
Complex Queries for Querying Linked Data

Abstract
:1. Introduction
- Identify the semantic relations between the NL query terms;
- Map these terms to specific entities of Linked Data;
- Combine the identified semantic relations, the matching entities, and the links between these matching entities in the datasets to form valid triples of the query;
- Formulate SPARQL queries based on all the valid triples.
2. Related Work
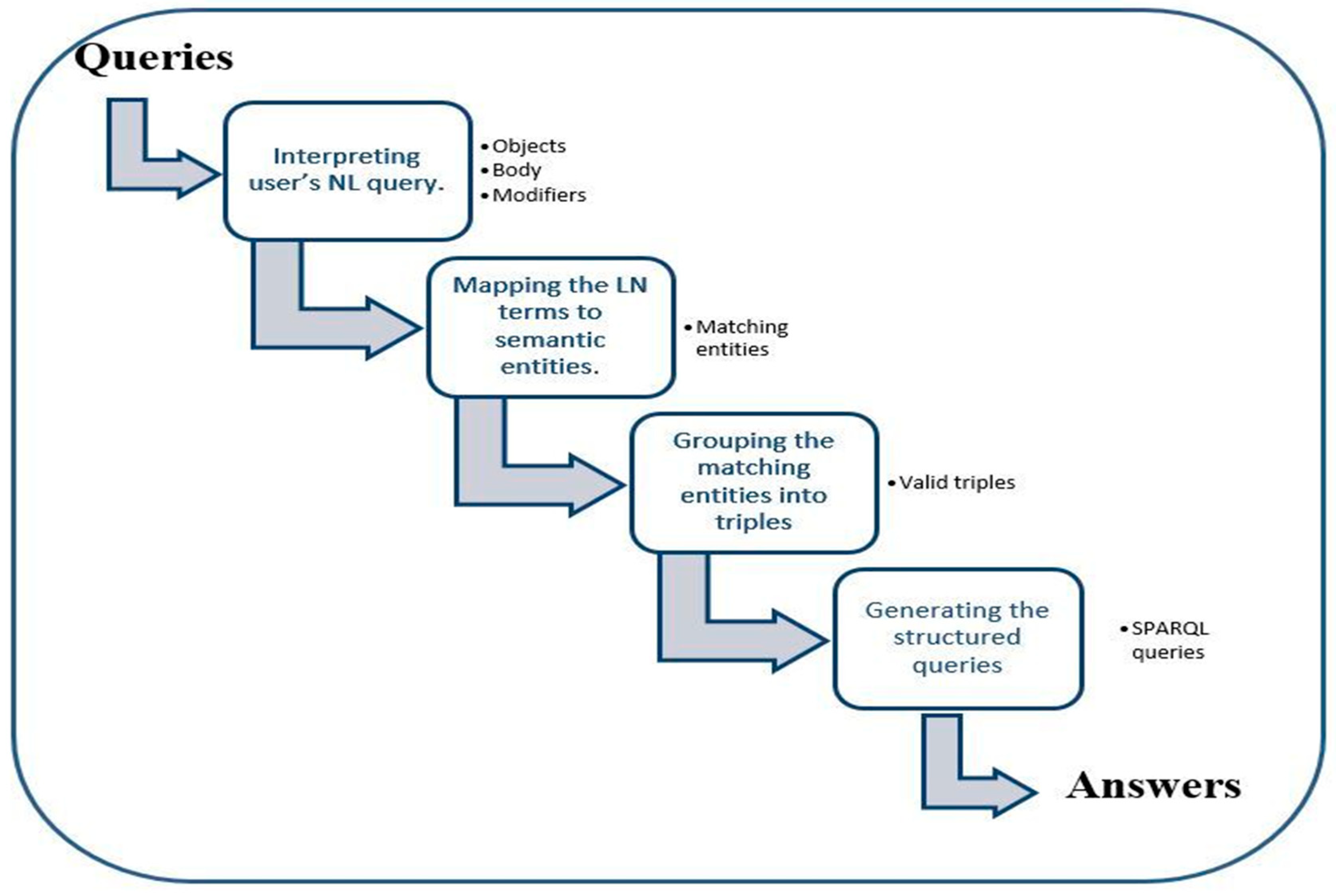
3. Proposed System
3.1. Interpreting the User’s NL Query
- The query object represents what the user wants in return.
- The query body consists of the semantic relations between the NL query terms.
- Libraries as a query object.
- {libraries—established before—1400} as the query body.
3.1.1. Identifying the Query Class
- Yes/no questions
- Wh questions
- Imperative queries
- Compound queries
| Algorithm 1: Identifying the query type |
 |
3.1.2. Identifying the Query Object
| Algorithm 2: Identifying the question object |
 |
- If the question word is “where” such as the query «where is Fort Knox located», the object here is a variable with category location.
- If the question word is “when” such as the query «when did Michael Jackson die», the object here is a variable with category date.
- If the question word is “how many”, the query object is the quantity of the followed noun after “how many”. There are two cases:
- (i)
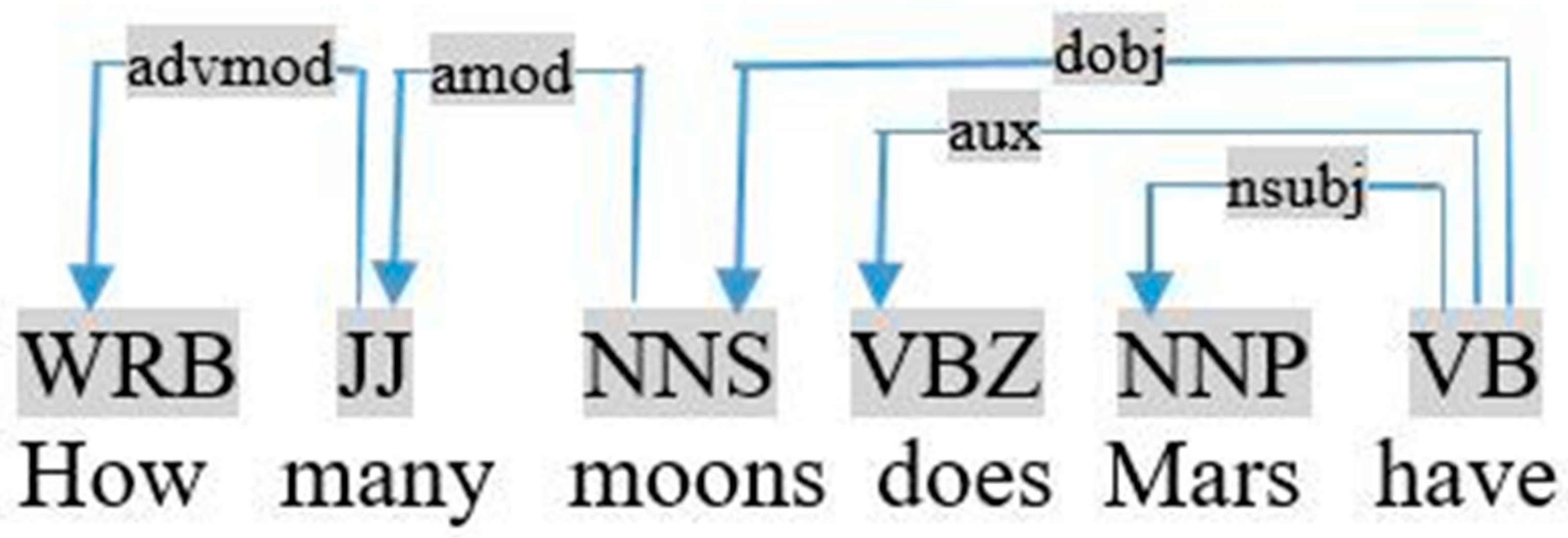
- Many is an adjectival modifier of the followed noun, as shown in the dependency graph of the query «how many moons does Mars have», visualized in Figure 3.
