Estimation Methods for Soil Mercury Content Using Hyperspectral Remote Sensing


 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
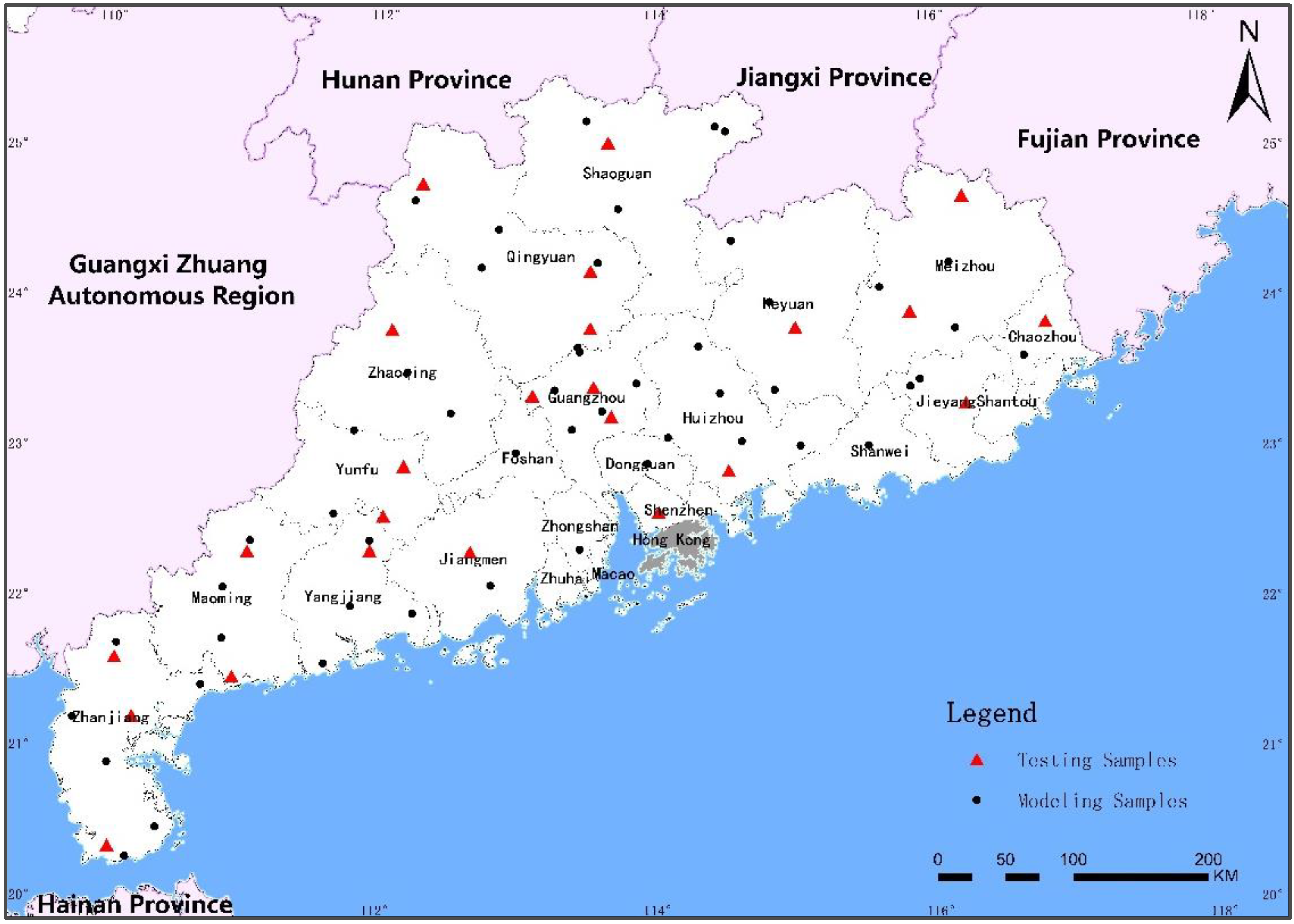
2.1. Study Area
2.2. Acquisition and Processing of Soil Data
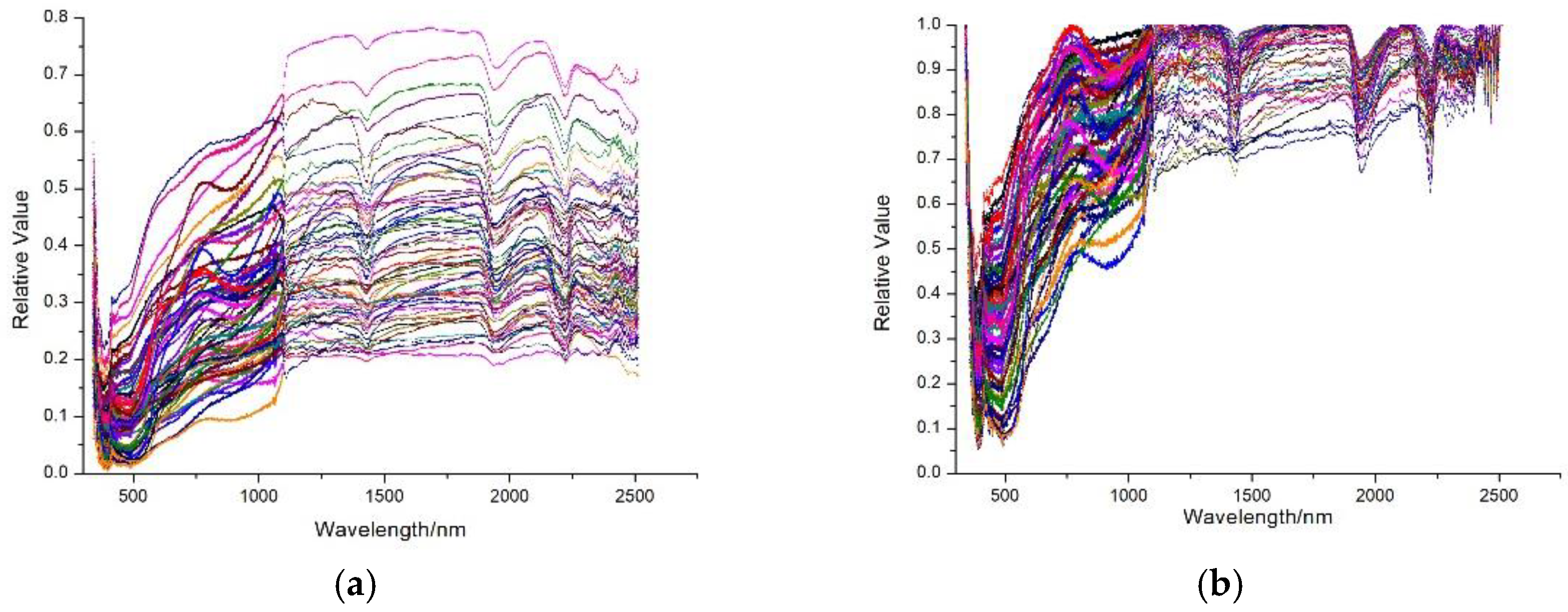
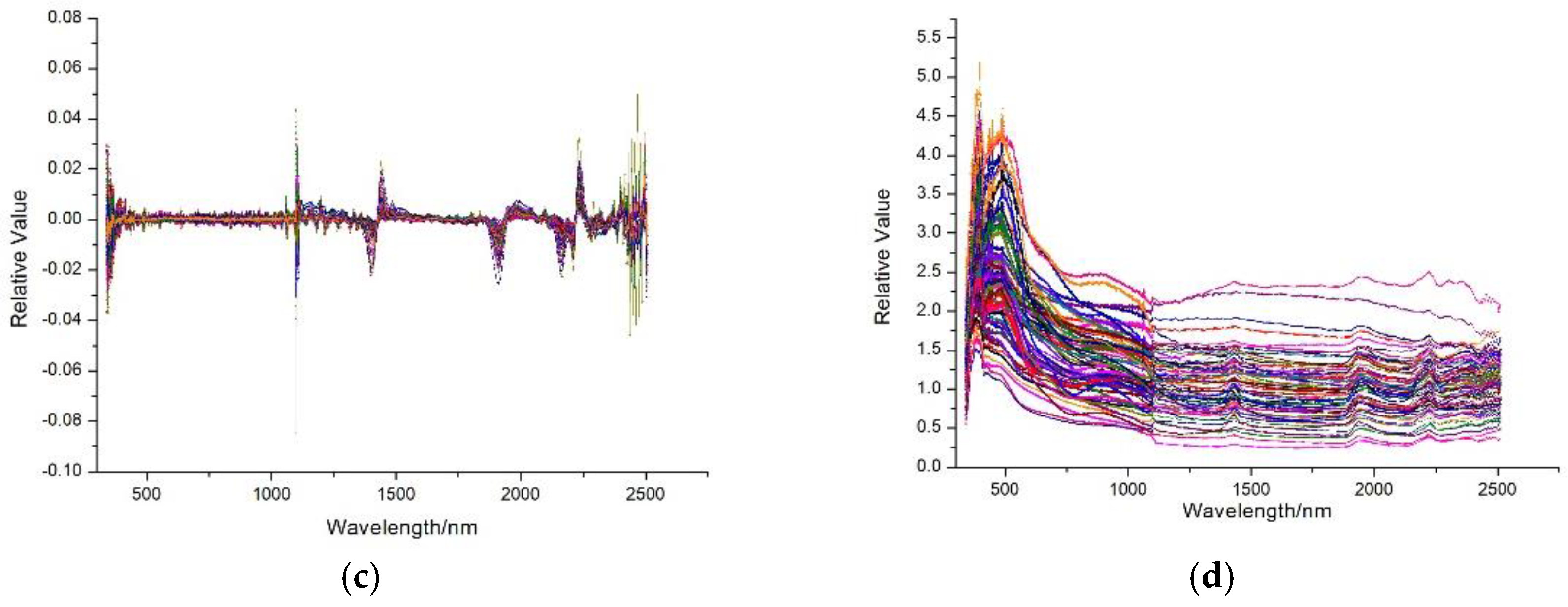
2.3. Collection and Processing of Soil Spectral Data
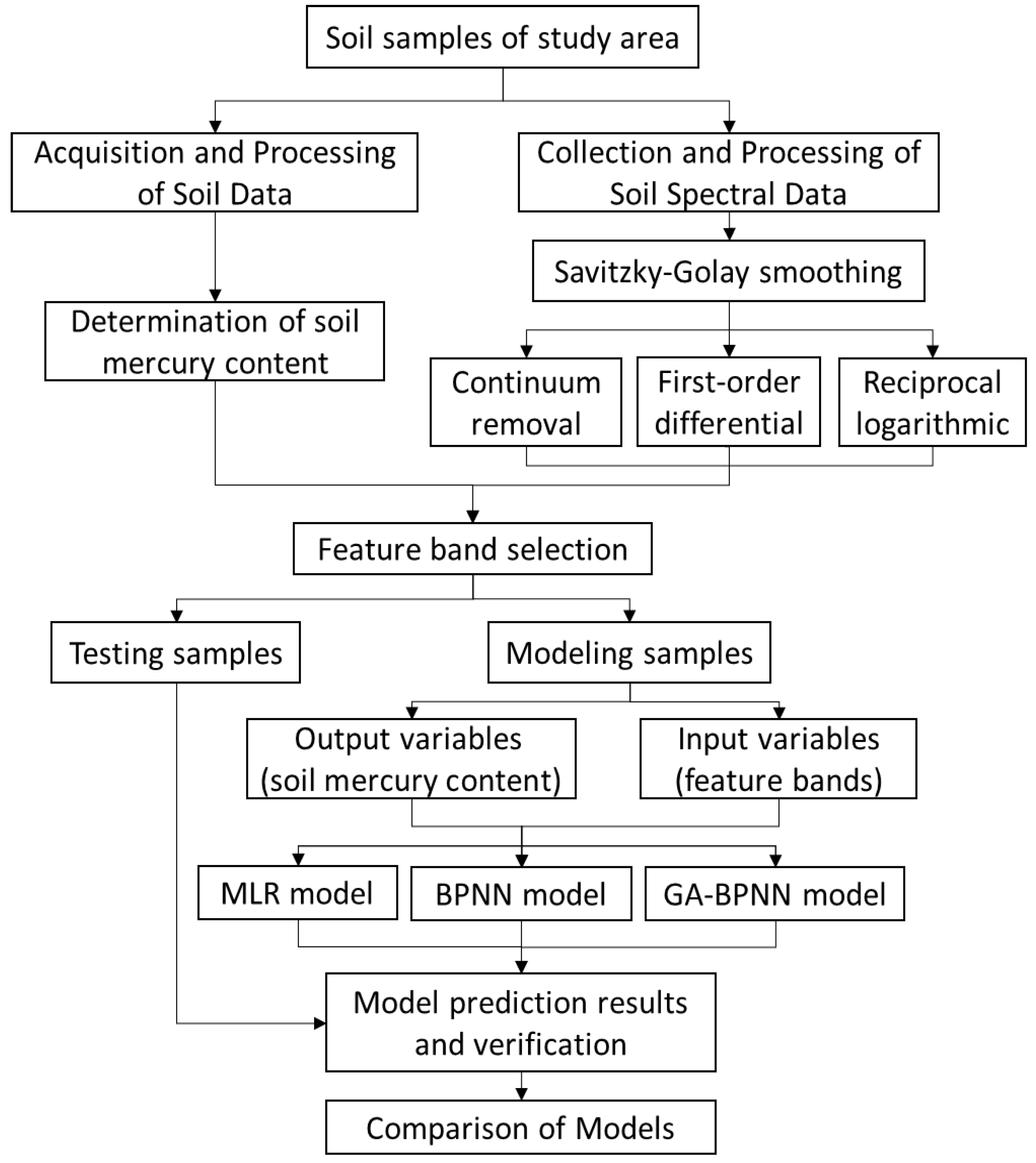
2.4. Modeling Method
2.4.1. Feature Band Selection
2.4.2. MLR Method for Determination of the Soil Mercury Content
2.4.3. BPNN Method for Determination of the Soil Mercury Content
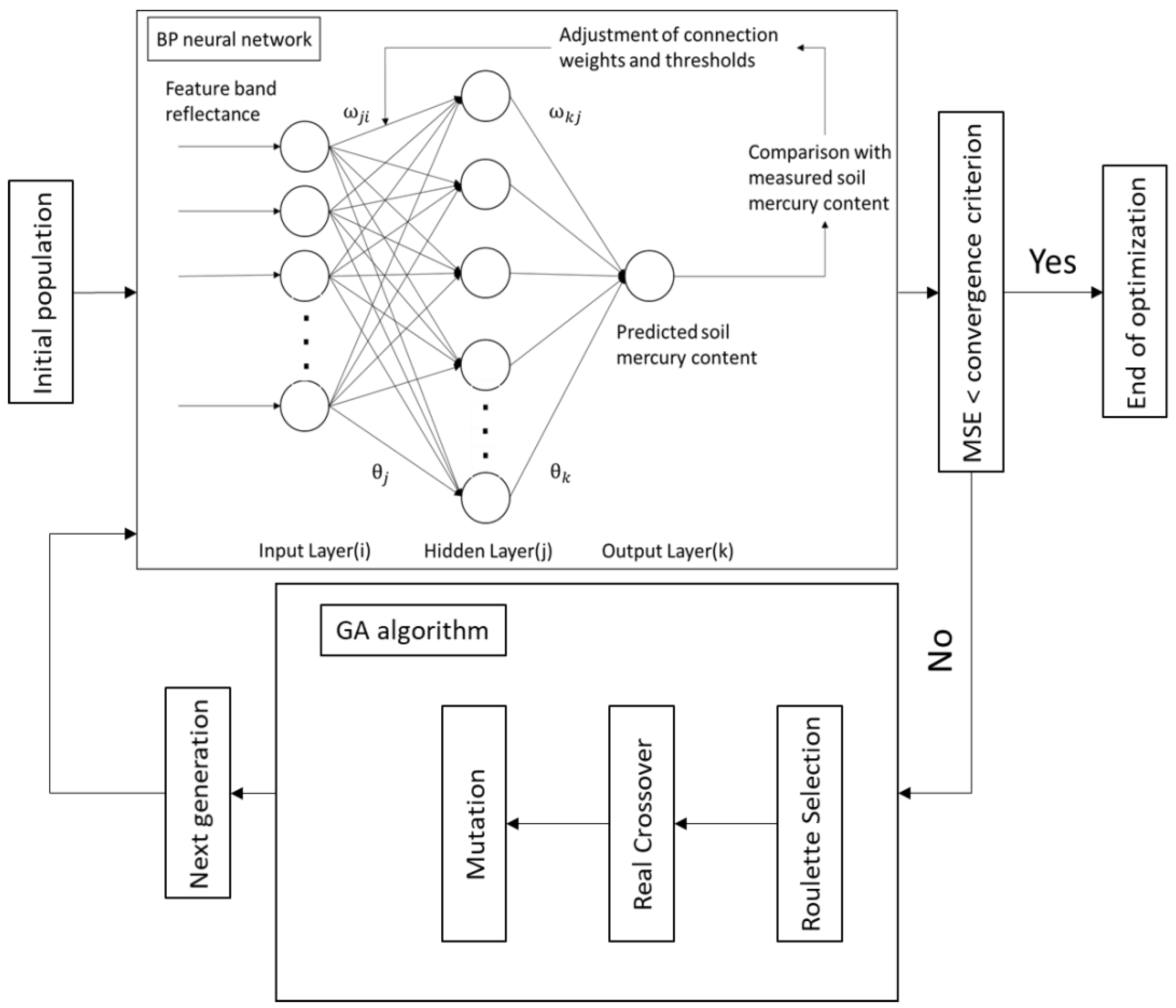
2.4.4. GA-BPNN Method for Determination of the Soil Mercury Content
3. Results
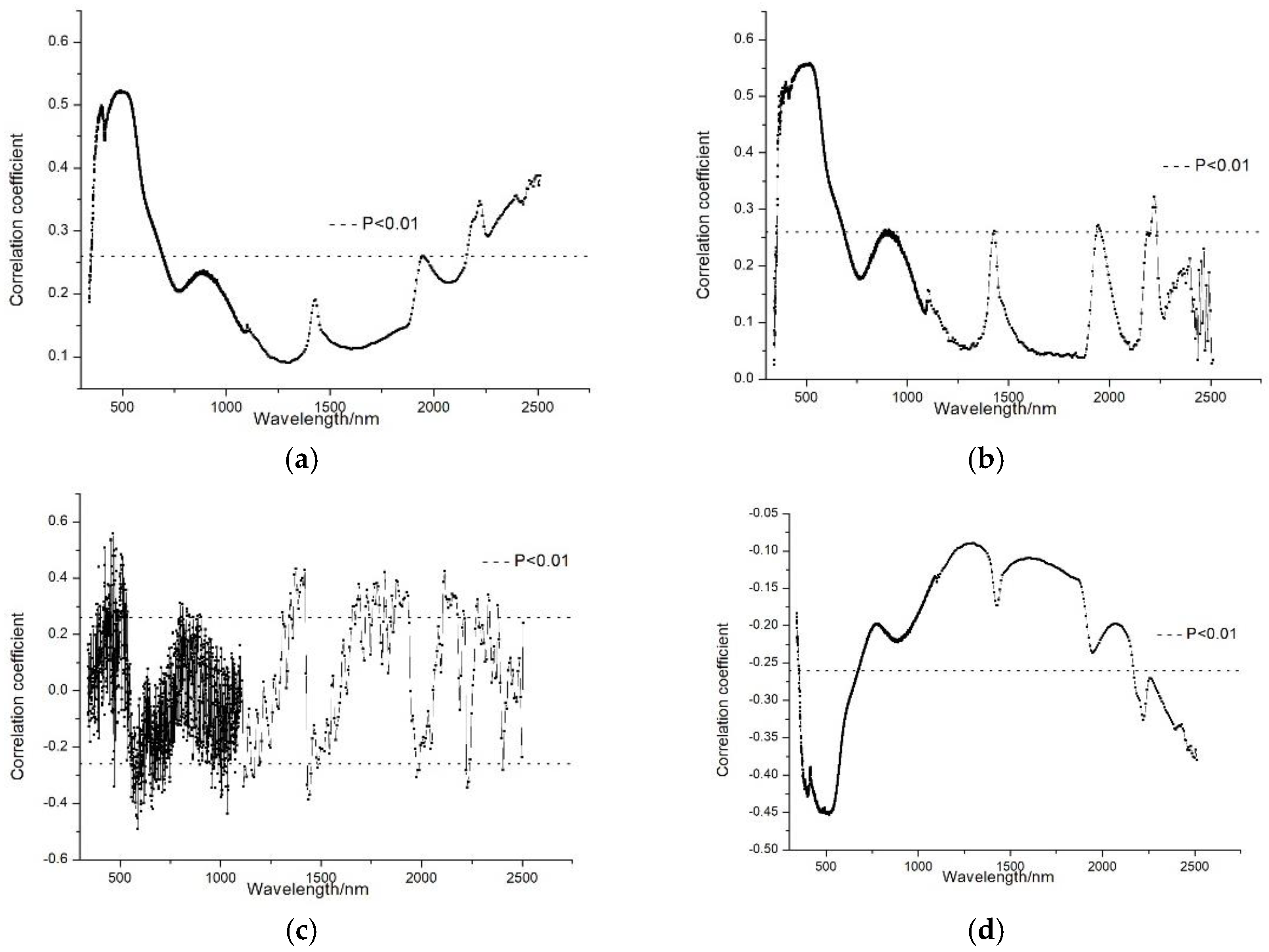
3.1. Feature Band Selection Results
3.2. Modeling Results
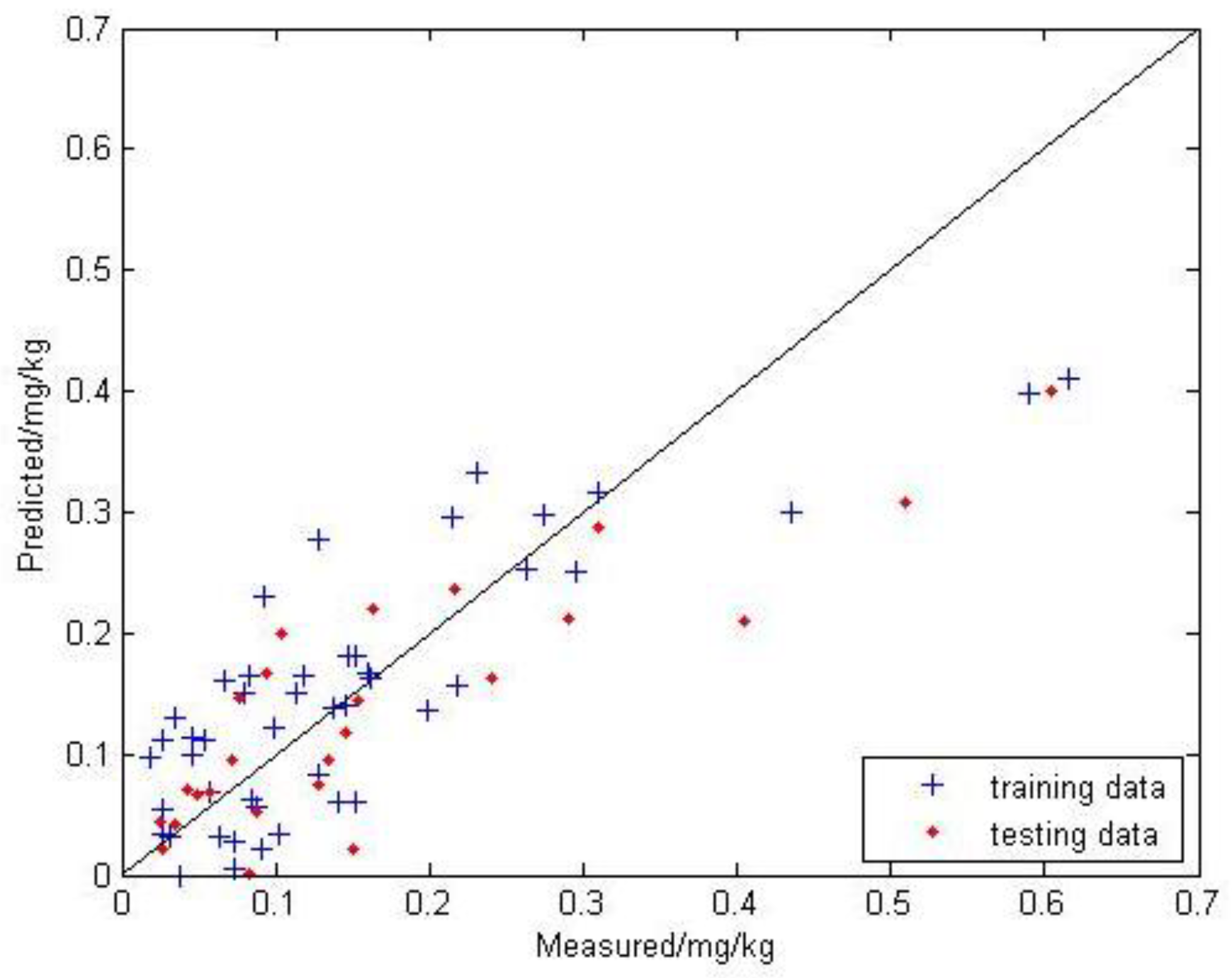
3.2.1. MLR Model Prediction Results of Soil Mercury Content
3.2.2. BPNN Model Prediction Results of Soil Mercury Content
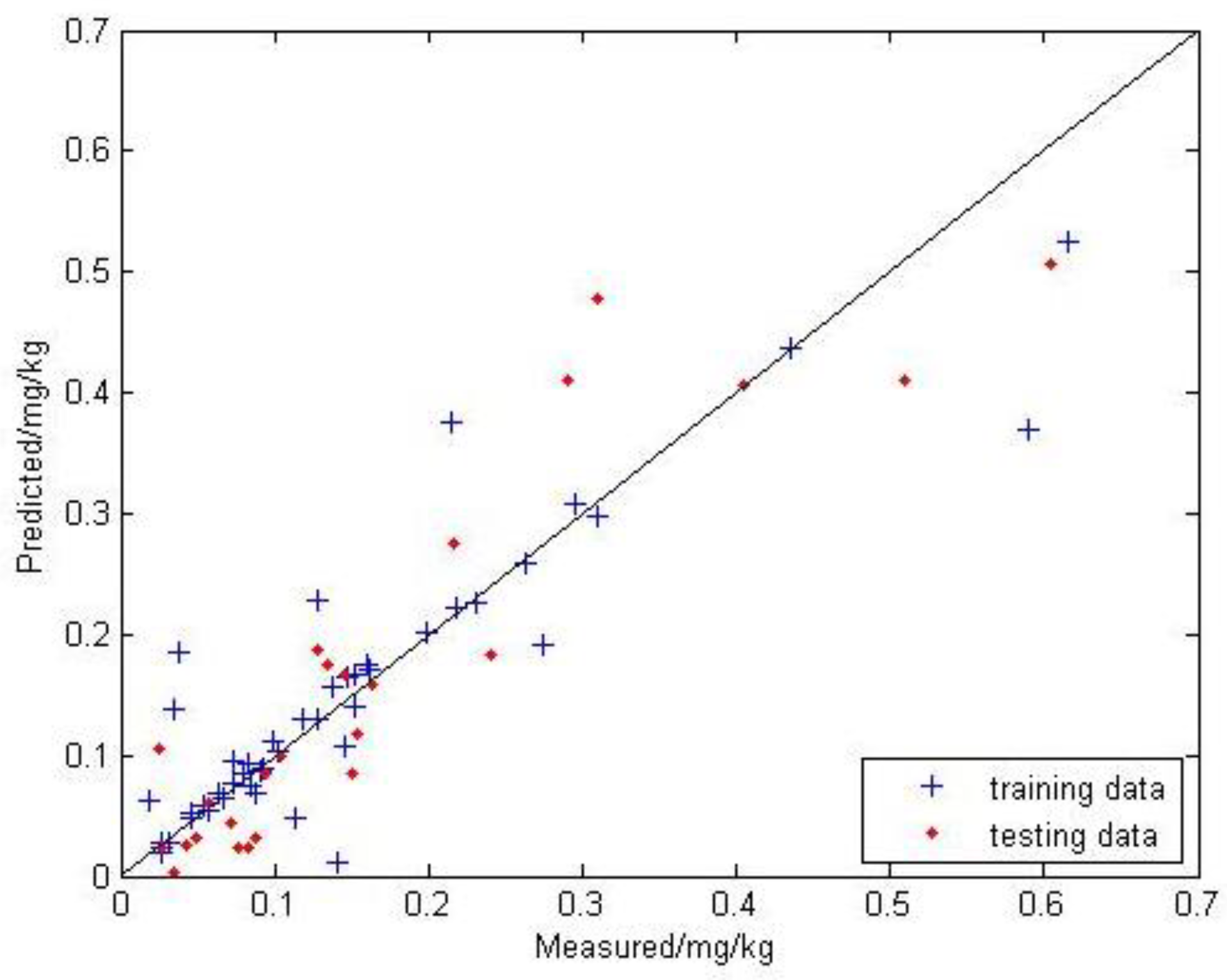
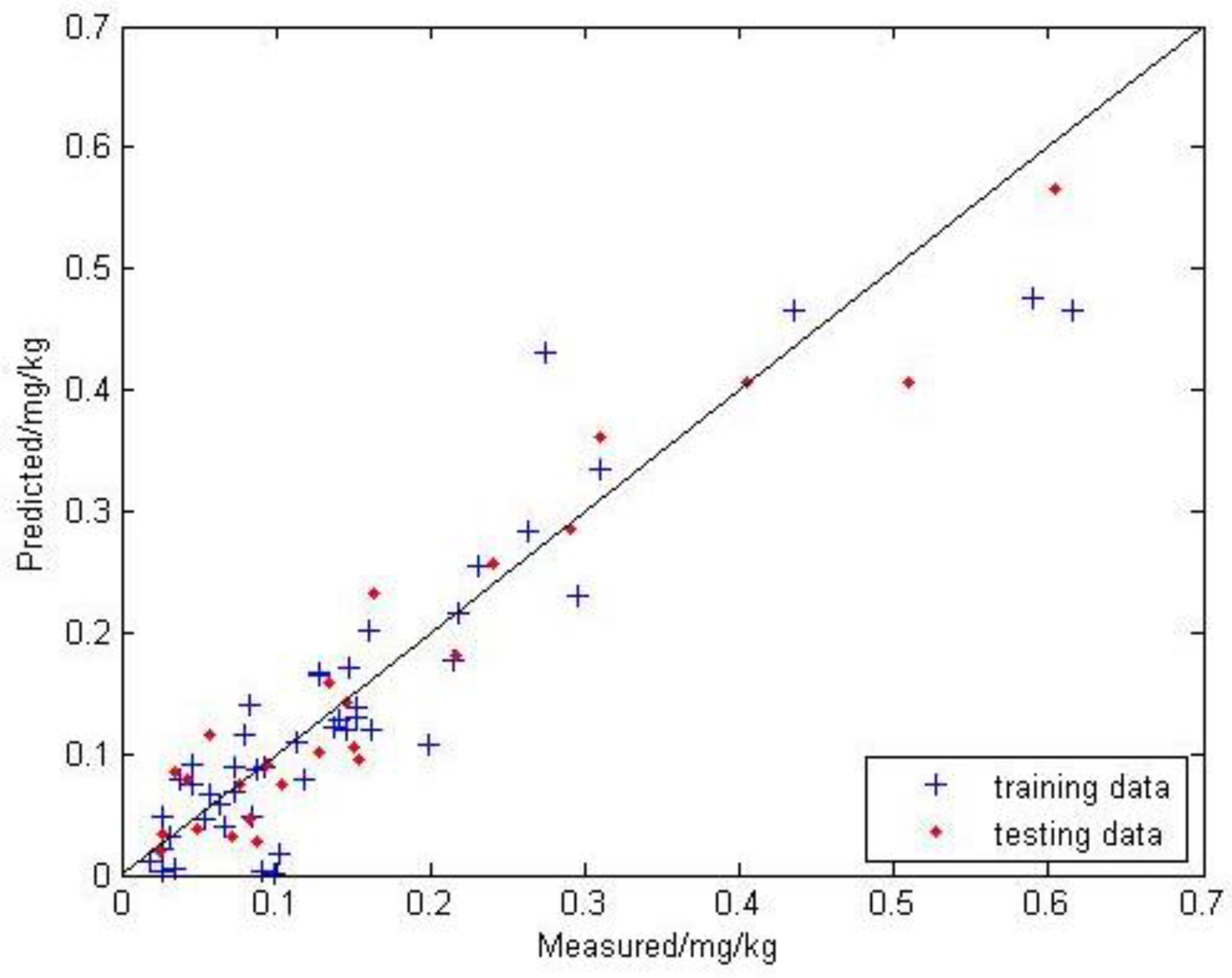
3.2.3. GA-BPNN Model Prediction Results of Soil Mercury Content
3.2.4. Comparison of Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pirrone, N.; Cinnirella, S.; Feng, X.; Finkelman, R.B.; Friedli, H.R.; Leaner, J.; Mason, R.; Mukherjee, A.B.; Stracher, G.B.; Streets, D.G.; et al. Global mercury emissions to the atmosphere from anthropogenic and natural sources. Atmos. Chem. Phys. Discuss. 2010, 10, 5951–5964. [Google Scholar] [CrossRef] [Green Version]
