Enabling Packet Classification with Low Update Latency for SDN Switch on FPGA

Abstract
:1. Introduction
- A novel architecture for packet classification, SplitBV. SplitBV divides the ruleset into independent sub-rulesets and uses BV-based pipelines to match the sub-rulesets in parallel.
- A recursive splitting algorithm based on greedy sorting, SplitAL. SplitAL first determines the searching steps of matching fields based on greedy strategy and then employs a constrained recursive algorithm to resolve the problem of exponential computational complexity.
- A hybrid matching pipeline on FPGA, SplitHP. SplitHP contains a hash element for mapping different sub-rulesets into different two-dimensional pipeline consisted of processing elements (PEs, proposed in [24])).
2. Background
2.1. Multi-Field Packet Classification
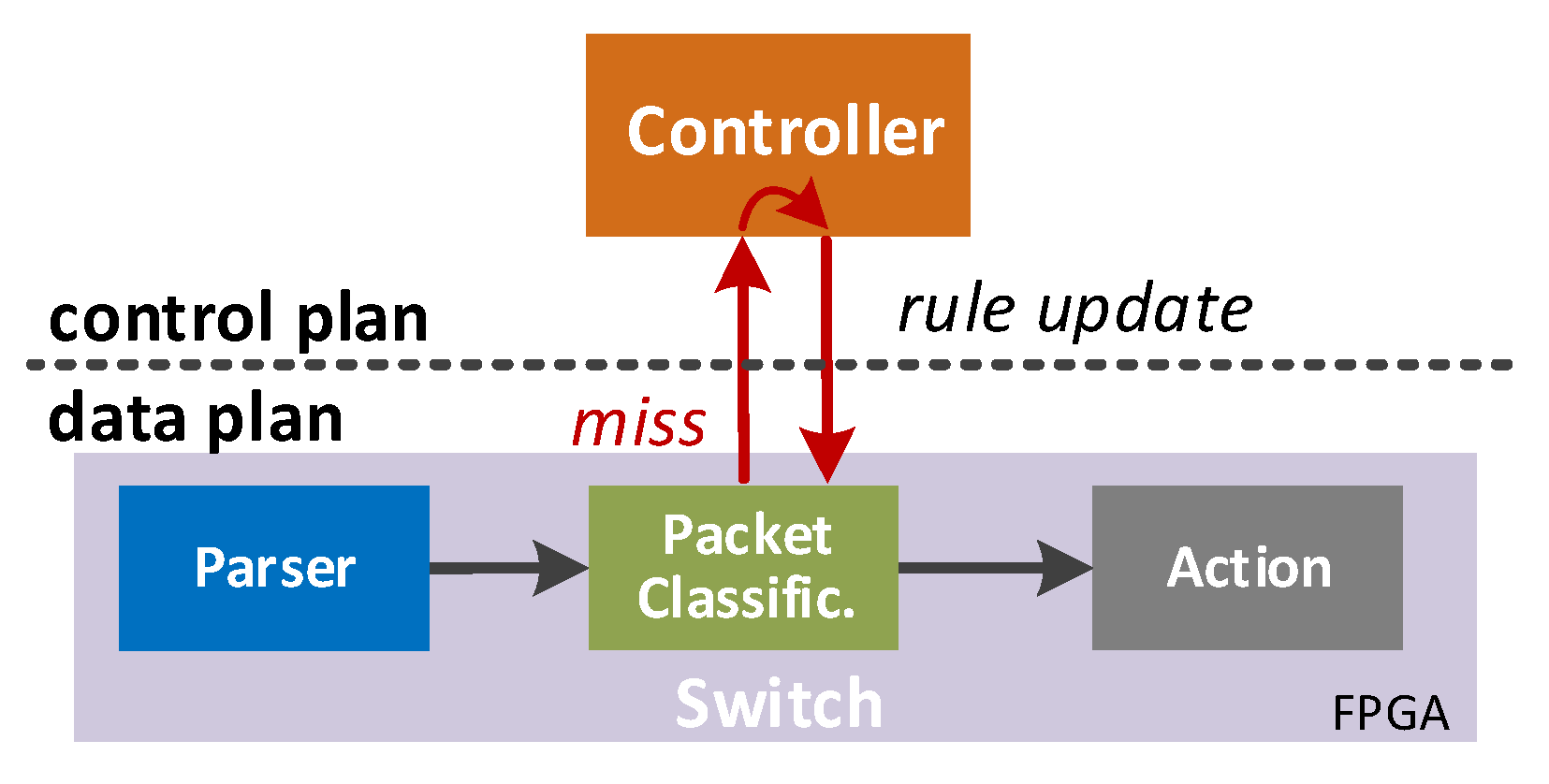
2.2. Rule Updates on SDN Switch
3. Prior Works
3.1. Packet Classification Algorithms
3.2. BV-Based Solutions Analyses
4. Proposed Scheme
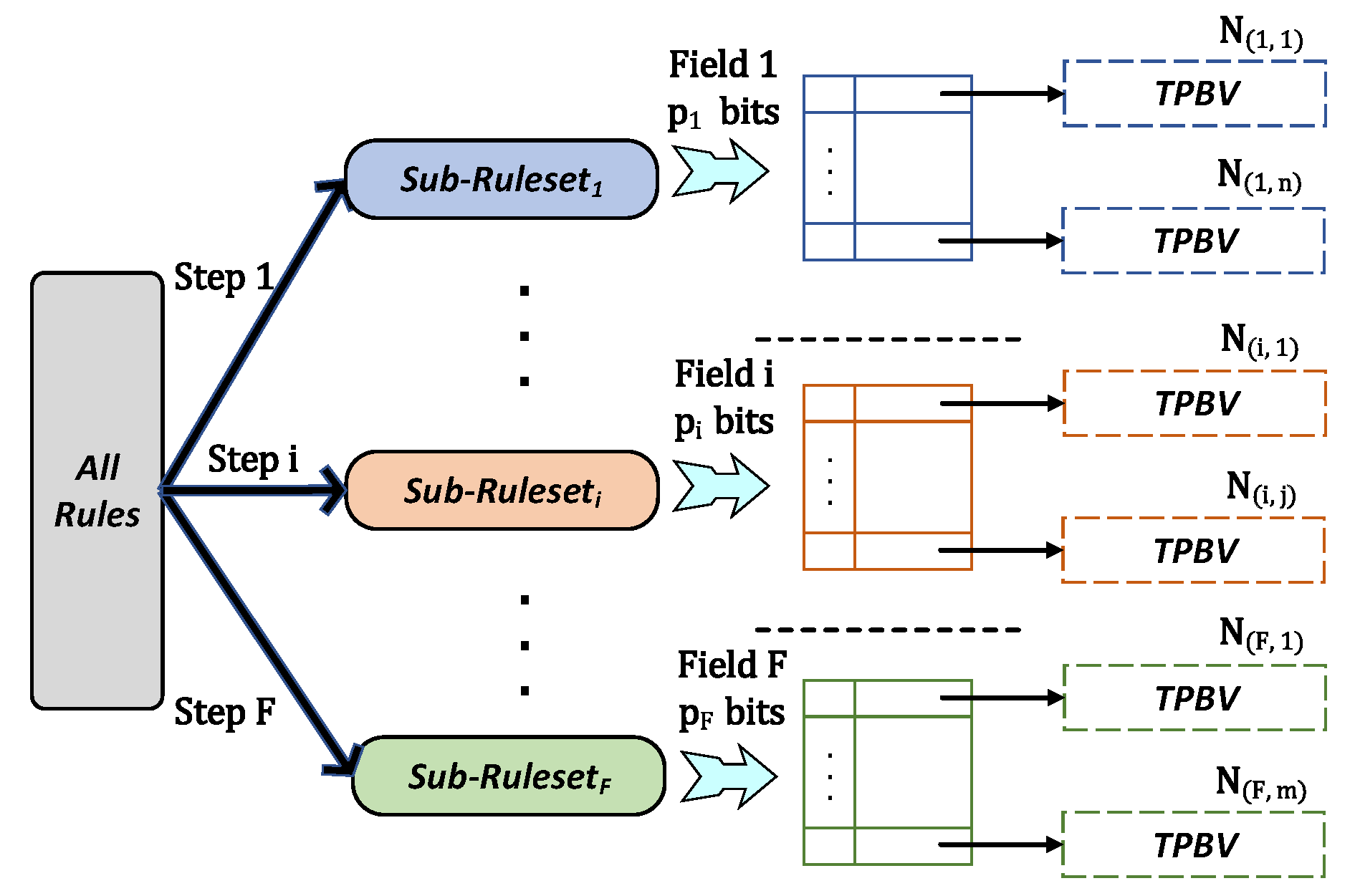
4.1. Ideas and Architecture
4.2. Brute Force Strategy
4.3. Split Algorithm
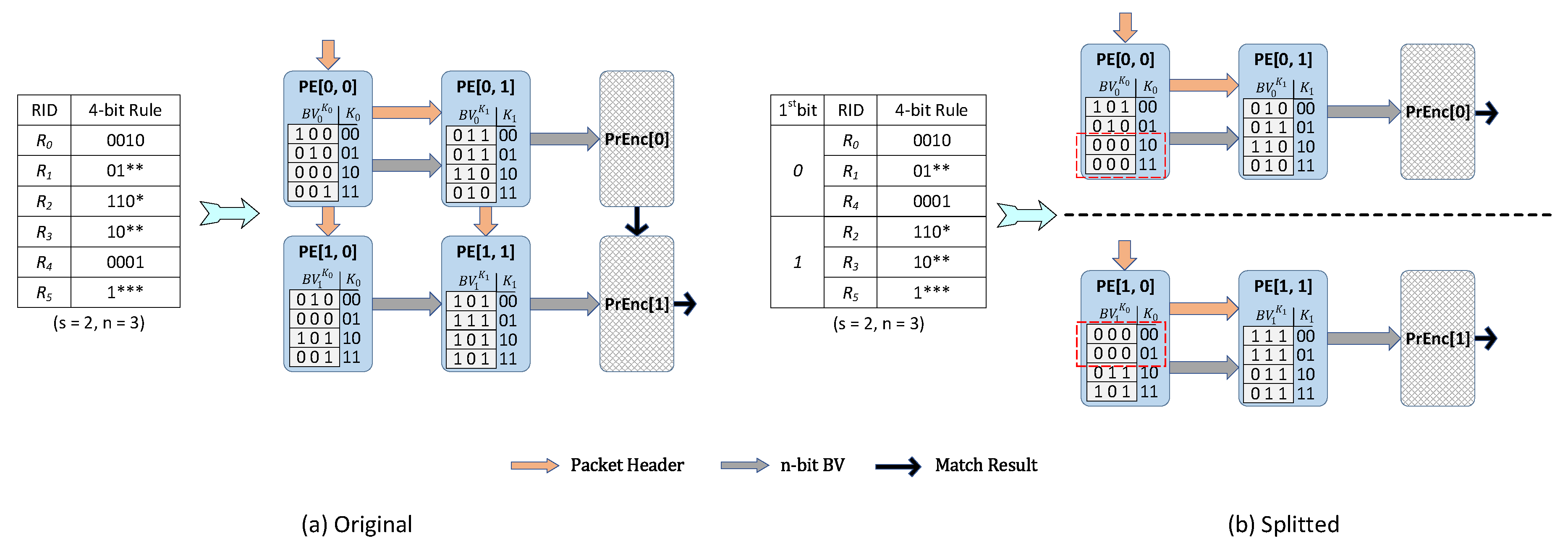
4.3.1. Distinguish by field
4.3.2. Select-Bits Combination
| Algorithm 1 SelectBits | |
| Input: The list of field information, The list of index of sorted in descending order of Dis, ; The current remaining rules for searching, ; The current value of step, ; The list of on each field, The number of cluster, n; | |
| Output: The global set of combination of on each field, ; | |
| 1: function SelectBits(CurRuleSet,CurStep,CurMax,PList) | |
| 2: if or then | |
| 3: if is then | ▹ return |
| 4: end if | |
| 5: + | ▹return |
| 6: end if | |
| 7: | |
| 8: for to do | |
| 9: for in do | |
| 10: if no in then | |
| 11: | |
| 12: end if | |
| 13: end for | |
| 14: if then | |
| 15: if then | |
| 16: + | ▹return |
| 17: else | |
| 18: SelectBits(, , , ) | ▹ return |