- (ii)
- The following noun is a nominal subject of the auxiliary verb, as shown in the dependency graph of the query «how many awards has Bertrand Russell», visualized in Figure 4.
- −
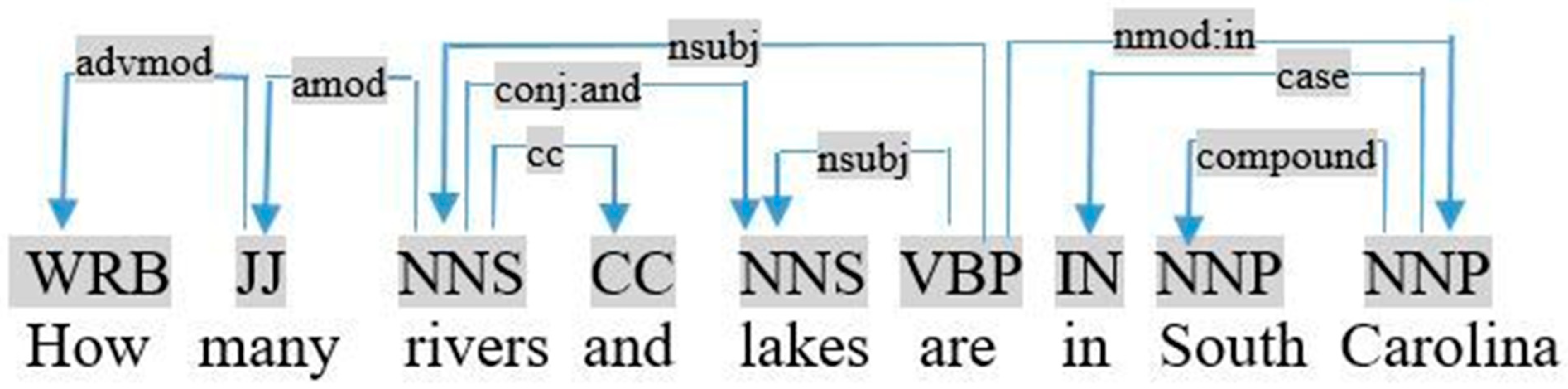
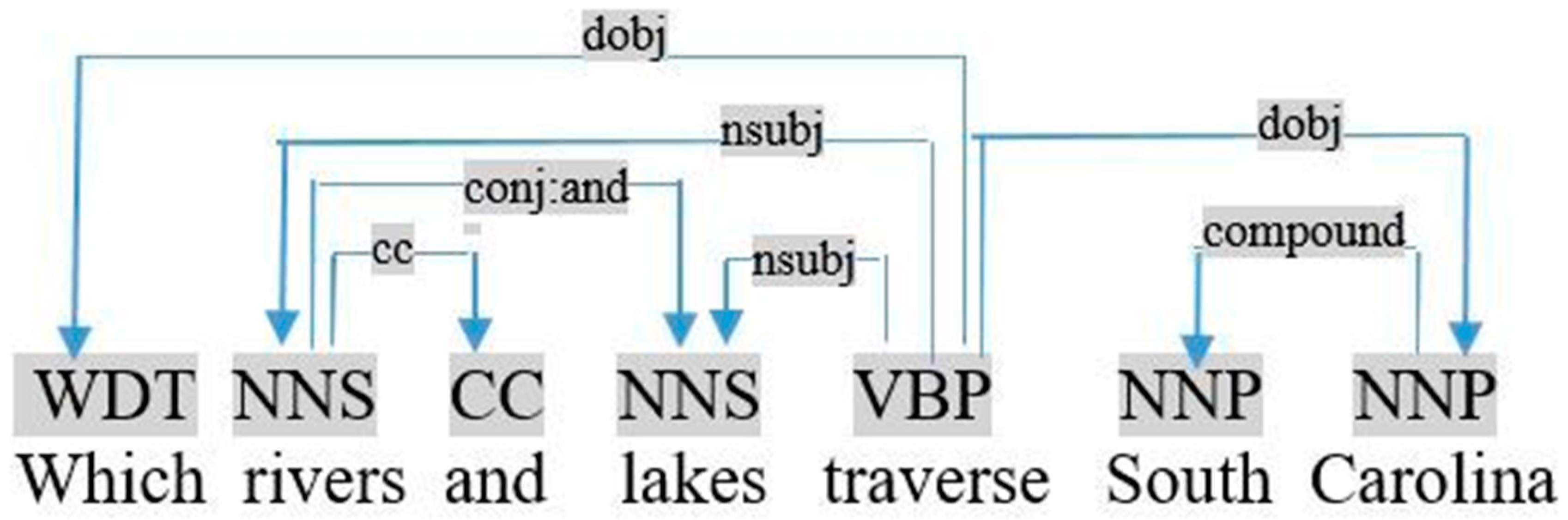
- In the two previous cases, if the followed noun is connected to another noun by conjunction (Structure (S6)), as shown in Figure 5, the object is the sum of the quantities of the two nouns (e.g., count (rivers) + count (lakes)).
- 4.
- If the question word is different from “how many”, there are two cases:
- (i)
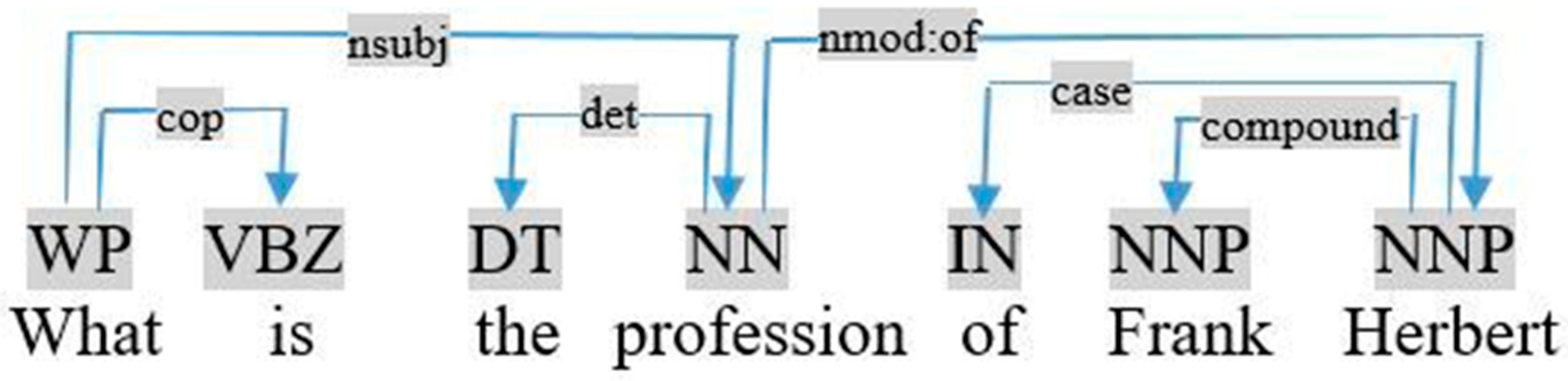
- If the query is in the active mode, the object is the noun relative by the dependency nsubj, as shown in the dependency graph of the query «what is the profession of Frank Herbert», visualized in Figure 6.
