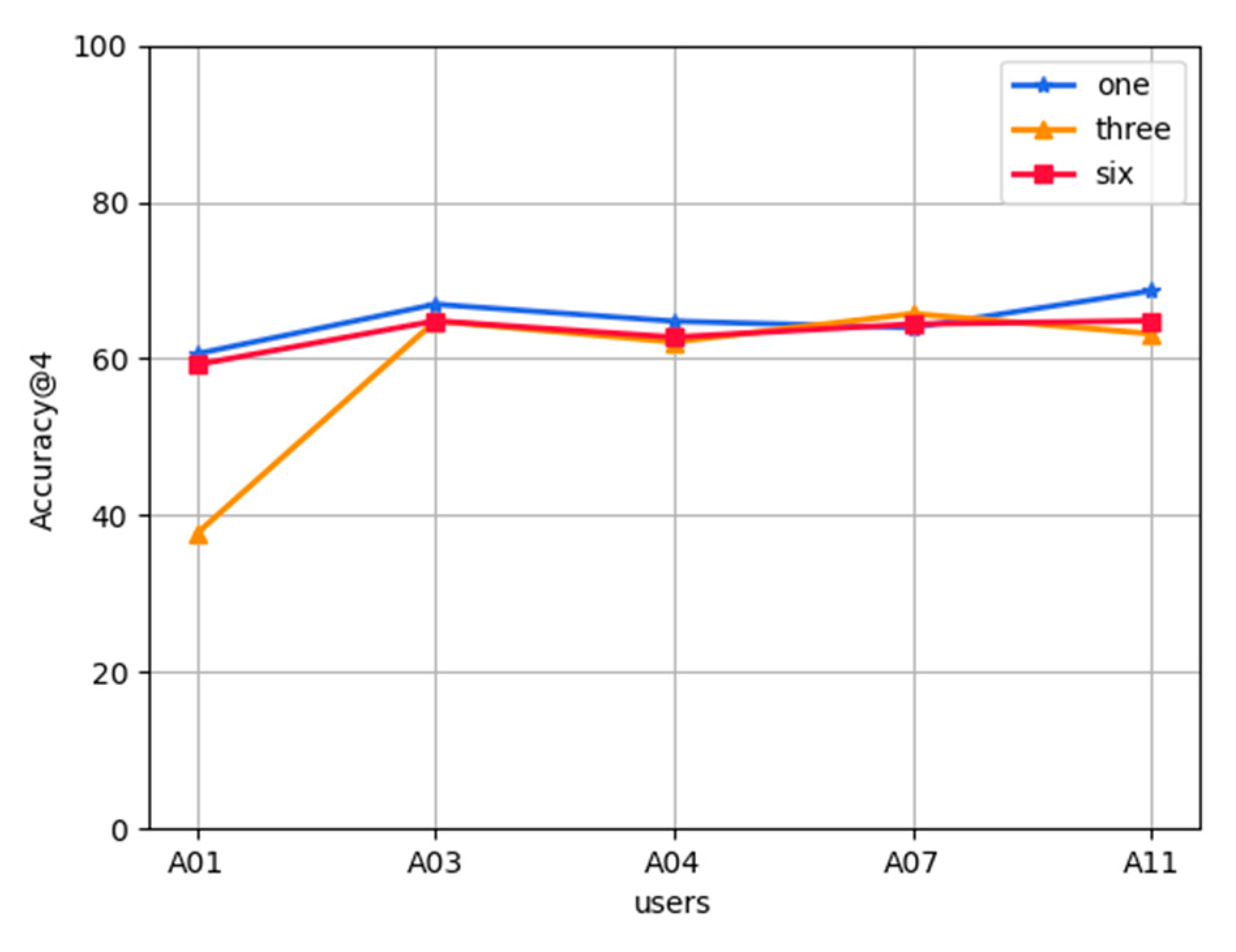
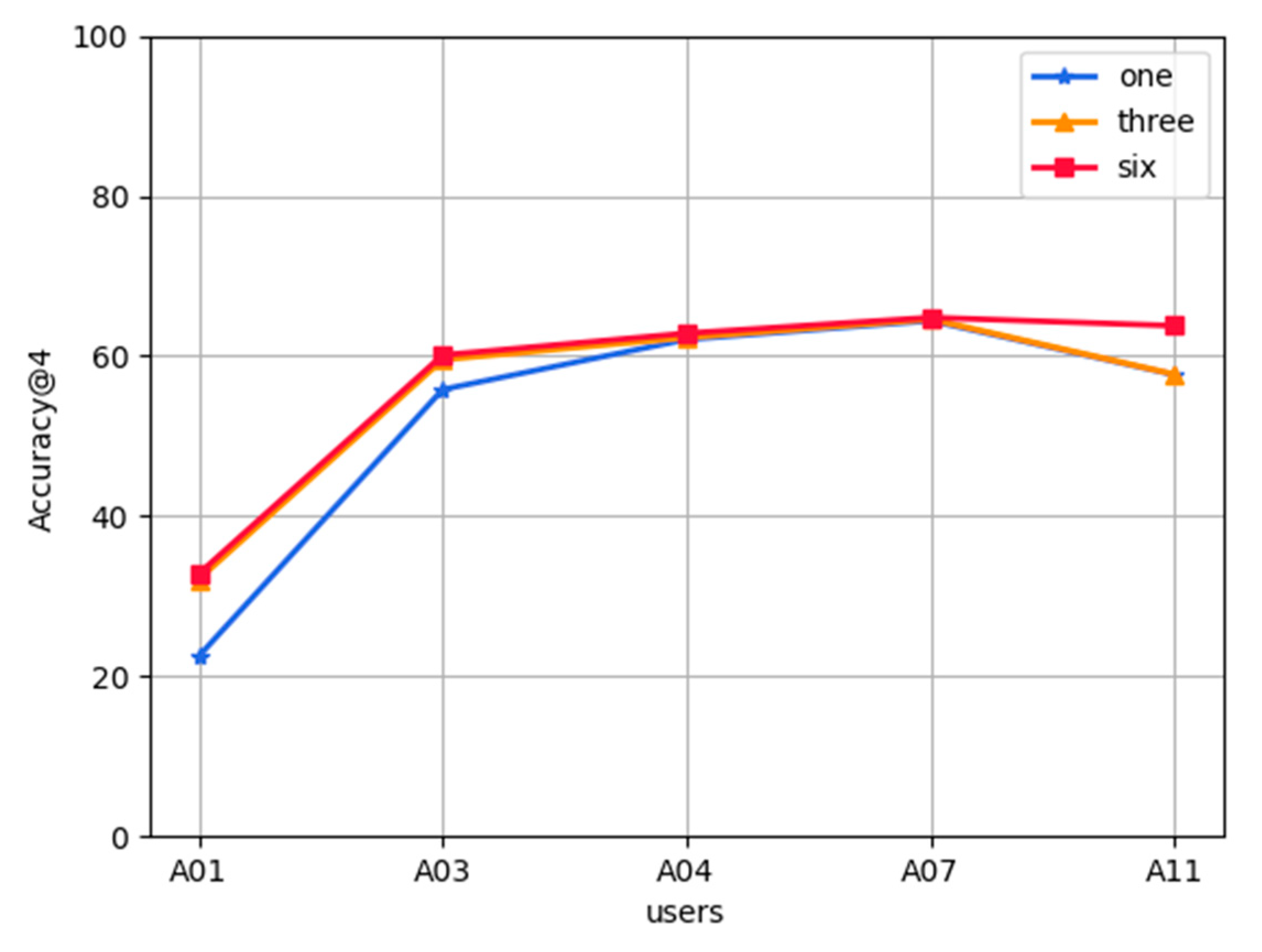
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ca, O.H.; Lin, M. Mining smartphone data for app usage prediction and recommendations: A survey. Pervasive Mob. Comput. 2017, 37, 1–22. [Google Scholar] [CrossRef]
- Han, D.; Li, J.; Lei, Y. A recommender system to address the Cold Start problem for App usage prediction. Int. J. Mach. Learn. Cybern. 2018, 10, 2257–2268. [Google Scholar] [CrossRef]
- Brendan Mcmahan, D.R. Federated Learning: Collaborative Machine Learning without Centralized Training Data [EB/OL]. 2017. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 27 September 2021).
