1. Introduction
Traffic assignment techniques can be used to assess traffic intensities on a track or road system based on its physical and functional characteristics and the potential traffic that can use it.
An assignment process has two stages. First, it is necessary to determine the possible traffic that can be used by the network, which is usually expressed through current and future origin/destination matrices. Based on this data, in the second stage of the process, this potential traffic is assigned to each of the sections of a given road network. There are a multitude of procedures for this purpose, most of which are empirical and based on statistical observations of user behavior, certain track conditions, and the traffic itself. Procedures with a higher level of precision are, of course, more complicated. However, we cannot forget that we are starting from an estimate of future potential traffic; therefore, each result must be studied by a decision-maker in order to develop appropriate contrasts and produce final results that are consistent with the analyzed situation.
There are several assignment methodologies, some of which have already been compared in certain case studies, although usually not all at once, and only sometimes using simulation techniques [
1,
2]. The assignment stage has been analyzed at times as an intermediate problem between optimization and equilibrium issues [
3]. We can also attempt to analyze the zonal distribution and assignment stages together, as was performed by Tan et al. [
4] in a study in which the use of Intelligent Transport Systems (ITS) was incorporated. The number of possible applications of assignment methodologies is enormous, among which we can include their adaptation to multimodal networks as especially novel [
5], their use to minimize the environmental impact of traffic [
6] and the damage caused to infrastructure by traffic [
7], or to optimize the process of searching for a place to park a vehicle [
8]. In addition, if we add the use of simulation with computer tools to this [
9,
10], the number of possibilities is greatly increased.
However, the assignment problem is not only associated with road traffic, but also with other means of transport. For example, within road networks, assignment methods are applied to private vehicles, including taxis and autonomous vehicles and public transportation (PT). For example, Long et al. [
11] introduced the concept of the expected rate of return of taxi drivers and performed a dynamic taxi traffic assignment problem supposing real-time traffic information provision; Bischoffa and Maciejewski [
12] analyzed the possible effect of a city-wide replacement of private cars with autonomous taxi fleets; Heilig et al. [
13] used a microscopic travel demand model to simulate the mode choice behavior in the assumption of the existence of a large autonomous mobility on demand service instead of private cars; and Poulhès and Berrada [
14,
15] analyzed the effect of dial-a-ride services on the assignment problem. Within the PT assignment problem, Liu and Ceder [
16] and Eltved et al. [
17] considered different schemes for that; Cats and Hartl [
18] focused on the discomfort that causes congestion on PT users and how it affects their choices; and Nuzzolo and Comi [
19] included big data issues to this modeling.
With railway transport, there are also interesting studies that employ these techniques to estimate the passenger load on each route. Thus, Lin et al. [
20] investigated the railway passenger pricing problem, supposing that operators could modify ticket prices to optimize the system’s performance; Xu et al. [
21] proposed a dynamic assignment problem for urban rail transit networks considering queuing process, capacity constraints, and congestion effects; and Gao and Wu [
22] proposed a method to calculate the proportion of passengers on each path based on the entry and exit time records of users.
In the maritime domain, assignment methods are also applicable and there are several studies that have analyzed the assignment problem by considering traffic assignment close to seaports. Venturini et al. [
23] and Iris et al. [
24] studied the integrated berth allocation in seaport container terminals; Li and Jia [
25] modeled the traffic scheduling problem as a mixed integer linear program to minimize the berthing and departure delays of vessels; Han et al. [
26] studied a storage yard management problem if the loading and unloading activities are both heavy and concentrated; and Iris et al. [
27] formulated a mathematical model for the containership loading problem, where the terminal has the right to decide which specific container to load for each slot.
In air transportation, we can find some examples of the application of assignment methods. For instance, Ganić et al. [
28] and Ho-Huu et al. [
29] developed mathematical models of air traffic assignment in order to minimize the noise effects on population, and Starita et al. [
30] considered future capacity provision in terms of the available man-hours of air traffic controllers.
Finally, several studies have considered two or more means of transport simultaneously in a multimodal scenario. Thus, Yu and Guo [
31] developed a tri-level combined-mode traffic assignment model; Pi et al. [
32] included heterogeneous traffic on roads, parking availability, and travel modes (such as solo-driving, carpooling, ride-hailing, public transit, and park-and-ride); Macedo et al. [
33] proposed an efficient traffic assignment, where users are not only concerned about travel times, but also about global and local pollutant emissions; Jiang et al. [
34] included the car–truck interaction paradox in assignment problems; and Dimitrov et al. [
35] modeled the interaction between buses, passengers, and cars on a bus route.
