
IoT Nodes Authentication and ID Spoofing Detection Based on Joint Use of Physical Layer Security and Machine Learning



Abstract
:1. Introduction
- Secret communications without encryption—with a suitable design of the transmitted waveform (coding, modulation, precoding schemes, etc.) together with the exploitation of the available channel state information, it is possible for the intended receiver to be enabled to successfully decode the data while the potential eavesdropper is not.
- Secure key generation—when the use of encryption is preferred, the randomness of the channel between two nodes can be exploited to generate keys to be used for symmetric encryption.
- Node authentication/spoofing detection—by means of the identification of specific distinguishing features of the wireless channel experienced by a node or of the transmitting device, the receiver can detect if the message has been illegitimately modified by a node other than its legitimate source.
1.1. Motivation and Related Literature
1.2. Paper Contribution
- Each transmitting node is identified by means of a ML supervised non-parametric classification algorithm where training data are labeled (i.e., it is associated to the corresponding user’s ID). It means that an eventual malicious node is not detected at this step, but it is classified as belonging to one of the authorized nodes’ class.
- In order to detect a spoofing attack, a successive cross-check of the PHY layer classification results and the ID declared by the transmitting node is performed.
- Proposal of a continuous authentication/spoofing detection system, suitable for an actual WSN, where multiple IoT nodes communicate with a sink node. Differently, previous works on PLA [16,17,18,19,20,21,22,23,24,25,26,27,28] were usually based on scenarios with a single authorized node that must be distinguished by the unauthorized one, and hence, only a binary decision is needed (i.e., binary classification). However, binary classification is not suitable for large-scale IoT networks, and extending these methods to a multi-user scenario may not be straightforward. In any case, it means seeking an optimal threshold individually for each IoT legitimate node, which is expensive in terms of resources and signaling. Moreover, adopting a ML approach means adopting and training one machine for each node. Here, instead, the malicious user must be distinguished by multiple authorized nodes using their WFs. This is a more complex scenario because there is a higher variability of legitimate channels, and the probability that the spoofing attacker is close to one of them is higher. The proposed approach allows to simultaneously distinguish the malicious node from all the legitimate ones, using a single machine.
- We propose a threshold-free method, thanks to the integration of the classification of devices using their PHY-layer attributes and the associated device ID. Differently, in most of the approaches proposed in the literature, a threshold is needed to distinguish between legitimate and malicious user data [16,17,18,19,20,21,24,26,26]. However, the threshold must be optimized for each scenario with a consequent performance degradation, especially in time-varying scenarios.
- We propose a method that does not require any knowledge and specific statistical distribution, neither for the PHY-layer attributes nor for the spoofing model. This makes the proposed system more applicable in actual contexts. Conversely, many of the proposed approaches in the literature make assumptions difficult to obtain in a real environment, such as specific channel models and knowledge of data belonging to the attacker [16,18,22,26,28].
- We investigate a solution for a supervised classification of devices based on CART and random forest algorithms that were not previously investigated in this context. Random forest was adopted in ref. [29], using channel and hardware features to distinguish different nodes; however, the investigation is limited to node identification (i.e., no spoofing detection) and is very limited and related to a single static experimental setup.
- The proposed approach integrates multiple-attributes to provide a higher identification accuracy. Differently, most of the papers in the literature use only one channel attribute [17,18,19,25,28,30] or multiple observations of the same attribute, exploiting time or spatial diversity [22,23,26,27]. However, attributes can be estimated with a different level of reliability; thus, having different attributes allows to compensate for low-reliable attributes with high-reliable ones. Only a few papers have integrated different attributes, but often these are limited, such as in ref. [16,31] where only CSI and delay are considered. A wide range of attributes are considered only in [24,29]. Moreover, the angle of arrival (AoA) attribute is rarely considered, and in different scenarios, such as in ref. [32], where AoA is used for improving the security of channel training authentication, integrating the AoA with the pilot randomization, or in ref. [33], where AoA information is cross checked with the GPS information for improving security. Finally, here, the effects of different attributes are separately evaluated. To our knowledge, only [24] provides an analysis based on the availability of different attributes but in a different context.
- The proposal of the use of sentinel nodes to improve spoofing detection in small networks. Cooperative solutions for PLA have been rarely considered as in ref. [23], but here the goal of sentinel nodes is completely different. These nodes do not have to perform any operation except sending periodical beaconing signals.
