2.1. Problem Description
The main objective of pattern recognition is to assure that the classification results are consistent with reality, while keeping the error rate as low as possible. Generally, the basic framework of pattern recognition can be divided into five parts, namely the acquisition of original data, data pre-processing, feature extraction and selection, classifier design, and the final classification. Apart from data, feature extraction and classifier design are also important factors affecting the recognition accuracy.
Feature extraction is based on data pre-processing. Through the analysis of the characteristics, the features that directly or indirectly exhibit similarity and difference between categories are extracted. The extraction of features will directly affect the accuracy of the classification results.
In existing literature, many scholars have extracted various features for travel mode identification. Stenneth et al. (2011) used average speed, average distance, frequency, gender, and age as characteristic parameters to classify the travel mode. Also, background information of traffic routes and travel information of travelers are included in their model [
22]. Wang and Chen (2018) used speed, acceleration, direction change rate, and individual traveler characteristics (age and disability) as input features combined with GIS information [
23]. In the study of Dabiri (2018), the speed, acceleration, speed curve smoothness, and direction change rate were used to identify the mode of travel, and the GPS trajectory data collected by the test was used to test and establish different classifications [
24,
25,
26]. In summary, at present, scholars often only consider the difference among travel modes in the temporal and spatial distribution of the trajectory classification problem. Generally, the selected features are limited to distance, time consumption, speed, etc. But in a complex traffic environment, under the influence of the different types of travel modes, the difference characteristics reflected in the travel trajectory will be disturbed. Further, there will be a crossover phenomenon, resulting in lower recognition accuracy. Therefore, finding new features from the data other than feature information from trajectory is the key to improving the feature extraction.
Classifier design is the rule designed for classifying objects. Traditional methods for mode identification often use statistical regression, such as linear regression, a polynomial logit model [
27], etc. However, these models have unrealistic assumptions and require a predefined relationship between the dependent variable and the explanatory variables. Compared with statistical models, machine-learning-based classifiers can be more effectively in mode identification. Its effectiveness has been confirmed in many studies involving decision trees, neural networks, and support vector machines [
14]. However, many errors and uncertainty exist in the case of MSD, which may lead to unstable performance of the model. Random forests are found to overcome these issues and have shown good learning ability to help solve predictions and classification problems. Thus, the random forest is chosen in the study as the classifier to identify the travel mode.
2.2. Point-to-Point Map Matching Based on Probability Statistics
From the perspective of travel mode identification, it is very important for the mining of travel mode characteristics to map the user base station trajectory sequence onto the road network to obtain the real travel trajectory. Through path matching, features can be extracted from a more accurate trajectory when the real travel trajectory on the road network is obtained. From the perspective of mode identification application, we match the user’s travel trajectory to the road network, so that more accurate traffic flow information can be obtained. With this information, we are able to achieve traffic condition identification and real-time traffic flow control. Therefore, this paper studies the map matching technology based on the location information of the mobile phone base station, which lays a foundation for feature mining in traffic pattern recognition.
Existing algorithms in map matching mainly include three categories: geometry, topology, and probability statistics. In addition, the map matching algorithm based on geometric analysis can be divided into point-to-point, point-to-line, and line-to-line matching. Point-to-point is a simple search algorithm that matches points to the nearest node on the road network. Point-to-line matches points to the nearest road section. The line-to-line matching algorithm connects the trajectory points as curves and then searches for the most similar road segments in the road network to the matched road segments. The matching algorithm based on topology analysis is based on the topological relationship of the road network, simultaneously considering the direction, speed, and road network connectivity [
28]. It then matches historical information with the actual road network information.
The main principle of the probability-based algorithm is to define a possible matching area as the center of the matching point according to the positioning accuracy of the track points, take the road section within the area as the possible matching road section and calculate its matching probability to determine the best matching road. In addition to the above map-matching algorithms, matching algorithms using complex mathematical theories have emerged in recent years, such as the Bayesian inference matching algorithm, Kalman filtering matching algorithm, fuzzy logic matching algorithm, and matching algorithm based on convex optimization [
29,
30,
31,
32].