Some researchers have applied these methodologies in a specific case study, often with the support of computer simulation [
36,
37,
38,
39], while others have attempted to assess different techniques or even propose novel ones [
40,
41,
42,
43,
44,
45]. Among the first ones, Zhang et al. [
36] integrated an activity-based travel demand model with a dynamic traffic assignment model for the Baltimore Metropolitan Council; Shafiei et al. [
37] developed a simulation-based dynamic traffic assignment model of Melbourne, Australia; Zhu et al. [
38] used dynamic traffic assignment for a case study in Maryland; and Kucharski and Gentile [
39] applied the Information Comply Model on different situations, including a corridor in the North of Kraków, Poland, and the Sioux-Falls network. Within the latter ones, Zhang et al. [
40] analyzed the calibration of dynamic traffic assignment models applying the extended Kalman filter; Prakash et al. [
41] presented a dimensionality reduction of the assignment model’s calibration problem based on principal components; Du et al. [
42] focused on the dynamic traffic assignment problem on large-scale expressway networks, especially under the condition of traffic events (such as severe weather, large traffic accidents, etc.) and proposed an approximate solution algorithm; Lin and Chen [
43] developed a simulation-based multiclass, multimodal traffic assignment model for evaluating the traffic control plans of planned special events; Batista and Leclercq [
44] studied a regional dynamic traffic assignment framework for a macroscopic fundamental diagram considering stochasticity on both the trip lengths and the regional mean speed; and Bagdasar et al. [
45] examined discrete and continuous optimization and equilibrium-type problems and made a comparison of them with the Beckmann cost function.
Finally, we can cite some interesting studies that consider multi-class, multi-modal, and elastic demand traffic for assignment models. Cascetta [
46] covered all the issues on traffic assignment; Cantarella [
47] provided a highlight on traffic assignment with elastic demand; and Cantarella et al. [
48,
49,
50] proposed an overview of solution algorithms for traffic assignment, presenting a general fixed-point formulation for the multi-user stochastic equilibrium assignment with variable and elastic demand and comparing it with other approaches.
Following this line of research, the main objectives of this study are: (1) to develop an assignment model for a specific case study (the new B-40 highway in Barcelona, Spain) and implement it using traffic macro-simulation tools; and (2) to evaluate the influence of the use of different assignment models on the results and the numbers of iterations in them.
This paper is structured as follows. After a brief introduction,
Section 2 outlines the main techniques used in the modeling work performed in this study.
Section 3 contains a description of the case study and the principles adopted for delimitation, zonification, and obtaining the base origin/destination matrix. The principles adopted for applying the general methodologies to the specific case study that is being analyzed are then set out in
Section 4.
Section 5 contains an evaluation of the best assignment methodology for the specific case study to be analyzed. Finally, in
Section 6, we discuss our results and the main conclusions drawn from the full study.
2. Methods for Traffic Assignment
Potential users of a transportation system in which there are different alternative itineraries generally have incomplete information about the conditions of each section; however, they must make their decision with these inaccurate data. These data include the length of each segment, the quality of the track (in terms of layout, pavement, and safety conditions), and, finally, the degree of congestion at all times, which decisively affects the vehicle’s speed and, therefore, the time spent on the route. The possibility of knowing the above data ranges from high to low. In addition, with regard to congestion, the knowledge that each driver has is very subjective and is generally based on his/her previous experiences, since in very few cases does he/she have information about the actual situation.
Typically, when choosing from several possible itineraries, we consider different types of factors (e.g., distance, travel time and/or cost, comfort, and toll, if any) that are usually grouped into a single variable called generalized cost. In practice, the process that we need to follow in order to assign traffic to the existing road network in a given area of study has the following steps:
Zone division. First, the entire study area to be analyzed must be divided into zones of more or less homogeneous characteristics.
Origin/destination matrix construction. Once the study area has been divided into zones, we need to construct a matrix that lists the movements of each origin/destination pair. We should also distinguish between light and heavy vehicles, since the conditions for the assignment of each type of vehicle are different.
Definition of road networks. Each defined zone is represented by its centroid, which is the fictional place that generates or attracts all trips in the area. All zones must be joined to one another through the existing transportation system and, if applicable, through the future one (constituting two separate transport networks: a current one and a future one).
Calculation of travel costs and/or times. For each of the sections of the considered network (current and future), the generalized cost of travelling along it under certain traffic conditions must be determined. It is desirable to calculate the costs for various traffic levels in order to take into account the capacity of each segment, or even do it dynamically at each iteration of the process, depending on the traffic supported by each part of the network.
