

Detection of Malicious Websites Using Symbolic Classifier





Abstract
:1. Introduction
1.1. Blacklisting or Heuristics Approach
1.2. Machine Learning Algorithms
1.3. Definition of the Research Idea, Novelty, Research Hypotheses, and Scientific Contributions
- Is it possible to utilize the GPSC algorithm in combination with random hyper-parameter search method to obtain simple symbolic expression which could be used for classification of malicious websites with high accuracy?
- Is it possible to utilize GPSC in combination with random hyper-parameter search and 5-fold cross-validation to improve the classification accuracy of malicious websites?
- Do dataset oversampling and undersampling methods have some influence on the classification accuracy of malicious websites?
- Investigate if GPSC can be applied to the dataset for the detection of malicious websites;
- Investigate if datasets balanced with undersampling and oversampling methods have any influence on classification accuracies of obtained symbolic expressions using GPSC algorithm;
- Investigate if the random hyperparameter search method, as well as 5-fold cross-validation, has any influence on the classification accuracy of obtained symbolic expressions in the detection of malicious websites.
2. Materials and Methods
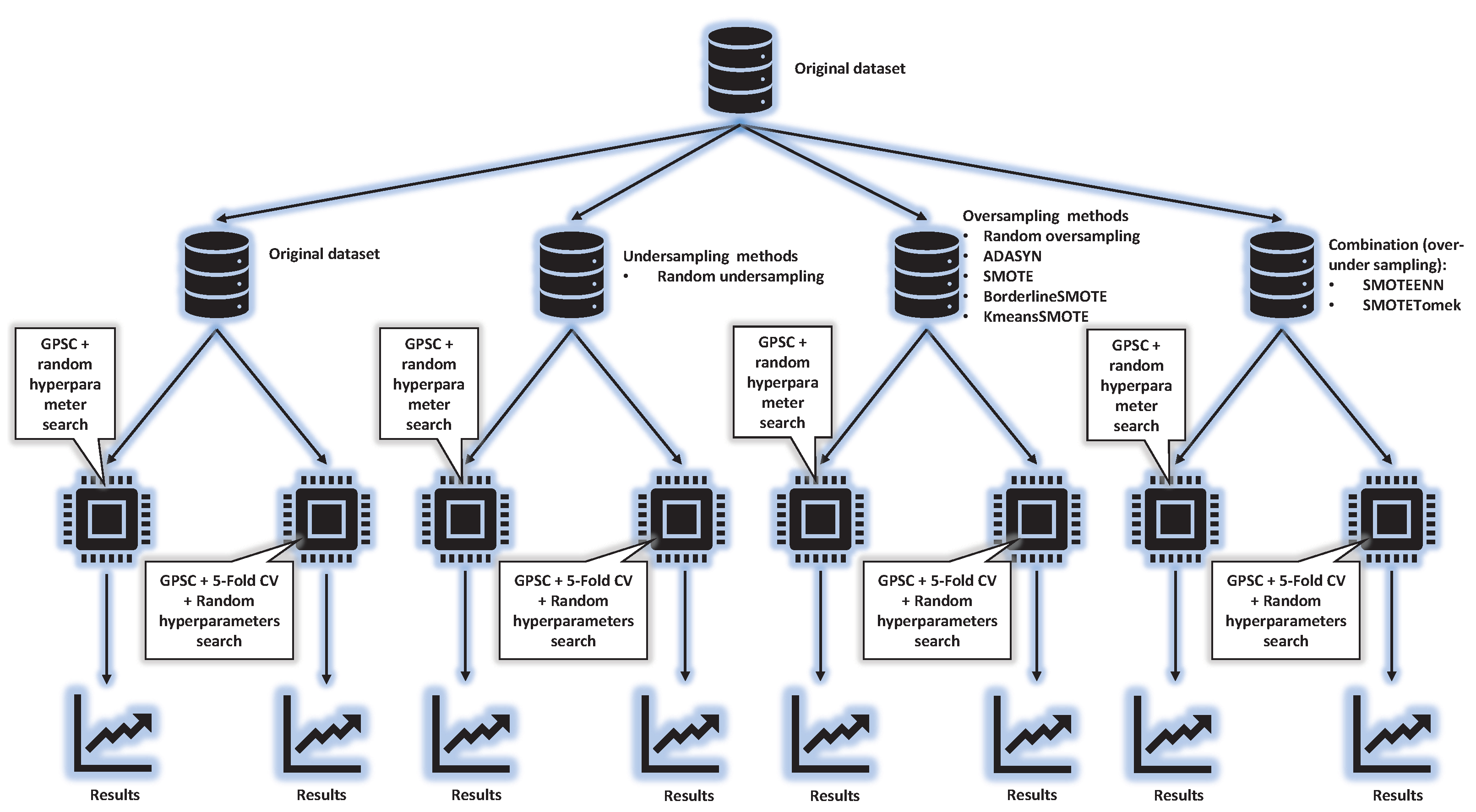
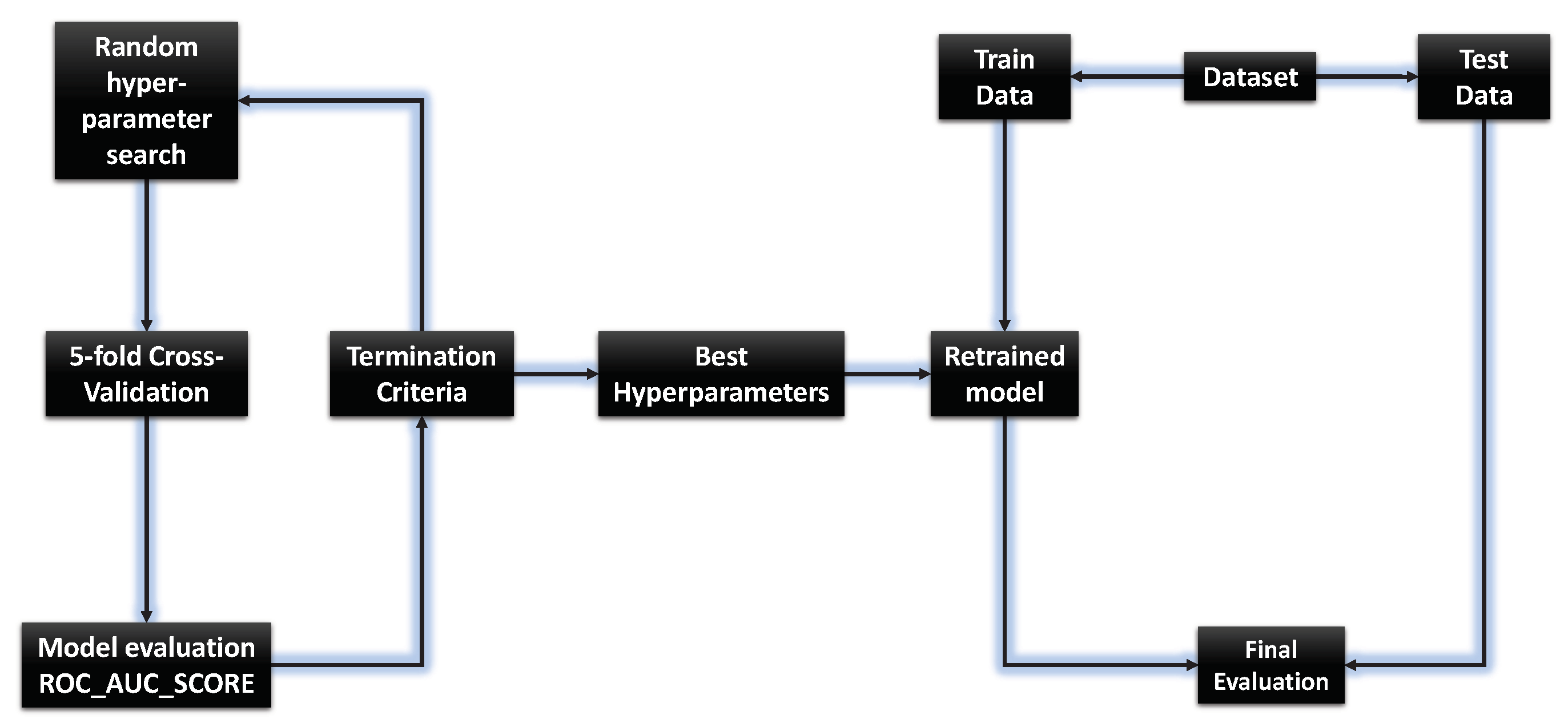
2.1. Research Methodology
- Random undersampling;
- Oversampling methods;
- –
- Random oversampling;
- –
- Adaptive Synthetic (ADASYN) method;
- –
- Synthetic Minority Oversampling TEchnique (SMOTE);
- –
- Borderline Synthetic Minority Oversampling TEchnique (BorderlineSMOTE), and
- –
- Application of KMeans clustering before oversampling using Synthetic Minority Oversampling Technique (KMeansSMOTE).
