
Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision


Abstract
:1. Introduction
2. Related Work
- They use datasets that are fairly small (less than 10,000 Tweets),
- they use datasets related to only a few events, and
- they rely on crowd sourcing for acquiring ground truth.
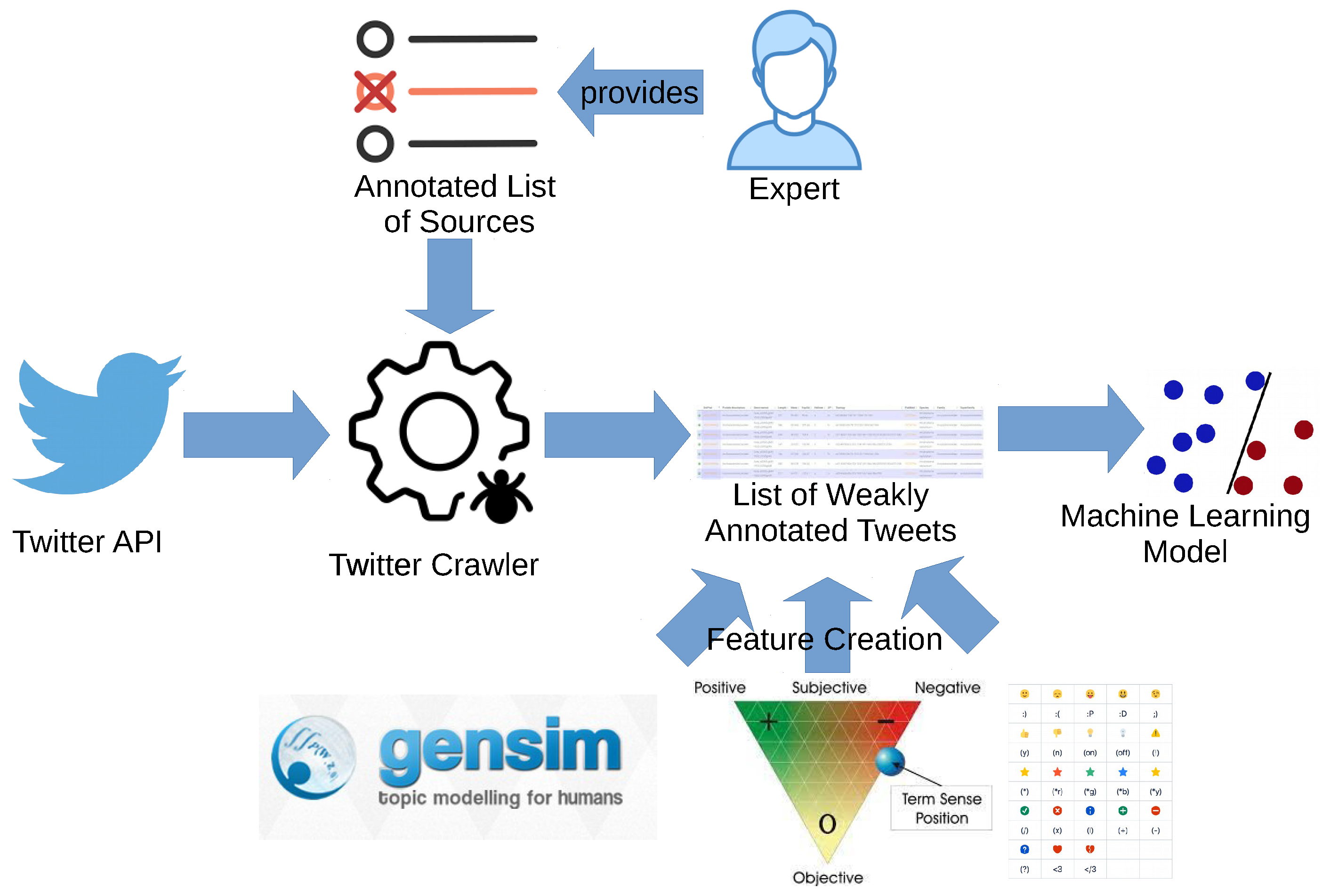
3. Datasets
- A large-scale training dataset is collected from Twitter and labeled automatically. For this dataset, we label tweets by their sources, i.e., tweets issued by accounts known to spread fake news are labeled as fake, tweets issued by accounts known as trustworthy are labeled as real.
- A smaller dataset is collected and labeled manually. This dataset is not used for training, only for validation.
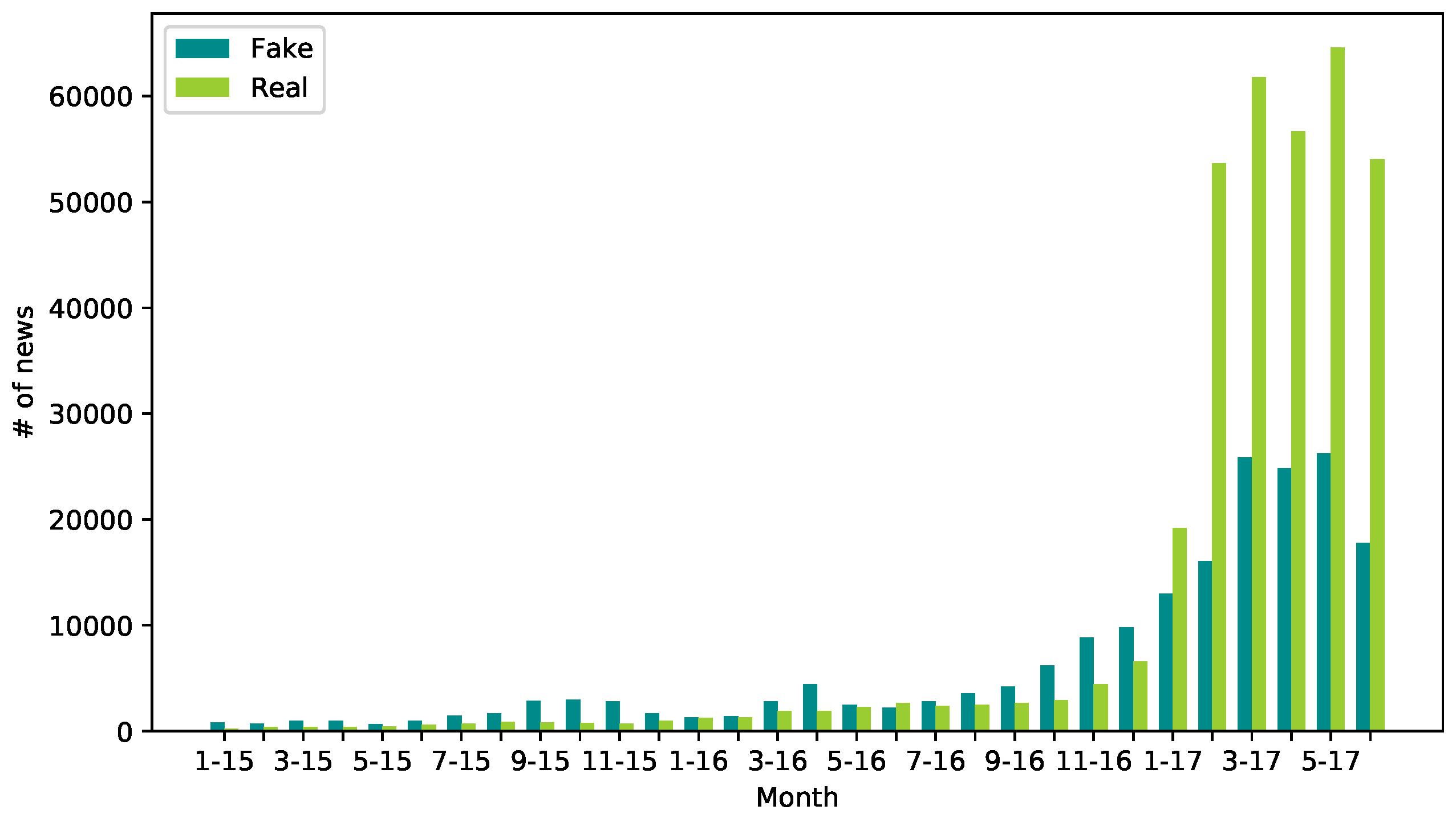
3.1. Large-Scale Training Dataset
- http://mashable.com/2012/04/20/twitter-parodies-news/#IdNx6sIG.Zqm (accessed on 24 February 2017)
- https://www.dailydot.com/layer8/fake-news-sites-list-facebook/ (accessed on 24 February 2017)
- https://www.cbsnews.com/pictures/dont-get-fooled-by-these-fake-news-sites/ (accessed on 24 February 2017)
- http://fakenewswatch.com/ (accessed on 24 February 2017)
- https://www.snopes.com/2016/01/14/fake-news-sites/ (accessed on 24 February 2017)
- https://www.thoughtco.com/guide-to-fake-news-websites-3298824 (accessed on 24 February 2017)
- https://newrepublic.com/article/118013/satire-news-websites-are-cashing-gullible-outraged-readers (accessed on 24 February 2017)
- http://www.opensources.co/ (accessed on 24 February 2017).