Assignment. Using the origin and destination data, it is advisable to calculate the traffic intensities for the existing network in the current situation, and then compare the results obtained with the traffic accounts that have been made. Once this check has been carried out, each of the movements in the origin/destination matrix is assigned to the current and future networks. A separate assignment should be performed for light and heavy vehicles and for various driving conditions. The application of computer tools to traffic assignment models has resulted in the creation of new methods that introduce a greater number of theoretical complications but are perfectly applicable nowadays.
Among the wide variety of methods for traffic assignment (or methods for calculating the traffic load on the network), we used the following, which are those that are used in practice in most cases [
51]:
2.1. All-or-Nothing Assignment
This is the simplest of all assignment methods and results from the load of all journeys to the minimum cost path between the nodes. The costs are initially fixed for all segments in the network: i.e., the speed/flow ratio function is not considered.
While it is simple, it has significant drawbacks. It is an unstable method because small changes in the travel time of a segment can drastically change which routes are chosen to form the minimum cost path. This method ignores limits on the capacity of each segment and the number of times that they have been used in the assignment, so the result may result in little relation to the real flow in the network. In addition, it does not allow for variations between users. For these reasons, if in a study we include a new alternative route and use this methodology, we usually find that all trips head for the new path (the so-called “vacuuming effect”), when, in reality, there will be a distribution of travel through the segments of the network.
A number of modifications have been made to this “base” methodology, such as the one by Lee and Oduor [
52], which includes parameters from a GIS (Geographic Information System) network that improve the model’s results.
2.2. Stochastic Assignment
Stochastic assignment distributes the trips of each O/D (Origin/Destination) pair between different paths of the multiple alternatives that connect them. We can sort these methodologies into two kinds: those based on simulation and those based on proportions.
In simulation-based methodologies, which often use the Monte Carlo simulation [
53] to represent the variability among users in terms of their perception of network costs, the following assumptions are often made:
For each segment, it is necessary to differentiate the objective costs, which are measured or estimated by an observer (modeler), from the subjective costs, which are perceived by each user. It is accepted that the target cost roughly matches the average of the subjective costs, which are randomly distributed according to a given probability function. By analyzing the literature on this topic, we can find different assumptions regarding the distribution of these subjective costs. For example, Burrel [
53] adopts a uniform distribution, while other authors adopt a normal distribution.
The distributions of costs perceived by users are independent.
Users choose the route that minimizes their perceived travel cost: i.e., the sum of the costs of each used section.
Although these methods are simple and relatively quick to apply, they have certain drawbacks. For instance, the assumption that the perceived costs of each section are independent may not be true when users have a certain predisposition to the use of certain types of infrastructure (high-capacity highways, as an example). In addition, the effect of congestion is not explicitly taken into account. However, these methods do allow us to distribute the trips in such a way that the “optimal” paths for the modeler turn out to be the ones with the highest amount of traffic; however, they do not convey the total number of trips. Moreover, it is not necessary to know the flow–speed functions of each section, which makes these methods easier to apply, although sometimes this can be a limitation.
In proportion-based methods, as their name suggests, the fraction of trips assigned to a particular path is equal to the probability of choosing it, which is calculated using a logit-type route choice model. The lower the generalized cost of one path as compared with the others, the greater its chance of being chosen. However, with this methodology, the only alternative paths that have traffic are those that are considered to be “reasonable”—that is, those that separate the user from the origin point and bring them to the destination point. The travel time for each segment in a stochastic assignment is a fixed set of input data and is not dependent on the volume that it supports. Therefore, these methods are not equilibrium methods, nor are they valid in situations of congestion.
According to the single path method [
54], the trips between an
i–
j origin/destination pair along the
r-path,
Tijr, would result in:
where
Tij is the total number of trips from
i to
j,
Cijk is the generalized cost from
i to
j using the
k-path, Ω is a parameter (usually 1), and
k is the number of reasonable paths from
i to
j. Ω can be used to control the distribution of trips between routes; thus, depending on their (always positive) value, cheaper routes tend to concentrate trips, or, on the contrary, distribute them more uniformly among the possible reasonable paths.
2.3. Assignment with Congestion
Regarding congestion-side assignment techniques, the methodologies that researchers most commonly use when requiring an adequate level of detail are equilibrium methods. These methods take into account the dependence between the flow of a section and its generalized travel cost, and calculate both of them simultaneously so that they are consistent. Equilibrium algorithms require the iteration of flow assignments and the recalculation of travel times. Despite the additional computational load, equilibrium methods are almost always preferable to other assignment methods.
