1. Introduction
Research on service robots has received increasing attention in recent years [
1,
2,
3]. In most scenarios, like nursing homes and offices, humans hope that robots can help them do many tasks, which include taking orders and serving drinks, welcoming and guiding guests, or just cleaning up. To achieve that goal, a service robot requires human-like information processing and the underlying mechanisms for dealing with the real world, especially the ability to communicate with humans, acquire the knowledge to complete tasks and adapt to the dynamic environment.
For most users, speech is preferable to other communication methods with a general-purpose service robot in most scenarios. Speech is also the primary communication method in General-Purpose Service Robot (GPSR) test defined by RoboCup@Home
https://athome.robocup.org (accessed on 12 February 2021). The user verbally assigns a complicated task to the robot that may require a set of skills. The robot needs to perform the task, report any problems, adapt to unexpected changes, and find alternative solutions with brief knowledge about the domain. Automated planning, which makes decisions about how to act in the world, requires symbolic representations of the robot’s environment and the actions the robot can perform, has been widely used for task planning and control in many service robot applications. In the open world, there are two main challenges for task planning: (1) the robot’s perception of the world is often incomplete, a command may refer to an object that is not in its knowledge base, lack of information will fail to generate a plan; (2) changes in the dynamic environment may not be expected by the robot, which will cause the planned action to fail.
This paper addresses these issues by developing a semantic task planning system, which combines natural language understanding, task-oriented knowledge acquisition, and semantic-based automated task planning.
Research in knowledge representation (KR) and logical reasoning has provided sophisticated algorithms [
4,
5,
6], which have been used on service robots for supporting task planning and execution. Stenmark et al. [
7] attempt to combine descriptions of robot tasks using natural language together with their realizations using robot hardware to representing knowledge about industrial processes. The Kejia robot [
8] represents domain knowledge learned through natural language processing and leverages a symbolic planner for problem-solving and planning to provide high-level functions [
9,
10]. The system has been extended to acquire task-oriented knowledge by interacting with the user and sensing the environment [
11]. By interacting and sensing and grounding useful sensing information, the robot can work with incomplete information and unexpected changes. Abukhalil et al. [
12] present a high-level configuration and task assignment software package that distributes algorithms on a swarm of robots, which allows them to operate in a swarm fashion. Savage et al. [
3] use a conceptual-dependency [
13] interpreter extracts semantic role structures from the input sentence and planning with the open-source expert system CLIPS [
14]. Puigbo et al. [
15] adopt Soar cognitive architecture [
16] to support understanding and executing human-specified commands. In [
17], the robot’s knowledge for safety is enhanced by using data coming from sensors with knowledge from reasoning. Respecting safety requirements, [
18] aims to redesign existing industrial robotic cells for executing a number of collaborative actions based on a knowledge base. In this work, the robot maintains a certain distance from obstacles or people to ensure safety. Moreover, voice is also used to remind users to pay attention to safety. Similar to these works, our system combines a KR system and an ASP planner for high-level planning.
Planning approaches that work in open-world scenarios often need to find a way to close the world. Using Open World Quantified Goal, [
19,
20] can bias the planner’s view of the search space towards finding plans that achieve additional reward in an open world. To address incomplete information in the open world, methods of planning with HRI and sensing actions are developed. Petric et al. utilize a collection of databases, each representing a different kind of knowledge [
21]. Some methods [
15,
22] collects information from user during natural language processing (NLP). representing HRI actions using planning actions [
23]. Some works collects task-oriented information by combining HRI with planning [
11,
24,
25,
26]. Some work focus on using open source knowledge to handle the incomplete information [
10,
27]. Planning with sensing actions has been investigated under different semantics and specific planning algorithms [
21,
28,
29]. Mininger and Laird [
30] use a Soar-based interactive task-learning system to learn strategies to handle references to unseen objects. The approach defines a “find” subtask with a special postcondition so the system can succeed in planning for tasks requiring direct interaction with unseen objects. In [
31], sensor information is used to update an ontology that is queried in each planning loop to populate a PDDL (Planning Domain Definition Language) [
32] problem file. Petrick et al. [
33] extensions to the knowledge-level PKS (Planning with Knowledge and Sensing) planner to improve the applicability of robot planning involving incomplete knowledge. Lim et al. [
34] present an ontology-based unified robot knowledge framework that integrates low-level data with high-level knowledge to enables reasoning to be performed when partial information is available. Hanheide et al. [
2] extends an active visual object search method [
35] to explain failures by planning over explicitly modeled additional action effects and assumptive actions. Jiang et al. [
1] provide an open-world task planning approach for service robots by forming hypotheses implied by commands of operators. Similar to [
1,
2], assumptions and grounding actions are adopted in this paper, but only when there are not enough objects to meet the user’s instructions, the corresponding assumptions will be generated.