| 19: end if | |
| 20: else | |
| 21: | |
| 22: = | |
| 23: SelectBits(, , , ) | |
| 24: end if | |
| 25: end for | |
| 26: end function | |
4.4. A Example
5. Hardware Design
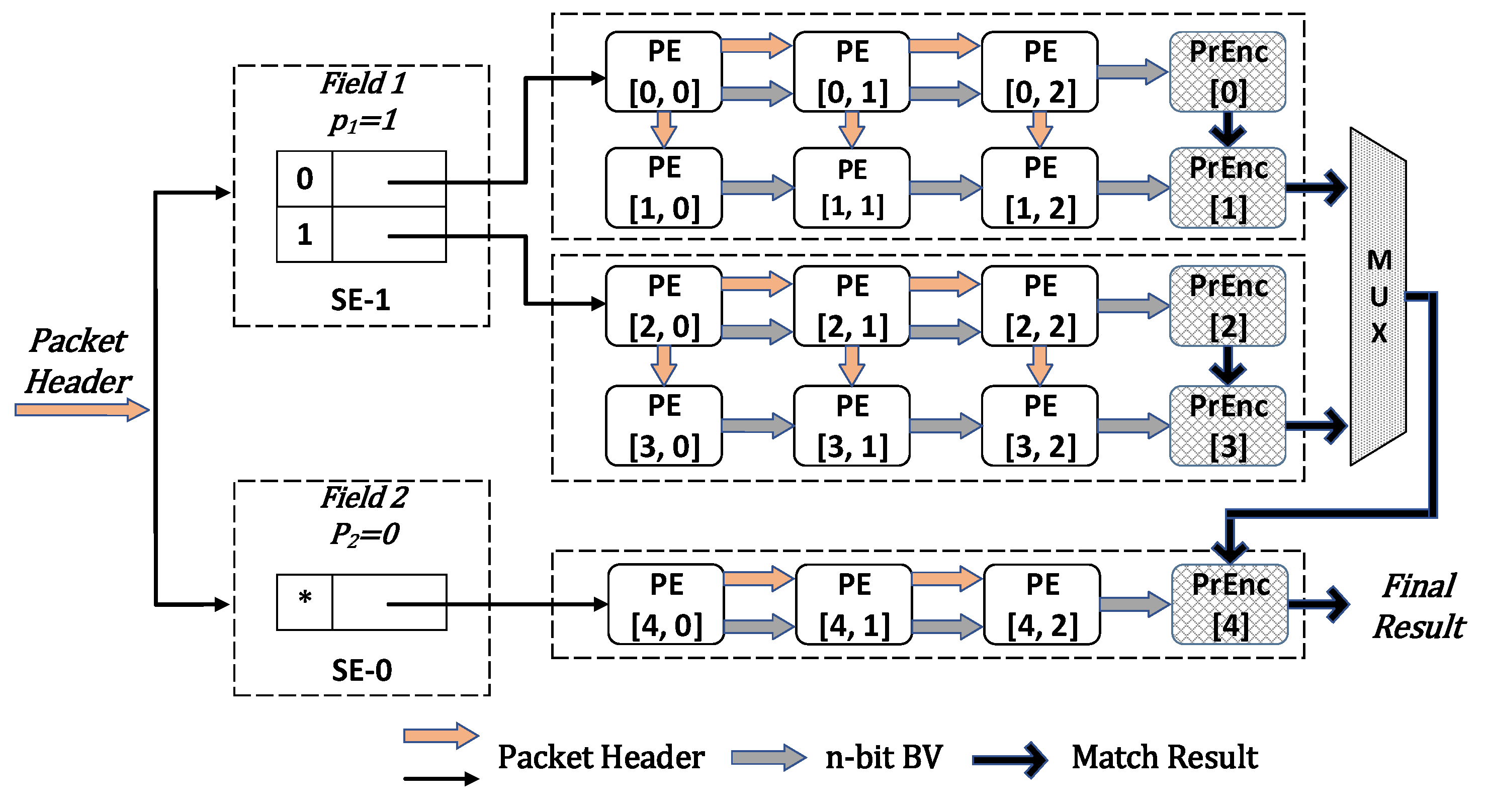
5.1. Hybrid SplitHP
5.1.1. Splitting Element (SE)
5.1.2. Process Element (PE)
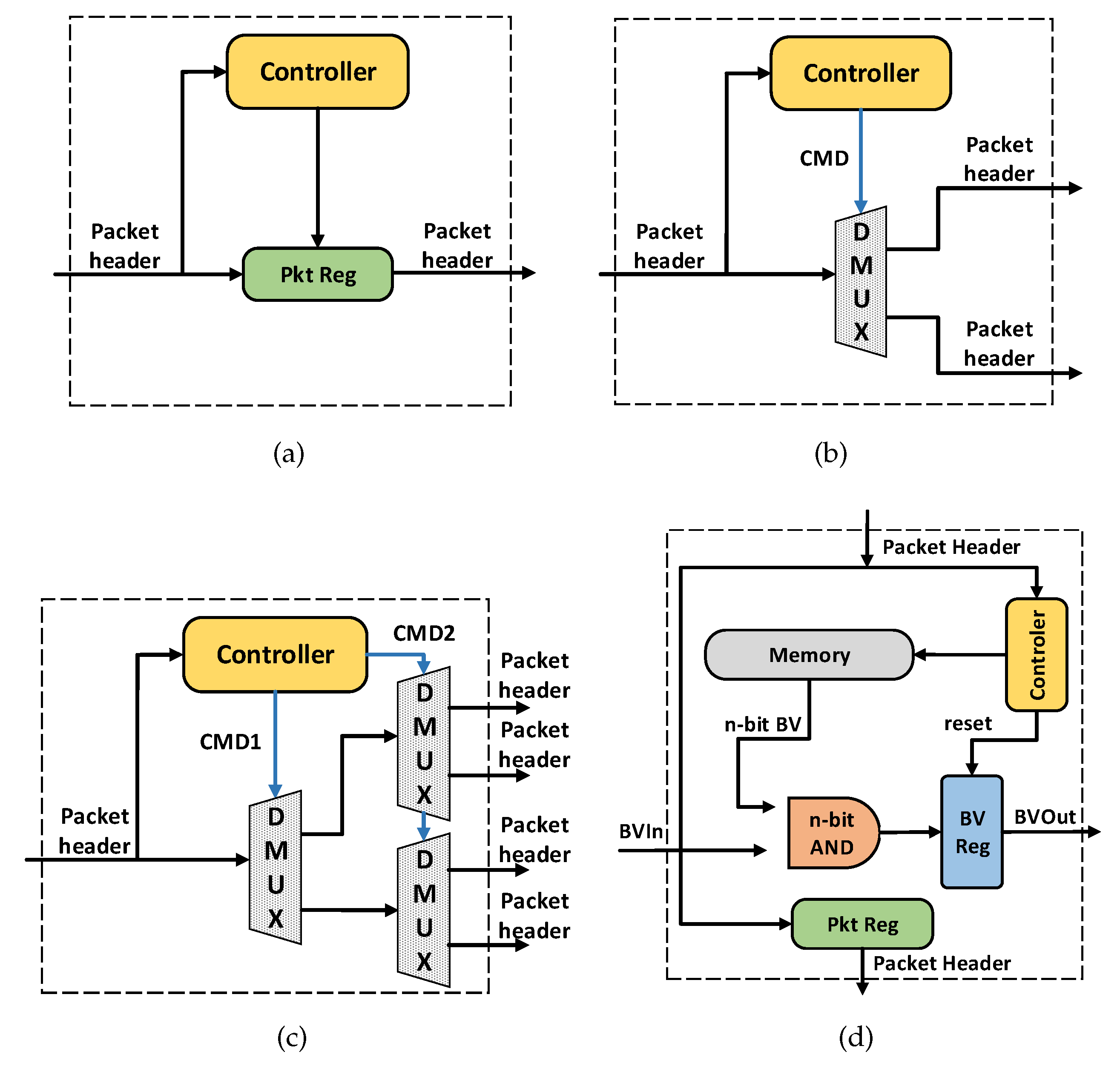
5.2. Update Strategy
6. Evaluation
6.1. Experimental Setup
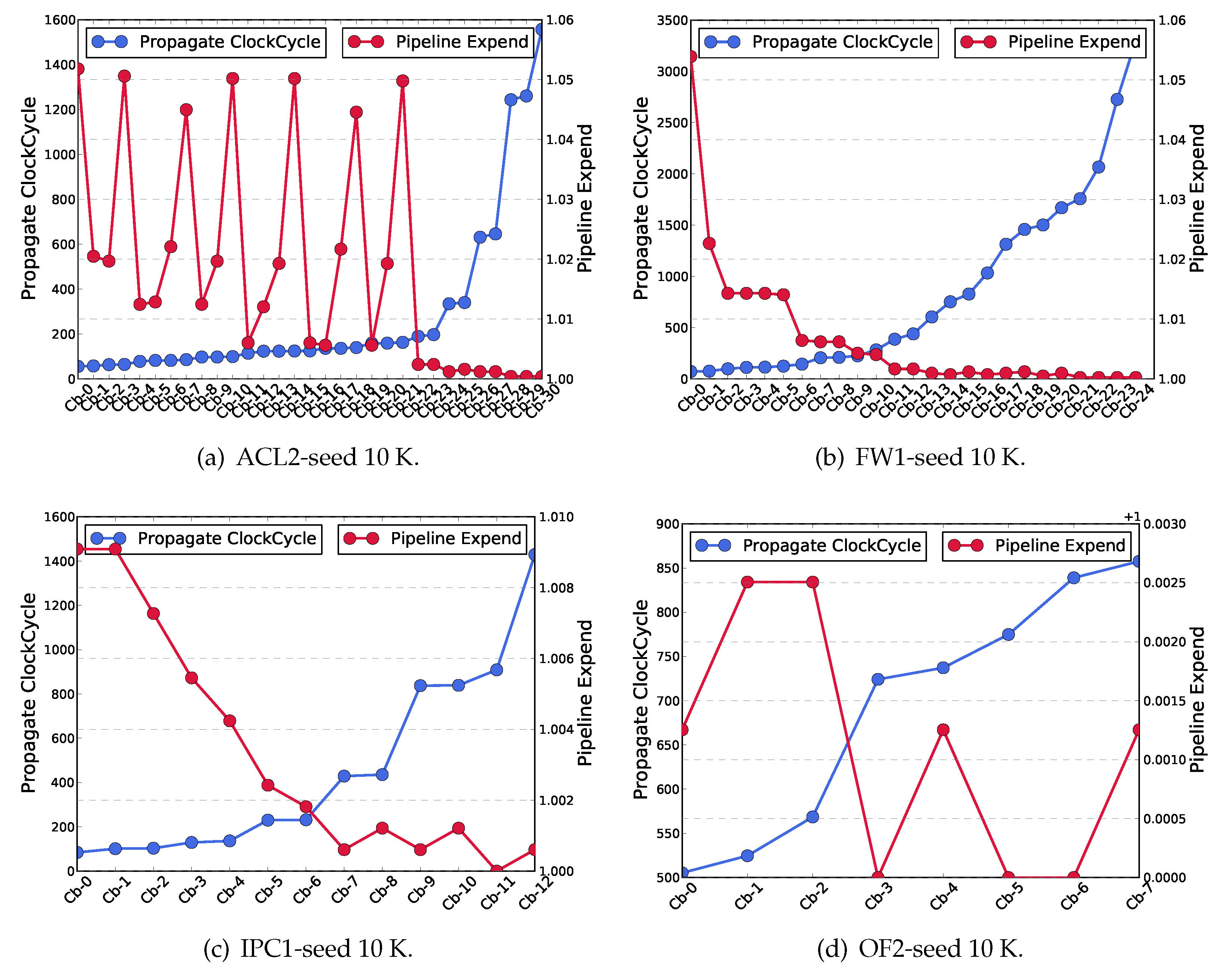
6.2. Split-Bits Trade-Off
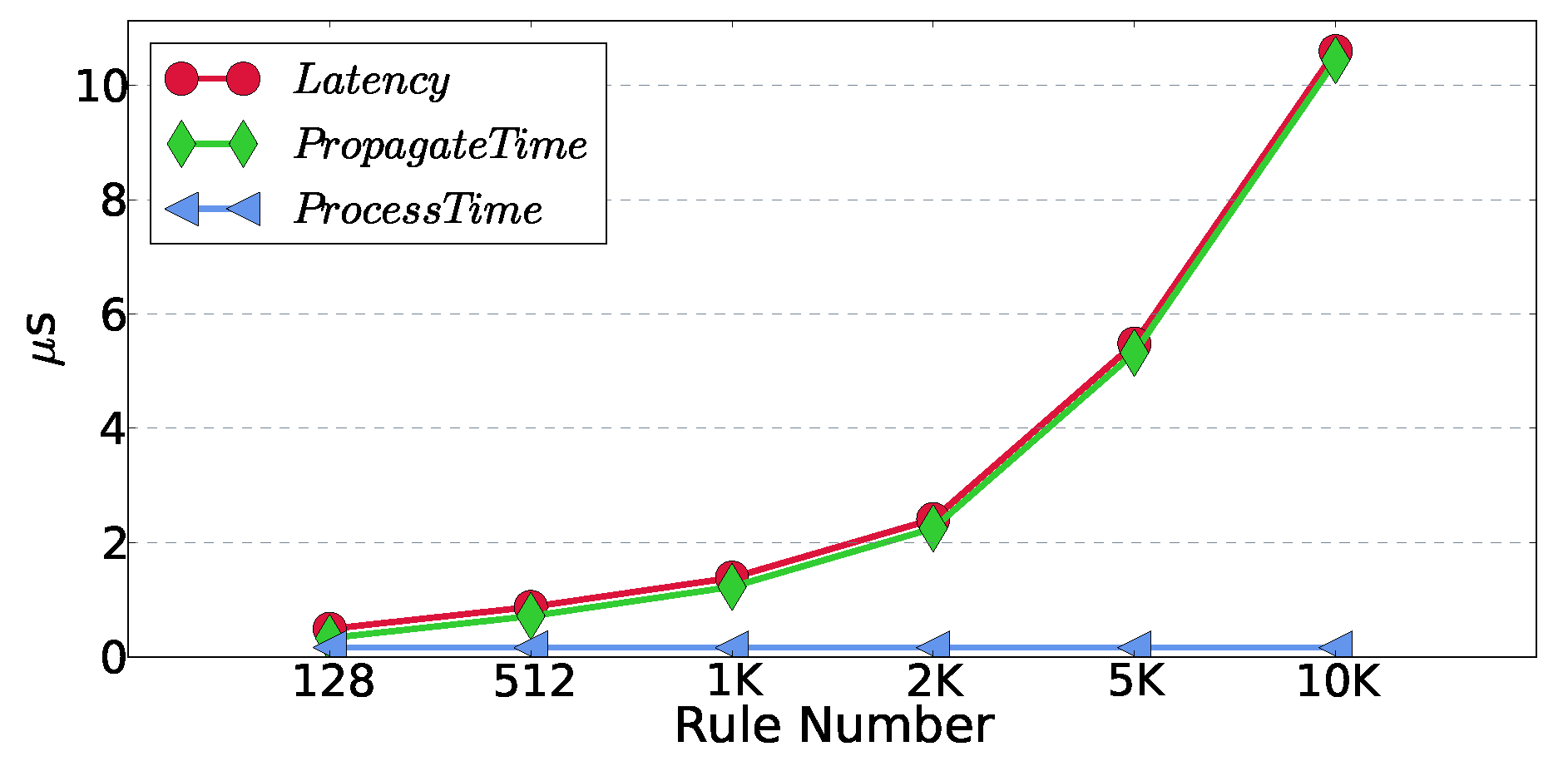
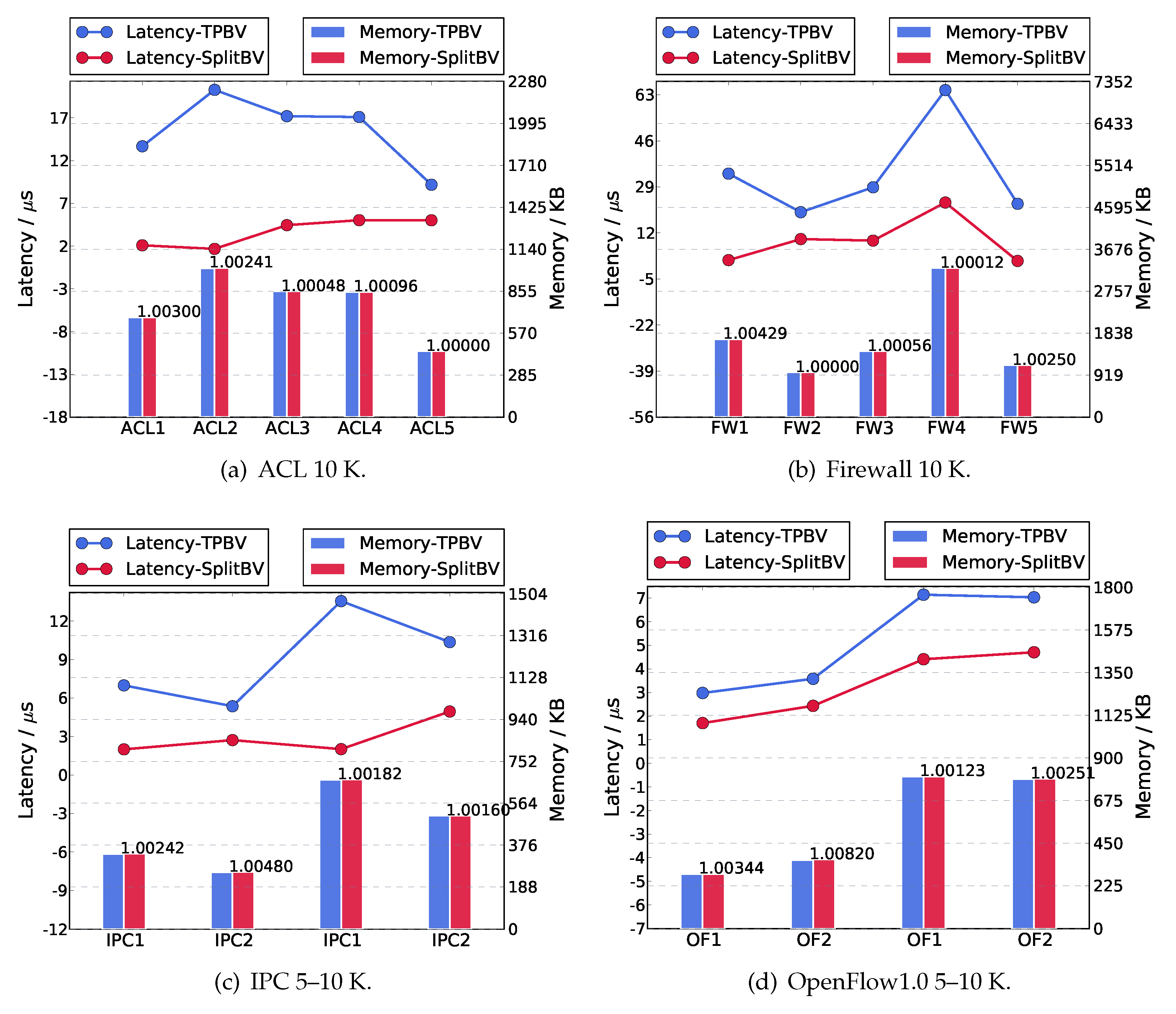
6.3. Update Latency
6.4. Memory Consumption
6.5. Resource and Throughput
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- O. N. F. (ONF). Software Defined Networking. Available online: https://www.opennetworking.org/software-defined-standards/overview/ (accessed on 9 April 2020).
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.M.; Peterson, L.L.; Rexford, J.; Shenker, S.; Turner, J.S. Openflow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Yang, T.; Liu, A.X.; Shen, Y.; Fu, Q.; Li, D.; Li, X. Fast openflow table lookup with fast update. In Proceedings of the 2018 IEEE Conference on Computer Communications, INFOCOM 2018, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2636–2644. [Google Scholar] [CrossRef]
- Lakshminarayanan, K.; Rangarajan, A.; Venkatachary, S. Algorithms for advanced packet classification with ternary cams. In Proceedings of the ACM SIGCOMM 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Philadelphia, PA, USA, 22–26 August 2005; Guérin, R., Govindan, R., Minshall, G., Eds.; ACM: New York, NY, USA, 2005; pp. 193–204. [Google Scholar] [CrossRef]
