
Assessing the Predictive Power of Online Social Media to Analyze COVID-19 Outbreaks in the 50 U.S. States



Abstract
:1. Introduction
2. Materials and Methods
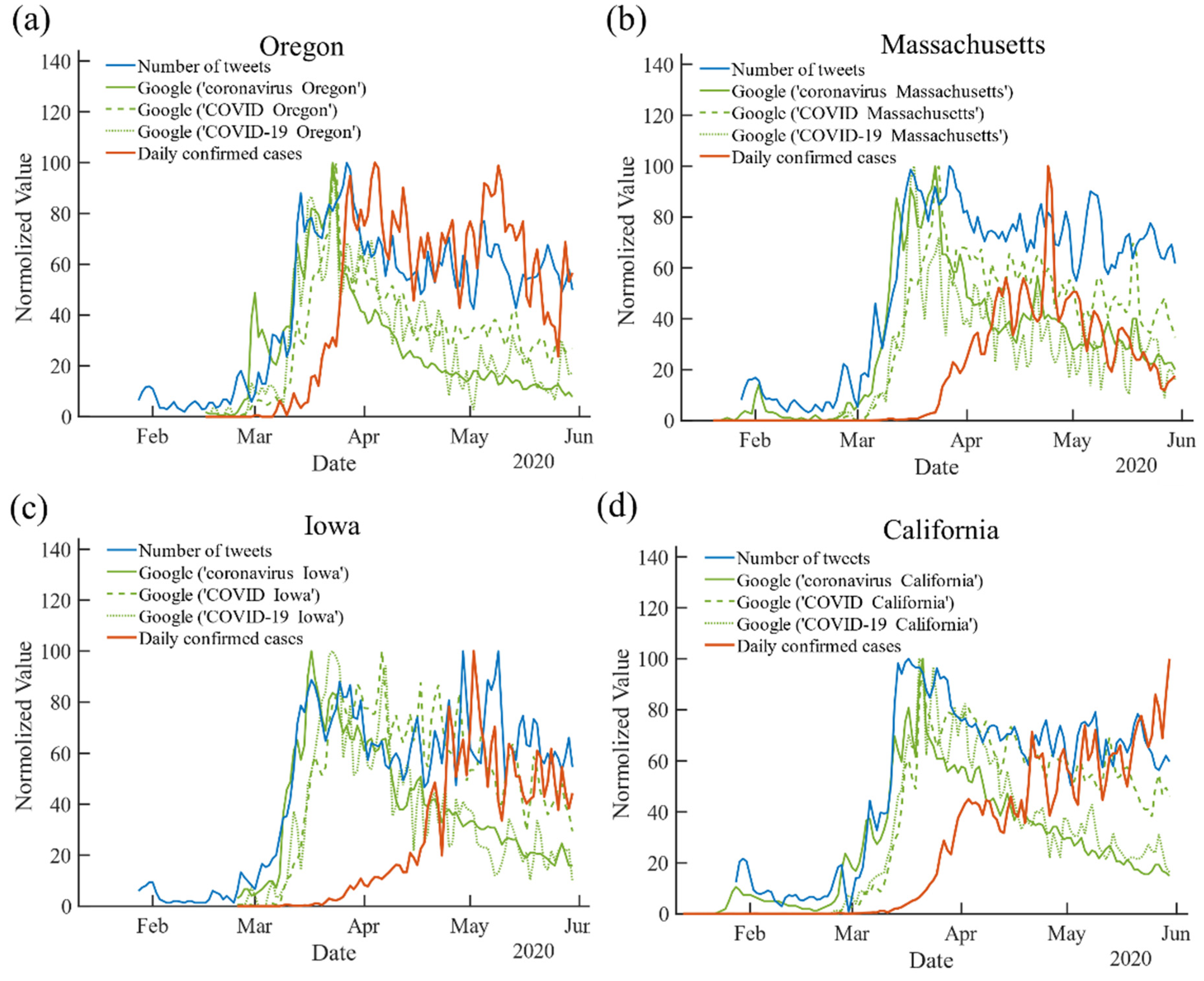
