

A Multiverse Graph to Help Scientific Reasoning from Web Usage: Interpretable Patterns of Assessor Shifts in GRAPHYP





Abstract
:
1. Introduction
1.1. Motivation: Turning Assistance to Scientific Reasoning into ‘Continuous Online Learning’
1.2. Modeling an ‘Assessor’s Shift’ in Assistance to Scientific Reasoning
1.3. Mapping Explainable Dialogue Search/Research with a Multiverse Graph
- –
- “indirect”: SKG GRAPHYP does not provide ‘results’, but a comprehensive representation of clickable maps of topologized results;
- –
- “intermediary”: It does not deliver any final scientific assessment, but a methodology to reach the documentary set that seems to a scientist as being best adjusted to the hypotheses that are under review, as well as those that the user expects to simulate;
- –
- “neutral”: Our typology of classification, not being referred to any assessment on the scientific content of captured documents, deals only with the information profile and content of user logs, formalized in a triplet of parameters measured from anonymized data (see [1] and Appendix A for more details): Intensity (How many readers?), Variety (How many documents?) and Attention (What degree of balance-ratio between the number of readers and number of documents?).
2. Background and Other Works
2.1. Background
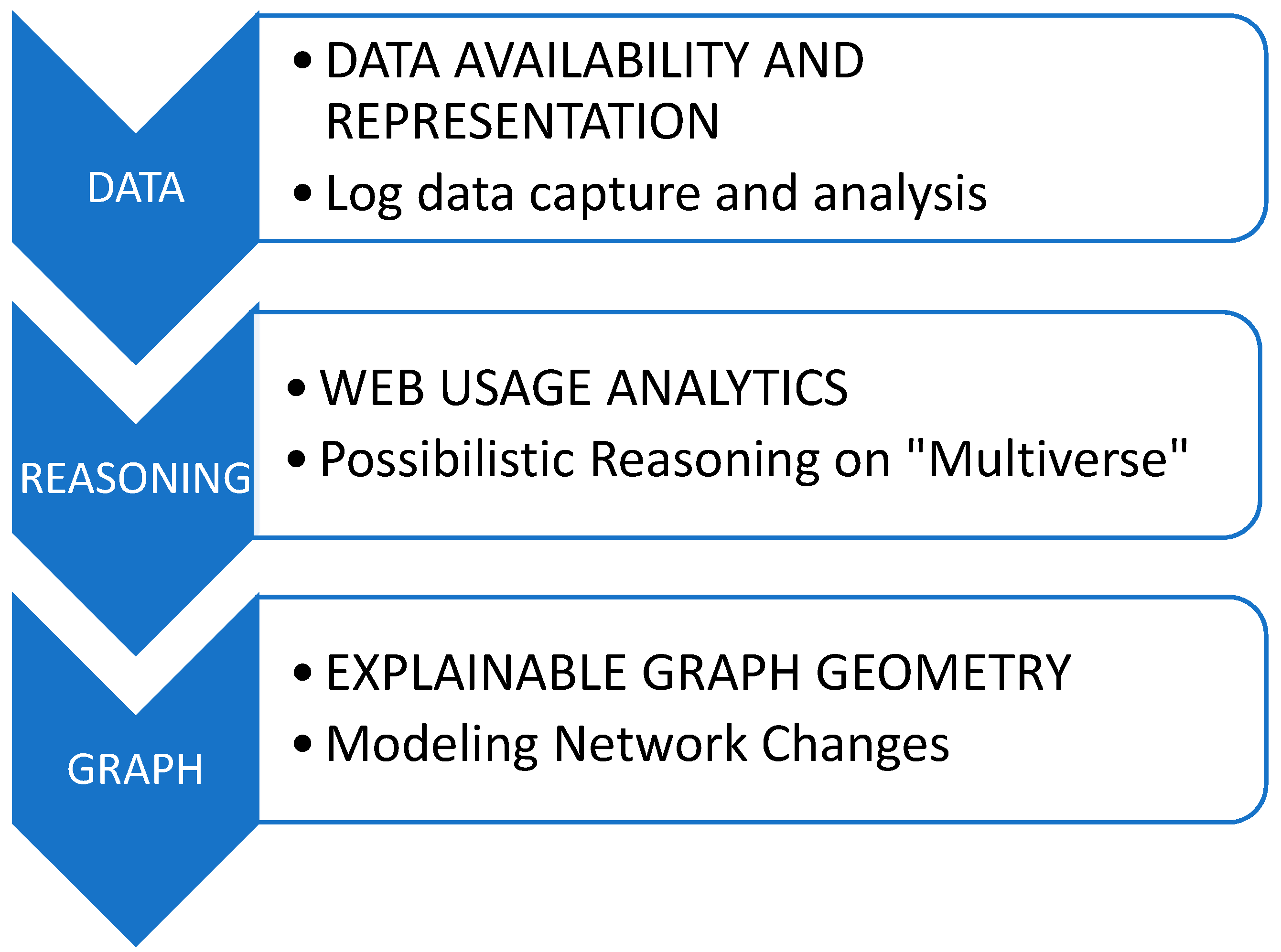
