
Task Offloading Based on LSTM Prediction and Deep Reinforcement Learning for Efficient Edge Computing in IoT


Abstract
:1. Introduction
- Modeling the problem of computing offloading in a multi-edge, multi-device computing scenario as a nonlinear optimization problem. Moreover, the goal of task offloading is minimizing long-term costs in terms of latency and energy consumption.
- By predicting the characteristics of tasks and edge server loads, tasks are dynamically offloaded to the optimal edge server. In the decision model, the prediction is combined with task decision to dynamically allocate resources for different tasks to further reduce latency and improve service quality.
- The proposed model and method are extensively evaluated with real-world datasets. The results reveal that the model developed in this paper can effectively reduce the cost using the DRL algorithm with Deep Q Network (DQN) and its variants. The OPO algorithm can maintain low task latency and task discard rate when facing large and complex scenarios.
2. Related Works
2.1. Offloading Methods with Different Modeling Objects
2.2. Offloading Methods with Different Problem Solving Strategies
3. System Model
3.1. Task Model
3.2. Decision Model
3.3. Computational Model
3.3.1. Terminal Layer Computing Model
3.3.2. Edge Layer Computing Model
3.4. Communication Model
3.5. Prediction Model
3.5.1. Task Prediction Model
3.5.2. Load Prediction Model
4. Model Solving
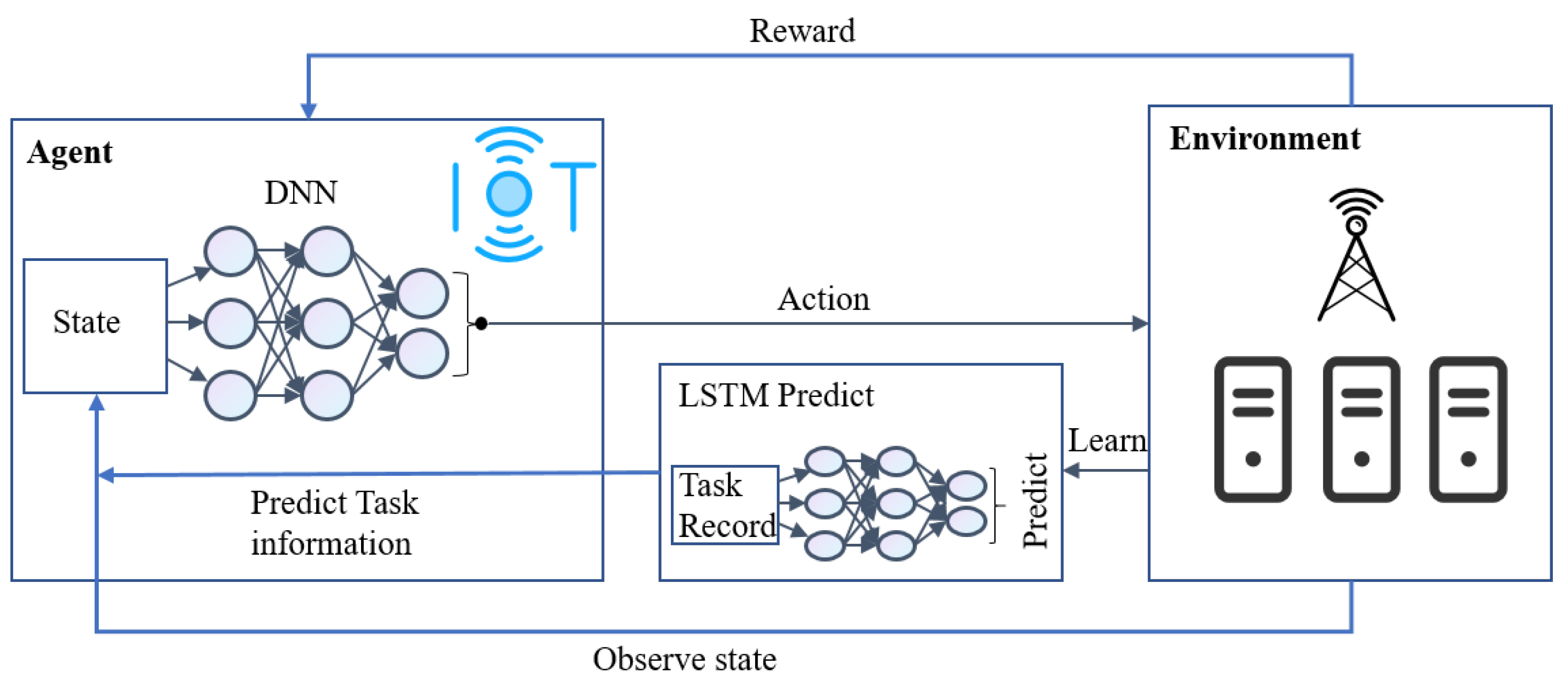
4.1. Overall Framework
4.1.1. Model Training Phase
4.1.2. Offloading Decision Phase
4.2. Algorithm Design
4.2.1. Decision Model Elements
4.2.2. Design of the Reward Function
| Algorithm 1 Online Predictive Offloading Algorithm. |
|
5. Experimental Evaluation
5.1. Experimental Setup
5.2. Task Prediction Experiment
5.3. Training Process of LSTM & DRL
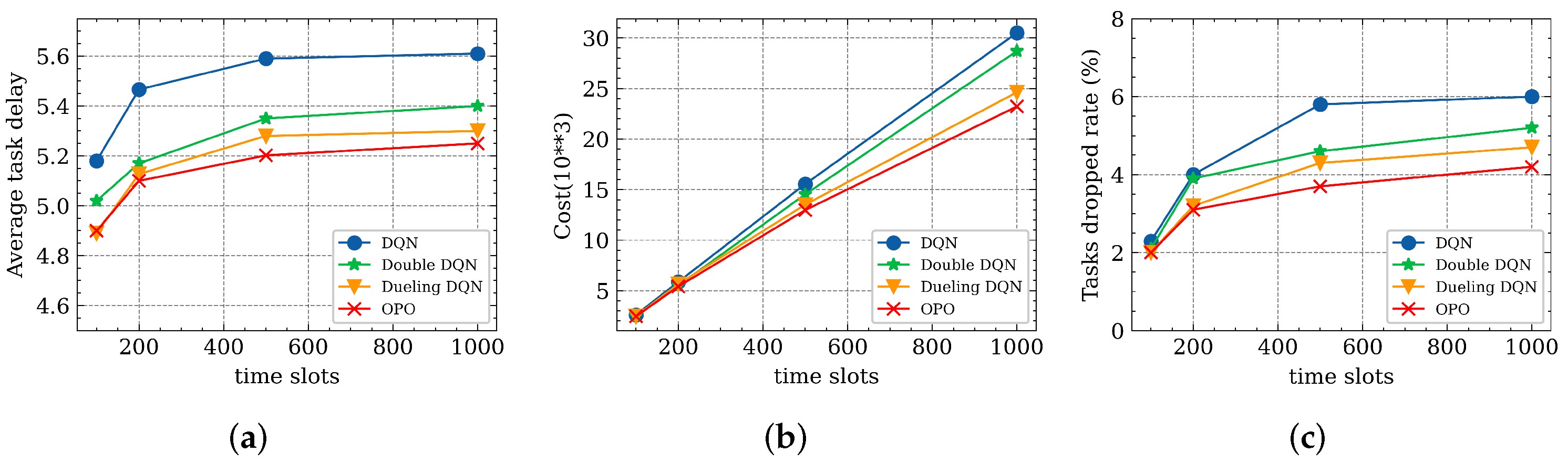
5.4. Performance Comparison
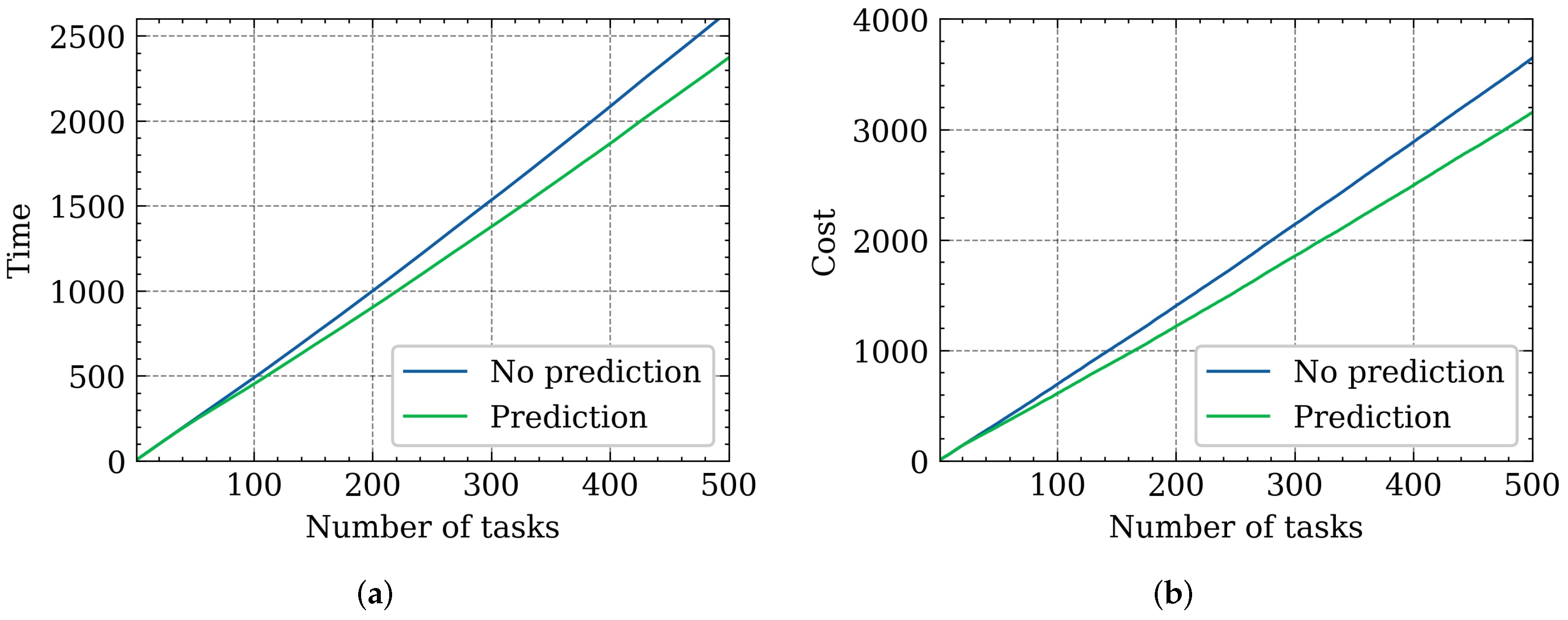
5.5. Impact of the Tasks Number
5.6. Impact of the Learning Rate
5.7. Simulation of Real-Time Decision
