Software-Defined Networking Approaches for Link Failure Recovery: A Survey




Abstract
:1. Introduction
- Vendors are hesitant in providing the source code of the protocols to the developer and user community because of being afraid of unverified changes to their devices that can lead to malfunctions in the networks [10].
- The co-existence of data and control planes also leads to an improper utilization of the bandwidth [13], as it is shared by both the planes. Thus, the packets are broadcasted to the network, which leads to low link utilization. Similarly, the ball game gets worse as soon as there is a link failure because the system tries to search alternate paths in the network for packet broadcasting, leading to network congestion.
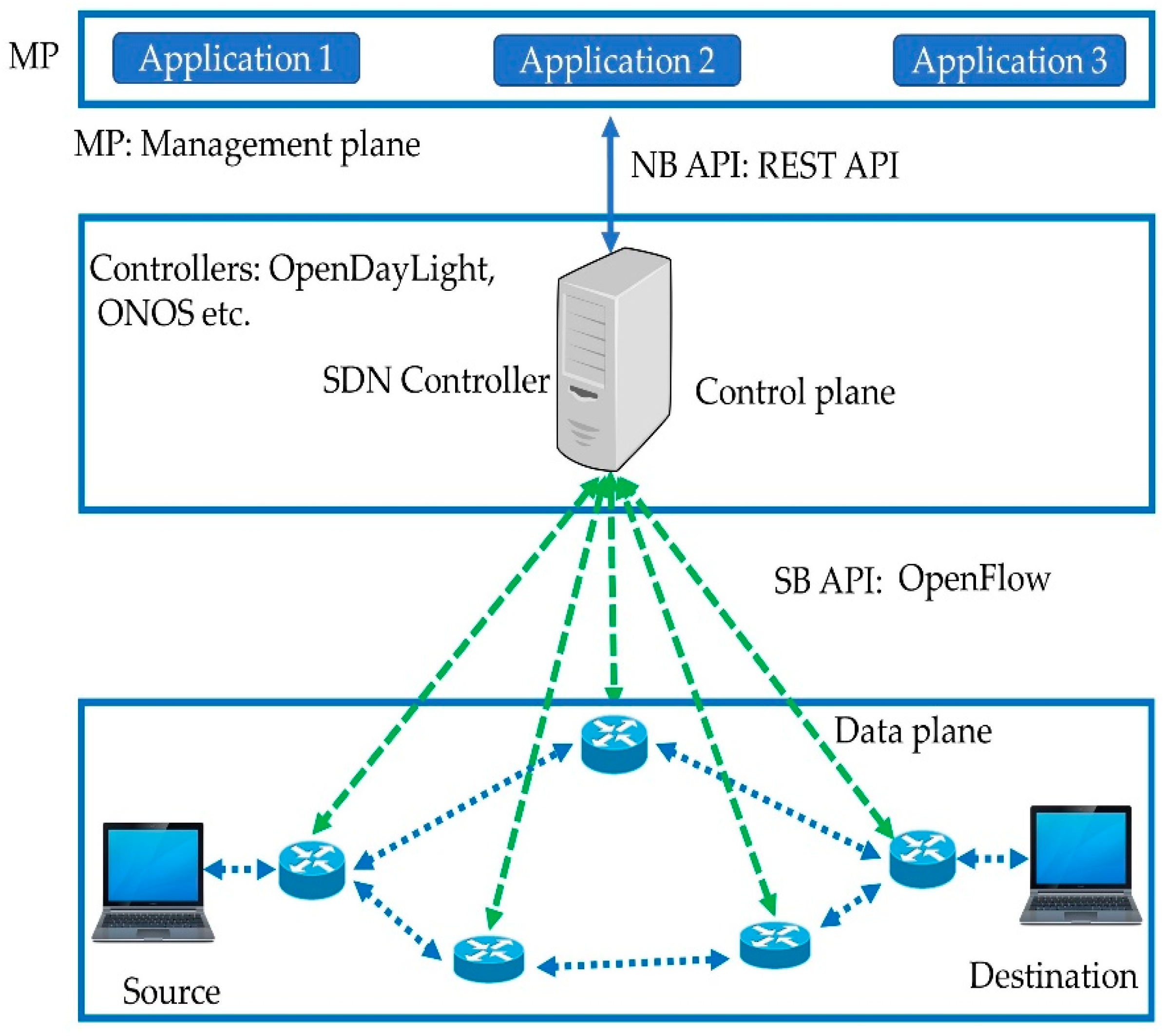
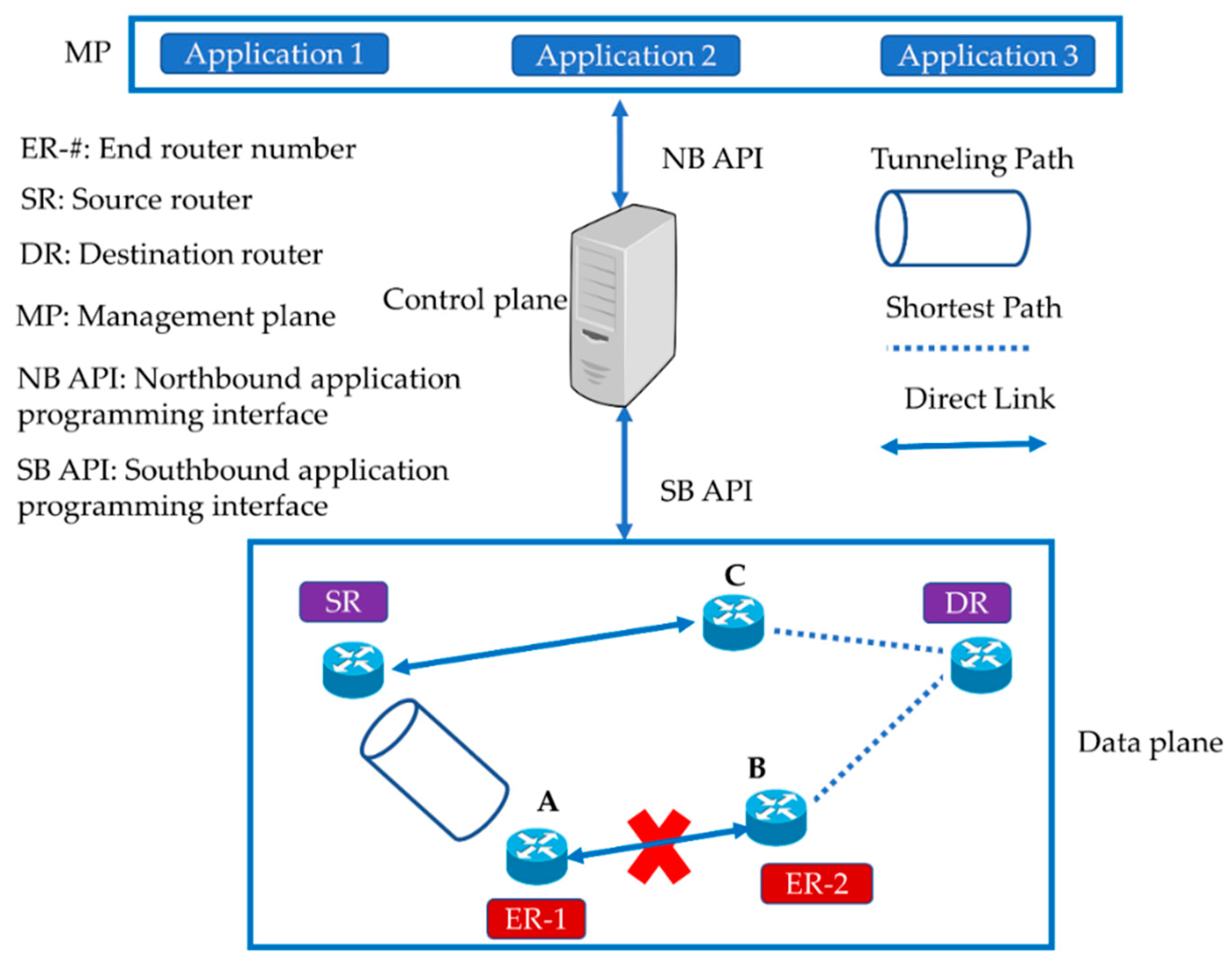
2. SDN Architecture
2.1. An Overview of SDN
2.2. A Global View of the Network
2.3. The Low Complexity of Data Plane
3. Link Failure Detection Mechanisms
4. Link Failure Recovery Approaches
4.1. Proactive Approaches in SDN for Link Failure Recovery
4.1.1. Link Status Detection with OpenFlow
4.1.2. BFD
4.1.3. SPIDER
4.1.4. Path Priority-Based Scheme
4.1.5. Congestion-Aware Proactive Schemes
4.1.6. Challenges in Proactive Recovery
- TCAM flow entries limitation: SDN switches have a limitation on the number of entries in their flow tables. State-of-the-art switches in the market can store up to 8000 flow rules. Therefore, the cost for TCAM [57] space can increase.
- Process of matching: In the proactive approach, the backup paths are preconfigured. Thus, it increases the number of flow entries in the switches, with a greater number of flow entries especially in large-scale networks. As discussed earlier, when a packet arrives at the data plane switch, it is matched with the flow entries to find the destination of the incoming packet. Consequently, this approach affects the process of matching the incoming packets to the switches.
- Large-scale networks: The proactive approach is not suitable for large-scale networks because of the enormous increase in the number of flow entries as the network scales upward caused by the presence of a preconfigured backup path for each switch in the data plane.
- Dynamic network conditions: There is a possibility that the backup path may fail earlier than the primary path owing to dynamic network updates. Therefore, when a link fails, the path configured proactively will not be available for routing the packets on the alternate path.
