1. Introduction
Nowadays, transportation systems have entered an era of data-driven intelligence [
1,
2] in order to alleviate the conventional but intractable problem of traffic congestion and further improve the efficiency. In other words, multisource traffic data should be fed into the intelligent transportation systems (ITS). Thanks to the advancement of data collection techniques, an abundance of traffic data can be obtained including loop detector data, GPS data [
3], automated fare collection (AFC) data [
4], cellular signaling data [
5] and automatic number plate recognition (ANPR) data [
6]. High-quality traffic data can support a diversity of transportation applications like dynamic traffic forecasting [
7], route planning [
8] and accident warning [
9].
Among those data sources, ANPR systems have attracted the most attention lately. Benefiting from the rapid development of infrastructure construction as well as the algorithms in computer vision, massive traffic data can be collected from the image-based sensors [
10]. The equipment is always installed at different directions of the intersections for violation monitoring and security surveillance. When a vehicle passes through, the camera detects its movement and takes a photograph of it. Then optical character recognition is applied to read vehicle license plates to create vehicle location data. These data include individual vehicle travel information as well as traffic state statistics, making them distinguished from traditional data. Therefore, such systems have been broadly deployed for personalized ITS applications, especially in China. Take Xuancheng, Anhui, for example; the deployment coverage had reached 85% (109 intersections of 129 in total) in the central area by the end of 2018.
Unfortunately, the ANPR data inevitably suffer from the missing data problem in the process of data collection [
11], which goes against sustainable development. Due to detection failure and device malfunction, we might see traffic data missing in certain spaces and times, which is ubiquitous in other systems and has been addressed by much research [
12,
13,
14,
15]. For individual level data, the missing case can be the loss of vehicle identities of certain records because of number plate recognition failure, which might influence the performance and reliability of individual travel data.
Table 1 shows several anonymous records from an ANPR database, in which there is one without an identification label. Besides, for the reason of different illuminations, resolutions and flow volumes, the missing rates vary along different times of day, as illustrated in
Figure 1. In this work, we aim at inferring the missing vehicle identities accurately given the raw ANPR records from a road network.
However, we are confronted with some challenges in order to address the above problem. First, taking the original data as independent records will lead to a sparsity problem as the features are not always adequate and the motion of vehicles at intersections act like cells. Therefore, we should take both the context records and the similar vehicles’ movements into account. For example, vehicles with similar travel sequences could help recover the missing information for each other. As a result, it requires us to model the interactions among the involved objects (e.g., vehicles, locations, times) properly, which gives rise to the second challenge. These interactions are so complex to model for their intrinsic heterogeneous and semi-structured characteristics as illustrated in
Figure 2. As we have the knowledge of vehicles’ traveling behaviors at intersections, we can integrate them into the modeling process to capture spatiotemporal relationships.
In this work, we propose an embedding-based framework with heterogeneous information networks (HINs) as the input for missing vehicle identity recovery. In particular, we first model the involved objects in the ANPR records as entities and their relations as edges in a HIN. Then, we combine the prior knowledge of vehicles’ movements with the HIN to produce higher level entities and utilize a spatiotemporal relation model to further capture the rich context information. Given the enhanced HIN as the input, we adopt knowledge embedding techniques to learn the representations for entities and relations in a low dimensional space where similarity between entities can be preserved. At last, we treat the original task as entity alignment in the latent space by finding the similar pairs.
The contributions of this work are summarized as follows:
We propose to recover missing vehicles’ identities in the ANPR records, which is different from the imputation of traffic state values but essential for personalized ITS applications.
We exploit HIN to model the complex traveling data and develop an enhanced graph structure to capture the spatiotemporal relations via vehicle grouping and context link extraction.
We treat the identities recovery problem of ANPR data as an entity alignment task on embeddings, which is evaluated on a real world dataset.
The remainder of this paper is organized as follows:
Section 2 summarizes related studies on the problem,
Section 3 introduces some concepts and describes the problem,
Section 4 details the proposed model,
Section 5 presents the experimental results and
Section 6 makes a conclusion.
3. Preliminaries
In this section, we introduce some important concepts to be appear in the context, followed by a formal description of the vehicle plate number recovery problem.