Another research area related to this work focuses on planning with dynamic change and uncertainty. Zhang et al. use commonsense reasoning to dynamically construct POMDPs (Partially Observable Markov Decision Processes) for adaptive robot planning [
36,
37]. Using theory of intensions [
38], which is based on scenario division, [
39] generates plan with loops to accommodate unknown information at planning time. In [
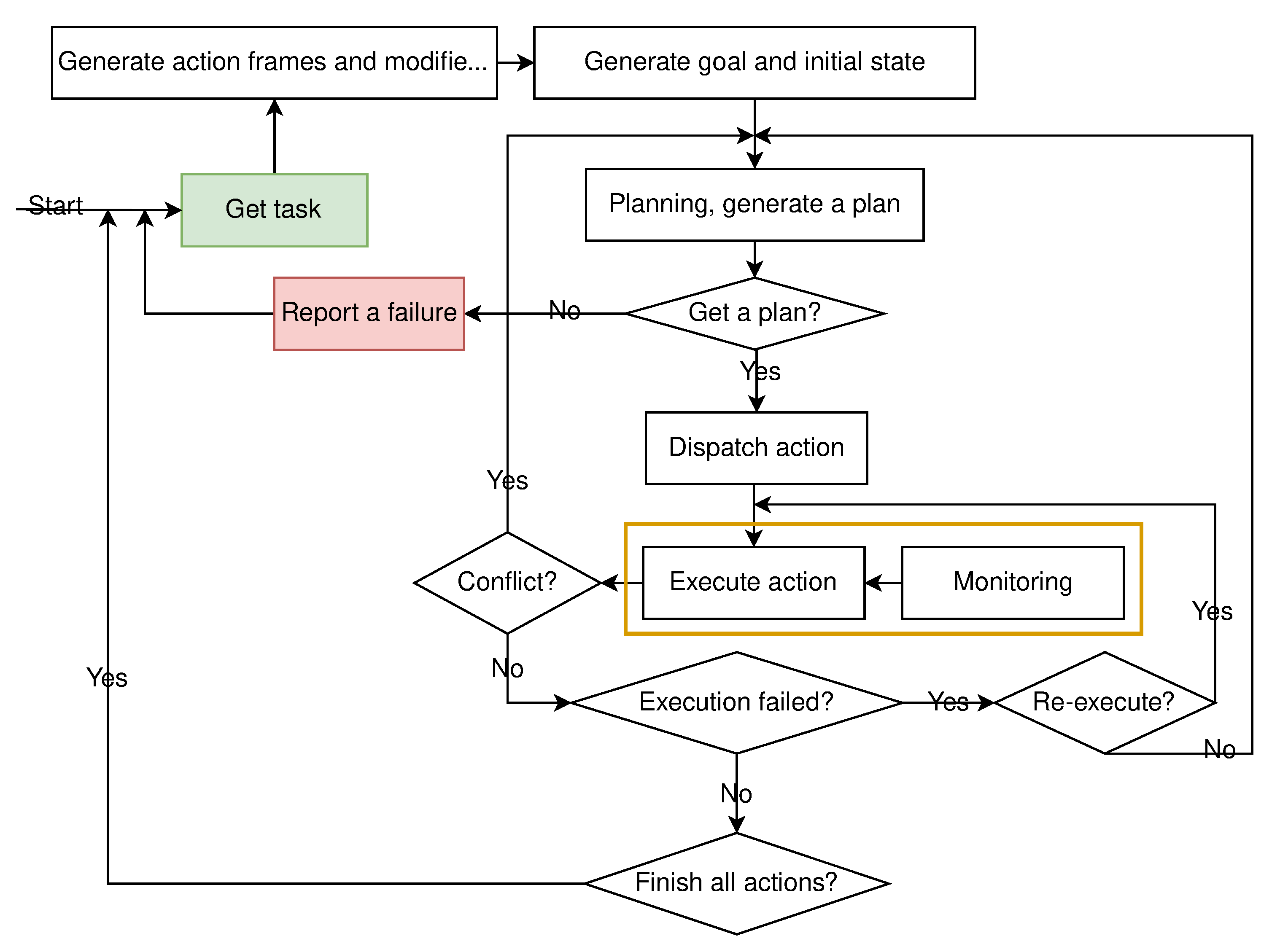
40], a semantic knowledge base is proposed to derive and check implicit information about the effects of actions during plan generation. In this paper, a classic “plan-execute-monitor-replan” is used to handle unexpected changes in the open world.
For the first problem (incomplete information), the idea is “close” the world, which means each object involved in the command must be known in the knowledge base. Assumption and grounding operations are involved to handle this. First, the natural language processing module will generate two outputs: (1) action frames and their relationships; (2) modifier used to indicate some property or characteristic of a variable in the action frame. Next, the action frame and modifiers are used to generate goals of the task. For the object in the command that is not in the knowledge base, an assumption will be added to the knowledge base. A grounding operation will finally check this assumption is true or not when the operation is executed.
For the second problem (dynamic environment), the environment is dynamic, and robots must be able to start from incomplete information, gather useful information, and achieve the goals. In order to response the dynamic environment,
continuous perception and
conflict detection are adopted. We formalize continuous sensing in a formal representation, which is transformed into Answer Set Programming (ASP) [
41] to generate plans by an ASP solver [
42], and the robot perform plans using the classical “plan-execute-monitor-replan” loop. The monitor checks if the change conflicts with actions in the plan, the action being performed and the subsequent actions, so the conflict can be detected and handled as early as possible. Our method features: (1) a method of confirming task type, extracting the roles of the task and the roles’ constrained information; (2) assumption and grounding methodology to “close” the open-world, it is only introduced when there are not enough instances, which can benefit from the use of existing knowledge; (3) continuous sensing and conflict detection mechanism for all actions not performed that captures dynamical changes in the environments and triggers special processing as soon as possible. Similar to our work is [
1] and [
11], compared with them, our algorithm can find potential conflicts earlier and better balance assumptions and existing knowledge to reduce the cost of the task.
This paper is organized as follows—we describe the overview of the system in
Section 2. Next, we describe the knowledge representation and domain formulation in
Section 4 and natural language understanding in
Section 3. Then in
Section 5, where the implemented “plan-execute-monitor-replan” techniques are described. Experimental results and evaluations are presented in
Section 6.
2. Framework Overview
An architecture is briefly introduced in this section. A central problem in robotic architectures is how to design a system to acquire a stable representation of the world suitable for planning and reasoning.
In general, a service robot should be able to perform basic functions:
Self-localization, autonomous mapping, and navigation.
Object detection, recognition, picking, and placement.
People detection, recognition, and tracking.
Speech recognition and Natural Language Understanding.
