
Reducing Videoconferencing Fatigue through Facial Emotion Recognition



Abstract
:1. Introduction
- The happier the speaker is, the happier and less neutral the audience is;
- The more neutral the speaker is, the less surprised the audience is;
- Triggering diverse emotions such as happiness, neutrality, and fear leads to a higher presentation score;
- Triggering too much neutrality among the participants leads to a lower presentation score.
2. Related Work
2.1. Facial Emotion Recognition
2.2. Presentations and Emotions
3. Data and Methods
3.1. Experimental Setup
3.2. Data Pre-Processing
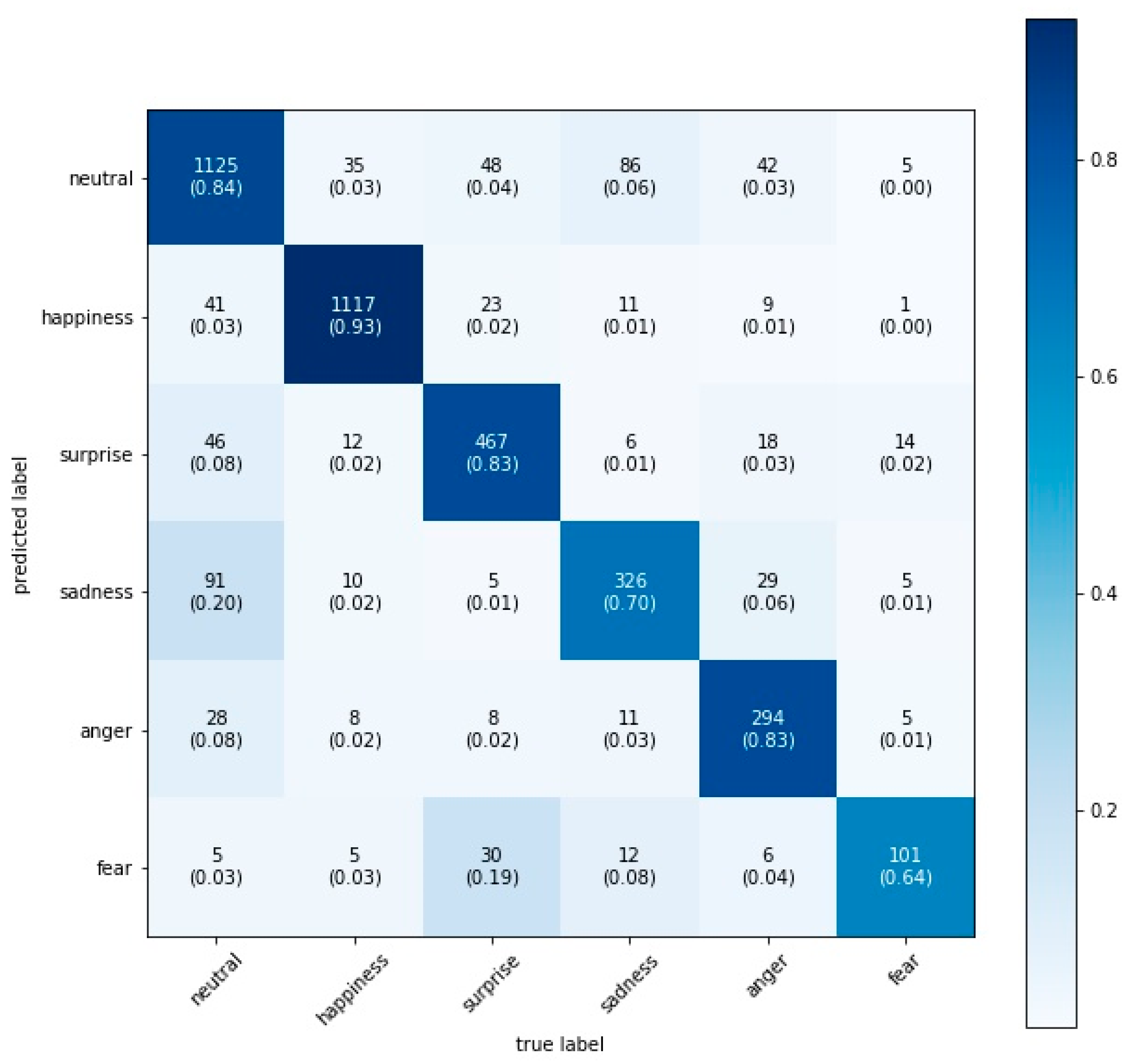