The main behavioral assumptions are that each traveler has all of the information about the attributes of network alternatives, all travelers choose routes that minimize their travel time or cost, and all travelers—of the same category—assign the same value to all of the network attributes.
According to the first equilibrium principle, which was proposed by Wardrop [
55] and is called “user equilibrium” (UE), no individual traveler can reduce his/her travel time unilaterally by changing his/her path [
56]. One consequence of the UE principle is that all of the roads that an O/D pair uses have the same minimum cost, while unused roads have equal or higher costs. Unfortunately, this is not an absolutely realistic description of congested traffic networks, although it can be considered to be sufficiently approximate. The mathematical notation for these expressions is as follows (bearing in mind that, in addition, the conditions of continuity, conservation, and non-negativity of flows must be met):
where
cp is the unit cost in the equilibrium state,
Pw is the set of paths that connect the pair
w, and
hp is the flow of path
p.
In addition, Wardrop [
55] proposed a second alternative to assigning traffic to the network, which takes the name of “system equilibrium.” According to this alternative, under balanced conditions, traffic should be distributed so that the total cost of operation of the network is the minimum possible cost. Computationally, it is similar to the first principle, as expressed in Equation (2), but it replaces unit costs with marginal costs:
where
fa and
hp are the flows of section
a and path
p, respectively,
CMa and
CMp are their respective marginal costs, and
ca and
cp are their respective unit costs.
In either case (the first principle is most commonly used, since it responds more to the actual “self-interested” behavior of users), we obtain a system of equations, the solution of which would be the flows in sections or on paths.
Another type of model is that of speed adaptation. The simplest of these models, called direct adaptation, is based on all-or-nothing methodologies. However, it differs from them in that, once it assigns traffic, it recalculates the travel times or costs of each section, and then reapplies the all-or-nothing method with the new values. This process can be iterated indefinitely. However, this approach has a major drawback, as the selected paths usually change at each iteration, and the method does not converge to a single solution.
Therefore, in order to try to reduce these oscillations, a methodology was proposed that uses the average of the speeds of two or more all-or-nothing assignments in each iteration. This methodology, called speed-weighted adaptation, is not a real improvement, as it continues to assign all traffic to a single minimum path, which is also usually different in each iteration.
The incremental assignment methodologies are, again, based on the all-or-nothing concept. In this case, however, they introduce a significant improvement by making the results more realistic. In the first step, the demand matrix is split into parts (not necessarily equal ones). The first portion is assigned using the all-or-nothing method and, once the flows are entered, the travel times of each section are recalculated. Then, with the new travel times, the second fraction of the demand matrix is allocated using the all-or-nothing method, and the travel times of each section are recalculated again. This continues until all of the fractions have been assigned. Commonly used values for the fractions are [
51]: 0.4, 0.3, 0.2, and 0.1. The end result provides us with flows that are distributed between routes and not assigned in their total to the initially shorter one, which more closely approximates reality.
Theoretically, the larger the number of fractions considered, the more likely it is that trips will be distributed among a greater number of roads. However, even if the demand matrix is divided into very small fractions, this method may never converge to the solution when using the Wardrop balance, as the flow that is already assigned to a section cannot be suppressed or modified. In any case, it is clear that its simplicity and ease of use and the possibility of interpreting its results as the accumulation of congestion during peak periods make it an interesting method.
Finally, the method of successive averages (MSA) is another variant of the all-or-nothing method. In each iteration, the flow of a section is calculated as a linear combination of the flows assigned in the previous iterations and the auxiliary flow resulting from an all-or-nothing assignment in that iteration. Thus, the resulting flow in each iteration is:
where
Van is the flow of section
a in iteration
n,
Fa is the auxiliary flow in section
a from an all-or-nothing assignment, and
ϕ is a value between 0 and 1. The different variations of this algorithm lie in the value of the parameter
ϕ. One approach is to assign it a fixed value of 0.5. However, one of the best-performing techniques [
57] assigns a value of
ϕ = 1/n. In this situation, each auxiliary flow
Fa always has the same weight, and that is why it is called the method of successive averages (MSA). In fact, it has been demonstrated [
56] that, with this value, it is possible to obtain a convergent solution with Wardrop’s equilibrium principles.
Frank and Wolfe’s algorithm [
58] aims to determine the optimal values of
ϕ in order to ensure a rapid convergence of the MSA methods with the user equilibrium principle. The problem of searching for “the lowest point of the valley on a day of thick fog” is often used as an allegory to explain it [
51]:
Since we do not know the optimal downward direction in global terms, we start by descending to where it looks optimal at that point.