- Train/test GP symbolic classifier with random hyper-parameter search method; and
- Train/test GP symbolic classifier with random hyper-parameters search and with 5-fold cross-validation on train dataset part.
2.2. Dataset Description and Preparation
2.2.1. Dataset Transformation
- The url variable was omitted from further analysis instead url_len is used which is the length of each url;
- The ip_add was replaced with net_type variable that is created as a classification process of IP addresses to classes A, B, and C, and later transformed into values 0, 1, and 2;
- The geo_location is transformed into numeric format using ISO 3166-1 numeric code format [26];
- The tld was transformed from string to number format using LabelEncoder [27]. The LabelEncoder encodes the labels with values between 0 and n_classes − 1. In this case, the tld variable has 1247 different types of tld-s, i.e., the range of possible numeric format values are 0–1246.
- The who_is was transformed from complete/incomplete to binary values 0 and 1.
- The initial https column values “yes” and “no” were transformed into binary values 1 and 0.
- The js_len represents the total length of JavaScript code embedded in HTML code of a website.
- The js_len and js_obf_len variables are already in numeric format and will remain unchanged
- The content variable will be used to develop two additional variables, i.e., content_len and special_char. The content_len is the length of the content variable value. The special_char represents the number of special characters in a string.
- Labels (output of symbolic classifier) were replaced with 1 and 0; 1 for a malicious website and 0 for a benign website.
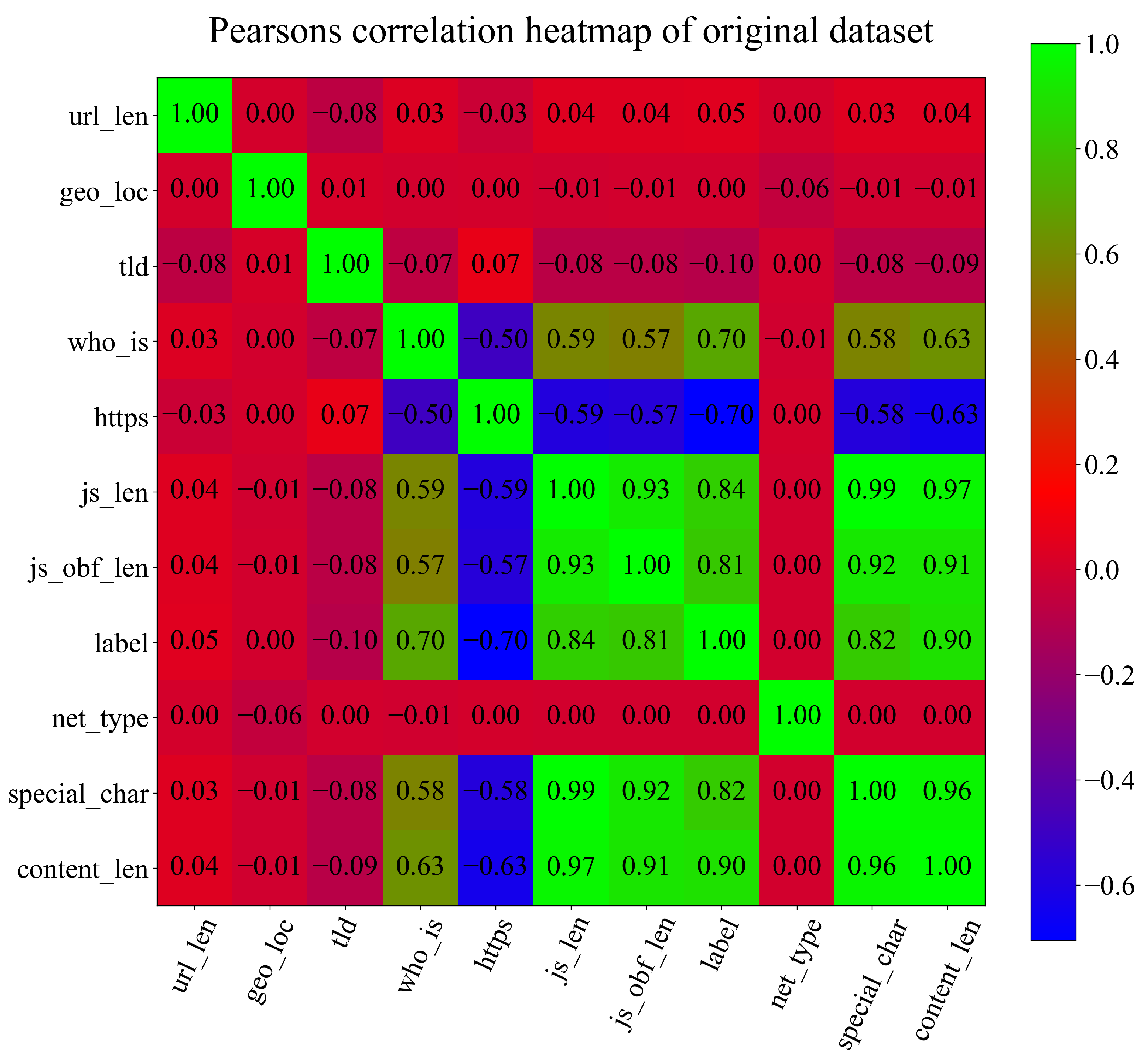
2.2.2. Statistical Data Analysis
2.3. Dataset Balancing Methods
- Undersampling methods, and
- Oversampling methods.