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aslanpour, M.S.; Gill, S.S.; Toosi, A.N. Performance Evaluation Metrics for Cloud, Fog and Edge Computing: A Review, Taxonomy, Benchmarks and Standards for Future Research. Internet Things 2020, 12, 100273. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Lin, L.; Liao, X.; Jin, H.; Li, P. Computation Offloading Toward Edge Computing. Proc. IEEE 2019, 107, 1584–1607. [Google Scholar] [CrossRef]
- Kuang, L.; Gong, T.; OuYang, S.; Gao, H.; Deng, S. Offloading Decision Methods for Multiple Users with Structured Tasks in Edge Computing for Smart Cities. Future Gener. Comput. Syst. 2020, 105, 717–729. [Google Scholar] [CrossRef]
- Thai, M.T.; Lin, Y.D.; Lai, Y.C.; Chien, H.T. Workload and Capacity Optimization for Cloud-Edge Computing Systems with Vertical and Horizontal Offloading. IEEE Trans. Netw. Serv. Manag. 2020, 17, 227–238. [Google Scholar] [CrossRef]
- Cui, L.; Xu, C.; Yang, S.; Huang, J.Z.; Li, J.; Wang, X.; Ming, Z.; Lu, N. Joint Optimization of Energy Consumption and Latency in Mobile Edge Computing for Internet of Things. IEEE Internet Things J. 2018, 6, 4791–4803. [Google Scholar] [CrossRef]
- Gu, Q.; Wang, G.; Liu, J.; Fan, R.; Fan, D.; Zhong, Z. Optimal Offloading with Non-Orthogonal Multiple Access in Mobile Edge Computing. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Mukherjee, M.; Kumar, V.; Kumar, S.; Matamy, R.; Mavromoustakis, C.X.; Zhang, Q.; Shojafar, M.; Mastorakis, G. Computation Offloading Strategy in Heterogeneous Fog Computing with Energy and Delay Constraints. In Proceedings of the IEEE International Conference on Communications (ICC), Online, 7–11 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, Y.; Shi, J.; Ni, K.; Qian, L.; Zhu, W.; Shi, Z.; Meng, L. Secrecy-Based Delay-Aware Computation Offloading via Mobile Edge Computing for Internet of Things. IEEE Internet Things J. 2019, 6, 4201–4213. [Google Scholar] [CrossRef]
- Meng, H.; Chao, D.; Guo, Q. Deep Reinforcement Learning Based Task Offloading Algorithm for Mobile-Edge Computing Systems. In Proceedings of the 2019 4th International Conference on Mathematics and Artificial Intelligence, Chegndu, China, 12–15 April 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 90–94. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef] [Green Version]