- The evaluation of the system performance in an actual and general time-varying channel, also considering different environment conditions, while most of the papers in the literature consider fixed channel parameters and simple channel models. Moreover, the effects of different channel attributes in classification results are evaluated.
2. System Model
- Attacks against security mechanisms;
- Attacks against basic mechanisms (such as routing mechanisms).
- is the coefficient of the i-th receiving antenna in the NLOS condition. The coefficients are correlated complex Gaussian random variables with zero mean and unitary variance;
- is the phase difference between the transmitting and the i-th receiving antenna;
- is the Ricean factor;
- is the mean power of the l-th path at the receiver.
3. Proposed System
- AoA: the direction of arrival of the signal at the sink node;
- Maximum delay spread (MDS): the time interval needed to collect all paths of the signal;
- Peak value: the maximum value of the channel impulse response;
- Energy: the sum of the squared absolute value of the signal;
- Received signal power (RSP): calculated as the ratio between the energy and the MDS.
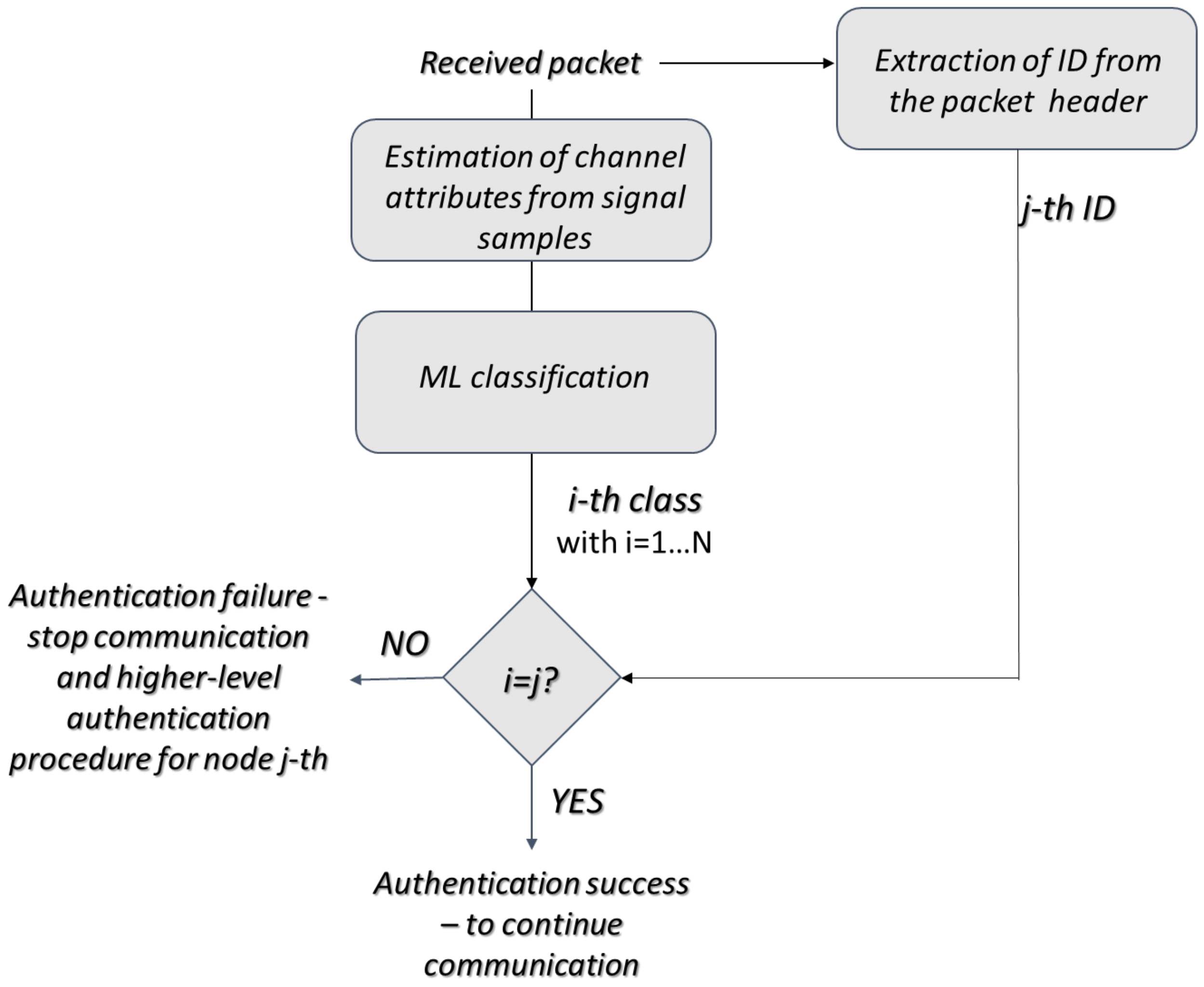
- During the training phase, the ML algorithm is trained using N-labeled training sequences belonging to the N legitimate sensor devices. Each one is composed of X samples of the received signal. Hence, only data of the authorized nodes are used for training, since it is impractical to assume to know the dataset of the spoofing node.