Although a range of research on map matching already exists, the MSD was not commonly used. This may be attributed to two reasons. Firstly, the algorithm involves a large amount of computation, especially in an area with a complex road network. Moreover, as the number of segments waiting for matching is large, the algorithm efficiency can be extremely low. Secondly, the accuracy of the algorithm depends mainly on the location frequency of signaling data. In this paper, to overcome the shortcomings of the path matching method using the existing map matching technology based on mobile base stations, a novel matching method based on base stations and intersections is proposed.
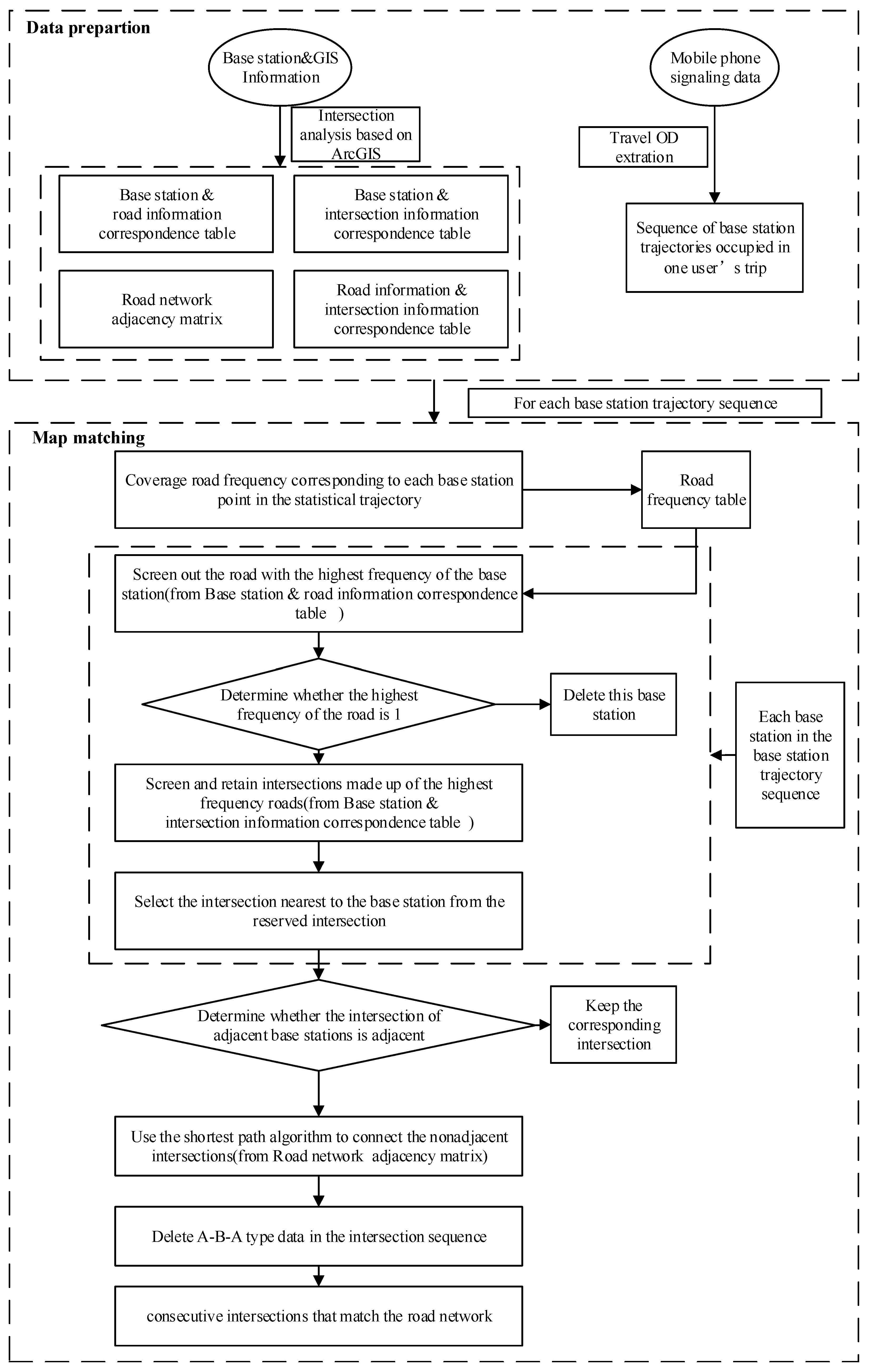
Based on the map-matching algorithm and the characteristics of positioning data, this paper proposes a road network matching algorithm suitable for base station positioning trajectory. The proposed algorithm allows for the spatial distance, coverage road frequency, and road network connectivity.