Random Undersampling and Oversampling Methods
2.4. Over-Sampling Methods
2.4.1. SMOTE
2.4.2. ADASYN
2.4.3. Borderline SMOTE
2.4.4. KMeansSMOTE
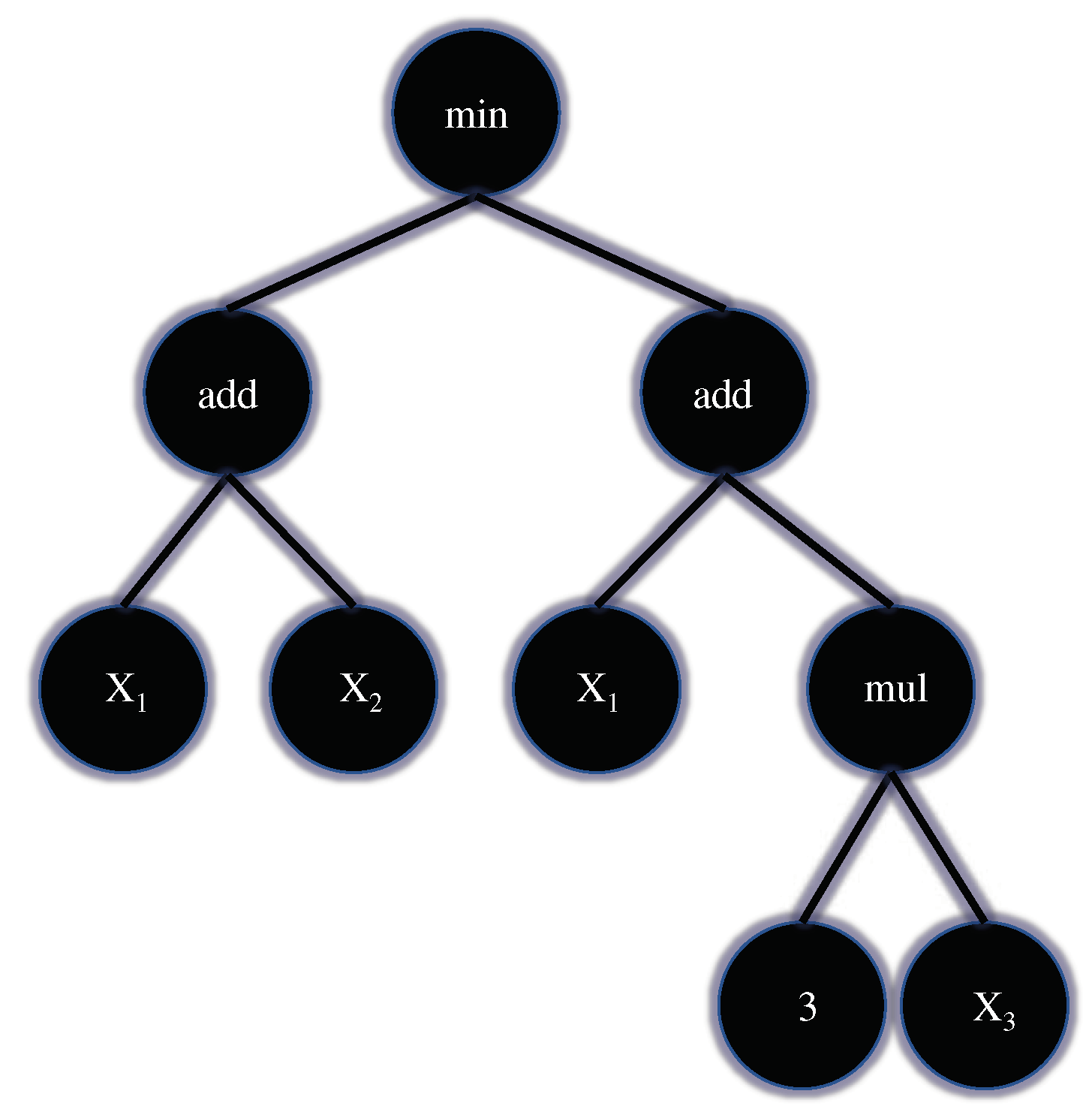
2.5. Genetic Programming—Symbolic Classifier
The Advantages and Disadvantages of GPSC Algorithm
- For any dataset with defined input variables and the target variable the GPSC will try during its execution to connect input variables with the target variable in a form of symbolic expression (mathematical equation);
- The obtained symbolic expressions are sometimes easier to understand and use than complex ML models;
- It is not necessary for an individual to have absolute knowledge of the problem and its solutions.