- Yan, P.; Choudhury, S. Optimizing Mobile Edge Computing Multi-Level Task Offloading via Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; IEEE: New York, NY, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Zhang, C.; Qian, L.; Wu, Y. Deep Reinforcement Learning-based Joint Task Offloading and Bandwidth Allocation for Multi-user Mobile Edge Computing. Digit. Commun. Netw. 2019, 5, 10–17. [Google Scholar] [CrossRef]
- Kumar, R.; Kumar, P.; Kumar, Y. Time Series Data Prediction using IoT and Machine Learning Technique. Procedia Comput. Sci. 2020, 167, 373–381. [Google Scholar] [CrossRef]
- Abdellah, A.R.; Mahmood, O.A.K.; Paramonov, A.; Koucheryavy, A. IoT Traffic Prediction Using Multi-step Ahead Prediction with Neural Network. In Proceedings of the 2019 11th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Dublin, Ireland, 28–30 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Gao, J.; Wang, H.; Shen, H. Machine Learning Based Workload Prediction in Cloud Computing. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Online, 3–6 August 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Sonmez, C.; Tunca, C.; Ozgovde, A.; Ersoy, C. Machine Learning-Based Workload Orchestrator for Vehicular Edge Computing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2239–2251. [Google Scholar] [CrossRef]
- Shu, C.; Zhao, Z.; Han, Y.; Min, G.; Duan, H. Multi-User Offloading for Edge Computing Networks: A Dependency-Aware and Latency-Optimal Approach. IEEE Internet Things J. 2020, 7, 1678–1689. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J. Collaborative Computation Offloading for Multiaccess Edge Computing Over Fiber–Wireless Networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Ali, R.; Zikria, Y.B.; Garg, S.; Bashir, A.K.; Obaidat, M.S.; Kim, H.S. A Federated Reinforcement Learning Framework for Incumbent Technologies in Beyond 5G Networks. IEEE Netw. 2021, 35, 152–159. [Google Scholar] [CrossRef]