After preparing the necessary information records, the sequence of the travel base station track is numbered. Suppose a track is expressed as set Si = {j1, j2, …, jn}, where ji represents the base station occupied in the trajectory. The following algorithm flow is then performed for each trajectory. The procedures for map matching is shown in Algorithm 1:
| Algorithm 1.Procedures for map matching. |
| Step 1: Add the road covered by each base station ji in track Si according to the base station and road information correspondence table. Obtain the frequency table of road coverage in the trajectory Fi. |
| Step 2: For each base station ji, the intersections set Ri in coverage area can be found according to the base station and interaction information correspondence table. |
| Step 3: According to the frequency table Fi obtained in Step 1, mark the road with the highest frequency in Ri and select the intersection composed of this road. Delete the base station ji, if . |
| Step 4: Calculate the distance D between the intersections screened from the previous step and the base station while reserving the intersection closest to the base station according to the principle of minimum distance, i.e., the intersection corresponding to the base station on the road network. |
| Step 5: Cyclic match all base stations in the trajectory sequence to obtain an intersection sequence Ci. For non-adjacent intersections, the shortest circuit function is used to connect them to obtain a fully connected intersection sequence on the road network. |
| Step 6: Judge whether C(i-1), Ci, and C(i+1), three adjacent data in the intersection sequence Ci are A-B-A type data. If yes, delete the intersection Ci and C(i+1). |
The path matching in the study was carried out using ArcGIS and Python. The fundamental geographic information data is stored in ArcGIS in the form of shapefile, while map matching is achieved using the NetworkX module in Python. The Dijkstra shortest path algorithm is used for the connection between the intersections. The advantages for choosing this method include high efficiency, high speed, and strong applicability in complex networks [
33]. The detailed flow chart is provided as follows in
Figure 1.
2.3. Sample Label Acquisition Based on Association Rules Mining
MSD is location data processed anonymously by mobile operators. On the one hand, it has been widely used in many research fields due to its advantages of protecting user privacy. On the other hand, anonymity also provides few obstacles to the research. In the research of individual trip chaining with fine granularity, it is difficult to obtain the user’s real travel information. Thus, it is impossible to create a link between the data and the actual scene. Further, it is difficult to verify the accuracy of scientific research results.
In previous studies, the sample data were collected by volunteers to record daily travel information. Meanwhile, the MSD was extracted from the communication operator if the volunteer consented to the data acquisition and signed the authorization letter. However, the economic cost of this method is relatively high and requires a large workforce to process the data, which is a fundamental reason for the small sample size in previous studies. Besides, due to the size and nature of the research institution, there may be a bias in the recruitment of volunteers and data collection, leading to the deviation/errors in the travel samples obtained. For example, Shafique et al. (2015) found that most volunteers for research institution projects in universities are students, whose activity scope, travel purpose, and travel mode are relatively limited [
33]. To handle the above shortcomings, this paper proposes a method for obtaining travel mode label samples based on mobile phone travel trajectory data and residents’ travel survey data.