3.1. Concept Definition
3.1.1. Heterogeneous Information Networks
With the equipment of different types of sensors, the acquisition of multisource data becomes more effortless [
1]. Their intrinsic characteristics of multitypes and interconnected naturally make themselves heterogeneous information networks [
27]. These complex networks are usually multimode and multirelational, carrying rich information of the real world.
Definition 1. An heterogeneous information network [27] is defined as a directed graph where is the set of entities and each entity belongs to a particular entity type in the type set . is the set of edges between the entities in . Similarly, involves multiple types of relations in set . Typically, it requires or . Otherwise, it will be degraded to a homogeneous network. In our case, the ANPR data naturally form a heterogeneous information network where , corresponding to the entity types of vehicle, passing event, camera location and time span respectively. As the extracted entities and their semantic relations in mainly describe the traveling behaviors of vehicles in the road network, we further call it a travel heterogeneous information network (THIN).
3.1.2. Vehicle Group
In the basic THIN, each detection record at a specific camera location is defined as a passing event entity with the corresponding vehicle entity connects to it. This setting models each detection record separately, making the network connectivity sparse and ignoring the relationship with other companion vehicles. Refs. [
28,
29] proposed to model a bunch of related vehicles as a vehicle group to capture the companion pattern among them. They define vehicle group based on the co-occurrence of detection as follows.
Definition 2. A vehicle group is defined as a crowd of vehicles passing a camera location within a certain time period . Consequently, vehicle group in camera location can be denoted as , where is a detection record specified by a vehicle ID and a passing timestamp . We can say that the members of co-occurred in location .
As we want to utilize the information from the co-occurred vehicles in the THIN, we apply vehicle group entity identification and then replace the passing event entities with them. Moreover, since we need to capture the traveling companion relationships between different camera locations, we extract links among vehicle group for the purpose of connecting the vehicle group entities which are topologically and temporally consecutive in the road network.
3.2. Problem Description
In this work, we aim to infer the missing vehicle identities of the incomplete detection records through finding the match vehicle entities. While there exists some similar techniques, like vehicle trajectory reconstruction, that can be adopted to recover the incomplete trajectory according to the historical route choice, they often fail to retrieve the real location and time of the passing event. In our scenario, we have the proper detection records of each passing event, although the vehicle IDs are lost; as a result, the real spatial and temporal information can be preserved.
The basic input is the set of detection records . For each record , we can describe it as where v is the identity of the vehicle but can be unknown if the plate number can not be recognized, l and t are the recorded location and timestamp, , and are vehicle type, vehicle color and plate color respectively which are appearance properties extracted from the raw images.
However, as we can observe, the entities of each record alone do not have adequate relevant features. Their interactions are so complicated that we can not model them via the classic matrix or tensor decomposition methods [
14,
30,
31] which have been proven to be the dominant approach in the field of missing data imputation. As the detection data themselves are well structured and the interactions among entities are defined in a traffic adapted manner, we construct a THIN
as the model input.
Finally, the output of the proposed model is the inferred vehicle identities for each detection record d. This can be done by finding the most nearest known vehicle entity from their embedding vector space and merging them as one entity.
4. Proposed Model
We present an overview of the proposed model in
Section 4.1. Then, we further detailed each part of it, including the travel heterogeneous network construction in
Section 4.2, embedding learning in
Section 4.3 and entity alignment in
Section 4.4.
4.1. Framework Overview
Figure 3 illustrates the overall embedding-based framework of the proposed model. Our goal is to learn the embeddings for all involved entities in travels (i.e., vehicles, locations, times) to infer the missing vehicle IDs. By introducing the vehicle group entities and the context relationships, they capture the spatiotemporal interactions and the proximities among different entities.
Our framework first requires the construction of a THIN, in which entities and relations are all defined elements. Intuitively, an ANPR record corresponds to a passing event entity, and then the vehicle and camera location entities can be further derived from it. For vehicle attributes, we directly treat them as property entities. With this basic THIN, we further apply vehicle grouping and context link extraction in order to model the companion interactions of vehicles and capture the semantic proximities among entities. Then we implement the latent feature based representation learning algorithms on the enhanced THIN to embed the entity features into the low dimensional space and produce a dense embedding vector for each entity e. Once we obtain the embeddings for all entities, the entity alignment unit finds every pair with a proper similarity score where entities and belong to the same type . whose identity is unknown is the entity extracted from an incomplete record.