- Yin, R.S.; Feng, X.B.; Shi, W.F. Application of the stable-isotope system to the study of sources and fate of Hg in the environment: A review. Appl. Geochem. 2010, 25, 1467–1477. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, X. Estimating soil zinc concentrations using reflectance spectroscopy. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 126–133. [Google Scholar] [CrossRef]
- Leenaers, H.; Okx, J.P.; Burrough, P.A. Employing elevation data for efficient mapping of soil pollution on floodplains. Soil Use Manag. 2010, 6, 105–114. [Google Scholar] [CrossRef]
- Choe, E.; van der Meer, F.; van Ruitenbeek, F.; van der Werff, H.; de Smeth, B.; Kim, K.W. Mapping of heavy metal pollution in stream sediments using combined geochemistry, field spectroscopy, and hyperspectral remote sensing: A case study of the Rodalquilar mining area, SE Spain. Remote Sens. Environ. 2008, 112, 3222–3233. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Ding, W.; Wu, L. Monitoring stress levels on rice with heavy metal pollution from hyperspectral reflectance data using wavelet-fractal analysis. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 246–255. [Google Scholar] [CrossRef]
- Idowu, O.J.; van Es, H.M.; Abawi, G.S.; Wolfe, D.W.; Ball, J.I.; Gugino, B.K.; Moebius, B.N.; Schindelbeck, R.R.; Bilgili, A.V. Farmer-oriented assessment of soil quality using field, laboratory, and VNIR spectroscopy methods. Plant Soil 2008, 307, 243–253. [Google Scholar] [CrossRef]
- Dong, J.; Dai, W.; Xu, J.; Li, S. Spectral Estimation Model Construction of Heavy Metals in Mining Reclamation Areas. Int. J. Environ. Res. Public Health 2016, 13, 640. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.Z.; Chen, J.; Ji, J.F.; Tian, Q.J.; Wu, X.M. Feasibility of reflectance spectroscopy for the assessment of soil mercury contamination. Environ. Sci. Technol. 2005, 39, 873–878. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Liu, G.; Song, H. Using hyperspectral image data to estimate soil mercury with stepwise multiple regression. In Proceedings of the Eighth International Conference on Digital Image Processing, Chengdu, China, 29 August 2016. 100333Q. [Google Scholar]
- Choe, E.; Kim, K.W.; Bang, S.; Yoon, I.H.; Lee, K.Y. Qualitative analysis and mapping of heavy metals in an abandoned Au–Ag mine area using NIR spectroscopy. Environ. Geol. 2009, 58, 477–482. [Google Scholar] [CrossRef]
- Chang, C.W.; Laird, D.A.; Mausbach, M.J.; Hurburgh, C.R. Near-Infrared Reflectance Spectroscopy–Principal Components Regression Analyses of Soil Properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef]