- Ma, Y.; Banerjee, S. A smart pre-classifier to reduce power consumption of tcams for multi-dimensional packet classification. In Proceedings of the ACM SIGCOMM 2012 Conference, SIGCOMM ’12, Helsinki, Finland, 13–17 August 2012; Eggert, L., Ott, J., Padmanabhan, V.N., Varghese, G., Eds.; ACM: New York, NY, USA, 2012; pp. 335–346. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Lin, Y.; Li, W. Greentcam: A memory- and energy-efficient tcam-based packet classification. In Proceedings of the 2016 International Conference on Computing, Networking and Communications, ICNC 2016, Kauai, HI, USA, 15–18 February 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Rottenstreich, O.; Keslassy, I.; Hassidim, A.; Kaplan, H.; Porat, E. Optimal in/out TCAM encodings of ranges. IEEE/ACM Trans. Netw. 2016, 24, 555–568. [Google Scholar] [CrossRef]
- Qu, Y.R.; Prasanna, V.K. Enabling high throughput and virtualization for traffic classification on FPGA. In Proceedings of the 23rd IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, FCCM 2015, Vancouver, BC, Canada, 2–6 May 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 44–51. [Google Scholar] [CrossRef]
- Li, B.; Tan, K.; Luo, L.L.; Peng, Y.; Luo, R.; Xu, N.; Xiong, Y.; Cheng, P. Clicknp: Highly flexible and high-performance network processing with reconfigurable hardware. In Proceedings of the ACM SIGCOMM 2016 Conference, Florianopolis, Brazil, 22–26 August 2016; Barcellos, M.P., Crowcroft, J., Vahdat, A., Katti, S., Eds.; ACM: New York, NY, USA, 2016; pp. 1–14. [Google Scholar] [CrossRef]
- Yang, X.; Sun, Z.; Li, J.; Yan, J.; Li, T.; Quan, W.; Xu, D.; Antichi, G. FAST: Enabling fast software/hardware prototype for network experimentation. In Proceedings of the International Symposium on Quality of Service, IWQoS 2019, Phoenix, AZ, USA, 24–25 June 2019; ACM: New York, NY, USA, 2019; pp. 32:1–32:10. [Google Scholar] [CrossRef]
- Zhao, T.; Li, T.; Han, B.; Sun, Z.; Huang, J. Design and implementation of software defined hardware counters for SDN. Comput. Netw. 2016, 102, 129–144. [Google Scholar] [CrossRef]