- Ali, R.; Ashraf, I.; Bashir, A.K.; Zikria, Y.B. Reinforcement-Learning-Enabled Massive Internet of Things for 6G Wireless Communications. IEEE Commun. Stand. Mag. 2021, 5, 126–131. [Google Scholar] [CrossRef]
- Zhao, T.; Zhou, S.; Song, L.; Jiang, Z.; Guo, X.; Niu, Z. Energy-optimal and Delay-bounded Computation Offloading in Mobile Edge Computing with Heterogeneous Clouds. China Commun. 2020, 17, 191–210. [Google Scholar] [CrossRef]
- Vu, T.T.; Huynh, N.V.; Hoang, D.T.; Nguyen, D.N.; Dutkiewicz, E. Offloading Energy Efficiency with Delay Constraint for Cooperative Mobile Edge Computing Networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Yuan, H.; Zhou, M. Profit-Maximized Collaborative Computation Offloading and Resource Allocation in Distributed Cloud and Edge Computing Systems. IEEE Trans. Autom. Sci. Eng. 2021, 18, 1277–1287. [Google Scholar] [CrossRef]
- Alqerm, I.; Pan, J. DeepEdge: A New QoE-Based Resource Allocation Framework Using Deep Reinforcement Learning for Future Heterogeneous Edge-IoT Applications. IEEE Trans. Netw. Serv. Manag. 2021, 18, 3942–3954. [Google Scholar] [CrossRef]
- Amin, F.; Ahmad, A.; Sang Choi, G. Towards Trust and Friendliness Approaches in the Social Internet of Things. Appl. Sci. 2019, 9, 166. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Qiu, X.; Cai, T.; Dai, H.N.; Zheng, Z.; Zhang, Y. Deep Reinforcement Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2021, 23, 1659–1692. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Feng, A.; Huang, Y.; Qian, L.P. Distributed Deep Learning-based Offloading for Mobile Edge Computing Networks. Mob. Netw. Appl. 2018, 1–8. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Mob. Comput. 2020, 1. [Google Scholar] [CrossRef]
- Jang, I.; Kim, H.; Lee, D.; Son, Y.S.; Kim, S. Knowledge Transfer for On-Device Deep Reinforcement Learning in Resource Constrained Edge Computing Systems. IEEE Access 2020, 8, 146588–146597. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, J.; Nie, T. Deep Reinforcement Learning Aided Computation Offloading and Resource Allocation for IoT. In Proceedings of the 2020 IEEE Computing, Communications and IoT Applications (ComComAp), Beijing, China, 5–8 November 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Wu, C.; Mao, S.; Ji, Y.; Bennis, M. Optimized Computation Offloading Performance in Virtual Edge Computing Systems Via Deep Reinforcement Learning. IEEE Internet Things J. 2019, 6, 4005–4018. [Google Scholar] [CrossRef] [Green Version]