3.2. Small-Scale Evaluation Dataset
3.3. Evaluation Scenarios
4. Approach
4.1. User-Level Features
- Features derived from the tweet time (e.g., day, month, weekday, time of day);
- features derived from the user’s description, such as its length, usage of URLs, hashtags, etc.;
- features derived from the user’s network, e.g., ratio of friends and followers;
- features describing the tweet activity, such as tweet, retweet, and quote frequency, number of replies, and mentions, etc.;
- features describing the user’s typical tweets, such as ratio of tweets containing hashtags, user mentions, or URLs.
4.2. Tweet-Level Features
- features characterizing the tweet’s contents, such as URLs, hashtags, user mentions, and emojis. For emojis, we also distinguish face positive, face negative, and face neutral emojis (http://unicode.org/emoji/charts/full-emoji-list.html, accessed on 20 May 2017, and http://datagenetics.com/blog/october52012/index.html, accessed on 9 May 2017);
- features characterizing the tweet’s language, such as punctuation characters, character repetitions, and ratio of uppercase letters;
- linguistic features, such as ratio of nouns, verbs, and adjectives (using WordNet [29] and NLTK [30], number of slang words, determined using Webopedia (http://www.webopedia.com/quick_ref/Twitter_Dictionary_Guide.asp, accessed on 27 April 2021) and noslang.com (http://www.noslang.com/dictionary/, accessed on 27 April 2021), and existence of spelling mistakes (determined using the pyenchant (https://pypi.org/project/pyenchant/, accessed on 28 April 2021) library).
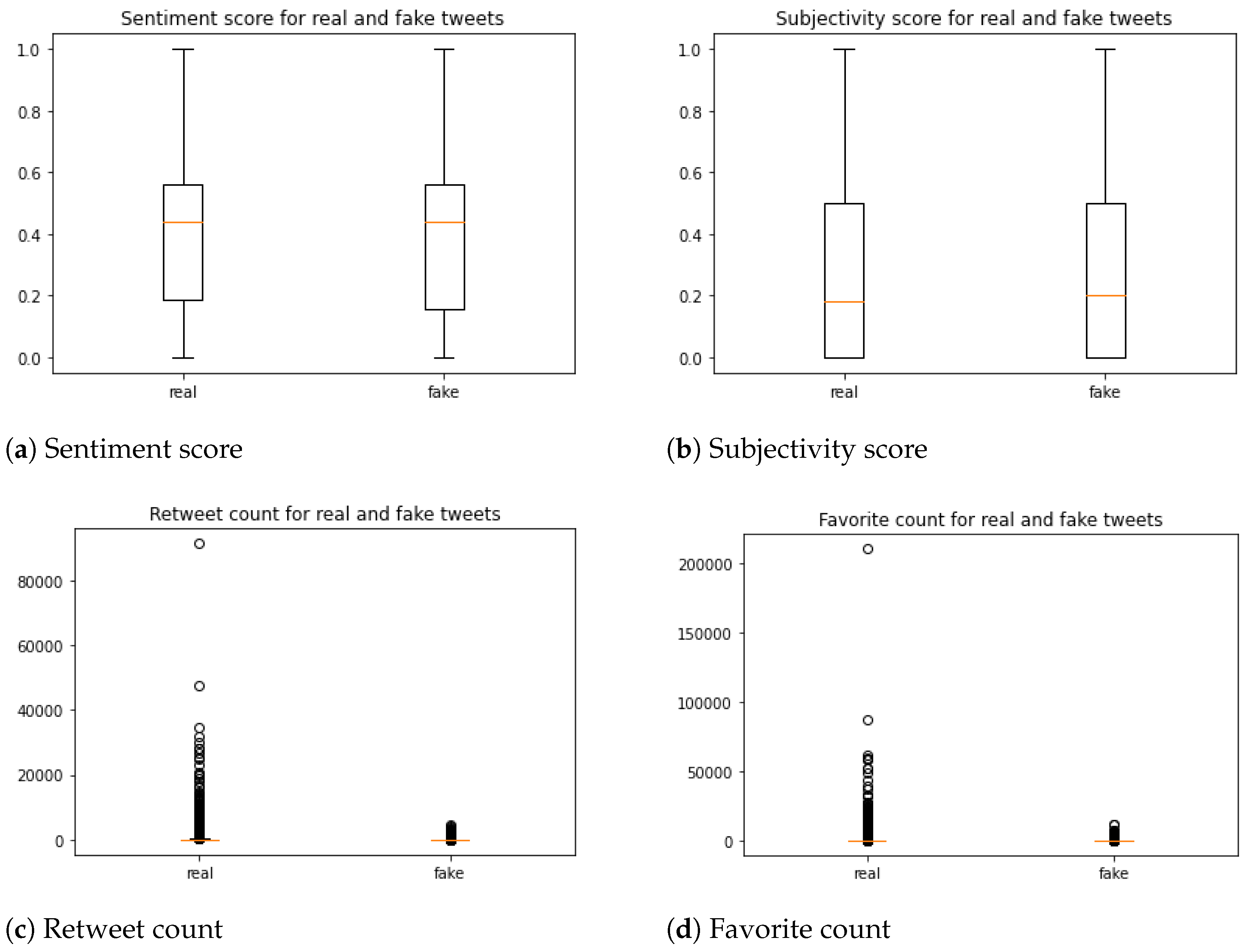
4.3. Text Features
4.4. Topic Features
4.5. Sentiment Features
4.6. Feature Scaling and Selection
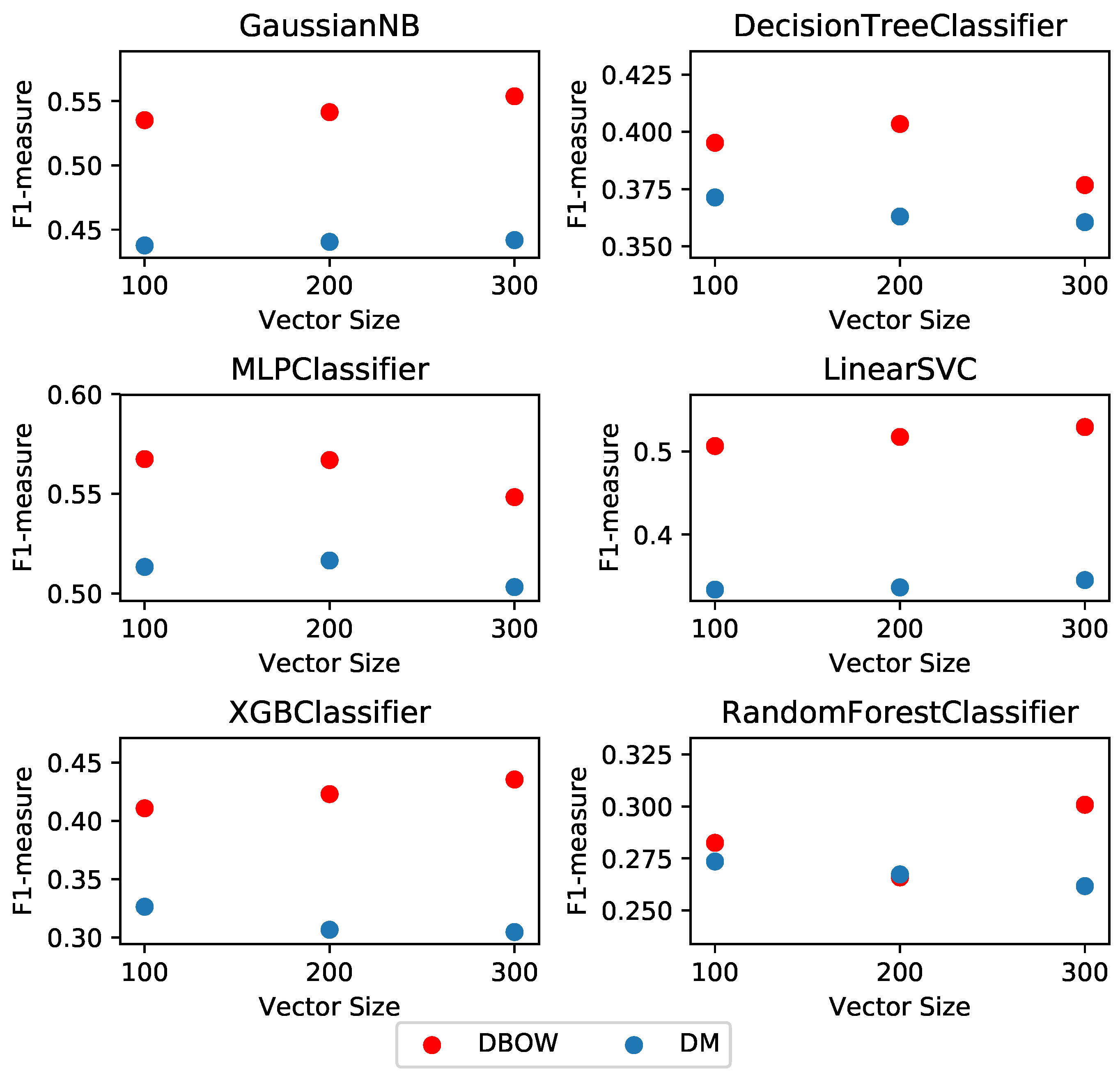
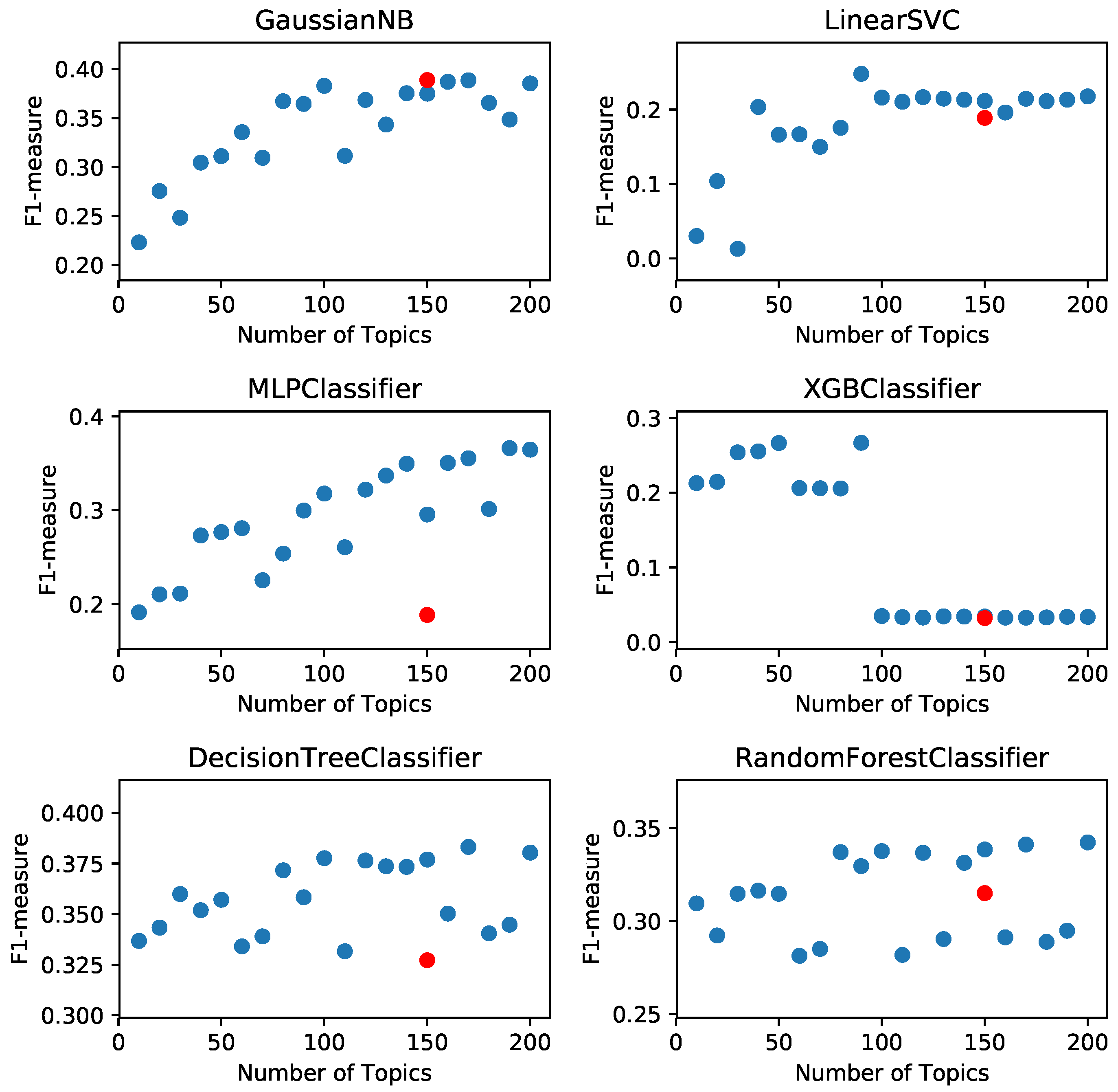
4.7. Learning Algorithms and Parameter Optimization
5. Evaluation
5.1. Setting 1: Cross-Validation on Training Dataset
5.2. Setting 2: Validation Against Gold Standard
5.3. Comparison to Training on Manually Labeled Data
- In the first setup, we have re-created all content features for the manually labeled dataset (On the manually labeled dataset, LDA was not able to generate meaningful results due to the very small dataset size. Hence, we have left out the LDA based features in the first setup).