4.2. Travel Heterogeneous Network Construction
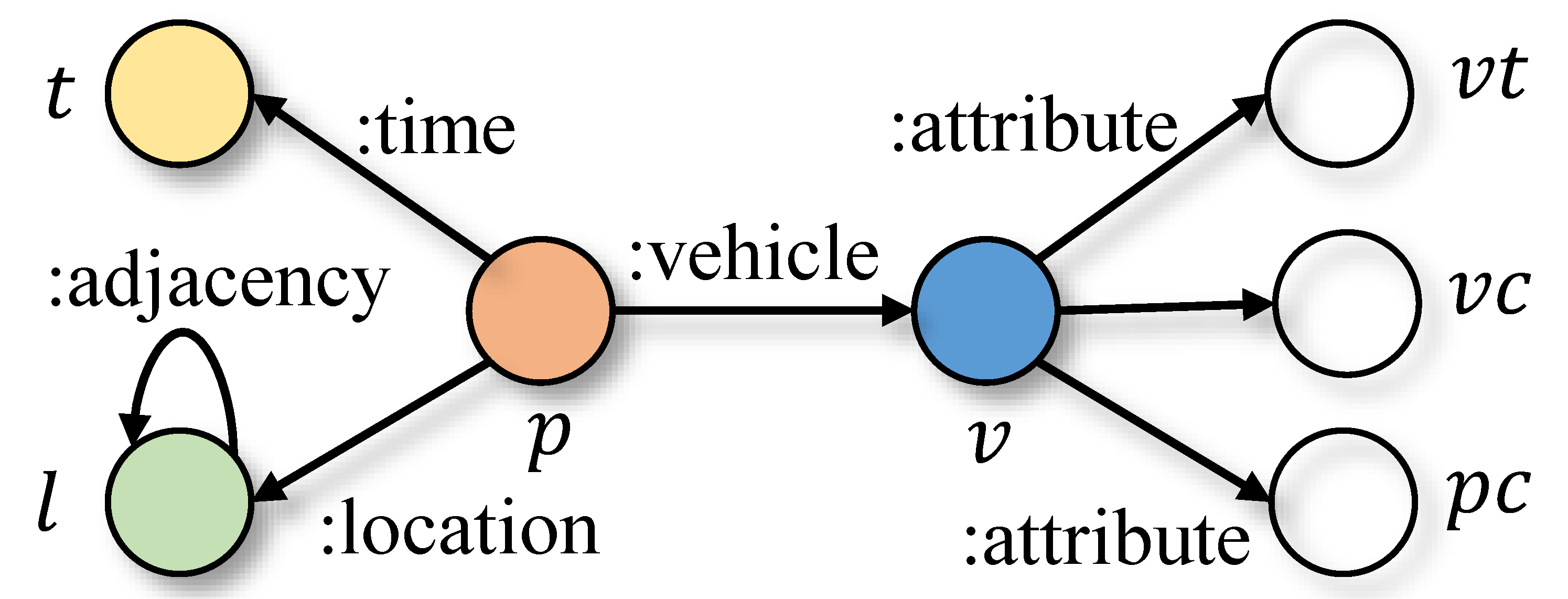
In this section, we construct a THIN, which has different types of entity and relation, to transform the ANPR data into a relational structure. Basically, we have seven types of original entities extracted from the raw data: vehicles, camera locations, passing events, timestamps, vehicle colors, vehicle types and plate colors. Among them, vehicles, camera locations, passing events and timestamps are object entities corresponding to the real world instances, while the rest are property entities serving as auxiliary entities. Particularly, passing events are objects describing the behaviour of real world entities (e.g., vehicles) happened at certain moments (or periods) and at specific locations.
Figure 4 illustrates the schema of the basic THIN.