- Fu, W.; Li, T.; Sun, Z. FAS: Using FPGA to accelerate and secure SDN software switches. Secur. Commun. Netw. 2018, 2018, 5650205:1–5650205:13. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Baboescu, F.; Varghese, G.; Wang, J. Packet classification using multidimensional cutting. In Proceedings of the ACM SIGCOMM 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Karlsruhe, Germany, 25–29 August 2003; Feldmann, A., Zitterbart, M., Crowcroft, J., Wetherall, D., Eds.; ACM: New York, NY, USA, 2003; pp. 213–224. [Google Scholar] [CrossRef] [Green Version]
- Vamanan, B.; Voskuilen, G.; Vijaykumar, T.N. Efficuts: Optimizing packet classification for memory and throughput. In Proceedings of the ACM SIGCOMM 2010 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, New Delhi, India, 30 August–3 September 2010; Kalyanaraman, S., Padmanabhan, V.N., Ramakrishnan, K.K., Shorey, R., Voelker, G.M., Eds.; ACM: New York, NY, USA, 2010; pp. 207–218. [Google Scholar] [CrossRef]
- He, P.; Xie, G.; Salamatian, K.; Mathy, L. Meta-algorithms for software-based packet classification. In Proceedings of the 22nd IEEE International Conference on Network Protocols, ICNP 2014, Raleigh, NC, USA, 21–24 October 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 308–319. [Google Scholar] [CrossRef]
- Li, W.; Li, X.; Li, H.; Xie, G. Cutsplit: A decision-tree combining cutting and splitting for scalable packet classification. In Proceedings of the 2018 IEEE Conference on Computer Communications, INFOCOM 2018, Honolulu, HI, USA, 16–19 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2645–2653. [Google Scholar] [CrossRef]
- Srinivasan, V.; Suri, S.; Varghese, G. Packet classification using tuple space search. In Proceedings of the SIGCOMM’99, Cambridge, MA, USA, 31 August–3 September 1999; pp. 135–146. [Google Scholar] [CrossRef] [Green Version]