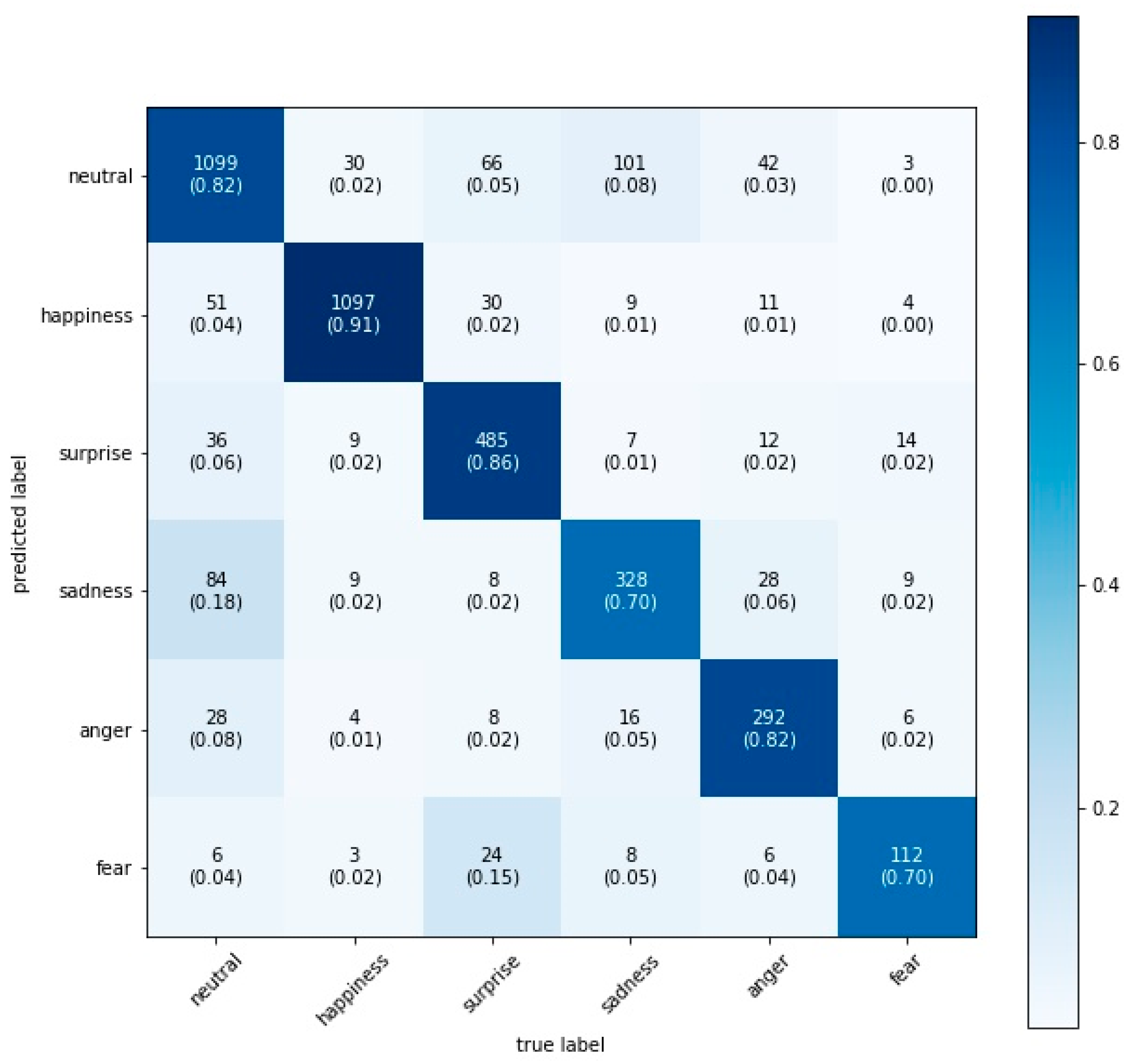
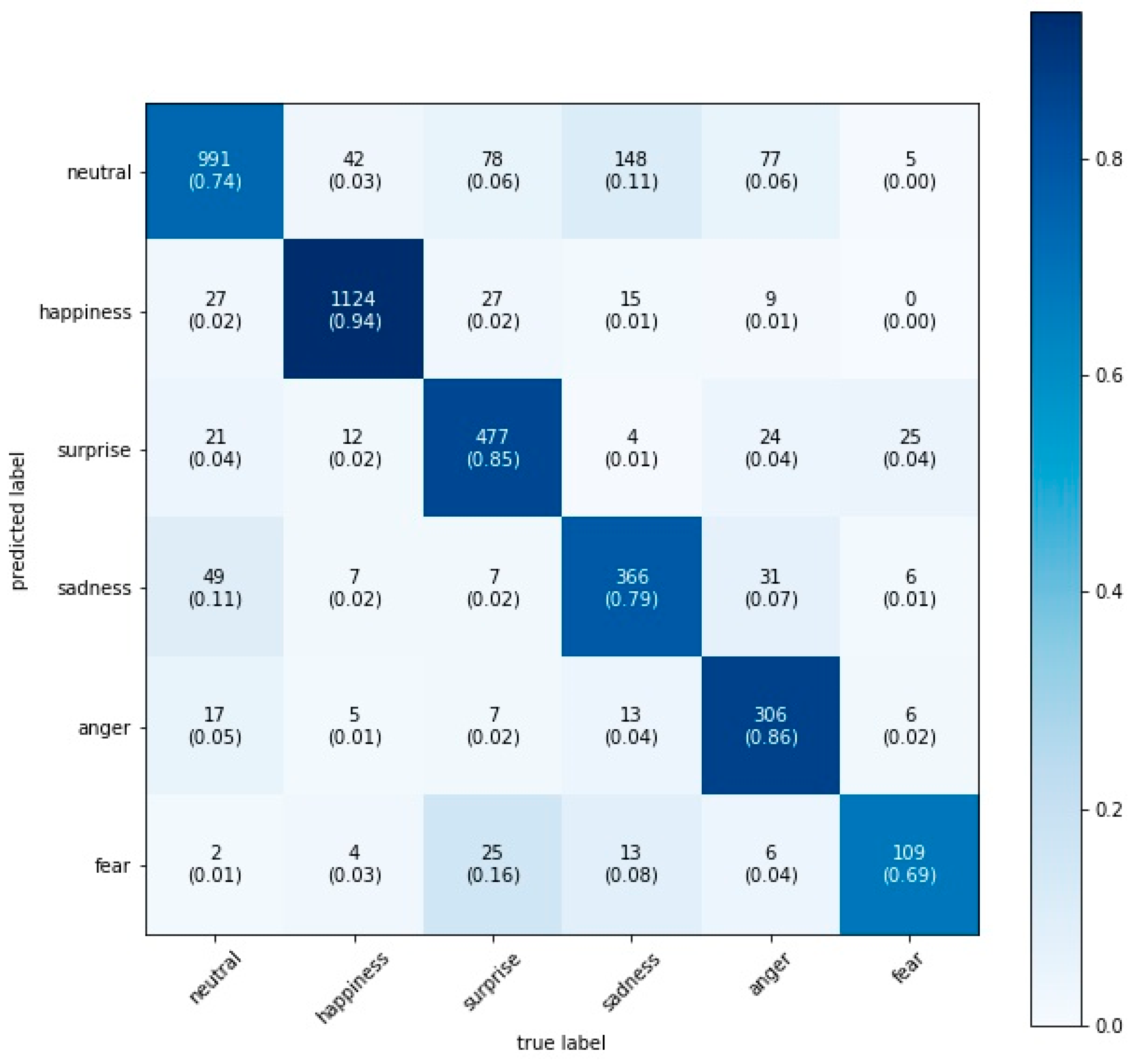
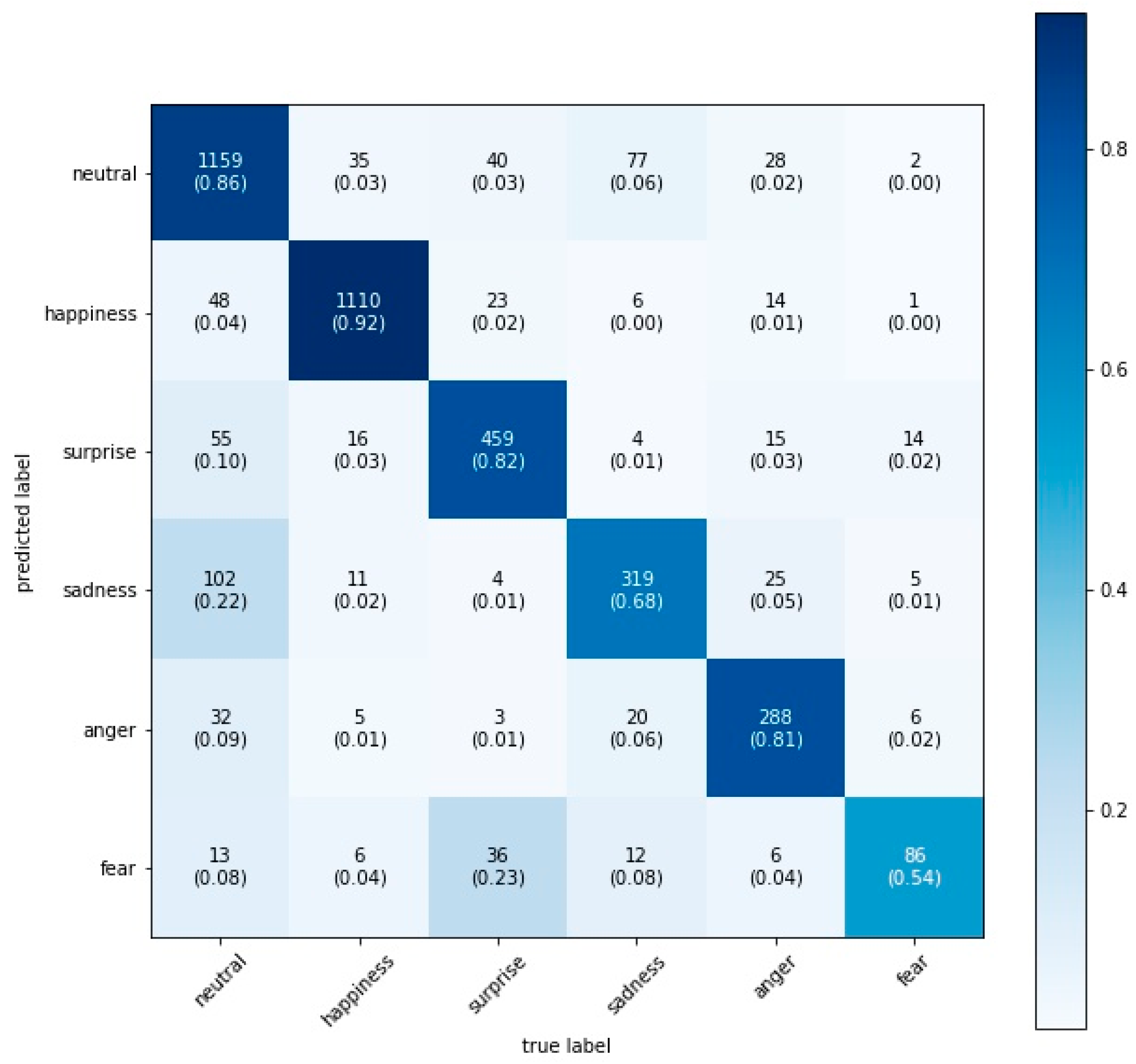
3.3. Facial Emotion Recognition
- 5405 images from AffectNet [19], which we labelled manually;
- 31,051 images from FERPlus (https://github.com/microsoft/FERPlus, accessed on 10 May 2021);
- 250 images from the Extended Cohn-Kanade Data set (CK+) [12];
- 184 images from the Japanese Female Facial Expressions (JAFFE) database [13];
- 522 images from BU-3DFE [14];
- 3455 images from FFQH (https://github.com/NVlabs/ffhq-dataset, accessed on 10 May 2021), which we labelled manually.