- In the second setup, we used the distributional text and topic features (doc2vec, LDA) created from the weakly supervised set.
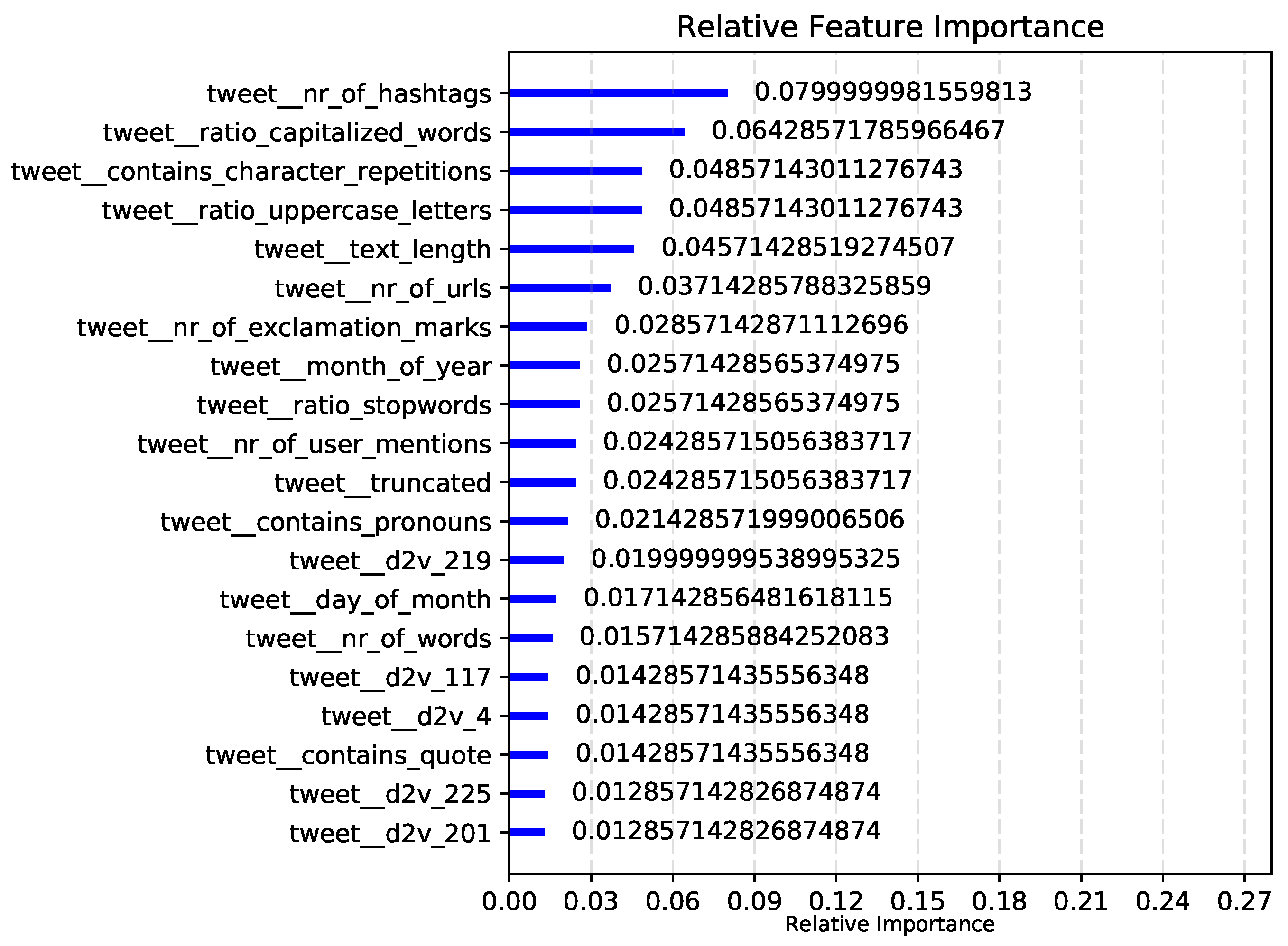
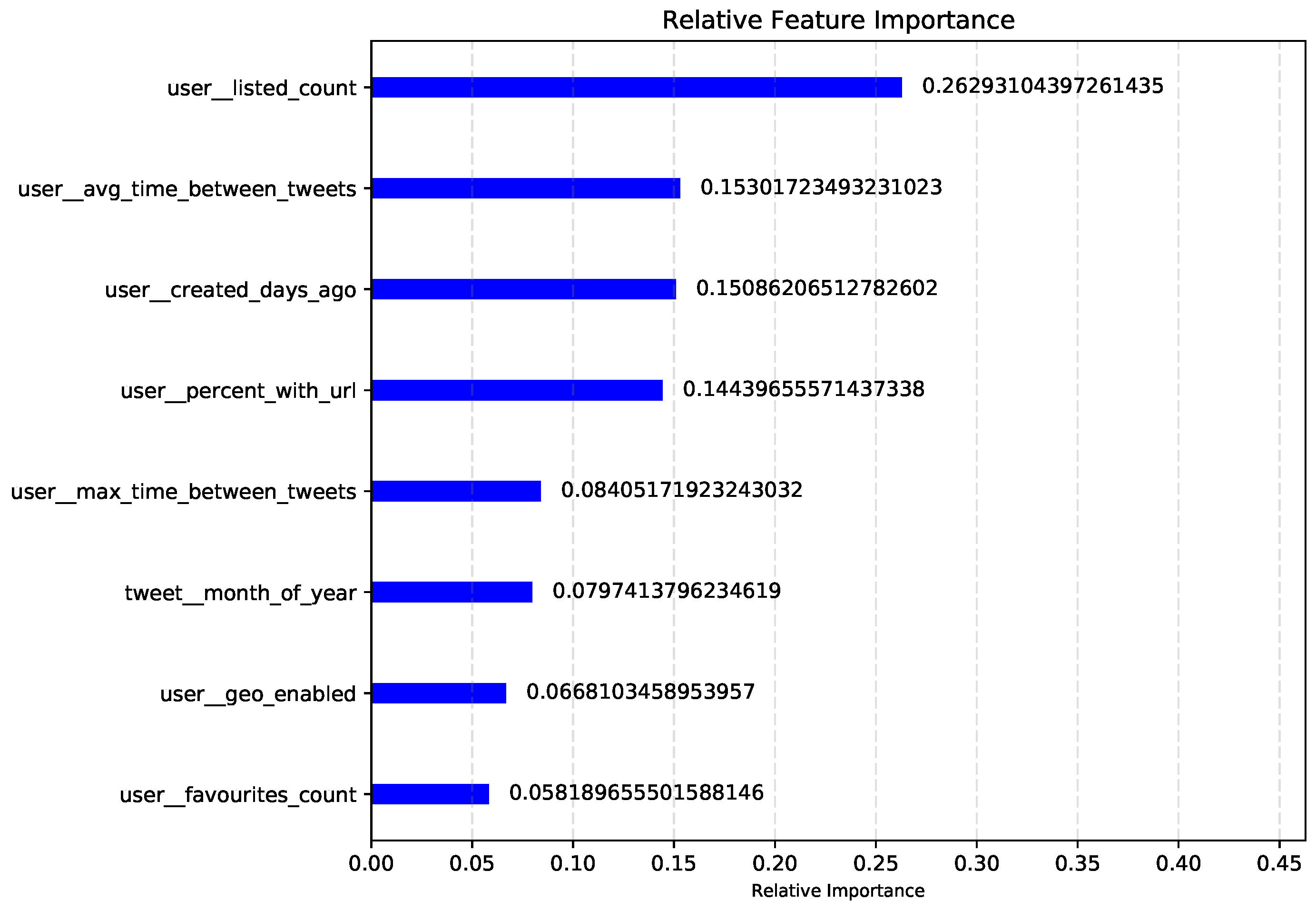
5.4. Feature Importance
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Features
Appendix A.1. User-Level Features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description |
|---|---|
| default_profile | Indicates that a user has not changed the theme or background |
| favourites_count | The number of tweets the user liked at the point of gathering |
| followers_count | The number of followers of an account at the point of gathering |
| friends_count | The number of users following the account at the point of gathering |
| geo_enabled | If true, the user has enabled the possibility of geotagging its tweets |
| listed_count | The number of public lists that a user is a member of |
| profile_background_tile | Indicates whether the URL of the background image should be tiled when displayed |
| profile_use_background _image | Indicates whether the user uses a background image |
| statuses_count | The number of tweets the user published at the point of gathering |
| verified | Indicates whether the account is verified |
| Feature Name | Description |
|---|---|
| has_desc | True if the user uses a description |
| has_location | Flag to indicate whether there is a user-defined location or not |
| desc_contains_hashtags | Specifies if there are hashtags within the description |
| desc_contains_user_mention | Specifies if there are user mentions in the description |
| desc_contains_url | Specifies if there is an URL in the description |
| desc_length | Counts the characters in the description |
| url_length | Specifies the length of the user URL |
| has_url | If true, the user stated a profile URL. |
| has_list | If true, the user was included in at least one list |
| has_favourites | If true, the account has liked tweets during its life time |
| has_friends | If true, the user follows other accounts |
| favourites_per_follower | Ratio between liked tweets and follower count |
| friends_per_follower | Ratio between the number of accounts the account follows and its follower count |
| is_following_more_than_100 | Indicates that the account follows at least 100 Twitter users |
| avg_user_mention_per_tweet | States the average number of user mentions per tweet in the collected data |
| avg_hashtags_per_tweet | States the average number of hashtags per tweet in the collected data |
| avg_urls_per_tweet | States the average number of URLs an account uses in the collected tweets |
| percent_with_url | States the ratio of the collected tweets that contains an URL |
| percent_with_hashtag | States the ratio of the collected tweets that contain a hashtag |
| percent_with_user_mention | States the ratio of the collected tweets that contains a user mention |
| created_days_ago | The number of days since the creation of the account. Depends on the time this feature was created. |
| created_hour_of_day | The hour the account was created in UTC time |
| avg_post_time | States the average post time of the user. If present, the UTC offset was taken into account otherwise the most frequent UTC offset across all collected accounts was used. |
| tweets_per_day | States the average number of status updates per day. The first and last day of the user’s collected tweets were omitted since they might not be complete. |
| tweets_per_week | States the average number of status updates per week. The first and last week of the user’s collected tweets were omitted since they might not be complete. |
| tweets_per_month | States the average number of status updates per month. The first and last month of the user’s collected tweets were omitted since they might not be complete. |
| min_time_between_tweets | States the minimum time between two of the user’s tweets in minutes |
| max_time_between_tweets | States the maximum time between two of the user’s tweets in minutes |
| median_time_between_tweets | States the median time between two of the user’s tweets in minutes |
| avg_time_between_tweets | States the average time between two of the user’s tweets in minutes |
| nr_of_retweets | States the number of retweets that were collected from the account |
| nr_of_retweets_per_tweet | The ratio between the frequency of retweets and the number of tweets in the collected data |
| nr_of_quotes | States the number of quotes that were collected from the account |
| nr_of_quotes_per_tweet | The ratio between the frequency of quotes and the number of tweets in the collected data |
| nr_of_replies | States the number of replies that were collected from the account |
| nr_of_replies_per_tweet | The ratio between the frequency of replies and the number of tweets in the collected data |
| has_profile_background _image | States whether a background image is used |
| is_translator_type_regular | If true, the user has type regular in the Twitter translator community |
| tweets_in_different_lang | If true, the account uses different languages in its tweets. A tweet’s languages is automatically specified by Twitter. |
| uses_retweets | If true, the collected data contains retweets by this account |
| uses_quotes | If true, the collected data contains quotes by this account |
| uses_replies | If true, the collected data contains replies by this account |
| url_tld_type | If false, the user’s URL has a generic top level domain otherwise its type is country-code |
Appendix A.2. Tweet-Level Features
| Feature Name | Description |
|---|---|