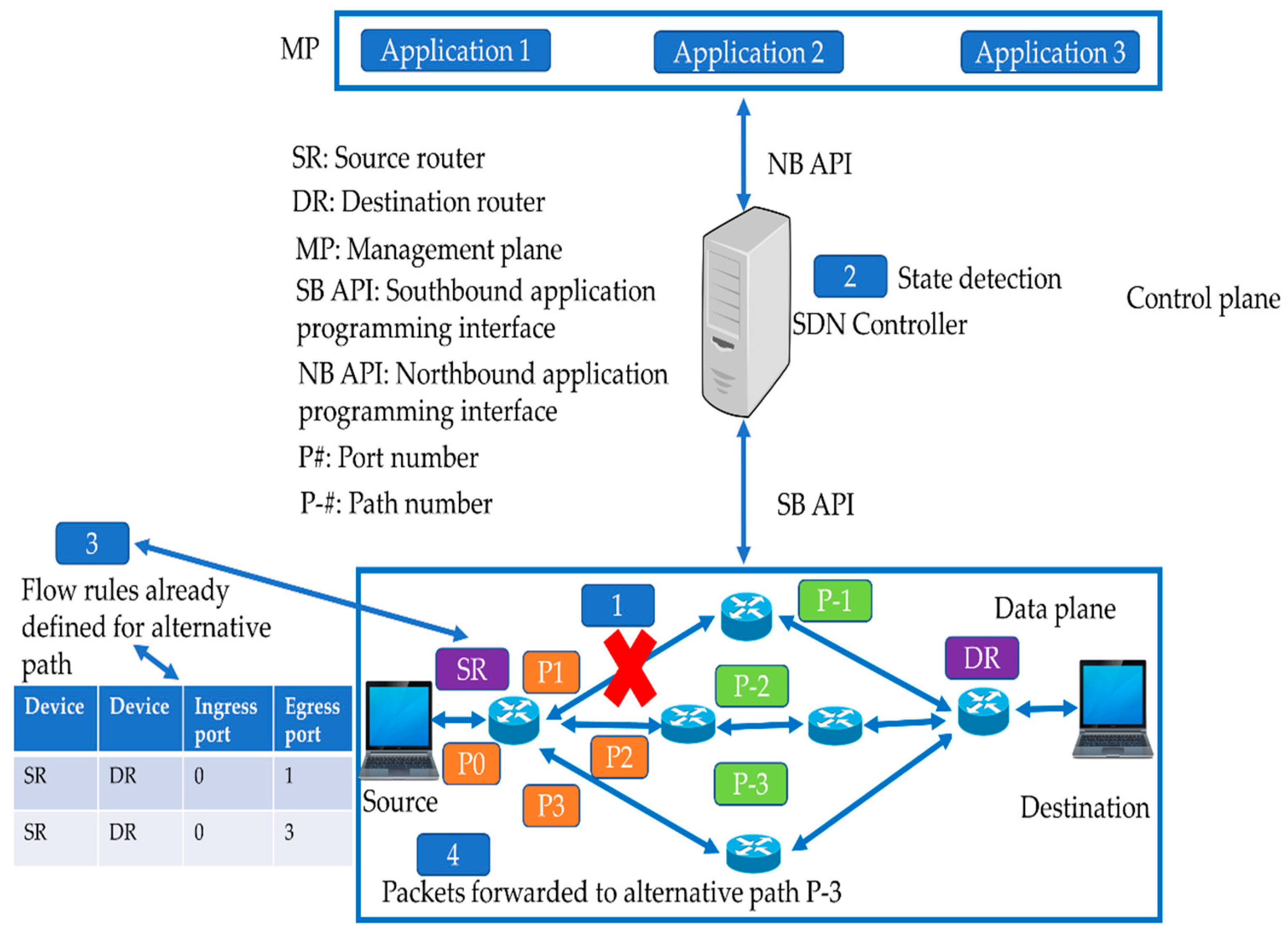
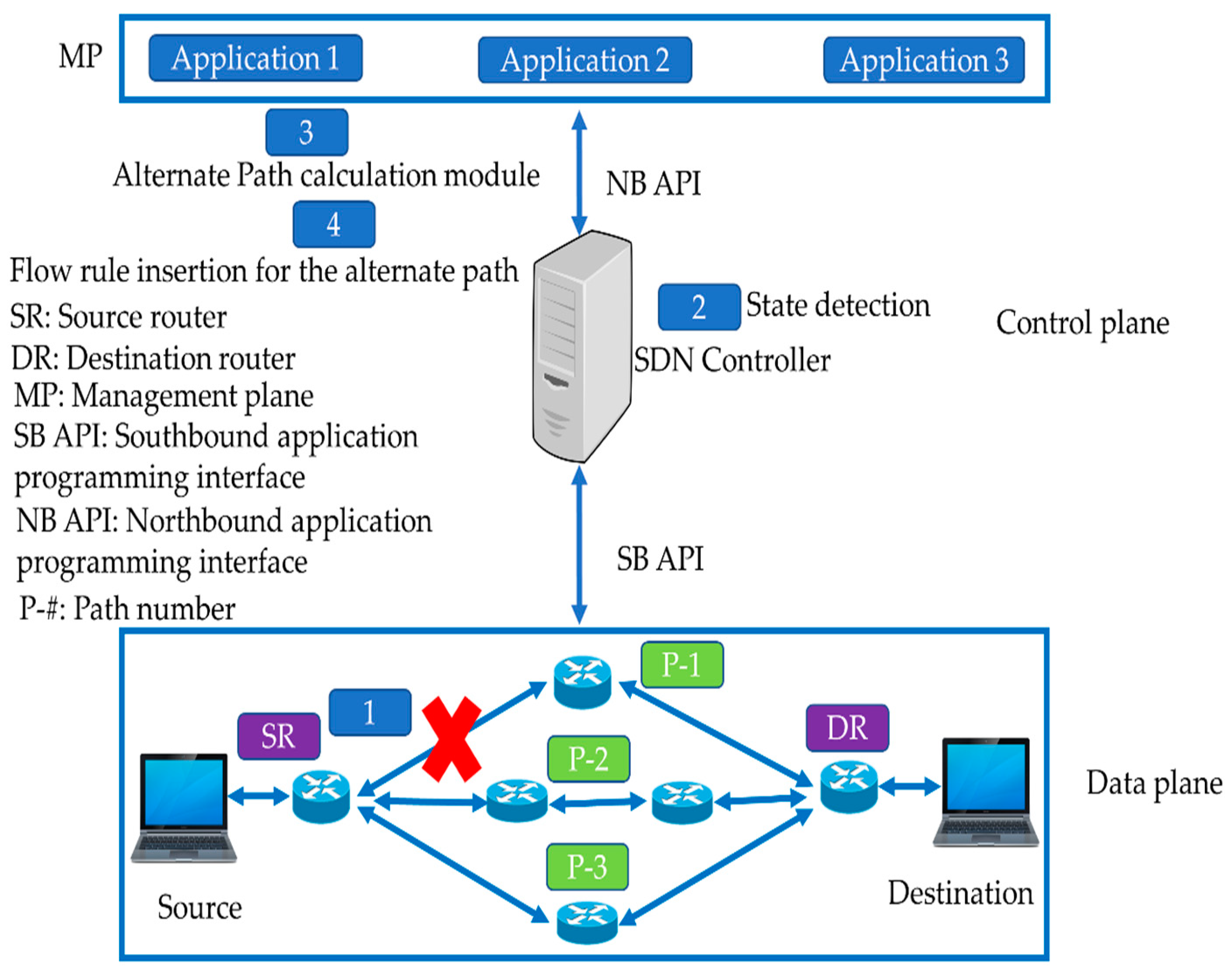
4.2. Reactive Approaches for Link Failure Recovery in SDN
- The controller monitors the status of the network by sending periodic heartbeat messages.
- The controller detects any case of failure.
- The controller searches an alternate path for the failed link.
- The controller deletes the old flow entries and adds new flow entries for the updated path in the SDN switches.
4.2.1. Reactive Approaches with the Shortest Path First
4.2.2. Reactive Approaches That Consider the Number of Flow Operations