3. Results
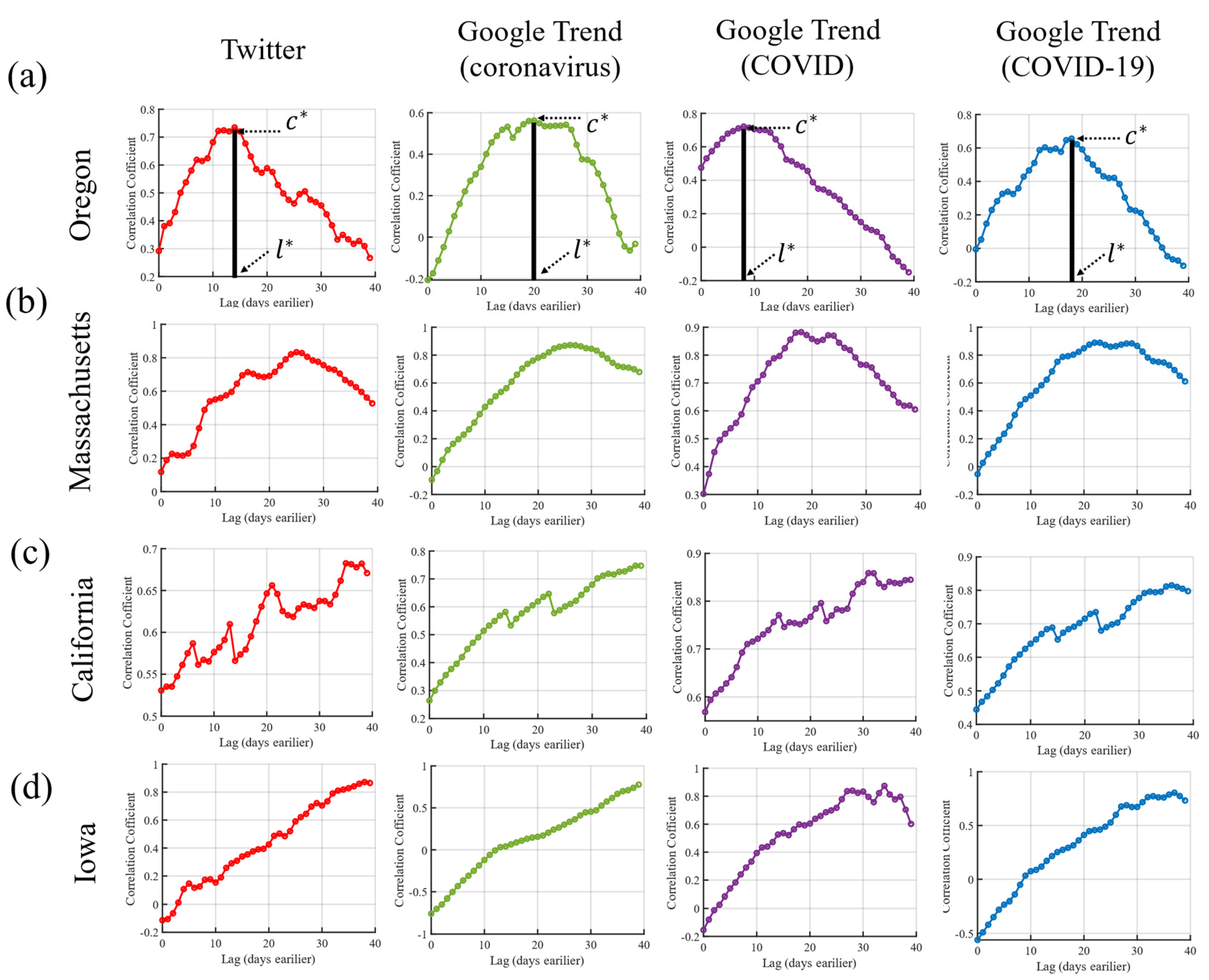
3.1. Lagged Correlations for Google Trend and Twitter
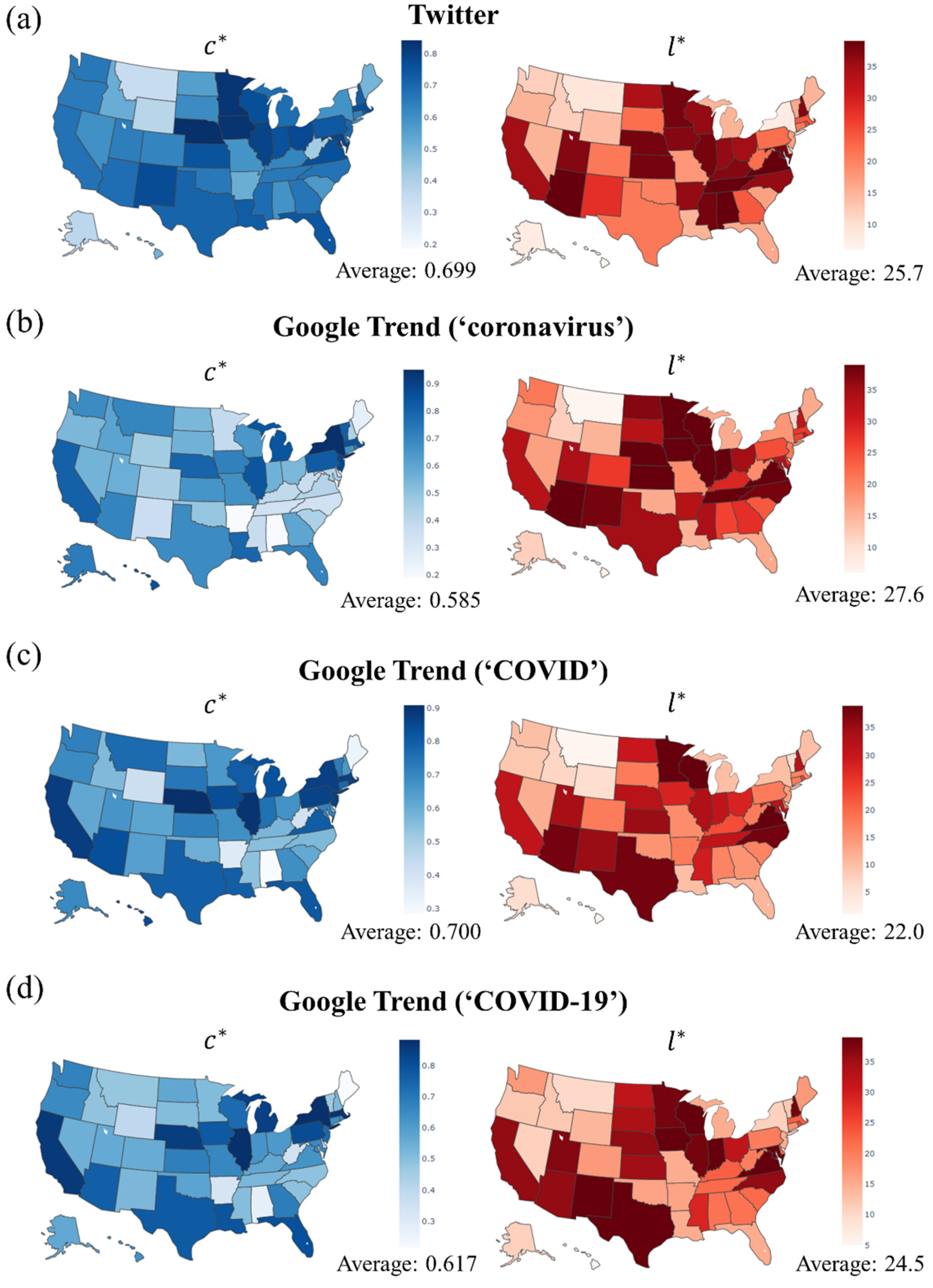