| favorite_count | The number of times a tweet has been liked by Twitter users |
| possibly_sensitive | Indicates that the URL in a tweet may contain sensitive content or media. This is only present if the tweet contains an URL. |
| retweeted_count | The number of times a tweet has been retweeted |
| truncated | Indicates that the tweet’s text was truncated because it exceeds the character limit |
| Feature Name | Description |
|---|---|
| has_place | If true, the API returned a place. Places are only associated to a tweet and are not necessarily the place where a tweet actually was created. |
| has_location | If true, the coordinates of the creation location were returned |
| nr_of_urls | Counts the number of URLs in a tweet. URLs not yet parsed out of the text by Twitter are included as well. |
| contains_urls | States whether a tweet contains URLs or not |
| avg_url_length | States the length of the URL or the average length in case there is more than one URL. |
| url_only | If true, there are no other characters but an URL |
| nr_of_hashtags | Counts the number of hashtags in a tweet |
| contains_hashtags | If true, the tweet contains at least one hashtag |
| nr_of_popular_hashtags | Counts the number of hashtags in a tweet that are in the top 100 most frequently used hashtags across all users. This avoids to include hashtags which are frequent but only used by a single user. |
| contains_popular_hashtag | If true, the tweet contains one of the 100 most frequently used hashtags across all users |
| nr_of_medias | The number of medias the tweet contains which, for example, includes a photo |
| contains_media | If true, the tweet contains media |
| nr_of_user_mentions | States the number of users mentioned in the tweet |
| contains_user_mention | If true, the tweet contains at least one user mention |
| nr_of_unicode_emojis | States the number of unicode emoticons that are in the tweet’s text |
| contains_unicode_emojis | If true, the tweet contains at least one unicode emoticon |
| contains_face_positive _emojis | If true, the tweet contains unicode emoticons from category face positive |
| contains_face_negative _emojis | If true, the tweet contains unicode emoticons from category face negative |
| contains_face_neutral _emojis | If true, the tweet contains unicode emoticons from category face neutral |
| nr_of_ascii_emojis | Counts the number of ASCII emoticons in the text |
| contains_ascii_emojis | If true, there are ASCII emoticons in the text |
| contains_stock_symbol | If true, there is at least one stock mention ($ followed by alphabet characters) in the text |
| nr_of_punctuation | Counts the number of punctuations in a tweet |
| contains_punctuation | If true, the tweet contains punctuation |
| ratio_punctuation_tokens | The ratio of tokens that are actually punctuation |
| nr_of_exclamation_marks | The number of exclamation marks in the tweet |
| contains_exclamation _mark | If true, the tweet contains at least one exclamation mark |
| multiple_exclamation _marks | If true, there are at least two exclamation marks |
| nr_of_question_marks | The number of question marks in the tweet |
| contains_question_mark | If true, the tweet contains at least one question mark |
| multiple_question_marks | If true, there are at least two question marks |
| contains_character _repetitions | If true, a character is followed by at least two repetitions of itself |
| contains_number | If true, the tweet contains a token that is a numerical |
| contains_quote | If true, there is a quoted text in the tweet |
| day_of_week | The day of the week the tweet was created |
| day_of_month | The day of the month the tweet was created |
| month_of_year | The month the tweet was created |
| am_pm | If true, the tweet was published after noon. If present, the users UTC offset was considered otherwise the most frequent offset was used. |
| hour_of_day | The hour the tweet was published in the 24 h format. If present, the users UTC offset was considered otherwise the most frequent offset was used. |
| quarter_of_year | The quarter of the year the tweet was published |
| no_text | If true, a tweet does not contain text. This is possible when the status update is an URL only. |
| avg_word_length | The average word length in the tweet. URLs are not counted. |
| text_length | The length of the text according to the Twitter character counting. User mentions are not counted. The feature is based on the raw text. |
| percent_of_text_used | The ratio of used characters to the 140 possible characters. |
| nr_of_words | Counts the words a in tweet. This feature is based on preprocessing stage two. Punctuation is not included into the count. |
| nr_of_tokens | Counts the number of tokens that were generated by the tokenizer. It considers preprocessing stage three. |
| ratio_words_tokens | States the ratio between words and tokens. |
| ratio_uppercase_letters | The ratio of uppercase letters to all cased characters in the tweet’s text |
| is_all_uppercase | If true, all characters in the raw text are uppercase |
| contains_uppercase_text | If true, the tweet contains a sequence of characters of length five or larger that contain only uppercase letters |
| ratio_capitalized_words | Counts the number of capitalized words and relates them to the word count. Words with only capitalized characters are not included in the count for capitalized words. |
| ratio_all_capitalized_words | Ratio of words that contain only capitalized letters to the total number of words. It is based on preprocessing stage two. |
| nr_of_sentences | Counts the number of sentences. If there is only one sentence, this does not necessarily mean that this is a complete sentence. Preprocessing stage seven refers to this feature. |