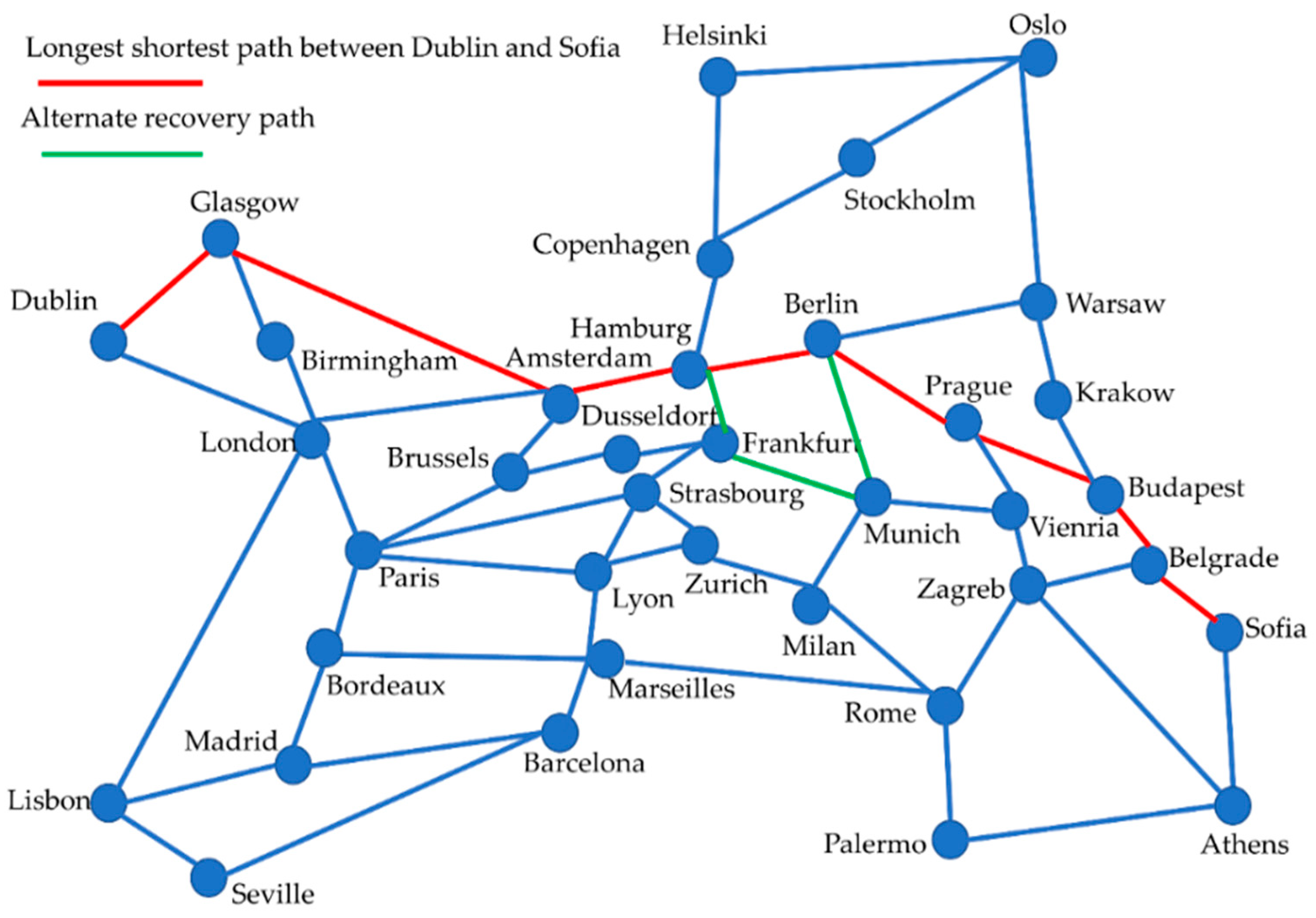
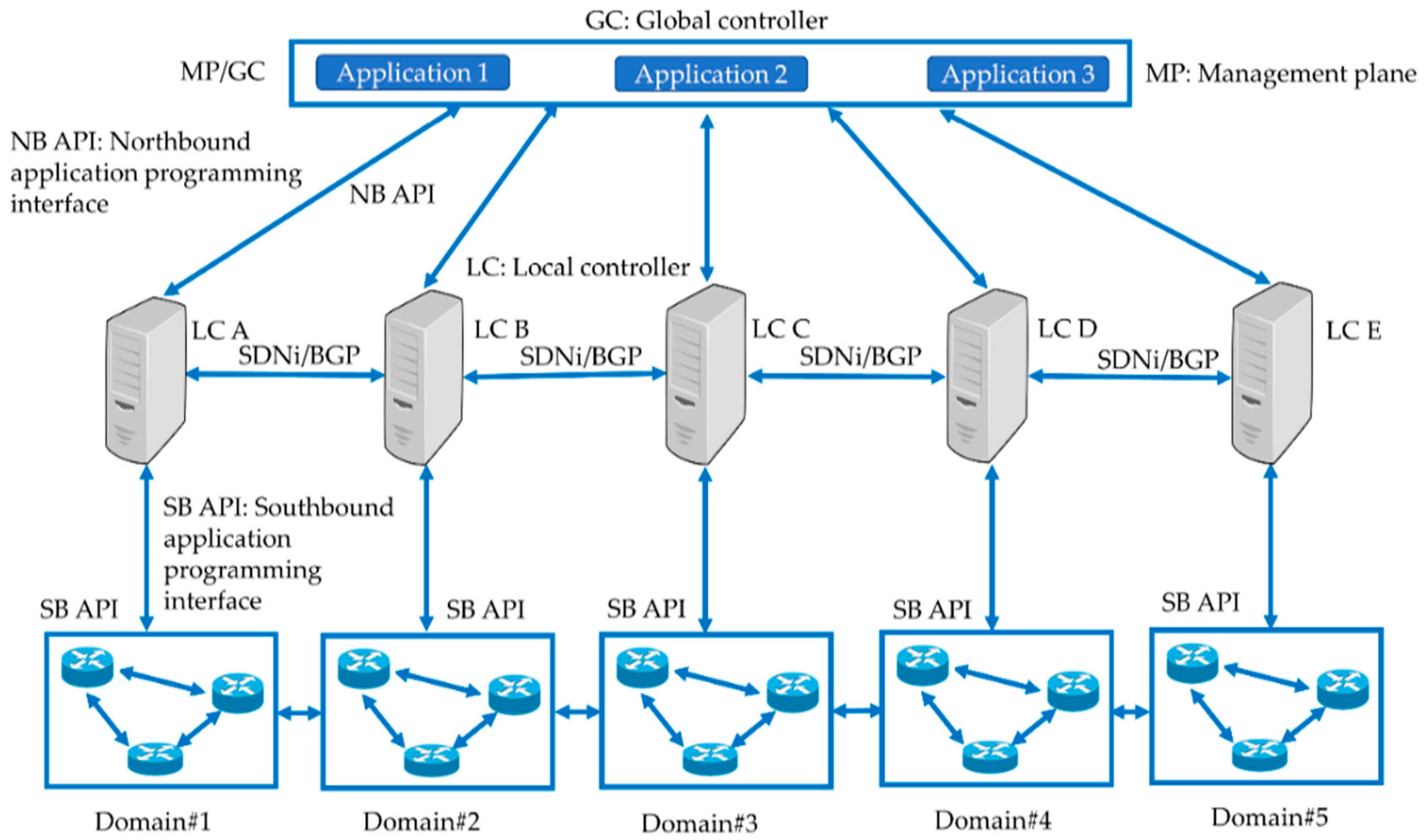
4.3. Large-Scale SDN
4.4. Hybrid SDN
4.5. Inter-Domain Approaches
4.6. In-Band Methods in SDN for Link Failure Recovery
4.7. ML in SDN for Link Failure Recovery
5. Application Scenarios
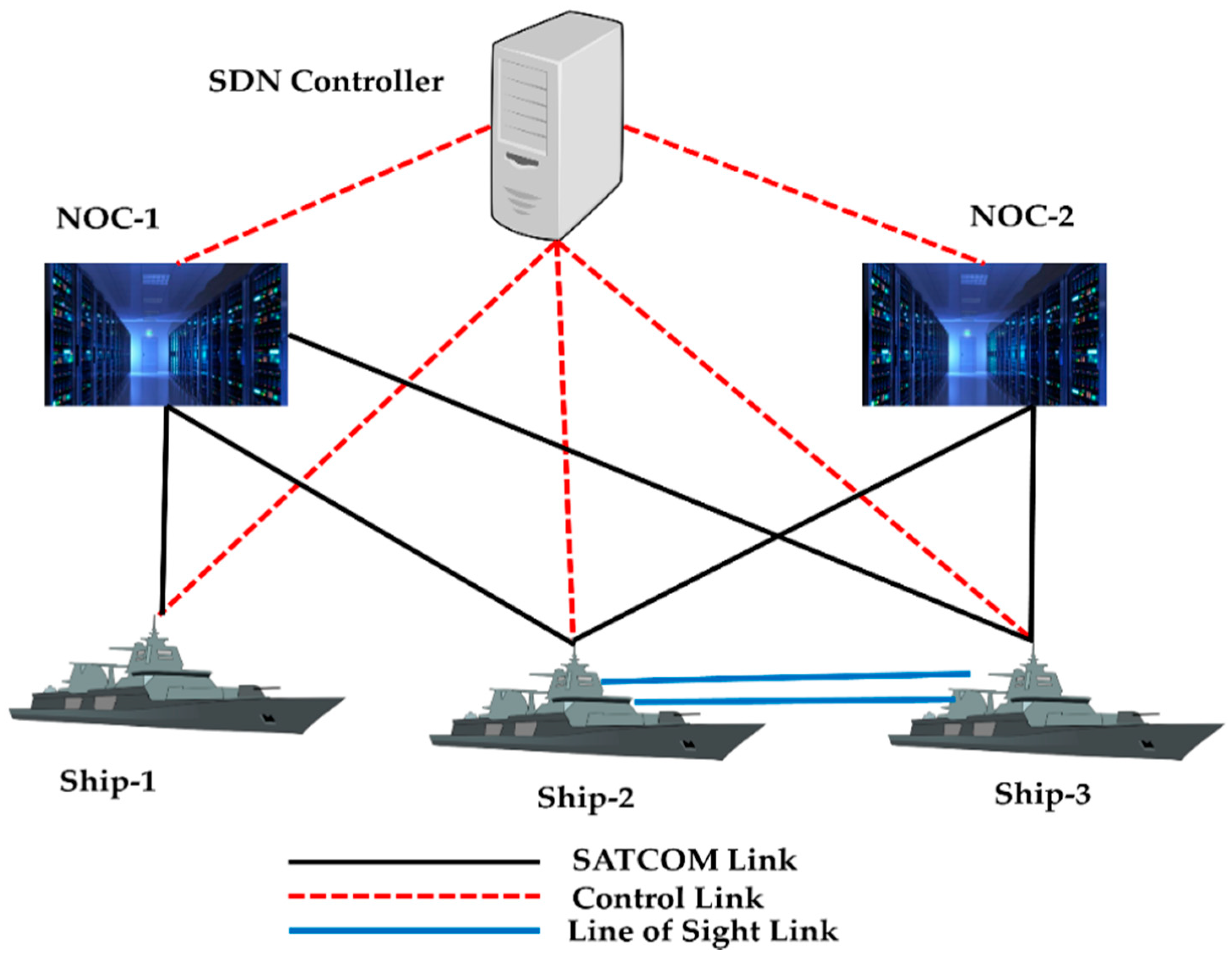
5.1. Link Failure Recovery in Tactical Networks
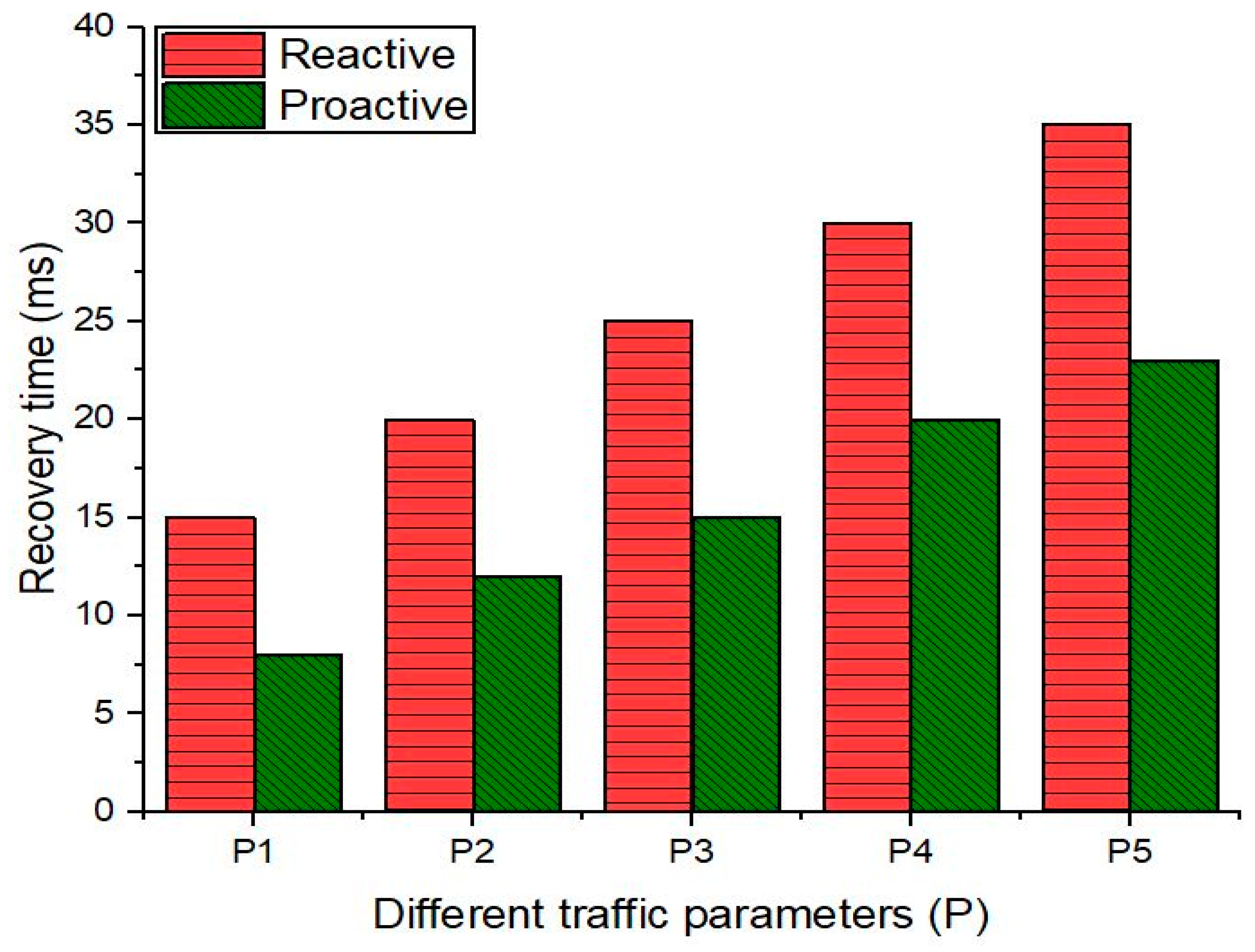
5.2. Experimental Setup and Calculation of Recovery Delay
- First, we configured the ODL controller in the proactive mode and then in the reactive mode.