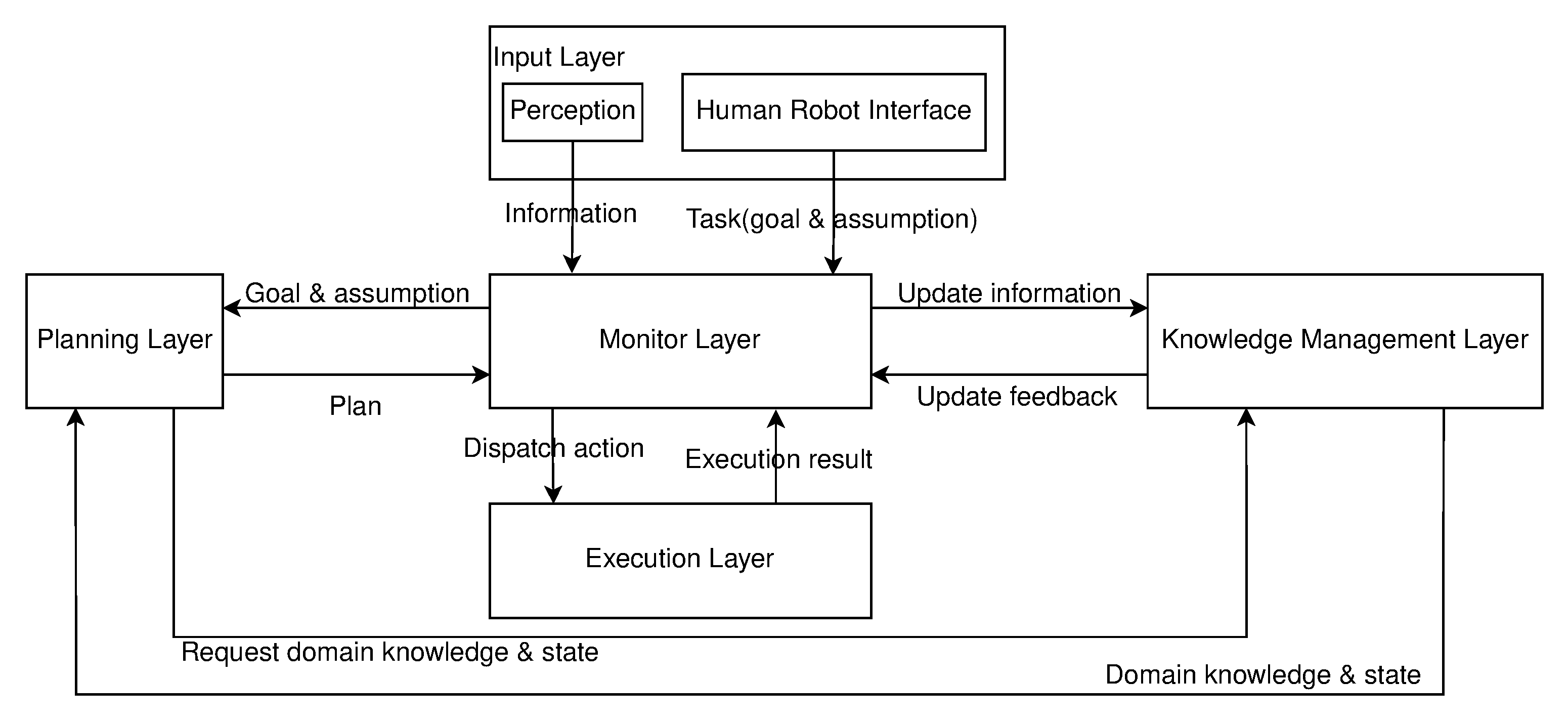
A long-standing challenge for robotics is how to act in the face of uncertain and incomplete information, and to handle task failure intelligently. To deal with these challenges, we propose a framework for service robots to behave intelligently in domains that contain incomplete information under specified goals and dynamic change. The framework is composed of five layers: Input, Knowledge Management, Planning, Execution, and Monitor.
This section will describe the most relevant modules categorized by layer.
Figure 1 depicts the information interaction between the layers.
2.1. Input Layer
This layer involves the modules that provide necessary facilities for sensing its environment and communication with other agents, mainly includes two modules: perception and human-robot interaction.
2.1.1. Perception
This module aims to sense the environment, which has several sub-modules.
Self-localization and autonomous mapping.
Object detection and recognition.
People detection and recognition.
This module generates beliefs about the possible states of the environment. Beliefs are based on the symbolic representation of the sensory information from internal and external sensors. These beliefs are finally transferred to Knowledge Management via Monitor and used to update the state of the world.
2.1.2. Human Robot Interface
This module contains two parts: Speech Recognition and Natural Language Understanding. HRI provides the interface for communication between users and the robot.
Speech Recognition uses the Speech Application Programming Interface (SAPI) developed by iFlytek The speech will be processed in the NLP module, as explained in
Section 3. Based on the user’s instructions, NLP generates assumptions about the possible states of the environment and goals that represent the user’s intents. These assumptions are based on the symbolic representation of the information from users. These assumptions and goals are transmitted to the Planner via Monitor to trigger a plan.
2.2. Knowledge Management Layer
This layer involves all modules that store and access the robot’s knowledge. Such knowledge, which is symbolic, includes structuring the informational state of the world, goals, and domain knowledge.
For high-level reasoning, a rule-based system is used. The facts and rules are written in ASP [
41] format and represent the robot’s knowledge as explained in detail in
Section 4.
2.3. Planning Layer
This layer is responsible for generating plans at a high level of abstraction and performing global reasoning.
Assumptions transferred are added into init states. Together with domain knowledge and goals, they are used to trigger the Action Planner, which will generate a sequence of actions to achieve the desired goals.
2.4. Monitor Layer
This layer dispatches the generated plan to the execution layer, monitors the execution and open-world changes. By “plan-execute-monitor-replan”, if something unexpected happens while executing a plan, the Monitor will interrupt the execution and trigger a new plan.
2.5. Execution Layer
This layer controls the robot to execute the generated plans. Each step of the plan is an atomic function that solves a specific problem. These functions should be simple, reusable, and easy to implement with a state machine.
3. Natural Language Understanding
This section describes the NLP technology employed by this work. The NLP is in charge of translating the speech from users into a symbolic representation used by the action planner.
For each sentence, NLP finds the main event. After finding the main event in such a sentence, it must determine the roles played by the sentence elements and the conditions under which the event takes place. The verb in a sentence usually is used to find a structure of the event composed of participants, objects, actions, and relationships between event elements. These relations can be temporal or spatial. For example, in “Robot, find Mary, and bring her an apple”, Robot is the actor, her is the recipient, apple is the object, and an represents the number of the apple. According to the context, the NLP module should figure out who her is referring to.