- Xia, F.; Peng, J.; Wang, Q.L.; Zhou, L.Q.; Shi, Z. Prediction of heavy metal content in soil of cultivated land: Hyperspectral technology at provincial scale. J. Infrared Millim. Waves 2015, 34, 593–598, 605. [Google Scholar]
- Rathod, P.H.; Müller, I.; Van der Meer, F.D.; de Smeth, B. Analysis of visible and near infrared spectral reflectance for assessing metals in soil. Environ. Monit. Assess. 2015, 188, 558. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Chen, J.; Wu, X.; Tian, Q.; Ji, J.; Qin, Z. Possibilities of reflectance spectroscopy for the assessment of contaminant elements in suburban soils. Appl. Geochem. 2005, 20, 1051–1059. [Google Scholar] [CrossRef]
- Tan, K.; Ye, Y.; Cao, Q.; Du, P.; Dong, J. Estimation of Arsenic Contamination in Reclaimed Agricultural Soils Using Reflectance Spectroscopy and ANFIS Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2540–2546. [Google Scholar] [CrossRef]
- Dou, Y.; Qu, N.; Wang, B.; Chi, Y.Z.; Ren, Y.L. Simultaneous determination of two active components in compound aspirin tablets using principal component artificial neural networks (PC-ANNs) on NIR spectroscopy. Eur. J. Pharm. Sci. 2007, 32, 193–199. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.-B.; Tan, K.; Li, H.-D.; Yan, Q.W. Hyperspectral Inversion of Heavy Metals in Soil of a Mining Area Using Extreme Learning Machine. J. Ecol. Rural Environ. 2016, 32, 213–218. [Google Scholar]