- We implemented the Naval tactical and DCN topologies in the Mininet emulator by calling the IP address of the ODL controller.
- The link bandwidths for the Naval tactical network operation centers (NOC-1 and NOC-2) was 4 Mbps, whereas it was 6 Mbps for the ships Ship-1, Ship-2, and Ship-3.
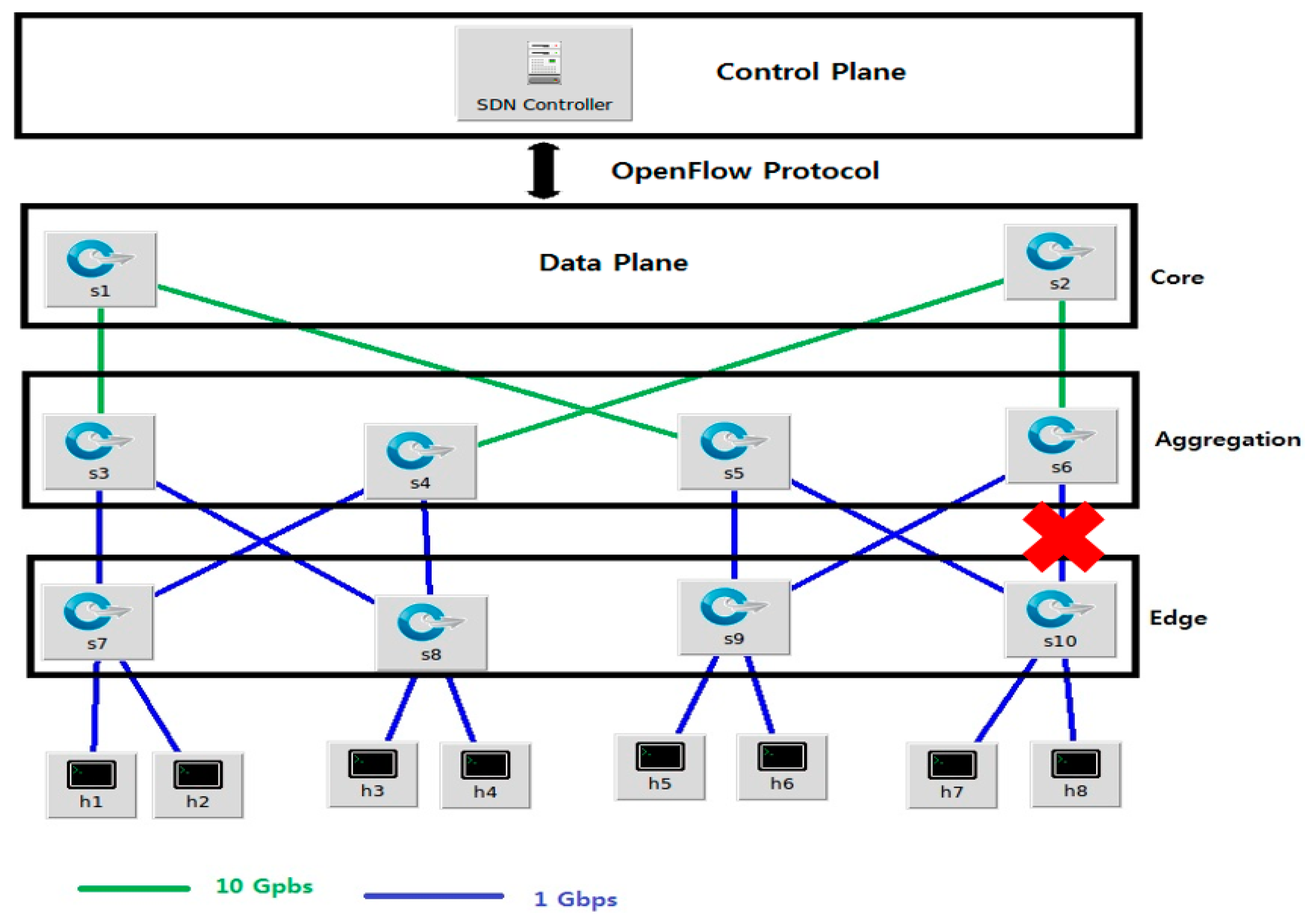
- The link bandwidth was 10 Gbps DCN core links and was 1 Gbps for the aggregate links.
- We then opened an x-terminal (a graphical terminal) on the source and destination hosts.
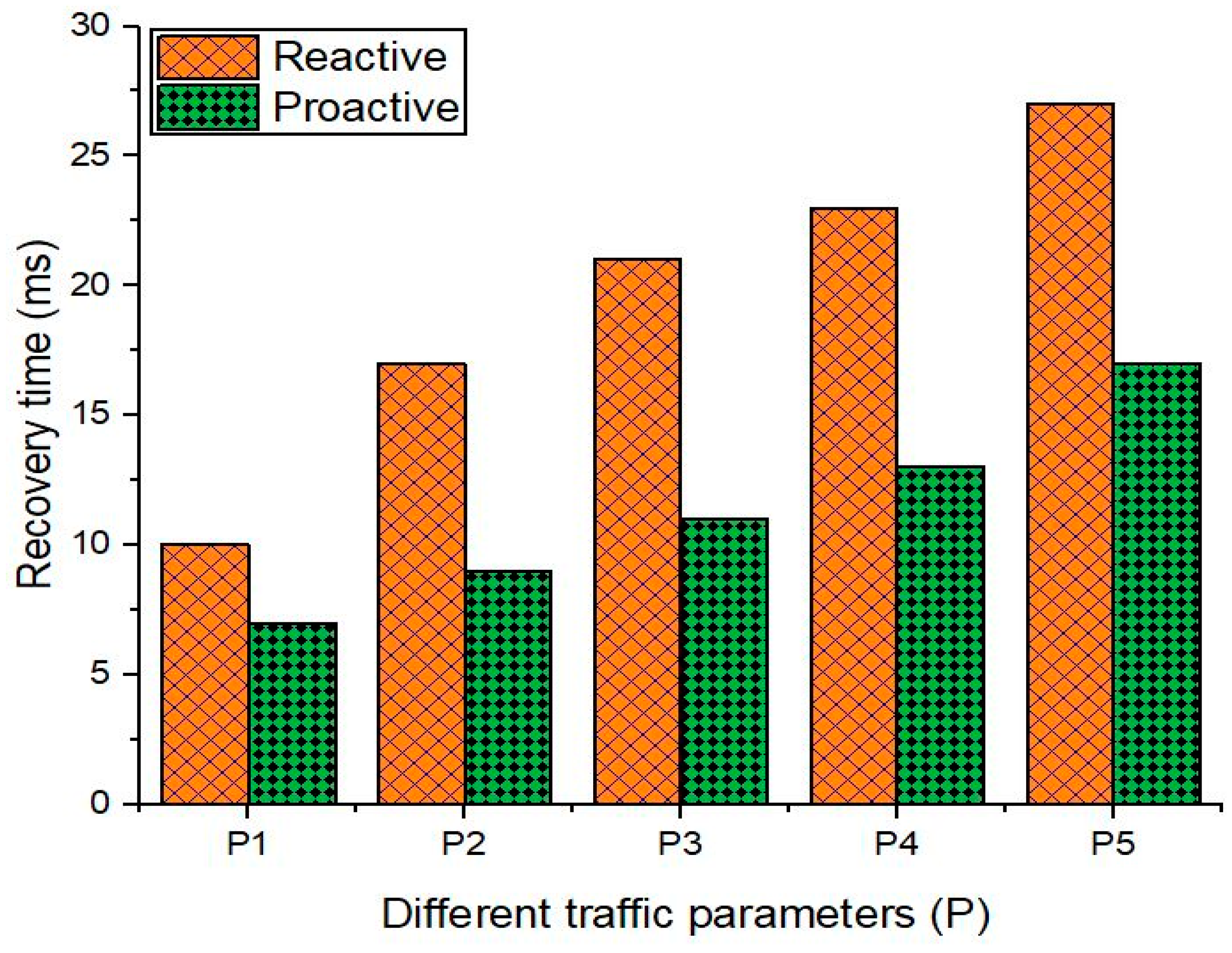
- We defined the traffic parameters to be used to evaluate the recovery delay as shown in Table 5.
- We employed a distributed internet traffic generator (D-ITG) [103] to initiate traffic between the source and destination hosts using the graphical terminals.