- The dataset size has some influence on GPSC performance. The larger the dataset the more memory is required to calculate the output of each population member;
- The correlation between some input variables and target (output) variable has to be high (Pearsons or Spearman correlation value in range −1.0 to −0.5 and 0.5 to 1.0). If all input variables have a low correlation value with the output variable (in the range of −0.5 to 0.5) the bloat phenomenon can occur during the training process (the rise of the size of population members without any benefit to the fitness value) and the obtain symbolic expression will have low accuracy;
- The choice of GPSC hyperparameters has a great influence on the training time of the GPSC algorithm as well as the performance of the obtained symbolic expression in terms of its accuracy;
- The most sensitive hyperparameter in the GPSC algorithm is the parsimony_coefficient value. If the value is too low the average size of population members can rapidly grow in a few generations which can result in a long training process or the end of Memory Overflow. If the value is too high (for example 10) it can result in choking the evolution process, i.e., poor performance of obtained symbolic expression.
2.6. Random Hyperparameter Search
2.7. Cross-Validation
2.8. Evaluation Metrics and Methodology
2.8.1. Evaluation Metrics
2.8.2. Evaluation Methodology
- First step—obtain and calculate the mean values of evaluation metric after performing 5-fold cross-validation and if the mean values of all evaluation metrics used was above 0.97 then perform second step (final train/test), otherwise perform 5-fold cross-validation with new randomly chosen hyperparameters; and
- Second step—perform final train/test with same hyperparameters used in 5-fold cross-validation. Obtain the values of each evaluation metric on the train and test dataset and calculate their mean and standard deviation values. If the mean value of each evaluation metric was above 0.97 then terminate the process. Otherwise, the algorithm starts from the beginning with GPSC with 5-fold cross-validation with randomly selected hyperparameters.
2.9. Computational Resources
3. Results
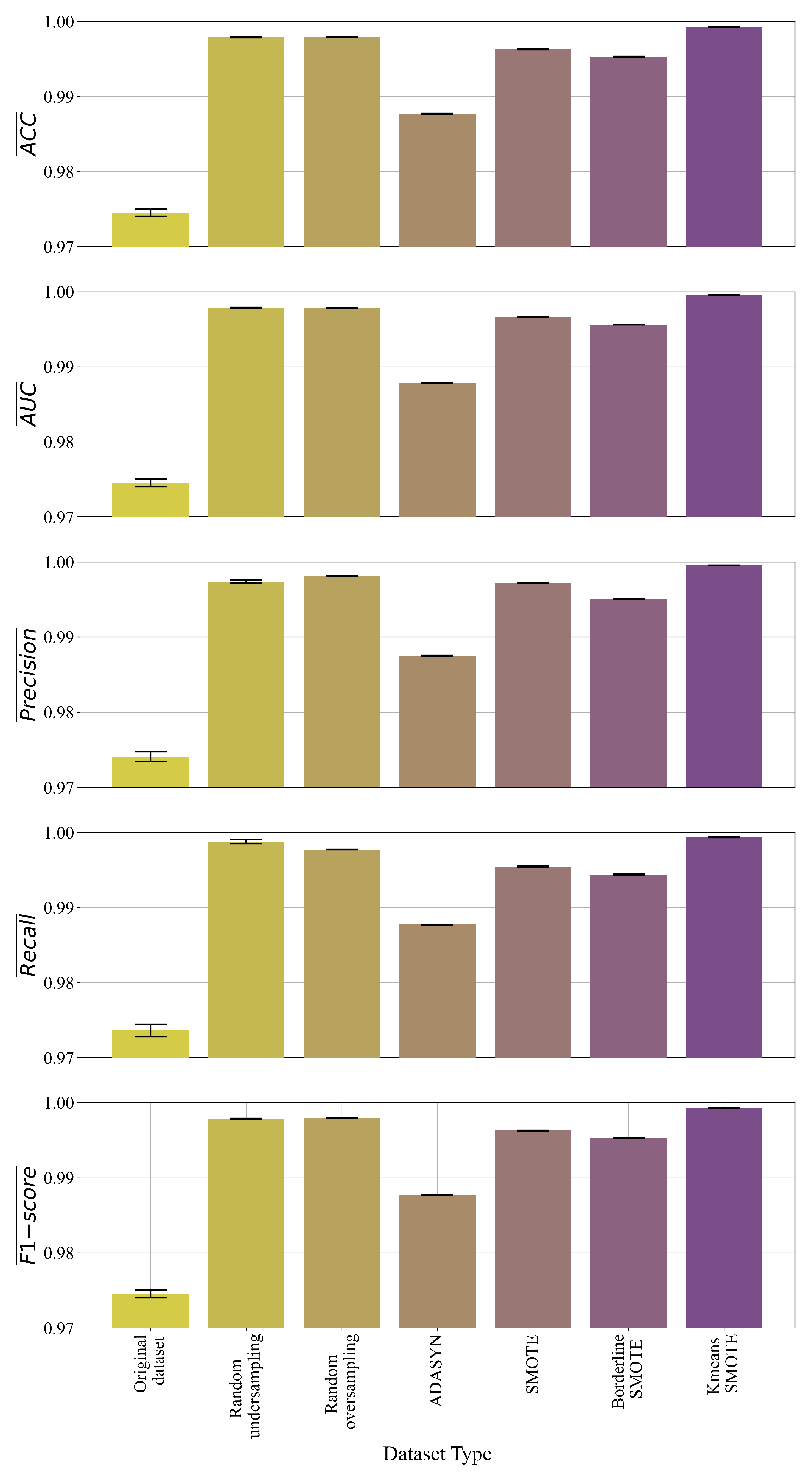
3.1. Results of GP Symbolic Classifier with Random Hyperparameter Search
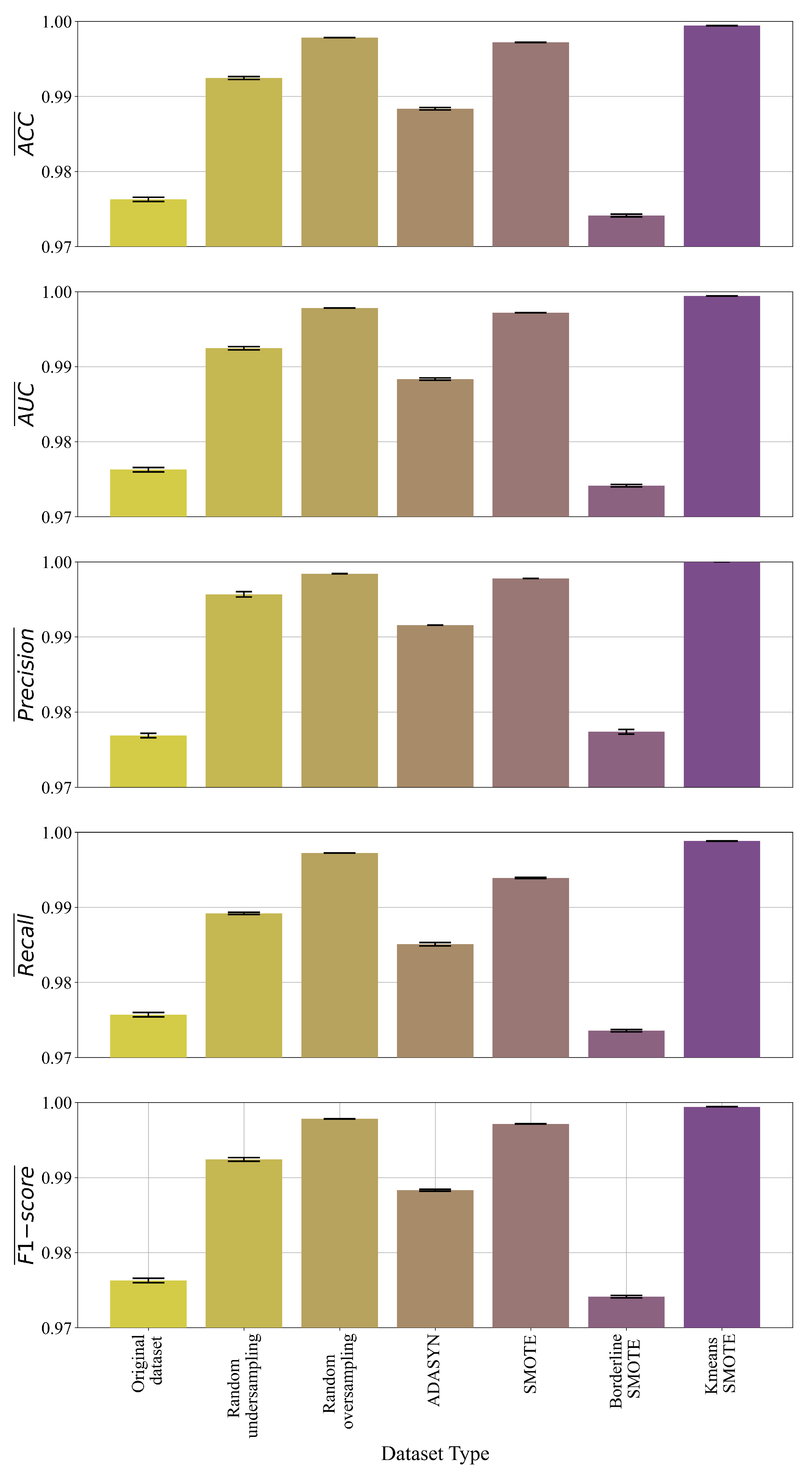
3.2. Results of GP Symbolic Classifier with Random Hyperparameter Search and 5-Fold Cross-Validation
3.3. Best Symbolic Expressions
- Data preparation—the procedure is described in the Materials and Methods section;
- Providing input variables to the symbolic expression and calculating numerical output;
- The obtained numerical output is provided as an argument of Sigmoid decision function (Equation (17)), and rounding the output of Sigmoid function to obtain 0/1 value.
4. Discussion
5. Conclusions
- The GPSC algorithm can be used to obtain symbolic expressions which could detect malicious websites with high classification accuracy;
- The application of GPSC with the random hyperparameter search method and 5-fold CV on various types of datasets achieved almost similar classification accuracy when compared to GPSC with the random hyperparameter search method;
- The application of oversampling methods showed that the samples of the minority class could be synthetically increased to balance the dataset classes and in the end improve classification accuracy. The KmeansSMOTE was the only dataset with which GPSC produced symbolic expression with high classification accuracy in both cases (with and without 5-fold CV).
- After training using GPSC, the symbolic expression (mathematical equation) is obtained;
- Dataset undersampling and oversampling methods can improve the classification accuracy of the obtained symbolic expressions;