- Then, during the communication phase, the received signal samples are classified as belonging to one of the N classes. However, in this way, even a malicious node is identified as a legitimate one, so an additional step is needed for its detection: the classification output is cross checked with the declared ID and if they match, the authentication is successful, while otherwise it fails. In the second case, the node communication is blocked and a new authentication at higher layers must be performed.
- The spoofing node is not present—the ML classification algorithm detects the class of the incoming authorized data and then cross checks the classification outcome with the declared ID: if the data belong to the node with claimed , the identification is successful if the ML classification result is j; otherwise, it fails and an alarm of spoofing is generated for the j-th node. Hence, the ML algorithm is defined as the probability of correctly identifying the class of an authorized user. At the opposite, if the ML classification fails, an authenticated user is erroneously blocked; hence, we define the probability of blocking an authorized node as .
- The spoofing node is present—if the transmission belongs to an authorized user, we fall into the previous case. If the transmission belongs to the spoofing node, the ML classification algorithm classifies it as an authorized node with and . At this stage, the spoofing node cannot be detected; hence, the probability of detection of a spoofing node does not directly depend on the ML algorithm. The spoofing node can be detected only by cross checking its declared ID with the classification result since each class is labeled with a specific node ID. The probability that a unauthorized node is classified as authorized, named the probability of miss spoofing detection, is the probability that an unauthorized node claiming the i-th ID is classified as belonging to the i-th class.
3.1. ML for Devices Classification
- The maximum number of split has been performed (it is set as a parameter);
- One leaf is “pure”, that is, all input data in the leaf belong to the same class;
- One leaf contains only one input sample.
Algorithm Considerations
- Suitable scenario: The proposed approach is suitable for a scenario with a limited variability on the network topology, where nodes are distributed in an area on almost-fixed positions, for example, for monitoring purposes (e.g., surveillance, anti-intrusion, and environment monitoring). When a new node is added to the network, the set-up phase has to be run again, i.e., the learning must be performed again to add the new class. However, this urgency is not present if a node leaves the network (and its ID is disabled). Indeed, in this case, the classification still works: if an attacker is classified as the disabled ID, it must be certainly blocked.
- Complexity and Scalability The complexity of the considered ML approaches must be evaluated separately for the two phases: training and test. During the training for each attribute (K), the information gain is calculated for the elements of the dataset (with complexity ) and values are sorted to find the right splitting threshold. The complexity of the sorting operation is that, asymptotically, is the complexity of the training phase. As the RF algorithm complexity must take into account the number of trees T, the complexity is . In our system, the number of attributes is , and, as shown in the numerical results section, both CART and RF need short training sequences, thus resulting in fast and limited complexity training. Obviously, the complexity increases as , as the number of nodes, N, increases. On the other side, the testing phase complexity is proportional to the tree depth P that depends on the number of splits that must be at least equal to N. In the numerical results section, we verified that selecting a number of splits slightly higher than N provides a slight improvement in the accuracy, but a further increase does not provide advantages. For simplicity, assuming that the number of split is N, in the best case (totally balanced-tree is ) and in the worst case is . Hence, in the classification (test) phase, the algorithm complexity in the worst case is linear with N, thus, scaling efficiently with N. Indeed, this aspect makes the decision tree algorithms very fast and resource efficient during the test stage, and hence, suitable even for real-time machine learning deployment and large scenarios.In terms of performance increasing the number of nodes in the area, we can expect two opposite behaviors, indeed, as explained before, the spoofing detection capability improves if N increases, but on the other side, the can increase due to a reduction of the accuracy of the classification since nodes are closer to each other and it is more difficult to discriminate them. However, in the numerical results section, we verified that the performance degradation is not significant within a certain value; we tested node density up to around . Obviously, the number of needed splits of the trees increases.