- (ii)
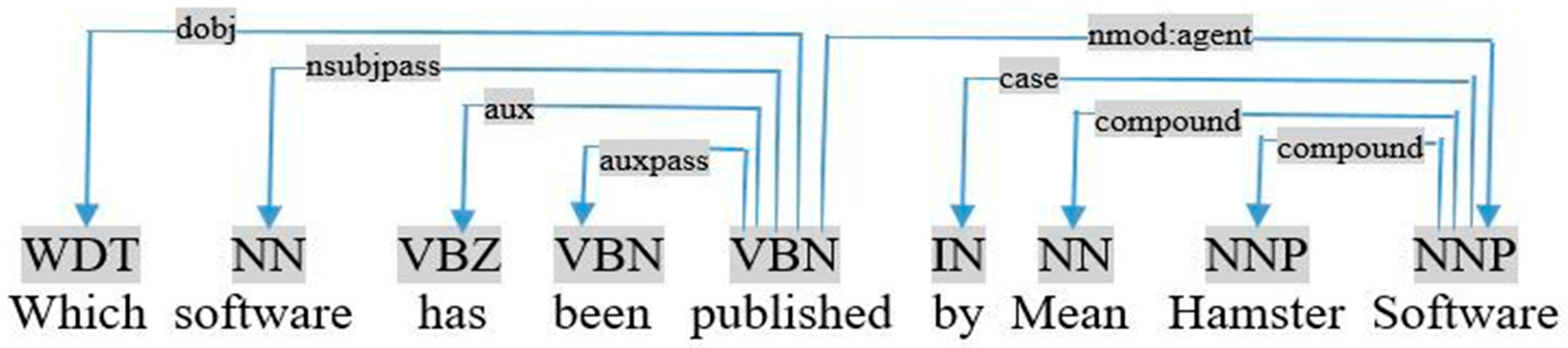
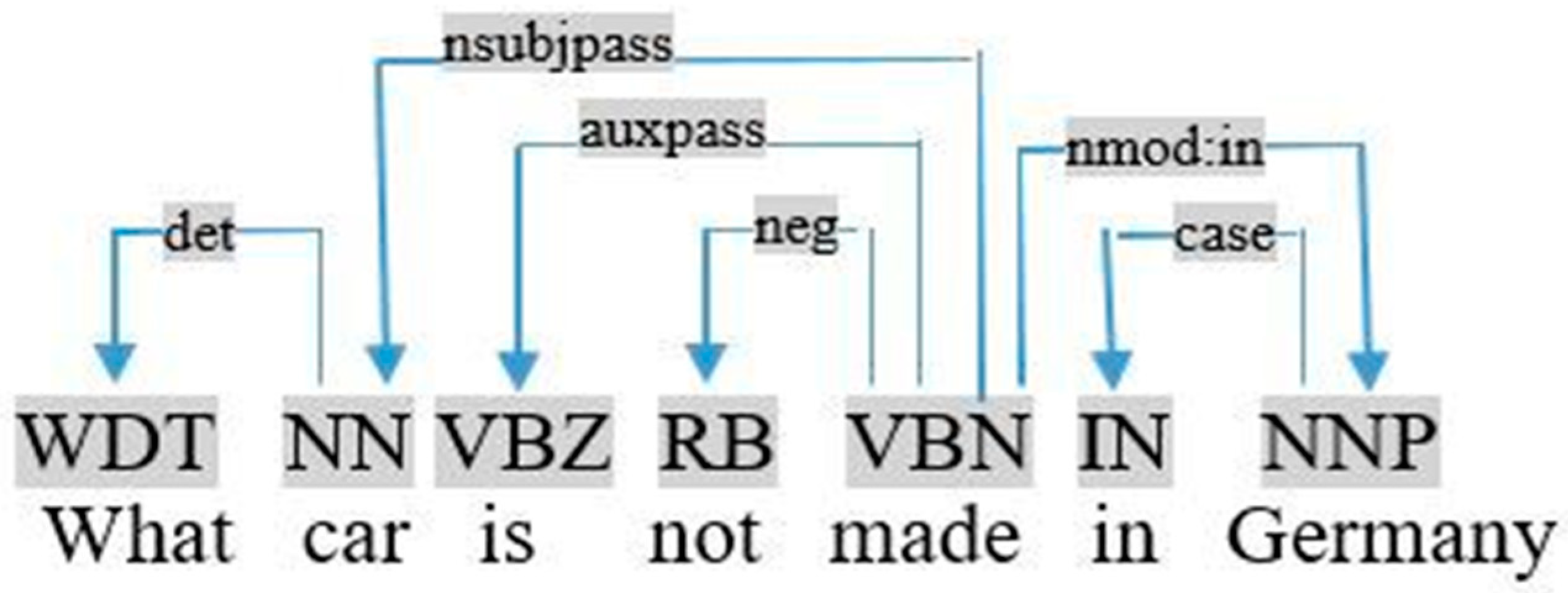
- If the query is in the passive mode, the object is the noun relative by the dependency nsubjpass, as shown in the dependency graph of the query «which software has been published by Mean Hamster Software», visualized in Figure 7.
- −
- In the two previous cases, if the noun is connected to another noun by conjunction, as shown in Figure 8, the object is the coordination of two nouns (e.g., rivers and lakes).
- −
- If this noun is connected to another noun by a conjunction, the object is the coordination of two nouns.
3.1.3. Identifying the Query Body
- (a)
- A triple consisting of three parts, i.e., subject, predicate, and object.
- (b)
- A relation consisting of two parts, i.e., Argument 1 and Argument 2.
- (c)
- A restriction is composed of some conditions in the query.