| contains_character _repetitions | If true, a character is followed by at least two repetitions of itself in the raw text from stage one. |
| nr_of_slang_words | The number of slang words in the tweet from the slang word dictionary. Preprocessing stage two was used here. |
| contains_slang | If true, the tweet contains at least one slang word |
| ratio_adjectives | The ratio of adjectives to the total number of words after POS tagging in stage four |
| ratio_nouns | The ratio of nouns to the total number of words after POS tagging in stage four |
| ratio_verbs | Ratio of verbs to the total number of words after POS tagging in stage four |
| contains_named_entity | If true, a token of the tweet was tagged as a named entity after POS tagging in stage four |
| contains_pronouns | If true, a token of the tweet was tagged as a pronoun after POS tagging in stage four |
| additional_preprocessed _is_empty | If true, after all text preprocessing steps in stage six no tokens are left |
| ratio_tokens_before_after _prepro | The ratio of the number of tokens before preprocessing (stage three) to the number of tokens afterwards (stage six). Can be greater than one since abbreviations are resolved after tokenization. |
| ratio_stopwords | The ratio of the tokens from preprocessing stage six where stopwords were removed to the number of tokens in stage five which includes stopwords |
| contains_spelling_mistake | If true, a spelling mistake was found through spell checking |
Appendix A.3. Sentiment Features
| Feature Name | Description |
|---|---|
| sentiment_score | The average sentiment of the words in a tweet |
| contains_sentiment | If true, the sentiment score is different from 0.5 |
| nr_pos_sentiment_words | The number of positive words in a tweet |
| nr_neg_sentiment_words | The number of negative words in a tweet |
| nr_of_sentiment_words | The total number of words that got a sentiment score in a tweet |
| ratio_pos_sentiment_words | The ratio of the number of positive words to the number of all sentiment words |
| ratio_neg_sentiment_words | The ratio of the number of negative words to the number of all sentiment words |
References
- Ratkiewicz, J.; Conover, M.; Meiss, M.R.; Gonçalves, B.; Flammini, A.; Menczer, F. Detecting and Tracking Political Abuse in Social Media. ICWSM 2011, 11, 297–304. [Google Scholar]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The rise of social bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election; Working Paper 23089; National Bureau of Economic Research: Cambridge, MA, USA, 2017. [Google Scholar] [CrossRef]
- Chen, E.; Chang, H.; Rao, A.; Lerman, K.; Cowan, G.; Ferrara, E. COVID-19 misinformation and the 2020 US presidential election. Harv. Kennedy Sch. Misinf. Rev. 2021. [Google Scholar] [CrossRef]
- Pennycook, G.; Rand, D.G. Research note: Examining false beliefs about voter fraud in the wake of the 2020 Presidential Election. Harv. Kennedy Sch. Misinf. Rev. 2021. [Google Scholar] [CrossRef]
- Deshwal, A.; Sharma, S.K. Twitter sentiment analysis using various classification algorithms. In Proceedings of the 2016 5th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 7–9 September 2016; pp. 251–257. [Google Scholar] [CrossRef]
- Selvaperumal, P.; Suruliandi, A. A short message classification algorithm for tweet classification. In Proceedings of the 2014 International Conference on Recent Trends in Information Technology, Chennai, India, 10–12 April 2014; pp. 1–3. [Google Scholar] [CrossRef]
- Rosenthal, S.; Nakov, P.; Kiritchenko, S.; Mohammad, S.; Ritter, A.; Stoyanov, V. SemEval-2015 Task 10: Sentiment Analysis in Twitter. In SemEval at NAACL-HLT; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 451–463. [Google Scholar]
- Zubiaga, A.; Spina, D.; Martinez, R.; Fresno, V. Real-time classification of twitter trends. J. Assoc. Inf. Sci. Technol. 2015, 66, 462–473. [Google Scholar] [CrossRef]
- Cole-Lewis, H.; Varghese, A.; Sanders, A.; Schwarz, M.; Pugatch, J.; Augustson, E. Assessing electronic cigarette-related tweets for sentiment and content using supervised machine learning. J. Med Internet Res. 2015, 17, e208. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.H.; Kolcz, A.; Schlaikjer, A.; Gupta, P. Large-scale high-precision topic modeling on twitter. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 1907–1916. [Google Scholar]
- Jo, E.S.; Gebru, T. Lessons from archives: Strategies for collecting sociocultural data in machine learning. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 306–316. [Google Scholar]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2017, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Helmstetter, S.; Paulheim, H. Weakly Supervised Learning for Fake News Detection on Twitter. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 274–277. [Google Scholar]
- Gupta, A.; Kumaraguru, P. Credibility Ranking of Tweets During High Impact Events. In Proceedings of the 1st Workshop on Privacy and Security in Online Social Media, Lyon, France, 17 April 2012; ACM: New York, NY, USA, 2012. PSOSM ’12. pp. 2:2–2:8. [Google Scholar] [CrossRef] [Green Version]
- Mohd Shariff, S.; Zhang, X.; Sanderson, M. User Perception of Information Credibility of News on Twitter. In Proceedings of the 36th European Conference on IR Research on Advances in Information Retrieval, ECIR 2014, Amsterdam, The Netherlands, 13–16 April 2014; Springer Inc.: New York, NY, USA, 2014; Volume 8416, pp. 513–518. [Google Scholar] [CrossRef]