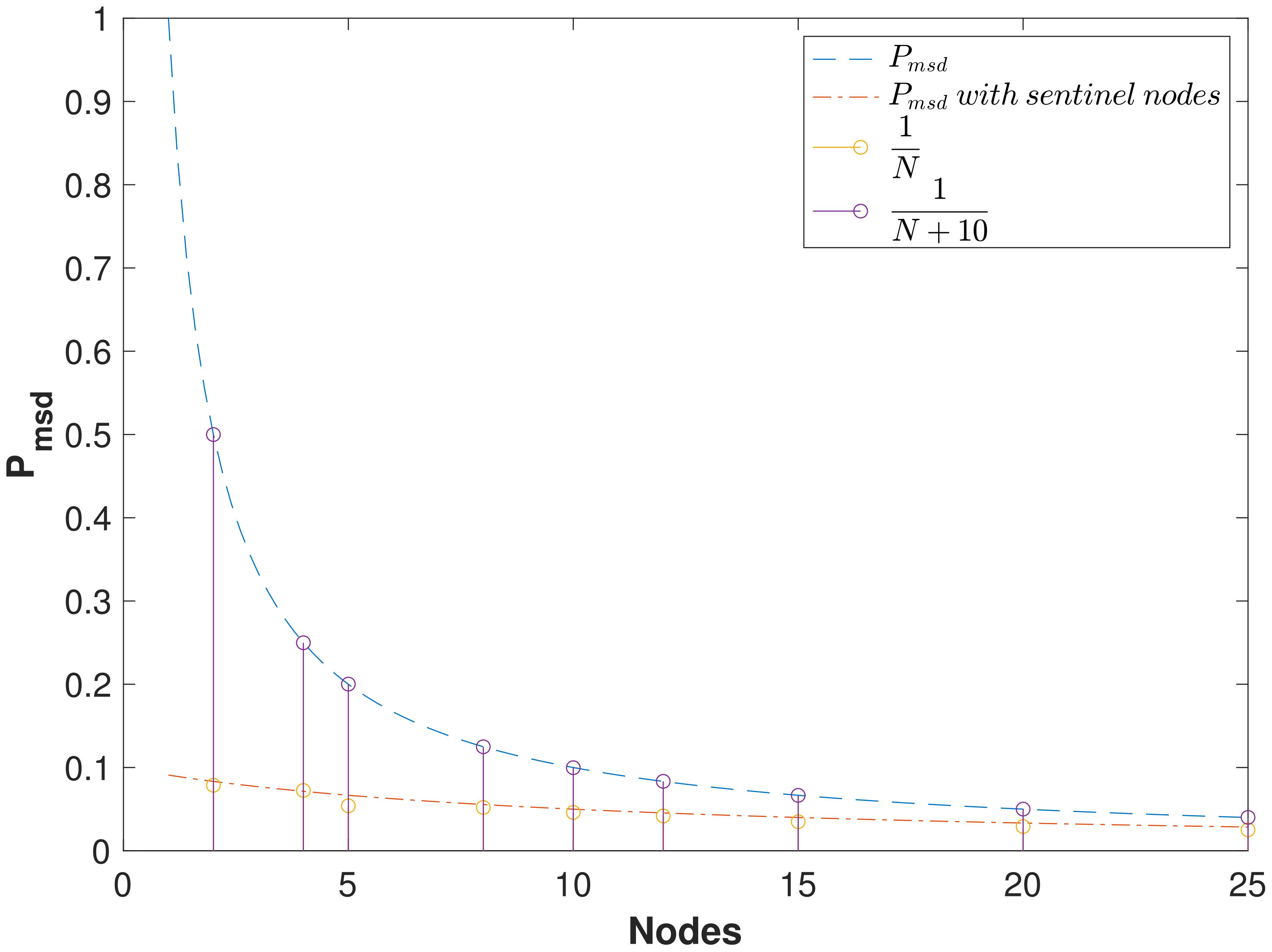
3.2. Sentinel Nodes
4. Numerical Results
4.1. Probability of Blocking an Authorized Node
- Scenario A1—nodes are randomly placed in according to a bidimensional probability distribution. The Doppler spread is related to a scatterers’ movement in the range [0–5] km/h;
- Scenario A2—nodes are randomly placed as in A1, but scatterers’ speeds are increased in the range [0–15] km/h;