We continue descending until the slope starts to rise again.
We stop at that point, look again for a new downward direction, and take it. We continue and repeat the previous step.
We continue like this until there are no downward directions. By that time, we will have reached the bottom of the valley.
In our case, in each iteration of the MSA method, a feasible solution (equivalent to a position in the valley) was obtained. The all-or-nothing assignment is the one that marks the direction of descent. The Frank–Wolfe algorithm tends to converge quickly in the first few iterations; however, it will converge more slowly as it approaches the optimal value [
59].
3. Case Study
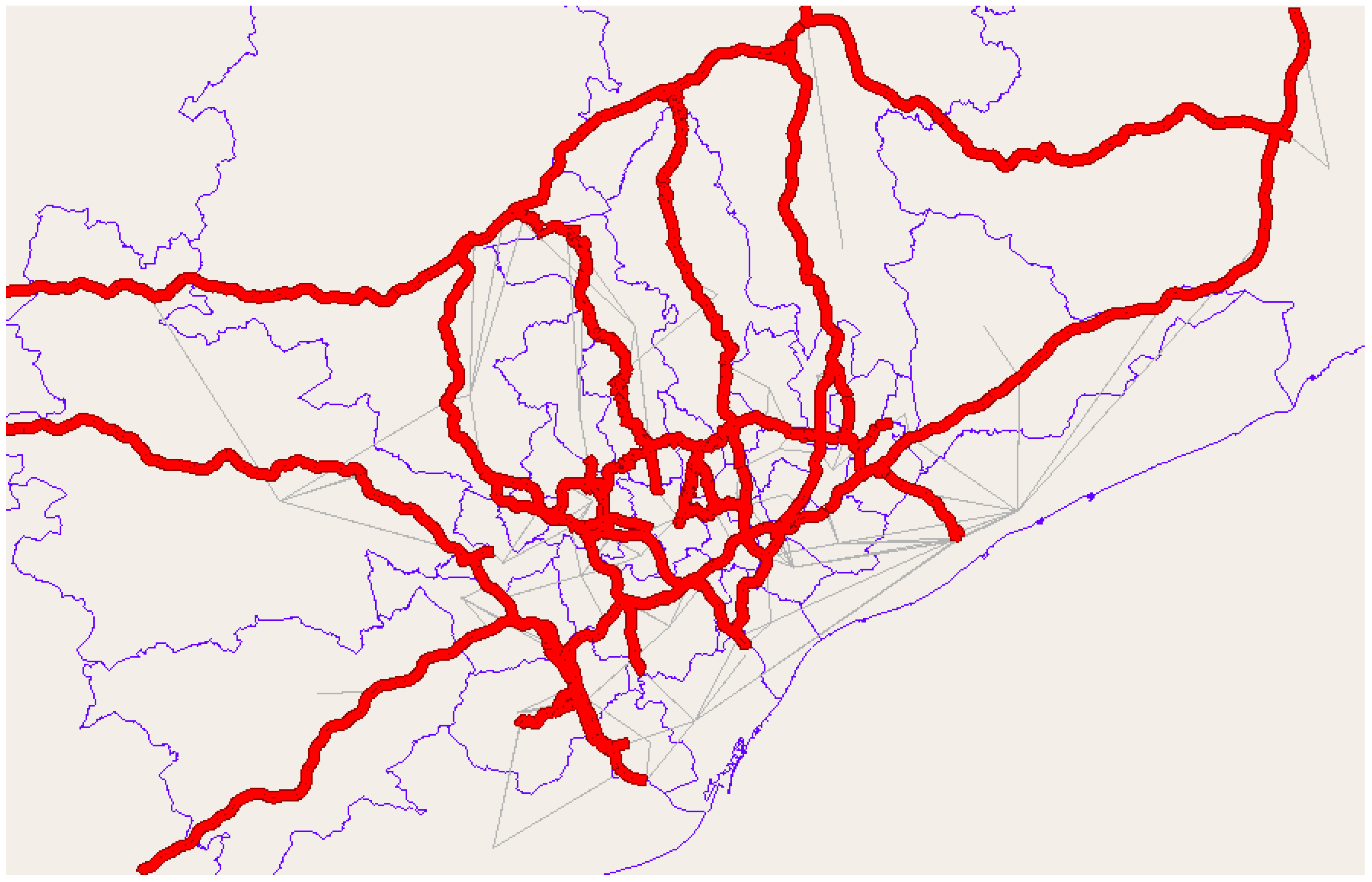
In the study report of the Barcelona Orbital Highway B-40 (from Terrassa to Granollers (link with AP-7/C60 roads)) it was necessary to carry out a traffic study in Barcelona, Spain to analyze the different considered alternatives. This traffic study was divided into two phases, each with a different scope:
Phase A. This phase included a comprehensive background study and the collection of numerous previous traffic, mobility, urban planning, and socio-economic data.