- (1)
- Nominal subject:
- (2)
- Passive nominal subject
- (3)
- Direct object
- (4)
- Adjectival modifier
- (5)
- Preposition
- (6)
- Compound term
- (7)
- Negation
- (8)
- Optimization rules
- (9)
- Comparative adjectives
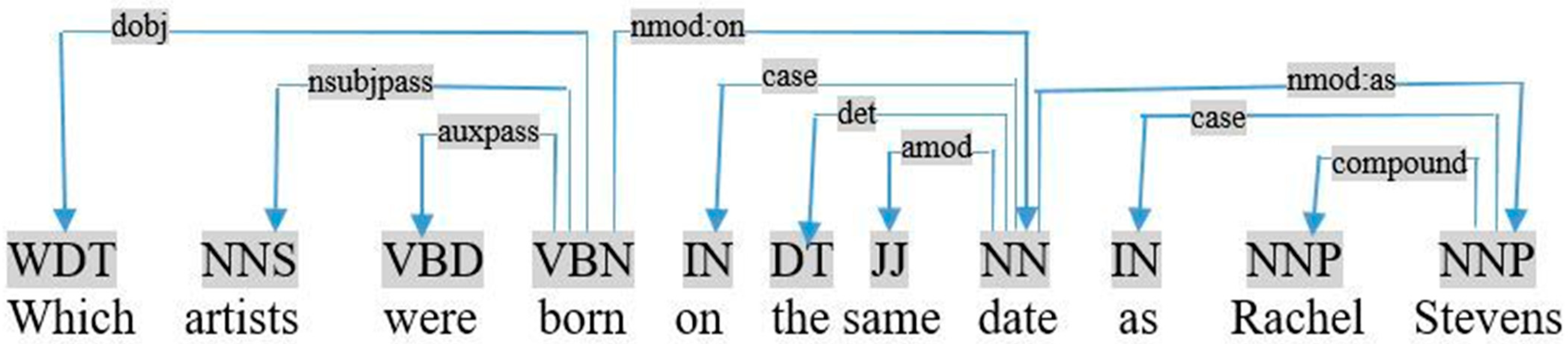
- SameThis adjective indicates that two or more things are exactly like one another. Especially, we use “same” as an adjective before a noun in two cases:
- (i)
- With “as” to compare two nouns in a simple query. In practice, we applied the following rule:If (triple <Ti, Tj, Tk> ∩ Relation <Tk, unknown, same> ∩ triple <Tk, as, Ts>) ⇒ add triple <Ts, Tj, Tk> ∩ Delete (Relation <Tk, unknown, same>) ∩ Delete (triple <Tk, as, Ts>)This rule is applied when the predicate Tj relates the two terms Ti and Ts to the same term Tk in the query. Therefore, we add a new triple to describe the relation between Ts and Tk. For example, in Figure 12, “artists” and “Rachel Stevens” are related by “born-on” to the same term “date” in the query «which artists were born on the same date as Rachel Stevens». Therefore, we add a new triple as follows:triple <artist, born-on, date> ∩ Relation <date, unknown, same> ∩ triple <date, as, Rachel- Stevens> ⇒ add triple <Rachel- Stevens, born-on, date> ∩ Delete (Relation <date, unknown, same>) ∩ Delete (triple <date, as, Rachel-Stevens>).
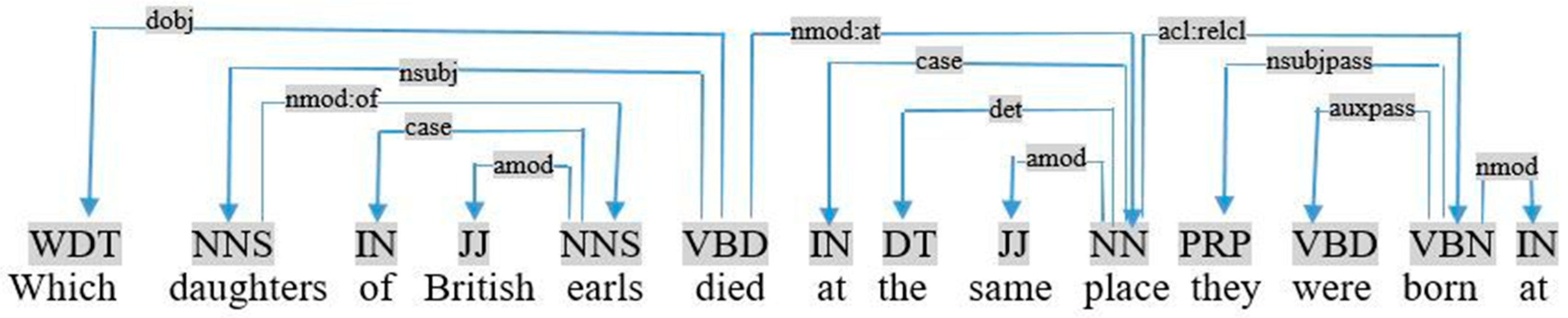
- (ii)
- To compare two nouns in a complex query. In practice, we apply the following rule:If (triple <Ti, Tj, Tk> ∩ Relation <Tk, unknown, same> ∩ triple <Ts, Tr, Tk>) ⇒ add triple <Ti, Tj, var1> ∩ add triple <Ts, Tr, var2> ∩ Delete (Relation <Tk, unknown, same>) ∩ Delete (triple <Ti, Tj, Tk>) ∩ Delete (triple triple <Ts, Tr, Tk>) ∩ add restriction (var1 = var2)This rule is applied when two terms, Ti and Ts, are related to the same term Tk, by different relations: Tj and Tr. We replace Tk in the two triples with variables: ?var1 and ?var2. We also add a restriction, indicating that “var1” and “var2” are equals. For example, in Figure 13, daughters and they (daughters) are related to the same term “place” by “died-at” and “born-at” in the complex query «which daughters of British earls died at the same place they were born at». Therefore, we add two triples and a restriction as follows:triple <daughters, died-at, place> ∩ Relation <place, unknown, same> ∩ triple <they, born-at, place> ⇒ add triple <daughters, died-at, ?var1> ∩ add triple <they, born-at, ?var2> ∩ Delete (triple <daughters, died-at, place>) ∩ Delete (Relation <place, unknown, same>) ∩ Delete (triple <they, born-at, place>) ∩ add restriction (?var1 = ?var2).