- Scenario A3—nodes and speeds are set as in A2, but also the angle and delay spread are increased, considering a variance that is three times the original one;
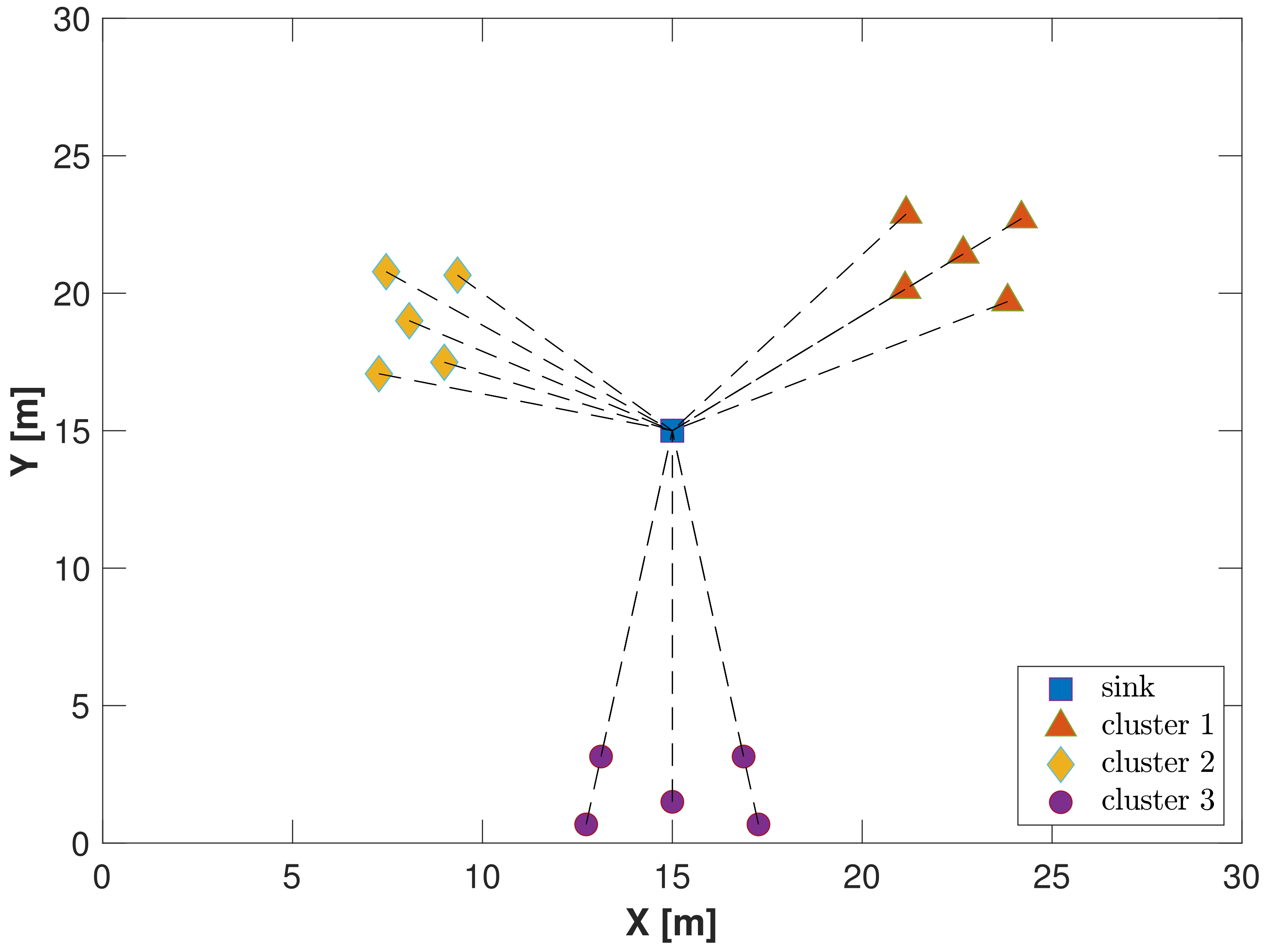
- Scenario B1—nodes are placed in clusters as shown in Figure 4, and the signals experience the Doppler effect under the same conditions as case A1;
- Scenario B2—clustered nodes are paired with the same environmental conditions of case A3.