Phase B. This phase contained the traffic study itself, including the complete modeling of the network, the network’s simulation via a computer, and the final results and conclusions.
In November, 2017, Phase A of the study was conducted. In September, 2018, Phase B was completed. We used the results obtained in this traffic study as the basis for a further assessment of the influence of the used type of model on the level of observed error.
In total terms, the road network of Catalonia (Spain) consists of 12,076 km of tracks, of which 1648 km are high capacity. The regional government is responsible for 50.4% of these tracks, the local government is responsible for 34.8% of them, and the country’s government is responsible for 14.9% of them [
60].
For the analysis of traffic in the area, all of the roads parallel and perpendicular to the new network were considered, regardless of their ownership. We collected data from the Ministry of Development of Spain [
61] and the Government of Catalonia [
62]. In particular, we collected information from 16 metering stations belonging to the Ministry of Development (three of them permanent ones) and 42 stations of the Government of Catalonia.
3.1. Zonification
Seventeen (17) municipalities were directly affected by the layout of the different considered corridors. All 17 belonged to the province of Barcelona (Spain). However, as the study area obviously could not be limited to these municipalities, we extended it to a much larger territorial area that included the entire province of Barcelona, the neighboring provinces, and the rest of Spain.
Therefore, we defined two distinct areas:
The internal area, which incorporated the areas on which the new infrastructure had a direct impact. This area included the municipalities directly affected by the new infrastructure and almost the entire Metropolitan Area of Barcelona.
The external area, which incorporated some areas that supported penetration or crossing trips and usually contained more than one municipality. In the external area, we had large areas that modeled long-distance relationships in the corridor, such as trips from the Mediterranean area or Portugal to Europe or Girona.
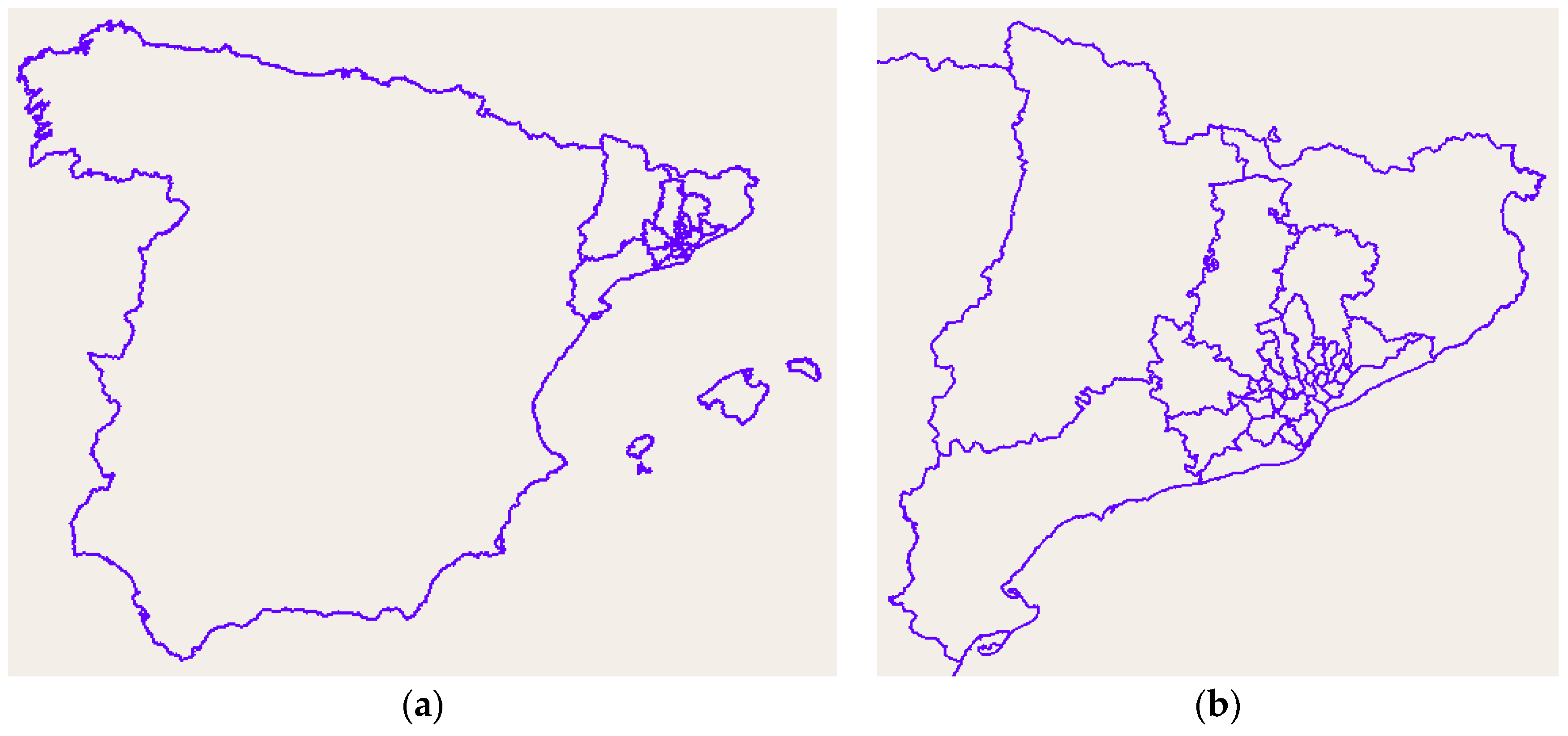
The model consisted of 38 zones (34 internal zones plus four external macro zones), with municipal disaggregation in the area most directly influenced by the new highway, and with less detail when moving away from the area of action. All areas were composed of individual municipalities or aggregations thereof. The final zonification set is shown in
Figure 1.
3.2. Determining the Basic Origin/Destination Matrix