3.4. Feature Engineering
4. Results
5. Discussion
6. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- D’Errico, F.; Poggi, I. Tracking a Leader’s Humility and Its Emotions from Body, Face and Voice. Web Intell. 2019, 17, 63–74. [Google Scholar] [CrossRef]
- Gallo, C. Talk Like TED: The 9 Public-Speaking Secrets of the World’s Top Minds; Macmillan: London, UK, 2014; ISBN 978-1-4472-6113-1. [Google Scholar]
- Damasio, A.R. Descartes’ Error: Emotion, Reason and the Human Brain; rev. ed. with a new preface; Vintage: London, UK, 2006; ISBN 978-0-09-950164-0. [Google Scholar]
- Tyng, C.M.; Amin, H.U.; Saad, M.N.M.; Malik, A.S. The Influences of Emotion on Learning and Memory. Front. Psychol. 2017, 8, 1454. [Google Scholar] [CrossRef] [PubMed]
- Zeng, H.; Wang, X.; Wu, A.; Wang, Y.; Li, Q.; Endert, A.; Qu, H. EmoCo: Visual Analysis of Emotion Coherence in Presentation Videos. IEEE Trans. Visual. Comput. Graph. 2019, 26, 927–937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ko, B.C. A Brief Review of Facial Emotion Recognition Based on Visual Information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Choi, D.Y.; Song, B.C. Facial Micro-Expression Recognition Using Two-Dimensional Landmark Feature Maps. IEEE Access 2020, 8, 121549–121563. [Google Scholar] [CrossRef]
- De Carolis, B.; D’Errico, F.; Macchiarulo, N.; Palestra, G. “Engaged Faces”: Measuring and Monitoring Student Engagement from Face and Gaze Behavior. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence-Companion Volume, New York, NY, USA, 14 October 2019; pp. 80–85. [Google Scholar]
- De Carolis, B.; D’Errico, F.; Macchiarulo, N.; Paciello, M.; Palestra, G. Recognizing Cognitive Emotions in E-Learning Environment. In Proceedings of the Bridges and Mediation in Higher Distance Education; Agrati, L.S., Burgos, D., Ducange, P., Limone, P., Perla, L., Picerno, P., Raviolo, P., Stracke, C.M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 17–27. [Google Scholar]
- De Carolis, B.; D’Errico, F.; Paciello, M.; Palestra, G. Cognitive Emotions Recognition in E-Learning: Exploring the Role of Age Differences and Personality Traits. In Proceedings of the Methodologies and Intelligent Systems for Technology Enhanced Learning, 9th International Conference; Gennari, R., Vittorini, P., De la Prieta, F., Di Mascio, T., Temperini, M., Azambuja Silveira, R., Ovalle Carranza, D.A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 97–104. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Available online: https://arxiv.org/pdf/1409.1556.pdf (accessed on 10 May 2021).
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A Complete Dataset for Action Unit and Emotion-Specified Expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Lyons, M.; Kamachi, M.; Gyoba, J. The Japanese Female Facial Expression (JAFFE) Dataset 1998; 1998. Available online: https://zenodo.org/record/3451524#.YJtUMqgzbIU (accessed on 10 May 2021).
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D Facial Expression Database for Facial Behavior Research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar]
- Jain, D.K.; Shamsolmoali, P.; Sehdev, P. Extended Deep Neural Network for Facial Emotion Recognition. Pattern Recognit. Lett. 2019, 120, 69–74. [Google Scholar] [CrossRef]
- Ekman, P.; Oster, H. Facial Expressions of Emotion. Annu. Rev. Psychol. 1979, 30, 527–554. [Google Scholar] [CrossRef]
- Rubin, D.C.; Talarico, J.M. A Comparison of Dimensional Models of Emotion: Evidence from Emotions, Prototypical Events, Autobiographical Memories, and Words. Memory 2009, 17, 802–808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Panksepp, J. Affective Neuroscience: The Foundations of Human and Animal Emotions; Oxford University Press: Oxford, UK, 2004; ISBN 978-0-19-802567-2. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Suk, M.; Prabhakaran, B. Real-Time Mobile Facial Expression Recognition System-A Case Study. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.1011.4398&rep=rep1&type=pdf (accessed on 10 May 2021).