- More/less
- (10)
- Superlative adjectivesSuperlative adjectives describe a person or thing at the upper or lower limit of a quality relative to all other people or things in a group. Superlative adjectives are generally used in the following query structure:WH word + noun (subject) + verb + the + superlative adjective + noun (object)These adjectives have three forms:
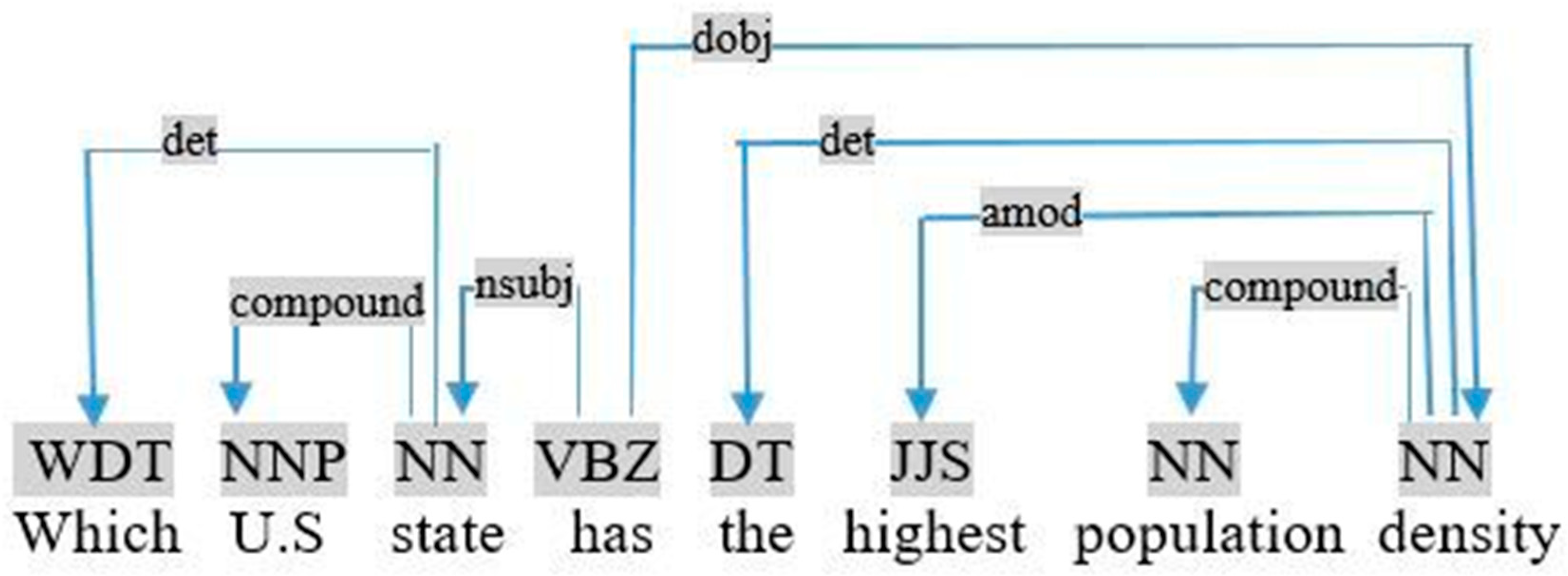
- (i)
- Adjective + est, such as “highest” in the query «which U.S. state has the highest population density», as shown in Figure 15. In this case, we applied the following rule:If (Relation <Ti, unknown, Tj> ∩ Pos (Tj) = JJS) ⇒ restriction (Ti, Sup, Tj)This rule identifies the relationship between the superlative adjective Tj and the noun Ti. Consider the previous query, this rule is used to generate the following restriction:Relation <density, unknown, highest> ∩ Pos (highest) = JJS ⇒ restriction (density, Sup, highest)
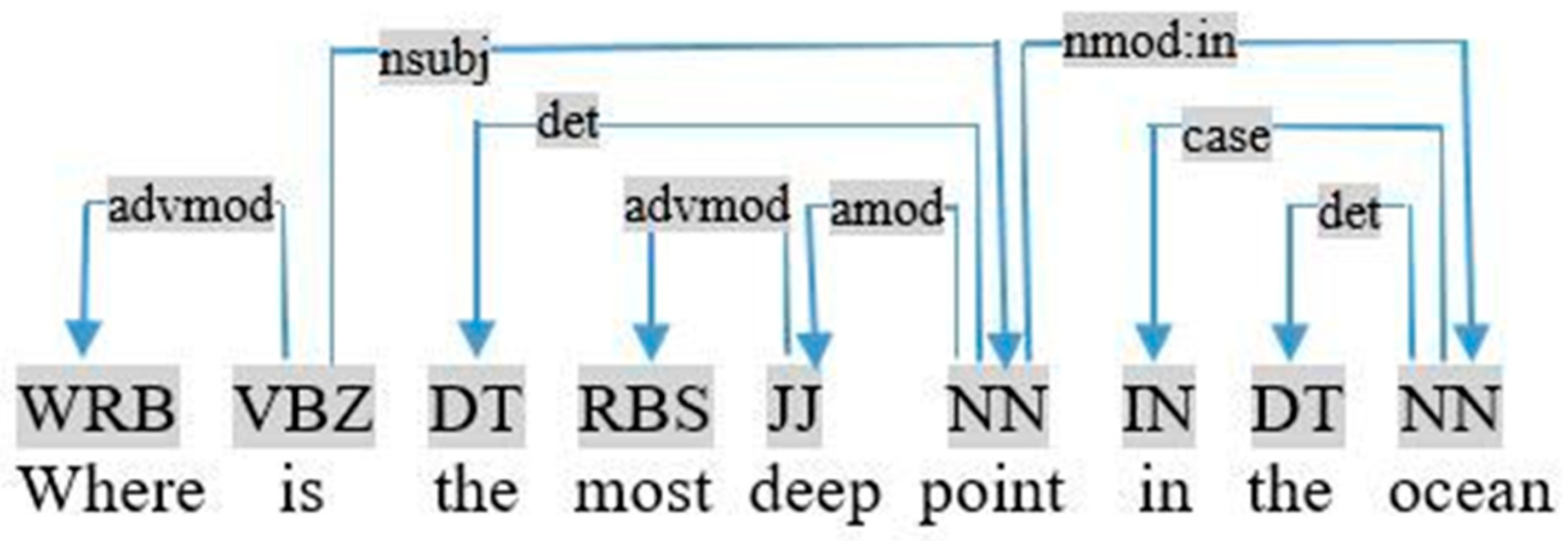
- (ii)
- most/least + adjective, such as “most deep” in the query «where is the most deep point in the ocean», as shown in Figure 16. In this case, we applied the following rule:If (advmod (Ti, most/least) ∩ Relation <Tj, unknown, Ti> ∩ Pos (Ti) = JJ) ⇒ restriction (Tj, Sup, most/least-Ti)This rule identifies the relationship between the most/least Ti superlative adjective and the noun Tj. Consider the previous query, this rule is used to generate the following restriction:advmod (deep, most) ∩ Relation <point, unknown, deep> ∩ Pos (deep) = JJ ⇒ restriction (point, Sup, most-deep)
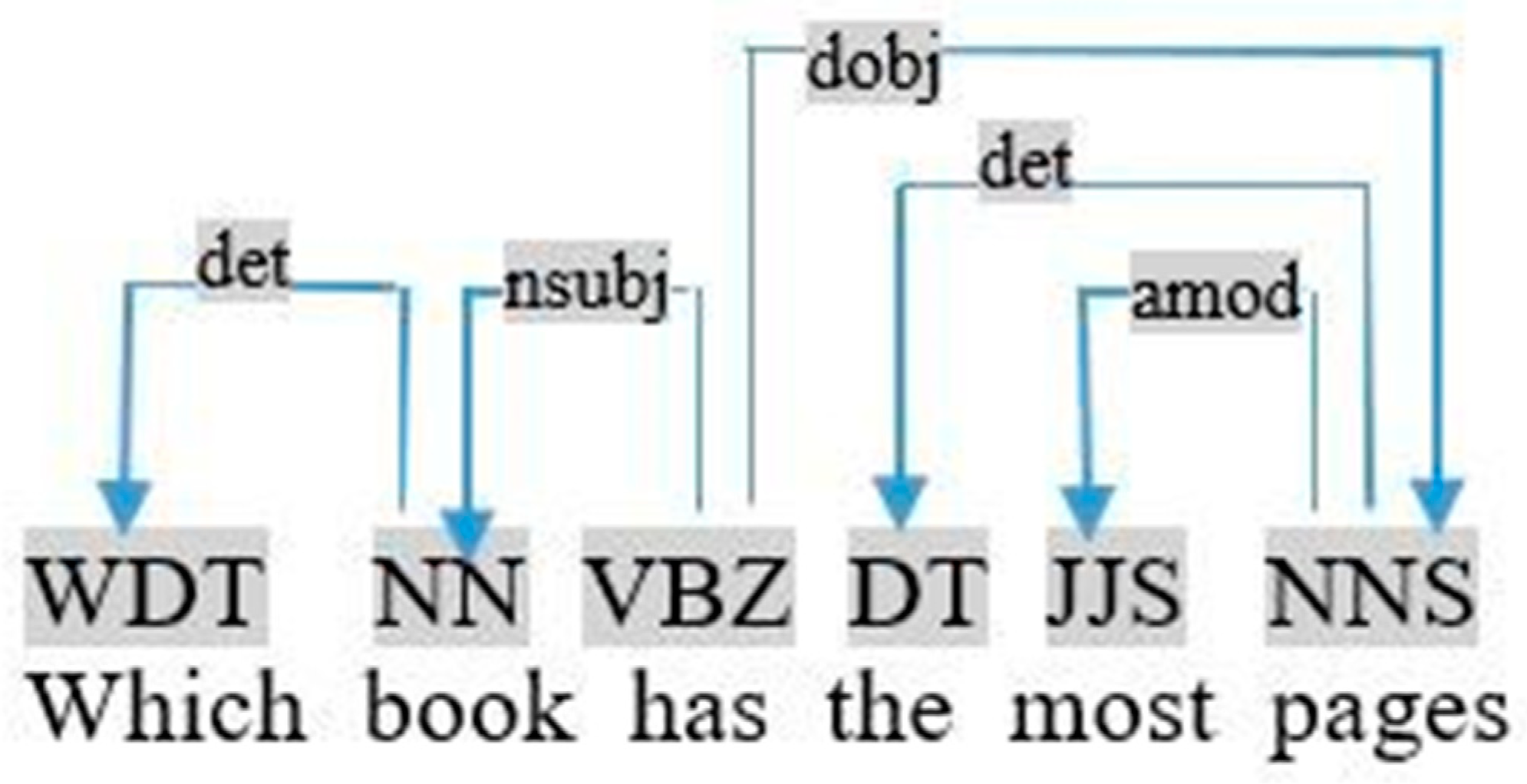
- (iii)
- Irregular adjective, such as “most” in the query «which book has the most pages», as shown in Figure 17. In this case, we applied the following rule:If (Relation <Ti, unknown, most/least> ⇒ restriction (Ti, Sup, most/least)
- (11)
- Numbers
3.2. Mapping the NL Terms to Semantic Entities
3.3. Grouping the Mapped Semantic Entities into Valid Triples
| PREFIX dbo: <http://dbpedia.org/ontology/> |
| PREFIX res: <http://dbpedia.org/resource/> |
| PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> |
| SELECT distinct ?prop where { |
| ?uri rdf:type dbo:River. |
| ?uri ?prop res:South_Carolina. |
- − If this SPARQL query has a result, we confirm that the two arguments are related, and we complete the triple with the relationship found. For example, dbo:location is the result of the previous SPARQL query. Therefore, the valid triple is: < dbo: River, dbo:location, dbr: South_Carolina>.
3.4. Generating the SPARQL Query and Extracting the Answers
| <Prefix declarations> |
| SELECT <query-objects> |
| WHERE <query-body> |
| <Query modifiers> |
| ?uri rdf:type dbo:River. |
| ?uri ?prop res:South_Carolina. |
- (1)