2.1.1. Data Availability and Representation
- EXTRACTION OF NEW KNOWLEDGE FROM LOGS
- DATA CAPTURE AND EXPLOITATION
- DATA REPRESENTATIONS
2.1.2. Reasoning Analytics
- Scientific reasoning and web usage analytics
- Modeling assessor shifts in a framework of possibilistic graphs
- Reasoning on assessor shifts from data logs of documentary tracks
- A multiverse graph structure of search for research

3. Results: Retrieval Modeling in Research
- GRAPHYP modeling: main steps (summarizing [1]);
- Research methods and range of applications;
- Additional retrieval strategies toward modeling web usage;
- Search exploration and pattern discovery;
- Qualitative vs. quantitative features of measured assessor shifts;
- New explainable patterns for the search profile.
3.1. GRAPHYP Modeling: Main Steps

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
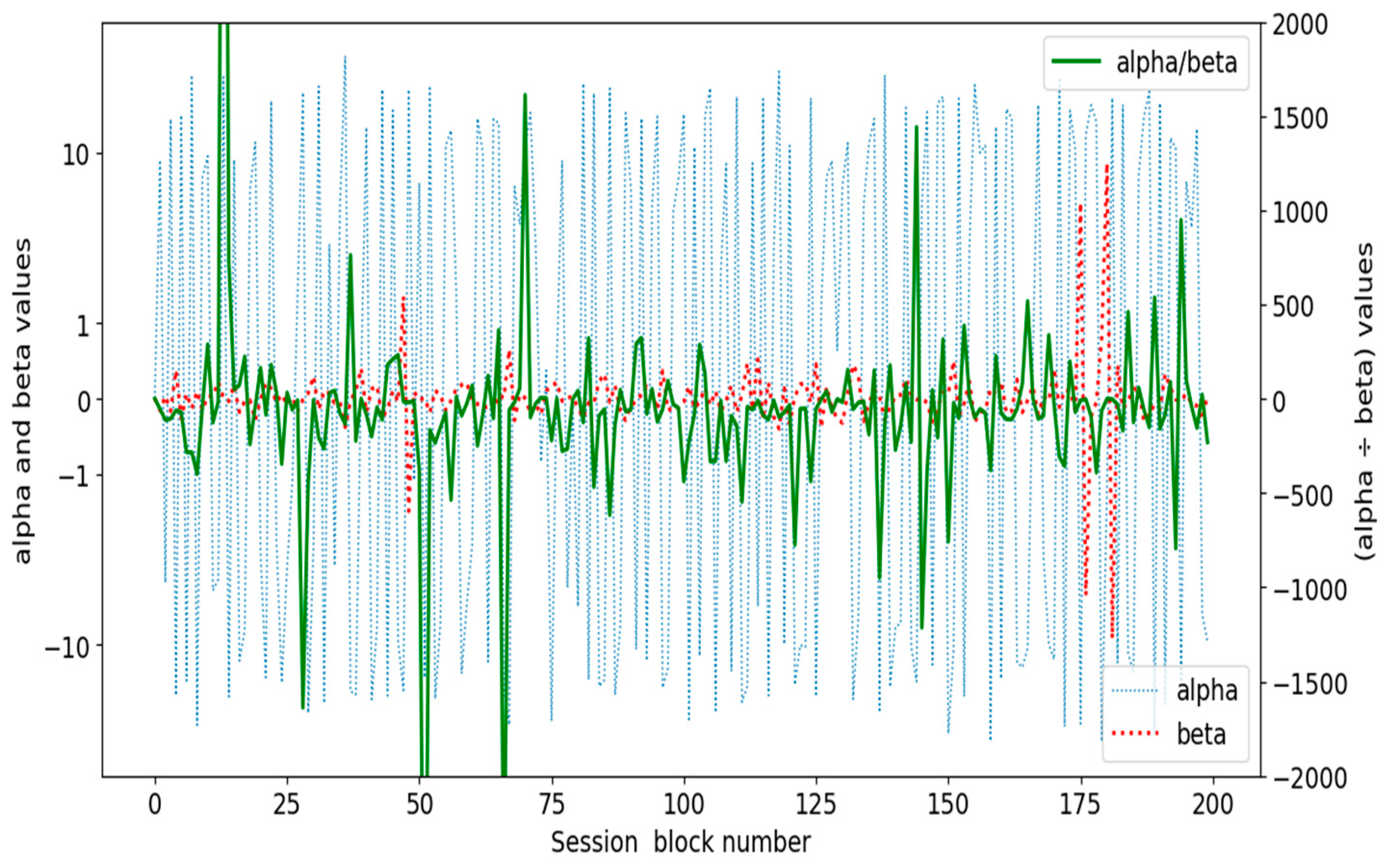
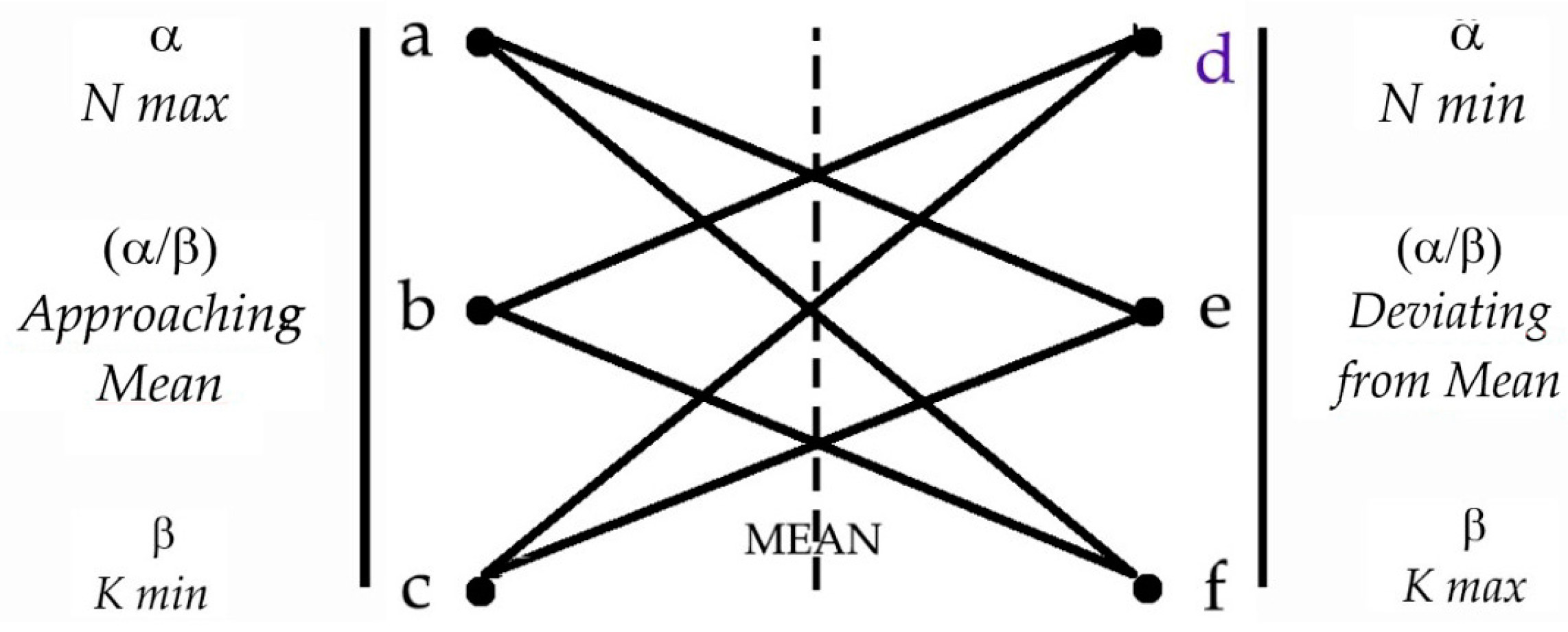
| A. Definition of documentary tracks: We note N, the number of users in a session log, and K, the number of documents read; we note α/β, the ratio of their average values over a series of different sessions. α/β is an “expression of stability/disruption of behaviors” 1. It expresses the degree of attention emerging in cliques of the cognitive community’s documentary practice and makes it possible to measure the ‘stability’ or ‘disruption’ of the behaviors of users over the considered search sessions. Therefore, the ‘attention’ parameter contributes to measured changes in the dynamic of the search of documents met on documentary tracks. B. Web usage classification of documentary tracks: Documentary tracks are being defined and measured with min and max values, and web usage logs find their explainable integration in the proposed modeling. This implies the classification of all non-contradictory solutions of the triplet parameters (N or K must be min or max and cannot be logically combined) with reference to their mean values measured for the whole sample (see Figure 1 in [1]). C. User’s documentary track positioning: According to A and B, users of GRAPHYP can localize identifiable types of classified documentary tracks on a research question and, with the help of the modeling, they can localize the interpreted selection of documents that the laboratory has realized, compared to other typologized practices on the same research question. |

3.2. Research Methods and Range of Applications
- position their own assessor shifts on the same research question;
- appreciate the conditions under which a given documentary track is selected (for example, many users, few items and an unbalanced ratio of users to items, relative to the sample mean).