- Ghimire, D.; Lee, J. Geometric Feature-Based Facial Expression Recognition in Image Sequences Using Multi-Class AdaBoost and Support Vector Machines. Sensors 2013, 13, 7714–7734. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Happy, S.L.; George, A.; Routray, A. A Real Time Facial Expression Classification System Using Local Binary Patterns. In Proceedings of the 2012 4th International Conference on Intelligent Human Computer Interaction (IHCI), Kharagpur, India, 27–29 December 2012; pp. 1–5. [Google Scholar]
- Szwoch, M.; Pieniążek, P. Facial Emotion Recognition Using Depth Data. In Proceedings of the 2015 8th International Conference on Human System Interaction (HSI), Warsaw, Poland, 25–27 June 2015; pp. 271–277. [Google Scholar]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition. 2015, pp. 2983–2991. Available online: https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Jung_Joint_Fine-Tuning_in_ICCV_2015_paper.pdf (accessed on 10 May 2021).
- Breuer, R.; Kimmel, R. A Deep Learning Perspective on the Origin of Facial Expressions. Available online: https://arxiv.org/pdf/1705.01842.pdf (accessed on 10 May 2021).
- Hasani, B.; Mahoor, M.H. Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks. Available online: https://arxiv.org/pdf/1705.07871.pdf (accessed on 10 May 2021).
- Kim, D.H.; Baddar, W.J.; Jang, J.; Ro, Y.M. Multi-Objective Based Spatio-Temporal Feature Representation Learning Robust to Expression Intensity Variations for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2019, 10, 223–236. [Google Scholar] [CrossRef]
- Ng, H.-W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep Learning for Emotion Recognition on Small Datasets Using Transfer Learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, New York, NY, USA, 9 November 2015; pp. 443–449. [Google Scholar]
- Gervasi, O.; Franzoni, V.; Riganelli, M.; Tasso, S. Automating Facial Emotion Recognition. Web Intell. 2019, 17, 17–27. [Google Scholar] [CrossRef]
- Chu, W.-S.; De la Torre, F.; Cohn, J.F. Learning Spatial and Temporal Cues for Multi-Label Facial Action Unit Detection. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 25–32. [Google Scholar]
- Graves, A.; Mayer, C.; Wimmer, M.; Radig, B. Facial Expression Recognition with Recurrent Neural Networks. Available online: https://www.cs.toronto.edu/~graves/cotesys_2008.pdf (accessed on 10 May 2021).
- Jain, D.K.; Zhang, Z.; Huang, K. Multi Angle Optimal Pattern-Based Deep Learning for Automatic Facial Expression Recognition. Pattern Recognit. Lett. 2020, 139, 157–165. [Google Scholar] [CrossRef]
- Ebrahimi Kahou, S.; Michalski, V.; Konda, K.; Memisevic, R.; Pal, C. Recurrent Neural Networks for Emotion Recognition in Video. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, New York, NY, USA, 9 November 2015; pp. 467–474. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Franzoni, V.; Biondi, G.; Perri, D.; Gervasi, O. Enhancing Mouth-Based Emotion Recognition Using Transfer Learning. Sensors 2020, 20, 5222. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Poulose, A.; Han, D.S. The Extensive Usage of the Facial Image Threshing Machine for Facial Emotion Recognition Performance. Sensors 2021, 21, 2026. [Google Scholar] [CrossRef] [PubMed]
- Kuo, C.; Lai, S.; Sarkis, M. A Compact Deep Learning Model for Robust Facial Expression Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2202–22028. [Google Scholar]
- Kaya, H.; Gürpınar, F.; Salah, A.A. Video-Based Emotion Recognition in the Wild Using Deep Transfer Learning and Score Fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Ye, N.; Wang, R. A Survey on Automatic Emotion Recognition Using Audio Big Data and Deep Learning Architectures. In Proceedings of the 2018 IEEE 4th International Conference on Big Data Security on Cloud (BigDataSecurity), Omaha, NE, USA, 3–5 May 2018; pp. 139–142. [Google Scholar]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion Recognition Using Multi-Modal Data and Machine Learning Techniques: A Tutorial and Review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Chen, L.; Feng, G.; Joe, J.; Leong, C.W.; Kitchen, C.; Lee, C.M. Towards Automated Assessment of Public Speaking Skills Using Multimodal Cues. In Proceedings of the Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12 November 2014; pp. 200–203. [Google Scholar]
- Gloor, P.A.; Paasivaara, M.; Miller, C.Z.; Lassenius, C. Lessons from the Collaborative Innovation Networks Seminar. IJODE 2016, 4, 3. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning With Depthwise Separable Convolutions. Available online: https://arxiv.org/pdf/1610.02357.pdf (accessed on 10 May 2021).