The main source of data used in the project was anonymized mobile phone data from a network operator with an important market share of total users in Spain. To do so, information on the geolocated positions of mobile devices was gathered and recorded during March, 2018. The study population consisted of residents of Spain over 16 years old. The resulting data from this process were: four origin/destination matrices for light vehicles (with different travel reasons) and one origin/destination matrix for heavy vehicles on an average working day.
After adding the different travel reasons, a global origin/destination matrix was obtained for an average working day. Finally, based on data collected from the Movilia survey [
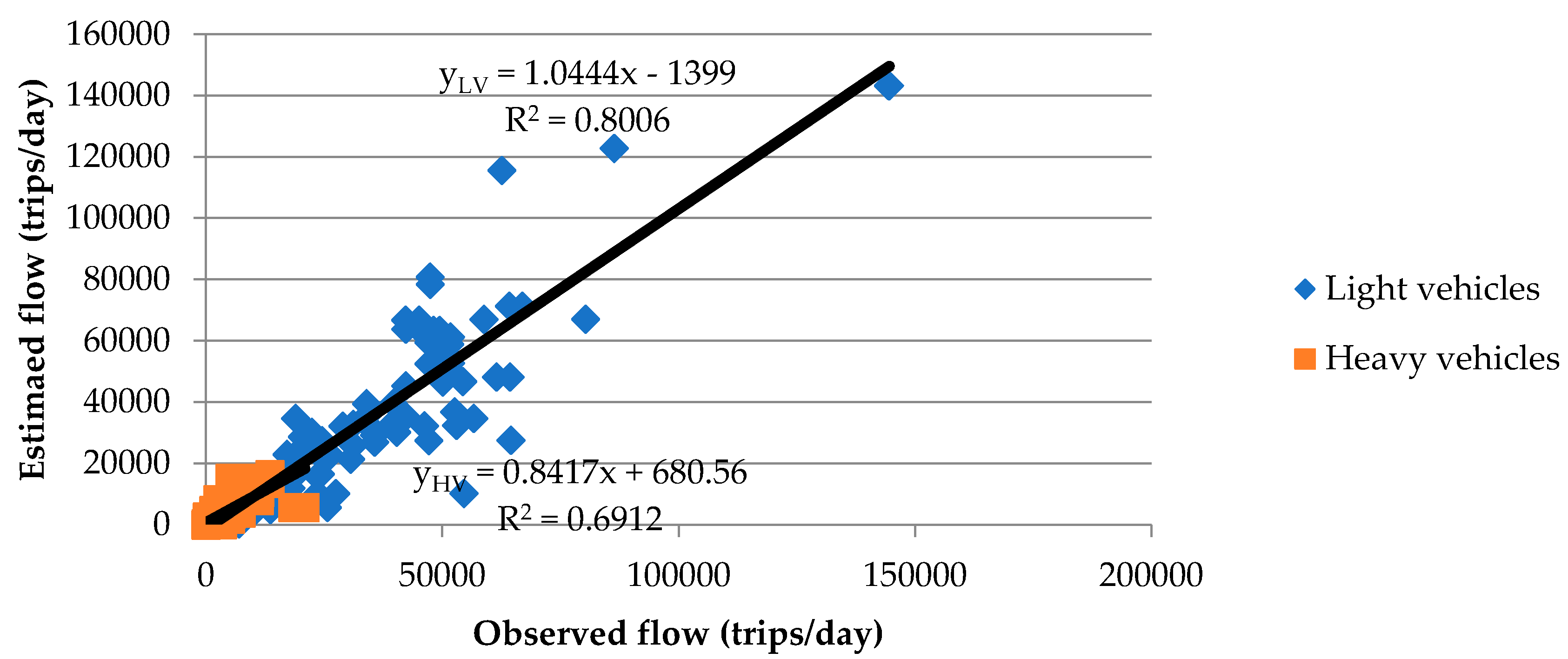
63], we noted that the proportion of private vehicle travel on a working day was 40.6%, and that the average occupancy of vehicles was 1.22 people/vehicle on a working day. Taking into account all of these corrective elements, the final base matrices of light and heavy vehicles were obtained for the 38 considered zones. These tables were found to yield values similar to those obtained in the Movilia survey for the province of Barcelona, which gave us some confidence in the reliability of the process.
However, when applying these matrices to the network model, the traffic values recorded at the actual metering stations were not accurately reproduced. Therefore, we needed to make one last adjustment after developing the offer model (or network model).
6. Discussion and Conclusions
From our analysis, we can draw the following conclusions:
The all-or-nothing and stochastic assignment methods are inadmissible in this particular case study. In our study, we did not obtain the same outcome as Chen and Pan [
69], who concluded that stochastic algorithms can produce similar results to the UE and MSA. This may be due to the size of the simulated network; the examples they used were small in size, while we analyzed a large area. Further research is needed to verify this point.
The incremental assignment algorithms are valid only when they have four or more demand partitions of equal size; thus, no individual partition can exceed 25% of the total.
The method of successive averages (MSA) algorithm is valid only when working with more than 10 iterations. This result is consistent with those of Ameli et al. [
1], who found that this method is good for small- and medium-sized networks, but is not the fastest one when estimating the traffic flow in a large network.
Finally, the user equilibrium methods (approximated by the Frank and Wolfe algorithm) were found to be valid in all of the considered cases (five or more iterations).
Table 10 shows a summary of the results obtained using those methodologies that were found to be valid for the case study.