3.3. Application Scope: Additional Retrieval Strategies toward Modeling Web Usage
- Items
- –
- First level: search optimization (search off the beaten track, search with a better method, search with better vocabulary…);
- –
- Second level: graph completion of documentation (Is a theory fully documented? In what unknown direction can new knowledge be expanded, and what are the best pathways?);
- –
- Third level: adversarial search experiences and adversarial theories (What are the items of correspondence between documents and eligible theories? Are there overlapping boundaries between a documentary track and an eligible theory?).
- Corpuses
3.4. Assessor Shift Modeling: A Grid for Usability Test Logs
- Usability test logs of documentary tracks
- Usability test log analysis grids
- help identify the optimal “route of preferences” of a user, according to relevant identified proximities of edges and nodes in a given documentary track;
- record any observed path of users that, during their past search sessions, have used a recorded method in their successive document assessments.
- –
- characterize their position from available data, around one of the six typical nodes of GRAPHYP;
- –
- assess, depending on the triplet values of the summit corresponding to their documentary track, which elements that this situation creates differences with other choices that could be preferable.
- –
- assess the steps by which a move can be executed from the current position, to any preferred one;
- –
- measure the distance between different positions and calculate the “length of the route” separating two possible courses.
3.5. Comparison of Assessor Shifts
3.5.1. A Tool for Qualitative Comparisons of Assessor Shifts
- –
- –
- Users’ exploration of ontologies on the web: In the already mentioned study of NCBO BioPortal usage logs [13], the authors remarked that “very little is known about how exactly users search and explore ontologies” and “what kind of usage patterns or user group exist in the first place”. They concluded that deeper insight into user support are requested, and they proposed browsing behavior types (see Section 2).
3.5.2. Additional Tests on the Added Value of the “Attention” Parameter
3.5.3. Visualization of User Selections of URLs Consulted during the Search
3.6. Possible New Patterns for Search Profile Retrieval
- A new conceptual venue of “modeling retrievability” (opportunities, behaviors)
- Real world practices and elaboration of patterns
- Routes of knowledge and rules of linkage
- Search patterns and the canonicalization of datasets
4. Discussion
5. Conclusions
6. Further Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Design of SKG GRAPHYP (Already Published in Paper GR1 [1])
- ○
- It allows each clique in its community to be positioned in the searchable space, according to the characteristics of its search history;
- ○
- It assists a clique inside a community in navigating on the graph, to reach the position of neighboring cliques in the same community, linked by the same characteristics of search goals (‘search goals’, as a generic term, encompasses similar queries, keywords or groups of URLs).
- ○
- Recording dynamics of search sessions: A third node measuring the value of a parameter of attention
- ○
- Networking search sessions and the detection of cliques in cognitive communities in the SKG

References
- Fabre, R.; Azeroual, O.; Bellot, P.; Schöpfel, J.; Egret, D. Retrieving Adversarial Cliques in Cognitive Communities: A New Conceptual Framework for Scientific Knowledge Graphs. Future Internet 2022, 14, 262. [Google Scholar] [CrossRef]
- Davis, E. Benchmarks for Automated Commonsense Reasoning: A Survey. arXiv 2023, arXiv:2302.04752. [Google Scholar]
- Cheng, X.; Lin, X.; Shen, X.-L.; Zarifis, A.; Mou, J. The dark sides of AI. Electron. Mark. 2022, 32, 11–15. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.-W.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef] [PubMed]
- Auer, S.; Oelen, A.; Haris, M.; Stocker, M.; D’Souza, J.; Farfar, K.E.; Vogt, L.; Prinz, M.; Wiens, V.; Jaradeh, M.Y. Improving Access to Scientific Literature with Knowledge Graphs. Bibl. Forsch. Und Prax. 2020, 44, 516–529. [Google Scholar] [CrossRef]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open Research Knowledge Graph: Next Generation Infrastructure for Semantic Scholarly Knowledge. In Proceedings of the 10th International Conference on Knowledge Capture (K-CAP’19), Del Rey, CA, USA, 19–21 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 243–246. [Google Scholar] [CrossRef]
- Fabre, R. A searchable space with routes for querying scientific information. In Proceedings of the 8th International Workshop on Bibliometric-Enhanced Information Retrieval (BIR 2019), Cologne, Germany, 14 April 2019; pp. 112–124. Available online: http://ceur-ws.org/Vol-2345/paper10.pdf (accessed on 2 August 2022).