3.2. Correlation between and State Conditions
3.3. Correlation between Early Infected Rate and /
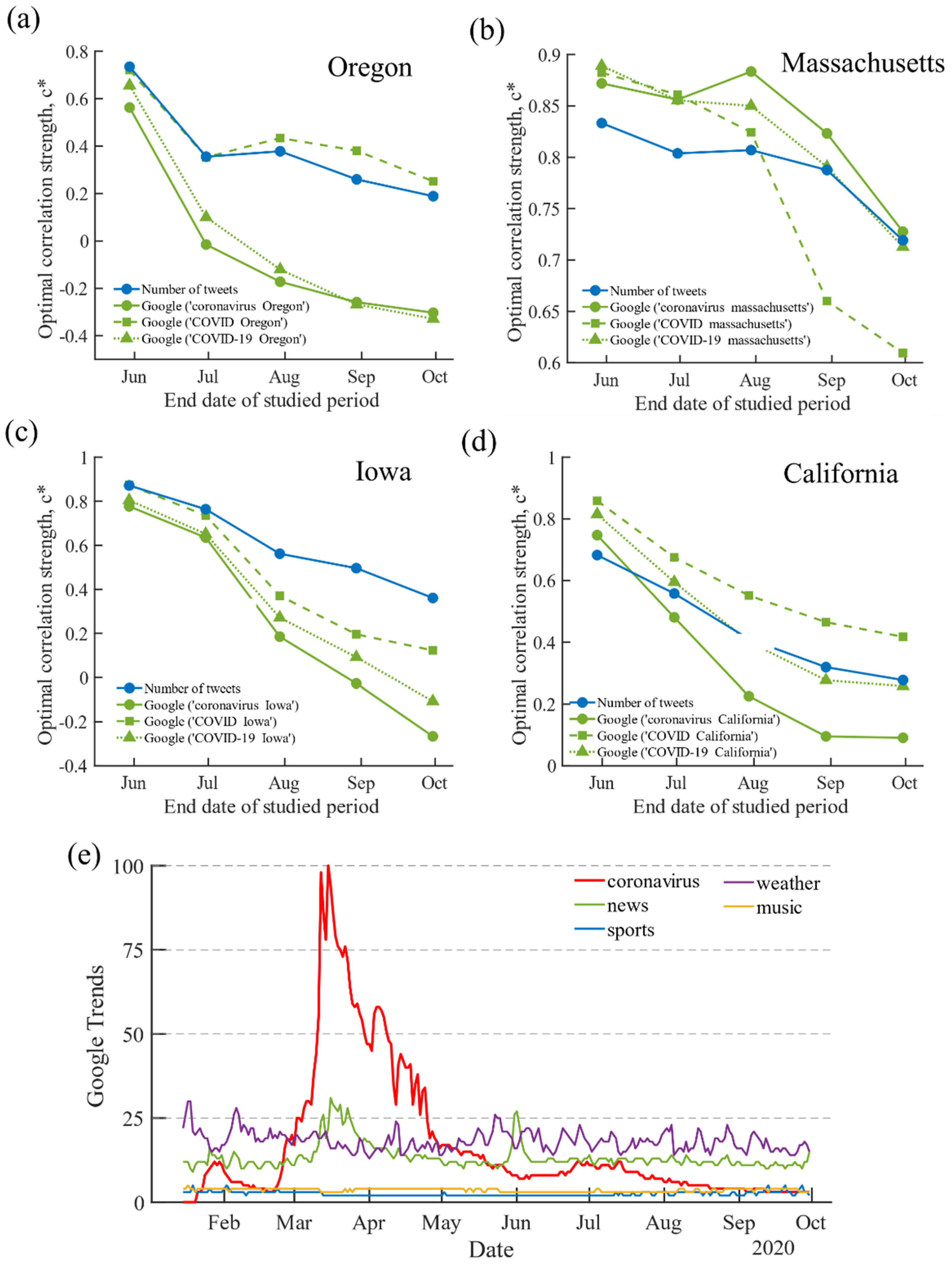
3.4. The Variation of Correlation Strength over Time