- Hamelin, N.; El Moujahid, O.; Thaichon, P. Emotion and advertising effectiveness: A novel facial expression analysis approach. J. Retail. Consum. Serv. 2017, 36, 103–111. [Google Scholar] [CrossRef]
- Franzoni, V.; Vallverdù, J.; Milani, A. Errors, biases and overconfidence in artificial emotional modeling. Available online: https://www.researchgate.net/publication/336626687_Errors_Biases_and_Overconfidence_in_Artificial_Emotional_Modeling (accessed on 10 May 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anger | Fear | Surprise | Sadness | Neutral | Happiness | Total | |
|---|---|---|---|---|---|---|---|
| AffectNet | 473 | 512 | 1379 | 569 | 1873 | 599 | 5405 |
| FERPlus | 2606 | 648 | 3950 | 3770 | 11,011 | 9066 | 31,051 |
| CK+ | 45 | 25 | 83 | 28 | 0 | 69 | 250 |
| JAFFE | 30 | 32 | 30 | 31 | 30 | 31 | 184 |
| BU-3DFE | 92 | 92 | 89 | 88 | 84 | 77 | 522 |
| FFQH | 260 | 22 | 114 | 193 | 540 | 2326 | 3455 |
| Total | 3506 | 1331 | 5645 | 4679 | 13,538 | 12,168 | 40,867 |
| Ratio_Speaker (Happy) | Ratio_Speaker (Neutral) | Ratio_Speaker (Fear) | Ratio_Speaker (Sad) | Ratio_Speaker (Surprise) | Ratio_Speaker (Angry) | |
|---|---|---|---|---|---|---|
| ratio_audience(happy) | 0.5107 *** | −0.0754 | 0.0544 | −0.0532 | −0.2369 | −0.2082 |
| ratio_audience(neutral) | −0.4347 *** | 0.0909 | −0.0432 | −0.0283 | 0.1850 | 0.1340 |
| ratio_audience(fear) | 0.2240 | 0.0983 | −0.1953 | 0.0210 | −0.3097 | 0.1471 |
| ratio_audience(sad) | −0.1185 | 0.0592 | 0.0165 | −0.0780 | −0.0153 | 0.2119 |
| ratio_audience(surprise) | 0.2059 | −0.3147 ** | 0.1163 | 0.1995 | 0.1952 | 0.1602 |