- Zhou, Y.; Li, S.; Liu, Y. Graph-based Method for App Usage Prediction with Attributed Heterogeneous Network Embedding. Future Internet 2020, 12, 58. [Google Scholar] [CrossRef] [Green Version]
- Lu, E.H.; Lin, Y.; Ciou, J. Mining mobile application sequential patterns for usage prediction. In Proceedings of the IEEE International Conference on Granular Computing, Noboribetsu, Japan, 22–24 October 2014; pp. 185–190. [Google Scholar]
- Liao, Z.; Lei, P.; Shen, T. Mining temporal profiles of mobile applications for usage prediction. In Proceedings of the 12th IEEE International Conference on Data Mining Workshops, Washington, DC, USA, 10 December 2012; pp. 890–893. [Google Scholar] [CrossRef] [Green Version]
- Baeza-Yates, R.; Jiang, D.; Silvestri, F. Predicting the next app that you are going to use. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 31 January–6 February 2015; pp. 285–294. [Google Scholar]
- Huang, K.; Zhang, C.; Ma, X. Predicting mobile application usage using contextual information. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, New York, NY, USA, 5 September 2012; pp. 1059–1065. [Google Scholar] [CrossRef] [Green Version]
- Chang, T.E.C.; Qi, L. Prediction for mobile application usage patterns. In Proceedings of the Nokia MDC Workshop, Newcastle, UK, 18–19 June 2012. [Google Scholar]
- Natarajan, N.; Shin, D.; Dhilloni, S. Which app will you use next?: Collaborative filtering with interactional context. In Proceedings of the Seventh ACM Conference on Recommender Systems, New York, NY, USA, 12 October 2013; pp. 201–208. [Google Scholar] [CrossRef]
- Zou, X.; Zhang, W.; Li, S. Prophet: What app you wish to use next. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, New York, NY, USA, 8–12 September 2013; pp. 167–170. [Google Scholar]
- Shin, C.; Hong, J.; Deya, K. Understanding and prediction of mobile application usage for smart phones. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, New York, NY, USA, 5–8 September 2012; pp. 173–182. [Google Scholar]
- Kostakos, V.; Ferreira, D.; Gonçalves, J. Modelling smart phone usage: A markov state transition model. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 486–497. [Google Scholar]
- Yan, T.; Chu, D.; Ganesan, D. Fast app launching for mobile devices using predictive user context. In Proceedings of the 10th International Conference on Mobile Systems, Applications, and Services, New York, NY, USA, 25–29 June 2012; pp. 113–126. [Google Scholar]
- Xusx, Z.; Li, W. Predicting Smart Phone App Usage with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Xu, Y.; Zhu, Y.; Shen, Y. Leveraging app usage contexts for app recommendation: A neural approach. World Wide Web 2019, 22, 2721–2745. [Google Scholar] [CrossRef]
- Tan, Y.; Yu, K.; Wu, X. Predicting app usage based on link prediction in user-app bipartite network. In Proceedings of the Smart Computing and Communication-Second International Conference, Shenzhen, China, 10–12 December 2017; Volume 10699, pp. 191–205. [Google Scholar]
- Chen, X.; Wang, Y.; He, J. CAP: Context-aware app usage prediction with heterogeneous graph embedding. IMWUT 2019, 3, 1–25. [Google Scholar] [CrossRef]
- Cen, Y.; Zou, X.; Zhang, J. Representation learning for attributed multiplex heterogeneous network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1358–1368. [Google Scholar]
- Mcmahan, B.; Moore, E.; Ramage, D. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20–22 April 2017; Volume 54, pp. 1273–1282. [Google Scholar]
- Pan, X.; Chen, J.; Monga, R.; Bengio, S.; Rafal, J. Revisiting distributed synchronous SGD. arXiv 2017, arXiv:1702.05800. [Google Scholar]
- Konecný, J.; Mcmahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Yang, K.; Fan, T.; Chen, T.; Shi, Y.; Yang, Q. A quasi-newton method based vertical federated learning framework for logistic regression. arXiv 2019, arXiv:1912.00513. [Google Scholar]