- Pfaff, B.; Pettit, J.; Koponen, T.; Jackson, E.J.; Zhou, A.; Rajahalme, J.; Gross, J.; Wang, A.; Stringer, J.; Shelar, P.; et al. The design and implementation of open vswitch. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation, NSDI 15, Oakland, CA, USA, 4–6 May 2015; USENIX Association: Berkeley, CA, USA, 2015; pp. 117–130. Available online: https://www.usenix.org/conference/nsdi15/technical-sessions/presentation/pfaff (accessed on 9 April 2020).
- Yingchareonthawornchai, S.; Daly, J.; Liu, A.X.; Torng, E. A sorted-partitioning approach to fast and scalable dynamic packet classification. IEEE/ACM Trans. Netw. 2018, 26, 1907–1920. [Google Scholar] [CrossRef]
- Daly, J.; Bruschi, V.; Linguaglossa, L.; Pontarelli, S.; Rossi, D.; Tollet, J.; Torng, E.; Yourtchenko, A. Tuplemerge: Fast software packet processing for online packet classification. IEEE/ACM Trans. Netw. 2019, 27, 1417–1431. [Google Scholar] [CrossRef]
- Lakshman, T.V.; Stiliadis, D. High-speed policy-based packet forwarding using efficient multi-dimensional range matching. In Proceedings of the SIGCOMM’98, Vancouver, BC, Canada, 31 August–4 September 1998; pp. 203–214. [Google Scholar] [CrossRef]
- Jiang, W.; Prasanna, V.K. Field-split parallel architecture for high performance multi-match packet classification using fpgas. In Proceedings of the SPAA 2009, 21st Annual ACM Symposium on Parallelism in Algorithms and Architectures, Calgary, AB, Canada, 11–13 August 2009; auf der Heide, F.M., Bender, M.A., Eds.; ACM: New York, NY, USA, 2009; pp. 188–196. [Google Scholar] [CrossRef]
- Ganegedara, T.; Jiang, W.; Prasanna, V.K. A scalable and modular architecture for high-performance packet classification. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1135–1144. [Google Scholar] [CrossRef]
- Qu, Y.R.; Prasanna, V.K. High-performance and dynamically updatable packet classification engine on FPGA. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 197–209. [Google Scholar] [CrossRef]