- Sanderson, M.; Scholer, F.; Turpin, A. Relatively Relevant: Assessor Shift in Document Judgements. Australasian Document Computing Symposium. 10 December 2010. Available online: http://www.cs.rmit.edu.au/adcs2010/proceedings/pdf/paper%2015.pdf (accessed on 11 February 2023).
- Schweinsberg, M.; Feldman, M.; Staub, N.; Akker, O.R.V.D.; van Aert, R.C.; van Assen, M.A.; Liu, Y.; Althoff, T.; Heer, J.; Kale, A.; et al. Same data, different conclusions: Radical dispersion in empirical results when independent analysts operationalize and test the same hypothesis. Organ. Behav. Hum. Decis. Process. 2021, 165, 228–249. [Google Scholar] [CrossRef]
- Zhang, J.; Jie, L.; Rahman, A.; Xie, S.; Chang, Y.; Yu, P.S. Learning Entity Types from Query Logs via Graph-Based Modeling. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (CIKM’15), Melbourne, Australia, 19–23 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 603–612. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Lamers, W.S.; Boyack, K.; Larivière, V.; Sugimoto, C.R.; van Eck, N.J.; Waltman, L.; Murray, D. Meta-Research: Investigating disagreement in the scientific literature. eLife 2021, 10, e72737. [Google Scholar] [CrossRef]
- Walk, S.; Esín-Noboa, E.; Helic, D.; Strohmaier, M.; Musen, M.A. How Users Explore Ontologies on the Web: A Study of NCBO’s BioPortal Usage Logs. In Proceedings of the 26th International Conference on World Wide Web (WWW’17), Geneva, Switzerland, 3–7 April 2017; pp. 775–784. [Google Scholar] [CrossRef]
- Yuan, H.; Yu, H.; Gui, S.; Ji, S. Explainability in Graph Neural Networks: A Taxonomic Survey. IEEE transactions on pattern analysis and machine intelligence. arXiv 2020, arXiv:2012.15445. [Google Scholar]
- Velickovic, P. Message Passing All the Way Up. ICLR 2022 Workshop on Geometrical and Topological Representation Learning. March 2022. Available online: https://openreview.net/forum?id=Bc8GiEZkTe5 (accessed on 11 February 2023).
- Kairouz, P.; Liao, J.; Huang, C.; Vyas, M.; Welfert, M.; Sankar, L. Generating Fair Universal Representations Using Adversarial Models. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1970–1985. [Google Scholar] [CrossRef]
- Borgelt, C.; Gebhardt, J.; Kruse, R. Possibilistic Graphical Models. In Computational Intelligence in Data Mining; International Centre for Mechanical Sciences; Della Riccia, G., Kruse, R., Lenz, H.J., Eds.; Springer: Vienna, Austria, 2000; Volume 408, pp. 51–67. [Google Scholar] [CrossRef] [Green Version]
- Causal Inference Interest Group at the Alan Turing Institute. Available online: https://www.turing.ac.uk/research/interest-groups/causal-inference (accessed on 10 March 2023).
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Afzal, Z.; Tsatsaronis, G.; Doornenbal, M.; Coupet, P.; Gregory, M. Learning Domain Labels Using Conceptual Fingerprints: An In-Use Case Study in the Neurology Domain. In Proceedings of the 20th International Conference on Knowledge Engineering and Knowledge Management—Volume 10024 (EKAW 2016), Bologna, Italy, 19–23 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 731–745. [Google Scholar] [CrossRef]
- Faghri, F.; Nalls, M.A. Uncovering the complexities of biological structures with network-based learning: An application in SARS-CoV-2. Patterns 2021, 2, 100259. [Google Scholar] [CrossRef] [PubMed]
- Herbster, M.; Pasteris, S.; Vitale, F.; Pontil, M. A Gang of Adversarial Bandits. In Advances in Neural Information Processing Systems; Beygelzimer, A., Dauphin, Y., Vaughan, J.W., Eds.; Openreview: Camarillo, CA, USA, 2021; Available online: https://openreview.net/forum?id=S9NmGEMkn29 (accessed on 12 February 2023).