For each input sentence, the NLP module works in three steps: (1) Parsing, in which Stanford Parser [
43] parses the sentences and outputs grammatical relations as typed dependencies; (2) Semantic analysis, in which typed dependencies are used to generate action frames; (3) Goals generation, in which action frames are translated into the logic predicates that can be recognized by an ASP solver.
3.1. Parsing
The NLP module’s input from the human-robot dialog is a string of words that is regarded as a sentence. This sentence is parsed by the Stanford parser, which works out the grammatical structure of sentences, can offer two kinds of information: a grammar tree with UPenn tagging style, and a set of typed dependencies with Universal Dependencies style or Stanford Dependencies style. These typed dependencies are otherwise known as grammatical relations.
In our system, we use universal dependencies v1 [
44]. The idea of universal dependencies is to propose universal grammatical relations that can be used with relative fidelity to capture any dependency relation between words in any language. There are 40 universal relations; here’s a brief introduction to part relationships that play an essential role in semantic analysis.
The core dependencies play the most important role in getting semantic elements of an action or event. We mainly consider three core dependencies:
nsubj: nominal subject. The governor of this relation is a verb in most cases, and it may be headed by a noun, or it may be a pronoun or relative pronoun.
dobj: direct object. Typically, the direct object of a verb is the noun phrase that denotes the entity acted upon or which changes state or motion.
iobj: indirect object. In many cases, the indirect object of a verb is the recipient of ditransitive verbs of exchange.
Modifier word is also an important type of dependency, we consider amod, nummod, det, neg, nmod in our system.
amod: adjectival modifier. An adjectival modifier of a noun is an adjectival phrase that serves to modify the meaning of the noun.
nummod: numeric modifier. A numeric modifier of a noun is any number phrase that serves to modify the meaning of the noun with a quantity.
det: determiner. The relation determiner (det) holds between a nominal head and its determiner. Determiners are words that modify nouns or noun phrases and express the reference of the noun phrase in context. That is, a determiner may indicate whether the noun is referring to a definite(words like many, few, several) or indefinite(words like much, little) element of a class, to an element belonging(words like your, his, its, our) to a specified person or thing, to a particular number or quantity(like words any, all), and so forth.
neg: negation modifier. The negation modifier is the relation between a negation word and the word it modifies.
nmod: nominal modifier. It is a noun (or noun phrase) functioning as a non-core (oblique) argument or adjunct. This means that it functionally corresponds to an adverbial when it attaches to a verb, adjective, or adverb. However, when attaching to a noun, it corresponds to an attribute or genitive complement (the terms are less standardized here).
3.2. Semantic Analysis
To get the semantic representation, which is a set of semantic elements, typed dependencies are required, and sometimes the syntactic categories of words and phrases are required, too. These typed dependencies are used to generate action frames and modifiers.
3.2.1. Action Frame
A semantic role refers to a noun phrase that fulfills a specific purpose for the action or state that describes the main verb of a statement. The complete description of the event can be modeled as a function with parameters that correspond to semantic roles in an event that describes the verb, such as actor, object, start and destination place. An action frame is generated from typed dependencies. The frame contains five elements: action(Actor, Action, Object, Source, Goal).
Actor: The entity that performs the Action, the Actor is an agent that usually is a person or a robot.
Action: Performed by the Actor, done to an Object. Each action primitive represents several verbs with a similar meaning. For instance, give, bring, and take have the same representation(the transfer of an object from one location to another).
Object: The entity the Action is performed on. It should be noted that the Object can also be a person or robot. For instance, from sentence “bring James to the office”, an action frame action(NIL, bring, James, NIL, office) is generated, where NIL represents an empty slot that needs to be filled according to the content and domain knowledge.
Source: The initial location of Object when the Action starts.
Goal: The final location of Object when the Action stops.
Usually, from the core dependencies, such as nsubj and dobj, an action frame’s Actor, Action, Object can be identified. The slots Source and Goal, both of them are always associated with prepositional phrase PP and dependency nmod.
For instance, with “take this book from the table to the bookshelf” as an input, Stanford Parser outputs the following result.
Parser tree:
(ROOT
(S
(VP (VB take)
(NP (DT this) (NN book))
(PP (IN from)
(NP
(NP (DT the) (NN table))
(PP (TO to)
(NP (DT the)
(NN bookshelf))))))))
Typed dependencies:
root(ROOT-0, take-1)
det(book-3, this-2)
dobj(take-1, book-3)
case(table-6, from-4)
det(table-6, the-5)
nmod:from(take-1, table-6)
case(bookshelf-9, to-7)
det(bookshelf-9, the-8)
nmod:to(table-6, bookshelf-9)
The tag VB is used to identify the Action, and the dependency dobj is the core relation used to determine the Object. From nmod:from and nmod:to, the Source and Goal location of the action frame are extracted. No Actors are found from the parsing result, obviously, the Actor can only be identified by content, and that will be the person or robot who talks to the person who said this sentence.
3.2.2. Modifier
A modifier is a word, phrase or clause that modifies other elements of a sentence. Nouns, adjectives, adjective clauses and participles can be used as modifiers of nouns or pronouns; A quantifier word is used in conjunction with a noun representing a countable or measurable object with a number, often used to indicate a category. To be more intuitive, there are some examples in
Table 1.
An Modifier, indicates some attribution of an object with some value. For example, dependency nummod(apples, two) is represented as number(apple, 2). The word number means the attribute, the number 2 is the value, and apple is the object. These modifiers provide conditionality for the elements in the action frame.
3.2.3. Pronoun
Pronouns are often used, so an important task is to figure out the noun substituted by the pronoun. It is necessary, or the robot has to ask who or what the pronoun refers to. Our system performs a primitive type of deduction according to the closest matching principle. In every sentence, the noun, such as actor, object or location recognized, is saved. When a pronoun appears in a later part or a new sentence, the saved nouns’ closest matching is used to replace the pronoun. Matching is based on the pronoun’s possible meaning and the restrictions in the sentence, such as the action acting on the pronoun. For instance, when the user says “grasp a cup, go to the living room, and give it to Mary”, it will be recognized as cup rather than living room due to the room is immovable.