- 5-fold cross-validation process with random hyper-parameter search proved to be a powerful tool in generating symbolic expressions with high classification accuracy in the detection of malicious websites.
- The CPU time needed to train the GPSC algorithm depends on dataset size and GPSC hyperparameter values, i.e., larger datasets, population size, and number of generations could prolong the GPSC execution time;
- The parsimony coefficient is one of the most sensitive hyperparameters in GPSC. The range which will be used in the investigation had to be defined initially through trial and error. The low values can result in a bloat phenomenon while large values can choke the population and prevent the growth of each population member in size.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sahoo, D.; Liu, C.; Hoi, S.C. Malicious URL detection using machine learning: A survey. arXiv 2017, arXiv:1701.07179. [Google Scholar]
- Sinha, S.; Bailey, M.; Jahanian, F. Shades of Grey: On the effectiveness of reputation-based “blacklists”. In Proceedings of the 2008 3rd International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 11–14 October 2008; pp. 57–64. [Google Scholar]
- Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.; Hong, J.; Zhang, C. An empirical analysis of phishing blacklists. In Proceedings of the CEAS 2009—Sixth Conference on Email and Anti-Spam, Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Eshete, B.; Villafiorita, A.; Weldemariam, K. Binspect: Holistic analysis and detection of malicious web pages. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Frankfurt am Main, Germany, 25–26 June 2012; pp. 149–166. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Identifying suspicious URLs: An application of large-scale online learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 681–688. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Learning to detect malicious urls. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Canfora, G.; Medvet, E.; Mercaldo, F.; Visaggio, C.A. Detection of malicious web pages using system calls sequences. In Proceedings of the International Conference on Availability, Reliability, and Security, Fribourg, Switzerland, 8–12 September 2014; pp. 226–238. [Google Scholar]
- Tao, Y. Suspicious URL and Device Detection by Log Mining. Ph.D. Thesis, Simon Fraser University, Burnaby, BC, Canada, 2014. [Google Scholar]
- He, M.; Horng, S.J.; Fan, P.; Khan, M.K.; Run, R.S.; Lai, J.L.; Chen, R.J.; Sutanto, A. An efficient phishing webpage detector. Expert Syst. Appl. 2011, 38, 12018–12027. [Google Scholar] [CrossRef]
- Hou, Y.T.; Chang, Y.; Chen, T.; Laih, C.S.; Chen, C.M. Malicious web content detection by machine learning. Expert Syst. Appl. 2010, 37, 55–60. [Google Scholar] [CrossRef]
- Xu, L.; Zhan, Z.; Xu, S.; Ye, K. Cross-layer detection of malicious websites. In Proceedings of the Third ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 18–20 February 2013; pp. 141–152. [Google Scholar]
- Canali, D.; Cova, M.; Vigna, G.; Kruegel, C. Prophiler: A fast filter for the large-scale detection of malicious web pages. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 197–206. [Google Scholar]
- Garera, S.; Provos, N.; Chew, M.; Rubin, A.D. A framework for detection and measurement of phishing attacks. In Proceedings of the 2007 ACM Workshop on Recurring Malcode, Alexandria, VA, USA, 2 November 2007; pp. 1–8. [Google Scholar]
- Wang, D.; Navathe, S.B.; Liu, L.; Irani, D.; Tamersoy, A.; Pu, C. Click traffic analysis of short url spam on twitter. In Proceedings of the 9th IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing, Austin, TX, USA, 20–23 October 2013; pp. 250–259. [Google Scholar]
- Cao, J.; Li, Q.; Ji, Y.; He, Y.; Guo, D. Detection of forwarding-based malicious URLs in online social networks. Int. J. Parallel Program. 2016, 44, 163–180. [Google Scholar] [CrossRef]