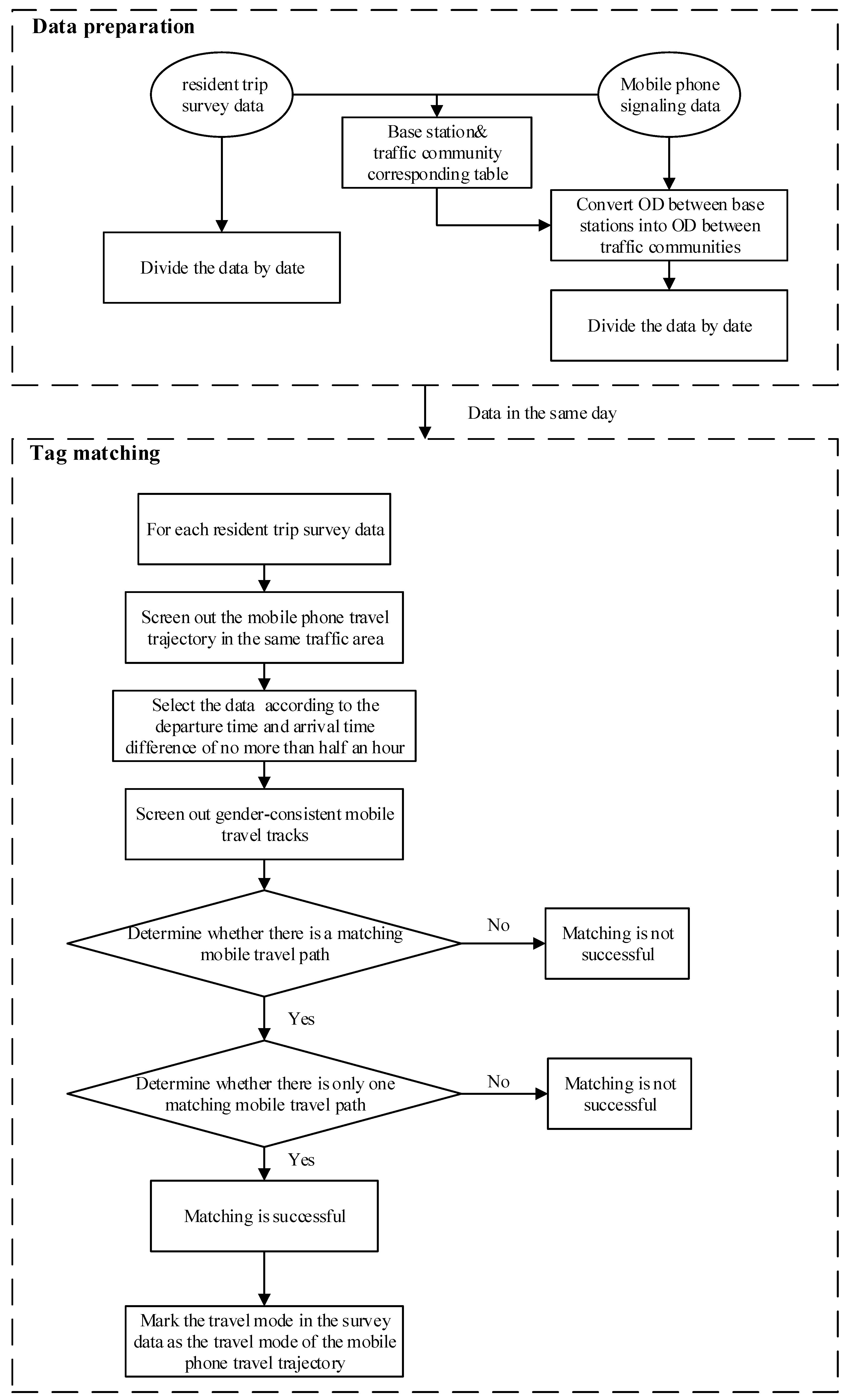
The residents’ travel survey data includes information like gender and the age of residents, the departure and arrival traffic zone number, and the departure time and arrival time of each travel record. The travel base station trajectory information extracted from MSD also contains the departure point and arrival point of each travel trajectory, the departure time and arrival time of each travel trajectory, and gender and age of the user corresponding to the IMSI number. Through connecting these attributes, the trajectory extracted from the MSD can be matched to the residents’ travel survey data. Therefore, the travel mode information of the mobile phone travel trajectory can be obtained once the two records match successfully under the set rules, elaborated as follows.
