A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning



Abstract
:1. Introduction
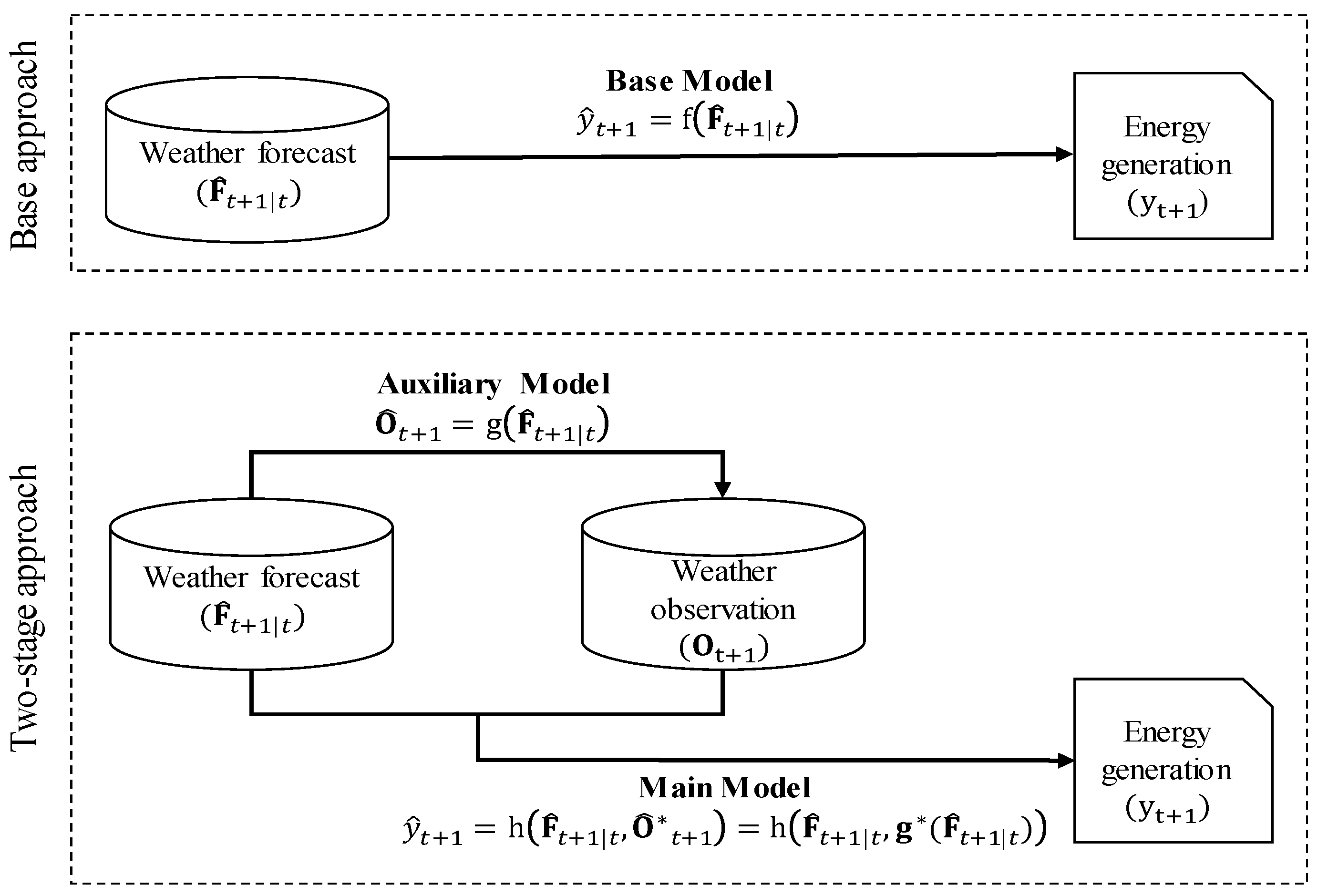
- This study proposes an approach to expanding predictors for the prediction of solar power generation. It exemplifies a practical application to include relevant but delayed climatic data that are not available in real-time.