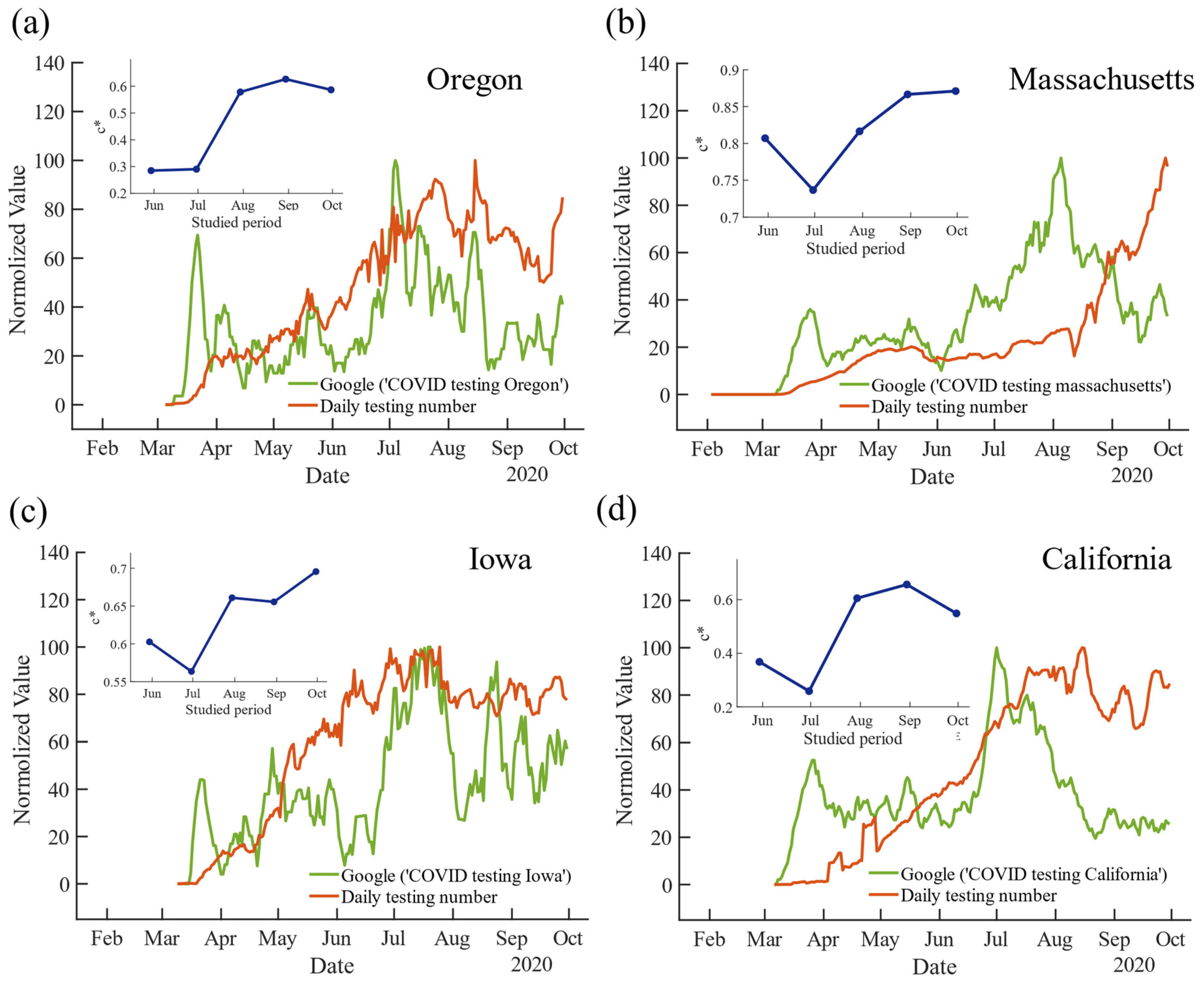
3.5. Correlation Strength of ‘COVID Testing’ on Google
4. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Watkins, D.; Holder, J.; Glans, J.; Cai, W.; Carey, B.; White, J. How the virus won. New York Times. 24 June 2020. Available online: https://www.nytimes.com/interactive/2020/us/coronavirus-spread.html (accessed on 30 June 2020).