3.3. Goals Generation
In our system, the ultimate goal of NLP is to generate goals that should be achieved by executing the plan solved by the solver according to the current world state.
Table 2 lists some actions and corresponding goals.
The predicate can be transformed into the required predicate according to the category of its parameters. For example, can converted into , which indicates O is held by A, when O is an graspable object and A is a person or robot. The assumption is information derived from the user’s instructions but has not yet been confirmed by the robot. Each assumption needs to be identified by the operator.
In the user’s instructions, the object or place may not be unique, and this generic object or place constraint needs to be added to the goal representation. Besides, the objects involved in the command may have additional constraints, which are usually represented by modifiers and need to be added to the target representation. For instance, “
give Mary two apples”, its corresponding action frame is
and corresponding modifier is
, its goal in a clingo program is shown below. (The encodings follow the style of the examples in the CLINGO guide:
https://github.com/potassco/guide (accessed on 12 February 2021).)
4. Knowledge Representation
Knowledge in this work represents type hierarchy, domain objects, states, and causal laws. The causal laws include the fluents of physical actions, HRI actions, and sensing actions. We particularly focus on three kinds of knowledge. (i) Domain knowledge, including causal laws that formalize the transition system and knowledge of entities(such as objects, furniture, rooms, people, etc.). (ii) Control knowledge. When the robot faces a dining table and about to pick up Pepsi, it will measure the distance of the object to determine if it should move closer, adjust its gripper, or fetch. (iii) Contingent knowledge. Throughout performing the task, the robot should continuously observe the environment, gather useful information, enrich its knowledge, and adapt to the change.
Answer Set Programming (ASP) [
41] is adopted as knowledge representation and reasoning tool. It is based on the stable model (answer set) semantics of logic programming. When ASP is used for planning, an action model is not divided into precondition and effect like PDDL [
32]. Our system needs to check preconditions and effects before or after performing each step in a plan, so we code the action model according to the precondition and effect, then convert it into an ASP program.
4.1. Domain Knowledge
Domain knowledge consists of two kinds of knowledge:
The information(type, position, etc.) related to objects(humans, objects, locations, rooms, and robots).
Causal laws that formalize the transition system.
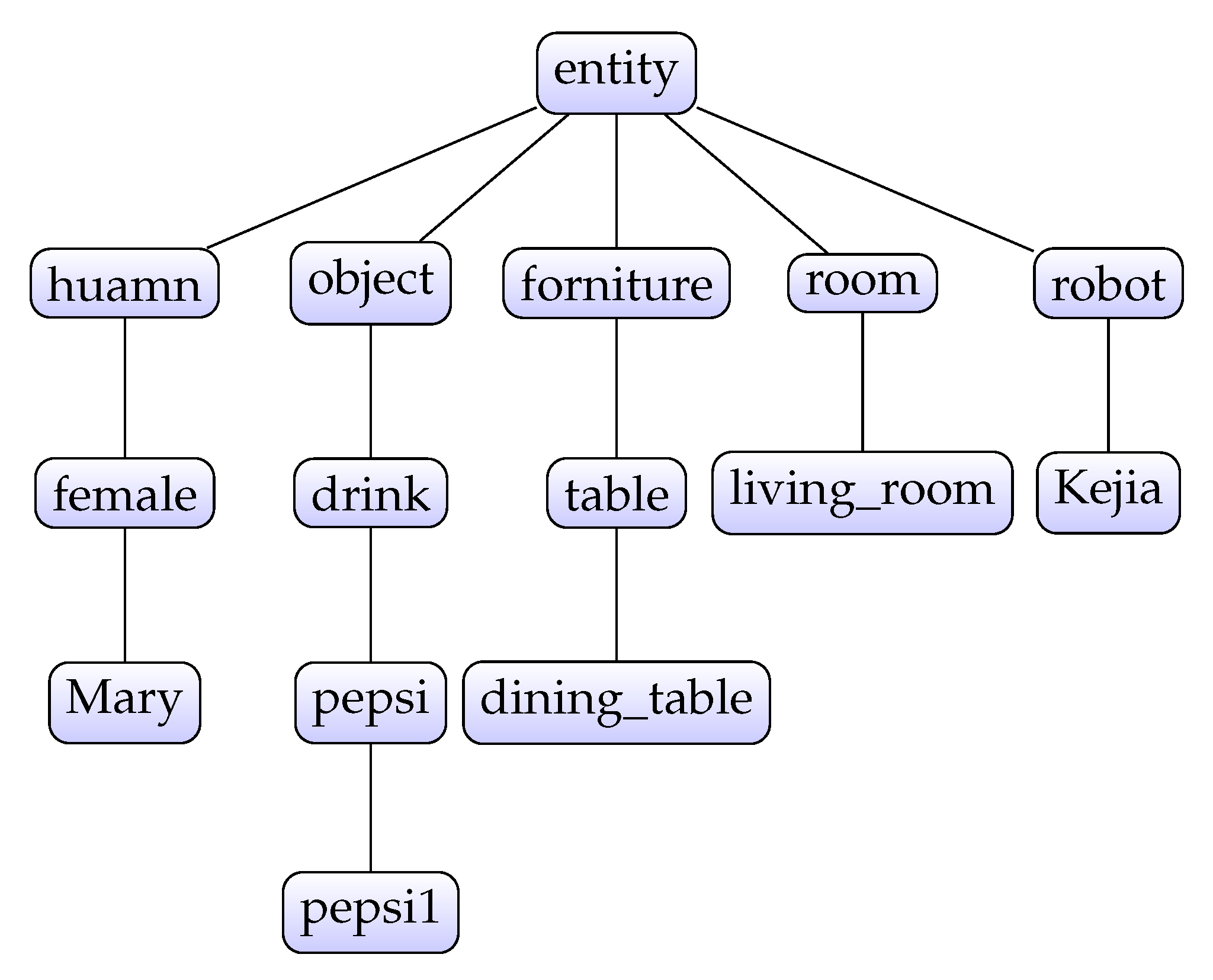
Types. We use a rigid (time-independent) fluent in denoting type and object membership. For instance, we denote
pepsi1 is a member of type
pepsi by pepsi(pepsi1). Type hierarchy and relations are formalized using static laws such as
obj(X) if
pepsi(X). There are five top types in our system, and each type has some sub-types. As
Figure 2 shows, the leaf nodes are memberships, and internal nodes are types of entities. The parent node of
pspsi1 is pepsi, and
pepsi’s parent node is
drink. Different types of entities have various properties. Each of them corresponds to a predicate, corresponding, and different information. These properties are used for object filtering.