From the results, we can conclude that the MSA and UE yield practically the same results when we have a sufficiently high number of iterations [
59]. However, for lower numbers of iterations, the results of the UE algorithm are clearly better. The incremental allocation method provides a significantly lower level of detail.
Therefore, we recommend the use of user equilibrium methodologies. To speed up the process, approximation with the Frank and Wolfe algorithm could be performed. This recommendation is in line with the results of Denoyelle et al. [
70], who determined, by applying numerical simulation techniques, that this method is versatile and superior to other methodologies.
However, as Bliemer et al. [
71] note, planners have to evaluate a methodology’s applicability in terms of both its adjustment to real-world data and its computational flexibility and speed. In our case study, the Frank and Wolfe algorithm was found to satisfy all of these criteria. We can infer that a network’s size is a crucial variable to take into account when choosing a method [
40,
41,
44,
69,
71].
To finish, we want to make a note about the limitations of this study and its scientific and practical implications. In this study, we used five different types of methods to estimate the traffic flow in a large network and compared the results with real-world data. These five methods were the ones included in the employed software. It would be interesting to use other methodologies, or even a higher number of different configurations within the considered ones. In addition, we determined whether the models complied with the Spanish regulations [
64], since their verification, through the R
2 and the RMSE indices, is a prerequisite of their use in our geographical area. However, it would have been interesting to use other goodness-of-fit indicators, or even to develop new ones, to enhance our knowledge of the adjustment of each methodology to real-world data. These are possible lines of future research in this field.
Regarding scientific and practical implications, we want to note that the results obtained in this study can be considered to be valid for both the case study and other areas with similar characteristics. However, although they cannot be directly extrapolated to different cases, it may be possible to develop a similar methodology that allows, under the same conditions, for the selection of the optimal assignment method in eacvv cfdh case. The results of this study and the employed procedure may be useful to researchers in the field of computer simulation and planners who apply these methodologies in similar cases.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}