- Li, C.; Li, T.; Li, J.; Yang, H.; Wang, B. A memory optimized architecture for multi-field packet classification (brief announcement). In Proceedings of the The 31st ACM on Symposium on Parallelism in Algorithms and Architectures, SPAA 2019, Phoenix, AZ, USA, 22–24 June 2019; Scheideler, C., Berenbrink, P., Eds.; ACM: New York, NY, USA, 2019; pp. 395–397. [Google Scholar] [CrossRef]
- Li, C.; Li, T.; Li, J.; Li, D.; Yang, H.; Wang, B. Memory optimization for bit-vector-based packet classification on fpga. Electronics 2019, 8, 1159. [Google Scholar] [CrossRef] [Green Version]
- Benson, T.; Akella, A.; Maltz, D.A. Network traffic characteristics of data centers in the wild. In Proceedings of the 10th ACM SIGCOMM Internet Measurement Conference, IMC 2010, Melbourne, Australia, 1–3 November 2010; Allman, M., Ed.; ACM: New York, NY, USA, 2010; pp. 267–280. [Google Scholar] [CrossRef]
- Chen, H.; Benson, T. Hermes: Providing tight control over high-performance SDN switches. In Proceedings of the 13th International Conference on emerging Networking EXperiments and Technologies, CoNEXT 2017, Incheon, Korea, 12–15 December 2017; ACM: New York, NY, USA, 2017; pp. 283–295. [Google Scholar] [CrossRef]
- Chowdhury, M.; Zhong, Y.; Stoica, I. Efficient coflow scheduling with varys. In Proceedings of the ACM SIGCOMM 2014 Conference, SIGCOMM’14, Chicago, IL, USA, 17–22 August 2014; Bustamante, F.E., Hu, Y.C., Krishnamurthy, A., Ratnasamy, S., Eds.; ACM: New York, NY, USA, 2014; pp. 443–454. [Google Scholar] [CrossRef]
- Taylor, D.E.; Turner, J.S. Classbench: A packet classification benchmark. IEEE/ACM Trans. Netw. 2007, 15, 499–511. [Google Scholar] [CrossRef] [Green Version]
- Matouvsek, J.; Antichi, G.; Lucansky, A.; Moore, A.W.; Korenek, J. Classbench-ng: Recasting classbench after a decade of network evolution. In Proceedings of the ACM/IEEE Symposium on Architectures for Networking and Communications Systems, ANCS 2017, Beijing, China, 18–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 204–216. [Google Scholar] [CrossRef]