- Prefix declarations
| PREFIX foaf: <http://xmlns.com/foaf/0.1/> |
| PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> |
| PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#/> |
| PREFIX dbo: <http://dbpedia.org/ontology/> |
| PREFIX dbp: <http://dbpedia.org/property/> |
| PREFIX dbr: http://dbpedia.org/resource/> |
| PREFIX dbc: http://dbpedia.org/resource/Category: |
| PREFIX yago: <http://dbpedia.org/class/yago/> |
- (2)
- Query objects
- If the query object is an entity of type RDF class, we interpret it as a variable prefixed with “?”after SELECT. We also interpret it in the query body as a triple pattern <?className rdf:type ClassName> after the “WHERE” clause. For example, the following query returns all instances of the class dbo:River:
| SELECT DISTINCT ?river WHERE { |
| ?river rdf:type dbo:River.} |
- If the query object is an entity of type RDF literal, we interpret it directly as a variable prefixed with “?” after SELECT. Similarly, we interpret it in the query body as a triple pattern <?x, DataProperty, ?L> after the “WHERE” clause, as shown in the following example:
| SELECT DISTINCT ?title WHERE { |
| ?book rdf:type dbo:Book. |
| ?book rdfs:label ?title} |
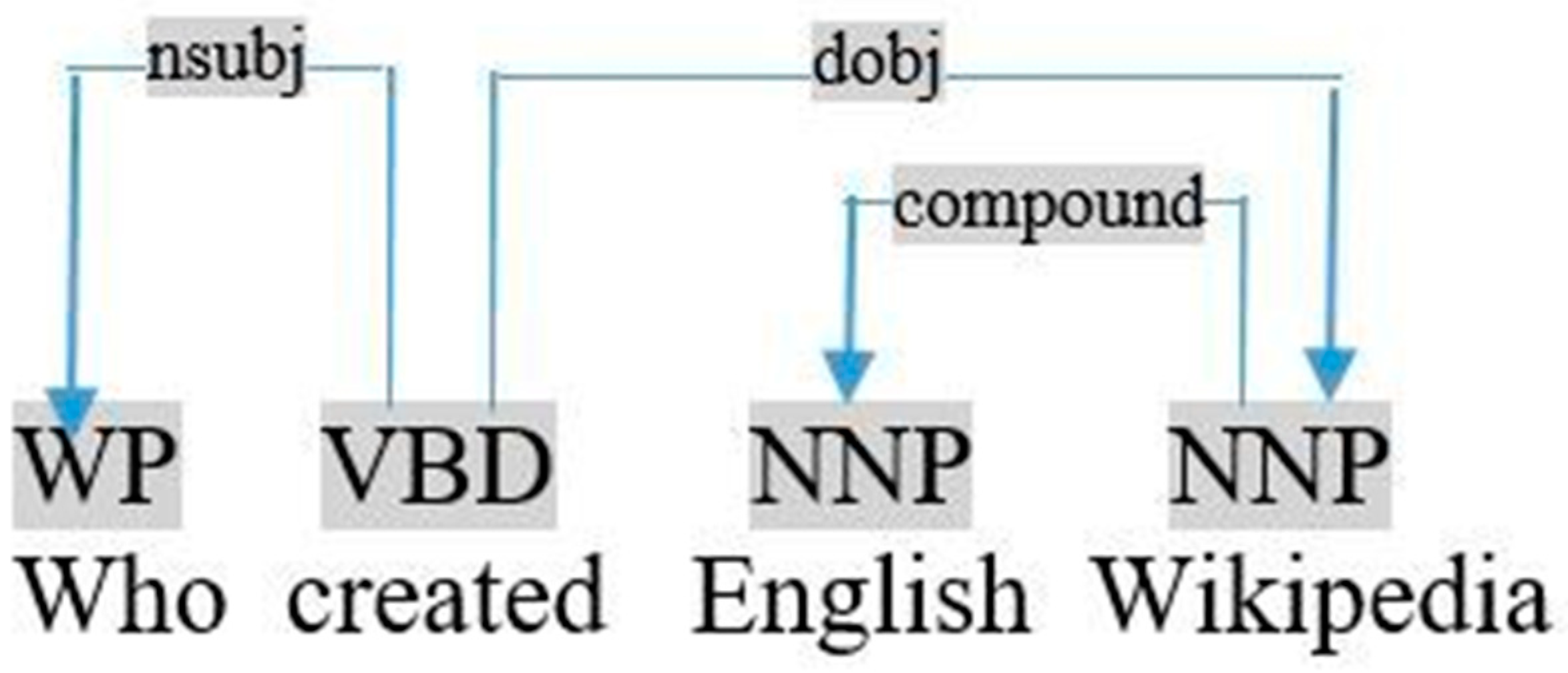
- If the query object is a variable, we interpret it as a variable “?uri” in the head and the body of the query, as shown in the following example:
| SELECT ?uri |
| WHERE { |
| dbr:Wikipedia dbo:author ?uri} |
- If the query object is a counted variable, we interpret it as the variable COUNT (?var) after SELECT, as shown in the following example:
| SELECT (COUNT(?Awards) AS ?Counter) |
| WHERE { |
| dbr:Bertrand_Russell dbp:awards ?Awards} |
- If the query object is the validation of the query in the dataset, we use ASK queries which intuitively correspond to a yes/no question in conversational language. For example, the previous query «is the wife of President Obama called Michelle» corresponds to a yes/no question, and has the following SPARQL query:
| ASK WHERE {res:Barack_Obama dbo:spouse ?spouse. ?spouse rdfs:label ?name FILTER regex (?name, \"Michelle\") |
- (3)
- Query body
- (4)
- Query modifiers
- FILTER (condition) is a clause inserted into the SPARQL query to filter the results. The condition inside the parentheses is a Boolean-type expression, and only those results where the expression returns true are used. FILTER functions can test the values of RDF literal strings. They can also restrict the numeric values and the dates by arithmetic expressions. For example, in the previous query «which daughters of British earls died at the same place they were born at», we interpret the restriction: Restriction (?var1 = ?var2) as follows:
| SELECT DISTINCT ?uri |