- Balabin, R.M.; Lomakina, E.I. Support vector machine regression (SVR/LS-SVM)—An alternative to neural networks (Ann) for analytical chemistry? Comparison of nonlinear methods on near infrared (NIR) spectroscopy data. Analyst 2011, 136, 1703–1712. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Deng, Z.; Xia, Y.; Fu, M. A new sampling method in particle filter based on Pearson correlation coefficient. Neurocomputing 2016, 216, 208–215. [Google Scholar] [CrossRef]
- He, F.; Zhang, L. Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network. J. Process Control 2018, 66, 51–58. [Google Scholar] [CrossRef]
- Haque, M.E.; Sudhakar, K.V. ANN back-propagation prediction model for fracture toughness in micro alloy steel. Int. J. Fatigue 2002, 24, 1003–1010. [Google Scholar] [CrossRef]
- Hoseinian, F.S.; Rezai, B.; Kowsari, E. The nickel ion removal prediction model from aqueous solutions using a hybrid neural genetic algorithm. J. Environ. Manag. 2017, 204, 311–317. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Dong, Z.; Sun, Z.; Ma, H.; Shi, L. Study on Hyperspectral Characteristics and Estimation Model of Soil Mercury Content. In Materials Science and Engineering Conference Series; IOP Publishing Ltd.: Bristol, UK, 2017. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Mean/(mg/kg) | Max/(mg/kg) | Min/(mg/kg) | Std. | Coefficient Variation/% | Background Value/(mg/kg) | Ratio |