- Croft, W.B. The Importance of Interaction for Information Retrieval. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’19), Paris, France, 21–25 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Ghosh, S.; Rath, M.; Shah, C. Searching as Learning: Exploring Search Behavior and Learning Outcomes in Learning-related Tasks. In Proceedings of the 2018 Conference on Human Information Interaction & Retrieval (CHIIR’18), New Brunswick, NJ, USA, 11–15 March 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 22–31. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, N.; Hu, X.B.; Jin, F. Tutorial on Deep Learning Interpretation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM’22), Atlanta, GA, USA, 17–21 October 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 5156–5159. [Google Scholar] [CrossRef]
- Cooper, M.D. Usage patterns of a web-based library catalog. JASIST 2001, 52, 137–148. [Google Scholar] [CrossRef]
- Vellino, A. Usage-based vs. Citation-based Methods for Recommending Scholarly Research Articles. arXiv 2013, arXiv:1303.7149. [Google Scholar]
- Carlesi, C. Semantic Query Analysis from the Global Science Gateway. DANS 2018. [Google Scholar] [CrossRef]
- Lim, S.; Sim, H.; Gunasekaran, R.; Vazhkudai, S.S. Scientific User Behavior and Data-Sharing Trends in A Petascale File System. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’17), Denver, CO, USA, 12–17 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Samanta, D.; Dutta, S.; Galety, M.G.; Pramanik, S. A Novel Approach for Web Mining Taxonomy for High-Performance Computing. In Cyber Intelligence and Information Retrieval; Lecture Notes in Networks and Systems; Tavares, J.M.R.S., Dutta, P., Dutta, S., Samanta, D., Eds.; Springer: Singapore, 2022; Volume 291. [Google Scholar] [CrossRef]
- Silvestri, F. Mining Query Logs: Turning Search Usage Data into Knowledge; Now Foundations and Trends: Hanover, MA, USA, 2009; 176p. [Google Scholar]
- Gregory, K. A dataset describing data discovery and reuse practices in research. Sci. Data 2020, 7, 232. [Google Scholar] [CrossRef] [PubMed]
- Grace, L.K.J.; Maheswari, V.; Nagamalai, D. Web log data analysis and mining. In Communications in Computer and Information Science; Advanced Computing. CCSIT, 2011, Meghanathan, N., Kaushik, B., Nagamalai, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 133, pp. 459–469. [Google Scholar] [CrossRef]
- Zhang, T.; Qiu, H.; Castellano, G.; Rifai, M.; Chen, C.S.; Pianese, F. System Log Parsing: A Survey. arXiv 2022, arXiv:2212.14277. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Velickovic, P. Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Reilly, F.E. Charles Peirce’s Theory of Scientific Method; Fordham University Press: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Jaradeh, M.Y.; Singh, K.; Stocker, M.; Both, A.; Auer, S. Information extraction pipelines for knowledge graphs. Knowl. Inf. Syst. 2023, 65, 1989–2016. [Google Scholar] [CrossRef]
- Sugimoto, C.R. Theories of Informetrics and Scholarly Communication; De Gruyter Saur: Berlin/Heidelberg, Germany; Boston, MA, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Dellsen, F.; Baghramian, M. Disagreement in science: Introduction to the special issue. Synthese 2021, 198 (Suppl. S25), 6011–6021. [Google Scholar] [CrossRef]
- Velickovic, P.; Blundell, C. Neural algorithmic reasoning. Patterns 2021, 2, 100273. [Google Scholar] [CrossRef]
- Bounhas, M.; Mellouli, K.; Prade, H.; Serrurier, M. Possibilistic classifiers for numerical data. Soft Comput. 2013, 17, 733–751. [Google Scholar] [CrossRef] [Green Version]
- Restivo, A.; Brunner, N.; Rosset, D. Possibilistic Approach to Network Nonlocality. arXiv 2022, arXiv:2208.13526. [Google Scholar]
- Hernandez, P.; Garrigos, I.; Mazon, J.-N. Modeling Web Logs to Enhance the Analysis of Web Usage Data. In Proceedings of the Workshops on Database and Expert Systems Applications, Bilbao, Spain, 30 August–3 September 2010; pp. 297–301. [Google Scholar] [CrossRef]
- Castillo, C.; Davison, B.D. Adversarial Web Search. Now Found. Trends 2011. Available online: https://ieeexplore.ieee.org/document/8187234 (accessed on 15 February 2023).