- Many practical applications, including renewable energy operations, call for predictions using weather information as predictors. The proposed approach can be applied to predictions for renewable energy operations, such as wind, tide, and geothermal power production.
- Generally, identifying latent variables and incorporating them in the prediction process often enhance the model performance. The proposed two-step approach does so with various machine learning algorithms.
- In applications of machine learning methods, identifying latent variable structures in prior often enhances the performance of resulting models. This study indirectly investigates how much each machine learning algorithm gains benefit from the intermediate latent variable identification process.
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Machine Learning Methods
2.3. Problem Statements
3. Results
3.1. Measures for Model Comparison
3.2. Performance of Auxiliary Model
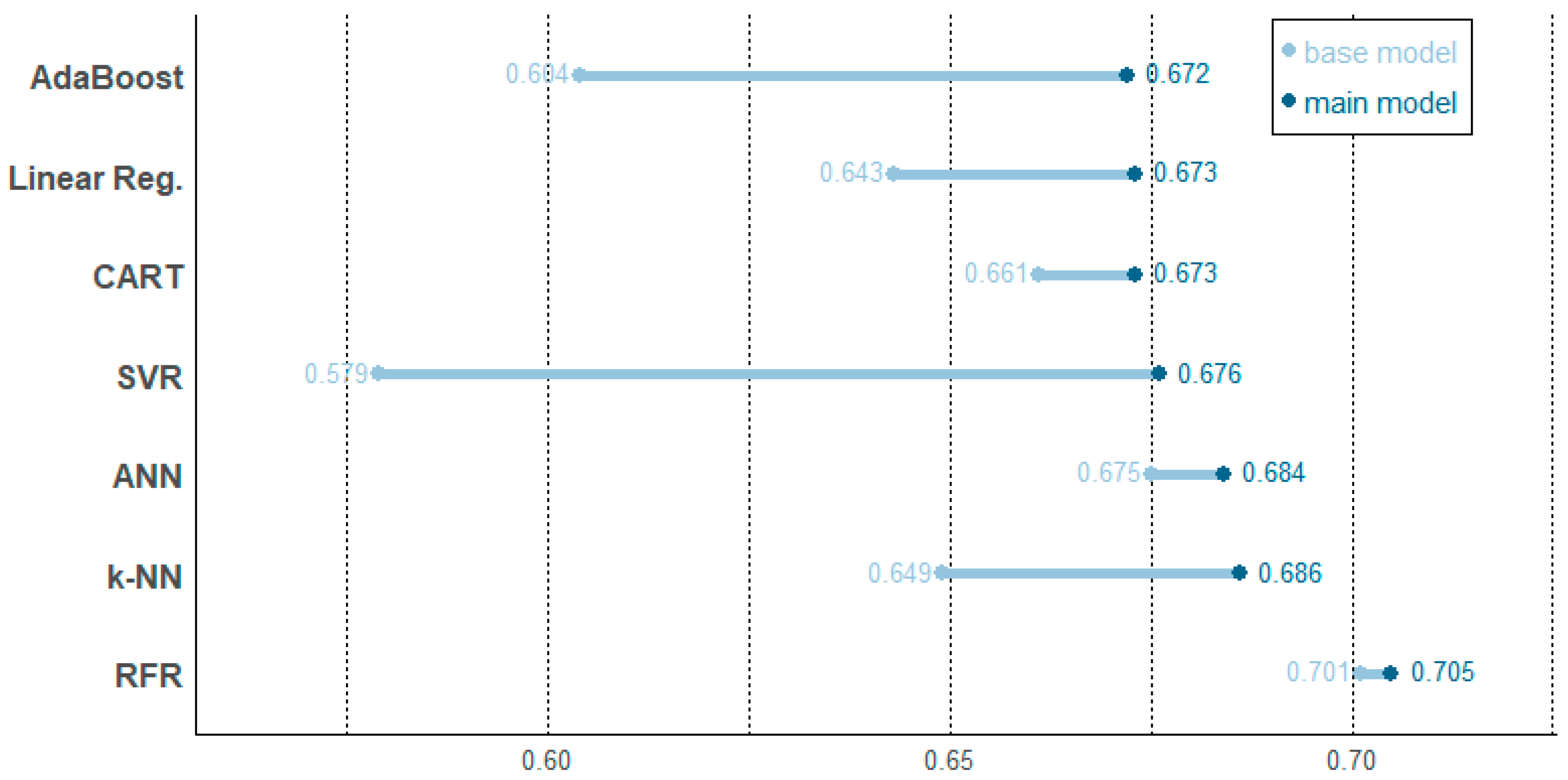
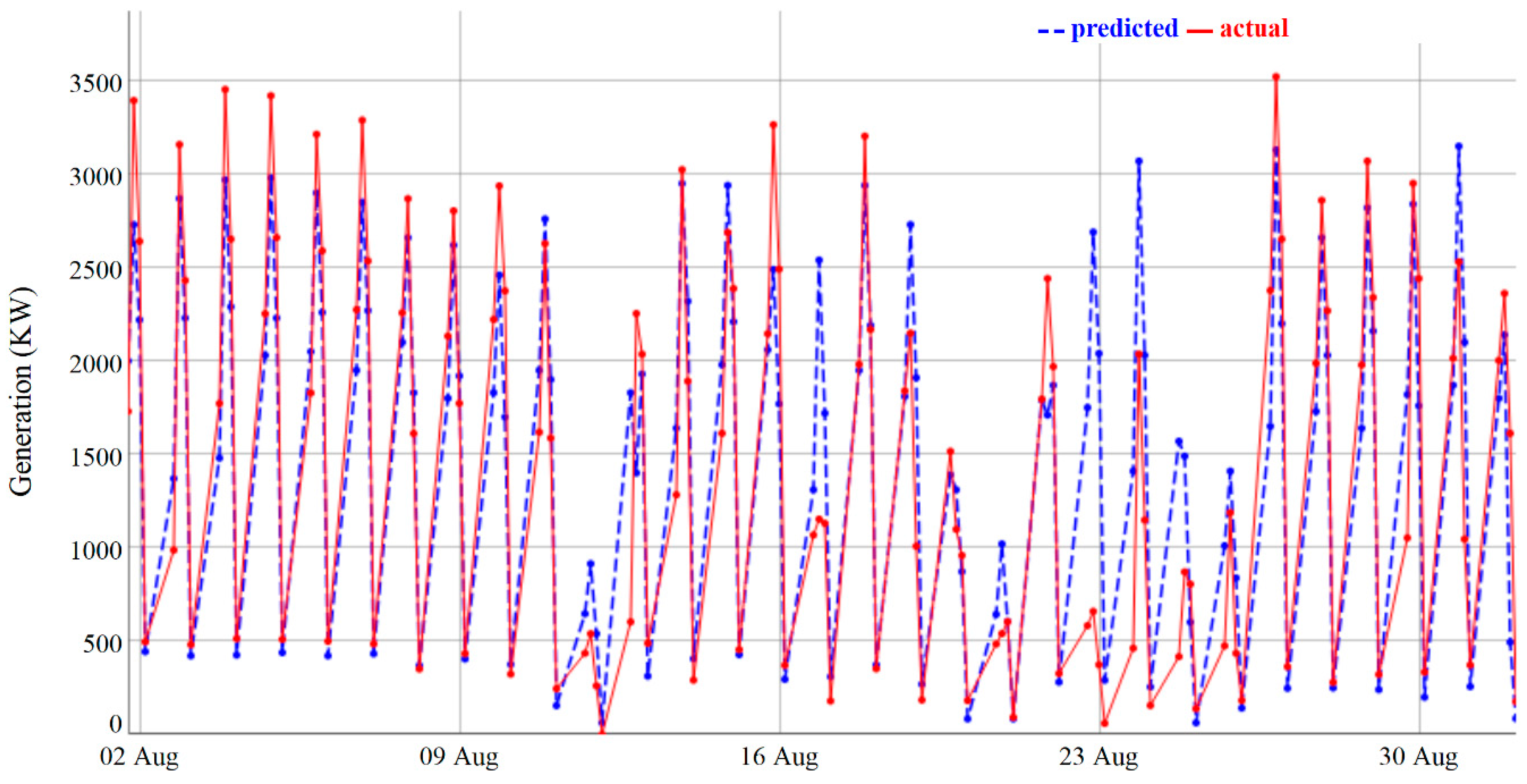
3.3. Performance of Base and Main Models
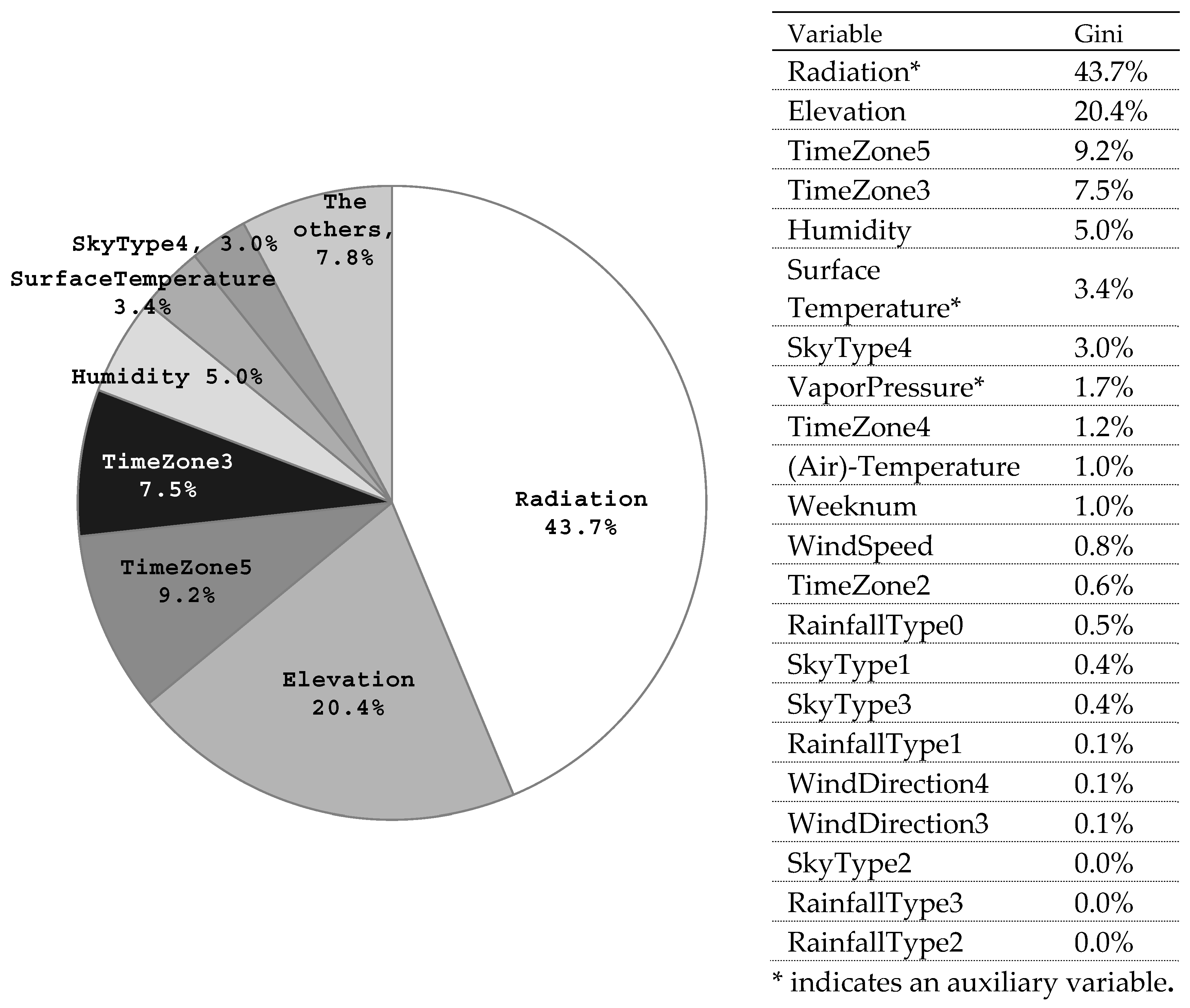
3.4. Importance of Variables
4. Discussion
- For predicting the solar power generation, the forecasts for the amount of solar radiation is the most important among the others, in terms of the Gini importance. The forecast for solar radiation is not directly available from the weather agency but can be indirectly generated by the proposed auxiliary model. Next, the position of the solar relative to the ground (Elevation) carries important information, and the operation time of the day affects the power generation. Since solar elevation can be accurately forecasted by astrophysics and the time of the day (TimeZone) is deterministic, the future information for these two variables are attainable accurately. The condition of the atmosphere (Humidity and VaporPressure) and the temperatures (SurfaceTemperature and Air-Temperature) also affect the power generation.