- The whole set;
- The whole set without AoA attribute;
- The whole set without delay attribute;
- Only attributes related to the signal intensity (i.e., RSP, peak value and energy) without AoA and delay;
- Only AoA and delay attributes.
4.2. Probability of Missed Spoofing Detection
4.3. Limits of the Proposed Solution and Future Works
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fang, H.; Wang, X.; Tomasin, S. Machine Learning for Intelligent Authentication in 5G and Beyond Wireless Networks. IEEE Wirel. Commun. 2019, 26, 55–61. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Wan, X.; Lu, X.; Zhang, Y.; Wu, D. IoT Security Techniques Based on Machine Learning: How Do IoT Devices Use AI to Enhance Security? IEEE Signal Process. Mag. 2018, 35, 41–49. [Google Scholar] [CrossRef]
- Wang, N.; Wang, P.; Alipour-Fanid, A.; Jiao, L.; Zeng, K. Physical-Layer Security of 5G Wireless Networks for IoT: Challenges and Opportunities. IEEE Internet Things J. 2019, 6, 8169–8181. [Google Scholar] [CrossRef]
- Restuccia, F.; D’Oro, S.; Melodia, T. Securing the Internet of Things in the Age of Machine Learning and Software-Defined Networking. IEEE Internet Things J. 2018, 5, 4829–4842. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Chen, H.; Wang, L. Physical Layer Security for Next Generation Wireless Networks: Theories, Technologies, and Challenges. IEEE Commun. Surv. Tutor. 2017, 19, 347–376. [Google Scholar] [CrossRef]
- Mukherjee, A. Physical-Layer Security in the Internet of Things: Sensing and Communication Confidentiality Under Resource Constraints. Proc. IEEE 2015, 103, 1747–1761. [Google Scholar] [CrossRef]
- Shiu, Y.S.; Chang, S.Y.; Wu, H.C.; Huang, S.C.H.; Chen, H.H. Physical layer security in wireless networks: A tutorial. IEEE Wirel. Commun. 2011, 18, 66–74. [Google Scholar] [CrossRef]
- Ometov, A.; Petrov, V.; Bezzateev, S.; Andreev, S.; Koucheryavy, Y.; Gerla, M. Challenges of Multi-Factor Authentication for Securing Advanced IoT Applications. IEEE Netw. 2019, 33, 82–88. [Google Scholar] [CrossRef]
- Trappe, W. The challenges facing physical layer security. IEEE Commun. Mag. 2015, 53, 16–20. [Google Scholar] [CrossRef]
- Mucchi, L.; Nizzi, F.; Pecorella, T.; Fantacci, R.; Esposito, F. Benefits of Physical Layer Security to Cryptography: Tradeoff and Applications. In Proceedings of the 2019 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Sochi, Russia, 3–6 June 2019; pp. 1–3. [Google Scholar] [CrossRef]
- Tsitroulis, A.; Lampoudis, D.; Tsekleves, E. Exposing WPA2 Security Protocol Vulnerabilities. Int. J. Inf. Comput. Secur. 2014, 6, 93–107. [Google Scholar] [CrossRef]
- Tomasin, S. Analysis of Channel-Based User Authentication by Key-Less and Key-Based Approaches. IEEE Trans. Wirel. Commun. 2018, 17, 5700–5712. [Google Scholar] [CrossRef]
- Wu, X.; Yang, Z.; Ling, C.; Xia, X. Artificial-Noise-Aided Physical Layer Phase Challenge-Response Authentication for Practical OFDM Transmission. IEEE Trans. Wirel. Commun. 2016, 15, 6611–6625. [Google Scholar] [CrossRef]
- Taha, H.; Alsusa, E. Secret Key Exchange and Authentication via Randomized Spatial Modulation and Phase Shifting. IEEE Trans. Veh. Technol. 2018, 67, 2165–2177. [Google Scholar] [CrossRef]
- Yu, P.L.; Sadler, B.M. MIMO Authentication via Deliberate Fingerprinting at the Physical Layer. IEEE Trans. Inf. Forensics Secur. 2011, 6, 606–615. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Physical Layer Authentication Enhancement Using Two-Dimensional Channel Quantization. IEEE Trans. Wirel. Commun. 2016, 15, 4171–4182. [Google Scholar] [CrossRef]
- Xiao, L.; Greenstein, L.J.; Mandayam, N.B.; Trappe, W. Channel-based spoofing detection in frequency-selective rayleigh channels. IEEE Trans. Wirel. Commun. 2009, 8, 5948–5956. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Greenstein, L.J.; Mandayam, N.B.; Trappe, W. Using the physical layer for wireless authentication in time-variant channels. IEEE Trans. Wirel. Commun. 2008, 7, 2571–2579. [Google Scholar] [CrossRef] [Green Version]