- Zhang, Z.; Johnson, C.; Venkatasubramanian, N.; Ren, S. Process scenario discovery from event logs based on activity and timing information. J. Syst. Archit. 2022, 125, 102435. [Google Scholar] [CrossRef]
- Derrida, J. Introduction. In Edmund Husserl, L’Origine de La Géométrie; coll. Épiméthée; Traduction et Introduction par Jacques Derrida; PUF: Paris, France, 1962; pp. 3–17. Available online: https://www.puf.com/content/Lorigine_de_la_g%C3%A9om%C3%A9trie (accessed on 12 February 2023).
- Tian, L.; Zhou, X.; Wu, Y.; Zhou, W.; Zhang, J.; Zhang, T. Knowledge graph and knowledge reasoning: A systematic review. J. Electron. Sci. Technol. 2022, 20, 100159. [Google Scholar] [CrossRef]
- Szabo, G.; Fath, G. Evolutionary games on graphs. Phys. Rep. 2007, 446, 97–216. [Google Scholar] [CrossRef] [Green Version]
- Zenil, H.; Kiani, N.A.; Marabita, F.; Deng, Y.; Elias, S.; Schmidt, A.; Ball, G.; Tegnér, J. An Algorithmic Information Calculus for Causal Discovery and Reprogramming Systems. iScience 2019, 19, 1160–1172. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Knyazeva, E.N. The idea of the multiverse: An interdisciplinary perspective. Philos. Sci. Technol. 2022, 27, 2. [Google Scholar] [CrossRef]
- Wilkinson, T. Fine-Tuning the Multiverse. Think 2013, 12, 89–101. [Google Scholar] [CrossRef]
- Bell, S.J.; Kampman, O.P.; Dodge, J.; Lawrence, N.D. Modeling the Machine Learning Multiverse. arXiv 2022. preprint. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Ivanova, I. The measurement of “interdisciplinarity” and “synergy” in scientific and extra-scientific collaborations. JASIST 2021, 72, 387–402. [Google Scholar] [CrossRef]
- Dafflon, J.; Da Costa, P.F.; Váša, F.; Monti, R.P.; Bzdok, D.; Hellyer, P.J.; Turkheimer, F.; Smallwood, J.; Jones, E.; Leech, R. A guided multiverse study of neuroimaging analyses. Nat. Commun. 2022, 13, 3758. [Google Scholar] [CrossRef] [PubMed]
- Ivanova, I. New Frontiers in the Theory of Meaning in Inter-Human Communications. Technol. Forecast. Soc. Chang. 2021, 167, 120672. [Google Scholar] [CrossRef]
- Maly, I.; Slavik, P. Towards Visual Analysis of Usability Test Logs Using Task Models. In Task Models and Diagrams for Users Interface Design; Lecture Notes in Computer Science TAMODIA 2006; Coninx, K., Luyten, K., Schneider, K.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4385, pp. 24–38. [Google Scholar] [CrossRef]
- Lin, Y.; Evans, J.A.; Wu, L. New directions in science emerge from disconnection and discord. J. Informetr. 2022, 16, 101234. [Google Scholar] [CrossRef]
- Sajeeda, A.; Hossain, B.M. Exploring generative adversarial networks and adversarial training. Int. J. Cogn. Comput. Eng. 2022, 3, 78–89. [Google Scholar] [CrossRef]
- Vivek, R.; Mirje, P.; Sushmitha, N. Recommendations for web service composition by mining usage logs. arXiv 2016, arXiv:1604.03212. [Google Scholar]
- Menezes, T.; Nonnecke, B. UX-Log: Understanding Website Usability through Recreating Users’ Experiences in Logfiles. Int. J. Virtual Worlds Hum. Comput. Interact. 2014, 2368, 6103. [Google Scholar] [CrossRef] [Green Version]
- Hoxha, J.; Junghans, M.; Agarwal, S. Enabling Semantic Analysis of User Browsing Patterns in the Web of Data. In Proceedings of the IEEE International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Lyon, France, 17 April 2012; Volume 1, pp. 488–495. [Google Scholar]
- Fujita, S.; Dupret, G.; Baeza-Yates, R. Learning to Rank Query Recommendations by Semantic Similarities. arXiv 2012, arXiv:1204.2712. [Google Scholar]
- Fortuna, B.; Mladenic, D.; Grobelnik, M. User Modeling Combining Access Logs, Page Content and Semantics. arXiv 2011, arXiv:1103.5002. [Google Scholar]
- How Researchers Search and Access New Data for Research. Available online: https://darchive.mblwhoilibrary.org/handle/1912/26285 (accessed on 10 March 2023).