- Kogan, K.; Nikolenko, S.I.; Rottenstreich, O.; Culhane, W.; Eugster, P. SAX-PAC (scalable and expressive packet classification). In Proceedings of the ACM SIGCOMM 2014 Conference, SIGCOMM’14, Chicago, IL, USA, 17–22 August 2014; Bustamante, F.E., Hu, Y.C., Krishnamurthy, A., Ratnasamy, S., Eds.; ACM: New York, NY, USA, 2014; pp. 15–26. [Google Scholar] [CrossRef]
- Hsieh, C.; Weng, N. Many-field packet classification for software-defined networking switches. In Proceedings of the 2016 Symposium on Architectures for Networking and Communications Systems, ANCS 2016, Santa Clara, CA, USA, 17–18 March 2016; Crowley, P., Rizzo, L., Mathy, L., Eds.; ACM: New York, NY, USA, 2016; pp. 13–24. [Google Scholar] [CrossRef]
- Kuzniar, M.; Peresíni, P.; Kostic, D. What you need to know about SDN flow tables. In Passive and Active Measurement, Proceedings of the 16th International Conference, PAM 2015, New York, NY, USA, 19–20 March 2015; ser. Lecture Notes in Computer Science; Mirkovic, J., Liu, Y., Eds.; Springer: Berlin, Germany, 2015; Volume 8995, pp. 347–359. [Google Scholar] [CrossRef] [Green Version]
- Taylor, D.E. Survey and taxonomy of packet classification techniques. ACM Comput. Surv. 2005, 37, 238–275. [Google Scholar] [CrossRef] [Green Version]
- Bremler-Barr, A.; Hendler, D. Space-efficient tcam-based classification using gray coding. IEEE Trans. Comput. 2012, 61, 18–30. [Google Scholar] [CrossRef]
- Bremler-Barr, A.; Hay, D.; Hendler, D. Layered interval codes for tcam-based classification. Comput. Netw. 2012, 56, 3023–3039. [Google Scholar] [CrossRef] [Green Version]
- Kuekes, P.J.; Williams, R.S. Demultiplexer for a Molecular Wire Crossbar Network (MWCN DEMUX). U.S. Patent 6,256,767, 3 July 2001. [Google Scholar]