| ratio_audience(angry) | −0.0123 | 0.0013 | −0.0569 | 0.1650 | 0.0089 | −0.1450 |
| Presentation Score | p-Value | |
|---|---|---|
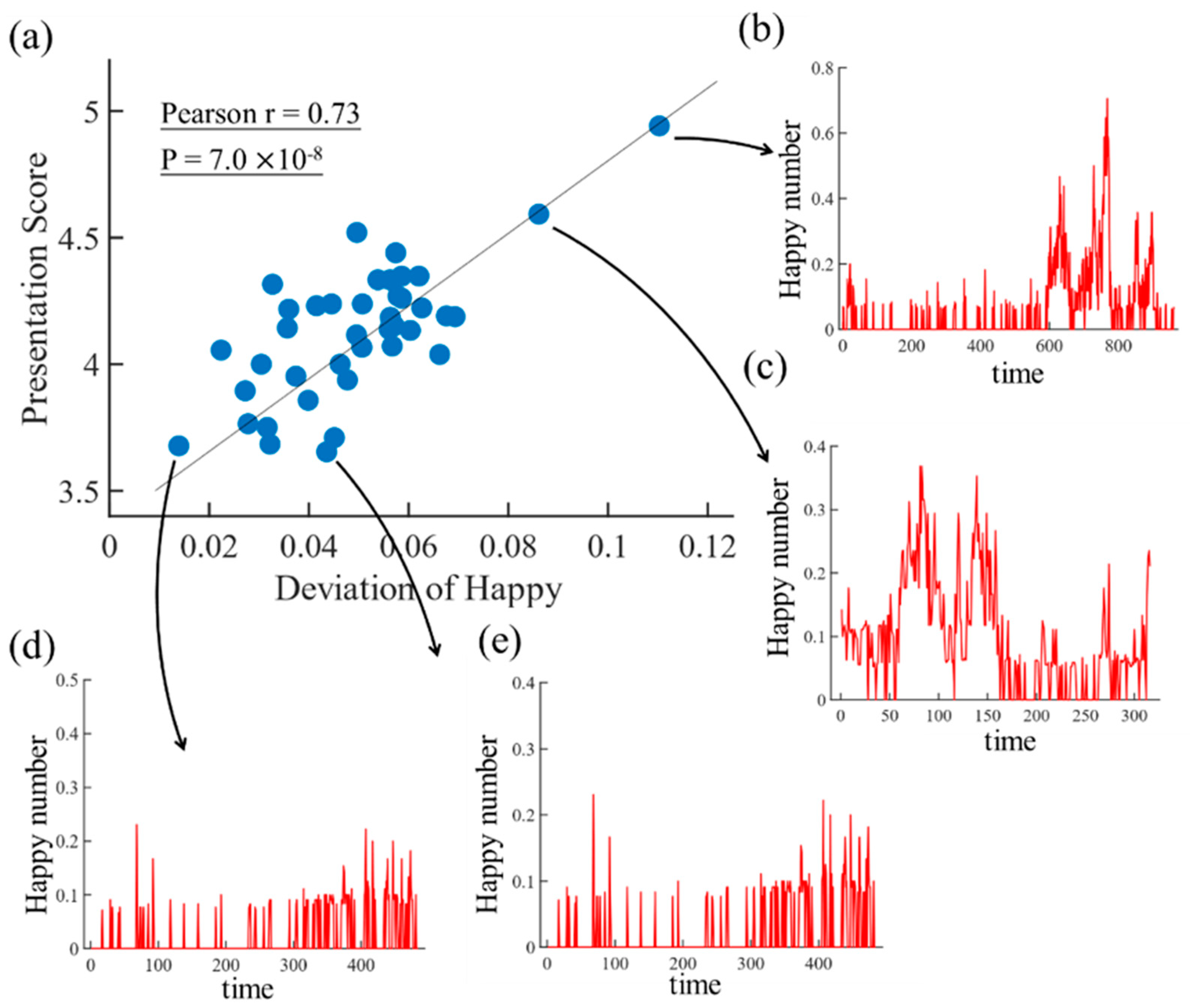
| deviation (happy) | 0.73 | 7 × 10−8 |
| deviation (neutral) | 0.50 | 8 × 10−4 |
| deviation (fear) | 0.34 | 0.025 |
| ratio_audience (happy) | 0.55 | 2 × 10−4 |
| ratio_audience (neutral) | −0.44 | 4 × 10−3 |
| ratio_audience (fear) | 0.38 | 0.010 |
| density (happy) | 0.44 | 4 × 10−3 |
| ratio_speaker (happy) | 0.35 | 0.026 |
| Variables | Coefficient | Standard Error | T-Statistics | p-Value |
|---|---|---|---|---|
| Intercept | −0.076 | 0.071 | −1.063 | 0.295 |
| deviation (happy) | 7.866 | 1.411 | 5.574 | 2.8 × 10−6 |
| deviation (fear) | 12.026 | 6.372 | 1.888 | 0.067 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rößler, J.; Sun, J.; Gloor, P. Reducing Videoconferencing Fatigue through Facial Emotion Recognition. Future Internet 2021, 13, 126. https://doi.org/10.3390/fi13050126
Rößler J, Sun J, Gloor P. Reducing Videoconferencing Fatigue through Facial Emotion Recognition. Future Internet. 2021; 13(5):126. https://doi.org/10.3390/fi13050126
Chicago/Turabian StyleRößler, Jannik, Jiachen Sun, and Peter Gloor. 2021. "Reducing Videoconferencing Fatigue through Facial Emotion Recognition" Future Internet 13, no. 5: 126. https://doi.org/10.3390/fi13050126
APA StyleRößler, J., Sun, J., & Gloor, P. (2021). Reducing Videoconferencing Fatigue through Facial Emotion Recognition. Future Internet, 13(5), 126. https://doi.org/10.3390/fi13050126