| WHERE {?uri rdf:type yago:WikicatDaughtersOfBritishEarls; |
| ?uri dbo:deathPlace ?var2. |
| FILTER (?var1 = ?var2)} |
- − We note that the negation is a special filter function by providing the operator “!” and the instruction “NOT EXISTS“.
| SELECT ?birth ?death ?person WHERE {?person dbo:birthPlace dbr:Berlin. |
| ?person dbo:birthDate ?birth. |
| ?person dbo:deathDate ?death. |
| FILTER NOT EXISTS {?person dbo:deathDate dbr:Berlin}} |
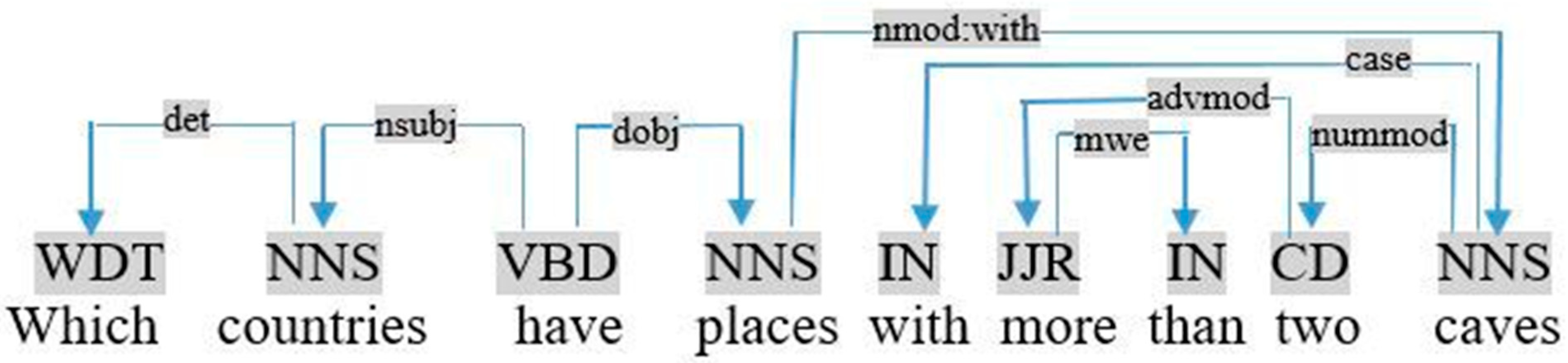
- HAVING (condition) is analogous to a FILTER expression but operates over groups rather than individual solutions. HAVING is always used with GROUP BY, a clause that groups query solutions according to one or more expressions. For example, in the query «which countries have places with more than two caves», we interpret the restriction: Restriction (count (caves), >, two) as follows:
| SELECT DISTINCT ?uri |
| WHERE {?uri rdf:type dbo:Country. |
| ?cave rdf:type dbo:Cave. |
| ?cave dbo:location ?uri. } |
| GROUP BY ?uri HAVING (COUNT(?cave) > 2) |
- The LIMIT number clause puts an upper bound on the number of solutions returned. If the number of actual solutions is greater than the limit, then at most, the limit number of solutions will be returned.
- The ORDER BY ASC/DESC clause establishes the order of a solution sequence. Each ordering comparator is either ascending, indicated by the ASC() modifier, or descending, indicated by the DESC() modifier. Generally, this clause is used to interpret the superlative adjectives as shown in the query «which book has the most pages»:
| SELECT DISTINCT ?uri |
| WHERE { ?uri rdf:type dbo:Book. |
| ?uri dbo:numberOfPages ?n.} |
| ORDER BY DESC(?n) LIMIT 1 |
4. Evaluation
- (1)
- The system fails to find the relations between the terms of some complex queries, such as «show me hiking trails in the Grand Canyon where there is no danger of flash floods». Therefore, this leads to misinterpretation of queries.
- (2)
- The system cannot find matching entities of a given term. For example, the term “grand-children” in the query «how many grand-children did Jacques Cousteau have» has no matching entities. Thus, the system must learn this kind of term in another way: uri1 child of uri2 and uri2 child of uri3.
- (3)
- Finally, the system cannot express some NL queries using the SPARQL language, such as the query «who became president after JFK died». It implies that we are limited by formal language syntax, which can produce irrelevant answers.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked Data—The Story So Far. J. Semant. Web Inf. Syst. 2009, 5, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Linked Data. Available online: http://www.w3.org/DesignIssues/LinkedData.html. (accessed on 18 June 2009).