- Liu, Y.; Kang, Y.; Zhang, X.; Li, L.; Cheng, Y.; Chen, T.; Hong, M.; Yang, Q. A communication efficient vertical federated learning framework. arXiv 2019, arXiv:1912.11187. [Google Scholar]
- Konecný, J.; Mcmahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Mcmahanh, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private language models without losing accuracy. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 30 October 2017; pp. 1175–1191. [Google Scholar] [CrossRef] [Green Version]
- Yang, Q.; Liu, Y.; Chen, T. Federated machine learning: Concept and applications. ACMTIST 2019, 10, 12:1–12:19. [Google Scholar] [CrossRef]
- Cheng, K.; Fan, T.; Jin, Y. Secure boost: A loss less federated learning framework. IEEE Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Malle, B.; Giuliani, N.; Kieseberg, P. The More the Merrier—Federated Learning from Local Sphere Recommendations. Lecture Notes in Computer Science: Volume 10410 Machine Learning and Knowledge Extraction-First IFIP TC5, WG8. 4,8.9, 12.9 International Cross-Domain Conference; Springer: Berlin/Heidelberg, Germany, 2017; pp. 367–373. [Google Scholar]
- Chen, F.; Dong, Z.; Li, Z.; He, X. Federated meta-learning for recommendation. arXiv 2018, arXiv:1802.07876. [Google Scholar]
- Wang, X.; Han, Y.; Wang, C. In edge AI: Intelligentizing mobile edge computing, caching and communication by federated learning. IEEE Netw. 2019, 33, 156–165. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Cheng, Y.; Liu, Y.; Wang, W.; Chen, T. Abnormal client behavior detection in federated learning. arXiv 2019, arXiv:1910.09933. [Google Scholar]
- Gao, D.; Ju, C.; Wei, X.; Liu, Y.; Chen, T.; Yang, Q. HHHFL: Hierarchical heterogeneous horizontal federated learning for electroencephalography. arXiv 2019, arXiv:1909.05784. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.-L. On-device federated learning via blockchain and its latency analysis. arXiv 2018, arXiv:1808.03949. [Google Scholar]
- Lin, Z.; Feng, M.; Dos Santos, C.N. A structured self-attentive sentence embedding. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Shi, L.; Zhao, W.X.; Shen, Y. Local representative-based matrix factorization for cold start recommendation. ACM Trans. Inf. Syst. 2017, 36, 22:1–22:28. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Meng, X.W. Research on Group Recommender Systems and Their Applications. Chin. J. Comput. 2016, 4, 745–764. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User | Number of Records | Number of Nodes | Training Sample Pairs | Data Processing Time | Total Running Time | |
|---|---|---|---|---|---|---|
| P20 | A11 | 745 | 170 | 2550 | 29″ | 1′20″ |
| D03 | 2718 | 570 | 6694 | 48″ | 3′7″ | |
| B02 | 14,565 | 3427 | 37,602 | 10′32″ | 37′09″ | |
| Nova2S | A11 | 745 | 170 | 2550 | 48″ | 2′18″ |
| D03 | 2718 | 570 | 6694 | 1′12″ | 4′35″ | |
| B02 | 14,565 | 3427 | 37,602 | 14′4″ | 56′47″ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Lv, L.; Li, X.; Ding, Z. Mobile App Start-Up Prediction Based on Federated Learning and Attributed Heterogeneous Network Embedding. Future Internet 2021, 13, 256. https://doi.org/10.3390/fi13100256
Li S, Lv L, Li X, Ding Z. Mobile App Start-Up Prediction Based on Federated Learning and Attributed Heterogeneous Network Embedding. Future Internet. 2021; 13(10):256. https://doi.org/10.3390/fi13100256
Chicago/Turabian StyleLi, Shaoyong, Liang Lv, Xiaoya Li, and Zhaoyun Ding. 2021. "Mobile App Start-Up Prediction Based on Federated Learning and Attributed Heterogeneous Network Embedding" Future Internet 13, no. 10: 256. https://doi.org/10.3390/fi13100256
APA StyleLi, S., Lv, L., Li, X., & Ding, Z. (2021). Mobile App Start-Up Prediction Based on Federated Learning and Attributed Heterogeneous Network Embedding. Future Internet, 13(10), 256. https://doi.org/10.3390/fi13100256