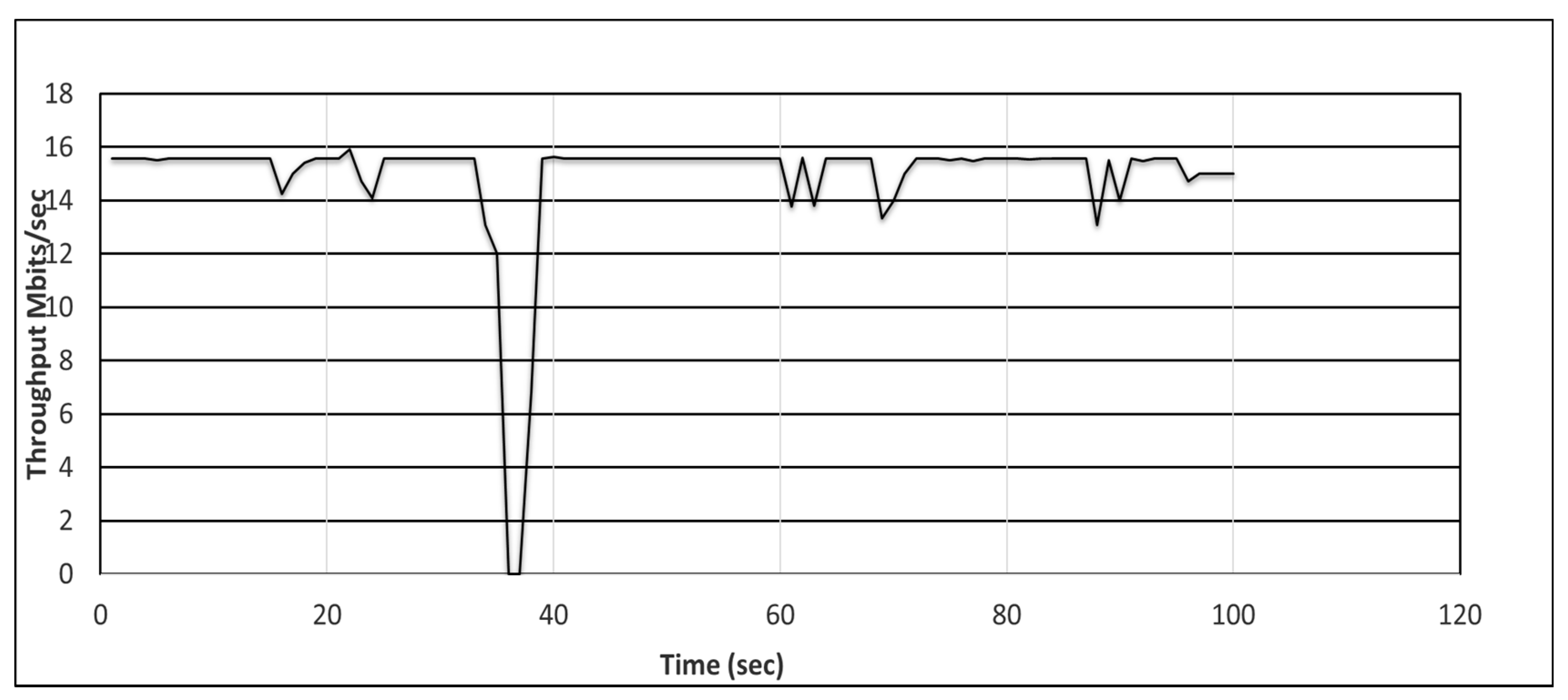
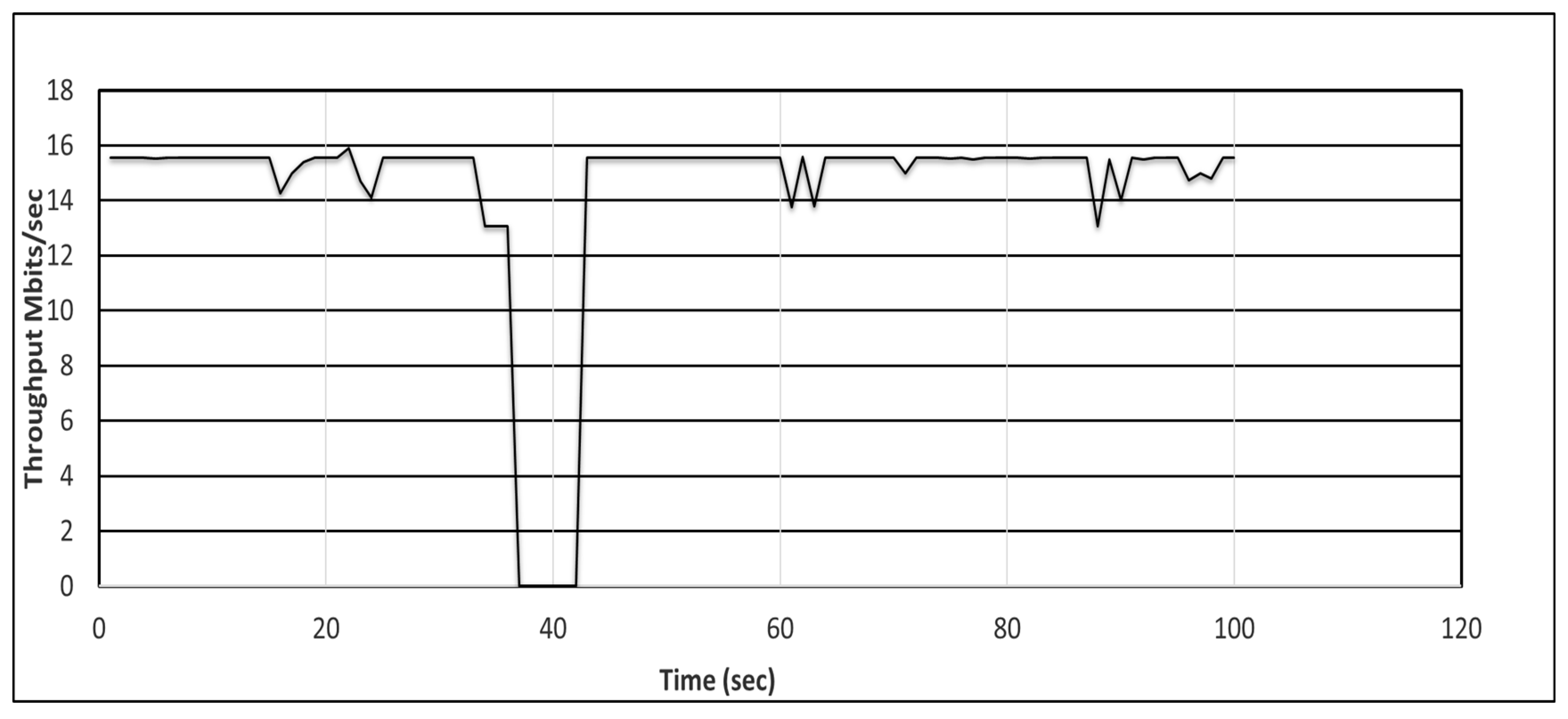
- We induced a link disruption (with link-down command) in the Mininet and recorded the delay using Equations (1) and (2) for the proactive and reactive schemes, respectively.
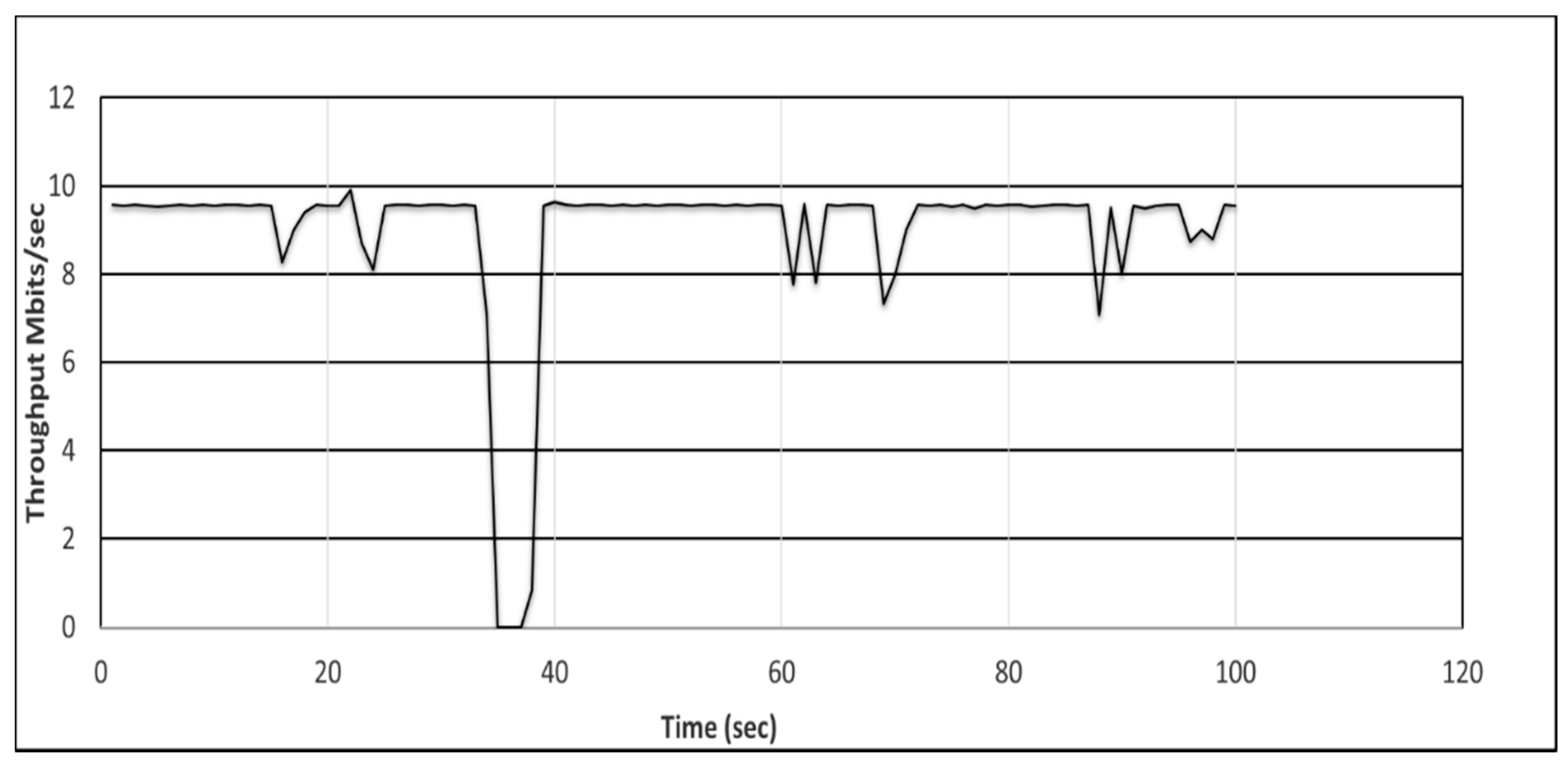
5.3. Evaluation of Proactive and Reactive Recovery in Tactical (Naval) Network
5.4. Link Failure Recovery in a Data Center Network
5.5. Testing Proactive and Reactive Recovery in DCN Using ODL Controller
6. Summary and Challenges of the SDN-Based Failure Recovery Approaches
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SDN | Software-defined networking |
| TCAM | Ternary content addressable memory |
| API | Application programming interface |
| NB/SB API | Northbound/Southbound API |
| E2E | end-to-end |
| BFD | Bidirectional forwarding protocol |
| ODL | OpenDaylight |
| BER | Bit-error-rate |
| SD-EON | Software-defined elastic optical network |
| SD-FRR | Software-defined fast re-routing |
| BGP | Border gateway protocol |
| CGN | Carrier grade network |
| FRR | Fast re-routing |
| LLDP | Link layer discovery protocol |
| RIP | Routing information protocol |
| OSPF | Open shortest path first protocol |
| AS | Autonomous system |
| STP | Spanning tree protocol |
| NOC | Network operations center |
| DCN | Data center network |
| ONOS | Open network operating system |
| QoS | Quality of service |
| QoE | Quality of experience |
| MPLS | Multi-protocol label switching |
| RSTP | Rapid spanning tree protocol |
| FDLM | Failure detection service with low mistake rates |
References
- Lara, A.; Kolasani, A.; Ramamurthy, B. Network Innovation Using OpenFlow: A Survey. IEEE Commun. Surv. Tutor. 2014, 16, 493–512. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Hao, Q.; Bao, K. A Survey on Software-Defined Network and OpenFlow: From Concept to Implementation. IEEE Commun. Surv. Tutor. 2014, 16, 2181–2206. [Google Scholar] [CrossRef]
- Ndiaye, M.; Hancke, G.P.; Abu-Mahfouz, A.M. Software Defined Networking for Improved Wireless Sensor Network Management: A Survey. Sensors 2017, 17, 1031. [Google Scholar] [CrossRef] [PubMed]
- Hakiri, A.; Berthou, P. Leveraging SDN for the 5G networks: Trends prospects and challenges. arXiv 2015, arXiv:1506.02876. [Google Scholar]
- Singh, S.; Jha, R.K. A Survey on Software Defined Networking: Architecture for Next Generation Network. J. Netw. Syst. Manag. 2017, 25, 321–374. [Google Scholar] [CrossRef]
- Rojas, E.; Doriguzzi-Corin, R.; Tamurejo, S.; Beato, A.; Schwabe, A.; Phemius, K.; Guerrero, C. Are We Ready to Drive Software-Defined Networks? A Comprehensive Survey on Management Tools and Techniques. ACM Comput. Surv. 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Retvari, G.; Csikor, L.; Tapolcai, J.; Enyedi, G.; Csaszar, A. Optimizing IGP link costs for improving IP-level resilience. In Proceedings of the 8th International Workshop on the Design of Reliable Communication Networks (DRCN), Krakow, Poland, 10–12 October 2011; pp. 62–69. [Google Scholar]
- Gill, P.; Jain, N.; Nagappan, J. Understanding Network Failures in Data Centers: Measurement, Analysis, and Implications. In ACM SIGCOMM Computer Communication Review; ACM: Toronto, ON, Canada, 2011; Volume 41, pp. 350–361. [Google Scholar]
- Benson, T.; Akella, A.; Maltz, D. Unraveling the complexity of network management. In Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, NSDI’09, USENIX Association, Berkeley, CA, USA, 22–24 April 2009; pp. 335–348. [Google Scholar]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling Innovation in Campus Networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Hedrick, C. Routing Information Protocol; Tech. Rep. RFC1058; Rutgers University: New Brunswick, NJ, USA, 1988. [Google Scholar]
- Moy, J.T. OSPF Version 2, Tech. Rep. RFC2328; IETF: USA, 1988.