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A Novel Coronavirus from Patients with Pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef] [PubMed]
- Tian, H.; Liu, Y.; Li, Y.; Wu, C.-H.; Chen, B.; Kraemer, M.U.G.; Li, B.; Cai, J.; Xu, B.; Yang, Q.; et al. An investigation of transmission control measures during the first 50 days of the COVID-19 epidemic in China. Science 2020, 368, 638–642. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, R.; Pei, S.; Chen, B.; Song, Y.; Zhang, T.; Yang, W.; Shaman, J. Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2). Science 2020, 368, 489–493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Remuzzi, A.; Remuzzi, G. COVID-19 and Italy: What next? Lancet 2020, 395, 1225–1228. [Google Scholar] [CrossRef]
- Lipton, E.; Sanger, E.D.; Haberman, M.; Shear, D.M.; Mazzetti, M.; Branes, E.J. He Could Have Seen What Was Coming: Behind Trump’s Failure on the Virus. New York Times. 26 April 2020. Available online: https://www.nytimes.com/2020/04/11/us/politics/coronavirus-trump-response.html (accessed on 30 June 2020).
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting influenza epidemics using search engine query data. Nature 2009, 457, 1012–1014. [Google Scholar] [CrossRef] [PubMed]
- Marques-Toledo, C.D.A.; Degener, C.M.; Vinhal, L.; Coelho, G.; Meira, W.; Codeço, C.T.; Teixeira, M.M. Dengue prediction by the web: Tweets are a useful tool for estimating and forecasting Dengue at country and city level. PLoS Negl. Trop. Dis. 2017, 11, e0005729. [Google Scholar] [CrossRef] [PubMed]
- Shin, S.-Y.; Seo, D.-W.; An, J.; Kwak, H.; Kim, S.-H.; Gwack, J.; Jo, M.-W. High correlation of Middle East respiratory syndrome spread with Google search and Twitter trends in Korea. Sci. Rep. 2016, 6, 32920. [Google Scholar] [CrossRef] [PubMed]
- Wilson, N.; Mason, K.; Tobias, M.; Peacey, M.; Huang, Q.S.; Baker, M. Interpreting “Google Flu Trends” data for pandemic H1N1 influenza: The New Zealand experience. Eurosurveillance 2009, 14, 19386. [Google Scholar] [CrossRef] [PubMed]
- Effenberger, M.; Kronbichler, A.; Shin, J.I.; Mayer, G.; Tilg, H.; Perco, P. Association of the COVID-19 pandemic with Internet Search Volumes: A Google TrendsTM Analysis. Int. J. Infect. Dis. 2020, 95, 192–197. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Chen, L.J.; Chen, X.; Zhang, M.; Pang, C.P.; Chen, H. Retrospective analysis of the possibility of predicting the COVID-19 outbreak from Internet searches and social media data, China, 2020. Eurosurveillance 2020, 25, 2000199. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.-H.; Liu, C.-H.; Chiu, Y.-C. Google searches for the keywords of “wash hands” predict the speed of national spread of COVID-19 outbreak among 21 countries. Brain Behav. Immun. 2020, 87, 30–32. [Google Scholar] [CrossRef]
- Walker, A.; Hopkins, C.; Surda, P. The use of google trends to investigate the loss of smell related searches during COVID-19 outbreak. Int. Forum Allergy Rhinol. 2020, 10, 839–847. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, K.; Tutubalina, E.; Chowell, G. A large-scale COVID-19 Twitter chatter dataset for open scientific research—An international collaboration. arXiv 2021, arXiv:2004.03688. [Google Scholar]
- Hinshaw, D.; Page, J.; McKay, B. Possible Early COVID-19 Cases in China Emerge During WHO Mission. The Wallstreet Journal. 10 February 2021. Available online: https://www.wsj.com/articles/possible-early-covid-19-cases-in-china-emerge-during-who-mission-11612996225?reflink=desktopwebshare_twitter (accessed on 12 February 2021).