- Hou, W.; Wang, X.; Chouinard, J.; Refaey, A. Physical Layer Authentication for Mobile Systems with Time-Varying Carrier Frequency Offsets. IEEE Trans. Commun. 2014, 62, 1658–1667. [Google Scholar] [CrossRef]
- Liu, F.J.; Wang, X.; Tang, H. Robust physical layer authentication using inherent properties of channel impulse response. In Proceedings of the 2011-MILCOM 2011 Military Communications Conference, Baltimore, MD, USA, 7–10 November 2011; pp. 538–542. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Y.; Han, G.; Liu, G.; Zhuang, W. PHY-Layer Spoofing Detection With Reinforcement Learning in Wireless Networks. IEEE Trans. Veh. Technol. 2016, 65, 10037–10047. [Google Scholar] [CrossRef]
- Wang, N.; Jiang, T.; Lv, S.; Xiao, L. Physical-Layer Authentication Based on Extreme Learning Machine. IEEE Commun. Lett. 2017, 21, 1557–1560. [Google Scholar] [CrossRef]
- Xiao, L.; Wan, X.; Han, Z. PHY-Layer Authentication With Multiple Landmarks With Reduced Overhead. IEEE Trans. Wirel. Commun. 2018, 17, 1676–1687. [Google Scholar] [CrossRef]
- Fang, H.; Wang, X.; Hanzo, L. Learning-Aided Physical Layer Authentication as an Intelligent Process. IEEE Trans. Commun. 2019, 67, 2260–2273. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Li, H.; Zhao, D.; Chen, Z.; Ye, S.; Cai, J. Deep Neural Networks for CSI-Based Authentication. IEEE Access 2019, 7, 123026–123034. [Google Scholar] [CrossRef]
- Senigagliesi, L.; Baldi, M.; Gambi, E. Comparison of Statistical and Machine Learning Techniques for Physical Layer Authentication. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1506–1521. [Google Scholar] [CrossRef]
- Yoon, J.; Lee, Y.; Hwang, E. Machine Learning-based Physical Layer Authentication using Neighborhood Component Analysis in MIMO Wireless Communications. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 16–18 October 2019; pp. 63–65. [Google Scholar] [CrossRef]
- Hoang, T.M.; Nguyen, N.M.; Duong, T.Q. Detection of Eavesdropping Attack in UAV-Aided Wireless Systems: Unsupervised Learning With One-Class SVM and K-Means Clustering. IEEE Wirel. Commun. Lett. 2020, 9, 139–142. [Google Scholar] [CrossRef] [Green Version]
- Adamsky, F.; Retunskaia, T.; Schiffner, S.; Köbel, C.; Engel, T. WLAN Device Fingerprinting using Channel State Information (CSI). In Proceedings of the WiSec ’18: Proceedings of the 11th ACM Conference on Security & Privacy in Wireless and Mobile Networks, Stockholm, Sweden, 18–20 June 2018; pp. 277–278. [Google Scholar] [CrossRef]
- Tugnait, J.K. Wireless User Authentication via Comparison of Power Spectral Densities. IEEE J. Sel. Areas Commun. 2013, 31, 1791–1802. [Google Scholar] [CrossRef]
- Liu, F.J.; Wang, X.; Primak, S.L. A two dimensional quantization algorithm for CIR-based physical layer authentication. In Proceedings of the 2013 IEEE International Conference on Communications (ICC), Budapest, Hungary, 9–13 June 2013; pp. 4724–4728. [Google Scholar] [CrossRef]
- Xu, D.; Ren, P.; Ritcey, J.A. Independence-Checking Coding for OFDM Channel Training Authentication: Protocol Design, Security, Stability, and Tradeoff Analysis. IEEE Trans. Inf. Forensics Secur. 2019, 14, 387–402. [Google Scholar] [CrossRef] [Green Version]
- Abdelaziz, A.; Burton, R.; Barickman, F.; Martin, J.; Weston, J.; Koksal, C.E. Enhanced Authentication Based on Angle of Signal Arrivals. IEEE Trans. Veh. Technol. 2019, 68, 4602–4614. [Google Scholar] [CrossRef]
- Kermoal, J.; Schumacher, L.; Pedersen, K.; Mogensen, P.; Frederiksen, F. A stochastic MIMO radio channel model with experimental validation. IEEE J. Sel. Areas Commun. 2002, 20, 1211–1226. [Google Scholar] [CrossRef] [Green Version]
- Erceg, V.; Schumacher, L.; Kyritsi, P.; Molisch, A.; Baum, D.S.; Gorokhov, A.Y.; Oestges, C.; Li, Q.; Yu, K.; Tal, K.N.; et al. Wireless LANs Indoor MIMO WLANTGn Channel Models. 2004. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.465.9926&rep=rep1&type=pdf (accessed on 20 January 2022).