- Song, S.; Fang, Z.; Zhang, Z.; Chen, C.L.; Sun, H. Semi-Online Computational Offloading by Dueling Deep-Q Network for User Behavior Prediction. IEEE Access 2020, 8, 118192–118204. [Google Scholar] [CrossRef]
- Zou, J.; Hao, T.; Yu, C.; Jin, H. A3C-DO: A Regional Resource Scheduling Framework Based on Deep Reinforcement Learning in Edge Scenario. IEEE Trans. Comput. 2021, 70, 228–239. [Google Scholar] [CrossRef]
- Liu, L.; Feng, J.; Pei, Q.; Chen, C.; Ming, Y.; Shang, B.; Dong, M. Blockchain-Enabled Secure Data Sharing Scheme in Mobile-Edge Computing: An Asynchronous Advantage Actor–Critic Learning Approach. IEEE Internet Things J. 2021, 8, 2342–2353. [Google Scholar] [CrossRef]
- Fu, F.; Kang, Y.; Zhang, Z.; Yu, F.R.; Wu, T. Soft Actor–Critic DRL for Live Transcoding and Streaming in Vehicular Fog-Computing-Enabled IoV. IEEE Internet Things J. 2021, 8, 1308–1321. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Wang, Q.; Cao, B.; Feng, G.; Hu, J. iRAF: A Deep Reinforcement Learning Approach for Collaborative Mobile Edge Computing IoT Networks. IEEE Internet Things J. 2019, 6, 7011–7024. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Luo, S.; Wang, Q.; Cao, B.; Li, X. An Intelligent Task Offloading Algorithm (iTOA) for UAV Edge Computing Network. Digit. Commun. Netw. 2020, 6, 433–443. [Google Scholar] [CrossRef]
- Yuan, H.; Tang, G.; Li, X.; Guo, D.; Luo, L.; Luo, X. Online Dispatching and Fair Scheduling of Edge Computing Tasks: A Learning-Based Approach. IEEE Internet Things J. 2021, 8, 14985–14998. [Google Scholar] [CrossRef]
- Chen, J.; Xing, H.; Xiao, Z.; Xu, L.; Tao, T. A DRL Agent for Jointly Optimizing Computation Offloading and Resource Allocation in MEC. IEEE Internet Things J. 2021, 8, 17508–17524. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Set of terminal layer devices | |
| Set of edge layer servers | |