- Alshboul, Y.; Nepali, R.; Wang, Y. Detecting malicious short URLs on Twitter. In Proceedings of the 6th NordiCHI Conference on Human-Computer Interaction, Reykjavik, Iceland, 16–20 October 2015; pp. 1–7. [Google Scholar]
- Zhang, W.; Jiang, Q.; Chen, L.; Li, C. Two-stage ELM for phishing Web pages detection using hybrid features. World Wide Web 2017, 20, 797–813. [Google Scholar] [CrossRef]
- Yu, B.; Pan, J.; Hu, J.; Nascimento, A.; De Cock, M. Character level based detection of DGA domain names. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Langdon, W.B.; Poli, R. Foundations of Genetic Programming; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Singh, A.; Goyal, N. Malcrawler: A crawler for seeking and crawling malicious websites. In Proceedings of the International Conference on Distributed Computing and Internet Technology, Bhubaneswar, India, 13–16 January 2017; pp. 210–223. [Google Scholar]
- Singh, A.; Goyal, N. A comparison of machine learning attributes for detecting malicious websites. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bangalore, India, 7–11 January 2019; pp. 352–358. [Google Scholar]
- Singh, A. Malicious and Benign Webpages Dataset. Data Brief 2020, 32, 106304. [Google Scholar] [CrossRef] [PubMed]
- WWW Consortium—Web Addresses in HTML 5. 2022. Available online: https://www.w3.org/html/wg/href/draft (accessed on 1 October 2022).
- Whois Search, Domain Name, Website, and IP Tools—who.is. Available online: https://who.is/ (accessed on 1 October 2022).
- ISO 3166—Country Codes. Available online: https://www.iso.org/iso-3166-country-codes.html (accessed on 10 October 2022).
- Bisong, E. Introduction to Scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019; pp. 215–229. [Google Scholar]
- Setting Up an IP Addressing Scheme. Available online: https://docs.oracle.com/cd/E19504-01/802-5753/6i9g71m2o/index.html (accessed on 1 October 2022).
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–6 June 2008; pp. 1322–1328. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Gplearn Python Library Webpage—Introduction to GP—gplearn 0.4.2 Documentation. Available online: https://gplearn.readthedocs.io/en/stable/intro.html (accessed on 10 October 2022).
- Poli, R.; Langdon, W.B.; McPhee, N.F. A Field Guide to Genetic Programming; LuLu: Morrisville, NC, USA, 2018; Available online: http://www.gp-field-guide.org.uk (accessed on 10 October 2022).
- Vovk, V. The fundamental nature of the log loss function. In Fields of Logic and Computation II; Springer: Berlin/Heidelberg, Germany, 2015; pp. 307–318. [Google Scholar]
- Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Poljak, I.; Mrzljak, V.; Car, Z. Use of Genetic Programming for the Estimation of CODLAG Propulsion System Parameters. J. Mar. Sci. Eng. 2021, 9, 612. [Google Scholar] [CrossRef]
- Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Mrzljak, V.; Car, Z. Estimation of COVID-19 epidemic curves using genetic programming algorithm. Health Inform. J. 2021, 27, 1460458220976728. [Google Scholar] [CrossRef] [PubMed]
- Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Car, Z. Estimation of gas turbine shaft torque and fuel flow of a CODLAG propulsion system using genetic programming algorithm. Pomorstvo 2020, 34, 323–337. [Google Scholar] [CrossRef]
- Anđelić, N.; Lorencin, I.; Glučina, M.; Car, Z. Mean Phase Voltages and Duty Cycles Estimation of a Three-Phase Inverter in a Drive System Using Machine Learning Algorithms. Electronics 2022, 11, 2623. [Google Scholar] [CrossRef]
- Sturm, B.L. Classification accuracy is not enough. J. Intell. Inf. Syst. 2013, 41, 371–406. [Google Scholar] [CrossRef]
- Flach, P.; Kull, M. Precision-recall-gain curves: PR analysis done right. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | ML or Deep Learning Classifiers | Results |