- Sikdar, S.; Adali, S.; Amin, M.; Abdelzaher, T.; Chan, K.; Cho, J.H.; Kang, B.; O’Donovan, J. Finding true and credible information on Twitter. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–8. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information Credibility on Twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; ACM: New York, NY, USA, 2011. WWW ’11. pp. 675–684. [Google Scholar] [CrossRef]
- Ahmed, H.; Traore, I.; Saad, S. Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. In Proceedings of the International Conference on Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments, Vancouver, BC, Canada, 26–28 October 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 127–138. [Google Scholar]
- Horne, B.D.; Adali, S. This just in: Fake news packs a lot in title, uses simpler, repetitive content in text body, more similar to satire than real news. arXiv 2017, arXiv:1703.09398. [Google Scholar]
- Zhao, Z.; Zhao, J.; Sano, Y.; Levy, O.; Takayasu, H.; Takayasu, M.; Li, D.; Havlin, S. Fake news propagate differently from real news even at early stages of spreading. arXiv 2018, arXiv:1803.03443. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Verstraete, M.; Bambauer, D.E.; Bambauer, J.R. Identifying and countering fake news. In Arizona Legal Studies Discussion Paper; SSRN: Rochester, NY, USA, 2017. [Google Scholar]
- Azab, A.E.; Idrees, A.M.; Mahmoud, M.A.; Hefny, H. Fake Account Detection in Twitter Based on Minimum Weighted Feature set. World Acad. Sci. Eng. Technol. Int. J. Comput. Electr. Autom. Control Inf. Eng. 2015, 10, 13–18. [Google Scholar]
- Benevenuto, F.; Magno, G.; Rodrigues, T.; Almeida, V. Detecting spammers on twitter. In Proceedings of the Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference (CEAS), Redmond, WA, USA, 13–14 July 2010. [Google Scholar]
- Gurajala, S.; White, J.S.; Hudson, B.; Matthews, J.N. Fake Twitter Accounts: Profile Characteristics Obtained Using an Activity-based Pattern Detection Approach. In Proceedings of the 2015 International Conference on Social Media & Society, Toronto, ON, Canada, 27–29 July 2015; ACM: New York, NY, USA, 2015. SMSociety ’15. pp. 9:1–9:7. [Google Scholar] [CrossRef]
- Stringhini, G.; Kruegel, C.; Vigna, G. Detecting Spammers on Social Networks. In Proceedings of the 26th Annual Computer Security Applications Conference, Orlando, FL, USA, 4–8 December 2010; ACM: New York, NY, USA, 2010. ACSAC ’10. pp. 1–9. [Google Scholar] [CrossRef]
- Fellbaum, C. WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Bird, S.; Loper, E. NLTK: The natural language toolkit. In Proceedings of the ACL 2004 on Interactive poster and demonstration sessions. Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 31. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In 31st International Conference on Machine Learning, Proceedings of the Machine Learning Research, Beijing, China, 21–26 June 2014; Xing, E.P., Jebara, T., Eds.; PMLR: Bejing, China, 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hoffman, M.; Bach, F.R.; Blei, D.M. Online Learning for Latent Dirichlet Allocation. In Advances in Neural Information Processing Systems 23; Lafferty, J.D., Williams, C.K.I., Shawe-Taylor, J., Zemel, R.S., Culotta, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2010; pp. 856–864. [Google Scholar]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet Processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Teh, Y.W.; Jordan, M.I. Hierarchical Bayesian Nonparametric Models with Applications. In Bayesian Nonparametrics: Principles and Practice; Hjort, N., Holmes, C., Müller, P., Walker, S., Eds.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Wang, C.; Paisley, J.W.; Blei, D.M. Online Variational Inference for the Hierarchical Dirichlet Process. In Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS-11), Ft. Lauderdale, FL, USA, 2011; Gordon, G.J., Dunson, D.B., Eds.; Proceedings of Machine Learning Research: Cambridge, UK, 2011; Volume 15, pp. 752–760. [Google Scholar]
- Lesk, M. Automatic Sense Disambiguation Using Machine Readable Dictionaries: How to Tell a Pine Cone from an Ice Cream Cone. In Proceedings of the 5th Annual International Conference on Systems Documentation, Toronto, ON, Canada, 8–11 June 1986; ACM: New York, NY, USA, 1986. SIGDOC ’86. pp. 24–26. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valetta, Malta, 17–23 May 2010; Chair, N.C.C., Choukri, K., Maegaard, B., Mariani, J., Odijk, J., Piperidis, S., Rosner, M., Tapias, D., Eds.; European Language Resources Association (ELRA): Valletta, Malta, 2010. [Google Scholar]
- Unicode Inc. Full Emoji Data, v5.0. Available online: http://unicode.org/emoji/charts/full-emoji-list.html (accessed on 20 May 2017).
- Berry, N. Emoticon Analysis in Twitter. Available online: http://datagenetics.com/blog/october52012/index.html (accessed on 9 May 2017).
- De Smedt, T.; Daelemans, W. Pattern for Python. J. Mach. Learn. Res. 2012, 13, 2063–2067. [Google Scholar]
- Smedt, T.D.; Daelemans, W. “Vreselijk mooi!” (terribly beautiful): A Subjectivity Lexicon for Dutch Adjectives. In LREC; Calzolari, N., Choukri, K., Declerck, T., Dogan, M.U., Maegaard, B., Mariani, J., Odijk, J., Piperidis, S., Eds.; European Language Resources Association (ELRA): Luxemburg, 2012; pp. 3568–3572. [Google Scholar]
- Molina, L.C.; Belanche, L.; Nebot, À. Feature selection algorithms: A survey and experimental evaluation. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; IEEE: Piscataway, NJ, USA, 2002; pp. 306–313. [Google Scholar]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. 2003. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 28 April 2021).