- Sezer, S.; Scott-Hayward, S.; Chouhan, P.; Fraser, B.; Lake, D.; Finnegan, J.; Viljoen, N.; Miller, M.; Rao, N. Are we ready for SDN? Implementation challenges for software-defined networks. Commun. Mag. IEEE 2013, 51, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, R.; Zhang, B.; Pei, D.; Zhang, L.; Izhak-Ratzin, R. Quantifying path exploration on the Internet. IEEE/ACM Trans. Netw. 2009, 17, 445–458. [Google Scholar] [CrossRef]
- Caesar, M.; Rexford, J. BGP routing policies in ISP networks. IEEE Netw. 2005, 19, 5–11. [Google Scholar] [CrossRef]
- Mcpherson, D.; Gill, V.; Walton, D.; Retana, A. Border Gateway Protocol (BGP) Persistent Route Oscillation Condition, Tech. Rep. RFC 3345; RFC Editor: USA, 2002.
- Griffin, T.G.; Wilfong, G. An analysis of BGP convergence properties. ACM SIGCOMM Comput. Commun. Rev. 1999, 29, 277–288. [Google Scholar] [CrossRef] [Green Version]
- Vilchez, J.M.S.; Yahia, I.G.B.; Crespi, N.; Rasheed, T.; Siracusa, D. Softwarized 5G networks resiliency with self-healing. In Proceedings of the 1st International Conference on 5G for Ubiquitous Connectivity (5GU), Akaslompolo, Finland, 26–28 November 2014; pp. 229–233. [Google Scholar]
- Zahariadis, T.; Voulkidis, A.; Karkazis, P.; Trakadas, P. Preventive maintenance of critical infrastructures using 5G networks drones. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–4. [Google Scholar]
- Rizou, S.; Athanasoulis, P.; Andriani, P.; Iadanza, F.; Carrozzo, G.; Breitgand, D.; Weit, A.; Griffin, D.; Jimenez, D.; Acar, U.; et al. A service platform architecture enabling programmable edge-to-cloud virtualization for the 5G media industry. In Proceedings of the 2018 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Valencia, Spain, 6–8 Jun 2018; pp. 1–6. [Google Scholar]
- Akyildiz, I.F.; Su, Y.; Sankarasubramaniam, Y.; Cayirci, E. Wireless sensor networks: A survey. Comput. Netw. 2002, 38, 393–422. [Google Scholar] [CrossRef] [Green Version]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A roadmap for traffic engineering in SDN—OpenFlow networks. Comput. Netw. 2014, 71, 1–30. [Google Scholar] [CrossRef]
- da Rocha, F.; Paulo, C.; Edjard, S.M. A survey on fault management in software-defined networks. IEEE Commun. Surv. Tutor. 2017, 19, 2284–2321. [Google Scholar]
- Muthumanikandan, V.; Valliyammai, C. A survey on link failures in software defined networks. In Proceedings of the 2015 Seventh International Conference on Advanced Computing (ICoAC), Chennai, India, 15–17 December 2015. [Google Scholar]
- Software-Defined Networking: The New Norm for Networks; ONF White Paper; Open Networking Foundation: Palo Alto, CA, USA, 2012.
- Crawshaw, J. NETCONF/YANG: What’s Holding Back Adoption & How to Accelarate It; Heavy Reading Reports; New York, NY, USA, 2017; Available online: https://www.oneaccess-net.com/images/public/wp_heavy_reading.pdf (accessed on 7 April 2020).
- POX Controller. Available online: https://github.com/noxrepo/pox (accessed on 10 January 2020).
- OpenDaylight. Available online: https://www.opendaylight.org/ (accessed on 3 February 2020).
- ONOS. Available online: http://onosproject.org/ (accessed on 20 February 2020).
- Floodlight. Available online: http://www.projectfloodlight.org/ (accessed on 11 January 2020).
- RYU. Available online: https://osrg.github.io/ryu/ (accessed on 7 March 2020).
- Kozat, U.C.; Liang, G.; Kokten, K. On diagnosis of forwarding plane via static forwarding rules in software defined networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Toronto, ON, Canada, 27 April–2 May 2014; pp. 1716–1724. [Google Scholar]
- Lee, S.S.W.; Li, K.Y.; Chan, K.Y.; Lai, G.H.; Chung, Y.C. Path layout planning and software based fast failure detection in survivable OpenFlow networks. In Proceedings of the 2014 10th International Conference on the Design of Reliable Communication Networks (DRCN), Ghent, Belgium, 1–3 April 2014; pp. 1–8. [Google Scholar]
- Lee, S.S.W.; Li, K.Y.; Chan, K.Y.; Lai, G.H.; Chung, Y.C. Software-based fast failure recovery for resilient OpenFlow networks. In Proceedings of the 2015 7th International Workshop on Reliable Networks Design and Modeling (RNDM), Munich, Germany, 5–7 October 2015; pp. 194–200. [Google Scholar]
- Ahr, D.; Reinelt, G. A tabu search algorithm for the min–max k-Chinese postman problem. Comput. Oper. Res. 2006, 33, 3403–3422. [Google Scholar] [CrossRef]
- Van Andrichem, N.L.M.; Van Asten, B.J.; Kuipers, F.A. Fast Recovery in Software-Defined Networks. In Proceedings of the 2014 Third European Workshop on Software Defined Networks, London, UK, 1–3 September 2014. [Google Scholar]
- Wang, L.; Chang, R.F.; Lin, E.; Yik, J. Apparatus for Link Failure Detection on High Availability Ethernet Backplane. US Patent 7,260,066, 21 August 2007. [Google Scholar]
- Levi, D.; Harrington, D. Definitions of Managed Objects for Bridges with Rapid Spanning Tree Protocol; RFC 4318 (Proposed Standard); Internet Engineering Task Force: Fremont, CA, USA, December 2005. [Google Scholar]
- Katz, D.; Ward, D. Bidirectional Forwarding Detection (BFD); RFC 5880 (Proposed Standard); Internet Engineering Task Force: Fremont, CA, USA, 2010. [Google Scholar]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Openflow: Meeting carrier-grade recovery requirements. Comput. Commun. 2013, 36, 656–665. [Google Scholar] [CrossRef]
- Lin, Y.D.; Teng, H.Y.; Hsu, C.R.; Liao, C.C.; Lai, Y.C. Fast failover and switchover for link failures and congestion in software defined networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Yang, T.W.; Wang, K. Failure Detection Service with Low Mistake Rates for SDN Controllers. In Proceedings of the 2016 18th Asia-Pacific Network Operations and Management Symposium (APNOMS), Kanazawa, Japan, 5–7 October 2016. [Google Scholar]
- Kempf, J.; Bellagamba, E.; Kern, A.; Jocha, D.; Takacs, A. Scalable fault management for OpenFlow. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 6606–6610. [Google Scholar]
- Aggarwal, R.; Kompella, K.; Nadeau, T.; Swallow, G. Bidirectional Forwarding Detection (BFD) for MPLS Label Switched Paths (LSPs); RFC 5884, RFC 7726; Internet Engineering Task Force: Fremont, CA, USA, 2010. [Google Scholar]
- Gyllstrom, D.; Braga, N.; Kurose, J. Recovery from link failures in a smart grid communication network using OpenFlow. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 254–259. [Google Scholar]
- Liu, L.; Choi, H.Y.; Tsuritani, T.; Morita, I.; Casellas, R.; Martinez, R.; Munoz, R. First proof-of-concept demonstration of OpenFlowcontrolled elastic optical networks employing flexible transmitter/receiver. In Proceedings of the International Conference on Photonics in Switching, Corsica, France, 11–14 September 2012; p. 5. [Google Scholar]
- Muthumanikandan, V.; Valliyammai, C.; Deepa, B.S. Switch Failure Detection in Software-Defined Networks. Adv. Big Data Cloud Comput. 2019, 750, 155–162. [Google Scholar]
- Cascone, C.; Sanvito, D.; Pollini, L.; Capone, A.; Sansò, B. Fast failure detection and recovery in SDN with stateful data plane. Int. J. Netw. Manag. 2017, 27, e1957. [Google Scholar] [CrossRef]
- Padma, V.; Yogesh, P. Proactive failure recovery in OpenFlow based Software Defined Networking. In Proceedings of the 3rd International Conference on Signal Processing, Communication and Networking (ICSCN), Chennai, India, 26–28 March 2015; pp. 1–6. [Google Scholar]
- Huang, L.; Shen, Q.; Shao, W. Congestion Aware Fast Link Failure Recovery of SDN Network Based on Source Routing. KSII Trans. Internet Inf. Syst. 2017, 11, 5200–5222. [Google Scholar]
- Capone, A.; Cascone, C.; Nguyen, A.Q.T.; Sanso, B. Detour planning for fast and reliable failure recovery in SDN with OpenState. In Proceedings of the International Conference on Design of Reliable Communication Networks, Kansas City, MO, USA, 24–27 March 2015; pp. 25–32. [Google Scholar]
- Ramos, R.M.; Martinello, M.; Rothenberg, C.E. SlickFlow: Resilient source routing in Data Center Networks unlocked by OpenFlow. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks, Sydney, Australia, 21–24 October 2013; pp. 606–613. [Google Scholar]
- Siminesh, C.N.; Grace, M.K.E.; Ranjitha, K. A proactive flow admission and re-routing scheme for load balancing and mitigation of congestion propagation in sdn data plane. Int. J. Comput. Netw. Commun. 2019, 10, 2018. [Google Scholar]