- Abel, N. Design and implementation of an object-oriented framework for dynamic partial reconfiguration. In Proceedings of the International Conference on Field Programmable Logic and Applications, FPL 2010, Milano, Italy, 31 August–2 September 2010; IEEE Computer Society: Washington, DC, USA, 2010; pp. 240–243. [Google Scholar] [CrossRef]
- Kalb, T.; Göhringer, D. Enabling dynamic and partial reconfiguration in xilinx sdsoc. In Proceedings of the International Conference on ReConFigurable Computing and FPGAs, ReConFig 2016, Cancun, Mexico, 30 November–2 December 2016; Athanas, P.M., Cumplido, R., Feregrino, C., Sass, R., Eds.; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RID | ||
|---|---|---|
| 0010 | 11 | |
| 1001 | 0 * | |
| 1110 | 10 | |
| 0000 | ** | |
| **** | 1 * | |
| 1001 | 10 | |
| 0101 | 1 * | |
| **** | 00 | |
| 0100 | 0 * | |
| **** | 00 | |
| 1101 | 0 * | |
| 1011 | 1 * |
| ALUTs | Registers | Clock Rate | |
|---|---|---|---|
| Number | Number | (MHz) | |
| TPBV [24] | 848 | 2501 | 158.63 |
| SplitBV = 1 | 1512 | 4421 | 152.0 |
| SplitBV = 2 | 1979 | 5873 | 145.45 |
| SplitBV = 3 | 3200 | 9379 | 145.33 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Li, T.; Li, J.; Shi, Z.; Wang, B. Enabling Packet Classification with Low Update Latency for SDN Switch on FPGA. Sustainability 2020, 12, 3068. https://doi.org/10.3390/su12083068
Li C, Li T, Li J, Shi Z, Wang B. Enabling Packet Classification with Low Update Latency for SDN Switch on FPGA. Sustainability. 2020; 12(8):3068. https://doi.org/10.3390/su12083068
Chicago/Turabian StyleLi, Chenglong, Tao Li, Junnan Li, Zilin Shi, and Baosheng Wang. 2020. "Enabling Packet Classification with Low Update Latency for SDN Switch on FPGA" Sustainability 12, no. 8: 3068. https://doi.org/10.3390/su12083068
APA StyleLi, C., Li, T., Li, J., Shi, Z., & Wang, B. (2020). Enabling Packet Classification with Low Update Latency for SDN Switch on FPGA. Sustainability, 12(8), 3068. https://doi.org/10.3390/su12083068