- Forecasts for auxiliary variables are not readily available during actual power generation operations, but their values are later realized and highly correlated to the solar power generation. This relationship is captured by the auxiliary model, and the main model exploits this information to outperform the base model regardless of the machine learning methods applied. This approach, regarded as identification of latent variables, enhances the performances of solar power prediction.
- On comparing the different machine learning methods, models with higher capacity, such as RFR, k-NN, and ANN, perform relatively well. RFR, the best performing method, is characterized by its ensemble approach with multiple randomized trees and known for its robustness in the test data set. It is generally known that RFR is especially suitable when multiple categorical variables are involved, as in our case. The main results support the robustness and good performance of RFR.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Candidates and Optimal Values of Proposed Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Set of Considered Hyperparameters (The Selected Value is in the Gray Box) | Description |
|---|---|---|
| AdaBoost |  | The maximum number of estimators at which boosting is terminated. |
| Learning rate of shrinking the contribution of each regressor. | ||
| The loss function to use when updating the weights after each boosting iteration. | ||
| Linear Reg. | fit_intercept = True | Whether to calculate the intercept for this model. |
| CART |  | The maximum depth of the tree. |
| The number of features to consider when looking for the best split. | ||
| The minimum number of samples required to split an internal node. | ||
| The minimum number of samples required to be at a leaf node. | ||
| SVR |  | Penalty parameter C of the error term. |
| ANN |  | The number of neurons in a single hidden layer. |
| The activation function for the hidden layer. | ||
| Learning rate schedule for weight updates. | ||
| The maximum number of iterations. | ||
| k-NN |  | The number of neighbors to use by default. |
| The algorithm used to compute the nearest neighbors. | ||
| Weight function used in the prediction | ||
| RFR |  | The number of trees in the forest. |
| The maximum depth of the tree. | ||
| The number of features to consider when looking for the best split. | ||
| The minimum number of samples required to split an internal node. | ||
| The minimum number of samples required to be at a leaf node. |
| Radiation | Vapor Pressure |
 |  |
| Surface Temperature | Atmospheric Pressure |
 |  |
| Method | Set of Considered Hyperparameters (The Selected Value is in the Gray Box) | Description |
|---|---|---|
| AdaBoost |  | The maximum number of estimators at which boosting is terminated. |
| Learning rate of shrinking the contribution of each regressor. | ||
| The loss function to use when updating the weights after each boosting iteration. | ||
| Linear Reg. | fit_intercept = True | Whether to calculate the intercept for this model. |
| CART |  | The maximum depth of the tree. |
| The number of features to consider when looking for the best split. | ||
| The minimum number of samples required to split an internal node. | ||
| The minimum number of samples required to be at a leaf node. | ||
| SVR |  | Penalty parameter C of the error term. |
| ANN |  | The number of neurons in a single hidden layer. |
| The activation function for the hidden layer. | ||