Note that when encountering an incomplete ANPR record, we still extract a vehicle entity from it in the same manner. However, the vehicle identity value of this entity is set as null or unknown as we are going to find the aligned entity for it to recover the missing vehicle identity.
To address the sparsity of spatiotemporal data and fully utilize the information from companion vehicle entities, we apply vehicle grouping and spatiotemporal relationships extraction to finally present the enhanced THIN.
4.2.1. Vehicle Grouping
As mentioned above, the current THIN models the vehicle passing events as different separate entities connecting to the camera location entity network and the timestamp entities. This graph model brings two challenges for the task of vehicle alignment. For a vehicle entity whose identity is unknown, its connections to the other entities in the network is sparse. In other words, there are not sufficient features can be utilized, making it difficult to model the travel pattern of the vehicle. Besides, we neglect the physical interactions of vehicles’ movements. When exploring a particular object (e.g., a vehicle here), it would be informative to take the instances when the object interacts with others into account. For example, two vehicles may travel together along the same sequence of intersections in a road network. If we could discover this companion pattern, the travel information of one vehicle can be used for inferring the trajectory of the another one. Therefore, it is intuitive to consider the spatiotemporal information from companion vehicles for assistance.
Based on the ideas above, we conduct vehicle grouping process to create a new type of entity. As defined in
Section 3.1, for each location
l of camera sites in time period
, we replace the passing event entities, which is linked to
l and
t between
with a single vehicle group entity
g.
Figure 5 illustrates the operation of vehicle grouping, where circles and ovals with dash border on the left are passing events of vehicles and vehicle group entities respectively. After that, entity
g is connected to
l and the relevant vehicle entities
on the right of
Figure 5.
However, while we succeed in discovering the companion structures in each camera location, the context patterns along different locations and time periods remain unrevealed. Next we further exploit it via vehicle group spatiotemporal relation extraction.
4.2.2. Vehicle Group Spatiotemporal Relation Extraction
In order to capture the companion traveling patterns beyond one stationary location, it is necessary to connect the vehicle group entities that appear in the context of nearby locations and time periods. Obviously, in the traveling scenario, we can observe that two vehicles are more likely to be the same vehicle if they appear in small space or time distance, otherwise the opposite. This procedure can help preserving proximities and further letting the expected aligned vehicle entities share similar embeddings.
With this in mind, context links are introduced among vehicle group entities to model the relationships between detected records spatially and temporally. As the vehicle group entities already hold both space and time information, the context connections between them are spatiotemporal relations. Specifically, for vehicle group entities
and
, we extract a spatiotemporal relation between them if they satisfy the following two conditions: (1) without loss of generality, the camera site
of
is located at the downstream intersection of
(i.e., the camera location of
); (2) the beginning time
of
has a time-delay (but within the limits of a threshold) after
of
according to the road segment between
and
.
Figure 6 gives an illustration of how spatiotemporal context links extract. After this process, the connection structure of certain entities have renewed which corresponds to the partial graph on the right.
4.2.3. Enhanced THIN Construction
After the above two procedures, we formally construct the enhanced THIN. Now we have 6 types of entities: vehicles, camera locations, vehicle groups, vehicle colors, vehicle types and plate colors. Comparing with the previous network schema, vehicle group entities take the place of passing event entities and timestamps entities are removed as the time information is encapsulated in the vehicle group entities and their relations. Moreover, embedding every timestamps entities is impractical in representation learning.
Next, we detail all kinds of edges in our enhanced THIN. First, for vehicles and their appearance properties, there are three attribute relationships, namely
vehicle–vehicle color edges,
vehicle–vehicle type edges and
vehicle–plate color edges. Then with regard to the relationships between the object entities, we treat vehicle group entities as central entities and their edges to other entities can be easily derived in accordance with the traveling semantic. As a result, we have location relations between
vehicle group and
camera location, member relations between
vehicle group and
vehicle and context relations between
vehicle group themselves. Finally, the adjacency relationships are reserved between
camera location entities adhering to the topology of the road network. The updated graph schema is illustrated in
Figure 7.
4.3. Embedding Learning
In this section, we resort to the latent feature models for representation learning on heterogeneous graph.