- Soliman, M.; Nandy, B.; Lambadaris, I.; Ashwood-Smith, P. Exploring source routed forwarding in SDN-based WANs. In Proceedings of the 2014 IEEE International Conference on Communications, Sydney, Australia, 10–14 June 2014; pp. 3070–3075. [Google Scholar]
- Soliman, M.; Nandy, B.; Lambadaris, I.; Ashwood-Smith, P. Source routed forwarding with software defined control, considerations and implications. In Proceedings of the 2012 ACM Conference on CONEXT Student Workshop, Nice, France, 10 December 2012; pp. 43–44. [Google Scholar]
- Sangeetha Abdu, J.; Dong, M.; Godfrey, P.B. Towards a flexible data center fabric with source routing. In Proceedings of the 2015 1st ACM SIGCOMM Symposium on Software Defined Networking Research, Santa Clara, CA, USA, 17–18 June 2015; pp. 1–8. [Google Scholar]
- Kreutz, D.; Ramos, F.M.V.; Veríssimo, P.E.; Rothenberg, C.E.; Azodolmolky, S.; Uhlig, S. Software-defined networking: A comprehensive survey. Proc. IEEE 2015, 103, 14–76. [Google Scholar] [CrossRef] [Green Version]
- Chang, D.F.; Govindan, R.; Heidemann, J. The temporal and topological characteristics of bgp path changes in Network Protocols. In Proceedings of the 11th IEEE International Conference on Network Protocols, 2003, Proceedings, Atlanta, GA, USA, 4–7 November 2003; pp. 190–199. [Google Scholar]
- Francois, P.; Bonaventure, O.; Decraene, B.; Coste, P.A. Avoiding disruptions during maintenance operations on bgp sessions. IEEE Trans. Netw. Serv. Manag. 2007, 4, 2007. [Google Scholar] [CrossRef]
- Iannaccone, G.; Chuah, C.N.; Mortier, R.; Bhattacharyya, S.; Diot, C. Analysis of link failures in an ip backbone. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet Measurment, Marseille, France, 6–8 November 2002; ACM: New York, NY, USA, 2002; pp. 237–242. [Google Scholar]
- Vissicchio, S.; Vanbever, L.; Pelsser, C.; Cittadini, L.; Francois, P.; Bonaventure, O. Improving network agility with seamless bgp reconfigurations. IEEE/ACM Trans. Netw. (TON) 2013, 21, 990–1002. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Enabling fast failure recovery in openflow networks. In Proceedings of the 2011 8th International Workshop on the Design of Reliable Communication Networks (DRCN), Kraków, Poland, 10–12 October 2011; pp. 164–171. [Google Scholar]
- Muthumanikandan, V.; Valliyammai1, C. Link Failure Recovery Using Shortest Path Fast Rerouting Technique in SDN. Wirel. Pers. Commun. 2017, 97, 2475–2495. [Google Scholar] [CrossRef]
- Astaneh, S.A.; Heydari, S.S. Optimization of SDN_ow operations in multi-failure restoration scenarios. IEEE Trans. Netw. Serv. Manag. 2016, 13, 421–432. [Google Scholar] [CrossRef]
- Astaneh, S.; Heydari, S.S. Multi-failure restoration with minimal flow operations in software defined networks. In Proceedings of the 2015 11th International Conference on the Design of Reliable Communication Networks (DRCN), Kansas City, MO, USA, 24–27 March 2015; pp. 263–266. [Google Scholar]
- Jin, X.; Liu, H.H.; Gandhi, R.; Kandula, S.; Mahajan, R.; Zhang, M.; Rexford, J.; Wattenhofer, R. Dynamic scheduling of network updates. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 539–550. [Google Scholar] [CrossRef]
- Malik, A.; Aziz, B.; Adda, M.; Ke, C.H. Optimisation Methods for Fast Restoration of Software-Defined Networks. IEEE Access 2017, 5, 16111–16123. [Google Scholar] [CrossRef] [Green Version]
- Maesschalck, S.D.; Colle, D.; Lievens, I.; Pickavet, M.; Demeester, P.; Muaz, C.; Jaeger, M.; Inkret, R.; Mikac, B.; Derkacz, J. Pan-European optical transport networks: An availability-based comparison. Photon. Netw. Commun. 2003, 5, 203–225. [Google Scholar] [CrossRef]
- Voellmy, A.; Wang, J. Scalable software defined network controllers. In Proceedings of the 2012 ACM SIGCOMM Conference, Helsinki, Finland, 13–17 August 2012; ACM: New York, NY, USA, 2012; pp. 289–290. [Google Scholar]
- Karakus, M.; Durresi, A. A Survey: Control Plane Scalability Issues and Approaches in Software-Defined Networking (SDN). Comput. Netw. 2017, 112, 279–293. [Google Scholar] [CrossRef] [Green Version]
- Qiu, K.; Yuan, J.; Zhao, J.; Wang, X.; Secci, S.; Fu, X. Efficient Recovery Path Computation for Fast Reroute in Large-scale Software Defined Networks. IEEE J. Sel. Areas Commun. 2018, 37, 1755–1768. [Google Scholar] [CrossRef] [Green Version]
- Abdelaziz, A.; Fong, A.T.; Gani, A.; Garba, U.; Khan, S.; Akhunzada, A.; Talebian, H.; Choo, K.W.R. Distributed controller clustering in software defined networks. PLoS ONE 2017. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sinha, Y.; Haribabu, K. A survey: Hybrid SDN. J. Netw. Comput. Appl. 2017, 100, 35–55. [Google Scholar]
- Caesar, M.; Caldwell, D.; Feamster, N.; Rexford, J.; Shaikh, A.; van der Merwe, J. Design and implementation of a routing control platform. In Proceedings of the 2nd Conference on Symposium on Networked Systems Design&Implementation-Volume 2, Boston, MA, USA, 2 May 2005; USENIX Association: Berkeley, CA, USA, 2005; pp. 15–28. [Google Scholar]
- Jin, C.; Lumezanu, C.; Xu, Q.; Zhang, Z.L.; Jiang, G. Telekinesis: Controlling legacy switch routing with OpenFlow in hybrid networks. In Proceedings of the 1st ACM SIGCOMM Symposium on Software Defined Networking Research, Santa Clara, CA, USA, 17–18 June 2015; ACM: New York, NY, USA, 2015; p. 20. [Google Scholar]
- Tilmans, O.; Vissicchio, S.; Vanbever, L.; Rexford, J. Fibbing in action: On-demand load-balancing for better video delivery. In Proceedings of the ACM SIGCOMM 2016 Conference, Florianopolis, Brazil, 22–26 August 2016; ACM: New York, NY, USA, 2016; pp. 619–620. [Google Scholar]
- Chu, C.Y.; Xi, K.; Luo, M.; Chao, H.J. Congestion-Aware Single Link Failure Recovery in Hybrid SDN Networks. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Kowloon, Hong Kong, 26 April–1 May 2015. [Google Scholar]
- Rothenberg, C.E.; Nascimento, M.R.; Salvador, M.R.; Correa, C.N.A.; Lucena, S.C.D.; Raszuk, R. Revisiting routing control platforms with the eyes and muscles of software-defined networking. In Proceedings of the first ACM SIGCOMM workshop on HotSDN, Helsinki, Finland, 13 August 2012; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar]
- Vissicchio, S.; Vanbever, L.; Cittadini, L.; Xie, G.; Bonaventure, O. Safe Updates of Hybrid SDN Networks. IEEE/ACM Trans. Netw. 2017, 25, 1649–1662. [Google Scholar] [CrossRef]
- Kvalbein, A.; Hansen, A.F.; Cicic, T.; Gjessing, S.; Lysne, O. Fast ip network recovery using multiple routing configurations. In Proceedings of the IEEE INFOCOM, Barcelona, Spain, 23–29 April 2006. [Google Scholar]
- Suchara, M.; Xu, D.; Doverspike, R.; Johnson, D.; Rexford, J. Network architecture for joint failure recovery and traffic engineering. ACM SIGMETRICS Perform. Eval. Rev. 2011, 39, 97–108. [Google Scholar]
- Reitblatt, M.; Canini, M.; Guha, A.; Foster, N. Fattire: Declarative fault tolerance for software-defined networks. In Proceedings of the second ACM SIGCOMM Workshop on HotSDN, Hong Kong, China, August 2013 ; Association for Computing Machinery: New York, NY, USA, 2013. [Google Scholar]
- Vissicchio, S.; Vanbever, L.; Bonaventure, O. Opportunities and research challenges of hybrid software defined networks. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 70–75. [Google Scholar] [CrossRef]
- Vissicchio, S.; Vanbever, L.; Cittadini, L.; Xie, G.G.; Bonaventure, O. Safe routing reconfigurations with route redistribution. In Proceedings of the IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 199–207. [Google Scholar]
- Chun-xiu, L.; Xin, L.; Ke, L.; Hong, Z.; Yu-long, S.; Shan-zhi, C. Toward software defined AS-level fast rerouting. J. China Univ. Posts Telecommun. 2014, 21, 100–108. [Google Scholar]
- Rekhter, Y.; Li, T. A Border Gateway Protocol 4 BGP-4; ARPANET Working Group Requests for Comment; RFC-1771; DDN Network Information Center: Menlo Park, CA, USA, March 1995. [Google Scholar]
- Skoldstrom, P.; Yedavalli, K. Network Virtualization and Resource Allocation in OpenFlow-Based Wide Area Networks. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012. [Google Scholar]
- OpenFlow Reference Switch Implementation. Available online: http://www.openflow.org/ (accessed on 27 January 2020).