| Learning rate schedule for weight updates. | ||
| The maximum number of iterations. | ||
| k-NN |  | The number of neighbors to use by default. |
| The algorithm used to compute the nearest neighbors. | ||
| Weight function used in the prediction. | ||
| RFR |  | The number of trees in the forest. |
| The maximum depth of the tree. | ||
| The number of features to consider when looking for the best split. | ||
| The minimum number of samples required to split an internal node. | ||
| The minimum number of samples required to be at a leaf node. |
References
- Kim, S.; Jung, J.-Y.; Sim, M. Machine Learning Methods for Solar Power Generation Prediction based on Weather Forecast. In Proceedings of the 6th International Conference on Big Data Applications and Services (BigDAS2018), Zhengzhou, China, 19–22 August 2018. [Google Scholar]
- Suri, M.; Huld, T.; Dunlop, E.D. Geographic aspects of photovoltaics in Europe: Contribution of the PVGIS website. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2008, 1, 34–41. [Google Scholar] [CrossRef]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de-Pison, F.J.; Antonanzas-Torres, F. Review of photovoltaic power forecasting. Sol. Energy 2016, 15, 78–111. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Kalogirou, S.; Nivet, M.L.; Paoli, C.; Motte, F.; Fouilloy, A. Machine learning methods for solar radiation forecasting: A review. Renew. Energy 2017, 1, 569–582. [Google Scholar] [CrossRef]
- Abedinia, O.; Raisz, D.; Amjady, N. Effective prediction model for Hungarian small-scale solar power output. IET Renew. Power Gener. 2017, 11, 1648–1658. [Google Scholar] [CrossRef]
- Abuella, M.; Chowdhury, B. Improving Combined Solar Power Forecasts Using Estimated Ramp Rates: Data-driven Post-processing Approach. IET Renew. Power Gener. 2018, 12, 1127–1135. [Google Scholar] [CrossRef]
- Chaouachi, A.; Kamel, R.M.; Nagasaka, K. Neural network ensemble-based solar power generation short-term forecasting. J. Adv. Comput. Intell. Intell. Inform. 2010, 14, 69–75. [Google Scholar] [CrossRef]
- Hossain, M.R.; Oo, A.M.; Ali, A.S. Hybrid prediction method of solar power using different computational intelligence algorithms. In Proceedings of the Power Engineering Conference (AUPEC), Christchurch, New Zealand, 26 September 2012. [Google Scholar]
- Li, L.L.; Cheng, P.; Lin, H.C.; Dong, H. Short-term output power forecasting of photovoltaic systems based on the deep belief net. Adv. Mech. Eng. 2017, 9, 1687814017715983. [Google Scholar] [CrossRef]
- David, M.; Ramahatana, F.; Trombe, P.J.; Lauret, P. Probabilistic forecasting of the solar irradiance with recursive ARMA and GARCH models. Sol. Energy 2016, 133, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Pedro, H.T.; Coimbra, C.F. Assessment of forecasting techniques for solar power production with no exogenous inputs. Sol. Energy 2012, 86, 2017–2028. [Google Scholar] [CrossRef]
- Phinikarides, A.; Makrides, G.; Kindyni, N.; Kyprianou, A.; Georghiou, G.E. ARIMA modeling of the performance of different photovoltaic technologies. In Proceedings of the 39th Photovoltaic Specialists Conference (PVSC), Tampa, FL, USA, 16–21 June 2013. [Google Scholar]
- Hassan, J. ARIMA and regression models for prediction of daily and monthly clearness index. Renew. Energy 2014, 68, 421–427. [Google Scholar] [CrossRef]
- Alzahrani, A.; Shamsi, P.; Dagli, C.; Ferdowsi, M. Solar irradiance forecasting using deep neural networks. Procedia Comput. Sci. 2017, 114, 304–313. [Google Scholar] [CrossRef]