States. Non-rigid fluents, each of them means a particular situation that the object is in: the location of objects, the position relation between objects, the gripper is empty or not, the object is on a table or not, a container or door is open or closed, the robot’s position, and so forth.
Static laws. The transformation of fluents is independent of actions and time. Static rules can describe category relations, inherent properties, and so forth. For instance, “
pepsi is a drink”, from
pepsi(pspsi1),
drink(pepsi1) can be generated by a static causal law:
Dynamic laws. The rules of describing the changing of fluents over time or actions play a core role in action planning. These rules fall into two categories:
The changing of states over time. In our system, A state will be transferred to the next moment without interference from external forces, as shown by Equation (1). In Equation (1), X means a state and means time (step).
The transition under an operation.
The transition with action has the following basic components:
Action, an operation that the robot can perform to interact with the environment.
Preconditions, a set of states, that need to be met before or during an action.
Effects, a set of states that can be achieved at the end of an action.
The following is the actions in our system.
moveTo(L,R): The robot navigates to the place L in the room R.
moveIn(R2,R1,D): The robot navigates to the room R2 through the door D from the room R1.
pickup(O,L,G): The robot pick up the object O from the location L that it will carry in its actuator G.
putdown(O,L,G): The robot releases the object O that it carries in its actuator G in the specified place L.
findPerson(H,R): The robot searches the target person H at the room R.
findObj(O,L): The robot activates object recognition to find a target object O from the location L.
handOver(O,H,G): The robot hands the person H the object O in its hand G.
Table 3 lists their preconditions and effects. Equation (2) describes that when the goals are not reached, only one action can occur at the same moment. In Equation (2),
A means an action and
means time (step),
is a state means at step
that there are some goals are not reached.
In the system, the action models are transformed into ASP. Taking action
as an example, its preconditions are transformed into Equations (3) and (4). If either of the two is satisfied, the action is allowed.
Its effects are transformed into Equations (5) and (6). The keyword
IF describes an accompanying state transition. The conditions defined by
IF is not necessary for the action, but when these conditions are met, the accompanying effects will be produced when the action occurs (as shown in Equation (6)).
4.2. Control Knowledge
Control knowledge is oriented to atomic operations in task planning in our system. Each atomic operation is implemented using one or more state machines. The goal of this knowledge is to accomplish tasks more efficiently. This knowledge is usually some control parameters applied to the state machine to complete the atomic operations.
For instance, when the robot performs a pick-up task, for example, grabbing a bottle of iced black tea, it will measure the distance between the object and the robot to determine if it should move closer, adjust its gripper, or fetch. The robot needs to figure out that the distance of objects may affect its manipulation strategy, figure out grabbing which part, and using which posture to grab to get a greater success rate. For a recognition task, like finding an apple, the sequence of searching places can be added to the domain language for task planning. However, the camera’s angle adjustment and the distance between the object and the robot to complete the identification task more efficiently belong to the control knowledge, which is integrated into the visual control system.
4.3. Contingent Knowledge
In performing tasks, robots should continuously observe the environment, collect useful information, enrich knowledge, and adapt to changes. This is particularly important because objects in a domestic environment are continually changing, and the information provided by a human can be fuzzy or wrong. Therefore, robots must start from a local, incomplete, and unreliable domain representation to generate plans to collect more information to achieve their goals.
Continuous sensing is a mechanism that updates the current state when the perception module finds new information. It allows the robot to reduce the uncertainty of the domain while executing the actions. Therefore, the robot has more robust adaptability and robustness to changing fields and irresponsible actions.
The information discovered by sensing are encoded as
States mentioned in
Section 4.1. There are two types of knowledge effects/states the robot’s actions can have:
belief (I believe X because I saw it) and
assumption (I’ll assume X to be true) [
2]. Assumptions are derived from the user’s speech or historical observations, and the transformation from
assumption to
belief is achieved through continuous sensing. In planning, realizer actions, such as
findPerson and
findObj, are used to complete this transformation.