| Set of time slots for task generation | |
| Task generated by terminal device m at time slot t | |
| Task of device m are offloaded to edge node n | |
| Device m offloading its task in time slot t while , Otherwise, | |
| The task is offloaded to the edge server while , Otherwise, | |
| Terminal layer device waiting delay in the task queue | |
| Terminal layer device processing delay in the computation queue | |
| Total time delay of the task generated by terminal devices m at time slot t | |
| Processing power of the task generated by terminal devices m at time slot t | |
| Waiting power of the terminal devices m | |
| Energy consumption of the device m | |
| Processing delay in the computation queue of the Edge server n | |
| Total time delay of the edge server n | |
| Transmission power of the device m offload to edge server n | |
| Transmission delay of the device m offload to edge server n | |
| Processing power of the edge server n | |
| Energy consumption of the edge sever n | |
| The trade off weight between energy consumption and delay in the system cost |
| Parameter | Value |
|---|---|
| 2.5 GHz | |
| 41.8 GHz | |
| 10 MHz | |
| 5 Watt | |
| 0.2 Watt | |
| 2 Watt | |
| 10 Watt |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, Y.; Chen, H.; Yan, L.; Zhou, X. Task Offloading Based on LSTM Prediction and Deep Reinforcement Learning for Efficient Edge Computing in IoT. Future Internet 2022, 14, 30. https://doi.org/10.3390/fi14020030
Tu Y, Chen H, Yan L, Zhou X. Task Offloading Based on LSTM Prediction and Deep Reinforcement Learning for Efficient Edge Computing in IoT. Future Internet. 2022; 14(2):30. https://doi.org/10.3390/fi14020030
Chicago/Turabian StyleTu, Youpeng, Haiming Chen, Linjie Yan, and Xinyan Zhou. 2022. "Task Offloading Based on LSTM Prediction and Deep Reinforcement Learning for Efficient Edge Computing in IoT" Future Internet 14, no. 2: 30. https://doi.org/10.3390/fi14020030
APA StyleTu, Y., Chen, H., Yan, L., & Zhou, X. (2022). Task Offloading Based on LSTM Prediction and Deep Reinforcement Learning for Efficient Edge Computing in IoT. Future Internet, 14(2), 30. https://doi.org/10.3390/fi14020030