To fuse these two types of data, the principal task is to establish a spatial correspondence between the base station and the traffic community. Then, the travel based on the mobile signaling data can be integrated into the travel based on the traffic community. Preliminary screening of mobile phone data can be conducted through the date of residents’ travel survey data, and the departure and arrival of the community. Then, the travel time in each survey data is screened again. Finally, the data are matched according to gender and age attributes. For successfully matched records, the travel mode recorded in the travel survey data of residents can be regarded as the travel mode corresponding to the mobile phone travel path.
Figure 2 shows the specific matching algorithm rules and procedures.
2.4. Feature Extraction and Selection
The identification of the travel mode based on MSD is essentially a pattern recognition problem. The selection of features is a crucial step in the pattern classification problem, directly impacting on the accuracy of the classification results. In the past, the extracted features in trajectory data mining were mostly limited to the temporal and spatial characteristics of the trajectory itself, and the data source was relatively simple. However, in the increasingly complex transportation system, the spatial and temporal distribution of different travel modes is getting smaller and smaller. It is often unsatisfactory to rely solely on the differences in the temporal and spatial characteristics to distinguish between different travel modes. Some scholars combined GIS in feature extraction and considered the differences among different travel modes in urban road network distribution, such as the similarity of travel routes and bus routes. However, few scholars were found to consider the relevant influencing factors involving traffic travel mode selection behavior and navigation path characteristics in their studies.
Different personal attributes, origin, and destination of the traffic in built environment affect the residents’ travel mode choice behavior. The addition of characteristic parameters that affect residents’ travel choice behavior may enhance the recognition capability of the model.
Moreover, in the case of different traffic conditions and departure times, the travel path and travel time required for each travel mode will be different. For example, in the morning and evening rush hours, the travel time required by cars on some congested roads is longer. To help consider the complexity of the traffic operating environment, Internet data was integrated into the feature extraction process. The travel distance and travel time between various travel modes were crawled from the Internet to help address the travel modes classification problem.