- Kyösti, P.; Meinilä, J.; Hentila, L.; Zhao, X.; Jämsä, T.; Schneider, C.; Narandzic, M.; Milojević, M.; Hong, A.; Ylitalo, J.; et al. WINNER II Channel Models. IST-4-027756 WINNER II D1.1.2 V1.2. 2008. Available online: http://www.ero.dk/93F2FC5C-0C4B-4E44-8931-00A5B05A331B?frames=no& (accessed on 20 January 2022).
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Min (n.Splits) | Max (n.Splits) |
|---|---|---|
| A1 | 95.28% (15) | 95.84% (20) |
| A2 | 95.00% (15) | 96.04% (20) |
| A3 | 91.02% (15) | 96.07% (25) |
| B1 | 88.19% (15) | 95.62% (25) |
| B2 | 86.04% (15) | 89.89% (40) |
| Scenario | CART Accuracy | Random Forest Accuracy |
|---|---|---|
| A1 | 95.43% | 95.49% |
| A2 | 95.95% | 96.14% |
| A3 | 96.53% | 96.66% |
| B1 | 93.91% | 95.04% |
| B2 | 87.96% | 89.74% |
| Scenario | Full | No AoA | No Delay | “Only Energy” | AoA & Delay |
|---|---|---|---|---|---|
| CART | |||||
| A1 | 95.43% | 90.64% | 94.67% | 55.88% | 90.70% |
| A2 | 95.95% | 89.92% | 94.87% | 55.94% | 90.80% |
| A3 | 96.53% | 83.78% | 81.08% | 52.11% | 95.40% |
| B1 | 93.91% | 75.32% | 76.96% | 51.43% | 91.69% |
| B2 | 87.96% | 68.76% | 77.44% | 51.82% | 81.84% |
| Random Forest | |||||
| A1 | 95.49% | 88.77% | 93.27% | 61.61% | 92.56% |
| A2 | 96.14% | 89.26% | 94.43% | 62.93% | 92.88% |
| A3 | 96.66% | 89.35% | 80.70% | 65.56% | 95.45% |
| B1 | 95.04% | 86.01% | 76.61% | 57.23% | 92.60% |
| B2 | 89.74% | 79.84% | 72.22% | 61.89% | 83.39% |
| CART | RF | SVM | k-NN |
|---|---|---|---|
| 95.43% | 95.49 | 95.59% | 94.59% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marabissi, D.; Mucchi, L.; Stomaci, A. IoT Nodes Authentication and ID Spoofing Detection Based on Joint Use of Physical Layer Security and Machine Learning. Future Internet 2022, 14, 61. https://doi.org/10.3390/fi14020061
Marabissi D, Mucchi L, Stomaci A. IoT Nodes Authentication and ID Spoofing Detection Based on Joint Use of Physical Layer Security and Machine Learning. Future Internet. 2022; 14(2):61. https://doi.org/10.3390/fi14020061
Chicago/Turabian StyleMarabissi, Dania, Lorenzo Mucchi, and Andrea Stomaci. 2022. "IoT Nodes Authentication and ID Spoofing Detection Based on Joint Use of Physical Layer Security and Machine Learning" Future Internet 14, no. 2: 61. https://doi.org/10.3390/fi14020061
APA StyleMarabissi, D., Mucchi, L., & Stomaci, A. (2022). IoT Nodes Authentication and ID Spoofing Detection Based on Joint Use of Physical Layer Security and Machine Learning. Future Internet, 14(2), 61. https://doi.org/10.3390/fi14020061