4.3.1. Generic Learning Setting
For the sake of clearness, we refer to each relational structure in an HIN as a SPO (i.e., subject, predicate, object) triplet where s and o are entities and p is the relation between them. Then function indicates whether or not it is a possible triplet of .
These models assume that the presence or absence of certain triplets is correlated with each other [
32]. And they explain triplets via embedded features of entities and relations which are composed of implicit components learned from relational data. To learn
of the triplets, we can transform it into a supervised learning problem by estimating the probability
. The formulation can be written as:
where
are learned representations of different vector spaces,
denotes the sigmoid function, parameter
denotes the set of all embeddings and
is called score function representing the confidence of the existence of triplet
. The score function is the key unit to model the interactions of the embeddings inside a triplet.
Given relational dataset
containing valid and invalid tuples, our goal is to learn the embeddings
that fits
best according to (
1). This can be done by optimizing the following pairwise ranking loss:
where
S,
denote the set of valid and invalid triplets respectively and
is a margin hyperparameter. As an HIN only stores valid relationships, the negative relations of
can be generated by corrupting the valid triplets from
S.
4.3.2. HolE
There are generally two kinds of embedding learning models according to whether they explicitly or not form compositional representations of the embeddings. For compositional vector space models, they adopt varied compositional operators such as tensor product [
21] to capture rich interactions. While the non-compositional methods introduce translations of entity embeddings.
Here, we exploit the difference by taking HolE [
23] and TransE [
24] as examples. HolE uses the circular correlation to model the interaction between
subject and
object which is defined as:
where
denotes the circular correlation operator. Further it computes the similarity between the intermedia result and the
predicate as the score of a triplet:
As for TransE, it directly measures the distance of the translations of entities in the score function:
Figure 8 shows the element-wise interactions among the embeddings. For TransE, the latent features of entities are combined (i.e., linear summation or subtraction) independently. In contrast, HolE explicitly models all relationships between the latent features of different entities via circular correlation which allows to capture the complex interaction between
subject and
object with the multiplicative forms. As a result, the modeling power of HolE is naturally more expressive.
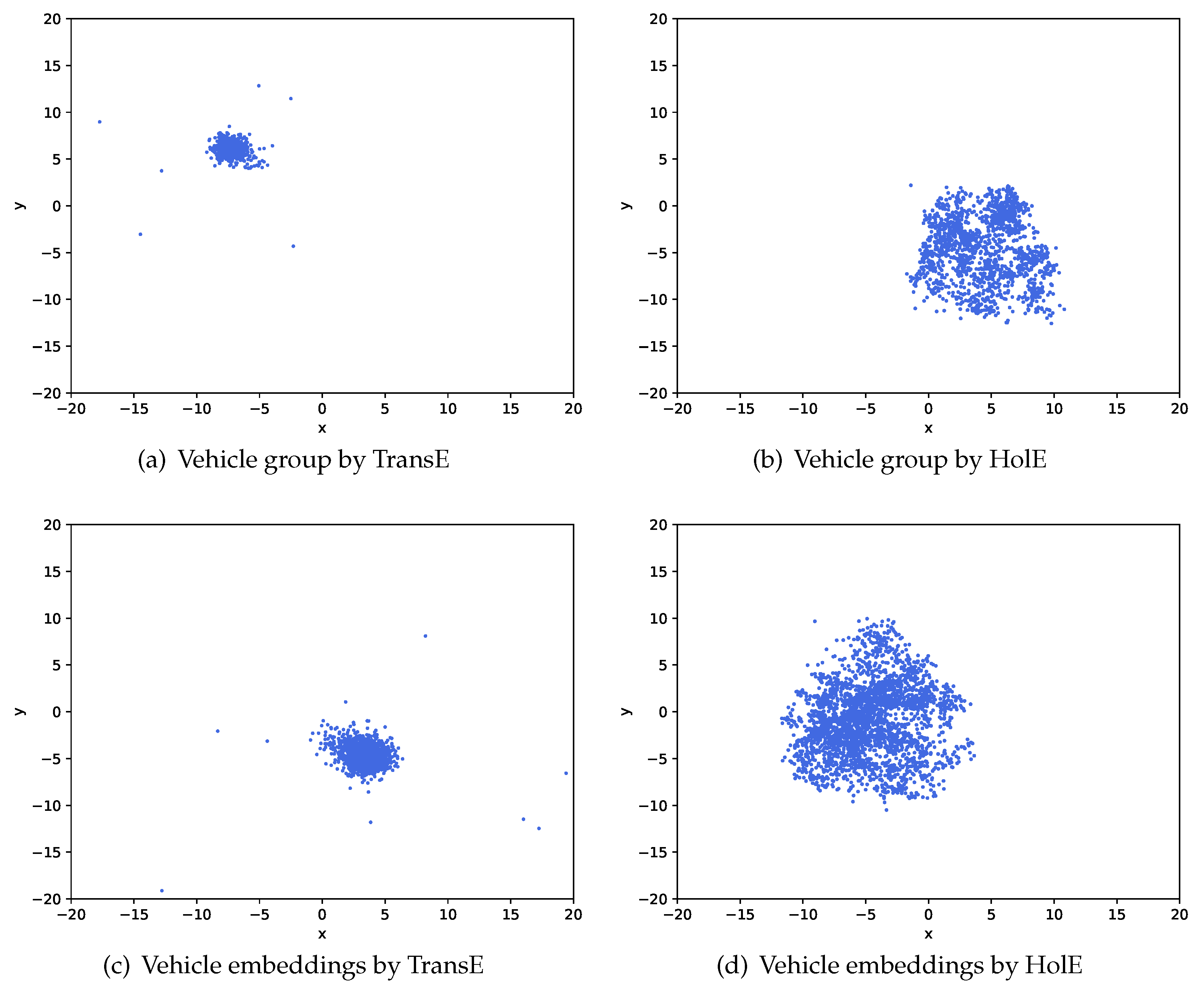
Moreover, different from quantifying the similarities with the circular correlation results in HolE, the
predicate in (
5) is modeled as the transition vectors between