Following the analysis above, the study divided the features into three categories. The first category is the temporal and spatial features of the trajectory itself. It is also the characteristic of different travel modes in the travel trajectory. The second category is the personal attributes and environmental characteristics related to travel mode selection. Finally, the third category is navigation data which features considering paths and road conditions.
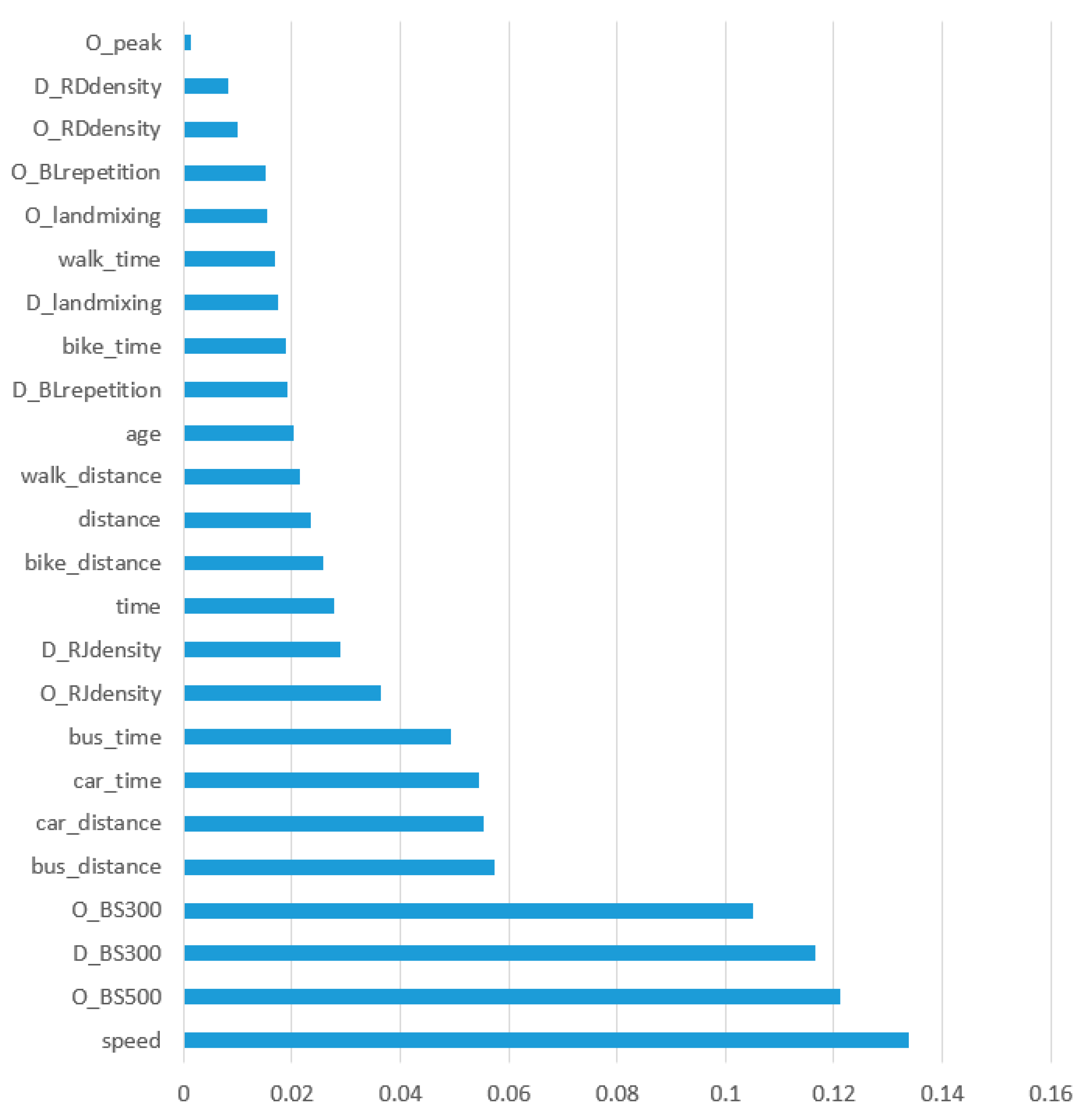
Seven temporal and spatial characteristics of the trajectory were extracted first. The travel distance “Distance” was calculated by distance of the travel track in the road network after map matching. The departure time “O_time” and the arrival time “D_time” were obtained from the track record in MSD, and travel time “Time” was obtained by subtracting these two characters. And the average speed “speed” was calculated by using “Distance” divided by “Time”. The last step was defining the morning peak from 7 to 9 and the evening peak from 17 to 19 to judge whether the departure time and arrival time was at a peak or not in order to get the “O_peak” and “D_peak”.
The personal attributes incorporated in the model include (i) the gender “Sex” by defining male as 1, female as 0; (ii) the age by defining 1 for travelers under 20 years old, 20~29 as 2, 30~39 as 3, 40~49 as 4, 50~59 as 5, and 60 years old or older as 6.
Then, we proceeded with the built environment features. A total of twenty features that can be divided into six categories were extracted. First is the coverage rate of a bus stop. After intersecting the 300 m and 500 m bus station buffer layer with the traffic zone layer in GIS, the area of the site coverage area corresponding to the service radius of each traffic community was obtained. Comparing the site coverage area of each traffic zone with the zone area, the 300 m bus station coverage rate and 500 m bus station coverage rate of the traffic community could be obtained. According to the spatial geographical location of the departure and arrival points of the track, four features including a 300 m coverage rate of a bus stop in the departure and arrival area “O_BS300” and “D_BS300”, as well as a 500 m coverage rate of a bus stop in the departure and arrival area “O_BS500” and “D_BS500” corresponding to the trajectory can be obtained. Next were the bus line repetition coefficient, intersection density, road network density, and land mix in the departure and arrival area. Similar to the acquisition method of the coverage rate of a bus stop, their calculation methods are not described in detail here. What worth noting is the land use mixing index, which refers to the relative proximity of different functional land in the area. In the paper, the land use type was reclassified and divided into office, commercial, and residential according to the type of land use plan. The entropy index was used to measure the mixing degree of land use, which can quantify the equilibrium of land use in a given area, and the calculation formula was shown as the following:
where k represents the ratio of the area of the
kth land type for the total area of the cell in the traffic zone
i and
n is the land type.