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Fast failure recovery for in-band OpenFlow netwoks. In Proceedings of the 2013 9th International Conference on the Design of Reliable Communication Networks (DRCN), Budapest, Hungary, 4–7 March 2013. [Google Scholar]
- Schiff, L.; Schmid, S.; Canini, M. Medieval: Towards A Self-Stabilizing Plug & Play In-Band SDN Control Network. In Proceedings of the ACM Sigcomm Symposium on SDN Research (SOSR), Santa Clara, CA, USA, 17–18 June 2015. [Google Scholar]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. In-Band Control Queuing and Failure Recovery Functionalities for OpenFlow. IEEE Netw. 2016, 30, 106–112. [Google Scholar] [CrossRef] [Green Version]
- Schiff, L.; Kuznetsov, P.; Schmid, S. In-Band Synchronization for Distributed SDN Control Planes. SIGCOMM Comput. Commun. Rev. 2016, 46, 37–43. [Google Scholar] [CrossRef]
- Evans, D. The Internet of Things: How the Next Evolution of the Internet Is Changing Everything; White Paper; Cisco: San Jose, CA, USA, 2011. [Google Scholar]
- Xu, W.; Zhou, H.; Cheng, N.; Lyu, F.; Shi, W.; Chen, J.; Shen, X. Internet of Vehicles in Big Data Era. IEEE/CAA J. Autom. Sin. 2018, 5, 19–35. [Google Scholar] [CrossRef]
- Wang, M.; Cui, Y.; Wang, X.; Xiao, S.; Jiang, J. Machine Learning for Networking: Workflow, Advances and Opportunities. IEEE Netw. 2018, 32, 92–99. [Google Scholar] [CrossRef] [Green Version]
- Klaine, P.V.; Imran, M.A.; Onireti, O.; Souza, R.D. A survey of machine learning techniques applied to self-organizing cellular networks. IEEE Commun. Surv. Tutor. 2017, 19, 2392–2431. [Google Scholar] [CrossRef] [Green Version]
- Khunteta, S.; Chavva, A.K.R. Deep Learning Based Link Failure Mitigation. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017. [Google Scholar]
- Srinivasan, S.M.; Truong-Huu, T.; Gurusamy, M. TE-Based Machine Learning Techniques for Link Fault Localization in Complex Networks. In Proceedings of the IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud), Barcelona, Spain, 6–8 August 2018. [Google Scholar]
- Truong-Huu, T.; Mohan, P.M. Fast and Adaptive Failure Recovery using Machine Learning in Software Defined Networks. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019. [Google Scholar]
- Dilmaghani, R.; Bottin, T. Evaluation of Software-Defined Networking for Mission Operations. In Proceedings of the 21st International Command and Control Research and Technology Symposium (ICCRTS), London, UK, 6–8 September 2016. [Google Scholar]
- Du, P.; Pang, E.; Braun, T.; Gerla, M.; Hoffmannn, C.; Kim, J. Traffic Optimization in Software Defined Naval Network for Satellite Communications. In Proceedings of the IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017. [Google Scholar]
- Lantz, B.; Heller, B.; McKeown, N. A Network in a Laptop: Rapid Prototyping for Software-Defined Networks. In Proceedings of the 9th ACM Workshop on Hot Topics in Networks, Monterey, CA, USA, 20–21 October 2010. [Google Scholar]
- Botta, A.; Dainotti, A.; Pescape, A. A Tool for the Generation of Realistic Network Workload for Emerging Networking Scenarios. In Computer Networks; Elsevier: Amsterdam, The Netherlands, 2012; Volume 56, pp. 3531–3547. [Google Scholar]
- Huang, W.Y.; Chou, T.Y.; Hu, J.W.; Liu, T.L. Automatical end to end topology discovery and ow viewer on SDN. In Proceedings of the 2014 28th International Conference on Advanced Information Networking and Applications Workshops (WAINA), Victoria, BC, Canada, 13–16 May 2014; pp. 910–915. [Google Scholar]
- Iperf. Available online: https://iperf.fr/ (accessed on 23 March 2020).
- Lebiednik, B.; Mangal, A.; Tiwari, N. A survey and evaluation of data center network topologies. arXiv 2016, arXiv:1605.01701. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Failure Detection Schemes | Mechanism for Detection | Problems |
|---|---|---|
| Circle paths monitoring [32,33] | Monitoring cycles | Minimizing the number of hops on the paths |
| Monitoring cycles [34,35] | Heuristic | Detection process is slow |
| OpenFlow based [36,37] | Heartbeat messages | Cannot ensure a delay of <50 ms |
| STP or RSTP [38] | Port status updating | Cannot ensure delay for modern technologies |
| Bidirectional forwarding detection (BFD) [36,39,40,41] | Exchange of hello packets | Large number of hello packet exchanges |
| FDLM [42] | Heartbeat messages | Cannot ensure a delay of <50 ms |
| MPLS BFD [43,44] | Packet generators | Large number of packet generators |
| Recovery in smart grids [45] | Packet tagging/BER threshold monitoring using OpenFlow | OpenFlow limitations |
| SDN-EON [46] | BER threshold monitoring/alarms | Applicable for optical networks only |
| SFD [47] | Packet loss ratio | Limited to node failures |
| Papers Reference | Proactive (P) | Reactive (R) | Large-Scale | Hybrid | Inter-Domain | In-Band | Machine Learning | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | P | R | P | R | P | R | P | R | |||
| [48,49,50,51,52,53,54,55,56,57,58,59,60,61,62] | √ | |||||||||||
| [63,64,65,66,67,68,69] | √ | |||||||||||
| [70,71,72,73] | √ | |||||||||||
| [74,75,76,77,78,79,80,81,82,83,84] | √ | |||||||||||
| [85] | √ | |||||||||||
| [86,87] | √ | |||||||||||
| [88,89,90,91] | √ | |||||||||||
| [92,93] | √ | |||||||||||
| [94,95,96,97,98] | √ | |||||||||||
| [99,100] | √ | |||||||||||
| Issues | Proactive | Reactive |
|---|---|---|
| Routing updates | Periodic advertisements | Requested when a failure occurs in the data plane |
| TCAM space | TCAM space limitation | More TCAM space |
| Match flow operations | More flow matching | Fewer flow entries matching |
| Configuration | Hard, because of the large number of backup paths | Easy |
| Dynamic network updates | No | Yes |
| Flow entries matching | More, because backup paths exist | Less, because the path is discovered on failure |
| Switches processing | High, due to more flow matching | Low |
| Controller overhead | Low | High |
| Switches overhead | High | Low |
| Latency | Small, due to preconfigured path | More, due to flow insertion delay |
| Routing overhead | Proportional to the number of switches in the data plane | Proportional to the number of nodes on the communication path |
| Routing information access | From the switches in the data plane | With controller interruption, discovery by the routing algorithm |
| Scalability | Not scalable for large networks | Scalable for large networks |
| Examples | Provided in [48,49,50,51,52,53,54,55,56,57,58,59,60,61] | Provided in [62,63,64,65,66,67] |
| Failure Recovery Scheme | Research Issues | Disadvantages |
|---|---|---|
| Large-scale SDN | Flow insertion delay minimization [69,70] | Large recovery delay |
| Efficient algorithms for re-routing the packets [71] | Complexity of algorithms running on SDN controller | |
| Synchronization among distributed controllers [72] | Inconsistency of information | |
| Hybrid SDN | Communication between traditional and SDN-based switches/routers [73,74,75,76,78,79,80,81] | Interoperability |
| Congestion and load balancing [77] | No consideration of a scenario with nil link failures in the network | |
| E2E synchronization of different domains [83] | BGP limitations on inter-domain co-ordination | |
| Inter-domain | Complex network update process [84] | Distributed control of E2E information |
| Increased overhead of SDN controllers [85] | High processing overhead | |
| In-band SDN | Efficient bandwidth utilization [87] | Inefficient utilization of resources |
| Increase in recovery delay [88] | High probability of backup timer delay | |
| Single point of failure [89] | Low performance, network collapse on controller failure | |
| Synchronization of distributed control plane [90,91] | Separation of control plane traffic from data plane traffic | |
| Consistency, reliability, performance [92] | Large delay | |
| ML | Limited to traditional networks [95,96,97,98] | Vendor interoperability |
| SVM, DT, RF, NN, LR [99], the flow match in switches will increase | No assurance of controller service in case of anomalies/attacks |
| Parameter | Payload Length (bytes) | Traffic Rate (Packets/sec) | Time (in Seconds) | TCP/UDP |
|---|---|---|---|---|
| P1 | 6000 | 60,000 | 100 | UDP |
| P2 | 7000 | 70,000 | 100 | TCP |
| P3 | 8000 | 80,000 | 100 | TCP |
| P4 | 9000 | 90,000 | 100 | TCP |
| P5 | 10,000 | 100,000 | 100 | TCP |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, J.; Lee, G.-m.; Roh, B.-h.; Ryu, D.K.; Park, G. Software-Defined Networking Approaches for Link Failure Recovery: A Survey. Sustainability 2020, 12, 4255. https://doi.org/10.3390/su12104255
Ali J, Lee G-m, Roh B-h, Ryu DK, Park G. Software-Defined Networking Approaches for Link Failure Recovery: A Survey. Sustainability. 2020; 12(10):4255. https://doi.org/10.3390/su12104255
Chicago/Turabian StyleAli, Jehad, Gyu-min Lee, Byeong-hee Roh, Dong Kuk Ryu, and Gyudong Park. 2020. "Software-Defined Networking Approaches for Link Failure Recovery: A Survey" Sustainability 12, no. 10: 4255. https://doi.org/10.3390/su12104255
APA StyleAli, J., Lee, G. -m., Roh, B. -h., Ryu, D. K., & Park, G. (2020). Software-Defined Networking Approaches for Link Failure Recovery: A Survey. Sustainability, 12(10), 4255. https://doi.org/10.3390/su12104255