- Heaton, J. Introduction to Neural Networks for Java, 2nd ed.; Heaton Research, Inc.: St. Louis, MO, USA, 2008. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Lawrence, N.D.; Schölkopf, B. Estimating a kernel Fisher discriminant in the presence of label noise. ICML 2001, 1, 306–313. [Google Scholar]
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.K.; Tewari, A. Learning with noisy labels. Adv. Neural Inf. Process. Syst. 2013, 26, 1196–1204. [Google Scholar]









| Category | Amount |
|---|---|
| Fake news | 15.0% |
| Real news | 40.0% |
| No news | 26.7% |
| Unclear | 18.3% |
| Learner | Variant | Precision | Recall | F1-Measure |
|---|---|---|---|---|
| Naive Bayes | unigram | 0.3943 | 0.6376 | 0.4873 |
| Decision Tree | unigram | 0.4219 | 0.4168 | 0.4193 |
| SVM | unigram | 0.5878 | 0.1559 | 0.2465 |
| Neural Network | unigram | 0.4471 | 0.3951 | 0.4195 |
| XGBoost | unigram | 0.6630 | 0.0641 | 0.1170 |
| Random Forest | unigram | 0.5226 | 0.4095 | 0.4592 |
| Naive Bayes | bigram | 0.4486 | 0.1320 | 0.2040 |
| Decision Tree | bigram | 0.4139 | 0.3178 | 0.3595 |
| SVM | bigram | 0.5930 | 0.1029 | 0.1754 |
| Neural Network | bigram | 0.3935 | 0.1414 | 0.2081 |
| XGBoost | bigram | 0.4083 | 0.0596 | 0.1040 |
| Random Forest | bigram | 0.4450 | 0.2945 | 0.3544 |
| Learner | #F | FS | Prec. | Rec. | F1 |
|---|---|---|---|---|---|
| NB | 409 | V | 0.7024 | 0.6080 | 0.6518 |
| DT | 845 | – | 0.6918 | 0.6401 | 0.6649 |
| NN | 463 | MI | 0.8428 | 0.6949 | 0.7618 |
| SVM | 565 | MI | 0.8492 | 0.6641 | 0.7453 |
| XGB | 106 | G | 0.8672 | 0.7018 | 0.7758 |
| RF | 873 | G | 0.8382 | 0.6494 | 0.7318 |
| V | – | – | 0.8650 | 0.7034 | 0.7759 |
| WV | – | – | 0.8682 | 0.7039 | 0.7775 |
| Learner | #F | FS | Prec. | Rec. | F1 |
|---|---|---|---|---|---|
| NB | 614 | V | 0.8704 | 0.8851 | 0.8777 |
| DT | 34 | G | 0.8814 | 0.9334 | 0.9067 |
| NN | 372 | V | 0.8752 | 0.8861 | 0.8806 |
| SVM | 595 | MI | 0.9315 | 0.7727 | 0.8447 |
| XGB | 8 | G | 0.8946 | 0.9589 | 0.9256 |
| RF | 790 | G | 0.8923 | 0.8291 | 0.8596 |
| V | – | – | 0.9305 | 0.9416 | 0.9360 |
| WV | – | – | 0.9274 | 0.9384 | 0.9329 |
| Learner | Precision | Recall | F1-Measure |
|---|---|---|---|
| NB | 0.6835 | 0.4655 | 0.5538 |
| DT | 0.7895 | 0.6466 | 0.7109 |
| NN | 0.7909 | 0.7500 | 0.7699 |
| SVM | 0.7961 | 0.7069 | 0.7489 |
| XGB | 0.8333 | 0.6897 | 0.7547 |
| RF | 0.8721 | 0.6466 | 0.7426 |
| V | 0.8200 | 0.7069 | 0.7593 |
| WV | 0.8478 | 0.6724 | 0.7500 |
| Learner | Precision | Recall | F1-Measure |
|---|---|---|---|
| NB | 0.8333 | 0.9052 | 0.8678 |
| DT | 0.8721 | 0.6466 | 0.7426 |
| NN | 0.9115 | 0.8879 | 0.8996 |
| SVM | 0.8942 | 0.8017 | 0.8455 |
| XGB | 0.8679 | 0.7931 | 0.8288 |
| RF | 0.8713 | 0.7586 | 0.8111 |
| V | 0.8870 | 0.8793 | 0.8831 |
| WV | 0.8761 | 0.8534 | 0.8646 |
| Identifying Fake News... | ||
|---|---|---|
| Sources | Tweets | |
| Tweet features only | 0.7775 (Table 3) | 0.7699 (Table 5) |
| Tweet and user features | 0.9360 (Table 4) | 0.8996 (Table 6) |
| Re-Created Features | Features from Large Set | |||||
|---|---|---|---|---|---|---|
| Learner | Precision | Recall | F1-Measure | Precision | Recall | F1-Measure |
| NB | 0.5912 | 0.6983 | 0.6403 | 0.4425 | 0.4310 | 0.4367 |
| DT | 0.6944 | 0.6466 | 0.6696 | 0.7156 | 0.6724 | 0.6933 |
| NN | 0.7500 | 0.8017 | 0.7750 | 0.6640 | 0.7155 | 0.6888 |
| SVM | 0.7311 | 0.7500 | 0.7404 | 0.8585 | 0.7845 | 0.8198 |
| XGB | 0.8000 | 0.7586 | 0.7788 | 0.7797 | 0.7931 | 0.7863 |
| RF | 0.7524 | 0.6810 | 0.7149 | 0.7938 | 0.6638 | 0.7230 |
| Re-Created Features | Features from Large Set | |||||
|---|---|---|---|---|---|---|
| Learner | Precision | Recall | F1-Measure | Precision | Recall | F1-Measure |
| NB | 0.8235 | 0.7241 | 0.7706 | 0.5619 | 0.6983 | 0.6255 |
| DT | 0.8750 | 0.9052 | 0.8898 | 0.8571 | 0.8793 | 0.8681 |
| NN | 0.8547 | 0.8621 | 0.8584 | 0.8110 | 0.8879 | 0.8477 |
| SVM | 0.8584 | 0.8362 | 0.8472 | 0.9299 | 0.9138 | 0.9217 |
| XGB | 0.8947 | 0.8793 | 0.8870 | 0.8983 | 0.9138 | 0.9059 |
| RF | 0.8618 | 0.9138 | 0.8870 | 0.8522 | 0.8448 | 0.8485 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Helmstetter, S.; Paulheim, H. Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision. Future Internet 2021, 13, 114. https://doi.org/10.3390/fi13050114
Helmstetter S, Paulheim H. Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision. Future Internet. 2021; 13(5):114. https://doi.org/10.3390/fi13050114
Chicago/Turabian StyleHelmstetter, Stefan, and Heiko Paulheim. 2021. "Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision" Future Internet 13, no. 5: 114. https://doi.org/10.3390/fi13050114
APA StyleHelmstetter, S., & Paulheim, H. (2021). Collecting a Large Scale Dataset for Classifying Fake News Tweets Using Weak Supervision. Future Internet, 13(5), 114. https://doi.org/10.3390/fi13050114