- Mapping research output to the Sustainable Development Goals. Available online: https://zenodo.org/record/3832090#.YzQvx3ZBxGM (accessed on 10 March 2023).
- Bramer, W.M.; Rethlefsen, M.L.; Kleijnen, J.; Franco, O.H.; Bramer, W.M.; Rethlefsen, M.L.; Kleijnen, J.; Franco, O.H. Optimal database combinations for literature searches in systematic reviews: A prospective exploratory study. Syst. Rev. 2017, 6, 245. [Google Scholar] [CrossRef]
- Kirrane, S.; Sabou, M.; Fernández, J.D.; Osborne, F.; Robin, C.; Buitelaar, P.; Motta, E.; Polleres, A. A decade of Semantic Web research through the lenses of a mixed methods approach. Semantic Web 2020, 11, 979–1005. [Google Scholar] [CrossRef]
- Nuti, S.V.; Wayda, B.; Ranasinghe, I.; Wang, S.; Dreyer, R.P.; Chen, S.I.; Murugiah, K. The Use of Google Trends in Health Care Research: A Systematic Review. PLoS ONE 2014, 9, e109583. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breja, M.; Jain, S.K. A Survey on Non-Factoid Question Answering Systems; Taylor & Francis: Abingdon, UK, 2021; Available online: https://tandf.figshare.com/articles/dataset/A_survey_on_nonfactoid_question_answering_systems/14963799/1 (accessed on 11 March 2023).
- Lefebvre, M.; Renard, J. The Circulation of Scientific Articles in the Sphere of Web-Based Media: Citation Practices, Communities of Interests and Local Ties. PLoS ONE 2016, 11, e0158393. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cabanac, G. Questioning Scientific Texts, Doctoral Thesis, Université de Toulouse. 2016. Available online: https://tel.archives-ouvertes.fr/tel-01413878/en (accessed on 30 March 2023).
- Fabre, F.; Schöpfel, J. L’hypertexte et les sciences (1991–2021): Des voies navigables pour les routes de connaissances. Hist. Rech. Contemp. 2021, 10. [Google Scholar] [CrossRef]
- Yu, C.; Wang, F.; Liu, Y.; An, L. Research on knowledge graph alignment model based on deep learning. Expert Syst. Appl. 2021, 186, 115768. [Google Scholar] [CrossRef]
- Yuan, H.; Yu, H.; Wang, J.; Li, K.; Ji, S. On Explainability of Graph Neural Networks via Subgraph Explorations. In International Conference on Machine Learning; PMLR: London, UK, 2021; Volume 139, pp. 12241–12252. Available online: http://proceedings.mlr.press/v139/yuan21c/yuan21c.pdf (accessed on 30 March 2023).





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fabre, R.; Azeroual, O.; Schöpfel, J.; Bellot, P.; Egret, D. A Multiverse Graph to Help Scientific Reasoning from Web Usage: Interpretable Patterns of Assessor Shifts in GRAPHYP. Future Internet 2023, 15, 147. https://doi.org/10.3390/fi15040147
Fabre R, Azeroual O, Schöpfel J, Bellot P, Egret D. A Multiverse Graph to Help Scientific Reasoning from Web Usage: Interpretable Patterns of Assessor Shifts in GRAPHYP. Future Internet. 2023; 15(4):147. https://doi.org/10.3390/fi15040147
Chicago/Turabian StyleFabre, Renaud, Otmane Azeroual, Joachim Schöpfel, Patrice Bellot, and Daniel Egret. 2023. "A Multiverse Graph to Help Scientific Reasoning from Web Usage: Interpretable Patterns of Assessor Shifts in GRAPHYP" Future Internet 15, no. 4: 147. https://doi.org/10.3390/fi15040147
APA StyleFabre, R., Azeroual, O., Schöpfel, J., Bellot, P., & Egret, D. (2023). A Multiverse Graph to Help Scientific Reasoning from Web Usage: Interpretable Patterns of Assessor Shifts in GRAPHYP. Future Internet, 15(4), 147. https://doi.org/10.3390/fi15040147