|---|---|---|---|---|---|---|---|
| 75 | 0.139 | 0.615 | 0.018 | 0.118 | 84.89 | 0.078 | 1.782 |
| Feature Bands | Correlation Coefficients |
|---|---|
| , | 0.521, 0.346 |
| , | 0.556, 0.323 |
| , , , , , , | 0.558, −0.492, 0.313, −0.438, 0.433, −0.307, 0.426 |
| , | −0.453, −0.326 |
| Model | Modeling | Testing | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | |||
| MLR | 0.665 | 0.076 | 0.059 | 0.665 | 0.087 | 0.063 |
| BPNN | 0.797 | 0.059 | 0.032 | 0.826 | 0.063 | 0.047 |
| GA-BPNN | 0.842 | 0.052 | 0.037 | 0.923 | 0.042 | 0.033 |
| No. | Predicted Value/(mg/kg) | Measured Value/(mg/kg) | Absolute Error | Relative Error | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MLR | BPNN | GA-BPNN | MLR | BPNN | GA-BPNN | MLR | BPNN | GA-BPNN | ||
| 1 | 0.400 | 0.507 | 0.565 | 0.605 | 0.205 | 0.098 | 0.04 | 0.339 | 0.162 | 0.066 |
| 2 | 0.307 | 0.410 | 0.405 | 0.509 | 0.202 | 0.099 | 0.104 | 0.397 | 0.194 | 0.204 |
| 3 | 0.210 | 0.407 | 0.405 | 0.405 | 0.195 | 0.002 | 0 | 0.481 | 0.005 | 0.000 |
| 4 | 0.287 | 0.477 | 0.361 | 0.310 | 0.023 | 0.167 | 0.051 | 0.074 | 0.539 | 0.165 |
| 5 | 0.211 | 0.411 | 0.286 | 0.291 | 0.08 | 0.12 | 0.005 | 0.275 | 0.412 | 0.017 |
| 6 | 0.162 | 0.183 | 0.257 | 0.240 | 0.078 | 0.057 | 0.017 | 0.325 | 0.238 | 0.071 |
| 7 | 0.237 | 0.275 | 0.181 | 0.217 | 0.02 | 0.058 | 0.036 | 0.092 | 0.267 | 0.166 |