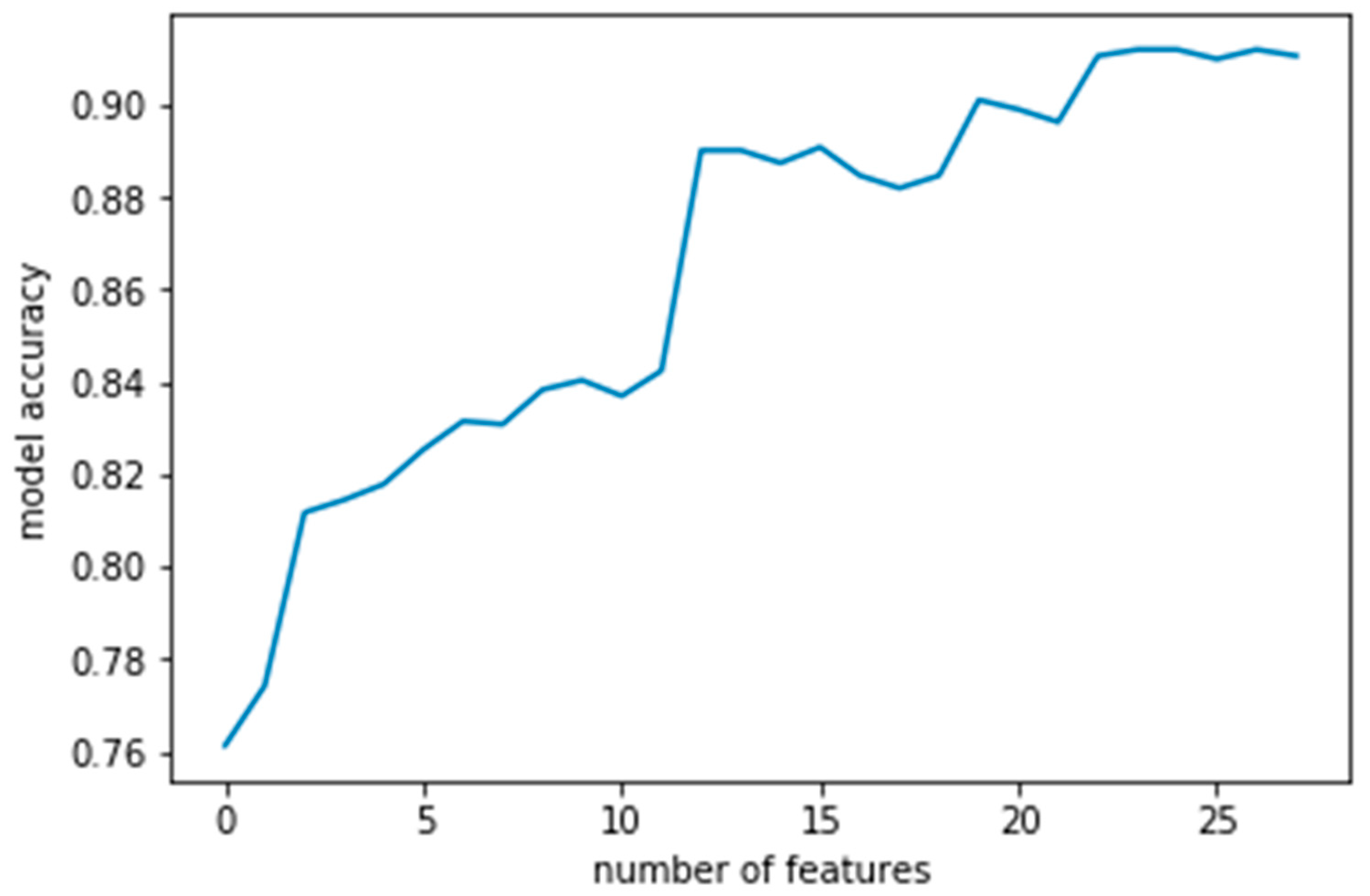
After feature extraction, feature selection, i.e., the selection of features from the original feature set to optimize the overall model performance, was carried out. Through the difference analysis of travel mode and travel behavior in the previous section, 29 features related to travel mode classification were extracted as the original features. After eliminating irrelevant and redundant features, the optimal feature subset was selected as an input to train the machine learning algorithms and models. In this study, filtered feature selection was adopted. The principle was to separately count the statistical indicators of each variable, according to which the characteristics were selected. This selection strategy is simple and easy to implement, and is beneficial to understanding the data. Chi-square test is often used for classification problems. The basic idea is to infer whether there is a significant difference between the overall distribution and the expected distribution based on the sample data or to infer whether the two categorical variables are related or independent.
where
A denotes the actual value,
T denotes the theoretical value.
The feature selection steps in the study are as follows in the Algorithm 2:
| Algorithm 2.Procedures for feature extraction. |
| Step 1: Traversing the number of features k. |
| Step 2: With the univariate feature selection, the chi-square test is used to select the optimal k features. |
| Step 3: Use the combination of k optimal variables to construct the classification model and calculate the model accuracy. |
| Step 4: Choose the combination of variables under the optimal model accuracy as the selected feature. |
2.5. Model Construction Based on Random Forest
Random Forest, also known as Random Decision Forest, is an ensemble learning algorithm composed of multiple decision trees and can be used for both classification and regression tasks. Firstly, through the bootstrap resampling technique,
k samples are randomly selected from the original training sample set to form a new training sample set. Then, the obtained training samples are used to construct a decision tree, together forming a random forest. Finally, the classification result is determined by the classification tree. The random forest algorithm has the following advantages over other machine learning methods [