- Abdel-Nasser, M.; Mahmoud, K. Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Comput. Appl. 2017, 1–4. [Google Scholar] [CrossRef]
- Sharma, N.; Gummeson, J.; Irwin, D.; Shenoy, P. Cloudy computing: Leveraging weather forecasts in energy harvesting sensor systems. In Proceedings of the 7th Annual IEEE Communications Society Conference, Sensor Mesh and Ad Hoc Communications and Networks (SECON), Boston, MA, USA, 21 June 2010. [Google Scholar]
- Sharma, N.; Sharma, P.; Irwin, D.; Shenoy, P. Predicting solar generation from weather forecasts using machine learning. In Proceedings of the 2nd IEEE International Conference, Smart Grid Communications (SmartGridComm), Brussels, Belgium, 17–20 October 2011. [Google Scholar]
- Amrouche, B.; Le Pivert, X. Artificial neural network based daily local forecasting for global solar radiation. Appl. Energy 2014, 130, 333–341. [Google Scholar] [CrossRef]
- Zamo, M.; Mestre, O.; Arbogast, P.; Pannekoucke, O. A benchmark of statistical regression methods for short-term forecasting of photovoltaic electricity production, part I: Deterministic forecast of hourly production. Sol. Energy 2014, 105, 792–803. [Google Scholar] [CrossRef]
- Gensler, A.; Henze, J.; Sick, B.; Raabe, N. Deep Learning for solar power forecasting-An approach using AutoEncoder and LSTM Neural Networks. In Proceedings of the 2016 IEEE International Conference, Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9 October 2016. [Google Scholar]
- Andrade, J.R.; Bessa, R.J. Improving renewable energy forecasting with a grid of numerical weather predictions. IEEE Trans. Sustain. Energy 2017, 8, 1571–1580. [Google Scholar] [CrossRef]
- Leva, S.; Dolara, A.; Grimaccia, F.; Mussetta, M.; Ogliari, E. Analysis and validation of 24 hours ahead neural network forecasting of photovoltaic output power. Math. Comput. Simul. 2017, 131, 88–100. [Google Scholar] [CrossRef] [Green Version]
- Persson, C.; Bacher, P.; Shiga, T.; Madsen, H. Multi-site solar power forecasting using gradient boosted regression trees. Sol. Energy 2017, 150, 423–436. [Google Scholar] [CrossRef]
- Detyniecki, M.; Marsala, C.; Krishnan, A.; Siegel, M. Weather-based solar energy prediction. In Proceedings of the 2012 IEEE International Conference, Fuzzy Systems (FUZZ-IEEE), Brisbane, Australia, 10 June 2012. [Google Scholar]
- Bacher, P.; Madsen, H.; Nielsen, H.A. Online short-term solar power forecasting. Sol. Energy 2009, 83, 1772–1783. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Jain, K.K.; Sharma, A. Solar cells: In research and applications—A review. Mater. Sci. Appl. 2015, 6, 1145. [Google Scholar] [CrossRef]
- Mori, H.; Takahashi, A. A data mining method for selecting input variables for forecasting model of global solar radiation. In Proceedings of the 2012 IEEE PES, Transmission and Distribution Conference and Exposition (T&D), Orlando, FL, USA, 7–10 May 2012. [Google Scholar]
- Voyant, C.; Paoli, C.; Muselli, M.; Nivet, M.L. Multi-horizon solar radiation forecasting for Mediterranean locations using time series models. Renew. Sustain. Energy Rev. 2013, 28, 44–52. [Google Scholar] [CrossRef]
- Pedro, H.T.; Coimbra, C.F. Nearest-neighbor methodology for prediction of intra-hour global horizontal and direct normal irradiances. Renew. Energy 2015, 80, 770–782. [Google Scholar] [CrossRef]
- Lee, K.; Kim, W.J. Forecasting of 24 hours Ahead Photovoltaic Power Output Using Support Vector Regression. J. Korean Inst. Inf. Technol. 2016, 14, 175–183. [Google Scholar] [CrossRef]