| 8 | 0.219 | 0.159 | 0.232 | 0.163 | 0.056 | 0.004 | 0.069 | 0.344 | 0.025 | 0.423 |
| 9 | 0.144 | 0.118 | 0.095 | 0.153 | 0.009 | 0.035 | 0.058 | 0.059 | 0.229 | 0.379 |
| 10 | 0.022 | 0.085 | 0.106 | 0.151 | 0.129 | 0.066 | 0.045 | 0.854 | 0.437 | 0.298 |
| 11 | 0.119 | 0.167 | 0.141 | 0.145 | 0.026 | 0.022 | 0.004 | 0.179 | 0.152 | 0.028 |
| 12 | 0.095 | 0.174 | 0.158 | 0.134 | 0.039 | 0.04 | 0.024 | 0.291 | 0.299 | 0.179 |
| 13 | 0.075 | 0.188 | 0.100 | 0.128 | 0.053 | 0.06 | 0.028 | 0.414 | 0.469 | 0.219 |
| 14 | 0.199 | 0.100 | 0.075 | 0.105 | 0.094 | 0.005 | 0.03 | 0.895 | 0.048 | 0.286 |
| 15 | 0.166 | 0.085 | 0.091 | 0.095 | 0.071 | 0.01 | 0.004 | 0.747 | 0.105 | 0.042 |
| 16 | 0.053 | 0.032 | 0.027 | 0.088 | 0.035 | 0.056 | 0.061 | 0.398 | 0.636 | 0.693 |
| 17 | 0.002 | 0.023 | 0.046 | 0.083 | 0.081 | 0.06 | 0.037 | 0.976 | 0.723 | 0.446 |
| 18 | 0.147 | 0.024 | 0.075 | 0.076 | 0.071 | 0.052 | 0.001 | 0.934 | 0.684 | 0.013 |
| 19 | 0.094 | 0.044 | 0.032 | 0.072 | 0.022 | 0.028 | 0.04 | 0.306 | 0.389 | 0.556 |
| 20 | 0.068 | 0.060 | 0.115 | 0.058 | 0.01 | 0.002 | 0.057 | 0.172 | 0.034 | 0.983 |
| 21 | 0.067 | 0.032 | 0.037 | 0.049 | 0.018 | 0.017 | 0.012 | 0.367 | 0.347 | 0.245 |
| 22 | 0.070 | 0.026 | 0.080 | 0.042 | 0.028 | 0.016 | 0.038 | 0.667 | 0.381 | 0.905 |
| 23 | 0.043 | 0.003 | 0.085 | 0.034 | 0.009 | 0.031 | 0.051 | 0.265 | 0.912 | 1.500 |
| 24 | 0.021 | 0.024 | 0.035 | 0.027 | 0.006 | 0.003 | 0.008 | 0.222 | 0.111 | 0.296 |