34]: (1) It has high accuracy among the classification algorithms widely used at present. (2) The importance of each feature vector in the feature space can be evaluated by indicators like the Gini index. The importance measure for a particular variable is obtained as the average decrease of Gini impurity index over all trees in the forest. For a candidate splitting variable
with a possible number of categories as
, the Gini impurity index for this variable can be calculated. (3) It can effectively deal with large data sets and data samples with high dimensional characteristics, so it does not need to conduct dimensionality reduction. (4) The accuracy of the model can be guaranteed even when there are many default data values. (5) The construction and execution speed of the model is fast and is not associated with the overfitting phenomenon.
where
denotes the Gini impurity index for the variable
;
represents the estimated category
probabilities. Once Gini impurity indices are calculated for each candidate splitting variable, the split is conducted on the variable that has the highest value.
The travel mode identification model based on the random forest algorithm mainly consists of four parts, namely the construction of training set and test set, the selection of feature vectors, the construction of decision tree, and voting to determine the optimal classification. The specific model construction process is as followed in Algorithm 3:
| Algorithm 3.Procedures for model construction. |
| Step 1: For the original travel path sample set, the samples were randomly divided following the ratio of 3:1 while 25% of the samples were taken as the test set. |
| Step 2: For the above-determined training sample set D(x1, x2, ..., xn), by taking k as random repeatable samples, construct the random vector set D1, D2, ..., Dk. |
| Step 3: In the selected features, m specific variables are randomly selected. Determine the optimal identification point using these variables. |
| Step 4: For each random vector Di, construct a decision tree. |
| Step 5: Repeat step 3 and step 4. Finally, construct k decision trees. |
| Step 6: For an input vector, each decision tree in the random forest votes. |
| Step 7: Finally, votes from all the decision trees are counted, among which the travel mode of this vector is the one with the majority of votes. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}