subject and
object, which brings restrictions to the distributions of entities and relations in the vector space. As illustrated in
Figure 9, we will get the same embeddings for vehicle group entities as well as vehicle entities (i.e.,
and
) since TransE can not deal with the one-to-many and many-to-one
member relation in the enhanced THIN. These embeddings ignore the difference among entities and thus contradict the truth. Considering the flexibility of circular correlation as well as the complex relation structure of the enhanced THIN, we adopt HolE to the embedding learning problem.
4.4. Entity Alignment
The above model learns embeddings for each entities and lets similar entities have similar embeddings. In the context of our problem, we care more about the entities of type vehicle
so we denote them as
. Then, we can compute the similarity using the result embedding vector with the following equation:
is a vehicle entity with unknown vehicle identity extracted from a corrupted detection record and indicates the set of vehicle entities except the ones with unknown vehicle identity. Our goal is to compute the similarity score between the target entity and all entities . As a result, is the expected aligned entity pair and we can recover the vehicle identity of by merging them into one entity . Note that to avoid the entities that are too dissimilar to be aligned, a threshold is introduced.
6. Conclusions
In this paper, we intend to recover the missing vehicle identities of the ANPR data which is an essential part of data driven transportation for intelligence and sustainability. To address the problem, we organize these records as a travel heterogeneous information network according to the heterogeneous interactions which exist among the entities involved in vehicles’ travel. In the THIN, the real world objects are extracted as entities and connected to each other according to their semantic relationships. To utilize the companion information from the peer vehicles as well as ease the problem of data sparsity, we further construct an enhanced THIN through vehicle grouping and context relation extraction, which is capable of capturing the spatiotemporal relationships along adjacent intersections. Given the novel THIN, we transform the recovery problem into the task of vehicle entity alignment, which is achieved by learning the embedding representations for different entities. Considering that there exists a large number of complex relations in the heterogeneous graph, we choose HolE to learn the embeddings for better performance. An experiment using real ANPR data from Xuancheng, China is conducted to evaluate the framework. The results demonstrate the effectiveness of the proposed enhanced THIN model and justify the advantages of holographic embeddings. The recovered records are important for downstream ANPR data mining, especially for personalized intelligent transportation.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}