- Almeida, M.P.; Perpinan, O.; Narvarte, L. PV power forecast using a nonparametric PV model. Sol. Energy 2015, 115, 354–368. [Google Scholar] [CrossRef] [Green Version]
- Song, J.J.; Jeong, Y.S.; Lee, S.H. Analysis of prediction model for solar power generation. J. Digit. Converg. 2014, 12, 243–248. [Google Scholar] [CrossRef] [Green Version]
- Yona, A.; Senjyu, T.; Funabshi, T.; Sekine, H. Application of neural network to 24-hours-ahead generating power forecasting for PV system. IEEJ Trans. Power Energy 2008, 128, 33–39. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Appl. Predict. Model, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Voyant, C.; Soubdhan, T.; Lauret, P.; David, M.; Muselli, M. Statistical parameters as a means to a priori assess the accuracy of solar forecasting models. Energy 2015, 90, 671–679. [Google Scholar] [CrossRef] [Green Version]
- Kalogirou, S.A. Artificial neural networks in renewable energy systems applications: A review. Renew. Sustain. Energy Rev. 2001, 5, 373–401. [Google Scholar] [CrossRef]
- Breiman, L. Classification and Regression Trees, 1st ed.; Routledge: New York, NY, USA, 1984. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]





| Source | Variable Name | Description | |
|---|---|---|---|
| Dependent variable | Power plant | Generation | Solar power generation (kWh) |
| Independent variable | Weather forecast ( | RainfallType | 0: none, 1: rain, 2: rain/snow, 3: snow |
| SkyType | 1: sunny, 2: a little cloudy, 3: cloudy, 4: overcast | ||
| WindDirection | 1: west, 2: east, 3: south, 4: north | ||
| WindSpeed | Wind speed (m/s) | ||
| Humidity | Humidity (%) | ||
| Temperature | Temperature (°C) | ||
| Elevation | Solar Elevation (0°–90°) by Stellarium® | ||
| Weather observation ( | Radiation | Radiation (MJ/m2) | |
| VaporPressure | Vapor pressure (hPa) | ||
| SurfaceTemperature | Surface temperature (°C) | ||
| AtmosphericPressure | Atmospheric Pressure (hPa) | ||
| Derived variables | Weeknum | Weekly index (1–53) | |
| TimeZone | 1: 09:00–12:00, 2: 12:00–15:00, 3: 15:00–18:00, 4: 18:00–21:00 |
| Radiation | 0.128 | 97.0 |
| VaporPressure | 0.743 | 99.3 |
| SurfaceTemperature | 1.252 | 98.7 |
| AtmosphericPressure | 4.288 | 72.4 |
| Algorithm | Base Model | Main Model | Improvement | |||
|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | ||||
| AdaBoost | 669.5 | 0.604 | 609.2 | 0.672 | 60.3 (9.0%) | 0.068 |
| Linear Reg. | 635.5 | 0.643 | 608.6 | 0.673 | 26.9 (4.2%) | 0.030 |
| CART | 619.2 | 0.661 | 607.9 | 0.673 | 11.3 (−1.8%) | 0.012 |
| SVR | 689.9 | 0.579 | 605.7 | 0.676 | 84.2 (12.2%) | 0.097 |
| ANN | 606.0 | 0.675 | 597.4 | 0.684 | −8.6 (1.4%) | 0.009 |
| k-NN | 630.2 | 0.649 | 596.4 | 0.686 | −35.8 (5.7%) | 0.037 |
| RFR | 581.5 | 0.701 | 577.5 | 0.705 | 4.0 (−0.7%) | 0.004 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-G.; Jung, J.-Y.; Sim, M.K. A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning. Sustainability 2019, 11, 1501. https://doi.org/10.3390/su11051501
Kim S-G, Jung J-Y, Sim MK. A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning. Sustainability. 2019; 11(5):1501. https://doi.org/10.3390/su11051501
Chicago/Turabian StyleKim, Seul-Gi, Jae-Yoon Jung, and Min Kyu Sim. 2019. "A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning" Sustainability 11, no. 5: 1501. https://doi.org/10.3390/su11051501
APA StyleKim, S. -G., Jung, J. -Y., & Sim, M. K. (2019). A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning. Sustainability, 11(5), 1501. https://doi.org/10.3390/su11051501