6. Simulations and Results
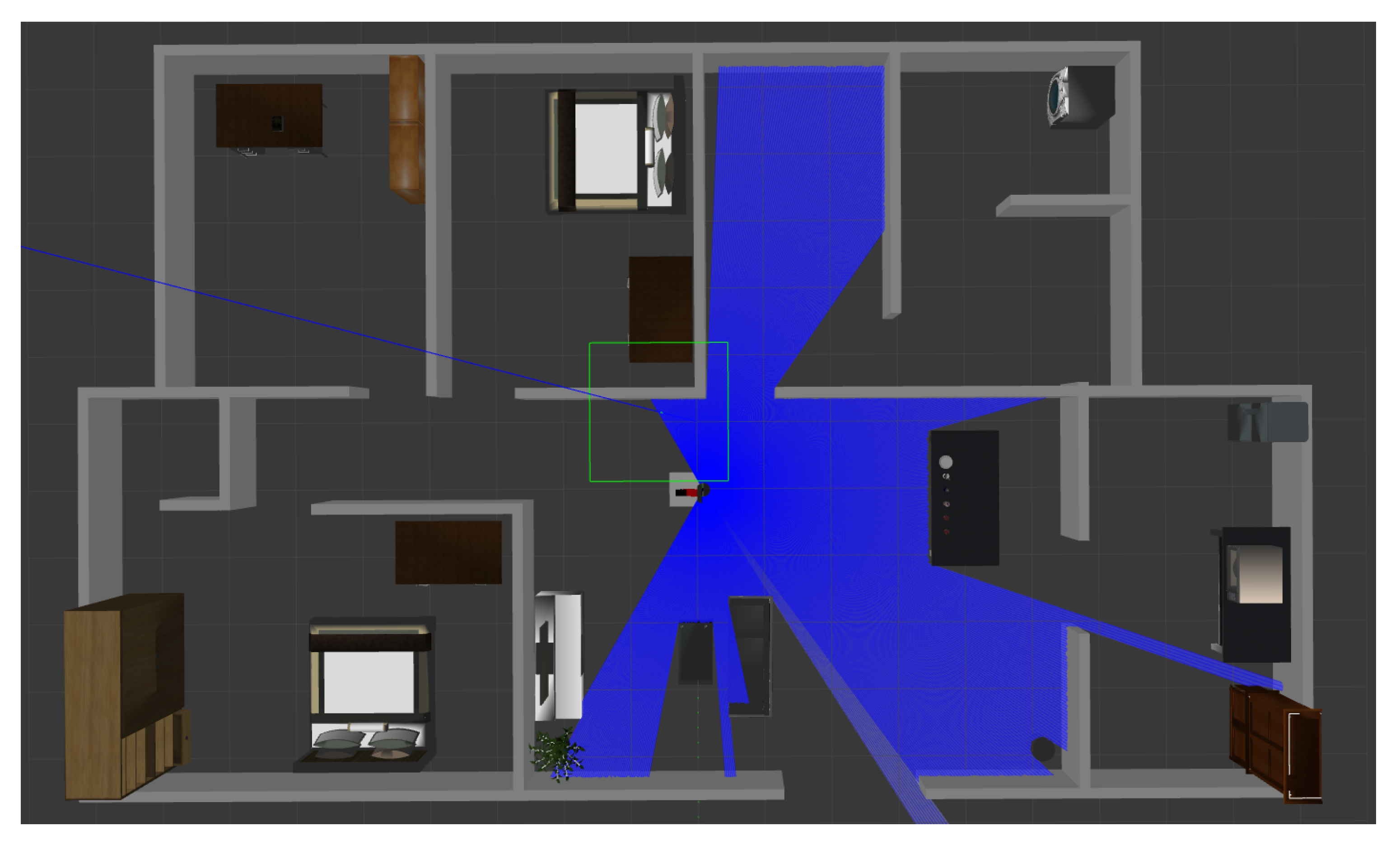
To evaluate the system, we have developed a simulation environment with GAZEBO
http://gazebosim.org (accessed on 12 February 2021). As shown in
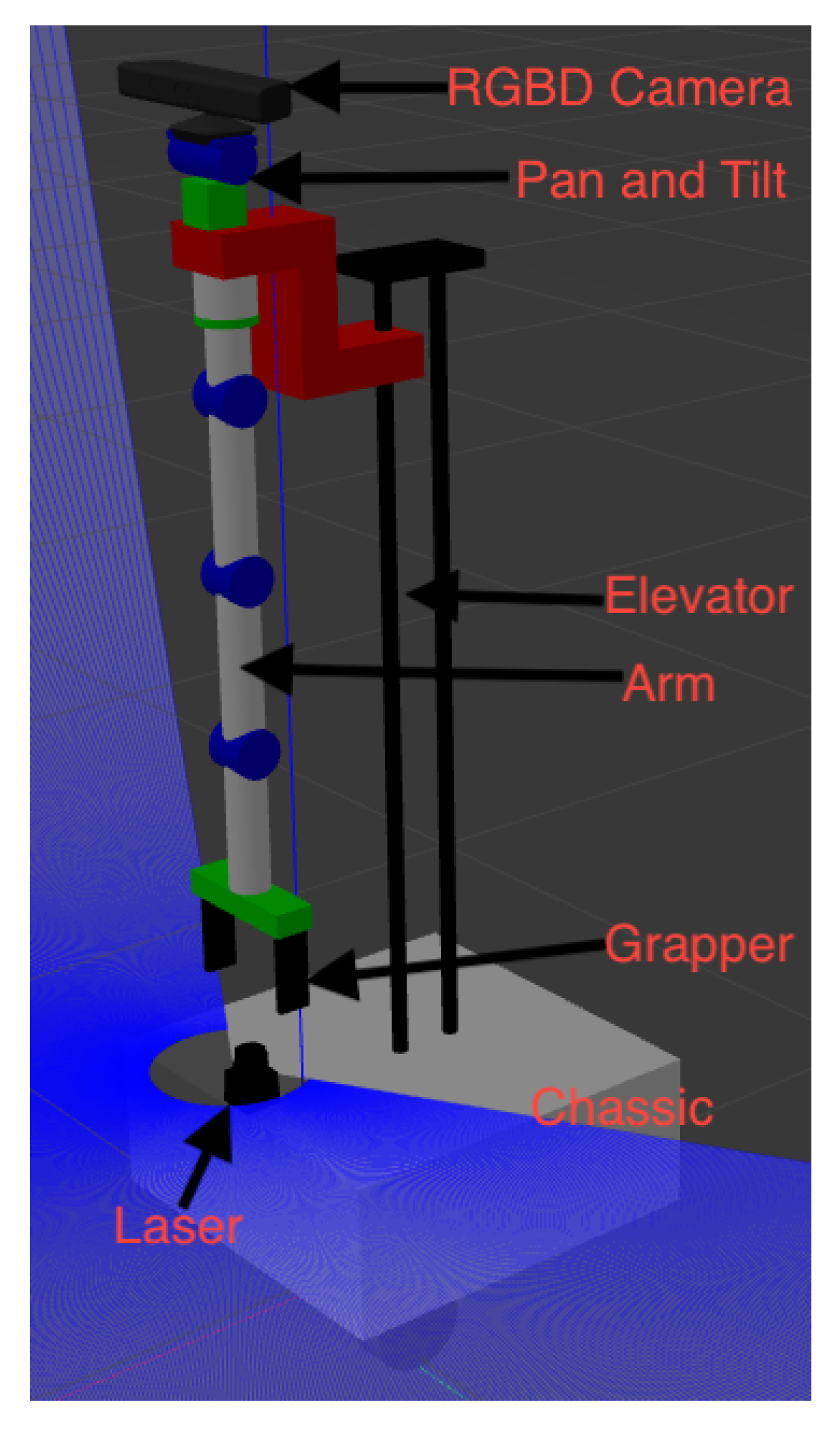
Figure 4, the environment contains a domestic house and the model of Kejia. As shown in
Figure 5, Kejia is equipped with a wheeled mobile base, a single 5-Degree-of-Freedom arm, a 2D laser range finder, an elevator, a pan-tilt, and an RGBD camera. Our system is implemented as nodes in ROS (Robot Operating System). It subscribes all necessary information (arm joint angles, robot pose, recognized objects, etc.) and publishes control messages (navigate to some location, turn on object recognition function to search some object, etc.), which affect the behavior of the robot. The domestic house contains several rooms (bedroom, living room, kitchen, etc.), furniture (bed, table, desk, cupboard, bookshelf, etc.) and some objects (cup, bottle, beer, coke, etc.). For all objects, there are two categories: specific and similar. The specific object has a unique label in the perception system, and this object is bound to this label. Similar objects (apples, same bowl, etc.) share a vision system label. For similar objects, their names in the knowledge base are different. The mapping between the vision system and knowledge base depends on location, size, and other properties.