- SPARQL Query Language for RDF. Available online: http://www.w3.org/TR/2008/REC-rdf-sparql-query-20080115/ (accessed on 26 March 2013).
- Moussa, A.M.; Abdel-Kader, R.F. QASYO: A Question Answering System for YAGO Ontology. Int. J. Database Theory Appl. 2011, 4, 99–112. [Google Scholar]
- Damljanovic, D.; Agatonovic, M.; Cunningham, H. FREyA: An Interactive Way of Querying Linked Data Using Natural Language. In Proceedings of the 1st Workshop on Question Answering over Linked Data (ESWC 2011), Heraklion, Greece, 30 May 2011. [Google Scholar] [CrossRef] [Green Version]
- Yahya, M.; Berberich, K.; Elbassuoni, S.; Ramanath, M.; Tresp, V.; Weikum, G. Natural Language Questions for the Web of Data. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP CoNLL 2012), Jeju Island, Republic of Korea, 12–14 July 2012. [Google Scholar]
- Marginean, A. GFMed: Question answering over biomedical linked data with grammatical framework. In Proceedings of the 1st International Workshop on Natural Language Interfaces for Web of Data (NLI-WoD 2014) co-located with the 13th International Semantic Web Conference (ISWC 2014), Riva del Garda, Italy, 19–23 October 2014. [Google Scholar] [CrossRef] [Green Version]
- Shizhu, H.; Yuanzhe, Z.; Liu, K.; Zhao, J. CASIA@V2: A MLN-based question answering system over linked data. In Proceedings of the Working Notes for {CLEF} 2014 Conference (CLEF 2014), Sheffield, UK, 15–18 September 2014. [Google Scholar]
- Zou, L.; Huang, R.; Wang, H.; Xu, Y.J.; He, W.; Zhao, D. Natural langauge question answering over RDF a graph data driven approach. In Proceedings of the SIGMOD ’14:International Conference on Management of Data, New York, NY, USA, 22–27 June 2014. [Google Scholar] [CrossRef]
- Xu, K.; Feng, Y.; Zhao, D. Xser@QALD-4: Answering natural language questions via phrasal semantic parsing. In Proceedings of the Working Notes for {CLEF} 2014 Conference (CLEF 2014), Sheffield, UK, 15–18 September 2014. [Google Scholar] [CrossRef]
- Diefenbach, D.; Deep Singh, K.; Maret, P. Wdaqua-core0: A question answering component for the research community. In Proceedings of the SemWebEval 2017, Portoroz, Slovenia, 28 May–1 June 2017. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Yu, J.X.; Zou, L.; Cheng, H. Question Answering Over Knowledge Graphs: Question Understanding Via Template Decomposition. Proc. VLDB Endow. 2018, 11, 1373–1386. [Google Scholar] [CrossRef] [Green Version]
- Kotnis, B.; Lawrence, C.; Niepert, M. Answering Complex Queries in Knowledge Graphs with Bidirectional Sequence Encoders. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Vancouver, BC, Canada, 2–9 February 2021. [Google Scholar] [CrossRef]
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K. Introduction to WordNet: An on-line lexical database. Int. J. Lexicogr. 1990, 3, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Kittredge, R.I. Sublanguages. In The Oxford Handbook of Computational Linguistics; Mitkov, R., Ed.; Oxford University Press, Inc.: New York, NY, USA, 2003; pp. 430–447. [Google Scholar] [CrossRef]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, R.S.; McClosky, D. The stanford corenlp natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL 2014), Stanford University, Baltimore, MD, USA, 22–27 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data in The semantic web. In Proceedings of the 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Republic of Korea, 11–15 November 2007. [Google Scholar] [CrossRef] [Green Version]
- Usbeck, R.; Gusmita, R.H.; Ngomo, A.N.; Saleem, M. 9th Challenge on Question Answering over Linked Data (QALD-9). In Proceedings of the 4th Workshop on Semantic Deep Learning (SemDeep-4) and NLIWoD4: Natural Language Interfaces for the Web of Data (NLIWOD-4) and 9th Question Answering over Linked Data Challenge (QALD-9) Co-Located with 17th International Semantic Web Conference (ISWC 2018), Monterey, CA, USA, 8–9 October 2018. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Query Terms | Matching Entities in DBpedia | Uri | Levenshtein Distance |
|---|---|---|---|
| Rivers | River | http://dbpedia.org/ontology/River | 2 |
| Lakes | Lake Place | http://dbpedia.org/resource/Lake http://dbpedia.org/ontology/Place | 2 3 |
| South-Carolina | South_Carolina | http://dbpedia.org/resource/South_Carolina | 1 |
| Queries | Average of Levenshtein Distances |
|---|---|
| <dbo (http://dbpedia.org/ontology/): River, unknown, dbr (http://dbpedia.org/resource/): South_Carolina> ∩ <dbr: Lake, unknown, dbr: South_Carolina> | 1.66 |
| <dbo: River, unknown, dbr: South_Carolina> ∩ < dbo: Place, uknown, dbr: South_Carolina> | 2 |
| Initial Relation | SPARQL Query | Result | Valid Triple |
|---|---|---|---|
| Relation <Argument1, unknown, Argument2> | Query 1: Select distinct ?prop where { ?uri rdf:type prefix: Argument1. ?uri ?prop prefix: Argument2. } | Prop | <Argument1, Prop, Argument2> |
| Relation <Argument1, relation, ?var> | Query 2: Select distinct ?Arg2 where {?uri rdf:type prefix: Argument1. ?uri prefix:relation ?Arg2. } | Arg2 | <Argument1, relation, Arg2> |
| Relation < ?var, relation, Argument2> | Query 3: Select distinct ?Arg1 where { ?uri rdf:type prefix: Argument2. ?Arg1 prefix: relation ?Argument2. } | Arg1 | <Arg1, relation, Argument2> |
| triple<Argument, relation, Argument> | Query1 Else Query2 Else Query3 | Prop Else Arg2 Else Arg1 | <Argument1, Prop, Argument2> Else <Argument1, relation, Arg2> Else < Arg1, relation, Argument2> |
| Queries | Total | Processed | Correct | Precision | Recall | F-Mesure |
|---|---|---|---|---|---|---|
| Simple | 100 | 95 | 80 | 0.84 | 0.8 | 0.82 |
| Complex | 50 | 40 | 30 | 0.75 | 0.6 | 0.66 |
| Total | 150 | 135 | 110 | 0.81 | 0.73 | 0.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boumechaal, H.; Boufaida, Z. Complex Queries for Querying Linked Data. Future Internet 2023, 15, 106. https://doi.org/10.3390/fi15030106
Boumechaal H, Boufaida Z. Complex Queries for Querying Linked Data. Future Internet. 2023; 15(3):106. https://doi.org/10.3390/fi15030106
Chicago/Turabian StyleBoumechaal, Hasna, and Zizette Boufaida. 2023. "Complex Queries for Querying Linked Data" Future Internet 15, no. 3: 106. https://doi.org/10.3390/fi15030106
APA StyleBoumechaal, H., & Boufaida, Z. (2023). Complex Queries for Querying Linked Data. Future Internet, 15(3), 106. https://doi.org/10.3390/fi15030106