|---|---|---|
| [14] | LR | ACC: 93.4% |
| [5] | Naïve Bayes, SVM, LR | ACC: 95–99% |
| [6] | MLP-Classifier, LR with SGD, PA, CW, | Acc. 99% |
| [11] | Decision Tree, Naïve Bayes, SVM, Boosted Decision Tree | ACC: 96% |
| [7] | Perceptron, LR with SGD, PA, CW | ACC: 99% |
| [10] | SVM | TP: 97.33%, FP: 1.45% |
| [4] | J48, Random Tree, Random forest, Naïve Bayes, Bayes Net, SVM, LR | ACC: 97% |
| [12] | Naïve Bayes, LR, SVM, J48 | ACC: 99.178%, FN: 2.284%; 0.422% |
| [15] | Random Tree, Random Forest, KStar, Decision Tree, Decision Table, Simple Logistic, SVM | ACC: 90.81%; F1-score: 91.3% |
| [8] | SVM | ACC: 96% |
| [16] | Bayes Net, J48, Random Forest | ACC: 84.74%; F1-score: 83% |
| [18] | ELM, BPNN, SVM, NB, k-NN, OPELM, Adaboost ELM, MV-ELM, LC-ELM | ACC: 9904% |
| [19] | CNN, RNN | ACC: 97–98% |
| url | url_len | ip_add | geo_loc | tld | who_is | https | js_len | js_obf_len | Content | Label |
|---|---|---|---|---|---|---|---|---|---|---|
| https://members.tripod.com/russiastation/ | 40 | 42.77. 221.155 | Taiwan | com | complete | yes | 58 | 0 | Named themselves charged … | good |
| https://www.ddj.com/cpp/184403822 | 32 | 3.211. 202.180 | United States | com | complete | yes | 52.5 | 0 | And filipino field …. | good |
| https://www.naef-usa.com/ | 24 | 24.232. 54.41 | Argentina | com | complete | yes | 103.5 | 0 | Took in cognitivism, whose … | good |
| http://www.ff-b2b.de/ | 21 | 147.22. 38.45 | United States | de | incomplete | no | 720 | 532.8 | fire sodomize footaction tortur … | bad |
| https://us.imdb.com/title/tt0176269/ | 35 | 205.30. 239.85 | United States | com | complete | yes | 46.5 | 0 | Levant, also monsignor georges … | good |
| https://efilmcritic.com/hbs.cgi?movie=311 | 40 | 8.28. 167.23 | United States | com | complete | yes | 39.5 | 0 | Signals … | good |
| https://christian.net/ | 21 | 125.223. 123.231 | China | net | complete | yes | 136 | 0 | Temperature variations … | good |
| https://www.indsource.com | 24 | 208.169. 193.185 | United States | com | complete | yes | 51 | 0 | Were; an optical physics; astrophysics … | good |
| https://www.greatestescapes.com | 30 | 32.130. 119.43 | United States | com | complete | yes | 183 | 0 | Working with run a. U.s., … | good |
| https://hdalter.tripod.com/ | 26 | 81.16. 157.227 | Austria | com | complete | yes | 79 | 0 | Cases, as places averaging…. | good |
| Network Class | Range | Network Address | Host Address |
|---|---|---|---|
| A | 0–127 | xxx | xxx.xxx.xxx |
| B | 128–191 | xxx.xxx | xxx.xxx |
| C | 192–223 | xxx.xxx.xxx | xxx |
| url_len | geo_loc | tld | who_is | https | js_len | js_obf_len | label | net_type | special_char | content_len | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Type of variable | y | ||||||||||
| count | 1,561,934 | ||||||||||
| mean | 35.8 | 154.1 | 328.1 | 0.21 | 0.78 | 119.09 | 8.1 | 0.02 | 0.57 | 144.77 | 1641 |
| std | 14.4 | 74.5 | 274.9 | 0.4 | 0.41 | 90.3 | 60.04 | 0.15 | 0.72 | 91.83 | 1074 |
| min | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 37 |
| max | 721 | 233 | 1245 | 1 | 1 | 854.1 | 802.8 | 1 | 2 | 975 | 10497 |
| Type of Dataset | Total Number of Samples | Number of Samples (Class: 0) | Number of Samples (Class: 1) |
|---|---|---|---|
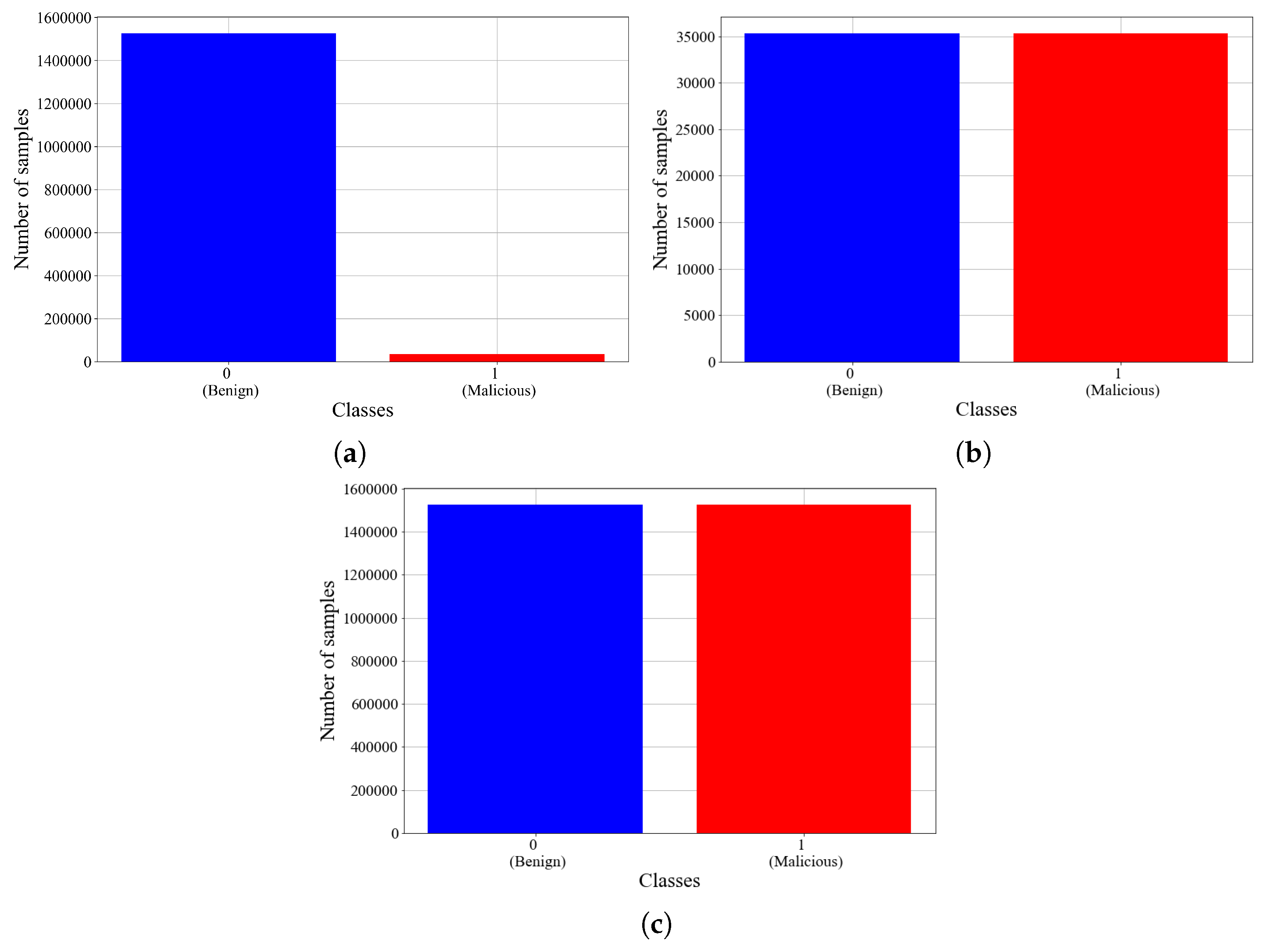
| Original dataset | 1,561,934 | 1,526,619 | 35,315 |
| Under-sampled dataset | 70,630 | 35,315 | 35,315 |
| Over-sampled dataset | 3,053,238 | 1,526,619 | 1,526,619 |
| Function Name | Arity |
|---|---|
| Addition | 2 |
| Subtraction | 2 |
| Multiplication | 2 |
| Division | 2 |
| Minimum | 2 |
| Maximum | 2 |
| Square root | 1 |
| Absolute value | 1 |
| Sine | 1 |
| Cosine | 1 |
| Tangent | 1 |
| Natural logarithm | 1 |
| Logarithm base 2 | 1 |
| Logarithm base 10 | 1 |
| Cube root | 1 |
| GPSC Hyperparameter | Values | |
|---|---|---|
| Lower Bound | Upper Bound | |