| 25 | 0.044 | 0.105 | 0.020 | 0.026 | 0.018 | 0.079 | 0.006 | 0.692 | 3.038 | 0.231 |
| Mean | 0.138 | 0.165 | 0.160 | 0.168 | 0.063 | 0.047 | 0.033 | 0.431 | 0.433 | 0.336 |
| Std. | 0.101 | 0.158 | 0.144 | 0.152 | ||||||
| MLR: 0.665 BPNN: 0.826 GA-BPNN: 0.923 | ||||||||||
| RMSE | MLR: 0.087 BPNN: 0.063 GA-BPNN: 0.042 | |||||||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Hu, Y.-M.; Zhou, W.; Liu, Z.-H.; Pan, Y.-C.; Shi, Z.; Wang, L.; Wang, G.-X. Estimation Methods for Soil Mercury Content Using Hyperspectral Remote Sensing. Sustainability 2018, 10, 2474. https://doi.org/10.3390/su10072474
Zhao L, Hu Y-M, Zhou W, Liu Z-H, Pan Y-C, Shi Z, Wang L, Wang G-X. Estimation Methods for Soil Mercury Content Using Hyperspectral Remote Sensing. Sustainability. 2018; 10(7):2474. https://doi.org/10.3390/su10072474
Chicago/Turabian StyleZhao, Li, Yue-Ming Hu, Wu Zhou, Zhen-Hua Liu, Yu-Chun Pan, Zhou Shi, Lu Wang, and Guang-Xing Wang. 2018. "Estimation Methods for Soil Mercury Content Using Hyperspectral Remote Sensing" Sustainability 10, no. 7: 2474. https://doi.org/10.3390/su10072474
APA StyleZhao, L., Hu, Y. -M., Zhou, W., Liu, Z. -H., Pan, Y. -C., Shi, Z., Wang, L., & Wang, G. -X. (2018). Estimation Methods for Soil Mercury Content Using Hyperspectral Remote Sensing. Sustainability, 10(7), 2474. https://doi.org/10.3390/su10072474