- Butler, D. When Google got flu wrong: US outbreak foxes a leading web-based method for tracking seasonal flu. Nature 2013, 494, 155–157. [Google Scholar] [CrossRef] [Green Version]
- Schoen, H.; Gayo-Avello, D.; Metaxas, P.T.; Mustafaraj, E.; Strohmaier, M.; Gloor, P. The power of prediction with social media. Internet Res. 2013, 23, 528–543. [Google Scholar] [CrossRef] [Green Version]
- Lenonhardt, D. The Virus in Three Charts. New York Times. 20 October 2020. Available online: https://www.nytimes.com/2020/10/20/briefing/presidential-debate-jeffrey-toobin-coronavirus.html (accessed on 25 October 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| c* | ||||
|---|---|---|---|---|
| Google Trend (coronavirus) | Google Trend (COVID) | Google Trend (COVID-19) | ||
| Population size (2019) | 0.377 *** | 0.153 | 0.348 ** | 0.407 *** |
| Population density (2019) | 0.381 *** | 0.268 * | 0.371 *** | 0.374 *** |
| Enplanements (2018) | 0.230 * | 0.234 * | 0.389 *** | 0.419 *** |
| Enplanements (2017) | 0.232 * | 0.237 * | 0.394 *** | 0.422 *** |
| GDP (2019 Q4) | 0.413 *** | 0.184 | 0.382 *** | 0.435 *** |
| GDP per capita (2019 Q4) | 0.208 | 0.418 *** | 0.504 *** | 0.403 *** |
| Early Infection Rate | ||||
|---|---|---|---|---|
| T = 7 | T = 14 | T = 21 | ||
| l* | −0.358 * | −0.439 ** | −0.416 ** | |
| Google Trend (coronavirus) | −0.480 *** | −0.570 *** | −0.535 *** | |
| Google Trend (COVID) | −0.454 *** | −0.544 *** | −0.549 *** | |
| Google Trend (COVID-19) | −0.402 *** | −0.488 *** | −0.505 *** | |
| c* | −0.442 *** | −0.459 *** | −0.377 *** | |
| Google Trend (coronavirus) | −0.100 | −0.011 | 0.117 | |
| Google Trend (COVID) | −0.395 ** | −0.346 ** | −0.186 | |
| Google Trend (COVID-19) | −0.363 *** | −0.289 ** | −0.163 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Gloor, P.A. Assessing the Predictive Power of Online Social Media to Analyze COVID-19 Outbreaks in the 50 U.S. States. Future Internet 2021, 13, 184. https://doi.org/10.3390/fi13070184
Sun J, Gloor PA. Assessing the Predictive Power of Online Social Media to Analyze COVID-19 Outbreaks in the 50 U.S. States. Future Internet. 2021; 13(7):184. https://doi.org/10.3390/fi13070184
Chicago/Turabian StyleSun, Jiachen, and Peter A. Gloor. 2021. "Assessing the Predictive Power of Online Social Media to Analyze COVID-19 Outbreaks in the 50 U.S. States" Future Internet 13, no. 7: 184. https://doi.org/10.3390/fi13070184
APA StyleSun, J., & Gloor, P. A. (2021). Assessing the Predictive Power of Online Social Media to Analyze COVID-19 Outbreaks in the 50 U.S. States. Future Internet, 13(7), 184. https://doi.org/10.3390/fi13070184