| population_size | 100 | 200 |
| generations | 100 | 200 |
| init_depth | 10 | 20 |
| p_crossover | 0.001 | 1 |
| p_subtree_mutation | 0.001 | 1 |
| p_hoist_mutation | 0.001 | 1 |
| p_point_mutation | 0.001 | 1 |
| stopping_criteria | ||
| max_samples | 0.6 | 1 |
| const_range | −1000 | 10,000 |
| parsimony_coefficient | ||
| Dataset Type | Hyperparameter values (population_size, generations, tournament_size, init_depth, p_crossover, p_subtree_mutation, p_hoist_mutation, p_point_mutation, stopping_criteria, max_samples, const_range, parsimony_coefficient) |
| Original dataset | 181, 100, 13, (6, 10), 0.36, 0.12, 0.49, 0.013, , 0.95, (−6.73, 9378.93), |
| Random undersampling | 129, 172, 23, (7, 10), 0.082, 0.65, 0.22, 0.032, , 0.76, (−992.64, 5971.66), |
| Random oversampling | 200, 147, 17, (6, 7), 0.6, 0.13, 0.17, 0.09, , 0.65, (−670.27, 8900.2), |
| SMOTE | 181, 105, 15, (4, 8), 0.44, 0.36, 0.053, 0.13, , 0.61, (−628.93, 1907.64), |
| ADASYN | 132, 202, 10, (7, 12), 0.37, 0.1, 0.17, 0.36, , 0.6, (−661.22, 6203.31), |
| Borderline SMOTE | 140, 197, 15, (6, 8), 0.017, 0.72, 0.14, 0.11, , 0.99, (−411.4, 8789.7), |
| Kmeans SMOTE | 151, 140, 12, (7, 9), 0.17, 0.32, 0.058, 0.44, 0.85, (−540.69, 7952.57), |
| Dataset Type | Average CPU Time per Simulation [min] | |||||
|---|---|---|---|---|---|---|
| Original Dataset | 45 | |||||
| Random undersampling | 20 | |||||
| Random oversampling | 60 | |||||
| ADASYN | 60 | |||||
| SMOTE | 60 | |||||
| Borderline SMOTE | 60 | |||||
| KMeans SMOTE | 60 |
| Dataset type | Hyperparameter values (population_size, generations, tournament_size, init_depth, p_crossover, p_subtree_mutation, p_hoist_mutation, p_point_mutation, stopping_criteria, max_samples, const_range, parsimony_coefficient) |
| Original dataset | 120,100, 20, (5, 10), 0.007, 0.83, 0.05, 0.1, , 0.63, (−761.24, 3968.75), |
| Random undersampling | 187, 159, 39, (6, 8), 0.24, 0.39, 0.32, 0.04, 0.0007, 0.6, (−80.5, 5509.26), |
| Random oversampling | 150, 197, 26, (6, 11), 0.14, 0.66, 0.07, 0.11, , 0.98, (−953.15, 9148.94), |
| SMOTE | 108, 180, 17, (7, 9), 0.44, 0.03, 0.17, 0.35, , 0.86, (−557.91, 103.76), |
| ADASYN | 157, 174, 18, (3, 8), 0.31, 0.33, 0.2, 0.15, , 0.74, (−566.18, 9234.9), |
| Borderline SMOTE | 182, 167, 20, (7, 11), 0.17, 0.74, 0.015, 0.065, , 0.62, (−316.14, 14.06), |
| Kmeans SMOTE | 103, 185, 17, (7, 9), 0.45, 0.36, 0.12, 0.064, , 0.77, (−687.65, 8699.9), |
| Dataset Type | Average CPU Time per Simulation [min] | |||||
|---|---|---|---|---|---|---|
| Original Dataset | 0.976 | 0.97627 | 0.9768 | 0.9756 | 0.9762 | 320 |
| Random undersampling | 0.992 | 0.9924 | 0.9956 | 0.9891 | 0.9924 | 140 |
| Random oversampling | 0.997 | 0.9978 | 0.9983 | 0.9972 | 0.9978 | 400 |
| ADASYN | 0.9883 | 0.9883 | 0.9915 | 0.985 | 0.9883 | 400 |
| SMOTE | 0.9971 | 0.9971 | 0.9977 | 0.9939 | 0.9971 | 400 |
| Borderline SMOTE | 0.9741 | 0.9741 | 0.9773 | 0.9735 | 0.9741 | 400 |
| Kmeans SMOTE | 0.9994 | 0.9994 | 1.0 | 0.9988 | 0.9994 | 400 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anđelić, N.; Baressi Šegota, S.; Lorencin, I.; Glučina, M. Detection of Malicious Websites Using Symbolic Classifier. Future Internet 2022, 14, 358. https://doi.org/10.3390/fi14120358
Anđelić N, Baressi Šegota S, Lorencin I, Glučina M. Detection of Malicious Websites Using Symbolic Classifier. Future Internet. 2022; 14(12):358. https://doi.org/10.3390/fi14120358
Chicago/Turabian StyleAnđelić, Nikola, Sandi Baressi Šegota, Ivan Lorencin, and Matko Glučina. 2022. "Detection of Malicious Websites Using Symbolic Classifier" Future Internet 14, no. 12: 358. https://doi.org/10.3390/fi14120358
APA StyleAnđelić, N., Baressi Šegota, S., Lorencin, I., & Glučina, M. (2022). Detection of Malicious Websites Using Symbolic Classifier. Future Internet, 14(12), 358. https://doi.org/10.3390/fi14120358