In the experiment, we mainly consider three kinds of uncertainties: HRI uncertainties (vague or erroneous information from users), changing environment (object removed from a known position or object appears in an unexpected place), and execution errors (failed grab or navigation). The required objects and their positions may be unknown to the robot, so the robot needs to assume that there are objects needed in the place given by the user. Here are five scenarios to show how robots respond to these challenges. (A demo video is available at
https://youtu.be/y4hJ1OODIG0 (accessed on 12 February 2021).)
Scenario 1 (vague information): Jamie requested a coke from the kitchen. Initially, Jamie and the robot were in the study, the doors from the study to the kitchen are unlocked, the robot knew nothing about coke. The robot got a command “bring a coke from the kitchen for me”, then denpendencies root(ROOT-0, bring-1), dobj(bring-1, coke-3), nmod:from(bring-1, kitchen-6) and nmod:for(kitchen-6, me-8) were generated, they assigened the Action, Object, Source and Goal of the action frame action(robot, bring, coke, kitchen, jamie), where “me” was replaced by the user’name. The robot got vague information: in the kitchen. The robot first assumed there was coke in the kitchen table, then started searching in the kitchen by visiting the kitchen table first. There was one cup, one bottle, and one bowl on the kitchen table, but no cokes. The robot made the second assumption: the coke was in the cupboard. It visited the cupboard and found two cokes and one beer, then bring one coke to Jamie.
Scenario 2 (error information): Jamie requested a cup from the living table. The robot got a command “get a cup from the living table for me”, then denpendencies root(ROOT-0, get-1), dobj(get-1, cup-3), nmod:from(get-1, table-7) and nmod:for(table-7, me-9) were generated, they assigened the Action, Object, Source and Goal of the action frame action(robot, get, cup, living_table, jamie), where “me” was replaced by the user’name and living_table generated based on a modifier amod(table-7, living-6). Jamie and the robot were in the study, and Jamie asked the robot to go to the living table and brought a cup. Though the robot knew a cup on the kitchen table, it first tried to get a cup from the living table. The robot first assumed there was a cup in the living table, then started searching by visiting the living table. There was nothing on the living table. The robot abandoned the information from Jamie. It got the information that a cup was on the kitchen table in Scenario 1. It visited the kitchen table and found one cup, one water bottle, and one bowl, then bring the cup to Jamie.
Scenario 3 (disappearing target): Jamie requested a coke. The robot got a command “get a coke for me”, then denpendencies root(ROOT-0, get-1), dobj(get-1, coke-3), and nmod:for(coke-3, me-5) were generated, they assigened the Action, Object, and Goal of the action frame action(robot, get, coke, none, jamie), where “me” was replaced by the user’name. Jamie and the robot were in the study, the robot knew there was one coke in the cupboard, it visited the cupboard, and started to search the coke, but did not found any coke. The robot removed the item from the knowledge base and made an textitassumption: there was coke on the kitchen table. However, after it reached the kitchen table, it found no coke on the kitchen table. It made another assumption: the coke was on the dining table. The robot navigated to the dining table and found two cokes, finally it taken a coke from the dining table and handed it over to Jamie.
Scenario 4 (unexpected target): Jamie requested a coke and a beer. The robot got a command “bring a coke for me, then bring a beer for me”, similar to scenario 3, two action frame action(robot, bring, coke, none, jamie) and action(robot, bring, beer, none, jamie) was generated. Jamie and the robot were in the study, the robot knew there was one coke in the dining table and a beer in the cupboard, it visited the dining table, and started to search the coke, then it found coke and a beer. An unexpected target (the beer) was found, the robot added a new item to the knowledge base and triggered to replan, a better solution was generated. The robot brought the coke from the dining table to Jamie and then navigated to the dining table, take the beer from the dining table to Jamie.
Scenario 5 (failed grab): Jamie requested a bowl from the kitchen table. The robot got a command “get a bowl from the kitchen table for me”, similar to scenario 1, action frame action(robot, get, bowl, kitchen_table, jamie) was generated. Jamie and the robot were in the study. The robot known there was one bowl on the kitchen table. It visited the kitchen table and started to search the bowl, and then it found the bowl. While when the robot picked up the bowl from the kitchen table, it tried twice, but both failed. So it navigated to Jamie and reported this failure.
The demonstration shows that the system can serve under an uncertain and changing environment by involving assumptions and changing detection. By identifying assumptions or detections inconsistent with the knowledge base or not, the robot performs the original plan or makes new assumptions or replans.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}